当代汉语文本语料库分词词性标注加工规范
浅谈《现代汉语词典》(第五版)词性标注的几个问题

浅谈《现代汉语词典》(第五版)词性标注的几个问题摘要:本文主要从功能的角度对《现代汉语词典》(第五版)的词性标注进行了初步的探索,主要涉及词性标注及其与释义和配例相一致、兼类词的释义等几个方面的问题,对《现汉》(五)的成功和不足之处作了一定说明。
关键词:《现代汉语词典》(第五版)词性标注释义《现代汉语词典》是目前国内最有影响的语文辞书之一。
对现代汉语词典质量产生影响的根本性因素,是词典的释义问题。
一、《现代汉语词典》(第五版)词性标注现代汉语词典标注词性,给汉语教学、用户的学习和使用和中文信息处理等带来了很大的方便。
标注词性必须要对词类系统和词与非词进行界定。
科学的给词归类,主要根据词的语法功能。
陆俭明提出的词类划分标准是:1、词充当句法成分的功能,2、词跟词结合的功能,3、词表示类别的功能,即语法意义。
《现代汉语词典》(第5版)依据的词类是中学语文课本的教学词类系统,是比较科学的。
如:集成:【动】同类著作汇集在一起(多用做书名):《丛书~》|《中国古典戏曲论著~》。
(《现汉》(五)p592)集锦:【名】编辑在一起的精彩的图画、诗文等(多用做标题):图片~|邮票~。
(《现汉》(五)p593)《现代汉语词典》(第5版)中的“集成”与“集锦”根据配例来看,“丛书集成”、“图片集锦”、“邮票集锦”,二者看似相同,但是语法意义不同。
根据“语料库在线”的检索结果,“集成”66条例句中,17个做谓语例句,13个做定语例句,且能带宾语;“集锦”6条例句中5个做中心语。
前者语法意义表示事物的动作、行为或变化、存在,后者的语法意义表示事物名称。
所以二者词性标注不同。
另外,在根据功能判断词性的基础上,也不能完全脱离意义。
“集成”与“集锦”词汇意义也不同,“集:1.集合;聚集”(《现汉》(五)p639),“成:3.【动】成为;变为”(《现汉》(五)p171),“集成”有“汇集成为”的意思,释义行文体现为动词性。
“锦:有彩色花纹的丝织品”(《古汉语常用字字》p150),这里应为比喻义,指美好的东西,所以“集锦”释义行文应体现为名词性。
对外汉语教学中的词类划分

对外汉语教学中的词类划分作者:朱芸来源:《现代语文(语言研究)》2008年第05期摘要:本文运用语料库的研究方法,对对外汉语教材《博雅汉语》中级冲刺篇中动词、名词、形容词的使用情况进行了调查研究,通过统计数据我们发现,其中部分动词和形容词具有名词用法。
但是,在词典和教材生词表上并未将这些动词和形容词归入兼类词,也未标明其具有名词用法。
本文试图通过描述这些动词、形容词的分布状态概括出其共性。
关键词:语料库词类活用词的兼类引言语料库是指存放在计算机里的原始语料文本或经过加工后带有语言学信息标注的文本。
语料库语言学是基于语料库提供的语言材料展开的语言研究。
近年来,随着计算机语言学和语料库语言学的发展,越来越多的人通过语料库所提供的语料进行汉语研究。
本文通过建立一个小型的对外汉语教材语料库,对其中的动词、名词、形容词的使用进行分类统计,从而为对外汉语中的词汇教学提供一些切实可行的建议。
一、语料库建设语料库素材:北大出版社《博雅汉语》中级上下两册,适用于已经基本掌握了基础语言知识和交际功能的学习者。
其中上册12课,下册10课,不包括标点在内共有53504字次,2044字;共有34530词次,4829词。
平均每篇课文2432字,1569词。
该语料库从2006年3月开始录入文本到6月完成词性标注及校对,历时三个月,实际总共耗时60小时左右。
词类标记:本语料库采取“973当代汉语文本语料库分词、词性标注加工规范”“北京大学现代汉语语料库基本加工规范”在实际操作中以前者为主,并采用后者中动词和形容词的特殊用法标记。
将这些特殊用法标注出来可以为词的兼类研究提供计量依据,主要词类标记如下:注:碍于语料和精力有限,本文集中考察动词和形容词的名词用法在语料库中的分布情况。
二、标注标准计算机对语料进行自动分词和标注词性后,人工校对的过程中发现了部分动词和形容词的词性标注存在问题。
即部分词性并不符合其在具体句子中的语法功能。
现代汉语语料库加工规范

