lzw实验报告
南昌大学物理实验报告

南昌大学物理实验报告课程名称:大学物理实验实验名称:分光计的调节与光栅系数的测量学院:化学学院专业班级:应用化学学生姓名:钟超学号:5503216049实验地点:311座位号:17实验时间:一、实验目的:1、了解分光计的结构,掌握调节分光计的方法;2、使用透射光栅和分光计测定光栅常数。
二、实验原理:1、目测调节:根据眼睛的粗略估计,调节望远镜和平行光管上的高低倾斜调节螺丝,使望远镜和平行光管光轴大致垂直于中心轴;调节载物台下的三个水平调节螺丝,使载物台面大致呈水平状态。
2、用自准法调整望远镜:(1)点亮照明小灯,调节目镜和分划板间的距离,看清分划板上的准线和和带有绿色的小十字窗口(目镜对分划板调焦)(2)将准直镜放在载物台上,使得准直镜的两反射面与望远镜大致垂直。
轻缓的转动载物台,从侧面观察,判断从准直镜正反两面反射的亮十字光线能否进入望远镜内。
(3)从望远镜的目镜中观察到亮的十字像,前后移动目镜对望远镜调焦,使得亮十字像成清晰像。
再调准线与目镜间的距离,使目镜中既能看清准线,又能看清亮十字像。
注意准线与亮十字像之间有无视差,如有视差,则需反复调节,予以消除。
3、用逐次逼近各半调整法调整望远镜光轴与分光计中心轴垂直:将准直镜仍竖直置于载物台上,转动载物台,使望远镜分别对准准直镜的反射面。
利用自准法可以分别观察到两个十字反射像。
分别调节望远镜方位和载物台平面,使准线和十字反射像重合。
即转动载物台使望远镜先对准准直镜的一个表面,若从望远镜中看到准线和十字反射像不重合,他们的交点在高低方面相差一段距离 ,此时调节望远镜倾斜度,使差距减小一半,再调节载物台螺丝,消除另一半距离使准线和十字反射像重合,然后将载物台旋转180°,使望远镜对着双面镜的另一面,采用同样的方法调节,如此重复调整数次,直到转动载物台时,从双面镜前后两表面反射回来的十字像都能与准线重合为止。
4.调整平行光管:(1)、目测粗调至平行光轴大致与望远镜光轴相一致(2)、打开狭缝,从望远镜中观察,同时调节目镜,直到看见清晰的狭缝像为止,然后调节缝宽,使望远镜视场中缝宽约为1mm。
健康评估实验报告册-LanzhouUniversity

兰州大学护理学院健康评估实验报告册专业:年级:班级:姓名:兰州大学护理学院2017年4月编写说明本报告册由护理学院史素杰、陈静教师编写,白凤霞老师主审。
由于能力水平有限,报告册难免会有疏漏之处。
同学在使用中如果发现任何问题,请及时与编写的教师联系,提出您宝贵的意见。
下面是编写内容及编写教师:编写内容 编写教师 主审教师 实验一:健康史采集实验七:脊柱与四肢、神经系统的评估史素杰 白凤霞实验九:实验室检查及X线阅片实验十:护理体检综合练习实验十一:护理病历书写实验二:一般状态、皮肤、浅表淋巴结评估实验三:头部与颈部评估实验四:胸廓、肺部的评估陈静 实验五:心脏的评估实验六:腹部的评估实验八:心电图检查学生实验守则一、实验前必须接受安全教育,认真预习实验指导书,如未预习或无故迟到者,指导教师有权停止其实验。
二、进入实验室不得高声喧嚷,不得随便串走,不准搬弄与本实验无关的仪器设备。
三、学生必须以实事求是的科学态度进行实验。
认真测定数据,严格要求,不得草率 从事,并应及时送交实验报告,不得抄袭或臆造。
四、严格遵守操作规程,服从实验指导教师指导。
如违犯操作或不听从指导而造成仪器设备损坏等事故者,应按学校有关规定进行处理赔偿。
五、在实验过程中,仪器设备如发生故障,应立即报告指导教师及时处理。
六、实验完毕后,应及时将设备、用具归还并对实验场地进行清理,经指导教师同意后,方可离开实验室。
目录实验一 健康史采集 (4)实验二 一般状态、皮肤、浅表淋巴结评估 (8)实验三 头部与颈部评估 (9)实验四 胸廓、肺部的评估 (10)实验五 心脏的评估 (11)实验六 腹部的评估 (12)实验七 脊柱与四肢、神经系统的评 (13)实验八 心电图检查 (14)实验九 实验室检查及X线阅片 (15)实验十 护理体检综合练习 (16)实验十一 护理病历书写 (20)实验一健康史采集方法实验目的1.掌握问诊的方法与技巧。
2.掌握问诊的模式与内容实验内容学生分为4人/组,依据患者入院护理评估表完成健康史的采集。
地理信息系统实验报告

