2+二+图与遍历算法+习题参考答案
深度优先遍历例题

深度优先遍历例题摘要:一、深度优先遍历概念介绍1.定义2.特点二、深度优先遍历算法应用1.图形遍历2.搜索算法三、深度优先遍历例题解析1.题目一:二叉树的深度优先遍历1.分析2.算法实现3.答案解析2.题目二:链式广度优先遍历1.分析2.算法实现3.答案解析四、深度优先遍历实战技巧与优化1.避免回溯2.提高效率正文:一、深度优先遍历概念介绍1.定义深度优先遍历(Depth-First Traversal,简称DFT)是一种遍历树或图的算法。
它沿着一个路径一直向前,直到达到最深的节点,然后回溯到上一个节点,继续沿着另一个路径遍历。
2.特点深度优先遍历的特点是访问一个节点后,会沿着该节点的子节点继续遍历,直到没有未访问的子节点为止。
此时,遍历过程会回溯到上一个节点,继续访问其未访问的子节点。
二、深度优先遍历算法应用1.图形遍历深度优先遍历在图形处理领域有广泛应用,如图像处理中的边缘检测、图像分割等。
通过遍历图像像素点,可以发现像素点之间的关系,从而实现图像处理任务。
2.搜索算法深度优先搜索(DFS)是一种经典的搜索算法,它采用深度优先策略在树或图中寻找目标节点。
DFS算法常用于解决迷宫问题、八皇后问题等。
三、深度优先遍历例题解析1.题目一:二叉树的深度优先遍历1.分析二叉树的深度优先遍历通常采用递归或栈实现。
递归方法简单,但效率较低;栈方法效率较高,但实现较复杂。
2.算法实现(递归)```def dfs(root):if not root:returnprint(root.val, end=" ")dfs(root.left)dfs(root.right)```3.答案解析按照题目给定的二叉树,进行深度优先遍历,得到的序列为:1 2 4 5 3 6 8。
2.题目二:链式广度优先遍历1.分析链式广度优先遍历与树的同层遍历类似,采用队列实现。
队列中的元素依次为当前层的节点,每次遍历时,取出队首节点,将其相邻节点加入队列,并将其标记为已访问。
数据结构习题二答案

数据结构习题二答案问题一:链表的基本操作链表是一种常见的线性数据结构,它由一系列节点组成,每个节点包含数据部分和指向下一个节点的指针。
链表的基本操作包括:1. 创建节点:定义一个节点类,包含数据域和指向下一个节点的指针域。
2. 插入操作:在链表的指定位置插入一个新的节点。
3. 删除操作:删除链表中的指定节点。
4. 遍历操作:从头节点开始,依次访问链表中的每个节点。
问题二:二叉树的遍历二叉树是一种特殊的树形数据结构,其中每个节点最多有两个子节点。
二叉树的遍历方式有:1. 前序遍历:首先访问根节点,然后递归地遍历左子树,最后递归地遍历右子树。
2. 中序遍历:首先递归地遍历左子树,然后访问根节点,最后递归地遍历右子树。
3. 后序遍历:首先递归地遍历左子树,然后递归地遍历右子树,最后访问根节点。
问题三:图的表示图是一种复杂的非线性数据结构,由顶点和边组成。
图的表示方法有:1. 邻接矩阵:使用一个二维数组来表示图,其中矩阵的元素表示两个顶点之间的边是否存在。
2. 邻接表:使用链表来表示每个顶点的邻接顶点。
问题四:排序算法排序算法是将一组数据按照特定顺序重新排列的过程。
常见的排序算法包括:1. 冒泡排序:通过重复遍历待排序的数列,比较每对相邻元素的大小,并在必要时交换它们的位置。
2. 选择排序:从未排序序列中找到最小(或最大)的元素,存放到排序序列的起始位置,然后从剩余未排序元素中继续寻找最小(或最大)元素,以此类推。
3. 快速排序:选择一个元素作为“基准”,通过一趟排序将待排序的数据分割成独立的两部分,其中一部分的所有数据都比另一部分的所有数据都要小,然后再递归地对这两部分数据分别进行快速排序。
总结数据结构习题二涵盖了链表、二叉树、图和排序算法等基本概念和操作。
掌握这些基础知识对于深入理解计算机科学和进行高效的程序设计至关重要。
希望以上答案能够帮助你更好地理解和应用这些概念。
请注意,这只是一个示例答案,具体的习题答案需要根据实际的习题内容来编写。
二叉树的遍历题目及答案

二叉树的遍历题目及答案1. 二叉树的基本组成部分是:根(N)、左子树(L)和右子树(R)。
因而二叉树的遍历次序有六种。
最常用的是三种:前序法(即按N L R次序),后序法(即按L R N 次序)和中序法(也称对称序法,即按L N R次序)。
这三种方法相互之间有关联。
若已知一棵二叉树的前序序列是BEFCGDH,中序序列是FEBGCHD,则它的后序序列必是 F E G H D C B 。
解:法1:先由已知条件画图,再后序遍历得到结果;法2:不画图也能快速得出后序序列,只要找到根的位置特征。
由前序先确定root,由中序先确定左子树。
例如,前序遍历BEFCGDH中,根结点在最前面,是B;则后序遍历中B一定在最后面。
法3:递归计算。
如B在前序序列中第一,中序中在中间(可知左右子树上有哪些元素),则在后序中必为最后。
如法对B的左右子树同样处理,则问题得解。
2.给定二叉树的两种遍历序列,分别是:前序遍历序列:D,A,C,E,B,H,F,G,I;中序遍历序列:D,C,B,E,H,A,G,I,F,试画出二叉树B,并简述由任意二叉树B的前序遍历序列和中序遍历序列求二叉树B的思想方法。
解:方法是:由前序先确定root,由中序可确定root的左、右子树。
然后由其左子树的元素集合和右子树的集合对应前序遍历序列中的元素集合,可继续确定root的左右孩子。
将他们分别作为新的root,不断递归,则所有元素都将被唯一确定,问题得解。
3、当一棵二叉树的前序序列和中序序列分别是HGEDBFCA和EGBDHFAC时,其后序序列必是A. BDEAGFHCB. EBDGACFHC. HGFEDCBAD. HFGDEABC答案:B4. 已知一棵二叉树的前序遍历为ABDECF,中序遍历为DBEAFC,则对该树进行后序遍历得到的序列为______。
A.DEBAFCB.DEFBCAC.DEBCFAD.DEBFCA[解析] 由二叉树前序遍历序列和中序遍历序列可以唯一确定一棵二叉树。
计算机二级数据结构与算法答案

第一章数据结构与算法一、选择题:1、栈和队列的共同特点是()A、都是先进先出B、都是后进先出C、只允许在端点处插入和删除数据D、没有共同点2、已知二叉树的后序遍历序列是dabec,中序遍历序列是debac,它的前序遍历序列是()A、acbedB、decabC、debacD、cedba3、下面叙述正确的是()A、算法的执行效率与数据的存储结构无关。
B、算法的空间复杂度是指算法程序中指令(或语句)的条数。
C、算法的有穷性是指算法必须能在执行有限个步骤之后终止。
D、算法的时间复杂度是指执行算法程序所需要的时间。
4、以下数据结构属于非线性数据结构的是()A、队列B、线性表C、二叉树D、栈5、算法一般都可以用哪几种控制结构组合而成?()A、循环、分支、递归B、顺序、循环、嵌套C、循环、递归、选择D、顺序、选择、循环6、数据的存储结构是指()A、数据所占的存储空间量B、数据的逻辑结构在计算机中的表示C、数据在计算机中的顺序存储方式D、存储在外存中的数据7、链表不具有的特点是()A、不必事先估计存储空间B、可随机访问任一元素C、插入删除不需要移动元素D、所需空间与线性表长度成正比8、算法的时间复杂度是指()A、执行算法程序所需要的时间B、算法程序的长度C、算法执行过程中所需要的基本运算次数D、算法程序中的指令条数9、在一棵二叉树上第八层的结点数最多是()A、8B、16C、128D、25610、若一棵二叉树中只有叶结点和左右子树皆非空的结点,设叶结点的个数为k,则左右子树皆非空的结点个数是()A、2kB、k-1C、2k-1D、2k-111、设无向树T有7片树叶,其余顶点数均为3,则T中3度顶点的个数为()A、3B、4C、5D、612、已知一棵二叉树前序遍历和中序遍历分别为ABDEGCFH 和DBGEACHF,则该二叉树的后序遍历为()A、GEDHFBCAB、DGEBFCAC、ABCDEFGHD、ACBFEDHG13、树是结点的集合,它的根结点数目是()A、有且只有1个B、1个或多于1个C、0个或1个D、至少2个14、下列叙述中正确的是()A\线性表是线性结构B、栈和队列是非线性结构C、线性链表是非线性结构D、二叉树是线性结构15、堆栈存储器存取数据的方式是()A、先进先出B、随机存取C\先进后出D、不同于前三种方式16、如果进栈序列为e1,e2,e3,e4,则可能的出栈序列是()A、e3,e1,e4,e2B、e4,e3,e2,e1C、e3,e4,e1,e2D、任意顺序17、在设计程序时应采用的原则之一是()A、不限制goto语句的使用B、减少或取消注释行C、程序越短越好D、程序结构应助于读者理解18、下面关于完全二叉树的叙述中,错误的是()A、除了最后一层外,每一层上的结点数均达到最大值B、可能缺少若干个左右叶子结点C、完全二叉树一般不是满二叉树D、具有几个结点的完全二叉树的深度为log2n+119、下列关于栈的叙述中正确的是()A、在栈中只能插入数据B、在栈中只能删除数据C、栈是先进先出的线性别D、栈是先进后出的线性表20、在深度为5的满二叉树中,叶子结点的个数为()A、32B、31C、16D、1521、一个算法应该具有“确定性”等五个特性,下面对另外四个特性的描述中错误的是()A、有零个或多个输入B、有零个或多个输出C、有穷形D、可行性22、若想将数据序列使用插入排序算法由小到大排序,则每次放到有序子列合适位置上的元素,应从无序序列中选择()A、固定位置的B、最小的C、任意的D、最大的23、算法的空间复杂度是指()A、算法程序的长度B、算法程序中的指令条数C、算法程序所占的存储空间D、执行过程中所需要的存储空间24、用链表表示线性表的优点是()A、便于随机存取B、花费的存储空间较顺序存储少C、便于插入和删除操作D、数据元素的物理顺序与逻辑顺序相同25、链表不具备的特点是()A、可随机访问任意一个结点B、插入和删除不需要移动任何元素C、不必事先估计存储空间D、所需空间与其长度成正比26、数据结构中,与所使用的计算机无关的是数据的()A、存储结构B、物理结构C、逻辑结构D、物理与逻辑结构27、希尔排序法属于()类型的排序法。
数据结构与算法题库(附参考答案)

