统计学符号及读音
统计学词汇及符号电子

统计学是一门研究数据收集、描述和分析的学科。
下面是一些常见的统计学词汇和符号:
•样本(sample) : 从总体中抽取的一部分数据
•总体(population) : 所有可能的数据的集合
•均值(mean) : 样本数据的平均数
•中位数(median) : 样本数据的中间值
•方差(variance) : 样本数据的离散程度
•标准差(standard deviation) : 样本数据的标准离散程度
•相关系数(correlation coefficient) : 两个变量间相关程度的数值
•置信区间(confidence interval) : 统计数据的可信度区间
•p值(p-value) : 统计检验中的显著性水平
•符号:
•(∑) 求和符号
•(x) 样本均值
•(s) 样本标准差
•(n) 样本大小
•(x) 某个样本值
•(p) 概率
统计学词汇和符号在电子表格和统计软件中也是通用的。
统计学术语及符号
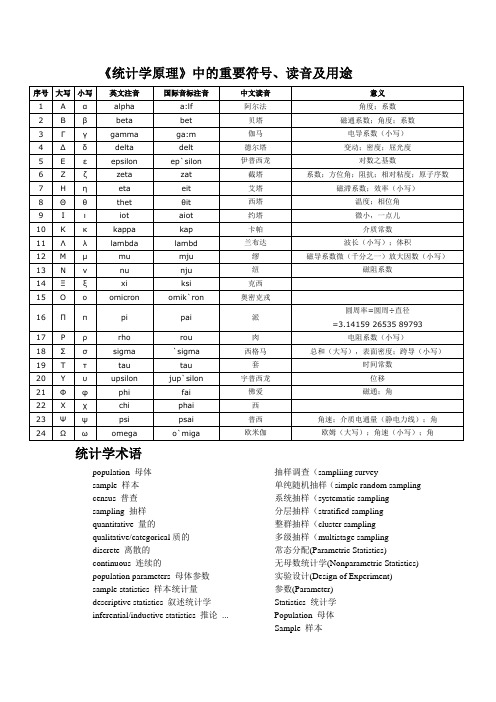
《统计学原理》中的重要符号、读音及用途统计学术语population 母体sample 样本census 普查sampling 抽样quantitative 量的qualitative/categorical质的discrete 离散的continuous 连续的population parameters 母体参数sample statistics 样本统计量descriptive statistics 叙述统计学inferential/inductive statistics 推论... 抽样调查(sampliing survey单纯随机抽样(simple random sampling 系统抽样(systematic sampling分层抽样(stratified sampling整群抽样(cluster sampling多级抽样(multistage sampling常态分配(Parametric Statistics)无母数统计学(Nonparametric Statistics) 实验设计(Design of Experiment)参数(Parameter)Statistics 统计学Population 母体Sample 样本Data analysis 资料分析Statistical table 统计表Statistical chart 统计图Pie chart 圆饼图Stem-and-leaf display 茎叶图Box plot 盒须图Histogram 直方图Bar Chart 长条图Polygon 次数多边图Ogive 肩形图Descriptive statistics 叙述统计学Expectation 期望值Mode 众数Mean 平均数V ariance 变异数Standard deviation 标准差Standard error 标准误Covariance matrix 共变异数矩阵Inferential statistics 推论统计学Point estimation 点估计Interval estimation 区间估计Confidence interval 信赖区间Confidence coefficient 信赖系数Testing statistical hypothesis 统计假设检定Regression analysis 回归分析Analysis of variance 变异数分析Correlation coefficient 相关系数Sampling survey 抽样调查Census 普查Sampling 抽样Reliability 信度V alidity 效度Sampling error 抽样误差Non-sampling error 非抽样误差Random sampling 随机抽样Simple random sampling 简单随机抽样法Stratified sampling 分层抽样法Cluster sampling 群集抽样法Systematic sampling 系统抽样法Two-stage random sampling 两段随机抽样法Convenience sampling 便利抽样Quota sampling 配额抽样Snowball sampling 雪球抽样Nonparametric statistics 无母数统计The sign test 等级检定Wilcoxon signed rank tests 魏克森讯号等级检定Wilcoxon rank sum tests 魏克森等级和检定Run test 连检定法Discrete uniform densities 离散的均匀密度Binomial densities 二项密度Hypergeometric densities 超几何密度Poisson densities 卜松密度Geometric densities 几何密度Negative binomial densities 负二项密度Continuous uniform densities 连续均匀密度Normal densities 常态密度Exponential densities 指数密度Gamma densities 伽玛密度Beta densities 贝他密度Multivariate analysis 多变量分析Principal components 主因子分析Discrimination analysis 区别分析Cluster analysis 群集分析Factor analysis 因素分析Survival analysis 存活分析Time series analysis 时间序列分析Linear models 线性模式Quality engineering 品质工程Probability theory 机率论Statistical computing 统计计算Statistical inference 统计推论Stochastic processes 随机过程Decision theory 决策理论Discrete analysis 离散分析Mathematical statistics 数理统计统计学: Statistics母体: Population样本: Sample资料分析: Data analysis统计表: Statistical table统计图: Statistical chart圆饼图: Pie chart茎叶图: Stem-and-leaf display盒须图: Box plot直方图: Histogram长条图: Bar Chart次数多边图: Polygon肩形图: Ogive叙述统计学: Descriptive statistics期望值: Expectation众数: Mode平均数: Mean变异数: V ariance标准差: Standard deviation标准误: Standard error共变异数矩阵: Covariance matrix推论统计学: Inferential statistics点估计: Point estimation区间估计: Interval estimation信赖区间: Confidence interval信赖系数: Confidence coefficient统计假设检定: Testing statistical hypothesis回归分析: Regression analysis变异数分析: Analysis of variance相关系数: Correlation coefficient抽样调查: Sampling survey普查: Census抽样: Sampling信度: Reliability效度: V alidity抽样误差: Sampling error非抽样误差: Non-sampling error随机抽样: Random sampling简单随机抽样法: Simple random sampling分层抽样法: Stratified sampling群集抽样法: Cluster sampling系统抽样法: Systematic