随机数的产生及统计特性分析-实验报告
随机实验的实验报告

随机实验的实验报告随机实验的实验报告引言:随机实验是科学研究中常用的一种实验方法,通过随机选择和处理实验对象,以消除主观因素的干扰,从而得到更加客观、准确的实验结果。
本实验旨在探究随机实验的原理和应用,并通过具体实验案例来展示其实验效果。
实验目的:探究随机实验的原理和应用,验证随机实验的有效性和可靠性。
实验材料与方法:1. 实验材料:一副标准扑克牌、一枚骰子、一台计算机、一组随机数生成器。
2. 实验方法:a. 实验一:随机抽取扑克牌- 将一副标准扑克牌洗牌,并放置在桌面上。
- 使用随机数生成器生成一个随机数,代表抽取的牌的位置。
- 根据生成的随机数,从洗好的扑克牌中抽取一张牌。
- 记录抽取的牌的花色和点数,并重复上述步骤10次。
b. 实验二:随机掷骰子- 将骰子放置在桌面上。
- 使用随机数生成器生成一个随机数,代表骰子的点数。
- 根据生成的随机数,掷骰子一次。
- 记录掷骰子的结果,并重复上述步骤10次。
c. 实验三:随机选择实验对象- 准备一组实验对象,如十个学生。
- 使用随机数生成器生成一个随机数,代表选择的实验对象的编号。
- 根据生成的随机数,选择对应编号的实验对象进行实验。
- 记录实验结果,并重复上述步骤10次。
实验结果与分析:1. 实验一:随机抽取扑克牌通过10次实验,我们得到了10张随机抽取的扑克牌,其中包括不同花色和点数的牌。
这表明通过随机实验,我们能够在一副标准扑克牌中以相等的概率抽取任意一张牌,从而达到随机选择的效果。
2. 实验二:随机掷骰子通过10次实验,我们得到了10次随机掷骰子的结果,其中包括1到6点的不同点数。
这表明通过随机实验,我们能够以相等的概率获得骰子的每个点数,从而达到随机选择的效果。
3. 实验三:随机选择实验对象通过10次实验,我们随机选择了10个实验对象进行实验,每个对象都有相等的机会被选择到。
这表明通过随机实验,我们能够以相等的概率选择实验对象,从而消除了主观因素的干扰,得到更加客观、准确的实验结果。
实验报告随机数

一、实验目的1. 理解随机数生成的原理和过程。
2. 掌握常见随机数生成算法。
3. 分析随机数生成的性能和特点。
二、实验原理随机数在计算机科学、密码学、统计学等领域有着广泛的应用。
随机数生成算法是指从某种随机过程中产生一系列看似随机数的算法。
本实验主要研究以下几种随机数生成算法:1. 线性同余法(Linear Congruential Generator,LCG)2. Xorshift算法3. Mersenne Twister算法三、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 实验工具:Jupyter Notebook四、实验步骤1. 线性同余法(LCG)实验(1)编写LCG算法函数```pythondef lcg(seed, a, c, m, n):random_numbers = []x = seedfor _ in range(n):x = (a x + c) % mreturn random_numbers```(2)设定参数并生成随机数```pythonseed = 12345a = 1103515245c = 12345m = 231n = 1000random_numbers = lcg(seed, a, c, m, n) print(random_numbers)```2. Xorshift算法实验(1)编写Xorshift算法函数```pythondef xorshift(seed, n):random_numbers = []x = seedfor _ in range(n):x ^= (x << 13)x ^= (x >> 17)x ^= (x << 5)return random_numbers```(2)设定参数并生成随机数```pythonseed = 12345n = 1000random_numbers = xorshift(seed, n)print(random_numbers)```3. Mersenne Twister算法实验(1)安装Mersenne Twister算法库```shellpip install numpy```(2)编写Mersenne Twister算法函数```pythonimport numpy as npdef mt19937(seed):random_numbers = np.random.RandomState(seed) return random_numbers.rand(n)n = 1000random_numbers = mt19937(12345)print(random_numbers)```五、实验结果与分析1. 线性同余法(LCG)生成的随机数序列具有较好的随机性,但存在周期性,当n足够大时,周期将变得非常明显。
随机数的产生和检验

随机数的产生和检验随机数的产生与检验摘要本文通过对常用的随机数的产生方法简单的分析和理论上的验证,对比研究随机数的产生机理以及产生的随机数的好坏,并以此为依据提出自己的一些改进方法,以便对随机模拟更好的利用。
关键词随机数、随机数的产生随机数的检验一、引言随机数的产生方法的研究已经有较长的历史.至今仍有统计学者继续研究随机数的产生的方法和理论.随机数的产生,最早的方法称为手工方法.即采用抽签、掷骰子、抽牌、摇号或者从搅乱的罐子中取带数字的球等方法,许多彩票的发行仍采用这种方法。
随着计算机和模拟方法的应用,计算机来产生随机数成为新的课题。
利用计算机产生随机数有两种方法,在计算机内输入随机数表和把具有随机性质的物理过程变换为随机数,如粒子的辐射性,裂变等等。
后者得到的随机数均匀性和随机性都很好,而且取之不尽的,但是缺点也明显,对计算的结果不能重复检验,这种物理随机数的产生需要大量的人力物力去检查和维修,成本过高。
而数学方法产生的随机数得到了广泛的应用,虽然产生的随机数为伪随机的,正是因为它的占用内存少、速度快、可重复性的优点。
<统计计算>论文随机数的应用范围很广,对于随机数的均匀性,随机性,独立性的检验也是不可缺少的,只有通过了检验的随机数才有更大的利用空间。
本文通过对几种常见的随机数的产生方法进行比较分析,总结其优缺点,并提出一些改进方法。
二、产生随机数的几种常用方法2.11线性同余法(LCG)初值线性同余法通过满足公式(2.1)产生随机序列,主要参数为a, c, M。
只有选择合适的参数才能得到随机数的周期接近或达到M。
我们把a=137,M=256,c=187用公式(2.1)产生的伪随机数产生方法称为方法T1(见附录1)(周期为256)。
类似的,我们把a=1103515245/65536,M=32768(Linux下M=2147483647),c=12345/65536用公式(2.1)产生的伪随机数称为方法MO(见附录2),它就是我们通常所使用的标准库函数rand。
课程设计一:随机数的产生及统计特性分析-实验报告

标准实验报告实验名称:随机数的产生及统计特性分析实验报告学生姓名:学号:指导教师:实验室名称:通信系统实验室实验项目名称:随机数的产生及统计特性分析实验学时:6(课外)【实验目的】随机数的产生与测量:产生瑞利分布随机数,测量它们的均值、方差、相关函数,分析其直方图、概率密度函数及分布函数。
通过本实验进一步理解随机信号的一、二阶矩特性及概率特性。
【实验原理】瑞利分布密度函数为:)0(,0,)(2222>⎪⎪⎩⎪⎪⎨⎧<≥=-σσσxxexxfx均值与方差:EX =σπ2,V ar(X)=2)22(σπ-相关函数:⎰+∞∞--=+=)(*)()()()(txtxdttxtxrxττ均值各态历经定义:E[X(t)]以概率1等于A[X(t)],则称X(t)均值各态历经。
物理含义为:只要观测的时间足够长,每个样本函数都将经历信号的所有状态,因此,从任一样本函数中可以计算出其均值。
——“各态历经性”、“遍历”。
于是,实验只需在其任何一个样本函数上进行就可以了,问题得到极大简化。
【实验记录】程序执行结果:rayl_mean =3.7523 err_mean = 0.7523 rayl_var = 3.8303 err_var = 0.8303【实验分析】可以看到,统计均值、统计方差与理论值都很接近。
当序列长度为1000时候,均值误差为5.63%,方差误差为12.19%;当序列长度为10000时,均值误差为0.79%,方差误差为1.04%,可以看到随着序列长度增大,样本的统计均值与统计方差与理论值得误差明显减小,当序列长度足够大的时候,样本的统计均值与统计方差会趋近与理论均值与理论方差,可以用统计均值、统计方差来计算理论均值与方差。
通过比较样本的直方图,与理论的瑞利分布概率密度函数图,发现样本出现的频率分布趋近于理论概率值,可见,当样本足够大的时候,随机变量取值的频率趋近于其概率,可以用频率分布近似概率分布。
随机信号分析实验报告(基于MATLAB语言)

