正规表达式
正规式的定义

正规式的定义在计算机科学中,正规式(Regular Expression),也被称为正则表达式,是一种用来描述字符序列的模式字符串。
它是一种强大的工具,广泛应用于文本处理和搜索算法中。
正规式不仅仅是一种语法规则,更是一种丰富的计算模型。
本文将探讨正规式的定义及其用途。
正规式是一种由字符和操作符构成的表达式,用来匹配特定的字符串。
它的核心思想是通过一种简洁而灵活的方式,定义字符序列的模式。
正规式并不是所有字符串的定义方式,而是一种特定的语法规则,用于描述字符串的结构和特征。
通过定义匹配规则,我们可以使用正规式来验证字符串是否符合预期,并从中提取出需要的信息。
正规式的基本字符包括字母、数字和特殊字符。
其中一些特殊字符具有特定的含义和用途,例如 "." 表示任意字符,"?" 表示匹配前一个字符零次或一次,"*" 表示匹配前一个字符零次或多次,"+" 表示匹配前一个字符一次或多次等等。
这些操作符的组合和嵌套可以构造出复杂而强大的匹配模式。
正规式有广泛的应用领域。
在文本处理中,我们常常需要对大量的文本数据进行搜索、替换、过滤等操作。
正规式可以帮助我们高效地定位和处理所需的文本片段。
例如,我们可以通过正规式来搜索包含特定关键词的文本,或者通过正规式来替换某些特定的字符。
另外,在编程领域,正规式也经常被用于输入验证和数据提取。
通过定义匹配规则,我们可以方便地验证用户输入的信息是否符合要求,并从中提取出所需的数据。
虽然正规式是一种强大的工具,但它并不适合解决所有问题。
正规式对于复杂的匹配模式和操作并不友好,而且容易出现过度匹配或不匹配的情况。
在处理复杂的文本结构或包含大量变种的字符串时,往往需要借助其他工具和算法来辅助。
此外,正规式也存在一些性能和安全性方面的考虑。
过于复杂的正规式可能导致性能下降,而不当的使用正规式可能导致安全漏洞。
编译原理 正规表达式

编译原理正规表达式
正规表达式是用来描述字符串模式的工具,通常用于文本搜索、文本解析和语言处理等领域。
它基于一组字符和特殊符号,可以定义字符串的可能模式,比如匹配具体的字符、字符集合、字符重复等。
使用正规表达式时,可以通过一系列特殊符号和字符来构建匹配规则。
例如,表达式中常见的符号包括:
1. 字符:匹配具体的字符。
2. 字符集合:使用方括号 [] 来指定匹配的字符集合,如 [abc]
表示匹配字符a、b或c。
3. 范围:使用短划线 - 在字符集合中指定范围,如 [a-z] 表示
匹配所有小写字母。
4. 量词:用来表示字符重复的次数,如 * 表示前面的字符可以重复0次或多次,+ 表示重复1次或多次,? 表示重复0次或
1次。
5. 元字符:具有特殊意义的字符,如 \d 表示匹配任意数字,
\w 表示匹配任意字母或数字。
6. 特殊符号:用于辅助构建表达式的符号,如 | 表示或,() 用
来分组。
例如,表达式 \d{3}-\d{4} 可以匹配形如 123-5678 的电话号码,其中 \d 表示匹配任意数字,{3} 表示前面的字符重复3次。
除了上述基本规则外,正规表达式还支持一些高级特性,如贪婪匹配和非贪婪匹配、边界匹配、分组和捕获等。
总之,正规表达式是一种强大的字符串模式匹配工具,通过使用特殊符号和字符,可以灵活地定义和匹配字符串模式。
在编译原理及相关领域中,正规表达式被广泛应用于词法分析和语法分析等过程中,可以方便地定义和识别词法单元和语法结构。
3.3.1-正规式

(4)仅由有限次使用上述三步骤而定义的表达式 才是Σ上的正规式,仅由这些正规式表示的 字集才是Σ上的正规集
规定算符的优先顺序 () *
·
|
令∑={a,b},∑上的正规式和相应的正规集 ∑={a,b},
正规式
a b a|b ab (a|b)(a|b) a* (a|b)*
正规集
{a} {b} {a, b} {ab} {aa, ab, ba, bb} {ε, a, aa, aaa, …} {ε, a, b, aa, ab …所有 由a或b组成的串} 补充例
·
* ( ) }
(1) (2)
正规集 {ε} { } {a}
Σ: 语言的字母表 VT
(3)假定U和V都是Σ上的正规式, 他们所表示的正规集分别为L(U)和L(V) 正规式 或 U|V U·V 连接积 闭包 (U)* 补充: ( ) (U) 正规集 L(U)∪L(V) L(U)·L(V) (L(U))* L(U)
4、正规式服从的代数规律 U,V,W为正规式 ① U|V=V|U ② U|(V|W)=(U|V)| W ③ (UV)W=U(VW) ④ U(V|W)=UV|UW , (V|W)U=VU|WU ⑤ εU=Uε=U
补充:正规式服从的代数规律 补充:
r为正规式 ⑥ r|r=r (r*)* = r* =ε|r|rr|… r*=ε|r|rr| ∑*=∑0 ∪∑1 ∪∑2 … ∪ ∑n ∪ …
课堂练习
r,s是正规式, 证明 (rs)*r = r(sr)*
补充例:定义无符号数的正规式 补充例:
2,12.59,3.6e2,471.88e-1 12.59,3.6e2,471.88e-
Σ = {d . e + -} d为0~9的数字, ‘.’表示小数点 d* (.dd*|ε) (e(+|-|ε)dd* |ε)
正则表示式

