基于二级Hash的快速最长匹配分词算法
Hash快速分词算法

字+以该首字开头的所有词(省去首字部分)组成。首先对原
词典正文按照汉字的机内码进行排序,然后执行以下算法:
①读入一个首字 ch。②根据式 (1) 算出其在首字 hash 表中的
位置。将首字结构中 ch 成员赋值为 ch。③读入一个词 (省掉
首字部分),是回车键 (说明只有单字词),则将首字结构 hash_
的随机变化,实验中词次字的 Hash 函数使用除留余数法来确
定。计算公式如下所示
offset =((ch1-0xB0)*94+(ch2-0xA1) ) mod len
(2)
式中:offset——该汉字在次字 Hash 表中的数组的下标,ch1,
ch2——此汉字的机内码,len——词次字 hash 表的长度。
(3) 词次字记录结构如下,其中 ch 记录该汉字,first 指向 剩余字在词典正文中第一次出现的位置,last 是最后出现的位 置,flag 记录是否只有该二字词 (即由首字和该词次字组成的 二字词),if_has 记录是否有此二字词,next 使产生冲突的词次 字结构组成链表。
ch
first last flag if_has next
Multi-hash indexing algorism for Chinese character segmentation
ZHANG Ke (College of Computer Science, Chongqing University, Chongqing 400044, China)
Abstract:Chinese word segmentation is a very important component and the preparation for Chinese information process. In a lot of application, the precision of word segmentation is paramount, at the same time the velocity is also needed. Through the analysis of the existing algorithms of Chinese word segmentation, especially the fast algorithms, a highly efficient algorithm for Chinese word segmentation is introduced, which is based on the improvement of existing data structure for Chinese dictionary. It not only supports hashing operation on the first Chinese character, but also on the other characters. In theory, the above data structure achieve much more efficiency than other methods. Key words:Chinese word segmentation; Chinese information processing; Hash; data structure; time complexity
基于Hash结构词典的双向最大匹配分词法

关键词 分词词典 , 双向最大 匹配法 , 基 于 Ha s h的单 字索引, 互信息歧义处理
中图法分类号 T P 3 9 1 . 1 文献标识码 A
Bi - di r e c t i o n Ma x i m m n Ma t c hi ng Me t ho d Ba s e d o n Ha s h St r uc t u r a l Di c t i o na r y
男硕士主要研究方向为大数据云计算email男高级工程师主要研究方向为大数据云计算email基于hash结构词典的双向最大匹配分词法针对当前自然语言处理中中文分词基于词典的机械分词方法正序词典不能作为逆向最大匹配分词词典以及反序词典维护困难的问题提出一种新的词典构造方法并设计了相应的双向最大匹配算法同时在算法中加入了互信息歧义处理模块来处理分词中出现的交集型歧义
p r o c e s s i n g b l o c k i n t h e a l g o r i t h m. Co mp a r e d wi t h t h e p r e v i o u s ma x i mu m ma t c h i n g me t h o d, t h i s a l g o r i t h m c a n i n c r e a s e t h e s e g me n t a t i o n a c c u r a c y s i g n i f i c a n t l y . I t i s a p p l i c a b l e t o s o me Ch i n e s e n a t u r a l l a n g u a g e p r o c e s s i n g s y s t e ms wh i c h h a v e h i g h s e g me n t a t i o n a c c u r a c y r e q u i r e me n t . Ke y wo r d s S e g me n t a t i o n d i c t i o n a r y , Bi — d i r e c t i o n ma imu x m ma t c h i n g me t h o d, S i n g l e wo r d i n d e x b a s e d o n Ha s h s t r u c — t u r e , Mu t u a l i n f o r ma t i o n a mb i g u i t y p r o c e s s i n g
哈希匹配算法

