实验五 视图的规划与操作
视图的使用---实验报告5

select学生档案.学号,姓名,性别,专业,班级,学生成绩表.课程ID,总成绩
from学生档案,学生成绩表
where学生档案.学号=学生成绩表.学号and学生档案.学号in(
select学号
from学生成绩表
where总成绩>=85)
运行结果如图所示:
五、教师评语பைடு நூலகம்
set课程名称='逻辑学'
where课程ID='RX0002'
运行结果如图所示:
6_4_10视图的删除
drop view管理学课程信息简表
运行结果如图所示:
6_4_11使用“企业管理器”创建视图
运行结果如图所示:
四、出现的问题及解决方案
在基于多张表嵌套查询的视图中,要对“学生成绩优秀表”进行查询,按书本上代码进行查询时出错,代码为:
6_4_4基于多张表连接的视图
create view学生课程成绩表
as
select学生档案.学号,姓名,性别,专业,班级,学生成绩表.课程ID,总成绩
from学生档案,学生成绩表
where学生档案.学号=学生成绩表.学号
运行结果如图所示:
6_4_5基于多张表嵌套查询的视图
create view学生成绩优秀表
as
select学生档案.学号,姓名,性别,专业,班级,学生成绩表.课程ID,总成绩
from学生档案,学生成绩表
where学生档案.学号in(
select学号
from学生成绩表
where总成绩>=85)
运行结果如图所示:
6_4_6含有虚字段的视图
create view学生期末平均成绩表
实验五 图

实验五、图一、实验项目名称图的存储遍历二、实验目的(1)了解熟知图的定义和图的基本术语,掌握图的几种存储结构。
(2)掌握灵界矩阵和邻接表定义的特点,并通过实例解析掌握邻接矩阵和邻接表的类型定义。
(3)掌握图的遍历定义、复杂性分析及应用,并掌握图的遍历方法及其基本思想。
三、实验要求(1)认真阅读和掌握和本实验相关的教材内容。
(2)掌握图的创建方法。
(3)掌握图的深度优先搜索和广度优先搜索方法。
四、实验原理C/C++程序设计基本原理五、实验内容(1)建立无向图的邻接矩阵或邻接表。
(2)图的深度优先搜索。
(3)图的广度优先搜索。
(4)编写测试主函数并上机运行。
打印出运行结果,并结合程序运行结果进行分析。
Part1:邻接表存储及遍历(侧重)1.邻接表的定义2.准备一个重要工具—定位函数:返回顶点在图中位置3.邻接表的创建4.图的深度优先遍历算法(DFS)5.图的广度优先遍历算法6.打印邻接表代码测试与结果:通过主函数,建立如有所示的有向图,并调用以上所有函数,测试其正确性并分析程序的运行结果。
主函数测试:PartII:图的邻接矩阵存储和遍历1.邻接矩阵的类型2.遍历矩阵要用的数据容器3.创建邻接矩阵4.深度优先遍历5.广度优先遍历代码测试与结果:通过主函数,建立如有所示的有向图,并调用以上所有函数,测试其正确性并分析程序的运行结果。
六、实验心得本次图上机实习,因为深度优先遍历与广度优先遍历用到了队列和栈,复习了原来的知识,同时也尝试将这两类基础函数作为头文件使用,收货颇丰。
同时在写线索二叉树时,遇到了一些理解困难,因为上课时这个知识点没怎么听,意识到了上课认真听讲的重要性,同时也要加强动手实践,拓宽知识面。
面对困难,比如说比较难懂的知识点,不要灰心,要坚持,在坚持不住时再坚持一下,你便做到了常人不能做到的事情,这才是成功者该有的品质。
我觉得自己要多努力,要见贤思齐,见不贤而内自省,才能让自己不再是井底之蛙,才能使自己的大学生活变得更充实。
实验五 视图的应用

实验五视图的应用5-1在实验二建立的基础表的基础上,设计和建立视图1、投影create view投影asselect教师编号,姓名from教师;2、选择create view选择asselect*from教师where职称='教授';3、投影和选择select*from投影和选择;select*from投影join选择on投影.教师编号=选择.教师编号;select*from投影where投影.教师编号in(select教师编号from虚字段where工资>=200)4、连接create view连接asselect教师编号,职称,课程编号,课程名称from教师join课程on教师.教师编号=课程编号;5、嵌套create view嵌套asselect*from教师where教师编号in(select责任教师from课程where性别='男')6、虚字段create view虚字段(教师编号,姓名,工资)asselect i.教师编号,i.姓名,i.工资from教师i,课程jwhere i.教师编号=j.责任教师;5-2分别在定义的视图上设计一些查询一般简单查询:select*from投影和选择;连接查询:select*from投影join选择on投影.教师编号=选择.教师编号;嵌套查询:select*from投影where投影.教师编号in(select教师编号from虚字段where工资>=200)^_^^_^^_^^_^^_^^_^^_^^_^^_^_^^_^宁十一^_^^_^^_^^_^^_^^_^^_^^_^^_^^_^_^^_^^_^5-3在不同的视图上分别设计一些插入、更新和删除操作,分情况讨论哪些操作可以完成,那些操作不能完成,并分析原因1、投影insert into投影values('56','吴宁');select*from投影;update投影set姓名='王宁'where教师编号='56';select*from投影;delete投影where教师编号='56';select*from投影;2、选择insert into选择values('25','9','钱小2','女','教授','软件','10');select*from选择;select*from教师;update选择set姓名='钱小二'where教师编号='25';select*from选择;select*from教师;delete选择where教师编号='25';select*from选择;select*from教师;3、投影和选择insert