数据结构与算法题库(附参考答案)一、单选题(共86题,每题1分,共86分)1.在快速排序的一趟划分过程中,当遇到与基准数相等的元素时,如果左右指针都不停止移动,那么当所有元素都相等时,算法的时间复杂度是多少?A、O(NlogN)B、O(N)C、O(N2)D、O(logN)正确答案:C2.一棵有 1001 个结点的完全二叉树,其叶子结点数为▁▁▁▁▁ 。
A、254B、250C、501D、500正确答案:C3.对于一个具有N个顶点的无向图,若采用邻接矩阵表示,则该矩阵的大小是:A、(N−1)2B、NC、N2D、N−1正确答案:C4.在有n(>1)个元素的最大堆(大根堆)中,最小元的数组下标可以是:A、⌊n/2⌋−1B、⌊n/2⌋+2C、1D、⌊n/2⌋正确答案:B5.一棵非空二叉树,若先序遍历与中序遍历的序列相同,则该二叉树▁▁▁▁▁ 。
A、所有结点均无左孩子B、所有结点均无右孩子C、只有一个叶子结点D、为任意二叉树正确答案:A6.度量结果集相关性时,如果准确率很高而召回率很低,则说明:A、大部分检索出的文件都是相关的,但还有很多相关文件没有被检索出来B、大部分相关文件被检索到,但基准数据集不够大C、大部分检索出的文件都是相关的,但基准数据集不够大D、大部分相关文件被检索到,但很多不相关的文件也在检索结果里正确答案:A7.若某表最常用的操作是在最后一个结点之后插入一个结点或删除最后一个结点。
则采用哪种存储方式最节省运算时间?A、单循环链表B、带头结点的双循环链表C、单链表D、双链表正确答案:B8.设数组 S[ ]={93, 946, 372, 9, 146, 151, 301, 485, 236, 327, 43, 892},采用最低位优先(LSD)基数排序将 S 排列成升序序列。
第1 趟分配、收集后,元素 372 之前、之后紧邻的元素分别是:A、43,892B、236,301C、301,892D、485,301正确答案:C9.在快速排序的一趟划分过程中,当遇到与基准数相等的元素时,如果左指针停止移动,而右指针在同样情况下却不停止移动,那么当所有元素都相等时,算法的时间复杂度是多少?A、O(NlogN)B、O(N2)C、O(N)D、O(logN)正确答案:B10.在快速排序的一趟划分过程中,当遇到与基准数相等的元素时,如果左右指针都会停止移动,那么当所有元素都相等时,算法的时间复杂度是多少?A、O(NlogN)B、O(N)C、O(logN)D、O(N2)正确答案:A11.如果AVL树的深度为6(空树的深度定义为−1),则此树最少有多少个结点?A、12B、20C、33D、64正确答案:C12.已知指针ha和hb分别是两个单链表的头指针,下列算法将这两个链表首尾相连在一起,并形成一个循环链表(即ha的最后一个结点链接hb 的第一个结点,hb的最后一个结点指向ha),返回ha作为该循环链表的头指针。
2 二 图与遍历算法 习题参考答案

第二章部分习题参考答案1.证明下列结论:1)在一个无向图中,如果每个顶点的度大于等于2,则该该图一定含有圈; 2)在一个有向图D 中,如果每个顶点的出度都大于等于1,则该图一定含有一个有向圈。
1)证明:设无向图最长的迹,10k V V V P =每个顶点度大于等于2,故存在与1V 相异的点'V 与0V 相邻,若,'P V ∉则得到比P 更长的迹,与P 的取法矛盾。
因此,P V ∈',是闭迹,从而存在圈.0'10V V V V证明*:设在无向图G 中,有n 个顶点,m 条边。
由题意知,m>=(2n)/2=n ,而一个含有n 个顶点的树有n-1条边。
因m>=n>n-1,故该图一定含有圈。
(定义:迹是指边不重复的途径,而顶点不重复的途径称为路。
起点和终点重合的途径称为闭途径,起点和终点重合的迹称为闭迹,顶点不重复的闭迹称为圈。
)2)证明:设有向图最长的有向迹,10k V V V P =每个顶点出度大于等于1,故存在'V 为k V 的出度连接点,使得'V V k 成为一条有向边,若,'P V ∉则得到比P 更长的有向迹,与P 矛盾,因此必有P V ∈',从而该图一定含有有向圈。
2.设D 是至少有三个顶点的连通有向图。
如果D 中包含有向的Euler 环游(即是通过D 中每条有向边恰好一次的闭迹),则D 中每一顶点的出度和入度相等。
反之,如果D 中每一顶点的出度与入度都相等,则D 一定包含有向的Euler 环游。
这两个结论是正确的吗?请说明理由。
如果G 是至少有三个顶点的无向图,则G 包含Euler 环游的条件是什么?证明:1)若图D 中包含有向Euler 环游,下证明每个顶点的入度和出度相等。
如果该有向图含有Euler 环游,那么该环游必经过每个顶点至少一次,每经过一次,必为“进”一次接着“出”一次,从而入度等于出度。
从而,对于任意顶点,不管该环游经过该顶点多少次,必有入度等于出度。
图练习与答案

一、应用题1. 首先将如下图所示的无向图给出其存储结构的邻接链表表示,然后写出对其分别进行深度,广度优先遍历的结果。
1题图答.深度优先遍历序列:4宽度优先遍历序列:9 & 注:(1)邻接表不唯一,这里顶点的邻接点按升序排列(2)在邻接表确定后,深度优先和宽度优先遍历序列唯一 (3)这里的遍历,均从顶点1开始 2.给出图G :(1).画出G 的邻接表表示图; (2).根据你画出的邻接表,以顶点①为根,画出G 的深度优先生成树和广度优先生成树。
~(3)宽度优先生成树~3.在什么情况下,Prim 算法与Kruskual 算法生成不同的MST答.在有相同权值边时生成不同的MST ,在这种情况下,用Prim 或Kruskal 也会生成不(同的MST4.已知一个无向图如下图所示,要求分别用Prim 和Kruskal 算法生成最小树(假设以①为起点,试画出构造过程)。
》答.Prim 算法构造最小生成树的步骤如24题所示,为节省篇幅,这里仅用Kruskal 算法,构造最小生成树过程如下:(下图也可选(2,4)代替(3,4),(5,6)代替(1,5)) !5.G=(V,E)是一个带有权的连通图,则:(1).请回答什么是G 的最小生成树; (2).G 为下图所示,请找出G 的所有最小生成树。
28题图:答.(1)最小生成树的定义见上面26题(2)最小生成树有两棵。
(限于篇幅,下面的生成树只给出顶点集合和边集合,边以三元组(Vi,Vj,W )形式),其中W 代表权值。
V (G )={1,2,3,4,5} E1(G)={(4,5,2),(2,5,4),(2,3,5),(1,2,7)};E2(G)={(4,5,2),(2,4,4),(2,3,5),(1,2,7)}6.请看下边的无向加权图。
(1).写出它的邻接矩阵。
(2).按Prim 算法求其最小生成树,并给出构造最小生成树过程中辅助数组的各分量值。
辅助数组内各分量值:/)7.已知世界六大城市为:北京(Pe)、纽约(N)、巴黎(Pa)、伦敦(L) 、东京(T) 、墨西哥(M),下表给定了这六大城市之间的交通里程:世界六大城市交通里程表(单位:百公里)](1).画出这六大城市的交通网络图;(2).画出该图的邻接表表示法;(3).画出该图按权值递增的顺序来构造的最小(代价)生成树.8.已知顶点1-6和输入边与权值的序列(如右图所示):每行三个数表示一条边的两个端点和其权值,共11行。
图论参考答案