哈希匹配算法哈希匹配算法是一种常用的字符串匹配算法,它通过将字符串映射为一个固定长度的哈希值来进行匹配。
在实际应用中,哈希匹配算法被广泛用于字符串匹配、模式匹配、数据索引等领域。
一、哈希匹配算法的基本原理哈希匹配算法的基本原理是将字符串通过一个哈希函数转换为一个唯一的哈希值,然后将这个哈希值与其他字符串进行比较,从而实现字符串匹配的功能。
哈希函数的设计非常重要,它应该具备以下特点:1. 输入相同的字符串,哈希函数应该返回相同的哈希值;2. 输入不同的字符串,哈希函数应该返回不同的哈希值。
1. 字符串匹配:在文本处理、搜索引擎等领域,哈希匹配算法常被用于字符串匹配。
通过将待匹配的字符串和已有的字符串进行哈希映射,可以快速地找到匹配的结果。
2. 模式匹配:在字符串处理、编译原理等领域,哈希匹配算法被用于模式匹配。
通过将模式串和待匹配的字符串进行哈希映射,可以高效地找到模式串在待匹配字符串中的位置。
3. 数据索引:在数据库、搜索引擎等领域,哈希匹配算法被用于数据索引。
通过将数据的关键字进行哈希映射,可以快速地找到对应的数据项。
三、哈希匹配算法的优缺点1. 优点:(1)高效性:哈希匹配算法通过哈希映射的方式进行匹配,能够快速定位到待匹配字符串的位置,从而提高匹配效率。
(2)灵活性:哈希匹配算法可以根据实际需求设计不同的哈希函数,适应不同的应用场景。
(3)可扩展性:哈希匹配算法可以通过调整哈希函数的参数来适应不同规模的数据集。
2. 缺点:(1)冲突问题:由于哈希函数的映射是将一个无限的输入域映射到一个有限的输出域,所以在实际应用中,哈希函数可能会出现冲突,导致多个不同的字符串映射到同一个哈希值上。
(2)哈希函数设计困难:设计一个好的哈希函数是非常困难的,需要考虑多个因素,并且需要保证输入相同的字符串一定能够得到相同的哈希值,输入不同的字符串一定能够得到不同的哈希值。
四、哈希匹配算法的改进方法1. 拉链法:当哈希函数出现冲突时,可以使用拉链法来解决。
中文分词入门之最大匹配法
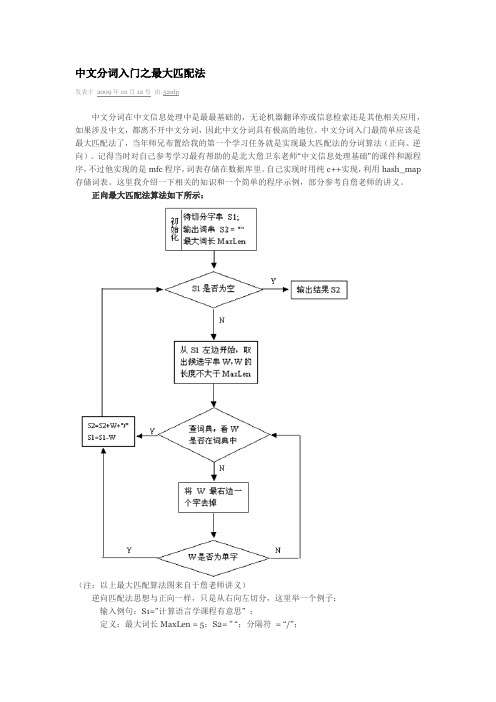
中文分词入门之最大匹配法发表于2009年01月12号由52nlp中文分词在中文信息处理中是最最基础的,无论机器翻译亦或信息检索还是其他相关应用,如果涉及中文,都离不开中文分词,因此中文分词具有极高的地位。
中文分词入门最简单应该是最大匹配法了,当年师兄布置给我的第一个学习任务就是实现最大匹配法的分词算法(正向、逆向)。
记得当时对自己参考学习最有帮助的是北大詹卫东老师“中文信息处理基础”的课件和源程序,不过他实现的是mfc程序,词表存储在数据库里。
自己实现时用纯c++实现,利用hash_map 存储词表。
这里我介绍一下相关的知识和一个简单的程序示例,部分参考自詹老师的讲义。
正向最大匹配法算法如下所示:(注:以上最大匹配算法图来自于詹老师讲义)逆向匹配法思想与正向一样,只是从右向左切分,这里举一个例子:输入例句:S1=”计算语言学课程有意思” ;定义:最大词长MaxLen = 5;S2= ” “;分隔符= “/”;假设存在词表:…,计算语言学,课程,意思,…;最大逆向匹配分词算法过程如下:(1)S2=”";S1不为空,从S1右边取出候选子串W=”课程有意思”;(2)查词表,W不在词表中,将W最左边一个字去掉,得到W=”程有意思”;(3)查词表,W不在词表中,将W最左边一个字去掉,得到W=”有意思”;(4)查词表,W不在词表中,将W最左边一个字去掉,得到W=”意思”(5)查词表,“意思”在词表中,将W加入到S2中,S2=” 意思/”,并将W从S1中去掉,此时S1=”计算语言学课程有”;(6)S1不为空,于是从S1左边取出候选子串W=”言学课程有”;(7)查词表,W不在词表中,将W最左边一个字去掉,得到W=”学课程有”;(8)查词表,W不在词表中,将W最左边一个字去掉,得到W=”课程有”;(9)查词表,W不在词表中,将W最左边一个字去掉,得到W=”程有”;(10)查词表,W不在词表中,将W最左边一个字去掉,得到W=”有”,这W是单字,将W 加入到S2中,S2=“ /有/意思”,并将W从S1中去掉,此时S1=”计算语言学课程”;(11)S1不为空,于是从S1左边取出候选子串W=”语言学课程”;(12)查词表,W不在词表中,将W最左边一个字去掉,得到W=”言学课程”;(13)查词表,W不在词表中,将W最左边一个字去掉,得到W=”学课程”;(14)查词表,W不在词表中,将W最左边一个字去掉,得到W=”课程”;(15)查词表,“意思”在词表中,将W加入到S2中,S2=“课程/ 有/ 意思/”,并将W从S1中去掉,此时S1=”计算语言学”;(16)S1不为空,于是从S1左边取出候选子串W=”计算语言学”;(17)查词表,“计算语言学”在词表中,将W加入到S2中,S2=“计算语言学/ 课程/ 有/ 意思/”,并将W从S1中去掉,此时S1=”";(18)S1为空,输出S2作为分词结果,分词过程结束。
一种用于图像匹配的快速有效的二分哈希搜索算法