into投影和选择values('13','清河');select*from投影和选择;select*from教师;update投影和选择set姓名='qh'where教师编号='19'; update投影和选择set姓名='zc';delete投影和选择where教师编号='19';delete投影和选择where教师编号='2';select*from投影和选择;4、连接insert into连接values('15','副教授','12','java'); update连接set职称='教授'where教师编号='2'; select*from连接;delete连接where教师编号='2';5、嵌套insert into嵌套values('24','2','cd','男','教授','软件','100'); select*from嵌套;select*from教师;update嵌套set姓名='dc'where教师编号='24'; select*from教师;update嵌套set姓名='dc'where教师编号='8'; select*from嵌套;select*from教师;delete嵌套where姓名='dc';select*from嵌套;select*from教师;6、虚字段insert into虚字段values('32','xx','200');select*from虚字段;select*from教师;update虚字段set姓名='b b q'where教师编号='2'; select*from虚字段;select*from教师;delete虚字段where教师编号='5';。
数据库实验报告视图

大连海事大学数据库原理课程实验大纲实验名称:实验五视图实验学时: 2适用专业:智能科学与技术实验环境: Microsoft SQL server 20141实验目的(1)掌握SQL视图语句的基本使用方法,如CREATE VIEW、DROP VIEW。
(2)掌握视图更新、WITH CHECK OPTION等高级功能的使用。
2实验内容2.1 掌握SQL视图语句的基本使用方法(1)创建视图(省略视图列名)。
(2)创建视图(不能省略列名的情况)。
(3)删除视图(RESTRICT / CASCADE)。
2.2 掌握视图更新和WITH CHECK OPTION的高级使用方法(1)创建视图(WITH CHECK OPTION),并利用INSERT、DELETE和UPDATE语句加以验证。
(2)创建一个行列子集可更新视图,并利用INSERT、DELETE和UPDATE语句加以验证。
(3)创建一个不可能更新的视图,并利用更新语句验证该视图不可更新。
3实验要求(1)深入复习教材第三章SQL有关视图语句。
(2)根据书上的例子,针对TPCH数据库模式设计各种视图语句,每种类型视图语句至少要设计一个,描述清楚视图要求,运行你所设计的视图语句,并截图相应的实验结果,每幅截图并要有较为详细的描述。
也可以按照附1所列示例做实验。
(3)实验步骤和实验总结中要详细描述实验过程中出现的问题、原因和解决方法。
(4)思考题:KingbaseES把视图的定义存储在那个系统表中?如何查看某个视图的定义?4实验步骤4.1 掌握SQL视图语句的基本使用方法(1)创建视图(省略视图列名)。
(2)创建视图(不能省略列名的情况)。
(3)删除视图(RESTRICT / CASCADE)。
4.2 掌握视图更新和WITH CHECK OPTION的高级使用方法(4)创建一个行列子集可更新视图,并利用INSERT、DELETE和UPDATE语句加以验证。
(5)创建视图(WITH CHECK OPTION),并利用INSERT、DELETE和UPDATE语句加以验证。
实验五__视图的创建与使用

视图的创建与使用一、实验目的(1)理解视图的概念。
(2)掌握创建视图、测试、加密视图的方法。
(3)掌握更改视图的方法。
(4)掌握用视图管理数据的方法。
二、实验内容1.创建视图(1)创建一个名为stuview2的水平视图,从数据库Student_info的Student表中查询出性别为“男”的所有学生的资料。
并在创建视图时使用with check option。
(注:该子句用于强制视图上执行的所有修改语句必须符合由Select语句where中的条件。
)create view stuview2asselect*from Studentwhere Sex='男'with check option查看视图:select*from stuview2(2)创建一个名为stuview3的投影视图,从数据库Student_info的Course表中查询学分大于3的所有课程的课程号、课程名、总学时。
并在创建时对该视图加密。
(提示:用with ENCRYPTION关键子句)create view stuview3with ENCRYPTIONasselect Cno,Cname,Total_perior from Coursewhere Credit>3查看视图:select*from stuview3(3)创建一个名为stuview4的视图,能检索出“051”班所有女生的学号、课程号及相应的成绩。
create view stuview4asselect*from SCwhere Sno=(select Sno from Studentwhere Classno='051'and Sex='女')查看视图:select*from stuview4(4)创建一个名为stuview5的视图,能检索出每位选课学生的学号、姓名、总成绩。
