3.15.嵌套中断,咬尾中断,晚到异常与中断延迟(1)
nvic嵌套向量中断控制器工作原理

一、引言Nvic嵌套向量中断控制器(Nested Vectored Interrupt Controller)是一种常见的中断控制器,它在嵌入式系统中扮演着重要的角色。
本文将介绍Nvic的工作原理,帮助读者更好地理解这一关键的硬件组件。
二、Nvic的基本概念Nvic是一种硬件组件,用于管理和分发系统中的中断请求。
在嵌入式系统中,当发生外部事件或者特定的处理器状态发生变化时,需要立即中断当前的程序执行,执行特定的中断服务程序。
而Nvic就是用来协调这些中断请求的,确保它们按照优先级和顺序得到正确的处理。
三、中断控制器的作用1.管理中断请求中断是在嵌入式系统中的一种重要的事件响应机制。
当外部设备(如传感器、通信接口等)产生需要处理的事件时,会向处理器发送中断请求。
而中断控制器就是负责接收、管理和分发这些中断请求的硬件组件。
2.中断优先级在一个嵌入式系统中,可能同时出现多个中断请求,此时中断控制器需要根据中断请求的优先级决定哪个中断将被优先处理。
Nvic通过优先级编码的方式,能够准确地确定中断的优先级,确保高优先级的中断能够得到及时处理。
四、Nvic的工作原理1.中断向量表Nvic通过中断向量表来实现对中断请求的管理。
中断向量表是一张表格,每个中断都有一个特定的中断向量号。
当中断控制器接收到中断请求时,根据中断向量号可以迅速定位到对应的中断服务程序的入口位置区域,从而进行中断处理。
2.中断优先级编码Nvic使用中断优先级编码的方式来确定中断的优先级。
在Nvic中,中断请求会按照其具体的中断向量号进行编码,从而确定其优先级。
当多个中断请求同时到达时,Nvic会根据优先级编码来决定哪个中断会被优先处理。
3.嵌套中断Nvic支持嵌套中断的机制,即在一个中断服务程序的执行过程中,如果遇到了更高优先级的中断请求,Nvic可以暂停当前中断服务程序的执行,转而处理更高优先级的中断请求。
这种机制可以确保高优先级的中断能够得到及时处理,提高系统的响应速度。
Cortex-M3咬尾中断与晚到中断

Cortex-M3咬尾中断与晚到中断【咬尾中断】在处理器在响应某些异常时,如果⼜发⽣其他异常,但它们优先级不够⾼,则它们会被阻塞。
那么,在当前的异常执⾏返回后,系统处理悬起的异常时,倘若还是先POP,然后⼜把POP处理的内容PUSH回去,那么就⽩⽩浪费CPU 时间了。
因此,Cortex-M3不会再POP这些寄存器,⽽是继续使⽤上⼀个异常已经PUSH好的结果,消除POP和PUSH操作的耗时。
这么⼀来,看上去好像后⼀个异常把前⼀个的尾巴要掉了,前前后后只执⾏了⼀次PUSH/POP操作。
于是,这两个异常之间的“时间沟”就变窄了很多,如图所⽰:和常规中断处理(ARM7)的⽐较:【晚到中断】Cortex-M3的中断处理还有另⼀个机制,它强调了优先级的作⽤,这就是“晚到的异常处理”。
当Cortex-M3对某异常的响应序列还处在早期:⼊栈的阶段,尚未执⾏其他服务程序时。
如果此时收到了更⾼优先级异常的请求,则本次⼊栈就成了⾼优先级中断做的了。
⼊栈后,将执⾏⾼优先级的异常服务程序。
可见,⾼优先级的异常虽然来晚了,却因为优先级⾼使得服务程序可以被先处理,低优先级异常的⼊栈操作则变成了为⾼优先级异常的⼊栈。
⽐如,若在响应某低优先级异常#1的早起,检测到了⾼优先级异常#2,则只要#2没有太晚,就能以“晚到中断”的⽅式处理,在⼊栈完毕后执⾏ISR#2。
如图所⽰:如果异常#2来得太晚,以⾄于已经执⾏了ISR#1的指令,则按普通的抢占处理,这会需要更多的处理器时间和额外32字节的堆栈空间。
在ISR#2执⾏完毕后,则以“咬尾中断”的⽅式来启动ISR#1的执⾏。
参考摘录:《Cortex-M内核系列和STM32-讲座2教程.pdf》《ARM Cortex-M3权威指南.pdf》。
关于单片机中断嵌套总结

关于单片机中断嵌套总结
什幺是单片机嵌套中断
所谓中断是处理事件的一个过程,这一过程一般是由计算机内部或外部某件紧急事件引起并向主机发出请求处理的信号,主机在允许的情况下响应请求,暂停正在执行的程序,保存好断点处的现场,转去执行中断处理程序,处理完中断服务程序后自动返回原断点处,继续执行原程序,这一处理过程称为中断。
以AT89S52为例,中断系统含有8个中断源,共有6个中断矢量:定时/计数器0、1、2,INT0、INT1和UART。
两级中断优先级,可实现两级中断嵌套。
用户可以很方便的通过软件实现对中断的控制。
既然系统含有8个中断源,就有可能出现数个中断源同时提出中断请求的情况,这样,设计人员必须事先根据它们的轻重缓急来为每个中断源确定CPU对其的响应顺序。
然而,对于中断优先级寄存器IP来说,只可能设定两级优先,即控制位为1时对应的中断源为高级中断,反之,控制位为0时对应的为低级中断。
LinkedIn下图为一声光报警电路,当按下S1时,蜂鸣器发音;当按下S2时,停止发音,但LED发光。
1、利用中断工作方式编写完整的单片机汇编语言程序。
嵌入式-中断实验