南阳师范学院本科学生实验报告姓名李想院(系)环境科学与旅游学院专业地理信息科学班级 13级4班实验课程名称地理信息系统原理及其应用指导教师及职称张海军讲师开课时间 2014 至 2015 学年一学期南阳师范学院教务处编印实验名称目录实验一:图像配准实验二:矢量化练习实验三:创建拓扑与拓扑改错实验四:几何纠正实验五:图幅接边处理实验六:实验七:实验八:实验九:实验十:学生姓名:李想专业:地理信息科学班级: 13级4班实验名称:图像配准实验编号:01课程名称:地理信息系统原理及其应用指导教师:张海军实验地点:六楼机房实验时间:10.25小组成员:小组合作:是()否(√)实验目的:对一幅地图录入真实世界的值,进行投影转换,赋予它真实世界的坐标值,进行地图配准。
实验设备:数据:南阳市地图计算机,Arc Map 10.1。
实验内容及步骤:加载地图(两种常用方式)(1)(2)Catalog→Foldex Connetions→新建文件夹→单机鼠标左键拖入快捷键:放大——Z 缩小——X 移动——C2)加载“Georeferencing”工具条3)设置数据框坐标系4)为控制点录入真实世界坐标值5)更新地理参考系6)图像纠正并保存Rectify(cell size 单位大小,即分辨率 NoData as 无数据表达Resample Type 重采样形式,一般采用Nesrest NeigborOutput Location路径信息 Compression Type压缩运行图像压缩格式JPEG 、LZW、 PACKBITS 、CCITTCID 、RLE (游程长度编码的压缩格式)、CCITT GROUP3 、CCITT GROUP4)7)投影:110,6344 、114,0308计算配准后图像的经度范围,并计算投影带进行投影转换(Arctoolbox→Date Mangment Tools→Projections and Transformations→Raster→Project Raster双击→OK→Project Raster√在ArcMap中数据格式:Shapefile 可以看成可编辑Coverage 只可以看,不可编辑,若想编辑需装个ArcInfo workstation Geodateba se采用面向对象的方法,简写GDB实验小结:通过此次实验操作,让我们掌握了Arc Map 的基本操作和原理,并知道一幅普通的地图和一幅在地理坐标系中的地图的区别是什么,如何对一幅地图录入真实世界的坐标值,如何进行投影转换等。
多媒体实验报告多篇

利用深度学习技术,对多媒体内容进行自动识别和分类,提高了识别的准确性和效率。
设计了多媒体数据可视化分析工具
通过可视化技术,将多媒体数据以直观、易懂的方式呈现给用户,方便用户进行数据分析和 挖掘。
存在问题分析及改进方向探讨
数据处理算法性能有待提 升
当前算法在处理大规模多媒体数据时性能较低, 需要进一步优化算法设计,提高处理效率。
02
多媒体数据处理基础
音频处理技术
01
02
03
音频信号数字化
包括采样、量化和编码三 个过程,将模拟音频信号 转换为数字信号。
音频压缩技术
通过去除冗余信息和人耳 不敏感的信息,降低音频 数据的存储空间和传输带 宽。
音频编辑和处理
包括剪切、复制、粘贴、 淡入淡出、音量调整等操 作,以及降噪、均衡、混 响等效果处理。
感谢您的观看
THANKS
UDP协议
与TCP不同,UDP是一种无连接 的协议,适用于实时性要求较高 的多媒体数据传输,如音频和视 频流。
RTP/RTCP协议
实时传输协议(RTP)用于在互 联网上传输音频或视频,而RTP 控制协议(RTCP)则提供流量控 制和拥塞控制机制。
存储介质选择与性能评估
存储介质类型
常见的存储介质包括硬盘、固态硬盘(SSD)、光盘、U盘等,各 有其优缺点和适用场景。
多媒体实验报告多篇
contents
目录
• 实验背景与目的 • 多媒体数据处理基础 • 多媒体数据压缩编码技术 • 多媒体数据传输与存储技术 • 多媒体系统设计与实现 • 多媒体应用案例分析 • 实验总结与展望
01
实验背景与目的
多媒体技术发展概述
lzw编码实验报告

