应用时间序列分析论文_应用统计18_陈叮_5061214012
时间序列分析论文

关于居民消费价格指数的时间序列分析摘要本文以我国1997年4月至2014年4月间每月的烟酒及用品类居民消费价格指数为原始数据,利用EVIEWS软件判断该序列为平稳序列且为非白噪声序列,通过对数据一系列的处理,建立AR(1)模型拟合时间序列,由于时间序列之间的相关关系和历史数据对未来的发展有一定的影响,对我国的烟酒及用品类居民消费价格指数进行了短期预测,阐述该价格指数所表现的变化规律。
关键字:烟酒及用品类居民消费价格指数,时间序列,AR模型,预测引言一、理论准备时间序列分析是按照时间顺序的一组数字序列.时间序列分析就是利用这组数列,应用数理统计方法加以处理,以预测未来事物的发展。
时间序列分析是定量预测方法之一.基本原理:1.承认事物发展的延续性。
应用过去数据,就能推测事物的发展趋势。
2。
考虑到事物发展的随机性.任何事物发展都可能受偶然因素影响,为此要利用统计分析中加权平均法对历史数据进行处理。
该方法简单易行,便于掌握,但准确性差,一般只适用于短期预测。
时间序列分析是根据系统观测得到的时间序列数据,通过曲线拟合和参数估计来建立数学模型的理论和方法.二、基本思想1. 拿到一个观测值序列之后,首先判断它的平稳性,通过平稳性检验,判断序列是平稳序列还是非平稳序列。
2.若为非平稳序列,则利用差分变换成平稳序列。
3。
对平稳序列,计算相关系数和偏相关系数,确定模型。
4.估计模型参数,并检验其显著性及模型本身的合理性.5.检验模型拟合的准确性。
6.根据过去行为对将来的发展做出预测。
三、背景知识CPI(居民消费价格指数),是反映与居民生活有关的商品及劳务价格统计出来的物价变动指标,通常作为观察通货膨胀水平的重要指标.居民消费价格指数,是对一个固定的消费品篮子价格的衡量,主要反映消费者支付商品和劳务的价格变化情况,也是一种通货膨胀水平的工具。
一般来说,当CPI>3%的增幅时我们称为通货膨胀。
国外许多发达国家非常重视消费价格统计,美国、加拿大等国家都计算和公布每月经过季节调整的消费价格指数,以满足不同信息使用者的要求。
时间序列分析论文

时间序列分析在我国居民消费价格指数预测上的引用摘要:时间序列是按照时间顺序取得的一系列数据,大多数的经济时间序列存在惯性,通过这种惯性分析可以由时间序列的历史数值对未来值进行预测。
文章主要利用时间序列的趋势外推方法对我国目前居民消费价格指数(CPI)进行了建模析和预测,以达到合理预期和分析的目的。
关键词:时间序列CPI 趋势预测1.我国居民消费价格指数的现状居民消费价格指数(Consumer Price Index,CPI)是一个反映居民家庭一般所购买的消费商品和服务价格水平变动情况的指标。
一般说来当CPI>3% 的增幅时我们称为通货膨胀;而当CPI>5% 的增幅时我们把他称为严重的通货膨胀。
如果消费价格指数升幅过大,表明通胀已经成为经济不稳定因素,央行会有紧缩货币政策和财政政策的风险,从而造成经济前景不明朗。
从国家统计局公布的2003年5月到2012年3月的数据可以明显的看出我国已经进入通货膨胀期,从2007年3月开始就超过3%的警戒线,然而从2007年7月开始更是每月都超过5%的严重通货膨胀的警戒线。
尽管国家已经采取了紧缩的货币政策如2007年6次上调存贷款基准利率;10次上调存款准备金率;加大央行票据发行力度和频率;以特别国债开展正回购操作等。
但是2011年3月以来我国还是维持在高的通货膨胀水平,因此进行居民消费价格指数的预测分析更显得尤为必要。
2.趋势模型的选择(时间数列分解模型)为了对我国CPI的变化有更加全面和深入的把握和认识,现观测从1994—2011年居民消费价格指数的全部数据,见表1。
表1 中国1994—2011 年居民消费价格指数由以上数据可以看出,因为居民消费价格指数受到如经济增长、特别是国家宏观货币政策等因素的影响,分析我国居民消费价格指数的变动不能简单地用一个线性模型来解释。
但是可以看出在一定的时期内,宏观经济波动不大的情况下,居民消费价格指数基本还是呈线性的。
因此笔者将这时间数列分段用线性模型分别分析居民消费价格指数在1994—1999 年、1999—2004年以及2004—2011 年这三个不同的经济状况下的变动情况。
时间序列分析小论文

时间序列分析小论文基于ARIMA模型的我国全社会固定资产投资预测摘要:本文采用ARIMA模型,用Eviews6.0软件对我国1980—2012年的全社会固定资产投资额进行了深入分析,并预测了2013年我国全社会固定资产投资额。
结果表明,ARIMA(4,1,3)模型能够提供较准确的预测效果,可以用于未来的预测,并为我国固定资产投资提供可靠的依据。
关键词:ARIMA模型固定资产投资额时间序列预测一、引言改革开放以来,我国的经济发展取得了举世瞩目的成就。
投资是拉动经济增长的三驾马车之一,因此研究我国全社会固定资产投资对研究我国经济增长有着重要的现实意义。
我国的全社会固定资产投资总额持续增加:1980年仅为910.9亿元,1993年首次突破10000亿元达到13072.3亿元;到2006年则猛增至109998.2亿元。
尤其是进入21世纪以来,随着中国加入WTO,外商投资大量增加,推动了经济政策的调整与完善,也给经济与投资增长增添了活力。
此前,已经有学者做过相关研究。
2010年李惠在《ARIMA模型在我国全社会固定资产投资预测中的应用》中,通过1980-2007年我国全社会固定资产投资的相关数据,运用统计学和计量经济学原理,从时间序列的定义出发,运用ARIMA建模方法,将ARIMA模型应用于我国历年全社会固定资产投资数据的分析与预测,检验得出ARIMA(4,2,4)模型为最佳,建议政府抓住投资机遇,合理安排投资比例和投资金额,促进经济的健康发展。
2007年靳宝琳和赫英迪在《ARIMA模型在太原市全社会固定资产投资预测中的应用》一文中采用Eviews软件系统中的时间序列建模方法对太原市的固定资产投资总额资料进行了分析,建立了ARIMA模型。
结果显示ARIMA(2,1,3)模型提供了较准确的预测效果,可用于未来的预测,为太原市全社套固定资产投资的预测提供了一种方便实用的方法。
王新华在《ARIMA模型在武汉市全社会固定投姿预测中的应用》中,采用ARIMA模型,对武汉市1950—2003年的全社会固定资产投资额进行了深入分析。
时间序列分析范文