基金项 目: 自然科A 0 Z3 ) “ 83 项 20A 0 Z1 、 9 A 132 及 新世纪优秀人才 ” 0 计划 ( C T N E- 0 - 8) 6 82 资助 0 作者简介 : 何周灿(94 , 18 一)西北工业大学硕士研究生 , 主要从事高维图像特征匹配及计算 机视觉 等研究 。
不变特性 。因此, 本文采用 s 描述 子用于 图像 wr
匹配 。
定查询半径 r 根据三角不等式确定查询范 围并执 , 行查询, 该方法建 立索引 的代 价 ( 主要是 聚类 ) 太
() 1 相关 工作
S T描述子达 18维 , I F 2 还有 的数据超过 1 0 0 0 维, 力求快速有效处理超高维数据 , 是一个研究热点 和难点。人们研究了大量高维数据搜索算法 , 从高 维数据集合的数据分布和空间分布角度 出发建立了 各种各样 的数据结构 , K —e 、 -e ¨ S . 如 D t e 】M t e 、P r r te 引 r e[ Rt e和 B F 、Ds Ie’等 。K .e —e r B [ iiac[ t1 Dt e通 r
体 , q 使 到 的每一个超平面的距离为 占 S N算 。N 法能处理维数达 3 维的数据 , 5 但被用于处理 18 2 维
或检索、 基于视频 或者 图像 的三 维场景 重构 等 的 SF IT特征 时 , 效率太 低。 iac( dx gte i s ne i ei Dt n n h 等。图像匹配包含 2个部分 : 建立特征描述子和 K Ds ne 采用 k en 聚类算法将数据空间划分为 iac ) t - as m 近邻搜索。M klcy 5 细总结 了近 年来 的局 n i a z .详 oj k 个不相交的类 , 每一个类被当成是一个超球体, 超 部不变描述子的发展 现状 , 并通过大量实验对各种 球体的中心作为参考点, 根据各个超球体 中数据点 描述子 的性 能 进行 对 比 , 果 表 明 SF … 在 缩 放 、 结 IT 到参考点的距离建立一棵 B+树。 对于查询点 g 给 , 旋转、 噪声甚至视点变换 的情况下表现出高可靠 的
分词 和数据库匹配算法

分词和数据库匹配算法分词和数据库匹配算法是自然语言处理领域中常用的技术手段,对于文本处理以及信息检索等任务具有重要的作用。
本文将从分词和数据库匹配算法的定义、常用方法以及实际应用等方面进行讨论。
一、分词算法分词是将连续的文本划分为一个个有意义的词语的过程,也是自然语言处理的基本任务之一。
常见的分词算法主要有基于规则的算法、基于统计的算法和基于深度学习的算法。
1.基于规则的算法:基于规则的分词算法主要依赖于一些预先设定好的规则来进行划分,比如根据词典进行最长匹配。
这类算法相对简单直观,但是需要大量的人工规则和对语料的分析处理。
2.基于统计的算法:基于统计的分词算法主要基于大规模语料库的统计信息来进行分词,比如根据词频和互信息等。
常见的统计模型有隐马尔可夫模型(HMM)和条件随机场(CRF)。
这类算法相对准确,但需要大规模的训练数据。
3.基于深度学习的算法:近年来,随着深度学习的发展,基于深度学习的分词算法也日渐兴起。
例如,可以使用循环神经网络(RNN)或者长短时记忆网络(LSTM)进行分词。
这类算法在大规模数据集上训练的情况下,可以达到较好的效果。
二、数据库匹配算法数据库匹配算法是用于在数据库中找到与给定查询条件最匹配的记录的算法。
常见的数据库匹配算法包括模糊匹配算法、全文检索算法和最邻近匹配算法等。
1.模糊匹配算法:模糊匹配算法用于在给定的查询条件下,对数据库中的记录进行模糊匹配。
最常见的模糊匹配算法是编辑距离算法,它可以计算两个字符串之间的相似程度。
通过计算编辑距离,可以找到与给定查询条件相似度最高的记录。
2.全文检索算法:全文检索算法用于对数据库中的文本进行全面的检索。
常见的算法有倒排索引算法,它通过构建索引数据结构,将每个词与包含该词的记录关联起来。
通过对查询条件进行分词,并在索引中进行检索,可以快速找到与查询条件相匹配的记录。
3.最邻近匹配算法:最邻近匹配算法主要用于在数据库中找到与给定查询条件最相似的记录。
二级Hash全局和局部索引筛选的长序列比对并行算法

