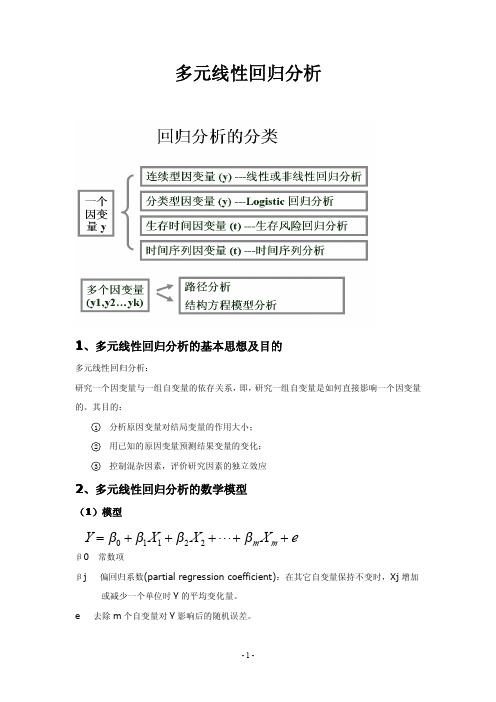
多重线性回归分析
第12章-多重线性回归分析

6 因变量总变异的分解
P
(X,Y)
Y
(Y Y) (Y Y)
(Y Y)
Y X
Y
Y
9
Y的总变异分解
Y Y Yˆ Y Y Yˆ
Y Y 2 Yˆ Y 2 Y Yˆ 2
总变异 SS总
回归平方和 剩余平方和
SS回
SS剩
10
Y的总变异分解
病程 (X2)
10.0 3.0 15.0 3.0 4.0 6.0 2.9 9.0 5.0 2.0 8.0 20.0
表 12-1 脂联素水平与相关因素的测量数据
空腹
回归模空型腹 ?
瘦素
脂联 BMI 病程 瘦素
脂联
(X3)
血糖 (X4)
素(Y)
(X1)
(X2)
(X3)
血糖 素(Y) (X4)
5.75 13.6 29.36 21.11 9.0 4.90 6.0 17.28
H 0: 1 2 3 4 0 ,即总体中各偏回归系数均为0; H 1:总体中各偏回归系数不为0或不全为0;
= 0.05。
2 计算检验统计量: 3 确定P值,作出推断结论。
拒绝H0,说明从整体上而言,用这四个自变量构成 的回归方程解释糖尿病患者体内脂联素的变化是有统 计学意义的。
的平方和 (Y Yˆ)2为最小。
只有一个自变量
两个自变量
例12-1 为了研究有关糖尿病患者体内脂联素水平的影响因 素,某医师测定30例患者的BMI、病程、瘦素、空腹血糖, 数据如表12-1所示。
BMI (X1)
24.22 24.22 19.03 23.39 19.49 24.38 19.03 21.11 23.32 24.34 23.82 22.86
多元线性回归分析

简介多元线性回归分析是一种统计技术,用于评估两个或多个自变量与因变量之间的关系。
它被用来解释基于自变量变化的因变量的变化。
这种技术被广泛用于许多领域,包括经济学、金融学、市场营销和社会科学。
在这篇文章中,我们将详细讨论多元线性回归分析。
我们将研究多元线性回归分析的假设,它是如何工作的,以及如何用它来进行预测。
最后,我们将讨论多元线性回归分析的一些限制,以及如何解决这些限制。
多元线性回归分析的假设在进行多元线性回归分析之前,有一些假设必须得到满足,才能使结果有效。
这些假设包括。
1)线性。
自变量和因变量之间的关系必须是线性的。
2)无多重共线性。
自变量之间不应高度相关。
3)无自相关性。
数据集内的连续观测值之间不应该有任何相关性。
4)同质性。
残差的方差应该在自变量的所有数值中保持不变。
5)正态性。
残差应遵循正态分布。
6)误差的独立性。
残差不应相互关联,也不应与数据集中的任何其他变量关联。
7)没有异常值。
数据集中不应有任何可能影响分析结果的异常值。
多重线性回归分析如何工作?多元线性回归分析是基于一个简单的数学方程,描述一个或多个自变量的变化如何影响因变量(Y)的变化。
这个方程被称为"回归方程",可以写成以下形式。
Y = β0 + β1X1 + β2X2 + ... + βnXn + ε 其中Y是因变量;X1到Xn是自变量;β0到βn是系数;ε是代表没有被任何自变量解释的随机变化的误差项(也被称为"噪音")。
系数(β0到βn)表示当所有其他因素保持不变时(即当所有其他自变量保持其平均值时),每个自变量对Y的变化有多大贡献。
例如,如果X1的系数为0.5,那么这意味着当所有其他因素保持不变时(即当所有其他独立变量保持其平均值时),X1每增加一单位,Y就会增加0.5单位。
同样,如果X2的系数为-0.3,那么这意味着当所有其他因素保持不变时(即所有其他独立变量保持其平均值时),X2每增加一个单位,Y就会减少0.3个单位。
线性相关与回归(简单线性相关与回归、多重线性回归、Spearman等级相关)