随机信号分析实验报告——基于MATLAB语言姓名:_班级:_学号:专业:目录实验一随机序列的产生及数字特征估计 (2)实验目的 (2)实验原理 (2)实验内容及实验结果 (3)实验小结 (6)实验二随机过程的模拟与数字特征 (7)实验目的 (7)实验原理 (7)实验内容及实验结果 (8)实验小结 (11)实验三随机过程通过线性系统的分析 (12)实验目的 (12)实验原理 (12)实验内容及实验结果 (13)实验小结 (17)实验四窄带随机过程的产生及其性能测试 (18)实验目的 (18)实验原理 (18)实验内容及实验结果 (18)实验小结 (23)实验总结 (23)实验一随机序列的产生及数字特征估计实验目的1.学习和掌握随机数的产生方法。
2.实现随机序列的数字特征估计。
实验原理1.随机数的产生随机数指的是各种不同分布随机变量的抽样序列(样本值序列)。
进行随机信号仿真分析时,需要模拟产生各种分布的随机数。
在计算机仿真时,通常利用数学方法产生随机数,这种随机数称为伪随机数。
伪随机数是按照一定的计算公式产生的,这个公式称为随机数发生器。
伪随机数本质上不是随机的,而且存在周期性,但是如果计算公式选择适当,所产生的数据看似随机的,与真正的随机数具有相近的统计特性,可以作为随机数使用。
(0,1)均匀分布随机数是最最基本、最简单的随机数。
(0,1)均匀分布指的是在[0,1]区间上的均匀分布, U(0,1)。
即实际应用中有许多现成的随机数发生器可以用于产生(0,1)均匀分布随机数,通常采用的方法为线性同余法,公式如下:,序列为产生的(0,1)均匀分布随机数。
定理1.1若随机变量X 具有连续分布函数,而R 为(0,1)均匀分布随机变量,则有2.MATLAB中产生随机序列的函数(1)(0,1)均匀分布的随机序列函数:rand用法:x = rand(m,n)功能:产生m×n 的均匀分布随机数矩阵。
(2)正态分布的随机序列函数:randn用法:x = randn(m,n)功能:产生m×n 的标准正态分布随机数矩阵。
随机信号分析实验:随机序列的产生及数字特征估计

实验一 随机序列的产生及数字特征估计实验目的1. 学习和掌握随机数的产生方法。
2. 实现随机序列的数字特征估计。
实验原理1.随机数的产生随机数指的是各种不同分布随机变量的抽样序列(样本值序列)。
进行随机信号仿真分析时,需要模拟产生各种分布的随机数。
在计算机仿真时,通常利用数学方法产生随机数,这种随机数称为伪随机数。
伪随机数是按照一定的计算公式产生的,这个公式称为随机数发生器。
伪随机数本质上不是随机的,而且存在周期性,但是如果计算公式选择适当,所产生的数据看似随机的,与真正的随机数具有相近的统计特性,可以作为随机数使用。
(0,1)均匀分布随机数是最最基本、最简单的随机数。
(0,1)均匀分布指的是在[0,1]区间上的均匀分布,即U(0,1)。
实际应用中有许多现成的随机数发生器可以用于产生(0,1)均匀分布随机数,通常采用的方法为线性同余法,公式如下:Ny x N ky y y nn n n ===-) (mod ,110 (1.1)序列{}n x 为产生的(0,1)均匀分布随机数。
下面给出了(1.1)式的3组常用参数:① 1010=N ,7=k ,周期7105⨯≈;②(IBM 随机数发生器)312=N ,3216+=k ,周期8105⨯≈; ③(ran0)1231-=N ,57=k ,周期9102⨯≈;由均匀分布随机数,可以利用反函数构造出任意分布的随机数。
定理1.1 若随机变量X 具有连续分布函数)(x F X ,而R 为(0,1)均匀分布随机变量,则有)(1R F X X -= (1.2)由这一定理可知,分布函数为)(x F X 的随机数可以由(0,1)均匀分布随机数按(1.2)式进行变换得到。
2.MATLAB 中产生随机序列的函数 (1)(0,1)均匀分布的随机序列函数:rand用法:x = rand(m,n)功能:产生m ×n 的均匀分布随机数矩阵。
(2)正态分布的随机序列 函数:randn用法:x = randn(m,n)功能:产生m ×n 的标准正态分布随机数矩阵。
随机数的产生及统计特性分析-实验报告

电子科技大学通信与信息工程学院标准实验报告实验名称:随机数的产生及统计特性分析电子科技大学教务处制表电子科技大学实验报告学生姓名:吴子文学号:2902111011 指导教师:周宁实验室名称:通信系统实验室实验项目名称:随机数的产生及统计特性分析实验学时:6(课外)【实验目的】随机数的产生与测量:分别产生正态分布、均匀分布、二项分布和泊松分布或感兴趣分布的随机数,测量它们的均值、方差、相关函数,分析其直方图、概率密度函数及分布函数。
通过本实验进一步理解随机信号的一、二阶矩特性及概率特性。
编写MATLAB程序,产生服从N(m, sigma2)的正态分布随机数,完成以下工作:(1)、测量该序列的均值,方差,并与理论值进行比较,测量其误差大小,改变序列长度观察结果变化;(2)、分析其直方图、概率密度函数及分布函数;(3)、计算其相关函数,检验是否满足Rx(0)=mu^2+sigma2,观察均值mu 为0和不为0时的图形变化;(4)、用变换法产生正态分布随机数,重新观察图形变化,与matlab函数产生的正态分布随机数的结果进行比较。
【实验原理】1、产生服从N(m, sigma2)的正态分布随机数,在本实验中用matlab中的函数normrnd()产生服从正态分布的随机数。
(1)R = normrnd(mu,sigma) 产生服从均值为mu,标准差为sigma的随机数,mu和sigma可以为向量、矩阵、或多维数组。
(2)R = normrnd(mu,sigma,v) 产生服从均值为mu 标准差为sigma的随机数,v是一个行向量。
如果v是一个1×2的向量,则R为一个1行2列的矩阵。
如果v 是1×n 的,那么R 是一个n 维数组。
(3)R = normrnd(mu,sigma,m,n) 产生服从均值为mu 标准差为sigma 的随机数,标量m 和n 是R 的行数和列数。
2、测量该序列的均值、方差,并与理论值进行比较,测量其误差大小,改变序列长度观察结果变化。
随机数讲解