create view stuview5asselect Student.Sno学号,Sname姓名,Grade成绩from Student,SCwhere Student.Sno=SC.Sno查看视图:select*from stuview5若出现如上图所示情况,单击“查询”→IntelliSense→刷新本地缓存然后就解决了。
实验报告五 视图与索引

实验五视图与索引一.实验目的1.学会使用企业管理器建立视图与索引2.掌握使用SQL语句建立视图与索引二.实验内容1.使用企业管理器建立视图索引2.使用SQL语句建立视图索引三.实验准备1.复习与本次实验内容相关知识2.对本次实验中要求自己完成的部分做好准备四.实验步骤1.用企业管理器建立一个基于学生表、课程表、成绩表的视图,要求该视图显示学号、姓名、课程、成绩o启动企业管理器、注册、连接o"新建视如下图所示o在新视图窗口内的关系图窗格内右击鼠标,弹出的菜单即为视图设计菜单,执行"添加表(B)...",如下图所示再在添加表对话框中选择SCORES表,再单击添加按钮。
依此操作,分别添加STUDENT、COURSES表,单击关闭按钮。
再在关系窗格内,拖动STUDENT表的"SID"至SCORES的STUDENT_ID,拖动COURSES表的"CNO"至SCORES的COURSE_ID,再分别选中STUDENT表的"SID","NAME"列(列前的复选框),COURSES表的"COURSE"列以及SCORES表的"SCORE"列,然后单击"!"按钮,显示视图结果,如下图所示:单击保存按钮,将视图保存为V_SCORES,单击确定.2.用查询分析器建立一个基于学生表、班级表的学生视图(V_STUDENTS),包括学号、姓名、班级、系,SQL语句如下:CREATE VIEW dbo.V_STUDENTSASSELECT dbo.U_STUDENTS.ID, dbo.U_,dbo.U_CLASSES.CLASS,dbo.U_CLASSES.DEPARTMENTFROM dbo.U_STUDENTS INNER JOINdbo.U_CLASSES ON dbo.U_STUDENTS.CLASS_ID = dbo.U_CLASSES.ID3.自己写一个SQL语句建立一个基于课程表的视图(V_COURSES),要求显示课程编号.课程名、学分。
实验5 视图的创建与使用
实验5 视图的创建和使用【实验目的】掌握创建与删除视图的方法掌握更新视图的方法掌握视图的查询操作【实验内容】一、创建视图1、用企业管理器创建视图此实验中以mydb1数据库中的test01、student、course、sc表为基础创建视图。
打开企业管理器,展开左侧窗口树形结构上的数据库节点,选中要创建视图的数据库(这里是mydb1),右击数据库中的“视图”对象,选择“新建视图”命令,如图1所示,就会弹出如图2所示的视图设计器窗口。
图【1】新建视图图【2】视图设计器在视图设计器窗口中右击选择“添加表”或单击工具栏上“添加表”按钮,添加所需要的表。
如图3所示。
图【3】添加表在表窗口中各字段名的前面方框里单击,选择相应的字段,或是在下面“列”的下拉列表框中选择字段,并可在“准则”列中输入提取记录时的过滤条件,在“或”列中输入提取记录所用的附加条件,最后在上面窗口中右击,选择“运行”,则在最下面的窗口中就能看到视图的结果。
如图4所示。
图【4】选择视图内容视图设计完后,点击保存图标,在弹出的“另存为”对话框中输入视图名,此实验为score_view ,最后点击“确定”按钮。
如图5所示。
图【5】保存视图2、使用向导创建视图(略)3、用T-SQL语句创建视图格式:CREATE VIEW view_name[(column1,column2,……)] Asselect_statement[with check option]例:创建所有选课学生的信息视图,如图6所示。
(3)重命名表test001为test01。
当发现表名不恰当的时候,需要为表重新命名。
使用系统存储过程sp_rename 可以为表重新命名,语法如下:sp_rename old_table_name , new_table_name请在查询管理器中输入如下的语句:Use mydb1Gosp_rename test001 , test01 /*EXEC sp_rename test001 , test01 也可以*/Go系统执行,将返回如图6所示的结果。
数据库 实验5 视图

实验5 索引和视图1.实验目的(1)掌握使用SQL Server管理平台和Transact-SQL语句CREA TE INDEX创建索引的方法。
(2)掌握使用SQL Server管理平台查看索引的方法。
(3)掌握使用SQL Server管理平台和Transact-SQL语句DROP INDEX删除索引的方法。
(4)掌握使用SQL Server管理平台和Transact-SQL语句CREA TE VIEW创建视图的用法。
(5)了解索引和视图更名的系统存储过程sp_rename的用法。
(6)掌握使用Transact-SQL语句ALTER VIEW修改视图的方法。
(7)了解删除视图的Transact-SQL语句DROP VIEW的用法。
2.实验内容及步骤说明:在SQL Server2005中,有三种视图:标准视图、索引视图和分区视图。
标准视图:组合了一个或多个表中的数据,用户可以获得使用视图的大多数好处。
包括将重点放在特定数据上以简化数据操作。
索引视图:适合聚合多行的查询,不太适合经常更新的基本数据集。
分区视图:支持大型多层网站的处理需要。
SQL Server2005提供了两种创建视图的方法。
SSMS和T-SQL语句。
create view语法形式:create view 【数据库名.】【拥有者.】视图名【(列名1,列名2【…..n】)】AS<select 语句>【with check option】其中,各参数说明如下:数据库名:当前数据库名称拥有者:当前数据库的拥有者,在绑定架构时不可缺。