4.剔除强影响点(Influential cases;或称为突出点, outliers)
通过标准化残差(Standardized Residuals)、学生氏残 差(Studentlized Residuals)来判断强影响点 。当指标 的绝对值大于3时,可以认为样本存在强影响点。
删除强影响点应该慎重,需要结合专业知识。以下两种情 况可以考虑删除强影响点:1.强影响点是由于数据记录错 误造成的;2.强影响点来自不同的总体。
r r t sr 1 r2 n2
只有当0时,才能根据|r|的大小判断相关 的密切程度。
4.相关与回归的区别和联系 (1)相关与回归的意义不同 相关表达两个变量 之间相互关系的密切程度和方向。回归表达两个变 量之间的数量关系,已知X值可以预测Y值。从散点 图上,散点围绕回归直线的分布越密集,则两变量 相关系数越大;回归直线的斜率越大,则回归系数 越大。 (2)r与b的符号一致 同正同负。
5.自变量之间不应存在共线性(Collinear)
当一个(或几个)自变量可以由其他自变量线性表示时,称 该自变量与其他自变量间存在共线性关系。常见于:1.一个 变量是由其他变量派生出来的,如:BMI由身高和体重计算 得出 ;2.一个变量与其他变量存在很强的相关性。 当自变量之间存在共线性时,会使回归系数的估计不确定、 预测值的精度降低以及对y有影响的重要自变量不能选入模 型。
P值
截距a 回归系数b sb 标准化回归系数 t值 P值
3.直线回归的预测及置信区间估计
给定X=X0, 预测Y
3.直线回归的预测及置信区间估计
因变量
自变量
保存(产生新变量,保 存在当前数据库) 统计
3.直线回归的预测及置信区间估计
11-多重线性回归分析

1个
1个
统计方法
简单线性相关
simple linear correlation
简单线性回归
simple linear regression
多重相关
multiple correlation
多重回归
multiple regression
典则相关
cononical correlation
多元回归
multivariate regression
量x 取值均为0时,y的平均估计值。
➢bi:变量xi的偏回归系数(partial regression coefficient),
是总体参数βi 的估计值;指在方程中其它自变量固定 不变的情况下, xi 每增加或减少一个计量单位,反应 变量Y 平均变化 bi个单位。
Yˆ b0 b1X1 b2 X 2 ... bp X p
问题:对NO浓度的贡献,哪个因素作用的大一点, 哪个小一些?
回归系数的标准化:
1.自变量数据的标准化: 2.求标准化偏回归系数:
X
' i
Xi Xi Si
用标准化的数据进行回归模型的拟合,算出它的方程,
此时所获得的偏回归系数b’,叫~。
b’无单位,可用来比较各个自变量对反应变量的贡献大小
比较:
未标准化的回归系数(偏回归系数):用来构建回归 方程,即方程中各自变量的斜率。
计值 Yˆ 之间的残差(样
本点到直线的垂直距离) 平方和达到最小。 .
两个自变量时回归平面示意图
通过SPSS等统计软件,拟合X1、X2 、X3 、X4关于空 气中NO浓度的多重线性回归方程,得:
Y 0.142 0.116X1 0.004X 2 6.55106 X3 0.035X 4
利用多元线性回归分析进行预测

