评分卡相关内容
食品安全评估卡

食品安全评估卡
食品安全评估卡是指使用评分卡的方法对食品安全进行评估的工具。
评分卡是一种将食品安全相关因素以指定权重进行评分和加权计算的方法。
食品安全评估卡通常包括以下几个方面的评估指标:
1.食品原料来源:评估食品使用的原料是否来自正规渠道,是
否符合相关的食品安全标准。
2.食品加工过程:评估食品的加工过程是否符合卫生要求,包
括加工设备的清洁程度、操作工艺的规范性等。
3.食品存储与运输:评估食品在存储和运输过程中是否符合相
关的温度要求,是否有防止污染的措施。
4.生产者的食品安全管理:评估生产者在食品生产过程中是否
建立了完善的食品安全管理体系,包括食品安全培训、采样检测、风险评估等措施的实施情况。
5.产品标签与说明:评估食品的标签是否合法、准确,并且是
否提供了必要的食品使用说明和储存条件。
通过对以上指标进行评分和加权计算,可以得出一个综合评分,用于评估食品安全的等级。
食品安全评估卡可以帮助监管部门、企业和消费者对食品进行科学、客观的评估,提高食品安全管理水平,保障消费者的食品安全。
评分卡

评分卡
姓名编号总得分
评分项目得分
1、举止仪表(大方、得体、礼貌、着装整齐)
差:0—2分一般:3—4分良好:5—6分优秀:7—8分
2、个人简历(个性、突出、一目了然)
差:0—4分一般:5—6分良好:7—8分优秀:9—10分
3、综合分析与思维能力(严密性、条理性、人际沟通)
差:0—8分一般:9—14分良好:15—17分优秀:18—20分
4、语言表达(简体、流畅、生动精确)
差:0—7分一般:8—10分良好:11—12分优秀:13—14分
5、组织协调能力(合作、沟通)
差:0—7分一般:8—10分良好:11—12分优秀:13—14分
6、责任心与进取心(诚实、责任)
差:0—7分一般:8—10分良好:11—12分优秀:13—14分
7、应变能力(沉着、冷静、灵活)
差:0—4分一般:5—6分良好:7—8分优秀:9—10分
8、总体印象
差:0—4分一般:5—6分良好:7—8分优秀:9—10分
评委点评:。
评分卡(销售员能力提升)

经销商: 序号 1 评分项目 评分标准 满分 得分 3
关键指标的汇总数仅用于指导 有针对汇总数制订的个人专项培训的记录计 培训改善的方向,不作为处罚的 满分;有汇总数无培训记录计50%;无汇总数或 依据 根据汇总结果进行处罚计0分 制定销售员产品知识、竞品知 有制定标准和更新且销售员均理解计满分;有 识、销售接待流程等考核标准, 制定标准没执行计50%;无标准计0分 并及时更新 销售员须通过考核后方可正式 上岗 在岗销售员定期培训每周不少 于1次 有培训记录和考核成绩等档案材料计满分;有 培训记录无考核成绩档案计50%;无培训记录 和考核成绩记录计0分 有培训计划、记录、考核成绩档案计满分;有 计划但培训和考核记录不完整计50%;无计划 计0分
访谈展厅主管,询问是否对销售员有阶 段性考核,以及在岗培训是否有针对性 访谈展厅主管,询问其现场演练是哪些 人参加?挑选演练人的标准怎样? 访谈展厅主管、培训专员定期调查培训 需求及OJT检讨情况,查阅相关记录
评分人: 改善建议 责任人 完成时间 工具表单 销售员关键能力指标汇总及培训计 划 产品知识FAB考核表、竞品知识及话 术(每月更新)、销售员销售流程 考核表 OJT档案包含:OJT实施成果报告 表,新销售员必修科目考核成绩表 销售部月度培训计划、OJT实施成果 报告表 销售部月度培训计划 、OJT实施成 果报告表、销售员销售流程考核表 、销售员“加油站”实施办法 销售话术脚本讨论,每日现场演练 人员选取办法 培训需求调查表、训练实施改善计 划
3
7
3
8
有定期调查、检讨改善并有文件记录计满 有无定期调查培训需求,检讨 分,不定期调查检讨,并有文件记录计50%, OJT方法和方向,改善培训效果 没有调查改善记录0分 合计
选手评分卡