正则表示式正则表达式,也称为”正规表达式”,是一种用于匹配字符串的表达式。
它使用特定的语法来描述一组字符串,并通过匹配这些字符串来实现文本搜索、替换和验证等功能。
正则表达式在许多编程语言和操作系统中被广泛使用,如Perl、Python、Java和UNIX等。
正则表达式中有许多字符和操作符,这些字符和操作符可以用来构建一个正则表达式。
以下是常用的正则表达式元字符、字符集和量词:1. 元字符:a. ^:表示以...开头,如^a表示以a开头的字符串;b. $:表示以...结尾,如a$表示以a结尾的字符串;c. .:表示任何单个字符,如a.表示以a开头,后面任意一个字符的字符串;d. []:表示字符集,如[a-z]表示任何小写字母;e. \:用来转义特殊字符,如\.表示匹配小数点;f. ():用来分组,如(a|b)表示匹配a或b;g. *:表示零个或多个,如a*表示匹配任意个a;h. +:表示一个或多个,如a+表示匹配至少一个a;i. ?:表示零个或一个,如a?表示匹配0或1个a;j. {}:表示重复次数,如a{3}表示匹配连续3个a,a{3,}表示至少匹配3个a。
2. 字符集:a. []:匹配括号内的任意一个字符,如[abc]表示匹配a、b或c;b. [^]:匹配除括号内的字符之外的任意一个字符,如[^abc]表示匹配除a、b、c之外的任意字符;c. -:表示定义某个范围的字符集,如[a-z]表示匹配小写字母。
3. 量词:a. *:匹配前面的元素零次或多次,如ab*表示匹配a、ab、abb等;b. +:匹配前面的元素一次或多次,如ab+表示匹配ab、abb、abbb等;c. ?:匹配前面的元素零次或一次,如ab?表示匹配a、ab等;d. {n}:匹配前面的元素恰好n次,如a{3}表示匹配连续3个a;e. {n,}:匹配前面的元素至少n次,如a{3,}表示至少匹配3个a。
以上是正则表达式中常见的一些元字符、字符集和量词,它们可以根据需要自由组合,构建出复杂的正则表达式。
8-18位数字英文正则

8-18位数字英文正则正则表达式,又称正规表达式、规则表达式,是计算机科学中的一种用来描述、匹配和处理字符串的方法。
它通过使用字符和特殊字符组成的模式,可以有效地对文本进行搜索、替换、验证等操作。
在实际应用中,正则表达式常被用于验证用户输入的内容,限制密码的格式,以及从大量的文本数据中提取所需信息等。
本文将介绍一种常见的需求,即8-18位数字英文正则,同时提供相应的正则表达式示例。
首先,我们需要明确需求:所谓8-18位数字英文正则,即输入的字符串由8到18位的数字和英文字母组成。
以下是一个满足该要求的正则表达式:^[a-zA-Z0-9]{8,18}$我们对上述正则表达式进行分析,其中^表示匹配字符串的开头,$表示匹配字符串的结尾。
[a-zA-Z0-9]表示匹配任意一个数字或英文字母,{8,18}表示该字符可以重复出现8到18次,即限制了字符串的长度范围。
接下来,我们通过几个示例来演示该正则表达式的使用。
例1:验证密码格式假设我们要验证一个密码是否符合8-18位数字英文的格式要求。
我们可以使用以下代码进行验证:```pythonimport redef check_password(password):pattern = r'^[a-zA-Z0-9]{8,18}$'if re.match(pattern, password):print("密码格式正确")else:print("密码格式错误")check_password("Passw0rd123") # 密码格式正确check_password("abc1234567890def") # 密码格式错误```例2:提取满足条件的字符串假设我们有一段文本,需要从中提取出满足8-18位数字英文格式的字符串。
我们可以使用以下代码进行提取:```pythonimport redef extract_string(text):pattern = r'[a-zA-Z0-9]{8,18}'result = re.findall(pattern, text)print("提取到的字符串列表:", result)text = "密码是Passw0rd123,用户名是user123456789。
regexp 常用表达式

regexp 常用表达式
正则表达式(RegExp,或称为正规表达式)是用于匹配字符串模式的强大工具。
以下是一些在正则表达式中常用的模式:
1. 匹配数字:
•匹配一个或多个数字:\d+
•匹配零或一个数字:\d?
•匹配一个数字范围:\d{2,4}(匹配2到4个数字)
2. 匹配字母:
•匹配一个或多个字母:[a-zA-Z]+
•匹配零或一个字母:[a-zA-Z]?
3. 匹配单词字符:
•匹配一个或多个单词字符(字母、数字、下划线):\w+
4. 匹配空格:
•匹配一个或多个空格:\s+
5. 匹配开头和结尾:
•匹配字符串开头:^
•匹配字符串结尾:$
6. 匹配任意字符:
•匹配除换行符外的任意字符:.
7. 转义特殊字符:
•如果要匹配特殊字符本身,需要使用反斜杠 \ 进行转义。
8. 匹配字符集:
•匹配字符集中的任何一个字符:[aeiou](匹配元音字母)
•匹配字符集中的任何一个字符的补集:[^0-9](匹配非数字字符)
9. 限定符:
•匹配零次或多次:*
•匹配一次或多次:+
•匹配零次或一次:?
•匹配固定次数:{n}、{n,}、{n,m}
10. 分组和引用:
•使用括号进行分组:(pattern)
•引用分组中匹配的文本:\1、\2 等
11. 或操作:
•匹配 A 或 B:A|B
这只是正则表达式的基础,正则表达式还有许多高级特性和用法。
根据具体需求,你可能需要深入学习更多关于正则表达式的内容。
编译原理正规表达式