时间序列分析范文时间序列分析是一种用来分析和预测时间序列数据的统计方法。
时间序列数据是按照时间顺序排列的观测数据,如股票价格、气温变化、销售数据等。
通过时间序列分析,我们可以了解时间序列数据的趋势、季节性变化和随机波动,以便做出准确的预测和决策。
首先,我们需要收集并整理时间序列数据。
数据可以通过实地观测、统计报告、调查问卷等方式获得。
数据的质量和准确性对于分析结果的可靠性至关重要。
接下来,我们需要对数据进行预处理。
这包括检查和处理数据中的缺失值、异常值和重复值。
同时,还需要进行数据的平稳性检验,即判断时间序列数据是否具有固定的均值和方差。
如果时间序列数据不平稳,需要进行差分或其他方法将其转化为平稳时间序列。
然后,我们可以选择适当的时间序列模型来拟合数据。
常用的时间序列模型包括移动平均模型(MA)、自回归模型(AR)、自回归移动平均模型(ARMA)和自回归积分移动平均模型(ARIMA)等。
选择合适的模型可以通过观察数据自相关图和偏自相关图,以及对各个模型的性质和参数估计方法的了解。
当模型被拟合后,我们还需要进行模型的检验和评估。
这包括检查模型的残差是否为白噪声序列,即不存在相关性和异方差性;评估模型的拟合优度和预测准确性。
常用的评估指标包括均方根误差(RMSE)、平均绝对百分比误差(MAPE)等。
最后,我们可以使用时间序列模型进行预测和决策。
预测是时间序列分析的主要目的之一,可以通过模型自动完成,也可以通过直观判断和经验方法进行。
预测结果可以用于制定生产计划、调整投资策略、优化供应链等。
时间序列分析在实际应用中有着广泛的应用。
在经济领域,时间序列分析可以用于预测股票价格、GDP增长、通胀率等,帮助决策者做出合理的经济政策。
在气象学中,时间序列分析可以用于预测天气变化,帮助人们做出出行计划。
在市场营销中,时间序列分析可以用于预测销售量、市场份额等,帮助企业做出营销决策。
总而言之,时间序列分析是一种重要的统计方法,被广泛应用于各个领域。
统计学专业优秀毕业论文范本经济数据的时间序列分析与

统计学专业优秀毕业论文范本经济数据的时间序列分析与预测在统计学专业的毕业论文中,经济数据的时间序列分析与预测是一个重要的研究方向。
本文将为大家提供一个优秀的论文范本,以展示在统计学专业中,如何进行经济数据的时间序列分析与预测。
一、引言经济数据是经济学研究的基础,而时间序列分析和预测是处理经济数据的重要方法之一。
时间序列分析旨在通过对历史数据的观察和分析,揭示数据内在的规律和趋势,为未来经济变化提供预测依据。
因此,时间序列分析在经济学中具有重要的研究价值和实际应用意义。
二、数据收集与整理经济数据的时间序列分析首先需要收集和整理相关的数据集。
收集数据的来源可以包括政府部门、研究机构、行业协会等。
在数据整理过程中,需要对数据进行清洗、处理异常值和缺失值,并将数据进行合适的时间区间划分。
三、时间序列模型的选择与建立时间序列模型是进行时间序列分析和预测的数学工具。
在选择时间序列模型时,需要根据数据的性质和特点进行合理的选择。
常用的时间序列模型包括ARMA模型、ARCH模型、GARCH模型等。
根据数据的特征,可以通过模型的拟合度、残差检验等指标进行模型的选择与建立。
四、模型参数估计与检验在时间序列模型建立完成后,需要对模型的参数进行估计和检验。
常用的参数估计方法包括极大似然估计、最小二乘估计等。
而模型的检验则可以通过残差分析、模型拟合度检验、序列平稳性检验等指标进行。
五、时间序列预测与评估时间序列预测是时间序列分析的重要任务之一。
通过对历史数据的观察和模型的建立,可以利用已有的信息对未来的经济发展进行预测。
常用的时间序列预测方法包括平滑法、回归法、ARIMA模型等。
在进行时间序列预测时,需要对预测结果进行评估,包括均方误差、平均绝对误差等指标。
六、实证分析与结果讨论在论文中,应该选取合适的经济数据进行实证分析,并对实证分析的结果进行详细的讨论和解释。
可以对模型的拟合度、稳定性、预测准确度等进行分析,并结合实际情况进行解释和推论。
应用时间序列分析课程论文

应用时间序列分析课程论文班级:13应用统计1班学号:20133695 :彭鹏学习了本学期的应用时间序列分析课程内容,学习了使用EVIEWS软件对平稳时间序列的平稳性进行分析,学习平稳时间序列模型的建立、学会根据自相关系数和偏自相关系数判断ARMA模型的阶数p 和q,学会利用信息准则对估计的ARMA模型进行诊断,以及掌握利用ARMA模型进行预测。
在统计研究中,有大量的数据是按照时间顺序排列的,用数学方法来表述就是使用一组随机序列表示随机事件的时间序列即为{Xt}通常的ARMR建模过程,B-J方法具体步骤如下:一、对时间序列进行特性分析。
从随机性、平稳性、季节性考虑。
对于一个非平稳时间序列,假设要建模首先将其平稳化,其方法有三种:1差分,一些序列可以通过差分使其平稳化。
2季节差分,如果序列具有周期波动特点,为了消除周期波动的影响,通常引用季节差分。
3函数变换与差分结合运用,某些序列如果具有某类函数趋势,我们可以先引入某种函数变换将序列转化为线性趋势,然后再进行差分以消除线性趋势。
二、模型识别与建立。
模型识别和模型定阶。
三、模型的评价,并利用模型进行评价。
下面从网上搜寻数据,1949-2014年城镇人口数(单位万人,其中有些年份缺失数据,数据来源于中国统计年鉴)。
进行处理分析绘制序列时序图有看来有明显增长趋势为非平稳序列,进行一阶差分y=d(r):由图得出序列y仍然非平稳1.对原序列进行二阶差分z=d(r,2) 相关图检验:序列z为平稳序列,进行单位根检验:拒绝有单位根的原假设,即为平稳序列。
有相关图看出为非白噪声序列。
可见均值非零;在原序列上生成0均值序列在输入x=z-28.59184得到序列x为0均值的平稳非白噪声序列由相关图看出自相关系数一阶截尾,考虑MA(1)模型Xt=εεt-1我们用拟合的有效模型进行短期预测,比方我们预预测未来5年的城镇人口,首先需要扩展样本期,在命令栏输入expand 1 56,回车则样本序列长度就变成56了,且最后面5个变量值为空。
《2024年时间序列数据分类、检索方法及应用研究》范文