图论参考答案图论参考答案图论作为一门数学分支,研究的是图的性质与关系。
图由节点(顶点)和连接节点的边组成,它可以用来解决许多实际问题,如网络规划、社交网络分析等。
本文将从图的基本概念、图的表示方法、图的遍历算法以及图的应用等方面进行探讨。
一、图的基本概念图由节点和边构成,节点表示对象,边表示节点之间的关系。
图可以分为有向图和无向图两种类型。
在有向图中,边有方向,表示从一个节点到另一个节点的箭头;而在无向图中,边没有方向,表示节点之间的双向关系。
图中的节点可以用来表示不同的实体,如人、地点、物品等。
而边则表示节点之间的关系,可以是实体之间的联系、交互或者依赖关系等。
图的度是指与节点相连的边的数量。
在无向图中,节点的度等于与之相连的边的数量;而在有向图中,节点的度分为入度和出度,入度表示指向该节点的边的数量,出度表示从该节点出发的边的数量。
二、图的表示方法图可以使用邻接矩阵和邻接表两种方式进行表示。
邻接矩阵是一个二维数组,其中的元素表示节点之间的关系。
如果节点i和节点j之间有边相连,则邻接矩阵中的第i行第j列的元素为1;否则为0。
邻接矩阵的优点是可以快速判断两个节点之间是否有边相连,但是对于稀疏图来说,会浪费大量的空间。
邻接表是一种链表的形式,其中每个节点都有一个指针指向与之相连的节点。
邻接表的优点是可以有效地节省空间,适用于稀疏图。
但是在判断两个节点之间是否有边相连时,需要遍历链表,效率较低。
三、图的遍历算法图的遍历算法是指以某个节点为起点,按照一定的规则依次访问图中的所有节点。
深度优先搜索(DFS)是一种常用的图遍历算法。
它的思想是从起始节点开始,沿着一条路径一直访问到最后一个节点,然后回溯到上一个节点,继续访问其他路径。
DFS可以用递归或者栈来实现。
广度优先搜索(BFS)是另一种常用的图遍历算法。
它的思想是从起始节点开始,先访问所有与起始节点直接相连的节点,然后再依次访问与这些节点相连的节点。
图论及应用习题答案

图论及应用习题答案图论及应用习题答案图论是数学中的一个分支,研究的是图的性质和图之间的关系。
图论在现实生活中有着广泛的应用,涵盖了许多领域,如计算机科学、通信网络、社交网络等。
本文将为读者提供一些关于图论及应用的习题答案,帮助读者更好地理解和应用图论知识。
1. 图的基本概念题目:下面哪个不是图的基本概念?A. 顶点B. 边C. 路径D. 线段答案:D. 线段。
图的基本概念包括顶点、边和路径。
线段是指两个点之间的连线,而在图论中,我们使用边来表示两个顶点之间的关系。
2. 图的表示方法题目:以下哪个不是图的表示方法?A. 邻接矩阵B. 邻接表C. 边列表D. 二叉树答案:D. 二叉树。
图的表示方法包括邻接矩阵、邻接表和边列表。
二叉树是一种特殊的树结构,与图的表示方法无关。
3. 图的遍历算法题目:以下哪个不是图的遍历算法?A. 深度优先搜索B. 广度优先搜索C. 迪杰斯特拉算法D. 克鲁斯卡尔算法答案:D. 克鲁斯卡尔算法。
图的遍历算法包括深度优先搜索和广度优先搜索,用于遍历图中的所有顶点。
迪杰斯特拉算法是用于求解最短路径的算法,与图的遍历算法有所不同。
4. 最小生成树题目:以下哪个算法不是用于求解最小生成树?A. 克鲁斯卡尔算法B. 普里姆算法C. 弗洛伊德算法D. 公交车换乘算法答案:D. 公交车换乘算法。
最小生成树是指包含图中所有顶点的一棵树,使得树的边的权重之和最小。
克鲁斯卡尔算法和普里姆算法是常用的求解最小生成树的算法,而弗洛伊德算法是用于求解最短路径的算法,与最小生成树问题有所不同。
5. 图的应用题目:以下哪个不是图的应用?A. 社交网络分析B. 路径规划C. 图像处理D. 数字逻辑电路设计答案:D. 数字逻辑电路设计。
图的应用广泛存在于社交网络分析、路径规划和图像处理等领域。
数字逻辑电路设计虽然也涉及到图的概念,但与图的应用有所不同。
总结:图论是一门重要的数学分支,具有广泛的应用价值。
通过本文提供的习题答案,读者可以更好地理解和应用图论知识。
数据结构与算法练习题库(含答案)

数据结构与算法练习题库(含答案)一、单选题(共80题,每题1分,共80分)1、对一棵二叉树的结点从 1 开始顺序编号。
要求每个结点的编号大于其左子树所有结点的编号、但小于右子树中所有结点的编号。
可采用▁▁▁▁▁ 实现编号。
A、中序遍历B、先序遍历C、层次遍历D、后序遍历正确答案:A2、设一段文本中包含4个对象{a,b,c,d},其出现次数相应为{4,2,5,1},则该段文本的哈夫曼编码比采用等长方式的编码节省了多少位数?A、5B、4C、2D、0正确答案:C3、两个有相同键值的元素具有不同的散列地址A、一定不会B、一定会C、可能会D、有万分之一的可能会正确答案:C4、将元素序列{18,23,11,20,2,7,27,33,42,15}按顺序插入一个初始为空的、大小为11的散列表中。
散列函数为:H(Key)=Key%11,采用线性探测法处理冲突。
问:当第一次发现有冲突时,散列表的装填因子大约是多少?A、0.73B、0.27C、0.64D、0.45正确答案:D5、对N个记录进行归并排序,归并趟数的数量级是:A、O(NlogN)B、O(logN)C、O(N)D、O(N2)正确答案:B6、下列说法不正确的是:A、图的遍历是从给定的源点出发每一个顶点仅被访问一次B、图的深度遍历不适用于有向图C、遍历的基本算法有两种:深度遍历和广度遍历D、图的深度遍历是一个递归过程正确答案:B7、二叉树的中序遍历也可以循环地完成。
给定循环中堆栈的操作序列如下(其中push为入栈,pop为出栈): push(1), push(2), push(3), pop(), push(4), pop(), pop(), push(5), pop(), pop(), push(6), pop()A、6是根结点B、2是4的父结点C、2和6是兄弟结点D、以上全不对正确答案:C8、设最小堆(小根堆)的层序遍历结果为{1, 3, 2, 5, 4, 7, 6}。
2022年9月青少年软件编程(Python)等级考试二级【答案版】

