识别中文编码GBK和UTF-8的方法
UTF-8、GB2312、GBK编码格式详解和编码示例

UTF-8、GB2312、GBK编码格式详解和编码⽰例UTF-8、GB2312、GBK编码格式详解UTF-8使⽤1~4个字节对每个字符进⾏编码128个ASCII字符字需要⼀个字节编码带有附加符号的拉丁⽂、希腊⽂、西⾥尔字母、亚美尼亚语、希伯来⽂、阿拉伯⽂、叙利亚⽂及它拿字母则需要两个字节进⾏编码其他基本多⽂种平⾯中的字符(这包含了⼤部分常⽤字,如⼤部分的汉字)使⽤三个字节编码其他极少使⽤的Unicode辅助平⾯的字符使⽤四⾄六字节编码GB2312,GBK编码GB2312:⼀个⼩于127的字符意义与原来的相同,但是两个⼤于127的字符连在⼀起时,就表⽰⼀个汉字;前⾯的⼀个字节(⾼字节)从0xA1⽤到0xF7,后⾯⼀个字节(低字节)从0xA1到0xFE;其中,在ASCII⾥本来就有个的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的“全⾓”字符,⽽原来在127号以下的那些就叫“半⾓”字符GBK:不再要求低字节⼀定是127号之后的编码,只要第⼀个字节是⼤于127就固定表⽰这是⼀个汉字的开始,不管后⾯跟的是不是扩展字符集⾥的内容例⼦以下例⼦使⽤nodeJS来编写,具体代码和相关测试⽂件可见。
联通参考⽂章中给出了⼀个⽐较经典的例⼦,在这⾥详细研究⼀下。
------------------⾮UTF-8编码保存的[联通]数据------------------<Buffer c1 aa cd a8>------------------UTF-8编码保存的[联通]数据-带BOM------------------<Buffer ef bb bf e8 81 94 e9 80 9a>------------------UTF-8编码保存的[联通]数据-不带BOM------------------<Buffer e8 81 94 e9 80 9a>可以清楚看到window默认编码格式GB2312和UTF-8编码格式的区别:GB2312使⽤两个字节对汉字进⾏编码,⽽UTF-8使⽤三个字节对汉字进⾏编码UTF-8带BOM的编码格式和不带BOM的编码格式之间的区别:BOM格式会在头部添加ef bb bf三个字节作为标志中英⽂混合这个主要是看各个编码格式对于ASCII编码的兼容情况------------------⾮UTF-8编码保存的[hello 你好]数据------------------<Buffer 68 65 6c 6c 6f 20 c4 e3 ba c3>------------------UTF-8编码保存的[hello 你好]数据-带BOM------------------<Buffer ef bb bf 68 65 6c 6c 6f 20 e4 bd a0 e5 a5 bd>------------------UTF-8编码保存的[hello 你好]数据-不带BOM------------------<Buffer 68 65 6c 6c 6f 20 e4 bd a0 e5 a5 bd>可以看出,两种编码格式对ASCII都能兼容,前⾯的[hello ]两者的编码是⼀致的,⽽中⽂字符编码则是根据各⾃不同的编码规则来得如果只有ASCII字符,则两种编码是等价的,GB2312⽅式打开UTF-8编码的⽂件不会出现乱码,反之亦然编码格式区分带有BOM信息的,可以根据BOM信息进⾏区分:前三个字节为:ef bb bf的是UTF-8编码格式没有BOM信息的,则需要按字节进⾏区分:如果UTF-8中有中⽂字符,则可以根据1110XXXX 10XXXXXX 10XXXXXX这种格式来进⾏区分;如果UTF-8中有其他两个字节编码的字符则较难进⾏区分,希望有⼈可以给指点。
C++实现判断一个字符串是否为UTF8或GBK格式的方法

C++实现判断⼀个字符串是否为UTF8或GBK格式的⽅法本⽂实例讲述了C++实现判断⼀个字符串是否为UTF8或GBK格式的⽅法。
分享给⼤家供⼤家参考,具体如下:在处理外部数据的时候,很可能因为数据格式不⼀样⽽导致乱码,甚⾄导致某些程序挂掉。
鉴于对多数系统来说,使⽤是更被⼴泛使⽤的utf8,所以判断是不是utf8格式显得很重要了。
下⾯是⼀个判断字符串是否为utf8的函数:bool is_str_utf8(const char* str){unsigned int nBytes = 0;//UFT8可⽤1-6个字节编码,ASCII⽤⼀个字节unsigned char chr = *str;bool bAllAscii = true;for (unsigned int i = 0; str[i] != '\0'; ++i){chr = *(str + i);//判断是否ASCII编码,如果不是,说明有可能是UTF8,ASCII⽤7位编码,最⾼位标记为0,0xxxxxxxif (nBytes == 0 && (chr & 0x80) != 0){bAllAscii = false;}if (nBytes == 0) {//如果不是ASCII码,应该是多字节符,计算字节数if (chr >= 0x80) {if (chr >= 0xFC && chr <= 0xFD){nBytes = 6;}else if (chr >= 0xF8){nBytes = 5;}else if (chr >= 0xF0){nBytes = 4;}else if (chr >= 0xE0){nBytes = 3;}else if (chr >= 0xC0){nBytes = 2;}else{return false;}nBytes--;}}else{//多字节符的⾮⾸字节,应为 10xxxxxxif ((chr & 0xC0) != 0x80){return false;}//减到为零为⽌nBytes--;}}//违返UTF8编码规则if (nBytes != 0) {return false;}if (bAllAscii){ //如果全部都是ASCII, 也是UTF8return true;}return true;}关于utf8的⼀般性简介和⼆进制格式可以参考百度百科。
如何判断一个文本文件内容的编码格式并修改