得分
选手表现内容(内容紧扣主题,格调积极向上,富有真情实感。)
10分
形象风度(衣着整洁,仪态端庄大方,举止自然、得体,体现朝气蓬勃的精神风貌;
上下场致意,答谢。)
10分
综合印象(由评委根据PPT展示的内容、及PPT演说、及户外工作表现给分)
30分
第三方陈述
由选手指定自己熟悉的同学或朋友为自己自强事迹做简述
15分
评委自由问答
评委向选手提出一些问题由选手现场回答,根据选手对问题的回答给分
20分
现场投票
(观众评分项)
由工作人员现场随机发放选票若干(盖有自立社专用章有效)最后比较谁的票最多
15分
“自强之星”评分卡
3号选手:张婷总得分:
项目
内容
分值
得分
选手表现
(评委评分项)
PPT
户外工作
内容(内容紧扣主题,格调积极向上,富有真情实感。)
20分
现场投票
(观众评分项)
由工作人员现场随机发放选票若干(盖有自立社专用章有效)最后比较谁的票最多
15分
“自强之星”评分卡
8号选手:侯茹总得分:
项目
内容
分值
得分
选手表现
(评委评分项)
PPT
户外工作
内容(内容紧扣主题,格调积极向上,富有真情实感。)
10分
形象风度(衣着整洁,仪态端庄大方,举止自然、得体,体现朝气蓬勃的精神风貌;
30分
第三方陈述
由选手指定自己熟悉的同学或朋友为自己自强事迹做简述
15分
评委自由问答
评委向选手提出一些问题由选手现场回答,根据选手对问题的回答给分
20分
现场投票
评分卡样表
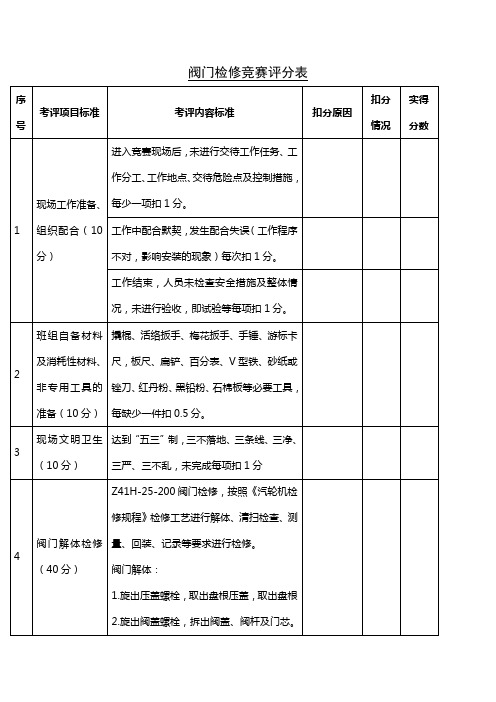
3、工器具、材料摆放混乱、无条理扣1分。
2
接线原理草图
1、草图原理正确无误。
2、符号标识正确、规范。
3、原理图卷面整洁,连接线横平竖直。
5
1、错误、涂抹1处扣1分。
2、符号标识不规范1处扣2分。
3、图纸卷面不整洁、连接线不规范扣1-2分
3
材料选择
1、根据电动机容量对安装材料进行选择。
2
班组自备材料及消耗性材料、非专用工具的准备(10分)
撬棍、活络扳手、梅花扳手、手锤、游标卡尺,板尺、扁铲、百分表、V型铁、砂纸或锉刀、红丹粉、黑铅粉、石棉板等必要工具,每缺少一件扣0.5分。
3
现场文明卫生(10分)
达到“五三”制,三不落地、三条线、三净、三严、三不乱,未完成每项扣1分
4
阀门解体检修(40分)
阀门检修竞赛评分表
序号
考评项目标准
考评内容标准
扣分原因
扣分情况
实得分数
1
现场工作准备、组织配合(10分)
进入竞赛现场后,未进行交待工作任务、工作分工、工作地点、交待危险点及控制措施,每少一项扣1分。
工作中配合默契,发生配合失误(工作程序不对,影响安装的现象)每次扣1分。
工作结束,人员未检查安全措施及整体情况,未进行验收,即试验等每项扣1分。
2.主线扎结紧凑,扎线间距均匀。
3.主线把应无交叉
4.主线把应横平竖直,排列整齐。
10
1.无规则形状扣2分。
2.间距不均匀或松动扣2分。
3.主线把交叉扣2分。
4.主线排线不横平竖直扣4分。
8
文明接线
1.做到工完料尽场地清。
2.举止文明,尊重裁判。
面试标准评分卡

面试标准评分卡
面试标准评分卡可以包含以下要素:
1. 仪容仪表:整洁得体的穿着和良好的精神状态可以展现出应聘者的专业素养和态度,因此,评分卡中应包含对应聘者仪容仪表的评价。
2. 语言表达:清晰的表达能力是面试中非常重要的素质,评分卡中应对应聘者的语言表达进行评价。
3. 逻辑思维:在面试过程中,逻辑思维清晰的应聘者能够更好地理解和分析问题,评分卡中应对此进行评价。
4. 工作经验:工作经验是评价应聘者能力和潜力的重要因素,评分卡中应对此进行评价。
5. 专业技能:对于特定岗位的应聘者,专业技能是非常重要的评价标准,评分卡中应包含对应聘者专业技能的评价。
6. 沟通能力:在工作中,良好的沟通能力对于团队的合作和工作的顺利进行非常重要,评分卡中应对此进行评价。
7. 学习能力:随着技术的不断发展和市场的变化,学习能力是保证员工能够持续进步的重要素质,评分卡中应对此进行评价。
8. 团队协作:团队合作是现代工作中不可或缺的一部分,评分卡中应对应聘者的团队协作能力进行评价。
9. 创新能力:在快速变化的环境中,创新能力是推动企业发展的重要动力,评分卡中应对此进行评价。
10. 个人品质:诚实、勤奋、责任心等个人品质也是评价应聘者的重要因素,评分卡中应对此进行评价。
具体评分标准可以根据实际情况进行调整,但总体来说,评分标准应尽可能客观、具体、可量化,以确保评价的准确性和公正性。
行为风险评分卡介绍材料

