时间序列分析上机操作题
8章 时间序列分析练习题参考答案

35.采用几何平均法计算平均发展速度的理由是( )。
A.各年环比发展速度之和等于总速度B.各年环比发展速度之积等于总速度
C.各年环比增长速度之积等于总速度D.各年环比增长速度之和等于总速度
B
36.计算平均发展速度应用几何平均法的目的在于考察( )。
A.最初时期发展水平B.全期发展水平
C.最末时期发展水平D.期中发展水平
B
3.发展速度属于( )
A比例相对数B比较相对数C动态相对数D强度相对数
C
4.计算发展速度的分母是( )
A报告期水平B基期水平C实际水平D计划水平
B
5.某车间月初工人人数资料如下:
月份
1
2
3
4
5
6
7
月初人数(人)
280
284
280
300
302
304
320
则该车间上半年的平均人数约为( )
A 296人B 292人C 295人D 300人
A.0.33倍B.0.50倍C.0.75倍D.2倍
D
16.已知一个数列的环比增长速度分别为3%、5%、8%,则该数列的定基增长速度为()
A.3%×5%×8%B.103%×105%×108%
C.(3%×5%×8%)+1D.(103%×105%×108%)-1
D
17.企业生产的某种产品2002年比2001年增长了8%,2003年比2001年增长了12%,则2003年比2002年增长了()。
时间第一年第二年第三年第四年第五年销售额万元10001100130013501400根据上述资料计算的下列数据正确的有a第二年的环比增长速度二定基增长速度10b第三年的累计增长量二逐期增长量200万元c第四年的定基发展速度为135d第五年增长1绝对值为14万元e第五年增长1绝对值为135万元ace7
8章时间序列分析练习题参考答案

8章时间序列分析练习题参考答案第⼋章时间数列分析⼀、单项选择题1.时间序列与变量数列( )A 都是根据时间顺序排列的B 都是根据变量值⼤⼩排列的C 前者是根据时间顺序排列的,后者是根据变量值⼤⼩排列的D 前者是根据变量值⼤⼩排列的,后者是根据时间顺序排列的 C2.时间序列中,数值⼤⼩与时间长短有直接关系的是( )A 平均数时间序列B 时期序列C 时点序列D 相对数时间序列 B3.发展速度属于( )A ⽐例相对数B ⽐较相对数C 动态相对数D 强度相对数 C4.计算发展速度的分母是( )A 报告期⽔平B 基期⽔平C 实际⽔平D 计划⽔平 B5.某车间⽉初⼯⼈⼈数资料如下:则该车间上半年的平均⼈数约为( )A 296⼈B 292⼈C 295 ⼈D 300⼈ C6.某地区某年9⽉末的⼈⼝数为150万⼈,10⽉末的⼈⼝数为150.2万⼈,该地区10⽉的⼈⼝平均数为( )A 150万⼈B 150.2万⼈C 150.1万⼈D ⽆法确定 C7.由⼀个9项的时间序列可以计算的环⽐发展速度( ) A 有8个 B 有9个 C 有10个 D 有7个 A8.采⽤⼏何平均法计算平均发展速度的依据是( )A 各年环⽐发展速度之积等于总速度B 各年环⽐发展速度之和等于总速度C 各年环⽐增长速度之积等于总速度D 各年环⽐增长速度之和等于总速度 A9.某企业的科技投⼊,2010年⽐2005年增长了58.6%,则该企业2006—2010年间科技投⼊的平均发展速度为( ) A5%6.58 B 5%6.158 C6%6.58 D 6%6.158B10.根据牧区每个⽉初的牲畜存栏数计算全牧区半年的牲畜平均存栏数,采⽤的公式是( ) A 简单平均法 B ⼏何平均法 C 加权序时平均法 D ⾸末折半法 D11.在测定长期趋势的⽅法中,可以形成数学模型的是( )A 时距扩⼤法B 移动平均法C 最⼩平⽅法D 季节指数法12.动态数列中,每个指标数值相加有意义的是()。
时间序列Stata操作题

《应用时间序列分析(第四版)》王燕编著中国人民大学出版社第四章习题71974年1月至1994年12月,某地胡椒价格数据如下:(21行*12列)1102 1151 1093 1118 1168 1118 1085 1135 1138 1135 1235 1301 1283 1250 1210 1135 1085 1060 1102 1151 1127 1226 1217 1215 1250 1210 1268 1402 1486 1534 1567 1585 1717 2002 2086 2059 1250 1210 1268 1402 1486 1534 1567 1585 1717 2002 2086 2059 2425 2326 2176 2121 2000 2000 1850 1640 1700 1925 1850 1830 1850 1790 1700 1700 1750 1775 1925 2000 1975 1940 1889 1881 2000 2024 1900 1750 1649 1601 1625 1609 1649 1640 1640 1620 1590 1526 1451 1424 1424 1329 1199 1179 1285 1349 1265 1299 1373 1440 1451 1376 1325 1261 1199 1219 1250 1274 1365 1424 1420 1385 1321 1235 1215 1310 1319 1319 1279 1481 1956 2165 2125 2087 1895 1840 1874 1863 1836 1894 2105 2159 2131 2029 2270 2411 2652 3294 3360 3686 3593 3482 3615 3963 4328 4309 4336 4382 4326 4009 4000 4070 4200 4278 4435 4772 4812 4908 4857 4865 4711 4640 4877 4902 4884 4833 4903 4963 4804 4679 4810 4571 4250 3850 3775 3357 2946 2342 1994 2420 2464 2763 2993 3108 2729 2525 2457 2136 2272 2175 2100 2068 1955 1950 1969 2025 1726 1579 1768 1766 1621 1692 1634 1750 1620 1515 1508 1525 1502 1374 1212 1198 1107 1052 1069 1050 1098 1150 1126 1200 1193 1058 1043 1026 980 976 1000 1210 1264 1150 1117 1188 1100 1040 1028 1113 1154 1350 1722 1616 1525 1403 1497 1522 1550 1575 1538 1650 1800 1933 2219 2606 2563 2433 1检验序列的平稳性(Stata 语句). drop B-T . generate n=_n . rename A price. tsset ntime variable:n, 1 to 252 delta: 1 unit . tsline price=>p r i c e{price}的时序图由时序图观测得price 变化落差很大,该序列不平稳...。
时间序列分析上机操作题
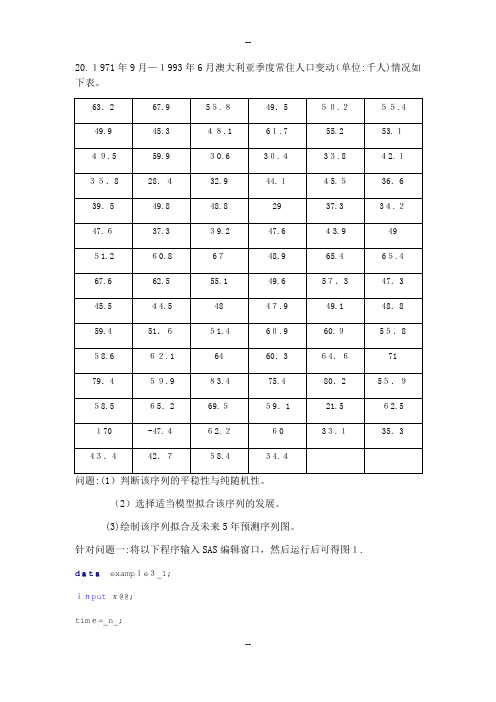
20.1971年9月—1993年6月澳大利亚季度常住人口变动(单位:千人)情况如下表。
问题:(1)判断该序列的平稳性与纯随机性。
(2)选择适当模型拟合该序列的发展。
(3)绘制该序列拟合及未来5年预测序列图。
针对问题一:将以下程序输入SAS编辑窗口,然后运行后可得图1.data example3_1;inputx@@;time=_n_;cards;63.26ﻩ7.95ﻩ5.8 49.5ﻩ50.255.4ﻩ49.9 45.348.1 61.755.2ﻩ 53.149.5ﻩ59.9ﻩ30.4ﻩ30.6ﻩ33.8 42.135.8ﻩ28.4ﻩ44.1ﻩ32.9ﻩ45.5 36.639.5 49.8 48.8 29 37.33ﻩ4.2 47.637ﻩ.339ﻩ.2 47.6 43.9ﻩ4951.2ﻩ60.8 67ﻩ 48.9 65.4ﻩ65.467.6 62.555.1 49.6ﻩ57.3 47.345.544.5ﻩ 4847.9 49.1 48.859.451ﻩ.651.4 60.9 60.9 55.8 58.662.1ﻩ64ﻩ 60.3 64.6ﻩ7179.459.983.4 75.4 80.255ﻩ.9 58.5 65.269.55ﻩ9.1 21.5 62.5 170 ﻩ-47.462.2ﻩ 60ﻩ33.135ﻩ.343.4ﻩ42.758ﻩ.434ﻩ.4;procgplotdata=example3_1;plotx*time=1;symbol1c=red I=join v=star;run;图1该序列的时序图由图1可读出:除图中170和-47.4这两个异常数据外,该时序图显示澳大利亚季度常住人口变动一般在在60附近随机波动,没有明显的趋势或周期,基本可视为平稳序列。
再接着输入以下程序运行后可输出五方面的信息。
具体见表1-表5.procarima data=example3_1;identifyVar=x nlag=8;run;表1 分析变量的描述性统计从表1可读出分析变量的名称、该序列的均值;标准差及观察值的个数(样本容量)。
时间序列分析上机操作题

