2011年国赛优秀论文
2011高教社杯全国大学生数学建模竞赛C题论文

摘要:本文对第一个问题做出了合理的假设,建立了阻滞增长模型预测2011后的工资增长,在确定工资的最大值时m x ,采用了经验估计的方法,根据我国经济发展战略目标和目前我国工资的实际水平,利用目前中等发达国家的工资来代替m x 。
在spss 中拟合出了以后每年的工资数据,与我国实际基本吻合。
问题二由于个人工资变化情况比较复杂,在具体计算过程中,为了将问题简化,引入平均工资增长率这一概念。
影响平均工资增长率的因素有两个:社会平均工资增长和企业平均工资增长。
利用题中的假设和附件给出的计算公式进行计算,算出本人指数化月平均缴费工资,进而算出基础养老金。
计算出职工退休前个人账户总额,进而算出个人账户养老金。
得出各种情况的替代率,并用表格进行了总结。
问题三在问题二的基础进行计算,对于职工个人账户余额所产生的利息进行了简化计算,不考虑复利的情况。
得出了个人缴存的养老金总额,利用问题二中算出的职工养老金额建立方程,可以解出收支平衡的月份,进而算出养老金的缺口。
但该方程编写程序比较,在具体计算时,查阅一个简单公式: (1/12)log 1/12r P l P Z r +=-⨯来计算收支平衡的月份。
进而算出各种情况下养老金的缺口。
问题四,在问题二和问题三的基础上,大致分析了影响替代率的因素,和影响收支平衡的因素。
建立了一个收支的不等式,讨论了既要维持收支平衡又要提高替代率所采取的措施:根据缴费月数12*m 来调整计划发养老金月数n ,使二者近似相等达到收支平衡,同时通过提高个人缴费比划C 和个人平均缴费指数R 来提高替代率。
最后对模型的优缺点进行了讨论。
关键词:替代率 SPSS 养老保险金缺口 收支平衡 阻滞模型1 问题重述养老金也称退休金,用于保障职工退休后的基本生活需要。
我国企业职工基本养老保险实行“社会统筹”与“个人账户”相结合的模式,即企业把职工工资总额按一定比例(20%)缴纳到社会统筹基金账户,再把职工个人工资按一定比例(8%)缴纳到个人账户。
2011年全国大学生数学建模竞赛A题论文

城市表层土壤重金属污染分析摘要土壤作为城市环境的重要组成部分,不仅提供人类生存所需的各种营养物质,而且接受来自工业和生活废水、固体废物、农药化肥、及大气降尘等物质的污染.很容易导致金属元素的蓄积,从而造成土壤重金属的污染.本文讨论了某城市表层土壤重金属污染的空间分布分布状况,地区污染程度,以及污染传播特征,污染源等,建立了相应的几何与数学模型或算法,得到了较好的结果,为防治城市表层重金属污染,保护和提高土壤资源和生态环境,提供参考.对于问题一:通过给定数据的相关分析,不考虑地形高低对污染浓度变化的影响,用Matlab 软件编程绘制个重金属元素污染浓度空间分布三维网格图和二维等高线图,综合研究该城市各功能区的空间分布以及污染程度分布.建立了Muller 地积累指数模分析模型:)]/([log 2Bn C Fn ⨯=ℜ,确定污染程度水平分级标准,通过统计计算,分析了各重金属在不同功能区的污染状况及程度.结论是:主干道路区和工业区的重金属元素的污染最严重,其他次之.对于问题二,为说明重金属元素污染的主要原因,采用单因子指数模型和内梅罗综合指数模型进行综合指标评价分析,结合问题一中统计数据进行综合分析,得到个重金属元素在各功能区及城区的综合污染程度指标.污染最严重的功能区是主干道路区,其次按照污染程度从大小的顺序依次为:工业区、生活区、公园绿地区、山区.主干道路区土壤表层重金属元素含量很高,且种类多.根据地区的差异性和元素的特殊性,分析出重金属污染Hg 和Cu 污染是最严重的污染源,且污染最严重的地区在主干道路区和工业区.这些污染主要由于含铅汽油的燃烧、汽车轮胎磨损产生的含锌粉尘、工业污水的排放、生活废水的排放、化肥农药的多度使用、金属矿山的开采.详细情况见正文.对于问题三,为了找出该城区的污染源,在分析出重金属元素的主要传播特征之后,考虑大气空间传播情况,建立了微分方程模型,通过模型求解分析,用其等效的向内(向污染浓度较高的方向搜索)搜索算法,计算确定了重金属元素主要污染源的位置,其中As 较严重的中心污染源坐标分别为:(5291,7349,10)、(12696,3024,27)、(18134、10046、41)、(17814,10707,64)、(27700,11609,165).这五个污染源主要分布在主干道路区.(5291,5739,10),(12696,3024,27),(17814,10707,64)分布在工业区,其它两种污染源分布在生活区.其余元素的中心污染源见正文.对于问题四,需对前面所建立的模型进行分析与评价并进行模型的优化,在详细分析了前三个问题的求解模型及过程之后,评价出所建立模型的优缺点.在问题三中,重金属元素除了在大气中传播以外,还通过水土流动传播.另外,前几个模型都是静态的,但污染物传播的过程与时间有关,是一个动态的过程.最后建立了一个扩算方程模型进行优化,能够为更好的研究城市地理环境的演变模式做贡献.关键词:重金属污染 地积累指数模型 单因子指数模型 内梅罗综合污染指数 微分方程模型一、问题重述1.1 问题背景随着工业发展和城市化进程的加剧,通过交通运输、工业排放、市政建设和大气沉降等造成城市重金属污染越来越严重.对城市土壤地质环境异常的查证,以及如何应用查证获得的海量数据资料开展城市环境质量评价,研究城市不同功能区表层土壤重金属污染特征和污染空间分布性,以便更好的研究人类活动影响下城市地质环境的演变模式.本文就如何应用查证获得的海量数据资料展开城市环境质量评价,研究地质环境的演变模式建立数学模型.附录1列出了采样点的位置、海拔高度及其所属功能区等信息,附录2列出了8种列出了8种主要重金属元素在采样点处的浓度,附录3列出了8种主要重金属元素的背景值.1.2 需要解决的问题有(1) 给出8种主要重金属元素在该城区的空间分布,并分析该城区内不同区域重金属的污染程度.(2) 通过数据分析,说明重金属污染的主要原因.(3) 分析重金属污染物的传播特征,由此建立数学模型,确定污染源的位置.(4) 分析所建立模型的优缺点,为更好的研究城市地质环境的演变模式,还应收集什么信息?有了这些信息,如何建立模型解决问题?二、问题分析该题目一方面通过GPS记录了该城市大量样本点的位置以及所属功能区,再应用专门仪器测试分析,获得了每个样本所含的多种化学元素的浓度数据,通过这两个表的数据就大致可以提取出一些对于解决问题的重要信息,另一方面,题目给出了自然区各样本点的重金属元素的背景值,作为重金属污染情况的指标.对于分析研究各个样本点的污染程度至关重要.利用Matlab软件进行三维网格图和等高线图的制作并结合相关的数据统计分析,可以分析该城区不同区域重金属的污染程度.后面利用地积累指数法和内梅尔综合评价指数对数据进行处理,分析污染严重的功能区和重金属.结合图形的分析以及模型的建立综合分析重金属污染物的传播特征.接着对模型进行一定的优化处理,使得处理的结果更准确.三、模型假设1、假设题目所给的数据合理正确.2、该区域的划分是稳定的,不会出现大的变动.3、不考虑观测误差、随机误差和其他外在因素所产生的误差.4、重金属在大气中无穷空间扩散,不受风的影响,其扩散服从热传导定律.5、重金属污染程度连续变化,大气中重金属元素浓度连续变化.6、界限不明显区域有扩大、缩小、消失的过程,穿过大气进入仪器的重金属含量只有浓度大小之分,浓度大小由仪器灵敏度确定.四、变量与符号说明eo lg地积累指数n ()8,7,6,5,4,3,2,1=n 分别表示As,Cd,Cr,Cu,Hg,Ni,Pb,Zn 元素Fn 污染物重金属元素n 的浓度 Bn第n 种重金属元素的背景值上限P 综综合污染指数 n C重金属n 的实测值(ug/g ) max (/)n n C S 重金属污染物中污染指数最大值 (/)n n wg C S重金属污染物中污染指数平均值 n χ 重金属污染物n 的环境质量指数;n α 重金属污染物n 的实测值 n β 重金属污染物的评价标准. Ω 重金属元素通过的平面t 时间 h 海拔高度 V体积五、模型建立与求解针对问题一,首先想到的是用Matlab 软件编程,进行三维网格图、三维曲面图、等高线图和散点图的制作.5.1 问题(1)的分析、模型建立与求解: 5.1.1 问题(1)的分析对于问题一,首先来分析一下, 要给出8种主要重金属在该城区的空间分布, 就必须确定每个重金属元素与他们所对应的地区之间的联系.刚好题目给出了每个样本点的各元素浓度,那么 是不是可以将每种重金属元素含量浓度含量与该目标点所在的功能区建立联系?由此 想到利用Matlab 软件画出每种元素在该城区的三维曲面和空间曲面图.同时 在分析不同区域重金属的污染程度时,考虑到这个污染程度是否可以量化.并且是否能够建立一种模型将这种指标量化.这道问题还要求考虑每个功能区的污染程度, 知道每个功能区的每种重金属污染程度又是不一样的.那 通过什么指标来判断每个功能区的污染程度大小,这也是 为什么用权重作为评价每个功能区的污染程度的指标.5.1.2 问题(1)的模型建立该城区受这八种重金属元素As 、Cd 、Cr 、Cu 、Hg 、Ni 、Pb 、Zn 污染程度不一样.题目提供了每种重金属元素的背景值,那么 怎么样利用这些背景值和每种元素相关的浓度确定不同区域重金属的污染程度?所以 需要找出一种方法来准确的分析该城区内不同区域重金属的污染程度,并且最好能够量化.建立8种主要重金属元素在该城区的空间分布模型如下:引入了一种用于研究沉积物及其他物质中重金属污染程度的该区内不同地域重金属的污染程度的定量指标——地积累指数又称Muller 指数法,Muller 指数法表达式为:)]/([log 2Bn C Fn ⨯=ℜ式中Fn 表示污染物重金属元素n 的浓度;Bn 表示第n 种重金属元素的背景值上限,C 为考虑各地岩石差异可能会引起背景值的变动而取得一系列系数(一般取值为1.5),用来表征沉积特征、岩石地质及其他影响.Muller 地积累指数评价和分级标准分级标准具体详见表1表1:地积累指数分级标准地积累指数ℜ 分级污染程度105≤ℜ<6及严重污染 54≤ℜ< 5强-及严重污染 43≤ℜ< 4强污染 32≤ℜ< 3中等-强污染 21≤ℜ< 2中等污染 10≤ℜ< 1轻度-中等污染 0≤ℜ 0无污染 该方法指标主要是通过每种重金属元素测得的实际浓度以及他们的相关背景值,计算出每种元素的地积累指数.然后根据上面这张表 就可以判断出每种元素的污染级别,这样就可以对每种元素的污染情况进行分析.然后 再利用Matlab 软件对题目所给数据进行处理,画出相应的网格曲面图和等高线曲线图.这里需要对Matlab 进行编程,首先利用每个样本点的横坐标、纵坐标、海拔高度建立等高线图,程序语句见附录一.通过该图,可以直观的看到该城区各功能区的空间分布.