现代汉语语料库加工规范——词语切分与词性标注1999年3月版北京大学计算语言学研究所1999年3月14日⒈ 前言北大计算语言学研究所从1992年开始进行汉语语料库的多级加工研究。
第一步是对原始语料进行切分和词性标注。
1994年制订了《现代汉语文本切分与词性标注规范V1.0》。
几年来已完成了约60万字语料的切分与标注,并在短语自动识别、树库构建等方向上进行了探索。
在积累了长期的实践经验之后,最近又进行了《人民日报》语料加工的实验。
为了保证大规模语料加工这一项重要的语言工程的顺利进行,北大计算语言学研究所于1998年10月制订了《现代汉语文本切分与词性标注规范V2.0》(征求意见稿)。
因这次加工的任务超出词语切分与词性标注的范围,故将新版的规范改名为《现代汉语语料库加工规范》。
制订《现代汉语语料库加工规范》的基本思路如下:⑴ ⑴ 词语的切分规范尽可能同中国国家标准GB13715“信息处理用现代汉语分词规范” (以下简称为“分词规范”)保持一致。
由于现在词语切分与词性标注是结合起来进行的,而且又有了一部《现代汉语语法信息词典》(以下有时简称“语法信息词典”或“语法词典”)可作为词语切分与词性标注的基本参照,这就有必要对“分词规范”作必要的调整和补充。
⑵ ⑵ 小标记集。
词性标注除了使用《现代汉语语法信息词典》中的26个词类标记(名词n、时间词t、处所词s、方位词f、数词m、量词q、区别词b、代词r、动词v、形容词a、状态词z、副词d、介词p、连词c、助词u、语气词y、叹词e、拟声词o、成语i、习用语l、简称j、前接成分h、后接成分k、语素g、非语素字x、标点符号w)外,增加了以下3类标记:①专有名词的分类标记,即人名nr,地名ns,团体机关单位名称nt,其他专有名词nz;②语素的子类标记,即名语素Ng,动语素Vg,形容语素Ag,时语素Tg,副语素Dg等;③动词和形容词的子类标记,即名动词vn(具有名词特性的动词),名形词an(具有名词特性的形容词),副动词vd(具有副词特性的动词),副形词ad(具有副词特性的形容词)。
当汉语语料库文本分词规范草案

973当代汉语文本语料库分词、词性标注加工规范(草案)山西大学从1988年开始进行汉语语料库的深加工研究,首先是对原始语料进行切分和词性标注,1992年制定了《信息处理用现代汉语文本分词规范》。
经过多年研究和修改,2000年又制定出《现代汉语语料库文本分词规范》和《现代汉语语料库文本词性体系》。
这次承担973任务后制定出本规范。
本规范主要吸收了语言学家的研究成果,并兼顾各家的词性分类体系,是一套从信息处理的实际要求出发的当代汉语文本加工规范。
本加工规范适用于汉语信息处理领域,具有开放性和灵活性,以便适用于不同的中文信息处理系统。
《973当代汉语文本语料库分词、词性标注加工规范》是根据以下资料提出的。
1.《信息处理用现代汉语分词规范》,中国国家标准GB13715,1992年2.《信息处理用现代汉语词类标记规范》,中华人民共和国教育部、国家语言文字工作委员会2003年发布3.《现代汉语语料库文本分词规范》(Ver 3.0),1998年北京语言文化大学语言信息处理研究所清华大学计算机科学与技术系4.《现代汉语语料库加工规范——词语切分与词性标注》,1999年北京大学计算语言学研究所5.《信息处理用现代汉语词类标记规范》,2002年,教育部语言文字应用研究所计算语言学研究室6.《现代汉语语料库文本分词规范说明》,2000年山西大学计算机科学系山西大学计算机应用研究所7.《資讯处理用中文分词标准》,1996年,台湾计算语言学学会一、分词总则1.词语的切分规范尽可能同中国国家标准GB13715《信息处理用现代汉语分词规范》(以下简称为“分词规范”)保持一致。
本规范规定了对现代汉语真实文本(语料库)进行分词的原则及规则。
追求分词后语料的一致性(consistency)是本规范的目标之一。
2.本规范中的“分词单位”主要是词,也包括了一部分结合紧密、使用稳定的词组以及在某些特殊情况下可能出现在切分序列中的孤立的语素或非语素字。
现代汉语语料库加工规范词语切分和词性标注词...
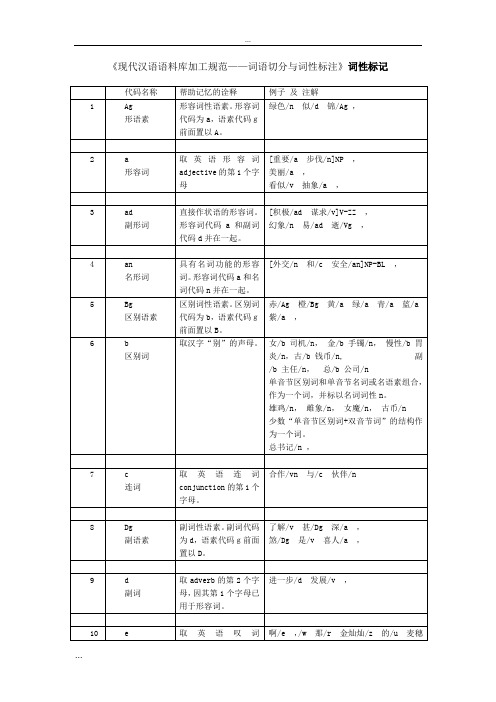
[芜湖/ns专区/n] NS,
[宣城/ns地区/n]ns,
[内蒙古/ns自治区/n]NS,
[深圳/ns特区/n]NS,
[厦门/ns经济/n特区/n]NS,
[香港/ns特别/a行政区/n]NS,
甲/Mg减下/v的/u人/n让/v乙/Mg背上/v ,
凡/d“/w寅/Mg年/n”/w中/f出生/v的/u人/n生肖/n都/d属/v虎/n ,
18
m数词
取英语numeral的第3个字母,n,u已有他用。
1.数量词组应切分为数词和量词。三/m个/q, 10/m公斤/q,一/m盒/q点心/n ,
但少数数量词已是词典的登录单位,则不再切分。
合作/vn与/c伙伴/n
8
Dg
副语素
副词性语素。副词代码为d,语素代码g前面置以D。
了解/v甚/Dg深/a,
煞/Dg是/v喜人/a,
9
d
副词
取adverb的第2个字母,因其第1个字母已用于形容词。
进一步/d发展/v,
10
e
叹词
取英语叹词exclamation的第1个字母。
啊/e,/w那/r金灿灿/z的/u麦穗/n,
约/d一百/m多/m万/m,仅/d一百/m个/q,四十/m来/m个/q,二十/m余/m只/q,十几/m个/q,三十/m左右/m,
两个数词相连的及“成百”、“上千”等则不予切分。
五六/m年/q,七八/m天/q,十七八/m岁/q,成百/m学生/n,上千/m人/n,
4.表序关系的“数+名”结构,应予切分。
[宝山/ns钢铁/n总/b公司/n]NT,(/w宝钢/j)/w
语料库

