无差检验、独立性检验 SPSS
SPSS两个独立样本秩和检验操作步骤

SPSS两个独立样本秩和检验操作步骤SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,可用于执行各种统计分析操作,包括独立样本秩和检验。
独立样本秩和检验是一种非参数检验方法,用于比较两个独立样本的中位数是否存在差异。
以下是在SPSS中执行独立样本秩和检验的操作步骤:1.打开SPSS软件,并导入相关数据。
- 单击"File"选项卡,然后选择"Open"选项,以选择要导入的数据文件。
-在导入数据文件之前,确保数据文件符合SPSS格式要求。
2.在SPSS中创建秩和检验数据。
- 单击"Transform"选项卡,然后选择"Rank Cases"选项,以创建秩和检验所需的秩序变量。
- 在弹出的"Rank Cases"对话框中,选择要进行秩和检验的变量,并为新的秩序变量指定名称。
-单击"OK"按钮以创建秩序变量。
3.执行秩和检验。
- 单击"Analyze"选项卡,然后选择"Nonparametric Tests"选项,以访问非参数测试工具。
- 在"Nonparametric Tests"子菜单中,选择"Legacy Dialogs"选项,以显示传统对话框。
- 在传统对话框中,选择"2 Independent Samples"选项,以执行独立样本秩和检验。
- 在弹出的"2 Independent Samples"对话框中,选择要进行秩和检验的变量,并将其添加至"Test Variables"框中。
- 单击"Options"按钮以访问进一步的选项。
在"Options"对话框中,您可以选择计算效应大小指标等。
spss非参数检验K多个独立样本检验KruskalWallis检验案例解析

spss-非参数检验-K多个独立样本检验
(Kruskal-Wallis检验)案例解析Kruskal-Wallis检验,也称为KW检验,是一种非参数检验方法,用于比较两个或多个独立样本的中位数是否相等。
它利用秩(等级)来进行统计分析,而不是直接使用原始数据。
假设有一个关于人们在不同饮料中的品尝体验的数据集。
数据集中包含了人们在红酒、白酒和啤酒中品尝的感受,包括甜度、酸度、苦度等。
现在想要比较这三种饮料在甜度方面的中位数是否有显著差异。
首先,对每种饮料的甜度进行排序,得到每个人的秩。
然后,将每个人的秩平均分到他们所对应的饮料中,得到每个饮料的平均秩。
接着,对这些平均秩进行比较。
如果红酒、白酒和啤酒的平均秩存在显著差异,则说明这三种饮料在甜度方面的中位数存在显著差异。
如果平均秩没有显著差异,则说明这三种饮料在甜度方面的中位数没有显著差异。
下面是一个具体的案例数据:
根据上述数据,我们可以计算出每种饮料的平均秩:
红酒: (2+1)/2 = 1.5
白酒: (4+3)/2 = 3.5
啤酒: (6+5)/2 = 5.5
然后对这些平均秩进行比较。
由于红酒的平均秩最小,白酒的平均秩次之,啤酒的平均秩最大,因此可以得出结论:这三种饮料在甜度方面的中位数存在显著差异,其中啤酒的甜度最高,白酒次之,红酒最低。
需要注意的是,KW检验的前提假设是各个样本是独立同分布的,且样本容量足够大。
如果样本不满足这些条件,可能会导致检验结果出现偏差。
此外,KW检验只能告诉我们是否存在显著差异,但不能告诉我们差异的具体原因。
如果想要了解更多信息,需要进行后续的统计分析。
(完整版)SPSS两个独立样本秩和检验操作步骤.doc
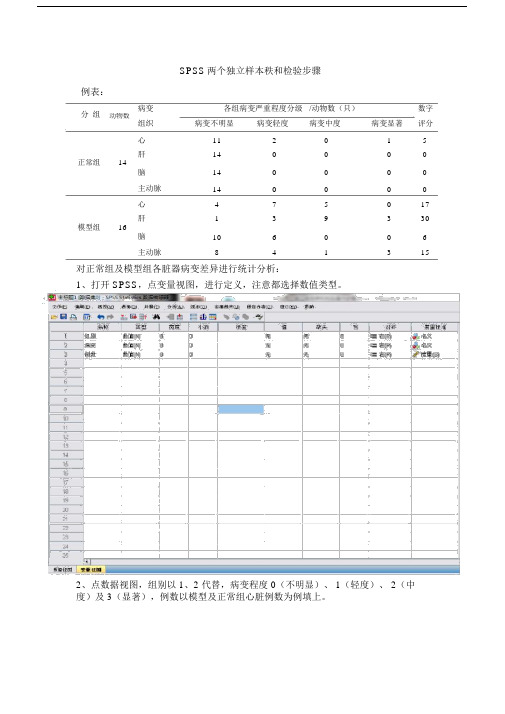
SPSS两个独立样本秩和检验步骤例表:
分组
病变各组病变严重程度分级/动物数(只)数字动物数
组织病变不明显病变轻度病变中度病变显著评分心11 2 0 1 5
肝14 0 0 0 0
正常组14
14 0 0 0 0
脑
主动脉14 0 0 0 0
心 4 7 5 0 17
肝 1 3 9 3 30 模型组16
10 6 0 0 6
脑
主动脉8 4 1 3 15 对正常组及模型组各脏器病变差异进行统计分析:
1、打开 SPSS,点变量视图,进行定义,注意都选择数值类型。
2、点数据视图,组别以 1、2 代替,病变程度 0(不明显)、 1(轻度)、 2(中度)及 3(显著),例数以模型及正常组心脏例数为例填上。
3、点数据→加权个案,频率变量选择例数,点确定,弹出输出数据对话框,可以选择不保存。
4、点击分析→非参数检验→2 个独立样本,检测变量列表选择病变,分组变量选择组别,点定义组,写上 1 和 2,再选择 Mann-Whitney U 检验,点确定。
5、分析结果看双侧P 值,示例结果为 0.008, P<0.01,具有显著性差异。
SPSS非参数检验—两独立样本检验_案例解析

