关于正态数据与非正态数据及其过程能力计算
过程能力分析.

0.6
均值 标准差 12 2 15 0.67
0.5 B 0.4
0.3
0.2 A 0.1
0.0 6 8 12 15 18
图7-9 过程输出从分布A变化到B
17
过程绩效指数 Pp和Ppk
• Cp及Cpk估计σ的方法:只考虑“短期”波动
– 单值时,用移动极差 – 可以分组时,若子组大小不超过6,用子组极差; 若子组大小超过6,用子组标准差
• 内部服务与外部服务
– 内部服务:公司内部的服务 – 外部服务:顾客付账单的服务
• 自愿服务与非自愿服务
– 自愿服务(voluntary services):主动寻求并自愿采纳的服 务:如加油站 – 非自愿服务(in voluntary services)
• 服务质量问题与制造质量问题相比,有何不同之 处?
非正态过程能力计算
• 一种方法
USL LSL Cp P 0.995 P 0.005 C pk USL P P 0.50 0.50 LSL min( , ) P P 0.995 P 0.50 0.50 P 0.005
WhereP
应用实例
..\数据源\SPC_钢珠直径.MTW ..\数据源\SPC_二极管不合格品率.MTW ..\数据源\SPC_BoxCox变换.MTW
• 二者之间的关系
– 过程的理想状态,受控状态
• 质量改进就是要持续减小设计、制造和服务过程的波动
• 在实际制造过程中,如果过程处于受控状态,则 过程输出的质量特性 X 通常服从正态分布, 即 X ~ N ( 。 , ) • 考察以标准差 为单位构造的三个典型区间:
[ , ]
6 Sigma BB 测量阶段 过程能力培训课件
MINITAB下数据的过程能力分析
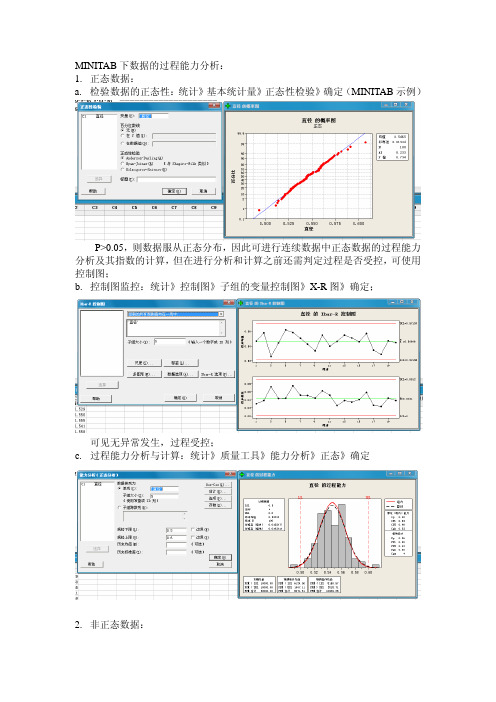
MINITAB下数据的过程能力分析:1.正态数据:a.检验数据的正态性:统计》基本统计量》正态性检验》确定(MINITAB示例)P>0.05,则数据服从正态分布,因此可进行连续数据中正态数据的过程能力分析及其指数的计算,但在进行分析和计算之前还需判定过程是否受控,可使用控制图;b.控制图监控:统计》控制图》子组的变量控制图》X-R图》确定;可见无异常发生,过程受控;c.过程能力分析与计算:统计》质量工具》能力分析》正态》确定2.非正态数据:a.数据的正态性检验:同上P<0.05,所以数据为非正态数据,需进行转换后方可进行过程能力分析,但这并不妨碍用原始数据进行控制图的绘制。
b.数据的转换:统计》控制图》BOX-COX变换》填入数据“扭曲”,子组大小填“10》选项》将变换后的数据存入“C2”中》确定;得到如下图,可知转换的λ=0.5,即对原始数据求平方根;c.控制图的绘制:步骤同上d. 过程能力分析:统计》质量工具》能力分析》正态》单列为“C2”,子组大小为“10”,规格上限为“2.82”,2.82=81/2,确定3. 离散数据: a . 计算DPMO ,公式参见SRINNI 培训:b .将DPMO 暂时理解为不合格品率,如果DPMO=66807.2,则不合格品率P=0.00668072;c . 计算》概率分布》正态分布》逆累计概率》输入常量“0.0668072”,,确定:d .根据正态分布的对称性:Z =︳-1.5︳+1.5=3,即相应的SIGMA 水平为3, 公式为: Z=︳x︳+1.5如果DPMO=1350,则P=0.00135,按照如上步骤,则有:逆累积分布函数正态分布,平均值 = 0 和标准差 = 1P( X <= x ) x0.00135 -2.99998,所以Z=2.99+1.5=4.5。
Minitab能力分析

