粒子群算法粒子群算法简介
粒子群算法原理

粒子群算法原理粒子群算法(ParticleSwarmOptimization,简称PSO)是一种基于群体智能的启发式算法,它由Ken Kennedy和James Kennedy在1995年发明,其目的是模拟物种在搜寻食物路线的过程。
PSO的思路同于生物群体中存在的社会行为,它根据所有参与计算的粒子(即搜索者)以及它们的历史经验进行搜索,以寻找最优解。
在这里,最优解是指可以满足我们的要求的最佳结果(给定的目标函数的最小值)。
PSO把一个群体看成一组搜索者,每个搜索者搜索有一个动态位置,每一步采用一个较优位置取代先前的位置,称之为粒子。
每个粒子都具有一个当前位置,一个速度,一个粒子最佳位置(全局最佳位置)和一个全局最佳位置(群体最佳位置)。
粒子群算法是一种迭代优化算法,它由以下4个步骤组成:1.始化粒子群:在此步骤中,使用随机算法给每个粒子分配初始位置和速度,通常使用均匀分布。
2.解目标函数:计算每个粒子的位置对应的目标函数值,并记录每个粒子的最佳位置以及群体最佳位置。
3.新粒子位置:根据群体最佳位置和每个粒子的最佳位置,更新每个粒子的位置以及速度,它们的新的位置和速度可以使用如下公式来计算:V(t+1)=V(t)+C1*rand(1)*(Pbest(t)-X(t))+C2*rand(2)*(Gbest(t) -X(t))X(t+1)=X(t)+V(t+1)其中,C1和C2是可调的引力系数,rand(1)和rand(2)是随机数,Pbest(t)和Gbest(t)分别表示每个粒子和群体中最佳位置。
4.复步骤2和3,直到收敛或者达到最大迭代次数。
由于粒子群算法有效而且简单,它已经在许多领域应用,比如多目标优化、复杂系统建模、神经网络训练等。
尽管PSO有许多优点,但它也有一些不足,比如,它可能不能收敛到全局最优解,可能会被局部最优解所困扰。
另外,由于其简单的搜索过程,它的计算速度很快,但是它的搜索效率可能不太高。
粒子群优化算法介绍

粒子群优化算法介绍
粒子群优化算法(Particle Swarm Optimization,PSO)是一种
基于群体智能的优化方法,其中包含了一组粒子(代表潜在解决方案)在n维空间中进行搜索,通过找到最优解来优化某个问题。
在PSO的
过程中,每个粒子根据自身当前的搜索位置和速度,在解空间中不断
地寻找最优解。
同时,粒子也会通过与周围粒子交换信息来寻找更好
的解。
这种信息交换模拟了鸟群或鱼群中的信息交流行为,因此PSO
算法也被称为群体智能算法。
由于其并行搜索和对局部最优解的较好处理,PSO算法在多个领
域均得到了广泛应用。
其中最常用的应用之一是在神经网络和其他机
器学习算法中用来寻找最优解。
此外,PSO算法在图像处理、数据挖掘、机器人控制、电力系统优化等领域也有着广泛的应用。
PSO算法的核心是描述每个粒子的一组速度和位置值,通常使用
向量来表示。
在PSO的初始化阶段,每个粒子在解空间中随机生成一
个初始位置和速度,并且将其当前位置作为当前最优解。
然后,每个
粒子在每次迭代(即搜索过程中的每一次)中根据当前速度和位置,
以及粒子群体中的最优解和全局最优解,更新其速度和位置。
PSO算法的重点在于如何更新各个粒子的速度向量,以期望他们能够快速、准
确地达到全局最优解。
总之, PSO算法是一种群体智能算法,目的是通过模拟粒子在解
空间中的移动来优化某个问题。
由于其简单、有效且易于实现,因此PSO算法在多个领域得到了广泛应用。
粒子群算法与麻雀算法

粒子群算法与麻雀算法
粒子群算法(Particle Swarm Optimization,PSO)是一种基于
群体智能的优化算法,灵感来自于鸟群或鱼群等集体群体的行为。
该算法通过模拟鸟群中的“探索-利用”策略来寻找优化问
题的最优解。
粒子群算法中,将问题的解空间看作是一群粒子组成的群体。
每个粒子代表一个潜在的解,具有位置和速度两个属性。
算法通过不断迭代更新粒子的位置和速度,使得群体中的每个粒子能够根据自己的历史经验和群体的经验进行自我调整,逐渐向最优解位置靠近。
麻雀算法(Sparrow Search Algorithm,SSA)是一种基于麻雀
搜索行为的优化算法。
麻雀在觅食过程中具有较强的搜索能力,其搜索行为灵活且高效。
麻雀算法通过模拟麻雀的觅食过程,以及麻雀之间的信息共享和学习行为,来求解优化问题。
麻雀算法中,将问题的解空间看作是一片区域,该区域被分为若干个小区域(称为“巢”),每个巢内栖息着一个麻雀(对应一个潜在的解)。
算法通过不断迭代更新麻雀的位置和速度,使得每只麻雀能够根据自身经验和周围麻雀的信息进行学习和搜索,进而逐渐找到最优解。
总的来说,粒子群算法和麻雀算法都是基于群体智能的优化算法,通过模拟群体行为来解决优化问题。
它们具有一定的相似之处,但也有着不同的算法机制和策略。
具体使用哪种算法取决于问题特点和求解需求。
粒子群算法简介

粒子群算法简介粒子群算法是一种常见的优化算法,它以鸟群捕食的过程为模型,通过模拟每个个体在搜索空间中的位置和速度变化,来寻找最优解。
本文将从算法流程、算法优势、应用领域等方面给出详细介绍。
一、算法流程1. 随机初始化群体中每个粒子的位置和速度;2. 评估每个粒子的适应度;3. 根据粒子历史最优位置和全局最优位置,更新粒子速度和位置;4. 重复步骤2、3直到满足停止条件。
粒子群算法的核心在于更新粒子速度和位置,其中位置表示搜索空间中的一个解,速度表示搜索方向和距离。
每个粒子具有自己的历史最优位置,同时全局最优位置则是所有粒子中适应度最优的解。
通过粒子之间的信息共享,使得整个群体能够从多个方向进行搜索,并最终收敛于全局最优解。
二、算法优势粒子群算法具有以下几个优势:1. 算法简单易于实现。
算法设计简单,无需求导和约束,易于编程实现。
2. 全局搜索能力强。
由于粒子之间的信息共享,整个群体具有多种搜索方向,可以有效避免局部最优解问题。
3. 收敛速度较快。
粒子搜索过程中,速度会受历史最优位置和全局最优位置的引导,使得整个群体能够较快向最优解方向靠近。
三、应用领域粒子群算法是一种通用的优化算法,广泛应用于各个领域,包括机器学习、智能控制、模式识别等。
具体应用场景如下:1. 遗传算法的优化问题,例如TSP问题等。
2. 数据挖掘中的聚类分析、神经网络训练等问题。
3. 工业控制、无人机路径规划等实际应用问题。
总之,粒子群算法是一种搜索优化方法,可以为我们解决各种实际应用问题提供帮助。
粒子群算法(基础精讲)课件

