Teradata分析
Teradata基础教程(中文)

Teradata SQL基础教程第一章关系数据库基础1.1关系数据库模型关系数据库理论最早是由Codd博士提出的,一个关系的数学描述其实就是一个二维表,这些二维表按照业务运行的规律组合起来,就是关系数据库模型。
这种模型可以简洁地表达出企业或机构的业务运作规律,抓住事物本质,因此非常实用。
每个二维表被称为一个实体(Entity),它可以是人、地点或者某种事物等。
表中的每个列被称为属性(Attribute)或者字段(Field),表中的每一行代表了该实体的一个特定实例,称为记录(Record)。
表1-1、1-2和1-3分别给出了一个雇员表、部门表和工作表的实例。
表1-1 雇员表(Employee Table)EMPLOYEE NUMBER MANAGEREMPLOYEENUMBERDEPARTMENT NUMBERJOBCODELASTNAMEFIRSTNAMEHIREDATEBIRTHDATESALARYAMOUNTPK FK FK FK1018 1017 501 512101RatzlaffLarry1978-07-151954-05-3154000.00 1022 1003 401 412102MachadoAlbert1979-03-011957-07-1432300.00 1014 1011 402 422101CraneRobert1978-01-151960-07-0424500.00 1003 801 401 411100TraderJames1976-07-311947-06-1937850.00 1007 1005 403 432101VillegasArnando1977-01-021937-01-3149700.00 1010 1003 401 412101RogersFrank1977-03-011935-04-2346000.00 表1-2 部门表(Department Table). 1 .department_number department_name budget_amount manager_employee_number PK FK308000.001011support402 software982300.001003support401 customer1025293800.00201 technicaloperations801100 president 400000.001017308000.00501 marketingsales1005403 education 932000.00表1-3 工作表(Job Table)job_code description hourly_billing_rate hourly_cost_rate PK421100 Manager - Software Support 0.00 0.00Rep 0.00 0.00512101 Sales511100 Manager - Marketing Sales 0.00 0.00Engineer 0.00 0.00312101 Software411100 Manager - Customer Support 0.00 0.00431100 Manager - Education 0.00 0.00413201 Dispatcher 0.00 0.00432101 Instructor 0.00 0.00Analyst 0.00 0.00422101 Software321100 Manager - Product Planning 0.00 0.00在一个关系数据库模型中,表和表之间是有关联的,这种关联常用所谓的E-R 图(Entity-Relationship Diagram)来表示。
NCR Teradata数据仓库

灵活的,可扩展的
+
Teradata CLDM包括:7 个主题域, 328个主实体,905 个属性和460个业务关系
公司主要产品
基于CLDM建立集中的业务模型,使业务人员能够轻松分析:
谁是我们最有价值的客户… 按在网时间,消费金额,收入,年龄,地域,业务规模... 按产品使用情况 (国内,国际,接线员服务,呼叫卡,全部) 在我们最好的客户中,谁最有可能流失? 我们的基站有问题吗? 我们可以将流失模式与用户的家庭关系或一个呼叫频繁的基 站对应起来吗? 按欺诈类型划分的欺诈模式? 我们的网络使用峰值占总使用的百分比? 我们应该向谁推销新产品或服务? 那些客户我们应该让给我们的竞争对手? 针对一个选定的用户群体,最赢利的产品/服务组合是什么? 吸引某一类用户的最恰当的消息,媒体,和渠道是什么? ……
在移动信息化领域提供完整的数据仓库解决方案h增值应用和服务基本应用基础设施系统集成项目实施客户分析收入分析高级应用opensystemwindow2000mppsmpdwplatformteradatardbms客户流失模型commldm欺诈管理fraud50产品服务分析市场份额分析服务质量分析市场促销分析etl业务系统源系统cdrtapdecode客户价值模型营销计划预演rps20客户关系管理crm40客户信用模型价格敏感度模型产品亲和度模型绩效管理pmm30催收管理collection40olapmdsdiskarrayopensystemncrunixbardatamining数据仓库在移动行业的基本应用基本应用客户分析收入分析产品服务分析市场份额分析服务质量分析市场促销分析客户分析收入分析产品服务分析?客户分群?客户总量多维分析?新增流失客户多维分析?客户通话行为多维分析?客户缴费行为多维分析?高风险高额客户多维分析?客户转网多维分析?各网元客户数及通信情况多维分析?特定时段通信时长最大前100名客户报表?特定时段通信费用最高前100名客户报表?互转客户统计报表?大客户特征多维分析?大客户业务量多维分析?前100名集团大客户报表?前100名个人大客户报表?高额客户前100名客户报表?各网元客户数及通信情况同期比较报表?收入总量多维分析?arpu多维分析?收入结构多维分析?网络多维分析?预付费多维分析?客户缴费多维分析?客户欠费多维分析?新增客户缴费欠费多维分析?业务量多维分析?业务资源使用特征多维分析?网络流向和流量特征多维分析?热点小区多维分析?业务量报表依业务种类?各类卡资源统计报表?号码资源统计报表?各基站交换机负载统计报表?各网元通信情况同期比较比报表数据仓库在移动行业的基本应用客户分析收入分析产品服务分析市场份额分析服务质量分析市场促销分析市场份额分析服务质量分析市场促销分析?市场占有率多维分析?竞争对手发展情况多维分析?供应商市场行为特征多维分析?合作商市场行为特征多维分析?各竞争对手市场占有率报表?同类设备供应商对比报表?合作商代收费报表?客户服务质量多维分析?客户服务时限多维分析?客户咨询查询焦点多维分析?客户投诉焦点多维分析?客户满意度多维分析?客户投诉状况报表?营销渠道多维分析?代理商客户发展多维分析?代理商业务发展多维分析?宣传促销多维分析?营销人员素质多维分析?最佳促销活动报表基本
TeradataCRM解决方案.ppt