随机数讲解随机数是指一个数列,其中的每个数是按照一定的规则排列的,看起来像是没有规律可循的。
在计算机科学中,随机数是非常重要的概念,它被应用于众多领域,例如密码学、模拟实验、数据分析等。
本文将从随机数的定义、分类、特性、产生方法、应用等方面进行讲解,以帮助读者更好地理解和应用随机数。
首先,让我们来了解什么是随机数。
随机数(Random Number)通常是指在一定范围内等可能地取得各个数值的数列。
按照这个定义,随机数具有以下特性:1.不可预测性:随机数的出现是随机的,没有规律可循,无法事先预测;2.均匀性:理想情况下,随机数应该是均匀分布的,即每个数值出现的概率相等;3.独立性:随机数之间应相互独立,前一个数的出现不应对后一个数的出现产生影响。
根据生成方法的不同,随机数可以分为伪随机数和真随机数。
伪随机数是通过算法和初始种子生成的,虽然看起来像是随机的,但实质上是重复周期性的。
真随机数则是通过物理过程产生的,例如大气噪声、放射性衰变等不可预测的事件。
本文将主要介绍伪随机数。
伪随机数的生成方法有很多种,常见的有线性同余法、离散均匀分布法和高斯分布法等。
其中,线性同余法是最常用的一种方法。
它的基本原理是通过迭代计算,在一定范围内产生一系列看起来随机的数值。
具体的计算公式为:X(n+1) = (a * X(n) + b) mod m其中,X(n)是当前随机数,X(n+1)是下一个随机数,a、b和m是常数。
通过调整这些参数的值,可以得到不同范围和分布的随机数。
随机数的应用非常广泛,下面是其中几个常见的应用领域:1.密码学:随机数在密码学中扮演着非常重要的角色,用于生成加密密钥、初始化向量等。
因为随机数具有不可预测性和均匀性,所以在密码学中可以保证密钥的安全性和难以破解性。
2.模拟实验:随机数在模拟实验中起到重要的作用,用于生成仿真数据、模拟实验的随机变量等。
通过引入随机数,可以使得模拟结果更加真实且具有统计学意义。
随机数的产生和特性曲线
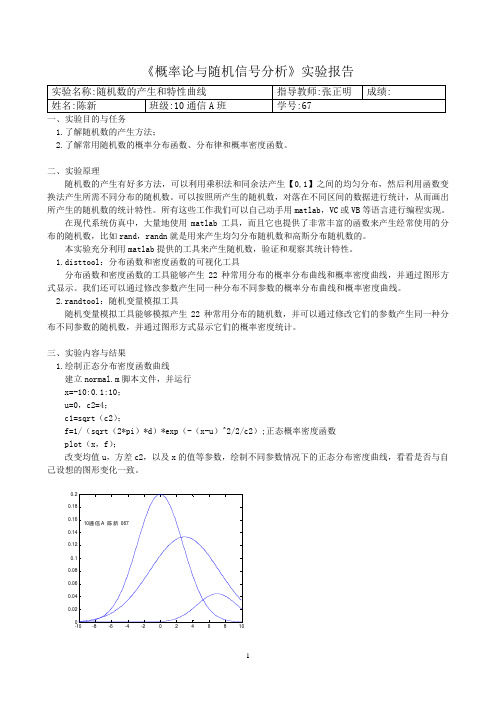
《概率论与随机信号分析》实验报告一、实验目的与任务1.了解随机数的产生方法;2.了解常用随机数的概率分布函数、分布律和概率密度函数。
二、实验原理随机数的产生有好多方法,可以利用乘积法和同余法产生【0,1】之间的均匀分布,然后利用函数变换法产生所需不同分布的随机数。
可以按照所产生的随机数,对落在不同区间的数据进行统计,从而画出所产生的随机数的统计特性。
所有这些工作我们可以自己动手用matlab,VC或VB等语言进行编程实现。
在现代系统仿真中,大量地使用matlab工具,而且它也提供了非常丰富的函数来产生经常使用的分布的随机数,比如rand,randn就是用来产生均匀分布随机数和高斯分布随机数的。
本实验充分利用matlab提供的工具来产生随机数,验证和观察其统计特性。
1.disttool:分布函数和密度函数的可视化工具分布函数和密度函数的工具能够产生22种常用分布的概率分布曲线和概率密度曲线,并通过图形方式显示。
我们还可以通过修改参数产生同一种分布不同参数的概率分布曲线和概率密度曲线。
2.randtool:随机变量模拟工具随机变量模拟工具能够模拟产生22种常用分布的随机数,并可以通过修改它们的参数产生同一种分布不同参数的随机数,并通过图形方式显示它们的概率密度统计。
三、实验内容与结果1.绘制正态分布密度函数曲线建立normal.m脚本文件,并运行x=-10:0.1:10;u=0,c2=4;c1=sqrt(c2);f=1/(sqrt(2*pi)*d)*exp(-(x-u)^2/2/c2);正态概率密度函数plot(x,f);改变均值u,方差c2,以及x的值等参数,绘制不同参数情况下的正态分布密度曲线,看看是否与自己设想的图形变化一致。
2.利用disttool产生不同分布、不同参数的分布函数和分布函数密度曲线,观察各种分布曲线的特点,并记录二项分布、正态分布、指数分布、瑞利分布曲线。
正态:二项分布:指数分布:瑞利分布:3.利用randtool工具,产生不同分布、不同参数的随机数并进行统计,绘制密度函数曲线,并观察和记录不同样本数时统计特性的差别。
随机数的产生