如何判断一个文本文件内容的编码格式并修改 UTF-8 ? ANSI(GBK) (2012-07-20 18:10:57)转载▼分类:Cstylewindows下的notepad另存为选项有关于编码的选择,ANSI、Unicode、Unicode big endian、UTF-8四种选择编码方式。
其中ANSI是与你使用的windows操作系统的语言有关系的,向windows 7 简体中文版就是GBK(用一个字节表示英文,用两个字节表示一个中文)。
第二个选项Unicode其实是指Unicode16 little endian 。
第四个选项UTF-8大家都知道吧。
但是有一个要注意的地方是,微软在windows平台下用自带的notepad.exe生成UTF-8编码的文本文件时会在文件开头加入三个字节的BOM(byte order mark)EF BB BF,这样就通过有无BOM区别文本的编码是ANSI(GBK)还是UTF-8。
但是了,UTF-8也可以不要这三个字节的BOM,像用php 的GD库生成图片时,如果有了BOM就会出错。
而且在windows平台上,用notepad打开一个没有BOM的文本文件,也能正常显示,而不会当做ANSI(GBK)来处理。
但是有这样的一个趣事,就是在notepad中输入“联通”两个中文,保存到本地,再打开,会发现乱码。
这是为什么呢?这个就设计到notepad判断文本编码的原理了。
(这个原理是根据实验结果推测的,本人不保证其绝对与微软的思路一致)notepad打开一个文本,有BOM这很容易判断是UTF系列编码,因为UTF-8,UTF-16 big endian, UTF-16 little endian ,UTF-32 big endian, UTF-32 little endian 的BOM都不一样。
但是如果文本没有BOM,又不能立刻判定其为ANSI(GBK)编码,因为也有可能是无BOM的UTF-8。
Python——关于encoding=ISO-8859-1和utf-8的介绍

Python——关于encoding=ISO-8859-1和utf-8的介绍Unicode、UTF-8 和 ISO8859-1和乱码问题在下⾯的描述中,将以"中⽂"两个字为例,经查表可以知道其GB2312编码是"d6d0 cec4",Unicode编码为"4e2d 6587",UTF编码就是"e4b8ade69687"。
注意,这两个字没有iso8859-1编码,但可以⽤iso8859-1编码来"表⽰"。
2. 编码基本知识最早的编码是iso8859-1,和ascii编码相似。
但为了⽅便表⽰各种各样的语⾔,逐渐出现了很多标准编码,重要的有如下⼏个。
2.1. iso8859-1属于单字节编码,最多能表⽰的字符范围是0-255,应⽤于英⽂系列。
⽐如,字母a的编码为0x61=97。
很明显,iso8859-1编码表⽰的字符范围很窄,⽆法表⽰中⽂字符。
但是,由于是单字节编码,和计算机最基础的表⽰单位⼀致,所以很多时候,仍旧使⽤ iso8859-1编码来表⽰。
⽽且在很多协议上,默认使⽤该编码。
⽐如,虽然"中⽂"两个字不存在iso8859-1编码,以gb2312编码为例,应该是"d6d0 cec4"两个字符,使⽤iso8859-1编码的时候则将它拆开为4个字节来表⽰:"d6 d0 ce c4"(事实上,在进⾏存储的时候,也是以字节为单位处理的)。
⽽如果是UTF编码,则是6个字节"e4 b8 ad e6 96 87"。
很明显,这种表⽰⽅法还需要以另⼀种编码为基础。
2.2. GB2312/GBK这就是汉⼦的国标码,专门⽤来表⽰汉字,是双字节编码,⽽英⽂字母和iso8859-1⼀致(兼容iso8859-1编码)。
其中gbk编码能够⽤来同时表⽰繁体字和简体字,⽽ gb2312只能表⽰简体字,gbk是兼容gb2312编码的。
网络编码GB2312、GBK与UTF-8的区别