利用多元线性回归分析进行预测多元线性回归是一种重要的统计分析方法,它可以使用多个自变量来预测一个连续的因变量。
在实际生活中,多元线性回归分析广泛应用于各个领域,如经济学、金融学、医学研究等等。
本文将介绍多元线性回归分析的基本原理、应用场景以及注意事项,并通过实例来展示如何进行预测。
首先,我们来了解一下多元线性回归的基本原理。
多元线性回归建立了一个线性模型,它通过多个自变量来预测一个因变量的值。
假设我们有p个自变量(x1, x2, ..., xp)和一个因变量(y),那么多元线性回归模型可以表示为:y = β0 + β1*x1 + β2*x2 + ... + βp*xp + ε其中,y是我们要预测的因变量值,β0是截距,β1, β2, ..., βp是自变量的系数,ε是误差项。
多元线性回归分析中,我们的目标就是求解最优的系数估计值β0, β1, β2, ..., βp,使得预测值y与实际观测值尽可能接近。
为了达到这个目标,我们需要借助最小二乘法来最小化残差平方和,即通过最小化误差平方和来找到最佳的系数估计值。
最小二乘法可以通过求解正规方程组来得到系数估计值的闭式解,也可以通过梯度下降等迭代方法来逼近最优解。
多元线性回归分析的应用场景非常广泛。
在经济学中,它可以用来研究经济增长、消费行为、价格变动等问题。
在金融学中,它可以用来预测股票价格、利率变动等。
在医学研究中,它可以用来研究疾病的风险因素、药物的疗效等。
除了以上领域外,多元线性回归分析还可以应用于市场营销、社会科学等各个领域。
然而,在进行多元线性回归分析时,我们需要注意一些问题。
首先,我们需要确保自变量之间不存在多重共线性。
多重共线性可能会导致模型结果不准确,甚至无法得出可靠的回归系数估计。
其次,我们需要检验误差项的独立性和常态性。
如果误差项不满足这些假设,那么回归结果可能是不可靠的。
此外,还需要注意样本的选取方式和样本量的大小,以及是否满足线性回归的基本假设。
SPSS多元线性回归分析实例操作步骤

SPSS多元线性回归分析实例操作步骤多元线性回归是一种常用的统计分析方法,用于探究多个自变量对因变量的影响程度。
SPSS(Statistical Package for the Social Sciences)是一款常用的统计软件,可以进行多元线性回归分析,并提供了简便易用的操作界面。
本文将介绍SPSS中进行多元线性回归分析的实例操作步骤,帮助您快速掌握该分析方法的使用。
步骤一:准备数据在进行多元线性回归分析之前,首先需要准备好相关的数据。
数据应包含一个或多个自变量和一个因变量,以便进行回归分析。
数据可以来自实验、调查或其他来源,但应确保数据的质量和可靠性。
步骤二:导入数据在SPSS软件中,打开或创建一个新的数据集,然后将准备好的数据导入到数据集中。
可以通过导入Excel、CSV等格式的文件或手动输入数据的方式进行数据导入。
确保数据被正确地导入到SPSS中,并正确地显示在数据集的各个变量列中。
步骤三:进行多元线性回归分析在SPSS软件中,通过依次点击"分析"-"回归"-"线性",打开线性回归分析对话框。
在对话框中,将因变量和自变量移入相应的输入框中。
可以使用鼠标拖拽或双击变量名称来快速进行变量的移动。
步骤四:设置分析选项在线性回归分析对话框中,可以设置一些分析选项,以满足具体的分析需求。
例如,可以选择是否计算标准化回归权重、残差和预测值,并选择是否进行方差分析和共线性统计检验等。
根据需要,适当调整这些选项。
步骤五:获取多元线性回归分析结果点击对话框中的"确定"按钮后,SPSS将自动进行多元线性回归分析,并生成相应的分析结果。
结果包括回归系数、显著性检验、残差统计和模型拟合度等信息,这些信息可以帮助我们理解自变量对因变量的贡献情况和模型的拟合程度。
步骤六:解读多元线性回归分析结果在获取多元线性回归分析结果之后,需要对结果进行解读,以得出准确的结论。
《医学统计学》之多元(重)线性回归

多元(重)线性回归模型的假设
1 线性关系
假设自变量与因变量之间存在线性关系,即因变量可以用自变量的线性组合来表示。
2 独立性
假设误差项之间相互独立,即每个观测值的误差项不受其他观测值的影响。
3 常数方差
假设误差项具有常数方差,即各个观测值的误差方差相同。
多元(重)线性回归模型的估计方法
最小二乘法
多元(重)线性回归模型的模型选择方法
前向选择法
从不包含自变量的空模型开 始,逐步添加自变量,选择 最佳的组合。
后向消除法
从包含所有自变量的全模型 开始,逐步删除自变量,选 择最简单且最有效的模型。
逐步回归法
结合前向选择法和后向消除 法,逐步调整自变量,找到 最优的模型。
多元(重)线性回归模型的实际应用
医学研究
用于分析多个影响因素对疾病发生、病程进展和治 疗效果的影响。
市场分析
用于预测市场需求和销售量,并确定最佳的市场推 广策略。
财务预测
社会科学
用于预测企业的财务状况,并制定相应的经营决策。
用于研究社会现象和群体行为,解释和预测社会现 象的变化。
通过方差膨胀因子等指标,判断自变量之间是否存在高度相关性,以避免估计结果的不 准确性。
多元(重)线性回归模型的模型检验
1
残差分析
通过观察残差的分布和模式,检验回归模型是否符合基本假设。
2
拟合优度检验
通过比较拟合优度指标(如决定系数R²)和假设分布,评估回归模型的拟合程度。
3
异常值检验
通过检测异常值对回归分析结果的影响,判断数据中是否存在异常观测值。
《医学统计学》之多元 (重)线性回归
在医学统计学中,多元(重)线性回归是一种强大的数据分析方法,可用于探索 和建立多个自变量与因变量之间的关系。
多元线性回归分析预测法