神经网络训练
神经网络训练是指通过训练神经网络来使其能够学习和模拟特定的输入输出关系 。粒子群算法可以应用于神经网络的训练过程中,通过优化神经网络的参数来提 高其性能。
例如,在机器视觉、语音识别、自然语言处理等领域中,神经网络被广泛应用于 各种任务。粒子群算法可以用于优化神经网络的结构和参数,从而提高其分类、 预测等任务的准确性。
优势
在许多优化问题中,粒子群算法表现出了良好的全局搜索能 力和鲁棒性,尤其在处理非线性、多峰值等复杂问题时具有 显著优势。
粒子群算法的核心要素
02
粒子个体
01
粒子
在粒子群算法中,每个解被称为一个粒子,代表问题的 一个潜在解。
02
粒子状态
每个粒子的位置和速度决定了其状态,其中位置表示解 的优劣,速度表示粒子改变方向的快慢。
社会认知策略的引入
总结词
引入社会认知策略可以增强粒子的社会性,提高算法的群体协作能力。
详细描述
社会认知策略是一种模拟群体行为的方法,通过引入社会认知策略,可以增强粒子的社会性,提高算 法的群体协作能力。在粒子群算法中引入社会认知策略,可以使粒子更加关注群体最优解,促进粒子 之间的信息交流和协作,从而提高算法的全局搜索能力和鲁棒性。
03 粒子群算法的实现步骤
初始化粒子群
随机初始化粒子群的 位置和速度。
初始化粒子的个体最 佳位置为随机位置, 全局最佳位置为随机 位置。
设置粒子的个体最佳 位置和全局最佳位置 。
更新粒子速度和位置
根据粒子个体和全局最佳位置计 算粒子的速度和位置更新公式。
更新粒子的速度和位置,使其向 全局最佳位置靠近。
每个粒子都有一个记录其历史最 佳位置的变量,用于指导粒子向
粒子群算法介绍

1.介绍:粒子群算法(Particle Swarm Optimization, PSO)最早是由Eberhart 和Kennedy于1995年提出,它的基本概念源于对鸟群觅食行为的研究。
设想这样一个场景:一群鸟在随机搜寻食物,在这个区域里只有一块食物,所有的鸟都不知道食物在哪里,但是它们知道当前的位置离食物还有多远。
那么找到食物的最优策略是什么呢?最简单有效的就是搜寻目前离食物最近的鸟的周围区域。
经过实践证明:全局版本的粒子群算法收敛速度快,但是容易陷入局部最优。
局部版本的粒子群算法收敛速度慢,但是很难陷入局部最优。
现在的粒子群算法大都在收敛速度与摆脱局部最优这两个方面下功夫。
其实这两个方面是矛盾的。
看如何更好的折中了。
粒子群算法主要分为4个大的分支:(1)标准粒子群算法的变形在这个分支中,主要是对标准粒子群算法的惯性因子、收敛因子(约束因子)、“认知”部分的c1,“社会”部分的c2进行变化与调节,希望获得好的效果。
惯性因子的原始版本是保持不变的,后来有人提出随着算法迭代的进行,惯性因子需要逐渐减小的思想。
算法开始阶段,大的惯性因子可以是算法不容易陷入局部最优,到算法的后期,小的惯性因子可以使收敛速度加快,使收敛更加平稳,不至于出现振荡现象。
经过本人测试,动态的减小惯性因子w,的确可以使算法更加稳定,效果比较好。
但是递减惯性因子采用什么样的方法呢?人们首先想到的是线型递减,这种策略的确很好,但是是不是最优的呢?于是有人对递减的策略作了研究,研究结果指出:线型函数的递减优于凸函数的递减策略,但是凹函数的递减策略又优于线型的递减,经过本人测试,实验结果基本符合这个结论,但是效果不是很明显。
对于收敛因子,经过证明如果收敛因子取0.729,可以确保算法的收敛,但是不能保证算法收敛到全局最优,经过本人测试,取收敛因子为0.729效果较好。
对于社会与认知的系数c2,c1也有人提出:c1先大后小,而c2先小后大的思想,因为在算法运行初期,每个鸟要有大的自己的认知部分而又比较小的社会部分,这个与我们自己一群人找东西的情形比较接近,因为在我们找东西的初期,我们基本依靠自己的知识取寻找,而后来,我们积累的经验越来越丰富,于是大家开始逐渐达成共识(社会知识),这样我们就开始依靠社会知识来寻找东西了。
粒子群算法、多目标粒子群算法、的关系