设计样本分布
表一:人文与社会科学类
科 目 比 例 字 数 1919-1925 1926-1949 1950-1965 1966-1976 19775% 哲学 历史 社会 经济 艺术 文学 其他 8.3% 8.3% 8.3% 8.3% 8.3% 50% 8.3% 250 250 250 250 250 1500 250 12.5 12.5 12.5 12.5 12.5 75 12.5 15% 37.5 37.5 37.5 37.5 37.5 225 37.5 25% 62.5 62.5 62.5 62.5 62.5 375 62.5 5% 12.5 12.5 12.5 12.5 12.5 75 12.5 50% 125 125 125 125 125 750 125
年份
标注语料库
词语切分
分词词表 词表结构化
词类标注
<信息处理用现代汉语词类标记集规范>
句法树库 已完成5000万字词语切分和词类标注语料库
语料库标注加工
语料库加工软件系统 分词词表
现代汉语词语切分歧义数据库
歧义点,歧义类型,歧义消解结果 基于国家语委语料库
超大规模通用平衡语料库
2002, 863项目 1亿字 基于国家语委语料库选材原则 网络电子文本为主 段落级XML标注
自然科学(含农业、医学、工程与技术) 类
目前比较通用的中、小学各科教材。 目前比较通用的具有通论性质的大学各 科基础必修课程的教材。 涉及自然科学各个门类的科普读物。
现代汉语语料库选材字数的分布
人文与社会科学的语言材料占全部5000万字 语料的60%,为3000万字。这3000万字在各 个学科的分布见表一。 文学的语言材料占人文与社会科学类的50%, 共1500万字。这1500万字在不同体裁、题材 的语料的分布见表二。 长、中、短篇小说的选取比例大致为: 长:中:短=1:2:3
自然语言处理 第四章汉语语料库多级加工

• 规则: 如果“顾”前有副词(只), 则“顾”不为姓氏。 • “黄”兼作形容词
– 黄曾阳研究概念层次网络 – 彩色的光带射到黄玻璃上
• 规则: 如果“黄”后有物质名词,则“黄”不为姓氏。 • “周”兼作量词
– 由周恩来任国务院总理 – 地球自转一周
• 规则: 如果“周”前有数词, 则“周”不为姓氏。
• 我读了几篇文章和报告 “文章”为名词,是非兼类词,“报告”为动-名兼类词,
由于处于联合结构中,故可判定“报告”为名词。
语料库中汉语书面文本的词性
标注
– 基于隐马尔可夫模型(HMM)的词性标注器
• 从语料库中选出一定数量的文本,作为训练集(training set),手工分析这个训练集,采用二元语法(bi-gram grammar),从中归纳出统计数据。
– 第一次出现的人名叫做“定义性出现”, 尔后出现 的人名叫做“使用性出现”。 为此, 在切分时可根 据人名在定义性出现时的限制性成分首先建立人名 表。
中国人名识别(2)
• 人名的限制性成分主要有
– 身份词:表示人的职务, 职位, 头衔的词语和亲属称 谓的词语. 有的出现在人名之前, 如“工人, 教师, 丈 夫, 妻子, 犯人”, 有的出现在人名之后, 如“先生, 女士”, 有的可以出现在人名的前面和后面, 如“教 授, 总理”。
– 我们也可以利用只能出现在外国人名首和外国人名 末的汉字作为特征字来判定外国人名的边界。这需 要分别建立相应的字表来作为判定外国人名左右边 界的依据。
外国人名识别(3)
• 还可以利用简单的上下文来进一步判定 外国人名的边界
– 标点符号, 数字, 空格, 西文字母, 译名连接符 号常常是人名的边界。
一种切词和词性标注相融合的汉语语料库多级加工方法