二级Hash全局和局部索引筛选的长序列比对并行算法
潘登;钟诚
【期刊名称】《小型微型计算机系统》
【年(卷),期】2022(43)9
【摘要】通过构建参考基因组的二级Hash索引,以快速筛选出测序长序列在参考基因组中可能匹配的候选区域;建立测序序列局部索引,以加速测序序列和参考基因组候选区域之间的映射定位;对每个候选区域里的k-mer与测序序列的索引命中进行左右扩展获得比对种子;采用等距离抽样方式对种子抽取多个位置,利用抽样结果建立判断依据来过滤掉那些不可能匹配的种子;建立处理包含“均聚物”类型错误的序列片段全局比对得分方程,并行填补比对骨架的空隙,并采取GPU显存预分配和后释放独立的并行比对策略,以提升序列片段全局并行比对效率.模拟与真实数据的实验结果表明,相较于已有同类的长序列比对并行算法,本文提出的并行算法获得整体上较高的比对敏感度、碱基层次灵敏度和准确度,且可有效处理第3代测序长序列含有的“均聚物”类型错误,显著加速了大规模长序列与参考基因组比对的完成.
【总页数】6页(P1999-2004)
【作者】潘登;钟诚
【作者单位】广西大学计算机与电子信息学院广西高校并行分布式计算技术重点实验室
【正文语种】中文
【中图分类】TP301
【相关文献】
1.异构机群系统上双序列全局比对并行算法
2.基于块排序索引的生物序列局部比对查询技术
3.基于Hash索引的高通量基因序列比对并行加速技术研究
4.一个新的核酸序列比对算法及其在序列全局比对中的应用
5.异构机群系统中序列比对并行算法进展
因版权原因,仅展示原文概要,查看原文内容请购买。
分词算法java

分词算法java
在Java中,常用的分词算法包括:
1. 最大匹配算法(MM):
最大匹配算法是一种基于词典的分词算法,它将待分词的文本从左到右进行扫描,根据词典中的词语进行匹配,选择最长的匹配词作为分词结果。
该算法简单高效,但对于歧义词和未登录词处理较差。
2. 正向最大匹配算法(FMM):
正向最大匹配算法与最大匹配算法类似,但它从文本的起始位置开始匹配。
首先取待分词文本中的前n个字符作为匹配字符串(通常取词典中最长的词的长度),如果这个字符串在词典中存在,则作为分词结果,否则取待分词文本的前n-1个字符,继续匹配,直到匹配到词典中的词为止。
3. 逆向最大匹配算法(BMM):
逆向最大匹配算法与正向最大匹配算法类似,但它从文本的末尾位置向前匹配。
首先取待分词文本中的后n个字符作为匹配字符串,如果这个字符串在词典中存在,则作为分词结果,否则取待分词文本的后n-1个字符,继续匹配,直到匹配到词典中的词为止。
4. 双向最大匹配算法(BiMM):
双向最大匹配算法结合了正向最大匹配算法和逆向最大匹配算法的优点。
它
从文本的起始位置和末尾位置同时进行匹配,选择两个结果中词数较少的分词结果作为最终的分词结果。
以上是一些常见的分词算法,你可以根据自己的需求选择合适的算法进行分词处理。
同时,还可以使用一些开源的中文分词库,例如HanLP、jieba等,它们已经实现了这些算法,并提供了丰富的功能和接口供你使用。
全二分最大匹配快速分词算法

全二分最大 匹配快速分词算法
李振 星 。 徐泽 平 唐 卫清 ‘ 唐 荣锡 ( 中国科 学院计 算技 术研 究所 , 北京 10 8 ) 00 0
( 京航 空航 天 大 学 机 械 工 程 及 自动 化 学 院 , 京 10 8 ) 北 北 0 0 3
Ab t a t C i e e wo d e me tt n s a v r i mr n o  ̄t n n s r c : h n s r s g n a i i e y ml t t c m[ l t i ma y f l f C ie e no mai n p o e sI o a e n i d o h n s if r t r c s . a e o n l Lo p l a in 【 u h a te tx u r i e rh e gn , t , e v le t f w r e me tt n s p r mo n . t t e 0 f a p i t c n s c s h e t q y n s a c n i e e c) t en i o o d s g n ai i a a u t a h h y o s ne t h p iin s as e d d B s d o t e e e r h f C ie e n o ig a c i c u e r h ag r h o aq i me t e  ̄e s i l n e e . a e n h r s a c o h n s e c d n r ht t r ai t e l o t ms fr o o e d i C iee h n s wo d e me tt n t i a e r s n s a e f a g r h f r r s g n i .h s a o p p r p e e t n w a l i m o Chn s w r s g n ain sn a e d a o t i ee o d e me tt u ig n w a o t sr cu e r C i e e w r n ie h i lme tt n n H s n h 0 a ay i tu t r h n s o d a d g v s t e mp e n ai O a d t e H n lss o r e
一种基于全hash的整词二分词典机制