视图名:用于指定包含的列名,符合标识符的命名规则。
列名:视图中包含的列名。
若使用与源表或视图中相同的列名时,则不必给出列名,如果是计算得到的值则必须指定列名。
select语句:定义视图的select语句。
在视图中可以使用的select语句有一些限制。
with check option:强制针对视图执行的所有数据修改语句都必须符合在select语句中设置的条件。
实验五图的操作及应用

实验五:图的操作及应用实验学时:4实验类型:综合型一、实验目的1.理解图的逻辑结构和物理结构;2.掌握图的邻接矩阵和邻接表存储表示的实现方法;3.掌握图的深度优先和广度优先遍历算法的实现;4.掌握拓扑排序算法的实现方法。
二、实验条件Visual C++ 6.0三、实验原理及相关知识1.图的邻接矩阵和邻接表存储结构的描述;2.图的邻接矩阵和邻接表存储表示的算法;3.图的深度优先和广度优先遍历算法;4.拓扑排序算法。
四、实验步骤1. 实现图的邻接矩阵的存储表示。
2. 实现图的邻接表存储表示。
3. 实现图的深度优先和广度优先遍历算法。
4. 实现拓扑排序算法。
5. 调用以上函数实现以下操作:(1) 建立图。
(2) 输出基于邻接表存储的深度优先和广度优先遍历序列。
(3) 输出有向图的拓扑排序序列。
参考代码:要求:补充完整以下代码使其能够运行通过。
#include "stdio.h"#include "malloc.h"#include "string.h"#define INFINITY 10000// 用整型最大值代替∞#define MAX_VERTEX_NUM 20 // 最大顶点个数#define OK 1#define ERROR 0#define FALSE 0#define TRUE 1#define MAXQSIZE100typedef int QElemType;typedef float VRType;typedef float InfoType;typedef char VertexType;typedef char VexType;//============邻接矩阵的定义============typedef struct {VRType adj;InfoType info; // 该弧相关信息的指针(可无)}ArcCell,AdjMatrix[MAX_VERTEX_NUM][MAX_VERTEX_NUM];typedef struct {VertexType vexs[MAX_VERTEX_NUM][100]; // 顶点向量AdjMatrix arcs; // 邻接矩阵int vexnum,arcnum; // 图的当前顶点数和弧数} MGraph ;//=======================邻接矩阵的定义========//=================================邻接表的定义========= typedef struct ArcNode{ // 表结点int adjvex; // 该弧所指向的顶点的位置struct ArcNode *nextarc; // 指向下一条弧的指针float info; // 网的权值指针} ArcNode;typedef struct{ // 头结点VertexType data[100]; // 顶点信息ArcNode *firstarc; // 第一个表结点的地址} VNode, AdjList[MAX_VERTEX_NUM];typedef struct {AdjList vertices;int vexnum,arcnum; // 图的当前顶点数和弧数}ALGraph;int visited[MAX_VERTEX_NUM];//=================邻接表的定义=========================//=========队列定义和基本操作=============== typedef struct QNode1{QElemType data;struct QNode1 *next;}QNode, *QueuePtr;typedef struct { //链队列的定义QElemType *base;int front;int rear;} SqQueue;typedef struct{QueuePtr front;QueuePtr rear;}LinkQueue;LinkQueue InitQueue(LinkQueue Q){Q.front=Q.rear=(QueuePtr)malloc(sizeof(QNode));if(!Q.front)exit(1);Q.front->next=NULL;return Q;}int EnQueue(LinkQueue* Q, QElemType e){QueuePtr p;if( !(p=(QueuePtr)malloc(sizeof(QNode))) )return ERROR;p->data = e;p->next = NULL;Q->rear->next = p;Q->rear = p;return OK;}int DeQueue(LinkQueue *Q, QElemType *e) {QueuePtr p;if( Q->front == Q->rear )return ERROR;p = Q->front->next;*e = p->data;Q->front->next = p->next;if(Q->rear == p) Q->rear = Q->front;free(p);return OK;}int QueueEmpty(LinkQueue *Q) {if(Q->front ==Q->rear) return 1;else return 0;}int DestroyQueue( LinkQueue *Q ){while(Q->front) {Q->rear=Q->front->next;free(Q->front);Q->front=Q->rear;}return