15
细分交叉分析
主要优点:
–识别客户群体之间 特征的交集
–发现并保存交叉特 征
–描述并分析细分和 属性之间的关系
July 21,
Copyright@2001 Teradata, a division of NCR, All Rights Reserved
17
细分交叉分析
可方便地行比较和分组交互
主要功能:
6
Teradata CRM 4.0版
Analysis 分析
• 细分* • 客户行为 • 产品选择 • 百分位分布 • 标准报告 • 细分 • 百分位图表 • 模式侦测
Modeling 建模
• 响应响应
Personalization 个性化
• 规则管理 • 个性化模板
Communication 沟通
Teradata CRM
优化客户关系 创造竞争优势
客户关系管理(CRM) 解决方案
客户关系管理是 …
…公司以理解和影响客户行为的手段,通过与客户 连续不断的沟通来扩大客户群体、增强客户保有 率和提高客户利润
分析&提炼 客户互动
学习 行动
知识发现 市场计划
·在适当的时间,
·使用适当的渠道
·向适当的客户,
主要优点:
– 提取所有活动和客户 交往历史
– 可根据数据库上任何 变量分析报表文件
– 报表可自动生成,并 通过电子邮件分发
– 摘要报表减少了报表 模板需要的数量
Copyright@2001 Teradata, a division of NCR, All Rights Reserved
13
百分比分析
种定制响应类型相连。 – “寄件人”、 “回复”和“抄送”地址可以动态赋值 – 为了保证渠道应用系统兼容,个性化变量标签和个性化向导
td数据库语法

td数据库语法
数据库是一种组织和存储数据的工具。
TD数据库(Teradata Database)是一种关系型数据库管理系统,用于处理大规模数据。
以下是TD数据库的一些基本语法:
1.数据定义语句:用于创建表、索引和其他数据库对象。
例如:
C R EATE TABLE表名(
列名1 数据类型,
列名2 数据类型,
...
);
2.数据操纵语句:用于插入、更新、删除和查询数据。
例如:
I NSERT INTO 表名(列名1,列名2,...)
V ALUES (值1,值2,...);
U PDATE 表名
S ET 列名1 = 值1,列名2 = 值2,...
W HERE 条件;
D ELETE FROM 表名
W HERE 条件;
S ELECT 列名1,列名2,...
F R OM 表名
W HERE 条件;
3.数据控制语句:用于控制数据库的访问权限和事务处理。
例如:
GRANT 权限名TO 用户名;
R EVOKE 权限名FROM 用户名;
B EGIN TRANSACTION;
C OMMIT;
R OLLBACK;
4.数据聚合函数:用于对数据进行汇总和统计。
例如:
S U M(列名),MAX(列名),MIN(列名),COUNT(*);
5.查询优化:使用EXPLAIN命令分析查询计划的执行计划。
例如:
E XPLAIN SELECT ...;
这些仅为TD数据库语法的基本概述。
Teradata大数据一体化平台介绍

产品说明
动态数据仓库产品,支持SSD 动态数据仓库产品,不支持SSD 数据仓库一体机 数据集市一体机,SMP节点 海量数据分析一体机 Hadoop一体机 Aster一体机 Aster数据库软件(仅限部分客户) Hadoop软件 Teradata提供企业云部署环境 双/多系统管理解决方案 虚拟存储/多级存储解决方案 Teradata平台互联互通解决方案 基本功能已集成在Teradata一体机中,数据实验室等额外功能需付费 整合营销解决方案 Teradata-SAS高性能分析一体机 Teradata-SAP分析解决方案 TD提供免费的ABU备份软件,由客户提供网络备份环境 TD提供备份插件,由客户提供带机、带库等备份架构 TD提供完整备份解决方案,包括NBU备份软件,以及Quantum,Da ta Domain等备份设备 包含元数据、数据质量、数据标准等 ETL调度工具 门户产品 管理驾驶舱 前端工具,数据挖掘分析工具
teradatagca可销售产品一览表产品类型产品定位最新产品型号产品说明teradata6750h6750hx动态数据仓库产品支持ssdteradata6700c动态数据仓库产品丌支持ssdteradata2800数据仓库一体机teradata670h670c数据集市一体机smp节点teradata1700海量数据分析一体机haddopappliancehadoop一体机探索平台asterapplianceaster一体机astersoftwareonlyaster数据库软件仅限部分客户hadoopsoftwareonlyhadoop软件teradatadatalabteradata提供企业云部署环境unity双多系统管理解决方案tvs虚拟存储多级存储解决方案querygridteradata平台互联互通解决方案viewpoint基本功能已集成在teradata一体机中数据实验室等额外功能需付费applicationcim整合营销解决方案teradataappliancesasteradatasas高性能分析一体机teradataanalyticssapteradatasap分析解决方案abuappliancebackuputilitytd提供免费的abu备份软件由客户提供网络备份环境tdeteradataextensiontd提供备份插件由客户提供带机带库等备份架构advocatedbartd提供完整备份解决方案包括nbu备份软件以及quantumdatadomain等备份设备数据管控teradata数据管控平台包含元数据数据质量数据标准等etlautomationetl调度工具teradataportal门户产品tetadatadashboard管理驾驶舱合作伙伴产品qlikviewspotfiretableaumicrostrategycelebrus前端工具数据挖掘分析工具其它工具其它产品数据库系统管理软件产品硬件产品数据平台数据仓库数据备份合作产品datamartapplianceintegratedbigdataplatformdatawarehouseapplianceactiveenterprisedatawarehouseappliancehadoopasterbiganalyticsappliancesashighperformanceanalytics规模up8tbup234pbup54p
Teradata和Oracle语法比较