嵌入式-中断实验
嵌入式中断实验是一种用来测试和学习嵌入式系统中断功能的实验。
中断是嵌入式系统中常用的一种机制,用于处理紧急事件或高优先级任务。
通过中断,系统可以立即响应外部事件,中断当前正在执行的任务,执行与中断事件相关的代码,然后返回到原来的任务中继续执行。
在进行中断实验时,通常需要以下步骤:
1. 确定中断源:确定要模拟的中断事件,比如外部输入的触发事件、定时器到达时间等。
2. 配置中断控制器:根据硬件平台和实验要求,配置中断控制器的相应寄存器,使其能够正确地处理中断信号。
3. 编写中断服务程序(ISR):定义一个中断服务程序,用于
处理中断事件。
ISR应当对事件进行必要的处理,然后返回到
原来的任务中。
4. 测试和调试:连接硬件平台,运行实验程序,并进行测试和调试,确保中断功能正常工作。
5. 扩展和优化:根据需要,可以进一步扩展和优化中断功能,比如增加多个中断源,实现优先级控制,提高系统响应速度等。
通过嵌入式中断实验,可以深入了解中断机制的工作原理和应用方法,提高对嵌入式系统的理解和能力。
STM32中断嵌套方法
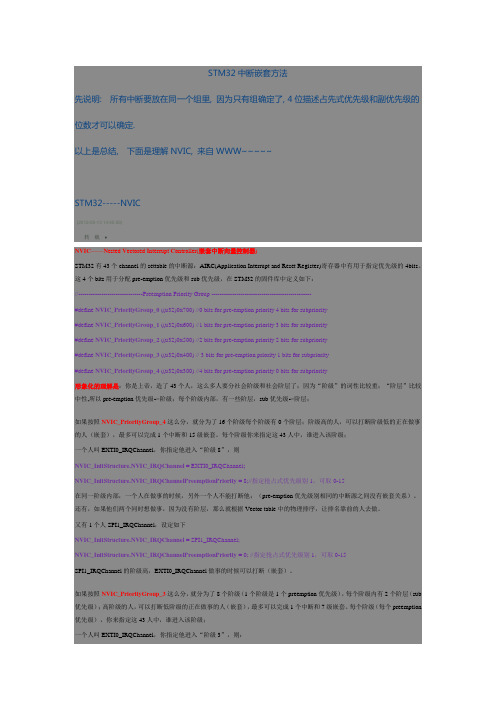
STM32中断嵌套方法先说明: 所有中断要放在同一个组里, 因为只有组确定了, 4位描述占先式优先级和副优先级的位数才可以确定.以上是总结, 下面是理解NVIC, 来自WWW~~~~~STM32-----NVIC(2012-05-13 14:45:56)转载▼NVIC——N ested V ectored I nterrupt C ontroller(嵌套中断向量控制器)STM32有43个channel的settable的中断源:AIRC(Application Interrupt and Reset Register)寄存器中有用于指定优先级的4bits。
这4个bits用于分配pre-emption优先级和sub优先级,在STM32的固件库中定义如下://-------------------------------Preemption Priority Group ------------------------------------------------#define NVIC_PriorityGroup_0 ((u32)0x700) //0 bits for pre-emption priority 4 bits for subpriority#define NVIC_PriorityGroup_1 ((u32)0x600) //1 bits for pre-emption priority 3 bits for subpriority#define NVIC_PriorityGroup_2 ((u32)0x500) //2 bits for pre-emption priority 2 bits for subpriority#define NVIC_PriorityGroup_3 ((u32)0x400) // 3 bits for pre-emption priority 1 bits for subpriority#define NVIC_PriorityGroup_4 ((u32)0x300) //4 bits for pre-emption priority 0 bits for subpriority形象化的理解是:你是上帝,造了43个人,这么多人要分社会阶级和社会阶层了;因为“阶级”的词性比较重;“阶层”比较中性,所以pre-emption优先级->阶级;每个阶级内部,有一些阶层,sub优先级->阶层;如果按照NVIC_PriorityGroup_4这么分,就分为了16个阶级每个阶级有0个阶层;阶级高的人,可以打断阶级低的正在做事的人(嵌套),最多可以完成1个中断和15级嵌套。
嵌入式系统基础第7章中断和异常