sampling两段随机抽样法: Two-stage random sampling便利抽样: Convenience sampling配额抽样: Quota sampling雪球抽样: Snowball sampling无母数统计: Nonparametric statistics等级检定: The sign test魏克森讯号等级检定: Wilcoxon signed rank tests魏克森等级和检定: Wilcoxon rank sum tests连检定法: Run test离散的均匀密度: Discrete uniform densities二项密度: Binomial densities超几何密度: Hypergeometric densities卜松密度: Poisson densities几何密度: Geometric densities负二项密度: Negative binomial densitie,连续均匀密度: Continuous uniformdensities常态密度: Normal densities指数密度: Exponential densities伽玛密度: Gamma densities贝他密度: Beta densities多变量分析: Multivariate analysis主因子分析: Principal components区别分析: Discrimination analysis群集分析: Cluster analysis因素分析: Factor analysis存活分析: Survival analysis时间序列分析: Time series analysis线性模式: Linear models品质工程: Quality engineering机率论: Probability theory统计计算: Statistical computing统计推论: Statistical inference随机过程: Stochastic processes决策理论: Decision theory离散分析: Discrete analysis数理统计: Mathematical statistics统计名词市调辞典众数(Mode) 普查(census)指数(Index) 问卷(Questionnaire)中位数(Median) 信度(Reliability)百分比(Percentage) 母群体(Population)信赖水准(Confidence level) 观察法(Observational Survey)假设检定(Hypothesis Testing) 综合法(Integrated Survey)卡方检定(Chi-square Test) 雪球抽样(Snowball Sampling)差距量表(Interval Scale) 序列偏差(Series Bias)类别量表(Nominal Scale) 次级资料(Secondary Data)顺序量表(Ordinal Scale) 抽样架构(Sampling frame)比率量表(Ratio Scale) 集群抽样(Cluster Sampling)连检定法(Run Test) 便利抽样(Convenience Sampling)符号检定(Sign Test) 抽样调查(Sampling Sur)算术平均数(Arithmetic Mean) 非抽样误差(non-sampling error)展示会法(Display Survey)调查名词准确效度(Criterion-Related V alidity)元素(Element) 邮寄问卷法(MailInterview)样本(Sample) 信抽样误差(Sampling error)效度(V alidity) 封闭式问题(Close Question)精确度(Precision) 电话访问法(Telephone Interview)准确度(V alidity) 随机抽样法(Random Sampling)实验法(Experiment Survey)抽样单位(Sampling unit) 资讯名词市场调查(Marketing Research) 决策树(Decision Trees)容忍误差(Tolerated erro) 资料采矿(Data Mining)初级资料(Primary Data) 时间序列(Time-Series Forecasting)目标母体(Target Population) 回归分析(Regression)抽样偏差(Sampling Bias) 趋势分析(Trend Analysis)抽样误差(sampling error) 罗吉斯回归(Logistic Regression)架构效度(Construct V alidity) 类神经网络(Neural Network)配额抽样(Quota Sampling) 无母数统计检定方法(Non-Parametric Test)人员访问法(Interview) 判别分析法(Discriminant Analysis)集群分析法(cluster analysis) 规则归纳法(Rules Induction)内容效度(Content V alidity) 判断抽样(Judgment Sampling)开放式问题(Open Question)OLAP(Online Analytical Process)分层随机抽样(Stratified Random sampling) 资料仓储(Data Warehouse)非随机抽样法(Nonrandom Sampling)知识发现(Knowledge Discover。
统计学符号及读音

统计学符号意义及读音按照国家标准GB3358-82《统计学名词及符号》的有关规定书写,常用如下:(1) 样本的算术平均数用英文小与x (中位数仍用M) ;(2) 标准差用英文小与s;(3) 标准误用英文小写Sx;(4) t检验用英文小写t;(5) F检验用英文大写F;(6) 卡方检验用希文小写字X2;(7) 相关系数用英文小写r;(8) 白由度用希文小写u;(9) 概率用英文大写P (P值前应给出具体检验值,如t值、字2值、q 值等)。
以上符号均用斜体。
拉丁字母假定均数X样本均数YY变量;变量值,观察值;回归中的应(因)变量y Y变换后的变量或变量值Y样本均数希腊字母符号名称符号名称α检验水准,显著性水准;第一类错误的概率1-α可信度,置信度β第二类错误的概率;总体回归系数1-β检验效能,把握度ν(n′)自由度π总体率μ总体均数ρ总体相关系数Σ求和的符号σ总体标准差σ2总体方差χ2χ2检验的统计量符号名称符号名称A X2检验中的实际频数A,b,c,d四格表中的实际频a样本回归直线在Y轴上的截距b样本回归系数C校正数;常量;x2检验中的列(栏)数CI可信区间--------------------------------------------------------------------------------CL可信限CV变异系数--------------------------------------------------------------------------------d两数之差值d差值的均数f(X)连续型分布密度函数,密度f观察频数,实际频数G几何均数;对数似然比检验的统计量H调和均数;H检验的统计量Hg检验假设,无效假设H1备择假设i组距;行次L下限M中位数N有限总体含量;各样本含量的总和n样本含量;各样本含量的总和P概率P(1)单侧检验的概率P(2)双侧检验的概率Px第x百分位数P样本率R极差;样本复相关系数;x2检验中的行数r样本相关系数RR相对危险度s样本标准差S2样本方差sb样本回归系数的标准误S02合并样本方差sd(样本)差值的标准差s-d(样本)差值均数的标准误sp样本率的标准误Sp1-p2两样本率差的标准误sX样本均数的标准误SD标准差SE标准误T X2检验的理论频数;Wilcoxon秩和检验的统计量t t检验的统计量u标准正态变量;标准正态(离)差;u检验的统计量X变量;变量值,观察值;回归中的自变量x X变换后的变量或变量值Xi变量X的第i个观察值;第i个变量XO这些都是希腊文序号大写小写英文注音国际音标注音中文注音1 Ααalpha a:lf 阿尔法2 Ββbeta bet 贝塔3 Γγgamma ga:m 伽马4 Δδdelta delt 德尔塔5 Εεepsilon ep`silon 伊普西龙6 Ζζzeta zat 截塔7 Ηηeta eit 艾塔8 Θθthet θit 西塔9 Ιιiot aiot 约塔10 Κκkappa kap 卡帕11 ∧λlambda lambd 兰布达12 Μμmu mju 缪13 Ννnu nju 纽14 Ξξxi ksi 克西15 Οοomicron omik`ron 奥密克戎16 ∏πpi pai 派17 Ρρrho rou 肉18 ∑σsigma `sigma 西格马19 Ττtau tau 套20 Υυupsilon jup`silon 宇普西龙21 Φφphi fai 佛爱22 Χχchi phai 西23 Ψψpsi psai 普西24 Ωωomega o`miga 欧米伽δ(德尔塔)ε(艾普西龙)。