一种基于全hash的整词二分词典机制
中文分词是中文自然语言处理领域中的一个重要问题。
分词的目的是将一篇中文文本切分成一个个合理的词语,为后续的文本处理提供基础。
目前,中文分词领域中已有很多相关的算法和技术,但是没有一种分词机制能够同时考虑分词效率和分词准确率。
本文介绍一种基于全hash的整词二分词典机制,可以高效地完成中文分词任务。
该机制针对中文语言的一些特点,采用了特殊的分词算法,并且引入了全hash索引技术,大大提高了分词效率。
同时,该机制采用二分法查找词典,保证了分词准确率。
1. 将中文文本作为输入,将其中的汉字字符以及标点符号按照一定规则转换成数字序列。
2. 建立词典数据库,将每个词语及其对应的出现频率存储在数据库中。
对于一个单独的汉字,其也视为一个词语。
3. 将词典按照一定顺序排序,然后利用hash函数将每个词语进行全hash索引,生成一个hash表。
该表的每个元素存储一个词语的索引值和其对应的出现频率。
4. 将输入的数字序列作为二分查找的输入,在hash表中进行查找。
具体地,根据输入的数字序列,通过hash函数得到一个索引值,然后利用二分法查找hash表,找到其对应的词语和出现频率。
5. 对于一个较长的数字序列(如一个句子),将其不断拆分成较短的数字序列,然后对每个数字序列利用步骤4的方法进行分词。
对于数字序列中的每一个子序列,记录其对应的词语和出现频率,最后得到整个句子的分词结果。
总之,基于全hash的整词二分词典机制可以高效地完成中文分词任务,可以为后续的文本处理提供更好的基础。
一种基于双哈希二叉树的中文分词词典机制

( 鞍 山师范学院高职院 辽宁 鞍 山 1 1 4 0 1 6 )
摘 要
汉语 自动分词是汉语信 息处理 的前提 , 词典是汉语 自动分 词的基础 , 分词 词典机制 的优 劣直接 影响到 中文分 词 的速 度
和效率。详细介绍汉语 自动分词 的三种方法及五种词典机 制, 提 出一种简洁 而有效 的中文分词 词典机制 , 并通过理论分 析和实验 对
Ab s t r a c t Au t o ma t i c Ch i n e s e wo r d s e g me n t a t i o n i s t h e p r e r e q u i s i t e f o r C h i n e s e i n f o r ma t i o n p r o c e s s i n g ,a n d d i c t i o n a r y i s t h e b a s i s o f
me c h a n i s ms a r e i n t r o d u c e d i n d e t a i l .I n t h e e n d,a s i mp l e a n d e f f e c t i v e d i c t i o n a y r me c h a n i s m f o r C h i n e s e w o r d s e g me n t a t i o n i s p r o p o s e d .
第3 0卷 第 5期
2 0 1 3年 5 月
计 算机 应 用与软件
Co mp u t e r App l i c a t i o n s a n d S o t f wa r e
V0 1 . 3 0 No. 5 Ma y 2 01 3
基于Hash结构的逆向最大匹配分词算法的改进

Ke r s Chn s e e tto ; ahs u tr; e es i cin l xmu thme o ; it n r c a im; ip l mb g i ywo d : ie esg n in h s t cu e rv re r t a i m mac t d d ci ayme h s d se iut m a r d e o ma h o n a y
bsd n ah t c r,ad ni rv d ees d et n l xmu ma h to (M M) ip tow d h ime o h s e ae s r t e n o e vre i ci amai m t h d R o h su u a mp r r o c me s u r a .T s t de f r h mp ai d z
Ab t a t T n l s h i e e s ma t h a e , o e mu td v d h e t n e n o wo d . Ch n s e me t t n i t e mo t s r c : o a a y e t e Ch n s e n i p r s s c n s i i e t e s n e c s i t r s i e e s g n ai s h s o
i o t n at f i e ei f r ai np o e s T es e d a d a c rc f e e t t n i fu n et er s l fi f r a in p o e s g mp r t r n s o m to r c s . h p e c u a y o g n i l e c e u t o o a p o Ch n n sm a o n h s n m t rc si . o n T a i o a it n r c a ims dwo d s g e tto t o a ei r v d M e wh l , e d ci n r c a im r v d d r d t n l c o a y me h n s r m n a i nme  ̄ r i d i n a e h mp o e . n a i an w i t a yme h s i p o ie e o n s
基于Trie树的最大长度匹配分词的Python实现

一是词典分词方法,该方法的主要任务就是构建词典,确定扫描方向,研究匹配原则。
二是理解分词方法,其主要是利用深度学习技术,把自动分词技术看作是基于知识的逻辑推理过程。
三是统计分词方法,其主要是基于上下文中汉字与汉字之间相邻出现的概率来实现自动分词。
本文旨在用Python语言实现词典分词方法中的正反向最大长度匹配。
1 实现过程■1.1 数据集本文采用的数据集是人名日报人工分词后的内容,部分数据状况如下:图1 部分数据集■1.2 构建正向匹配词典树首先,把数据集里的每个不重复的词读到变量word_list下,对应代码如下:def get_word_list():IN=open(“train.txt”, “r”, encoding=”gb18030”,errors=’ignore’)word_list = []for line in IN:single_sen = line.strip()if not single_sen:continueelse:single_sen = single_sen.split(“ “)for word in single_sen:word_list.append(word)return list(set(word_list))树结构如图2所示。
图2 正向匹配例子词典树结构使用嵌套字典的数据结构来保存词典树,效果如图3所示。
图3 例子的词典树数据结构词的第一个字作为最外层字典的Key,例如“中”,“打”和“地”,词的第二个字以Key的方式保存在第一个字字典的Value当中,例如“间”和“国”保存在“中”的词典下面。
以此类推,根据数据集里的所有词构建完整的词典树。
对应代码如下:def create_single_tree(flag,cur_dict,word,cur_word,cur_num,length_of_word):if flag == 0:returnif not cur_dict.get(cur_word):cur_dict[cur_word]={}cur_num+=1if cur_num==length_of_word:flag=0returnreturncreate_single_tree(flag,cur_dict[cur_word],word,word[cur_num],cur_num,length_of_word)def create_whole_dict_tree(dict_tree,word_list):56 | 电子制作 2020年09月www�ele169�com | 57软件开发for word in word_list:try:create_single_tree(1,dict_tree,word,word[0],0, len(word))except IndexError:continue return dict_treecreate_single_tree 函数每次取word_list 里的一个词来填充词典树。
二次Hash+二分最大匹配快速分词算法