实验报告(一)——LZW编码的C++编程实现时间:2011.4.27一、实验目的及要求使用C++编程实现LZW编码、解码。
二、源程序设计思路1.编码程序:步骤一:开始时的词典包含所有可能的根,而当前前缀P是空的。
步骤二:当前字符C:=字符流中的下一个字符。
步骤三:判断P+C是否在词典中:(1)如果“是”,P:=P+C。
(2)如果“否”,则:①把代表当前前缀P的码字输出到码字流。
②把缀-符串P+C添加到词典中。
③令P:=C。
(3)判断字符流中是否还有字符需要编码:①如果“是”,返回到步骤二。
②如果“否”:输出相应于当前前缀P的码字。
结束编码。
2.译码程序:步骤一:在开始译码时,词典包含所有可能的前缀根。
步骤二:当前码字cW:=码字流中的第一个码字。
步骤三:输出当前缀-符串string.cW到字符流。
步骤四:先前码字pW:=当前码字cW。
步骤五:当前码字cW:=码字流中的下一个码字。
步骤六:判断当前缀-符串string.cW是否在词典中:(1)如果“是”,则:①当前缀-符串string.cW输出到字符流。
②当前前缀P:=先前缀-符串string.pW。
③当前字符C:=当前前缀-符串string.cW的第一个字符。
④把缀-符串P+C添加到词典。
(2)如果“否”,则:①当前前缀P:=先前缀-符串string.pW。
②当前字符C:=当前缀-符串string.pW的第一个字符。
③输出缀-符串P+C到字符流,然后把它添加到词典中。
步骤七:判断码字流中是否还有码字要译:(1)如果“是”,就返回到步骤四。
(2)如果“否”,结束。
三、程序框图词典初始化选择编码(1)或译码(2)?将第一个字符赋给前缀P结束是否有码字要译?字符串P+C 是否在词典中?是P :=P+C是输出代表当前前缀P 的码字否将P+C 添加到词典中P:=C 输出代表前缀P 的码字否C :=字符流中下一个字符 1 编码当前码字cW:=码字流中第一个码字输出对应字符string.cW先前码字pW:=当前码字cW;cW:=下一个码字是否有码字要译?否2 译码String.cW 是否在词典中?是输出string.cW是P :=string.pW C :=string.cW首字符将P+C 添加到词典P:=string.pW C:=string.pW 首字符输出P+C否四、程序设计代码及注释#include <iostream> #include <string> #include <iomanip> using namespace std;string dic[30]; int n;int find(string s) //字典中寻找,返回序号 { int temp=-1; for(int i=0;i<30;i++) { if(dic[i]==s) temp=i+1;}return temp;}void init() //字典初始化{dic[0]="a"; //开始时词典包含所有可能的根dic[1]="b";dic[2]="c";for(int i=3;i<30;i++) //其余为空{dic[i]="";}}void code(string str){init(); //初始化char temp[2];temp[0]=str[0]; //取第一个字符temp[1]='\0';string P=temp; //P为前缀int i=1;int j=3; //目前字典存储的最后一个位置cout<<"编码为:";while(1){char t[2];t[0]=str[i]; //取下一字符t[1]='\0';string C=t; //C为字符流中下一个字符if(C=="") //无码字要译,结束{cout<<" "<<find(P); //输出代表当前前缀的码字break; //退出循环,编码结束}if(find(P+C)>-1) //有码字要译,如果P+C在词典中,则用C扩展P,进行下一步:{P=P+C;i++;}else //如果P+C不在词典中,则将P+C添加到词典中,令P:=C{cout<<" "<<find(P);string PC=P+C;dic[j++]=PC;P=C;i++;}}cout<<endl;cout<<"生成的词典为:"<<endl;for(i=0;i<j;i++) //输出词典中的内容,j为词典的长度{cout<<setw(12)<<i+1<<setw(12)<<dic[i]<<endl;}cout<<endl;}void decode(int c[]){init(); //译码词典与编码词典相同,将a,b,c设为初始的前缀int pw,cw; //pw:先前码字,cw:当前码字cw=c[0]; //输入码字流的第一个码字,赋给当前码字int j=2,i;cout<<"译码为:";cout<<dic[cw-1]; //输出当前字符串到字符流for(int m=0;m<n-1;m++){pw=cw; //当前码字赋给先前码字cw=c[m+1];if(cw<=j+1) //若当前码字在词典中{cout<<dic[cw-1]; //输出当前码字锁代表的字符串char t[2];t[0]=dic[cw-1][0];t[1]='\0';string k=t;j++;dic[j]=dic[pw-1]+k; //将先前码字与当前码字所代表的字符串的首字符连接而成的字符串添加到词典中}else //若当前码字不在词典中{char t[2];t[0]=dic[pw-1][0];t[1]='\0';string k=t;j++;dic[j]=dic[pw-1]+k; //将先前码字与当前码字所代表的字符串的首字符连接而成的字符串添加到词典中cout<<dic[cw-1]; //输出该字符串}}cout<<endl;cout<<"生成的词典为:"<<endl;for(i=0;i<j;i++) //输出词典中的内容,j为词典的长度{cout<<setw(12)<<i+1<<setw(12)<<dic[i]<<endl;}cout<<endl;}int main() //主程序{string str;char choice;while(1){cout<<"\n\n\t"<<"1.编码"<<"\t"<<"2.译码\n\n";cout<<"请选择:";cin>>choice;if(choice=='1') //若选择a则编码{cout<<"\n输入要编码的字符串(由a、b、c组成):";cin>>str;code(str);}else if(choice=='2') //若选择b则译码{int c[30];cout<<"\n消息序列长度是:";cin>>n;cout<<"\n消息码字依次是:";for(int i=0;i<n;i++){cin>>c[i];}decode(c);}else return 0; //其他选择则退出程序}}五、程序运行结果。
LZW算法实验报告

LZW编解码的VB界面化实现通俗的讲,LZW就是通过建立一个字符串表,用较短的代码来表示较长的字符串来实现压缩。
LZW压缩算法的基本原理:提取原始文本文件数据中的不同字符,基于这些字符创建一个编译表,然后用编译表中的字符的索引来替代原始文本文件数据中的相应字符,减少原始数据大小。
LZW编码算法的具体执行步骤如下:1. 开始时的字典包含所有可能的根,而当前前缀P是空的2. 当前的字符(C)=字符流中的下一个字符3. 判断缀-字符串P+C是否在字典中(1)如果在字典中:P=P+C(2)如果不在字典中,则:a. 把当前前缀P的码字输出到码字流b. 把缀-符串P+C添加到字典c. 令P=C4. 判断码字流中是否还有码字要译(1)如果有,返回到步骤2(2)如果没有,则:a. 把代表当前前缀P的码字输出到码字流b. 结束伪码描述:dic[j]<-all n single character ,j=1,2,3…nj=n+1prefix<-read first character in charstreamwhile ((C<-nextcharacter)!=null)beginif prefix.c is in dicprefix<-prefix.celsecodestream<-cW for Prefixdic[j]<-prefix.cj=n+1Prefix<-CEndcodestream <-cW for PrefixLZW译码算法的具体执行步骤如下:1.在开始译码时,词典包含所有可能的前缀根2.当前码字cW=码字流中的第一个码字3.输出当前缀-符串 .cW到字符流中4.先前码字pW=当前码字cW5.当前码字cW=码字流中的下一个码字6.判断当前缀-符串sting.cW是否在词典中:(1)如果是,则:a.当前缀-符串string.cW输出到字符流b.当前前缀P=先前缀-符串string.pWc.当前字符C=当前前缀-符串string.pW的第一个字符d.把缀-符串P+C添加到词典(2)如果否,则:a.当前前缀P=先前缀-符串string.pWb.当前字符C=当前缀-符串string.pW的第一个字符c.输出缀-符串P+C到字符流,然后把它添加到词典中7.判断码字流中是否还有码字要译(1)如果是,返回到第四步(2)否,结束伪码描述:Dic[j]<-all n single-character,j=1,2,3…nJ=n+1cW<-first code from codestreamcharstream<-dic[cW]pW<-cWwhile ((cW<-next code word)!=null)beginif cW is in diccharstream<-dic[cW]prefix<-dic[pW]cW<-first character of dic[cW]dic[j]<-prefix.cWj=n+1pW=cWelseprefix<-dic[pW]cW<-first character of prefixcharstream<-prefix.cWdic[j]<-prefix.CpW<-cWj<-n+1endend按照上述伪码描述,将其转为VB语言,并加上简单界面。
2021年重庆科技学院学生实验报告