均数和标准差的符号

均数和标准差的符号
在统计学中,均数和标准差是两个非常重要的概念,它们可以帮助我们更好地
理解和描述数据的分布特征。
在本文中,我们将介绍均数和标准差的符号表示方法,希望能够帮助读者更好地理解这两个概念。
首先,让我们来看一下均数的符号表示。
在统计学中,均数通常用希腊字母μ(读作mu)来表示。
μ是一个常数,表示总体的均数。
总体均数是指对整个总体
进行统计得到的均数,通常用来描述总体的平均水平。
而样本均数通常用x(读作
x bar)来表示,它是根据样本数据计算得到的均数,用来估计总体的均数。
接下来,让我们来看一下标准差的符号表示。
标准差通常用希腊字母σ(读作sigma)来表示。
σ是一个常数,表示总体的标准差。
总体标准差是指对整个总体
进行统计得到的标准差,用来描述总体数据的离散程度。
而样本标准差通常用s来
表示,它是根据样本数据计算得到的标准差,用来估计总体的标准差。
在实际应用中,我们经常会用到均数和标准差来描述数据的分布特征。
均数可
以帮助我们了解数据的平均水平,而标准差可以帮助我们了解数据的离散程度。
通过对均数和标准差的分析,我们可以更好地理解数据的特点,从而做出更准确的推断和决策。
总之,均数和标准差是统计学中非常重要的概念,它们可以帮助我们更好地理
解和描述数据的分布特征。
通过对均数和标准差的符号表示方法的了解,我们可以更好地应用这两个概念,从而更好地分析和解释数据。
希望本文对读者能够有所帮助,谢谢阅读!。
统计学符号及读音【爆款】.docx

统计学符号意义及读音按照国家标准GB3358-82《统计学名词及符号》的有关规定书写,常用如下:(1) 样本的算术平均数用英文小与x (中位数仍用M) ;(2) 标准差用英文小与s;(3) 标准误用英文小写Sx;(4) t检验用英文小写t;(5) F检验用英文大写F;(6) 卡方检验用希文小写字X2;(7) 相关系数用英文小写r;(8) 白由度用希文小写u;(9) 概率用英文大写P (P值前应给出具体检验值,如t值、字2值、q 值等)。
以上符号均用斜体。
拉丁字母假定均数X样本均数YY变量;变量值,观察值;回归中的应(因)变量y Y变换后的变量或变量值Y样本均数希腊字母符号名称符号名称α检验水准,显著性水准;第一类错误的概率1-α可信度,置信度β第二类错误的概率;总体回归系数1-β检验效能,把握度ν(n′)自由度π总体率μ总体均数ρ总体相关系数Σ求和的符号σ总体标准差σ2总体方差χ2χ2检验的统计量符号名称符号名称A X2检验中的实际频数A,b,c,d四格表中的实际频a样本回归直线在Y轴上的截距b样本回归系数C校正数;常量;x2检验中的列(栏)数CI可信区间--------------------------------------------------------------------------------CL可信限CV变异系数--------------------------------------------------------------------------------d两数之差值d差值的均数f(X)连续型分布密度函数,密度f观察频数,实际频数G几何均数;对数似然比检验的统计量H调和均数;H检验的统计量Hg检验假设,无效假设H1备择假设i组距;行次L下限M中位数N有限总体含量;各样本含量的总和n样本含量;各样本含量的总和P概率P(1)单侧检验的概率P(2)双侧检验的概率Px第x百分位数P样本率R极差;样本复相关系数;x2检验中的行数r样本相关系数RR相对危险度s样本标准差S2样本方差sb样本回归系数的标准误S02合并样本方差sd(样本)差值的标准差s-d(样本)差值均数的标准误sp样本率的标准误Sp1-p2两样本率差的标准误sX样本均数的标准误SD标准差SE标准误T X2检验的理论频数;Wilcoxon秩和检验的统计量t t检验的统计量u标准正态变量;标准正态(离)差;u检验的统计量X变量;变量值,观察值;回归中的自变量x X变换后的变量或变量值Xi变量X的第i个观察值;第i个变量XO这些都是希腊文序号大写小写英文注音国际音标注音中文注音1 Ααalpha a:lf 阿尔法2 Ββbeta bet 贝塔3 Γγgamma ga:m 伽马4 Δδdelta delt 德尔塔5 Εεepsilon ep`silon 伊普西龙6 Ζζzeta zat 截塔7 Ηηeta eit 艾塔8 Θθthet θit 西塔9 Ιιiot aiot 约塔10 Κκkappa kap 卡帕11 ∧λlambda lambd 兰布达12 Μμmu mju 缪13 Ννnu nju 纽14 Ξξxi ksi 克西15 Οοomicron omik`ron 奥密克戎16 ∏πpi pai 派17 Ρρrho rou 肉18 ∑σsigma `sigma 西格马19 Ττtau tau 套20 Υυupsilon jup`silon 宇普西龙21 Φφphi fai 佛爱22 Χχchi phai 西23 Ψψpsi psai 普西24 Ωωomega o`miga 欧米伽δ(德尔塔)ε(艾普西龙)。
统计学符号及读音

统计学符号意义及读音按照国家标准GB3358-82《统计学名词及符号》的有关规定书写,常用如下:(1) 样本的算术平均数用英文小与x (中位数仍用M) ;(2) 标准差用英文小与s;(3) 标准误用英文小写Sx;(4) t检验用英文小写t;(5) F检验用英文大写F;(6) 卡方检验用希文小写字X2;(7) 相关系数用英文小写r;(8) 白由度用希文小写u;(9) 概率用英文大写P (P值前应给出具体检验值,如t值、字2值、q值等)。
以上符号均用斜体。
拉丁字母假定均数 X 样本均数YY 变量;变量值,观察值;回归中的应(因)变量 y Y变换后的变量或变量值Y 样本均数希腊字母符号名称符号名称α检验水准,显著性水准;第一类错误的概率 1-α可信度,置信度β第二类错误的概率;总体回归系数 1-β检验效能,把握度ν(n′)自由度π总体率μ总体均数ρ总体相关系数Σ求和的符号σ总体标准差σ2 总体方差χ2 χ2检验的统计量符号名称符号名称A X2检验中的实际频数 A,b,c,d 四格表中的实际频a 样本回归直线在Y轴上的截距b 样本回归系数C 校正数;常量;x2检验中的列(栏)数 CI 可信区间--------------------------------------------------------------------------------CL 可信限 CV 变异系数--------------------------------------------------------------------------------d 两数之差值 d 差值的均数f(X)连续型分布密度函数,密度 f 观察频数,实际频数G 几何均数;对数似然比检验的统计量 H 调和均数;H检验的统计量Hg 检验假设,无效假设 H1 备择假设i 组距;行次 L 下限M 中位数 N 有限总体含量;各样本含量的总和n 样本含量;各样本含量的总和 P 概率P(1)单侧检验的概率 P(2)双侧检验的概率Px 