SPSS非参数检验—两独立样本检验_案例解析非参数检验是一种在统计学中常用于比较两个或多个独立样本的方法。
与参数检验不同,非参数检验不需要对数据的分布进行假设,并且适用于非正态分布的数据。
SPSS(统计软件包for社会科学)是一个广泛使用的统计分析软件,它提供了许多非参数检验的功能。
本文将以一个案例为例,解析如何使用SPSS进行两独立样本的非参数检验。
案例描述:一家公司正在评估一个新的培训课程对员工的绩效是否有显著影响。
为了评估培训课程的效果,研究人员随机选择了两组员工,一组接受了培训课程(实验组),另一组没有接受培训课程(对照组)。
研究人员想要比较两组员工在绩效上的差异。
步骤一:导入数据首先,将实验组和对照组的数据分别导入SPSS中。
假设每个样本中有n个观测值。
在SPSS中,每一组数据应该是一个独立的变量(或列),并且每个观测值应该占据矩阵中的一个单元格。
步骤二:选择非参数检验方法在SPSS中,可以使用Mann-Whitney U检验来比较两组独立样本的绩效差异。
该检验的原假设是两组样本来自同一个总体,备择假设是两组样本来自不同的总体。
步骤三:运行非参数检验在SPSS的菜单栏中,依次选择"分析" - "非参数检验" - "独立样本检验(Mann-Whitney U)"。
将实验组和对照组的变量分别输入到"因子1"和"因子2"中。
在"可选"选项中,可以选择在报告中包含各种统计量。
步骤四:解读结果SPSS将输出很多统计信息,包括推断统计、置信区间、效应大小等。
其中,最重要的是U值和显著性。
U值是用来检验两组样本是否来自同一个总体的统计量,显著性则是用来判断差异是否显著。
如果显著性小于0.05,则可以拒绝原假设,认为两组样本在绩效上存在显著差异。
总结:通过上述步骤,我们可以利用SPSS进行两独立样本的非参数检验。
SPSS检验步骤总结

SPSS检验步骤总结SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,广泛应用于社科、医学、生物、市场调研等领域。
SPSS 提供了众多的统计分析方法和功能,可以用来处理和分析数据,进行假设检验、回归分析等统计操作。
在使用SPSS进行假设检验时,通常有以下几个步骤:1. 数据导入:首先需要将待分析的数据导入SPSS软件。
SPSS支持导入各种格式的数据,包括Excel、CSV、文本文件等。
导入数据后,可以查看数据的基本信息和属性。
2.数据清理:数据清理是数据分析的重要步骤。
在数据清理过程中,需要检查数据的完整性和准确性,删除缺失值、异常值等不符合要求的数据。
SPSS提供了丰富的数据处理和清理工具,可以帮助用户轻松完成数据清理操作。
3.描述性统计分析:在进行假设检验之前,可以先对数据进行描述性统计分析。
描述性统计分析可以提供数据的基本统计信息,包括均值、标准差、频数分布等。
SPSS提供了简单和直观的功能来生成这些统计结果。
4. 建立假设:在进行假设检验之前,需要先建立研究假设。
研究假设通常包括原假设(null hypothesis)和备择假设(alternative hypothesis)。
原假设是指对现象或关系的默认假设,备择假设则是指要证明的假设。
5.选择合适的统计检验方法:根据研究问题的性质和变量类型,选择合适的统计检验方法。
SPSS提供了多种常见的假设检验方法,如t检验、方差分析(ANOVA)、卡方检验等。
不同的检验方法适用于不同类型的数据和研究设计。
6.进行假设检验:一旦选定了合适的统计检验方法,就可以进行假设检验了。
SPSS提供了简便的功能来执行各种假设检验操作。
用户需要输入所需参数和所需样本,之后SPSS将生成检验结果,包括显著性水平(P 值)和置信区间等。
7.结果解释:假设检验完成后,需要对结果进行解释。
如果P值小于设定显著性水平(通常为0.05),则可以拒绝原假设,接受备择假设。
独立性检验基本思想及应用

独立性检验基本思想及应用独立性检验是一种用于确定两个变量之间是否存在关联的统计方法。
其基本思想是通过比较观察到的数据与预期的数据之间的差异来推断这两个变量之间的关系。
独立性检验的应用非常广泛。
在社会科学中,独立性检验常被用于研究两个分类变量之间是否存在关联,例如性别和职业、教育水平和政治倾向等。
在医学研究中,独立性检验也可以用来检查某种治疗方法是否与疾病的发展有关,以及风险因素和某种疾病之间的关系。
此外,独立性检验还被广泛应用于市场调查、品牌定位以及质量控制等领域。
独立性检验的基本思想是建立一个零假设(H0)和一个备择假设(H1)。
零假设认为两个变量是独立的,即它们之间没有关联;备择假设则认为两个变量之间存在关联。
独立性检验的步骤可以分为以下几步:1. 收集数据:需要收集两个分类变量的数据,例如通过问卷调查或观察获得数据。
2. 建立列联表:将数据整理成列联表形式,列联表是一种用于描述两个或多个分类变量之间关系的矩阵。
表格的行表示一个变量的不同类别,列表示另一个变量的不同类别,表格中的每个单元格表示两个类别的交叉数量。
3. 计算期望频数:在独立性检验中,我们假设两个变量是独立的,因此可以基于各类别的边际总数以及样本总数来计算期望频数。
期望频数是在两个变量独立情况下,各个类别的交叉数量。
4. 计算卡方统计量:卡方统计量用于衡量观察到的数据与期望数据之间的差异程度。
计算公式为:χ2 = Σ((观察频数- 期望频数)^2 / 期望频数)。
其中,Σ表示对所有单元格进行求和。
5. 设定显著性水平:显著性水平α为决策的临界点,用于决定是否拒绝零假设。
通常,α的常见选择为0.05或0.01。
6. 判断和解释结果:根据计算出的卡方统计量与临界值进行比较,如果计算出的卡方值大于临界值,拒绝零假设,认为两个变量之间存在关联;反之,接受零假设,认为两个变量是独立的。
独立性检验的结果常常以卡方统计量和p值的形式呈现。
p值是在零假设成立的条件下,观察到的数据与期望数据之间差异的概率。
SPSS卡方检验操作大全