重庆科技学院学生试验汇报重庆科技学院学生试验汇报重庆科技学院学生试验汇报重庆科技学院学生试验汇报重庆科技学院学生试验汇报重庆科技学院学生试验汇报五、试验统计和处理1.试验装置原始数据轴颈直径d= mm轴承有效宽度B= mm驱动电机类型: ; 功率kW; 额定转速n d= r/min压力变送器类型: ; 量程: MPa拉力传感器类型: ; 量程: kg试验油品2.测定油膜压力分布时选择工况参数轴颈转速n= r/min静压加载油腔油压p0= Mpa轴承循环润滑系统油P L= Mpa3.试验数据统计(1)测得轴瓦圆周上均布1~7点周向油膜压力数值p1= MPa; p2= MPa; p3= MPa; p4= MPap5= MPa; p6= MPa; p7= MPa(2)测得第8点轴瓦上轴向油膜压力p8= Mpa4.据测得p1、p2、…、p8, 绘制油膜压力分布曲线, 完成下列要求(1) 绘制周向油膜压力分布曲线: 按一定百分比在附图1从圆周上开始沿径向延长线方向截''并连成一光滑曲线, 即为周向油膜压力分布曲线。
取试验数据统计中周向油膜压力值, 得点1~7附图1 周向油膜压力分布图(2) 绘制轴向油膜压力分布曲线: 依据位置4和位置8处油膜压力大小按一定百分比在附图2上对应位置上描点, 得8'、4'、8'点, 并将点0、8'、4'、8'、0连成一光滑曲线, 即为轴向油膜压力分布曲线。
附图2 轴向油膜压力分布图5.求动压滑动轴承端泄影响系数K(1) 依据附图1周向油膜压力分布图, 在方格纸上绘制其承载分量曲线(机械设计试验指导书图6-1b图)。
按数方格数方法, 求出油膜平均压力p m。
(将方格纸粘贴在下面)重庆科技学院学生试验汇报重庆科技学院学生试验汇报重庆科技学院学生试验汇报。
LZW编码实验报告

【实验环境】
1.软件环境:windows vista
结论
本实验实现了对简单字符串的LZW编码和解码。通过本次实验,加深了对字典编码(LZW编码)原理的理解,基本达到实验目的。
为提高编码效率,对本实现方法可以提出以下改进:监视压缩比变化,当字符串表填充满后,开始监视压缩比。若压缩比降低到某一程度,即重新建立字符串表。这样应该能有效的提高编码效率,具体实现方法有待研究。
华南理工大学
数据压缩课程实验报告
实验题目:____LZW编码
姓名:苏启院学号:200820110730
班级:计算机应用2班组别:
合作者:
指导教师:________沃焱___________
实验概述
【实验目的及要求】
1.理解和掌握各种字典编码方法的基本原理
2.编程实现LZW编码方法,实现基本的压缩、解压过程。
ELSE
输出STRING的编码
将STRING+CHARACTER添加到字符串表中
STRING = CHARACTER
END of IF
END of WHILE
output the code for STRING
2.LZW编码解压算法的伪码描述如下:
读取OLD_CODE
输出OLD_CODE
WHILE仍然有输入DO
读取NEW_CODE
STRING =根据字符串表转换NEW_CODE
铁道车辆用LZW车轴钢晶粒度研究

第36卷 第8期钢 铁V o l.36,N o.8 2001年8月IRON AN D S T EEL Aug ust2001铁道车辆用LZW车轴钢晶粒度研究李学锋 王玉玲(太原钢铁(集团)有限公司)摘 要 研究了铝、钒、氮等微量元素对LZW车轴钢奥氏体晶粒度粒度的影响。
研究结果表明:为保证LZW 车轴钢坯奥氏体晶粒度符合标准要求,应将钢中酸溶铝控制在适当含量范围;钢中加入微量钒可明显细化奥氏体晶粒,提高奥氏体晶粒粗化温度;转炉炼L ZW车轴钢在高真空度下长时间脱气处理对奥氏体晶粒度不利。
关键词 车轴钢 晶粒度⒇STUDY ON THE GRAIN SIZE OF LZW AXLETREESTEEL US ED FOR RAIL WAY VEHICLELI Xuefeng W ANG Yuling(Taiyuan Iron and Steel(Group)Co.,Ltd.)ABSTRACT Effect o f micro-a lloying element Al,V,N on the grain size of LZW ax letree steel hav e been inv estig ated in this paper.The results indica te that the pro per rang e of acid-so luble Al co ntent should be controlled to sa tisfy the g rain size requirement.The addition of micro-alloying V into steel refines g rain and increases g rain coa rsening temperature.Trea t-ment in high-vacuum conditio n for lo ng time is ha rmful to g rain size of LZW axletree steel melted w ith LD.KEY W ORDS ax letree steel,g rain size1 前言随着铁道车辆的提速加载,40轴将很快被力学性能、高、低倍组织和晶粒度等要求更高的50轴所取代。
中国石油大学(华东)油田化学实验报告 实验七