随机数的产生青岛理工大学精品课程《概率论与数理统计科学实验》(实验三)35 实验三随机数的生成一、实验问题1. 问题背景多次重复地抛掷一枚匀质的硬币是一个古老而现实的实验问题, 通过分析“正面向上”出现的频率, 我们可以从中得出许多结论. 但要做这个简单而重复的试验, 很多人没有多余的时间或耐心来完成它, 现在借助于计算机的帮助,人人都可以在很短的时间内完成它. 因此,借助于计算机进行模拟随机试验, 产生服从各类分布的随机数, 通过数据处理和分析, 我们可以从中发现许多有用的规律, 或者来验证我们理论推导的结论是否正确. 本实验的主要目的是产生服从某种分布的随机数.2. 实验目的与要求(1) 熟悉常见分布的随机数产生的有关命令;(2) 掌握随机模拟的方法;(3) 提高读者观察实验现象或处理数据方面的能力.二、实验操作过程随机数生成的基本原理生成服从给定分布的随机数, 需要首先生成服从均匀分布的随机数. 常用的生成均匀分布随机数的方法是同余法, 其递推公式为xi = (axi-1+c) modm.给定初值x0, 可以迭代出均匀随机数x1, x2, …, xn, 将它们进行标准化(此时随机数界于0和1之间)或极差标准化(此时随机数界于-1和1之间), 可以得到均匀分布的随机数.获得均匀分布的随机数以后, 可以用多种方法构造基于该随机数的随机变量, 常用的方法是反函数法, 即利用随机变量x 的分布函数F(x)的反函数F -1 (x)来推求随机变量. 基本算法是:(1) 产生均匀分布随机数ri;(2) 令xi = F -1 (ri), 然后返回.下面结合正态分布随机变量的生成进行具体介绍:正态分布的分布函数为2 11()exp[()]d2 2 x x.青岛理工大学精品课程《概率论与数理统计科学实验》(实验三) 36 式中μ 为期望, σ 2 为方差. 由中心极限定理, 有1 12()2niixnr n,当n = 12 时, 可达到较好精度, 故121 (6) ii xr,x 就是基于均匀分布随机数ri 的服从正态分布的随机数.1. 二项分布的随机数的产生基本数学原理: 设X 服从参数为n, p 的二项分布, 具体概率分布见第18页实验二, 二, 1.在MATLAB 中用函数binornd产生参数为n, p 的二项分布的随机数,其基本的调用格式如下:·R = binornd(N, P) % N, P为二项分布的两个参数, 返回服从参数为N, P 的二项分布的一个随机数;·R = binornd(N, P, m, n) % m, n分别表示随机数产生的行数和列数. 例3-1 产生参数为10, 概率为0.5 的二项分布的随机数.(1) 产生1 个随机数;(2) 产生10 个随机数;(3) 产生6(要求2 行3 列)个随机数.解只需在命令窗口中依次输入下列命令:R1=binornd(10,0.5), %产生一个随机数5.R2=binornd(10,0.5,1,10), %产生1 行10 列共10 个随机R3=binornd(10,0.5,[2,3]). %同命令binornd(10,0.5,2,3).2.均匀分布的随机数的产生基本数学原理:设X在区间(a,b)上服从均匀分布, 具体概率密度见第23页实验二, 二, 5.在MATLAB 中用函数unifrnd产生均匀分布的随机数,其基本调用格式如下:·R = unifrnd(a, b) %返回参数为a,b的连续型均匀分布的随机数; ·R = unifrnd(a, b, m) % m 指定产生m 行m列个随机数;·R = unifrnd(a, b, m, n) % m, n分别表示产生的随机数的行数和列数. 青岛理工大学精品课程《概率论与数理统计科学实验》(实验三) 37 例3-2 产生区间(0, 1)上的连续型均匀分布的随机数.(1) 产生6×6个随机数;(2) 产生6(要求2 行3 列)个随机数.解只需在命令窗口中依次输入下列命令:random1= unifrnd(0, 1, 6), % 产生6 行6 列个随机数.random2= unifrnd(0, 1, 2, 3). % 产生2 行3 列个随机数.注意命令unidrnd(N, 2, 3) 产生2 行3 列个离散型均匀分布的随机数.3. 正态分布的随机数的产生基本数学原理: 设X 服从参数为μ 和σ 2 的正态分布, 具体概率密度见第25 页实验二, 二, 7.在MATLAB 中用函数normrnd产生参数为μ, σ的正态分布的随机数,其基本的调用格式如下:·R = normrnd(MU, SIGMA) %返回均值为MU, 标准差为SIGMA 的正态分布的随机数, R可以是向量或矩阵;·R = normrnd(MU, SIGMA, m) % m 指定随机数的行数与列数, 与R 同维数, 产生m 行m 列个随机数;·R = normrnd(MU, SIGMA, m, n) %m, n分别表示R 的行数和列数. 例3-3 生成满足下列情形的正态分布随机数:(1) 均值和标准差变化;(2) 随机数输出为矩阵;(3) 均值为矩阵.解(1) 在命令窗口中输入:n1 = normrnd(1:6, 1./(1:6)) %1./(1:6)运算结果是1,,,,,23456.n1 =2.1650 2.31343.02504.0879 4.8607 6.2827结果表示: 均值μ为1,2, 3, 4, 5,6, 标准差σ对应地为1,11111,,,,23456的正态随机数. 注意, 大多数随机数在均值附近产生, 其它分布也有类似情形.(2) 在命令窗口再输入:n2=normrnd(10, 0.5, [2, 3]) %与命令normrnd(10, 0.5, 2, 3)效果相同.回车后显示:青岛理工大学精品课程《概率论与数理统计科学实验》(实验三) 38 n2 =9.7837 10.0627 9.42689.1672 10.1438 10.5955结果表示: 均值μ为10, 标准差σ为0.5 的2 行3 列个正态随机数.(3) 在命令窗口再输入:n3 = normrnd([1 2 3;4 5 6],0.1,2,3)n3 =0.9299 1.9361 2.96405.0577 5.9864结果表示: 均值μ 为矩阵123456,标准差σ 为0.1 的2 行3 列个正态随机数.4. 常见分布的随机数的产生常见分布的随机数产生的使用格式与上面相同,见表3-1.3-1 常见分布的随机数产生函数表函数名调用形式注释betarnd betarnd(A, B,m,n) 参数为A, B的β分布随机数binornd binornd(N,P,m,n) 参数为N, p的二项分布随机数chi2rnd chi2rnd(N, m, n) 自由度为N的χ 2 分布随机数exprnd exprnd(Lambda,m,n) 参数为Lambda的指数分布随机数frnd frnd(N1, N2, m,n) 第一自由度为N1,第二自由度为N2 的F 分布随机数gamrnd gamrnd(A, B, m,n) 参数为A, B的γ分布随机数geornd geornd(P,m,n) 参数为P的几何分布随机数hygernd hygernd(M,K,N,m,n) 参数为M,K,N的超几何分布随机数lognrnd lognrnd(MU, SIGMA, m, n) 参数为MU, SIGMA 的对数正态分布随机数nbinrnd nbinrnd(R, P,m,n) 参数为R, P的负二项式分布随机数ncfrnd ncfrnd(N1, N2, delta,m,n) 参数为N1,N2, delta的非中心F 分布随机数nctrnd nctrnd(N, delta, m,n) 参数为N, delta的非中心t分布随机数ncx2rnd ncx2rnd(N, delta, m,n) 参数为N, delta的非中心卡方分布随机数normrnd normrnd(MU, SIGMA, m,n) 参数为MU, SIGMA的正态分布随机数青岛理工大学精品课程《概率论与数理统计科学实验》(实验三) 39 poissrnd poissrnd(Lambda,m,n) 参数为Lambda的泊松分布随机数raylrnd raylrnd(B, m,n) 参数为B的瑞利分布随机数trnd trnd(N, m,n) 自由度为N的t分布随机数unidrnd unidrnd(N,m, n) 离散型均匀分布随机数unifrnd unifrnd ( A,B,m,n) (A,B)上连续型均匀分布随机数weibrnd weibrnd(A, B,m, n) 参数为A, B的威布尔分布随机数5.通用函数求各分布的随机数在MATLAB 中用函数random产生指定分布的随机数,其基本的调用格式如下:·y = random('name',A1,A2,A3, m, n) %name为分布函数名, 其取值见表3-2; A1, A2,A3 为分布的参数;m, n 指定产生随机数的行数和列数.表3-2 常见分布函数名称表name的取值函数说明'beta' 或'beta' beta分布'bino' 或'binomial' 二项分布'chi2' 或'chisquare' χ 2 分布'exp' 或'exponential' 指数分布'f' 或'f' F分布'gam' 或'gamma' γ分布'geo' 或'geometric' 几何分布'hyge' 或'hypergeometric' 超几何分布'logn' 或'lognormal' 对数正态分布'nbin' 或'negative Binomial' 负二项式分布'ncf' 或'Noncentral F' 非中心F分布'nct' 或'Noncentral t' 非中心t分布'ncx2' 或'noncentralchi-square' 非中心χ 2 分布'norm' 或'normal' 正态分布'poiss' 或'poisson' 泊松分布'rayl' 或'rayleigh' 瑞利分布't' 或't' t分布'unif' 或'uniform' 连续型均匀分布'unid' 或'discreteuniform' 离散型均匀分布'weib' 或'weibull' Weibull分布青岛理工大学精品课程《概率论与数理统计科学实验》(实验三) 40 例3-4 用函数“random”产生12(含 3 行 4 列)个均值为2, 标准差为0.3的正态分布随机数.解在命令窗口输入:y=random('norm', 2, 0.3, 3, 4)回车后显示:y =2.3567 2.0524 1.8235 2.03421.9887 1.94402.6550 2.32002.0982 2.2177 1.9591 2.01786. 随机数生成工具箱MATLAB 提供了随机数生成工具箱, 使用图形用户界面, 可以交互式地生成常用的各种随机数.调用格式:·randtool说明: randtool 命令打开一个图形用户界面, 可以观察在服从一定概率分布的随机样本直方图上改变参数和样本大小带来的变化.单击“Export…”(即“输出”按钮)按钮, 输出随机数的当前位置. 结果保存在变量“ans”中.单击“Resample” (即“重复取样”按钮)按钮, 从同一分布的总体中进行重复取样.在图形上方的函数“Distribution”(即“分布类型”按钮)弹出式菜单中进行选择, 可以改变分布函数类型.移动滚动条或在参数名右方的编辑框中输入数值, 可以改变参数的设置.在滚动条的顶部或底部编辑框中输入数值, 可以改变参数的上下界设置.在“Sample” (即“样本”按钮)编辑框中输入数值, 可以改变样本容量的大小.完成上面的操作后, 单击右上方的“关闭”按钮, 关闭图形用户界面. 例3-5 用随机数生成工具箱, 生成正态分布随机数和均匀分布随机数的直方图.解在命令窗口输入: randtool 命令, 打开随机数生成界面, 如图3-1 所示.在“Distribution”下拉式列表框中进行选择, 确定生成什么分布的随机数. 在“Samples”窗口中输入样本的大小. 在图形下方输入对应分布的参数及其上下界区间. 单击“Resample”按钮, 生成随机数并用直方图表示.在“Distribution”下拉式列表框中选择“Uniform”选项, 将生成服从均匀分青岛理工大学精品课程《概率论与数理统计科学实验》(实验三) 41 布的随机数. 如图3-2 所示.图3-1 正态分布的随机数的直方图图3-2 均匀分布的随机数的直方图三、实验结论与总结产生各种随机数, 是我们进行科学试验经常使用的一种试验手段和方法,通过产生满足某些条件的随机数, 画出它们的散点图, 利用概率统计的方法,可以分析随机数分布的规律, 进而找寻事物本身隐含的关系, 或者验证理论结果的正确性.四、实验习题1. 产生区间(-1, 1 )上的12 个连续型与离散型的均匀分布随机数.2. 产生12(要求3行4 列)个标准正态分布随机数.3. 产生20个λ=1 的指数分布随机数.4. 产生32(要求4行8 列)个参数λ=3 的泊松分布随机数.5. 用函数“random”分别产生20 (要求4行5 列)个均值为10, 标准差为6的正态分布随机数和20 个均匀分布随机数.6.利用随机数生成工具箱, 生成二项分布、泊松分布、指数分布和F 分布的随机数的直方图.。
概率统计随机数应用实验

