粒子群算法粒子个数
第6章粒子群优化算法

第6章粒子群优化算法PSO算法的基本原理是通过模拟粒子在空间中的移动,从而找到最优解。
每个粒子代表一个可能的解,并根据自身的经验和群体的经验进行。
粒子的速度和位置的更新使用以下公式:v(t+1) = w * v(t) + c1 * rand( * (pbest - x(t)) + c2 *rand( * (gbest - x(t))x(t+1)=x(t)+v(t+1)其中,v(t)代表粒子的当前速度,x(t)代表粒子的当前位置,w是惯性权重,c1和c2是学习因子,rand(是一个0到1之间的随机数,pbest 是粒子自身的最佳位置,gbest是整个群体的最佳位置。
PSO算法的过程如下:1.初始化粒子的位置和速度。
2.计算每个粒子的适应度值。
3. 更新每个粒子的pbest和gbest。
4.根据公式更新每个粒子的速度和位置。
5.重复步骤2到4,直到达到终止条件。
PSO算法有几个重要的参数需要设置:-群体大小:确定PSO算法中粒子的数量。
较大的群体大小可以增加整个空间的探索能力,但也增加了计算复杂度。
-惯性权重:控制粒子速度变化的因素。
较大的惯性权重可以增加粒子的飞行距离,但可能导致过程陷入局部最优解。
-学习因子:用于调节个体经验和群体经验的权重。
c1用于调节个体经验的权重,c2用于调节群体经验的权重。
较大的学习因子可以增加粒子的探索能力,但也可能增加时间。
PSO算法的优点是简单、易实现,收敛速度较快,对于多维、非线性、离散等问题具有良好的适应性。
然而,PSO算法也存在一些缺点,如易陷入局部最优解、对参数的敏感性等。
总之,粒子群优化算法是一种基于群体智能的优化算法,在求解复杂问题方面具有出色的性能。
它的基本原理是通过模拟粒子的移动来最优解,利用个体经验和群体经验进行自适应。
PSO算法在多个领域都有成功的应用,可以帮助解决实际问题。
matlab粒子群算法默认种群规模

【主题】matlab粒子裙算法默认种裙规模【内容】一、介绍matlab粒子裙算法matlab粒子裙算法(Particle Swarm Optimization,简称PSO)是一种启发式优化算法,源自于鸟裙觅食的行为。
PSO算法通过迭代搜索空间中的潜在解,寻找最优解。
其基本思想是模拟鸟裙觅食的行为,在搜索空间中不断调整潜在解的位置,直至找到最优解。
二、 PSO算法的种裙规模在matlab中,PSO算法的种裙规模即为裙体中粒子的数量,它决定了搜索空间的范围和算法的性能。
PSO算法的默认种裙规模为50。
种裙规模的设定直接影响算法的搜索速度和全局最优解的找寻能力。
三、种裙规模的设置原则1. 确定问题的复杂度:种裙规模应根据待解决问题的复杂度来设定。
对于复杂、高维度的问题,适当增加种裙规模有助于提高搜索效率。
2. 计算资源的限制:种裙规模的增加会带来更高的计算开销,因此在资源有限的情况下,需要平衡种裙规模和计算性能。
3. 经验设定:在实际应用中,也可根据经验和实验结果来调整种裙规模,找到最适合问题的设置。
四、调整种裙规模的方法1. 网格搜索法:通过在一定范围内以一定步长遍历种裙规模,评估不同规模下算法的性能和收敛速度,找到最佳的种裙规模。
2. 实验验证法:在实际问题中,通过对不同种裙规模下算法的性能进行实验验证,找到最适合问题的种裙规模。
3. 算法迭代法:根据算法的迭代次数和搜索效果来动态调整种裙规模,逐步优化算法的性能。
五、结语种裙规模是PSO算法中一个重要的参数,它直接关系到算法的搜索效率和性能。
在使用matlab的PSO算法时,合理设置种裙规模对于解决实际问题非常重要。
需要根据问题本身的特点、计算资源的限制以及实际应用情况来进行合理的选择和调整。
希望本文对于matlab粒子裙算法默认种裙规模的设置能够提供一些参考和帮助。
六、种裙规模与算法性能的关系种裙规模是PSO算法中最为关键的参数之一,其大小直接影响算法的搜索效率和全局最优解的寻找能力。
粒子群算法