Like 进行模糊匹配的函数 通配符的使用 EXTRACT
1 如何计算百分比的问题 2.如何进行取前几名的操作 3.如何分页 4.指明区分大小写 5.Cast 函数 6.关于日期格式以及日期之间的加减操作
7.EXTRACT 函数对日期的截取 8.子查询的使用 in 和 exists 函数的联合使用
在 bteq 命令行的模式下才能看到分组进项小计的效果
使用 with by 进行小计的在命令行的模式下进行显示的作用
创建表 contact 顾客交流表的时候
CREATE SET TABLE SQL18.contact ,NO FALLBACK , NO BEFORE JOURNAL, NO AFTER JOURNAL, CHECKSUM = DEFAULT, DEFAULT MERGEBLOCKRATIO ( contact_number INTEGER, contact_name CHAR(30) CHARACTER SET LATIN NOT CASESPECIFIC, area_code SMALLINT, phone INTEGER, extension INTEGER, last_call_date DATE FORMAT 'YY/MM/DD')
--创建一张表contact1
select database; create set table student_test (
sno integer, sname char(30) not casespecific, birthday date format 'yy/mm/dd' ) ---往表中插入相关的数据 insert into student_test(sno,sname,birthday) values(1001,'黄新','1990-10-17'); --错误的数据 insert into student_test(sno,sname,birthday) values(1002,'小华','1990-10-18'); --日期格式的数据也要加上单引号 insert into student_test(sno,sname,birthday) values(1003,'小华',1990-10-18); -select * from sturom student_test where sno=1002; select * from student_test;
Teradata案例分析

话费流失预防系统 5.报表管理子系统(FraudSentry*Reporter) 提供一些预定义的统计和管理报表,提供欺 诈记录及客户信息。这些表报是用OLAP动态 报表工具实现的。如主叫号码通话报警统计、 最可疑的前100个通话、按通话类型分析报警 情况、可疑事件详细报表、可疑事件分析与 处理、欺诈事件统计表、反欺诈小组处理事 件统计等等。
话费流失预防系统 介绍
话费流失预防系统(FraudSENTRY)是通过对大 量的客户档案和通话历史数据的分析从而获 取客户的通话行为信息,采用传统的基于规 则的侦测方法和现代先进的神经网络智能技 术为综合分析手段,建立一个通话行为智能 库,可以侦测漫游、客户欺诈、代理商欺诈、 利用盗窃手机通话等几类欺诈行为,当通话 记录或交易出现在正常模式以外时,系统能 马上识别,实时地现场侦测、追踪潜在的恶 意盗打电话者,和预测可能会恶意盗打电话 的客户,防盗打小组在电信公司的经营政策 为指导的原则下,对违反规定的客户采取必 要的措施,以追回损失、降低电信公司经营 风险和防止资产流失的决策支持系统。
7.预测模型子系统(FraudSentry*Predictor)
8.客户分析子系统(CustomerBI)
话费流失预防系统
1.维护界面子系统(FraudSentry*Profiler)
结构
是客户端的交互窗口。Profiler主要用于设 置和修改报警和界限。报警设置将侦测识别 所有通话记录中的各类欺诈行为,知道侦测 什么和如何侦测。正常情况下,报警参数仅 在第一次安装时设置一次。
案例:远传电信(FarEasTone)
降低经营成本 相 互 矛 相 盾 互 矛 盾
提高客户满意度 案例 分析解决? 如何解决?
案例:远传电信(FarEasTone) 降低经营成本
Teradata数据库介绍

SMP 体系架构
Multi-Node MPP
NCR Rack-Based Cabinets
NCR MPP系统的一些特性
Teradata数据库软件:它允许多个SMP运行在Teradata数据库上,并扮演单个 实例角色.
可升级的BYNET连接:当增加节点时,相应的增加了带宽. 并行可升级性:通过安装/升级多个SMPs 实现软件的并行安装和升级. AWS(Administration Workstation) :单点操作控制及升级服务管理. SMP:SMP只需要负责管理各自资源 还有一些冗余的组件:两个BYNET,在一个磁盘组中有两个磁盘控制器,又模
Network-Attached client software Overview
CLI提供对Teradata最大限度的连接和访问性,ODBC作为业内标准是更多的应用程序 可以连接到Teradata
Micro Teradata Director Program (MTDP) 是Teradata 提供的网络连接环境下的TDP实现,它和渠道连接下的TDP功能基本一致,唯一的区别 是它不负责session在多个PEs之间的分配,此功能由运行在Teradata系统上的Connect and Assign Servers 实现
据集成的企业范围的数据库,保证数据的一致性 高可用性 并行装载及卸数处理
强大的并行装载,load与unload工具可升级性,这些工具如:Fastload、 Multiload、TPump、and FastExport
主题
What is Teradata? Teradata数据库竞争优势 Teradata RDBMS 架构 Teradata 系统架构 Teradata 数据库与数据库用户的比较 数据存储和访问
数据仓库的工具

数据仓库的工具数据仓库是一个用于集中存储、管理和分析大量数据的系统。
为了有效地构建和维护数据仓库,许多工具和技术已被开发出来。
这些工具可以帮助企业在提供高性能数据存储和处理能力的同时,实现对数据的高效管理和分析。
下面是一些常用的数据仓库工具的简介:1. ETL工具:ETL(抽取、转换和加载)工具用于从各种数据源抽取数据并将其加载到数据仓库中。
这些工具不仅可以确保数据的有效传输和处理,还可以进行数据清洗、转换和整合,以使其符合数据仓库的要求。
常见的ETL工具包括Informatica PowerCenter、IBM InfoSphere DataStage和Microsoft SSIS(SQL Server Integration Services)等。
2. 数据仓库管理工具:数据仓库管理工具用于管理数据仓库的各种操作和维护任务。
它们可以提供数据仓库的配置、监控、备份和恢复等功能。
这些工具还可以帮助管理员监控数据仓库的性能,并提供报告和分析功能。
常见的数据仓库管理工具包括Teradata Viewpoint、Oracle Enterprise Manager和Microsoft SQL Server Management Studio等。
3. 数据挖掘工具:数据挖掘工具用于从数据仓库中发现隐藏的模式和信息。
它们使用各种算法和技术来分析大量的数据,以提取有用的信息和洞察。
数据挖掘工具可以帮助企业预测趋势、识别关联性和制定智能决策。
常见的数据挖掘工具包括IBM SPSS Modeler、SAS Enterprise Miner和RapidMiner等。
4. 可视化工具:可视化工具用于将数据仓库中的数据转化为易于理解和解释的图形和图表。
这些工具帮助用户直观地理解数据关系、趋势和模式,并提供交互式的数据探索和筛选功能。
常见的可视化工具包括Tableau、QlikView和Power BI等。
5. 查询和报告工具:查询和报告工具用于从数据仓库中提取数据并生成定制的报告和查询结果。
teradata主题模型设计方法论