二次Hash+二分最大匹配快速分词算法
杨安生
【期刊名称】《情报探索》
【年(卷),期】2009(000)008
【摘要】通过对已有的分词算法尤其是快速分词算法的分析,提出了一种新的分词词典结构.并据此提出了二次Hash+二分最大匹配快速分词算法.该算法具有较快的分词速度.
【总页数】3页(P90-92)
【作者】杨安生
【作者单位】广东惠州学院,惠州,516015
【正文语种】中文
【中图分类】TP391.12
【相关文献】
1.全二分快速自动分词算法构建 [J], 张海营
2.全二分最大匹配快速分词算法 [J], 李振星;徐泽平;唐卫清;唐荣锡
3.中文分词算法之最大匹配算法的研究 [J], 张玉茹
4.一种基于改进最大匹配快速中文分词算法 [J], 林浩;韩冰;杨乐华
5.基于逆向最大匹配分词算法的汉盲翻译系统 [J], 杨文珍;徐豪杰;汪文妃;宣建强;赵维;吴新丽;潘海鹏
因版权原因,仅展示原文概要,查看原文内容请购买。
基于哈希表的最长前缀匹配算法改进

基于哈希表的最长前缀匹配算法改进
刘舱强;邓昌胜;余谅
【期刊名称】《微计算机信息》
【年(卷),期】2009(025)030
【摘要】在实际应用中经常需要查找某IP地址其在数据库中对应的真实的物理地址,而数据库的数据量往往很大,显然直接去查询数据库不能满足大量数据以及高速查找的要求.在最长前缀匹配算法的基础上,提出了一种基于哈希查找表的IP地址查找算法.将数据库中的信息建立为一个哈希表,并将点分十进制IP地址的部分前缀作为键值,映射到哈希表中的一条记录,从而得到所需的信息.最后用C#语言实现了该算法,实验表明该算法具有很高的效率.
【总页数】3页(P143-144,142)
【作者】刘舱强;邓昌胜;余谅
【作者单位】610064,成都,四川大学计算机学院;610064,成都,四川大学计算机学院;610064,成都,四川大学计算机学院
【正文语种】中文
【中图分类】TP393
【相关文献】
1.一种改进的IPV6最长前缀匹配路由查找算法 [J], 刘阳;高仲合
2.一种无回溯的最长前缀匹配搜索算法 [J], 张飞飞;李华伟;韩银和
3.一种基于最长前缀匹配的分段式IP查表方法 [J], 张文柱;王炫
4.一种基于模式最长前缀正文分割的串匹配新算法 [J], 庞善臣;王淑栋
5.可加速最长前缀匹配的布隆过滤查找方案 [J], 王乾;乔庐峰;陈庆华
因版权原因,仅展示原文概要,查看原文内容请购买。
一种基于模式最长前缀正文分割的串匹配新算法