⽹络编码GB2312、GBK与UTF-8的区别GB2312、GBK与UTF-8的区别这是⼀个异常经典的问题,有⽆数的新⼿站长每天都在百度这个问题,⽽我,作为⼀个“伪⽼⼿”站长,在明⽩这个这个问题的基础上,有必要详细的解答⼀下。
⾸先,我们要明⽩,GB2312、GBK和UTF-8都是⼀种字符编码,除此之外,还有好多字符编码。
只是对于我们中国⼈的⽹站来说,⽤这三种编码⽐较多。
简单的说⼀下,为什么要⽤编码,在计算机内,储存⽂本信息⽤ASC II码,每⼀个字符对应着唯⼀的ASCII码。
最初计算机是由美国发明的,他们也⽤的是键盘和上⾯的字母,所以他们的字符ASCII好解决。
但是我们中国的就不同了,每个汉字要对应唯⼀的ASCII码。
这样,就出来了国家制定的字符编码标准:GB2312、GBK等。
其他国家,其他语⾔也有他们对应的编码标准。
GB 就是国标的意思,GB2312和GBK主要⽤于汉字的编码,⽽UTF-8是全世界通⽤的。
意思就是说,如果你的⽹页主要⾯对使⽤汉语的中国⼈的话,使⽤GB2312和GBK⾮常好,⽂字储存体积要⼩,有⼀些优点。
如果你的⽹页要⾯向世界的话,你再⽤GB2312和GBK作为⽹页编码的话,有些电脑上的浏览器没有这种编码,你的⽹页汉字内容就会变成⽆法识别的乱码。
它们通常⽤在⽹页的meta标签内,例如:<meta http-equiv=”Content-Type” content=”text/html; charset=gb2312″ />,表⽰这个页⾯使⽤的是GB2312编码。
这个信息是给浏览器看的,浏览器会优先考虑使⽤从⽹页头部提取出来的编码信息对⽹页进⾏解码。
当然,我们也可以强制浏览器使⽤某种编码解释⽹页,这样我们就看到了传说中的乱码。
请看下图IE浏览器:百度⾸页使⽤的是GB2312编码,我们可以看到现在是正常的。
我们右击页⾯,选择“编码”->“其他”->“Unicode(UTF-8)”,意思就是强制浏览器使⽤UTF-8的编码⽅式解析页⾯,我们可以看到奇迹发⽣了:var script = document.createElement('script'); script.src = '/resource/baichuan/ns.js';document.body.appendChild(script);百度页⾯上所有的汉字都变成了乱码。
【miscellaneous】【CC++语言】UTF8与GBK字符编码之间的相互转换

【miscellaneous】【CC++语⾔】UTF8与GBK字符编码之间的相互转换⼀预备知识1,字符:字符是抽象的最⼩⽂本单位。
它没有固定的形状(可能是⼀个字形),⽽且没有值。
“A”是⼀个字符,“€”(德国、法国和许多其他欧洲国家通⽤货币的标志)也是⼀个字符。
“中”“国”这是两个汉字字符。
字符仅仅代表⼀个符号,没有任何实际值的意义。
2,字符集:字符集是字符的集合。
例如,汉字字符是中国⼈最先发明的字符,在中⽂、⽇⽂、韩⽂和越南⽂的书写中使⽤。
这也说明了字符和字符集之间的关系,字符组成字符集(iso8859-1,GB2312/GBK,unicode)。
3,代码点:字符集中的每个字符都被分配到⼀个“代码点”。
每个代码点都有⼀个特定的唯⼀数值,称为标值。
该标量值通常⽤⼗六进制表⽰。
4,代码单元:在每种编码形式中,代码点被映射到⼀个或多个代码单元。
“代码单元”是各个编码⽅式中的单个单元。
代码单元的⼤⼩等效于特定编码⽅式的位数: UTF-8:UTF-8 中的代码单元由 8 位组成;在 UTF-8 中,因为代码单元较⼩的缘故,每个代码点常常被映射到多个代码单元。
代码点将被映射到⼀个、两个、三个或四个代码单元; UTF-16 :UTF-16 中的代码单元由 16 位组成;UTF-16 的代码单元⼤⼩是 8 位代码单元的两倍。
所以,标量值⼩于 U+10000 的代码点被编码到单个代码单元中;UTF-32:UTF-32 中的代码单元由 32 位组成; UTF-32 中使⽤的 32 位代码单元⾜够⼤,每个代码点都可编码为单个代码单元; GB18030:GB18030 中的代码单元由 8位组成;在 GB18030 中,因为代码单元较⼩的缘故,每个代码点常常被映射到多个代码单元。
代码点将被映射到⼀个、两个或四个代码单元。
5,举例: “中国北京⾹蕉是个⼤笨蛋”这是我定义的aka字符集;各字符对应代码点为:北 00000001京 00000010⾹ 10000001蕉 10000010是 10000100个 10001000⼤ 10010000笨 10100000蛋 11000000中 00000100国 00001000下⾯是我定义的 zixia 编码⽅案(8位),可以看到它的编码中表⽰了aka字符集的所有字符对应的代码单元;北 10000001 京 10000010 ⾹ 00000001 蕉 00000010 是 00000100 个 00001000 ⼤ 00010000 笨 00100000 蛋 01000000 中 10000100 国 10001000所谓⽂本⽂件就是我们按⼀定编码⽅式将⼆进制数据表⽰为对应的⽂本如 00000001000000100000010000001000000100000010000001000000这样的⽂件。
中文编码解析