时间序列分析上机操作题20.1971年9月—1993年6月澳大利亚季度常住人口变动(单位:千人)情况如下表。
问题:(1)判断该序列的平稳性与纯随机性。
(2)选择适当模型拟合该序列的发展。
(3)绘制该序列拟合及未来5年预测序列图。
针对问题一:将以下程序输入SAS编辑窗口,然后运行后可得图1.data example3_1;input x@@;time=_n_;cards;63.2 67.9 55.8 49.5 50.2 55.4 49.9 45.3 48.1 61.7 55.2 53.1 49.5 59.9 30.6 30.4 33.8 42.1 35.8 28.4 32.9 44.1 45.5 36.6 39.5 49.8 48.8 29 37.3 34.2 47.6 37.3 39.2 47.6 43.9 49 51.2 60.8 67 48.9 65.4 65.4 67.6 62.5 55.1 49.6 57.3 47.3 45.5 44.5 48 47.9 49.1 48.8 59.4 51.6 51.4 60.9 60.9 55.8 58.6 62.1 64 60.3 64.6 71 79.4 59.9 83.4 75.4 80.2 55.9 58.5 65.2 69.5 59.1 21.5 62.5 170 -47.4 62.2 60 33.1 35.3 43.4 42.7 58.4 34.4;proc gplot data=example3_1;plot x*time=1;symbol1c=red I=join v=star;run;图1 该序列的时序图由图1可读出:除图中170和-47.4这两个异常数据外,该时序图显示澳大利亚季度常住人口变动一般在在60附近随机波动,没有明显的趋势或周期,基本可视为平稳序列。
再接着输入以下程序运行后可输出五方面的信息。
具体见表1-表5.proc arima data= example3_1;identify Var=x nlag=8;run;表1 分析变量的描述性统计从表1可读出分析变量的名称、该序列的均值;标准差及观察值的个数(样本容量)。
时间序列上机操作

时间序列上机操作第⼀讲:基本的eviews操作(包括试验⼀和实验⼆)实验⼀ EVIEWS中时间序列相关函数操作【实验⽬的】熟悉Eviews的操作:菜单⽅式,命令⽅式;练习并掌握与时间序列分析相关的函数操作。
【实验内容】⼀、EViews软件的常⽤菜单⽅式和命令⽅式;⼆、各种常⽤差分函数表达式;三、时间序列的⾃相关和偏⾃相关图与函数;【实验步骤】⼀、EViews软件的常⽤菜单⽅式和命令⽅式;㈠创建⼯作⽂件⒈菜单⽅式启动EViews软件之后,进⼊EViews主窗⼝在主菜单上依次点击File/New/Workfile,即选择新建对象的类型为⼯作⽂件,将弹出⼀个对话框,由⽤户选择数据的时间频率(frequency)、起始期和终⽌期。
选择时间频率为Annual(年度),再分别点击起始期栏(Start date)和终⽌期栏(End date),输⼊相应的⽇期,然后点击OK按钮,将在EViews软件的主显⽰窗⼝显⽰相应的⼯作⽂件窗⼝。
⼯作⽂件窗⼝是EViews的⼦窗⼝,⼯作⽂件⼀开始其中就包含了两个对象,⼀个是系数向量C(保存估计系数⽤),另⼀个是残差序列RESID(实际值与拟合值之差)。
⒉命令⽅式在EViews软件的命令窗⼝中直接键⼊CREATE命令,也可以建⽴⼯作⽂件。
命令格式为:CREATE 时间频率类型起始期终⽌期则菜单⽅式过程可写为:CREATE A 1985 1998㈡输⼊Y、X的数据⒈DATA命令⽅式在EViews软件的命令窗⼝键⼊DATA命令,命令格式为:DATA <序列名1> <序列名2>…<序列名n>本例中可在命令窗⼝键⼊如下命令:DATA Y X⒉⿏标图形界⾯⽅式在EViews软件主窗⼝或⼯作⽂件窗⼝点击Objects/New Object,对象类型选择Series,并给定序列名,⼀次只能创建⼀个新序列。
再从⼯作⽂件⽬录中选取并双击所创建的新序列就可以展⽰该对象,选择Edit+/-,进⼊编辑状态,输⼊数据。
第五章时间序列分析习题