编译原理正规表达式
正规表达式是描述字符序列模式的工具。
它由一系列字符和特殊符号组成,用于匹配符合特定模式的输入字符串。
在正规表达式中,字符通常表示自己本身,例如字母a表示字符"a"。
然而,一些字符具有特殊含义,需要使用转义符号来
表示它们,例如"\d"表示匹配任意一个数字字符。
除了普通字符之外,还有一些特殊符号用于描述字符序列的各种属性。
例如,星号(*)代表前面的字符可以出现零次或多次,加号(+)代表前面的字符可以出现一次或多次,问号(?)代表前
面的字符可以出现零次或一次。
此外,一些特殊符号用于描述字符的范围。
例如,方括号([])
表示匹配括号内的任意一个字符,连字符(-)表示匹配连续的字符范围,例如[a-z]表示匹配任意一个小写字母。
正规表达式还可以使用圆括号来分组,并使用垂线(|)表示或逻辑。
这样可以更复杂地描述字符序列的模式。
在编译原理中,正规表达式常用于词法分析器中的模式匹配。
它们可以用来识别各种标识符、关键字、运算符、常量等。
正规表达式不仅在编译原理中有广泛应用,在其他领域如文本处理、数据抽取等方面也有很高的实用性。
综上所述,正规表达式是一种用于描述字符序列模式的工具,
通过使用特殊字符和符号,可以灵活地匹配符合特定模式的输入字符串。
它在编译原理和其他领域有广泛的应用。
sourceinsight 正规表达式

sourceinsight 正规表达式Source Insight是一款功能强大的源代码编辑器和代码浏览工具,它能够帮助开发人员更高效地阅读、编辑和维护源代码。
其中一个非常有用的功能就是支持正规表达式搜索和替换。
正规表达式是一种强大的模式匹配工具,通过使用特定的语法规则,可以在文本中快速定位和处理符合特定模式的字符串。
正规表达式可以在Source Insight的搜索和替换功能中使用,帮助开发人员进行高级搜索和批量替换操作。
使用正规表达式,我们可以完成一些复杂的搜索任务,比如查找所有以"get"开头并且以"()"结尾的函数调用,或者查找所有以"m_"开头并且以"()"结尾的成员变量。
在正规表达式中,有一些特殊字符和操作符具有特殊的含义。
比如,字符 "." 用来匹配任意一个字符,字符 "*" 表示前面的字符可以重复出现0次或多次,字符 "+" 表示前面的字符可以重复出现1次或多次,字符 "?" 表示前面的字符可以重复出现0次或1次。
此外,还有一些用于匹配特定字符类的操作符,比如 "\d" 表示匹配任意一个数字字符,"\w" 表示匹配任意一个字母或数字字符。
正规表达式的使用可以大大提高搜索和替换的效率和准确性。
比如,如果我们要查找所有以"set"开头并且以"()"结尾的函数调用,我们可以使用正规表达式"set\(\)"来进行搜索。
如果我们要将所有以"get"开头并且以"()"结尾的函数调用替换为"get()",我们可以使用正规表达式"get\(\)"进行替换。
除了基本的字符匹配和重复操作,正规表达式还支持一些高级的操作,比如分组、选择和反向引用。
以10结尾的二进制串的正规表达式

正规表达式是一种用来匹配字符串的模式。
它是使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串的规则。
在计算机科学中,正规表达式通常被用来检索、替换那些符合某个模式的文本。
在二进制串中,正规表达式同样可以发挥作用。
特别是对于以10结尾的二进制串,我们可以利用正规表达式来进行匹配。
以下是关于以10结尾的二进制串的正规表达式的内容:1. 以10结尾的二进制串的正规表达式以10结尾的二进制串的正规表达式为:`[01]*(10)$`2. 解释- `[01]*`表示可以包含0或1的任意数量的字符,包括空字符串。
- `(10)`表示以10结尾。
- `$`表示匹配输入的结尾。
3. 例子对于正规表达式`[01]*(10)$`,它可以匹配的字符串包括:"10"、"1110"、"1010"等,但不能匹配"110"、"xxx"等不以10结尾的字符串。
4. 用途使用这个正规表达式可以帮助我们在文本中快速地找到以10结尾的二进制串,省去了人工逐个检查的麻烦。
5. 实际应用在计算机科学和信息技术领域中,以10结尾的二进制串的正规表达式常常被用于编程中,比如在处理数据时筛选符合条件的二进制串。
总结:正规表达式是一种强大的工具,它可以帮助我们在文本中快速地匹配符合某种模式的字符串。
在二进制串中,以10结尾的字符串同样可以通过正规表达式来匹配。
掌握正规表达式的匹配规则对于计算机科学和信息技术领域的从业者来说是十分重要的。
通过学习和掌握正规表达式,我们能够更高效地处理文本数据,提高工作效率。
在计算机科学和信息技术领域,正规表达式是一项非常重要的技能。
它不仅可以用于检索、替换文本中符合某种模式的字符串,还可以在编程中发挥重要作用。
在处理二进制数据时,正规表达式同样可以派上用场。
特别是对于以10结尾的二进制串,我们可以通过正规表达式来快速准确地筛选出符合条件的字符串。
2.1 正规表达式

右线性文法→ 右线性文法→为正规式
• 例1 用规则R将例2.3中的右线性文法转化为等价的 正规式。 • 解法: 1)根据右线性文法,列出正规式方程组。 2)反复使用规则R、代入并应用正规式的等价性 质。 • 例2 求下列文法的等价正规式: S→aA|bB|b A→bA|ε B→bS
正规式→ 正规式→右线性文法
举例
(0+1)8 表示所有长度为 8 的 0-1 串。 表示所有长度为 [0-9]+ 表示所有十进制自然数。 表示所有十进制自然数。 [1-9][0-9]+ 表示不以 0 开头的所有十进制自然数 [A-Z][a-z]* ([a-z]+[A-Z]) ([a-z]+[A-Z]+[0-9])*
定义 2.2
设 Σ = {a, b},那么根据 1) 、2) 、3) φ ,ε , a, b 都是∑上的正规表达式, 根据规则 4) φ +a, ε +a, a+b φ a, ε a, ab φ *, ε *, a*, b * 例 等也是正规表达式。 再以上述正规表达式为基础,根据 4) ,又可以得到许多正规 表达式。而且这种做法可以反复进行下去,得到的∑的正规表达 式是没有穷尽的。 a*b*, (a+b)*, (0+1)*, 1(0+1)*1
扩充的正规表达式 1. r+ 表示集合 L(r)的正闭包, 的正闭包, 的正闭包 2. rk 表示集合 L(r)的 k 次幂, 的 次幂, 3. {r}表示 r* 表示 4. [0-9]表示 ,1,2,3,4,5,6,7,8,9}, 表示{0, , , , , , , , , , 表示 [a-z]表示 26 个小写拉丁字母, 表示 个小写拉丁字母, [A-Z]表示 26 个大写拉丁字母, 表示 个大写拉丁字母, 5. Σ 表示在字母表中任何符号。 表示在字母表中任何符号 在字母表中任何符号。
正则表达式起源