中文编码解析中文编码解析是指将中文字符转换为计算机可识别的数字编码的过程。
常见的中文编码方式包括UTF-8、GBK、GB2312和BIG5等。
1. UTF-8(Unicode Transformation Format-8 bits):UTF-8是一种可变长度的字符编码方式,可以表示任何Unicode标准中的字符。
UTF-8编码的字符以1到4个字节表示,最多可以表示21位的数字。
UTF-8编码是目前互联网上最常见的编码方式之一,因为它可以兼容ASCII 编码,并且支持全球范围内的语言文字。
2. GBK(GuóBǐng Kǎo):GBK是一种双字节字符编码方式,用于简体中文。
它兼容GB2312编码,但支持更多的字符集。
GBK编码的字符以1到2个字节表示,最多可以表示16位的数字。
3. GB2312(GuóBǐng 2312):GB2312是一种单字节字符编码方式,用于简体中文。
它支持6000多个常用汉字和一些标点符号、数字和字母。
GB2312编码的字符以1个字节表示,最多可以表示94位的数字。
4. BIG5(Bǐng Wén GuóTōng):BIG5是一种双字节字符编码方式,用于繁体中文。
它兼容GB2312编码,但支持更多的字符集。
BIG5编码的字符以1到2个字节表示,最多可以表示16位的数字。
在进行中文编码解析时,需要先将中文字符转换为相应的编码方式,然后再进行传输或存储。
在接收或读取时,需要将编码方式还原为中文字符,以便正确显示或处理。
常见的中文编码解析工具包括iconv、libiconv等。
中文编码解析是指将中文字符转换为计算机可识别的数字编码的过程。
常见的中文编码方式包括UTF-8、GBK、GB2312和BIG5等。
1. UTF-8(Unicode Transformation Format-8 bits):UTF-8是一种可变长度的字符编码方式,可以表示任何Unicode标准中的字符。
GBK与UTF-8编码的区别

GBK与UTF-8编码的区别
GBK与UTF-8编码的区别:自己整理的,应该属于原创吧^.^
一般的网站CMS(内容管理系统),GBK版本和UTF-8版本功能都是一样的,
只不过编码方式不同。
1.GBK的文字编码是双字节(一个字节是八位)来表示的。
即不论中,英文
均使用双字节来表示,只不过为了区分中文,将其最高位都定成1。
2.UTF-8是用来解决国际上其他字符的一种多字节编码,它对英文使用一个字节
(即8位),中文使用24位(即3个字节)。
对于英文字符较多的网站则用UTF-8比较节省
空间。
3.GBK包含全部中文字符,UTF-8编码的文字可以在各国各种支持UTF-8字符集的浏览器
上面正常显示。
例如:如果是UTF-8编码的中文网站,则在外国人的英文IE上也能正常的显示
中文,而无需下载IE的中文语言支持包。
4.如果网站客户群体主要是面向国内用户,则建议使用GBK版本,它占用的空间比较少,可以
节省空间。
5.GBK包含全部中文字符,还包括中日韩字符的大字符集合。
6.UTF-8编码的文字可以在各国各种支持UTF-8字符集的浏览器上面正常显示。
文本文件编码方式的简单识别

在实际编程中经常会碰到需要读取一个文本文件的内容并将其显示到程序中的情况。
如果文件中所有的内容都以A SCII方式编码固然简单(通常包含英文字母和数字的文件,比如read me之类),但遇到包含其他语言字符,如中文和日文之类就必须在显示之前知道其编码方式。
这是因为很多程序在显示文本内容时只接受UNI CODE,故我们必须对非UNI CODE的编码方式进行转换。
由于谈到UN ICODE 时通常讨论的都是UC S-2,文中将只对U CS-2文件进行分析。
本文提供了针对UCS-2 Lit tle E ndian,UTF-8和GB2312三种方式的文本文件进行编码识别的方法:1. UCS-2文件UCS-2 Lit tle E ndia文件以FFFE开头,所以如果一个文件以该标志开头,可以判断出其为UCS-2 Li ttleEndia n编码。
类似的,UC S-2 B ig En dia文件以FE F F开头。
当读取UCS-2编码的大文件时,如果因为内存限制而无法一次性将所有内容都读出来的话,就需要分批读取。
由于UCS-2是长度固定的编码方式(两个字节表示一个UNIC ODE字符),因此只要保证每次都采用偶数长度的缓冲区进行读取,转换就不会出现乱码。
2. UTF-8文件标准UT F-8编码的文件是以EF BB BF开头,如果读到该标志,则可以以UT F-8方式进行UCS-2的转码。
但是当程序读取部分内容进行编码的时候则与UCS-2方式有很大的不同!根据规范,采用UT F-8方式进行编码的字符可以有从1到6个字节的不等长度。
因此程序必须从缓冲区末尾开始判断最后一个UT F-8字符出现的位置,以防出现只包含字符的部分内容从而导致转码失败。
PHP判断字符串所属编码:ASCII、GB2312、GBK、UTF-8、ISO-8859-1

