一个实用化的俄汉机器翻译系统.
《西里尔蒙古文—汉文机器翻译系统的实现》范文

《西里尔蒙古文—汉文机器翻译系统的实现》篇一一、引言随着全球化的推进和信息技术的飞速发展,跨语言交流变得越来越重要。
为了满足西里尔蒙古文与汉文之间的翻译需求,开发一款高效的机器翻译系统变得尤为重要。
本文将详细介绍西里尔蒙古文—汉文机器翻译系统的实现过程,包括系统设计、关键技术、实现方法以及实验结果分析等方面。
二、系统设计1. 需求分析在系统设计阶段,首先需要进行需求分析。
该翻译系统需满足以下需求:实现西里尔蒙古文与汉文之间的双向翻译,支持文本和语音输入输出,具备高翻译准确率和快速响应能力。
2. 系统架构根据需求分析,设计出系统的整体架构。
该系统采用客户端-服务器架构,其中客户端负责用户界面和用户交互,服务器端负责翻译任务的执行。
系统架构包括数据预处理模块、翻译引擎模块、后处理模块等。
三、关键技术1. 数据预处理数据预处理是机器翻译的重要环节。
针对西里尔蒙古文和汉文的特性,需要进行词法分析、句法分析和语义理解等预处理工作。
此外,还需要进行语料库的构建和优化,以提高翻译的准确性和流畅性。
2. 翻译引擎翻译引擎是机器翻译系统的核心部分。
采用基于深度学习的翻译模型,如神经网络翻译模型(NMT)等,实现西里尔蒙古文与汉文之间的翻译。
在训练过程中,需要使用大量的平行语料库,以提高模型的翻译性能。
3. 后处理后处理是对翻译结果进行优化和处理的过程。
包括对翻译结果进行语法检查、语义校对、语言风格调整等操作,以提高翻译质量。
四、实现方法1. 技术路线系统实现的技术路线包括数据收集与预处理、模型训练与优化、系统开发与测试等步骤。
在每个步骤中,都需要进行详细的规划和实施。
2. 具体实现在具体实现过程中,需要使用相关的技术和工具,如自然语言处理技术、深度学习框架、语音合成与识别技术等。
同时,还需要进行大量的实验和调试,以优化系统的性能和翻译质量。
五、实验结果分析1. 实验设计为了评估系统的性能和翻译质量,需要进行实验设计。
2017北京外国语大学考研—俄语学院导师介绍

王立业 职称:教授 专业方向:俄罗斯文学 主要从事的学术研究领域: 十九、二十世纪的俄罗斯文学 屠格涅夫的研究,屠格涅夫与布宁、陀思妥耶夫斯基等作家的比较研究,屠格涅 夫“白银时代”文学批评与接受,侨民诗人霍达谢维奇的研究以及俄罗斯诗歌研 究。中俄文学比较研究。 学术成果: 在国内外发表论文约 30 篇,专著一部。 指导研究生的学术方向:十九、二十世纪的作家、诗人及其作品研究,比较研究 与国别文学比较研究
4
改革比较》论文集,当代世界出版社,2003 年 10 月出版 3.《当代俄罗斯民族意识剖析》,《俄罗斯思想与俄罗斯道路》论文集, 外文出 版社,2004 年 7 月出版 4.《罗斯庄园文化与普希金抒情诗》,台湾政治大学俄国语文学系 2003 年国际学 术研讨会论文集《俄国文学经典与人生》,2004 年 11 月出版 5.《哈尔滨和上海俄侨诗歌中的中国形象》,《俄罗斯侨民文学史》,人民文学出 版社,2004 年 12 月版 6.《转型时期的俄罗斯民族意识》,《转型理论与俄罗斯政治改革》第十一章 上 海人民出版社 2005 年 4 月版 7.《俄罗斯多媒体教程》:《俄罗斯地理》,外语教学与研究出版社 2005 年 6 月 8.《苏联解体后的俄语新变化》,《俄罗斯研究》2005 年第 3 期 9.《俄罗斯国情多媒体教程》,《俄罗斯历史》,外语教学与研究出版社 2006 年 3 月 指导研究生的学术方向:俄罗斯社会与文化
机器翻译系统的使用教程