行为风险评分卡介绍信贷政策部2009年7月2一、开发目的本次开发的是行为风险评分模型;目的:根据信用卡帐户历史上表现出来的各种行为特征来预测该帐户在未来一定时间内变坏的概率;每一个客户得到唯一的客户级评分;二、评分卡预测效果6三、评分分布拟显示在发卡系统中,以分数段的形式以下客户将没有评分:(1)当前逾期;(2)风险管制(帐户D/H/V/Z 卡片F/O/U/I/X/5/9/7);(3)销户(C/D/E/G/K/Q/R/V/W/Z/2);(4)测试卡;(5)公务卡;(6)睡眠户(近6个月无消费、取现、还款);(7)持卡不足6个月;10四、评分应用策略——调额(讨论稿)根据各分数段资产品质及分数分布情况,初步拟定如下调额规则:1、信用条件:评分大于640;2、其他条件:(1)当前未逾期、未超限、状态正常(含贷后管理、低零扣率用卡);(2)额度使用率大于10%;(3)最近一次调额时间达到要求;(4)调额后额度不超过月收入6倍;(5)排除疑似套现;(6)排除行员、学生;(7)排除各类黑名单;12五、与现有调额政策比较用早期批量调额名单进行验证;2008年五一批量调额,共调升67.7万户;将调额规则和评分模型筛选的客户进行比较:1、已调额但未被评分实际调额客户中,有20万客户没有分数,占比29%。
未被评分原因:该次批量调额未做额度使用率要求,因而可对睡眠户调额,但评分标准却排除睡眠户。
2、已调额并且获得评分整体来看,调额并且有评分的客户(48万)资质较好,10年新增坏帐率为0.74%;但640分以下客户风险水平明显较高,10年新增坏帐率为2.61%。
(需要说明的是,已调额且有评分的帐户实际上是既满足评分标准又满足调额筛选条件的客户,因而其风险水平会低于对应分数段的全体客户。
)3、未被调额但依据评分可调额客户在未被调额客户中共有18万客户分数在640分以上,进一步在其中排除掉因政策原因而未被调额的客户,剩余的4.9万调额时由于风险原因没有调额,但根据评分规则,将对这部分客户调额。
员工绩效考核评分卡

公
棋塞门
考核
要素
考核
指标
姓名
主要工作职责及工作负荷
(40分)
专业知识
和技能
(10分)
能力和行为
(20分)
工作态度
(20分)
现场情况
(10分)
合计
得分
公司下达
任务
完成情况
(10分)
本岗位
工作
完成情况
(10分)
工
作
质
量
(10分)
工
作
效
率
(10分)
专
业
知
识
(5分)
员工
岗位
技能
(5分)
学
习
能
力
(5分)
团
队
合
作
(5分)
事假
病假
旷工
(5分)
上班时间
不抽烟
不喝酒
不脱岗
(5分)
责
任
心
(7分)
主
动
性
(4分)
服
从
性
(4分)
出
勤
率
(5分)
维护
公共
卫生
(5分)
防
火
防
盗
(5分)
100分
韩雪松
于东阳
吴磊
祖晓鹏
许敬国
任晓峰
张大地
张丽
赵兰新
刘小燕
述职评分卡
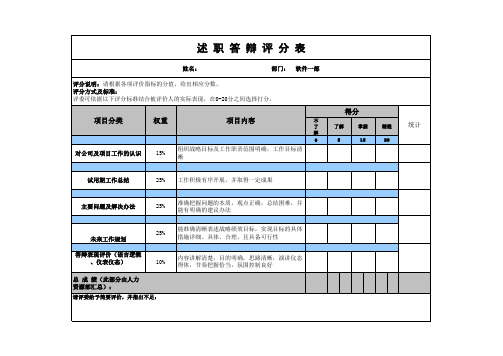
25%
10%
内容讲解清楚,目的明确,思路清晰,演讲仪态 得体,节奏把握恰当,氛围控制良好
请评委给予简要评价,并指出不足:
试用期工作总结
25%
工作积极有序开展,并取得一定成果
主要问题及解决办法
25%
准确把握问题的本质,观点正确,总结困难,并 能有明确的建议办法 能准确清晰表述战略绩效目标,实现目标的具体 措施详细、具体、合理,且具备可行性
未来工作规划 答辩表现评价(语言逻辑 、仪表仪态) 总 成 绩(此部分由人力 资源部汇总):
述 职 答 辩 评 分 表
姓名: 部门: 软件一部
评分说明:请根据各项评价指标的分值,给出相应分数。 评分方式及标准: 评委可依据以下评分标准结合被评价人的实际表现,在0-20分之间选择打分。
得分 项目分类 权重 项目内容
不 了 解 了解 掌握 精通
统计
0
5
15
20
对公司及项目工作的认识
15%Βιβλιοθήκη 组织战略目标及工作职责范围明确,工作目标清 晰
面试标准评分卡