为减少延时,ARM在快中断中采取了 两个措施: (1)专门为快中断FIQ设置了一个FIQ模式, 并为这个模式配置了较多的私有寄存器, 从而可使中断服务程序有足够的寄存
器来使用,而不必与被中断服务程序使用 同一组寄存器,这样就免去了因寄存器冲 突而必需的保护及恢复现场工作。
(2)ARM把FIQ的中断向量放在了中断 (异常)向量表末尾0X0000001C处,因此 它后面没有其它中断向量,允许用户将中 断服务车工许程序直接放在这里。
除了外部设备可以发出可以发出中断 请求之后,处理器内部也会有一些事件可 以发出中断请求,例如读取指令出错或在 进行除法运算时除数为零等。为了与外部 事件引起的中断相区别,人们把这种由内 部事件引起的中断叫做异常。
7.1.2
中断请求信号的屏蔽
处理器中用来屏蔽中断的积存器和开 关如下:
1、可屏ห้องสมุดไป่ตู้中断
1、低端和高端向量表
ARM有低端和高端两种向量表,用户可 以根据需要选用其中一种,如下所示:
ARM中断(异常)的各个向量在向量表 中的分配如下:
中断(异常) 复位(RESET) 未定义指令(UNDEF) 向量在低端向量表的地址 0x00000000 0x00000004 向量在高端向量表的地址 0xFFFF0000 0xFFFF0004
一般情况下,这个优先排队机构可能 在处理器中有一套,在中断控制器中也有 一套,甚至在借口电路中也会有一套。
(2)软件实现方法
就是把所有中断源的中断请求信号分 成两路,其中一路经“或”逻辑送到处理 器的中断请求输入端,而另一路则送入中 断接口电路经数据总线送入处理器。
中断源的软件查询法电路的接线如下 图所示:
异常/中断 复位(RESET) 未定义指令(UNDEF) 软中断(SWI) 地址 LR LR 说明 指向未定义指令的下一条指令 指向SWI指令的下一条指令
Cortex-M0微控制器概述及性能分析

Cortex-M0微控制器概述及性能分析目录•NXP 微控制器介绍•Cortex-M0介绍•LPC111x系列产品介绍•LPC111x微控制器性能分析•开发工具NXP 微控制器介绍NXP微控制器所有的微控制器都是不同的ARM公司提供了同样的物理IP–处理器核、内部总线和中断控制器等–但最终的结果是不一样的架构选择、实现、性能优化及电源管理等带来很大的不同–微控制器厂商的实现将会影响到芯片的性能、功耗和应用难度等例如:–Flash存储器性能–外设稳定性–集成度–调试功能改变微控制器世界Cortex-M0介绍ARM Cortex-M0处理器32为ARM RISC处理器–16位Thumb指令集功耗与面积高度优化–设计专用于低成本、低功耗场合中断现场自动保存–极低的进入与退出中断的软件开销确定的指令执行时间–指令总是同时执行Thumb指令集32位的操作码,16位的指令系统–应用于ARM7TDMI(‘T’代表Thumb)–自ARM处理器问世以来都支持Thumb指令集–更小的代码规模Thumb2指令集–处理器所有的操作都能在Thumb状态下完成–16位指令与32位指令并存–Cortex系列处理器都能支持指令集系统基于ARM7TDMI的16位Thumb指令系统–仅56条指令,且指令执行时间都是确定的–完成8、16或32位的数据传输只需一条指令Dhrystone –0.9DMIPS/MHz内部寄存器所有的寄存器都是32位的–特殊指令能够支持对8/16/32位数据的处理13个通用寄存器(R0 ~ R12)–R0–R7(低位寄存器)–R8 –R12(高位寄存器)3个特殊功能寄存器(R13 ~ R15)–堆栈指针R13(SP)–连接寄存器R14(LR)–程序计数器R15(PC)程序状态寄存器组(xPSR)指令行为绝大多数指令占用2字节的存储空间指令执行占用确定的时间–数据处理(例如加,移位,逻辑或)1个时钟周期内完成–数据传送(例如加载,存储)需2个时钟周期–分支转移指令只需3个时钟周期指令都是基于32位的数值操作–处理器的寄存器和算术逻辑单元(ALU)都是32位宽的!示例:16位乘法下面以对一个设备的10位模数转换器(ADC)操作处理的来作比较–转换数据基本的滤除处理操作需一次16位的乘法操作–对16位乘法操作对比如下嵌套向量中断控制器(NVIC)NVIC更有效地处理异常中断–集成于处理器内部,与CPU 内核紧密耦合–高效处理系统异常(Exceptions)和中断(Interrupts)NVIC具有以下特性–异常优先级设置–“咬尾中断”机制和晚到异常处理完全确定的异常处理时间–异常处理花销的周期总是保持一定–16个时钟周期的固定开销–特定寄存器用来消除不确定延迟只要会C就能编写程序中断具体行为当中断发生时,硬件自动将相关寄存器的值压入堆栈中断处理程序可完全用C语言编写–堆栈内容支持ARM架构C/C++函数调用标准复位后初始堆栈指针指向0x00处中断处理程序的编写传统途径异常向量表–分支取指顶级处理–异常重入处理中断处理程序的编写ARM Cortex-M体系NVIC自动处理–保存相关寄存器–中断优先级–中断嵌套中断服务程序(ISR)可直接用C语言编写–完全支持C语言指针向量–ISR就是一个C函数快速中断响应–软件开销更小等待中断(WFI),执行该指令退出睡眠模式软件控制睡眠模式ARM Cortex-M系列具很好的睡眠模式控制–极低的待机功耗–非常适用于电池便携设备–包含一个唤醒中断控制器(WIC)Sleep(睡眠)–内核时钟停止–NVIC继续对中断有效软件控制睡眠模式Deep sleep(深度睡眠)–WIC对指定中断有效–Cortex-M0可进入状态保持WIC唤醒信号传递给PMU(电源管理单元)–内核立即被唤醒–立即响应关键事件指令集比较LPC111x系列产品介绍LPC111x的特点电源效率高性能优越应用简单LPC111x Cortex-M0的配置单周期乘法器小端模式操作系统扩展–24位系统节拍–堆栈指针寄存器–高级访问指令调试–支持串行调试(SWD),–不支持串行线跟踪输出(SWO)–支持4个断点,2个观察点LPC111x系列芯片信息LPC111x的系统框图存储系统M0核具有零延迟的32位接口Thumb指令集(16位)Flash总线宽度和系统总线宽度匹配–使用自定义时间的读时序–相比两次16位读取操作,一次32位读取消耗的电流更小–增强处理器性能串行接口UART(通用异步收发器)–用于控制波特率的小数分频器,并具赖以实现软件或硬件流控制的自动波特率检测能力–16字节的接收和发送FIFO可配置触发点–支持EIA-485/RS-485的9位模式·同时支持9位模式的软件地址检测和自动地址检测·自动方向控制–完全支持Modem控制串行接口I2C接口(Inter-Integrated Circuit)–可配置为主机、从机或主/从机–主、从机之间双向数据传输–支持快速模式Plus,符合I2C总线规范(运行速度高达1MHz)–可编程时钟允许I2C可以在不同的传输速率下运行–支持监控模式–能同时响应多个I2C从机地址I2C输出端衰减特性串行接口SSP控制器(Synchronous Serial Communication)–8帧收发FIFO–每帧4 ~ 16位–兼容多种总线协议·SPI总线(Motorola)·SSI总线(TI)·Microwire总线(National)–最大速率·25Mbits/s(主机模式)·6Mbits/s(从机模式)定时器/计数器2个通用32位可编程定时器/计数器–具有捕获输入、比较输出功能–可配置为作计数器或定时器模式–匹配输出可执行翻转电平、输出高电平、输出低电平或不执行任何操作–PWM模式2个通用16位可编程定时器/计数器定时器/计数器系统节拍定时器(系统内置)32位WDT(看门狗定时器)–若未周期性重载则复位芯片–支持调试模式–用作系统时钟源(看门狗振荡器、内部RC振荡器、主振荡器)LPC111x时钟发送模块框图LPC111x时钟特征输出外部时钟–任何一个内部时钟均可作为输出外部时钟源–集成时钟分频器通用输入输出口(GPIO)多达42个高速GPIO(LQFP48)14个可产生中断的数字端口所有引脚都可配置为使能/禁止的上拉/下拉功能14个可产生中断的数字端口支持总线保持模式特定端口支持大电流输出5V电压下仍能正常工作A/D转换器(ADC)10位逐次逼近式模数转换器8个引脚复用为A/D输入脚具有掉电模式测量范围为0V ~ VDD(3V3)10位转换时间大于等于2.44us一个或多个输入的Burst转换模式可选择由输入跳变或定时器匹配信号触发转换每个通道都有各自的转换结果寄存器,大大减小中断开销复位源RESETN引脚复位看门狗(WDT)复位上电复位(POR)掉电检测复位(BOD)–4级电压监测–BOD触发产生有效中断信号,发到NVIC –BOD触发复位信号功率控制睡眠模式–内核时钟停止–复位或者中断都会将CPU内核唤醒–外设在CPU睡眠模式期间继续运转深度睡眠模式–所有时钟停止(状态被保存)–多种功率选择深度掉电模式–整个芯片电源被关闭(状态丢失)–时钟域寄存器组保持不变。
ARMCortex-M3权威指南-基础(1)