机器翻译系统的使用教程机器翻译系统是一种能够将一种语言自动转换为另外一种语言的工具。
它使用了先进的机器学习和自然语言处理技术,能够有效地提高翻译的速度和准确性。
本文将介绍如何使用机器翻译系统进行翻译,并提供一些技巧和注意事项,帮助您更好地利用该系统。
第一步,选择合适的机器翻译系统。
目前市场上有许多不同的机器翻译系统可供选择,例如谷歌翻译、百度翻译、有道翻译等。
在选择机器翻译系统时,您可以考虑以下几个因素:1. 常用语言:确保机器翻译系统支持您需要翻译的语言对。
例如,如果您需要进行英文和中文之间的翻译,那么选择一个同时支持这两种语言的系统会更加方便和高效。
2. 准确性和流畅度:不同的机器翻译系统在准确性和流畅度上有所差异。
您可以尝试使用不同系统进行比较,选择那个最符合您需求的系统。
3. 用户评价和反馈:了解其他用户对机器翻译系统的评价和反馈,可以帮助您更好地了解系统的优缺点。
在选择之前,可以搜索一些用户评论或者咨询一些已经使用的人的意见。
第二步,学习机器翻译系统的基本操作。
每个机器翻译系统都有自己的用户界面和操作方式。
在开始使用之前,您可以阅读系统提供的帮助文档,学习系统的基本操作。
一般来说,以下是一些常见的操作步骤:1. 选择语言对:打开机器翻译系统后,您需要选择源语言和目标语言。
源语言是您要翻译的原文的语言,目标语言则是您希望将原文翻译成的语言。
2. 输入原文:将需要翻译的文本输入到源语言文本框中。
有些系统还支持直接输入文件或者链接,方便您进行批量翻译或者翻译长文本。
3. 进行翻译:点击“翻译”按钮或者相应的操作键,系统将会开始进行翻译。
在短时间内,您就能够得到一份初步的翻译结果。
4. 优化翻译:机器翻译系统的翻译结果可能不够准确或者流畅,您可以通过修改文本、更换词汇、调整语法等方式来优化翻译结果。
一些系统还提供了编辑和修改的功能,您可以直接在文本框中进行修改。
第三步,优化机器翻译系统的翻译结果。
俄汉翻译系统解决方案

俄汉翻译系统解决方案
俄汉中文翻译系统的解决方案可以分为以下几个步骤:
1.数据收集和预处理:收集大量的俄汉双语数据,包括书籍、新闻、
文章、对话等,同时进行数据清洗和预处理,包括去除特殊字符、标点符号,分词等。
2. 特征工程:对预处理后的数据进行特征工程,提取有效的特征,
如n-gram特征、词性标注特征、命名实体识别特征等。
3.模型选择和训练:选择合适的机器翻译模型,如统计机器翻译模型、神经网络机器翻译模型等,并使用收集到的数据进行模型训练。
4.参数调优:对模型进行参数调优,如调整学习率、批大小、正则化等,以提高翻译质量。
5.评估和优化:使用评估指标对翻译系统进行评估,如BLEU分数等,根据评估结果进行系统优化和改进。
6.后处理:对翻译结果进行后处理,包括去除语法错误、调整词序等,以提高翻译的流畅度和准确性。
7.部署和应用:将训练好的翻译模型部署到线上系统中,通过API接
口或其他方式提供翻译服务,以满足用户的翻译需求。
需要注意的是,俄汉中文翻译是一个复杂的任务,翻译质量的提高需
要不断地进行数据更新和模型优化。
此外,考虑到俄语和汉语在语言结构
和语法上的差异,可能还需要进行针对性的特定领域的训练和优化。
俄汉翻译系统解决方案