《时间序列数据分类、检索方法及应用研究》篇一一、引言时间序列数据,指按时间顺序排列的一系列数据点,常用于各种领域,如金融市场、气象观测、工业生产等。
对时间序列数据进行有效的分类和检索,是众多研究领域的热点和难点。
本文旨在研究时间序列数据的分类、检索方法,以及在各个领域的应用情况。
二、时间序列数据的分类1. 基于统计学方法的时间序列数据分类根据统计学原理,我们可以通过时间序列数据的特征参数进行分类,如均值、方差、自相关等。
例如,我们可以将金融市场中的股票价格时间序列数据分为上涨趋势、下跌趋势和稳定趋势等。
2. 基于机器学习的时间序列数据分类随着机器学习技术的发展,越来越多的研究者开始使用机器学习算法对时间序列数据进行分类。
如使用神经网络、支持向量机等算法,根据历史数据预测未来趋势,从而进行分类。
3. 基于模式识别的时序数据分类通过对时序数据进行模式识别,可以找到具有特定规律的模式。
比如对气象数据进行分析,找到风速、风向的变化模式,并据此进行时序数据的分类。
三、时间序列数据的检索方法1. 相似性检索相似性检索是时间序列数据检索的主要方法之一。
通过计算两个时间序列的相似度,找到与查询序列最相似的序列。
常用的相似度计算方法有欧氏距离、动态时间弯曲距离等。
2. 索引技术为了加快检索速度,研究者们提出了各种索引技术。
如基于分段的方法、基于树形结构的方法等。
这些方法可以在一定程度上降低计算复杂度,提高检索效率。
四、时间序列数据的应用研究1. 金融领域应用在金融领域,时间序列数据广泛应用于股票价格预测、市场趋势分析等。
通过机器学习算法对历史数据进行学习,可以预测未来股票价格的变化趋势,为投资者提供决策支持。
2. 气象领域应用在气象领域,时间序列数据用于预测天气变化、气候变化等。
通过对历史气象数据进行模式识别和特征提取,可以找到气候变化规律,为气象预报提供支持。
3. 工业生产应用在工业生产中,时间序列数据常用于设备故障诊断和预测性维护。
时间序列分析期末论文

课程论文时间序列分析题目时间序列模型在人口增长中的应用学院数学与统计学院专业统计学班级统计〔二〕班学生殷婷2021101217指导教师翠霞职称2021 年10 月29 日引言人口问题是一个世界各国普遍关注的问题。
人作为一种资源,主要表达在人既是生产者,又是消费者。
作为生产者,人能够发挥主观能动性,加速科技进步,促进社会经济的开展;作为消费者,面对有限的自然资源,人在开展的同时却又不得不考虑人口数量的问题。
我国是一个人口大国,人口数量多,增长快,人口素质低;由于人口众多,不仅造成人均资源的数量很少,而且造成住房、教育、就业等方面的很大压力。
所以人口数量是社会最为关注的问题,每年新增加的国民生产总值有相当一局部被新增加的人口所抵消,从而造成社会再生产投入缺乏,严重影响了国民经济的可持续开展。
因此,认真分析研究我国目前的人口开展现状和特点,采取切实可行的措施控制人口的高速增长,已经成为我国目前经济开展中需要解决的首要问题。
本文通过时间序列模型对人口的增长进展预测,制定未来人口开展目标和生育政策等有关人口政策的根底,对于国民经济方案的制定和社会战略目标的决策具有重要参考价值。
人口的预测,作为经济、社会研究的需要,应用越来越广泛,也越来越受到人们的重视。
在描绘未来小康社会的蓝图时,首先应要考虑的是未来中国的人口数量、构造、分布、劳动力、负担系数等等,而这又必须通过人口的预测来一一显示。
人口数量在时间上的变化,可以用时间序列模型来预测其继后期的数量。
本文通过时间序列分析的方法对人口增长建立模型,取得了较好的预测结果。
时间序列分析是研究动态数据的动态构造和开展变化规律的统计方法。
以1990年至2021年中国人口总数为例,用时间序列分析Eviews软件建立模型,并对人口的增长进展预测,研究时间序列模型在人口增长中的应用。
根本假设(1) 在预测中国人口的增长趋势时,假设全国人口数量的变化是封闭的即人口的出生率和死亡率是自然变化的,而不考虑与其他的迁移状况;(2)在预测的年限,不会出现意外事件使人口发生很大的波动,如战争,疾病;(3) 题目数据能够代表全国的整体人数。
应用时间序列分析
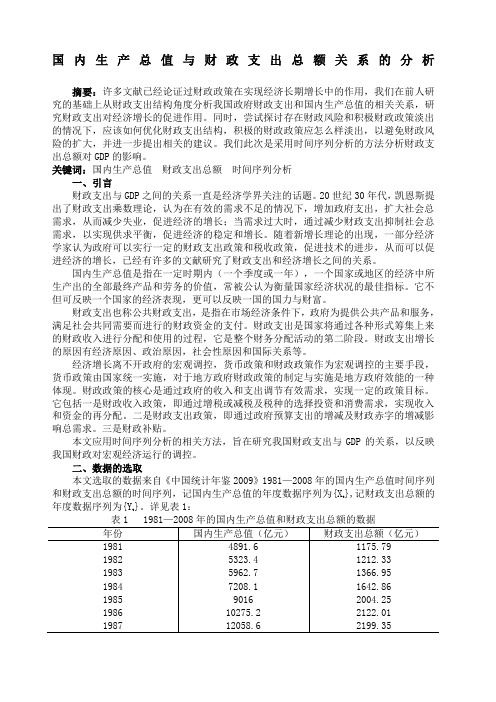
国内生产总值与财政支出总额关系的分析摘要:许多文献已经论证过财政政策在实现经济长期增长中的作用,我们在前人研究的基础上从财政支出结构角度分析我国政府财政支出和国内生产总值的相关关系,研究财政支出对经济增长的促进作用。
同时,尝试探讨存在财政风险和积极财政政策淡出的情况下,应该如何优化财政支出结构,积极的财政政策应怎么样淡出,以避免财政风险的扩大,并进一步提出相关的建议。
我们此次是采用时间序列分析的方法分析财政支出总额对GDP的影响。
关键词:国内生产总值财政支出总额时间序列分析一、引言财政支出与GDP之间的关系一直是经济学界关注的话题。
20世纪30年代,凯恩斯提出了财政支出乘数理论,认为在有效的需求不足的情况下,增加政府支出,扩大社会总需求,从而减少失业,促进经济的增长;当需求过大时,通过减少财政支出抑制社会总需求,以实现供求平衡,促进经济的稳定和增长。
随着新增长理论的出现,一部分经济学家认为政府可以实行一定的财政支出政策和税收政策,促进技术的进步,从而可以促进经济的增长,已经有许多的文献研究了财政支出和经济增长之间的关系。
国内生产总值是指在一定时期内(一个季度或一年),一个国家或地区的经济中所生产出的全部最终产品和劳务的价值,常被公认为衡量国家经济状况的最佳指标。
它不但可反映一个国家的经济表现,更可以反映一国的国力与财富。
财政支出也称公共财政支出,是指在市场经济条件下,政府为提供公共产品和服务,满足社会共同需要而进行的财政资金的支付。
财政支出是国家将通过各种形式筹集上来的财政收入进行分配和使用的过程,它是整个财务分配活动的第二阶段。
财政支出增长的原因有经济原因、政治原因,社会性原因和国际关系等。
经济增长离不开政府的宏观调控,货币政策和财政政策作为宏观调控的主要手段,货币政策由国家统一实施,对于地方政府财政政策的制定与实施是地方政府效能的一种体现。
财政政策的核心是通过政府的收入和支出调节有效需求,实现一定的政策目标。
应用时间序列分析期末论文