粒子群算法、多目标粒子群算法、的关系
粒子群算法(PSO)是一种优化算法,其灵感来源于鸟群的行为。
多目标粒子群算法(MOPSO)是在PSO基础上发展出来的多目标优化算法。
它们之间有以下关系:
1. PSO是MOPSO的基础
MOPSO是在PSO算法基础上发展而成的,因此PSO算法可以看作是MOPSO的基础。
PSO算法是单目标优化算法,即优化过程中只考虑一个目标函数的优化。
而MOPSO算
法则是多目标优化算法,它能够同时考虑多个目标函数的优化。
在MOPSO算法中,每个粒
子都有多个适应度值,称为解的评价指标。
3. MOPSO涉及到Pareto前沿思想
MOPSO算法是建立在Pareto优化理论的基础上的。
通过Pareto前沿思想,它能够找到一组最优解,这些最优解在所有评价指标上都是最优的,而且它们之间是非支配的。
4. MOPSO使用非支配排序技术和拥挤度算子
为了提高MOPSO算法的搜索效率和优化结果的多样性,MOPSO引入了非支配排序技术
和拥挤度算子。
非支配排序技术可以将所有解分为几个等级,拥挤度算子则能够增加解的
多样性,以保证搜索空间较为均匀地被覆盖。
在求解真实问题时,PSO和MOPSO都有很广泛的应用领域。
PSO通常用于单目标优化问题、动态优化问题和基于约束的优化问题等。
MOPSO则更多地应用于多目标优化问题领域,如飞行器设计、供应链优化、水资源管理等。
粒子群算法粒子群算法简介
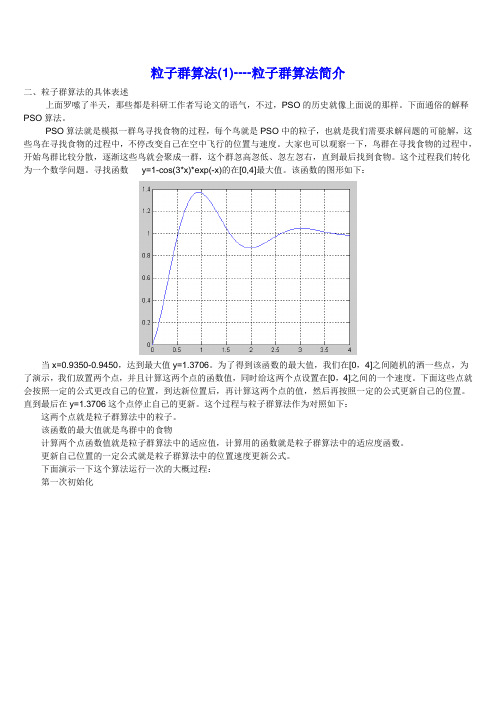
粒子群算法(1)----粒子群算法简介二、粒子群算法的具体表述上面罗嗦了半天,那些都是科研工作者写论文的语气,不过,PSO的历史就像上面说的那样。
下面通俗的解释PSO算法。
PSO算法就是模拟一群鸟寻找食物的过程,每个鸟就是PSO中的粒子,也就是我们需要求解问题的可能解,这些鸟在寻找食物的过程中,不停改变自己在空中飞行的位置与速度。
大家也可以观察一下,鸟群在寻找食物的过程中,开始鸟群比较分散,逐渐这些鸟就会聚成一群,这个群忽高忽低、忽左忽右,直到最后找到食物。
这个过程我们转化为一个数学问题。
寻找函数y=1-cos(3*x)*exp(-x)的在[0,4]最大值。
该函数的图形如下:当x=0.9350-0.9450,达到最大值y=1.3706。
为了得到该函数的最大值,我们在[0,4]之间随机的洒一些点,为了演示,我们放置两个点,并且计算这两个点的函数值,同时给这两个点设置在[0,4]之间的一个速度。
下面这些点就会按照一定的公式更改自己的位置,到达新位置后,再计算这两个点的值,然后再按照一定的公式更新自己的位置。
直到最后在y=1.3706这个点停止自己的更新。
这个过程与粒子群算法作为对照如下:这两个点就是粒子群算法中的粒子。
该函数的最大值就是鸟群中的食物计算两个点函数值就是粒子群算法中的适应值,计算用的函数就是粒子群算法中的适应度函数。
更新自己位置的一定公式就是粒子群算法中的位置速度更新公式。
下面演示一下这个算法运行一次的大概过程:第一次初始化第一次更新位置第二次更新位置第21次更新最后的结果(30次迭代)最后所有的点都集中在最大值的地方。
粒子群算法(2)----标准的粒子群算法在上一节的叙述中,唯一没有给大家介绍的就是函数的这些随机的点(粒子)是如何运动的,只是说按照一定的公式更新。
这个公式就是粒子群算法中的位置速度更新公式。
下面就介绍这个公式是什么。
在上一节中我们求取函数y=1-cos(3*x)*exp(-x)的在[0,4]最大值。
进化算法粒子群算法

进化算法粒子群算法一、概述粒子群优化算法(Particle Swarm Optimization, PSO)是模拟自然界中鸟群行为的一种进化计算算法。
算法最初由Kenny Eberhart和Russel Eberhart在1995年提出,它受到知名的“遗传算法”的启发,也可以被看作是“社会学”的一种延伸。
粒子群算法由一系列算法组成,是多目标优化的一种重要方法,它的理论较少,只是建立在适者生存的自然进化和社群行为的建模的基础之上。
二、工作原理粒子群优化算法包含以下步骤:1. 用随机方式在给定搜索空间内选取N个粒子,每个粒子即为一个个体,用位置X和速度V表示;2. 根据位置X计算每个粒子的适应值,即其个体的得分;3. 根据每个粒子的位置和适应值,计算通知搜索位置,如最大有效值;4. 更新每个粒子的位置和速度,以致贴近最大有效值;5. 重复步骤2~4计算每一代中粒子位置和速度,直到最大有效值稳定或达到最大迭代次数;6. 终止迭代,输出找到的最大有效值及粒子位置。
三、几何表示$$V_i = (v_{ix}, v_{iy})$其中P为每个粒子的位置,V为每个粒子的速度,i为第i个粒子的的索引。
四、优势PSO算法有着快速收敛、拓展性强等好处:(1)PSO算法在搜索收敛非常快,往往可以在1000步之内就能够找到较优解。
(2)PSO算法可以实现多维度和多域的搜索,不仅可以应用于多变量函数最优化,也可以应用于多维度及多域场景,而且简单易行。
(3)PSO算法可以有效解决经典最优化问题,比如坐标计算、非线性方程组等,也可以应用于机器学习、数据挖掘等,但这些应用仍处于探索阶段。
粒子群算法简介优缺点及其应用