粒子群算法原理及简单案例[ python ]介绍粒子群算法(Particle swarm optimization,PSO)是模拟群体智能所建立起来的一种优化算法,主要用于解决最优化问题(optimization problems)。
1995年由 Eberhart和Kennedy 提出,是基于对鸟群觅食行为的研究和模拟而来的。
假设一群鸟在觅食,在觅食范围内,只在一个地方有食物,所有鸟儿都看不到食物(即不知道食物的具体位置。
当然不知道了,知道了就不用觅食了),但是能闻到食物的味道(即能知道食物距离自己是远是近。
鸟的嗅觉是很灵敏的)。
假设鸟与鸟之间能共享信息(即互相知道每个鸟离食物多远。
这个是人工假定,实际上鸟们肯定不会也不愿意),那么最好的策略就是结合自己离食物最近的位置和鸟群中其他鸟距离食物最近的位置这2个因素综合考虑找到最好的搜索位置。
粒子群算法与《遗传算法》等进化算法有很多相似之处。
也需要初始化种群,计算适应度值,通过进化进行迭代等。
但是与遗传算法不同,它没有交叉,变异等进化操作。
与遗传算法比较,PSO的优势在于很容易编码,需要调整的参数也很少。
一、基本概念与遗传算法类似,PSO也有几个核心概念。
粒子(particle):一只鸟。
类似于遗传算法中的个体。
1.种群(population):一群鸟。
类似于遗传算法中的种群。
2.位置(position):一个粒子(鸟)当前所在的位置。
3.经验(best):一个粒子(鸟)自身曾经离食物最近的位置。
4.速度(velocity ):一个粒子(鸟)飞行的速度。
5.适应度(fitness):一个粒子(鸟)距离食物的远近。
与遗传算法中的适应度类似。
二、粒子群算法的过程可以看出,粒子群算法的过程比遗传算法还要简单。
1)根据问题需要,随机生成粒子,粒子的数量可自行控制。
2)将粒子组成一个种群。
这前2个过程一般合并在一起。
3)计算粒子适应度值。
4)更新种群中每个粒子的位置和速度。
mopso算法参数

mopso算法参数MOPSO算法参数MOPSO(Multi-Objective Particle Swarm Optimization)算法是一种多目标粒子群优化算法,通过模拟鸟群觅食行为来解决多目标优化问题。
在使用MOPSO算法时,需要设置一些参数来指导算法的运行过程,以达到更好的优化效果。
1. 粒子数量(Particle Number):粒子数量是指算法中参与搜索的粒子个数。
粒子数量的选择应根据问题的复杂度和计算资源进行合理的设定。
粒子数量过少可能导致搜索空间未被充分探索,粒子数量过多则可能增加计算负担。
2. 迭代次数(Iteration Number):迭代次数是指算法运行的代数。
迭代次数越多,算法搜索的空间范围越大,但也会增加计算时间。
迭代次数的选择应综合考虑问题的复杂度和计算资源。
3. 粒子速度(Particle Velocity):粒子速度决定了粒子在搜索空间中的移动步长和方向。
通过调整粒子速度的范围和变化规律,可以控制搜索过程的探索和局部优化能力。
4. 惯性权重(Inertia Weight):惯性权重用于调节粒子速度的更新,影响粒子的全局搜索和局部搜索能力。
惯性权重越大,粒子在搜索空间中的移动越迅速,全局搜索能力增强;惯性权重越小,粒子在局部区域的搜索能力增强。
5. 个体学习因子(Cognitive Learning Factor)和社会学习因子(Social Learning Factor):个体学习因子和社会学习因子用于计算粒子的速度更新值。
个体学习因子决定了粒子根据自身经验调整速度的程度,而社会学习因子决定了粒子根据邻域中优秀粒子的经验调整速度的程度。
6. 邻域大小(Neighborhood Size):邻域大小定义了每个粒子周围的邻域,用于计算粒子的社会学习因子。
较大的邻域大小能够增加粒子之间的信息交流,促进全局搜索;较小的邻域大小则更侧重于局部搜索。
7. 外部存档容量(Archive Size):外部存档容量用于存储搜索过程中的非支配解集合。
粒子群算法详解

粒子群算法详解粒子群算法(Particle Swarm Optimization,PSO)是一种模拟鸟群觅食行为的优化算法,通过模拟个体之间的协作和信息共享来寻找最优解。
它是一种全局优化算法,可以应用于各种问题的求解。
粒子群算法的基本思想是通过模拟鸟群的行为来寻找最优解。
在算法中,将待优化问题看作一个多维空间中的搜索问题,将问题的解看作空间中的一个点。
每个解被称为一个粒子,粒子的位置代表当前解的状态,速度代表解的更新方向和速度。
粒子之间通过互相交流信息,以共同寻找最优解。
在粒子群算法中,每个粒子都有自己的位置和速度。
每个粒子根据自身的经验和邻域中最优解的经验来更新自己的速度和位置。
速度的更新由三个因素决定:当前速度、个体最优解和全局最优解。
粒子根据这些因素调整速度和位置,以期望找到更优的解。
通过不断迭代更新,粒子群逐渐收敛于最优解。
粒子群算法的核心是更新速度和位置。
速度的更新公式如下:v(t+1) = w * v(t) + c1 * rand() * (pbest - x(t)) + c2 * rand() * (gbest - x(t))其中,v(t+1)为下一时刻的速度,v(t)为当前速度,w为惯性权重,c1和c2为学习因子,rand()为[0,1]之间的随机数,pbest为个体最优解,gbest为全局最优解,x(t)为当前位置。
位置的更新公式如下:x(t+1) = x(t) + v(t+1)通过调整学习因子和惯性权重,可以影响粒子的搜索能力和收敛速度。
较大的学习因子和较小的惯性权重可以增强粒子的探索能力,但可能导致算法陷入局部最优解;较小的学习因子和较大的惯性权重可以加快算法的收敛速度,但可能导致算法过早收敛。
粒子群算法的优点是简单易实现,收敛速度较快,对于大多数问题都能得到较好的结果。
然而,粒子群算法也存在一些缺点。
首先,算法对于问题的初始解和参数设置较为敏感,不同的初始解和参数可能导致不同的结果。
遗传算法,粒子群算法和蚁群算法的异同点