课程论文学生姓名曹天裕所在院系数理学院专业统计学学号************* 指导教师实证项目研究(课程论文)--------货币数量论的实证分析一问题的提出近几十年来,国内的房地产业发展迅速,开发的面积和规模也越来越大。
大多数国人对房地产这个话题的热情是经久不衰,房地产业内任何重大的政策和举措都对普通老百姓的生活产生深刻的影响。
2010年上半年,全国房地产开发投资19747亿元,同比增长38.1%,其中,商品住宅投资13692亿元,同比增长34.4%,占房地产开发投资的比重为69.3%。
6月当月,房地产开发完成投资5830亿元,比上月增加1845亿元,增长46.3%。
2010年上半年,全国房地产开发企业房屋施工面积30.84亿平方米,同比增长28.7%;房屋新开工面积8.05亿平方米,同比增长67.9%;房屋竣工面积2.44亿平方米,同比增长18.2%,其中,住宅竣工面积1.96亿平方米,增长15.5%。
2010年上半年,全国房地产开发企业完成土地购置面积18501万平方米,同比增长35.6%,土地购置费4221亿元,同比增长84.0%。
那么,房地产销售价格指数是否存在一定的内在规律呢,我们是否可以对其进行预测从而指导居民做出正确的选择呢?这便是本文所要探求和解决的问题。
理论综述时间序列分析就是对一组按时间顺序排列的随机变量进行统计分析,建立模型并对未来的趋势走向进行分析的统计方法。
本文运用时间序列分析软件SAS 进行分析。
数据的收集本文获取了我国1998-3-31到2009-12-31的房地产销售价格指数数据数据来源:8080productcommonmain.jsp模型的估计与调整首先,作出时序图,观察它的平稳性。
发现存在明显的长期趋势,做一阶差分。
从时序图可以认为序列基本平稳,再去观察它的自相关图。
自相关图显示序列平稳,考察差分后序列的随机性。
残差白噪声检验显示差分后序列蕴含着很强的相关信息,不能视为白噪声序列。
时间序列分析课程论文

摘要时间序列分析是应用广泛的数量分析方法,主要描述和探索事物随时间发生变化的数量规律,时间序列分析中最典型的ARMA 模型和ARIMA 模型在近几年的相关研究中有较多的应用并得到广泛关注,而本文基于国家统计局公布的江西省1978—2014 年的城镇化水平为分析数据,选择ARIMA 模型进行建模处理,一方面是因为ARIMA 模型在非平稳时间时间序列分析方面具有独特的优势,另一方面是模型能很好地拟合江西省城镇化发展水平的走势,模型的精度较好反映数据的真实水平。
对于实际问题的分析,结合当前我省城镇化发展水平的形势,本文以有明确记录以来的江西省城镇化率统计数据为依据,并根据SAS 软件对这些数据序列的平稳性与纯随机性进行检验,并利用SAS 软件处理的结果判断该数据是否为平稳序列且为非白噪声序列,通过对数据进行一阶差分等一系列处理,运用模型拟合数据时间序列,由于时间序列数据之间的相关关系,且历史数据对未来的发展有一定影响,结合对模型有很好预测结果,得出所有预测误差均没有超过1 %, 而且用来预测未来五年江西省城镇化发展水平达到60%,与省政府预计2020 年常住人口城镇化率达到或接近60%的目标基本保持一致,进一步体现了模型拟合的优越性,为对本省未来实现户籍改革一体化、全面提高城市化水平提供了可借鉴的参考且为省政府在制定健全人口信息管理体系政策方面提出建议。
针对分析出的结果以及相关文献资料的查阅,为江西省城镇化发展总结以下几点政策建议:(1)以人为本,科学发展;(2)改革旧体制,消除体制障碍;(3)加大投融资体制改革,多渠道筹措城市建设资金;(4)改善和加强归城镇化的宏观调控。
一、引言所谓城市化便是伴随经济增长城市增多和城市人口比重上升,首先,城市化是工业化推动的结果,即工业和商业发展形成聚集经济、进而产生对农村劳动力的持续不断的需求;其次,城市预期收入远高于农村,生活条件和个人发展条件比农村优越,因而吸引农村人口大量涌入城市;再次,农村劳动生产率的提高将越来越多的农村劳动力排挤出了农业生产领域,于是农村剩余劳动力就不得不去非农领域特别是城市寻找就业机会。
《2024年时间序列数据分类、检索方法及应用研究》范文