类似于人的“原动力”,如果原动力比较大,当达到某个目 标的时候,会继续向前实现更高的目标:如果原动力较小,到 达某个目标就停滞。
2024/2/19
第18页/共29页
17
Shi和Eberhart提出了一种随着算法迭代次数的增加惯性权重线 性下降的方法。
惯性权重的计算公式如下:
max
max min
kmax
kn
max和min分别表示权重的最大及最小值,kn为当前迭代次数, kmax表示最大迭代次数。
文献试验了将设置为从0.9到0.4的线性下降,使得PSO在开 始时探索较大的区域,较快地定位最优解的大致位置,随着 逐渐减小,粒子速度减慢,开始精细的局部搜索。该方法使 PSO更好地控制exploration和exploitation能力,加快了收敛速 度,提高了算法的性能,称之为权重线性下降的粒子群算法, 简记为LDW(Linearly Decreasing Inertia Weight)。
速度为 vi vi1, vi2,viN T
在找到两个最优解后,粒子即可根据下式来更新自己的速度和 位置:
vk 1 id
vikd
c1 rand1k
(Pbestikd
xikd ) c2
rand
k 2
(Gbest
k d
xikd
)
(1)
x k 1 id
xikd
v k 1 id
(2)
vikd :是粒子i在第k次迭代中第d维的速度;
公式(1)的第一项对应多样化(diversification)的特点,第二项、 第三项对应于搜索过程的集中化(intensification)特点,这三项之 间的相互平衡和制约决定了算法的主要性能。
粒子群算法多维度应用实例

粒子群算法多维度应用实例全文共四篇示例,供读者参考第一篇示例:粒子群算法(Particle Swarm Optimization,PSO)是一种启发式优化算法,模拟了鸟群、鱼群等群体协作的行为,通过不断调整粒子的位置和速度来搜索最优解。
近年来,粒子群算法在多个领域中得到了广泛应用,特别是在多维度应用方面,展现出了强大的优化性能和较好的收敛速度。
本文将介绍粒子群算法在多维度应用中的实例,并探讨其优势和局限性。
一、多维度优化问题概述二、粒子群算法原理及优化过程粒子群算法是由Kennedy和Eberhart于1995年提出的,其基本思想是模拟鸟群或鱼群等群体在搜索空间中寻找目标的行为。
在粒子群算法中,每个粒子表示一个潜在的解,其位置和速度都会根据其个体最优解和全局最优解而不断更新。
粒子群算法的优化过程如下:(1)初始化粒子群:随机生成一定数量的粒子,并为每个粒子设定初始位置和速度。
(2)评估粒子适应度:计算每个粒子的适应度值,即目标函数的值。
(3)更新粒子速度和位置:根据粒子历史最优解和全局最优解来更新粒子的速度和位置。
(4)重复步骤(2)和(3)直到满足停止条件:当满足一定停止条件时,算法停止,并输出全局最优解。
三、粒子群算法在多维度应用中的实例1. 工程设计优化在工程设计中,往往需要优化多个设计参数以满足多个性能指标。
飞机机翼的设计中需要考虑多个参数,如翼展、翼型、翼厚等。
通过粒子群算法可以有效地搜索这些参数的最优组合,从而使飞机性能达到最佳。
2. 机器学习参数优化在机器学习中,通常需要调整多个超参数(如学习率、正则化系数等)以优化模型的性能。
粒子群算法可以应用于优化这些超参数,从而提高机器学习模型的泛化能力和准确度。
3. 经济模型参数拟合在经济模型中,经常需要通过拟合参数来分析经济现象和预测未来走势。
粒子群算法可以用来调整模型参数,从而使模型更好地拟合实际数据,提高预测准确度。
1. 全局搜索能力强:粒子群算法具有很强的全局搜索能力,能够在高维度空间中搜索到全局最优解。
粒子群算法论文

VS
详细描述
组合优化问题是指在一组离散的元素中寻 找最优解的问题,如旅行商问题、背包问 题等。粒子群算法通过模拟群体行为进行 寻优,能够有效地求解这类问题。例如, 在旅行商问题中,粒子群算法可以用来寻 找最短路径;在背包问题中,粒子群算法 可以用来寻找最大化的物品价值。
粒子群算法在组合优化问题中的应用
粒子群算法论文
目录
CONTENTS
• 粒子群算法概述 • 粒子群算法的理论基础 • 粒子群算法的改进与优化 • 粒子群算法的实际应用 • 粒子群算法的未来展望
01 粒子群算法概述
粒子群算法的基本原理
粒子群算法是一种基于群体智能的优化算法,通过模拟鸟群、鱼群等生物群体的行 为规律,利用粒子间的信息共享和协作机制,寻找最优解。
高模型的决策能力和性能。
05 粒子群算法的未来展望
粒子群算法与其他智能算法的融合研究
融合遗传算法
通过引入遗传算法的变异、交叉和选 择机制,增强粒子群算法的搜索能力 和全局寻优能力。
混合粒子群优化
结合其他优化算法,如模拟退火、蚁 群算法等,形成混合优化策略,以处 理多目标、约束和大规模优化问题。
粒子群算法的理论基础深入研究
通过对粒子群算法的收敛性进行分析, 可以发现算法在迭代过程中粒子的分 布规律以及最优解的稳定性,有助于 优化算法参数和提高算法性能。
粒子群算法的参数优化
参数优化是提高粒子群算法性能 的关键步骤之一,主要涉及粒子 数量、惯性权重、学习因子等参
数的调整。
通过对参数进行优化,可以改善 粒子的搜索能力和全局寻优能力,
总结词
粒子群算法在机器学习中可以用于特征选择、模型选择 和超参数调整等方面。
详细描述
机器学习是人工智能领域的一个重要分支,旨在通过训 练数据自动地学习和提取有用的特征和规律。粒子群算 法可以应用于机器学习的不同方面,如特征选择、模型 选择和超参数调整等。通过模拟群体行为进行寻优,粒 子群算法可以帮助机器学习模型找到最优的特征组合、 模型参数和超参数配置,从而提高模型的性能和泛化能 力。
粒子群算法基本流程