但是这张图不能反映出8种主要元素在城区的污染情况, 需要借助于各种主要元素的浓度.所以 需要再建立一张等高曲线图以及相应的网格曲面图,将主要元素的浓度作为第三坐标,命令语句见附录一.5.1.3 问题(1)的求解过程首先通过Matlab 软件,调用每个样本点的位置相关数据.就是以海拔为第三坐标,并且对每个功能区进行颜色区分,画出该城区每个功能区的二维等高线图.最后把每个样本点显示在图上.得到如下这张图:图一:重金属As空间二维等高线分布图这张图只反映出了该城区各功能区的空间分布,还不能看出每种重金属污染的情况.将每种重金属元素的浓度在图上反应出来,做出该城区重金属污染的二维等高线图.具体程序语句见附录二,得到如下这张图:图二:重金属As分布平面图同时为了对应这张As含量分布平面图,也画出了三维网格曲面图(图三).图三:重金属As含量分布的空间三维图从空间三维图三中可以看到,有一处的波峰很高说明该处污染情况很严重,有二处处于波峰说明污染情况比较严重的主要有二处,还有一处面积比较广且所处高度稍微低一点这表明该处所受污染情况相对严重且污染的范围较广;同样分析二维等高线图二,图中有一处等高线之间的间距越来越密集且颜色很深表明该处受污染情况很严重,有二处等高线比较密集颜色相对较深表明这二处的污染情况相对严重,还有一处等高线间的距离较密集但是所包围的面积较广说明该处的污染也较严重且污染的面积很广.再结合前面的数据他们中心污染源的坐标分别为:(5291,5739),(12696,3024),(17814,10707).都是分布在工业区,还有一处污染级别不是特别严重,但是在该处存在着污染源,此处刚好是山林密集区.通过观察图三,会发现刚好有三个点处于波峰,还有个点波峰稍微偏低,但还是能很直观的看出来.再来看一下,Cd这种重金属的城区各功能区的二维等高线图,分布平面图,空间分布图(图四、图五):图四:重金属Cd空间二维等高线分布图图五:重金属Cd含量空间分布平面图以及相应的三维网格曲面图(图六):图六:重金属Cd含量空间分布图从空间分布图六中可以看到,污染情况比较严重且面积比较广的主要有一处,还有五处污染也相对严重.以及几处小的污染;同样从二维分布图五可以看出等高曲线所谓面积有一处颜色很深,说明该区域污染情况很严重,同时也观察到又五处等高曲线所围的面积颜色比较深,这说明了这五处区域污染情况相对严重,很明显的是有一处等高曲线所围成的面积比较广且颜色较深,表明了该区域有一处污染情况较严重且污染面积比较广,由此可见不管是从二维还是三维图形进行分析的结果是相吻合的.再结合前面的数据它金属Cd中心污染源的坐标为:(22304,10527).分布在主干道路区,还有一处污染级别不是特别严重.再观察图三,会发现刚好有三个点处于波峰.如此,通过同样的方法,都能够得到对其它六种种重金属在该城区的空间分布以及污染情况的了解(参见附录三)通过观察每种元素的三维曲面图以及等高曲线图.很容易观察到,每种重金属对该城区都存在或大或小的污染.其中有些地区是存在多种重金属污染,并且污染很严重,通过观察这8张图会发现这六种元素Cd,Cr,Cu,Hg,Ni,Pb 在横坐标在[3000,4000],纵坐标在[3000,6000]这个区域内含量都非常高,大致可以判定这段区域属于重度污染区.下面将题目中所给的数据用excel进行分类处理,得到样本点的地积累指数.然后运用数学统计法得到各种元素污染程度数据分布表,通过这些表就可以确定该城区内不同区域重金属的污染程度.统计该表时,是通过统计每个功能区的总样本点个数,然后通过地积累指数法分别计算出每种样本点的地积累指数,并判断他们的所在的污染级别.然后统计每种污染级别下,各功能区的污染点数占总点数的百分比也就是说的权重,通过该权重就能够分析出每种重金属元素的污染程度大小,以及污染所波及的范围.从而得到每种重金属元素污染最严重的地区.通过Excel对数据运算,得到重金属元素As 污染情况分布表:表二:As污染程度分布数据表下面通过同样的数据处理,得到Cd污染程度数据分布表:表三:Cd污染程度数据分布表其它六种元素的污染程度数据分布表见附录三.表中数值0的意义是在该污染级别下不存在观测的样本点.这是个大样本事件,可以认为该级别污染很轻微,甚至不存在这种级别的污染.而百分比越大,就说明在该污染级别下涉及的样本点比较多,污染波及范围较广.5.1.4问题(1)的结果分析5.1.4.1 As这种重金属污染情况分析由该表可以看出各个区域受As的污染程度,其中一类区即是生活区31.82%无污染,63.64%轻度—中度污染,4.55%为中等污染,无强污染和及严重污染的情况;二类区即是工业区38.89%不受重金属污染,52.78%受轻度—中度污染,5.56%受中等污染,2.78%受中等—强污染;三类区即是山区大多数不受污染,只有15.15%受轻度—中度污染,1.51%受中等污染;四类区即是主干路区47.83%不受污染,50.00%受轻度—中度污染,0.72%受中等污染,1.45%受中等—强污染;五类区即是公园绿地区大多数受轻度—中度污染,25.71%不受污染,2.86%受中等污染.再结合相应的几何图形,会发现在四区存在三个很明显的污染源,在污染源附近会看到,有很多二区的样本点.有个别一区的点,说明这种元素对一区的影响相对来说轻点.所以由分析可知工业区受污染最严重,污染面积达到了61.11%,其次是生活区、主干道路区,生活区污染面积都达到了50%以上,也就是说这三个区有至少一半的土壤受到该元素的不同程度的污染.其余功能区受污染程度就次之.5.1.4.2 Cd这种重金属污染情况分析由该表可以看出各个区域受Cd的污染程度,其中一类区即是生活区29.55%无污染,54.55%轻度—中度污染,13.64%为中等污染,无强污染和及严重污染的情况;二类区即是工业区16.77%不受重金属污染,44.44%受轻度—中度污染,30.56%受中等污染,8.33%受中等—强污染;三类区即是山区大多数不受污染,只有75.76%受轻度—中度污染,21.21%受中等污染;四类区即是主干路区23.91%不受污染,44.2%受轻度—中度污染,26.09%受中等污染,5.07%受中等—强污染;五类区即是公园绿地区大多数受轻度—中度污染,48.57%不受污染,31.43%受轻度-重度污染,11.43%受中等污染,8.57%受中等-强污染.再结合相应的几何图形,会发现在四区存在三个很明显的污染源,在污染源附近会看到,有很多二区的样本点.有个别一区的点,说明这种元素对一区的影响相对来说轻点.所以由分析可知工业区受污染最严重,污染面积达到了61.11%,其次是生活区、主干道路区,生活区污染面积都达到了50%以上,也就是说这三个区有至少一半的土壤受到该元素的不同程度的污染.其余功能区受污染程度就次之.5.1 这六种重金属Cr、Cu、Hg、Ni、Pb、Zn污染情况分析由于重金属含量越多,说明该地区的重金属污染程度越严重.Cr污染最严重的有一处,该中心污染源的坐标为:(3299,6018),所在地区为主干道路区,一定程度上波及到了生活区.一区和四区存在强-及严重污染,一区波及面积达到了52.27%,四区波及面积达到了41.3%,该元素污染最严重的就是生活区.Cu污染最严重的有一处,该中心污染源的坐标为:(2427,3971),所在地区为生活区,一定程度上波及到了工业区和主干道路区.一区和四区存在及严重污染,一区污染波及范围达到了84.09%,四区污染波及范围达到了84.06%,该元素污染最严重的就是生活区和主干道路区.Hg污染最严重的有一处,中心污染源的坐标为:(3299,6018),所在地区为主干道路区,一定程度上波及到了生活区.一区和四区存在及严重污染,一区污染波及范围达到了54.55%,四区污染波及范围达到了50.74%,该元素污染最严重的就是主干道路区.Ni污染最严重的有一处,中心污染源的坐标为:(3299,6018),所在地区为主干道路区,一定程度上波及到了生活区.一区、二区和四区存在及严重污染,一区污染波及范围达到了90.91%,二区污染波及范围达到了94.44%,四区污染波及范围达到了93.48%,该元素污染最严重的就是主干道路区和生活区.Pb污染最严重的有二处,中心污染源的坐标为:(2383,3692)、(5062,4339),所在地区为生活区和主干道路区,一定程度上波及到了工业区.一区和四区存在及严重污染,一区污染波及范围达到了52.73%,四区污染波及范围达到了80.87%,该元素污染最严重的就是主干道路区.Zn污染最严重的有一处,中心污染源的坐标为:(14065,10987),所在地区为主干道路区,一定程度上波及到了工业区.四区存在及严重污染,四区污染波及范围达到了67.39%,该元素污染最严重的就是主干道路区.所以,该城区不同区域重金属污染最严重的区域是主干道路区和工业区,其次是生活区、公园绿地区、山区.5.2 问题(2)的求解:5.2.1问题(2)的分析通过问题一的分析,可粗劣的判断哪几种元素污染比较大,哪个功能区污染比较严重,但是怎么样才能具体到哪个功能区污染最严重,被污染的功能区的土壤哪种重金属污染最严重?所以,针对问题二给出的数据分析,不能简单的进行数据处理.为了使得所寻找出来的原因更有说服力,用两种方法分别进行说明和验证,还要进行综合指标评价.最后确定了最严重的污染地区以及污染最严重的相关元素,根据地区的差异性和元素的特殊性,才能说明重金属污染的主要原因.5.2.2数据的统计分析首先通过数据的处理,建立每个功能区各重金属元素的污染程度样本所占的百分比表.一功能区的相关百分比数据如下:表四:一功能区各重金属污染程度所占百分比在此功能区从总体来看,重金属污染程度处于中等-强污染,其中主要污染来自重金属元素Ni,另外在该区域有少数地方Cu污染及严重.表五: 二功能区各重金属污染程度所占百分比在该功能区重金属Hg 和重金属Ni 的污染极为严重,尤其是在该区域的某些地方.由此可见,在此功能区照成重金属污染的罪魁祸首为重金属元素Hg 和重金属元素Ni . 通过这两张表, 会发现有些地区之所以污染严重,主要是因为个别元素污染所导致的.所以 要分析重金属污染的原因,就得分析该重金属在该功能区为什么会产生污染.其它三个功能区各重金属污染程度百分比见附录三.通过该附录表 可以看到在该功能区里,重金属污染程度较轻,污染等级集中在轻度污染及以下. 再观察功能区四,重金属污染十分严重,大多数重金属污染元素都集中在在各个功能区,但是在这个功能区,Pb 污染级别比较轻,没有中度甚至以上级别的污染. 再看功能区五,从总体上分析,该地区重金属污染中等、强污染几乎没有,正因如此造成重金属污染的少数种类重金属元素就凸显出来了——Ni 元素和Hg 元素.纵观整体,分析所有的功能区, 很容易发现造成重金属污染的主要重金属元素,他们就是Ni 元素和Hg 元素.知道前面的数据分析理由不充分,只是一个粗劣的判断.为了综合前面处理的数据,准确找出各个功能区污染的主要元素. 需要利用单因子指数法和内梅罗综合污染指数法进行综合评价.5.2.3 单因子指数法和内梅罗综合污染指数法的建立与求解单因子指数法是目前国内土壤重金属的单项污染指数评价方法之一,其计算公式为:n n n βαχ=,式中n χ为重金属污染物n 的环境质量指数;n α为重金属污染物i 的实测值;n β为重金属污染物的评价标准.n χ﹥1表示污染;n χ=1或n χ﹤1表示无污染;且n χ值越大,则污染物越严重.为了更全面的反应各重金属对土壤的不同作用.突出高浓度重金属对环境质量的影响, 采用内梅罗综合污染指数法.其计算公式为:2)/(/22max n wgn n n S C S C P +=)(综,式中max )(n n βα表示重金属污染物种污染指数nn βα的最大值;(/)n n wg C S 表示重金属污染物中污染指数的平均值.土壤污染水平分级标准采用国家土壤环境二级标准.土壤污染综合污染指数分级标准为综合污染指数>3为重污染,2~3为中污染,1~2为轻污染,0.7~1为警戒级,≤ 0.7为安全级.下面为了找到每种元素在该城区的综合污染指数,借助于Matlab 循环计算.编写如下系列命令见附录七.运行程序结果为As 综合污染指数:p=4.0093,分别运行另外几种程序,得到每种重金属元素的综合评价指标,简单结果如下表:。