《时间序列数据分类、检索方法及应用研究》篇一一、引言时间序列数据是指以时间先后顺序记录的连续数据集合,在金融、气象、交通、医疗等众多领域具有广泛应用。
如何对时间序列数据进行有效的分类、检索成为当前研究的热点问题。
本文将重点研究时间序列数据的分类和检索方法,以及在具体领域的应用研究。
二、时间序列数据分类与检索方法1. 时间序列数据分类时间序列数据的分类主要是基于其特性进行的。
目前常见的分类方法包括基于聚类分析、基于模型分析和基于模式识别等方法。
其中,聚类分析是一种无监督学习方法,通过计算数据间的相似性,将具有相似特性的数据归为一类。
模型分析则是通过建立数学模型,对时间序列数据进行预测和分类。
模式识别则主要是通过提取数据的特征,利用机器学习算法进行分类。
2. 时间序列数据检索时间序列数据的检索主要是通过建立索引和查询机制实现的。
常见的检索方法包括基于关键字的检索和基于内容的检索。
基于关键字的检索主要是通过匹配数据中的关键字进行检索。
而基于内容的检索则是通过提取数据的特征,如时间、数值等,建立索引,然后根据用户的查询条件进行检索。
三、时间序列数据应用研究1. 金融领域应用在金融领域,时间序列数据主要用于股票价格、汇率、利率等数据的分析和预测。
通过采用聚类分析、模型分析等方法,可以对金融市场进行风险评估和投资决策。
同时,基于内容的检索方法可以快速找到历史数据中的相似模式,为金融决策提供有力支持。
2. 气象领域应用在气象领域,时间序列数据主要用于气象预报和气候变化研究。
通过建立气象模型,利用历史气象数据进行训练和预测,为天气预报提供支持。
同时,通过对历史气象数据的检索和分析,可以研究气候变化规律,为应对气候变化提供科学依据。
3. 医疗领域应用在医疗领域,时间序列数据主要用于病历管理和疾病预测。
通过对患者的生理指标、病史等数据进行分类和检索,可以帮助医生更好地了解患者的病情,制定合适的治疗方案。
同时,通过对大量医疗数据的分析和挖掘,可以发现疾病的发生规律和影响因素,为预防和治疗提供有力支持。
论文写作中的时间序列分析

论文写作中的时间序列分析时间序列分析是一种在论文写作中应用广泛的统计分析方法,它可以帮助研究者对数据中的时间序列模式进行识别和预测。
在本文中,我们将探讨时间序列分析在论文写作中的重要性及其具体应用。
一、时间序列分析的基本概念时间序列是指在时间上按照一定间隔取得的一系列观测值,例如每日、每月或每年的数据收集。
时间序列分析旨在揭示数据中的趋势、周期性和不规则变化,并利用这些信息进行预测和决策。
二、时间序列分析在论文写作中的重要性通过时间序列分析,研究者可以对数据的演变规律进行深入研究,从而有助于解答研究问题。
特别是对于与时间相关的现象或变量,时间序列分析可以提供一种可靠的量化方法,帮助研究者更准确地了解和预测未来的发展趋势。
三、时间序列分析的应用领域时间序列分析在各个学科领域的研究中都得到了广泛的应用,包括经济学、金融学、环境科学、医学等。
以下将举例阐述时间序列分析在论文写作中的应用。
1. 经济学领域:时间序列分析广泛应用于宏观经济指标的预测,如国内生产总值(GDP)、通货膨胀率等。
研究者可以利用时间序列模型对过去的经济数据进行拟合和预测,从而为经济政策制定者提供决策依据。
2. 金融学领域:时间序列分析在股市、外汇市场等金融市场的研究中具有重要的应用。
通过对金融资产价格的时间序列模型建立和预测,研究者可以评估风险和制定投资策略。
3. 环境科学领域:时间序列分析在气候变化、环境污染等领域的研究中也具有重要意义。
通过对气温、降水量等气象数据的时间序列建模,研究者可以预测未来的气候趋势,并评估各种环境政策对气候变化的影响。
4. 医学领域:时间序列分析在医学研究中的应用也十分广泛。
例如,通过对病人的生理指标(如心率、血压)进行时间序列分析,医生可以更好地了解疾病的发展过程,制定更精确的治疗方案。
四、时间序列分析的方法和技术时间序列分析的方法和技术有很多,这里只简要介绍几种常用的方法。
1. 分解法:将时间序列分解为趋势、季节性和随机成分,以便更好地了解数据的特征。
《2024年时间序列数据分类、检索方法及应用研究》范文

《时间序列数据分类、检索方法及应用研究》篇一一、引言随着信息技术的飞速发展,时间序列数据在各个领域的应用越来越广泛。
时间序列数据分类、检索方法的研究对于提高数据处理效率、优化决策过程具有重要意义。
本文旨在探讨时间序列数据的分类、检索方法及其应用研究,以期为相关领域的研究与实践提供参考。
二、时间序列数据概述时间序列数据是指按照时间顺序记录的数据,具有明显的时序特性。
这类数据广泛应用于金融、气象、医疗、工业等领域。
时间序列数据的分类主要依据数据的性质、来源及研究目的。
常见的分类方法包括按数据类型分类、按领域分类及按数据粒度分类等。
三、时间序列数据分类方法(一)基于数据类型的分类根据数据类型的不同,时间序列数据可分为数值型时间序列、文本型时间序列及混合型时间序列。
数值型时间序列主要涉及数值数据的时序变化,如股票价格、气温等;文本型时间序列则主要涉及文本数据的时序变化,如社交媒体舆情等;混合型时间序列则同时包含数值和文本数据。
(二)基于领域的分类根据应用领域的不同,时间序列数据可分为金融领域时间序列、气象领域时间序列、医疗领域时间序列等。
不同领域的时间序列数据具有不同的特性和处理方法。
(三)基于数据粒度的分类根据数据粒度的不同,时间序列数据可分为粗粒度时间序列和细粒度时间序列。
粗粒度时间序列通常以较大的时间间隔进行采样,如日、周、月等;细粒度时间序列则以较小的时间间隔进行采样,如秒、毫秒等。
四、时间序列数据检索方法(一)基于相似性的检索方法基于相似性的检索方法主要通过计算时间序列数据之间的相似度来实现在线检索。
常见的相似度计算方法包括欧氏距离、动态时间规整算法等。
这种方法适用于具有相似特性的时间序列数据的检索。
(二)基于模式的检索方法基于模式的检索方法主要通过提取时间序列数据的模式特征,如趋势、周期性等,来实现检索。
这种方法适用于具有明显模式特征的时间序列数据的检索。
(三)混合检索方法混合检索方法结合了基于相似性和基于模式的检索方法的优点,通过综合利用多种特征和算法来提高检索效果。
统计技术应用 时间序列分析