指令和存储总线:有两条代码存储区总线负责对代码存储区的访问,分别是 I-Code 总线和 D-Code 总线。前者用于取指,后者用于查 表等操作,它们按最佳执行速度进行优化。 系统总线:用于访问内存和外设,覆盖的区域包括 SRAM,片上外设,片外 RAM,片外扩展设备,以及系统级存储区的部分空间。 私有外设总线:负责一部分私有外设的访问,主要就是访问调试组件。它们也在系统级存储区。
2. CONTROL[0]:仅当在特权级下操作时才允许写该位。一旦进入了用户级,唯一返回特权级的途径,就是触发一个(软)中断,再由 服务例程改写该位。
操作模式和特权级别
操作模式:处理者模式(handler mode)和线程模式(thread mode)。引入两个模式的本意,是用于区别普通应用程序的代码和异常服 务例程的代码——包括中断服务例程的代码。 特权分级:特权级和用户级。这可以提供一种存储器访问的保护机制,使得普通的用户程序代码不能意外地,甚至是恶意地执行涉及 到要害的操作。处理器支持两种特权级,这也是一个基本的安全模型。
特权级和用户级区别:在 CM3 运行主应用程序时(线程模式),既可以使用特权级,也可以使用用户级;但是异常服务例程必须在特 权级下执行。复位后,处理器默认进入线程模式,特权极访问。在特权级下,程序可以访问所有范围的存储器并且可以执行所有指 令。
特权级和用户级切换:在特权级下的程序可以为所欲为,但也可能会把自己给玩进去——切换到用户级。一旦进入用户级,再想回来 就得走“法律程序”了——用户级的程序不能简简单单地试图改写 CONTROL 寄存器就回到特权级,它必须先“申诉”:执行一条系统调用 指令(SVC)。这会触发 SVC 异常,然后由异常服务例程(通常是操作系统的一部分)接管,如果批准了进入,则异常服务例程修改 CONTROL 寄存器,才能在用户级的线程模式下重新进入特权级。事实上,从用户级到特权级的唯一途径就是异常:如果在程序执行 过程中触发了一个异常,处理器总是先切换入特权级, 并且在异常服务例程执行完毕退出时,返回先前的状态。 引入特权级和用户级目的:能够在硬件水平上限制某些不受信任的或者还没有调试好的程序,不让它们随便地配置涉及要害的寄存 器,因而系统的可靠性得到了提高。
中断嵌套的概念