多元线性回归分析预测法(重定向自多元线性回归预测法)多元线性回归分析预测法(Multi factor line regression method,多元线性回归分析法)[编辑]多元线性回归分析预测法概述在市场的经济活动中,经常会遇到某一市场现象的发展和变化取决于几个影响因素的情况,也就是一个因变量和几个自变量有依存关系的情况。
而且有时几个影响因素主次难以区分,或者有的因素虽属次要,但也不能略去其作用。
例如,某一商品的销售量既与人口的增长变化有关,也与商品价格变化有关。
这时采用一元回归分析预测法进行预测是难以奏效的,需要采用多元回归分析预测法。
多元回归分析预测法,是指通过对两上或两个以上的自变量与一个因变量的相关分析,建立预测模型进行预测的方法。
当自变量与因变量之间存在线性关系时,称为多元线性回归分析。
[编辑]多元线性回归的计算模型[1]一元线性回归是一个主要影响因素作为自变量来解释因变量的变化,在现实问题研究中,因变量的变化往往受几个重要因素的影响,此时就需要用两个或两个以上的影响因素作为自变量来解释因变量的变化,这就是多元回归亦称多重回归。
当多个自变量与因变量之间是线性关系时,所进行的回归分析就是多元性回归。
设y为因变量,为自变量,并且自变量与因变量之间为线性关系时,则多元线性回归模型为:其中,b0为常数项,为回归系数,b1为固定时,x1每增加一个单位对y的效应,即x1对y的偏回归系数;同理b2为固定时,x2每增加一个单位对y的效应,即,x2对y的偏回归系数,等等。
如果两个自变量x1,x2同一个因变量y呈线相关时,可用二元线性回归模型描述为:其中,b0为常数项,为回归系数,b1为固定时,x2每增加一个单位对y的效应,即x2对y的偏回归系数,等等。
如果两个自变量x1,x2同一个因变量y呈线相关时,可用二元线性回归模型描述为:y = b0 + b1x1 + b2x2 + e建立多元性回归模型时,为了保证回归模型具有优良的解释能力和预测效果,应首先注意自变量的选择,其准则是:(1)自变量对因变量必须有显著的影响,并呈密切的线性相关;(2)自变量与因变量之间的线性相关必须是真实的,而不是形式上的;(3)自变量之彰应具有一定的互斥性,即自变量之彰的相关程度不应高于自变量与因变量之因的相关程度;(4)自变量应具有完整的统计数据,其预测值容易确定。
多元线性回归分析的参数估计方法

多元线性回归分析的参数估计方法多元线性回归是一种常用的数据分析方法,用于探究自变量与因变量之间的关系。
在多元线性回归中,参数估计方法有多种,包括最小二乘估计、最大似然估计和贝叶斯估计等。
本文将重点讨论多元线性回归中的参数估计方法。
在多元线性回归中,最常用的参数估计方法是最小二乘估计(Ordinary Least Squares,OLS)。
最小二乘估计是一种求解最优参数的方法,通过最小化残差平方和来估计参数的取值。
具体而言,对于给定的自变量和因变量数据,最小二乘估计方法试图找到一组参数,使得预测值与观测值之间的残差平方和最小。
这样的估计方法具有几何和统计意义,可以用来描述变量之间的线性关系。
最小二乘估计方法有一系列优良的性质,比如无偏性、一致性和有效性。
其中,无偏性是指估计值的期望等于真实参数的值,即估计值不会出现系统性的偏差。
一致性是指当样本容量趋近无穷时,估计值趋近于真实参数的值。
有效性是指最小二乘估计具有最小的方差,即估计值的波动最小。
这些性质使得最小二乘估计成为了多元线性回归中最常用的参数估计方法。
然而,最小二乘估计方法在面对一些特殊情况时可能会出现问题。
比如,当自变量之间存在多重共线性时,最小二乘估计的解不存在或不唯一。
多重共线性是指自变量之间存在较高的相关性,导致在估计回归系数时出现不稳定或不准确的情况。
为了解决多重共线性问题,可以采用一些技术手段,如主成分回归和岭回归等。
另外一个常用的参数估计方法是最大似然估计(Maximum Likelihood Estimation,MLE)。
最大似然估计方法试图找到一组参数,使得给定样本观测值的条件下,观测到这些值的概率最大。
具体而言,最大似然估计方法通过构建似然函数,并对似然函数求导,找到能够最大化似然函数的参数取值。
最大似然估计方法在一定条件下具有良好的性质,比如一致性和渐近正态分布。
但是,在实际应用中,最大似然估计方法可能存在计算复杂度高、估计值不唯一等问题。
多元线性回归