第五章时间序列分析习题第五章时间序列分析习题⼀、填空题1.时间序列有两个组成要素:⼀是,⼆是。
2.在⼀个时间序列中,最早出现的数值称为,最晚出现的数值称为。
3.时间序列可以分为时间序列、时间序列和时间序列三种。
其中是最基本的序列。
4.绝对数时间序列可以分为和两种,其中,序列中不同时间的数值相加有实际意义的是序列,不同时间的数值相加没有实际意义的是序列。
5.已知某油⽥1995年的原油总产量为200万吨,2000年的原油总产量是459万吨,则“九五”计划期间该油⽥原油总产量年平均增长速度的算式为。
6.发展速度由于采⽤的基期不同,分为和两种,它们之间的关系可以表达为。
7.设i=1,2,3,…,n,a i为第i个时期经济⽔平,则a i/a0是发展速度,a i/a i-1是发展速度。
8.计算平均发展速度的常⽤⽅法有⽅程式法和.9.某产品产量1995年⽐1990年增长了105%,2000年⽐1990年增长了306.8%,则该产品2000年⽐1995增长速度的算式是。
10.如果移动时间长度适当,采⽤移动平均法能有效地消除循环变动和。
11.时间序列的波动可分解为长期趋势变动、、循环变动和不规则变动。
12.⽤最⼩⼆乘法测定长期趋势,采⽤的标准⽅程组是。
⼆、单项选择题1.时间序列与变量数列( )A都是根据时间顺序排列的B都是根据变量值⼤⼩排列的C前者是根据时间顺序排列的,后者是根据变量值⼤⼩排列的D前者是根据变量值⼤⼩排列的,后者是根据时间顺序排列的2.时间序列中,数值⼤⼩与时间长短有直接关系的是( )A平均数时间序列B时期序列C时点序列D相对数时间序列3.发展速度属于( )A⽐例相对数B⽐较相对数C动态相对数D强度相对数4.计算发展速度的分母是( )A报告期⽔平B基期⽔平C实际⽔平D计划⽔平5.某车间⽉初⼯⼈⼈数资料如下:A 296⼈B 292⼈C 295 ⼈D 300⼈6.某地区某年9⽉末的⼈⼝数为150万⼈,10⽉末的⼈⼝数为150.2万⼈,该地区10⽉的⼈⼝平均数为( )A150万⼈ B150.2万⼈ C150.1万⼈ D ⽆法确定 7.由⼀个9项的时间序列可以计算的环⽐发展速度( ) A 有8个 B 有9个 C 有10个 D 有7个 8.采⽤⼏何平均法计算平均发展速度的依据是( )A 各年环⽐发展速度之积等于总速度B 各年环⽐发展速度之和等于总速度C 各年环⽐增长速度之积等于总速度D 各年环⽐增长速度之和等于总速度9.某企业的科技投,3,2000年⽐1995年增长了58.6%,则该企业1996—2000年间科技投⼊的平均发展速度为( ) A5%6.58 B5%6.158 C6%6.58 D6%6.15810.根据牧区每个⽉初的牲畜存栏数计算全牧区半年的牲畜平均存栏数,采⽤的公式是( )A 简单平均法B ⼏何平均法C 加权序时平均法D ⾸末折半法 11.在测定长期趋势的⽅法中,可以形成数学模型的是( )A 时距扩⼤法B 移动平均法C 最⼩平⽅法D 季节指数法三、多项选择题1.对于时间序列,下列说法正确的有( )A 序列是按数值⼤⼩顺序排列的B 序列是按时间顺序排列的C 序列中的数值都有可加性D 序列是进⾏动态分析的基础E 编制时应注意数值间的可⽐性 2.时点序列的特点有( )A 数值⼤⼩与间隔长短有关B 数值⼤⼩与间隔长短⽆关C 数值相加有实际意义D 数值相加没有实际意义E 数值是连续登记得到的3.下列说法正确的有( )A 平均增长速度⼤于平均发展速度B 平均增长速度⼩于平均发展速度C 平均增长速度=平均发展速度-1D 平均发展速度=平均增长速度-1E 平均发展速度×平均增长速度=14.下列计算增长速度的公式正确的有( )A 增长速度=%100?基期⽔平增长量 B 增长速度=%100?报告期⽔平增长量C 增长速度= 发展速度—100%D 增长速度=%100?-基期⽔平基期⽔平报告期⽔平E 增长速度= %100?基期⽔平报告期⽔平5.采⽤⼏何平均法计算平均发展速度的公式有( ) A 1 231201-?=n n a a a a a a a a nx B 0a a nx n =C 1a a nx n = D R n x = E nx x ∑=A 第⼆年的环⽐增长速度⼆定基增长速度=10%B 第三年的累计增长量⼆逐期增长量=200万元C 第四年的定基发展速度为135%D 第五年增长1%绝对值为14万元E 第五年增长1%绝对值为13.5万元7.下列关系正确的有( )A 环⽐发展速度的连乘积等于相应的定基发展速度B 定基发展速度的连乘积等于相应的环⽐发展速度C 环⽐增长速度的连乘积等于相应的定基增长速度D 环⽐发展速度的连乘积等于相应的定基增长速度E 平均增长速度=平均发展速度-1 8.测定长期趋势的⽅法主要有( )A 时距扩⼤法B ⽅程法C 最⼩平⽅法D 移动平均法E ⼏何平均法 9.关于季节变动的测定,下列说法正确的是( ) A ⽬的在于掌握事物变动的季节周期性 B 常⽤的⽅法是按⽉(季)平均法C 需要计算季节⽐率D 按⽉计算的季节⽐率之和应等于400%E 季节⽐率越⼤,说明事物的变动越处于淡季 10.时间序列的可⽐性原则主要指( )A 时间长度要⼀致B 经济内容要⼀致C 计算⽅法要⼀致D 总体范围要⼀致E 计算价格和单位要⼀致四、判断题1.时间序列中的发展⽔平都是统计绝对数。
统计学习题答案 第9章 时间序列分析

第9章 时间序列分析——练习题●1. 某汽车制造厂2003年产量为30万辆。
(1)若规定2004—2006年年递增率不低于6%,其后年递增率不低于5%,2008年该厂汽车产量将达到多少?(2)若规定2013年汽车产量在2003年的基础上翻一番,而2004年的增长速度可望达到7.8%,问以后9年应以怎样的速度增长才能达到预定目标?(3)若规定2013年汽车产量在2003年的基础上翻一番,并要求每年保持7.4%的增长速度,问能提前多少时间达到预定目标?解:设i 年的环比发展水平为x i ,则由已知得:x 2003=30, (1)又知:320042005200620032004200516%x x x x x x ≥+(),2200720082006200715%x x x x ≥+(),求x 2008由上得32200820072008200320032007(16%)(15%)x x x x x x =≥++ 即为3220081.061.0530x ≥,从而2008年该厂汽车产量将达到 得 x 2008≥30× 31.06×21.05= 30×1.3131 = 39.393(万辆) 从而按假定计算,2008年该厂汽车产量将达到39.393万辆以上。
(2)规定201320032x x =,20042003x x =1+7.8%由上得=107.11%==可知,2004年以后9年应以7.11%的速度增长,才能达到2013年汽车产量在2003年的基础上翻一番的目标。
(3)设:按每年7.4%的增长速度n 年可翻一番, 则有 201320031.0742na a == 所以 1.074log 20.30103log 29.70939log1.0740.031004n ====(年)可知,按每年保持7.4%的增长速度,约9.71年汽车产量可达到在2003年基础上翻一番的预定目标。
原规定翻一番的时间从2003年到2013年为10年,故按每年保持7.4%的增长速度,能提前0.29年即3个月另14天达到翻一番的预定目标。
统计基础知识第五章时间序列分析习题及答案