第x百分位数 P 样本率R 极差;样本复相关系数;x2检验中的行数 r 样本相关系数RR 相对危险度 s 样本标准差S2 样本方差 sb 样本回归系数的标准误S02 合并样本方差 sd (样本)差值的标准差s-d (样本)差值均数的标准误 sp 样本率的标准误Sp1-p2 两样本率差的标准误 sX 样本均数的标准误SD 标准差 SE 标准误T X2检验的理论频数;Wilcoxon秩和检验的统计量 t t检验的统计量u 标准正态变量;标准正态(离)差;u检验的统计量 X 变量;变量值,观察值;回归中的自变量x X变换后的变量或变量值 Xi 变量X的第i个观察值;第i个变量XO这些都是希腊文序号大写小写英文注音国际音标注音中文注音1 Αα alpha a:lf 阿尔法2 Ββ beta bet 贝塔3 Γγ gamma ga:m 伽马4 Δδ delta delt 德尔塔5 Εε epsilon ep`silon 伊普西龙6 Ζζ zeta zat 截塔7 Ηη eta eit 艾塔8 Θθ thet θit 西塔9 Ιι iot aiot 约塔10 Κκ kappa kap 卡帕11 ∧λ lambda lambd 兰布达12 Μμ mu mju 缪13 Νν nu nju 纽14 Ξξ xi ksi 克西15 Οο omicron omik`ron 奥密克戎16 ∏π pi pai 派17 Ρρ rho rou 肉18 ∑σ sigma `sigma 西格马19 Ττ tau tau 套20 Υυ upsilon jup`silon 宇普西龙21 Φφ phi fai 佛爱。
统计学符号及读音

统计学符号意义及读音按照国家标准GB3358-82《统计学名词及符号》的有关规定书写,常用如下:(1) 样本的算术平均数用英文小与x ( 中位数仍用M) ;(2) 标准差用英文小与s;(3) 标准误用英文小写Sx;(4) t 检验用英文小写t;(5) F 检验用英文大写F;(6) 卡方检验用希文小写字X2;(7) 相关系数用英文小写r;(8) 白由度用希文小写u;(9) 概率用英文大写P (P 值前应给出具体检验值,如t 值、字2值、q 值等) 。
以上符号均用斜体。
拉丁字母假定均数X 样本均数YY 变量;变量值,观察值;回归中的应(因)变量y Y 变换后的变量或变量值Y 样本均数希腊字母符号名称符号名称a 检验水准,显著性水准;第一类错误的概率1- a 可信度,置信度B 第二类错误的概率;总体回归系数1- B 检验效能,把握度v(n') 自由度n 总体率卩总体均数p 总体相关系数艺求和的符号(T 总体标准差(T 2 总体方差x 2 x 2检验的统计量符号名称符号名称A X2 检验中的实际频数A,b,c,d 四格表中的实际频a 样本回归直线在丫轴上的截距b 样本回归系数C 校正数;常量;x2 检验中的列(栏)数CI 可信区间CL 可信限CV 变异系数d 两数之差值d 差值的均数f ( X) 连续型分布密度函数,密度f 观察频数,实际频数G 几何均数;对数似然比检验的统计量H 调和均数;H 检验的统计量Hg检验假设,无效假设H1备择假设i组距;行次L 下限各样本含量的总和M中位数N 有限总体含量;n样本含量;各样本含量的总和P 概率P(1)单侧检验的概率P (2)双侧检验的概率Px 第x 百分位数P 样本率R 极差;样本复相关系数;x2 检验中的行数r 样本相关系数RR 相对危险度s 样本标准差S2 样本方差sb 样本回归系数的标准误S02 合并样本方差sd (样本)差值的标准差s-d (样本)差值均数的标准误sp 样本率的标准误Sp1-p2 两样本率差的标准误sX 样本均数的标准误SD 标准差SE 标准误T X2 检验的理论频数;Wilcoxon 秩和检验的统计量t t 检验的统计量u 标准正态变量;标准正态(离)差;u 检验的统计量X 变量;变量值,观察值;回归中的自变量x X 变换后的变量或变量值Xi 变量X 的第i 个观察值;第i 个变量XO这些都是希腊文序号大写小写英文注音国际音标注音中文注音1 A a alpha a:lf 阿尔法2 B B beta bet 贝塔3 r Y gamma ga:m 伽马4 A S delta delt 德尔塔5 E e epsilon ep'silon 伊普西龙6 Z Z zeta zat 截塔7 H n eta eit 艾塔8 0 0 thet 0 it 西塔9 I i iot aiot 约塔10 K K kappa kap 卡帕11 A 入lambda lambd 兰布达12 M 卩mu mju 缪13 N v nu nju 纽14 S E xi ksi 克西15 O o omicron omik'ron 奥密克戎16 n n pi pai 派17 P p rho rou 肉18 刀c sigma 'sigma 西格马19 T T tau tau 套20 Y u upsilon jup'silon 宇普西龙21①© phi fai 佛爱22 X x chi phai 西23 W psi psai 普西24 Q 3 omega o'miga 欧米伽3(德尔塔)£ (艾普西龙)欢迎您的下载,资料仅供参考!致力为企业和个人提供合同协议,策划案计划书,学习资料等等打造全网一站式需求。
统计学符号及读音

统计学符号意义及读音按照国家标准GB3358-82《统计学名词及符号》的有关规定书写,常用如下:(1) 样本的算术平均数用英文小与x (中位数仍用M) ;(2) 标准差用英文小与s;(3) 标准误用英文小写Sx;(4) t检验用英文小写t;(5) F检验用英文大写F;(6) 卡方检验用希文小写字X2;(7) 相关系数用英文小写r;(8) 白由度用希文小写u;(9) 概率用英文大写P (P值前应给出具体检验值,如t值、字2值、q值等)。
以上符号均用斜体。
拉丁字母假定均数X样本均数YY变量;变量值,观察值;回归中的应(因)变量y Y变换后的变量或变量值Y样本均数希腊字母符号名称符号名称α检验水准,显著性水准;第一类错误的概率1-α可信度,置信度β第二类错误的概率;总体回归系数1-β检验效能,把握度ν(n′)自由度π总体率μ总体均数ρ总体相关系数Σ求与的符号σ总体标准差σ2总体方差χ2χ2检验的统计量符号名称符号名称A X2检验中的实际频数A,b,c,d四格表中的实际频a样本回归直线在Y轴上的截距b样本回归系数C校正数;常量;x2检验中的列(栏)数CI可信区间--------------------------------------------------------------------------------CL可信限CV变异系数--------------------------------------------------------------------------------d两数之差值d差值的均数f(X)连续型分布密度函数,密度f观察频数,实际频数G几何均数;对数似然比检验的统计量H调与均数;H检验的统计量Hg检验假设,无效假设H1备择假设i组距;行次L下限M中位数N有限总体含量;各样本含量的总与n样本含量;各样本含量的总与P概率P(1)单侧检验的概率P(2)双侧检验的概率Px第x百分位数P样本率R极差;样本复相关系数;x2检验中的行数r样本相关系数RR相对危险度s样本标准差S2样本方差sb样本回归系数的标准误S02合并样本方差sd(样本)差值的标准差s-d(样本)差值均数的标准误sp样本率的标准误Sp1-p2两样本率差的标准误sX样本均数的标准误SD标准差SE标准误T X2检验的理论频数;Wilcoxon秩与检验的统计量t t检验的统计量u标准正态变量;标准正态(离)差;u检验的统计量X变量;变量值,观察值;回归中的自变量x X变换后的变量或变量值Xi变量X的第i个观察值;第i个变量XO这些都就是希腊文序号大写小写英文注音国际音标注音中文注音1 Ααalpha a:lf 阿尔法2 Ββbeta bet 贝塔3 Γγgamma ga:m 伽马4 Δδdelta delt 德尔塔5 Εεepsilon ep`silon 伊普西龙6 Ζζzeta zat 截塔7 Ηηeta eit 艾塔8 Θθthet θit 西塔9 Ιιiot aiot 约塔10 Κκkappa kap 卡帕11 ∧λlambda lambd 兰布达12 Μμmu mju 缪13 Ννnu nju 纽14 Ξξxi ksi 克西15 Οοomicron omik`ron 奥密克戎16 ∏πpi pai 派17 Ρρrho rou 肉18 ∑σsigma `sigma 西格马19 Ττtau tau 套20 Υυupsilon jup`silon 宇普西龙21 Φφphi fai 佛爱22 Χχchi phai 西23 Ψψpsi psai 普西24 Ωωomega o`miga 欧米伽δ(德尔塔) ε(艾普西龙)。