2011年“第四届全国中学理科实验教学与小学科学教研优秀论文”评选结果
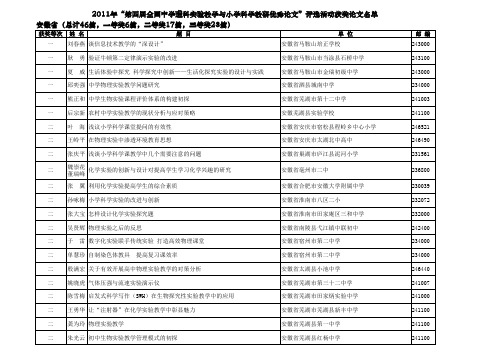
李玺贤 因地制宜扬优势 因势利导促教学—农村小学科学课教学实践与认识 田 滨 景永海 测电源电动势和内阻的误差分析及改进 李永祥 化学教学中学生能力的培养 王志兰 康占军 被子植物导管的比较
二 三 三 三 三 三 三 三 三 三 三 三 三 三 三 三 三 三 三 三 三
贺过长 谈“图导、口诀”教学对中学生物课堂教学的有效性 李 马 琼
241100 236800 238100 230061 246100 236500 236500 236500 243221 231500 242400 231300 246521 246500
三 三 三 三 三 三 三 三 三
安徽省宿州市第二中学 安徽省宿州市第二中学 安徽省宿州市泗县黑塔镇朱钱小学 安徽省太湖县弥陀镇河口中学 安徽省桐城市吕亭镇板桥小学 安徽省铜陵市三中 安徽省芜湖县二中 安徽省芜湖县红杨中学 安徽省芜湖县红杨中学
孙咏梅 小学科学实验的改进与创新 张大宝 怎样设计化学实验探究题 吴贤辉 物理实验之后的反思 于 雷 数字化实验联手传统实验 打造高效物理课堂
单慧珍 自制染色体教具 提高复习课效率 殷满宏 关于有效开展高中物理实验教学的对策分析 姚晓虎 气体压强与流速实验演示仪 陈雪梅 启发式科学写作(SWH)在生物探究性实验教学中的应用 王勇华 让“注射器”在化学实验教学中彰显魅力 龚为玲 物理实验教学 朱光云 初中生物实验教学管理模式的初探
二 三 三 三 三 三 三 三 三 三 三 三 三 三
舒守军 也谈实验资源的开发 孙同林 小学科学课教学中学生创新能力的培养 汤玉宏 关于人教版九年级化学教材中实验的几点思考 俞建生 提高学生实验有效性的实践研究 敬小容 刘成立 引领学生主动参与 提高科学教学效果 张登堃 新教材与化学实验教学功能的开发 聂祥峰 高中生物学实验教学初探 冯云光 在新课程改革下如何进行高中物理实验探究式教学 周玉红 摭谈中学化学实验室的管理 王红霞 有关实验室的建设和管理模式的探讨 张友庆 初中物理实验改进和自制教具的几点探索 赵业根 加强实验教学 培养实验能力 提高物理教学质量 朱菊凤 浅谈科学课的教学 陈 荣 科学课更要培养学生的动手能力 唐玉萍 马新亚 朱同发 数字化实验在高中物理实验中的妙用例谈 马增学 周 莉 浅析科学探究题
2011年电赛陕西赛区上报国家参赛队设计报告论文1

2011年电赛陕西赛区上报国家参赛队设计报告论文模板(1)光伏并网发电模拟装置学校:********作者:*** *** ***指导教师:***中文摘要:本制作采用模拟锁频-锁相技术~实现了对基准正弦信号相位的精确跟踪,利用PWM调制技术的D类功放~实现了DC-AC的高效变换,输出级功率VMOSFET管采用H桥结构~实现了输出正弦电压的无缝交接和功率拓展,采用负反馈电压调整技术~实现了U = U/2的精确跟踪~采用AD+CPU的方法实现了过流过压保护点的精确设定。
实测dS结果表明~该装置实现了题目要求的全部功能~多项指标优于题目要求。
英文摘要:***************关键词:DC-AC;PWM;D类功放,负反馈调整,锁频-锁相一、方案论证1(DC-AC变换与功率放大方案有三种方案可供选择。
一是直接线性功率放大方案:将基准电压直接进行线性功率放大,实现DC-AC变换。
此方法虽简单,若选放大器为A、B、C类则效率都不高。
二是斩波方案:利用开关管将直流电压斩波为与基准正弦信号周期相同的方波,再通过低通滤波器滤出基频。
优点是方案简单,效率高,缺点是滤波电路复杂,输出波形失真太大。
三是PWM调制的D类功率放大方案:此方案效率高,失真小。
经比较,采用方案三。
DC-AC变换器采用PWM调制的D类功率放大器,其除了具有极高的效率,还具有良好的线性。
为了满足输出电压幅度(或输出功率)的要求,输出开关功率管必须接成H桥的形式。
2(频率-相位跟踪方案方案一:数字锁频—锁相方案,此方案采用数字锁相环,同时对频率和相位进行跟踪。
先将基准信号和输入电压采样信号分别变换为矩形脉冲,送数字锁相环进行处理,然后再变换成正弦电压信号,将其作为控制电路的新基准。
该方案最大优点是硬件结构简单,实现灵活方便。
方案二:模拟锁频-锁相方案,此方案采用模拟方法进行频率和相位的跟踪。
一般的模拟锁相环,锁相后往往存在固定相差,本方案采用矢量旋转合成技术,即将U和U通过reffo鉴相、相位误差比较放大后,去压控与U互成?90的矢量的幅度,最后再与U 矢量进行refref叠加,形成旋转合成矢量,作为逆变器的输入电压,最终实现U 和U几乎零相差的相位跟fr踪。
2011年全国大学生数学建模竞赛B题一等奖论文

我们参赛选择的题号是(从 A/B/C/D 中选择一项填写) : 我们的参赛报名号为(如果赛区设置报名号的话) : 所属学校(请填写完整的全名) : 参赛队员 (打印并签名) :1. 赵东辉 2. 张晓凤 3. 汪立 指导教师或指导教师组负责人 (打印并签名) : 林军 日期: 日 西
交巡警服务平台的设置与调度
摘要:在我国经济社会快速发展进程中, 警察的工作任务日益繁重。由于警 务资源是有限的,如何根据城市的实际情况与需求合理地设置交巡警服务平台、 分配各平台的管辖范围、调度警务资源是警务部门面临的一个实际课题。 问题一: (1)题目要求在城区 A 的 20 个巡警服务台位置确定的情况下,按照尽量 3min 到达案发地的原则为各服务平台分配管辖范围。对于此问题本文建立最大 集合覆盖模型,并利用数学软件 MATLAB 进行分配求解,最后得到 A 区现有每个 巡警服务台的管辖范围如表 1。 (2)我们对于 13 条交通要道实现快速全封锁的问题,以所用时间最小为目 标,引入 0-1 变量,建立该问题的 0-1 规划模型,并借助数学软件 LINGO 进行求 解,求解结果见表 4。 (3)由问题(1)的分配结果可知,在现有巡警服务台的设置下:①还有 6 个路口在案发时巡警不能在 3min 之内到达, 即必然导致某些地方出警时间过长; ②我们根据每个巡警服务台的工作量的方差定义了工作量不均衡度,结果显示: 此时服务台的工作量不均衡度为 8.4314。 为了解决上述出警时间过长与工作量不均衡的问题。我们建立集合覆盖的 0-1 规划模型,求解结果表明:在增加 4 个平台的情况下,可以解决出警时间过 长的问题。 在此基础上我们又解决了工作量不均衡的问题,在增加 4 个巡警服务 台的情况下, 使平台的工作量的不均衡度降为 3.0742。 增加的 4 个巡警服务台的 路口标号见表 8。 问题二: (1) 本文定义了两个评价原则, 原则一: 巡警能在 3min 之内到达案发路口; 原则二: 巡警服务台的工作量均衡度尽量小。 根据以上两个原则对该市现有巡警 服务台的设置方案的合理性进行评价, 评价结果显示, 有下述两种不合理的情况: ①有 138 个路口,在案发时巡警不能在 3min 之内到达;②此时的不均衡度已达 40.3。基于上述两点,现有的巡警服务台设置极其不合理。 针对现有巡警服务台设置不合理的情况下, 本文提出三种方案对设置进行优 化调整。方案一:保持现有巡警服务台的个数和位置,再在其他路口增设巡警服 务台;方案二:保持现有巡警服务台的个数,但对其位置进行调整;方案三:不 考虑现有巡警服务台的设置情况,重新确定全城的最佳巡警服务台数目与位置。 (2)本问题实质是单目标规划问题,以巡警围堵时间最短为目标,以成功围 堵为条件。对于巡警的成功围堵,可以转化为二部图的完全匹配,利用匈牙利算 法,求得最佳围堵方案。
2011年国赛优秀论文

3
五、模型的建立与求解
5.1 问题 1 的模型建立与求解
该问题要求在交巡警平台管辖范围内发生突发事件时,能尽量使交巡警能在 3 分
钟内到达,而题目给出警车的时速为 60km/h,则可得警车在 3 分钟内的行车路程为:
L3 = V *T =3km
(1)
由于这一问题中主要是为了处理突发事件而给 A 区中的 20 个交巡警服务平台分配
二、问题分析
本题为交巡警服务平台优化问题,需要结合警务资源有限的客观因素以及城市道 路、案发率等具体情况,合理分配平台管辖范围、调度警力资源、判断平台设置合理 性以及规划平台分布。
问题 1:为了满足在突发事件发生时,警车尽量在 3 分钟以内到达的具体要求,本 文制定了平台管辖范围的分配原则:(1) 突发事件发生时,警车到达事发地的行车路程 尽量在 3km 以内;(2) 对于某些同属于多平台管辖范围内的路段和节点和某些不属于 任何平台管辖范围内的路段和节点,采取路程最短原则进行分配;(3) 使用城市道路作 为管辖范围的界线,便于标识和指挥调度;(4) 对于相邻的两个交巡警服务平台,尽量 使其管辖范围界线上的点距这两个交巡警服务平台的距离相等。依据原则首先运用弗 洛伊德算法确定离平台 Ai 路程在三千米以内的节点集 SA′ i ,同属于多个节点集 SA′ i 的节 点依据就近原则确定其所属平台,两平台之间的距其都超过三千米的道路部分按平均 分配原则进行分配。由此可得到 A 区平台管辖范围。
我们参赛选择的题号是(从A/B/C/D中选择一项填写): B
我们的参赛报名号为(如果赛区设置报名号的话):
所属学校(请填写完整的全名):
西南大学
参赛队员 (打印并签名) :1.