粒子群算法基本流程粒子群算法(Particle Swarm Optimization, PSO)是一种基于自然界群体智能现象的优化算法,常用于解决各种优化问题,如函数优化、组合优化、机器学习等。
本文将详细介绍粒子群算法的基本流程,包括初始化、适应度评价、移动、更新等环节,希望能对读者理解该算法提供一定的帮助。
一、算法介绍粒子群算法最初由Kennedy和Eberhart于1995年提出 [1],其基本思想来源于鸟群觅食行为。
在野外觅食时,鸟群中的鸟会根据所找到的食物数量来确定自己下一步的移动方向。
PSO算法中的“粒子”类似于鸟群中的鸟,它们以个体和群体为导向,通过速度和位置的调整来进行优化搜索。
PSO算法的目标是寻找最优解,通常是最小化或最大化一个函数的值,可表示为:f(x)=\sum_{i=1}^n{f_i(x)}x 是 n 维实数向量,f_i(x) 表示第 i 个函数。
寻找最优解的目标就是在 x 的搜索空间中寻找函数 f(x) 的全局最优解或局部最优解。
二、基本流程粒子群算法的基本流程如下:1. 初始化:随机生成一群粒子,每个粒子的位置和速度都是随机的。
2. 适应度评价:计算每个粒子的适应度值,也就是函数 f(x) 所对应的值,用来表示该粒子所处的位置的优劣程度。
3. 移动:根据当前位置和速度,移动粒子到新的位置。
4. 更新:根据历史上最好的粒子位置和当前最好的粒子位置,更新每个粒子的历史最好位置和当前最好位置,并更新全局最优位置。
5. 终止:当满足一定的终止条件时,停止迭代,并输出最终的粒子位置和最优解。
下文将分别对各环节进行详细介绍。
三、初始化在PSO算法中,粒子的位置和速度都是随机的。
对于每个粒子,需要随机生成一个 n 维实数向量表示其位置,一个同维度的实数向量表示其速度。
可以采用如下方法进行初始化:1. 对于每一个维度,随机生成一个实数范围内的数值,表示该维度上的位置和速度。
2. 在满足约束条件的前提下,生成一个可行解,作为初始化的位置。
matlab工具箱粒子群算法

MATLAB工具箱是一款强大的工具软件,可以用来进行各种科学计算和工程设计。
其中,粒子裙算法(PSO)作为一种优化算法,被广泛应用于多个领域,例如机器学习、智能优化、控制系统等。
本文将详细介绍PSO算法及其在MATLAB工具箱中的应用。
一、粒子裙算法的基本原理粒子裙算法是一种模拟自然界裙体行为的优化算法,其基本原理是模拟鸟裙或鱼裙在搜索食物或迁徙时的行为。
在PSO算法中,被优化的问题被视为一个多维空间中的搜索空间,而每个“粒子”则代表了空间中的一个候选解。
这些粒子在空间中移动,并根据自身的经验和裙体的协作信息来调整其移动方向和速度,最终找到最优解。
二、PSO算法的优化流程1.初始化种裙:在开始时,随机生成一定数量的粒子,并为每个粒子随机分配初始位置和速度。
2.评估粒子适应度:根据问题的特定目标函数,计算每个粒子在当前位置的适应度值。
3.更新粒子速度和位置:根据粒子的个体经验和裙体协作信息,更新每个粒子的速度和位置。
4.更新全局最优解:根据所有粒子的适应度值,更新全局最优解。
5.检查停止条件:重复步骤2-4,直到满足停止条件。
三、PSO算法在MATLAB工具箱中的应用在MATLAB工具箱中,PSO算法被实现为一个函数,可以通过简单的调用来进行优化问题的求解。
以下是一个简单的PSO算法示例:```matlab定义目标函数objFunc = (x) x(1)^2 + x(2)^2;设置PSO参数options = optimoptions(particleswarm, 'SwarmSize', 100,'MaxIterations', 100);调用PSO算法[x, fval] = particleswarm(objFunc, 2, [], [], options);```以上代码中,首先定义了一个目标函数objFunc,然后设置了PSO算法的参数options,最后通过调用particleswarm函数来进行优化求解。
粒子群算法

粒子群算法(PSO)
算法在迭代30次后跳出循环,输出最优解为[0.0202,0.0426],此时目标函数值为 因为我们选用的例子为二次型规划,显然最优解为[0,0],最优值为0。 最后,我们用一个三维动画来展示一下粒子群算法的寻优过程。
粒子群算法(PSO)
一、粒子群算法的概述 粒子群算法(PSO)属于群智能算法的一种,是通过模拟鸟群捕食行为设计的。假设区域里就只有一块 食物(即通常优化问题中所讲的最优解),鸟群的任务是找到这个食物源。鸟群在整个搜寻的过程中,通 过相互传递各自的信息,让其他的鸟知道自己的位置,通过这样的协作,来判断自己找到的是不是最优解, 同时也将最优解的信息传递给整个鸟群,最终,整个鸟群都能聚集在食物源周围,即我们所说的找到了最 优解,即问题收敛。
粒子群算法(PSO)
粒子群算法(PSO)
粒子群算法(PSO)
粒子群算法(PSO)
粒子群优化算法(Particle Swarm Optimization,简称PSO), 由1995年Eberhart博士和Kennedy 博士共同提出,它源于对鸟群捕食行为的研究。粒子群优化算法的基本核心是利用群体中的个体对信息的 共享,从而使得整个群体的运动在问题求解空间中产生从无序到有序的演化过程,从而获得问题的最优解。 假设自己是一只身处鸟群中的鸟,现在要跟随头领去森林里找食物,我们每一只鸟都知道自己离食物的距 离,却又不知道食物在哪个方向。 所以,我们在森林里漫无目地的飞啊飞,每隔一段时间,大家会在微信群里共享一次各自与食物的距离。 然后鸟A发现自己与食物的距离是5公里,而群里鸟Z距离食物最近,只有50米的距离。 鸟A当机立断,在群里说:“我要去那看看!”然后一呼百应,鸟B、鸟C等都往鸟Z方向飞去,在鸟Z的周 围寻找食物。 就这样,本来大家都在沿着自己的方向飞,现在都要向鸟Z的位置靠拢,所以大家需要修改自己的飞行速 度和方向。 但是,当所有鸟儿准备调整自己的飞行轨迹时,鸟H突然想到:虽然现在鸟Z离食物只有50米,但是自己 曾经路过点P,那个位置离食物只有40米,所以它不知道自己是应该往点P方向还是往鸟Z的位置飞去。 鸟H就把自己的纠结发到了微信群里,然后大家一致决定,还是两者平衡一下,对两个位置进行矢量相加, 所以大家共同商量出了速度更新公式粒子群算法源自PSO)粒子群算法(PSO)
粒子群算法原理