统计学符号及读音

统计学符号意义及读音按照国家标准GB3358-82《统计学名词及符号》的有关规定书写,常用如下:(1) 样本的算术平均数用英文小与x (中位数仍用M) ;(2) 标准差用英文小与s;(3) 标准误用英文小写Sx;(4) t检验用英文小写t;(5) F检验用英文大写F;(6) 卡方检验用希文小写字X2;(7) 相关系数用英文小写r;(8) 白由度用希文小写u;(9) 概率用英文大写P (P值前应给出具体检验值,如t值、字2值、q 值等)。
以上符号均用斜体。
拉丁字母假定均数X 样本均数YY 变量;变量值,观察值;回归中的应(因)变量y Y变换后的变量或变量值Y 样本均数希腊字母符号名称符号名称α检验水准,显著性水准;第一类错误的概率1-α可信度,置信度β第二类错误的概率;总体回归系数1-β检验效能,把握度ν(n′)自由度π总体率μ总体均数ρ总体相关系数Σ求和的符号σ总体标准差σ2 总体方差χ2 χ2检验的统计量符号名称符号名称A X2检验中的实际频数A,b,c,d 四格表中的实际频a 样本回归直线在Y轴上的截距b 样本回归系数C 校正数;常量;x2检验中的列(栏)数CI 可信区间--------------------------------------------------------------------------------CL 可信限CV 变异系数--------------------------------------------------------------------------------d 两数之差值 d 差值的均数f(X)连续型分布密度函数,密度 f 观察频数,实际频数G 几何均数;对数似然比检验的统计量H 调和均数;H检验的统计量Hg 检验假设,无效假设H1 备择假设i 组距;行次L 下限M 中位数N 有限总体含量;各样本含量的总和n 样本含量;各样本含量的总和P 概率P(1)单侧检验的概率P(2)双侧检验的概率Px 第x百分位数P 样本率R 极差;样本复相关系数;x2检验中的行数r 样本相关系数RR 相对危险度s 样本标准差S2 样本方差sb 样本回归系数的标准误S02 合并样本方差sd (样本)差值的标准差s-d (样本)差值均数的标准误sp 样本率的标准误Sp1-p2 两样本率差的标准误sX 样本均数的标准误SD 标准差SE 标准误T X2检验的理论频数;Wilcoxon秩和检验的统计量t t检验的统计量u 标准正态变量;标准正态(离)差;u检验的统计量X 变量;变量值,观察值;回归中的自变量x X变换后的变量或变量值Xi 变量X的第i个观察值;第i个变量XO这些都是希腊文序号大写小写英文注音国际音标注音中文注音1 Ααalpha a:lf 阿尔法2 Ββbeta bet 贝塔3 Γγgamma ga:m 伽马4 Δδdelta delt 德尔塔5 Εεepsilon ep`silon 伊普西龙6 Ζζzeta zat 截塔7 Ηηeta eit 艾塔8 Θθthet θit 西塔9 Ιιiot aiot 约塔10 Κκkappa kap 卡帕11 ∧λlambda lambd 兰布达12 Μμmu mju 缪13 Ννnu nju 纽14 Ξξxi ksi 克西15 Οοomicron omik`ron 奥密克戎16 ∏πpi pai 派17 Ρρrho rou 肉18 ∑σsigma `sigma 西格马19 Ττtau tau 套20 Υυupsilon jup`silon 宇普西龙21 Φφphi fai 佛爱22 Χχchi phai 西23 Ψψpsi psai 普西24 Ωωomega o`miga 欧米伽δ(德尔塔)ε(艾普西龙)(此文档部分内容来源于网络,如有侵权请告知删除,文档可自行编辑修改内容,供参考,感谢您的配合和支持)。
统计学符号大全及读法

统计学符号大全及读法以下是统计学中的一些重要符号及其读音和意义:1.希腊字母:(1)α (alpha) 阿尔法:读作“阿尔法”,表示角度、系数、磁通系数等。
(2)β (beta) 贝塔:读作“贝塔”,表示磁通系数、角度、系数等。
(3)γ (gamma) 伽马:读作“伽马”,表示变动、密度、屈光度等。
(4)δ (delta) 德尔塔:读作“德尔塔”,表示变动、密度、屈光度等。
(5)ε (epsilon) 伊普西龙:读作“伊普西龙”,表示对数之基数系数、方位角、阻抗等。
(6)ζ (zeta) 截塔:读作“截塔”,表示磁滞系数、效率等。
(7)η (eta) 艾塔:读作“艾塔”,表示微小、一点儿、介质常数等。
(8)θ (theta) 西塔:读作“西塔”,表示温度、相位角等。
(9)ι (iota) 约塔:读作“约塔”,表示微小、一点儿等。
(10)κ (kappa) 卡帕:读作“卡帕”,表示卡帕。
(11)λ (lambda) 兰布达:读作“兰布达”,表示波长、体积等。
(12)μ (mu) 缪:读作“缪”,表示磁导系数、微(千分之一)、放大因数(小写)等。
(13)ν (nu) 纽:读作“纽”,表示磁阻系数等。
(14)ξ (xi) 克西:读作“克西”,表示克西。
(15)ο (omicron) 奥密克戎:读作“奥密克戎”。
(16)π (pi) 派:读作“派”,表示圆周率=圆周÷直径=3.1415926535 8979317。
(17)Ρ (rho) 肉:读作“肉”,表示电阻系数(小写)。
(18)σ (sigma) 西格马:读作“西格马”,表示总和(大写)、表面密度、跨导(小写)等。
(19)τ (tau) 套:读作“套”,表示时间常数等。
(20)φ (phi) 佛爱:读作“佛爱”,表示角速、介质电通量(静电力线)、角等。
(21)χ (chi) 西:读作“西”,表示西卡方等。
(22)ψ (psi) 西普西:读作“西普西”,表示角速、介质电通量(静电力线)、角等。
统计学符号及读音

统计学符号意义及读音按照国家标准GB3358-82《统计学名词及符号》的有关规定书写,常用如下:(1) 样本的算术平均数用英文小与x (中位数仍用M) ;(2) 标准差用英文小与s;(3) 标准误用英文小写Sx;(4) t检验用英文小写t;(5) F检验用英文大写F;(6) 卡方检验用希文小写字X2;(7) 相关系数用英文小写r;(8) 白由度用希文小写u;(9) 概率用英文大写P (P值前应给出具体检验值,如t值、字2值、q 值等)。
以上符号均用斜体。