一种切词和词性标注相融合的汉语语料库多级加工方法*周强, 俞士汶(北京大学计算语言学研究所北京100871)摘要 : 本文通过深入研究汉语切词和词性标注处理的内在联系,提出了一种将两者结合起来处理的方法,并详细介绍了词性标注的基本设计思想,讨论了规则方法和统计方法相结合的排歧策略。
用此方法对约40万字的语料进行了实际的切分和标注处理,其准确度分别达到了96%和94%。
关键词 : 汉语自动切词,语料库词性标注。
一引言在汉语中,短语(与词组同义)类型,是一种很特殊的语法形式。
它具有与汉语句子结构相类似的主谓、述宾、联合等种种不同的构造方法,这和英语中的短语有很大差别。
“如果我们把各类词组的结构和功能都足够详细地描写清楚了,那么句子的结构实际上也就描写清楚了,因为句子不过是独立的词组而已。
”[1]从这个意义上看,现代汉语短语结构研究的重要性是不言而明的。
要进行汉语短语结构的研究,就必须对大量的汉语语言事实进行调查研究,从中总结出有关短语组成的规律。
在这方面,一个带多种标记的大规模汉语语料库就可以提供大量有用的信息。
从本质上看,汉语语料库的多级加工,即从文本语料库(‘生’语料库),经过自动切词,词性标注及短语结构标注而得到带不同标记的‘熟’语料库,和汉语短语分析处理中的切词,词性标注,短语结构分析等各个阶段有着内在联系,完全可以把两者结合起来处理。
一方面,利用短语分析中的各种技术对语料库进行多级自动标注,形成准确度较高的带多标记的语料库;另一方面,以新的语料库为基础,利用不同的统计工具,从中提取出大量的汉语语言事实,通过总结提炼,再结合到自动分析程序中,可以大大提高自动分析的效率和准确性。
正是基于这个基本思路,笔者实现了一个汉语短语分析和语料库多级标注处理相结合的系统。
从结构上看,此系统分为两大处理系统:切词及词性标注处理和短语结构分析。
本文主要介绍一下切词和词性标注处理的基本思想和相关的处理技术。
有关短语分析的处理将另行撰文介绍。
当代汉语文本分词、词性标注加工规范

当代汉语文本分词、词性标注加工规范973当代汉语文本语料库分词、词性标注加工规范(草案)山西大学从1988年开始进行汉语语料库的深加工研究,首先是对原始语料进行切分和词性标注,1992年制定了《信息处理用现代汉语文本分词规范》。
经过多年研究和修改,2000年又制定出《现代汉语语料库文本分词规范》和《现代汉语语料库文本词性体系》。
这次承担973任务后制定出本规范。
本规范主要吸收了语言学家的研究成果,并兼顾各家的词性分类体系,是一套从信息处理的实际要求出发的当代汉语文本加工规范。
本加工规范适用于汉语信息处理领域,具有开放性和灵活性,以便适用于不同的中文信息处理系统。
《973当代汉语文本语料库分词、词性标注加工规范》是根据以下资料提出的。
1.《信息处理用现代汉语分词规范》,中国国家标准GB13715,1992年2.《信息处理用现代汉语词类标记规范》,中华人民共和国教育部、国家语言文字工作委员会2003年发布3.《现代汉语语料库文本分词规范》(Ver 3.0),1998年北京语言文化大学语言信息处理研究所清华大学计算机科学与技术系4.《现代汉语语料库加工规范——词语切分与词性标注》,1999年北京大学计算语言学研究所5.《信息处理用现代汉语词类标记规范》,2002年,教育部语言文字应用研究所计算语言学研究室6.《现代汉语语料库文本分词规范说明》,2000年山西大学计算机科学系山西大学计算机应用研究所7.《資讯处理用中文分词标准》,1996年,台湾计算语言学学会一、分词总则1.词语的切分规范尽可能同中国国家标准GB13715《信息处理用现代汉语分词规范》(以下简称为“分词规范”)保持一致。
本规范规定了对现代汉语真实文本(语料库)进行分词的原则及规则。
追求分词后语料的一致性(consistency)是本规范的目标之一。
2.本规范中的“分词单位”主要是词,也包括了一部分结合紧密、使用稳定的词组以及在某些特殊情况下可能出现在切分序列中的孤立的语素或非语素字。
汉语文本短语结构的人工标注语料库的加工与应用