正则表达式起源
正则表达式(RegularExpression),也称作“正规表示式”、“规则表达式”、“常规表示法”等,是计算机科学中的一种语法规则,用来表示一定模式的字符串。
正则表达式最早起源于20世纪50年代的美国,当时负责维护美国西海岸电话网的电信工程师肯·汤普逊(Ken Thompson)发明了一种文本处理工具——文本编辑器QED(QuickEditor),并在其中加入了一种新的搜索与替换功能——正则表达式。
1970年代,汤普逊在贝尔实验室开发了Unix操作系统,并将正则表达式引入了Unix命令行界面中。
他还开发了一个新的文本编辑器——ed,并将其加入了正则表达式搜索与替换的功能。
随着Unix系统的广泛应用,正则表达式也被越来越多的程序员
所接受和使用。
1986年,Perl语言的创造者拉里·沃尔(Larry Wall)在Perl语言中加入了正则表达式的支持,使得正则表达式在编程领
域得到了普及和广泛应用。
如今,正则表达式已经成为计算机编程领域不可或缺的工具之一,被广泛应用于文本处理、数据分析、网络编程等领域。
虽然它的语法规则比较复杂,但只要掌握了基本的语法和常用的函数,就可以轻松地实现复杂的字符串处理功能。
- 1 -。
包含奇数个1或奇数个0的二进制数串的正规表达式

包含奇数个1或奇数个0的二进制数串的正规表达式正规表达式是用来描述一类字符串的模式的工具。
它能够帮助我们在文本处理、编程和数据处理中进行匹配和搜索。
在本文中,我将介绍如何使用正规表达式来匹配包含奇数个1或奇数个0的二进制数串。
我们知道,二进制数串由0和1组成,可以表示计算机中的数字和字符。
在正规表达式中,我们可以使用特定的语法来描述和匹配二进制数串中特定的模式。
让我们来看看如何匹配包含奇数个1的二进制数串。
在正规表达式中,我们可以使用括号和量词来描述模式。
具体来说,我们可以使用括号将1括起来,然后使用量词{n}来表示重复出现n次。
要匹配包含奇数个1的二进制数串,我们可以使用以下正规表达式:(1(01*01*)*)*让我们来逐步解析这个正规表达式:1. (01*01*)表示一个以0开头和结束的字符串,中间包含0个或多个1。
这部分模式可以匹配一个奇数个1的二进制数串。
2. (1(01*01*)*)表示一个以1开头,并且中间包含一个奇数个1的二进制数串。
这部分模式可以匹配一个包含奇数个1的二进制数串。
3. 最外层的量词*表示这个模式可以重复0次或多次,从而匹配包含任意个包含奇数个1的二进制数串的字符串。
接下来,让我们看看如何匹配包含奇数个0的二进制数串。
与匹配包含奇数个1的二进制数串类似,我们可以使用括号和量词来描述模式。
正则表达式为:(0(10*10*)*)*解析这个正则表达式:1. (10*10*)表示一个以1开头和结束的字符串,中间包含0个或多个0。
这部分模式可以匹配一个奇数个0的二进制数串。
2. (0(10*10*)*)表示一个以0开头,并且中间包含一个奇数个0的二进制数串。
这部分模式可以匹配一个包含奇数个0的二进制数串。
3. 最外层的量词*表示这个模式可以重复0次或多次,从而匹配包含任意个包含奇数个0的二进制数串的字符串。
我们可以通过使用括号和量词来描述和匹配包含奇数个1或奇数个0的二进制数串。
18位阿拉伯数字或大写英文字母 正则表达式

在日常生活中,我们经常会遇到各种需要匹配和验证身份、信息的场景。
其中,18位阿拉伯数字或大写英文字母的正则表达式就是一个常见且十分重要的工具。
在本篇文章中,我将深入探讨这个主题,从简单到复杂,由浅入深地介绍18位阿拉伯数字或大写英文字母的正则表达式。
让我们了解一下什么是正则表达式。
正则表达式,又称正规表示式、常规表示式、正规表达式,是一种字符串匹配的工具。
它的应用领域非常广泛,包括文本处理、表单验证、日志分析等,而18位阿拉伯数字或大写英文字母的正则表达式则是其中的一个具体应用场景。
接下来,让我们先从简单的正则表达式开始。
对于18位阿拉伯数字的正则表达式,可以使用\d{18}来匹配。
其中,\d表示匹配任意一个数字字符,{18}表示前面的\d需要连续匹配18次。
这样就可以准确地匹配到18位的数字序列,从000000000000000001到999999999999999999。
在现实生活中,我们可能会遇到需要验证输入是否为18位阿拉伯数字的场景,比如唯一识别信息号码的输入框。
通过使用\d{18}的正则表达式,我们可以轻松地对用户输入的唯一识别信息号码进行验证,确保其格式的正确性。
而对于大写英文字母的正则表达式,则可以使用[A-Z]{18}来匹配。
其中,[A-Z]表示匹配任意一个大写英文字母,{18}表示前面的[A-Z]需要连续匹配18次。
通过这样的正则表达式,我们可以精确地匹配到由18个大写英文字母组成的序列,从AAAAAAAAAAAAAAAAAA到ZZZZZZZZZZZZZZZZZZ。
在实际应用中,我们可能会需要验证输入是否为18位由大写英文字母组成的序列,比如一些特定的产品编码。
通过使用[A-Z]{18}的正则表达式,我们可以快速地判断用户输入的产品编码是否符合规定的格式,从而有效地提高输入内容的准确性。
18位阿拉伯数字或大写英文字母的正则表达式在日常生活中有着重要的作用。
它不仅可以用于验证唯一识别信息号码、产品编码等特定格式的输入,也可以用于筛选、匹配文本信息,是一种非常实用的工具。
十二正规表达式