多元线性回归方程
Y=a+b1X1+b2X2+…+bkXk
自变量
自变量是指研究者主动操纵,而引起因变量发生变化的因素或条件,因此 自变量被看作是因变量的原因。自变量有连续变量和类别变量之分。如果实 验者操纵的自变量是连续变量,则实验是函数型实验。如实验者操纵的自变 量是类别变量,则实验是因素型的。 在心理实验中,自变量是由实验者操纵、掌握的变量。自变量一词来自数 学。在数学中,y=f(x)。在这一方程中自变量是x,因变量是y。将这个方 程运用到心理学的研究中,自变量是指研究者主动操纵,而引起因变量发生 变化的因素或条件,因此自变量被看作是因变量的原因。自变量有连续变量 和类别变量之分。如果实验者操纵的自变量是连续变量,则实验是函数型实 验。如实验者操纵的自变量是类别变量,则实验是因素型的。在心理学实验 中,一个明显的问题是要有一个有机体作为被试(符号O)对刺激(符号S) 作反应(符号R),即S-O—R。显然,这里刺激变量就是自变量。
多元回归分析数据格式
例号 X1 1 X11 2 X21 ┇ ┇ n Xn1 X2 … X m X12 X22 ┇ Xn2 … … … … X1m X2m ┇ Xnm Y Y1 Y2 ┇ Yn
条件
(1)Y 与X1 , X2 ,…, Xm 之间具有线性关系。 (2)各例观测值Yi (i = 1,2,,n)相互独立。 (3)残差 e服从均数为 0﹑方差为σ2 的正态分布,它等价于对任意 一组自变量X1 , X 2,…, Xm 值,应变量 Y 具有相同方差,并且服从正态 分布。
10个50mL的容量瓶中分别加人不 同体积的Ca2+、Mg2+标准溶液 (所加入的体积数由计算机随机函数计算得到 ),2.00 mLHg(Ⅱ)一 EDTA溶液,5.0rnL的三乙醇溶液和1mLNa2S溶液,用水稀释至刻度。 溶液转入电解池后插入电极,用EDTA标准溶液滴定并记录滴定曲线。
第4章多元线性回归分析

4.2.1回归系数估计
结论
4.2 多元线性回归模型参数估计
结论1: OLS估计的一致性 ˆj 如果回归模型误差项满足假设1和假设2,OLS估计 为一致估计,即
ˆ , j 0, 1, 2, , k p limn j j
结论2: OLS估计的无偏性 如果回归模型误差项满足假设1和假设2,OLS估计 ˆj 为无偏估计: ˆ ) , j 0, 1, , k E( j j
4.9 自变量共线性 重要概念Biblioteka 4.1 多元线性回归模型设定
模型设定:
假设1(零条件均值:zero conditonal mean)
给定解释变量,误差项条件数学期望为0,即
E(u | X1 , X 2 ,, X k ) 0
Y 0 1 X1 2 X 2 k X k u
4.8 假设条件的放松
4.8.1 假设条件的放松(一)—非正态分 布误差项 4.8.2 假设条件的放松(二)—异方差 4.8.3 假设条件的放松(三)—非随机抽 样和序列相关 4.8.4 假设条件的放松(四)—内生性
4.8 假设条件的放松
4.8.1 假设条件的放松(一)—非正态分 布误差项
• 去掉假设5不影响OLS估计的一致性、无偏性和渐 近正态性。 • 不能采用t-检验来进行参数的显著性检验,也不能 用F检验进行整体模型检验。 • 大样本情况下,t统计量往往服从标准正态分布 (在原假设下)。
…
xk ( X k1 , X k 2 ,, X kn )
假设2’(样本无共线性:no colinearity)
不存在不全为零的一组数 c0 , c1,, ck使得
c0 c1x1 xk 0
4.2 多元线性回归模型参数估计
1 多元线性回归分析