俄汉翻译系统解决方案行业: 跨行业功能:俄汉翻译,软件供应商: 中国软件股份集团方案正文:中软从1984年开展机器翻译的研究工作以来,长期从事机器翻译、多语平台等中文信息处理的研究与产品开发工作,其翻译技术不断更新,在机器翻译技术、跨语言平台的输入方法等方面具有国际先进水平,是国内机器翻译语种最多的公司。
国际软件开发部凭借在语言信息处理、智能翻译软件开发方面的技术储备与开发经验,针对客户方的实际需要,成功开发、建立一套俄汉翻译系统,能够优质、高效的完成对俄文信息资料的翻译处理,博得了业界人士的关注与好评。
一、俄汉翻译系统1、主要特点:(1)、通过人机交互的方式取代手工翻译部分过程,使翻译流程自动化,大幅度提高翻译效率和翻译质量。
(2)、能够为情报信息、装备资料的俄汉翻译提供技术支撑。
(3)、提供俄汉电子词典,完全代替人工查询书本词典。
(4)、系统的开发完全符合软件开发体系要求。
(5)、用户词典库的使用和建库应该符合客户方的要求和XX体系的要求。
2、体系结构针对客户方的翻译应用需求,系统将开发并集成以下主要功能模块:俄汉翻译引擎、全文翻译、嵌入翻译(Word 嵌入翻译)、批量翻译、电子词典、用户词典、用户词典网络共享。
翻译文件的类型支持*.rtf和*.txt,以及其它能在Microsoft Word中打开的文件类型。
系统的体系结构(图1)。
图1:系统体系结构(1)、翻译引擎翻译引擎是一套翻译体系的核心。
它就象一个人的心脏在支撑人的生命一样,支撑着翻译体系完成高质高效的翻译工作。
在该系统中,我们将配备最高版本的翻译引擎作为整个翻译体系的核心。
该翻译引擎融合了计算语言学在语义理论方面的突破,采用了格语法、语义网络理论、框架和优先语义学等等一系列描述语言深层机制的语言理论,吸纳了人工智能技术的知识库、世界模型和常规推理规则等知识信息处理原则,基于语法分析和逻辑语义分析,将逻辑语义与语法有机结合,从而从根本上避免了顾此失彼所带来的缺陷。
《2024年西里尔蒙古文—汉文机器翻译系统的实现》范文

《西里尔蒙古文—汉文机器翻译系统的实现》篇一一、引言随着全球化的推进和信息技术的飞速发展,跨语言交流变得越来越重要。
为了满足西里尔蒙古文与汉文之间的翻译需求,开发一款高效的机器翻译系统显得尤为重要。
本文将详细介绍西里尔蒙古文—汉文机器翻译系统的实现过程,包括系统设计、关键技术、实现方法和应用场景等方面。
二、系统设计1. 系统架构西里尔蒙古文—汉文机器翻译系统采用分层架构设计,包括数据层、算法层和应用层。
数据层负责存储和管理翻译所需的数据资源,如词典、语料库等;算法层是实现翻译功能的核心部分,包括自然语言处理、机器学习等算法;应用层则是用户与系统交互的界面,提供用户友好的操作体验。
2. 需求分析在系统设计阶段,我们需要对用户需求进行深入分析。
西里尔蒙古文—汉文机器翻译系统的用户主要包括需要进行跨语言交流的蒙古族和汉族人群。
因此,系统需要具备高准确率、高效率的翻译能力,同时要考虑到不同用户的语言习惯和表达方式。
三、关键技术1. 自然语言处理技术自然语言处理技术是机器翻译系统的核心技术之一。
在西里尔蒙古文—汉文机器翻译系统中,自然语言处理技术主要用于对输入的文本进行分词、词性标注、句法分析等预处理工作,以便后续的翻译工作能够更加准确地进行。
2. 机器学习技术机器学习技术是提高机器翻译系统性能的关键。
在西里尔蒙古文—汉文机器翻译系统中,我们采用了深度学习等机器学习技术,通过训练大量的语料数据,使系统能够自动学习和优化翻译模型,提高翻译的准确率和流畅度。
四、实现方法1. 数据准备在实现西里尔蒙古文—汉文机器翻译系统的过程中,我们需要准备大量的翻译语料数据。
这些数据包括平行的蒙古文和汉文文本数据、词典等。
我们通过爬取互联网上的多源数据,并结合人工校对和标注,形成了高质量的翻译语料库。
2. 算法实现在算法实现阶段,我们采用了基于深度学习的神经网络模型进行翻译。
具体而言,我们使用了循环神经网络(RNN)和长短时记忆网络(LSTM)等模型,对输入的文本进行编码和解码,生成对应的翻译结果。
《西里尔蒙古文—汉文机器翻译系统的实现》范文