遗传算法,粒子群算法和蚁群算法的异同点
遗传算法、粒子群算法和蚁群算法是三种不同的优化算法,它们的异同点如下:
1. 原理不同:
遗传算法是一种模拟自然进化过程的优化算法,主要利用遗传和交叉等运算来产生下一代候选解,通过适应度函数来评价每个候选解的好坏,最终选出最优解。
粒子群算法基于对群体智能的理解和研究,模拟了鸟群或鱼群等动物群体的行为,将每个解看作一个粒子,粒子通过跟踪历史最佳解的方式来更新自己的位置与速度,直到达到最佳解。
蚁群算法是基于模拟蚂蚁在食物和家之间寻找最短路径的行为,将每个解看作一只蚂蚁,通过随机选择路径并留下信息素来搜索最优解。
2. 适用场景不同:
遗传算法适用于具有较大搜索空间、多个可行解且无法枚举的问题,如旅行商问题、无序机器调度问题等。
粒子群算法适用于具有连续参数、寻求全局最优解的问题,如函数优化、神经网络训练等。
蚁群算法适用于具有连续、离散或混合型参数的优化问题,如
路径规划、图像分割等。
3. 参数设置不同:
遗传算法的参数包括个体数、交叉概率、变异概率等。
粒子群算法的参数包括粒子数、权重因子、学习因子等。
蚁群算法的参数包括蚂蚁数量、信息素挥发率、信息素初始值等。
4. 收敛速度不同:
遗传算法需要较多的迭代次数才能得到较优解,但一旦找到最优解,一般能够较好地保持其稳定性,不太容易陷入局部最优。
粒子群算法的收敛速度较快,但对参数设置较为敏感,可能会陷入局部最优。
蚁群算法的收敛速度中等,能够较好地避免局部最优,但也容易出现算法早熟和陷入局部最优的情况。
粒子群算法的参数及选择

粒子群算法的参数及选择粒子群算法,听上去是不是有点高深莫测?其实这玩意儿就像我们生活中的寻宝游戏,参与者在一片“宝藏”中飞来飞去,试图找到最闪亮的那颗。
说到这里,可能有人会问:这个算法里到底有哪些参数呀?咱们今天就来聊聊这些参数,以及怎么选择它们,让大家在“寻宝”过程中不至于迷了路。
我们得了解粒子群算法的基本组成部分。
想象一下,算法里的每一个粒子就像一个小小的探险家,它们在一个多维空间里飞来飞去,试图找到最好的解决方案。
这个时候,粒子的“速度”和“位置”就显得特别重要。
速度决定了粒子在空间中的移动速度,而位置则是它目前在“寻宝”中的位置。
想要找到最优解,得调整这两个参数,听上去是不是像在开车?控制好油门和方向,才能不至于迷失在路上。
咱们再说说“个体学习因子”和“社会学习因子”。
这个俩家伙就是粒子群的灵魂。
个体学习因子就像你身边那个爱分享经验的朋友,他总是愿意告诉你自己找宝藏的心得;而社会学习因子则是大家一起讨论的氛围,越热烈,越能激发每个人的灵感。
选择这两个因子的时候,得根据具体情况来定。
团队合作显得特别重要;个人独立思考又不能少。
可以说,这就是个“平衡”的艺术了。
再聊聊“惯性权重”。
哎呀,这个词听起来有点拗口,其实说白了就是粒子在前进过程中对自己前进方向的依赖程度。
如果惯性权重设置得高,粒子就像开着车的老司机,能保持原有的方向;如果设置得低,那就像新手司机,左右摇摆不定,容易迷路。
所以,设置这个参数的时候,得谨慎点,不能一味追求速度,要有稳定性才行。
说完这些参数,咱们得讨论一下怎么选择它们了。
就像打麻将,手里有一副好牌,但怎么玩才是关键。
得考虑问题的复杂程度。
有些问题就像是小儿科,简单明了;而有些问题则复杂得像天上的星星,让人眼花缭乱。
根据问题的复杂程度来选择参数,才能事半功倍。
数据的性质也得考虑。
有些数据分布得很均匀,有些则像一团乱麻。
这时候,参数的选择得灵活变通,适应不同的数据特点。
就像做饭一样,材料不同,调料的配比也得随之调整。
粒子群算法步骤