語料的加工
對”北大加工規範”做的介紹及調整 人名:nr 姓與名都分開 nrx nrm
不易或不知道姓與名就記作nr 王/nr建民/nr 王/nrx 建民/nrm 大衛‧歐提茲/nr 大衛/nrm‧/w歐提茲/nrx
地名:nd 長的國名要考慮切割 中華人民共和國/nd ﹛中華/ab 人民/ng 共和國/ng﹜nd 只有在行政區名稱是單音節且前面成分也是單音節為一切分 單位:{台北/nd市/n}nd 台州/nd 長江/nd etc
語料的加工
與”北大加工規範”不同之處︰
1.
2.
3.
4. 5.
時間詞(nt)、處所詞(ns)放在名詞大類下面,如果 要單一查某類,可用小類標記符號查尋 區別詞(ab)放在形容詞大類中 五種語素標記法,顛倒字母次序,方便找查 Ng Vg Ag Dg Tg gN gV gA gD gT 去掉名動詞vn、名形詞an、副動詞vd、副形詞 ad 在10個大類中設立了10個其他的小類,記做~g
單音節動詞的重疊式加“看”
語料的加工 短語標注源自 前人的短語標注與樹庫建立
Lancaster-Leeds Penn
英語樹庫加工目的
提供一些具體服務(翻譯 檢索 索引等)
方法及特點
人機互助(人注-機注-人校) 朝機器自動化發展
語料的加工
現有漢語短語句法標
記集描述
語料的加工
詞性標記
現有詞性標注集
27大類 有些分類細
有些分類粗
語料的加工
自定標注集
標注細一點,因
沒詞典做支撐 適當吸收現代漢 語研究結果來做 分類
語料的加工
23個大類,用英文字母表示,有11個大類下面有
(整理)现代汉语语料库加工规范词语切分与词性标注词
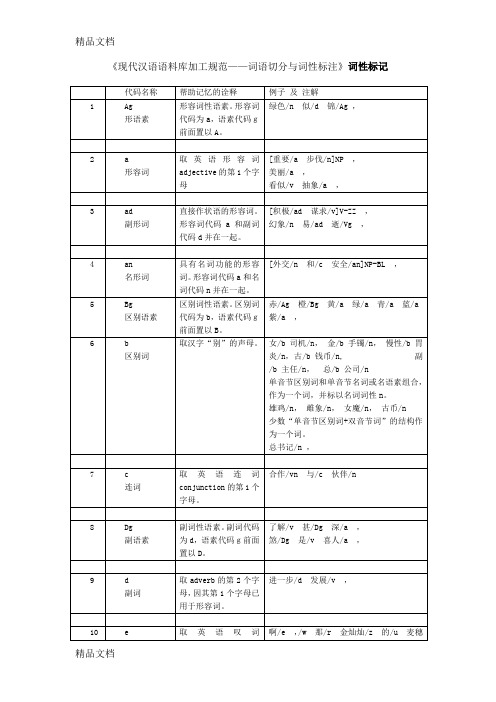
出/v过/u两/m天/q差/Ng,
疾病成本法和人力资本法将环境污染引起人体健康的经济损失分为直接经济损失和间接经济损失两部分。直接经济损失有:预防和医疗费用、死亡丧葬费;间接经济损失有:影响劳动工时造成的损失(包括病人和非医务人员护理、陪住费)。这种方法一般通常用在对环境有明显毒害作用的特大型项目。理/v了/u一/m次/q发/Ng,
一个/m ,一些/m ,
2.基数、序数、小数、分数、百分数一律不予切分,为一个切分单位,标注为m。
一百二十三/m,20万/m,123.54/m,一个/m,第一/m,第三十五/m,20%/m,三分之二/m,千分之三十/m,几十/m人/n,十几万/m元/q,第一百零一/m个/q ,
3.约数,前加副词、形容词或后加“来、多、左右”等助数词的应予分开。
岗位/n ,城市/n ,机会/n ,
[例题-2006年真题]下列关于建设项目环境影响评价实行分类管理的表述,正确的是( )她/r是/v责任/n编辑/n ,
(编辑/v科技/n文献/n )
21
nr人名
名词代码n和“人(ren)”的声母并在一起。
1.汉族人及与汉族起名方式相同的非汉族人的姓和名单独切分,并分别标注为nr。
张/nr仁伟/nr,欧阳/nr修/nr,阮/nr志雄/nr,朴/nr贞爱/nr
汉族人除有单姓和复姓外,还有双姓,即有的女子出嫁后,在原来的姓上加上丈夫的姓。如:陈方安生。这种情况切分、标注为:陈/nr方/nr安生/nr;唐姜氏,切分、标注为:唐/nr姜氏/nr。
2.姓名后的职务、职称或称呼要分开。
江/nr主席/n,小平/nr同志/n,江/nr总书记/n,张/nr教授/n,王/nr部长/n,陈/nr老总/n,李/nr大娘/n,刘/nr阿姨/n,龙/nr姑姑/n
现代汉语语料库加工规范词语切分与词性标注词

代码名称
帮助记忆的诠释
例子及注解
1
Ag
形语素
形容词性语素。形容词代码为a,语素代码g前面置以A。
绿色/n似/d锦/Ag,
2
a
形容词
取英语形容词adjective的第1个字母
[重要/a步伐/n]NP,
美丽/a,
看似/v抽象/a,
3
ad
副形词
直接作状语的形容词。形容词代码a和副词代码d并在一起。
3.专有名称后接多音节的名词,如“语言”、“文学”、“文化”、“方式”、“精神”等,失去专指性,则应分开。
欧洲/ns语言/n,法国/ns文学/n,西方/ns文化/n,贝多芬/nr交响乐/n,雷锋/nr精神/n,美国/ns方式/n,日本/ns料理/n,宋朝/t古董/n
4.商标(包括专名及后接的“牌”、“型”等)是专指的,标以nz,但其后所接的商品仍标以普通名词n。
二/m连/n, 三/m部/n ,
19
Ng名语素
名词性语素。名词代码为n,语素代码g前面置以N。
出/v过/u两/m天/q差/Ng,
理/v了/u一/m次/q发/Ng,
20
n名词
取英语名词noun的第1个字母。
(参见动词--v)
岗位/n ,城市/n ,机会/n ,
她/r是/v责任/n编辑/n ,(编辑/v科技/n文献/n )
克林顿/nr,叶利钦/nr,才旦卓玛/nr,小林多喜二/nr,北研二/nr,
华盛顿/nr,爱因斯坦/nr
有些西方人的姓名中有小圆点,也不分开。
卡尔·马克思/nr
22
ns地名
名词代码n和处所词代码s并在一起。
对外汉语教学中的词类划分