面试标准评分卡全文共四篇示例,供读者参考第一篇示例:一、面试评分卡的制作1. 设计评分项目:面试评分卡应包含面试项目、评分标准和评分范围等内容。
评分项目可以根据招聘职位的要求确定,一般包括技能、知识、经验、沟通能力、团队合作能力等方面。
2. 制定评分标准:对每个评分项目都要设定明确的评分标准,如优秀、良好、一般、较差等级,以便能够客观准确地评价每位面试者的表现。
3. 设定评分权重:不同的评分项目对于招聘职位的重要性不同,因此可以为每个评分项目设定相应的权重,以便能够更加准确地评价面试者的整体表现。
4. 培训面试官:在使用面试评分卡之前,应对面试官进行相应的培训,让他们了解如何正确使用评分卡,如何准确评价面试者,并严格按照评分标准进行评分。
1. 评价面试者:面试评分卡可以帮助面试官更加客观地评价每位面试者的表现,避免主观偏见和情绪因素的影响,提高评价的准确性和公正性。
2. 比较面试者:通过面试评分卡可以方便地比较不同面试者的表现,从而更好地选择最适合企业需求的人才,提高招聘的效率和成功率。
3. 提供反馈:面试评分卡也可以作为提供反馈的工具,帮助面试者了解自己在面试过程中的表现情况,从而更好地改进和提高自己,为未来的面试做准备。
1. 提高招聘效率:面试评分卡能够帮助企业更加准确快速地评价面试者,提高招聘效率,节省人力和时间成本。
2. 提高招聘准确性:面试评分卡能够减少主观偏见和情绪因素的影响,提高评价的准确性和公正性,从而更好地选择适合企业需求的人才。
第二篇示例:面试是企业招聘新员工的重要环节,通过面试可以了解应聘者的能力、素质和适应性,从而为企业选择合适的人才提供参考。
为了规范面试程序,让面试评分更加客观和科学,很多企业会制定面试标准评分卡。
下面我们就来探讨一下面试标准评分卡的制作及应用。
一、面试标准评分卡的定义面试标准评分卡是为了规范面试程序,提高面试评分的客观性和科学性而设计的一种工具。
通过面试标准评分卡,面试官可以按照事先设定的标准和评分维度来进行评分,从而避免主观评价和偏见,确保评分结果的公正和客观性。
评分卡
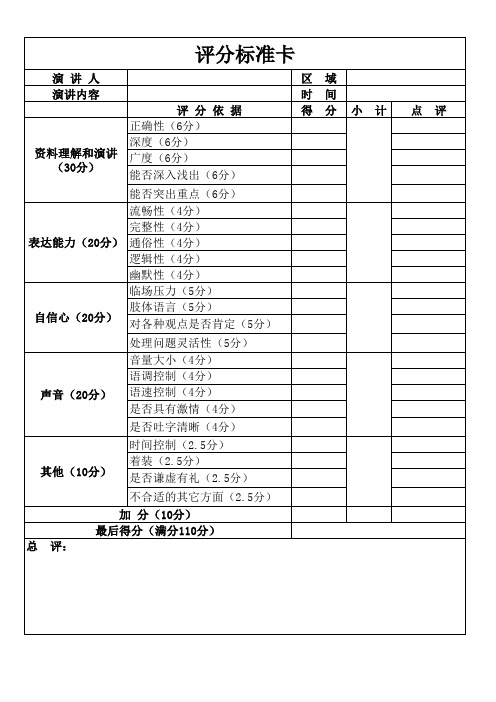
声音(20分)
其他(10分)
不合适的其它方面(2.5分) 加 分(10分) 最后得分(满分110分) 总 评:
评分标准卡
演 讲 人 演讲内容 评 分 依 据 正确性(6分 深度(6分) 广度(6分) 能否深入浅出(6分) 区 时 得 域 间 分 小 计 点 评
资料理解和演讲 (30分)
能否突出重点(6分) 流畅性(4分) 完整性(4分) 表达能力(20分) 通俗性(4分) 逻辑性(4分) 幽默性(4分) 临场压力(5分) 肢体语言(5分) 自信心(20分) 对各种观点是否肯定(5分) 处理问题灵活性(5分) 音量大小(4分) 语调控制(4分) 语速控制(4分) 是否具有激情(4分) 是否吐字清晰(4分) 时间控制(2.5分) 着装(2.5分) 是否谦虚有礼(2.5分)
脑卒中风险评分卡

脑卒中风险评分卡脑卒中风险评分卡是一种用于评估个体患脑卒中风险的工具,通过对一系列风险因素进行评估和计算,可以匡助医生和患者了解患脑卒中的可能性,并采取相应的预防措施。
下面将详细介绍脑卒中风险评分卡的标准格式及其相关内容。
一、引言脑卒中是一种常见的致残和死亡疾病,严重影响人们的生活质量和寿命。
早期预防和干预对于降低脑卒中的发生率和病死率至关重要。
脑卒中风险评分卡作为一种简单、快速、可靠的工具,可以匡助医生和患者评估患脑卒中的风险,及时采取预防措施,降低脑卒中的风险。
二、脑卒中风险评分卡的构成脑卒中风险评分卡通常由以下几个方面的风险因素组成:1. 年龄:年龄是患脑卒中的重要风险因素之一。
通常将年龄分为不同的组别,每一个组别对应不同的分数。
2. 性别:性别也与脑卒中的风险相关。
男性和女性的风险评分可能不同。
3. 血压:高血压是脑卒中的主要危(wei)险因素之一。
血压水平的高低将影响风险评分。
4. 糖尿病:糖尿病是脑卒中的独立危(wei)险因素。
是否有糖尿病将对风险评分产生影响。
5. 吸烟:吸烟是导致脑卒中的重要可修改危(wei)险因素之一。
吸烟与脑卒中的风险呈正相关。
6. 心脏病史:有心脏病史的人群患脑卒中的风险较高。
7. 高脂血症:高胆固醇和高甘油三酯是脑卒中的危(wei)险因素。
是否有高脂血症将对风险评分产生影响。
三、脑卒中风险评分卡的计算方法脑卒中风险评分卡通过对以上风险因素进行评估和计算,得出一个总分,根据总分的不同,将个体的脑卒中风险分为不同的等级,如低风险、中风险和高风险。
不同的等级对应不同的预防措施。
四、脑卒中风险评分卡的应用脑卒中风险评分卡可用于以下几个方面:1. 临床应用:医生可以根据患者的风险因素情况,使用脑卒中风险评分卡评估患者的脑卒中风险,并根据风险等级制定个体化的预防措施和治疗方案。
2. 健康教育:脑卒中风险评分卡可以用于健康教育,匡助人们了解脑卒中的风险因素,提高对脑卒中的认知,并采取积极的生活方式和行为改变,降低患脑卒中的风险。
供应商表现评分计分卡