以及什 么调整 可能对过程趋 向某些 目 标值 产生影响 、或什么调
整能减少过程变异。
( ) 3 单击 【 选项 】 ,打开趋势分析 一 选项对话框 ,如图 3 。
5 局 限性 和 注 意事 项
当为 了了解原 因和结 果而建立过程模型时 ,需要具备选择
' 0' ・ 4 1 2 t O 3 l
日用 电 器 fEe tc l pl n e lcr a i Ap i c s a
本例标题 为 “ 线性模型拟合趋势分析 ”。
( ) 4 单击 【 存储 】 ,打开趋势分析 一 存储对话框 , 如图 4 。 本例存储选中 “ 拟合值 ”和 “ 预测值 ”。
最适宜模型和使用诊断工具以改进模 型的技能水平。
表 1 某 企 业 19 9 0年 至 2 0 0 5年 的 各 年利 润 率
不 同 的时 间序 列 估 计 技 术 可能 具 有 不 同 的成 功 程 度 ,这 主
方差函数 的估计等 ;
4 应用建立 的模型进行 预测预报 。 )
3 时 间序 列 分析 的用 途
时间序列分析的用途可 以概括为 :
要取决 于时间序列的形态 ,以及针 对可获得的时间序列数据的 时 间周期数量所期望 的预测 周期的数量。模 型的选 择应 考虑分 析 的目标 、数据 的性质 、相关成本 以及各种模型 的分析和 预计
热 点 追 踪 ・ otc H t ak r
E 1 t e c r i 1 e a A p p l i c e a n 8
3 对建立 的模 型进 行检验 ,常用的方法有均值估计 、自协 )
在 分析 中,包括或 遗漏某个观测值或一小组观测值 ,都可 能对模型产生重要影响 。因此 ,应理解有影响的观测值并与数 据中的 “ 离群值 ”相 区别 。
时间序列分析范文

时间序列分析范文时间序列分析是一种统计学方法,用于分析和预测一系列按时间顺序排列的观测数据。
时间序列数据是在不同时间点上观察到的变量的连续观察结果。
这些变量可以是股票价格、气温、销售数据等。
通过对时间序列数据进行分析,可以揭示数据背后的规律、趋势和周期性,并基于这些规律进行预测和决策。
首先,描述性分析旨在理解和总结时间序列数据的特征和变化趋势。
描述性分析的常见方法包括绘制时间序列图、计算均值、方差和自相关系数等。
时间序列图是展示时间序列数据的最常见方法。
通过绘制时间序列图,我们可以观察到数据的趋势、季节性和异常值。
在时间序列图中,时间通常放在横轴上,变量的取值放在纵轴上。
均值是时间序列数据的一个重要统计量。
它表示了数据的中心趋势。
通过计算均值,我们可以判断数据整体上是向上还是向下变化,以及变化的幅度。
方差是数据分布的一个关键指标,它衡量了数据点相对于均值的离散程度。
自相关系数(ACF)是描述时间序列数据观察之间相关性的一种指标。
它可以帮助我们发现数据中的周期性和趋势。
其次,预测分析旨在使用时间序列数据来预测未来的趋势和变化。
预测分析的常见方法包括移动平均法、指数平滑法和自回归集成滑动平均法(ARIMA)等。
移动平均法是一种简单的预测方法,它基于数据在不同时间点上的平均值。
通过移动平均法,我们可以平滑数据的波动,并预测未来的变化趋势。
指数平滑法基于数据的指数加权平均值来进行预测。
指数平滑法给予最近观测值更大的权重,对过去的观测值赋予较小的权重。
这样可以适应数据的变动并提高预测的准确性。
ARIMA是一种广泛使用的时间序列预测方法,它结合了自回归(AR)、差分(I)和移动平均(MA)的元素。
ARIMA模型可以捕捉到时间序列数据中的趋势和周期性,并用于预测未来的值。
除了描述性分析和预测分析之外,时间序列分析还包括模型诊断和评估。
模型诊断可以通过检查模型的拟合程度来验证模型的准确性。
拟合程度可以通过计算残差的均方差或平均绝对误差来确定。
时间序列分析范文

时间序列分析范文
时间序列分析是利用统计学和计算机技术来研究和预测未来时期观测
到的系列观测值的趋势,它是一种重要的风险管理工具,主要用于金融信
息的预测、量化投资、金融市场的异动检测以及过去的趋势推测和预测。
时间序列分析可以帮助企业和个人快速、准确地了解过去的行业动态,预
测未来的发展趋势。
时间序列分析的基本概念可以分为三个层次,宏观部分,定义有关系
统的趋势和变化的综述;微观部分,关注各种因素与变量之间的关系;趋
势部分,注重系统的演化过程,考虑未来变化的方向,可以通过回归模型
等方法来进行实证研究。
ARIMA模型是建立在自回归模型和移动平均模型之上的,自回归模型
可以用来描述和预测时间序列中残差序列的趋势,移动平均模型可以用来
描述和预测时间序列中的反复性,ARIMA模型集合了以上两种模型的优点,使其成为预测时间序列最常用的模型。
ARIMA模型可以在任何时期预测,如短期预测,如一个月内预测,中
期预测,如一年内预测,长期预测。
应用时间序列分析课程论文