OK;}//===================队列定义和基本操作===============int LocateVex(MGraph G,char *vert){ int i;for(i=0; i<G.vexnum; i++)if(strcmp(G.vexs[i],vert)==0)return i;return -1;}int LocateVex1(ALGraph G,char *vert){ int i;for(i=0; i<G.vexnum; i++)if(strcmp(G.vertices[i].data,vert)==0)return i;return -1;}MGraph CreateGraph_UDN( MGraph G ){//建立无向网G的邻接矩阵int i, j,k;float w;VexType v1[100], v2[100];printf("输入顶点数,数边数:");scanf("%d %d", &G.vexnum, &G.arcnum);for(i=0; i<G.vexnum; i++) // 读入所有的顶点{ printf("输入第%d个顶点的信息:",i+1);scanf("%s", &G.vexs[i]);}for(i=0; i <G.vexnum; i++) //初始化邻接矩阵for(j=0; j<G.vexnum; j++)G.arcs[i][j].adj=INFINITY;for(k=0; k<G.arcnum; k++) { // 输入所有的边printf("输入第%d条边依附的两个顶点和边上的权值:",k+1);scanf("%s %s %f", &v1, &v2, &w);// 查询两个顶点在图中存储的位置i = LocateVex(G, v1);j = LocateVex(G, v2);if (i==-1 || j==-1){printf("输入的边不正确\n"); return;}G.arcs[i][j].adj = w;G.arcs[j][i].adj = G.arcs[i][j].adj;}return G;}ALGraph CreateALGraph_UDN(ALGraph G )//建立无向网G的邻接表{int i,j,k;float w;ArcNode * p;VexType v1[100], v2[100];printf("输入顶点数,数边数:");scanf("%d %d",&(G.vexnum),&(G.arcnum)); /* 读入顶点数和边数*/for(i=0;i<G.vexnum;i++) /* 建立有n个顶点的顶点表*/{printf("输入第%d个顶点的信息:",i+1);scanf("%s",&(G.vertices[i].data)) ; /* 读入顶点信息*/G.vertices[i].firstarc=NULL; /* 顶点的边表头指针设为空*/}for(k=0;k<G.arcnum;k++ ) /* 建立边表*/{printf("输入一条边依附的两个顶点和边上的权值:");scanf("%s %s %f",&v1,&v2,&w) ; /* 读入边<Vi,Vj>的顶点对应序号*/i = LocateVex1(G, v1);j = LocateVex1(G, v2);if (i==-1 || j==-1){printf("输入的边不正确\n"); return;}p=(ArcNode*)malloc(sizeof(ArcNode) ); /* 生成新边表结点p */p->adjvex=j; /* 邻接点序号为j */p->info =w;p->nextarc=G.vertices[i].firstarc; /* 将新边表结点p插入到顶点Vi的链表头部*/G.vertices[i].firstarc=p;p=(ArcNode*)malloc(sizeof(ArcNode) ); /* 生成新边表结点p */p->adjvex=i; /* 邻接点序号为i */p->info =w;p->nextarc=G.vertices[j].firstarc; /* 将新边表结点p插入到顶点Vj的链表头部*/G.vertices[j].firstarc=p;}return G;} /*CreateALGraph*/VisitFunc(char *ch)//输出顶点的信息{printf("%s ",ch);}void DFS(ALGraph G, int v ) {int j;ArcNode *p;VisitFunc(G.vertices[v].data); // 访问第v个顶点visited[v]=TRUE; // 设置访问标志为TRUE(已访问)for(p=G.vertices[v].firstarc; p;p=p->nextarc){j=p->adjvex;if( !visited[j] ) DFS(G, j);}}void DFSTraverse( ALGraph G){//图的深度优先遍历算法int v;for(v=0; v<G.vexnum; v++)visited[v]=FALSE; // 访问标志数组初始化(未被访问) for(v=0;v<G.vexnum;v++)if(!visited[v])DFS(G,v); // 对尚未访问的顶点调用DFS }void BFSTraverse(ALGraph G) //图的广度优先遍历算法{int v,j,u ;ArcNode *p;LinkQueue Q;Q=InitQueue(Q); // 置空的辅助队列Qfor(v=0; v<G.vexnum; v++)visited[v]=FALSE; // 置初值for(v=0; v<G.vexnum; v++)if(!visited[v]){visited[v]=TRUE; // 设置访问标志为TRUE(已访问)VisitFunc(G.vertices[v].data);EnQueue( &Q, v ); // v入队列while(!QueueEmpty(&Q)){DeQueue(&Q,&u); // 队头元素出队并置为ufor(p=G.vertices[u].firstarc; p;p=p->nextarc){j=p->adjvex;if( !visited[j] ){visited[j]=TRUE;VisitFunc(G.vertices[j].data);EnQueue(&Q, j);}}}}DestroyQueue( &Q );}//实现建立有向网的邻接矩阵和邻接表的函数MGraph CreateGraph_DN( MGraph G ){//建立有向网G的邻接矩阵{}ALGraph CreateALGraph_DN(ALGraph G )//建立有向网G的邻接表{}Print_MGraph(MGraph G)//输出图的邻接矩阵表示{int i,j;for(i=0;i<G.vexnum;i++){ for(j=0;j<G.vexnum;j++)printf("%f ",G.arcs[i][j].adj ); /*邻接矩阵*/printf("\n");}}Print_ALGraph(ALGraph G) //输出图的邻接表表示{int i,j;ArcNode *p;for(i=0;i<G.vexnum;i++){printf("%s",G.vertices[i].data ); /* 顶点信息*/p=G.vertices[i].firstarc ;while(p!=NULL) /* 表节点信息*/{printf("->%s",G.vertices[p->adjvex ].data);p=p->nextarc ;} /* 顶点的边表头指针设为空*/printf("\n");}}void FindInDegree(ALGraph G, int *indegree){int i,k;ArcNode *p;for (i=0; i<G.vexnum; ++i){for (p=G.vertices[i].firstarc; p; p=p->nextarc) {{k = p->adjvex;indegree[k]++; }}}}//===================拓扑排序==============================int TopologicalSort(ALGraph G) {// 有向图G采用邻接表存储结构。
数据库实验五:视图的应用

数据库实验五:视图的应用一、实验目的与要求:1.实验目的(1)理解视图的概念;(2)掌握视图的使用方法。
(3)理解视图和基本表的异同之处。
2.实验要求(1)参照实验五中完成的查询,按如下要求设计和建立视图:1)基于单个表按投影操作定义视图。
2)基于单个表按选择操作定义视图。
3)基于单个表按选择和投影操作定义视图。
4)基于多个表根据连接操作定义视图。
5)基于多个表根据嵌套操作定义视图。
6)定义含有虚字段的视图。
(2)分别在定义的视图设计一些查询(包括基于视图和基本表的连接或嵌套查询)。
(3)在定义的视图上进行插入、更新和删除操作,分情况讨论哪些操作可以成功完成,哪些操作不能完成,并分析原因。
(4)在实验报告中要给出具体的视图定义要求和操作要求,并针对各种情况做出具体的分析和讨论。
二、实验内容1、实验原理(1)视图是用SQL SELECT查询定义的,创建视图命令格式如下:CREATE VIEW <视图名> AS <SELECT-查询块>(2)删除视图的命令格式如下:DROP VIEW <视图名>2、实验步骤与结果(1)调出SQL Server2005软件的用户界面,进入SQL SERVER MANAGEMENT STUDIO。
(2)输入自己编好的程序。
(3)检查已输入的程序正确与否。
(4)运行程序,并分析运行结果是否合理和正确。
在运行时要注意当输入不同的数据时所得到的结果是否正确。
(5)输出程序清单和运行结果。
(1)参照实验五中完成的查询,按如下要求设计和建立视图:1)基于单个表按投影操作定义视图。
create view v asselect教师编号,姓名from教师create view v_order asselect*from教师where职称='教授'3)基于单个表按选择和投影操作定义视图。
create view v_cuss asselect教师编号,姓名,职称from教师where职称='教授'4)基于多个表根据连接操作定义视图。
实验五 视图的使用
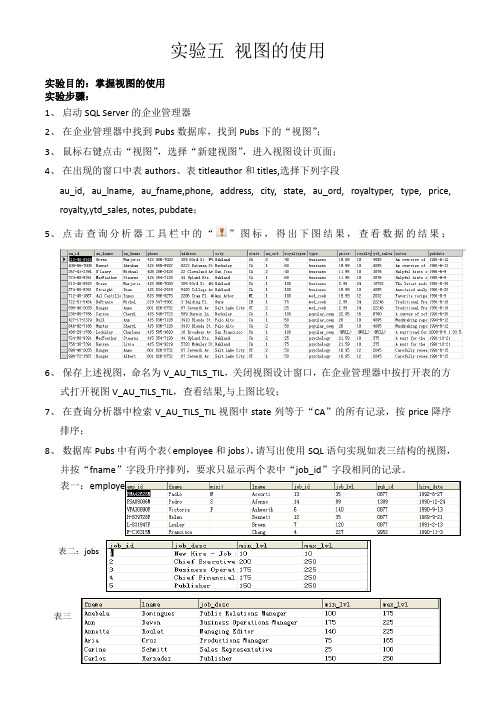
实验五视图的使用
实验目的:掌握视图的使用
实验步骤:
1、启动SQL Server的企业管理器
2、在企业管理器中找到Pubs数据库,找到Pubs下的“视图”;
3、鼠标右键点击“视图”,选择“新建视图”,进入视图设计页面;
4、在出现的窗口中表authors、表titleauthor和titles,选择下列字段
au_id, au_lname, au_fname,phone, address, city, state, au_ord, royaltyper, type, price, royalty,ytd_sales, notes, pubdate;
5、点击查询分析器工具栏中的“”图标,得出下图结果,查看数据的结果;
6、保存上述视图,命名为V_AU_TILS_TIL,关闭视图设计窗口,在企业管理器中按打开表的方
式打开视图V_AU_TILS_TIL,查看结果,与上图比较;
7、在查询分析器中检索V_AU_TILS_TIL视图中state列等于“CA”的所有记录,按price降序
排序;
8、数据库Pubs中有两个表(employee和jobs),请写出使用SQL语句实现如表三结构的视图,
并按“fname”字段升序排列,要求只显示两个表中“job_id”字段相同的记录。
表一:employee