两种治疗方法的疗效比较
浙江大学医学院流行病与卫生统计学教研室
沈毅
四格表卡方检验
首先建立数据文件,如下。
浙江大学医学院流行病与卫生统计学教研室Leabharlann 沈毅四格表卡方检验
注意:由于上表给出的不是原始数据,而是频数表数据,应 该进行预处理。
浙江大学医学院流行病与卫生统计学教研室
沈毅
一致性检验
结果分析
如果在crosstab过程的 statistics子对话框中勾选上Kappa 复选框,则有以下结果:
Symmetric Measures Asymp. a b Value Std. ErrorApprox. T Approx. Sig. Measure of Agree Kappa N of Valid Cases a.Not assuming the null hypothesis. ing the asymptotic standard error assuming the null hypothesis. .455 58 .115 3.762 .000
浙江大学医学院流行病与卫生统计学教研室
沈毅
两分类变量间关联程度的度量 χ2检验可以从定性的角度说明两个变量是否存在关联,当
拒绝原假设时,在统计上有把握认为两个变量存在相关。 但接下来的问题是,如果两变量之间存在相关性,它们之 间的关联程度有多大?针对不同的变量类型,在SPSS中可 以计算各种各样的相关指标,而且Crosstabs过程也对此提 供了完整的支持,此处只涉及两分类变量间关联程度的指 标,更系统的相关程度指标见相关与回归一章。
Value Pearson Chi-Square Likelihood Ratio Fisher's Exact Test Linear-by-Linear Association McNemar Test N of Valid Cases a. Computed only for a 2x2 table 14.154b 14.550
用SPSS进行T检验

用SPSS进行T检验什么是T检验?T检验是统计学中的常用方法之一,用于检验两组样本的均值是否有显著差异。
它是通过计算样本的t值来确定两组样本均值差异是否显著。
因此,如果两组样本的t值越大,则它们之间的差异就越明显。
在进行T检验之前,我们首先需要明确两组样本是否满足正态分布的要求。
如果样本呈正态分布,则我们可以使用独立样本T检验或配对样本T检验进行检验。
如果不符合正态分布条件,我们需要使用非参数检验方法,例如Wilcoxon符号秩检验或Mann-Whitney U检验。
如何用SPSS进行T检验?下面我们将演示如何使用SPSS进行独立样本T检验和配对样本T检验。
独立样本T检验独立样本T检验用于检验两个独立样本的均值是否有差异。
例如,我们想知道男性和女性在身高上是否有显著差异,则可以使用独立样本T检验来验证。
我们使用一个示例数据集来展示如何进行独立样本T检验。
该数据集包含两组样本:一组是男子的身高,另一组是女子的身高。
在SPSS中,我们可以按照以下步骤进行独立样本T检验:1.打开SPSS软件并载入数据集。
2.单击菜单栏中的“分析”(Analyze),然后选择“比较均值”(CompareMeans),再选“独立样本T检验”(Independent-Samples T Test)。
3.在“独立样本T检验”对话框中,将男性身高和女性身高变量分别放到“变量1”和“变量2”框中。
4.点击“OK”按钮,SPSS将自动计算并输出T检验的结果和描述性统计数据。
下面是一个示例的SPSS的输出:执行男子控制女子均值174.609 161.164标准差 6.971 6.098标准误差均值 1.760 1.53595% CI(下限)171.023 158.126T 17.915df 38Sig。
(双尾).000T检验结果显示,在本例中,男性和女性的身高之间存在显著差异。
T值为17.915,df值为38,Sig值小于0.05,表明这两组数据的差异不是由于随机因素导致的,而是由于不同的性别所导致的。
独立样本t检验spss的步骤

独立样本t检验spss的步骤独立样本t检验SPSS的步骤概述:独立样本t检验(Independent Samples t-test)是一种常见的统计方法,用于比较两组独立样本的均值是否存在显著差异。
在SPSS (Statistical Package for the Social Sciences)软件中进行独立样本t检验是一项相对简单而又方便的任务。
本文将详细介绍如何使用SPSS进行独立样本t检验的步骤。
步骤一:准备数据和SPSS环境在进行独立样本t检验之前,首先需要准备好需要进行比较的两组数据以及将其输入到SPSS软件中。
确保数据的格式正确,即每一组数据都应该是一个单独的变量。
打开SPSS软件,并在数据编辑器中将这两组数据输入到不同的变量列中。
步骤二:指定假设在进行独立样本t检验之前,需要明确要比较的两组数据的假设。
独立样本t检验有一对假设需要检验,分别是零假设(H0)和备择假设(H1)。
零假设(H0):两组数据的均值相等。
备择假设(H1):两组数据的均值不相等。
步骤三:进行独立样本t检验在SPSS软件中,进行独立样本t检验需要使用“Analyze”和“Compare Means”菜单。
按照以下步骤进行操作:1. 选择菜单栏中的“Analyze”。
2. 选择“Compare Means”。
3. 在“Compare Means”菜单下,选择“Independent-Samples T Test”。
在弹出的对话框中,将需要比较的两组数据变量选择到“Test Variables”框中。
点击“箭头”按钮将其移至“Grouping Variable”框中。
点击“OK”按钮,SPSS将自动为你进行独立样本t检验,并生成相应的结果报告。
步骤四:解读结果SPSS生成的独立样本t检验结果报告包含了一些关键的统计信息。
以下是一些常见的结果:1. “Mean Difference”(平均数差异):表示两组数据均值之间的差异。
SPSS两独立样本T检验结果解析