汪娅
2.
李玲
天然肠衣搭配问题 2011年全国大学生数学建模竞赛 A题 优秀论文设计
天然肠衣搭配问题摘要本文针对天然肠衣原料的搭配方案进展设计,充分考虑最优化原如此,在满足搭配方案具体要求同时兼顾效率的情况下,设计线性规划模型,并借助软件Lingo求解出最理想的捆数与搭配方案。
对于题目给出的五个具体要求,我们经过分析之后将其划分优先级,逐层递进地找出答案。
首先我们将条件〔1〕设为最优先条件即对于给定的一批原料,装出的成品捆数越多越好。
在此根底上,条件〔2〕的优先级次之。
对于条件〔3〕和〔4〕,我们经过讨论后认为其意在于放宽较为苛刻的长度与每捆根数要求以符合实际生产。
因而理想情况应是所有捆的根数与长度都恰好满足规格。
当由于给定数据原因使得理想情况不能实现时,再考虑放宽剩余原料的组装长度与根数要求,条件〔3〕与〔4〕的优先级最次。
在建模过程中,我们先对各规格在不考虑〔3〕与〔4〕的情况下进展线性规划,求每种每捆可行搭配方案所能组装出的最大捆数,再将其加和得出各规格的最大捆数。
这种方法在数据量较大的情况下兼顾了准确度与效率。
对上述不能组合的剩余材料我们如此放宽条件。
因条件〔2〕要求最短长度最长的成品数量尽可能多,再结合条件〔4〕中原料可以降级使用的规如此,故我们采用先从规格三的剩余原料考虑,再依次降级并入次级的原料使用考虑搭配。
由于剩余材料数量较少,故可以不必考虑效率问题。
最后满足条件〔5〕将结果求解。
利用上述模型和Lingo软件最后求解出了最大捆数183。
并可以根据原料数量求出具体的搭配方案。
关键词:搭配方案线性规划 Lingo1.问题重述天然肠衣〔以下简称肠衣〕制作加工是我国的一个传统产业,出口量占世界首位。
肠衣经过清洗整理后被分割成长度不等的小段〔原料〕,进入组装工序。
传统的生产方式依靠人工,边丈量原料长度边心算,将原材料按指定根数和总长度组装出成品〔捆〕。
为了提高生产效率,公司计划改变组装工艺,先丈量所有原料,建立一个原料表。
原料按长度分档,通常以为一档,如:3按3米计算,按计算,其余的依此类推。
2011年全国数学建模竞赛论文省一等奖(安徽赛区)

关于企业退休职工养老金收支平衡的研究孙善朋朱敬男潘小强一、摘要中国养老保险制度经历了20多年的发展历程,已经初步取得成效,随着社会的不断改革和发展,养老保险制度出现了一些值得深入研究的问题。
通过理论和实证研究这些问题,寻求其根源和解决方法,对改革和完善养老保险制度具有重要意义。
本文问题一以附件1“2009山东省职工历年平均工资数据”为依据,采用增长阻滞模型,用非线性最小二乘法进行拟合,预测出了从2011年至2035年山东省职工的年平均工资(单位:元):40060,45510,51640,58520,66230,74830,84390,95000,106710,119570,133640,148940,165470,183230,202170,222230,243310,265270,287960,311210,334800,358530,382180,405530,428380。
问题二根据附件2“2009年山东省某企业各年龄段工资分布表”,结合问题一中所预测的结果,用Matlab、Excel等软件计算了2009年该企业各年龄段职工工资与该企业平均工资之比分别为:0.669244,0.804936,0.982526,1.066681,1.172819,1.266639,1.208533,1.155055。
多种情况下的养老金替代率分别为:30.77%,33.81%,35.25%,19.34%,26.08%,32.97%。
问题三以该企业某职工为例,以问题一中得出的山东省职工历年平均工资平均增长率为依据,采用非线性拟合,计算和预测了该职工自30岁至65岁的历年工资情况,并给出了多种情况下的养老保险基金的缺口情况,求出了当养老保险基金与其领取的养老金之间达到收支平衡时该职工的年龄。
求得养老保险基金的缺口情况如下:30岁交纳养老保险,55岁退休时,缺口为国亏685790元;30岁交纳养老保险,60岁退休时,缺口为国亏831840元;30岁交纳养老保险,65岁退休时,缺口为国亏511950元。
A-20001001-张三,李四,王五(数学建模竞赛论文写作模板)

承诺书我们仔细阅读了中国大学生数学建模竞赛的竞赛规则.我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。
我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。
我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。
如有违反竞赛规则的行为,我们将受到严肃处理。
我们参赛选择的题号是(从A/B/C/D中选择一项填写): A我们的参赛报名号为(如果赛区设置报名号的话):所属学校(请填写完整的全名):参赛队员(打印并签名) :1.2.3.指导教师或指导教师组负责人(打印并签名):日期:年月日赛区评阅编号(由赛区组委会评阅前进行编号):编号专用页赛区评阅编号(由赛区组委会评阅前进行编号):全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号):城市表层土壤重金属污染分析摘 要上海世博会对上海的经济、文化、政治、科技等领域产生了巨大的影响。
其中,交通运输业受其影响显著,因此,合理评估世博会对上海交通的影响力具有重要的意义。
为了定量评估上海世博会对交通的影响,首先从整体上分析,建立了交通运输业生产总值回归评价模型;然后针对运行可靠度和畅通可靠度两个具体指标,分别建立了运行可靠度指数评价模型和畅通可靠度加权评价模型。
具体模型说明如下:模型一:为了定量评估世博会对交通运输业生产总值的影响,我们运用逐步回归方法建立了动态的交通运输业生产总值评价模型:Y = 4005.865+0.3902-t d -3.8652-t c依据该模型可计算出交通运输业生产总值Y 的变化趋势,计算结果表明世博会在很大程度上拉动了上海交通运输业的发展。
模型二:为了定量评估世博会对运行可靠度的影响,我们建立了运行可靠度指数评估模型:βα)()(22111N nN n A ⨯= 引用等待时间作为衡量权重的指标,结合互联网数据,可得出世博会的举行使得上海市运行可靠度提高了2%。
2011年全国大学生统计建模大赛获奖论文

不良产品返回数预测统计模型华南师范大学莫祺、张先灯、杨鑫目录摘要 (1)一、引言 (2)二、数据来源及介绍 (2)三、数据分析 (3)四、模型一:联合多项分布概率模型 (4)五、模型二:基于联合多项分布的logistic概率模型 (9)六、模型改进和解释 (14)七、两个模型的讨论与分析 (17)八、模型的不足与改进 (18)参考文献 (19)附件 (20)摘要随着质量监管部门监管力度的加大和消费者维权意识的增强,生产商必须更好地履行质量三包的协议.然而产品的失效有一定的随机性,而生产商又想知道该安排多少维修工人参与售后服务,因此就有必要预测每一批生产产品的不良返回数(失效产品的数目).本文根据恩斯迈电子(深圳)有限公司数据部提供的产品的一些月份的生产数据和相应的月份在一些月线的不良产品返回情况,提出了联合多项分布概率模型和基于联合多项分布的logistic概率模型两个模型,利用excel和sas求出一段时间内的失效率,进而预测不良返回数.通过实例数据和模型计算结果发现,模型一较差,通过加入生产总数和月份等协变量结合logistic 回归得到模型二,预测结果有了很大的改进.另外,我们模型中的区间估计的区间长度相对来说较短,验证的真实值落入的百分率不高,但只要做一点调整就可达到超过80%的准确率.也许是我们模型的拟合度不是特别高,也许是数据方面的问题,有几个月线的不良返回数的偏差较大,我们认为结合产品的专业知识来寻找一些显著的协变量可能对模型会有更大的改进.关键词:失效不良返回数多项分布logistic 协变量区间估计一、引言随着人们法律意识的增强,消费者的维权意识也越来越强.每年的3.15消费者权益保护日报道出来的消费者投诉的事件也越来越多,消费者对产品的质量也越来越重视,国家也在逐渐完善质量监管体系.但是从概率的角度来说,谁也不能保证某件产品的寿命.并且产品质检的时候不可能每个产品都来检测,一来耗费人力物力,二来对有些产品是有毁坏性的.为了保证消费者的权益,商家就必须对自己的产品承诺质量三包,尤其是电子产品,并且商家的售后服务对于商家的声誉和销售都很重要[1].每个厂家几乎都有售后服务部,而售后服务需要投入多少维修人员合适也是一个值得考虑的问题,换句话说就是要知道有多少产品有质量问题,需要返厂.所以从生产商的角度来说,预测一批产品有多少不良产品需要返厂维修就显得尤为重要了[2].二、数据来源及介绍我们的数据来源于恩斯迈电子(深圳)有限公司数据部.恩斯迈电子(深圳)有限公司为台湾股票上市公司微星科技股份有限公司(计算机主板、显卡、伺服器全球前五大生产企业)投资于大陆的全资子公司,主要经营电子产品.而电子产品的保修期一般都是三年,因此有必要对一批产品出厂后三年内的不良产品的返厂数进行统计和估计.考虑现实情况和经验,他们对一批产品的返厂数目一般分了六个特殊时间段进行统计,分别记为一月线不良返回数,三月线不良返回数,六月线不良返回数,十二月线不良返回数,二十四月线不良返回数,三十六月线不良返回数.而其实一月线的返回数是指这批产品出厂后的三个月内的不良返回数,三月线是指这批产品出厂后的五个月内的不良返回数,六月线不良返回数指的是八个月内的返回数,同理十二月线、二十四月线、三十六月线都要往后推迟两个月,这样的话就基本上可以统计保修期内返回数,反过来又可以判断这批产品的质量情况.他们把2007年一月至2010年十一月的部分返回数据统计出来了.由于最初拿到数据在2011年二月统计完的,所以2010年十月和十一月我们只能统计这两批产品的一月线的返回数,2010年六、七、八月可以得到一月线和三月线的返回数,2010年一月至六月可以得到一月线、三月线和六月线的返回数,2009年一月至十二月可以得到一、三、六、十二月线的返回数,2008整年只是不能得到三十六月线的不良返回数,而2007年就可以得到各个月线的返回数据.而作为生产商来说,就想知道08年各月的三十六月线的返回情况,09年的二十四月线及以后的返回情况,10年的一月至六月的十二月线及以后的返回情况,等等.后来,我们还得到该公司MB、VGA、DT-BB、EPS四种电子产品的各月三十六个月线的不良数的返回情况,这对我们的预测提供了很大的帮助.三、数据分析这里的数据预测其实就是要求预测每个月相应的各个月线的不良数的返回情况,可以看做一个纵向数据的类型,每个月的各月线数据组合在一起就变成了一个联合纵向数据类型.尽管纵向数据已经有很多研究方法,尤其在心理学的研究中占据着重要的地位,比如时间序列的方法,混合效应模型,潜变量增长模型,多层线性模型等等[3].对于时间序列来说,需要的时间数据多些效果才会比较好,一般来说至少需要50个,而我们这里只提供6个时间点的数据,显然不合适.后面几种方法都是基于回归的思想发展起来的方法,本文根据数据的特点,将联合多项分布与logistic 回归结合起来,来预测产品在每个时间区间的失效率,进表1中一类月的数据类型就和07年的各月的数据类型一样的,知道各个月线的不良返回数情况,二类月与08年各月的数据类型一样的,仅仅不知道三十六月线的返回情况,同理知,三类月与09月的一样,四类月与10年一月至六月一样,五类月与10年七、八、九月一样,六类月与10年十月和十一月一样.