拉丁字母假定均数X 样本均数YY 变量;变量值,观察值;回归中的应(因)变量y Y 变换后的变量或变量值Y 样本均数希腊字母符号名称符号名称a 检验水准,显著性水准;第一类错误的概率1-a 可信度,置信度B 第二类错误的概率;总体回归系数1-B 检验效能,把握度v(n') 自由度n 总体率卩总体均数p 总体相关系数艺求和的符号(T 总体标准差(T 2 总体方差x 2 x 2检验的统计量符号名称符号名称A X2检验中的实际频数A,b,c,d 四格表中的实际频a 样本回归直线在丫轴上的截距b 样本回归系数C 校正数;常量;x2 检验中的列(栏)数CI 可信区间CL 可信限CV 变异系数d 两数之差值d 差值的均数f( X) 连续型分布密度函数,密度f 观察频数,实际频数G 几何均数;对数似然比检验的统计量H 调和均数;H检验的统计量Hg 检验假设,无效假设H1 备择假设i 组距;行次L 下限M 中位数N 有限总体含量;各样本含量的总和n 样本含量;各样本含量的总和P 概率P(1)单侧检验的概率P(2)双侧检验的概率Px 第x 百分位数P 样本率R 极差;样本复相关系数;x2 检验中的行数r 样本相关系数RR 相对危险度s 样本标准差S2 样本方差sb 样本回归系数的标准误S02 合并样本方差sd (样本)差值的标准差s-d (样本)差值均数的标准误sp 样本率的标准误Sp1-p2 两样本率差的标准误sX 样本均数的标准误SD 标准差SE 标准误T X2 检验的理论频数;Wilcoxon 秩和检验的统计量t t 检验的统计量u 标准正态变量;标准正态(离)差;u 检验的统计量X 变量;变量值,观察值;回归中的自变量x X 变换后的变量或变量值Xi 变量X 的第i 个观察值;第i 个变量XO这些都是希腊文序号大写小写英文注音国际音标注音中文注音1 A a alpha a:lf 阿尔法2B beta bet 贝塔3r Y gamma ga:m 伽马4△S delta delt 德尔塔5E£epsilon ep silon 伊普西龙6Z z zeta zat 截塔7H n eta eit 艾塔8O0thet 0 it 西塔9I i iot aiot 约塔10K K kappa kap 卡帕11A入lambda lambd 兰布达12Ma mu mju 缪13N V nu nju 纽14S E xi ksi 克西15O0omicron omik'ron 奥密克戎16n n pi pai 派17p P rho rou 肉18E(Tsigma 'sigma 西格马19T T tau tau 套20Y U upsilon jup'silon 宇普西龙21①©phi fai 佛爱22X X chi phai 西23psi psai 普西24 Q 3 omega o'miga 欧米伽S (德尔塔)£ (艾普西龙)。
标准差的符号怎么读

标准差的符号怎么读标准差是统计学中常用的一个概念,用来衡量一组数据的离散程度。
在统计学中,标准差通常用希腊字母σ表示。
标准差的符号怎么读呢?下面我们来详细解释一下。
首先,标准差的符号是希腊字母σ,读音为希腊语字母σ的英文音标是/sɪɡmə/,中文读音为“西格玛”。
在统计学中,标准差是对数据离散程度的一种度量,它可以帮助我们了解数据的分布情况,以及数据点与均值的偏离程度。
标准差的计算公式为,σ = √(∑(X-μ)²/n),其中σ表示标准差,X表示每个数据点,μ表示数据的均值,n表示数据的个数。
这个公式的意思是,首先计算每个数据点与均值的差值的平方,然后将所有差值的平方相加,再除以数据个数,最后取平方根即可得到标准差。
标准差的计算过程可能有些复杂,但是它在统计学中有着非常重要的作用。
通过标准差,我们可以了解数据的稳定性和可靠性,帮助我们做出科学的数据分析和决策。
除了标准差的符号和计算方法外,我们还需要了解标准差的意义。
标准差越大,代表数据的离散程度越大,数据点与均值的偏离程度也越大。
而标准差越小,代表数据的离散程度越小,数据点与均值的偏离程度也越小。
因此,标准差可以帮助我们判断数据的稳定性和一致性,对数据的分析和解释有着重要的指导作用。
在实际应用中,标准差的概念经常被用于各种领域,比如财务、经济、医学、工程等。
通过对数据的标准差进行分析,我们可以更好地了解数据的特点和规律,为决策提供科学依据。
总之,标准差是统计学中一个重要的概念,它的符号是希腊字母σ,读音为“西格玛”。
标准差可以帮助我们衡量数据的离散程度,了解数据的稳定性和一致性,对数据的分析和解释具有重要的指导作用。
希望通过本文的介绍,您对标准差有了更深入的了解,能够更好地应用于实际工作和生活中。
最新希腊字母的读音-常用数学符号大全、关系代数符号
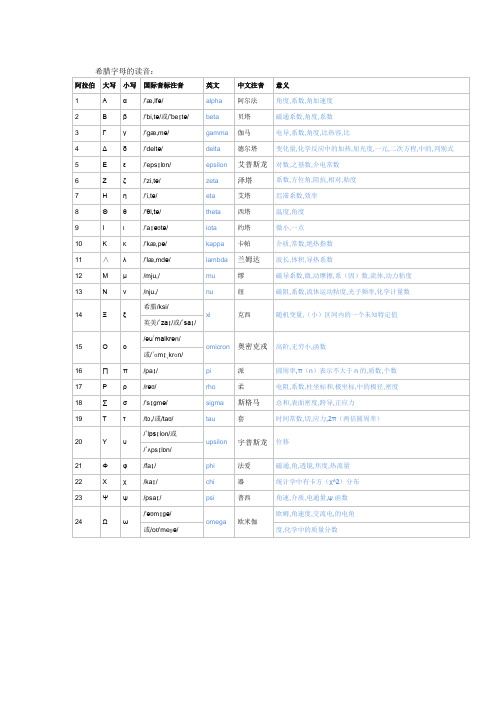
希腊字母读音及科学方面应用希腊字母中文读音及常用意义一览表常用数学符号大全、关系代数符号1、几何符号⊥∥∠⌒⊙≡≌△2、代数符号∝∧∨~∫≠≤≥≈∞∶3、运算符号如加号(+),减号(-),乘号(×或·),除号(÷或/),两个集合的并集(∪),交集(∩),根号(√),对数(log,lg,ln),比(:),微分(dx),积分(∫),曲线积分(∮)等。
4、集合符号∪∩∈5、特殊符号∑π(圆周率)6、推理符号|a| ⊥∽△∠∩∪≠≡±≥≤∈←↑→↓↖↗↘↙∥∧∨&; §①②③④⑤⑥⑦⑧⑨⑩ΓΔΘΛΞΟΠΣΦΧΨΩαβγδεζηθικλμνξοπρστυφχψωⅠⅡⅢⅣⅤⅥⅦⅧⅨⅩⅪⅫⅰⅱⅲⅳⅴⅵⅶⅷⅸⅹ∈∏∑∕√∝∞∟∠∣∥∧∨∩∪∫∮∴∵∶∷∽≈≌≒≠≡≤≥≦≧≮≯⊕⊙⊥⊿⌒℃指数0123:o1237、数量符号如:i,2+i,a,x,自然对数底e,圆周率π。
8、关系符号如“=”是等号,“≈”是近似符号,“≠”是不等号,“>”是大于符号,“<”是小于符号,“≥”是大于或等于符号(也可写作“≮”),“≤”是小于或等于符号(也可写作“≯”),。
“→”表示变量变化的趋势,“∽”是相似符号,“≌”是全等号,“∥”是平行符号,“⊥”是垂直符号,“∝”是成正比符号,(没有成反比符号,但可以用成正比符号配倒数当作成反比)“∈”是属于符号,“??”是“包含”符号等。
9、结合符号如小括号“()”中括号“[]”,大括号“{}”横线“—”10、性质符号如正号“+”,负号“-”,绝对值符号“| |”正负号“±”11、省略符号如三角形(△),直角三角形(Rt△),正弦(sin),余弦(cos),x的函数(f(x)),极限(lim),角(∠),∵因为,(一个脚站着的,站不住)∴所以,(两个脚站着的,能站住)总和(∑),连乘(∏),从n个元素中每次取出r 个元素所有不同的组合数(C(r)(n) ),幂(A,Ac,Aq,x^n)等。
统计学术语及符号
《统计学原理》中的重要符号、读音及用途统计学术语population 母体sample 样本census 普查sampling 抽样quantitative 量的qualitative/categorical质的discrete 离散的continuous 连续的population parameters 母体参数sample statistics 样本统计量descriptive statistics 叙述统计学inferential/inductive statistics 推论... 抽样调查(sampliing survey单纯随机抽样(simple random sampling 系统抽样(systematic sampling分层抽样(stratified sampling整群抽样(cluster sampling多级抽样(multistage sampling常态分配(Parametric Statistics)无母数统计学(Nonparametric Statistics) 实验设计(Design of Experiment)参数(Parameter)Statistics 统计学Population 母体Sample 样本Data analysis 资料分析Statistical table 统计表Statistical chart 统计图Pie chart 圆饼图Stem-and-leaf display 茎叶图Box plot 盒须图Histogram 直方图Bar Chart 长条图Polygon 次数多边图Ogive 肩形图Descriptive statistics 叙述统计学Expectation 期望值Mode 众数Mean 平均数V ariance 变异数Standard deviation 标准差Standard error 标准误Covariance matrix 共变异数矩阵Inferential statistics 推论统计学Point estimation 点估计Interval estimation 区间估计Confidence interval 信赖区间Confidence coefficient 信赖系数Testing statistical hypothesis 统计假设检定Regression analysis 回归分析Analysis of variance 变异数分析Correlation coefficient 相关系数Sampling survey 抽样调查Census 