对外汉语教学中的词类划分本文运用语料库的研究方法,对对外汉语教材《博雅汉语》中级冲刺篇中动词、名词、形容词的使用情况进行了调查研究,通过统计数据我们发现,其中部分动词和形容词具有名词用法。
但是,在词典和教材生词表上并未将这些动词和形容词归入兼类词,也未标明其具有名词用法。
本文试图通过描述这些动词、形容词的分布状态概括出其共性。
标签:语料库词类活用词的兼类引言语料库是指存放在计算机里的原始语料文本或经过加工后带有语言学信息标注的文本。
语料库语言学是基于语料库提供的语言材料展开的语言研究。
近年来,随着计算机语言学和语料库语言学的发展,越来越多的人通过语料库所提供的语料进行汉语研究。
本文通过建立一个小型的对外汉语教材语料库,对其中的动词、名词、形容词的使用进行分类统计,从而为对外汉语中的词汇教学提供一些切实可行的建议。
一、语料库建设语料库素材:北大出版社《博雅汉语》中级上下两册,适用于已经基本掌握了基础语言知识和交际功能的学习者。
其中上册12课,下册10课,不包括标点在内共有53504字次,2044字;共有34530词次,4829词。
平均每篇课文2432字,1569词。
该语料库从2006年3月开始录入文本到6月完成词性标注及校对,历时三个月,实际总共耗时60小时左右。
词类标记:本语料库采取“973当代汉语文本语料库分词、词性标注加工规范”“北京大学现代汉语语料库基本加工规范”在实际操作中以前者为主,并采用后者中动词和形容词的特殊用法标记。
将这些特殊用法标注出来可以为词的兼类研究提供计量依据,主要词类标记如下:注:碍于语料和精力有限,本文集中考察动词和形容词的名词用法在语料库中的分布情况。
二、标注标准计算机对语料进行自动分词和标注词性后,人工校对的过程中发现了部分动词和形容词的词性标注存在问题。
即部分词性并不符合其在具体句子中的语法功能。
所以,作者在校对中根据实际情况增加了动词的名词用法(vn)和形容词的名词用法(an)两类。
试析中文分词国家规范

试析中文分词国家规范许顺吕强(苏州大学计算机科学与技术学院,江苏省计算机信息处理技术重点实验室,江苏苏州215006)摘要:中文自动分词是计算机中文信息处理的基础难题,而分词标准又是中文自动分词的首要问题。
中文分词规范提出了切分单位的概念,定义了中文信息处理的一系列分词规则。
而目前的分词研究对分词规范的作用重视不够。
本文首先强调了分词规范应该成为分词问题本身的标准描述。
然后本文详细分析了中文分词国家分词规范的完备性和一致性,论述了相应的不够完善的地方。
最后总结了应用国家分词规范的重要意义,提出分词规范还需要进一步研究。
关键词:中文分词规范,中文自动分词,完备性,一致性中图法分类号:TP391Towards Chinese Word Segmentation SpecificationXu Shun Lv Qiang(School of Computer Science and Technology, Suzhou University)( Jiangsu Key Laboratory of Information Processing Technology)Suzhou, 215006, ChinaAbstract:Chinese automatic segmentation is a fundamental hard problem in Chinese information processing (CIP). And segmentation standard is the principal problem in Chinese automatic segmentation. Chinese word segmentation specification has proposed the definition of segmentation unit and some rules for Chinese segmentation, while the current research has a little bit underestimated the importance of this specification. Firstly this paper emphasizes that the segmentation specification should be the only answer of the question what is the segmentation problem. Secondly this paper analyzes the completeness and consistency of the National Chinese Language Word Segmentation Specification for Information Processing, and points out the related flaw. Finally the authors summarize the importance of application of the segmentation specification, and strongly propose that the research on the segmentation specification should be investigated furthermore.Keywords: Chinese segmentation specification, automatic segmentation, completeness, consistency1问题的提出随着计算机技术日新月异的发展,中文信息处理的应用更加广泛,例如语音识别,信息检索,文本分类,自然语言的理解和机器翻译等。
词性标注规范化探索

词性标注规范化探索词性标注问题一直是计算语言学中的一个难点问题,对于一些词类的标注标准和方法,至今仍未统一,如兼类词、区别词,这给进一步的句法分析和语料库的共享带来了很大困难,甚至有时候会造成资源的浪费。
本着实用的目的,在参考各家标注策略的基础上,本文对兼类词、区别词和状态词的标注给出了统一的标注策略。
标签:词性标注句法分析兼类词区别词状态词一、引言在大多数情况下,对语料进行词性标注,只是语料库建设的一个开始,而不是终点。
句法标注是当前的一个研究热点,是建立在词性标注基础上的一项工作。
我们在对语料进行句法标注的过程中发现,分词系统中一些词类标记会给句法分析工作带来一些困扰。
这些问题不仅影响到句法标注的效率,也影响到标注的准确性和一致性。
因此,在分词及词性标注阶段,应考虑词类标记对句法层面的影响,以节省人力、物力。
首先,分词类别(或POS标记)应该在句法上有功能意义,例如名词、动词等。
因为那些不是从句法层面划分出来的标记,即使标示出来也无法在句法分析中进行处理。
其次,在有意义的基础上,我们需要把握一个度。
因为与语言本体或语言理论研究追求细致和完美的目的不同,语言工程更多地是要求时效性和可行性。
在语料库的标注过程中,词类划分不宜过多或过少。
词类过少,对句法分析的深度和精度不够。
词类过多,又会使语言分析和处理的过程太复杂,代价太高。
那么,到底划分多少词类才能在句法层面达到自足呢?对世界上13种语言依存句法的考察表明,在进行自动句法分析时,一种语言所划分出的词类数量一般应当控制在在10~20之间。
本文通过系统①,探讨了兼类词以及区别词和状态词的词性标注问题。
我们将首先对所讨论的标记概念进行界定,然后对比当今国内几大分词系统对其的处理,最后经过综合分析探讨之后,提出一些具有可行性的建议。
二、兼类词兼类词从狭义上讲是指同一个义项(严格说是同一概括词)兼属多个词类。
如“小时(n/q)”。
从广义上讲还包括意义上有联系的几个义项属于不同词类。
国家语委现代汉语通用平衡语料库 标注语料库数据及使用说明