• 组内曲线使用子组内方差,整体曲线使用整体样 本方差。
能力直方图
Minitab
• 可通过将曲线与条形相比较来评估数据的正态性。
• 检查曲线,看看它们之间的距离有多近。组内曲 线和整体曲线之间的差别很大表明过程不受控制。
能力
Minitab
• 什么是能力? • 有能力的过程(生产过程)可以生产符合规格的 产品或服务。 • 可以评估生产单位生产“在规格之内”的能力, 并预测超出规格的部件数量。
Minitab
• 能力是通过将过程展开与规格展开进行比较来确 定的。也就是说,将过程变异的宽度与规格区间 的宽度进行比较。 • 希望的结果是:过程展开小于规格展开,并包括 在规格展开内。 • 能力指数是规格展开和过程展开的比率。它们是 无单位的值,可用于比较不同过程的能力。 • 一般认为 1.33 是能力指数的可接受的最小值, 而大多数实践者认为小于 1 的值是不可接受的。
过程平均值
Minitab
• 过程平均值
• 过程测量值的平均值。
• 可从数据估计过程平均值,也可以由用户 根据历史记录和工程知识来指定过程平均 值。
返回
规格上限和规格下限
• 规格上限和规格下限
Minitab
• 规格上限和规格下限是用户根据客户要求 指定的。为过程建立的限制 - 它们不反映 实际上过程是如何执行的。USL 和 LSL 可 确定部件、产品或服务是否符合要求。
PPM < LSL 预期的组内性能
• PPM < LSL 预期的组内性能
Minitab
• PPM(百万分数)< LSL 是测量值低于规 格下限的预期百万分数。该值定义为 1,000,000 乘以从子组内分布随机选择的部 件的测量值低于规格下限的概率。
非正态数据转换及过程能力分析V0课件

Q-Q图法
将数据绘制在分位数-分位数坐 标系上,与正态分布曲线进行 比较,判断数据的正态性。
P-P图法
将数据绘制在概率-概率坐标系 上,与正态分布曲线进行比较, 判断数据的正态性。
偏度和峰度检验
通过计算数据的偏度和峰度, 并与标准正态分布的偏度和峰 度进行比较,判断数据的正态性。
非正态数据的过程能计算过程能力 指数,包括CPK、PPK等,以评估生 产过程的稳定性和性能。
数据转换方法
采用Box-Cox变换方法对数据进行转 换,使其接近正态分布。通过选择适 当的λ值,实现了数据的正态化。
结论
通过数据转换和过程能力分析,该制 造企业识别了生产过程中的瓶颈和改 进机会,提高了产品质量和生产效率。
平方根转换
总结词
平方根转换适用于数据分布为幂律分布的情况,可以改善数据分布的偏度。
详细描述
平方根转换是将数据取平方根。平方根转换可以降低数据分布的偏度,使其更接 近正态分布。平方根转换在统计分析中常用于处理一些具有幂律分布特征的数据。
倒数转换
总结词
倒数转换适用于数据分布为倒指数分布的情况,可以改善数 据分布的偏度。
偏态分布
数据分布形态不对称,偏向某一方向。
离群值分布
多峰分布
数据分布有多个峰值,不遵循单一分 布形态。
数据中出现较多远离均值的异常值。
非正态数据的特点与影响
偏态分布可能导致平均值和众数不一 致,影响对数据的整体理解。
多峰分布可能掩盖数据之间的差异, 难以进行比较和分析。
离群值可能导致数据方差增大,影响 统计分析的准确性。
收集数据
收集足够的过程数据,以评估 过程的稳定性和一致性。
计算过程能力指数
质量控制中非正态分布数据过程能力算法研究

=
() 1
其 中 U L 为 规 范 - ,S 为 规 范 下 S t限 L L . 限 , 为 过 程 的 标 准差 。 ( ) 控 过 程 中 心与 规 范 中心 不 重合 时 , 2受
过 程 能力 指 数 ( ) 汁算公 式 为 : () 2
0 前 言
6 管 理 … 一 种 全 新 的 管 珲 手 段 和 方 . o 是
这 类 数 据 的 过 程 能 力 计 算 方 法 , 给 在 服 务 这 业 中推 行 6 管理 造 成 了严 重 困难 。为 了能 " o 在 服 务业 中推 行 6 管 理 ,必 须 解 决 评 估 和 " o 测 量 非 1 态 分 布 数 据 的 过 程 能 力 指 数 的 计 E 算 问 题 。本 文将 提 出一 种 针 时 非 正 态分 布 数
维普资讯
质量控制中非正态分布数据 过程 能力算法研 究
徐月芳 , 云苗 桂
( 南京航 空航 天 大学 民航 学 院, 苏 南京 2 0 1 ) 江 10 6
摘 要 : 程 能 力 是 6- 过 o 管理 中 质 量控 制 的重 要 指 标 , 控 制 过 程 中会 出现 各 种 类 型 数 据 , 6 管理 现 有控 制 系 在 而 o .
法 , 种 灵 活 的 综 合 性 系 统 方 法 。通 过 实 施 一
6 管理 , . o 企业 能 够 准 确 理 解 顾 客需 求 , 范 规 使 用 和 统计 处 理 事 实 和数 据 , 切 关 注 和优 密 化 企 业 流 程 , 企 业 获 得 和 保 持 在 经 营上 的 使 成 功 , 经 营业 绩 最 大 化 , 可 不 断 获 得 新 使 并 的 企业 知 识 , 建 企 业 的 核心 竞 争 力 。在 6- 创 o
202.流程能力分析