teradata主题模型设计方法论Teradata主题模型设计是一种应用于大数据分析和数据挖掘的方法论。
它通过挖掘数据背后的隐藏主题,发现数据中的潜在模式和关系,以帮助企业做出更具优势的业务决策。
本文将介绍Teradata主题模型设计的基本原理、方法和应用。
一、Teradata主题模型设计的基本原理Teradata主题模型设计基于主题模型的概念,主题模型是一种统计模型,用于描述文档集合中的主题和词汇之间的关系。
在Teradata主题模型设计中,主题是指数据中的抽象概念,可以用一组关键词来表示。
每个文档可以包含多个主题,主题模型设计的目标是通过对文档和主题的分析,发现主题之间的关系和文档的隐含模式。
Teradata主题模型设计的基本原理包括两个关键步骤:主题抽取和主题关联。
主题抽取是指从给定的文档集合中提取主题的过程,通常使用词频统计、TF-IDF等方法来计算每个词汇在每个主题中的权重,然后根据权重进行主题排序。
主题关联是指通过分析主题之间的相关性,发现主题之间的关系,可以使用关联规则、聚类分析等方法来实现。
二、Teradata主题模型设计的方法Teradata主题模型设计的具体方法包括以下几个方面:1.数据预处理:在进行主题模型设计之前,需要对原始数据进行预处理,包括去除噪声数据、进行数据清洗和标准化等操作,以确保数据的质量和准确性。
2.特征选择:在进行主题抽取时,需要选择适合的特征集合,通常选择关键词或词组作为特征。
可以使用TF-IDF等方法来计算特征的权重,以识别主题相关的词汇。
3.主题抽取:使用统计算法或机器学习算法从文档集合中抽取主题。
其中,LDA(Latent Dirichlet Allocation)是一种常用的主题抽取算法。
LDA假设文档是由多个主题生成的,每个主题又由词汇生成,通过对文档和词汇的分析,可以得到主题和主题词。
4.主题关联:通过分析主题之间的相关性,可以发现主题之间的关系和隐含模式。
TREADATA数据分析方法

• 与题分析重点关注
> 描述事物的变化趋势或潜在模式 > 量化和预测事物的収展趋势
3 > 3/19/2012
Teradata Confidential
趋势分析的图表表达
• 趋势分析通常用以时间为横坐标的折线图或者连续排列的柱状图来 表达
说明:宽带和手机上半年的趋势丌断上升, 下半年有下降的趋势,在9月的收入出现拐 点。固话的收入持续下降。
分析结果示例 说明问题 •说明:宏观比较一段时间的发展趋 势,而对象大于3个以上的对比情 况。了解各地区一段时间内的収展 趋势对比,区分哪些地区的収展状 况较差,哪些相对比较好。 计算方法 •在各时间段内,把各地区的离网用 户数按口徂统计出来
8 > 3/19/2012
Teradata Confidential
10 > 3/19/2012 Teradata Confidential
数据分析方法概觅
趋
势
11 > 3/19/2012
结
构
Teradata Confidential
对
比
关
系
结构分析法的概念
• 结构分析法
> 结构分析是对问题的构成要素迚行分析的方法。其目的是为了寻找主因,调
整结构。
• 结构分析法可以分为以下几种类型:
> 经验或理论标准:经验标准是通过对大量历叱资料的归纳总结而得到的标准 。如衡量生活质量的恩格尔系数。理论标准则是通过已知理论经过推理得到
的依据。
> 计划标准:计划标准即不计划数、定额数、目标数对比。
21 > 3/19/2012 Teradata Confidential
对比的指标
Teradata FS-LDM-模型介绍与建模过程-经典收藏

产品 产品号
账户
账号
客 户 号 (FK) 产 品 号 (FK) 机 构 号 (FK) 员 工 号 (FK) 渠 道 号 (FK)
员工 员工号
渠道 渠道号
交易的 操作员
交易 流水号
账 号 (FK) 渠 道 号 (FK) 员 工 号 (FK)
机构 机构号
财务 财务科目
交易系统数据模型-交易与其他实体的关系
LDM
•数据清洗/转换/加载 •文本文件
Teradata金融业逻辑数据模型FS-LDM
• 交易系统数据模型 • 什么是逻辑数据模型LDM? • 为什么EDW需要逻辑数据模型? • 什么是Teradata FS-LDM ? • Teradata FS-LDM主题介绍 • Teradata FS-LDM建模过程
客户 客户号
产品 产品号
账户
账号
客 户 号 (FK) 产 品 号 (FK) 机 构 号 (FK) 员 工 号 (FK) 渠 道 号 (FK)
渠道 渠道号
员工 员工号
交易
流水号
账 号 (FK) 渠 道 号 (FK) 员 工 号 (FK) 机 构 号 (FK)
机构 机构号
交易相关 的机构
财务 财务科目
交易系统数据模型-交易与其他实体的关系
什么是Teradata FS-LDM?
• Teradata FS-LDM是为金融机构和保险公司预先构建的逻
辑数据模型,通过它可以直接开始数据仓库模型设计
• 它是我们授权给用户使用的一种产品
• 它可以在一个集成的模型内支持银行、保险、以及证券代理业 务
• 它为您提供投资保护
Party
Party Asset
机构 机构号
teradata 学习总结笔记