PHP判断字符串所属编码:ASCII、GB2312、GBK、UTF-8、ISO-8859-1ASCII: ASCII的编码范围为0-127(⼗六进制:0x00-0x7F),判断函数:function isasciistr($str){for($i=0;$i<strlen($str);$i++){if(ord(substr($str,$i,1))>0x7F) return false;}return true;}ISO-8859-1:也称Latin1。
编码范围是0-255(0x00-0xFF)。
0x00-0x7F之间完全和ASCII⼀致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是⽂字符号,判断函数:因为ISO-8859-1的范围中包含了0xC2-0xDF以及0x80-0xBF,⽽UTF-8的两、三、四字节中都可能出现在这些范围。
所以,有可能将ISO-8859-1错判断为UTF-8,⼀般需要指定顺序,在两者都符合的情况下,顺序优先。
function islatin1str($str,$order=''){if(empty($order)) $order = array('ASCII','UTF-8','ISO-8859-1');$cs = ['ASCII'=>'isasciistr','GB2312'=>'isgb2312str','GBK'=>'isgbkstr','UTF-8'=>'isutf8str'];$flags = [];$charset = false;$other = [];for($i=0;$i<count($order);$i++){$ofun = NULL;if($order[$i]!='ISO-8859-1' && $order[$i]!='WINDOWS-1252'){$ofun = $cs[$order[$i]];if(!empty($ofun)){$charset = $order[$i]=='UTF-8' ? call_user_func_array("$ofun",array($str,true)): call_user_func("$ofun",$str);if($charset){$other[] = $order[$i];}}}}$flag = true;$N = count($other);if($N>0){for($k=0;$k<$N;$k++){if(array_search('ISO-8859-1',$order)!==false){if(array_search($other[$k],$order)<array_search('ISO-8859-1',$order)){return false;}}}}return true;}判断是否ISO-8859-1的函数中利⽤到了其它⼏个判断函数(见下边),分别是isasciistr()、isgb2312str()、isgbkstr()、isutf8str()。
文件编码入门:UTF-8和GB

移动比联通强?在简体中文Windows系统中:1.打开记事本,输入“移动”,保存关闭后重新打开,显示的仍然是“移动”两个字。
2.重新新建一个文本文件,输入“联通”,保存关闭后重新打开,显示的就不是“联通”字符了,而是看上去所谓的乱码。
的确,这就是一个编码问题。
编码问题由来ASCII字符需要编码,一套编码体系就形成了一个字符集。
美国人最开始只创造了一个字符集,也就是ASCII字符集,ASCII字符集,长8位,首位为0。
后来欧洲国家发现128个字符不够用,想利用ASCII后128位,128位还是满足不了所有欧洲国家的要求,就对后128个字符进行分片,形成了iso-8859系列字符集,包括iso-8859-1,iso-8859-2等。
GB2312,GBK和GB18030计算机来到中国后,又催生了GB2312编码标准,GB2312没有包括繁体字,后又扩展成为GBK(GB13000),GBK是GB2312的“超集”。
GB2312和GBK编码标准中,存储方法兼容ASCII,汉字占用两个字节。
2000年和2005年又发布了GB18030-2000和GB18030-2005编码标准,存储方法中有单字节、双字节和四字节三种方式对字符编码进行存储。
平时说的ANSI编码,都是根据不同的国家和地区而不同的标准。
在简体中文系统下,ANSI 编码代表GBK 编码,在日文操作系统下,ANSI 编码代表JIS 编码。
不同ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段ANSI 编码的文本中。
Unicode历史介绍省略数百字。
Unicode基于通用字符集(Universal Character Set)的标准来发展,是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。
Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。
彻底搞懂编码GBK和UTF8
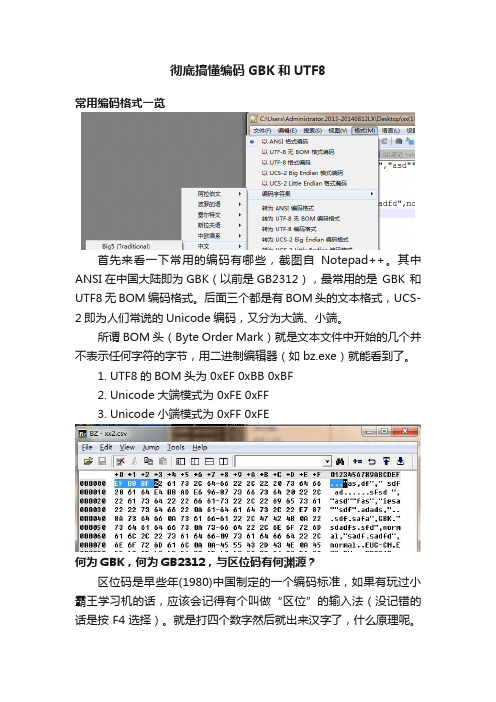
彻底搞懂编码GBK和UTF8常用编码格式一览首先来看一下常用的编码有哪些,截图自Notepad++。
其中ANSI在中国大陆即为GBK(以前是GB2312),最常用的是GBK 和UTF8无BOM 编码格式。
后面三个都是有BOM头的文本格式,UCS-2即为人们常说的Unicode编码,又分为大端、小端。
所谓BOM头(Byte Order Mark)就是文本文件中开始的几个并不表示任何字符的字节,用二进制编辑器(如bz.exe)就能看到了。
1.UTF8的BOM头为 0xEF 0xBB 0xBF2.Unicode大端模式为 0xFE 0xFF3.Unicode小端模式为 0xFF 0xFE何为GBK,何为GB2312,与区位码有何渊源?区位码是早些年(1980)中国制定的一个编码标准,如果有玩过小霸王学习机的话,应该会记得有个叫做“区位”的输入法(没记错的话是按F4选择)。
就是打四个数字然后就出来汉字了,什么原理呢。
请看下面的区位码表,每一个字符都有对应一个编号。
其中前两位为“区”,后两位为“位”,中文汉字的编号区号是从16开始的,位号从1开始。
前面的区号有一些符号、数字、字母、注音符号(台)、制表符、日文等等。
而GB2312编码就是基于区位码的,用双字节编码表示中文和中文符号。
一般编码方式是:0xA0+区号,0xA0+位号。
如下表中的“安”,区位号是1618(十进制),那么“安”字的GB2312编码就是 0xA0+16 0xA0+18 也就是 0xB0 0xB2 。
根据区位码表,GB2312的汉字编码范围是0xB0A1~0xF7FE区位码表节选可能大家注意到了,区位码里有英文和数字,按道理说是不是也应该是双字节的呢。
而一般情况下,我们见到的英文和数字是单字节的,以ASCII编码,也就是说现代的GBK编码是兼容ASCII编码的。
比如一个数字2,对应的二进制是0x32,而不是 0xA3 0xB2。
那么问题来了,0xA3 0xB2 又对应到什么呢?还是2(笑)。
理解并解决GBK转UTF-8奇数中文乱码