SPSS两独立样本T检验结果解析SPSS(Statistical Package for the Social Sciences)是一款广泛使用的统计分析软件,可以进行各种复杂的数据分析。
其中,两独立样本T检验是SPSS中的常用统计方法之一、下面将对SPSS进行两独立样本T检验结果进行详细解析。
首先要明确两独立样本T检验的目的是比较两个独立样本之间的平均值是否存在显著差异。
在SPSS中,进行两独立样本T检验的步骤如下:1. 打开数据文件(Data Editor)并导入数据。
3. 在下拉菜单中选择“Independent-Samples T Test”(独立样本T检验)。
4. 将需要进行比较的两个变量移动到“Test Variable List”(测试变量列表)中。
5.点击“OK”进行分析。
对于两独立样本T检验的结果解析,主要关注以下几个方面的内容:1. 描述统计(Descriptive Statistics):此部分显示了两个样本的基本统计信息,包括平均值(Mean)、标准差(Standard Deviation)等。
通过比较两个样本的均值可以初步判断是否存在差异。
2. 独立样本T检验(Independent Samples Test):此部分给出了两独立样本T检验的结果。
主要包括t值(t),自由度(df),显著性水平(Sig.)和均值差(Mean Difference)等。
其中,t值用于判断两个样本均值之间的差异是否显著,自由度表示模型中自由变量的约束条件的数量。
显著性水平表示差异的统计显著程度,一般选择显著性水平为0.05,即p值小于0.05时,差异是显著的。
均值差可以用来衡量两个样本之间的差异的大小。
3. Levene's Test for Equality of Variances(Levene方差齐性检验):此部分用于判断两个样本的方差是否相等。
若显著性水平小于0.05,则认为两个样本的方差不相等,这将影响到独立样本T检验的结果。
SPSS数据分析的统计方法选择

SPSS数据分析的统计方法选择SPSS(Statistical Package for the Social Sciences)是一款广泛应用于社会科学领域的统计分析软件。
在进行数据分析时,选择合适的统计方法非常重要,因为不同的问题需要不同的统计方法来解决。
下面是一些常用的统计方法及其在SPSS中的应用。
1.描述统计:描述统计是对数据的基本特征进行汇总和整理的方法。
SPSS提供了丰富的描述统计方法,如变量的均值、中位数、标准差、最小值、最大值、分位数等。
2.t检验:t检验用于比较两个群体均值是否有显著差异。
SPSS中提供了独立样本t检验和配对样本t检验两种方式来进行t检验。
3.方差分析:方差分析用于比较多个群体均值是否有显著差异。
SPSS 中的一元方差分析可以用于比较一个因变量在一个自变量有多个水平时的均值差异。
4. 相关分析:相关分析用于研究两个变量之间的关系。
在SPSS中,可以通过计算Pearson相关系数或Spearman等级相关系数来进行相关分析。
5.回归分析:回归分析用于研究因变量与自变量之间的关系和预测。
SPSS中提供了多种回归方法,包括线性回归、逐步回归、逐级回归等。
6.卡方检验:卡方检验用于检验观察频数与期望频数之间的差异。
SPSS中提供了卡方检验方法,包括卡方独立性检验和卡方拟合度检验。
7.方差分析:方差分析(ANOVA)是一种用于比较多个组均值的统计方法。
在SPSS中,可以进行一元方差分析或多元方差分析来评估组间差异的显著性。
8. 非参数检验:非参数检验用于在不满足正态分布假设的情况下比较群体差异。
SPSS中提供了一些非参数检验方法,如Wilcoxon符号秩检验、Mann-Whitney U检验、Kruskal-Wallis H检验等。
9.因素分析:因素分析用于降维和提取潜在变量。
在SPSS中,可以进行主成分分析或因子分析来研究变量之间的相关结构。
10.聚类分析:聚类分析用于将相似的个体或因素分组。
SPSS数据分析—卡方检验

SPSS数据分析—卡方检验卡方统计量是基于卡方分布的一种检验方法,根据频数值来构造统计量,是一种非参数检验方法。
SPSS中在交叉表和非参数检验中,都可调用卡方检验。
卡方检验的主要有两类应用一、拟合度检验1.检验单个无序分类变量各分类的实际观察次数和理论次数是否一致此类问题为单变量检验,首先要明确理论次数,这个理论次数是根据专业或经验已知的,原假设为观察次数与理论次数一致例】:随机抽取60名高一学生,问他们文理要不要分科,回答赞成的39人,反对的21人,问对分科的意见是否有显著的差异。
分析:如果意见没有差异,那么赞成反对的人数应该各半,即30次,因此理论次数为30例】:一周内各日患忧郁症的人数漫衍如下表所示,请检验一周内各日人们忧郁数是否满足1:1:2:2:1:1:1例】:一个骰子投掷120次,记录掷得每个点数的次数,问该骰子是否存在问题如果骰子是正常的,那么每个点数掷得的概率应该相等,操作方法和前面一样,也使用非参数检验过程,选择默认的所有类别相等卡方检验主要用于分类变量,但是也可以用于对连续变量的拟合度检验上,此类问题的基本思想是:将总体X的取值范围分成k个互不重叠的小区间A1.A2.Ak,把落入第i个小区间的样本值个数作为实际频数,所有实际频数之和等于样本容量,根据理论分布,可以算出总体X的值落入每个小区间Ai的概率Pi,于是nPi就是落入Ai的样本值的理论频数。
有了实际频数和理论频数,就可以计算卡方统计量并进行卡方检验了。
二、独立性检验独立性检验分析两变量之间是否相互独立或有无分歧,也可以在控制某种因素之后,分析两变量之间是否相互独立或有无分歧。
原假设为两变量相互独立或两变量间的相互作用没有分歧。
对于两变量一般采用列联表的形式记录观察数据,分为四格表和R*C列联表,根据卡方统计量和分类变量的类型,又衍生出一些相关系数,这在相关分析中已经讲过。
例】:为了解男女在公开场合禁烟上的态度,随机调查100名男性和80名女性。
spss独立样本t检验