方法:利用B0X-COX转换,转换成正态布
MINITAB演示
步骤一:打开数据包BOX-COX.MTV中的D3数据 LSL=0.06,USL=0.15
步骤二:数据非正态
步骤三:转换数据
非正态数据的流程能力计算
二项分布MINITAB演示
用途:已知单位时间的产品总数和不合格数,计算流程能 力
步骤一:打开MINITAB数据包(Camshaft.mtv)
步骤二:流程基本稳定
步骤三:正态检验(方法1)
P〉0.05流 程基本正态
步骤三:正态检验(方法2)
P〉0.05流 程基本正态
步骤四:选择工具
看西格玛水平
该流程的长期sigma水平为2.4,短期sigma水平为3.9
Sigma水平的另一种算法
选择逆累积概率
输入标准正态分 布的均值和偏差
输入合格率 1-0.008082
上页步骤导出结果
逆累积分布函数
正态分布,平均值 = 0 和标准差 = 1
P( X <= x ) x 0.991918 2.40519
该流程的长期sigma水平为2.4,短期sigma水平为3.9
非正态数据的流程能力计算
• 从小范围数据收集而来
• 从一个班次收集而来 • 仅使用一台机器
• 仅有一个操作者
• 仅使用一批原材料
长期
长期样本: • 反映 了普通原因和特殊 原因的影响 • 从大范围数据收集而来 • 从许多班次收集而来 • 使用许多机器 • 有许多作者 • 使用多批原材料
从大多数流程所收集的数据都代表长期流程
CPK的计算方法

CPK的计算方法首先,CPK(Capability Index)是一种用来度量过程能力的统计指标,用于评估一个过程能否满足所设定的规范要求。
它衡量了实际过程偏离目标值的程度,以及过程的稳定性。
CPK的计算方法可以根据数据的类型分为两种情况。
1.对于符合正态分布的数据:假设目标值为T,标准差为σ,而实际过程数据的上限和下限分别为USL和LSL。
首先,计算出过程的标准差:σ=(USL-LSL)/6然后,计算过程的CPK值:CPK = min((T - LSL) / (3σ), (USL - T) / (3σ))其中,(T-LSL)/(3σ)表示过程的偏差程度,(USL-T)/(3σ)表示过程的右侧能力。
如果CPK值大于1,则表示该过程能够满足规范要求。
2.对于不符合正态分布的数据:当数据不符合正态分布时,可以使用非参数方法计算CPK值。
非参数方法不依赖于数据的分布假设,而是使用经验公式来估计过程的能力。
首先,对过程数据进行排序,然后计算出中位数Md和四分位距(上四分位数Q3减去下四分位数Q1)IQR。
接下来,计算过程的CPK值:CPK = min((T - (Md - 1.5 * I QR)) / (3 * σ), ((Md + 1.5 * IQR) - T) / (3 * σ))其中,(T-(Md-1.5*IQR))/(3*σ)表示过程的偏差程度,((Md+1.5*IQR)-T)/(3*σ)表示过程的右侧能力。
同样,如果CPK值大于1,则表示该过程能够满足规范要求。
需要注意的是,上述计算方法中的标准差σ可以通过样本标准差估计,也可以通过过程的长期标准差估算得到。
对于稳定的过程来说,推荐使用长期标准差作为σ的估计值。
最后,CPK值不仅可以用来评估一个过程能否满足规范要求,还可以用来比较不同过程的能力。
一般来说,CPK值越大表示过程的能力越高,变异程度越小。
通常,CPK值大于1.33可以认为是一个良好的过程能力水平,而CPK值大于1.67则可以认为是一个出色的过程能力水平。
非正态的数据

规格上限 Z 值 0.91
Ppk
0.30
Cpm
*
1.0 1.5 2.0 2.5 3.0 3.5 4.0
实测性能
% < LSL
*
% > USL 18.00
% 合计 18.00
预期组内性能
% < LSL*
*
% > USL* 17.93
% 合计 17.93
预期整体性能
% < LSL*
*
% > USL* 18.21
变换后
LSL* 目标* USL* 样本均值* 标准差(组内)* 标准差(整体)*
* * 2.89037 2.26918 0.676702 0.684493
Time 的过程能力
使用 Box-Cox 变换,Lambda = 0
USL*
已变换数据
组内 整体
潜在(组内)能力
基准Z值
0.92
规格下限 Z 值 *
正态性检验
统计>基础统计量>正态性检验
正态性检验
百分比
99.9
99
95 90
80 70 60 50 40 30 20 10
5
1
0.1
-20 -10
0
Time 的概率图
正态
均值 标准差 N AD P值
12.31 9.656
100 5.738 <0.005
P值小于 .05 表示 数据不是正态分布
。
10
20
30
40
50
60
Time
检查分层数据
图形>点图
检查分层数据
Time 的点图
Decision Zone
计算过程能力指数前需对过程判稳吗2011-10-02