十二正规表达式正规表示表示出来字符串的一种表示方法。
Alnum 大小写和数字,alpha大小写,blank空格键和tab键,digit数字,lower 小写,upper大写Grep 【-acinv】-A -B --color=auto ‘字符串’ 文件:A后加数字,为除该行外,后续n行列出来,B相反before.a将binary档案以text档案的方式搜寻数据,c计算找到‘搜寻字符串’的次数,i忽略大小写的不同,所以大小写视为相同。
n顺便输出行号,v反向选择,即显示没有改字符串内容的一行。
Dmesg可以列出核心产生的讯息。
该字符串可以:搜寻test或taste,字符串写成t[ae]st,无论括号中有几个字符,他都只代表一个字符。
如果我们想搜寻‘00’,但不想前面有g就用’[^g]oo’。
(gooooooogle,存在o前面是g和0的可能,所以也要显示。
)不想要小写就用[^a-z],也可以用[:lower:](包括括号)表示。
搜寻字符串出现在首用^,尾用$,在开头有小写^[a-z];在开头没有小写^[^a-z], 尾上有小数点\.$,widows 的断行字符为^M$,linux的为$。
所以windows尾$前面的是M不是点,就选不出来。
空格行用^$,在正规表达式中,小数点代表一定有一个任意字符的意思,*代表重复前一个0或无穷多次的意思,为组合形态。
如o*这个组合代表有0个以上各o。
.*这个组合代表0到无穷多个任意字符。
o\{2\}=ooo*,o\{2,5\}表示只有2-5个o,o\{2,\}表示2个以上o,a[asy]y代表搜寻a和y中间有1个字符是来源与括号中的。
Sed是管线命令,分析标准输出。
Sed -nefr 动作:n:使用安静模式。
在一般的sed的用法中,所有来自STDIN的数据一般都会被列出到屏幕上。
但是加上-n参数后,则只有经过sed特殊处理的那一行(或动作)才会被列出来。
E直接在指令列模式上进行sed的动作编辑。
python常用正规表达式

python常用正规表达式Python中的正则表达式是用于匹配字符串的强大工具。
它们可以用于各种目的,例如:1.验证数据2.提取信息3.替换文本Python中的正则表达式使用re模块来实现。
该模块提供了各种方法来匹配和操作字符串。
以下是一些Python中常用的正则表达式:匹配数字●import re●匹配任意数字●pattern=d+●匹配至少一位数字●pattern=d{1,}●匹配1到2位数字●pattern=d{1,2}匹配字母●Python●import re●匹配任意字母●pattern=[a-zA-Z]+●匹配至少一位字母●pattern=[a-zA-Z]{1,}●匹配1到2位字母●pattern=[a-zA-Z]{1,2}匹配特定字符●Python●import re●匹配字符a●pattern=a●匹配字符a或b●pattern=a|b●匹配字符串abc●pattern=abc匹配特殊字符●Python●import re●匹配空格●pattern=s●匹配换行符●pattern=n●匹配点号●pattern=.匹配模式●Python●import re●匹配任意字符,至少一次●pattern=.+●匹配任意字符,最多一次●pattern=.●匹配零次或一次●pattern=.?组合模式●Python●import re●匹配字符串abc●pattern=(abc)●匹配字符串a后跟任意字符●pattern=a.●匹配字符串a后跟零次或一次任意字符●pattern=a.?边界符●import re●匹配字符串abc开头●pattern=^abc●匹配字符串abc结尾●pattern=abc$●匹配字符串abc两侧有空格●pattern=sabc\s反向引用●Python●import re●匹配字符串abc两侧有空格●pattern=s(abc)\s●匹配字符串abc后跟任意字符,但不能是d ●pattern=abc(?!d)其他模式●import re●匹配字符串abc的所有匹配项●pattern=abc●result=re.findall(pattern,abcabcabc)●print(result)●[abc,abc,abc]●匹配字符串abc的第一个匹配项●pattern=abc●result=re.search(pattern,abcabcabc)●print(result)●<_sre.SRE_Match object;span=(0,3),match=abc>●匹配字符串abc是否存在●pattern=abc●result=re.search(pattern,abcabcabc)●print(result is not None)●TruePython中的正则表达式非常强大,可以用于各种目的。
skill语言中的正则表达式