D.平均数数列二、多项选择题1.将不同时期的发展水平加以平均而得到的平均数称为 A. 序时平均数2.定基发展速度和环比发展速度的关系是 ( BD A 相邻两个环比发展速度之商等于相应的定基发展速度B. 环比发展速度的连乘积等于定基发展速度一、单项选择题 第五章 时间序列分析1.构成时间数列的两个基本要素是 ( A.主词和宾词 )(20XX 年 1 月) B. 变量和次数 C.现象所属的时间及其统计指标数值 D.时间和次数2.某地区历年出生人口数是一个 ( A 时期数列 B ) (20XX 年 10月)B.时点数列C.分配数列 3. 某商场销售洗衣机, 共销售 6000 台, 年 10) 年底库存 50 台,这两个指标是 ( C ) 20XXA. 时期指标B. 时点指标C. 前者是时期指标,后者是时点指标 4.累计增长量(A ) (20XX 年 10)A. 等于逐期增长量之和 D. 前者是时点指标,后者是时期指标B. 等于逐期增长量之积C. 等于逐期增长量之差D .与逐期增长量没有关系5. 某企业银行存款余额 4 月初为 80 万元, 160 万元,则该企业第二季度的平均存款余额为( 5 月初为 150 万元, 6 月初为 210 万元, 7 月初为10)A.140 万元B.150 万元6. 下列指标中属于时点指标的是 ( A ) C.160 万元 D.170 万元A. 商品库存量 (10)B .商品销售C. 平均每人销售额D .商品销售额 7. 时间数列中,各项指标数值可以相加的是A. 时期数列10)( A )B.相对数时间数列C.平均数时间数列D.时点数列8. 时期数列中各项指标数值( A A. 可以相加 1月)B. 不可以相C.绝大部分可以相加D. 绝大部分不可以相加10. 某校学生人数 比 增长了 8%,增长了( D )( 10 月)比 增长了 15%, 比 增长了 18%,则 2004- 学生人数共A.8%+15%+18%B. 8 %X 15%X 18%C. (108%+115%+118%) -1D.108 %X 115%X 118% -1( ABD B.动态平均数)(20XX 年 1 月) C.静态平均数 D.平均发展水平 E. 般平均数 )(20XX 年 10 月)B. 数列中各个指标数值不具有可加性C. 指标数值是通过一次登记取得的D. 指标数值的大小与时期长短没有直接的联系E.指标数值是通过连续不断的登记取得的 )(20XX 年 1)B. 增加一个百分点所增加的相对量E. 环比增长量除以100再除以环比发展速度7. 增长速度( ADE )( 1 月)A.等于增长量与基期水平之比6. 计算平均发展速度常用的方法有( A.几何平均法(水平法)C.方程式法(累计法)E.加权算术平均法 AC)(10)B.调和平均法 D.简单算术平均法C.累计增长量与前一期水平之比D. 等于发展速度 -1E.包括环比增长速度和定基增长速度 8. 序时平均数是( CE )( 10 月)A.反映总体各单位标志值的一般水平B. 根据同一时期标志总量和单位总量计算C. 说明某一现象的数值在不同时间上的一般水平D.由变量数列计算E. 由动态数列计算三、判断题 1 .职工人数、产量、产值、商品库存额、工资总额指标都属于时点指标。
人大(王燕)时间序列课后习题问题详解)2-5(含上机的)

第二章P34 1、(1)因为序列具有明显的趋势,所以序列非平稳。
(2)样本自相关系数:∑∑=-=+---≅=nt tkn t k t tk x xx x x xk 121)())(()0()(ˆγγρ5.10)2021(20111=+++==∑= n t t x n x =-=∑=2201)(201)0(x x t t γ35 =--=+=∑))((191)1(1191x x x x t t t γ29.75 =--=+=∑))((181)2(2181x x x x t t t γ25.9167=--=+=∑))((171)3(3171x x x x t t t γ21.75γ(4)=17.25 γ(5)=12.4167 γ(6)=7.251ρ=0.85(0.85) 2ρ=0.7405(0.702) 3ρ=0.6214(0.556) 4ρ=0.4929(0.415) 5ρ=0.3548(0.280) 6ρ=0.2071(0.153) 注:括号的结果为近似公式所计算。
(3)样本自相关图:Autocorrelation Partial Correlation AC PACProb . |*******| . |*******| 1 0.850 0.850 16.732 0.000 . |***** | . *| . | 2 0.702 -0.07628.7610.000 . |**** | . *| . | 3 0.556 -0.07636.7620.000 . |*** | . *| . | 4 0.415 -0.07741.5000.000 . |**. | . *| . | 5 0.280 -0.07743.8000.000 . |* . | . *| . | 6 0.153 -0.07844.5330.000 . | . |. *| . |7 0.034 -0.07744.5720.000. *| . | . *| . | 8 -0.074-0.07744.7710.000 . *| . | . *| . | 9 -0.17-0.07545.9210.000 .**| . | . *| . | 10 -0.252-0.07248.7130.000 .**| . | . *| . | 11 -0.319-0.06753.6930.000 ***| . |. *| . |12 -0.37-0.0661.2200.000该图的自相关系数衰减为0的速度缓慢,可认为非平稳。
(精校版)时间序列分析试卷及答案

(完整word版)时间序列分析试卷及答案编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望((完整word版)时间序列分析试卷及答案)的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为(完整word版)时间序列分析试卷及答案的全部内容。
时间序列分析试卷1一、 填空题(每小题2分,共计20分)1. ARMA (p , q)模型_________________________________,其中模型参数为____________________.2. 设时间序列{}t X ,则其一阶差分为_________________________。
3. 设ARMA (2, 1):1210.50.40.3t t t t t X X X εε---=++-则所对应的特征方程为_______________________.4. 对于一阶自回归模型AR(1): 110t t t X X φε-=++,其特征根为_________,平稳域是_______________________.5. 设ARMA(2, 1):1210.50.1t t t t t X X aX εε---=++-,当a 满足_________时,模型平稳.6. 对于一阶自回归模型MA (1): 10.3t t t X εε-=-,其自相关函数为______________________.7. 对于二阶自回归模型AR (2):120.50.2t t t t X X X ε--=++则模型所满足的Yule-Walker 方程是______________________。
8. 设时间序列{}t X 为来自ARMA (p,q )模型:1111t t p t p t t q t q X X X φφεθεθε----=++++++则预测方差为___________________.9. 对于时间序列{}t X ,如果___________________,则()~t X I d .10. 设时间序列{}t X 为来自GARCH (p ,q )模型,则其模型结构可写为_____________。
(整理)时间序列分析试题