spss中有关独立样本T检验的详细介绍包含操作过程和结果分析分析>比较平均值3.独立样本T检验独立样本T检验类似于单样本T检验,不过独立样本T检验的内容比单样本T检验要复杂的多,特别是对其结果的分析,而独立样本T检验被使用的情况也比单样本T检验更广泛(因此也可以看到网络上关于独立样本T检验的文章远比关于单样本T检验的文章多)对比:二者都是将数据的平均值进行比较,不同之处在于单样本T检验是将一个样本与某一特定值进行对比,而独立样本T检验是对多个样本之间的平均值进行对比。
独立样本是指进行对比的多个样本之间是相互独立、互不干扰的,通过独立样本T检验我们可以判断多个样本之间的平均值是否可以认为是相等的。
没有什么比举个例子更容易理解独立样本T检验的用途了:假如我们有两个样本,分别是来自农村和城市两个不同地方的人们的身高数据,我们的目的是探讨农村和城市的差异会不会给当地的人们带来身高上的影。
这时我们算出城市的人群的平均身高为168.38cm,而农村的人们的平均身高为164.58cm,二者差了3.8cm,那我们是否就可以认为这3.8cm就可以很好的说明农村和城市的人们身高有差异呢?那如果是差了3cm呢?如果是差了1cm呢?这种时候就不可以单靠感觉来评判了,而是应该使用独立样本T检验来帮助我们判断得出结论检验变量——需要进行平均值比较的数据分组变量——用于区分不同样本的变量选项——选择置信区间百分比以及缺失值的处理方法对于分组变量我们操作时需要注意一下,在我们选入了分组变量后,我们必须要对其进行定义组操作,因为SPSS无法自行判断如何通过分组变量对数据进行分组点击定义组我们有两种分类的方法,分别是使用指定的值与分割点,指定值就是将所有分类变量等于该输入的数值的样本划分为一组,分割点就是以该输入的数值为分割点划分出大于和小于该值的两组进行比较,这些都是很简单的,不多废话了~~接下来就是重头戏了——对结果的分析简洁解释:得到结果后,首先将独立样本检验表格中莱文方差等同性检验的显著性数值与0.05进行比较大于0.05,两组假定等方差,看第一行数据的显著性(双尾)数值,如果大于0.05,两组差异不显著;如果小于0.05,两组差异显著;小于0.05,两组不假定等方差,看第二行数据的显著性(双尾)数值,如果大于0.05,两组差异不显著;如果小于0.05,两组差异显著。
spss整理(大题目)

1 / 12Spass整理第三章统计假设检验二、两样本平均数统计假设检验例3-11.随机抽取2个品种的苹果果实的果肉硬度(磅/cm 2),试比较2品种苹果的果肉硬度是否存在显著差异?SPSS 操作:菜单Analyze —Independent-Samples T Test在独立样本T检验(成组T检验)比较中,结果会分2种情况输出,对应着结果表的数据是2行,第一行是假设方差相等的数据,第二行是假设方差不相等的数据。
最终的结果是看第一行还是第二行,需要看Levene's Test for Equality of Variances(方差齐性检验)的结果。
如果Levene's Test for Equality of Variances 结果是方差相齐的,则看第一行数据,否则看第二行数据。
分析过程:首先,Levene's Test for Equality of Variances H0:2组数据方差相等(相齐),检验结果显著值(Sig.)为0.947 > 0.05,接受H0,2组数据方差相等,看第一行数据.其次,T检验的显著值(Sig.)是0.458 > 0.05,说明接受T检验的H0:2组数据对应总体的均值无显著差异,即2个品种的苹果果实的果肉硬度无显著差异。
例3-12.选用10个品种的草莓进行电渗处理和传统方法对草莓果实中钙离子含量的影响,结果如下,请问电渗处理和传统处理方法对草莓果实中钙离子含量是否有显著的差异?SPSS 操作:因为该试验是对10个品种的每个品种进行2种方法测试,因此需要使用成对样本均值的T 检验,而不能用成组样本的T检验在成对样本T 检验结果表中,需要看T检验的显著值。
2 / 12分析过程:成对样本T 检验(Paired-Samples T Test)结果,显著值(Sig.)为0 < 0.05( 0.01),否定H0:2种处理方法对应的总体均值相等,说明传统方法和电渗处理2种方法测试的草莓果实中钙离子含量之间有显著(极显著)差异,根据分析结果,对照—电渗处理的均值小于0,说明电渗处理法测试的草莓果实中钙离子含量显著提高。
SPSS非参数检验—两独立样本检验_案例解析