表中生产数表示这个月生产产品的数目,各个月线的返回数与数据来源中的介绍是一样的.表中i n 表示第i 类月生产的产品数,ij n 表示第i 类月生产的产品数在j 月线的不良产品返回数(,1,2,,6)i j ,而作为厂家来说,就希望将这个表中那些空白的部分预测出来.四、模型一:联合多项分布概率模型1、建立模型和模型求解假设所有产品的生产工艺和技术都是一样的,对于一个产品是否失效可以看作一个随机事件,根据题中数据的分布情况,我们可以假设每件产品在出厂后三个月内月损坏的概率为1p ,第四个月到和五个月之间损坏的概率为2p ,第六个月至第八个月损坏的概率为3p ,第九个月至第十四个月之间损坏的概率为4p ,第十五个月至第二十六个月之间损坏的概率为5p ,第二十七个月至第三十八个月之间损坏的概率为6p .那么对于一类月的数据的分布情况,每件产品在一月线时间内损坏的概率为1p ,第四个月到和五个月之间损坏的概率为2p (一月线内没有损坏,三月线内损坏的概率为2p ),第六个月至第八个月损坏的概率为3p (三月线内没有损坏,六月线内损坏的概率为3p ),第九个月至第十四个月之间损坏的概率为4p (六月线内没有损坏,十二月线内损坏的概率为4p ),第十五个月至第二十六个月之间损坏的概率为5p (十二月线内没有损坏,二十四月线内损坏的概率为5p ),第二十七个月至第三十八个月之间损坏的概率为6p (二十四月线内没有损坏,三十六月线内损坏的概率为6p ),三十六月线以内不坏的概率为1234561p p p p p p ------.同理我们也可知道二类月、三类月、四类月、五类月、其中11i i x n =,,1(2)ij ij i j x n n j -=-≥,这样做之后相当于将原始数据中的累积不良返回数换成了各个时间段增加的不良返回数.这样的话,我们可以把一类月的生产数与各月线增加的返回的情况看做一个总数为1n 七项分布,并且一类月的数据的似然函数131516111121314151611121411123456123456X (1)x x x n x x x x x x x x x L C p p p p p p p p p p p p ------=------1()其中111112131415161111213141516!!!!!!!()!n C x x x x x x n x x x x x x =------111213141516X (,,,,,)x x x x x x =1同理我们知道二类月的数据可以看做一个六项分布,相应的似然函数为2325221222324252122242221234512345X (1)x x n x x x x x x x x L C p p p p p p p p p p -----=-----()而 22212223242522122232425!!!!!!()!n C x x x x x n x x x x x =-----2122232425X (,,,,)x x x x x =2类似地一直到六类月,分别是五项分布,四项分布,三项分布,二项分布,我们也可以得到相应的似然函数3456,,,L L L L [4].利用上表中所有数据建立的似然函数为65432123451111116111121314151622122232425331323334123456123456123456123451234(,,,,,)(1)(1)(1)(1i i i i i i i i i i x x x x x x n x x x x x x n x x x x x n x x x x L X X X X X X Cp p p p p p p p p p p p p p p p p p p p p =====---------------∑∑∑∑∑=----------------441424355152661123121)(1)(1)n x x x n x x n x p p p p p p -----------这里面有123456,,,,,p p p p p p 六个参数,对上述似然函数取对数,然后分别对123456,,,,,p p p p p p 求偏导可以得到的123456,,,,,p p p p p p 的极大似然估计的递推关系式(1)(2)(3)(4)(5)(6)1121314151611121314151611123456123456x x x x x x n p n p n p n p n p n p p n n n n n n n n n n n n ∧++++++++++==++++++++++122232425221111221331441551(1)(2)(3)(4)(5)12223242521(1)(2)(3)(4)(5)1121314151(1)()()()()()(1)11111x x x x x p p n x n x n x n x n x n p n p n p n p n p p n p n p n p n p n p ∧∧∧++++=--+-+-+-+-++++=--+-+-+-+-()()()()()1323334331211112221223313244142(1)(2)(3)(4)1323334312(1)(1)(2)(2)(3)(3)(4)(4)112212312412(1)()()()()(1)1111x x x x p p p n x x n x x n x x n x x n p n p n p n p p p n p p n p p n p p n p p ∧∧∧∧∧+++=----+--+--+--+++=---+-+-+-(-)(-)(-)(-)1424344123111121322122233313233(1)(2)(3)142434123(1)(1)(1)(2)(2)(2)(3)(3)(3)112321233123(1)()()()(1)111x x x p p p p n x x x n x x x n x x x n p n p n p p p p n p p p n p p p n p p p ∧∧∧∧∧∧∧++=------+---+---++=----+-+-(--)(--)(--)152551234111121314221222324(1)(2)15251234(1)(1)(1)(1)(2)(2)(2)(2)1123421234(1)()()(1)11x x p p p p p n x x x x n x x x x n p n p p p p p n p p p p n p p p p ∧∧∧∧∧∧∧∧∧+=--------+----+=-----+-(---)(---)1661234511112131415(1)()1612345(1)(1)(1)(1)(1)112345(1)()(1)1ij i j ix p p p p p p n x x x x x x n p p p p p p p n p p p p p n ∧∧∧∧∧∧∧∧∧∧∧=----------=-----=-其中(----)()i j p 为单独用第i 类月的数据对j p 的似然估计.当(1,2,,6)i n i =很大的时候,并且(1,2,,6)j p j =很小的时候,123456,,,,,p p p p p p 的估计值可以近似简化为(1)(2)(3)(4)(5)122232425211212345,n p n p n p n p n p p p p n n n n n ∧∧∧''++++==++++(1)(2)(3)(4)(1)(2)(3)13233343142434341234123,n p n p n p n p n p n p n p p p n n n n n n n ∧∧''+++++==+++++(1)(2)(1)(1)152516566121,n p n p n p p p p n n n ∧∧''+===+ 此时j p 的估计j p ∧'可以看做是各个月估计()i jp 的加权平均值,相比较前面递推关系式,可以简便很多计算,而且估计也不会差很远.并且由于i n 一般都很大,j p 比较小,由多项分布的性质知,(,)(,1,2,,6)m n r p p m n m n ∧∧=≠且几乎趋于0,也就是说m p ∧与n p ∧可以看做是不相关的,也即是相互独立的.一旦把123456,,,,,p p p p p p 估计出来,我们就可估计表中空着的数据ij i j x n p ∧∧=, 比如二类月的三十六月线增加的返回数2626x n p ∧∧=,因此二月的三十六月线的返回数的估计就为2526x x ∧+.2、区间估计我们知道点估计对样本的依赖性很大,而且有很大的误差,并且没办法衡量偏差程度.区间估计则可以按一定的可靠性对待估参数给出一个区间范围,因此我们有必要估出不良返回数的置信区间.多项分布的边际分布是二项分布,所以(),()(1)ij i j ij i j j E x n p D x n p p ==- 当i n 和ij x 的个数比较多时,我们可以近似认为(1)ij i j i j j x n p n p p -~N(,,同理我们也知道(1~)j j j j ip p p p n ∧-)N(,,因此(1))i j i j i j j n p n p n p p ∧-~N(,,所以对于概率()()()()22ij i j ij j j i j ij j j i j c cP x n p c P x np np n p c P x np P np n p ∧∧∧->=-+->≤->+->000()0.005()0.00522ij j j i j c cc P x np P np n p ∧->=->=如果我们找到某个使得,所以0()0.01ij j P x n p c ∧->≤,因此ij x 的99%置信区间为00i j i j n p c n p c ∧∧⎛⎫-+ ⎪⎝⎭,查表知0c =,但是为了方便我们就取0c =到置信度更高的区间.例如26x 的置信度为99%的置信区间为:2626n p n p ∧∧⎛-+ ⎝ 因此二类月中三十六月线不良返回数的99%置信区间为25262526x n p x n p ∧∧⎛+-++ ⎝3、模型结果模型一中我们并没有假定123456,,,,,p p p p p p 分布情况,对123456,,,,,p p p p p p 的估计完全依赖于样本,借助于47个月的部分数据情况建立的似然函数1247(,,...)L X X X 取对数,再123456,,,,,p p p p p p 分别求偏导数,借助于excel 里面的菜单操作计算功能可以得到估计值1230.002846,0.003875,0.005573p p p ∧∧∧===,40.009478p ∧=,560.01655,0.008133p p ∧∧==.而后来我们得到了三个月之后的一些不良返回数据,其实就是2010年十月和十一月的三月线,2010年七月至九月的六月线,2010年一月至三月的十二月线,2009年一月至三月的二十四月线,2008年一月至三月的三十六月线,我们刚好用这些数据来验证的我们的模型,得到如表3注:表中的置信区间是99%置信区间,偏差=估计值—真实值.有阴影月份的月线表示真实值落在我们预测的置信区间内.从表3的验证结果可以看出,我们的预测效果并不怎么好,14个月份的月线预测结果只有5次落在置信区间内,准确率不到40%,并且不在置信区间内的月份的偏差大多数都比较大,结果比较糟糕.