1、自变量筛选的标准与原则
① 残差平方和SSE缩小与确定系数增大 ② 残差均方缩小与调整确定系数增大 ③ Cp统计量
2、自变量筛选的常用方法
① 所有可能自变量子集选择 ② Forward:前进法(向前选择法) ③ Backward:后退法(向后剔除法) ④ Stepwise:逐步回归法
♦ 是选择变量的有效方法。
前进法、后退法、逐步回归法的侧重点不
同。
当自变量之间不存在简单线性相关关系时,三种方法计算结果 是一致的。 当自变量之间存在简单线性相关关系时,前进法侧重于向模型 中引入单独作用较强的变量,后退法侧重于引入联合作用较强 的变量,逐步回归法则介于两者之间。
注意:剔除变量的标准(0.1)应 大于或等于引入变量的标准 (0.05)。
ANOVA b
Model
Sum of Squares
1
Regression 133.711
Residual Total
88.841 222.552
df Mean Square
4
33.428
22
4.038
26
F 8.278
Sig. .000a
a.Predictors: (Constant), 糖化血红蛋白, 甘油三酯, 胰岛素, 总胆固醇
总变异 23 0.08123
R2=0.06396/0.08123=0.7874
确定系数的取值范围为0≤R2≤1。直接反映了 回归方程中所有自变量解释了反应变量总变异 的百分比。其值越接近于1,表示回归模型的拟 合效果越好。
3、调整的确定系数
调整的R2:记为
R2 = R 2 k(1 R2 )
多重线性回归分析方法

多重线性回归分析方法多重线性回归分析是一种常用的统计方法,用于揭示自变量对因变量的影响。
它可以帮助我们理解多个自变量如何共同影响因变量,并通过建立一个数学模型来预测因变量的值。
本文将介绍多重线性回归分析的基本原理、步骤以及常见的模型评估方法。
一、基本原理多重线性回归分析是建立在线性回归模型的基础上的。
在简单线性回归模型中,只有一个自变量可以解释因变量的变化;而在多重线性回归模型中,有多个自变量同时对因变量产生影响。
其模型可表示为:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε其中,Y代表因变量,X1, X2, ..., Xn代表自变量,β0, β1, β2, ..., βn代表回归系数,ε代表误差项。
二、分析步骤进行多重线性回归分析时,通常可以遵循以下步骤:1. 收集数据:首先,需要收集相关的自变量和因变量的数据,并确保数据的准确性和完整性。
2. 建立模型:根据收集到的数据,可以利用统计软件或编程工具建立多重线性回归模型。
确保选择合适的自变量,并对数据进行预处理,如去除异常值、处理缺失值等。
3. 模型拟合:利用最小二乘法或其他拟合方法,对模型进行拟合,找到最优的回归系数。
4. 模型评估:通过各种统计指标来评估模型的拟合效果,比如决定系数(R^2)、调整决定系数、F统计量等。
这些指标可以帮助我们判断模型的可靠性和解释力。
5. 解释结果:根据回归系数的正负和大小,以及显著性水平,解释不同自变量对因变量的影响。
同时,可以进行预测分析,根据模型的结果预测未来的因变量值。
三、模型评估方法在多重线性回归分析中,有多种方法可评估模型的拟合效果。
以下是几种常见的模型评估方法:1. 决定系数(R^2):决定系数是用来衡量模型拟合数据的程度,取值范围为0到1。
其值越接近1,表示模型能够较好地解释数据的变异。
2. 调整决定系数:调整决定系数是在决定系数的基础上,考虑自变量的数量和样本量后进行修正。
多元线性回归分析及其应用