8)teradata定义了long varchar字段,最大为64000个字符。还定义了可变长度以及固定长度的二进制数据:BYTE,varByte,最大长度:64000字节
9)teradat的日期在数据库存为整数,计算方式为:((YEAR - 1900) * 10000) + (MONTH * 100) + DAY
JOHNS
TRADE
11)teradata宏:macro
i)宏特性:
! 可以包含一条或多条SQL语句
! 可以中
CREATE MACRO macroname AS ( . . . ); 定义宏
4)FREESPACE用来定义在每个磁盘柱面上保留的空间(0-75%)
sample:CREATE MULTISET TABLE table_1
, FALLBACK, NO JOURNAL
, FREESPACE = 10 PERCENT
, DATABLOCKSIZE = 16384 BYTES
EXECUTE macroname; 执行宏语句
SHOW MACRO macroname; 显示宏定义
REPLACE MACRO macroname AS (. . . ); 改变宏定义
DROP MACRO macroname; 从字典中删除宏定义
EXPLAIN EXEC macroname; 显示宏执行的解释
SELECT EXTRACT (DAY FROM DATE + 2); 09
SELECT TIME; 14:52:32
SELECT EXTRACT (HOUR FROM TIME); 14
SELECT EXTRACT (MINUTE FROM TIME); 52
全球顶尖大数据公司一览

全球顶尖大数据公司一览2013-07-04 11:06 佚名国脉物联网我要评论(0)字号:T | T“大数据”近几年来可谓蓬勃发展,它不仅是企业趋势,也是一个改变了人类生活的技术创新。
在大数据的帮助下,警察可以通过犯罪数据和社会信息来预测犯罪率,部分科学家通过遗传数据预测疾病的早期迹象。
可以说,现在整个行业都非常看好大数据。
以下是小编为您搜罗的全球顶尖大数据公司。
AD:2013云计算架构师峰会精彩课程曝光“大数据”近几年来可谓蓬勃发展,它不仅是企业趋势,也是一个改变了人类生活的技术创新。
在大数据的帮助下,警察可以通过犯罪数据和社会信息来预测犯罪率,部分科学家通过遗传数据预测疾病的早期迹象。
可以说,现在整个行业都非常看好大数据。
以下是小编为您搜罗的全球顶尖大数据公司。
企业名称:IBM2011年5月,IBM正式推出InfoSphere大数据分析平台。
InfoSphere大数据分析平台包括 BigInsights和Streams,二者互补,Biglnsights基于Hadoop,对大规模的静态数据进行分析,它提供多节点的分布式计算,可以随时增加节点,提升数据处理能力。
Streams 采用内存计算方式分析实时数据。
InfoSphere大数据分析平台还集成了数据仓库、数据库、数据集成、业务流程管理等组件。
企业名称:亚马逊对于云计算和大数据,亚马逊绝对具有先见之明,早在2009年就推出了亚马逊弹性MapReduce(Amazon Elastic MapReduce),亚马逊对Hadoop的需求和应用可谓了若指掌,无论是中小型企业还是大型组织。
弹性MapReduce是一项能够迅速扩展的Web服务,运行在亚马逊弹性计算云(Amazon EC2)和亚马逊简单存储服务(Amazon S3)上。
这可是货真价实的云:面对数据密集型任务,比如互联网索引、数据挖掘、日志文件分析、机器学习、金融分析、科学模拟和生物信息学研究,用户需要多大容量,立即就能配置到多大容量。
网络信令分析
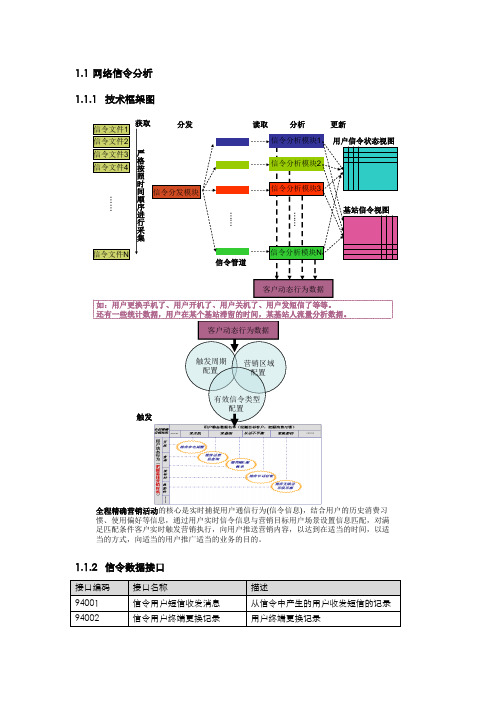
1.1 网络信令分析 1.1.1 技术框架图全程精确营销活动的核心是实时捕捉用户通信行为(信令信息),结合用户的历史消费习惯、使用偏好等信息,通过用户实时信令信息与营销目标用户场景设置信息匹配,对满足匹配条件客户实时触发营销执行,向用户推送营销内容,以达到在适当的时间,以适当的方式,向适当的用户推广适当的业务的目的。
1.1.2 信令数据接口1.1.3信令数据处理要求【数据量与处理性能】据调研,信令数据的量大约是清单的4-10倍,【接口方式】文件接口方式。
【数据同步时限】理应比清单接口的频率还要高,规范要求在15分钟之内。
【数据处理流程】信令接口文件主要经过数据采集、分发,并行处理、并行分析、并行更新视图、并根据触发规则判断是否需要触发实时营销。
1.1.4功能模块1.1.5软件部署整个软件部署可与ETL流程调度部署在同一主机上,也可单独部署。
1.1.6存储周期信令数据由于其自身特点,更新快,因此无须保存很久。
“用户信令状态视图”和“基站信令视图”只需要保留当前最新信息即可,而其它接口信息根据实际需要设置最大保存时间即可。
网络信令技术实现框架信令采集系统信令分析节点文件预处理节点文件获取节点获取层数据层信令文件信令分析结果数据原始信令数据入库加载节点信令状态视图信令数据采集原理1.2网络信令分析在经营分析系统中引入实时/准实时的网络信令数据将进一步丰富系统应用能力。
它可以帮助市场管理和营销人员更为准确的把握用户的行为特征,实现基于事件的营销,为网络规划优化、发现新的业务机遇提供必要的数据支持。
Teradata公司在网络信令应用方面有较为成熟的解决方案,拥有在国外运营商NIW 的成功部署经验。
基于本公司既有经验,并结合中国移动NG-BASS1规范要求,Teradata 提出如下方案建议。
4.8.1 技术框架图网络信令分析方案的体系架构如图所示。
为了降低投资,提高现有设施的利用率,建议复用现有的小区短信系统和信令监测系统做为获取信令信息的数据源(即信令采集子系统)。
TERADATA OLAP函数