一、单选题(共25题,共50分)1. 运行以下代码,结果输出的是?()means=['Thank','You']print(len(means))A. 8B. 6C. 2D. 12. 下列语句中变量i取值范围是1~10的是?()A. for i in range(11)B. for i in range(1,10)C. for i in range(0,10)D. for i in range(1,11)3.今天编程课的主要内容是字典的遍历。
已知字典dt={'a':[1,3,5],'b':[3,4,7],'c':[2,5,9]},老师要求用四种不同的方法遍历字典,都要获得如下结果[1, 3, 5][3, 4, 7][2, 5, 9]小程同学尝试写了四段程序,请你帮他检查一下哪个程序的打印结果不符合要求?()A. dt={'a':[1,3,5],'b':[3,4,7],'c':[2,5,9]}ls=[]for i in dt.values():ls.append(i)print(i)B. dt={'a':[1,3,5],'b':[3,4,7],'c':[2,5,9]}ls=[]for i in dt:ls.append(dt[i])for j in ls:print(j) C. dt={'a':[1,3,5],'b':[3,4,7],'c':[2,5,9]}ls=[]for k in dt.keys():ls.append(dt[k])for j in ls:print(j)D. dt={'a':[1,3,5],'b':[3,4,7],'c':[2,5,9]}ls=[]for k in dt.items():print(k)4. 执行以下代码后输出的结果是?()d={1:'monkey',2:'panda',3:'bird',4:'fish'}d[5]='sheep'del d[3]d[3]='dog'print(d)A. {1: 'monkey', 2: 'panda', 4: 'fish', 5: 'sheep', 3: 'cat'}B. {1: 'monkey', 2: 'panda', 4: 'fish', 5: 'sheep', 3: 'dog'}C. {1: 'monkey', 2: 'panda', 3: 'dog, 5: 'sheep', 4: 'duck'}D. {1: 'monkey', 2: 'panda', 3: 'cat', 5: 'sheep', 4: 'duck'}5. tp=(3,6,9,11),以下操作正确的是?()A. x=tp[2]B. x=tp(2)C. tp[3]=12D. tp(3)=126. 列表a=list(range(2,10)),下列选项中可以获取列表中最后一个元素?()A. a[8]B. a[7]C. a[9]D. a[10]7. 表达式tuple(list('Python'))的运算结果是?()A. ['Python']B. ('P', 'y', 't', 'h','o', 'n')C. ['P', 'y', 't', 'h','o', 'n']D. ('Python')8. 若list_a = [5, 4, 1, 2, 3],以下选项中能够输出 [5, 4, 3, 2, 1] 的是?()A. list_a = sorted(list_a)print(list_a)B. list_a.sort()print(list_a) C. list_a.sort(reverse=True)print(list_a)D. list_a.sort(reverse=False)print(list_a)9. 以下代码的输出结果是?()s= list(range(10))print(10 not in s)A. TrueB. FalseC. 0D. -110. 以下代码运行结果正确的是?()list1 = [[[[['a']],['冰墩墩']],6],['雪容融']]print(len(list1))A. 5B. 4C. 3D. 211. 请为下列程序空白处选出合适的选项,输出结果为['a', 'A', 9, 'a'] ?()ls1 = ['a','A','a',9,'a']______print(ls1)A. del ls1('a')B. ls1.pop(2)C. ls1.clear()D. ls1.remove('a')12. 以下代码的输出结果是?()ls = [1,2,[3,4],[5,6]]print(ls[2][1])A. 6B. 2C. 3D. 413. 下面代码的输出结果是?()for i in range(1,6):if i%3==0:breakelse:print(i,end=",")A. 1,2,B. 1,2,3,C. 1,2,3,4,5,D. 1,2,3,4,5,6,14. 给定字典d,哪个选项对x in d的描述是正确的?()A. 判断x是否是字典d中的键B. x是一个二元元组,判断x是否是字典d中的键值对C. 判断x是否是字典d中的值D. 判断x是否是在字典d中以键或值方式存在15. 下列程序的运行结果是?()str1='0123456789'str2=str1[1:9:2]print(str2)A. 1357B. 024C. 13579D. 024616. 小明用元组a存储小组同学的身高,a=(136.0,135.0,142.0,140.0),则min(a)的值是?()A. 136.0B. 135.0C. 142.0D. 140.017. 下列语句运行后,输出结果为2022的是哪个?()A. print("20"+"22")B. print(20+22)C. print("2022"in"2022")D. s="你好2022"print(s[3:4])18. 已知元组tup2=(1,14,51,4,19,198,10),下列说法有错误的是?()A. print(tup2[1:-1])可以截取元组的一部分,输出的结果为(14,51,4,19,198,10)B. print(tup2[3:])可以截取元组的一部分,输出的结果为(4,19,198,10)C. print(tup2[3:6])可以截取元组的一部分,输出的结果为(4,19,198)D. print(tup2[5])可以访问元组的第六个元素,输出的结果为19819. 下列说法错误的是?()A. 列表的大小是固定的,不可以改变B. len()方法可以返回列表的元素个数C. 假设list2列表有十个元素,则list2[2]可以读取list2列表中的第三个元素D. 列表的数据项不需要具有相同的类型20. 请根据运行结果将代码空白处填上合适的选项?()代码:num1=1while num1 <= 5:num2=1while num2 <= 5: ___________num2 += 1print()num1 += 1 运行结果:1 1 1 1 12 2 2 2 23 3 3 3 34 4 4 4 45 5 5 5 5A. print(num2,end="")B. print(num2,end =" ")C. print(num1)D. print(num1,end =" ")21. 关于下列伪代码(虚拟代码)说法正确的是?()if x<10:代码块Aelif x>=10 and x<20:代码块Belse:代码块CA. 如果x=200,代码块ABC都不会被执行B. 如果x=20,执行代码块CC. 如果x=20,执行代码块BD. 程序先执行C,再执行B,最后执行A22. 执行以下程序,输入"中国梦2022",输出结果是?()w = input()for x in w:if x=='0'or x =='2':continueelse:w.replace(x,'@')print(w)A. 中国梦2022B. 中国@2022C. @@@2022D. 2022中国梦23. 字典dic={'Name': 'Runoob','Age': 7,'Class': 'First'},len(dic)的结果是?()A. 3B. 6C. 9D. 1224. 以下不能创建一个字典的语句是?()A. dic={"name":"python"}B. dic={"age":13}C. dic={[1,2]:"user"}D. dic={}25. 关于字符串的操作,下列说法错误的是?()A. len()返回字符串长度B. count()统计字符或者字符串在整个字符串中的个数C. sort()可以给字符串排序D. split()是给字符串进行分割二、判断题(共10题,共20分)26. 字典中的键是唯一的,不能重复。
图与遍历算法 习题参考答案

第二章部分习题参考答案1.证明下列结论:1)在一个无向图中,如果每个顶点的度大于等于2,则该该图一定含有圈; 2)在一个有向图D 中,如果每个顶点的出度都大于等于1,则该图一定含有一个有向圈。
1)证明:设无向图最长的迹,10k V V V P =每个顶点度大于等于2,故存在与1V 相异的点'V 与0V 相邻,若,'P V ∉则得到比P 更长的迹,与P 的取法矛盾。
因此,P V ∈',是闭迹,从而存在圈.0'10V V V V(定义:迹是指边不重复的途径,而顶点不重复的途径称为路。
起点和终点重合的途径称为闭途径,起点和终点重合的迹称为闭迹,顶点不重复的闭迹称为圈。
)2)证明:设有向图最长的有向迹,10k V V V P =每个顶点出度大于等于1,故存在'V 为k V 的出度连接到点,'V V k 成为一条有向边,若,'P V ∉则得到比P 更长的有向迹,与P 矛盾,因此必有P V ∈',从而该图一定含有有向圈。
2.设D 是至少有三个顶点的连通有向图。
如果D 中包含有向的Euler 环游(即是通过D 中每条有向边恰好一次的闭迹),则D 中每一顶点的出度和入度相等。
反之,如果D 中每一顶点的出度与入度都相等,则D 一定包含有向的Euler 环游。
这两个结论是正确的吗?请说明理由。
如果G 是至少有三个顶点的无向图,则G 包含Euler 环游的条件是什么?证明:1)若图D 中包含有向Euler 环游,下证明每个顶点的入度和出度相等。
如果该有向图含有Euler 环游,那么该环游必经过每个顶点至少一次,每经过一次,必为“进”一次接着“出”一次,从而入度等于出度。
从而,对于任意顶点,不管该环游经过该顶点多少次,必有入度等于出度。
2)若图D 中每个顶点的入度和出度相等,则该图D 包含Euler 环游。
证明如下。
对顶点个数进行归纳。
当顶点数|v(D)|=2时,因为每个点的入度和出度相等,易得构成有向Euler 环游。
算法考卷参考答案

一、选择题(每题1分,共5分)A. Dijkstra算法B. Kruskal算法C. Huffman编码D. 动态规划算法2. 下列排序算法中,哪个算法的时间复杂度最稳定?A. 冒泡排序B. 快速排序C. 堆排序D. 插入排序A. 二分查找B. 深度优先搜索C. 广度优先搜索D. 动态规划A. 初始化状态B. 确定状态转移方程C. 计算最优值D. ABC都是A. Floyd算法B. Warshall算法C. Prim算法D. BellmanFord算法二、判断题(每题1分,共5分)1. 算法的空间复杂度与时间复杂度成正比。
(×)2. 贪心算法总能得到最优解。
(×)3. 快速排序的平均时间复杂度为O(nlogn)。
(√)4. 二分查找算法适用于顺序存储的有序表。
(√)5. 深度优先搜索和广度优先搜索在遍历图时,时间复杂度相同。
(×)三、填空题(每题1分,共5分)1. 算法的五个基本特性分别是:可行性、确定性、______、有穷性和输入输出。
2. 在排序算法中,堆排序的时间复杂度为______。
3. 求解背包问题通常采用______算法。
4. 图的遍历方法有深度优先搜索和______。
5. 在动态规划算法中,状态转移方程描述了______之间的关系。
四、简答题(每题2分,共10分)1. 简述冒泡排序的基本思想。
2. 什么是贪心算法?请举例说明。
3. 简述二分查找算法的基本步骤。
4. 什么是动态规划算法?它适用于哪些问题?5. 请列举三种常见的图遍历算法。
五、应用题(每题2分,共10分)1. 设有数组arr = [3, 5, 1, 4, 2],请用冒泡排序算法对数组进行排序。
2. 给定一个整数数组nums,请找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
3. 编写一个递归函数,实现求斐波那契数列的第n项。
A B| |C DA B (3)| |C D (4)六、分析题(每题5分,共10分)def func(n):sum = 0for i in range(n):for j in range(i):sum += 1return sum2. 给定一个字符串str,请设计一个算法,找出最长不重复子串的长度。
全国计算机等级考试二级Python真题及解析(2)