在数据分析中的应用
随机抽样
在数据分析中,随机抽样是一种常用 的方法,通过生成随机数来从总体中 抽取样本,从而进行数据分析。
随机森林算法
随机森林是一种基于决策树的集成学 习算法,其中的特征选择和样本分割 都是通过随机抽样实现的。
05
实验步骤与结果分析
实验步骤设计
步骤一
确定实验目标
步骤二
选择随机数生成方法
真随机数生成器的缺点是速度慢、不易于集成到微处理器中。
随机数质量评估
1
评估随机数的质量是确保随机数在应用中有效性 的重要步骤,包括统计测试和密码学测试。
2
统计测试包括频率测试、累积和测试、离散概率 分布测试等,用于检验随机数的统计特性是否符 合预期。
3
密码学测试包括强度测试、随机性测试、密钥生 成测试等,用于检验随机数的安全性是否满足密 码学应用的要求。
02
概率统计基础
概率论基本概念
概率
描述随机事件发生的可能性大小。
独立事件
两个事件之间没有相互影响。
条件概率
在某一事件发生的条下,另一事件发生的概 率。
统计推断方法
参数估计
通过样本数据估计总体参数的方法。
假设检验
根据样本数据对某一假设进行检验的方法。
方差分析
比较不同组数据的变异程度。
随机变量及其分布
04
随机数在实验中的应用
在模拟中的应用
模拟实验
随机数可用于模拟各种实验条件,如模拟物理过程、化学反应、生物实验等。 通过生成随机数,可以模拟实验中的随机因素,从而更准确地预测实验结果。
蒙特卡洛方法
蒙特卡洛方法是一种基于随机抽样的数值计算方法,通过生成大量随机数,可 以对复杂问题进行分析和求解,例如计算圆周率、求解数学优化问题等。
随机数实验报告

云南大学软件学院实验报告姓名:学号:班级:信息安全日期:成绩:f[i]=(float)n[i]/(MAX*2);//因为生成的是MAX个8bit的数据,换成16进制(4bit)//就是2MAX个16进制的数字了}for(int k=0;k<16;k++){printf("%2d出现的次数为:%2d , ",k,n[k]);printf("%2d出现的频率为:%f\n",k,f[k]); }最后看看每个随机数出现了多少次,和随机数出现的次数在总的数字里占的比例。
看看每个随机数的次数和频率是否大致相等。
比较接近就可以证明是随机的。
下面的数据记录和计算模块,将会对统计结果进行详细说明。
数据记录和计算当从键盘输入“abcd”的初始向量时,产生的2*MAX(即20000)随机数情况如下:从上述的统计结果可以看书0-15出现的次数大致都为1200多,频率大致都为0.06多,结果都比较接近。
再来测一组数据,从键盘输入“12eh5”的初始向量时,产生的2*MAX(即20000)随机数情况如下:从上述的统计结果可以看书0-15出现的次数大致都为1200多,频率大致都为0.06多,结果都比较接近。
之后又测了N多组数据,每组数据的0-15的次数和频率都大致相等,这里就不一一展示了。
从这N组数据的统计结果中,可以看出此次生成的这个20000个数字时随机产生的,符合随机数的定义。
结论(结果)1、本次实验用以前学过的密码技术实验中的RC4算法产生密钥流的思想来生成随机数。
2、通过统计每个随机数出现的次数和频率来判断是否是随机序列。
3、观察出现的次数和频率大致相近,可以判断此次实验中产生的序列是随机序列。
源代码#include <stdio.h>#include <stdlib.h>#include <string.h>#define MAX 10000typedef unsigned char unchar;//交换函数,用来交换两个变量void Swap(unchar *a,unchar *b)。
概率论与数理统计实验 实验2 随机数的产生 数据的统计描述

分布峰度
其估计量为:
g2
E ( X E ( X ))4
4
1 4 ( X X ) i G2 n s4
1 2 ( X X ) i n
其中
s
峰度是分布形状的另一种度量,正态分布 的峰度为3,若g2比3大很多,表示分布有沉 重的尾巴,说明样本中含有较多远离均值的 数据,因而峰度可用作衡量偏离正态分布的 尺度之一 命令:y=kurtosis(x) 若x为矢量,返回x的样本峰度,若x为矩 阵,结果为行向量,每个元素对应x中列 元素的样本峰度。
本值,将其按由小到大的顺序排列,并 重新编号,记为
x x x
* 1 * 2
* n
则经验分布函数为:
0 k Fn ( x) n 1
4、二项分布随机数
1) R = binornd(n, p):产生一个二项分布随机数 2) R = binornd(n,p,m,n)产生m行n列的二项分布随机数 例4、产生B(10,0.8)上的一个随机数,15个随机数, 3行6列的随机数。 命令 (1) y1=binornd(10,0.8) (2) y2=binornd(10,0.8,1,15) (3) y3=binornd(10,0.8,3,6)
3、指数分布随机数
1) R = exprnd(λ):产生一个指数分布随机数 2)R = exprnd(λ,m,n)产生m行n列的指数分布随机数
例3、产生E(0.1)上的一个随机数,20个随机数, 2行6列的随机数。
命令 (1) y1=exprnd(0.1) (2) y2=exprnd(0.1,1,20) (3) y3=exprnd(0.1,2,6)
① 产生均匀随机数R,即R~U(0,1)
北理工随机信号分析实验报告
本科实验报告实验名称:随机信号分析实验实验一 随机序列的产生及数字特征估计一、实验目的1、学习和掌握随机数的产生方法。
2、实现随机序列的数字特征估计。
二、实验原理1、随机数的产生随机数指的是各种不同分布随机变量的抽样序列(样本值序列)。
进行随机信号仿真分析时,需要模拟产生各种分布的随机数。
在计算机仿真时,通常利用数学方法产生随机数,这种随机数称为伪随机数。
伪随机数是按照一定的计算公式产生的,这个公式称为随机数发生器。
伪随机数本质上不是随机的,而且存在周期性,但是如果计算公式选择适当,所产生的数据看似随机的,与真正的随机数具有相近的统计特性,可以作为随机数使用。
(0,1)均匀分布随机数是最最基本、最简单的随机数。
(0,1)均匀分布指的是在[0,1]区间上的均匀分布,即 U(0,1)。
实际应用中有许多现成的随机数发生器可以用于产生(0,1)均匀分布随机数,通常采用的方法为线性同余法,公式如下:)(m od ,110N ky y y n n -=N y x n n /=序列{}n x 为产生的(0,1)均匀分布随机数。
下面给出了上式的3组常用参数: 1、10N 10,k 7==,周期7510≈⨯;2、(IBM 随机数发生器)3116N 2,k 23,==+周期8510≈⨯; 3、(ran0)315N 21,k 7,=-=周期9210≈⨯;由均匀分布随机数,可以利用反函数构造出任意分布的随机数。
定理 1.1 若随机变量 X 具有连续分布函数F X (x),而R 为(0,1)均匀分布随机变量,则有)(1R F X x -=由这一定理可知,分布函数为F X (x)的随机数可以由(0,1)均匀分布随机数按上式进行变换得到。
2、MATLAB 中产生随机序列的函数(1)(0,1)均匀分布的随机序列 函数:rand 用法:x = rand(m,n)功能:产生m ×n 的均匀分布随机数矩阵。
(2)正态分布的随机序列 函数:randn 用法:x = randn(m,n)功能:产生m ×n 的标准正态分布随机数矩阵。
第4讲 随机数的生成及随机变量抽样