粒子群算法(Particle Swarm Optimization,PSO)是一种基于群体智能的优化算法,用于解决优化问题。
下面是粒子群算法的一般步骤:1. 初始化参数:- 定义问题的适应度函数。
- 设置群体规模(粒子数量)和迭代次数。
- 随机初始化每个粒子的位置和速度。
- 设置每个粒子的个体最佳位置和整个群体的全局最佳位置。
2. 迭代优化:- 对于每个粒子:- 根据当前位置和速度更新粒子的新速度。
- 根据新速度更新粒子的新位置。
- 根据新位置计算适应度函数值。
- 更新粒子的个体最佳位置和整个群体的全局最佳位置。
- 结束条件判断:达到预设的迭代次数或满足特定的停止条件。
3. 输出结果:- 输出全局最佳位置对应的解作为优化问题的最优解。
在更新粒子的速度和位置时,通常使用以下公式:速度更新:v(t+1) = w * v(t) + c1 * r1 * (pbest - x(t)) + c2 * r2 * (gbest - x(t))位置更新:x(t+1) = x(t) + v(t+1)其中:- v(t) 是粒子在时间t 的速度。
- x(t) 是粒子在时间t 的位置。
- w 是惯性权重,用于平衡粒子的历史速度和当前速度的影响。
- c1 和c2 是加速因子,控制个体和全局最佳位置对粒子速度的影响。
- r1 和r2 是随机数,用于引入随机性。
- pbest 是粒子的个体最佳位置。
- gbest 是整个群体的全局最佳位置。
以上是粒子群算法的基本步骤,您可以根据具体的优化问题进行调整和扩展。
粒子群算法粒子群算法简介
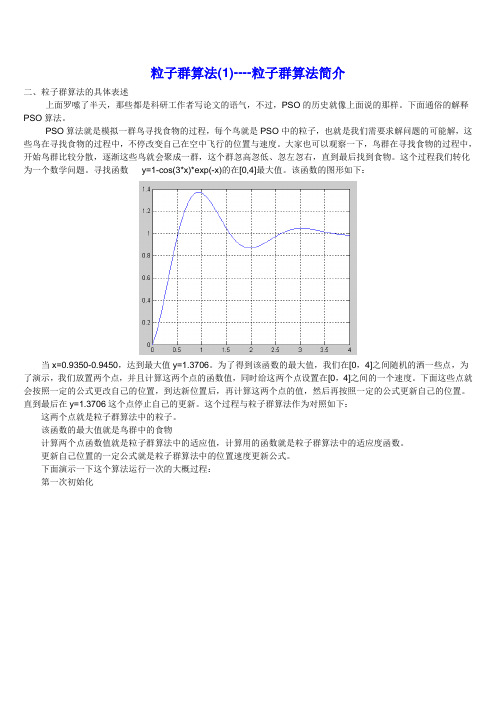
粒子群算法(1)----粒子群算法简介二、粒子群算法的具体表述上面罗嗦了半天,那些都是科研工作者写论文的语气,不过,PSO的历史就像上面说的那样。
下面通俗的解释PSO算法。
PSO算法就是模拟一群鸟寻找食物的过程,每个鸟就是PSO中的粒子,也就是我们需要求解问题的可能解,这些鸟在寻找食物的过程中,不停改变自己在空中飞行的位置与速度。
大家也可以观察一下,鸟群在寻找食物的过程中,开始鸟群比较分散,逐渐这些鸟就会聚成一群,这个群忽高忽低、忽左忽右,直到最后找到食物。
这个过程我们转化为一个数学问题。
寻找函数y=1-cos(3*x)*exp(-x)的在[0,4]最大值。
该函数的图形如下:当x=0.9350-0.9450,达到最大值y=1.3706。
为了得到该函数的最大值,我们在[0,4]之间随机的洒一些点,为了演示,我们放置两个点,并且计算这两个点的函数值,同时给这两个点设置在[0,4]之间的一个速度。
下面这些点就会按照一定的公式更改自己的位置,到达新位置后,再计算这两个点的值,然后再按照一定的公式更新自己的位置。
直到最后在y=1.3706这个点停止自己的更新。
这个过程与粒子群算法作为对照如下:这两个点就是粒子群算法中的粒子。
该函数的最大值就是鸟群中的食物计算两个点函数值就是粒子群算法中的适应值,计算用的函数就是粒子群算法中的适应度函数。
更新自己位置的一定公式就是粒子群算法中的位置速度更新公式。
下面演示一下这个算法运行一次的大概过程:第一次初始化第一次更新位置第二次更新位置第21次更新最后的结果(30次迭代)最后所有的点都集中在最大值的地方。
粒子群算法(2)----标准的粒子群算法在上一节的叙述中,唯一没有给大家介绍的就是函数的这些随机的点(粒子)是如何运动的,只是说按照一定的公式更新。
这个公式就是粒子群算法中的位置速度更新公式。
下面就介绍这个公式是什么。
在上一节中我们求取函数y=1-cos(3*x)*exp(-x)的在[0,4]最大值。
粒子群算法实例讲解