skill语言中的正则表达式摘要:一、正则表达式的基本概念1.正则表达式的定义2.正则表达式的作用二、正则表达式的语法规则1.字符类2.量词3.选择与分组4.锚点与环视三、正则表达式的应用场景1.字符串匹配2.字符串替换3.字符串分割四、正则表达式在skill 语言中的实践1.使用正则表达式进行字符串匹配2.使用正则表达式进行字符串替换3.使用正则表达式进行字符串分割正文:在skill 语言中,正则表达式是一种强大的文本处理工具,它可以帮助我们快速地查找、替换和分割字符串。
正则表达式,又称正规表达式、regex,是一种用于描述字符或字符序列的语法规则。
通过使用正则表达式,我们可以更加灵活地处理文本数据,提高编程效率。
正则表达式的基本概念包括两个方面:定义和作用。
正则表达式是一种用来描述字符或字符序列的文本模式,它可以用来检查一个字符串是否符合某种模式,也可以用来从字符串中提取符合某种模式的部分。
正则表达式的核心是语法规则,它由一系列特殊的字符和元字符组成,用于表示不同的匹配策略。
正则表达式的语法规则包括四个方面:字符类、量词、选择与分组、锚点与环视。
字符类用于匹配某一类字符,如字母、数字、空白字符等。
量词用于指定字符或字符类出现的次数,如“*”表示零次或多次,“+”表示一次或多次。
选择与分组用于根据不同的条件选择不同的匹配策略,如“|”表示或操作,“()”表示分组。
锚点与环视用于指定匹配的位置,如“^”表示字符串开头,“$”表示字符串结尾,“1”表示引用前一个分组的内容。
正则表达式的应用场景主要包括字符串匹配、字符串替换和字符串分割。
字符串匹配是指在一个字符串中查找是否包含某个子串,如查找所有的数字。
字符串替换是指将一个字符串中的某些内容替换为其他内容,如将所有的“skill”替换为“AI”。
字符串分割是指将一个字符串按照一定的规则分割成多个子串,如将一个句子按照逗号分割成多个单词。
在skill 语言中,正则表达式的实践主要包括使用正则表达式进行字符串匹配、替换和分割。
正规表达式和有穷自动机,编辑原理
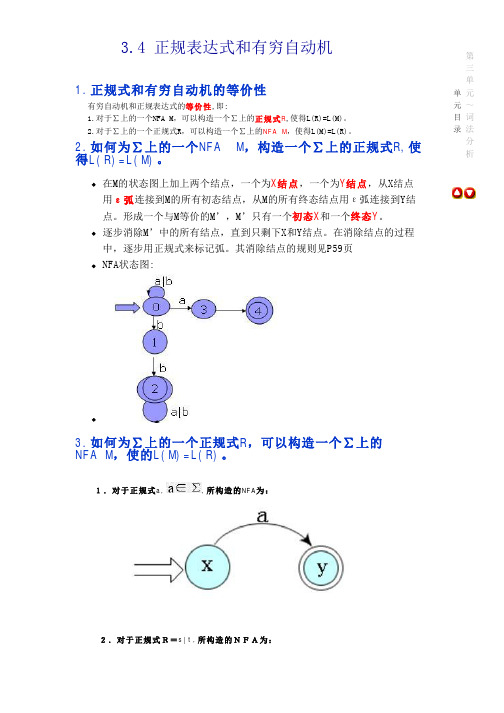
单元目录 第三单元~词法分
析 3.4 正规表达式和有穷自动机
1.正规式和有穷自动机的等价性 有穷自动机和正规表达式的等价性,即: 1.对于∑上的一个NFA M ,可以构造一个∑上的正规式R ,使得L(R)=L(M)。
2.对于∑上的一个正规式R ,可以构造一个∑上的NFA M ,使得L(M)=L(R)。
2.如何为∑上的一个NFA M ,构造一个∑上的正规式R,使
得L(R)=L(M)。
在M 的状态图上加上两个结点,一个为X 结点,一个为Y 结点,从X 结点用ε弧连接到M 的所有初态结点,从M 的所有终态结点用ε弧连接到Y 结点。
形成一个与M 等价的M ’,M ’只有一个初态X 和一个终态Y 。
逐步消除M ’中的所有结点,直到只剩下X 和Y 结点。
在消除结点的过程中,逐步用正规式来标记弧。
其消除结点的规则见P59
页
NFA 状态图:
3.如何为∑上的一个正规式R ,可以构造一个∑上的NFA M ,使的L(M)=L(R)。
1.对于正规式
a,,所构造的NFA 为:
2.对于正规式R=s|t,所构造的NFA为:
3.对于正规式R=st,所构造的NFA(R)为:
4.对于正规式R=S*,NFA(R)为:
例:为R=(a|b)* abb构造NFA? N,使得
L(N)=L(R)。
正规式定义——精选推荐

博客园 用户登录 代码改变世界 密码登录 短信登录 忘记登录用户名 忘记密码 记住我 登录 第三方登录/注册 没有账户, 立即注册
正规式定义
正则表达式
正则表达式最早是由数学家Stephen Kleene于1956年提出,他是在对自然语言的递增研究成果的基础上提出来的。具有完整语法的 正则表达式使用在字符的格式匹配方面上,后来被应用到熔融信息技术领域。自从那时起,正则表达式经过几个时期的发展,现在的标准 已经被ISO(国际标准组织)批准和被Open Group组织认定。
正规式也称正则表达式,也是表示正规集的数学工具。下面是正规式和它所表示的正规集的递归定义。定义(正规式和它所表示的正 规集):
设字母表为Σ,辅助字母表ΣFra bibliotek={Φ,ε,|,·,*,(,),}。 ① ε和Φ都是Σ上的正规式,它们所表示的正规集分别为{ε}和{ }; ② 任何a∈Σ,a是Σ上的一个正规式,它所表示的正规集为{a}; ③ 假定e1和e2都是Σ上的正规式,它们所表示的正规集分别为L(e1)和L(e2),那么,(e1), e1|e2, e1·e2, e1*也都是正规式,它们所表示的 正规集分别为L(e1), L(e1)∪L(e2), L(e1)L(e2)和(L(e1))*。 ④ 仅由有限次使用上述三步骤而定义的表达式才是Σ上的正规式,仅由这些正规式所表示的字集才是Σ上的正规集。
正规集也就是有正规式可以确定的串的集合。
设r,s,t为正规式,正规式服从以下代数规律
① r|s=s|r "或"服从交换律 ② r|(s|t)=(r|s) | t "或"的可结合律 ③ (rs)t=r(st) "连接"的可结合律 ④ r(s|t)=rs|rt;(s|t)r=sr|tr 分配律 ⑤ εr=r, rε=r ε是"连接"的恒等元素零一律 ⑥ r|r=r;r*=ε|r|rr|… "或"的抽取律
idea 正则子表达式