但是我们观察原始数据中的累积不良率AFR (()t AFR t 时刻累积的不良数生产总数)发现,各个月在同一个时间点的AFR差异还是很大的,譬如一月线的AFR,07年2月的一月线AFR 才0.12%,而08年5月的一月线AFR 却为0.53%,可见AFR 在一月线这个时间点的时间点的跨度是很大的,再看三月线的AFR ,最小的才0.35%,最大的达到1.1%,后面的月线也出现类似的结果,而我们的模型中在产品的失效率只与时间段或点有关,其实也就是只与月线有关,只要是同一月线我们认为失效率都是一样的.而样本数据告诉我们,同一月线在不同的月份的失效率差异很大,所以我们的模型单用纵向时间来来估计失效率是不好的,因此我们还要寻找其他的因素来估计在某个时间段的失效率,因而我们就提出了模型二.五、模型二:基于联合多项分布的logistic 概率模型1、模型建立由模型一知,我们数据中失效率不仅仅与纵向时间有关.虽然从可靠性理论来说[5],一件产品的失效主要是与使用时间有关,但是也不能排除某些协变量会对我们的失效率有影响.由于在某一个月份时对123456,,,,,p p p p p p 的估计我们是用对应的不良返回数除以该月的生产总数,所以我们就有必要考虑生产总数对123456,,,,,p p p p p p 的影响,所以就把生产总数当作协变量进我们的模型中.由于123456,,,,,p p p p p p 的范围都在0~1,而生产总数的值与他们之间的相差很大,因此我们考虑logistic 模型,对123456,,,,,p p p p p p 作logistic 变换,从而可以使得它们的范围变成负无穷到正无穷[6].对于我们要研究的数据,有K=47个月的生产的产品要来估计不良返回数. 假定每个月的观察的时间010(6)m t t t m =<<⋅⋅⋅<=.由给定的六个月线的时间关系知,1234563,5,8,14,26,38,t t t t t t ======各个月累积的不良返回数和新增的不良数可以表示为{(,):1,,6;1,,47}kj kj d x j k ==,其中1k =表示07年一月,2k =表示07年二月,以次类推,47k =表示10年十一月,kj d 表示第k 月在j t 时刻累积的不良返回数,kj x 表示第k 月生产的产品在时间段1(,)i j j t t I -=期间即将失效的产品个数,用kj p 表示失效率,可以解释为第k 月生产的一件产品在时间段j I 的失效率,同时我们用k n 表示第k 月生产的产品总数,那么第k 月在j t 时刻还没有失效的产品总数可以表示为kj k kj r n d =-,根据模型一中我们对数据的纵向分析易知,在时间段j I 期间第k月中将要失效的产品服从二项分布,即,1~(;)kj k j kj x B r p -.我们建立logit 链接函数log ()log()()1kjkj k j kj kjp it p m g t e p γβ'==++-[7](1)这里g γ是具有未知参数γ的一个已知函数,k m 是模型的协变量,可能的向量取值12(1,,)kk k m m m '=,012(,,)ββββ'=是对于于协变量的回归系数向量.而kj e 是时间区间j I 内第k 月产品失效率的随机效应.设1(,,),k k km e e e '=其中1,2.k K = 假定这些随机效应kj e 在同一个月中相关,而在任两个不同的月中相互独立.设12(,,,)m A diag a a a =,这里1/21()(1,,)j j j a t t j m -=-=是连续的时间长度的平方根.我们用m 维多元正态分布来建立每个月的相关结构,满足2~(0,)k m e N σ∑这里∑是m m ⨯矩阵,定义为212123111m m m m m A A ρρρρρρρρρ-----⎛⎫ ⎪⎪=⎪ ⎪⎝⎭∑()g t γ是未知参数γ确定的时间函数,()g t γ的选定依赖于这类失效数据的反应—时间模型.最简单的形式是线性,即1()g t t γγ=,没有常数项的是为了保证模型的可识别性.对()g t γ的选择还有很多其它的形式.如二次式212()g t t t γγγ=+,甚至更复杂的.但是()g t γ并不见得越复杂越好,比如Waterloo 大学生物系进行的一系列的大种系动物的毒理实验中多元数据分析来看,他们用贝叶斯的方法来选择()g t γ时发现,最佳的模型是12()g t t γγγ=+[10][11].对于此时模型的区间估计,我们的思路和模型一的原理是一样的.这里也从多项分布和二项分布之间的关系出发,结合正态分布来寻找的置信区间.由于不同月份生产的产品在同一个时间段内的失效率是不同的,所以模型一区间估计中的j p 要换成(1,2,)ij p i K =.2、模型结果我们同样利用模型一的数据来拟合模型,并且也同样用那14个返回数据来验证模型,由于此时的数据不多,我们只加入各月的生产总数作为协变量,()g t γ我们就选择了关于时间的一次函数,利用sas 编程[6][8]得到的结果如下:从方差分析的p 值小于0.0001知,模型拟合数据时显著性有效的,而对于未知参数估计的p 值也都显著性不为0,所以我们的模型为log() 3.77912770.36456 6.701401kjk j kjp E n t p =-+-- (2)也即是( 3.77912770.36456 6.70140)11k j kj E n t p e---+=+ (3)这里kj p 表示第k 月产品的在j I 时间段的失效率,k n 表示第k 月的生产的产品总数.而j t 代表的月线,也就是分布为一月线、三月线、六月线、十二月线、二十四月线、三十六月线,但是在我们的模型中的取值分别为1,、2、3、4、5、6.我们也将j t 分别取3、5、8、14、26、38时的取值来拟合模型,但是最后的预测效果没有我们的模型好.为了直观地评估模型的拟合度,模型的学生化残差的散点图如下:图1从图1我们可以看出大多数标准化残差点都在两倍标准差之内,只有少数点落在之外,此时对于十四个验证的数据的估计如下:从表4知,有7个月的月线的真实值在预测的区间内,但仔细观察你会发现,10年一月、二月的十二月线的的真实值与预测的置信的区间的置信上限只不过相差100左右,只要我们稍作调整就可以落入置信区间内.而对于08年一月、二月的三十六月线与09年三月二十月线,它们预测值与真实值之间的偏差大约都在2000左右,这个偏差还不到真实值的1/20,在要求不是很严的前提下还是可以接受的.而对于09年一月二十四月线和10年十月的三月线感觉就不是很让人接受,但仔细观察原始数据发现,09年一月二十四月线的不良返回数为20274,09年二月二十四月线的不良返回数为22820,而09年一月三十六月线的真实不良返回数为38119,09年二月三十六月线的真实不良返回数为36450,二十四月线是09年一月比二月时的返回数少了2546,但是在三十六月线时一月的返回数比二月的返回数却多了1669,所以09年一月的数据变异性较大.但总体来说,比模型一的结果还是好了很多.六、模型改进和解释1、模型改进由于后来我们得到了这个产品(MB )一些月份三十六个月线的返回数据,所以此时我们就用了每个月一月线、二月线、一直到三十六月的数据来拟合模型二.由于这时的数据多了很多,所以此时的协变量只取每个月的生产总数显然不合适.我们就想是否具有季节性,因此在协变量中加入了月份,但是月份的影响是周期性的,故构造了周期为12的三角函数对失效率的影响,模型为:log ()log()(,)1kjkj k j k kj kjp it p m g t n e p γβ'==++- (4)此时的(1,,cos(),sin())66kk m n s s ππ'=其中mod(,12)s k =,另外我们还加入了生产总数与月线的交互项k j n t ,拟合数据得到的结果如下:从sas 运行的结果可以看出,模型的检验和系数的检验都可以通过.其中sn 表示的是sin()6s π,cn 表示的是cos()6s π,故此时的模型可写为: log() 1.44029170.05936 2.5182380.04607sin()0.18730cos() 6.33065166kj k j k j kj p E n t E n t s s p ππ=--+-•++--也即是( 1.44029170.05936 2.5182380.04607sin()0.18730cos() 6.33065)661(5)1k j k j kj E n t E n t s s p eππ--+--•--+=+ 这里kj p 表示第k 月产品的在j I 时间段的失效率,k n 表示第k 月的生产的产品总数.而j t 代表的月线,也就是分别为一月线、二月线、三月线、、三十六月线,但是在我们的模型中的取值分别为1,、2、3、、36.而s 表示的是将k 对12取余,即mod(,12)sk ,得到的标准化残差图:图2从标准化的残差图2可以看出,数据几乎都落在2倍标准差范围之内,只有极少落在之外.我们后来也做了将标准差之外点剔除再来拟合模型,但是由于偏从表5可以看出,此时由于我们月份之间的跨度比较小,所以此时置信区间的长度也比较短,所以此时的偏差总体上也比之前小了很多.08年一月、三月的三十六月线和09年二月二十四月线的真实值与置信区间的界限最近也就相差一百多,经过小小调整就可以了.从上面的偏差知,偏差最大的也不过六百多,离落入置信区间最大也不过三百左右,如果对精度不是要求很高的话,完全可以通过增大区间的长度来落入置信区间内. 2、模型解释对于上面式(5)中关于kj p 的关系式,当k n 变大时,由于k n 前面的系数是负的,kj p 也将会变大.这很容易理解,因为当一个月的生产总数增加了,而此时工人的生产任务就加大了,而工人的精力有限,从而生产效率降低,因而就会有更多的次品.当j t 变大时,由于j t 前面的系数是正的,kj p 反而会减小.从可靠性理论的角度来说,一个产品的失效的概率分布通常可以看做一个指数函数,由于指数函数的分布函数()1tF t eλ-=-,我们可假设一个相隔一个时间间隔的概率函数(1)()()(1)t t Q t F t F t e e λλ---=--=-,而求导得(1)()()t t Q t e e λλλ---'=--所以()Q t 是一个关于t 的减函数,也就是说随着时间的增大,相等的时间间隔内失效的概率是减小的,这刚好也我们的模型是吻合的.而对于月份的影响也是很容易解释的,由于每个月之间的气候、湿度等等自然因素的不同,对产品的保存也会造成一定的影响,故月份也是有影响的,只是说相对来说小点而已.七、两个模型的讨论与分析两个模型从预测的方式来说可以说方式是一样的,都是先预测一段时间内的失效率,再用失效率乘以生产总数得到增加的不良返回数,但是预测失效率的方法是不一样的,并且引入的参数也不一样.模型一中我们的模型假设是在每一件生产产品在出厂后的相同的一段时间内的概率是相同的,只依赖产品的出厂时间,从而借助多项分布来构造样本的似然函数来估计各个区间的失效率.但是例子验证的结果并不理想,区间准确率约为36%,而其他落在区间外的月份的月线的预测都离区间比较远,所以效果并不好.而模型二就引入了协变量来估计失效率.除了考虑出厂时间,我们还考虑了生产总数的影响和月份的季节性影响,甚至还考虑他们的之间的交互,准确率大约维持在50%多,但是我们发现还有几个月的真实值离我们的预测区间只有100左右的偏差,我们的预测区间本来是就比较短,只要区间稍微放大,我们就可以使得准确率超过80%.对于改进的模型来说,偏差最大也就600左右,也就是说如果我们把置信区间的长度放大到1200多,那我们就有可能全部预测对.此时的预测都是基于上一月线已知的不良数加上新增的不良数来预测下一月线的不良数,因此我们就想能不能跳跃性地预测,预测之后几个月线的.