粒子群算法实例讲解
粒子群算法是一种优化算法,可以用于解决许多实际问题。
本文将通过实例讲解粒子群算法的原理和应用。
首先介绍粒子群算法的基本原理:在一个多维空间中,有多个粒子,每个粒子代表一个解,粒子的位置表示解的参数值。
每个粒子有一个速度,可以通过速度来改变位置。
所有粒子共同搜索最优解,每个粒子通过与自己的历史最优解和全局最优解进行比较,调整自身位置和速度。
通过不断迭代,最终可以找到全局最优解。
然后介绍一个实际应用场景:假设有一个工厂,需要生产多种产品,每种产品需要使用不同数量的原材料和人力资源,同时还要满足生产线的生产能力。
如何在满足这些条件的前提下,最大化利润呢?可以使用粒子群算法来求解这个问题。
具体做法是将每种产品的利润作为目标函数,原材料和人力资源的数量作为变量,限制条件是生产线的生产能力。
然后使用粒子群算法进行优化,不断迭代,直到得到最优解,即每种产品的最佳生产数量和使用的原材料和人力资源的数量。
通过这个实例,可以看出粒子群算法的优点:可以处理多维问题,不需要求导,可以避免陷入局部最优解,并且可以处理非线性问题。
同时,粒子群算法还有一些变种和改进,可以进一步提高算法的性能和效率。
综上所述,粒子群算法是一种非常有用的优化算法,可以应用于多种实际问题的求解。
粒子群算法原理

粒子群算法原理
粒子群算法(Particle Swarm Optimization,PSO)是一种基于群体智能的优化算法。
其原理受到鸟群觅食行为的启发,通过模拟鸟群中的协同学习和合作行为来寻求最优解。
PSO算法中,解空间被划分为一定数量的“粒子”。
每个粒子代表一个解,并具有自己的位置和速度。
粒子通过在解空间中移动来逐步搜索最优解。
粒子的速度是算法的核心,它决定了粒子下一步的移动方向和距离。
每个粒子的速度包括两个部分:当前速度和历史最优速度。
当前速度代表了粒子当前的移动方向和距离,历史最优速度代表了粒子在过去的搜索过程中达到的最优速度。
在每一次迭代中,粒子会根据当前速度和历史最优速度进行位置更新。
位置更新的方法是通过加速度来实现的。
加速度由两个部分组成:自身速度和与最优解的距离。
粒子倾向于保持自身速度的一部分,同时也受到距离最优解的吸引力影响。
通过不断迭代,粒子群逐渐向最优解靠近。
在搜索过程中,粒子会根据当前解的适应度评估情况来确定自己的历史最优解,并且会与群体中其他粒子进行信息共享,以便更好地利用群体智慧。
PSO算法的优点是简单、易于理解和实现。
然而,它也存在一些缺点,例如易陷入局部最优解、收敛速度较慢等。
因此,
在具体应用中需要根据问题的特点选择适当的参数和改进方法,以获得更好的优化效果。
粒子群优化算法参数设置

一.粒子群优化算法综述1.6粒子群优化算法的参数设置1.6.1粒子群优化算法的参数设置—种群规模N种群规模N影响着算法的搜索能力和计算量:PSO对种群规模要求不高,一般取20-40就可以达到很好的求解效果,不过对于比较难的问题或者特定类别的问题,粒子数可以取到100或200。
1.6.2粒子的长度D粒子的长度D由优化问题本身决定,就是问题解的长度。
粒子的范围R由优化问题本身决定,每一维可以设定不同的范围。
1.6.3最大速度Vmax决定粒子每一次的最大移动距离,制约着算法的探索和开发能力Vmax的每一维一般可以取相应维搜索空间的10%-20%,甚至100% ,也有研究使用将Vmax按照进化代数从大到小递减的设置方案。
1.6.4惯性权重控制着前一速度对当前速度的影响,用于平衡算法的探索和开发能力一般设置为从0.9线性递减到0.4,也有非线性递减的设置方案;可以采用模糊控制的方式设定,或者在[0.5, 1.0]之间随机取值;设为0.729的同时将c1和c2设1.49445,有利于算法的收敛。
1.6.5压缩因子限制粒子的飞行速度的,保证算法的有效收敛Clerc等人通过数学计算得到取值0.729,同时c1和c2设为2.05 。
1.6.6加速系数c1和c2加速系数c1和c2代表了粒子向自身极值pBest和全局极值gBest推进的加速权值。
c1和c2通常都等于2.0,代表着对两个引导方向的同等重视,也存在一些c1和c2不相等的设置,但其范围一般都在0和4之间。
研究对c1和c2的自适应调整方案对算法性能的增强有重要意义。
1.6.7终止条件终止条件决定算法运行的结束,由具体的应用和问题本身确定。
将最大循环数设定为500,1000,5000,或者最大的函数评估次数,等等。
也可以使用算法求解得到一个可接受的解作为终止条件,或者是当算法在很长一段迭代中没有得到任何改善,则可以终止算法。
1.6.8全局和局部PSO决定算法如何选择两种版本的粒子群优化算法—全局版PSO和局部版PSO,全局版本PSO速度快,不过有时会陷入局部最优;局部版本PSO收敛速度慢一点,不过不容易陷入局部最优。
粒子群算法(PSO)详解