《西里尔蒙古文—汉文机器翻译系统的实现》篇一一、引言随着全球化的不断推进,跨语言交流变得越来越重要。
为了满足不同语言群体之间的交流需求,机器翻译系统的开发显得尤为重要。
本文将详细介绍西里尔蒙古文—汉文机器翻译系统的实现过程,包括系统设计、技术实现和测试评估等方面。
二、系统设计1. 需求分析在系统设计阶段,首先需要进行需求分析。
西里尔蒙古文—汉文机器翻译系统的目标是为用户提供高效、准确的翻译服务。
因此,系统需要具备以下功能:支持西里尔蒙古文和汉文之间的互译、支持多种文本格式的输入和输出、支持实时翻译等。
2. 技术架构系统采用基于深度学习的神经网络技术,包括编码器-解码器模型和注意力机制等。
技术架构主要包括数据预处理、模型训练、翻译执行和用户界面等模块。
其中,数据预处理模块负责对输入文本进行清洗、分词和词性标注等操作;模型训练模块采用大规模语料库进行训练,以提高翻译的准确性和流畅性;翻译执行模块负责将输入文本通过模型进行翻译;用户界面模块则提供用户与系统之间的交互界面。
三、技术实现1. 数据预处理数据预处理是机器翻译系统中非常重要的一环。
首先,需要对西里尔蒙古文和汉文文本进行清洗,去除无关信息和噪声。
然后,进行分词和词性标注等操作,以便后续的模型训练和翻译执行。
在分词过程中,可以采用基于规则或统计的方法进行分词,同时结合词性标注信息进一步提高分词的准确性。
2. 模型训练模型训练是机器翻译系统的核心部分。
在训练过程中,需要使用大规模的平行语料库,包括西里尔蒙古文和汉文的双语语料库以及单语语料库等。
在模型选择方面,可以采用基于编码器-解码器模型的神经网络结构,并结合注意力机制等技巧提高翻译的准确性和流畅性。
在训练过程中,需要使用优化算法对模型参数进行优化,以提高模型的性能。
3. 翻译执行翻译执行是将输入文本通过已训练好的模型进行翻译的过程。
在翻译过程中,需要将输入文本进行编码,然后通过解码器生成对应的译文。
21世纪中俄机器翻译现状对比研究

21世纪中俄机器翻译现状对比研究孙爽;陈晓曦【摘要】Basing on reviewed of generations history and development process of machine translation, the state of machine translation developing in China and Russia by twenty - first century has been deeply analyzed in this article, including the introduction of typical machine translation system, its main characters and designing principle. This paper raises a proposal for discussing on how to enhance the research level of Russian - Chinese/Chinese- Russian machine translation system.%在回顾机器翻译产生历史及发展历程的基础上,对 21 世纪中国和俄罗斯机器翻译发展现状进行了深入分析,主要包括代表性机器翻译系统、特点及设计原理,目的在于探讨如何加强我国对俄汉/汉俄机器翻译系统的研究。
【期刊名称】《哈尔滨师范大学社会科学学报》【年(卷),期】2012(000)002【总页数】4页(P74-77)【关键词】机器翻译;俄汉/汉俄;翻译系统【作者】孙爽;陈晓曦【作者单位】东北林业大学,黑龙江哈尔滨150080;东北林业大学,黑龙江哈尔滨150080【正文语种】中文【中图分类】H085机器翻译 (machine translation)是使用电子计算机把一种语言 (源语言)翻译成另外一种语言 (目标语言)的一门新学科。
介绍几个在线翻译网站