粒子群算法原理粒子群算法原理是一种基于优化的算法,它利用一组无序的粒子来搜索整个可能的解决方案空间,以找出最佳的解决方案。
粒子群算法(PSO)是一种迭代优化算法,它采用群体行为思想,相当于一群鸟类在搜寻食物,以及其他任何生活必需品,它们通过互相之间的协作来实现,而不是通过教师或者其他外部干预。
粒子群算法由三个基本要素组成:粒子、适应度函数和社会因素。
粒子代表算法中的搜索空间,每个粒子都有一个位置和一个速度,它们根据适应度函数和社会因素来移动,最终形成群体行为模式。
粒子群算法的运行有两个步骤:第一步是更新粒子的位置,第二步是更新粒子的速度。
在更新粒子的位置时,粒子的位置由其当前位置,当前速度,以及社会因素和个体因素(如最优位置)的影响共同决定。
更新粒子的速度时,粒子的速度由其当前位置,当前速度,最优位置,个体因素和社会因素的影响共同决定。
粒子群算法还有一个自适应模块,可以根据算法的运行状态和工作情况,动态调整粒子的速度和位置,以达到更好的优化效果。
最后,算法将根据粒子群当前的位置,最优位置,以及其他因素,来搜索出最优解。
粒子群算法能够有效解决多维非线性优化问题,并且能够找到更加优化的解决方案。
它的优势在于可以解决复杂的最优化问题,而且可以快速逼近最优解,运行时间比较短。
粒子群算法也有一些缺点,其中最大的缺点就是可能会陷入局部最优解,而不能找到全局最优解。
此外,粒子群算法还存在参数设置的难度,它需要调整大量的参数以获得最佳的性能,而且可能会出现运行时间过长的情况。
总之,粒子群算法是一种有效的优化算法,它可以有效地解决多维非线性优化问题,并且可以快速找到更优的解决方案。
但是在使用这种算法时,需要注意参数设置和潜在的陷入局部最优解的风险。
粒子群算法

粒子群算法粒子群算法(Particle Swarm Optimization,PSO)是一种群体智能优化算法,它模拟了鸟群觅食行为中个体在信息交流、合作与竞争中寻找最优解的过程。
粒子群算法在解决优化问题中具有较好的效果,尤其适用于连续优化问题。
粒子群算法的基本思想是模拟粒子在解空间中的移动过程,每个粒子代表一个候选解,粒子的位置表示解的一组参数。
每个粒子都有一个速度向量,表示粒子在解空间中的移动方向和速率。
算法的核心是通过更新粒子的位置和速度来搜索目标函数的最优解。
具体来说,粒子的位置和速度更新通过以下公式计算:$$v_i^{t+1} = w\cdot v_i^{t} + c_1 \cdot rand() \cdot (p_i^{best}-x_i^{t}) + c_2 \cdot rand() \cdot (p_g^{best}-x_i^{t})$$$$x_i^{t+1} = x_i^{t} + v_i^{t+1}$$其中,$v_i^{t}$是粒子$i$在时间$t$的速度,$x_i^{t}$是粒子$i$在时间$t$的位置,$p_i^{best}$是粒子$i$自身经历过的最好位置,$p_g^{best}$是整个种群中经历过的最好位置,$w$是惯性权重,$c_1$和$c_2$是加速度因子,$rand()$是一个0到1的随机数。
粒子群算法的优点在于简单、易于理解和实现,同时具有较好的全局搜索能力。
其收敛速度较快,可以处理多维、非线性和非光滑的优化问题。
另外,粒子群算法有较少的参数需要调节,因此适用于许多实际应用中的优化问题。
粒子群算法的应用领域非常广泛,包括机器学习、数据挖掘、图像处理、模式识别、人工智能等。
例如,在机器学习中,粒子群算法可以应用于神经网络的训练和参数优化;在数据挖掘中,粒子群算法可以用于聚类、分类和关联规则挖掘等任务;在图像处理中,粒子群算法可以用于图像分割、边缘检测和特征提取等;在模式识别中,粒子群算法可以用于目标检测和模式匹配等。
粒子群算法简介优缺点及其应用

3
PSO算法就从这种生物种群行为特性中得到启发并用于求解优化 问题。
在PSO中,把一个优化问题看作是在空中觅食的鸟群,那么“食 物”就是优化问题的最优解,而在空中飞行的每一只觅食的 “鸟”就是PSO算法中在解空间中进行搜索的一个“粒 子”(Particle)。
“群”(Swarm)的概念来自于人工生命,满足人工生命的五个基 本原则。因此PSO算法也可看作是对简化了的社会模型的模拟, 这其中最重要的是社会群体中的信息共享机制,这是推动算法 的主要机制。
——Update particle position according equation (2)
— End
While maximum iterations or minimum error criteria is not attained
2020/3/3
16
PSO的各种改进算法
PSO收敛速度快,特别是在算法的早期,但也存在着精度较低, 易发散等缺点。
为非负数,称为惯性因子,惯性权重,是控制速度的权重
2020/3/3
18
(1)线性调整的策略
允许的最大速度vmax实际上作为一个约束,控制PSO能够具有的 最大全局搜索能力。如果vmax较小,那么最大的全局搜索能力将 被限制,不论惯性权重的大小,PSO只支持局部搜索;如果设 置vmax较大,那么PSO通过选择 ,有一个可供很多选择的搜索 能力范围。
2020/3/3
6
粒子群算法的基本思想
用随机解初始化一群随机粒子,然后通过迭代找到最优解。在 每一次迭代中,粒子通过跟踪两个“极值”来更新自己:
一个是粒子本身所找到的最好解,即个体极值(pbest),另一个 极值是整个粒子群中所有粒子在历代搜索过程中所达到的最优 解(gbest)即全局极值。
第6章粒子群算法基本理论