表示出产品质量的波动范围,故用6σ定量地表示过程能力B=6σ。显然,σ越小,质量特性值 的离散程度越小,产幅度 T 除以 6σ 来定义的。目前,凡涉及到过程能力指数的 教材、发表的过程能力指数论文、甚至涉及到过程能力及过程能力指数术语的标准以及涉及 到过程能力指数计算的标准等,几乎都强调在过程处于统计控制状态(统计稳态,简称稳态) 时才能计算过程能力指数,否则便认为计算结果没有意义。这一观点的影响甚至波及到过程 能力的概念,连计算过程能力 6σ 也要接受判稳的约束。例如,国家标准 GB/T3358.2–93《统 计学术语 第二部分 统计质量控制术语》对过程能力的解释是:过程固有变异的一种度量, 而对过程固有变异的进一步解释是:过程处于统计控制状态时的变异。再如,文献[1]称:“过 程能力反映了当过程处于统计控制状态时所表现出来的过程自身的性能。”这就意味着在计 算过程能力 6σ 前需要运用控制图对过程判稳。笔者认为,这种观点是错误的。其实,过程 未处于统计控制状态,照样可以谈过程能力。众所周知,休哈特博士利用正态分布 3σ 原则 创建了统计过程控制(SPC)理论基础。在休哈特博士发明控制图前,统计学中的标准差 σ 概 念已经建立,这就意味着标准差 σ 的概念在前,控制图判稳在后,也即计算统计学中的标准 差 σ 无需判稳!统计学中的标准差 σ 的计算不需要附加任何条件。只要过程的样本数据服从 正态分布,就可以用标准差公式计算 σ,无需判断过程是否处于稳态!既然质量界借用统计 学中的 σ,将 6σ 定义为过程能力,那么质量界在计算 σ 时就不能别出心裁,单方面要求在 计算过程能力 6σ 前需对过程进行判稳,而应循规蹈矩,只要将统计学中的标准差 σ 乘以 6 就得到过程能力 B 的大小。反之,若在计算过程能力 6σ 前要求对过程判稳,等于硬性规定 在计算统计学中的标准差 σ 前要求对过程判稳,这不是给统计学中的标准差 σ 的计算硬性添 加了一个条件限制?!请问,统计学专家教授同意这种提法吗?!质量管理学中的统计过程 控制是建立在数理统计学基础上,在此笔者呼吁质量界专家教授,在没有充足的理论依据说 明这种提法的正确性之前,请勿轻易颠覆质量管理学的根基——数理统计学中的基本概念和 公式。这充分说明质量管理学中的过程能力及过程能力指数等基本概念和计算公式在质量界 是一个必须要探讨而且一定要探讨清楚的问题。
非正态分布数据的过程能力分析方法

非正态分布数据的过程能力分析方法王雪情【摘要】Process capability analysis of the non-normal is becoming an imperative problem. In this paper, three different methods of calculating the process capability index of non-normal data are briefly introduced. Based on the shortcomings of existing research, the process capability index is calculated by three different methods, and then the analysis and comparison are made according to the calculation results. Finally, the conclusions will be applied to the actual analysis. Although there are many ways to estimate process capability of non-normal data, results of the first two ways is not robust. Meanwhile, the parameters are not limited to any kind of distributions whose result is low accuracy.%非正态过程能力分析的方法的研究一直以来广受关注.简要介绍了三种不同的计算非正态数据的过程能力指数的方法后,针对现有研究的不足,分别使用三种不同的方法计算过程能力指数,然后根据计算结果做出了分析和比较,最后将得到的结论应用到实际中进行分析,研究表明:虽然进行非正态分布数据的过程能力分析的方法很多,但是正态性转换的方法不具有稳健性,而非参数的方法的精度虽然不高,但对任何一种分布都是可以使用的.【期刊名称】《价值工程》【年(卷),期】2017(036)019【总页数】5页(P209-213)【关键词】非正态分布;过程能力指数;Minitab【作者】王雪情【作者单位】郑州大学管理工程学院,郑州 450001【正文语种】中文【中图分类】F224.0过程能力指数(Process Capability Index,PCIs)是用来度量过程能力的相对高低。
如何计算非正态数据的过程能力指数Cp_Cpk