介绍几个准确好用的免费在线翻译网站本人女研究僧一枚,白天愁论文,晚上愁嫁人。
越来越同意大家说的,没发表论文就跟在后宫没孩子似的~写论文也像十月怀胎一样,不容易哇~ 每天就得看文献啊看文献。
要是不想拼拼粘粘,还得去看国外文献,实在是太花时间,所以必须得先在线翻译一下,不过在线翻译这么多,能选出个靠谱的也不容易哇,要是选不好,浪费时间还错误百出的;(估计大家也有这方面困扰吧?根据我这段时间写论文做翻译的心得,老女纸在这也为大家分析比较一下各大翻译网站,方便各位童鞋日后选择合适的。
大家都知道,国内常用的在线机器翻译有谷歌、有道、百度、爱词霸啊神马的。
还有一些新的在线翻译品牌也开始冒泡了,大有后来居上的架势,最近我还发现SDL 公司新推出的FreeTranslation也很不错哇,居然可以直接上传*word, *ppt, *pdf, *txt, *odt文件进行翻译, 输出的文件和原文件格式居然高度一致,灰常方便。
下面偶来给大家一一分析。
Google 翻译想必这个大家都很熟悉吧~以前看文献以英译汉为主,用的最多的就是Google 翻译了。
Google 的翻译网站由强大的谷歌搜索引擎所储存的众多语料、网页资源做后盾,翻译量大、语种多(貌似有71种)、速度快,是个平易近人的好助手。
不过,这种机器翻译往往不能直接满足人们的需求,需要经过后期人工编辑,Google能在译文基础上给出不同的措辞供用户选择,增加用户的介入程度。
而且,在翻译的时候我们也会不仅仅遇到英语,在出现其它语言时Google也可以自动识别呢。
另外,Google对term的翻译准确性很高,尤其是在航空航天、医疗、计算机等科技领域优势显著。
但是,它的文学翻译却表现平平,甚至令人捧腹。
Google的网页翻译也很有名,我们浏览英文网站时只需一个按钮就可以快速变成中文。
当然,这一切都得在能登陆Google 的前提下进行,你们懂得,Google 在中国总出问题,有时登陆Google比登陆12306都难,真可谓:不要相信“歌”,“歌”只是个传说。
《西里尔蒙古文—汉文机器翻译系统的实现》范文

《西里尔蒙古文—汉文机器翻译系统的实现》篇一一、引言随着科技的发展,人工智能领域中机器翻译技术得到了广泛的应用。
西里尔蒙古文与汉文之间的交流日益频繁,因此,开发一款高效、准确的西里尔蒙古文—汉文机器翻译系统变得尤为重要。
本文旨在探讨该系统的实现方法,分析其关键技术,以期为相关研究和应用提供参考。
二、系统需求分析1. 功能需求:该系统应具备西里尔蒙古文到汉文的翻译功能,支持文本和语音输入输出,并保证翻译的准确性和实时性。
2. 性能需求:系统应具备良好的性能,包括高吞吐量、低延迟和良好的用户体验。
3. 安全与可靠性需求:系统应保证数据的安全性,防止数据泄露和未经授权的访问,同时应具备故障恢复和容错能力。
三、关键技术分析1. 自然语言处理技术:自然语言处理是机器翻译的核心技术,包括分词、词性标注、句法分析、语义理解等。
在西里尔蒙古文到汉文的翻译过程中,需要利用这些技术对源语言进行解析,生成中间表示形式,再将其转换为目标语言。
2. 深度学习技术:深度学习在机器翻译领域取得了显著的成果。
通过训练大量的双语语料库,可以学习到语言之间的映射关系,提高翻译的准确性和流畅度。
在本系统中,我们采用基于深度学习的神经网络模型进行翻译。
3. 文本编码与解码技术:为了实现文本的输入输出,需要采用合适的文本编码与解码技术。
在西里尔蒙古文到汉文的翻译过程中,应确保编码与解码的兼容性和准确性。
四、系统设计1. 系统架构:本系统采用分层架构设计,包括数据层、业务逻辑层和用户界面层。
数据层负责存储和管理语料库、模型等数据;业务逻辑层负责实现翻译算法和业务逻辑;用户界面层提供用户与系统的交互界面。
2. 算法流程:系统首先对输入的西里尔蒙古文进行解析,提取关键信息,然后通过神经网络模型进行翻译,最后将生成的汉文文本或语音输出给用户。
3. 技术选型:采用Python作为开发语言,利用TensorFlow 等深度学习框架实现神经网络模型。
《西里尔蒙古文—汉文机器翻译系统的实现》范文