供应商表现评分计分卡
1.目的
供应商评分卡是公司根据其供应商每月的各项表现来对供应商进行全面的评价,其目的是使和供应商加强合作关系。
2.范围
适用于公司的高产量、高采购成本的供应商(如电镀供应商、点胶供应商、机加供应商)。
3.评分标准
B. 质量(52%)
C.商业贸易(13%)
D.服务(10%)
5.2评分结果的跟进
根据供应商评分标准,所有供应商都分为三类。
1>类别A≥80
现有供应商在物流,质量,业务及服务上符合的期望。
2>类别B70~79
当供应商分数在70~79之间,供应商要基于其评分类别中的表现,提交改善表现而制定发展计划给评估。
3>类别C60~69
当供应商分数在60~69之间,供应商要提交纠正预防措施给,并按通知的时间到公司进行研讨,必要时将对其进行现场审核重新评估。
4>类别D < 60
如果分数低于60,第一步行动是分析造成不符合的根本原因,及供应商实施的纠正措施。
如果实施的纠正措施不能达到预期效果,连续三个月都小于60分,我们将停止发货给该供应商生产。
供应商表现评分卡供应商:评分日期:。
班级文化建设评分卡

年 班 得 分
项目
整体要求
1、室内整洁,其中课桌摆放整齐,物品有序摆放,无闲置 物,室内地面、天面、墙壁、走廊及门窗洁净。卫生清扫 工具摆放整齐,垃圾桶清理干净,其周边没有杂乱物。 2、室内整体设计美观,色调搭配合理,能给人视觉和感官 上的愉悦感,能给人以文化氛围的陶冶. 1、班级的组织机构,值岗学生安排表等完整,设置合理, 职责明确,布局合理。 2、课程表、值日生轮流表、作息时间表、《班级公约》、 《日常行为规范》等上墙,并张贴有序。 1、班级应形成具有自己班级特色的板报或者专栏。突显本 班特色。如图书角、卫生角、绿化角、公告栏等。
环境建设 (30分)
制度、管理建 设(20分)
特色建设 (30分)
2、班级应设立荣誉专栏,有集体的荣誉,也有同学个人的 荣誉。 3、班牌端正完好,摆放位置适当,饮水机、图书角、卫生 角等张贴文明、健康、激励性标语。 1、班级整体穿校服比例超过90%。讲文明、懂礼貌。
2、男生:不留长发、不打耳洞,女生发型:前额刘海不过 班风、班貌、 眉、侧面鬓角不过腮、不剃怪发;不烫发、不染发;。 不 仪容仪表建设 留披肩发;不佩戴各种首饰。不涂脂,不纹眉,不描眼, (20分) 不抹口红。不纹身或使用文身贴纸,不刻字 3、班级不存放危险物品,如:管制刀具,甩棍等,学生不 得佩戴手机 ,不得将火机、香烟、不良书籍等带入校园。
总分(100分) 明水县滨泉中学
Hale Waihona Puke
质检评分卡
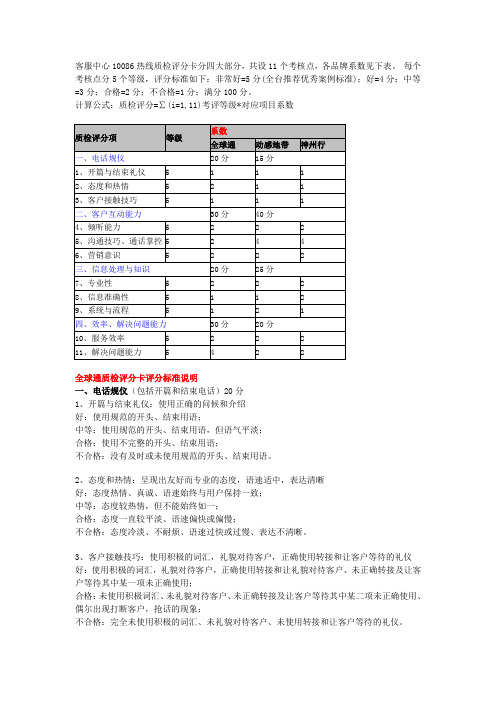
客服中心10086热线质检评分卡分四大部分,共设11个考核点,各品牌系数见下表。
每个考核点分5个等级,评分标准如下:非常好=5分(全台推荐优秀案例标准);好=4分;中等=3分;合格=2分;不合格=1分;满分100分。
计算公式:质检评分=∑(i=1,11)考评等级*对应项目系数全球通质检评分卡评分标准说明一、电话规仪(包括开篇和结束电话)20分1、开篇与结束礼仪:使用正确的问候和介绍好:使用规范的开头、结束用语;中等:使用规范的开头、结束用语,但语气平淡;合格:使用不完整的开头、结束用语;不合格:没有及时或未使用规范的开头、结束用语。
2、态度和热情:呈现出友好而专业的态度,语速适中,表达清晰好:态度热情、真诚、语速始终与用户保持一致;中等:态度较热情,但不能始终如一;合格:态度一直较平淡、语速偏快或偏慢;不合格:态度冷淡、不耐烦、语速过快或过慢、表达不清晰。
3、客户接触技巧:使用积极的词汇,礼貌对待客户,正确使用转接和让客户等待的礼仪好:使用积极的词汇,礼貌对待客户,正确使用转接和让礼貌对待客户、未正确转接及让客户等待其中某一项未正确使用;合格:未使用积极词汇、未礼貌对待客户、未正确转接及让客户等待其中某二项未正确使用、偶尔出现打断客户,抢话的现象;不合格:完全未使用积极的词汇、未礼貌对待客户、未使用转接和让客户等待的礼仪。
二、客户互动能力30分1、倾听能力:运用倾听技巧,并了解客户的重点好:能快速领会用户客户的重点;中等:已认真倾听用户问题,但不能快速领会用户的重点;合格:用户已明确清晰表达意思,但由于客户代表原因要求用户重复才能领会到客户重点;不合格:完全不能领会客户重点。
2、沟通技巧、通话掌控:完整清晰的解释客户的问题,能较好的引导用户,而不是用户问,我们单一的回答,应围绕用户需要解决的问题进行交流并给出适当的建议 2好:灵活的运用沟通技巧收集信息,通过清晰的解释获得用户充分信任;一直能很好地引导用户,同时得到用户积极响应;中等:运用一定沟通技巧收集信息,能解答用户问题且获得用户信任;接续过程中能正确引导用户,但未获得用户积极响应;合格:沟通不充分,收集信息不全面,不能完整解释用户的问题,且未获得用户的信任;接续过程中能引导用户,存在中途被用户主导现象,但是最终掌控主动权;不合格:技巧运用不恰当,且不能够解释用户的问题,引起用户反感;接续过程中不能引导用户或偏离用户问题。
心肺复苏比赛评分卡