SPSS非参数检验—两独立样本检验_案例解析非参数检验是一种不基于总体分布特征的统计方法,适用于数据分布未知、非正态分布或无法满足参数检验假设的情况。
其中一种非参数检验是两独立样本检验,用于比较两组独立样本之间的统计差异。
本篇文章将结合案例解析,详细介绍SPSS软件中如何进行非参数检验的两独立样本检验。
案例背景:工厂生产两种不同形状的零件,为了比较两种零件的尺寸是否存在差异,随机选取了30个零件进行测量。
现在需要使用两独立样本检验来研究这两种零件的尺寸是否存在显著差异。
步骤一:数据导入首先,将收集到的数据导入SPSS软件中。
数据包括两个变量:零件类型(Group)和尺寸(Size)。
将数据按照Excel或CSV格式保存,然后在SPSS中选择"文件"->"导入"->"数据",选择导入文件,并进行数据格式定义。
步骤二:描述性统计分析在进行假设检验之前,首先进行描述性统计分析,以了解样本数据的基本特点。
在SPSS中,选择"分析"->"描述性统计"->"描述性统计",将"Size"变量拖入"变量"框中,然后点击"统计"按钮,选择要统计的统计量(如均值、标准差等),最后点击"确定"按钮进行计算。
步骤三:正态性检验在进行非参数检验之前,需要进行正态性检验,以确定数据是否满足参数检验的假设。
在SPSS中,选择"分析"->"非参数检验"->"单样本分布检验",将"Size"变量拖入"变量"框中,然后点击"选项"按钮,选择要进行的正态性检验方法,如Kolmogorov-Smirnov检验或Shapiro-Wilk检验等。
SPSS操作步骤讲解系列--非参数K个独立样本检验
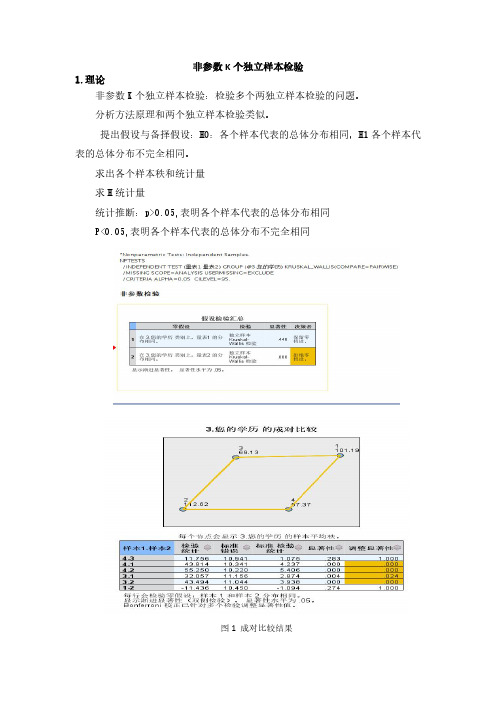
非参数K个独立样本检验1.理论非参数K个独立样本检验:检验多个两独立样本检验的问题。
分析方法原理和两个独立样本检验类似。
提出假设与备择假设:H0:各个样本代表的总体分布相同,H1各个样本代表的总体分布不完全相同。
求出各个样本秩和统计量求H统计量统计推断:p>0.05,表明各个样本代表的总体分布相同P<0.05,表明各个样本代表的总体分布不完全相同图1成对比较结果2.非参数K个独立样本检验操作步骤先导入数据后点击分析、非参数检验、旧对话框、K个独立样本。
图2操作步骤第一步第二步:进入图对话框后将因变量放入检验变量框中,后将分组变量放入分组变量框中后定义范围,填入分组变量赋值时的最大值和最小值,后点击继续、确定。
图3检验方法勾选及定义分组范围第三步:若需要看描述统计表结果,点击选项勾选描述、四分位数。
图4描述统计勾选第四步:若需要修改检验标准、点击精确、勾选蒙特卡洛法填入对应的检验标准置信区间。
图5检验标准置信区间修改3.非参数K个独立样本检验结果后K个独立样本检验的结果就出来了。
图6结果4.两两比较结果操作步骤第一步:如需要看两两比较结果,点击分析、非参数检验、独立样本。
图7两两比较结果第一步第二步:进入图中对话框后点击、字段、将对应变量放入对应的变量框中。
图8定义字段点击设置、勾选定制检验、克鲁卡尔沃利斯单因素ANOVA检验(K个样本)在多重比较里勾选:全部成对。
点击运行。
图9定义设置5.两两比较结果然后K个独立样本检验两两比较的假设检验结果就出来了。
图10假设检验结果第一步:双击假设检验中的一个结果(一般都是双击显著的结果),及可以进入图中结果查看器。
图11结果查看器第二步:在模型查看器中找到查看并点击其中的成对比较。
图12成对比较选择进入图中两两比较的结果框查看结果。
图13两两比较结果6.结果整理将结果粘贴复制到Excel表格中进行整理,将克鲁斯卡尔-沃利斯检验结果粘贴复制到表格中,后将检验统计放入卡方和p值,且把两两比较结果放入表格中。
SPSS简易分析流程详解
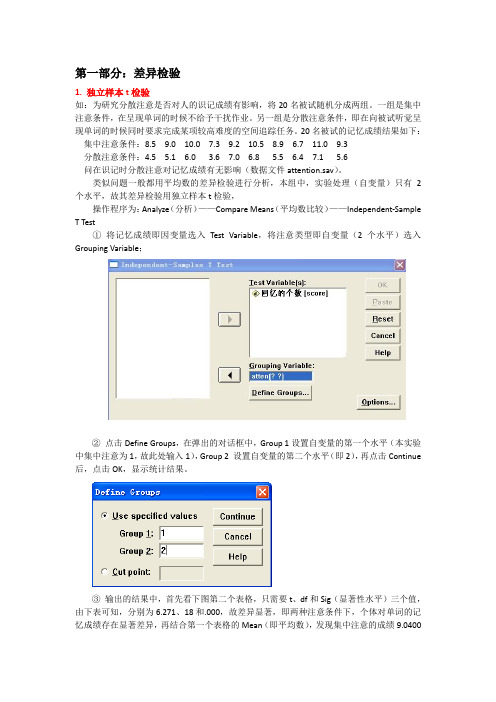
第一部分:差异检验1. 独立样本t检验如:为研究分散注意是否对人的识记成绩有影响,将20名被试随机分成两组。
一组是集中注意条件,在呈现单词的时候不给予干扰作业。
另一组是分散注意条件,即在向被试听觉呈现单词的时候同时要求完成某项较高难度的空间追踪任务。
20名被试的记忆成绩结果如下:集中注意条件:8.5 9.0 10.0 7.3 9.2 10.5 8.9 6.7 11.0 9.3分散注意条件:4.5 5.1 6.0 3.6 7.0 6.8 5.5 6.4 7.1 5.6问在识记时分散注意对记忆成绩有无影响(数据文件attention.sav)。
类似问题一般都用平均数的差异检验进行分析,本组中,实验处理(自变量)只有2个水平,故其差异检验用独立样本t检验,操作程序为:Analyze(分析)——Compare Means(平均数比较)——Independent-Sample T Test①将记忆成绩即因变量选入Test Variable,将注意类型即自变量(2个水平)选入Grouping Variable;②点击Define Groups,在弹出的对话框中,Group 1设置自变量的第一个水平(本实验中集中注意为1,故此处输入1),Group 2 设置自变量的第二个水平(即2),再点击Continue 后,点击OK,显示统计结果。
③输出的结果中,首先看下图第二个表格,只需要t、df和Sig(显著性水平)三个值,由下表可知,分别为6.271、18和.000,故差异显著,即两种注意条件下,个体对单词的记忆成绩存在显著差异,再结合第一个表格的Mean(即平均数),发现集中注意的成绩9.0400大于分散注意的成绩5.4600,故集中注意的记忆效果显著高于分散注意。
2. 相关样本t检验基本过程与独立样本t检验类似,操作程序为:Analyze(分析)——Compare Means(平均数比较)——Paired-Sample T Test例题:从某小学三年级随机抽取20名儿童做样本,分别在学期初和学期末进行了推理测验,结果如下(数据文件:Test.sav):学生编号 1 2 3 4 5 6 7 8 9 10学期初 12 13 12 11 10 13 14 15 15 11学期末 14 14 11 15 11 14 14 17 15 14学生编号 11 12 13 14 15 16 17 18 19 20学期初 13 12 11 10 13 14 15 15 11 12学期末 14 14 11 15 14 14 16 18 15 14①分两次分别点击“学期初成绩”和“学期末成绩”两个变量,如下图所示,Current Selections 显示两个变量后,点击中间的小三角选入Paired Variables后点击OK,显示结果;②输出结果的理解和分析与独立样本t检验相同。
SPSS检验步骤总结