第二十三章OLAP函数完成本章学习后,将能够:.. 使用标准SQL进行数据挖掘.. 在标准SQL中使用OLAP函数.. 执行统计方面的采样(samplings)、排队(rankings)和分位数(quantiles).. 了解OLAP统计函数23.1 OLAP函数简介OLAP即联机分析处理(On-Line Analytical Process)。
Teradata数据库本身提供了一些OLAP 函数,包括:RANK - 排队(Rankings)QUANTILE - 分位数(Quantiles)CSUM - 累计(Cumulation)MAVG - 移动平均(Moving Averages)MSUM - 移动合计(Moving Sums)MDIFF - 移动差分(Moving Differences)MLINREG - 移动线性回归(Moving Linear Regression)OLAP函数与聚合函数有类似的地方:.. 对数据进行分组操作 (类似于GROUP BY 子句).. 能够使用QUALIFY子句过滤组 (类似于HAVING 子句)OLAP函数又与聚合函数不同,因为:.. 返回满足条件的每行的数据值,而不是组的值.. 不能在子查询内使用OLAP函数可以对下面的数据库对象或动作使用:.. Tables (Perm, Temp, Derived).. Views.. INSERT/SELECT23.2 累计函数累计函数(CSUM) 计算一列的连续的累计的值。
语法为:CSUM(colname, sort list)表'daily_sales'在许多查询中都将使用,其定义如下。
CREATE SET TABLE daily_sales ,NO FALLBACK,NO BEFORE JOURNAL,NO AFTER JOURNAL(itemid INTEGER,salesdate DATE FORMAT 'YY/MM/DD',sales DECIMAL(9,2))PRIMARY INDEX ( itemid );问题创建item 10从1998年1月和2月的连续的日汇总报表。
Teradata分析

1、 Teradata 优势 ,能否打数据并发 1)优势以下是部分Teradata 客户数据仓库管理的内容,可说明Teradata 系统的强大处理能力: •多达千亿行数据的数据库表格 •每天数据加载超过30亿条记录 •每天捕获3000万笔客户交易 •每天为消费者在线提供150万种个性化产品和服务 •每小时处理100万次数据库查询 •每天响应1万个并发数据仓库用户 • 业务查询响应时间仅为40-50毫秒2)并发问题:机制 :Teradata 巨表数据存放机制好像是每个节点均匀分布表中一部分数据,当查询的时候每个节点并行查询,结果汇总到某个节点反馈给查询者。
这个复杂查询的实例形象地说明了Teradata 的多维并行处理机制。
Multi-Step 并 行并 行 作2. 搜 索 Orders3. 联 接 Lineitem & Orders 并 行同 时与 各 自 相 关据图8-16 Teradata 内部并行处理机制说明这里假设系统配置有4个虚拟处理器(VPROC),某个复杂查询被优化器分解成了7个步骤,图中SUPPLIERS、PARTS、PARTSUPP等为数据库中表的名字。
在每个步骤执行时,4个VPROC 同时处理与各自相关的数据块,例如搜索SUPPLIERS表,该表的记录是通过HASH算法均匀分布在四个VPROC各自负责的磁盘中的,搜索时4个VPROC将同时进行,把相关的记录搜索出来,这就是所谓的查询并行。
例子:例如:使用NCR 5300服务器,2个节点,存储为2TB,RAID1,在业务高峰期,系统并发查询用户在300个以上,最高到1000个,此时系统响应速度有些缓慢大概业务查询响应时间30秒,峰值过后速度就加快了。
主要进行的操作就是表之间的关联查询,4张表,每张6-7千万条记录,ETL加载的数据量不算太大。
2、Teradata内外部集建立原则针对实际的应用,采用内外部集市可以有效的发挥起各自的优势:1)松耦合原则介于要将整个系统划分为数据和应用层,相互存在很多密切关联,在设计库表时要充分考虑数据和应用的相互影响,做到应用不影响到数据的处理,数据处理不直接针对应用的松耦合技术架构2)任务明确原则数据处理层和应用层在处理具体业务时,必然存在既可以在数据层处理有可以在应用层处理的问题,需要在设计时充分讨论业务需求,做到责任明确,任务单一,各负其责。
td数据库的index函数