国家语委现代汉语通用平衡语料库标注语料库数据及使用说明肖航教育部语言文字应用研究所1. 国家语委现代汉语通用平衡语料库1.1 语料库全库国家语委现代汉语通用平衡语料库全库约为1亿字符,其中1997年以前的语料约7000万字符,均为手工录入印刷版语料;1997之后的语料约为3000万字符,手工录入和取自电子文本各半。
语料库的通用性和平衡性通过语料样本的广泛分布和比例控制实现。
语料库类别分布如下所示:1.2 标注语料库标注语料库为国家语委现代汉语通用平衡语料库全库的子集,约5000万字符。
标注是指分词和词类标注,已经经过3次人工校对,准确率大于>98%。
语料库全库按照预先设计的选材原则进行平衡抽样,以期达到更好的代表性。
标注语料库在样本分布方面近似于全库,不破坏语料选材的平衡原则。
标注语料库类别分布如下所示:标注语料库与全库的样本分布比较如下所示:(蓝色曲线为语料库全库;红色曲线为标注语料库)2. 国家语委现代汉语通用平衡语料库语料选材与样本分布2.1 选材原则依据材料内容,选材大体作如下分类:(下文字数为建库时数据)2.1.1 教材大中小学教材单作一类,约2000万字。
2.1.2 人文与社会科学的语言材料约占全库的60%,共3000万字,包括:·政法(含哲学、政治、宗教、法律等);·历史(含民族等)·社会(含社会学、心理、语言、教育、文艺理论、新闻学、民俗学等);·经济;·艺术(含音乐、美术、舞蹈、戏剧等);·文学(含口语);·军体;·生活(含衣食住行等方面的普及读物)。
2.1.3 自然科学(含农业、医学、工程与技术)的语言材料,应涉及其发展的各个领域。
拟从大、中、小学教材和科普读物中选取。
其中,科普读物约占6%,共300万字。
教材字数另计。
2.1.4 报刊。
以1949年以后正式出版的由国家、省、市及各个部委主办的报纸和综合性刊物为主,兼顾1949年以前的报纸和综合性刊物。
现代汉语语料库加工中的切词与词性标注处理