多元线性回归分析及其应用一、本文概述《多元线性回归分析及其应用》这篇文章旨在深入探讨多元线性回归分析的基本原理、方法以及在实际应用中的广泛运用。
文章首先将对多元线性回归分析的基本概念进行阐述,包括其定义、特点以及与其他统计分析方法的区别。
随后,文章将详细介绍多元线性回归分析的数学模型、参数估计方法以及模型的检验与优化。
在介绍完多元线性回归分析的基本理论后,文章将重点探讨其在各个领域的应用。
通过具体案例分析,展示多元线性回归分析在解决实际问题中的强大作用,如经济预测、市场研究、医学统计等。
文章还将讨论多元线性回归分析在实际应用中可能遇到的问题,如多重共线性、异方差性等,并提出相应的解决方法。
文章将对多元线性回归分析的发展趋势进行展望,探讨其在大数据时代背景下的应用前景以及面临的挑战。
通过本文的阅读,读者可以全面了解多元线性回归分析的基本理论、方法以及实际应用,为相关领域的研究与实践提供有力支持。
二、多元线性回归分析的基本原理多元线性回归分析是一种预测性的建模技术,它研究的是因变量(一个或多个)和自变量(一个或多个)之间的关系。
这种技术通过建立一个包含多个自变量的线性方程,来预测因变量的值。
这个方程描述了因变量如何依赖于自变量,并且提供了自变量对因变量的影响的量化估计。
在多元线性回归分析中,我们假设因变量和自变量之间存在线性关系,即因变量可以表示为自变量的线性组合加上一个误差项。
这个误差项表示了模型中未能解释的部分,通常假设它服从某种概率分布,如正态分布。
多元线性回归模型的参数估计通常通过最小二乘法来实现。
最小二乘法的基本思想是通过最小化预测值与实际值之间的残差平方和来求解模型的参数。
这个过程可以通过数学上的最优化方法来完成,例如梯度下降法或者正规方程法。
除了参数估计外,多元线性回归分析还需要进行模型的诊断和验证。
这包括检查模型的拟合优度(如R方值)、检验自变量的显著性(如t检验或F检验)、评估模型的预测能力(如交叉验证)以及检查模型的假设是否成立(如残差的正态性、同方差性等)。
卫生统计学课件12多重线性回归分析(研)

多重线性回归分析的步骤
(一)估计各项参数,建立多重线性回归方程模型 (二)对整个模型进行假设检验,模型有意义的前提 下,再分别对各偏回归系数进行假设检验。 (三)计算相应指标,对模型的拟合效果进行评价。
多重线性回归方程的建立
Analyze→Regression→Linear Dependent :Y Independent(s):X1、X2、X3 Method:Enter OK
Mo del S um mary
Model 1
Std. Error of
R R Square Adju sted R Square the E stimate
.8 84a .7 81
.7 40 216.0570 680
a. Predictors: (Constant), X3, X2, X1
R (复相关系数)
(二)偏回归系数的假设检验及其评价
各偏回归系数的t检验
C oe fficien tas
Unstand ardized Co efficients
St an d ard ized Co efficients
Model
B
Std. Error
Bet a
1
(Constant) -2262.081 1081 .870
(三)有关评价指标
R (复相关系数)
0.884
R Square (决定系数)
0.781
Adj R-Sq (校正决定系数)
0.740
Std.Error of the Estimate (剩余标准差)
216.0570680
Std.Error of the Estimate (剩余标准差)
SY ,12...m
多元线性回归分析