td数据库的index函数
Index函数是Teradata数据库中一种非常重要的函数,它有助于提高数据库性能,提高查询和更新数据的效率和性能。
Index函数在Teradata中一般用于优化查询语句。
它可以在SELECT查询中用于访问特定
的表或索引中的行,以及在UPDATE和DELETE查询中用于访问特定的表或索引中的行。
这种方法有助于提高查询的性能,因为系统可以更快地访问需要的数据,而不是遍历整个表。
Index函数可以以单列或多列方式定义索引,它们可以是数字,字符串或日期类型。
索引
允许系统以指数级的时间搜索特定表列中的数据,这样用户就可以更快地检索所需的信息。
例如,一个索引可以按姓氏或生日排序,从而大大提高了在一大堆人名中搜索特定人的效率。
Index函数也可以被用来构建视图,它们可以有助于加快特定表的访问速度,也可以用于
在存储过程中检索记录。
此外,它可以帮助消除两个或以上表之间的重复内容,这将有助
于改善数据库的存储性能。
因此,Index函数可以有效地提高Teradata数据库的性能,提高查询和更新数据的效率。
它可以减少查询的执行时间,并且提高了系统的查询和更新性能。
也可以消除两个或以上
表之间的重复内容,从而节省系统的存储空间。
简而言之,Index函数在Teradata数据库
中非常重要,它既方便又有效,能够大大提高数据库的性能。
数据仓库(Teradata)