普查Sampling 抽样Reliability 信度V alidity 效度Sampling error 抽样误差Non-sampling error 非抽样误差Random sampling 随机抽样Simple random sampling 简单随机抽样法Stratified sampling 分层抽样法Cluster sampling 群集抽样法Systematic sampling 系统抽样法Two-stage random sampling 两段随机抽样法Convenience sampling 便利抽样Quota sampling 配额抽样Snowball sampling 雪球抽样Nonparametric statistics 无母数统计The sign test 等级检定Wilcoxon signed rank tests 魏克森讯号等级检定Wilcoxon rank sum tests 魏克森等级和检定Run test 连检定法Discrete uniform densities 离散的均匀密度Binomial densities 二项密度Hypergeometric densities 超几何密度Poisson densities 卜松密度Geometric densities 几何密度Negative binomial densities 负二项密度Continuous uniform densities 连续均匀密度Normal densities 常态密度Exponential densities 指数密度Gamma densities 伽玛密度Beta densities 贝他密度Multivariate analysis 多变量分析Principal components 主因子分析Discrimination analysis 区别分析Cluster analysis 群集分析Factor analysis 因素分析Survival analysis 存活分析Time series analysis 时间序列分析Linear models 线性模式Quality engineering 品质工程Probability theory 机率论Statistical computing 统计计算Statistical inference 统计推论Stochastic processes 随机过程Decision theory 决策理论Discrete analysis 离散分析Mathematical statistics 数理统计统计学: Statistics母体: Population样本: Sample资料分析: Data analysis统计表: Statistical table统计图: Statistical chart圆饼图: Pie chart茎叶图: Stem-and-leaf display盒须图: Box plot直方图: Histogram长条图: Bar Chart次数多边图: Polygon肩形图: Ogive叙述统计学: Descriptive statistics期望值: Expectation众数: Mode平均数: Mean变异数: V ariance标准差: Standard deviation标准误: Standard error共变异数矩阵: Covariance matrix推论统计学: Inferential statistics点估计: Point estimation区间估计: Interval estimation信赖区间: Confidence interval信赖系数: Confidence coefficient统计假设检定: Testing statistical hypothesis回归分析: Regression analysis变异数分析: Analysis of variance相关系数: Correlation coefficient抽样调查: Sampling survey普查: Census抽样: Sampling信度: Reliability效度: V alidity抽样误差: Sampling error非抽样误差: Non-sampling error随机抽样: Random sampling简单随机抽样法: Simple random sampling分层抽样法: Stratified sampling群集抽样法: Cluster sampling系统抽样法: Systematic sampling两段随机抽样法: Two-stage random sampling便利抽样: Convenience sampling配额抽样: Quota sampling雪球抽样: Snowball sampling无母数统计: Nonparametric statistics等级检定: The sign test魏克森讯号等级检定: Wilcoxon signed rank tests魏克森等级和检定: Wilcoxon rank sum tests连检定法: Run test离散的均匀密度: Discrete uniform densities二项密度: Binomial densities超几何密度: Hypergeometric densities卜松密度: Poisson densities几何密度: Geometric densities负二项密度: Negative binomial densitie,连续均匀密度: Continuous uniformdensities常态密度: Normal densities指数密度: Exponential densities伽玛密度: Gamma densities贝他密度: Beta densities多变量分析: Multivariate analysis主因子分析: Principal components区别分析: Discrimination analysis群集分析: Cluster analysis因素分析: Factor analysis存活分析: Survival analysis时间序列分析: Time series analysis线性模式: Linear models品质工程: Quality engineering机率论: Probability theory统计计算: Statistical computing统计推论: Statistical inference随机过程: Stochastic processes决策理论: Decision theory离散分析: Discrete analysis数理统计: Mathematical statistics统计名词市调辞典众数(Mode) 普查(census)指数(Index) 问卷(Questionnaire)中位数(Median) 信度(Reliability)百分比(Percentage) 母群体(Population)信赖水准(Confidence level) 观察法(Observational Survey)假设检定(Hypothesis Testing) 综合法(Integrated Survey)卡方检定(Chi-square Test) 雪球抽样(Snowball Sampling)差距量表(Interval Scale) 序列偏差(Series Bias)类别量表(Nominal Scale) 次级资料(Secondary Data)顺序量表(Ordinal Scale) 抽样架构(Sampling frame)比率量表(Ratio Scale) 集群抽样(Cluster Sampling)连检定法(Run Test) 便利抽样(Convenience Sampling)符号检定(Sign Test) 抽样调查(Sampling Sur)算术平均数(Arithmetic Mean) 非抽样误差(non-sampling error)展示会法(Display Survey)调查名词准确效度(Criterion-Related V alidity)元素(Element) 邮寄问卷法(MailInterview)样本(Sample) 