全国计算机等级考试二级Python真题及解析(2)全国计算机等级考试二级Python真题及解析(2)一、选择题1.关于算法的描述,以下选项中错误的是A算法具有可行性、确定性、有穷性的基本特征B算法的复杂度主要包括时间复杂度和数据复杂度C算法的基本要素包括数据对象的运算和操作及算法的控制结构D 算法是指解题方案的准确而完整的描述正确答案:B2.关于数据结构的描述,以下选项中正确的是A数据的存储结构是指反映数据元素之间逻辑关系的数据结构B数据的逻辑结构有顺序、链接、索引等存储方式C数据结构不可以直观地用图形表示D数据结构指相互有关联的数据元素的集合正确答案:D3.在深度为7的满二叉树中,结点个数总共是A 64B 127C 63D 32正确答案:B4.对长度为n的线性表进行顺序查找,在最坏的情况下所需要的比力次数是A n×(n+1)B n-1C nD n+11正确答案:C5.关于布局化步伐设想办法准绳的描绘,以下选项中毛病的是A逐步求精B多态担当C模块化D自顶向下正确答案:B6.与信息隐蔽的概念直接相关的概念是A模块独立性C模块耦合度D软件布局界说正确答案:A7.关于软件工程的描述,以下选项中描述正确的是A软件工程包括3要素:结构化、模块化、面向对象B软件工程工具是完成软件工程项目的技术手段C软件工程办法支持软件的开发、管理、文档生成D软件工程是使用于计算机软件的界说、开发和保护的一整套方案、工具、文档和理论尺度和工序正确答案:D8.在软件工程详细设计阶段,以下选项中不是详细设计工具的是A程序流程图B CSSC PALD判断表正确答案:B29.以下选项中透露表现干系表中的每一横行的是A属性B列C码D元组正确答案:D10.将E-R图转换为关系模式时,可以表示实体与联系的是A关系B键C域D属性正确答案:A11.以下选项中Python用于异常处理结构中用来捕获特定类型的异常的保留字是A exceptB doC passD while正确答案:A12.以下选项中符合Python语言变量命名规则的是A *iB 3_1C AI!D Templist正确答案:D13.关于赋值语句,以下选项中描绘毛病的是3A在Python言语中,有一种赋值语句,可以同时给多个变量赋值B设x = "alice";y = "kate",履行x,y = y,x可以实现变量x和y值的互换C设a = 10;b = 20,履行a,b = a,a + bprint(a,b)和a = b,b = a + bprint(a,b)之后,获得同样的输出成效:10 30D在Python言语中,“=”透露表现赋值,行将“=”右侧的计算成效赋值给左侧变量,包含“=”的语句称为赋值语句正确答案:C14.关于eval函数,以下选项中描绘毛病的是A eval函数的作用是将输入的字符串转为Python语句,并执行该语句B如果用户希望输入一个数字,并用程序对这个数字进行计算,可以采用eval(input(<输入提示字符串>))组合C执行eval("Hello")和执行eval(" 'Hello' ")得到相同的结果D eval函数的定义为:eval(source, globals=None, locals=None, /)正确答案:C15.关于Python语言的特点,以下选项中描述错误的是A Python语言是非开源语言B Python语言是跨平台语言C Python语言是多模型语言D Python语言是脚本语言正确答案:AB Python语言要求所有浮点数必须带有小数部分D Python语言提供int、float、complex等数字类型4正确答案:C17.关于Python循环结构,以下选项中描述错误的是A遍历循环中的遍历结构可以是字符串、文件、组合数据类型和range()函数等B break用来跳出最内层for或者while循环,脱离该循环后程序从循环代码后继续执行C每个continue语句只有能力跳出当前层次的循环 D Python通过for、while等保留字提供遍历循环和无限循环结构正确答案:C18.关于Python的全局变量和部分变量,以下选项中描绘毛病的是A部分变量指在函数内部使用的变量,当函数退出时,变量仍然存在,下次函数调用可以连续使用D全局变量指在函数之外界说的变量,一般没有缩进,在步伐履行全过程有用正确答案:A19.关于Python的lambda函数,以下选项中描绘毛病的是A可以使用lambda函数界说列表的排序准绳B f = lambda x,y:x+y执行后,f的类型为数字类型C lambda函数将函数名作为函数成效返回D lambda用于界说简单的、可以在一行内透露表现的函数正确答案:B20.下面代码实现的功能描述的是def fact(n):5if n==0:return 1XXX:return n*fact(n-1)num =eval(input("请输入一个整数:"))print(fact(abs(int(num))))A接受用户输入的整数n,判别n是不是是素数并输出结论B接受用户输入的整数n,判别n是不是是完数并输出结论C接受用户输入的整数n,判别n是不是是水仙花数D接受用户输入的整数n,输出n的阶乘值正确答案:D21.执行如下代码:import timeprint(time.time())以下选项中描绘毛病的是A time库是Python的标准库B可使用time.ctime(),显示为更可读的形式C time.sleep(5)推迟调用线程的运行,单位为毫秒D输出自1970年1月1日00:00:00 AM以来的秒数正确答案:C22.执行后可以查看Python的版本的是A import sysprint(sys.Version)B import systemprint(system.version)C import systemprint(system.Version)D import sysprint(sys.version)正确答案:D23.关于Python的组合数据类型,以下选项中描述错误的是A组合数据类型可以分为3类:序列类型、集合类型和映射类型6B序列类型是二维元素向量,元素之间存在先后关系,通过序号访问C Python的str、tuple和list类型都属于序列类型正确答案:B24.以下选项中,不是Python对文件的读操纵办法的是XXXB readallC readtextD read正确答案:C25.关于Python文件处理,以下选项中描述错误的是 A Python能处理JPG图像文件B Python不可以处理PDF文件C Python能处理CSV文件D Python能处理Excel文件正确答案:B26.以下选项中,不是Python对文件的打开方式的是A 'w'B '+'C 'c'D 'r'正确答案:C7D数据组织存在维度,字典类型用于表示一维和二维数据正确答案:D28. Python数据分析方向的第三方库是A pdfminerB beautifulsoup4C timeD numpy正确答案:D29. Python呆板进修偏向的第三方库是A PILB PyQt5C TensorFlowD random正确答案:C30. Python Web开发方向的第三方库是A DjangoB scipyC XXXD requests正确答案:A31.下面代码的输出结果是x=0b1010print(x)A16B256C1024D10正确答案:D832.下面代码的输出成效是x=10y=-1+2j print(x+y)A9B2jC11D(9+2j)正确答案:D33.下面代码的输出结果是x=3.print(round(x,2) ,round(x))A3 3.14B2 2C6.28 3D3.14 3正确答案:D34.下面代码的输出结果是for s in "HelloWorld":if s=="W":breakprint(s, end="")AHelloBWorldCHelloWorldXXX正确答案:A35.以下选项中,输出结果是False的是A >>> 5 is not 4B >>> 5 != 49C >>> False != 0D >>> 5 is 5正确答案:C36.下面代码的输出成效是a =b = "-"print("{0:{2}^{1},}\n{0:{2}>{1},}\n{0:{2}<{1},}".format(a,30, b))A1,000,000------------------------------------------1,000,000---------1,000,000-----------B---------------------1,000,0001,000,000-------------------------------1,000,000-----------C---------------------1,000,000----------1,000,000-----------1,000,000---------------------D----------1,000,000--------------------------------1,000,0001,000,000---------------------正确答案:D37.下面代码的输出结果是s=["seashell","gold","pink","brown","purple","tomato"]print(s[4:]) A['purple']B['seashell', 'gold', 'pink', 'brown']C['gold', 'pink', 'brown', 'purple', 'tomato']D['purple', 'tomato']正确答案:D1038.执行如下代码:import turtle as tdef DrawCctCircle(n):t.penup()t.XXX(0,-n)t.pendown()t.circle(n)for i in range(20,80,20):DrawCctCircle(i)t.done()在Python XXX Graphics中,绘制的图形是A同切圆B同心圆CXXX心形D太极正确答案:B39.给出如下代码:XXX("请输入要打开的文件: ")fo = open(fname, "r")for line in fo.readlines():print(line)fo.close()关于上述代码的描绘,以下选项中毛病的是A经由过程fo.readlines()办法将文件的全部内容读入一个字典foB经由过程fo.readlines()办法将文件的全部内容读入一个列表foC上述代码可以优化为:XXX("请输入要打开的文件: ")fo = open(fname, "r")for line in fo.readlines():print(line)fo.close()D用户输入文件路径,以文本文件体式格局读入文件内容并逐行打印11正确答案:A40.能实现将一维数据写入CSV文件中的是Afo = open("price2016bj.csv", "w")ls = ['AAA', 'BBB', 'CCC', 'DDD']fo.write(",".XXX(ls)+ "\n")fo.close()Bfr = open("price2016.csv", "w")ls = []for line in fo:line = line.replace("\n","")ls.XXX(line.split(","))print(ls)fo.close()Cfo = open("price2016bj.csv", "r")ls = ['AAA', 'BBB', 'CCC', 'DDD']fo.write(",".XXX(ls)+ "\n")fo.close()DXXX("请输入要写入的文件: ")fo = open(fname, "w+")ls = ["AAA", "BBB", "CCC"]fo.writelines(ls)for line in fo:print(line)fo.close()正确答案:A二、操作题1.编写Python步伐输出一个具有如下风格成效的文本,用作文本进度条样式,部分代码如下,填写空格处。
数据结构二叉树习题含答案