服务使用的财务信息 / 财务记录产品的成本和付款
OFFER (服务)
产品产生事件 / 事件包括产品类
定位网络/ 网络支持的位置
NETWORK (网络)
服务通过网络实现 / 网络支持服务
网络产生事件 / 事件包括网络类
广告针对特定产品 /
产品通过广告实现营销
cLDM – 核心主题
ETL服务器
AT&T
中央数据库
Fload Mload Fexport TPump Access Module
End Users
Teradata电信业cLDM的商业价值
使你能够轻松回答下列业务问题…
▪ 谁是我们最有价值的客户… ▪ 按在网时间、消费金额、收入、年龄、地域、业务规模... ▪ 按产品使用情况 (国内、国际、接线员服务、呼叫卡、全部)
▪ 在我们最好的客户中,谁最有可能流失? ▪ 我们的基站有问题吗? 我们可以将流失模式与用户的家庭关系或一个呼叫
Teradata数据仓库
Dr. Zhang Jian Senior Technical Consultant TD China, Apr., 2009
公司介绍
NCR公司介绍
▪ 创建于1884年,120年历史 ▪ 包括三大部门
– 数据仓库事业部 / Teradata – 金融服务 / ATM – 零售服务 / POS
•LDM逻辑数据模型 •详细交易数据 •面向主题 •3NF
•数据清洗/转换/加载 •文本文件
结算
•数据转换/压缩/传输 •文本文件 •标准数据接口
•面向业务流程 其他 •3NF
Teradata电信业cLDM
ADVERTISEMENT (广告)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1、 Teradata 优势 ,能否打数据并发 1)优势
以下是部分Teradata 客户数据仓库管理的内容,可说明Teradata 系统的强大处理能力: •
多达千亿行数据的数据库表格 •
每天数据加载超过30亿条记录 •
每天捕获3000万笔客户交易 •
每天为消费者在线提供150万种个性化产品和服务 •
每小时处理100万次数据库查询 •
每天响应1万个并发数据仓库用户 • 业务查询响应时间仅为40-50毫秒
2)并发问题:
机制 :Teradata 巨表数据存放机制好像是每个节点均匀分布表中一部分数据,当查询的时候每个节点并行查询,结果汇总到某个节点反馈给查询者。
这个复杂查询的实例形象地说明了Teradata 的多维并行处理机制。
Multi-Step 并 行
并 行 作2. 搜 索 Orders
3. 联 接 Lineitem & Orders 并 行同 时与 各 自 相 关据
图8-16 Teradata 内部并行处理机制说明
这里假设系统配置有4个虚拟处理器(VPROC),某个复杂查询被优化器分解成了7个步骤,
图中SUPPLIERS、PARTS、PARTSUPP等为数据库中表的名字。
在每个步骤执行时,4个VPROC 同时处理与各自相关的数据块,例如搜索SUPPLIERS表,该表的记录是通过HASH算法均匀分布在四个VPROC各自负责的磁盘中的,搜索时4个VPROC将同时进行,把相关的记录搜索出来,这就是所谓的查询并行。
例子:
例如:使用NCR 5300服务器,2个节点,存储为2TB,RAID1,在业务高峰期,系统并发查询用户在300个以上,最高到1000个,此时系统响应速度有些缓慢大概业务查询响应时间30秒,峰值过后速度就加快了。
主要进行的操作就是表之间的关联查询,4张表,每张6-7千万条记录,ETL加载的数据量不算太大。
2、Teradata内外部集建立原则
针对实际的应用,采用内外部集市可以有效的发挥起各自的优势:
1)松耦合原则
介于要将整个系统划分为数据和应用层,相互存在很多密切关联,在设计库表时要充分考虑数据和应用的相互影响,做到应用不影响到数据的处理,数据处理不直接针对应用的松耦合技术架构
2)任务明确原则
数据处理层和应用层在处理具体业务时,必然存在既可以在数据层处理有可以在应用层处理的问题,需要在设计时充分讨论业务需求,做到责任明确,任务单一,各负其责。
3、teradata比较oracle的优缺点
Teradata是专为数据仓库OLAP设计的,主要用来进行数据的综合分析和处理,
Oracle更多的适合联机事务处理的OLTP应用,针对DW 数据仓库从以下几个角度对teradata进行分析:
1、数据管理能力(Data Management)
数据自动分配
Teradata中只有一种基于HASH算法的数据分配机制,当要插入一条记录时,根据主索引计算出相应的AMP,该条记录即通过此AMP存到其对应的磁盘上。
由于主索引值的不同,一个表的各条记录将通过各AMP均匀地分布到各个磁盘上。
分配过程完全自动进行,不需要DBA干预,这一点和其它OLTP DBMS有很大的区别。
Teradata的HASHING算法经过长期的发展,已经十分完善。
它采用了一个类似矩阵的HASH MAP,将计算出来的HASH值通过此矩阵
的映射与AMP进行联系。
这样,当重新配置AMP数时,只需要变动HASH MAP,速度非常快。
对于OLTP系统而言,其查询的特点是预先知道要回答什么样的问题,因此,DBA会根据业务问题的特点把数据按照相应的规律进行分配,例如把数据按照时间的不同分配到不同的硬盘上。
这种由DBA手工进行的数据分配机制对OLTP系统而言是有意义的,也确实能提高系统性能。
但对数据仓库系统来说,其查询往往比较复杂而且具有不确定性,不同的业务部门可能会提出各种不同的问题,如果再按照一种规律进行数据的分配,则有可能对某些问题系统的响应速度很快,而对另外一些问题的反应则很慢。
在Teradata数据库中,通过选择合适的主索引就可以保证数据在各磁盘上的自动均匀分配,使得其并行处理性能得以充分的发挥,特别适合于数据仓库环境下各种不确定的、动态的业务问题。
另一方面,所有记录的插入、更新都按同样的HASHING算法进行,使得各磁盘上的数据总是混合存储而且是均衡的,不存在“有序”或者“无序”的概念,因而也就不存在数据库的重组问题(Reorganization)。
对于传统的OLTP RDBMS而言,投产运行一段时间后系统性能常常因某种原因(如不断追加记录后造成数据存储不平衡)下降,这时就要考虑对数据库的重组。
这是一项非常耗时而且需要经验丰富DBA参与的工作。
在Teradata中,由于不存在数据库重组这类的工作,使得其管理十分简单。
2、系统管理能力(Data Administration)
Teradata易于管理
Teradata 数据库提供了一整套齐全的工具和功能,可对数据库操作、管理和维护进行控制,您只需通过一个普通的 Windows 用户界面——Teradata 管理器——即可使用这些工具和功能,包括:
•Teradata 备份、存档和恢复解决方案,结合了行业领先合作伙伴和 Teradata 专业技术的实力
•Teradata 仪表盘,用于状态和绩效统计
•管理工作站,用于对整个 Teradata 系统进行单点管理控制
•Teradata 动态工作量管理器,用于查询工作量管理情况
•Teradata 工作量分析器,用于查询绩效分析结果以及对工作量分组和资源分配提出的建议
3、扩充能力和适应能力(Platform Suitability & Scalability )
teradata线性可扩展能力
一般来说,当数据仓库投产以后,随着应用的增加,其数据量也增长得非常快,因此,数据仓库系统对扩展性的要求很高。
可扩展包含两方面的含义,即硬件平台的可扩展和软件平台的可扩展,两者必须相互配合,相辅相成,任何一方存在瓶颈都会影响整个系统的扩充能力。
Teradata的操作系统是Microsoft Windows NT/2000或者是NCR UNIX,如果使用Windows,则可用使用任何支持Windows的服务器,如果使用NCR UNIX,则只能使用NCR的MPP服务器。
之所以存在这种限制的主要原因就在于扩展能力上,因为目前NCR的 MPP服务器是业界扩展能力最强的计算机系统,它配合Teradata,形成了扩展能力最强、并行处理能力最佳的数据仓库基础平台。
考虑一个系统的线性可扩展能力,可以从以下三个方面来进行评估:
▪数据量增长时的线性度:当用户数据量成倍增加时,对于同一个系统(指硬件配置不变),响应时间是按比例线性增加的;
▪硬件平台的线性度:对于同一个查询,当硬件平台的配置增加一倍时,响应时间应减少一半;
▪并发用户增加时的线性:对于同一个系统,当并发用户的数目增加时,响应时间也按比例线性增加。
对基于Teradata实施的数据仓库系统的扩充是很容易的,可以采用现场升级(Field Upgrade)方式。
下图举例说明了将一个四节点的系统扩充到六节点的情况,首先将新增加的两个节点通过BYNET与原系统联接,然后运行Teradata提供的一个名叫RECONFIG的工具,它将自动把原系统磁盘阵列中1/3的数据按照HASH算法均匀地分布到新节点所控制的磁盘中。
这个过程完全自动进行,不需要DBA过多地干预。
这个特性也是为什么说由Teradata 组成的数据仓库系统比较容易管理的原因之一。
转移1/3 的数据至 ...这里
图8-17 Teradata线性扩展说明
4、并发查询管理能力(Concurrent Query Management)
Teradata最显著的特色之一是其强大的并行处理能力,这也是为什么说它是数据仓库专用引擎的主要原因之一。
其实现方式被称为多维并行处理机制,简单描述如下:
查询并行(Query并行):这种并行处理是基于上面介绍的HASHING数据分配机制实现的。
每个AMP都是一个VPROC,各自独立负责一部分数据的处理,相互之间没有关系,每个节点一般配置4至16个这样的VPROC。
所有关系运算如表的搜索、索引检索、投影、选择、联接、聚集、排序等都是由各个VPROC并行进行的。
步内并行(Within-a-Step并行):一个SQL查询进入系统后,首先由优化器进行优化处理,分解成一些小的步骤(Step),然后再分发给各VPROC进行处理。
一个步骤可能非常简单,如“搜索一个表并返回结果”,也可能非常复杂,如“按照某条件搜索两个表,然后联接,结果投影到某几个列,对它们加和(SUM)后返回结果”。
象这种复杂查询将处理多个关系运算,每个关系运算在一个VPROC内将启动多个进程来实现并行处理,称为步内并行。
多步并行(Multi-Step并行):上面说过,一个SQL被分解成多个小的步骤,这些步骤的执行将同时进行,称为多步并行。
优化器分解一个SQL查询请求的原则是尽可能使各步独立。
在目前所有的DBMS产品中,只有Teradata实现了多步并行。