一、均匀分布U(0,1)的随机数的产生
• 产生均匀分布的标准算法在很多高级计算机语 言的书都可以看到。算法简单,容易实现。使用者 可以自己手动编程实现。Matlab 中也提供给我们 用于产生均匀分布的各种函数。我们的重点是怎样 通过均匀分布产生服从其他分布的随机数。因此, 直接使用Matlab提供的可靠安全的标准函数,当然 不用费事了。
学习主要的随机变量抽样方法1均匀分布u01的随机数的产生2其他各种分布的随机数的产生方法3随机数生成实例4实验作业随机数的生成及随机变量抽样随机数的产生是实现mc计算的先决条件
随机数的生成及随机变 量抽样 实验目的
学习主要的随机变量抽样方法
实验内容
1、均匀分布U(0,1)的随机数的产生 2、其他各种分布的随机数的产生方法 3、随机数生成实例 4、实验作业
随机向量的抽样方法
在用Monte Carlo等方法解应用问题时,随机 向量的抽样也是经常用到的. 若随机向量各分量相互独立,则它等价于多个 一元随机变量的抽样。
例8 生成单位正方形内均匀分布的1行10000列随机 数,并画散点图。 mm=10000 xRandnum=unifrnd(0,1,1,mm); yRandnum=unifrnd(0,1,1,mm); plot(xRandnum,yRandnum,'.')
0.25
0.05
F(X4)=0.95
F(X5)=1.00
( .70 -- .95]
( .95 – 1)
随机变量生成的算法为 ①产生一个u(0,1),并令i=0; ②令i=i+1; ③若u>F(xi),转回到第②步,否则转至④;
mm=10000;Randnum=unifrnd(0,1,1,mm);xRandnum=zeros(1,mm); for ii=1:mm if Randnum(1,ii)<=0.1 xRandnum(1,ii)=10; else if Randnum(1,ii)<=0.3 xRandnum(1,ii)=20; else if Randnum(1,ii)<=0.7 xRandnum(1,ii)=30; else if Randnum(1,ii)<=0.95 xRandnum(1,ii)=40; else xRandnum(1,ii)=50; end end end end end cdfplot(xRandnum)
随机信号分析实验报告范文

随机信号分析实验报告范文HaarrbbiinnIInnttiittuutteeooffTTeecchhnnoollooggyy实验报告告课程名称:院系:电子与信息工程学院班级:姓名:学号:指导教师:实验时间:实验一、各种分布随机数得产生(一)实验原理1、、均匀分布随机数得产生原理产生伪随机数得一种实用方法就是同余法,它利用同余运算递推产生伪随机数序列.最简单得方法就是加同余法为了保证产生得伪随机数能在[0,1]内均匀分布,需要M为正整数,此外常数c与初值y0亦为正整数。
加同余法虽然简单,但产生得伪随机数效果不好。
另一种同余法为乘同余法,它需要两次乘法才能产生一个[0,1]上均匀分布得随机数ﻩﻩﻩ式中,a为正整数。
用加法与乘法完成递推运算得称为混合同余法,即ﻩﻩﻩ用混合同余法产生得伪随机数具有较好得特性,一些程序库中都有成熟得程序供选择。
常用得计算语言如Baic、C与Matlab都有产生均匀分布随机数得函数可以调用,只就是用各种编程语言对应得函数产生得均匀分布随机数得范围不同,有得函数可能还需要提供种子或初始化。
Matlab提供得函数rand()可以产生一个在[0,1]区间分布得随机数,rand(2,4)则可以产生一个在[0,1]区间分布得随机数矩阵,矩阵为2行4列。
Matlab提供得另一个产生随机数得函数就是random(’unif’,a,b,N,M),unif表示均匀分布,a与b就是均匀分布区间得上下界,N与M分别就是矩阵得行与列。
2、、随机变量得仿真根据随机变量函数变换得原理,如果能将两个分布之间得函数关系用显式表达,那么就可以利用一种分布得随机变量通过变换得到另一种分布得随机变量。
若X就是分布函数为F(某)得随机变量,且分布函数F(某)为严格单调升函数,令Y=F(某),则Y必为在[0,1]上均匀分布得随机变量.反之,若Y就是在[0,1]上均匀分布得随机变量,那么即就是分布函数为F某(某)得随机变量。
《基于宽带混沌激光熵源实现高速真随机数的产生》范文

《基于宽带混沌激光熵源实现高速真随机数的产生》篇一一、引言随着信息技术的发展,随机数在密码学、安全通信、数据分析等领域的应用越来越广泛。
真随机数因其不可预测性和不可重复性,成为了保障信息安全的重要基石。
近年来,基于物理现象产生真随机数的方法受到了广泛关注,其中,宽带混沌激光熵源因其高熵、快速度、良好的抗干扰性等优点,成为了真随机数产生的重要物理源。
本文将介绍基于宽带混沌激光熵源实现高速真随机数产生的方法及其应用。
二、宽带混沌激光熵源的原理与特点宽带混沌激光熵源是一种基于激光混沌现象的物理熵源。
其原理是利用激光器在非线性区域运行,产生混沌激光信号,从而获得高熵的随机数。
该熵源具有以下特点:1. 高熵:宽带混沌激光熵源产生的随机数具有较高的信息熵,保证了随机数的质量。
2. 快速度:由于激光混沌现象的快速变化,使得产生的随机数具有较高的生成速度。
3. 抗干扰能力强:宽带混沌激光熵源对外部干扰具有较好的抗干扰能力,保证了随机数的稳定性和可靠性。
三、基于宽带混沌激光熵源的真随机数产生方法基于宽带混沌激光熵源的真随机数产生方法主要包括以下步骤:1. 激光器运行:使激光器在非线性区域运行,产生混沌激光信号。
2. 信号采集与处理:通过高速采样器对混沌激光信号进行采样,并经过数字信号处理技术提取出高熵的随机数序列。
3. 后处理与输出:对提取的随机数序列进行后处理,如去重、均匀化等,最终输出真随机数。
四、真随机数的应用真随机数在密码学、安全通信、数据分析等领域有着广泛的应用。
基于宽带混沌激光熵源产生的真随机数具有以下应用:1. 密码学:真随机数可用于加密算法中的密钥生成,提高密码系统的安全性。
2. 安全通信:真随机数可用于通信系统中的一次一密加密,保障通信安全。
3. 数据分析:真随机数可用于大数据分析中的抽样、初始化等方面,提高数据分析的准确性和可靠性。
五、实验结果与分析我们通过实验验证了基于宽带混沌激光熵源的真随机数产生方法的可行性和性能。
简单的随机实验报告