现代汉语语料库加工中的切词与词性标注处理周强, 段惠明北京大学计算语言学研究所北京,100871目前,大规模真实文本处理已成为计算语言学界的一个热门话题。
一个重要的原因是因为它给我们提供了一种新的研究思路,即从大规模的语料库中提取所需要的知识。
而汉语语料库的加工和处理,又涉及到汉语语法研究的许多问题,如:词的定义,词类的划分,短语的确定等等。
在这方面,我们进行了一些探索,积累了一些经验。
本文只讨论切词与词性标注问题。
1. 汉语语料库的多级加工总结国内外语料库建设的经验,可以看到:一个计算机语料库的功能主要和下面三种因素密切相关,即库的规模、语料分布和语料的加工深度。
因为库容量的大小直接影响到统计结果的可靠性,语料分布的考虑则关系到统计结果的适用范围,而加工深度则决定了该语料库能为自然语言处理提供什么样的知识。
对于汉语语料库的处理,可以设想有以下几个阶段,如图1所示[5]。
这样,经过不同阶段的处理,语料库所携带的各类消息也不断增加,最终将成为一个名副其实的语言知识库。
这样的知识库可以为汉语统计分析、汉语理解和机器翻译提供重要的资源和有力的支持。
┌────┐┌────┐┌────┐┌────┐│"生图 1 库存语料的加工顺序2. 关于切词和标注结合处理的规范从92年初开始, 北大计算语言学研究所开始进行汉语语料库的多级加工处理的研究,其第一步工作是对原始语料进行切分和词性标注, 并且我们是将切词和标注结合起来进行的。
通过使用一个带词类标记的切词词典, 在自动切词的同时, 给每个切分单位标上初始词性标记, 然后通过规则与统计相结合的方法排歧, 实现词类的自动标注, 再利用构词规则, 发现一些符合汉语构词规律的未定义词并确定其词类。
[6]以上工作的基础是“信息处理用现代汉语分词规范”[1](下简称为“分词规范”)、现代汉语词语分类体系[2]、汉语构词法理论[3]和现代汉语语法电子词典[4]。
在对约40万字语料的切分与标注的实践基础上, 我们发现了一些新的处理规律, 积累了许多有益的经验。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
973当代汉语文本语料库分词、词性标注加工规范
(草案)
山西大学从1988年开始进行汉语语料库的深加工研究,首先是对原始语料进行切分和词性标注,1992年制定了《信息处理用现代汉语文本分词规范》。
经过多年研究和修改,2000年又制定出《现代汉语语料库文本分词规范》和《现代汉语语料库文本词性体系》。
这次承担973任务后制定出本规范。
本规范主要吸收了语言学家的研究成果,并兼顾各家的词性分类体系,是一套从信息处理的实际要求出发的当代汉语文本加工规范。
本加工规范适用于汉语信息处理领域,具有开放性和灵活性,以便适用于不同的中文信息处理系统。
《973当代汉语文本语料库分词、词性标注加工规范》是根据以下资料提出的。
1.《信息处理用现代汉语分词规范》,中国国家标准GB13715,1992年
2.《信息处理用现代汉语词类标记规范》,中华人民共和国教育部、国家语言文字工作委员会2003年发布
3.《现代汉语语料库文本分词规范》(Ver 3.0),1998年
北京语言文化大学语言信息处理研究所清华大学计算机科学与技术系4.《现代汉语语料库加工规范——词语切分与词性标注》,1999年
北京大学计算语言学研究所
5.《信息处理用现代汉语词类标记规范》,2002年,
教育部语言文字应用研究所计算语言学研究室
6.《现代汉语语料库文本分词规范说明》,2000年
山西大学计算机科学系山西大学计算机应用研究所
7.《資讯处理用中文分词标准》,1996年,台湾计算语言学学会
一、分词总则
1.词语的切分规范尽可能同中国国家标准GB13715《信息处理用现代汉语分词规范》(以下简称为“分词规范”)保持一致。
本规范规定了对现代汉语真实文本(语料库)进行分词的原则及规则。
追求分词后语料的一致性(consistency)是本规范的目标之一。
2.本规范中的“分词单位”主要是词,也包括了一部分结合紧密、使用稳定的词组以及在某些特殊情况下可能出现在切分序列中的孤立的语素或非语素字。
本文中仍用“词”来称谓“分词单位”。
3.分词中充分考虑形式与意义的统一。
形式上要看一个结构体的组成成分能否单用,结构体能否扩展,组成成分的结构关系,以及结构体的音节结构;意义上要看结构体的整体意义是否具有组合性。
4. 本规范规定的分词原则及规则,既要适应语言信息处理与语料库语言学研究的需要,又力求与传统的语言学研究成果保持一致;既要适合计算机自动处理,又要便于人工校对。
5.分词时遵循从大到小的原则逐层顺序切分。
一时难以判定是否切分的结构体,暂不切分。
二、词性标注总则
信息处理用现代汉语词性标注主要原则有三个:
(1)语法功能原则。
语法功能是词类划分的主要依据。
词的意义不作为划分词类的主要依据,但有时也起着某些参考作用。
(2)允许有兼类。
根据各种统计研究,现代汉语的某些词具有多种语法功能,但这多种功能的分布概率不同。
在信息处理用现代汉语词类体系中,各词类的确立要根据词的主要语法功能。
(3)词类加工规范的标记集中的大类应能覆盖现代汉语的全部词。
为满足计算机处理真实文本词类标注的需要,本规范所定义的标记集,覆盖了比词小的单位,如前接成分(前缀)、后接成分(后缀)、语素字、非语素字等;比词更大的单位,如习用语、简称和略语,以及标点符号、非汉字符号等。
三、词类标记集
本规范的词类标记集采用《信息处理用现代汉语词类标记规范》的大类,只增加了部分细类。
本规范的词类标记集规定,每个分词单位的标记由英文字母串构成。
标记的第一位代码,表示信息处理用现代汉语词类的基本词类,共20类,标记的第二、三位代码,表示信息处理用现代汉语基本词类下的细类。
词类分别为:
(1)名词n:
普通名词(n)
时间名词(nt)
方位名词(nd)
处所名词(nl)
人名(nh)
汉族或类汉族人名(人名 nhh:姓nhf, 名nhg)
音译名或类音译名(nhy)
日本人名(nhr)
其他(nhw):如绰号,笔名,尊称等。
地名(ns)
族名(nn)
团体机构名(ni)
其他专有名词(nz)
(2)动词v:
普通动词(v)
能愿动词(vu)
趋向动词(vd)
系动词(vl)
(3)形容词:
性质形容词(aq)
状态形容词(as)
(4)区别词f
(5)数词m
(6)量词q
(7)副词d
(8)代词r
(9)介词p
(10)连词c
(11)助词u
(12)叹词e
(13)拟声词o
(14)习用语i
名词性习用语(in)
动词性习用语(iv)
形容词性习用语 (ia)
连词性习用语(ic)
(15)简称和略语j
名词性简称和略语 jn
动词性简称和略语 jv
形容词性简称和略语 ja
(16)前接成分h
(17)后接成分k
(18)语素字g
(19)非语素字x
(20)其它w:
标点符号 (wp)
非汉字字符串(ws)
其他未知的符号(wu)
四、细则
1.本规范参照 GB/T 13715-92的做法,以词类为纲对各类单位作具体切分与词性标注规
定。
2.本次加工规定,凡是收入词表中的词语,不再遵循本规范进行切分。
所使用词表的收
词原则遵从清华大学《信息处理用现代汉语分词词表》规范。
3.独立性较强的语素字均标注词类,减少语素字标记的比例。
4.大类与细类可兼类。
五、分词与词性标注的详细说明
1.名词(n)
表示人和事物的名称或时间、处所等,在句中主要充当主语和宾语。
1.l 普通名词(n)
表示人和事物的名称
1.1.l 合成式
[1] 并列关系
凡是使用稳定、结合紧密的二字并列关系名词一律为分词单位。
如:
省市/n 房屋/n 资金/n
其余双音节的只要能扩展,则可切分。
三音节以上的结构体能扩展的应切分。
例如:
省/n市/n县/n。