京泰发电公司心肺复苏操作技能比赛评分卡(一)参赛选手编号:总成绩评价人
京泰发电公司心肺复苏操作技能比赛评分卡(一)参赛选手编号:总成绩评价人
参赛选手编号:总成绩评价人
京泰发电公司心肺复苏操作技能比赛评分卡(二)参赛选手编号:总成绩评价人
参赛选手编号:总成绩评价人
京泰发电公司心肺复苏操作技能比赛评分卡(三)参赛选手编号:总成绩评价人
京泰发电公司心肺复苏操作技能比赛成绩参赛选手编号:总成绩:计分人
京泰发电公司心肺复苏操作技能比赛成绩参赛选手编号:总成绩:计分人。
K歌评分卡

评分卡项目单项得分总分1、歌曲内容思想性强、健康向上、符合活动主题。
(1分)2、歌唱咬字清晰,音色统一,气息流畅,声音优美。
(3分)3、歌唱表现力强,理解歌曲内涵,熟练把握到位。
(2分)4、舞台表演得体,演唱感染力强,自然大方。
(3分)5、舞台服装符合歌曲演唱风格。
(1分)。
评分卡项目单项得分总分1、歌曲内容思想性强、健康向上、符合活动主题。
(1分)2、歌唱咬字清晰,音色统一,气息流畅,声音优美。
(3分)3、歌唱表现力强,理解歌曲内涵,熟练把握到位。
(2分)4、舞台表演得体,演唱感染力强,自然大方。
(3分)5、舞台服装符合歌曲演唱风格。
(1分)。
评分卡项目单项得分总分1、歌曲内容思想性强、健康向上、符合活动主题。
(1分)2、歌唱咬字清晰,音色统一,气息流畅,声音优美。
(3分)3、歌唱表现力强,理解歌曲内涵,熟练把握到位。
(2分)4、舞台表演得体,演唱感染力强,自然大方。
(3分)5、舞台服装符合歌曲演唱风格。
(1分)。
评分卡项目单项得分总分1、歌曲内容思想性强、健康向上、符合活动主题。
(1分)2、歌唱咬字清晰,音色统一,气息流畅,声音优美。
(3分)3、歌唱表现力强,理解歌曲内涵,熟练把握到位。
(2分)4、舞台表演得体,演唱感染力强,自然大方。
(3分)5、舞台服装符合歌曲演唱风格。
(1分)。
评分卡相关内容61页PPT

梦 境
3、人生就像一杯没有加糖的咖啡,喝起来是苦涩的,回味起来却有 久久不会退去的余香。
评分卡相关内容 4、守业的最好办法就是不断的发展。 5、当爱不能完美,我宁愿选择无悔,不管来生多么美丽,我不愿失 去今生对你的记忆,我不求天长地久的美景,我只要生生世世的轮 回里有你。
31、只有永远躺在泥坑里的人,才不会再掉进坑里。——黑格尔 32、希望的灯一旦熄灭,生活刹那间变成了一片黑暗。——普列姆昌德 33、希望是人生的乳母。——科策布 34、形成天才的决定因素应该是勤奋。——郭沫若 35、学到很多东西的诀窍,就是一下子不要学很多。——洛克
评分卡相关内容