一种基于模式最长前缀正文分割的串匹配新算法
庞善臣;王淑栋
【期刊名称】《小型微型计算机系统》
【年(卷),期】2004(025)003
【摘要】字符串的模式匹配问题是计算机科学的基本问题之一,本文提出了基于模式最长前缀正文分割的匹配新算法(Text Divided Algorithm,以下简称TD算法).首先在模式P中寻找最长的前缀子串subp,使其末字符在subp中只出现一次;然后根据subp末字符的特点,将正文T进行分段,按段对模式P进行匹配.新算法有以下重要的特点:1. 最坏情况下,本算法有效地减少了字符重复比较的次数,从而提高了算法的匹配效率;2. 匹配算法在二维匹配和不精确匹配中较易推广;3. 匹配过程近似于直接算法,便于接受和理解.
【总页数】3页(P404-406)
【作者】庞善臣;王淑栋
【作者单位】山东科技大学,信息科学与工程学院,山东,泰安,271019;山东科技大学,信息科学与工程学院,山东,泰安,271019;华中科技大学,控制科学与工程系,湖北,武汉,430074
【正文语种】中文
【中图分类】TP301
【相关文献】
1.FilterFA:一种基于字符集规约的模式串匹配算法 [J], 张萍;何慧敏;张春燕;曹聪;刘燕兵;谭建龙
2.一种基于循环前缀的OFDM时频同步新算法 [J], 刘平
3.一种基于压缩前缀树的频繁模式挖掘算法 [J], 郭云峰;张集祥
4.一种基于子串识别的多模式串匹配算法 [J], 何慧敏;刘燕兵;谭建龙;郭莉
5.一种基于魂芯DSP的单模式位并行串匹配算法 [J], 陈瑞;顾乃杰;叶鸿
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
由首字 Hash 表的长度和长度 Hash 表的 平局长度,可以得出一共有 6763×4=27052 个词条队列。每个词条队列为存储词条需要 额外的 2 个 byte 表示队列的长度,因此所有 词条队列需要 27052×2,约 53Kb 的存储空 间。
可以得出,除去词条所占存储空间,为 了维持词典结构,需要 47+132+53= 232Kb 的附加存储空间,低于文献[6]的存储 空间。
基于二级 Hash 的快速最长匹配分词算法
殷鹏程,谭献海
西南交通大学,四川成都(610031)
E-mail:ypc_swjtu@
摘 要:中文分词是中文信息处理的基础,在海量的中文信息处理中,分词速度至关重要。 本文根据中文单词的特点,通过分析现有词典分词算法,提出了一种基于二级 Hash 的快速 最长匹配分词算法。试验结果表明,该算法保证了分词的最长匹配,同时提高了分词的速度, 适用于小型搜索引擎和自动文本分类等应用。 关键词:中文分词;Hash 词典;最长匹配
现行常用的词典数据结构主要基于 Hash 方法和索引树方法,根据汉字编码的 一对一映射关系,实现了词典的快速查询, 但两种方法在构造词典时都没有考虑词语 的长度这个关键信息,因此不适合最长匹配 算法。本文在 Hash 方法的基础上,提出一 种新的词典结构,不仅对词语的首字进行 Hash,而且根据词语的长度进行二次 Hash。 实验证明,新的词典结构不仅提高了分词速
4.2 算法复杂性分析
由于使用了二级 Hash 结构,无论什么 词语,只需要两次定位就能确定应该包含该 词语的词条队列,然后只需要查询该词条队 列是否包含该词语。词条队列中的词语已经 根据词典顺序进行了升序排列,如果采用二 分查找,可以在 log2N(N 为词条队列长度) 的时间复杂度内得出结果。
根据(1)的分析,可知当有 21 万词条时, 平均每个词条队列有 21 万/27052,约为 8 个词条。为此可以得出以下结论:基于二级 Hash 词典的查询性能平均查询次数为 log28 = 3 次。明显优于文献[2] 的 12.32 次,略低 于于文献 [6] 的 2.89 次。由于在构造词典 时加入了词条长度的信息,所以在最长匹配 算法上有其它词典无法比拟的优势。
首字 Hash 表
长度 Hash 表 词
电
L=2 L=3 L=4 L=5
结
构
电影 电视网 电视直播
典
电视 电视机 电影公司
自
电脑 电路版 电算中心
中
电子 电烙铁
最短词条的长度——L,进行如下操作: 从待分词文本的当前位置截取长度为 L 的子字符串,用二分查找算法查询该子 字符串是否存在于长度为 L 的词条队列 中,如果存在,那么子字符串为分出的 词语,Pos=Pos+length,继续从①执行; 如果都不存在,则 Pos=Pos+1,继续从 ①执行; ③ 分词结束。
现有的分词算法可分为三大类:基于词 典的分词方法、基于理解的分词方法和基于 统计的分词方法。无论哪种分词方法都需要 将大量时间用于将待切分语句的切分为可 能的词,然后再依据统计或语法方面的规则 对切分出的词进行处理,得到一种最有可能 的切分结果。如果能加快初始切分的速度, 对于提高整个分词算法的速度也会有很大 帮助。由于词语信息都以词典的形式存储, 所以在整个汉语分词过程中, 都需要频繁地 访问词典以获得词语信息。因此词典的查询 速度是整个分词系统处理效率的关键所在。
对于首字的 Hash 采用文献[3]中提到的 方法,GB2312 编码表中的每一个汉字在首 字 Hash 表中都有唯一的一项与其对应,首 字 Hash 表中每一项的结构如下,其中 Ch 为该汉字,P1 是指向二级 Hash 表的指针, flag 指示以该字为前缀的词条是否为单字
词,如果是单字词,则 P1 为 null。
4. 性能分析和实验
4.1 存储空间分析