粒子群算法(PSO)详解粒子群算法(Particle Swarm Optimization,PSO)是一种优化算法,通过模拟鸟群中的行为来最优解。
它由美国社会心理学家James Kennedy和Russell Eberhart于1995年提出,被广泛应用于求解各种最优化问题。
PSO算法的基本思想是模拟一群鸟在过程中的行为,每只鸟代表一个解,在解空间中通过调整位置来最优解。
鸟群中的每只鸟都有自己的速度和位置。
整个过程可以描述为以下几个步骤:1.初始化粒子群:随机生成一群粒子的初始位置和速度。
2.计算适应度:对每个粒子,根据其位置计算适应度值。
3.更新全局最优:将最优的粒子的位置作为全局最优位置,用于引导整个群体的。
4.更新速度和位置:每个粒子根据自己的速度和群体的最优位置,更新自己的速度和位置。
5.判断停止条件:判断是否满足停止条件,如果满足则结束,否则返回第3步。
PSO算法的关键在于粒子的速度和位置的更新。
粒子的速度可以看作是粒子在解空间中的方向和速度,而粒子的位置则是根据速度来更新的。
速度和位置的更新可以通过以下公式来实现:速度更新公式:v_i(t + 1) = w * v_i(t) + c1 * rand( *(pbest_i - x_i(t)) + c2 * rand( * (gbest - x_i(t))位置更新公式:x_i(t+1)=x_i(t)+v_i(t+1)其中,v_i(t)表示第i个粒子在时刻t的速度,x_i(t)表示第i个粒子在时刻t的位置,pbest_i表示第i个粒子的个体最优位置,gbest表示全局最优位置,w、c1和c2分别为惯性权重、加速常数1和加速常数2 PSO算法的性能受到参数设置的影响,如权重因子w、加速常数c1和c2的选择,以及粒子数目等。
通常,这些参数需要通过实验进行调整来获得更好的性能。
PSO算法具有以下优点:1.算法原理简单,易于实现。
2.可以在全局和局部之间进行,有较好的收敛性和多样性。
粒子群算法

粒子群算法(PSO)
算法在迭代30次后跳出循环,输出最优解为[0.0202,0.0426],此时目标函数值为 因为我们选用的例子为二次型规划,显然最优解为[0,0],最优值为0。 最后,我们用一个三维动画来展示一下粒子群算法的寻优过程。
粒子群算法(PSO)
一、粒子群算法的概述 粒子群算法(PSO)属于群智能算法的一种,是通过模拟鸟群捕食行为设计的。假设区域里就只有一块 食物(即通常优化问题中所讲的最优解),鸟群的任务是找到这个食物源。鸟群在整个搜寻的过程中,通 过相互传递各自的信息,让其他的鸟知道自己的位置,通过这样的协作,来判断自己找到的是不是最优解, 同时也将最优解的信息传递给整个鸟群,最终,整个鸟群都能聚集在食物源周围,即我们所说的找到了最 优解,即问题收敛。
粒子群算法(PSO)
粒子群算法(PSO)
粒子群算法(PSO)
粒子群算法(PSO)
粒子群优化算法(Particle Swarm Optimization,简称PSO), 由1995年Eberhart博士和Kennedy 博士共同提出,它源于对鸟群捕食行为的研究。粒子群优化算法的基本核心是利用群体中的个体对信息的 共享,从而使得整个群体的运动在问题求解空间中产生从无序到有序的演化过程,从而获得问题的最优解。 假设自己是一只身处鸟群中的鸟,现在要跟随头领去森林里找食物,我们每一只鸟都知道自己离食物的距 离,却又不知道食物在哪个方向。 所以,我们在森林里漫无目地的飞啊飞,每隔一段时间,大家会在微信群里共享一次各自与食物的距离。 然后鸟A发现自己与食物的距离是5公里,而群里鸟Z距离食物最近,只有50米的距离。 鸟A当机立断,在群里说:“我要去那看看!”然后一呼百应,鸟B、鸟C等都往鸟Z方向飞去,在鸟Z的周 围寻找食物。 就这样,本来大家都在沿着自己的方向飞,现在都要向鸟Z的位置靠拢,所以大家需要修改自己的飞行速 度和方向。 但是,当所有鸟儿准备调整自己的飞行轨迹时,鸟H突然想到:虽然现在鸟Z离食物只有50米,但是自己 曾经路过点P,那个位置离食物只有40米,所以它不知道自己是应该往点P方向还是往鸟Z的位置飞去。 鸟H就把自己的纠结发到了微信群里,然后大家一致决定,还是两者平衡一下,对两个位置进行矢量相加, 所以大家共同商量出了速度更新公式粒子群算法源自PSO)粒子群算法(PSO)
粒子群算法求解函数最大值