2.1 创建一颗二叉树创建一颗二叉树,可以创建先序二叉树,中序二叉树,后序二叉树。
我们在创建的时候为了方便,不妨用‘#’表示空节点,这时如果先序序列是:6 4 2 3 # # # # 5 1 # # 7 # #,那么创建的二叉树如下:下面是创建二叉树的完整代码:穿件一颗二叉树,返回二叉树的根2.2 二叉树的遍历二叉树的遍历分为:先序遍历,中序遍历和后序遍历,这三种遍历的写法是很相似的,利用递归程序完成也是灰常简单的:2.3 层次遍历层次遍历也是二叉树遍历的一种方式,二叉树的层次遍历更像是一种广度优先搜索(BFS)。
因此二叉树的层次遍历利用队列来完成是最好不过啦,当然不是说利用别的数据结构不能完成。
2.4 求二叉树中叶子节点的个数树中的叶子节点的个数= 左子树中叶子节点的个数+ 右子树中叶子节点的个数。
利用递归代码也是相当的简单,2.5 求二叉树的高度求二叉树的高度也是非常简单,不用多说:树的高度= max(左子树的高度,右子树的高度) + 12.6 交换二叉树的左右儿子交换二叉树的左右儿子,可以先交换根节点的左右儿子节点,然后递归以左右儿子节点为根节点继续进行交换。
树中的操作有先天的递归性。
2.7 判断一个节点是否在一颗子树中可以和当前根节点相等,也可以在左子树或者右子树中。
2.8 求两个节点的最近公共祖先求两个节点的公共祖先可以用到上面的:判断一个节点是否在一颗子树中。
(1)如果两个节点同时在根节点的右子树中,则最近公共祖先一定在根节点的右子树中。
(2)如果两个节点同时在根节点的左子树中,则最近公共祖先一定在根节点的左子树中。
(3)如果两个节点一个在根节点的右子树中,一个在根节点的左子树中,则最近公共祖先一定是根节点。
当然,要注意的是:可能一个节点pNode1在以另一个节点pNode2为根的子树中,这时pNode2就是这两个节点的最近公共祖先了。
显然这也是一个递归的过程啦:可以看到这种做法,进行了大量的重复搜素,其实有另外一种做法,那就是存储找到这两个节点的过程中经过的所有节点到两个容器中,然后遍历这两个容器,第一个不同的节点的父节点就是我们要找的节点啦。
高中信息竞赛-数据结构-图基本概念及搜索遍历

壹
贰
强连通图和强连通分支
上图不是强连通的,因为v3到v2不存在路径.它含有两个强连通分支
若对于有向图的任意两个结点vi、vj间(vi≠vj),都有一条从vi到vj的有向路径,同时还有一条从vj到vi的有向路径,则称该有向图是强连通的。有向图中强连通的最大子图称为该图的强连通分支。
图的相邻矩阵表示法
图的存储结构
相邻矩阵是表示结点间相邻关系的矩阵。若G=(V,E)是一个具有n个结点的图,则G的相邻矩阵是如下定义的二维数组a,其规模为n*n;a[n+1][n+1] 1(或权值) 表示顶点i和顶点j有边(i和j的路程) a[i][j]= 顶点j无边 int a[maxn+1][maxn+1]; bool f[maxn+1];{顶点的访问标志序列}
给出一个图G和其中任意一个结点V0,从V0出发系统地访问G中所有结点,每一个结点被访问一次,这就叫图的遍历。遍历图的结果是按访问顺序将结点排成一个线性序列。遍历图的算法是求解图的连通性问题、拓朴排序和求关键路径等算法的基础。通常有两种遍历方法:
深度优先搜索(dfs)
广度优先搜索(bfs) 它们对无向图和有向图都适用。我们以相邻矩阵存储结构给出深度优先搜索和广度优先搜索的程序。
调用一次bfs(i)可按广度优先搜索的顺序访问处理结点i所在的连通分支(或强连通分支)。整个图按广度优先搜索顺序遍历的过程如下: void travel() { memset(f,0,sizeof(f)); //置所有结点未访问标志 for(i=1;i<=n;i++) if(!f[i]) bfs(i); //广度优先搜索每一个未访问的结点 }
全国计算机等级考试二级Python真题及解析(5)