应用时间序列分析课程论文一 时间序列模型简介总结时间序列模型可以大致分为自回归过程模型和移动平均过程模型两大类。
前者以其滞后变量为依据,推算其未来值,后者是以过去的误差项为依据,推算其未来值。
有时需两者并用,便产生自回归移动平均模型。
自回归模型(AR )Mt m t m tm x a x e -==+∑在AR 模型中,序列{}t x 的当前值由序列{}t e 的当前值和序列{}t x 的前一个长度为M 的窗口内序列值决定。
自回归过程是一个变量在时间的某一点的变化,相对于前期的变化是线性的。
一般来说相关性随着时间呈指数下降,且在比较短的周期内消失。
移动平均模型(MA )0110Nt n t n t t n t n n x b e b e b e b e ---===++⋅⋅⋅+∑这个式子说明序列{}t x 的当前值由序列{}t e 从当前值前推长度为N 的窗口内序列值决定。
在平均移动模型(MA )中,时间序列是一种未观测到的时间序列的平均移动的结果,如下:1n n n C c e e -=⨯+e 为一个独立同分布的随即变量,c 为常数,且 c ≤1。
在平均移动参数c 上的限制保证了过程是可以转换的。
表明未来事件不太可能影响现在的事件,而且此过程是稳定的;对于e 的限制,如同 AR 过程中的e ,是一个具有零均值和方差为r 的独立同分布随机变量。
已观测到的时间序列 C 是未来观测到随机时间序列平均移动的结果。
由于平均移动过程,所有过去和短期记忆的结果存在一个线性的依赖。
自回归-移动平均模型(ARMA )ARMA 由AR 和MA 两个部分组成,形式如下:1MNt m t mt t t n m n x axe b e --===++∑∑在ARMA 模型中,序列{}t x 的当前值由序列{}t e 的当前值从当前值前推长度为N 的窗口内序列值以及序列{}t x 的前一个长度为M 的窗口内序列值一起决定。
在自回归-移动平均模型中,既存在自回归项,又有平均移动项:11n n l l C a C e b e --=⨯+-⨯此模型属于混合模型,称为 ARMA( p ,q)。
应用时间序列分析