因此我们用改进的模型基于二十四月线的数据来直接预测三十六月线的数据,也就是我们要求二十四月线至三十六月线之间增加的不良数,我们利用模型分别算出了二十四月线至二十五月线的增加数,二十五月线至二十六月线的增加数,,三十五月线至三十六月线的增加数,再加这十二个间隔的增加数加起来预测二十四至三十六月线的增加数,我们计算出来的结果发现全部偏差很大,甚至还比不上我们之前就只用一、三、六、十二、二十四、三十六月线的数据拟合的模型,也就是说我们这个模型只适合预测一个时间点的数据,并且这个数据只与上一个时间点数据有关的数据类型,与更前面的的数据关联不大,因此也不适合作跳跃性的时间预测.对于模型二中存在小部分数据的学生化残差不在两倍标准差以内的数据,我们剔除了这些点再来拟合模型,结果发现对最后的结果影响不大,也就那些数据对模型的贡献不怎么大.对于模型中出现的生产总数与月线的交叉项,我们也用过不含交叉项的模型去拟合数据,结果和我们上面的差不多,都只是有小小的变动,所以也可以考虑用不含交叉项的模型拟合.从实例的结果来看,尽管模型二的结果相对于模型一的结果来说有所改进,但是结果还不是特别满意,也只能说还可以,虽然改进的模型中预测的最大偏差不过600多,但是我们仔细观察数据,发现从上一月线到下一月线增加的不良返回数也不过就是2000左右,这样来说600也还是比较大的偏差.对于此例的偏差,我们分析可能有以下两方面的原因:(1)一方面可能来自于我们的模型,可能是我们的模型不是太适合这个数据,可能是有某些重要的协变量我们没有找到,这可能涉及到电子产品制造的某些专业知识,也正是我们所欠缺的.(2)另一方面可能来自于数据,我们的数据来源于回收的不良产品数,而我们的模型是应用于产品的失效前提下,这两者是不等同的.因为有些产品失效了,但是可能却没有及时回收.有些人怕麻烦或者比较忙没有及时将自己的失效的产品返厂,可能就不返厂了或者拖到下个月、下下个月甚至更晚返厂.这样的话就会导致数据会有偏差.。
2011年全国大学生统计建模大赛获奖论文

上海与伦敦黄金市场价格相互波动传导演变的实证研究——基于SVAR模型的分阶段比较中南大学高涛、戴超逸、彭锦摘要:摘要:黄金是一种重要的投资与保值的金融工具,金融危机爆发后其价格的波动特征往往成为各国央行和投资者迫切需要掌握的信息。
伦敦黄金市场作为全球最大的黄金市场,从诞生以来一直引导着其他黄金市场的价格走势,而近年来随着中国经济实力增强和对黄金消费与投资比重不断攀升,研究上海黄金价格与伦敦黄金价格之间的相互影响力如何变化对于促进我国黄金市场的健康发展以及维护我国金融系统抵御风险的能力具有很强的现实意义。
本文吸取了Hasbrouck基于VEC模型提出的信息份额模型中用方差分解表现各个市场不同的价格反映能力的思想,用SV AR模型中的预测方差分解与脉冲响应函数来描述市场间的价格波动传导,并且克服了Hasbrouck模型中使用Cholesky分解而无法反映市场间双向同期相关性的缺点。
由于各价格间存在正负交替的冲击力,利用累计脉冲响应和预测方差分解虽然在一些情况下出现不同结果,但恰好站在不同角度度量了各市场对共同价格波动的绝对和相对贡献程度。
本文以2005年上海黄金夜市开放和2007年金融危机作为分界点。
研究结果表明上海黄金夜市开放之后,上海黄金价格对伦敦黄金价格的波动解释能力显著提升;在金融危机之后,上海黄金市场开盘价对伦敦黄金市场价格波动的引导能力下降,伦敦黄金市场的下午价对上海黄金市场价格波动的引导能力上升。
本文还发现存在一个市场上的任意一个价格对另外一个市场上的两个价格存在影响力相似的现象。
关键词:上海与伦敦黄金市场波动传导SV AR模型脉冲响应函数方差分解目录一引言 (3)二文献回顾 (3)三研究角度 (4)四研究方法 (5)4.1变量选择 (5)4.2模型设定 (6)4.3数据处理与统计检验 (7)五实证分析 (10)六结论与分析 (15)参考文献 (16)附表 (18)一引言黄金一直以来作为贵重金属占有重要的国际地位,在金本位时期(1880到1971年)它作为货币本位而存在,发挥着价值标尺的功能。
2011年百篇优秀博士论文公示

2011年全国优秀博士学位论文评选专家审定会日前在京结束,共有98篇博士学位论文入选。目前,此次评选活动进入公示异议期。异议期自公示之日起为期60天。
本次全国优秀博士学位论文评选是继1999年首届评选后的第十三次评选,评选对象为全国所有博士学位授予单位2008年9月至2009年8月间的博士学位获得者的学位论文,2004年9月至2008年8月间的少量论文也参加了评选。经过学位授予单位推荐、省级学位委员会或研究生教育主管部门初选、同行专家通讯评议三个阶段,由专家审定会最后确定入选论文名单。
中国农业大学
园艺学
夏晓剑
喻景权
油菜素内酯调控黄瓜光合作用、抗逆性及农药代谢的生理与分子机理研究
浙江大学
农业资源与环境
陈爱群
徐国华
三种茄科作物Pht1家族磷转运蛋白基因的克隆及表达调控分析
南京农业大学
植物保护
王晓杰
康振生
小麦与条锈菌互作机理研究及抗条锈相关基因的功能分析
西北农林科技大学
兽医学
王林
刘宗平
湘潭大学
付晓玉
张旭
分布参数系统能控能观性问题的统一处理
四川大学
物理学
马仁敏
戴伦
一维纳米半导体材料及其电子与光子器件研究
北京大学
郑坤
韩晓东
原位原子尺度下纳米线室温力学性能与行为的研究
北京工业大学
沈大伟
封东来
2H结构过渡族金属二硫属化物电子结构的高分辨角分辨光电子能谱研究
复旦大学
陈焕阳
马红孺
各向异性材料中的波:隐身衣、旋转衣和声子晶体
全国优秀博士学位论文评选异议期的设立是为了更好地保证所评选出的全国优秀博士学位论文的质量,提高评选结果的公正性和准确性,树立良好的学术风气和维护科学道德。自公示之日起60日内,有发现入选论文存在学术失范行为,或论文的主要研究成果不能成立等严重问题者,可以书面方式向教育部学位管理与研究生教育司提出异议。提出异议的书面材料应包括异议论文的题目、作者姓名、学位授予单位名称、异议内容,支持异议的具体证据或科学依据,以及提起异议者的真实姓名、工作单位、联系地址、联系电话等(如需保密,请注明)。有关材料请直接寄送教育部学位管理与研究生教育司(地址:北京市西单大木仓胡同35号,邮政编码:100816)。
2011年国赛A题参考论文

城市表层土壤重金属污染分析摘要:随着全球经济化的迅速发展,含重金属的污染物通过各种途径进入土壤,造成土壤严重污染。
土壤重金属污染可影响农作物产量和质量的下降,并可通过食物链危害人类的健康,也可以导致大气和水环境质量的进一步恶化。
因此引起世界各国的广泛重视。
目前,世界各国土壤存在不同程度的重金属污染,全世界平均每年排放Hg约1.5万t、Cu为340万t、Pb为500万t、Mn为1500万t、Ni为100万t。
中国北方大城市的蔬菜基地和部分商品粮基地也存在着不同程度的重金属污染,如北京、天津、西安、沈阳、济南、长春、郑州等地。
南方相对较轻,如福州、宁波、上海、武汉、成都等地。
土壤重金属污染将会造成生态系统的严重破坏。
从中国土壤资源状况看,到2000年底中国人均耕地仅为0.1 hm2,而且随着今后中国经济社会的发展如生态退耕、农业结构调整及自然灾害损毁等,土壤资源将进一步减少。
因而如何有效地控制及治理土壤重金属的污染,改良土壤质量,将成为生态环境保护工作中十分重要的一项内容。
本文主要从土壤中重金属污染物来源与分布入手,通过建立数学模型找到污染源的位置,并分析产生重金属污染的主要原因。
从而为保护环境,提高土壤的环境质量贡献一份力量。
关键词:数学模型;单因子分析法;重金属污染目录一、问题的重述 (3)二、问题的分析..................................... 错误!未定义书签。
三、模型的假设与符号说明........................... 错误!未定义书签。
四、模型的建立与求解............................... 错误!未定义书签。
4.1重金属元素的空间分布及污染程度.............. 错误!未定义书签。
4.1.1 重金属元素的空间分布.................. 错误!未定义书签。
4.1.2 不同区域重金属的污染程度的分析........ 错误!未定义书签。
数学建模2011D - 参考论文
2011高教社杯全国大学生数学建模竞赛题目
D题天然肠衣搭配问题
天然肠衣(以下简称肠衣)制作加工是我国的一个传统产业,出口量占世界首位。
肠衣经过清洗整理后被分割成长度不等的小段(原料),进入组装工序。
传统的生产方式依靠人工,边丈量原料长度边心算,将原材料按指定根数和总长度组装出成品(捆)。
原料按长度分档,通常以0.5米为一档,如:3-3.4米按3米计算,3.5米-3.9米按3.5米计算,其余的依此类推。
表1是几种常见成品的规格,长度单位为米,∞表示没有上限,但实际长度小于26米。
为了提高生产效率,公司计划改变组装工艺,先丈量所有原料,建立一个原料表。
表2为某批次原料描述。
根据以上成品和原料描述,设计一个原料搭配方案,工人根据这个方案“照方抓药”进行生产。
公司对搭配方案有以下具体要求:
(1) 对于给定的一批原料,装出的成品捆数越多越好;
(2) 对于成品捆数相同的方案,最短长度最长的成品越多,方案越好;
(3) 为提高原料使用率,总长度允许有± 0.5米的误差,总根数允许比标准少
1根;
(4) 某种规格对应原料如果出现剩余,可以降级使用。
如长度为14米的原料可以和长度介于7-13.5米的进行捆扎,成品属于7-13.5米的规格;
(5) 为了食品保鲜,要求在30分钟内产生方案。
请建立上述问题的数学模型,给出求解方法,并对表1、表2给出的实际数据进行求解,给出搭配方案。
2011高教社杯全国大学生数学建模竞赛全国一等奖A题城市表层土壤重金属污染分析(1)

2011高教社杯全国大学生数学建模竞赛城市表层土壤重金属污染分析摘要本文主要研究重金属对城市表层土壤污染的问题,我们根据题目所给定的一些数据和信息分析并建立了扩散传播模型、权重分配模型、对比模型和转换模型解决问题。
首先,我们利用Matlab 软件拟出该城区地势图(图1),根据所给数据绘出该地区的三维地势及采样点在其上的综合空间分布图。
之后将8种重金属的浓度等高线投影到该地区三维地形图曲面上,接着分别计算8种重金属在五个区域的平均值,立体图和平面图(图1附件)相结合便可得出8种重金属元素在该城区的空间分布。
其次,在确定该城区内不同区域重金属的污染程度时,我们运用两种方法进行解答。
先假设各重金属毒性及其它性质相同,运用公式ij ij P C P ='求出各区域各金属相对于背景平均值的比值作为金属污染程度,再运用1ji ij j C C ==∑求出各区域重金属污染程度,并将各区进行比较。
之后,我们加上各重金属的毒性,对各重金属求出权数,再结合国标重金属污染等级和已知的各组数据来确定金属的污染程度。
由上述两种方法的对比,更准确地得出重金属对各区的影响程度。
即: 工业区>交通区>生活区>公园绿地区>山区并根据第一个模型的数据来说明重金属污染的主要原因。
再次,对重金属污染物的传播特征进行了分析,判断出重金属污染物主要是通过大气、土壤和水流进行传播。
在分析之中,我们得出这三种状态的传播并不是孤立存在的,而是可以相互影响和叠加的,因此,我们分别建立三个传播模型,再对这三个传播模型进行了时间和空间上的拟合,得出重金属浓度最高的区域图,并结合各重金属的分布图(图6)来确定各污染源的位置。