简单的随机实验报告实验名称:随机抽样实验实验目的:本实验旨在通过随机抽样的方式获取一组数据,以便进行统计分析和讨论。
实验过程:1. 确定样本集合:在进行实验之前,我们需要确定实验所涉及的总体,即我们想要研究的对象。
在本实验中,我们选择了一个购物网站的用户总体作为研究对象。
2. 确定样本容量:由于总体数量通常很大,很难对每个个体进行观察或调查,因此我们需要确定适当的样本容量。
在本实验中,我们选择了100个用户作为样本。
3. 随机抽样:通过使用随机数生成器或其他方法,从总体中随机选择100个用户作为样本。
确保每个用户有相同的机会被选中。
4. 数据收集:针对选中的100个用户,我们进行了一次调查,收集了他们的一些基本信息,如年龄、性别、购买习惯等。
这些数据将用于后续统计分析。
5. 数据分析:收集完数据后,我们对数据进行了统计分析,包括计算样本的平均值、标准差等。
6. 结果解释:根据对样本的统计分析结果,我们对总体进行了一些推断和解释。
比如,根据样本的平均年龄,我们可以推断总体的平均年龄大致在某个范围内。
实验结果与讨论:通过对样本数据的统计分析,我们得到了以下结果:1. 样本平均年龄为30岁,标准差为5岁。
2. 样本中男性用户占60%,女性用户占40%。
3. 样本中有70%的用户每周购买1-3次商品,30%的用户每周购买4次以上商品。
基于这些结果,我们可以进行一些讨论和推断:1. 样本平均年龄为30岁,可以推断总体的平均年龄大致在该范围内。
这对于商家来说,是了解目标消费群体的重要信息。
2. 样本中男性用户占比更高,这可能意味着该网站的商品更受男性用户欢迎,商家可以针对性地开展推广活动。
3. 大部分用户每周购买1-3次商品,商家可以结合这个数据,制定更合理的促销策略,吸引更多用户进行购买。
结论:通过本次随机抽样实验,我们获取了一组有代表性的样本数据,并进行了统计分析和讨论。
通过对样本数据的分析,我们可以对总体做出一些推断和解释,这对于商家制定营销策略具有指导意义。
随机数生成方法、随机数生成法比较以及检验生成的随机序列的随机性的方法