粒子群优化算法(Particle Swarm Optimization,PSO)是一种基于群体智能的优化算法,它通过模拟鸟群、鱼群等生物群体的行为模式来寻找最优解。
在PSO中,每个解被称为一个粒子,所有的粒子在解空间中飞行,通过不断更新粒子的速度和位置来寻找最优解。
下面是一个简单的粒子群优化算法求解函数最大值的示例代码:pythonimport numpy as np# 目标函数def func(x):return np.sin(5 * x) + np.cos(7 * x)# 粒子群优化算法参数设置num_particles = 100 # 粒子数量num_iterations = 100 # 迭代次数c1 = 2 # 认知因子c2 = 2 # 社会因子w = 0.9 # 惯性权重# 初始化粒子群particles = np.random.rand(num_particles, 1) # 粒子的位置velocities = np.zeros((num_particles, 1)) # 粒子的速度p_best = particles # 每个粒子的最优位置g_best = particles[np.argmax(p_best)] # 全局最优位置# 迭代优化for i in range(num_iterations):for j in range(num_particles):f = func(particles[j]) # 计算粒子适应度值if f > p_best[j]: # 如果找到更好的解,更新个体最优位置p_best[j] = fif max(p_best) > g_best: # 如果找到更好的全局最优位置,更新全局最优位置g_best = max(p_best)velocities = w * velocities + c1 * np.random.rand() * (p_best - particles) + c2 * np.random.rand() * (g_best - particles) # 更新粒子速度和位置particles = particles + velocities # 更新粒子位置print("全局最优位置:", g_best) # 输出全局最优位置和函数值在这个示例代码中,我们使用粒子群优化算法来求解一个简单的目标函数func(x) 的最大值。
粒子群算法

粒子群算法粒子群算法(Particle Swarm Optimization,PSO)是一种群体智能优化算法,它模拟了鸟群觅食行为中个体在信息交流、合作与竞争中寻找最优解的过程。
粒子群算法在解决优化问题中具有较好的效果,尤其适用于连续优化问题。
粒子群算法的基本思想是模拟粒子在解空间中的移动过程,每个粒子代表一个候选解,粒子的位置表示解的一组参数。
每个粒子都有一个速度向量,表示粒子在解空间中的移动方向和速率。
算法的核心是通过更新粒子的位置和速度来搜索目标函数的最优解。
具体来说,粒子的位置和速度更新通过以下公式计算:$$v_i^{t+1} = w\cdot v_i^{t} + c_1 \cdot rand() \cdot (p_i^{best}-x_i^{t}) + c_2 \cdot rand() \cdot (p_g^{best}-x_i^{t})$$$$x_i^{t+1} = x_i^{t} + v_i^{t+1}$$其中,$v_i^{t}$是粒子$i$在时间$t$的速度,$x_i^{t}$是粒子$i$在时间$t$的位置,$p_i^{best}$是粒子$i$自身经历过的最好位置,$p_g^{best}$是整个种群中经历过的最好位置,$w$是惯性权重,$c_1$和$c_2$是加速度因子,$rand()$是一个0到1的随机数。
粒子群算法的优点在于简单、易于理解和实现,同时具有较好的全局搜索能力。
其收敛速度较快,可以处理多维、非线性和非光滑的优化问题。
另外,粒子群算法有较少的参数需要调节,因此适用于许多实际应用中的优化问题。
粒子群算法的应用领域非常广泛,包括机器学习、数据挖掘、图像处理、模式识别、人工智能等。
例如,在机器学习中,粒子群算法可以应用于神经网络的训练和参数优化;在数据挖掘中,粒子群算法可以用于聚类、分类和关联规则挖掘等任务;在图像处理中,粒子群算法可以用于图像分割、边缘检测和特征提取等;在模式识别中,粒子群算法可以用于目标检测和模式匹配等。
粒子群算法ppt课件