表二:jobs
表三。
实验五 图的基本操作17735

实验五图的基本操作一、实验目的1、使学生可以巩固所学的有关图的基本知识。
2、熟练掌握图的存储结构。
3、熟练掌握图的两种遍历算法。
二、实验内容本次实验提供4个题目,难度相当,学生可以根据自己的情况选做,其中题目一是必做题,其它选作!题目一:图的遍历(必做)[问题描述]对给定图,实现图的深度优先遍历和广度优先遍历。
[基本要求]以邻接表为存储结构,实现连通无向图的深度优先和广度优先遍历。
以用户指定的结点为起点,分别输出每种遍历下的结点访问序列。
【测试数据】由学生依据软件工程的测试技术自己确定。
题目二:在图G中求一条从顶点 i 到顶点 s 的简单路径[测试数据]自行设计[题目三]:在图G中求一条从顶点 i 到顶点 s 且长度为K的简单路径[测试数据]自行设计三、实验前的准备工作1、掌握图的相关概念。
2、掌握图的逻辑结构和存储结构。
3、掌握图的两种遍历算法的实现。
四、实验报告要求1、实验报告要按照实验报告格式规范书写。
2、实验上要写出多批测试数据的运行结果。
3、结合运行结果,对程序进行分析。
一.实验内容定义结构体QueueNode,并完成队列的基本操作,利用队列先进先出的性质,在广度优先遍历时将队列作为辅助工具来完成广度优先遍历。
void EnQueue(QueueList* Q,int e)函数实现进队操作,if-else语句完成函数的具体操作void DeQueue(QueueList* Q,int* e)函数实现出队操作,if-else语句完成函数的具体操作void CreatAdjList(Graph* G)函数用来完成创建图的操作,其中使用两次for循环语句第一次用循环语句输入顶点,第二次建立无向图中的边和表,流程图如图表1所示void dfs(Graph *G,int i,int visit[])函数是从第i个顶点出发递归的深度优先遍历图G深度优先搜索:dfs():寻找v的还没有访问过的邻接点,循环找到v的所有的邻接点,每找到一个都以该邻接点为新的起点递归调用深度优先搜索,找下一个邻接点。
实验五 视图

《实验五视图》实验说明一、适用专业和课程:计算机专业《数据库》实验学时:2二、实验目的:(1) 熟悉SQL Server 2005的交互式SQL工具;(2) 掌握视图的建立和使用方法。
三、实验内容:视图的定义(创建和删除),查询,更新(注意更新的条件)。
四、实验要求:(1) 熟悉SQL支持的有关视图的操作,能够熟练使用SQL创建各类视图;(2) 熟练使用SQL对视图进行查询;(3) 体会视图的删除机制;(4) 保存上机过程中的所有SQL操作,SQL文件命名:姓名学号后四位-4.sql,如xukai3112-4.sql;(5) 完成上机练习;(6) 记录所有的实验用例,根据要求认真填写实验报告。
五、实验环境和仪器(软件、硬件):(1) 硬件环境:普通联网的PC机;(2) 操作系统:Windows 2000或者Windows XP;(3) 数据库管理系统:MS SQL Server 2005。
六、实验步骤(程序,流程等):(包含实验记录,提供的数据、图表等资料内容)(一)针对学生-课程数据库1、定义视图①建立信息系学生的视图,并要求透过该视图进行更新操作只涉及信息系学生②建立信息系选修了1号课程的学生视图③建立信息系选修了1号课程且成绩在90分以上的学生的视图④定义一个反映学生出生年份的视图⑤将学生的学号及他选修的课程数和课程的平均成绩定义为一个视图⑥将Student表中所有女生记录定义为一个视图⑦定义一个学生查询所有选课成绩的视图,要求显示学号、学生姓名、课程名、学分、成绩2、查询视图①在信息系学生的视图中找出年龄小于20岁的学生②查询信息系选修了1号课程的学生③在学生平均成绩视图中查询平均成绩在90分以上的学生学号和平均成绩④在学生选课成绩视图中查询学号为20060702所选课程的成绩3、更新视图①将信息系学生视图中学号20060702的学生姓名改为“刘辰”②向信息系学生视图中插入一个新的学生记录:95029,赵新,20岁③删除信息系学生视图中学号为20060702的记录(用实例验证各种不可更新视图)4、删除所有视图①创建一个视图,包含选课成绩合格的学生编号、课程号、成绩,并带有WITH CHECK OPTION子句。
实验五视图的创建和使用

实验五视图的创立和使用5.1概述5.1.1任务一理解视图的概念视图是一个虚拟表,其内容由查询定义。
同真实的表一样,视图包含一系列带有名称的列和行数据。
但是,视图并不在数据库中以存储的数据集合形式存在。
行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。
对其中所引用的基表来说,视图的作用类似于挑选。
定义视图的挑选可以来自当前或其他数据库的一个或多个表,或者其他视图。
视图被定义后便存放在数据库中,对视图中的数据的操作与对表的操作一样,可以对其进展查询、修改和删除,但对数据的操作要满足一定的条件。
当对视图所看到的数据进展修改时,相应的基表的数据也会发生变化,同时,假设基表的数据发生变化,这种变化也会自动地反映到视图中。
5.1.2任务二理解视图的优点用户可以根据自己的实际需要创立视图,使用视图有很多优点,主要有以下几点:1、简单性视图可以屏蔽数据的复杂性,简化用户对数据库的操作。
使用视图,用户可以不必理解数据库的构造,就可以方便地使用和管理数据。
那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。
2、逻辑数据独立性视图可以使应用程序和数据库表在一定程度上独立。
假设没有视图,应用一定是建立在表上的。
有了视图之后,程序可以建立在视图之上,从而程序与数据库表被视图分割开来。
3、平安性通过视图用户只能查询和修改他们所能见到的数据。
数据库中的其他数据那么既看不见也取不到。