B.大于100%表示各月(季)水平比全期平均水平高,现象处于旺季
C.小于100%表示各月(季)水平比全期水平低,现象处于淡季
D.小于100%表示各月(季)水平比全期平均水平低,现象处于淡季
E.等于100%表示无季节变化
答案:BD.E
12、循环变动指数C%()。
3月
4月
5月
6月
7月
月初应收账款余额
(万元)
690
850
930
915
890
968
1020
则该企业2005年上半年平均每个月的应收账款余额为()。
A.
B.
C.
D.
答案:A
10、采用几何平均法计算平均发展速度时,侧重于考察()。
A.现象的全期水平,它要求实际各期水平等于各期计算水平
B.现象全期水平的总和,它要求实际各期水平之和等于各期计算水平之和
答案:A
14、元宵的销售一般在“元宵节”前后达到旺季,1月份、2月份的季节指数将()。
A.小于100% B.大于100%
C.等于100% D.大于1200%
答案:B
15、空调的销售量一般在夏季前后最多,其主要原因是空调的供求(),可以通过计算()来测定夏季期间空调的销售量高出平时的幅度。
A.受气候变化的影响;循环指数
答案:D.
17、当时间序列的二级增长量大体相同时,适宜拟合()。
A.抛物线B.指数曲线
C.直线D.对数曲线
答案:A
18、国家统计局2005年2月28日公告,经初步核算,2004年我国的国内生产总值按可比价格计算比上年增长9.5%。这个指标是一个()。
时间序列分析试卷及答案

时间序列分析试卷及答案时间序列分析试卷1一、填空题(每小题2分, 共计20分)1.ARMA(p,q)模型是一种常用的时间序列模型, 其中模型参数为p和q。
2.设时间序列{Xt}, 则其一阶差分为Xt-Xt-1.3.设ARMA (2.1): Xt=0.5Xt-1+0.4Xt-2+εt-0.3εt-1, 则所对应的特征方程为1-0.5B-0.4B^2+0.3B。
4.对于一阶自回归模型AR(1):Xt=10+φXt-1+εt, 其特征根为φ, 平稳域是|φ|<1.5.设ARMA(2.1):Xt=0.5Xt-1+aXt-2+εt-0.1εt-1, 当a满足|a|<1时, 模型平稳。
6.对于一阶自回归模型Xt=φXt-1+εt, 其平稳条件是|φ|<1.7.对于二阶自回归模型AR(2):MA(1):Xt=εt-0.3εt-1, 其自相关函数为Xt=0.5Xt-1+0.2Xt-2+εt, 则模型所满足的XXX-Walker方程是ρ1-0.5ρ2=0.2, ρ2-0.5ρ1=1.8.设时间序列{Xt}为来自ARMA(p,q)模型: Xt=φ1Xt-1+。
+φpXt-p+εt+θ1εt-1+。
+θqεt-q, 则预测方差为σ^2(1+θ1^2+。
+θq^2)。
9.对于时间序列{Xt}, 如果它的差分序列{ΔXt}是平稳的, 则Xt~I(d)。
10.设时间序列{Xt}为来自GARCH(p,q)模型, 则其模型结构可写为σt^2=α0+α1εt-1^2+。
+αpεt-p^2+β1σt-1^2+。
+βqσt-q^2.二、(10分)设时间序列{Xt}来自ARMA(2,1)过程, 满足(1-B+0.5B^2)Xt=(1+0.4B)εt, 其中{εt}是白噪声序列, 并且E(εt)=0, Var(εt)=σ^2.1)判断ARMA(2,1)模型的平稳性。
根据特征方程1-φ1B-φ2B^2, 求得其根为0.5±0.5i, 因此模型的平稳条件是|φ1-0.5i|<1和|φ1+0.5i|<1, 即-1<φ1<1.因为0.5i不在实轴上, 所以模型不是严平稳的, 但是是宽平稳的。
统计学:时间序列分析习题与答案

一、单选题1、根据季度数据测定季节比率时,各季节比率之和为()。
A.100%B.0C.400%D.1200%正确答案:C2、增长1%水平值的表达式是()。
A.报告期增长量/增长速度B.报告期发展水平/100C.基期发展水平/100D.基期发展水平/1%正确答案:C3、若报告期水平是基期水平的8倍,则我们称之为()。
A.翻了 3番B.翻了 8番C.发展速度为700%D.增长速度为800%正确答案:A4、若时间数列呈现出长时间围绕水平线的周期变化,这种现象属于()。
A.无长期趋势、有循环变动B.有长期趋势、有循环变动C.无长期趋势、无循环变动D.有长期趋势、无循环变动正确答案:B5、银行年末存款余额时间数列属于()。
A.平均指标数列B.时点数列C.时期数列D.相对指标数列正确答案:B6、某一时间数列,当时间变量t=1,2,3,...,n时,得到趋势方程为y=38+72t,那么,取t=0,2,4,6,8,...时,方程中的b将为()。
A.36B.34C.110D.144正确答案:A7、某企业2018年的产值比2014年增长了 200%,则年平均增长速度为()。
A.50%B.13.89%C.29.73%D.31.61%正确答案:D8、2010年某市年末人口为120万人,2020年年末达到153万人,则年平均增长量为()万人。
A. 3B.33C. 3.3D.30正确答案:C9、在测定长期趋势时,如果时间数列逐期增长量大体相等,则宜拟合()。
A.抛物线模型B.直线模型C.曲线模型D.指数曲线模型正确答案:B10、在测定长期趋势时,当时间数列的逐期增长速度基本不变时,宜拟合()。
A.逻辑曲线模型B.二次曲线模型C.直线模型D.指数曲线模型正确答案:D二、多选题1、编制时间数列的原则有()。
A.经济内容的一致性B.计算方法的一致性C.时间的一致性D.总体范围的一致性正确答案:A、B、C、D2、以下表述正确的有()。
时间序列上机作业一