检验步骤总结:1、t检验2、方差分析3、卡方检验4、秩和检验5、相关分析6、线性回归1、t检验(要求数据来自正态总体,可能需要先做正态检验)(1)单一样本t检验数据特征:单一样本变量均数与某固定已知均数进行比较方法:ANALYZE-COMPARE MEANS-ONE SAMPLE t TEST(2)独立样本t检验数据特征:两个独立、没有配对关系的样本(有专门变量表示组数)方法:ANALYZE-COMPARE MEANS-INDEPENDENT SAMPLES t TEST注意观察方差分析结果,判断查看的数据是哪一行!(3)配对样本t检验数据特征:两个不独立的,有配对关系的样本(没有专门变量表示组数)方法:ANALYZE-COMPARE MEANS-PAIRED SAMPLES t TEST不需要方差分析结果检验步骤:(1)正态性检验1(有同学推荐,老师没有强调,但依据理论应进行)(2)建立假设(H0:。
来自同一样本。
H1:。
不来自同一样本)(3)确定检验水准(4)计算统计量(依据上面不同样本类型选择检验方法,注意独立样本t检验要先注明方差分析结果)(5)确定概率值P(6)得出结论2、方差分析(要求数据来自正态总体,可能需要先做正态检验)(1)单因素方差分析数据特征:相互独立、来自正态总体、随机、方差齐性的多样本(有专门变量表示组数,且组数大于2)方法:ANALYZE-COMPARE MEANS-ONE WAY ANOVA注意需要在options 里面选择 homogeneity variance test 做方差分析符合方差齐性才可以得出结论!(>0.1)(2)双因素方差分析1正态性检验方法:analyze-explore-plot里面选择normality test数据特征:有三列数据,1列是主要研究因素,1列是配伍组因素,1列是研究数据。
方法:GENERAL LINEAR MODEL-UNIVARIATE (注意选择model里的custom,type是main effect,注意把两个因素选择为fixed factor)检验步骤:(1)正态性检验(有同学推荐,老师没有强调,但依据理论应进行)(2)建立假设(H0:。
无差检验、独立性检验 SPSS