最后,本题中只给出了重金属对土壤的污染,对于研究城市地质环境的演变模式,还需要搜集一些信息(图7)。
根据每种因素对地质环境的影响程度进行由定性到定量的转化。
建立同一地质时期地质环境中各因素的正影响和负影响的权重分配模型,再对这些权重进行验算和修正。
2011年度优秀论文

柳 州钢铁 ( 集团)公司扩建 3 0m 烧结机项 目职业 6
橡皮胶布缠指 法防止护士锐器伤的效果观察 3 M透 明敷料在深静脉置管中的应用
病危害预评价 针 灸结合温 中健脾中药治疗慢性 胃炎 4 2例
舒 芬太尼复合小剂量氯胺酮用于烧伤术后镇痛 高位颈 内静脉穿刺置管术 的临床应用体会 3 2例小儿 中重度烧伤手术麻醉 回顾分析 C P动态监测在早期防治经尿道 前列腺切除综合症 V
温度和变形参数对 Q 4 c钢连铸坯热塑性的影响 35 完善柳钢轧钢工艺技术 的探讨 高层住宅项 目工程成本控制 铝合金 门窗雨水渗漏原 因分析及处理方法 三种方法测定金属 薄板塑性应变 比值 的结果 比较 柳钢焦炉煤气氨回收技术改造 钢铁企业除尘系统设计节能探讨 我 院 19例 “ 6 特殊使用 ”类抗菌药物应用分析
上肢动静脉彩超在血液透析造瘘术前的应用价值 探讨彩超检查 维持性血液透析患者甲状旁腺增大 的
多层砌体结构房屋 的抗震设计
浅谈建筑结构设计 与 P P K M软件应用
浅谈建筑设计 在工业厂房 中的重要性 浅议工业厂房设计 中的钢结构 ’ 浅谈砌体结构设计
论土建结构安全性设置水准及耐水性
的体会
带锁髓 内钉治疗股骨干骨折并发症原 因分析及处理
对策
细菌检验标本的质量分析及体会
不 同治法干预焦虑障碍 的疗效 比较 依 照指南规范使用基本药物
糖 尿病 肾衰 患 者 透 析过 程 的护 理
经皮椎体成形 术治疗老年骨质疏松脊柱压缩骨折 4 o 例的体会
静脉输液外渗 护理新进展
衄_
21 0 1年度 优秀 论 文
一
等奖 ( 2篇 ) 1
柳 钢 球 式 热 风 炉 大 型化 发 展 技 术
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
其方案如下:B 区:在节点 153 增设一个平台;C 区:在节点 317,239,207 处各增 设一个平台;D 区:将节点 321 号处的平台改建在 369 号节点处;E 区:在节点 392 号 增设一个平台,再将 430 号节点的平台改建在 438 号节点处;F 区:在节点 518 增设一 个平台。
问题 3:为评价 A 区交巡警平台设置的合理性,给出增设平台的具体个数和位置, 提出工作力度指标。某节点的工作力度为其所属平台到其的出警路程与该点发案率的 乘积,某平台的工作力度为其管辖范围内的所有节点的工作力度之和。根据模型算出 各个平台的工作力度并计算出平均值,在工作力度较大的几个平台的邻接区域节点处 确立增设平台数及其准确位置,使得各个平台工作力度达到平衡。得出在节点 29、30、 39、92 处增设平台。
L3 :警车 3 分钟的行车路程;
nj :节点 j 处的发案率;
WAi :交巡警服务平台 Ai 的工作力度;
W A :A 区增设新平台之前的交巡警服务平台的平均工作力度; ΔWi :第 i 平台的工作力度与平局工作力度差值的平均值; Ln :第 n 种搜索方案中的最长路程; Ln−m :第 n 种搜索方案中的所有路程和;
2011 高教社杯全国大学生数学建模竞赛
承诺书
我们仔细阅读了中国大学生数学建模竞赛的竞赛规则. 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网 上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的 资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参 考文献中明确列出。 我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反竞赛规 则的行为,我们将受到严肃处理。
二、问题分析
本题为交巡警服务平台优化问题,需要结合警务资源有限的客观因素以及城市道 路、案发率等具体情况,合理分配平台管辖范围、调度警力资源、判断平台设置合理 性以及规划平台分布。
问题 1:为了满足在突发事件发生时,警车尽量在 3 分钟以内到达的具体要求,本 文制定了平台管辖范围的分配原则:(1) 突发事件发生时,警车到达事发地的行车路程 尽量在 3km 以内;(2) 对于某些同属于多平台管辖范围内的路段和节点和某些不属于 任何平台管辖范围内的路段和节点,采取路程最短原则进行分配;(3) 使用城市道路作 为管辖范围的界线,便于标识和指挥调度;(4) 对于相邻的两个交巡警服务平台,尽量 使其管辖范围界线上的点距这两个交巡警服务平台的距离相等。依据原则首先运用弗 洛伊德算法确定离平台 Ai 路程在三千米以内的节点集 SA′ i ,同属于多个节点集 SA′ i 的节 点依据就近原则确定其所属平台,两平台之间的距其都超过三千米的道路部分按平均 分配原则进行分配。由此可得到 A 区平台管辖范围。
问题 1:确定 A 区各交巡警服务平台管辖范围。本文根据题目要求制定了平台管辖 范围的分配原则;依据原则首先运用弗洛伊德算法确定离平台 Ai 路程在三千米以内的 节点集 SA′ i ,同属于多个节点集 SA′ i 的节点依据就近原则确定其所属平台,两平台之间 的距其都超过三千米的道路部分按平均分配原则进行分配。由此得到平台管辖范围如 图 1 所示。
2011 高教社杯全国大学生数学建模竞赛
编号专用页
赛区评阅编号(由赛区组委会评阅前进行编号):
赛区评阅记录(可供赛区评阅时使用): 评 阅 人 评 分 备 注
全国统一编号(由赛区组委会送交全国前编号):
全国评阅编号(由全国组委会评阅前进行编号):交巡警服务平台的设置与调度
摘要
由于警务资源有限,各个城市的实际情况不同,则需要考虑如何合理的设置交巡警 服务平台,如何评价交巡警平台设置的合理性,如何恰当的分配交巡警服务平台的管 辖范围,如何在突发事件发生时最快最好的调度警务资源。本文即针对这些问题建立 了相应的数学模型。
问题 3:平台工作量不均衡和有些地方出警时间过长,主要是由发案率大小和出警 路程的长短决定;为此本文提出 A 区工作力度指标:将某节点的发案率和其所属平台 到其出警路程的乘积作为该节点工作力度;某平台的工作力度为其管辖范围内的所有 节点的工作力度之和。首先利用 MATLAB 实现所有出警路线的长度计算,然后通过计算 每个平台的工作力度以及平均值,求出每个平台工作力度与平均值的差值的绝对值的
三、模型假设
1、假设突发事件只发生在交叉路口(全文简称节点)处; 2、假设相邻两个节点之间的道路为直线; 3、假设单一管辖区域内某一时间无并发事件; 4、假设警车到事发地之间道路通畅,无特殊路况,且警车能由最短路径到达事发 地点; 5、假设出警过程中警车无故障发生; 6、假设该市所有道路都是双行道路; 7、假设犯罪嫌疑人逃跑的车速与警车的车速相等。
关键词:最短路径;弗洛伊德算法;工作力度;树状模型;
1
一、问题重述
为了更有效地贯彻实施警察职能,需要在市区的一些交通要道和重要部位设置交 巡警服务平台。每个交巡警服务平台的职能和警力配备基本相同。由于警务资源有限, 需要根据实际情况与需求合理地设置交巡警服务平台、分配各平台的管辖范围和调度 警务资源。该类问题都是图论中的典型问题。根据题意,本问题可细分为如下问题:
我们参赛选择的题号是(从A/B/C/D中选择一项填写): B
我们的参赛报名号为(如果赛区设置报名号的话):
所属学校(请填写完整的全名):
西南大学
参赛队员 (打印并签名) :1.
汪娅
2.
李玲
3.
史江南
指导教师或指导教师组负责人 (打印并签名): 彭作祥
日期: 2009 年 9 月 12 日
赛区评阅编号(由赛区组委会评阅前进行编号):
问题 2:突发事件需要封锁全部出入城区节点属于最优化问题。按 A 区 13 个交通 要道节点的分布以及道路情况将 A 区分为三个区,分别对其进行搜索最优路径。用 MATLAB 搜索出所有调度方案,将每一方案中的最长路径作为该方案的路径,比较所有 方案的路径,取最短路径的方案为最优调度方案;若存在多个方案最短路径相等,则 取方案中所有路径和最小的为最优调度方案(见表 2)。
最佳的管辖范围,那么如何才能使得警车最快到达案发地是最重要的,因而在这一问
中我们主要考虑交巡警服务平台到其管辖范围内的节点路径最短,为此制定如下平台
管辖范围分配的原则:
(1)突发事件发生时,警车到达事发地的行车路程尽量在 3km 以内;
(2)对于某些同属于多平台管辖范围内的路段和节点和某些不属于任何平台管辖
3
五、模型的建立与求解
5.1 问题 1 的模型建立与求解
该问题要求在交巡警平台管辖范围内发生突发事件时,能尽量使交巡警能在 3 分
钟内到达,而题目给出警车的时速为 60km/h,则可得警车在 3 分钟内的行车路程为:
L3 = V *T =3km
(1)
由于这一问题中主要是为了处理突发事件而给 A 区中的 20 个交巡警服务平台分配
2
平均值,并将差值的绝对值与差值平均值进行比较,如果差值的绝对值大于平均值则 表明平台的工作力度过大,需要调整。最后为了使得各个平台工作力度达到均衡,在 工作力度较大的几个平台的邻接区域节点处确立增设平台数及其准确位置。
问题 4:考虑全市的具体情况,将问题 3 中工作力度指标进行改进推广,增加了人 口密度因素对工作力度的影响,即将某节点的工作力度定义为其所属平台到其的出警 路程、该点发案率及其所属区域的人口密度的乘积。为了实现对全市平台合理性的判 断并提出最佳平台规划方案,首先类似问题 1 的分析,将全市的各个交巡警服务平台 划分管辖范围,然后类似问题 3 的分析,实现对全市平台合理性的判断并提出最佳平 台规划方案。
四、符号说明
vj :标号为 j 的节点;
Ai : A 区中标号为 i 的交巡警服务平台, i = 1,..., 20 ;
SAi :与交巡警服务平台 Ai 的最短距离不大于 3km 的节点集合;
S
′
Ai
:交巡警服务平台
Ai
管辖范围内的节点集合;
LAi− j :由交巡警服务平台 Ai 到节点 j 警车行车路程;
(1) 要求节点 vj 到 Ai 的最短路径。如果 vj 到 Ai 有折线,则从 vj 到 Ai 存在一条长度
为 cos t[ j,i] 的路径,该路径不一定是最短路径,尚需进行 n 次试探。
(2) 考虑路径 (v j , v1, Ai ) 是否存在,即判别折线 (v j , v1) 和 (v1, Ai ) 是否存在。如果存
范围内的路段和节点,采取路程最短原则进行分配;
(3)使用城市道路作为管辖范围的界线,便于标识和指挥调度;
(4)对于相邻的两个交巡警服务平台,尽量使其管辖范围界线上的点距这两个交
巡警服务平台的距离相等。
根据第一条分配原则,本文首先采用弗洛伊德算法确定与平台 Ai 的最短距离不大 于 3km 的节点集合 SAi 。具体算法如下:
问题 5:对于设计最佳围堵方案,本文给出最佳围堵方案的原则,即在保证围堵成 功的基础上尽量使搜捕时间最短;并假设嫌疑犯与警车的速度一致。因此本文在安排 警力对全市出入市区节点进行封锁,保证围堵一定成功的同时,也从 P 点开始建立树 状模型,得到搜捕时间尽量短封锁方案。该树状模型是依次对由 P 点出发的每条可能 路线上每个节点搜索离该节点最近的平台,以 P 点到该节点的路程与 3 分钟路程的差 和平台到该节点的路程比较,来判定是否能够成功围堵,直到找到这样的节点为止。 围堵方案见表 5、表 6。