对计量型的过程数据而言,如果数据服从正态分布,我们可以很方便地计算出相应的过程能力指数 Cp,Cpk 等。但当数据呈现非正态分布状态时,如果直接按普通的计算过程能力的方法处理就会存在较大 的风险。一般而言,对此类数据计算过程能力的方法主要有如下几类:
第一类方法是将非正态数据转换成正态数据进行计算,常用的转换方式包括我们在 Minitab 软件中经 常用到的 Box-Cox 转换和 Johnson 转换等;第二类方法是拟合数据的实际分布,然后根据实际的分布估算 其均值、标准差等,进而计算过程能力指数(比如在 Minitab 和 JMP 中,我们都可以比较方便地拟合所有 连续分布) ;第三类方法以非参数统计方法为基础,基于百分位数方法来计算过程能力。下面分别进行简 单说明:
过程能力分析是统计过程控制 SPC,工业统计及六西格玛持续改进 DMAIC 中十分重要的内容,也是我 们评价过程基线及改进方向和目标的重要工具。因此,在六西格玛项目中,过程能力分析是测量阶段的一 项重要工作,其中,检验数据的正态性以及采用相应的方法计算过程能力就显得尤为重要了。
本文主要参考文献包括: 1. QuAInS 系统开发手册 2.《六西格玛管理》及《六西格玛管理统计指南》 ,中国人民大学出版社 3. ISO 21747 相关内容 4. Minitab 及 JMP 软件相关技术文献
如何计算非正态数据的过程能力指数(Cp,Cpk)
在精益六西格玛持续改进、统计质量管理和 SPC 中,评价过程的过程能力(Process Capability)都是 必不可少的重要步骤。在用控制图确认过程处于统计受控状态之后,进行过程能力分析可以进一步判断过 程能力是否达到客户的要求。过程能力分析也是六西格玛项目中评价过程基线和改进方向的重要手段。
过程能力分析

±6σ
过程有±1.5σ偏移时产品特征正态分布图
Cpk: 只有单边公差限
• 单边公差——上限(USL)
USL C pk C pu 3
• 单边公差——下限(LSL)
LSL C pk C pl 3
• 为了进一步强调质量特偏离设计目标值造成的质量损 失,88年提出了
E( X T ) ( T )
• SERVQUAL包括两部分:顾客期望 (expectations)和顾客感知(perceptions) • 差距(gap),顾客期望与顾客感知之差 • 调查表
[ 2 , 2 ]
[ 3 , 3 ]
3
2
µ 68.26%
2
3
95.46% 99.73%
(i 1, 2,3)
图7.1 正态分布和落入
[ i , i ]
的概率
5
如何估计参数
• 分布规律 • 参数估计
– 过程短期波动(样本内波动),R-bar/d2, s/c4 – 过程长期波动
• 过程能力 • 过程绩效
过程能力指数
• 假设
– 过程输出质量特性x服从正态分布 – 过程输出中心 x 与设计目标值T(target value )重 合
• 分析 • 过程能力(区间长度6σ)
– 刻画了过程的自然输出能力 – 与设计目标值无关
• 过程能力指数的评注
– 目前,至少也有20种单变量过程能力指数,都是在这三代 过程能力指数的基础上发展起来的,适用于不同的应用背 景。 – 正态性假设 – 每一种过程能力的评价方法都有局限性。相比之下,不合 格品率是最自然的方法,但也有自身的局限性。 – 企业文化对采用过程能力指数的影响。
非正态数据的过程能力分析

非正态数据的过程能力分析在用控制图确认过程处于统计控制状态之后,可以进行一些过程能力分析,进一步判断过程能力是否达到顾客的要求。
过程能力分析也是六西格玛项目中评价过程基线和改进方向的重要工具。
但当需要进行过程能力分析的计量数据呈非正态分布时,直接按普通的计数数据过程能力分析的方法处理会有很大的风险。
一般解决方案的原则有两大类:一类是设法将非正态数据转换成正态数据,然后就可按正态数据的计算方法进行分析;另一类是根据以非参数统计方法为基础,推导出一套新的计算方法进行分析。
遵循这两大类原则,在实际工作中成熟的实现方法主要有三种,现在简要介绍每种方法的操作步骤。
非正态数据的过程能力分析方法1:Box-Cox变换法1.估计合适的Lambda(λ)值;2.计算求出变换后的数据Y x,3.根据原来给定的USL和LSL,计算求出变换后的USL x和LSL x,4.对Y x用USL x和LSL x求出过程能力指数。
非正态数据的过程能力分析方法2:Johnson变换法1.根据Johnson判别原则确定转换方式;2.计算求出变换后的数据Y x,3.计算求出变换后的USL x和LSL x,4.对Y x用USL x和LSL x求出过程能力指数。
非正态数据的过程能力分析方法3:非参数计算法当第一种、第二种方法无法适用,即均无法找到合适的转换方法时,还有第三种方法可供尝试,即以非参数方法为基数,不需对原始数据做任何转换,直接按以下数学公式就可进行过程能力指数CP和CPK的计算和分析。
公式中,Xa是数据X分布的a分位数,例如X0.005表示随机变量X分布的0.005(即0.5%)分位数。
过程能力分析是在六西格玛DMAIC项目中十分重要,他是评价过程基线及改进方向和目标的重要工具。
因此,过程能力分析是测量阶段的一项重要工作。
本文主要介绍的是特殊的非正态数据的过程能力分析方法,从而帮助某些特定行业或环境下的相关统计和分析。
短期、长期标准差及过程能力指数的计算和应用