实验七 堵水剂的制备与性质一、实验目的1. 学会几种堵水剂的制备方法。
2. 掌握几种堵水剂的形成机理及其使用性质。
二、实验原理堵水剂是指从油、水井注入地层,能减少地层产出水的物质。
从油井注入地层的堵水剂称油井堵水剂(或简称堵水剂),从水井注入地层的堵水剂称为调剖剂。
常用的堵水剂有冻胶型堵水剂、凝胶型堵水剂、沉淀型堵水剂和分散体型堵水剂,这些堵水剂的形成机理和使用性质各不相同。
1. 冻胶型堵水剂冻胶(如锆冻胶)是由高分子(如HPAM)溶液转变而来,交联剂(如锆的多核羟桥络离子)可以使高分子间发生交联,形成网络结构,将液体(如水)包在其中,从而使高分子溶液失去流动性,即转变为冻胶。
锆冻胶是油田常用的冻胶型堵水剂。
锆冻胶是由锆的多核羟桥络离子与HPAM 中的羧基发生交联反应而形成的。
体系的pH 值可影响多核羟桥络离子的形成及HPAM 分子中羧基的量,因此,pH 值可影响锆冻胶的成冻时间和冻胶强度。
2. 凝胶型堵水剂凝胶是由溶胶转变而来。
当溶胶由于种种原因(如电解质加入引起溶胶粒子部分失去稳定性而产生有限度聚结)形成网络结构,将液体包在其中,从而使整个体系失去流动性时,即转变为凝胶。
油田堵水中常用的是硅酸凝胶。
硅酸凝胶由硅酸溶胶转化而来,硅酸溶胶由水玻璃(又名硅酸钠,分子式Na2O·mSO2)与活化剂反应生成。
活化剂是指可使水玻璃先变成溶胶而随后又变成凝胶的物质。
盐酸是常用的活化剂,它与水玻璃的反应如下:2222 2 2Na O mSiO HCl H O mSiO NaCl +→+由于制备方法不同,可得两种硅酸溶胶,即酸性硅酸溶胶和碱性硅酸溶胶。
这两种硅酸溶胶都可在一定的条件(如温度、pH 值和硅酸含量)下,在一定时间内胶凝。
评价硅酸凝胶堵水剂常用两个指标,即胶凝时间和凝胶强度。
胶凝时间是指硅酸体系自生成至失去流动性的时间。
凝胶强度是指凝胶单位表面积上所能承受的压力。
3. 沉淀型堵水剂沉淀型堵水剂由两种可反应产生沉淀的物质组成。
多媒体技术LZW编码实验报告(word文档良心出品)