首字 Hash 表的长度由标准的汉字编码 的个数决定。GB2312 汉字编码包括一级、 二级汉字共 6763 个,所以表的长度固定为 6763。每个首字 Hash 表项占用 7 个 byte, 因此整个首字 Hash 表占用 6763×7byte,约 47Kb 存储空间。
字开头的所有词条散列在不同的队列上,比
如以“电”开头的所有词条电影、电视、电路、
电视迷、电视网、电视机、电视公司、电视
直播、电视接收、电算中心、电视接收机,
会被散列到二字词、三自词、四字词、五字
词这四个队列上。这样增加了队列个数,减
少了队列长度,不仅提高了查询命中率,而
且由于最长词条的长度是已知的,所以能极
2.1 汉字编码体系
汉字在计算机内部是以内码的形式进 行存储的,汉字内码是汉字在汉字信息处理 系统中最基本的表达形式,它与汉字交换 码、汉字区位码有一定的对应关系。由于自 定义编码顺序的特殊性,因而,可通过计算 偏移量的方法来定位该汉字在编码表中任 意的位置。国标 GB2312 汉字编码表共收录 了 6763 个汉字,汉字在编码表中的偏移量 计算公式如下:
大提高最长匹配分词的效率。长度 Hash 表
每一项的结构如下,其中 Length 为该项词
条的长度,P1 为指向相应词条队列的指针。
Length P1
(3) 词条队列
词条队列包含一组首字相同、长度相同
的词条。一个词的首字和长度决定了它所在
的词条队列,因此当查询一个词是否在现有
词典中时最终变成查询该词是否存在于特
定的词条队列里。词条队列的结构如下,其中 k 为该词条队列的长度,word1,word2, word3…wordk 为 K 个词条。队列中的词条根 据词典排序规则进行升序排列。
K
word1,word2,word3…wordk
最终词典在内存中的形式如图 1 所示
-2-
offset = (ch1 – 0xB0) * 94 + (ch2 – 0xA1) (1)
其中,offset 代表某汉字在编码表中的 位置, ch1、ch2 代表汉字的内部码。
2.2 汉语词的特点
-1-
词是最小的、能独立活动的、有意义的 语言成分,它是构成和分析语言的基本单 位,汉语的词是一个开放的集合,其数量可 以认为是接近无穷的,没有哪一部词典能够 收集所有的词。文献[1]收录了 10 万多词条, 文献[3]收录了 12 万多词条。本论文采用的 词库收录了 21 万多词条,通过对这些词条 的统计分析,可以发现不同字开头的词条数 目变化很大,有多达数百的(比如“多”、“大” 等),也有一个的(比如“褙”、“褚”)或者没 有。这些词条的长短也不尽相同,有一个字 的单字词,也有 7 个字的多字词(比如“中 华人民共和国”),其中以二字词为最,具体 情况见表 1。
Ch
P1
Flag
(2) 长度 Hash 表
对于不同的首字来说,以其开头的词不
仅数量变化很大,而且没有明显的特征规
律。如果想要只通过首字 Hash 表进行查找
不仅需要多次比较,而且不容易找出最长的
词条。为了减少查询、比较次数,同时最精
确的找出最长词条,本文对以某个字开头的
所有词的长度进行第二次 Hash,将以某个
表 2 时间统计
分词算法
测试 1/ms
基于二级 Hash 最大匹 137
配
ቤተ መጻሕፍቲ ባይዱ
Lucene
156
测试 2/ms 1205 1321
表 3 分词结果统计
分词算法
分词个数
基于二级 Hash 最大匹配 788982
Lucene
806596
平局词长 2.7 2.6
从表 2 可以看出,基于二级 Hash 的快 速最长匹配算法比 Lucene 的中文分词模块 在速度上有了较大的提高;从表 3 可以看 出,基于二级 Hash 的快速最长匹配算法分 出的词汇更少,平均词长更长,因此从某种 程度上可以认为基于二级 Hash 的快速最长 匹配算法分词结果比 Lucene 的中文分词模 块更精确,效率更高。
长度 Hash 表的长度由以某字开头的词 条的所有长度决定。统计发现,本文所使用 的词典最大长度为 7,因此长度 Hash 表的 最长为 6,统计表明平均长度为 4。每个长 度 Hash 表项占用 5 个 byte,所以长度 Hash 表占用 6763×4×5,约 132Kb 存储空间。
-3-
1. 引言
在中文信息处理中, 如机器翻译、自动 分类等等,词是最小的具有独立活动的有意 义的语言成分。然而中文文本在计算机内部 表示时,不像英文中词与词之间都有空格隔 开,中文词与词之间没有明显的分隔标记, 而是连续的汉字串。因此, 自动识别词的边 界, 将连续的汉字串切分为带有分割标记的 词串将是实现中文信息处理的首要问题。
4.3 实验结果
Lucene 是著名的开源软件,其中包含有 一个中文分词模块被广泛使用。本实验用 Lucene 的中文分词模块与本文所采用的基 于二级 Hash 的快速最长匹配算法进行比 较。实验内容包括两个方面的测试:
(1) 对词典中所有词条依次查询 1 次。 (2) 在网络上任取一段文本(大小约 2M),用两种方法分别进行切分。 实验环境 CPU:1GHz;RAM:256M。
度,而且满足最长匹配的分词需求。
2.二级 Hash 词典的设计
为了提高分词的准确度,基于词典的分 词方法通常采用最长匹配算法。实验证明, 如果分成的词语越长、分出的词语越少,分 词的精确度就越高。通常基于 Hash 方法的 词典只对词语的首字符进行了 Hash,这样 的词典虽然能实现快速查询,但是如果采用 最长匹配算法,则需要对词典进行多次查 询,影响算法速度。 为了使词典更适合最 长匹配算法,通过对对汉字编码体系、汉语 词语特点的分析,针对传统 Hash 词典的缺 点,本文设计了一种基于二级 Hash 的词典 结构。