P(μ-1σ<X<μ+1σ)=0.6827 P(μ-2σ<X<μ+2σ)=0.9545 P(μ-3σ<X<μ+3σ)=0.9973 P(μ-6σ<X<μ+6σ)=0.9999997141
3
正态分布的两个基本统计量
标准偏差(Standard Deviation)
表征Data的 离散程度
方差(Variance) 全距(Range) 百分比(Percentile)
• 产品的变异性(休哈特
Shewhart对过程变异的观点)
---相同的原料、设备所生产的制品,其产品的品质特性还存在着一定 程度的差异。 ---因此如何判定过程(制程)是否处于稳定的状态?这些问题需借助 于统计过程控制来探讨。 ---在购买新设备或开始进行新过程量产前,如何判定其是否处于稳定 状态下,是否可以进行验收或进行批量生产?
对制造商来说,按照“公差要求”生产出来的零件还不够好!
35
提高过程能力
调整过程分布中心,减少偏移量ε。
— 工具磨损、加工条件随时间变化的规律,采取调整和补偿。
— 通过首件检查,调整定位装置。
— 改变操作者的不良加工习惯。 — 采用更精密的量规。
提高过程能力,减少分散程度 — 改进工艺方法,优化过程参数,使用新材料,新技术。 — 更新设备,提高工装精度。 — 减少材料批次间的波动。 修订公差范围 必须保证不影响产品质量,可修订不切实际的过高公差。
• 工程平均和规格中心不一致时
σ st=
R d2
R d2
Cpk Min(Cp , Cpu )
l
控制图常数 (常用 n=5时,d2=2.326 n=6时,d2=2.534)
---
极差平均值
非正态分布数据的过程能力分析方法

非正态分布数据的过程能力分析方法作者:王雪情来源:《价值工程》2017年第19期摘要:非正态过程能力分析的方法的研究一直以来广受关注。
简要介绍了三种不同的计算非正态数据的过程能力指数的方法后,针对现有研究的不足,分别使用三种不同的方法计算过程能力指数,然后根据计算结果做出了分析和比较,最后将得到的结论应用到实际中进行分析,研究表明:虽然进行非正态分布数据的过程能力分析的方法很多,但是正态性转换的方法不具有稳健性,而非参数的方法的精度虽然不高,但对任何一种分布都是可以使用的。
Abstract: Process capability analysis of the non-normal is becoming an imperative problem. In this paper, three different methods of calculating the process capability index of non-normal data are briefly introduced. Based on the shortcomings of existing research, the process capability index is calculated by three different methods, and then the analysis and comparison are made according to the calculation results. Finally, the conclusions will be applied to the actual analysis. Although there are many ways to estimate process capability of non-normal data, results of the first two ways is not robust. Meanwhile, the parameters are not limited to any kind of distributions whose result is low accuracy.关键词:非正态分布;过程能力指数;MinitabKey words: non-normal distribution;process capability index;Minitab中图分类号:F224.0 文献标识码:A 文章编号:1006-4311(2017)19-0209-050 引言过程能力指数(Process Capability Index,PCIs)是用来度量过程能力的相对高低。
如何使用MINITAB正确计算CPK

资料范本本资料为word版本,可以直接编辑和打印,感谢您的下载如何使用MINITAB正确计算CPK地点:__________________时间:__________________说明:本资料适用于约定双方经过谈判,协商而共同承认,共同遵守的责任与义务,仅供参考,文档可直接下载或修改,不需要的部分可直接删除,使用时请详细阅读内容如何使用MINITAB正确计算CPK [摘要]:本文通过错误使用MINITAB计算CPK的案例,介绍如何正确使用MINITAB计算CPK的一种有效方法。
对初步涉及MINITAB使用的人员具有较好的推广意义。
[关键词]:MINITAB、CPK、PPK、样本、数据分析、正态Minitab软件是现代质量管理统计的领先者,全球六西格玛实施的共同语言,以无可比拟的强大功能和简易的可视化操作深受广大质量学者和统计专家的青睐。
Minitab软件是为质量改善、教育和研究应用领域提供统计软件和服务的先导。
是一个很好的质量管理和质量设计的软件工具,更是持续质量改进的良好工具软件。
Minitab软件在我公司广泛用于问题原因的分析,数据整理及过程能力研究。
过程能力是指加工方面满足加工质量的能力。
此种能力表现在过程稳定的程度,σ越小,过程能力越稳定。
评价过程能力的两个指标分别是CPK和PPK。
首先,我们来一起回顾一下过程能力CPK、PPK的概念。
CPK——过程能力指数(短期的)CPK的评价过程是稳定过程,CPK的样本容量是30~50,CPK评价的是单批(几小时或几天),CPK=1.33(1.5的偏离)是4σ的水平,合格率达到99.379%。
CPK,是进入大批量生产后,为保证批量生产下的产品的品质状况不至于下降,且为保证与小批生产具有同样的控制能力,所进行的生产能力的评价,一般要求≥1.33。
PPK——过程性能指数(长期的)PPK可以不是稳定的过程;PPK的样本容量是大于或等于100, PPK评价的是多批(几周或几个月)。
过程能力