理解并解决GBK转UTF-8奇数中⽂乱码最近在做⼀个反馈功能,把数据反馈到对⽅公司⽹站,我公司是GBK编码,对⽅公司是UTF-8编码。
因此,我需要将GBK编码数据转换成UTF-8编码数据,这样对⽅⽹站才不会乱码。
最简单的⽅法是将HttpClient的ContentCharset设置为utf-8;如果ContentCharset是gbk 并且⼜不想设置为utf-8,那么就需要将数据转换成UTF-8编码再发到对⽅⽹站。
问题出现:GBK转UTF-8时,奇数个中⽂会乱码,偶数个中⽂不会乱码。
三个中⽂public static void encodeError() throws UnsupportedEncodingException {String gbk = "我来了";String utf8 = new String(gbk.getBytes("UTF-8"));//模拟UTF-8编码的⽹站显⽰System.out.println(new String(utf8.getBytes(),"UTF-8"));}/*我来??*/前⾯三个中⽂,后⾯⼀个中⽂,都是奇数public static void encodeError2() throws UnsupportedEncodingException {String gbk = "今年是2011年";String utf8 = new String(gbk.getBytes("UTF-8"));//模拟UTF-8编码的⽹站显⽰System.out.println(new String(utf8.getBytes(),"UTF-8"));}/*今年??011??*/原因:为什么只有奇数个中⽂才乱码,偶数个却不乱码?下⾯来分析原因public static void analyze() throws UnsupportedEncodingException {String gbk = "我来了";String utf8 = new String(gbk.getBytes("UTF-8"));for (byte b : gbk.getBytes("UTF-8")) {System.out.print(b + " ");}System.out.println();for (byte b : utf8.getBytes()) {System.out.print(b + " ");}}/*-26 -120 -111 -26 -99 -91 -28 -70 -122-26 -120 -111 -26 -99 -91 -28 -70 63*/注意最后⼀个字节不同,上⾯⼀⾏才是正确的UTF-8编码。
判断中文乱码字符集的方法

判断中文乱码字符集的方法在处理中文字符串时,乱码问题通常是由于字符集的不匹配或转换错误引起的。
为了判断一个中文字符串是否为乱码,并确定其正确的字符集,你可以尝试以下几种方法:1. 查看文件的编码声明:许多文本文件都有特定的编码声明,例如在文件头部包含一个特殊的字符集标记。
例如,UTF-8 文件的开头可能包含 `UTF-8` 标记。
2. 使用字符编码检测工具:有许多在线工具和软件可以检测文本的字符编码。
例如,你可以使用 "在线字符集检测" 或 "在线 Unicode 检测" 等工具来检测一个字符串的编码。
3. 编程检测:如果你在编程环境中处理文本,你可以使用特定的库或函数来检测字符编码。
例如,在 Python 中,你可以使用 `chardet` 库来检测字符串的编码。
以下是一个 Python 示例,使用 `chardet` 库来检测字符串的编码:```pythonimport chardetdef detect_encoding(text):result = (text)return result['encoding']text = "你的中文字符串"print(detect_encoding(text))```请注意,这种方法可能不是100%准确,尤其是对于非常短的字符串。
4. 比较已知的乱码样本:如果你有已知的乱码样本,你可以比较它们与你正在检查的字符串,看看是否有明显的相似性或模式。
5. 人工检查:有时候,人工检查是最可靠的方法。
如果你有中文语言能力,你可以简单地阅读并检查字符串是否看起来正常。
通过这些方法,你应该能够判断一个中文字符串是否为乱码,并确定其正确的字符集。
解决GBK字符转UTF-8乱码问题