评分卡模型开发与 验证
• 业务调研和数据采集 • 数据质量分析 • 数据清洗 • 衍生变量设计 • 数据进一步分析
评分卡应用策略开 发
监控报表
|
|
数据处理和分析—业务调研和数据采集
通过设计问卷调查、访谈、统计分析等专业数据分析方式,对公司进行业务调研,了解公司 的前端业务流、后台数据采集点、数据库设计及存储情况,深刻理解公司当前的数据现状、 业务实际及系统运行环境和产品结构,分析公司自有数据存在的缺失敞口,包括申请表数据、 央行征信数据、业务表现数据和其他三方数据等。该部分工作包括:
• 单变量分析
• 生成双向或多维交叉表报告
• 账户状态的账龄分析(Vintage Analysis)
|
数据处理和分析—数据质量分析
单变量分析
• 对字符型变量和某些连续性变量进行频数分析,进而了解数据中该字段的分布情况,判断是否符合逻辑 和业务实际,同时了解各个产品的特点。
• 审批决策容易受主观因素影响、审批结果不一致,审批政策调控能力相对薄弱。 • 不利于量化风险级别,无法进行风险分级管理,影响风险控制的能力及灵活度,难以在风险与市场之间寻求合适的平衡点。 • 审批效率还有较大提升空间。
|
01
评分卡简介
原理:利用历史贷款客户数据预测未来申请贷款客户违约概率
• 信用评分是指根据客户的各种历史资料,利用一定的信用评分模型,得到不同等级的信用分数,根据客户的信用分数,授信者可以通过分析客户按时还 款的可能性,据此决定是否给予授信以及授信的额度和利率。
• 信用评分卡可以极大地提高审批效率
由于信用评分卡是在申请处理系统中自动实施,只要输入相关信息,就可以在几秒中内自动评估新客户的信用风险程度,给出 推荐意见,帮助审批部门更好地管理申请表的批核工作。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
•
审批决策容易受主观因素影响、审批结果不一致,审批政策调控能力相对薄弱。
•
不利于量化风险级别,无法进行风险分级管理,影响风险控制的能力及灵活度,难以在风险与市场之间寻求合适的平衡点。
•
审批效率还有较大提升空间。
风险管理部
|
2 / 59
|
3 / 59
01
评分卡简介
原理:利用历史贷款客户数据预测未来申请贷款客户违约概率
• 数据的完备性 • 数据的有效性 • 数据的一致性
• 数据的完整性
• 数据的及时性 • 业务要求
风险管理部
|
10 / 59
数据处理和分析
—数据质量分析
为了满足建模要求,需要对经过质量控制的数据进行数据质量分析,得出多种统计指标。通过 对每个字段的统计指标的观察,初步判断该字段是否可以建模的过程中使用。数据质量分析主 要有以下两项:
• 信用评分卡具有一致性
在实施过程中前后一致,无论是哪个审批员,只要用同一个评分卡,其评估和决策的标准都是一样的。
• 信用评分卡具有准确性
它是依据大数原理、运用统计技术科学地发展出来的,预测了客户各方面表现的概率,使银行能比较准确地衡量风险、收益等 各方面的交换关系,找出适合自己的风险和收益的最佳平衡点。
—数据质量分析
含义 缺失值个数 0值个数 总个数 不同值个数 缺失值占比 0值占比 最小值 最大值 均值 方差 1分位数 5分位数 10分位数 25分位数 50分位数 75分位数 90分位数 95分位数 99分位数
变量类型
字符型变量
变量类别 类别1 类别2 …… MISSING 0值
变量分析指标 count count% total_count total_count%
新开账户数
个人住房贷款-# 个人住房贷款平均-$
350,000
平均每户合同金额
300,000 250,000
150,000 100,000 50,000 0
200,000 150,000 100,000 50,000 0
2004Q1 2004Q3 2005Q1 2005Q3 2006Q1 2006Q3 2007Q1 2007Q3 2008Q1 2008Q3
含义 个数 百分比 累计个数 累计百分比 缺失值个数 0值个数
变量类型
日期范围 最小年月 …… 最大年月 MISSING 0值
变量分析指标 count count% total_count total_count%
含义 个数 百分比 累计个数 累计百分比 缺失值个数 0值个数
日期型变量
风险管理部
|
13 / 59
开户时间 征信查询次数 逾期30天拖欠次数 居住状态 工作时间 现有客户 破产标识 审批决策 违约概率
25个月 0次 1次 租房 5+年 是 无
42 25 20 15 38 30 35 205 批准
+ + + + +
+ + +
+
批准
拒绝
2%
?
?
风险管理部
评分卡优势
• 信用评分卡具有客观性
它是根据从大量数据中提炼出来的预测信息和行为模式制定的,反映了借款人信用表现的普遍性规律,在实施过程中不会因审 批人员的主观感受、个人偏见、个人好恶和情绪等改变,减少了审批员过去单凭人工经验进行审批的随意性和不合理性。
理解数据的存储系统及彼此关系,知晓其历史变更情况及其对数据获取及质量的可能产生的影响。
风险管理部
|
8 / 59
数据处理和分析
—业务调研和数据采集
提取数据:根据项目需求结合不同的产品特点和业务应用需求,提供具体的数据提取模板。
• 开发样本:开发样本包括开发开发风险模型,制定业务策略和跟踪报表所需要的数据。
首次放款日(季)
风险管理部
|
15 / 59
数据处理和分析
—数据质量分析
账户状态的账龄分析(Vintage Analysis)