多媒体技术LZW编码实验报告班级姓名学号实验名称:LZW算法的编程实现实验内容:用C++语言编写程序来实现LZW算法一、LZW定义:LZW就是通过建立一个字符串表,用较短的代码来表示较长的字符串来实现压缩. 字符串和编码的对应关系是在压缩过程中动态生成的,并且隐含在压缩数据中,解压的时候根据表来进行恢复,算是一种无损压缩.在本次实验中我们就进行了LZW编码以及译码简单算法的编写。
LZW编码又称字串表编码,是无损压缩技术改进后的压缩方法。
它采用了一种先进的串表压缩,将每个第一次出现的串放在一个串表当中,用一个数字来表示串,压缩文件只进行数字的存贮,则不存贮串,从而使图像文件的压缩效率得到了较大的提高。
LZW编码算法的原理是首先建立一个词典,即跟缀表。
对于字符串流,我们要进行分析,从词典中寻找最长匹配串,即字符串P在词典中,而字符串P+后一个字符C不在词典中。
此时,输出P对应的码字,将P+C放入词典中。
经过老师的举例,我初步知道了对于一个字符串进行编码的过程。
二、编码的部分算法与分析如下:首先根据需要得建立一个初始化词典。
这里字根分别为 A B C。
具体的初始化算法如下:void init()//词典初始化{dic[0]="A";dic[1]="B";dic[2]="C";//字根为A,B,Cfor(int i=3;i<30;i++)//其余为空{dic[i]="";}}对于编码算法的建立,则需先建立一个查找函数,用于查找返回序号:int find(string s){int temp=-1;for(int i=0;i<30;i++){if(dic[i]==s) temp=i+1;}return temp;}接下来就可以编写编码算法了。
void code(string str){init();//初始化char temp[2];temp[0]=str[0];//取第一个字符temp[1]='\0';string w=temp;int i=1;int j=3;//目前字典存储的最后一个位置cout<<"\n 编码为:";for(;;){char t[2];t[0]=str[i];//取下一字符t[1]='\0';string k=t;if(k=="") //为空,字符串结束{cout<<" "<<find(w);break;//退出for循环,编码结束}if(find(w+k)>-1){w=w+k;i++;}else{cout<<" "<<find(w);string wk=w+k;dic[j++]=wk;w=k;i++;}}cout<<endl;for(i=0;i<j;i++){cout<<setw(45)<<i+1<<setw(12)<<dic[i]<<endl;}cout<<endl;}三、译码是编码的逆过程:在译码中根缀表仍为A,B,C。
中国海洋大学声学基础实验报告
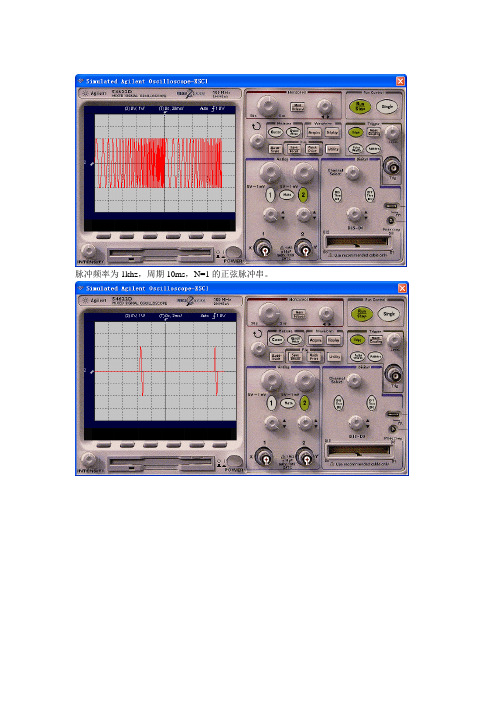
脉冲频率为1khz,周期10ms,N=1的正弦脉冲串。
0.020.040.060.080.10.120.140.160.180.2time/sm a g n i t u d esignal x=10*sin(2*pi*f1*t+angle1)+sin(2*pi*f2*t+angle2)+2x 104butterworth 低通滤波器频响曲线f/hzm ag n i t u d e /d b0500100015002000250030003500400045005000f/hzm a g n i t u d e两次鱼叫的频谱01002003004005006007008009001000滤波前后的频谱f/hzm a g n i t u d e0.0050.010.0150.020.0250.030.0350.040.045t/sm a g n i t u d e低通滤波后的时域波形00.20.40.60.81 1.2 1.4 1.6 1.82x 10-3t/sm a g n i t u d e高通滤波后的时域波形0.511.522.5x 1044f/hzm a g n i t u d e原信号频谱0.511.522.5x 1044f/hzm a g n i t u d e低通滤波后信号频谱0.511.522.5x 1044f/hzm a g n i t u d e高通滤波后信号频谱Fp=2500hz;Fs=3000hz;rp=1db,as=30db,前两个需要13阶,椭圆只需4阶。
0.511.522.533.54频率(kHz )幅度(d B )巴特沃斯模拟滤波器0.511.522.533.54频率(kHz )幅度(d B )切比雪夫I 模拟滤波器频率(kHz )幅度(d B )椭圆模拟滤波器02000400060008000100001200010002000300040005000600070008000900010000f/hz幅度海洋环境噪声频谱00.51 1.52 2.53 3.54 4.55Frequency (kHz)P o w e r /f r e q u e n c y (d B /H z )Welch Power Spectral Density Estimate05001000150020002500300035004000f/hza m p l i t u d eNI 采集卡所得正弦线性调频信号相关系数0.99,时间间隔104ms.开始50hz ,结束500hz,采样时间500ms,采样率10000hz 。
物化二

(3)纯液体饱和蒸汽压测定能否用于测定溶液的蒸汽压,为什么?
南昌大学物理化学实验报告
学生姓名: 彭文冰 学号:5702111077 专业班级: 本硕 111
实验时间: 14 时 00 分 第 五 周 座位号: 3- 实验成绩: 答:不可以,因为在纯液体的测定中,液体会随温度的升高而蒸发,如果是 溶液,其溶剂挥发后浓度将会改变。不同浓度的溶液其饱和蒸汽压不同。其沸点 不稳定,实验操作过程中很难判断是否已达到其沸点。
3、排除 AB 弯管空间内的空气 AB 弯管空间内的压力包括两部分:一是待测液的蒸气压;另一部分是空
气的压力。测定时,必须将其中的空气排除后,才能保证 B 管液面上的压力为液 体的蒸气压。排除方法为:先将恒温槽温度调至第一个温度值(一般比室温高 2℃ 左右)接通冷凝水,抽气降压至液体轻微沸腾,此时 AB 弯管内的空气不断随蒸气 经 C 管逸出,如此沸腾数分钟,可认为空气被排除干净。
实验时间: 14 时 00 分 第 五 周 座位号: 3- 实验成绩:
图一 、饱和蒸汽压测定装置
平衡管由 A 球和 U 形管 B、C 组成。平衡管上接一冷凝
管。A 中装待测液体,当 A 球的液面上纯粹是待测液体的蒸
汽,而 B 管和 C 管的液面处于同一水平时,则表示 B 管液面
上的(即 A 球液面上的蒸汽压)与加在 C 管液面上的外压相
南昌大学物理化学实验报告
学生姓名: 彭文冰 学号:5702111077 专业班级: 本硕 111
实验时间: 14 时 00 分 第 五 周 座位号: 3- 实验成绩:
纯液体饱和蒸汽压的测定
一、实验目的
成都理工大学层析成像实验报告