中断嵌套是指中断系统正在执行一个中断服务时,有另一个优先级更高的中断提出中断请求,这时会暂时终止当前正在执行的级别较低的中断源的服务程序,去处理级别更高的中断源,待处理完毕,再返回到被中断了的中断服务程序继续执行的过程。
简介其实就是更高一级的中断的“加塞”,处理器正在执行着中断,又接受了更急的另一件“急件”,转而处理更高一级的中断的行为!中断优先级定义优先级高的中断源可以中断优先级低的中断服务程序,这就形成了中断服务程序中套着中断服务程序的情况,即形成了所谓的中断嵌套。
MCU暂停现行程序而转去响应中断请求的过程称为中断响应;为使系统能及时响应并处理发生的所有中断,系统根据引起中断事件的重要性和紧迫程序,硬件将中断源分为若干个级别,称作中断优先级。
查询优先级中断的优先级有两个:查询优先级和执行优先级。
查询优先级是datasheet或书上的默认(IP寄存器不做设置,上电复位后为00H)的优先级:外部中断0> 定时/计数器0 > 外部中断1 > 定时/计数器1 > 串行中断或int0,timer0,int1,timer1,serial port 或 INT0、T0、INT1、T1、UART或PX0>PT0>PX1>PT1>PS>......其实都是查询优级。
首先查询优先级是不可以更改和设置的。
这是一个中断优先权排队的问题,是指多个中断源同时产生中断信号时,中断仲裁器选择对哪个中断源优先处理的顺序。
而这与是否发生中断服务程序的嵌套毫不相干。
当CPU查询各个中断标志位的时候,会依照上述5个查询优先级顺序依次查询,当数个中断同时请求的时候,会优先查询到高优查询先级的中断标志位,但并不代表高查询优先级的中断可以打断已经并且正在执行的低查询优先级的中断服务。
例如:当计数器0中断和外部中断1(按查询优先级,计数器0中断>外部中断1)同时到达时,会进入计时器0的中断服务函数;但是在外部中断1的中断服务函数正在服务的情况下,这时候任何中断都是打断不了它的,包括逻辑优先级比它高的外部中断0计数器0中断。
嵌入式系统的异常和中断

大多数嵌入式处理器体系结构提供异常和中断机制,允许处理器中断正常的执行路径。
这个中断可能有应用软件有意的触发,或者由一个错误的、不寻常的条件或某些非计划的外部事件触发。
许多实时操作系统提供处理异常和中断的封装器功能,以便保护嵌入式系统开发者避开低层的细节。
这种应用编程层允许程序员把精力集中在必须处理的高层异常处理上,而不是在处理那些冗长的序言和结束语的系统层次上。
然而,当程序员从一个嵌入式应用程序员过渡到一个嵌入式系统程序员的时候,这种隔离可能产生误会并且变成一种障碍。
一、什么是异常和中断一个异常是指任何打断处理器正常执行,并且迫使处理器进入一个由有特权的特殊指令执行的事件。
异常可以分为两类:同步异常和异步异常。
由内部事件(像处理器指令运行产生的事件)引起的异常称为同步异常。
同步异常的例子包括下列各项:1.在某些处理器体系结构中,对于确定的数据尺寸必须从内存的偶数地址进行读和写操作。
从一个奇数内存地址的读或写操作将引起存储器存取一个错误事件并引起一个异常(称为校准异常)。
2.造成被零除的算术运算引发一个异常。
由外部事件(与处理器指令执行不相关的事件)引发的异常,称为异步异常。
一般,这些外部事件与硬件信号相关。
这些硬件信号典型的来源于外部硬件装置。
异步异常的例子包括下列各项:1.按下嵌入式板上的复位按钮,触发一个异步的异常(称为系统复位异常)。
2.另外一个外部设备的例子是,通信处理器模块已经成为许多嵌入式设计的一个完整部分,当它接收数据包时引发异步异常。
一个中断,有时称为一个外部中断,是一个由外部硬件装置产生的事件引起的异步异常。
中断是异常的一类。
中断区别于其它类型的异常,或更精确地说,同步异常区别于异步异常的地方是事件的来源。
同步异常事件是由于执行某些指令而从处理器内部产生的。
而异步异常事件的来源是外部硬件装置。
异常和中断是大多数嵌入式系统中必须存在的精灵。
这个设施是处理器体系结构特定的;如果误用,将成为混乱的设计源。
嵌入式实时操作系统题库1