PSO算法作为一种新兴智能仿生算法,目前还没有完备 的数学理论基础,但作为新兴优化算法已在诸多领域得到广 泛应用。
6.1 粒子群算法的概述
6.1.3 粒子群算法的特点
粒子群算法的优点 ① 粒子群算法依靠粒子速度完成搜索,在迭代进化中只 有最优的粒子将信息传递给其他粒子,搜索速度快。 ② 粒子群算法具有记忆性,粒子群体的历史最好位置可 以记忆,并传递给其他粒子。 ③ 需调整的参数较少,结构简单,易于工程实现。 ④ 采用实数编码,直接由问题的解决定,问题解的变量 数直接作为粒子的维数。
[2] Eberhart R,Kennedy J,A new optimizer using particle swarm theory,Proceeding of the 6th International Symposium on Micro-Machine and Human Science, 1995,39~43
粒子群算法的基本思想是通过群体中个体之间的协作和 信息共享来寻找最优解。
6.1 粒子群算法的概述
6.1.2 粒子群算法的发展
萌芽阶段
1986年,人工生命、计算机图形 学专家 Craig Reynolds提出了简单的 人工生命系统——boid模型(解释为 bird like object),模拟了鸟类在飞行 过程中分离、列队和聚集三种聚群飞 行行为,并能感知到周围一定范围内 其他boid的飞行信息。boid根据该信 息,结合当前自身的飞行状态,在三 条简单行为规则的指导下,做出下一 步的飞行决策。
Step2:评价每个微粒的适应度值。 Step3:将每个微粒的适应度值与其经过的最好位置 pbest进行比较,如果较好则将其作为当前的最好位置pbest。 Step4:将每个微粒的适应度值与种群的最好位置gbest 进行比较,如果较好则将其作为种群的最好位置gbest。 Step5:根据速度和位置公式调整粒子的飞行速度和所 处位置。 Step6:判断是否达到结束条件,若未达到转到Step2。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
粒子群算法(1)----粒子群算法简介二、粒子群算法的具体表述上面罗嗦了半天,那些都是科研工作者写论文的语气,不过,PSO的历史就像上面说的那样。
下面通俗的解释PSO算法。
PSO算法就是模拟一群鸟寻找食物的过程,每个鸟就是PSO中的粒子,也就是我们需要求解问题的可能解,这些鸟在寻找食物的过程中,不停改变自己在空中飞行的位置与速度。
大家也可以观察一下,鸟群在寻找食物的过程中,开始鸟群比较分散,逐渐这些鸟就会聚成一群,这个群忽高忽低、忽左忽右,直到最后找到食物。
这个过程我们转化为一个数学问题。
寻找函数y=1-cos(3*x)*exp(-x)的在[0,4]最大值。
该函数的图形如下:当x=0.9350-0.9450,达到最大值y=1.3706。
为了得到该函数的最大值,我们在[0,4]之间随机的洒一些点,为了演示,我们放置两个点,并且计算这两个点的函数值,同时给这两个点设置在[0,4]之间的一个速度。
下面这些点就会按照一定的公式更改自己的位置,到达新位置后,再计算这两个点的值,然后再按照一定的公式更新自己的位置。
直到最后在y=1.3706这个点停止自己的更新。
这个过程与粒子群算法作为对照如下:这两个点就是粒子群算法中的粒子。
该函数的最大值就是鸟群中的食物计算两个点函数值就是粒子群算法中的适应值,计算用的函数就是粒子群算法中的适应度函数。
更新自己位置的一定公式就是粒子群算法中的位置速度更新公式。
下面演示一下这个算法运行一次的大概过程:第一次初始化第一次更新位置第二次更新位置第21次更新最后的结果(30次迭代)最后所有的点都集中在最大值的地方。
粒子群算法(2)----标准的粒子群算法在上一节的叙述中,唯一没有给大家介绍的就是函数的这些随机的点(粒子)是如何运动的,只是说按照一定的公式更新。
这个公式就是粒子群算法中的位置速度更新公式。
下面就介绍这个公式是什么。
在上一节中我们求取函数y=1-cos(3*x)*exp(-x)的在[0,4]最大值。
并在[0,4]之间放置了两个随机的点,这些点的坐标假设为x1=1.5;x2=2.5;这里的点是一个标量,但是我们经常遇到的问题可能是更一般的情况--x为一个矢量的情况,比如二维的情况z=2*x1+3*x22的情况。
这个时候我们的每个粒子为二维,记粒子P1=(x11,x12),P2=(x21,x22),P3=(x31,x32),......Pn=(xn1,xn2)。
这里n为粒子群群体的规模,也就是这个群中粒子的个数,每个粒子的维数为2。
更一般的是粒子的维数为q,这样在这个种群中有n个粒子,每个粒子为q 维。
由n个粒子组成的群体对Q维(就是每个粒子的维数)空间进行搜索。
每个粒子表示为:x i=(x i1,x i2,x i3,...,x iQ),每个粒子对应的速度可以表示为v i=(v i1,v i2,v i3,....,v iQ),每个粒子在搜索时要考虑两个因素:1。
自己搜索到的历史最优值p i ,p i=(p i1,p i2,....,p iQ),i=1,2,3,....,n。
2。
全部粒子搜索到的最优值p g,p g=(p g1,p g2,....,p gQ),注意这里的p g只有一个。
下面给出粒子群算法的位置速度更新公式:这里有几个重要的参数需要大家记忆,因为在以后的讲解中将会经常用到:它们是:是保持原来速度的系数,所以叫做惯性权重。
是粒子跟踪自己历史最优值的权重系数,它表示粒子自身的认识,所以叫“认知”。
通常设置为2。
是粒子跟踪群体最优值的权重系数,它表示粒子对整个群体知识的认识,所以叫做“社会知识”,经常叫做“社会”。
通常设置为2。
是[0,1]区间内均匀分布的随机数。
是对位置更新的时候,在速度前面加的一个系数,这个系数我们叫做约束因子。
通常设置为1。
这样一个标准的粒子群算法就结束了。
下面对整个基本的粒子群的过程给一个简单的图形表示:判断终止条件可是设置适应值到达一定的数值或者循环一定的次数。
注意:这里的粒子是同时跟踪自己的历史最优值与全局(群体)最优值来改变自己的位置预速度的,所以又叫做全局版本的标准粒子群优化算法。
粒子群算法(3)----标准的粒子群算法(局部版本)在全局版的标准粒子群算法中,每个粒子的速度的更新是根据两个因素来变化的,这两个因素是:1. 粒子自己历史最优值p i。
2. 粒子群体的全局最优值p g。
如果改变粒子速度更新公式,让每个粒子的速度的更新根据以下两个因素更新,A. 粒子自己历史最优值p i。
B. 粒子邻域内粒子的最优值pn k。
其余保持跟全局版的标准粒子群算法一样,这个算法就变为局部版的粒子群算法。
一般一个粒子i 的邻域随着迭代次数的增加而逐渐增加,开始第一次迭代,它的邻域为0,随着迭代次数邻域线性变大,最后邻域扩展到整个粒子群,这时就变成全局版本的粒子群算法了。
经过实践证明:全局版本的粒子群算法收敛速度快,但是容易陷入局部最优。
局部版本的粒子群算法收敛速度慢,但是很难陷入局部最优。
现在的粒子群算法大都在收敛速度与摆脱局部最优这两个方面下功夫。
其实这两个方面是矛盾的。
看如何更好的折中了。