多元线性回归分析多元线性回归分析是一种常用的统计方法,用于研究多个自变量与因变量之间的关系。
它可以帮助我们理解多个因素对于一个目标变量的影响程度,同时也可以用于预测和解释因变量的变化。
本文将介绍多元线性回归的原理、应用和解读结果的方法。
在多元线性回归分析中,我们假设因变量与自变量之间存在线性关系。
具体而言,我们假设因变量是自变量的线性组合,加上一个误差项。
通过最小二乘法可以求得最佳拟合直线,从而获得自变量对因变量的影响。
多元线性回归分析的第一步是建立模型。
我们需要选择一个合适的因变量和若干个自变量,从而构建一个多元线性回归模型。
在选择自变量时,我们可以通过领域知识、经验和统计方法来确定。
同时,我们还需要确保自变量之间没有高度相关性,以避免多重共线性问题。
建立好模型之后,我们需要对数据进行拟合,从而确定回归系数。
回归系数代表了自变量对因变量的影响大小和方向。
通过最小二乘法可以求得使残差平方和最小的回归系数。
拟合好模型之后,我们还需要进行模型检验,以评估模型拟合的好坏。
模型检验包括对回归方程的显著性检验和对模型的拟合程度进行评估。
回归方程的显著性检验可以通过F检验来完成,判断回归方程是否显著。
而对模型的拟合程度进行评估可以通过判断决定系数R-squared的大小来完成。
解读多元线性回归结果时,首先需要看回归方程的显著性检验结果。
如果回归方程显著,说明至少一个自变量对因变量的影响是显著的。
接下来,可以观察回归系数的符号和大小,从中判断自变量对因变量的影响方向和相对大小。
此外,还可以通过计算标准化回归系数来比较不同自变量对因变量的相对重要性。
标准化回归系数表示自变量单位变化对因变量的单位变化的影响程度,可用于比较不同变量的重要性。
另外,决定系数R-squared可以用来评估模型对观测数据的拟合程度。
R-squared的取值范围在0到1之间,越接近1说明模型对数据的拟合越好。
但需要注意的是,R-squared并不能反映因果关系和预测能力。
多元线性回归分析
' j
=
X
j
− X Sj
j
标准化回归方程
标准化回归系数 bj ’ 的绝对值用来比较各个自变量 Xj 对 Y 的影响程度大小; 绝对值越大影响越大。标准化回归方程的截距为 0。 标准化回归系数与一般回归方程的回归系数的关系:
b 'j = b j
l jj l YY
⎛ Sj ⎞ = b j⎜ ⎜S ⎟ ⎟ ⎝ Y⎠
R = R2
^
�
说明所有自变量与 Y 间的线性相关程度。即 Y 与 Y 间的相关程度。联系了回归和相关
-5-
�
如果只有一个自变量,此时
R=r 。
3) 剩余标准差( Root MSE )
SY |12... p =
∑ (Y − Yˆ )
2
/( n − p − 1)
= SS 残 (n − p − 1 ) = MS 残 = 46.04488 = 6.78564 反映了回归方程的精度,其值越小说明回归效果越好
(SS 残) p Cp = − [n − 2(p + 1)] ( MS 残) m p≤m
2
P 为方程中自变量个数。 最优方程的 Cp 期望值是 p+1。应选择 Cp 最接近 P+1 的回归方程为最优。
5、决定模型好坏的常用指标和注意事项:
• 决定模型好坏的常用指标有三个:检验总体模型的 p-值,确定系数 R2 值和检验每一 个回归系数 bj 的 p-值。 • 这三个指标都是样本数 n、模型中参数的个数 k 的函数。样本量增大或参数的个数增 多,都可以引起 p-值和 R2 值的变化。但由于受到自由度的影响,这些变化是复杂 的。 • 判断一个模型是否是一个最优模型,除了评估各种统计检验指标外,还要结合专业知 识全面权衡各个指标变量系数的实际意义,如符号,数值大小等。 • 对于比较重要的自变量,它的留舍和进入模型的顺序要倍加小心。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、作业
教材P214 三。
二、自我练习
(一)教材P213 一。
(二)是非题
1.当一组资料的自变量为分类变量时,对这组资料不能做多重线性回归分析。
( )
2.若多重线性方程模型有意义.则各个偏回归系数也均有统计学意义。
〔)
3.回归模型变量的正确选择在根本上依赖于所研究问题本身的专业知识。
()
4.从各自变量偏回归系数的大小.可以反映出各自变量对应变量单位变化贡献的大小。
( )
5.在多元回归中,若对某个自变量的值都增加一个常数,则相应的偏回归系数不变。
( )
(三)选择题
1. 多重线性回归分析中,共线性是指(),导致的某一自变量对Y的作用可以由其他自变量的线性函数表示。
A. 自变量相互之间存在高度相关关系
B. 因变量与各个自变量的相关系数相同
C. 因变量与自变量间有较高的复相关关系
D. 因变量与各个自变量之间的回归系数相同
2. 多重线性回归和Logistic 回归都可应用于()。
A. 预测自变量
B. 预测因变量Y 取某个值的概率π
C. 预测风险函数h
D. 筛选影响因素(自变量)
3.在多重回归中,若对某个自变量的值都增加一个常数,则相应的偏回归系数:
A.不变
B.增加相同的常数
C.减少相同的常数
D.增加但数值不定
4.在多元回归中,若对某个自变量的值都乘以一个相同的常数k,则:
A.该偏回归系数不变
B.该偏回归系数变为原来的 1/k倍
C.所有偏回归系数均发生改变
D.该偏回归系数改变,但数值不定
5.作多重线性回归分析时,若降低进入的F 界值,则进入方程的变量一般会:
A.增多 B.减少 C.不变 D.可增多也可减少(四)筒答题
1.为什么要做多重线性回归分析?
2.多重线性模型中,标准化偏回归系数的解释意义是什么?
3.简述确定系数的定义及意义。
4.多重线性回归中自变量的筛选共有哪几种方法.请比较它们的优缺点?
5.何谓多重共线性,多重共线性对资料分析有何影响?。