上机作业一程序:习题3.8(a)library(TSA)data(retail)plot(retail,type='l',ylab='sales')points(y=retail,x=time(retail),pch=as.vector(season(retail)))(b)library(TSA)data(retail)retailmonth=season(retail)monthreg=lm(retail~month+time(retail))summary(reg)(c)plot(y=rstudent(reg),x=as.vector(time(retail)),type='l',ylab='Standardized residuals',xlab= ' Time') points(y=rstudent(reg),x=as.vector(time(retail)),pch=as.vector(season(retail)))结果输出:(a)reg=lm(retail~month+time(retail))> summary(reg)Call:lm(formula = retail ~ month + time(retail))Residuals:Min 1Q Median 3Q Max-19.8950 -2.4440 -0.3518 2.1971 16.2045Coefficients:Estimate Std. Error t value Pr(>|t|) (Intercept) -7.249e+03 8.724e+01 -83.099 < 2e-16 *** monthFebruary -3.015e+00 1.290e+00 -2.337 0.02024 * monthMarch 7.469e-02 1.290e+00 0.058 0.95387 monthApril 3.447e+00 1.305e+00 2.641 0.00880 ** monthMay 3.108e+00 1.305e+00 2.381 0.01803 * monthJune 3.074e+00 1.305e+00 2.355 0.01932 * monthJuly 6.053e+00 1.305e+00 4.638 5.76e-06 *** monthAugust 3.138e+00 1.305e+00 2.404 0.01695 * monthSeptember 3.428e+00 1.305e+00 2.626 0.00919 ** monthOctober 8.555e+00 1.305e+00 6.555 3.34e-10 *** monthNovember 2.082e+01 1.305e+00 15.948 < 2e-16 *** monthDecember 5.254e+01 1.305e+00 40.255 < 2e-16 *** time(retail) 3.670e+00 4.369e-02 83.995 < 2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 4.278 on 242 degrees of freedomMultiple R-squared: 0.9767, Adjusted R-squared: 0.9755F-statistic: 845 on 12 and 242 DF, p-value: < 2.2e-16习题3.14程序:(a)library(TSA)data(retail)retailmonth=season(retail)monthreg=lm(retail~month+time(retail))summary(reg)(b)runs(rstudent(reg))(c)acf(rstudent(reg))(d) qqnorm(rstudent(reg))qqline(rstudent(reg))hist(rstudent(reg),xlab='Standardized Residuals')shapiro.test(rstudent(reg))结果输出:(a)> library(TSA)> data(retail)> retailJan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 1986 42.4 39.2 42.2 43.9 43.7 45.5 47.1 46.4 47.7 49.4 57.1 75.31987 45.9 44.0 45.0 49.3 47.0 48.9 52.2 51.1 51.5 54.6 62.7 83.51988 53.4 49.0 50.8 53.4 53.8 54.3 58.5 57.3 56.9 60.8 69.2 93.71989 57.8 53.9 56.6 57.5 59.5 57.5 60.1 60.0 60.3 63.5 71.6 99.51990 61.4 58.5 60.0 62.6 63.6 61.4 65.4 63.3 63.1 65.7 72.9 103.41991 61.0 56.7 63.6 63.2 63.7 63.2 67.6 64.1 64.2 68.2 78.2 104.31992 61.9 59.6 60.9 65.3 64.9 64.2 66.2 66.2 66.0 69.7 78.8 106.61993 64.6 62.6 64.7 68.4 66.8 68.4 70.2 69.4 70.5 74.6 84.5 113.81994 69.3 64.8 69.0 70.5 70.6 71.2 72.9 71.9 74.4 77.8 87.3 122.01995 69.5 67.7 69.8 74.1 72.7 73.5 76.7 72.8 76.2 80.0 91.1 126.71996 71.1 70.3 73.4 78.5 77.1 79.7 81.0 78.9 81.6 86.4 101.0 130.61997 76.7 75.8 80.6 82.9 82.0 86.5 88.8 83.9 84.7 92.6 105.7 139.81998 83.0 80.2 82.7 87.0 87.7 86.1 91.5 87.7 87.3 92.5 107.2 139.61999 85.2 81.5 85.1 88.2 90.1 90.1 94.5 91.7 89.7 97.3 111.8 144.52000 91.1 85.3 88.4 92.5 92.8 92.7 97.1 94.0 93.0 100.8 114.0 151.92001 93.9 90.3 92.4 98.6 100.1 99.0 103.5 100.4 101.0 107.4 123.3 164.12002 98.5 97.3 102.7 106.2 105.3 102.0 108.6 103.4 104.1 113.2 131.3 165.32003 100.1 99.3 102.7 108.1 106.3 106.7 111.2 105.9 108.0 116.7 134.0 170.82004 106.3 103.7 107.6 113.5 113.6 113.7 116.6 112.4 113.8 120.4 138.0 172.12005 106.0 102.7 109.1 109.6 110.7 112.7 114.8 111.1 111.5 118.8 136.9 177.52006 105.4 102.6 106.7 114.1 114.7 115.1 116.9 114.7 113.6 122.8 140.5 184.82007 107.6 107.5 113.2> month=season(retail)> month[1] January February March April May June July[8] August September October November December January February [15] March April May June July August September [22] October November December January February March April[29] May June July August September October November [36] December January February March April May June[43] July August September October November December January[50] February March April May June July August[57] September October November December January February March[64] April May June July August September October[71] November December January February March April May[78] June July August September October November December [85] January February March April May June July[92] August September October November December January February [99] March April May June July August September [106] October November December January February March April [113] May June July August September October November [120] December January February March April May June [127] July August September October November December January [134] February March April May June July August [141] September October November December January February March [148] April May June July August September October [155] November December January February March April May [162] June July August September October November December [169] January February March April May June July [176] August September October November December January February [183] March April May June July August September [190] October November December January February March April [197] May June July August September October November [204] December January February March April May June [211] July August September October November December January [218] February March April May June July August [225] September October November December January February March [232] April May June July August September October [239] November December January February March April May [246] June July August September October November December [253] January February March12 Levels: January February March April May June July August ... December> reg=lm(retail~month+time(retail))> summary(reg)Call:lm(formula = retail ~ month + time(retail))Residuals:Min 1Q Median 3Q Max-19.8950 -2.4440 -0.3518 2.1971 16.2045Coefficients:Estimate Std. Error t value Pr(>|t|)(Intercept) -7.249e+03 8.724e+01 -83.099 < 2e-16 ***monthFebruary -3.015e+00 1.290e+00 -2.337 0.02024 *monthMarch 7.469e-02 1.290e+00 0.058 0.95387monthApril 3.447e+00 1.305e+00 2.641 0.00880 **monthMay 3.108e+00 1.305e+00 2.381 0.01803 *monthJune 3.074e+00 1.305e+00 2.355 0.01932 *monthJuly 6.053e+00 1.305e+00 4.638 5.76e-06 ***monthAugust 3.138e+00 1.305e+00 2.404 0.01695 * monthSeptember 3.428e+00 1.305e+00 2.626 0.00919 ** monthOctober 8.555e+00 1.305e+00 6.555 3.34e-10 *** monthNovember 2.082e+01 1.305e+00 15.948 < 2e-16 *** monthDecember 5.254e+01 1.305e+00 40.255 < 2e-16 *** time(retail) 3.670e+00 4.369e-02 83.995 < 2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 4.278 on 242 degrees of freedomMultiple R-squared: 0.9767, Adjusted R-squared: 0.9755F-statistic: 845 on 12 and 242 DF, p-value: < 2.2e-16(b)> runs(rstudent(reg))$pvalue[1] 9.19e-23$observed.runs[1] 52$expected.runs[1] 127.9333$n1[1] 136$n2[1] 119$k[1] 0(c)(d)> shapiro.test(rstudent(reg))Shapiro-Wilk normality test data: rstudent(reg)W = 0.939, p-value = 8.534e-09>。
时间序列分析习题解答(2):上课展示的典型题