根据取邻域的方式的不同,局部版本的粒子群算法有很多不同的实现方法。
第一种方法:按照粒子的编号取粒子的邻域,取法有四种:1,环形取法2,随机环形取法3,轮形取法4,随机轮形取法。
1环形 2 随机环形3 轮形4随机轮形因为后面有以环形取法实现的算法,对环形取法在这里做一点点说明:以粒子1为例,当邻域是0的时候,邻域是它本身,当邻域是1时,邻域为2,8;当邻域是2时,邻域是2,3,7,8;......,以此类推,一直到邻域为4,这个时候,邻域扩展到整个例子群体。
据文献介绍(国外的文献),采用轮形拓扑结构,PSO的效果很好。
第二种方法:按照粒子的欧式距离取粒子的邻域在第一种方法中,按照粒子的编号来得到粒子的邻域,但是这些粒子其实可能在实际位置上并不相邻,于是Suganthan提出基于空间距离的划分方案,在迭代中计算每一个粒子与群中其他粒子的距离。
记录任何2个粒子间的的最大距离为dm。
对每一粒子按照||x a-x b||/dm计算一个比值。
其中||x a-x b||是当前粒子a到b的距离。
而选择阈值frac 根据迭代次数而变化。
当另一粒子b满足||x a-x b||/dm<frac时,认为b成为当前粒子的邻域。
这种办法经过实验,取得较好的应用效果,但是由于要计算所有粒子之间的距离,计算量大,且需要很大的存储空间,所以,该方法一般不经常使用。
粒子群算法(5)-----标准粒子群算法的实现标准粒子群算法的实现思想基本按照粒子群算法(2)----标准的粒子群算法的讲述实现。
主要分为3个函数。
第一个函数为粒子群初始化函数InitSwarm(SwarmSize......AdaptFunc)其主要作用是初始化粒子群的粒子,并设定粒子的速度、位置在一定的范围内。
本函数所采用的数据结构如下所示:表ParSwarm记录的是粒子的位置、速度与当前的适应度值,我们用W来表示位置,用V来代表速度,用F D。
表优解。
用Wg代表全局最优解,W.,1代表每个粒子的历史最优解。
粒子群初始化阶段表OptSwarm的前N行与表ParSwarm根据这样的思想MATLAB代码如下:function [ParSwarm,OptSwarm]=InitSwarm(SwarmSize,ParticleSize,ParticleScope,AdaptFunc)%功能描述:初始化粒子群,限定粒子群的位置以及速度在指定的范围内%[ParSwarm,OptSwarm,BadSwarm]=InitSwarm(SwarmSize,ParticleSize,ParticleScope,AdaptFunc) %%输入参数:SwarmSize:种群大小的个数%输入参数:ParticleSize:一个粒子的维数%输入参数:ParticleScope:一个粒子在运算中各维的范围;%ParticleScope格式:%3维粒子的ParticleScope格式:%[x1Min,x1Max%x2Min,x2Max%x3Min,x3Max]%%输入参数:AdaptFunc:适应度函数%%输出:ParSwarm初始化的粒子群%输出:OptSwarm粒子群当前最优解与全局最优解%%用法[ParSwarm,OptSwarm,BadSwarm]=InitSwarm(SwarmSize,ParticleSize,ParticleScope,AdaptFunc); %%异常:首先保证该文件在Matlab的搜索路径中,然后查看相关的提示信息。
%%编制人:XXX%编制时间:2007.3.26%参考文献:无%%容错控制if nargin~=4error('输入的参数个数错误。
')endif nargout<2error('输出的参数的个数太少,不能保证以后的运行。
');end[row,colum]=size(ParticleSize);if row>1|colum>1error('输入的粒子的维数错误,是一个1行1列的数据。
');end[row,colum]=size(ParticleScope);if row~=ParticleSize|colum~=2error('输入的粒子的维数范围错误。
');end%初始化粒子群矩阵%初始化粒子群矩阵,全部设为[0-1]随机数%rand('state',0);ParSwarm=rand(SwarmSize,2*ParticleSize+1);%对粒子群中位置,速度的范围进行调节for k=1:ParticleSizeParSwarm(:,k)=ParSwarm(:,k)*(ParticleScope(k,2)-ParticleScope(k,1))+ParticleScope(k,1);%调节速度,使速度与位置的范围一致ParSwarm(:,ParticleSize+k)=ParSwarm(:,ParticleSize+k)*(ParticleScope(k,2)-ParticleScope(k,1))+Pa rticleScope(k,1);end%对每一个粒子计算其适应度函数的值for k=1:SwarmSizeParSwarm(k,2*ParticleSize+1)=AdaptFunc(ParSwarm(k,1:ParticleSize));end%初始化粒子群最优解矩阵OptSwarm=zeros(SwarmSize+1,ParticleSize);%粒子群最优解矩阵全部设为零[maxValue,row]=max(ParSwarm(:,2*ParticleSize+1));%寻找适应度函数值最大的解在矩阵中的位置(行数)OptSwarm=ParSwarm(1:SwarmSize,1:ParticleSize);OptSwarm(SwarmSize+1,:)=ParSwarm(row,1:ParticleSize);下面的函数BaseStepPso实现了标准全局版粒子群算法的单步更新位置速度的功能function[ParSwarm,OptSwarm]=BaseStepPso(ParSwarm,OptSwarm,AdaptFunc,ParticleScope,MaxW,MinW, LoopCount,CurCount)%功能描述:全局版本:基本的粒子群算法的单步更新位置,速度的算法%%[ParSwarm,OptSwarm]=BaseStepPso(ParSwarm,OptSwarm,AdaptFunc,ParticleScope,MaxW,Min W,LoopCount,CurCount)%%输入参数:ParSwarm:粒子群矩阵,包含粒子的位置,速度与当前的目标函数值%输入参数:OptSwarm:包含粒子群个体最优解与全局最优解的矩阵%输入参数:ParticleScope:一个粒子在运算中各维的范围;%输入参数:AdaptFunc:适应度函数%输入参数:LoopCount:迭代的总次数%输入参数:CurCount:当前迭代的次数%%返回值:含意同输入的同名参数%%用法:[ParSwarm,OptSwarm]=BaseStepPso(ParSwarm,OptSwarm,AdaptFunc,ParticleScope,MaxW,MinW, LoopCount,CurCount)%%异常:首先保证该文件在Matlab的搜索路径中,然后查看相关的提示信息。