5.2创立视图创立视图的方法有三种:在创立视图前请考虑如下原那么:➢只能在当前数据库中创立视图.➢视图名称必须遵循标识符的规那么,且对每个用户必须为唯一.此外,该名称不得与该用户拥有的任何表的名称一样.➢可在其他视图和引用视图的过程之上建立视图.SQLServer 2000允许嵌套多达32级视图➢假设要创立视图,数据库所有者必须授予用户创立视图的权限,并且用户对视图定义中所引用的表或视图要有适当的权限5.2.1任务一使用企业管理器创立视图使用企业管理器创立视图的详细操作步骤如下:1、翻开企业管理器窗口,翻开“新建视图〞对话框。
实验5 视图 实验报告模板

(数据库原理与应用)实验报告实验名称视图的应用实验地点60#504实验时间1.实验目的:掌握视图的知识,体会视图与基本表的区别。
2.实验内容:按教材P176实验5的要求。
3.实验要求:按教材P176实验5的要求。
4.实验准备:认真阅读实验要求,分析各种情况作出具体分析明确要求,复习实验二、三,了解各表之间关系设计记录时要符合实际情况,注意实验二各种约束5.实验过程(含代码、实验过程、遇到的问题和解决方法等):1、建立视图单表、投影、建立视图前后对比单表、选择、建立视图前后对比单表、投影和选择、建立视图前后对比多表、连接、建立视图前后对比多表、嵌套、建立视图前后对比含虚字段的视图2、设计一些查询一般:连接:嵌套:3、1.投影:投影操作中:插入、更新、删除都正常2.选择:宁十一宁十一宁十一宁十一宁十一宁十一选择操作中:插入、更新、删除都正常投影和选择:投影和选择操作中:更新、删除可正常执行插入操作时,插入的数据没有进入视图中,而是仅仅进入视图对应的表中Select*from投影和选择/表名,可知连接:连接操作中:更新可正常执行,而使用插入、删除操作时,出现提示:不可更新,因为修改会影响多个基表嵌套:嵌套操作中:插入的数据仅仅进入视图对应的表中,没有在视图中体现;更新、删除可正常操作虚字段:虚字段操作中:插入仅仅进入表中,不进入视图中;删除时显示:不可更新,因为修改会影响多个基表更新正常6.实验总结:在SQL中,视图是基于SQL语句的结果集的可视化的表。
视图包含行和列,就像一个真实的表。
视图中的字段就是来自一个或多个数据库中的真实的表中的字段。
我们可以向视图添加SQL函数、WHERE以及JOIN语句,我们也可以提交数据,就像这些来自于某个单一的表。
视图可以快速访问两表或多表连接所组成的数据。
有时要访问表间连接所组成的数据集,可以把查询出来的数据集定义成视图,可以帮助快速访问所需的数据。
但是当用户试图修改视图的某些行时,SQL Server必须把它转化为对基本表的某些行的修改。
视图的规划与操作

视图的作用与规划 视图操作
9.3
视图应用综合实例分析
9.1 视图的作用与规划
视图是关系数据库系统提供给用户以多种角度观察数据 库中数据的重要机制。 视图对应于三级模式中的外模式(用户模式),它是从 一个或几个基本表导出的表,由CREATE VIEW命令创建。 视图又称为虚拟表,因为数据库中存放着视图的定义及 其关联的基本表名等信息,而不存放视图对应的数据。 视图一经定义,就可以和基本表一样被查询、被删除, 但对视图的更新(增加、删除、修改)操作则有一定的 限制 。
1.使用SQL SERVER企业管理器来创建视图
在SQL SERVER中使用SSMS来创建视图。 步骤如下: ① 启动SSMS ,登录到指定的服务器; ② 打开要创建视图的数据库文件夹,选中‘视图’ 图标,此时在右面的窗格中显示当前数据库的所 有视图,右击图标,在弹出菜单中选择‘新建视 图’选项,打开‘新建视图’对话框。在‘新建 视图’对话框中共有四个区:表区、列区SQL script 区、数据结果区,当然刚打开时是空白。
insert into isonly values('s060501','11111111','张','男','1111','宁波',' 会计学','会计学院',162)
【例9-4】如果如本章第一节概述所述,若某一全国连锁的 销售企业将销售数据表按照省份进行水平分割,那我们 可以使用以下视图重新装载表的数据。 Create view sales_table As Select * from sales_beijing
3.视图创建实例
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验五视图的规划与操作
实验目的和任务
1)理解视图的概念
2)掌握创建视图和加密视图的方法
3)掌握视图带检查项和不带检查项的区别
4)掌握视图更新的概念和方法
实验内容
1)针对员工表创建一个视图, 取员工表的前4个属性,要求带WITH ENCRYPTION。
使用sp_helptext和在syscomments表中分别观察定义的文本。
最后利用定义的视图进行查询。
2)创建一个查询参加所有项目的员工视图“V1_视图”,包括员工号、姓名,所在部门名。
并进行查询。
3)创建只包含部门名是“人事处”的显示部门信息的视图“V2_视图”,不带WITH CHECK OPTION 。
①在该视图上分别插入部门是“办公室”和“人事处”观察执行结果。
②分别修改该视图针对部门是“办公室”和“人事处”的其他属性数据,观察执行结果。
③分别删除部门是“办公室”和“人事处”的记录,分别观察执行情况。
4)创建只包含部门名是“人事处”的显示部门信息的视图“V3_视图”,带WITH CHECK OPTION 。
①在该视图上分别插入部门是“办公室”和“人事处”的部门数据,观察执行结果。
②分别修改该视图针对部门是“办公室”和“人事处”的其他属性数据,观察执行结果。
③分别删除部门是“办公室”和“人事处”的记录,分别观察执行情况。
5)创建查询员工叫“张三”是哪个部门的视图“V4_视图”,然后在该视图里删除“张三”的所有信息,观察执行情况。
为什么是这样?
问题思考
1)向视图插入的数据能进入基本表吗?
2)修改基本表的数据能自动反映到相应的视图中去吗?。