信抽样误差(Sampling error)效度(V alidity) 封闭式问题(Close Question)精确度(Precision) 电话访问法(Telephone Interview)准确度(V alidity) 随机抽样法(Random Sampling)实验法(Experiment Survey)抽样单位(Sampling unit) 资讯名词市场调查(Marketing Research) 决策树(Decision Trees)容忍误差(Tolerated erro) 资料采矿(Data Mining)初级资料(Primary Data) 时间序列(Time-Series Forecasting)目标母体(Target Population) 回归分析(Regression)抽样偏差(Sampling Bias) 趋势分析(Trend Analysis)抽样误差(sampling error) 罗吉斯回归(Logistic Regression)架构效度(Construct V alidity) 类神经网络(Neural Network)配额抽样(Quota Sampling) 无母数统计检定方法(Non-Parametric Test)人员访问法(Interview) 判别分析法(Discriminant Analysis)集群分析法(cluster analysis) 规则归纳法(Rules Induction)内容效度(Content V alidity) 判断抽样(Judgment Sampling)开放式问题(Open Question)OLAP(Online Analytical Process)分层随机抽样(Stratified Random sampling) 资料仓储(Data Warehouse)非随机抽样法(Nonrandom Sampling)知识发现(Knowledge Discover。
统计学符号书写、发音及其统计学意义

21 产生统计学符号的方法 产生表 1 中的希腊字母可以采用两种方法 ,即采
·554 ·
Chinese Journal of Healt h Statistics ,Oct 2007 ,Vol. 24 ,No . 5
用数学公式编辑器和采用微软 Office Symbol 字体 : (1) 数学公式编辑器 微软 Office 软 件 ( 包 括 Word 、Excel 、Power Point
英文字母
小写
大写
a
A
b
B
c
C
d
D
e
E
f
F
j
g
G
hHiFra bibliotekIk
K
l
L
m
M
n
标准差符号怎么读

标准差符号怎么读标准差是统计学中常用的一个概念,它是用来衡量一组数据的离散程度或者波动程度的。
在统计学中,我们经常会用到标准差来描述数据的分布情况,因此对于标准差符号的读法,是非常重要的。
标准差的符号是一个希腊字母σ,它的读音是“西格玛”。
在希腊字母中,σ是第18个字母,它在统计学中代表着标准差这一重要的概念。
标准差的计算公式为σ=√∑(x-μ)²/n,其中∑表示求和,x表示每个数据点,μ表示数据的平均值,n表示数据的个数。
这个公式描述了标准差是如何根据数据的离散程度来计算的。
标准差的大小可以反映出数据的波动程度,如果标准差较大,说明数据的波动较大,反之则波动较小。
通过标准差的计算,我们可以更好地理解数据的分布情况,从而作出更准确的统计推断。
在实际应用中,标准差经常被用来衡量风险的大小。
例如在金融领域,标准差可以用来衡量投资组合的波动性,从而帮助投资者评估风险。
另外,在质量管理中,标准差也被用来衡量产品质量的稳定程度,以及生产过程的稳定性。
除了标准差外,还有其他一些与之相关的概念,例如方差。
方差是标准差的平方,它也可以用来衡量数据的离散程度。
在一些情况下,方差更容易计算和理解,但在实际应用中,标准差更为常用,因为它具有与原始数据相同的量纲,更容易和原始数据进行比较和解释。
总的来说,标准差是统计学中一个非常重要的概念,它可以帮助我们更好地理解数据的分布情况,从而作出更准确的统计分析。
标准差的符号σ,读音是“西格玛”,它代表了数据的离散程度,是统计学中不可或缺的重要概念之一。
通过对标准差的理解和运用,我们可以更好地处理和分析各种类型的数据,为决策提供更可靠的依据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
统计学符号意义及读音
按照国家标准GB3358-82《统计学名词及符号》的有关规定书写,常用如下:
(1) 样本的算术平均数用英文小与x (中位数仍用M) ;
(2) 标准差用英文小与s;
(3) 标准误用英文小写Sx;
(4) t检验用英文小写t;
(5) F检验用英文大写F;
(6) 卡方检验用希文小写字X2;
(7) 相关系数用英文小写r;
(8) 白由度用希文小写u;
(9) 概率用英文大写P (P值前应给出具体检验值,如t值、字2值、q 值等)。
以上符号均用斜体。
拉丁字母
假定均数X样本均数Y
Y变量;变量值,观察值;回归中的应(因)变量y Y变换后的变量或变量值
Y样本均数
希腊字母
符号名称符号名称
α检验水准,显着性水准;第一类错误的概率1-α可信度,置信度
β第二类错误的概率;总体回归系数1-β检验效能,把握度
ν(n′)自由度π总体率
μ总体均数ρ总体相关系数
Σ求和的符号σ总体标准差
σ2总体方差χ2χ2检验的统计量
符号名称符号名称
A X2检验中的实际频数A,b,c,d四格表中的实际频
a样本回归直线在Y轴上的截距b样本回归系数
C校正数;常量;x2检验中的列(栏)数CI可信区间
--------------------------------------------------------------------------------
CL可信限CV变异系数
--------------------------------------------------------------------------------
d两数之差值d差值的均数
f(X)连续型分布密度函数,密度f观察频数,实际频数
G几何均数;对数似然比检验的统计量H调和均数;H检验的统计量
Hg检验假设,无效假设H1备择假设
i组距;行次L下限
M中位数N有限总体含量;各样本含量的总和
n样本含量;各样本含量的总和P概率
P(1)单侧检验的概率P(2)双侧检验的概率
Px第x百分位数P样本率
R极差;样本复相关系数;x2检验中的行数r样本相关系数
RR相对危险度s样本标准差
S2样本方差sb样本回归系数的标准误
S02合并样本方差sd(样本)差值的标准差
s-d(样本)差值均数的标准误sp样本率的标准误
Sp1-p2两样本率差的标准误sX样本均数的标准误
SD标准差SE标准误
T X2检验的理论频数;Wilcoxon秩和检验的统计量t t检验的统计量
u标准正态变量;标准正态(离)差;u检验的统计量X变量;变量值,观察值;回归中的自变量
x X变换后的变量或变量值Xi变量X的第i个观察值;第i个变量XO
这些都是希腊文
序号大写小写英文注音国际音标注音中文注音
1 Ααalpha a:lf 阿尔法
2 Ββbeta bet 贝塔
3 Γγgamma ga:m 伽马
4 Δδdelta delt 德尔塔
5 Εεepsilon ep`silon 伊普西龙
6 Ζζzeta zat 截塔
7 Ηηeta eit 艾塔
8 Θθthet θit 西塔
9 Ιιiot aiot 约塔
10 Κκkappa kap 卡帕
11 ∧λlambda lambd 兰布达
12 Μμmu mju 缪
13 Ννnu nju 纽
14 Ξξxi ksi 克西
15 Οοomicron omik`ron 奥密克戎
16 ∏πpi pai 派
17 Ρρrho rou 肉
18 ∑σsigma `sigma 西格马
19 Ττtau tau 套
20 Υυupsilon jup`silon 宇普西龙
21 Φφphi fai 佛爱
22 Χχchi phai 西
23 Ψψpsi psai 普西
24 Ωωomega o`miga 欧米伽
δ(德尔塔)
ε(艾普西龙)。