n-1
1
2
3
7
13
40
∞
p(%)
80
90
95
98
99
99.5
99.73
从表一可以看出,只有当测量次数n→∞时,对应KPt=3时的置信概率p才为99.73%也就是说,只有这时t-分布才趋于正态分布。这说明,当t-分布时,对应置信系数KPt=3(即±3 为极限误差),其置信概率并不永远是99.73%,而是随测量次数的减少而降低。
在进行有限次测量时,为了取得高精度的结果,一般使用t-分布分析。
1.正态分布与t-分布的参数值。
无限次测量中,服从正态分布的随机变量,其真值µ与标准差δ定义如下:
n
µ=
1
∑
Xi
,(n→∞)
n
i=1
√
δ=
n
1
∑
(Xi-µ)2
,(n→∞)
n
i=1
在进行有限次测量时,上述参数的估计值分别为:
n
û=
=
1
∑
Xi
过程能力的确认方法
ISO 9001:2000标准的7.5.2条款规定:“当生产和服务提供过程的输出不能由后续的影视或测量加以验证时,组织应对任何这样的过程实施确认。这包括仅在产品使用或服务已交付之后问题才显现的过程。”实际上,这里所说的需要实施确认的过程就是特殊过程。由于许多企业对这个条款的规定感到难以实施,笔者谈一些对过程能力实施确认的方法。
6.分析过程数据,判定过程分布中心的相对偏移性。
通过使用直方图等方法,初步判定过程是否为近似正态分布。如果基本形成正态分布,再计算过程分布中心µ(可用近似值代替)和相对公差中心M的偏移性。如果偏移较大并影响产品质量应,分析原因并采取措施。如果偏移量在允许的范围内,在计算过程能力指数CP时,可按有偏移的情况计算。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
关于正态数据与非正态数据及其过程能力计算
摘要本文从企业生产现场的实际情况出发,提出数据呈正态或非正态分布时,如何对这些数据进行分析,并准确计算过程能力,将在本文进行讨论。
关键词正态;非正态数据;过程能力
1 对数据的管控误区
目前企业在流程中对所收集数据的统计、分析以及使用情况,较以前来说,规范性有了长足的进步,但与要求还是存在一定差距,可以通过以下几个方面来说明:
1.1 数据来源可评价性差
要想弄清楚一件事情,必须要获得现场数据,通过数据还原事实。
但现场数据并非是现存的,要经过人们的有效收集、传递,然后才有数据可以分析。
在此需要强调的是原始记录一定要整洁、规范,只有数据完整,后续才能进行推断性分析,但现实是部分数据在源头上就存在偏差。
这给后续的评价在客观上就带来极大影响。
因此,对数据进行策划和管理时务必确保数据来源的可靠。
1.2 异常数据混在正常数据中
通常大家有这样的习惯,在对现场调查时,会对数据进行直接收集,完毕后,会对数据直接使用,所以在此就会存在一个误区,我们分析的数据能代表过程的正常情况吗?
当你所收集的数据不能代表这个过程,也就是说数据来源于异常原因而非普通原因时,那所收集的数据就不能代表这个过程的正常情况,所以一定要将异常情况排除后,留下普通原因所引起的质量数据,这样就可以进行分析了。
我们可以通过箱线图进行数据的初步分析,如果数据跑到箱线图的两个尾巴之外的话,说明这样的数据属于异常数据,这样的数据要进行过程改善并予以剔除。
1.3 过程数据的‘伪’正态性
在进行过程能力计算前,必须要看数据的分布情况是否符合正态。
在验证数据的时候,我们要关注子组容量的大小,因为子组容量的大小对我们数据的正态性研究也有一定的影响,我们可以通过模拟的125个数据来进行分析。
对于同样的125个数据,当子组容量分别为1和5时,我们可以看到数据正态性的表现情况。
当子组为1时,该125个数据的p值是小于0.05的,是呈非
正态分布的。
当子组为5时,该25个数据的p值是大于0.05的,是呈正态分布的。
通过上面的信息,我们可以发现在处理同类数据的时候一定要关注这个特性,千万不要出现‘伪’正态性的数据。
2 生产过程中正态数据的能力分析
作为生产制造业,我们要想拥有一个稳定可靠的过程以及符合顾客满意度要求的产品是非常有必要的,想要实现这点,除了从项目管理、产品设计、过程开发、制造工程以及5M1E等各方面进行努力之外,同时不要忘记数据这个关键环节,因为数据不但可以作为过程、产品以及法律的证据,更是我们整体能力提升与改善的基础,必须认真得去对待它。
2.1 正态数据分布模型的理论基础