嵌入式实时操作系统题库一、填空题1.uC/OS-II是一个简洁、易用的基于优先级的嵌入式(抢占式)多任务实时内核。
2.任务是一个无返回的无穷循环。
uc/os-ii总是运行进入就绪状态的(最高优先级)的任务。
3.因为uc/os-ii总是运行进入就绪状态的最高优先级的任务。
所以,确定哪个任务优先级最高,下面该哪个任务运行,这个工作就是由(调度器(scheduler))来完成的。
4.(任务级)的调度是由函数OSSched()完成的,而(中断级)的调度是由函数OSIntExt() 完成。
对于OSSched(),它内部调用的是(OS_TASK_SW())完成实际的调度;OSIntExt()内部调用的是(OSCtxSw())实现调度。
5.任务切换其实很简单,由如下2步完成:(1)将被挂起任务的处理器寄存器推入自己的(任务堆栈)。
(2)然后将进入就绪状态的最高优先级的任务的寄存器值从堆栈中恢复到(寄存器)中。
6.任务的5种状态。
(睡眠态(task dormat)):任务驻留于程序空间(rom或ram)中,暂时没交给ucos-ii处理。
(就绪态(task ready)):任务一旦建立,这个任务就进入了就绪态。
(运行态(task running)):调用OSStart()可以启动多任务。
OSStart()函数只能调用一次,一旦调用,系统将运行进入就绪态并且优先级最高的任务。
(等待状态(task waiting)):正在运行的任务,通过延迟函数或pend(挂起)相关函数后,将进入等待状态。
(中断状态(ISR running)):正在运行的任务是可以被中断的,除非该任务将中断关闭或者ucos-ii将中断关闭。
7.(不可剥夺型)内核要求每个任务自我放弃CPU的所有权。
不可剥夺型调度法也称作合作型多任务,各个任务彼此合作共享一个CPU。
8.当系统响应时间很重要时,要使用(可剥夺型)内核。
最高优先级的任务一旦就绪,总能得到CPU的控制权。
stm32中断嵌套规则

stm32中断嵌套规则
在STM32微控制器中,中断是实现多任务处理和事件驱动程序的关键机制之一。
中断嵌套是指在一个中断服务程序(ISR)执行过程中,另一个中断发生并且
执行相应的ISR。
然而,为了确保中断嵌套的正确执行,需要遵守一些嵌套规则。
首先,在STM32中,不同的中断具有不同的优先级。
中断优先级通过使用相
应的寄存器进行配置,具有较低数值的中断优先级将具有较高的优先级。
这意味着,在一个中断服务程序中,如果发生了比当前正在执行ISR的中断优先级更高的中断,系统将中断当前正在执行的中断并执行较高优先级的中断程序。
其次,如果两个中断具有相同的优先级,则优先级有效性取决于初始的中断请
求时刻的先后顺序。
这称为优先级争夺。
在这种情况下,第一个发生的中断请求将被优先执行,而第二个被挂起,直到第一个中断服务程序执行结束。
此外,在编写中断服务程序时,需要注意中断服务函数(ISF)的执行时间。
较长的中断服务程序将导致较长的响应时间和延迟,从而可能影响系统的实时性。
因此,为了提高系统的实时性和响应能力,应将中断服务程序设计为尽可能短小和高效。
最后,在STM32中,还提供了一种特殊类型的中断服务程序,称为嵌套向量
中断控制器(NVIC)。
NVIC负责管理和控制所有中断请求,并根据其优先级和
嵌套规则决定执行的中断服务程序。
总之,在STM32中,遵循中断嵌套规则非常重要,以确保中断的正确执行和
系统的实时性。
通过正确配置中断优先级、处理争夺情况、优化中断服务程序的执行时间,并合理使用NVIC,可以有效地实现多任务处理和事件驱动的功能。
ARM CORTEX-M3 内核架构理解归纳

在我看来,Cotex-M3内核的主要包括:嵌套向量中断控制器(NVIC),取值单元,指令译码器,算数逻辑单元(ALU),寄存器组,存储器映射(4GB统一编址各区域功能的划分与界定),对于开发者而言,其实主要关注的主要分为三大块:1、寄存器组2、地址功能划分映射3、中断机制(NVIC)。
1)寄存器组Cortex-M3内核共有19组32位寄存器:R0——R12(通用寄存器);低寄存器组R0——R732位Thumb-2指令与16位Thumb指令均可访问高寄存器组R8——R1232位Thumb-2指令与极少数16位Thumb指令可访问R13(堆栈指针寄存器);主堆栈寄存器MSP(main-SP)/进程堆栈寄存器PSP(Process-SP)同一时间只能使用其中一个。
MSP供操作系统内核及中断(异常)处理子程序使用,PSP只供用户的应用程序代码使用(详细使用详见3、嵌套向量中断控制器(NVIC)的总结)。
堆栈指针是4字节对齐的,故最低两位永远是00;R14(连接寄存器)用于存储程序返回的地址及PC的返回地址;R15(程序寄存器)指向当前程序执行的地址;2)特殊功能寄存器组xPSR(程序状态字寄存器组),32位,可分为三个寄存器分别进行访问,也可以PSR或xPSR 的名字直接组合访问。
应用程序PSR(APSR)中断号PSR(IPSR)执行PSR(EPSR)中断屏蔽寄存器PRIMASK 单一比特位,置位后,除NMI与硬fault外,其他中断都不响应;FAULTMASK 单一比特位,置位后,除NMI外,其他中断都不响应;BASEPRI 共有9位,中断号小于等于该寄存器设置值的中断都不响应;控制寄存器controlControl[0] 0决定特权级线程模式;1用户级线程模式;Control[1] 0主堆栈;1进程堆栈;控制寄存器只能在特权级模式下改写,handler模式永远是特权级,且只允许使用主堆栈MSP 复位后,处理器进入特权级+线程模式下;2、地址功能划分映射Cortex-m3是一个32位处理器,其地址总线、数据总线都是32位的,故可在4G的地址范围上资源寻址。
cortex m3权威指南