• 通过账户状态的账龄分析(Vintage Analysis),可以了解不同产品在不同时间点或不同时间段的账户的 逾期比例的变化,从而了解资产质量变化。
个人购房贷款
30.00% 25.00%
• 对公司产品和数据现状的理解 • 提取数据
风险管理部
|
7 / 59
数据处理和分析
—业务调研和数据采集
对公司产品和数据现状的理解
• 理解公司产品特点
理解产品风险暴露的特点,包括产品的定义,审批过程,审批政策和策略,管理策略,历史上的重大变迁,及未来发展趋势等。
• 理解公司和本项目相关产品数据存储结构及数据内容
%逾期
20.00% 15.00% 10.00% 5.00% 0.00% 0 5 10 15 20 25 30 35
MOB
Jan-06 Jun-06 Jan-07 Jun-07 Jan-08
风险管理部
|
16 / 59
数据处理和分析
—数据清洗
数据清洗:高质量的决策必然依赖于高质量的数据,数据清洗可以改进数据的质量,从而有助 于提高其后的数据挖掘过程的精度和效率。本项目数据清洗所采用的方法主要有以下三种:
数据处理和分析
—数据质量分析
风险管理部
|
14 / 59
数据处理和分析
—数据质量分析
生成双向或多维交叉表报告
• 双变量分析报告可帮助检测变量之间关系的正确性。多维交叉表报告方便工作人员全面地理解公司数据, 并更有助于发现潜在的异常情况。
个人住房贷款新开账户数和平均每户合同金额
250,000 200,000
• 验证样本
模型开发结果必须经过验证,不论何种风险模型。在模型的开发过程中需要进行预留样本的验证和跨时间样本的验证。 预留样本验证是通过随机抽样的方式,选取一定比例的样本进行评分模型的开发,并用余下的样本进行评分模型的检验。其目的在于 使用未在任何建模过程使用的独立样本来判断评分模型的辨别力及其稳定性。 跨时间验证是一个在模型开发之后进行的验证工作。该验证的目是检验基于开发样本建立的模型在不同时点的样本上,是否有相似的 预测和排序能力及其跨时间稳定性。
• 忽略样本。若该条样本有多个变量存在缺失值,一般采取直接删除的方法。 • 使用一个全局量填充。将遗漏的变量用同一个常数(如“unknown”)替换。这样数据挖掘程序可能会 认为此数据项形成了一个新的概念,即都有一个相同的值—“unknown”。 • 均值/中位数补救法:对于数值型字段,可以使用样本均值或中位数补救;对于分类型字段,可以使用 中位数补救。 • 频度最高值补救法:对于分类型字段,使用出现频度最高的类别补救;对于数值型字段,可以通过先分 箱,然后使用出现频度最高的分箱的均值或者中位数进行补救。 • 使用推导的值填充值。使用聚类的均值补救或者基于分类的插值补救、回归、贝叶斯形式化方法或者判 定树归纳等基于推导的工具预测缺失值。
• 分箱。分箱的方法通过考察临近变量来平滑存储数据的值,存储的值被分布到一些箱中,拥箱中的中值 或者均值等替代箱中的变量,进行局部平滑。 • 聚类。将近似的值组织成“类”,然后用同一个值代表这一类。 • 计算机和人工检验结合。通过计算机和人工检查的办法来识别异常值。例如,制定一个规则找出可能有 异常的数据,然后人工筛选出真正的异常数据。
评分卡相关流程介绍
2017年9月
人工审批难题
人工审批作业形式,审批依据是审批政策、客户提供的资料及审批人员的个人经验进行审批判断,存在 以下问题:
•
信审人员对申请人所提交申请资料真实性的认定基本依赖于受理申请资料的信贷业务员的职业操守和业务素质,审批人员对申请人资料的核实手段基本 依赖于电话核查,对申请核准与否基本依赖于自己的信审业务经验,授信审查成本高、效率低而又面临很大的欺诈风险,这种状况很难应对业务需要。
• 对于连续性变量,不能直接由频数分析得到其分布,而需要通过均值类统计方法检测均值、中位数、极 大值、极小值和一些区间值,从而进一步地检查数据的准确性以及判断该字段的分布是否符合逻辑和业 务实际。 一般来说,单变量分析主要检验主键唯一性(数据集)、缺失率(数据集)、逻辑性检查和其他检查(业 务范围场景)。
风险管理部
|
9 / 59
数据处理和分析
—数据质量分析
根据数据提取需求模块进行数据提取后,为了保证后续的分析工作建立在高质量数据的基础上, 需从以下6个维度建立一系列测量指标,对数据进行评估,确保数据可用状态,识别数据中可 能存在的各种问题,探究数据缺陷的成因,制定数据清洗规则和实施框架,完成对原始数据的 整理,并对未能达到建模要求的数据提出补救方案,找到适合建模的数据维度。
|
5 / 59
数据处理和分析
数据处理和分析 评分卡模型开发与 验证 评分卡应用策略开 发 监控报表
• • • • •
业务调研和数据采集 数据质量分析 数据清洗 衍生变量设计 数据进一步分析
风险管理部
|
6 / 59
数据处理和分析
—业务调研和数据采集
通过设计问卷调查、访谈、统计分析等专业数据分析方式,对公司进行业务调研,了解公司 的前端业务流、后台数据采集点、数据库设计及存储情况,深刻理解公司当前的数据现状、 业务实际及系统运行环境和产品结构,分析公司自有数据存在的缺失敞口,包括申请表数据、 央行征信数据、业务表现数据和其他三方数据等。该部分工作包括:
•
信用评分是指根据客户的各种历史资料,利用一定的信用评分模型,得到不同等级的信用分数,根据客户的信用分数,授信者可以通过分析客户按时还 款的可能性,据此决定是否给予授信以及授信的额度和利率。
•
虽然授信者通过人工分析客户的历史信用资料,同样可以得到这样的分析结果,但利用信用评分却更加快速、更加客观、更具有一致性。 预测变量 变量值 分数 审批人1 审批人2