全国计算机等级考试二级Python真题及解析(5)一、选择题1. 关于二叉树的遍历,以下选项中描述错误的是A二叉树的遍历可以分为三种:前序遍历、中序遍历、后序遍历B前序遍历是先遍历左子树,然后访问根结点,最后遍历右子树C后序遍历二叉树的过程是一个递归的过程D二叉树的遍历是指不重复地访问二叉树中的所有结点正确答案: B2. 关于二叉树的描述,以下选项中错误的是A二叉树具有两个特点:非空二叉树只有一个根结点;每一个结点最多有两棵子树,且分别称为该结点的左子树与右子树B在任意一棵二叉树中,度为0的结点(叶子结点)比度为2的结点多一个C深度为m的二叉树最多有2的m次幂个结点D二叉树是一种非线性结构正确答案: C3. 关于查找技术的描述,以下选项中错误的是A如果采用链式存储结构的有序线性表,只能用顺序查找B二分查找只适用于顺序存储的有序表C顺序查找的效率很高D查找是指在一个给定的数据结构中查找某个特定的元素正确答案: C4. 关于排序技术的描述,以下选项中错误的是A选择排序法在最坏的情况下需要比较n(n–1)/2次B快速排序法比冒泡排序法的速度快C冒泡排序法是通过相邻数据元素的交换逐步将线性表变成有序D简单插入排序在最坏的情况下需要比较n的1.5幂次正确答案: D5. 关于面向对象的程序设计,以下选项中描述错误的是A面向对象方法可重用性好B Python 3.x 解释器内部采用完全面向对象的方式实现C用面向对象方法开发的软件不容易理解D面向对象方法与人类习惯的思维方法一致正确答案: C6. 在软件生命周期中,能准确地确定软件系统必须做什么和必须具备哪些功能的阶段是A需求设计B详细设计C可行性分析D概要设计正确答案: A7. 以下选项中,用于检测软件产品是否符合需求定义的是A集成测试B验证测试C验收测试D确认测试正确答案: C8. 在PFD图中用箭头表示A数据流B调用关系C组成关系D控制流正确答案: D9. 关于软件调试方法,以下选项中描述错误的是A软件调试可以分为静态调试和动态调试B软件调试的主要方法有强行排错法、回溯法、原因排除法等C软件调试的目的是发现错误D软件调试的关键在于推断程序内部的错误位置及原因正确答案: C10. 关于数据库设计,以下选项中描述错误的是A数据库设计可以采用生命周期法B数据库设计是数据库应用的核心C数据库设计的四个阶段按顺序为概念设计、需求分析、逻辑设计、物理设计D数据库设计的基本任务是根据用户对象的信息需求、处理需求和数据库的支持环境设计出数据模式正确答案: C11. 以下选项中值为False的是A 'abc' <'abcd'B ' ' <'a'C 'Hello' >'hello'D 'abcd' <'ad'正确答案: C12. Python语言中用来定义函数的关键字是A returnB defC functionD define正确答案: B13. 以下选项中,对文件的描述错误的是A文件中可以包含任何数据内容B文本文件和二进制文件都是文件C文本文件不能用二进制文件方式读入D文件是一个存储在辅助存储器上的数据序列正确答案: C14. ls = [3.5, "Python", [10, "LIST"], 3.6],ls[2][ –1][1]的运行结果是A IB PC YD L正确答案: A15. 以下用于绘制弧形的函数是A turtle.seth()B turtle.right()C turtle.circle()D turtle.fd()正确答案: C16. 对于turtle绘图中颜色值的表示,以下选项中错误的是A (190, 190, 190)B BEBEBEC #BEBEBED “grey”正确答案: B17. 以下选项中不属于组合数据类型的是A变体类型B字典类型C映射类型D序列类型正确答案: A18. 关于random库,以下选项中描述错误的是A设定相同种子,每次调用随机函数生成的随机数相同B通过from random import *可以引入random随机库C通过import random可以引入random随机库D生成随机数之前必须要指定随机数种子正确答案: D19. 关于函数的可变参数,可变参数*args传入函数时存储的类型是A listB setC dictD tuple正确答案: D20. 关于局部变量和全局变量,以下选项中描述错误的是A局部变量和全局变量是不同的变量,但可以使用global保留字在函数内部使用全局变量B局部变量是函数内部的占位符,与全局变量可能重名但不同C函数运算结束后,局部变量不会被释放D局部变量为组合数据类型且未创建,等同于全局变量正确答案: C21.下面代码的输出结果是ls = ["F","f"]def fun(a):ls.append(a)returnfun("C")print(ls)A ['F', 'f']B ['C']C 出错D ['F', 'f', 'C']正确答案: D22. 关于函数作用的描述,以下选项中错误的是A复用代码B增强代码的可读性C降低编程复杂度D提高代码执行速度正确答案: D23. 假设函数中不包括global保留字,对于改变参数值的方法,以下选项中错误的是A参数是int类型时,不改变原参数的值B参数是组合类型(可变对象)时,改变原参数的值C参数的值是否改变与函数中对变量的操作有关,与参数类型无关D参数是list类型时,改变原参数的值正确答案: C24. 关于形参和实参的描述,以下选项中正确的是A参数列表中给出要传入函数内部的参数,这类参数称为形式参数,简称形参B函数调用时,实参默认采用按照位置顺序的方式传递给函数,Python也提供了按照形参名称输入实参的方式C程序在调用时,将形参复制给函数的实参D函数定义中参数列表里面的参数是实际参数,简称实参正确答案: B25. 以下选项中,正确地描述了浮点数0.0和整数0相同性的是A它们使用相同的计算机指令处理方法B它们具有相同的数据类型C它们具有相同的值D它们使用相同的硬件执行单元正确答案: C26. 关于random.uniform(a,b)的作用描述,以下选项中正确的是A生成一个[a, b]之间的随机小数B生成一个均值为a,方差为b的正态分布C生成一个(a, b)之间的随机数D生成一个[a, b]之间的随机整数正确答案: A27. 关于Python语句P = –P,以下选项中描述正确的是A P和P的负数相等B P和P的绝对值相等C给P赋值为它的负数D .P的值为0正确答案: C28. 以下选项中,用于文本处理方向的第三方库是A pdfminerB TVTKC matplotlibD mayavi正确答案: A29. 以下选项中,用于机器学习方向的第三方库是A jiebaB SnowNLPC losoD TensorFlow正确答案: D30. 以下选项中,用于Web开发方向的第三方库是A Panda3DB cocos2dC DjangoD Pygame正确答案: C31.下面代码的输出结果是x = 0x0101print(x)A 101B 257C 65D 5正确答案: B32.下面代码的输出结果是sum = 1.0for num in range(1,4):sum+=numprint(sum)A 6B 7.0C 1.0D 7正确答案: B33. 下面代码的输出结果是a = 4.2e–1b = 1.3e2print(a+b)A 130.042B 5.5e31C 130.42D 5.5e3正确答案: C34.下面代码的输出结果是name = "Python语言程序设计"print(name[2: –2])A thon语言程序B thon语言程序设C ython语言程序D ython语言程序设正确答案: A35. 下面代码的输出结果是weekstr = "星期一星期二星期三星期四星期五星期六星期日" weekid = 3print(weekstr[weekid*3: weekid*3+3])A 星期二B星期三C星期四D星期一正确答案: C36.下面代码的输出结果是a = [5,1,3,4]print(sorted(a,reverse = True))A [5, 1, 3, 4]B [5, 4, 3, 1]C [4, 3, 1, 5]D [1, 3, 4, 5]正确答案: B37.下面代码的输出结果是for s in "abc":for i in range(3):print (s,end="")if s=="c":breakA aaabcccB aaabbbcC abbbcccD aaabbbccc正确答案: B38.下面代码的输出结果是for i in range(10):if i%2==0: continueelse:print(i, end=",")A 2,4,6,8,B 0,2,4,6,8,C 0,2,4,6,8,10,D 1,3,5,7,9,正确答案: D39. 下面代码的输出结果是ls = list(range(1,4))print(ls)A{0,1,2,3}B[1,2,3]C{1,2,3}D[0,1,2,3]正确答案: B40.下面代码的输出结果是def change(a,b):a = 10b += aa = 4b = 5change(a,b)print(a,b)A 10 5B 4 15C 10 15D 4 5正确答案: D二、操作题1.编写程序,从键盘上获得用户连续输入且用逗号分隔的若干个数字(不必以逗号结尾),计算所有输入数字的和并输出,给出代码提示如下。
CPA-Scratch图形化编程二级答案解析
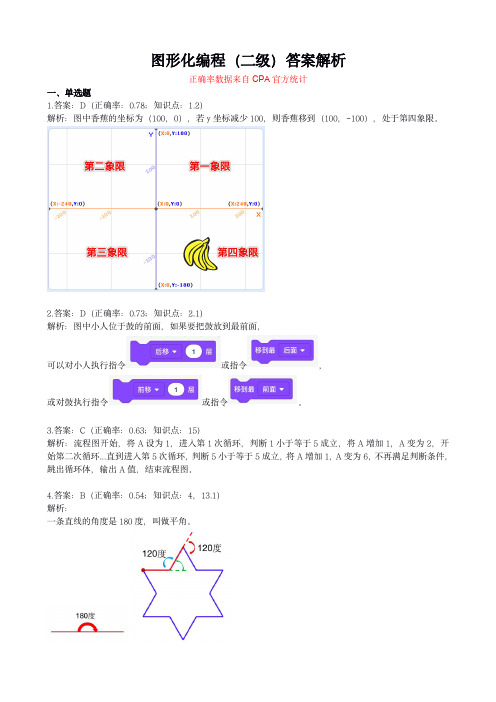
图形化编程(二级)答案解析正确率数据来自CPA官方统计一、单选题1.答案:D(正确率:0.78;知识点:1.2)解析:图中香蕉的坐标为(100,0),若y坐标减少100,则香蕉移到(100,-100),处于第四象限。
2.答案:D(正确率:0.73;知识点:2.1)解析:图中小人位于鼓的前面,如果要把鼓放到最前面,可以对小人执行指令或指令,或对鼓执行指令或指令。
3.答案:C(正确率:0.63;知识点:15)解析:流程图开始,将A设为1,进入第1次循环,判断1小于等于5成立,将A增加1,A变为2,开始第二次循环...直到进入第5次循环,判断5小于等于5成立,将A增加1,A变为6,不再满足判断条件,跳出循环体,输出A值,结束流程图。
4.答案:B(正确率:0.54;知识点:4,13.1)解析:一条直线的角度是180度,叫做平角。
在题目中,当绿旗被点击,角色面向90方向,也就是面朝右侧,起点位置为图中红点处。
自制积木“画折线次数”中,角色每次先移动50步,左转xx度,即绿色箭头标识角度,接着移动50步,右转120度,即红色箭头标识角度。
观察发现,图中蓝色角度和红色角度相同,也是120度。
它和绿色角度位于一条直线上,组成一个180度的平角。
所以绿色的左转角度为180-120=60度。
5.答案:C(正确率:0.7;知识点:7)解析:当绿旗被点击,角色移到(0,0)。