idea 正则子表达式关于正则表达式:正则表达式(Regular Expression),又称正规表达式、规则表达式或标准表达式,是一种用于描述字符串规则的工具。
它是计算机领域中处理字符串的强大工具之一,广泛应用于文本处理、数据提取、匹配、替换等各种场景。
正则表达式的语法非常灵活,可以根据需求使用不同的元字符(Metacharacter)和特殊字符(Special Characters)进行匹配。
其中,中括号[]在正则表达式中扮演着非常重要的角色,它被用来表示一个字符类(Character Class)。
中括号内的内容可以是单个字符或一组字符,用来匹配字符串中的任意一个字符。
这种形式的表示方式使得正则表达式具有了更大的灵活性和强大的功能。
在使用中括号表示字符类时,可以使用连字符(-)表示一个字符范围,例如[a-z]表示小写字母,[0-9]表示数字等。
此外,中括号内的字符可以通过互相排斥来取反。
例如,[^a-z]表示匹配不是小写字母的任意一个字符。
中括号的另一个重要作用是可以指定一组可选项,并且只匹配其中的一个。
例如,[abc]表示匹配a、b或c中的任意一个字符。
这种形式的字符类可以在需要匹配多个字符时提供更简洁的表示方式。
除了单个字符外,中括号还可以包含多个字符或字符范围。
例如,[aeiou]表示匹配任意一个元音字母,[A-Za-z]表示匹配任意一个字母(大小写不限)。
在使用中括号时,需要注意一些特殊字符的转义。
例如,如果要匹配中括号本身,需要使用反斜杠进行转义。
因此,要匹配字符串中的"[]",应该使用"\[\]"。
除了上述的基本用法,中括号还可以与其他元字符组合使用,提供更复杂的匹配需求。
例如,[^0-9a-zA-Z]表示匹配任意一个不是数字和字母的字符。
正则表达式的中括号不仅可以在匹配时使用,还可以在替换时使用。
通过使用中括号,在替换过程中可以按照不同的规则进行处理,从而实现对字符串的灵活控制。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Javascript与正则表达式个人总结与收录--基础篇一、正则表达式的定义正则表达式是一种可以用于模式匹配和替换的强有力的工具。
二、正则表达式的作用1、测试字符串的某个模式。
例如,可以对一个输入字符串进行测试,看在该字符串是否存在一个模式,这也称为数据有效性验证。
2、替换文本。
可以在文档中使用一个正则表达式来标识特定文字,然后将其删除,或者替换为别的内容。
3、根据模式匹配从字符串中提取一个子字符串。
随后可以用来在文本或输入字段中查找特定文字。
三、正则表达式的常见写法现在很多正则表达式都采用了perl风格的写法,即把正则表达式的内容放在/ /中间,看起美观,最主要的是实用,方便辨别。
当然,如果不闲麻烦也可以写成如下的格式:var re = new RegExp (“regContent”);四、正则表达式的“元字符”所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
较为常用的元字符如下:“+”元字符规定其前导字符必须在目标对象中连续出现一次或多次。
示例:/Ro+/因为上述正则表达式中包含“+”元字符,所以可以与类似“Ro”,“Rocky”,“Roof”等在字母R后面连续出现一个或多个字母o的字符串相匹配。
“*”元字符规定其前导字符必须在目标对象中出现零次或多次。
示例:/Ro*/因为上述正则表达式中包含“*”元字符,所以可以与类似“Ricky”,“Rocky”或者“Roof”等在字母R后面连续出现零个或多个字母o的字符串匹配。
“?”元字符规定其前导对象必须在目标对象中连续出现零次或一次。
示例:/Ro?/因为上述正则表达式中包含“?”元字符,所以可以与目标对象中的“Ricky”,“Rocky”这样在字母R后面连续出现零个或一个字母o的字符串匹配。
五、正则表达式的限定符有时候不知道要匹配多少字符。
为了能适应这种不确定性,需要用到正则表达式中的限定符。
{n}:n 是一个非负整数,表示匹配确定的n 次。
例如,o{2} 不能匹配“Rocky” 中的o,但是能匹配“Roof” 中的两个o。
{n,}:n 是一个非负整数,表示至少匹配n 次。
例如,o{2,} 不能匹配“Rocky” 中的o,但能匹配“Roof”或“Whoooooa” 中的o。
{n,m}:m 和n 均为非负整数,其中n <= m,表示最少匹配n 次且最多匹配m 次。
例如,"o{1,3}" 将匹配“Whoooooa” 中的前三个o六、正则表达式中的定位符正则表达式中的定位符用于规定匹配模式在目标对象中的出现位置。
“^”——定位符规定匹配模式必须出现在目标字符串的开头“$”——定位符规定匹配模式必须出现在目标对象的结尾“\b”——定位符规定匹配模式必须出现在目标字符串的开头或结尾的两个边界之一“\B”——定位符则规定匹配对象必须位于目标字符串的开头和结尾两个边界之内,即匹配对象既不能作为目标字符串的开头,也不能作为目标字符串的结尾。
示例:/^Ro/可以与类似“Rocky”,“Rock”或“Roof”的字符串相匹配。
/ball$/可以与类似“football”,“basketball”或“baseball”的字符串相匹配。
/\bon/可以与类似“one”,“once”的字符串相匹配。
/on\b/ 可以与类似“sensation”,“generation”的字符串相匹配/on\B/可以与类似“song”,“tone”,“tongue”的字符串相匹配()注:/\Bon此处匹配作用相同/七、正则表达式中的其他常见符号“()”:在正则表达式中使用括号把字符串组合在一起。
“()”符号包含的内容必须同时出现在目标对象中才可匹配,当然有时在功能没有影响的情况下,会为了方便代码检查等加上括号运算符。
“|”:在正则表达式中实现类似编程逻辑中的“或”运算。
例如:/Rocky|Ricky/上述正则表达式将会与目标对象中的“Rocky”或“Ricky”。
“[]”:指定可以取的字符范围,如[0-9] 可以匹配从0到9范围内的任何一个数字。
“[^]”:规定目标对象中不能存在模式中所规定的字符串,即否定符。
例如:/[^A-C]/上述字符串将会与目标对象中除A,B,和C之外的任何字符相匹配。