实验课程 学院名称 专业名称 学生姓名 学生学号 指导教师 实验地点 实验成绩
地球物理层析成像 地球物理学院 勘查技术与工程
曹俊兴 5417
二〇一五 年 三 月,收获了很多专业知识,比如 学会了利用层析成像的手段反演出地下地质体的异常,同时也学会 学 了利用我们的专业知识解决不同的地质问题。程序语言作为一种工 生 具一方面起到了辅助作用,另一方面我们也学会了一种思维方式, 实 如何设计程序,如何用程序解决我们的复杂问题。在今后的学习工 验 作当中,进一步拓宽思路,勇于创新,能够获得更多的知识。 心 得 2015 年 4 月 28 日 学 生 ( 签 名 ) :
xl[i][j]=(y_js[j]-y_jf[i])/(45-0);//斜率 printf("%f\n",xl[i][j]); } } for(i=0;i<12;i++) { b[i]=1.5+i*3;//每条射线截距 } //以上在求射线的斜率和射线在纵轴上的截距 // double ft_t=0.0; //每一格的时间; double fl[12][12][12][9]; //每一格射线的长度; double Time[12][12]; //每条射线的时间; double X0,Y0; //第一个点坐标; double X1,Y1; //第二个点坐标; double x_0,x_1,y_0,y_1; //判定的 x,y; double x0,x1,y0,y1; //小格的边界; FILE *fp_ds; fp_ds=fopen("每一小格的距离.dat","w"); for(i=0;i<12;i++) { for(j=0;j<12;j++) { Time[i][j]=0.0; for(n=0;n<12;n++) { for(m=0;m<9;m++) { fl[i][j][n][m]=0; x0=5*m; x1=x0+5; y0=3*n; y1=y0+3; y_0=xl[i][j]*x0+b[i]; if(y_0<=y1&&y_0>=y0) { X0=x0; Y0=y_0; y_1=xl[i][j]*x1+b[i]; if((y_1<=y1)&&(y_1>=y0)) { Y1=y_1; X1=x1; } else
lzw实验报告

多媒体实验LZW编码算法1.实验目的1)通过实验进一步掌握LZW编码的原理;2)用C/C++等高级程序设计语言实现LZW编码。
2.实验设备硬件:装有32M以上内存MPC;软件:Windows 9X/NT/XP/2000操作系统、TC 或C++等高级语言环境。
3.实验设计原理LZW编码思想:(1)在压缩过程中动态形成一个字符列表(字典)。
(2)每当压缩扫描图像发现一个词典中没有的字符序列,就把该字符序列存到字典中,并用字典的地址(编码)作为这个字符序列的代码,替换原图像中的字符序列,下次再碰到相同的字符序列,就用字典的地址代替字符序列。
LZW编码算法的具体执行步骤如下:步骤1:开始时的词典包含所有可能的根(Root),而当前前缀P是空的;步骤2:当前字符(C):=字符流中的下一个字符;步骤3:判断缀-符串P+C是否在词典中(1)如果“是”:P:=P+C//(用C扩展P);(2)如果“否”①把代表当前前缀P的码字输出到码字流;②把缀-符串P+C添加到词典;③令P:=C//(现在的P仅包含一个字符C); 步骤4:判断码字流中是否还有码字要译(1)如果“是”,就返回到步骤2;(2)如果“否”①把代表当前前缀P的码字输出到码字流;②结束。
4.程序框图5.程序设计代码#include<iostream> #include<string> using namespace std; const int N=200;class LZW{private: string Dic[200];int code[N]; public: LZW(){Dic[0]='a';Dic[1]='b';Dic[2]='c';string *p=Dic;}void Bianma(string cs[N]); int IsDic(string e);int codeDic(string f); void display(int g);};void LZW::Bianma(string cs[N]){ string P,C,K;P=cs[0];int l=0;for(int i=1;i<N;i++){C=cs[i];K=P+C;if(IsDic(K)) P=K;else{code[l]=codeDic(P);Dic[3+l]=K;P=C;l++;}if(N-1==i)code[l]=codeDic(P);}display(l);}int LZW::IsDic(string e){for(int b=0; b<200; b++) { if(e==Dic[b]) return 1; } return 0;}int LZW::codeDic(string f){ int w=0;。
数据紧缩实验指导书

《数字据紧缩》实验指导书北方民族大学电气信息工程系2021年5月目录《数据紧缩》实验教学大纲.....................................错误!未定义书签。
实验一RL编码解码...............................................错误!未定义书签。
实验二HUFFMAN编码算法 ................................错误!未定义书签。
实验三LZW编码与解码算法 ...............................错误!未定义书签。
实验四JPEG2000编码解码...................................错误!未定义书签。
实验五A VC编码解码............................................错误!未定义书签。
《数据紧缩》实验教学大纲(供信息工程本科专业利用)适用专业:通信工程、信息工程课程类别:专业任选课课程性质:选修课实验类别:专业实验一、学时与学分1.课程总学时:462.课程总学分:23.实验学时:104.实验学分:0二、实验教学目标与大体要求本课程是理论性较强的课程,实验教学能够加深学生对理论教学的明白得,提高学习的爱好和动手能力,为以后进一步有关数据紧缩知识的学习与利用打下基础。
设置《数据紧缩》实验的目的是要让学生把握数据紧缩方式的经典算法;其要紧任务是使学生深切明白得和把握几种数据紧缩技术及这些技术在视频标准中的综合应用。
三、实验内容实验内容要紧包括:实验一RL编码。
设计RL编码的流程,并写出程序,能够将输入的数据进行RL编码,并输出结果。
实验二HUFFMAN编码与解码算法。
设计HUFFMAN编码的流程,并写出程序,能够将输入的数据进行HUFFMAN编码,并输出结果。
实验三LZW编码与解码算法。
设计LZW编码的流程,并写出程序,能够将输入的数据进行LZW 编码,并输出结果。
压缩实验报告