第零章绪论阅读可以是一见主动的事,阅读越主动,效果越好。
作为Cortex系列的处女作,为了让32位处理器坐庄单片机市场,CM3轰轰烈烈的诞生了!由于采用了最新的设计技术,它的门数更低,性能却更强。
许多曾经只能求助于高级32位处理器或DSP的软件设计,都能在CM3跑得很快。
嵌入式处理器市场正在32位化,相信用不了多久,CM3就一定会在这美丽新世界中脱颖而出,比当年8051推动整个业界还有过之而无不及,再次放飞工程师的梦想,让深埋于心多年的夙愿迎来dreams come true的激动!完整的基于CM3内核的MCU还需要很多其它组件。
芯片制造商得到CM3内核的使用授权后,就可以把CM3内核用在自己的硅片设计中,添加存储器、外设、I/0以及其它功能块。
不同厂家设计出的单片机会有不同的配置,包括存储器容量、类型、外设等都各具特色。
Thumb-2真不愧是一个突破性的指令集。
它强大、易用、轻佻、高效。
Thumb-2是16位Thumb指令集的一个超集,在Thumb-2中,16位指令首次与32位指令并存,结果在Thumb状态下可以做的事情一下子丰富了许多,同样工作需要的指令周期数也明显下降。
Cortex-M3处理器的舞台●低成本单片机●汽车电子●数据通信●工业控制●消费类产品第一章Cortex-M3概览最淡的墨水也胜于最强的记忆1.1 CM3是一个32位处理器内核,内部数据路径是32位,寄存器是32位,存储器接口也是32位。
CM3采用哈佛结构,拥有独立的指令总线和数据总线,可以让取指与数据访问并行不悖。
这样一来,数据访问不再占用指令总线,从而提升了性能。
为了实现这个特性,CM3内部含有好几条总线接口,每条都为自己的应用场合优化过,并且可以并行工作。
但是,指令总线和数据总线共享同一个存储器空间(一个统一的存储器系统)。
也就是说,不是因为有两条总线,可寻址空间就变成了8G。
比较复杂的应用可能需要更多的存储系统功能,为此CM3提供了一个可选的MPU(存储器保护单元),而且在需要的情况下也可以使用外部的cache。
中断优先级以及中断嵌套

中断优先级以及中断嵌套
中断优先级有两种,叫默认优先级和嵌套优先级,假如A,B两个中断,如果A比B 嵌套优先级(通过优先级寄存器设置)更高,就不需要看默认优先级了,A、B同时发生中断时A中断先执行而B后执行,而且B中断执行之间A可以抢断(嵌套)B的中断服务程序,B不可以抢断A;而如果嵌套优先级一样的话,只是A默认优先级比B更高(不需要设置),只能支持A、B同时中断时A先执行,而A不能嵌套B了,有的CPU甚至硬件上不支持嵌套,需要模拟嵌套,这个跟CPU平台有关。
关于嵌套的寄存器备份是这样进行的,进入一级中断便进行一次全套寄存器的压栈操作,压栈是把寄存器里面的值保存到栈区(属于内存区域,而并非你说的后背状态寄存器SPSR,其实后背状态寄存器SPSR也要一起压入栈区),每压入一个寄存器,SP会移动相应的距离,不会重叠;每退出一级中断便进行一次全套寄存器的出栈操作,这样就实现了保护现场和恢复现场。
可以通过编译器反汇编码窗口查看中断压栈、出栈的实现。
430网络学习心得

Timer_A有个中断请求寄存器TAIV用来确定中断请求的中断源。
该寄存器共16位,位5-15与位0全为0,位1-4的数据有相应的中断标志产生。
1.中断嵌套,优先级430总中断的控制位是状态寄存器内的GIE位(该位在SR寄存器内),该位在复位状态下,所有的可屏蔽中断都不会发生响应。
可屏蔽中断又分为单中断源和多中断源的。
单中断源的一般响应了中断服务程序中断标志位就自动清零,而多中断源的则要求查询某个寄存器后中断标志位才会清零。
由于大多数人接触的第一款单片机通常是51,51单片机CPU在响应低优先级的中断程序过程中若有更高优先级的中断发生,单片机就会去执行高优先级,这个过程已经产生了中断嵌套。
而430单片机则不同,如果在响应低优先级中断服务程序的时候,即使来了更高优先级的中断服务请求,430也会置之不理,直至低优先级中断服务程序执行完毕,才会去响应高优先级中断。
这是因为430在响应中断程序的时候,总中断GIE 是复位状态的,如果要产生类似51的中断嵌套,只能在中断函数内再次置位GIE位。
2.定时器TATimerA有2个中断向量。
TIMERA0,TIMERA1TIMERA0只针对CCR0的计数溢出TIMERA1再查询TAIV后可知道是CCR1,还是CCR2,亦或TAIFG引起的,至于TAIFG 是什么情况下置位的,则要看TA工作的模式具体看用户手册。
还有一点TA本身有PWM输出功能,无须借用中断功能。
在这个问题上经常出现应用弯路的是如何结合TA和AD实行定时采样的问题,很多人都是在TA中断里打开AD这样来做。
这是不适宜的,因为430 的ADC10,ADC12(SD16不熟悉,没发言权)模块均有脉冲采样模式和扩展采样模式。
只要选择AD是由TA触发采样,然后把TA 设置成PWM输出模式,当然输出PWM波的都是特殊功能脚,但是在这里它是不需要输出的,所以引脚设置不必理会。
值得关心的就是PWM的频率,也就是你AD的采样率。
中断嵌套和咬尾中断和迟到中断的工作原理