摘要摘要本文着重讨论了随机数生成方法、随机数生成法比较以及检验生成的随机序列的随机性的方法。
在随机序列生成方面,本文讨论了平方取中法、斐波那契法、滞后斐波那契法、移位法、线性同余法、非线性同余法、取小数法等,并比较了各方法的优劣性。
在统计检验方面,介绍了统计检验的方法,并用其检验几种随机数生成器生成的随机数的随机性。
最后介绍了两种新的随机数生成法,并统计检验了生成随机序列的随机性。
关键词:随机数,随机数生成法,统计检验IABSTRACTABSTRACTThis article focuses on methods of random number generator, random number generation method comparison and test the randomness of the generated random sequence method.In random sequence generation, the article discusses the square method, Fibonacci method, lagged Fibonacci method, the shift method, linear congruential method, linear congruence method, taking minority law, and Comparison of advantages and disadvantages of each method.In statistical test, the introduction of the statistical test method, and used to test some random number generator random random numbers generated.Finally, two new random number generation method, and statistical tests of randomness to generate a random sequence.Key Words: random number,random number generator,statistical testII目录第1章引言 (1)1.1 课题背景 (1)1.2 课题的价值及意义 (1)1.3 课题的难点、重点、核心问题及方向 (1)第2章随机数 (3)2.1 基本概念 (3)2.2 产生随机数的一般方法 (3)2.3 随机数生成的数学方法 (4)2.4 产生随机数的方法种类 (5)2.5 随机数的应用 (6)第3章常见随机数生成法与比较 (7)3.1 平方取中法 (7)3.1.1 迭代算法 (7)3.1.2 平方取中法的优缺点 (7)3.2 斐波那契(Fibonacci)法 (8)3.3 滞后斐波那契(Fibonacci)法 (9)3.4 移位法 (9)3.5 线性同余法 (10)3.5.1 模数的选取 (10)3.5.2 乘数的选取 (11)3.5.3 线性同余法的缺陷 (12)3.5.4 广义线性同余法 (12)3.6 非线性同余法 (13)3.6.1 逆同余法 (13)3.6.2 二次同余法 (14)3.6.3 三次同余法 (14)3.6.4 BBS法 (14)3.7 取小数法 (14)III3.8 常见随机数生成法的比较 (15)第4章随机数生成法的统计和检验 (16)4.1 检验类型 (16)4.2 统计检验的一般方法 (16)4.2.1 参数检验 (17)4.2.2 均匀性检验 (18)4.2.3 重要分布 (18)4.2.4 重要定理 (19)4.2.5 卡方检验 (20)4.2.6 柯氏检验 (20)4.2.7 序列检验 (21)4.3 独立性检验 (22)4.4 对线性同余法和取小数法进行随机性检验 (22)第5章新的随机数生成法 (24)5.1 开方取小数法 (24)5.2 一种混合型随机数发生器 (28)5.2.1 超素数长周期法 (28)5.2.2 组合发生器的研究 (30)5.2.3 随机数算法统计检验结果 (30)结束语 (32)参考文献 (33)致谢 (34)外文资料原文 (35)翻译文稿 (37)IV第1章引言第1章引言1.1课题背景随机数(随机序列)在不同的领域有许多不同类型的应用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
电子科技大学通信与信息工程学院标准实验报告实验名称:随机数的产生及统计特性分析电子科技大学教务处制表电子科技大学实验报告学生姓名:吴子文学号:2902111011 指导教师:周宁实验室名称:通信系统实验室实验项目名称:随机数的产生及统计特性分析实验学时:6(课外)【实验目的】随机数的产生与测量:分别产生正态分布、均匀分布、二项分布和泊松分布或感兴趣分布的随机数,测量它们的均值、方差、相关函数,分析其直方图、概率密度函数及分布函数。
通过本实验进一步理解随机信号的一、二阶矩特性及概率特性。
编写MATLAB程序,产生服从N(m, sigma2)的正态分布随机数,完成以下工作:(1)、测量该序列的均值,方差,并与理论值进行比较,测量其误差大小,改变序列长度观察结果变化;(2)、分析其直方图、概率密度函数及分布函数;(3)、计算其相关函数,检验是否满足Rx(0)=mu^2+sigma2,观察均值mu 为0和不为0时的图形变化;(4)、用变换法产生正态分布随机数,重新观察图形变化,与matlab函数产生的正态分布随机数的结果进行比较。
【实验原理】1、产生服从N(m, sigma2)的正态分布随机数,在本实验中用matlab中的函数normrnd()产生服从正态分布的随机数。
(1)R = normrnd(mu,sigma) 产生服从均值为mu,标准差为sigma的随机数,mu和sigma可以为向量、矩阵、或多维数组。
(2)R = normrnd(mu,sigma,v) 产生服从均值为mu 标准差为sigma的随机数,v是一个行向量。
如果v是一个1×2的向量,则R为一个1行2列的矩阵。
如果v 是1×n 的,那么R 是一个n 维数组。
(3)R = normrnd(mu,sigma,m,n) 产生服从均值为mu 标准差为sigma 的随机数,标量m 和n 是R 的行数和列数。
2、测量该序列的均值、方差,并与理论值进行比较,测量其误差大小,改变序列长度观察结果变化。
(1)用mean()函数测量序列的均值:M = mean(A) 如果A 是一个向量,则返回A 的均值。
如果A 是一个矩阵,则把A 的每一列看成一个矩阵,返回一个均值(每一列的均值)行矩阵。
(2)用函数var()求序列的方差:V = var(X) 返回X 的每一列的方差,即返回一个行向量。
3、分析其直方图、概率密度函数及分布函数。
(1)用hist()函数画出M 、V 的直方图:n = hist(Y)将向量Y 中的元素分成10个等长的区间,再返回每区间中元素个数,是个行向量;n = hist(Y ,x)画以x 元素为中心的柱状图;n = hist(Y ,nbins)画以nbins 为宽度的柱状图。
(2)用normpdf()求正态分布概率密度函数值:Y = normpdf(X,mu,sigma)对每一个X 中的值返回参数为mu,sigma 的正态分布概率密度函数值。
(3)normcdf()求正态分布概率密度函数值:Y = normpdf(X,mu,sigma)对每一个X 中的值返回参数为mu,sigma 的累计分布函数值。
4、计算其相关函数,检验是否满足Rx(0)=mu^2+sigma^2,观察均值mu 为0和不为0时的图形变化。
(1)用xcorr()计算互相关。
用[cor2 lag2] = xcorr(x2,'unbiased')计算R 的自相关。
5、用变换法产生正态分布随机数,重新观察图形变化,与matlab 函数产生的正态分布随机数的结果进行比较。
在本实验中采用Box-Muller 变换法:变换法是通过一个变换将一个分布的随机数变换成一个不同分布的随机数。
高斯分布的密度函数()22()2,x f x μσ-=通过Box-Muller 变换,它可以产生精确的正态分布的随机变量。
其变换式如下:1)y v π= (3-6)2)y v π= (3-7)式中u ,v 是在区间[0,1]上服从均匀分布,且相互独立的随机变量,所以得到的随机变量1y ,2y 也应该是相互独立的,且服从N ~(0,1)的标准正态分布。
【实验记录】1、产生随机数,并测量该序列的均值、方差,与理论值进行比较,测量其误差大小,改变序列长度观察结果变化。
代码如下:mu=input('请输入均值=');sigma=input('请输入标准差=');m=input('输入产生的序列的长度='); %m为序列的长度n=input('输入产生的序列个数=');%n为序列的个数R = normrnd(mu,sigma,m,n); %产生服从均值为mu,标准差为sigma的随机数,序列个数为n,序列长度为m。
figure;hist(R);title('正态分布');M = mean(R);%计算均值A=var(R); %计算方差%均值、方差与理论值的比较dm=M-mu;%均值的差值向量dA=A-sigma;%方差的差值向量figure;subplot(2,1,1);plot(dm);title('均值的差值');subplot(2,1,2);plot(dA);title('方差的差值');运行结果:当输入为:均值=0;标准差=1;序列的长度=40;序列个数=40。
结果为当改变序列的长度而其他值没有改变时:令均值=0;标准差=1;序列的长度=200;序列个数=40时。
结果为对照前后两次的结果可以看出,当序列的长度变大时,实验得到的数据与理论值相差变少。
2、分析其直方图、概率密度函数及分布函数;代码如下:mu=input('请输入均值=');sigma=input('请输入标准差=');m=input('输入产生的序列的长度='); %m为序列的长度n=input('输入产生的序列个数=');%n为序列的个数R = normrnd(mu,sigma,m,n); %产生服从均值为mu,标准差为sigma的随机数,序列个数为n,序列长度为m。
figure;subplot(2,2,1);hist(R);title('正态分布');M = mean(R);%计算均值subplot(2,2,2);hist(M);title('均值');A=var(R); %计算方差subplot(2,2,3);hist(A);title('方差');x=-5:0.1:5;y=normpdf(x,mu,sigma);%正态分布概率密度函数figure;subplot(2,1,1);plot(x,y);title('均值为mu、标准差为sigma的正态随机变量的概率分布曲线');P = normcdf(x,mu,sigma); %正态分布的累计分布函数subplot(2,1,2);plot(x,P);title('均值为mu、标准差为sigma的正态随机变量的分布函数曲线');当输入为:均值=0;标准差=1;序列的长度=40;序列个数=40。
结果为3、计算其相关函数,检验是否满足Rx(0)=mu^2+sigma^2,观察均值mu为0和不为0时的图形变化。
代码如下:mu=input('请输入均值=');sigma=input('请输入标准差=');m=input('输入产生的序列的长度='); %m为序列的长度x2 = normrnd(mu,sigma,1,m);[cor2 lag2] = xcorr(x2,'unbiased');plot(lag2,cor2),title('(mu,sigma)正态分布的自相关函数');从上图中可以看出,R(0)=1=mu^2+sigma^2。
5、用Box-Muller变换法产生正态分布随机数,重新观察图形变化,与matlab 函数产生的正态分布随机数的结果进行比较。
代码如下:n=input('请输入产生的均匀分布数的个数=');v=rand(n,n);u=rand(n,n);a=cos(2*pi*v);b=(-2*log(u)).^(1/2);y1=a*b;subplot(2,1,1);hist(y1);title('用变换法产生的直方图');mu=0;sigma=1;R = normrnd(mu,sigma,n,n);subplot(2,1,2);hist(R);title('用normrnd函数产生的直方图');当输入n=40时,得到的结果如下:【实验分析】(1)、在实验中成功产生了均值为mu,方差为sigma(实验中输入的是mu=0,sigma=1),计算出了所得序列的均值和方差,并与理论值进行比较,测量其误差大小。
当改变序列的长度时,误差会减小,因为序列越长,数据越接近真实的正态分布,这样得到的误差越小。
(2)、在画其直方图时,由于序列的个数没有统一,图形的坐标没有归一化,在一定程度上影响了结果的比较,只能从图形的起伏来看正态分布的特征。
用normpdf函数和normcdf函数来得到概率密度函数及分布函数,与直接用函数得到的一样。
(3)、在本次实验中,用函数xcorr()计算其相关函数,从得到的图形中可以看出,当x=0时,图形的取值为1,满足Rx(0)=mu^2+sigma2=0^2+1^2=1。
还可以验证其他取值时的情况,这里不一一举例。
(4)、用Box-Muller变换法产生正态分布随机数,得到的直方图的结果与matlab函数产生的正态分布随机数的结果很相似。
【思考题】1、为什么当均值mu不为0时,()R 的图形是三角形?X2、实验中的样本数都设定为1000,试简述样本数对于结果的影响?答:当设定样本数为1000时,在计算自相关时数据量太大,超出了内存的存储范围,在运行程序时会报错。
【总结及心得体会】在用matlab对正态分布的特性进行研究时,一定要对matlab函数的使用有清楚的认识,不然很容易出错。
例如:在使用函数xcorr()算正态分布的自相关函数时,我开始就直接使用y=xcorr(R)进行计算,得到了一个错误的结果,后来通过反复的查资料才得到函数xcorr()在计算正确用法。
在本次实验中matlab的算法不是很复杂,但内容比较多,需要做大量的工作。
做这些工作一定要仔细认真,不然很容易就犯下简单的错误。
【对本实验过程及方法、手段的改进建议】对本实验的过程及方法、手段没有改进的建议。