压缩实验报告压缩实验报告引言:压缩技术是现代信息技术中不可或缺的一部分。
它可以将大量的数据压缩成较小的体积,从而节省存储空间和传输带宽。
本实验旨在探究不同压缩算法的效果,并比较它们的优缺点。
一、实验设备和方法本实验使用了一台配置较高的计算机,并安装了常用的压缩软件。
实验过程中,我们选择了两种常见的压缩算法:Huffman编码和Lempel-Ziv-Welch(LZW)算法。
二、实验过程1. Huffman编码:Huffman编码是一种基于字符出现频率的压缩算法。
它通过构建哈夫曼树,将出现频率较高的字符用较短的编码表示,而出现频率较低的字符用较长的编码表示。
我们首先选择了一个文本文件进行压缩实验。
通过对文件进行统计分析,我们得到了每个字符的出现频率。
然后,根据频率构建了一棵哈夫曼树,并生成了对应的编码表。
最后,我们将原始文本文件使用Huffman编码进行压缩,并记录了压缩后的文件大小。
2. LZW算法:LZW算法是一种基于字典的压缩算法。
它通过建立字典并将输入文本与字典中的条目进行匹配,从而实现压缩。
当输入文本中的字符序列在字典中不存在时,将其添加到字典中,并输出前一个匹配的条目的编码。
我们选择了一段音频文件进行LZW算法的压缩实验。
首先,我们将音频文件转化为二进制数据,并建立一个初始字典,包含所有可能的字符。
然后,按照LZW算法的步骤,将输入文本与字典中的条目进行匹配,并输出对应的编码。
最后,我们记录了压缩后的文件大小。
三、实验结果与分析通过对压缩后的文件大小进行比较,我们得出了以下结论:1. Huffman编码相对于LZW算法,在处理文本文件时具有更好的压缩效果。
这是因为文本文件中存在大量重复的字符,而Huffman编码可以根据字符的出现频率进行编码,从而实现较高的压缩比。
2. LZW算法在处理音频文件时表现更好。
音频文件中的数据通常具有较高的连续性,而LZW算法可以通过建立字典并匹配连续的字符序列,实现较好的压缩效果。
LZW编码 多媒体技术实验报告

i++;
//但此码字并未确定除非下当前前缀
rear=new word;
//增加一个当前字符后不在词典中
now->next=rear;
//给当前前缀增加一个当前字符
now=rear;
rear->letter=input[i];
rear->next=NULL;
}
} } } ⑥ 输出模块 void display() 将存放输出码字流的数组输出。程序如下: void display() { int i; for(i=0;i<=k;i++)
cout<<output[i]<<endl; } 3) 编码算法程序: #include<iostream> #include<string.h> using namespace std; int x,j,k; int output[10]; struct word { char letter; word *next; }; struct wordlist { int number; word *w_head; wordlist *next; }; wordlist *wl_head,*wl_rear,*wl_now; void dictionary(char* input) { void set_root(char*); void update_wordlist(char*); wordlist* check_prefix(word*); int check_word(word*,word*); void display(); wl_head=NULL; set_root(input); update_wordlist(input); display(); } int check_word(word* w_head1,word*w_head2) { int check=1;
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
多媒体实验
LZW编码算法
1.实验目的
1)通过实验进一步掌握LZW编码的原理;
2)用C/C++等高级程序设计语言实现LZW编码。
2.实验设备
硬件:装有32M以上内存MPC;
软件:Windows 9X/NT/XP/2000操作系统、TC 或C++等高级语言环境。
3.实验设计原理
LZW编码思想:
(1)在压缩过程中动态形成一个字符列表(字典)。
(2)每当压缩扫描图像发现一个词典中没有的字符序列,就把该字符序列存到字典中,并用字典的地址(编码)作为这个字符序列的代码,替换原图像中的字符序列,下次再碰到相同的字符序列,就用字典的地址代替字符序列。
LZW编码算法的具体执行步骤如下:
步骤1:开始时的词典包含所有可能的根(Root),而当前前缀P是空的;
步骤2:当前字符(C):=字符流中的下一个字符;
步骤3:判断缀-符串P+C是否在词典中
(1)如果“是”:P:=P+C//(用C扩展P);
(2)如果“否”
①把代表当前前缀P的码字输出到码字流;
②把缀-符串P+C添加到词典;
③令P:=C//(现在的P仅包含一个字符C); 步骤4:判断码字流中是否还有码字要译
(1)如果“是”,就返回到步骤2;
(2)如果“否”
①把代表当前前缀P的码字输出到码字流;
②结束。
4.程序框图
5.程序设计代码#include<iostream> #include<string> using namespace std; const int N=200;
class LZW{
private: string Dic[200];
int code[N]; public: LZW(){
Dic[0]='a';
Dic[1]='b';
Dic[2]='c';
string *p=Dic;
}
void Bianma(string cs[N]); int IsDic(string e);
int codeDic(string f); void display(int g);
};
void LZW::Bianma(string cs[N]){ string P,C,K;
P=cs[0];
int l=0;
for(int i=1;i<N;i++){
C=cs[i];
K=P+C;
if(IsDic(K)) P=K;
else{
code[l]=codeDic(P);
Dic[3+l]=K;
P=C;
l++;
}
if(N-1==i)
code[l]=codeDic(P);
}
display(l);
}
int LZW::IsDic(string e){
for(int b=0; b<200; b++) { if(e==Dic[b]) return 1; } return 0;
}
int LZW::codeDic(string f){ int w=0;。