时间序列分析习题解答(2):上课展⽰的典型题由于本答案由少部分⼈完成,难免存在错误,如有不同意见欢迎在评论区提出。
第⼀题⼀、已知零均值平稳序列{X t}的⾃协⽅差函数为γ0=1,γ±1=ρ,γk=0,|k|≥2.计算{X t}的偏相关系数a1,1,a2,2。
计算最佳线性预测L(X3|X2),L(X3|X2,X1)。
计算预测的均⽅误差E[X3−L(X3|X2)]2,E[X3−L(X3|X2,X1)]2。
证明:ρ应满⾜|ρ|≤1 2。
若ρ=0.4,计算{X t}的谱密度函数,给出{X t}所满⾜的模型。
解:(1)由Yule-Walker⽅程,a1,1=γ1/γ0=ρ,1ρρ1a2,1a2,2=ρ,解得a2,2=−ρ2 1−ρ2.(2)由预测⽅程,有L(X3|X2)=ρX2。
设L(X3|X2,X1)=a2X2+a1X1,则1ρρ1a1a2=ρ,a1=−ρ21−ρ2,a2=ρ1−ρ2.所以L(X3|X2,X1)=−ρ2X1+ρX21−ρ2.(3)预测的均⽅误差是E(X3−ρX2)2=(1+ρ2)γ0−2ργ1=1−ρ2,E X3−−ρ2X1+ρX21−ρ22=(1−ρ2)2+ρ4+ρ2(1−ρ2)2−2ρρ3+ρ(1−ρ2)(1−ρ2)2 =2ρ4−3ρ2+1(1−ρ2)2=1−2ρ21−ρ2.(4)由于{X t}的⾃协⽅差函数1后截尾,所以它是⼀个MA(1)模型,即存在b≤1,⽩噪声εt∼WN(0,σ2)使得X t=εt+bεt−1.于是γ0=(1+b2)σ2=1,γ1=bσ2=ρ,所以ρ(b)=b1+b2,在b∈[−1,1]上ρ(b)是单调的,所以−12≤ρ(−1)≤ρ≤ρ(1)=12.(5)由谱密度反演公式,容易得到[][][][][][]()[][]Processing math: 49%f(λ)=12π[1+0.8cosλ]=12π451+cosλ+14=(2/√5)22π1+12(e iλ)2.所以X t=εt+12εt−1,{εt}∼WN0,45.第⼆题⼆、设零均值平稳序列{X t}的⾃协⽅差函数满⾜γk=187×25|k|,k≠0,k∈Z.当γ0取何值时,该序列为AR(1)序列?说明理由并给出相应的模型。
时间序列分析考试卷及答案