例如:alert(/[^A-C]/.test('A')); //falsealert(/[^A-C]/.test('AB')); //falsealert(/[^A-C]/.test('AD')); //truealert(/[^A-C]/.test('DF')); //true“\”:转义符。
当用户需要在正则表达式的模式中加入元字符,并查找其匹配对象时,可以使用转义符。
例如:/R\*/会与“R*”匹配而非“Ro”或“Ri”等相匹配。
八、常用正则表达式匹配\s:用于匹配单个空格符,包括tab键和换行符;\S:用于匹配除单个空格符之外的所有字符;\d:用于匹配从0到9的数字;\w:用于匹配字母,数字或下划线字符;\W:用于匹配所有与\w不匹配的字符;:用于匹配除换行符之外的所有字符。
九、正则表达式常见的运算符等价转化关系o{1,} <=> o+o{0,} <=> o*o{0,1} <=> o?\d <=> [0-9]\w <=> [a-zA-Z0-9_]十、正则表达式运算符优先级1.\ 转义符2.(),(?:),(?=),[] 圆括号和方括号3.*,+,?,{n},{n,},{n,m} 限定符4.^,$,\anymetacharacter 位置和顺序5.| “或”操作一、正则表达式中的量词贪婪量词:先看整个字符串是不是一个匹配。
如果没有发现匹配,它去掉最后字符串中的最后一个字符,并再次尝试。
如果还是没有发现匹配,那么再次去掉最后一个字符串,这个过程会一直重复直到发现一个匹配或者字符串不剩任何字符。
简单量词都是贪婪量词。
惰性量词:先看字符串中的第一个字母是不是一个匹配,如果单独着一个字符还不够,就读入下一个字符,组成两个字符的字符串。
如果还没有发现匹配,惰性量词继续从字符串中添加字符直到发现一个匹配或者整个字符串都检查过也没有匹配。
惰性量词和贪婪量词的工作方式恰好相反。
支配量词:只尝试匹配整个字符串。
如果整个字符串不能产生匹配,不做进一步尝试。
?:当该字符紧跟在任何一个其他限制符(*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。
非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。
例如,对于字符串"oooo",'o+?' 将匹配单个"o",而'o+' 将匹配所有'o'。
二、正则表达式高级使用(?:pattern) :匹配pattern 但不获取匹配结果,也就是说这是一个非捕获型匹配,不进行存储供以后使用。
这在使用"|" 字符来组合一个模式的各个部分是很有用。
例如要匹配Rocky 和Ricky,那么R(?:o|i)cky较之Rocky |Ricky 表达更为简略。
(?=pattern) :正向预查,在任何匹配pattern 的字符串开始处匹配查找字符串,匹配pattern前面的位置。
这是一个非捕获型匹配,也就是说,该匹配不需要获取供以后使用。
示例:alert(/Windows(?=95|98|NT|2000)/.test('Windows 2000')); //truealert(/Windows(?=95|98|NT|2000)/.test('Windows 2000')); //falsealert(/Windows(?=95|98|NT|2000)/.test('Windows 3.1')); //false预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?!pattern) :负向预查,在任何不匹配pattern的字符串开始处匹配查找字符串, 匹配后面不是pattern的位置,这也是一个非捕获型匹配。
示例:alert(/Windows (?!95|98|NT|2000)/.test('Windows2000')); // falsealert(/Windows(?!95|98|NT|2000)/.test('Windows2000')); // truealert(/Windows (?!95|98|NT|2000)/.test('Windows3.1')); // true\数字:反向引用,通过数字编号引用前面的内容示例:alert(/ba(na)\1/.test('banana')); //truealert(/(\d{4})\1(\d{2})\1/.test('12341234121234')); //t ruealert(/(\d{4})\1(\d{2})\2/.test('123412341212')); //t rue三、正则表达式中参数的使用1、g:表明可以进行全局匹配。
①对于表达式对象的exec方法,不加入g,则只返回第一个匹配,无论执行多少次均是如此,如果加入g,则第一次执行也返回第一个匹配,再执行返回第二个匹配,依次类推。
例如:var regx=/user\d/;var str=“user18dsdfuser2dsfsd”;var rs=regx.exec(str);//此时rs的值为{user1}var rs2=regx.exec(str);//此时rs的值依然为{user1}如果regx=/user\d/g;则rs的值为{user1},rs2的值为{user2} 通过这个例子说明:对于exec方法,表达式加入了g,并不是说执行exec方法就可以返回所有的匹配,而是说加入了g之后,我可以通过某种方式得到所有的匹配,这里的方式对于exec而言,就是依次执行这个方法即可。
②对于match方法,不加入g,只是返回第一个匹配,而且一直执行match方法也总是返回第一个匹配,但加入g,则一次返回所有的匹配(注意是“所有”)。
例如:var regx=/user\d/;var str=“user1sdfsffuser2dfsdf”;var rs=str.match(regx);//此时rs的值为{user1}var rs2=str.match(regx);//此时rs的值依然为{user1}如果regx=/user\d/g,则rs的值为{user1,user2},rs2的值也为{user1,user2}③对于String对象的replace方法,表达式不加入g,则只替换第一个匹配,如果加入g,则替换所有匹配。