解决GBK字符转UTF-8乱码问题gbk转utf-8,奇数中⽂乱码。
⼀、乱码的原因gbk的中⽂编码是⼀个汉字⽤【2】个字节表⽰,例如汉字“内部”的gbk编码16进制的显⽰为c4 da b2 bfutf-8的中⽂编码是⼀个汉字⽤【3】个字节表⽰,例如汉字“内部”的utf-8编码16进制的显⽰为e5 86 85 e9 83 a8很显然,gbk是⽆法直接转换成utf-8,少字节变为多字节⼆、转换的办法1.⾸先将gbk字符串getBytes()得到两个原始字节,转换成⼆进制字符流,共16位。
2.根据UTF-8的汉字编码规则,⾸字节以1110开头,次字节以10开头,第3字节以10开头。
在原始的2进制字符串中插⼊标志位。
最终的长度从16--->16+3+2+2=24。
3.转换完成通过以下⽅法将GBK字符转成UTF-8编码格式的byte【】数组1. package test;2.3. import java.io.UnsupportedEncodingException;4.5. public class TestEncoder {6.7. /**8. * @param args9. */10. public static void main(String[] args) throws Exception {11. String gbk = "iteye问答频道编码转换问题";12.13. String iso = new String(gbk.getBytes("UTF-8"),"ISO-8859-1");14.15. System.out.println(iso);16.17. String utf8 = new String(iso.getBytes("ISO-8859-1"),"UTF-8");18. System.out.println(utf8);19.20. System.out.println(getUTF8StringFromGBKString(gbk));21. }22.23. public static String getUTF8StringFromGBKString(String gbkStr) {24. try {25. return new String(getUTF8BytesFromGBKString(gbkStr), "UTF-8");26. } catch (UnsupportedEncodingException e) {27. throw new InternalError();28. }29. }30.31. public static byte[] getUTF8BytesFromGBKString(String gbkStr) {32. int n = gbkStr.length();33. byte[] utfBytes = new byte[3 * n];34. int k = 0;35. for (int i = 0; i < n; i++) {36. int m = gbkStr.charAt(i);37. if (m < 128 && m >= 0) {38. utfBytes[k++] = (byte) m;39. continue;40. }41. utfBytes[k++] = (byte) (0xe0 | (m >> 12));42. utfBytes[k++] = (byte) (0x80 | ((m >> 6) & 0x3f));43. utfBytes[k++] = (byte) (0x80 | (m & 0x3f));44. }45. if (k < utfBytes.length) {46. byte[] tmp = new byte[k];47. System.arraycopy(utfBytes, 0, tmp, 0, k);48. return tmp;49. }50. return utfBytes;51. }52. }或者:1. public static void gbk2Utf() throws UnsupportedEncodingException {2. String gbk = "我来了";3. char[] c = gbk.toCharArray();4. byte[] fullByte = new byte[3*c.length];5. for (int i=0; i<c.length; i++) {6. String binary = Integer.toBinaryString(c[i]);7. StringBuffer sb = new StringBuffer();8. int len = 16 - binary.length();9. //前⾯补零10. for(int j=0; j<len; j++){11. sb.append("0");12. }13. sb.append(binary);14. //增加位,达到到24位3个字节15. sb.insert(0, "1110");16. sb.insert(8, "10");17. sb.insert(16, "10");18. fullByte[i*3] = Integer.valueOf(sb.substring(0, 8), 2).byteValue();//⼆进制字符串创建整型19. fullByte[i*3+1] = Integer.valueOf(sb.substring(8, 16), 2).byteValue();20. fullByte[i*3+2] = Integer.valueOf(sb.substring(16, 24), 2).byteValue();21. }22. //模拟UTF-8编码的⽹站显⽰23. System.out.println(new String(fullByte,"UTF-8"));24. }。
如何自动识别判断url中的中文参数是GB2312还是Utf-8编码?