考核课程 时间序列分析(B 卷) 考核方式 闭卷 考核时间 120 分钟注:B 为延迟算子,使得1-=t t Y BY ;∇为差分算子,。
一、单项选择题(每小题3 分,共24 分。
)1. 若零均值平稳序列{}t X ,其样本ACF 和样本PACF 都呈现拖尾性,则对{}t X 可能建立( B )模型。
A. MA(2)B.ARMA(1,1)C.AR(2)D.MA(1)2.下图是某时间序列的样本偏自相关函数图,则恰当的模型是( B )。
A. )1(MAB.)1(ARC.)1,1(ARMAD.)2(MA3. 考虑MA(2)模型212.09.0--+-=t t t t e e e Y ,则其MA 特征方程的根是( C )。
(A )5.0,4.021==λλ (B )5.0,4.021-=-=λλ (C )5.2221==λλ, (D ) 5.2221=-=λλ,4. 设有模型112111)1(----=++-t t t t t e e X X X θφφ,其中11<φ,则该模型属于( B )。
A.ARMA(2,1) B.ARIMA(1,1,1) C.ARIMA(0,1,1) D.ARIMA(1,2,1)5. AR(2)模型t t t t e Y Y Y +-=--215.04.0,其中64.0)(=t e Var ,则=)(t t e Y E ( B )。
A.0 B.64.0 C. 16.0 D. 2.06.对于一阶滑动平均模型MA(1): 15.0--=t t t e e Y ,则其一阶自相关函数为( C )。
A.5.0- B. 25.0 C. 4.0- D. 8.07. 若零均值平稳序列{}t X ∇,其样本ACF 呈现二阶截尾性,其样本PACF 呈现拖尾性,则可初步认为对{}t X 应该建立( B )模型。
A. MA(2)B.)2,1(IMAC.)1,2(ARID.ARIMA(2,1,2)8. 记∇为差分算子,则下列不正确的是( C )。
时间序列分析习题及答案
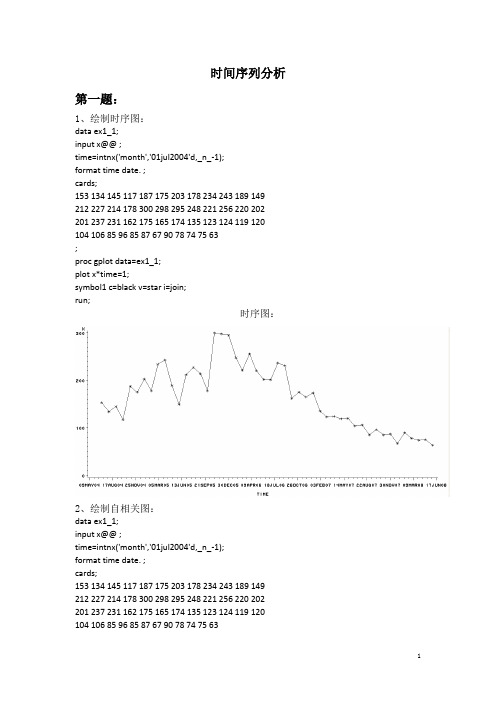
时间序列分析第一题:1、绘制时序图:data ex1_1;input x@@ ;time=intnx('month','01jul2004'd,_n_-1);format time date. ;cards;153 134 145 117 187 175 203 178 234 243 189 149 212 227 214 178 300 298 295 248 221 256 220 202 201 237 231 162 175 165 174 135 123 124 119 120 104 106 85 96 85 87 67 90 78 74 75 63;proc gplot data=ex1_1;plot x*time=1;symbol1 c=black v=star i=join;run;时序图:2、绘制自相关图:data ex1_1;input x@@ ;time=intnx('month','01jul2004'd,_n_-1);format time date. ;cards;153 134 145 117 187 175 203 178 234 243 189 149 212 227 214 178 300 298 295 248 221 256 220 202 201 237 231 162 175 165 174 135 123 124 119 120 104 106 85 96 85 87 67 90 78 74 75 63;proc arima data=ex1_1;identify var=x;run;样本自相关图:白噪声检验输出结果:因为P值小于α,所以该序列为非白噪声序列,根据时序图看出数据并不在一个常数值附近随机波动,后期有递减的趋势,所以不是平稳序列。
第二题:1、选择拟合模型方法一:首先绘制该序列的时序图,直观检验序列平稳性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
时间序列分析上机操作题-CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN(2)选择适当模型拟合该序列的发展。
(3)绘制该序列拟合及未来5年预测序列图。
针对问题一:将以下程序输入SAS编辑窗口,然后运行后可得图1. data example3_1;input x@@;time=_n_;cards;2949674864 71170 60;proc gplot data=example3_1;plot x*time=1;symbol1c=red I=join v=star;run;图1 该序列的时序图由图1可读出:除图中170和这两个异常数据外,该时序图显示澳大利亚季度常住人口变动一般在在60附近随机波动,没有明显的趋势或周期,基本可视为平稳序列。
再接着输入以下程序运行后可输出五方面的信息。
具体见表1-表5.proc arima data= example3_1;identify Var=x nlag=8;run;表1 分析变量的描述性统计从表1可读出分析变量的名称、该序列的均值;标准差及观察值的个数(样本容量)。
表2 样本自相关图由表2可知:样本自相图延迟3阶之后,自相关系数都落入2倍标准差范围以内,而且自相关系数向零衰减的速度非常快,故可以认为该序列平稳。
表3 样本自相关系数该图从左到右输出的信息分别为:延迟阶数、逆自相关系数值和逆自相关图。
表4 样本偏自相关图该图从左到右输出信息是:延迟阶数、偏自相关系数值和偏自相关图。
表5 纯随机性检验结果由上表可知在延迟阶数为6阶时,LB检验统计量的P值很小,所以可以断定该序列属于非白噪声序列。
针对问题二:将IDENTIFY命令中增加一个可选命令MINIC,运行以下程序可得到表6.表6 IDENTIFY命令输出的最小信息量结果通过上表可知:在自相关延迟阶数小于等于5,移动平均延迟阶数也小于等于5的所有ARMA(p,q)模型中,BIC信息量相对最小的是ARMA(1,3)模型。
进行参数估计,输入以下命令,运行可得到表7—表10estimate p=1q=3;run;表7 ESTIMATE命令输出的位置参数估计结果表8 ESTIMATE命令输出的拟合统计量的值表9 ESTIMATE命令输出的系数相关阵表10 ESTIMATE命令输出的残差自相关检验结果拟合模型的具体形式如表11所示。
表11 ESTIMATE命令输出的拟合模型形式针对问题三:对拟合好的模型进行短期预测。
输入以下命令,运行可得表12和图2.forecast lead=5id=time out=results;run;proc gplot data=results;plot x*time=1 forecast*time=2 l95*time=3 u95*time=3/overlay;symbol1c=black i=none v=star;symbol2c=red i=join v=none;symbol3c=green i=join v=none l=32;run;表12 forecast命令输出的预测结果图2 拟合效果图5416755196563005748258796602666146562828 6465365994672076620765859672956917270499 7253874542763687853480671829928522987177 8921190859924209371794974962599754298705 100072101654103008104357105851107507109300111026 112704114333115823117171118517119850121121122389 123626124761125786126743127627128453129227129988 130756131448132129132802采用SAS软件运行下列程序:data example5_1;input x@@;t=_n_;cards;54167 55196 56300 57482 58796 60266 61465 6282864653 65994 67207 66207 65859 67295 69172 7049972538 74542 76368 78534 80671 82992 85229 8717789211 90859 92420 93717 94974 96259 97542 98705100072 101654 103008 104357 105851 107507 109300 111026112704 114333 115823 117171 118517 119850 121121 122389123626 124761 125786 126743 127627 128453 129227 129988130756 131448 132129 132802;proc gplot;plot x*t=1;symbol1i=join v=none c=blavk;run;图3 该序列的时序图通过时序图可以得知,该序列有明显的线性递增趋势,故用线性回归模型来拟合。
在接着在编辑窗口输入以下命令,运行程序:proc autoreg data=example5_1;model x=t;run;表12 AUTOREG过程输出线性拟合结果通过该表可得知:(1)因变量的名称,本例中因变量为x。
(2)普通最小二乘统计量,误差平方和、均方误差、SBC信息量、回归模型的R^2、DW统计量、误差平方和的自由度、均方根误差、AIC信息量、包括自回归误差过程在内的整体模型R^2。
(3)参数估计量。
该部分从左到右输出的信息分别是:变量名、自由度、估计值、估计值的标准差、t值以及统计量的t值的近似概率P值。
对于进行5期预测,再接着输入以下命令运行:proc forecast data=example5_1 method=stepar trend=2 lead=5out=out outfull outtest=est;id t;var x;proc gplot data=out;plot x*t= _type_ / href=2008;symbol1i=none v=star c=black;symbol2i=join v=none c=red;symbol3i=join v=none c=green l=2;symbol4i=join v=none c=green l=2;run;表13 FORECAST过程OUT命令输出数据集图示该表有四个变量:时间变量,类型变量,预测时期标示变量,序列值变量。
表14 FORECAST过程OUTSET命令输出数据集图示此表可以查看预测过程中相关参数及拟合效果。
这些信息分为三部分:(1)关于序列的基本信息。
序列样本个数、非缺失数据个数、拟合模型自由度、残差标准差。
(2)关玉预测模型的参数估计信息。
线性模型的常数估计值、线性模型的斜率、残差自回归的参数估计值。
(3)拟合优度统计量信息。
图4 FORECAST过程预测效果图589561640656727697640599568577553582 600566653673742716660617583587565598 62861866705770736678639604611594634 658622709722782756702653615621602635 677635736755811798735697661667645688 713667762784837817767722681687660698 717696775796858826783740701706677711 734690785805871845801764725723690734 750707807824886859819783740747711751(2)使用X-11方法,确定该序列的趋势。
针对问题一:运行以下程序可得到该序列的时序图,见图5。
data example4_3;input x@@;time=intnx ('month','01jan1962'd, _n_-1);format time data;cards;589 561 640 656 727 697 640 599 568 577 553 582 600 566 653 673 742 716 660 617 583 587 565 598 628 618 688 705 770 736 678 639 604 611 594 634 658 622 709 722 782 756 702 653 615 621 602 635 677 635 736 755 811 798 735 697 661 667 645 688 713 667 762 784 837 817 767 722 681 687 660 698 717 696 775 796 858 826 783 740 701 706 677 711 734 690 785 805 871 845 801 764 725 723 690 734 750 707 807 824 886 859 819 783 740 747 711 751 ;proc gplot data=example4_3;plot x*time=1;symbol1c=red I=join v=star;run;图5 1962-1970年平均每头奶牛的月度产奶量的时序图通过时序图,我们可以发现1962-1970年平均每头奶牛的月度奶产量随着月度的变动有着非常明显的规律变化,此外该序列有线性递增趋势,故此时序图具有“季节”效应。
针对问题二:采用x-11过程。
在编辑窗口输入以下命令,然后运行后可得到以下几个表和图。
data example4_3;input x@@;t=intnx ('monthly','1jan1962'd, _n_-1);cards;589 561 640 656 727 697 640 599 568 577 553 582 600 566 653 673 742 716 660 617 583 587 565 598 628 618 688 705 770 736 678 639 604 611 594 634 658 622 709 722 782 756 702 653 615 621 602 635 677 635 736 755 811 798 735 697 661 667 645 688 713 667 762 784 837 817 767 722 681 687 660 698 717 696 775 796 858 826 783 740 701 706 677 711 734 690 785 805 871 845 801 764 725 723 690 734 750 707 807 824 886 859 819 783 740 747 711 751 ;proc x11 data=example4_3;monthly date=t;var x;output out=out b1=x d10=season d11=adjusted d12=trend d13=irr;data out;set out;estimate=trend*saeson/100;proc gplot data=out;plot x*t=1 estimate*t=2/overlay;plot adjusted*t=1trend *t=1irr*t=1;symbol1c=black i=join v=star;symbol2c=red i=join v=none w=2l=3;run;消除季节趋势,得到调整后的序列图,见图6。