作业6:1.无差检验随机从某市抽取90名教师,其中高级职称有30名,中级职称有42名,初级职称有18名。
若假设规定高、中、初级职称比为2:6:2,试问这一调查结果是否与规定相一致?注:上表中“1”表示高级职称、“2”表示中级职称、“3”表示初级职称。
(2)研究假设零假设:这一调查结果与规定一致。
备择假设:这一调查结果与规定不一致。
(3)操作说明1.输入数据。
保存为“数据1”。
2.对观测量进行加权。
单击“数据”菜单下的“加权个案”,在弹出的“加权个案”对话框中,选择“加权个案”单选项,并选择“人数”变量,单击“添加”按钮使之添加到“频率变量”框中,定义该变量为权数,然后单击“确定”按钮,返回数据编辑框。
3.卡方检验。
单击“分析”菜单下的“非参数检验”,选项中得“卡方检验”命令。
在弹出的“卡方检验”对话框中,因为要对高级职称、中级职称、初级职称的人数进行分析,所以在对话框左侧的列表中选择“职称”变量,单击“添加”按钮使之添加到“检测变量列表”框中。
在“期望值”框中得“数值”处输入理论上高级职称、中级职称、初级职称的比例2:6:2,然后单击“确定”按钮,SPSS开始进行卡方检验。
(4)生成图表及结果解释从第一个表格中可以看出高、中、初级职称的实际观测值、理论值和两者之间的差异个数;从第二个表格中可以看出自由度df=2,X2=10.667>9.210= X20.01 (2), P<0.01,所以拒绝零假设,支持备择假设,即这一调查结果与规定不一致。
2.独立性检验在研究初中厌学学生意志力时,某研究得到下表样本资料,试问厌学学生的意志力水平是否与年级有关?(1)原始数据(2)研究假设零假设:厌学学生的意志力水平与年级无关。
备择假设:厌学学生的意志力水平与年级有关。
(3)操作说明1. 输入数据。
保存为“数据2”。
2.对观测量进行加权。
单击“数据”菜单下的“加权个案”,在弹出的“加权个案”对话框中,选择“加权个案”单选项,并选择“人数”变量,单击“添加”按钮使之添加到“频率变量”框中,定义该变量为权数,然后单击“确定”按钮,返回数据编辑框。
SPSS统计分析教程-独立样本T检验
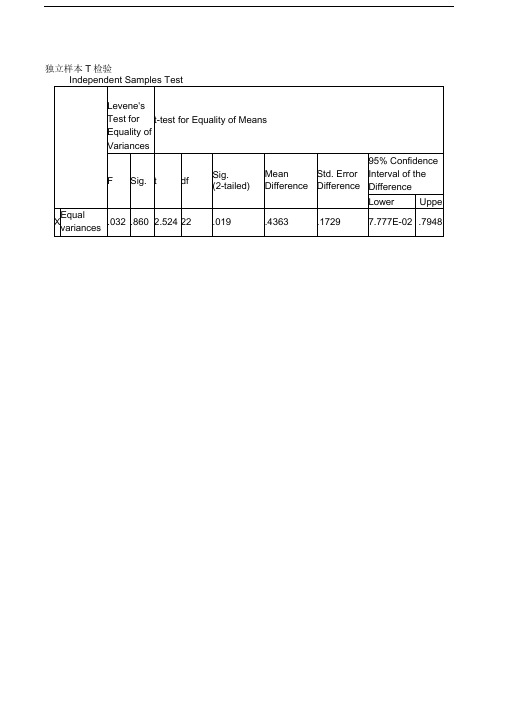
独立样本T检验
可见该结果分为两大部分:第一部分为Levene's方差齐性检验,用丁判断两总体方差是否齐,这里的戒严结果为 F = 0.032 , p = 0.860 ,可见在本例中方差是齐的;第二部分则分别给出两组所在总体方差齐和方差不齐时的t检验结果,由丁前面的方差齐性检验结果
为方差齐,第二部分就应选用方差齐时的t检验结果,即上面一行列出的t= 2.524 , v =22,
p=0.019。
从而最终的统计结论为按a =0.05水准,拒绝H0,认为克山病患者与健康人的血磷值不同,从样本均数来看,可认为克山病患者的血磷值较高。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
作业6:
1.无差检验
随机从某市抽取90名教师,其中高级职称有30名,中级职称有42名,初级职称有18名。
若假设规定高、中、初级职称比为2:6:2,试问这一调查结果是否与规定相一致?
注:上表中“1”表示高级职称、“2”表示中级职称、“3”表示初级职称。
(2)研究假设
零假设:这一调查结果与规定一致。
备择假设:这一调查结果与规定不一致。
(3)操作说明
1.输入数据。
保存为“数据1”。
2.对观测量进行加权。
单击“数据”菜单下的“加权个案”,在弹出的“加权个案”
对话框中,选择“加权个案”单选项,并选择“人数”变量,单击“添加”按钮使
之添加到“频率变量”框中,定义该变量为权数,然后单击“确定”按钮,返回数
据编辑框。
3.卡方检验。
单击“分析”菜单下的“非参数检验”,选项中得“卡方检验”命令。
在弹出的“卡方检验”对话框中,因为要对高级职称、中级职称、初级职称的人数
进行分析,所以在对话框左侧的列表中选择“职称”变量,单击“添加”按钮使之
添加到“检测变量列表”框中。
在“期望值”框中得“数值”处输入理论上高级职
称、中级职称、初级职称的比例2:6:2,然后单击“确定”按钮,SPSS开始进行卡
方检验。
(4)生成图表及结果解释
从第一个表格中可以看出高、中、初级职称的实际观测值、理论值和两者之间的差异个数;从第二个表格中可以看出自由度df=2,X2=10.667>9.210= X20.01 (2), P<0.01,所以拒绝零假设,支持备择假设,即这一调查结果与规定不一致。
2.独立性检验
在研究初中厌学学生意志力时,某研究得到下表样本资料,试问厌学学生的意志力水平是否与年级有关?
(1)原始数据
(2)研究假设
零假设:厌学学生的意志力水平与年级无关。
备择假设:厌学学生的意志力水平与年级有关。
(3)操作说明
1. 输入数据。
保存为“数据2”。
2.对观测量进行加权。
单击“数据”菜单下的“加权个案”,在弹出的“加权个案”对
话框中,选择“加权个案”单选项,并选择“人数”变量,单击“添加”按钮使之添加到“频率变量”框中,定义该变量为权数,然后单击“确定”按钮,返回数据编辑框。
3.独立性检验。
单击“分析”菜单下的“描述统计”中得“交叉表”选项,在弹出的“交叉表”对话框中,将左边列表中得“年级”添加到“行”变量框中,将左边列表框中得“意志力水平”添加到“列”变量中。
点击“统计量”按钮,在弹出的对话框中,选择“卡方检验”单选项。
点击“继续”按钮,返回到“交叉表”对话框中,点击“确定”。
SPSS开始进行独立性检验。
(4)生成图表及结果解释。
从上面的第一个表格中,可以看出年级和意志力水平的交叉关系。
从第二个表格中看出,自由度为df=4,Pearson卡方的P=0.034,这个P值小于0.05.说明拒绝零假设,也就是说厌学学生的意志力水平与年级有关的。