在质量界有一位泰斗级的人物,那就是休哈特,被誉为质量统计控制之父,他创建了控制图,控制图的理论依据就是在正负3倍西格玛的基础上进行讨论的,包括我们后面要进行的过程能力计算,也是建立在正负3倍西格玛的基础上的。
另外,选择正负3倍西格玛对我们质量控制是比较经济的,同时也可以尽可能将两类误差(漏检与误检,该两类误差是不可能完全避免的,而且存在此消彼长的特性)控制在生产制造方和产品接收方都能合理接收的范围。
2.2 数据正态性和非正态性的判断
接下来我们要对制造过程中的数据进行正态性的识别,判断是否满足正态性的特性。
判断的依据就是进行假设检验。
进行数据的正态性检验,主要看数据所表现出来的p值是处于接受域还是拒绝域,然后判断我们的数据是否呈正态性分布。
在这里有一个临界值判断值,那就是0.05,大于0.05就说明落在接收域,反之落在拒绝域。
在接收域就说明是正态分布,反之是非正态分布。
通过上面的手段進行常规识别的话,可能发现我们的过程数据是属于正态分布类型,那就可以直接进行过程能力的计算了。
万一发现我们的数据是落在拒绝域,也就是拒绝原假设,接受备择假设,则说明数据是非正态的,遇到非正态的数据,我们不能直接进行能力计算,接下来我们应该怎么办呢?在后面的讨论中,我們特别针对非正态的数据进行了分析。
2.3 正态数据的分析控制以及能力计算
如果我们收集过来的数据经过前期的判断是呈正态分布的话,那这些数据就
可以进行使用了,为什么数据为正态分布时就可以直接进行使用了呢?因为前面我们说过,我们研究数据的基础是休哈特的正负3倍西格玛作为研究基础的,如果不是正态分布数据的话,就等于我们拿两个不一样的模型进行数据对比和数据分析,那当然分析的结果就会不一致。
控制分析主要进行数据控制线的计算,然后进行描点,并进行过程的判异,如都属于正常情况,那我们计算的控制线可以进行延长使用,并作为今后过程的比较基准,但要记住,该基准一定要进行阶段性的修正。
对于工序能力的计算主要将公差带和3倍西格玛进行比较,在公差带内存在的西格玛数量越多的话,我们的工序能力就越强。
3 对非正态数据的能力分析
眼下,有许多企业在认真的收集资料、并整理和分析它们,这样分析的结果可以反过来指导和促进过程的改善,在这个过程中有很多企业都做得很好。
只是有部分企业还没有理解和掌握如何分析数据的要点,比如我们在谈到SPC统计过程控制工作和能力分析时,它的前提就是数据要具备正态性。
通过大数据研究来看目前仅仅有2%左右的数据完全符合正态性的需要,在此种情况下,就面临这样的问题,数据如果不具备正态性,我们应当如何处理呢?
3.1 非正态数据的转换
如果数据经过分析,知道它是非正态的,那就要对数据的实际分布情况进行具体的识别,因为数据分布的类型实在太多,所以要找到和样本数据最接近的分布模型,也就是要进行数据分布识别。
通过数据的识别,马上就能找到样本数据的最佳匹配,主要参照指标是特征值P,对于P值最大的就是最佳数据模型匹配结果,然后我们建议选择该分布识别结果。
我们发现该样本数据的最佳匹配模型是Johnson变换,所以就按照这个路径去分析,使用Johnson变换,将原来非正态的数据变换成正态数据,它的基本原理就是取对数,这样获得的数据就会呈正态分布。
接下来就可以使用这些转换后的数据了。
3.2 对转换后数据进行过程控制和能力计算
通过变换,发现原来的数据又形成新的数据,新数据是符合正态性的,接下来要针对新数据进行能力分析,同时对于相应的规格线也要进行逆函数的计算,以便于在使用转换后新数据计算过程能力的时候可以使用新的规格线。
其实,通过上面系列步骤和相关计算,基本的思路可以弄清楚,想要计算过程能力,就必须保持数据正态性,如果数据不能保证正态性,就尽可能进行过程改善,但如果经过了改善还是无法满足正态性的,在这种情况下,就要找到和该数据最匹配的数据分布模型了,当找到匹配的数据模型后,按照和该模型匹配的方式来进行能力计算就可以了,这样计算的能力就比较精准了,否则,出来的数
据会存在一定的误差。
因此,建议在使用数据的时候,一定要对数据进行系统的处理。
4 结束语
在对现场数据进行收集完毕之后,如果要进行数据分析的话,务必要对数据进行异常数据的剔除。
其次要对数据进行分布模型的有效识别,判断数据是否为正态分布。
如果数据为正态分布的话,才能使用休哈特控制图以及相关的工序能力指数的计算,否则要进行相关的数据转换后才能进行分析。