中断嵌套和咬尾中断和迟到中断的工作原理下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!本店铺为大家提供各种类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you! In addition, this shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!中断嵌套和咬尾中断以及迟到中断的工作原理引言在计算机科学领域,中断是一种处理器的异步事件,能够打断当前正在执行的程序,转而执行另一段代码。
ARM中断嵌套

谈谈ARM中断嵌套1何为中断嵌套中断嵌套就是指高优先级的事件可以打断低优先级的事件(反过来不可以),而处理完高优先级事件后还得回来继续处理低优先级事件。
打个比方,你在看电视(一般任务),你妈叫你洗2只碗(中断来了),你刚洗完一只,你爸叫你去打水(中断也被中断了,还让不让人活啊),由于你爸更有威信(优先级更高),所以你必须得先去打水,等你打完水,还得回来继续洗碗,洗完碗才能继续看电视。
这个过程就是带中断嵌套的中断。
还有一种使用错误的中断嵌套,就是高优先级事件可以被低优先级事件打断,这是个比较严重的问题,虽然也是嵌套了,但完全偏离的中断嵌套的初衷,后面会分析这种情况。
下文提到的中断嵌套都指的是高优先级事件打断低优先级事件的中断嵌套。
2为什么需要中断嵌套对最紧急的事件进行相应是实时系统的关键,紧急事件有很多,但总有轻重,如果最紧急的事件得不到处理,就可能酿成灾难。
3处理器是否支持中断嵌套你可能会问,我的处理器能支持中断嵌套吗,这个还要具体情况具体分析。
一款处理器能否支持中断嵌套,最重要的是看它是否具有保存中断现场的能力,这个包括两方面,一是保存处理器的寄存器文件,二是保存中断控制器的硬件环境。
保存处理器的寄存器文件很简单,直接压栈就可以了,而保存中断控制器的硬件环境就不一定能实现了,这要求中断控制器具有硬件栈(因为软件是无法访问中断控制器的内部环境的)。
下面就具体进行分析,分析对象:STM32F(CORTEX-M3)NXP的LPC系列(ARM7)ST的STR7(ARM7)先透露一下结论,支持中断嵌套的只有STM32F和STR7。
3.1LPC系列先谈谈ARM7TDMI(以下简称ARM7)。
ARM7本身没有集成中断控制器,而是由芯片厂商自己实现,市场上出现了形形色色的基于ARM7的微控制器。
ARM7大部分中断都在IRQ下处理,而进入IRQ后是无法再被中断的(就好像你妈叫你洗碗的时候,你带着耳机听歌,所以听不到你爸的命令)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
CM3中断的嵌套、尾链、晚到与延迟
用户程序
优先级3 中断1
优先级2 中断2
继续压栈
中断1
压栈
中 断
中断2
1的
入
迟来
出栈
口 地
出
址
栈
CM3中断的嵌套、尾链、晚到与延迟
中断延迟 从检测到某中断请求,到执行了其服务例程的第一条指令时,所经
➢ 对于除法指令和双字传送指令( LDRD/STRD ),CM3将为了保证中断及时 响应而取消它们的执行,待返回后重新开始;
➢ 对于多寄存器传送指令(LDM/STM) ,为了加速中断的响应,CM3支持指令 执行的中止和继续。
感谢
谢谢,精品课件
资料搜集
ARM Cortex-M3 的STM32系列 嵌套中断,咬尾中断,晚到异常与中断延迟(1)
CM3中断的嵌套、尾链、晚到与延迟
中断嵌套 在Cortex-M3内核以及NVIC,已经内建了对中断嵌套的支持:➢ NVIC会排出优先级解码的顺序; ➢ 自动的硬件入栈和出栈。
注意:使用中断嵌套时,必须仔细计算主堆栈容量,避免堆栈溢出。
过的时间。 在CM3中,若存储器系统够快,且总线系统允许入栈与取指同时进行,
同时该中断可以立即响应,则中断延迟是固定的12周期。 处理尾链中断时,省去了堆栈操作,因此切入新异常服务例程的延迟可
以缩短至6周期。
CM3中断的嵌套、尾链、晚到与延迟
为了不影响中断延迟,对于需要较多的周期才能完成的指令,CM3采用了 以下两种处理方法:
CM3中断的嵌套、尾链、晚到与延迟
尾链中断
当上一个异常处理返回, Cortex-M3响应挂起的异常时,为了 避免浪费CPU时间,继续使用上一个异常已经入栈好的寄存器数据。两 个异常只执行了一次入栈/出栈操作。
Cortex-M3利用“尾链中断”缩短了挂起中断的延迟时间,提高 中断响应速度。
CM3中断的嵌套、尾链、晚到与延迟
用户程序
优先级2 中断1
优先级3 中断2
压栈
无压栈
中断1
中断2
中断1 结束
出栈
如果此时中断1 已经 完成,不出栈也不压 栈,直接跳至中断2 程序
尾链中断也叫咬尾中 断
CM3中断的嵌套、尾链、晚到与延迟
晚到的异常处理
当异常产生时,处理器会接受异常请求并开始入栈操作。若在入栈操 作期间产生了另外一个更高优先级的异常,则后到的高优先级异常会首先得 到服务。