总的来说,ARIMA模型的建立过程已经结束,模型整体好,达到预期效果。ARMA模型从定量的角度反应了一定的问题,作出了较为精确的预测,尽管不能完全代表现实,但对我国教育事业蒸蒸日上的今天,我们把握教育支出的趋势具有较好的借鉴意义。
参考文献
[1]高铁梅.计量经济分析方法与建模[M].北京:清华大学出版社,2009,5.
ARIMA模型是迄今为止运用最广泛的时间序列预测方法。ARIMA模型是通过差分等方法将非平稳序列转变为平稳随机序列,再运用目前已经相当成熟的ARMA模型进行拟合,效果十分显著。对于非平稳时间序列,首先必须将其差分d次,把它变为平稳的,然后用ARMA(p,q)作为它的模型,那么就说这个原始的时间序列是ARIMA(p,d,q),即自回归求和移动平均模型(其中p指自回归项数,d指序列成为平稳之前必须取其差分的次数,而q指移动平均数)。显然,ARIMA(p,d,q)模型的实质就是d阶差分运算与ARMA(p,q)模型的组合。
从图可以看出,预测值与实际值的相对误差小,说明该模型在短期内预测比较准确,但随着预测期的逐渐增大,预测误差可能会逐渐增大。下面是对2011年到2013年的情况进行预测:(单位:亿元)
ARIMA(0,1,(6,7))对2011年-2013年预测
时间
2011
2012
2013
预测值
7337.182
8020.689
实际值
预测值
绝对误差
相对误差(%)
相对误差平均值(%)
2008年
5389.397
5416.991
27.59361
0.1200
0.853
2009年
6006.770
6080.457
73.68692
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
应用时间序列分析大作业*名:**学号: **********专业班级:应用统计18院系:信息工程学院数学系时间: 2017/5/22题目:对苏格兰异性结婚数据的时序分析摘要:本文以苏格兰1855年至2015年异性结婚数据为研究对象,首先运用R软件对1855-2010年的结婚数据绘制时序图、自相关图和做差分进行相关分析,得出一阶差分后的数据是趋于平稳的,然后根据主观确定拟合模型为)2(MA,并运用R软件里面的()ARIMA模型即auto函数进行模型的自动选择,得出)2,1,0(.arimaMA是最优的,最后运用)2(MA模MA模型最优,故我们所选择的拟合模型)2()2(型预测并进行预测残差检验,得出了苏格兰2011-2015年异性结婚数据的预测值(29200.45,28905.94,28905.94,28905.94,28905.94)与实际值(29135,30534,27547,28702,28020)相比,相差不大,这说明模型拟合较好,能反映数据的真实水平,而且残差检验也表明预测残差是平均值为0且方差为常数的正态分MA模型是可以提供非常合适布(服从零均值、方差不变的正态分布),这进一步说明)2(预测的模型。
关键词:苏格兰;()arima函数;auto.()arima函数;R软件;预测二、数据来源本文的数据是1855-2015年苏格兰的结婚数据(Marriages, Scotland, 1855 to 2015 ),数据可以从网上(https:///statistics-and-data/statistics/statistics-by-theme/vital-events/marriages-and-ci vil-partnerships/marriages-time-series-data)下载,数据见附件一。
三、模型的定阶与确定3.1模型的定阶3.1.1序列预处理[1]首先,我们对苏格兰1855年至2010年的时间序列进行时序图和自相关分析,分析结果如图3.1.1.1和图3.1.1.2所示,程序见附录一。
1855-2010年苏格兰结婚数据的时序图时间结婚数据185019001950200020000350005000图3.1.1.1 苏格兰1855年至2010年异性结婚数据的时序图05101520-0.20.20.61.0LagA C FSeries dataseries图3.1.1.2 苏格兰1855年至2010年异性结婚数据的自相关图图 3.1.1.1显示苏格兰的结婚数值的均值和方差变动很大,随着时间的增加,具有明显的上升趋势,是典型的非平稳序列。
图3.1.1.2显示该序列的自相关系数都超出了两倍标准误差,所以进一步证明了该序列是非平稳的。
综上所述,该序列是非平稳序列。
对于该非平稳时间序列,首先我们对数据进行1阶差分处理,以便消除其具有的强烈的趋势性,来观察数据是否大致趋于平稳。
因此得到的1阶差分时间序列图如下:1855-2010年苏格兰一阶差分结婚数据的时序图时间一阶差分数据1850190019502000-100000500图3.1.1.3 苏格兰1855年至2010年异性结婚数据1阶差分后的时序图从图3.1.1.3中我们可以看出,经过1阶差分后,该序列的平均值和方差是大致平稳的,所以我们使用ARMIA(p,1,d)模型是很合适的。
通过一阶差分,我们去除了结婚数据的趋势部分,剩下了不规则部分。
接下来我们可以检验不规则部分中邻项数数值是否具有相关性;如果有的话,可以帮助我们建立一个预测模型来预测苏格兰异性结婚数据的数值趋势。
3.1.2平稳性检验由图3.1.1.3可以认为该序列一阶差分后,序列基本平稳,为了进一步判断其平稳性,考察差分序列的自相关图和偏自相关图,如图五和图六所示。
图3.1.2.1自相关图显示延迟2阶、3阶、4阶和5阶时的自相关值超出了2倍标准差范围,但是其他在延迟1-25阶的自相关系数都落入2倍标准差范围以内,从而判断该序列有很强的短期相关性,是2阶截尾,所以可以初步认为1阶差分后序列平稳。
图3.1.2.2偏自相关图显示,在延迟2阶和4阶时的偏自相关系数超出了2倍标准差范围,从lag4之后缩小至0,是4阶截尾,该序列趋于平稳。
综上所述,我们可以认为该序列的一阶差分序列自相关图2阶截尾和偏自相关图4阶截尾。
0510152025-0.20.20.61.0LagA C FSeries dataseriesdiff1图3.1.2.1 该序列一阶差分后的自相关图510152025-0.3-0.10.1LagP a r t i a l A C FSeries dataseriesdiff1图3.1.2.2 该序列一阶差分后的偏自相关图3.1.3纯随机性检验为了判断序列是否有分析价值,必须对序列进行纯随机性检验,即白噪声检验。
如表3.1.3.1所示,P 值远远小于0.05的临界值,因此,拒绝原假设,即可以认定1阶差分后的序列是平稳非白噪声序列,需要建立模型来拟合该序列的变化趋势。
表3.1.3.1 纯随机性检验代码Box.test(dataseriesdiff1,type="Ljung-Box",lag=30); Box-Ljung testData: Dataseriesdiff1 X-squared=83.411 Df=30 P-value=6.313e-073.2模型确定3.2.1根据阶数确定模型由该序列一阶差分的自相关图和偏自相关图,知道自相关值在滞后2阶之后为0,且偏自相关值在滞后4阶之后缩小至0,那么意味着接下来的ARIMA 模型对于一阶时间序列有如下性质:1、(4,0)ARMA 模型:即偏自相关值在滞后4阶之后缩小至0且自相关值缩小至0,则是一个阶层p=4自回归模型。
2、(0,2)ARMA 模型:即自相关图在滞后2阶之后为0且偏自相关图缩小至0,则是一个阶数q=2的移动平均模型。
3、(p,)ARMA q 模型:即自相关图和偏自相关都缩小至0,则是一个具有p 和q 大于0的混合模型。
接下来我们利用简单的原则来确定哪个模型是最好的:即我们认为具有最少参数的模型是最好的。
(4,0)ARMA 有4个参数,(0,2)ARMA 有2个参数,而(,)ARMA p q至少有两个变量。
因此,(0,2)ARMA 模型被认为是最好的模型。
(02)ARMA ,模型是二阶的移动平均模型,或者称作(2)MA 。
这个模型可以写作:t 1122t t t X εθεθε--=-- (3.2.1)移动平均模型通常用于建模一个时间序列,此序列具有邻项观测值之间短期的相关特征。
直观地,可以很好理解MA 模型可以用来描述苏格兰异性结婚数据中的不规则部分。
3.2.2运用().arima auto 函数[2]自动选择模型表3.2.2.1 ().arima auto 函数运行的结果代码 auto.arima(dataseries);Series: dataseries最优模型(0,1,2)ARIMACoefficients:Ma1 Ma2 0.1022 -0.4311 s.e 0.0763 0.0800sigma^2 estimated as 4121992: log likelihood=-1399.62 AIC=2805.24 AICc=2805.4 BIC=2814.37 从表3.2.1.1中可以得出(0,1,2)ARIMA 模型最适合该序列,这与我们前面通过主观确定的模型一样,这说明(0,1,2)ARIMA 非常适合拟合该序列。
3.3模型的参数检验对于(0,1,2)ARIMA 模型的参数估计问题,我们运用()arima 函数来估计,估计结果如下:表3.3.1 (0,1,2)ARIMA 模型的参数检验代码dataseriesarima=arima(dataseries,order=c(0,1,2));dataseriesarima Call:arima(x = dataseries, order = c(0, 1, 2))Coefficients:Ma1Ma2续表:0.1022 -0.4311 s.e.0.07630.0800sigma^2 estimated as 4068802: log likelihood = -1399.62, aic = 2805.24表3.3.1显示,1022.01=∧θ,4311.02-=∧θ是比较显著地参数,所以模型的方程式确定为:t 120.10220.4311t t t X εεε--=--- 3.3.13.4模型预测以及预测误差的检验3.4.1 模型的预测预测就是要利用已观测到的样本值对序列在未来某个时刻的取值进行估计。
为了对随机序列未来发展进行预测,我们对原序列进行短期(h=5)预测,并与实际值进行对比,观测预测效果,预测结果如下表3.4.1.1所示。
表3.4.1.1 运用(0,1,2)ARIMA 模型预测2010-2015年的结婚数据year Point Forecast 实际观测值 Lo 80 Hi 80 Lo 95 Hi 95 2011 29200.45 29135 26615.40 31785.50 25246.95 33153.95 2012 28905.94 30534 25058.73 32753.16 23022.14 34789.75 2013 28905.94 27547 24685.64 33126.25 22451.54 35360.35 2014 28905.94 28702 24342.95 33468.94 21927.44 35884.44 201528905.942802024024.2633787.6321440.0536371.84表3.4.1.1显示预测值与实际值十分接近,这说明(012)ARIMA ,,模型的拟合效果非常好,很适合该时间序列的拟合。
接下来,我们通过绘制预测图,直观的看预测效果,预测图表明预测效果很好。
Forecasts from ARIMA(0,1,2)1850190019502000200003500050000图3.4.1.1 (0,1,2)ARIMA 预测图3.4.2预测误差的检验在指数平滑模型下,观测ARIMA 模型的预测误差是否是平均值为0且方差为常数的正态分布(服从零均值、方差不变的正态分布)是个好主意,同时也要观测连续预测误差是否自相关。
表3.4.2.1 预测误差的纯随机性检验代码 Box.test(dataforecast$residuals,type="Ljung-Box",lag=30);Box-Ljung testData: dataforecast$residualsX-squared=42.036 Df=30 P-value=0.0710705101520-0.20.20.61.0LagA C FSeries dataforecast$residuals图3.4.2.1 预测误差的自相关图相关图显示出在滞后1-20阶中样本自相关值都没有超出显著边界,而且Ljung-Box 检验的p 值为0.7107,所以我们推断在滞后1-20阶中没有明显证据说明预测误差是非零自相关的。