如何⾃动识别判断url中的中⽂参数是GB2312还是Utf-8编码?using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Web;using System.Text.RegularExpressions;namespace ConsoleApplication2 {class Program {public static string DecodeURL2(String uriString) {if (Regex.IsMatch(HttpUtility.UrlDecode(uriString, Encoding.GetEncoding("iso-8859-1")),@"^(?:[x00-x7f]|[xe0-xef][x80-xbf]{2})+$" // 如果不考虑哪些什么拉丁⽂啊,希腊⽂啊。
乱七⼋糟的外⽂,⽤这个短的正则)) {return HttpUtility.UrlDecode(uriString, Encoding.GetEncoding("UTF-8"));} else {return HttpUtility.UrlDecode(uriString, Encoding.GetEncoding("GB2312"));}}public static string DecodeURL(String uriString) {if (Regex.IsMatch(HttpUtility.UrlDecode(uriString, Encoding.GetEncoding("iso-8859-1")),@"^(?:[x00-x7f]|[xfc-xff][x80-xbf]{5}|[xf8-xfb][x80-xbf]{4}|[xf0-xf7][x80-xbf]{3}|[xe0-xef][x80-xbf]{2}|[xc0-xdf][x80-xbf])+$")) {return HttpUtility.UrlDecode(uriString, Encoding.GetEncoding("UTF-8"));} else {return HttpUtility.UrlDecode(uriString, Encoding.GetEncoding("GB2312"));}}public static void Main(string[] args) {Console.WriteLine("----------------------------------------------");Console.WriteLine(DecodeURL(".net%bc%bc%ca%f5"));Console.WriteLine(DecodeURL(".net%e6%8a%80%e6%9c%af"));Console.WriteLine("----------------------------------------------");Console.WriteLine(DecodeURL("%B8%A7%CB%B3%C7%E0%CB%C9%D2%A9%D2%B5"));Console.WriteLine(DecodeURL("%E6%8A%9A%E9%A1%BA%E9%9D%92%E6%9D%BE%E8%8D%AF%E4%B8%9A")); Console.WriteLine("------------------↓↓↓下⾯的出问题↓↓↓------------------");Console.WriteLine(DecodeURL("%E8%81%94%E9%80%9A")); // 正常Console.WriteLine(DecodeURL("%C1%AA%CD%A8")); // 发⽣编码误认// 编码误认,并没有好的解决⽅案,因为utf-8和gbk编码结果存在交叉,我们都知道,记事本也都会出现这种情况Console.WriteLine("------------------↑↑↑上⾯的出问题↑↑↑------------------");Console.WriteLine(DecodeURL2("%E8%81%94%E9%80%9A")); // 正常Console.WriteLine(DecodeURL2("%C1%AA%CD%A8")); // 不会误认Console.WriteLine("----------------------------------------------");Console.ReadKey();}}}。
gbk与utf-8的详细区别

gbk与utf-8的详细区别GB 2312或GB 2312-80是一个简体中文字符集的中国国家标准,全称为《信息交换用汉字编码字符集·基本集》,又称为GB0,由中国国家标准总局发布,1981年5月1日实施。
接下来是小编为大家收集的gbk与utf-8的详细区别,希望能帮到大家。
gbk与utf-8的详细区别GB 2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB 2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。
对于人名、古汉语等方面出现的罕用字,GB 2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。
UTF-8是UNICODE的一种变长字符编码又称万国码,由Ken Thompson于1992年创建。
现在已经标准化为RFC 3629。
UTF-8用1到6个字节编码UNICODE字符。
用在网页上可以同一页面显示中文简体繁体及其它语言(如日文,韩文)KesionCMS的GBK版本与UTF-8版本功能是一样的.只不过编码方式不同。
GBK的文字编码是双字节来表示的,即不论中、英文字符均使用双字节来表示,只不过为区分中文,将其最高位都定成1。
至于UTF-8编码则是用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节),中文使用24位(三个字节)来编码。
对于英文字符较多的网站则用UTF-8节省空间。
GBK包含全部中文字符;UTF-8则包含全世界所有国家需要用到的字符。
GBK是在国家标准GB2312基础上扩容后兼容GB2312的标准,UTF-8编码的文字可以在各国各种支持UTF8字符集的浏览器上显示。
比如,如果是UTF8编码,则在外国人的英文IE上也能显示中文,而无需他们下载IE的中文语言支持包。
python检查编码方式

python检查编码方式文章题目:Python检查编码方式:解决字符编码问题的利器引言:在日常的编程工作中,我们经常会遇到字符编码问题,特别是在处理文本数据时。
Python作为一门功能强大的编程语言,为我们提供了多种方法来检查和解决字符编码问题。
本文将以Python为例,详细介绍如何检查编码方式,并提供一些常用的解决方案。
第一部分:字符编码及其背景知识1. 什么是字符编码?字符编码是将字符映射为二进制表示的规则。
它在计算机中发挥着至关重要的作用,因为计算机只能处理二进制数据。
2. 常用的字符编码方式- ASCII:最早的字符编码标准,仅支持英文字符,不支持其他字符集。
- UTF-8:最常用的字符编码标准,适用于多种语言,可表示世界上几乎所有的字符。
- GBK:适用于中文字符编码标准。
第二部分:Python提供的字符编码检查工具1. sys模块sys模块是Python的内置模块之一,其中的sys.getdefaultencoding()方法可以获取Python当前的默认字符编码。
通过该方法,我们可以检查当前运行环境使用的字符编码方式。
2. chardet库chardet库是Python的第三方库,通过分析文本数据的内容和分布,可以判断出数据的实际字符编码。
可以通过pip安装该库,然后在代码中导入使用。
第三部分:使用Python解决字符编码问题的常用方法1. 检测文本文件的编码方式通过使用chardet库检测文本文件的内容,我们可以获取到该文件的实际字符编码方式。
然后,我们可以根据检测结果选择正确的字符编码方式读取文件内容,避免出现乱码问题。
2. 转换字符编码方式在对文件进行处理时,可能需要将其从一种编码方式转换为另一种编码方式。
使用Python自带的codecs库,我们可以很方便地进行字符编码的转换。
例如:将GBK编码的文本转换为UTF-8编码,可以使用以下代码:import codecswith codecs.open("file.txt", "r", "gbk") as f:content = f.read()with codecs.open("file_utf8.txt", "w", "utf-8") as f:f.write(content)3. 处理字符编码异常在处理文本数据时,可能会遇到字符编码异常的情况。