粒子群算法Reynolds,Heppner,Grenader等发现,鸟群在行进过程中会突然同步地改变方向,散开或聚集。
一定有种潜在的规则在起作用,据此他们提出了对鸟群行为的模拟。
在他们的早期模型中,仅仅依赖个体间距的操作,即群体的同步是个体之间努力保持最优距离的结果。
1987年Reynolds对鸟群社会系统的仿真研究,一群鸟在空中飞行,每个鸟遵守以下三条规则:1)避免与相邻的鸟发生碰撞冲突;2)尽量与自己周围的鸟在速度上保持协调和一致;3)尽量试图向自己所认为的群体中靠近。
仅通过使用这三条规则,系统就出现非常逼真的群体聚集行为,鸟成群地在空中飞行,当遇到障碍时它们会分开绕行而过,随后又会重新形成群体。
作为CASKennedy和Eberhart在CAS中加入了一个特定点,定义为食物,鸟根据周围鸟的觅食行为来寻找食物。
他们的初衷是希望通过这种模型来模拟鸟群寻找食源的现象,然而实验结果却揭示这个仿真模型中蕴涵着很强的优化能力,尤其是在多维空间寻优中。
鸟群觅食行为Food Global BestSolutionPast BestSolution车辆路径问题构造一个2L维的空间对应有L个发货点任务的VRP问题,每个发货点任务对应两维:完成该任务车辆的编号k,该任务在k车行驶路径中的次序r为表达和计算方便,将每个粒子对应的2L维向量X分成两个L维向量:Xv(表示各任务对应的车辆)和Xr(表示各任务在对应的车辆路径中的执行次序)。
例如,设VRP问题中发货点任务数为7,车辆数为3,若某粒子的位置向量X为:发货点任务号: 1 2 3 4 5 6 7Xv : 1 2 2 2 2 3 3Xr : 1 4 3 1 2 2 1则该粒子对应解路径为:车1:0 → 1 → 0车2:0 → 4 →5 → 3→ 2→ 0车3:0 → 7→ 6→ 0粒子速度向量V与之对应表示为Vv和Vr。
该表示方法的最大优点是使每个发货点都得到车辆的配送服务,并限制每个发货点的需求仅能由某一车辆来完成,使解的可行化过程计算大大减少。
粒子群算法因子取值

粒子群算法因子取值粒子群算法(Particle Swarm Optimization, PSO)是一种模拟自然界中鸟群鱼群等群体行为的优化算法,其原理是通过信息交流和个体学习来寻找问题的最优解。
在实际应用中,粒子群算法的效果很大程度上取决于一系列因素的取值。
本文将就粒子群算法中常见的因素进行详细介绍和讨论。
1. 群体大小(Swarm Size)群体大小是指粒子群算法中同时运行的粒子数量。
一般情况下,群体的大小越大,算法搜索效果越好,但同时也会带来更高的计算代价和更长的计算时间。
因此,一般而言,群体大小不宜过大,通常为几百到一千个粒子。
2. 惯性权重(Inertia Weight)惯性权重是指粒子在运动中保持原有速度的程度,主要用于控制粒子的移动距离和速度,从而影响算法的全局搜索和局部搜索能力。
一般来说,惯性权重的取值范围为(0,1),在初始阶段一般取值较大以快速搜索整个解空间,而在后期逐渐减小以便更好地找到全局最优解。
目前较为常用的惯性权重下降方式有线性下降、非线性下降和宽广式下降三种。
3. 加速常数(Acceleration Coefficients)加速常数是指用于计算粒子速度的常数,主要分为个体加速常数和社会加速常数。
其中,个体加速常数表示粒子在搜索过程中被自身最优解所吸引的程度,社会加速常数表示粒子被全局最优解所吸引的程度。
一般来说,个体加速常数和社会加速常数的取值范围为(0,1.5),其中个体加速常数的取值比较敏感,一般取0.5左右较为合适。
4. 粒子位置初始化范围(Position Range)粒子位置初始化范围表示粒子初始位置的取值范围,一般来说,粒子初始位置的随机性对于算法的全局搜索和局部搜索效果都有很大影响。
经验上,较好的取值范围为[-5,5]到[-10,10]之间。
6. 最大迭代次数(Maximum Iterations)最大迭代次数是指算法最大的运行次数。
一般来说,当算法达到最大迭代次数后,即停止迭代并返回当前的最优解。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
粒子群算法粒子个数
粒子群算法中粒子个数的计算方法通常有以下几种:
1. 经验法则:根据经验公式来设定。
例如,对于一般性问题,粒子数一般取20~40;对于较为复杂的问题,粒子数则取50~100。
2. 实验法则:通过一定的实验来确定。
从小到大逐渐增加粒子数,直到算法的收敛速度趋于平缓,此时的粒子数即为最优粒子数。
3. 网格法则:根据问题的维数来设定。
一般来说,对于每个维度,将其范围等分为10~20份,粒子数取各维度粒子数之积。
需要注意的是,粒子数的多少对算法的运行效率和结果质量都有影响。
过少的粒子数会导致算法的局限性,而过多的粒子数则会使算法的收敛速度变慢。
因此,选择合适的粒子数是粒子群算法优化的关键。