将变量a设为0,将a增加(0+5),a变成5。
重复执行5次“将x坐标增加a”,x坐标增加5+5+5+5+5=25,角色的x坐标为0+25=25,y坐标为0。
所以,选项C正确。
6.答案:A(正确率:0.69;知识点:3.1)解析:在Scratch中,每一个运算符都自带一个括号,所以对应的数学算式是(5+4)-(3×1)。
7.答案:B(正确率:0.59;知识点:3.2,3.3)解析:“降水量小于25”不成立,也就是降水量大于等于25,且降水量小于50,即降水量的取值范围是25≤降水量<50。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第二章部分习题参考答案1.证明下列结论:1)在一个无向图中,如果每个顶点的度大于等于2,则该图一定含有圈; 证明:设无向图最长的无重复顶点的迹,10k V V V P =(若含有重复顶点,则取重复顶点及其之间的点,即可构成一个圈)。
由于每个顶点度大于等于2,故存在与1V 相异的点'V 与0V 相邻,若,'P V ∉则得到比P 更长的迹,与P 的取法矛盾。
因此,P V ∈',从而0'10V V V V 是闭迹,又顶点无重复故存在圈.0'10V V V V 其他证明方式二:设在无向图G 中,有n 个顶点,m 条边。
由题意知,m>=(2n)/2=n ,而一个含有n 个顶点的树有n-1条边。
因m>=n>n-1,故该图一定含有圈。
证明方式三:(201228015029012 皇甫杨)逆否命题:在一个无向图中,若该图没有圈,则必存在顶点的度数小于2。
∵ 该图没有圈 ∴ 该图为森林∵ 森林是由树组成的,且树中必包含叶子结点 ∵ 叶子结点的度为1 ∴逆否命题得证。
(定义:迹是指边不重复的途径,而顶点不重复的途径称为路。
起点和终点重合的途径称为闭途径,起点和终点重合的迹称为闭迹,顶点不重复的闭迹称为圈。
) 2)在一个有向图D 中,如果每个顶点的出度都大于等于1,则该图一定含有一个有向圈。
证明:同上,设有向图最长的无重复顶点的有向迹,10k V V V P =每个顶点出度大于等于1,故存在'V 为k V 的出度连接点,使得'V V k 成为一条有向边,若,'P V ∉则得到比P 更长的有向迹,与P 矛盾,因此必有P V ∈',从而该图一定含有有向圈。
2.设D 是至少有三个顶点的连通有向图。
如果D 中包含有向的Euler 环游(即是通过D 中每条有向边恰好一次的闭迹),则D 中每一顶点的出度和入度相等。
反之,如果D 中每一顶点的出度与入度都相等,则D 一定包含有向的Euler 环游。
这两个结论是正确的吗?请说明理由。
如果G 是至少有三个顶点的无向图,则G 包含Euler 环游的条件是什么?证明:1)若图D 中包含有向Euler 环游,下证明每个顶点的入度和出度相等。
如果该有向图含有Euler 环游,那么该环游必经过每个顶点至少一次,每经过一次,必为“进”一次接着“出”一次,从而入度等于出度。
从而,对于任意顶点,不管该环游经过该顶点多少次,必有入度等于出度。
2)若图D 中每个顶点的入度和出度相等,则该图D 包含Euler 环游。
证明如下。
对顶点个数进行归纳。
当顶点数|v(D)|=2时,因为每个点的入度和出度相等,易得构成有向Euler 环游。
假设顶点数|v(D)|=k 时结论成立,则当顶点数|v(D)|=k + 1时,任取v ∈v(D).设S={以v 为终点的边},K={以v 为始点的边},因为v 的入度和出度相等,故S 和K 中边数相等。
记G=D-v.对G 做如下操作:任取S 和K 中各一条边21e e 、,设在D 中v v e 11=,22vv e =,则对G 和S 做如下操作 21v v G G +=, }{2e S S -=,重复此步骤直到S 为空。
这个过程最终得到的G 有k 个顶点,且每个顶点的度与在G 中完全一样。
由归纳假设,G 中存在有向Euler 环游,设为C 。
在G 中从任一点出发沿C 的对应边前行,每当遇到上述添加边v1v2时,都用对应的两条边e1,e2代替,这样可以获得有向Euler 环游。
3)G 是至少有三个顶点的无向图,则G 包含Euler 环游等价于G 中无奇度顶点。
(即任意顶点的度为偶数)。
3.设G 是具有n 个顶点和m 条边的无向图,如果G 是连通的,而且满足m = n-1,证明G 是树。
证明:思路一:只需证明G 中无圈。
若G 中有圈,则删去圈上任一条边G 仍连通。
而每个连通图边数e>=n(顶点数) – 1,但删去一条边后G 中只有n-2条边,此时不连通,从而矛盾,故G 中无圈,所以G 为树。
思路二:当2=n 时,112=-=m ,两个顶点一条边且连通无环路,显然是树。
设当)2,(1≥∈-=k N k k n 时,命题成立,则当k n =时,因为G 连通且无环路,所以至少存在一个顶点1V ,他的度数为1,设该顶点所关联的边为).,(211V V e =那么去掉顶点1V 和1e ,便得到了一个有k-1个顶点的连通无向无环路的子图'G ,且'G 的边数1'-=m m ,顶点数1'-=n n 。
由于m=n-1,所以11)1(1''-=--=-=n n m m ,由归纳假设知,'G 是树。
由于G 相当于在'G 中为2V 添加了一个子节点,所以G 也是树。
由(1),(2)原命题得证。
4. 假设用一个n n ⨯的数组来描述一个有向图的n n ⨯邻接矩阵,完成下面工作:1)编写一个函数以确定顶点的出度,函数的复杂性应为);(n Θ: 2)编写一个函数以确定图中边的数目,函数的复杂性应为);(2n Θ 3)编写一个函数删除边),(j i ,并确定代码的复杂性。
解答:(1)邻接矩阵表示为n n a ⨯,待确定的顶点为第m 个顶点m vint CountV out(int *a,int n,int m){ int out = 0; for(int i=0;i<n;i++) if(a [m-1][i]==1) out++; return out; }(2)确定图中边的数目的函数如下:int EdgeNumber(int*a,int n){ int num =0; for(int i=0;i<n;i++) for(int j=0;j<n;j++) if(a[i][j]==1) num++; return num; }(3)删除边(i , j)的函数如下:void deleteEdge(int *a,int i ,int j){if(a[i-1][j-1]==0) return;a[i-1][j-1] = 0;return;}代码的时间复杂性为Θ(1)5.实现图的D-搜索算法,要求用SPARKS语言写出算法的伪代码,或者用一种计算机高级语言写出程序。
解:D搜索算法的基本思想是,用栈代替BFS中的队列,先将起始顶点存入栈中,搜索时,取出栈顶的元素,遍历搜索其相邻接点,若其邻接点还未搜索,则存入栈中并标记,遍历所有邻接点后,取出此时栈顶的元素转入下一轮遍历搜索,直至栈变为空栈。
Proc DBFS (v) //从顶点v开始,数组visited标示顶点被访问的顺序;PushS(v , S); //首先访问v,将S初始化为只含有一个元素v的栈count :=count +1; visited[v] := count;While S 非空dou :=PullHead(S); count :=count +1; visited[w] := count; //区别队列先进先出,此先进后出for 邻接于u的所有顶点w doif s[w] = 0 thenPushS(w,S); //将w存入栈Ss[w]:= 1;end{if}end{for}end{while}end{DBFS}注:PushS(w,S)将w存入栈S; PullHead(S)为取出栈最上面的元素,并从栈中删除Proc DBFT(G,m) //m为不连通分支数count:=0 ;计数器,标示已经被访问的顶点个数for i to n dos[i]:=0; //数组s 用来标示各顶点是否曾被搜索,是则标记为1,否则标记为0; end{for}for i to m do //遍历不连通分支的情况 if s[i]=0 thenDBFS (i); end{if}end{for} end{DBFT}6.下面的无向图以邻接链表存储,而且在关于每个顶点的链表中与该顶点相邻的顶点是按照字母顺序排列的。
试以此图为例描述讲义中算法DFNL 的执行过程。
邻接链表A->B->E|0 B->A->C|0 C->B->D->E|0 D->C|0E->A->C->F->G|0 F->E->G|0 G->E->F|0解:初始化 数组DFN:=0, num=1; A 为树的根节点,对A 计算DFNL(A,null),DFN(A):=num=1; L(A):=num=1; num:=1+1=2。
从邻接链表查到A 的邻接点B , 因为DFN(B)=0,对B 计算DFNL(B,A)DFN(B):= num=2; L(B):=num=2; num :=2+1=3。
查邻接链表得到B 的邻接点A ,因为DFN(A)=1 0, 但A=A,即是B 的父节点,无操作。
接着查找邻接链表得到B 的邻接点C , 因为DFN(C)=0,对C 计算DFNL(C,B)55DFN(C):= num=3; L(C):=num=3; num:=3+1=4。
查找C的邻接点B,因为DFN(B)=1 0, 但B=B,即是C的父节点,无操作。
接着查找邻接链表得到C的邻接点D,因为DFN(D)=0,对D计算DFNL(D,C),DFN(D):= num=4; L(D):=num=4; num:=4+1=5。
查找得D邻接点C,而DFN(C)=3≠0,但C=C,为D的父节点, L(D)保持不变。
D的邻接链表结束,DFNL(D,C)的计算结束。
返回到D的父节点C,查找邻接链表得到C的邻接点E,因为DFN(E)=0,对E计算DFNL(E,C),DFN(E):=num=5; L(E):=num=5; num:5+1=6;查找得E邻接点A,因DFN(A)=1≠0,又A≠C,变换L(E)=min(L(E),DFN(A))=1。
查找得E邻接点C,因DFN(C)=3≠0,但C=C,无操作。
查找得E邻接点F,因DFN(F)=0,对F计算DFNL(F,E),DFN(F):=num=6; L(F):=num=6; num:=6+1=7;查找得F邻接点E,因DFN(E)=5≠0,但E=E,无操作。
查找得F邻接点G,因DFN(G)=0,对G计算DFNL(G,F),DFN(G):=num=7; L(G):=num=7; num=7+1=8;查找G邻接点E,因DFN(E)=5≠0,又E≠F,L(G)=min(L(G),DFN(E))=5查找得G邻接点F,因DFN(F)=6≠0,但F=F,无操作。
G的邻接链表结束,DFNL(G,F)的计算结束。