《西里尔蒙古文—汉文机器翻译系统的实现》篇一一、引言随着科技的不断发展,人工智能技术在各个领域都得到了广泛的应用。
其中,机器翻译技术在跨国交流、文献翻译等方面扮演着重要的角色。
西里尔蒙古文作为蒙古国的官方文字,与汉语之间的交流日益频繁,因此,开发一款西里尔蒙古文—汉文机器翻译系统具有重要的现实意义。
本文将详细介绍该系统的实现过程。
二、系统需求分析在系统开发之前,我们需要对需求进行详细的分析。
西里尔蒙古文—汉文机器翻译系统的主要目标是实现两种语言之间的准确、高效的翻译。
因此,我们需要考虑以下几个方面:1. 翻译准确性:系统应具备较高的翻译准确性,保证译文与原文意思一致。
2. 翻译速度:系统应具备较快的翻译速度,以满足实时翻译的需求。
3. 用户友好性:系统界面应简洁明了,方便用户操作。
4. 支持多种场景:系统应支持文本、语音、图像等多种输入方式,以满足不同场景的需求。
三、系统技术实现1. 技术架构该系统采用分层架构,包括数据层、业务逻辑层和表示层。
数据层负责存储和管理蒙古文和汉语的语料库;业务逻辑层负责实现翻译算法和业务逻辑;表示层负责与用户进行交互。
2. 算法实现(1)语言处理:系统采用自然语言处理技术,对蒙古文和汉语进行分词、词性标注等预处理工作。
(2)翻译模型:系统采用基于深度学习的神经网络模型,通过大量语料库的训练,实现蒙古文到汉语的翻译。
(3)优化算法:系统采用优化算法,对翻译结果进行优化,提高翻译准确性和流畅性。
3. 编程语言及工具系统采用Python语言进行开发,使用TensorFlow等深度学习框架实现神经网络模型。
同时,借助PyQt等工具实现用户界面开发。
四、系统测试与优化在系统开发完成后,我们需要进行测试与优化工作,以确保系统的稳定性和性能。
1. 功能测试:对系统的各项功能进行测试,确保系统能够正常工作。
2. 性能测试:对系统的翻译速度、准确性等性能进行测试,根据测试结果进行优化。
关于俄罗斯计算语言学和机器翻译

在计算语言学方面,早在1913年,俄罗斯著名数学家马尔可夫(А. А. Марков 1856-1922)就注意到语言符号出现概率之间的相互影响,他试图以语言符号的出现概率为实例,来研究随机过程的数学理论,提出了马尔可夫链的思想。后来马尔可夫的这一思想发展成为在计算语言学中广为使用的马尔可夫模型(Markov model),是当代计算语言学最重要的理论支柱之一。在用数学思想来研究语言的创新性研究中,我们甚至可以追溯到19世纪中叶,早在1847年的时候,俄罗斯数学家布良柯夫斯基(Б. Буляковский)就提出了用概率论方法来进行语法、词源和语言历史比较研究的卓越见解了。1958年,苏联数学家库拉金娜(С. С. Кулагина)采用集合论描述了基本的语法概念,为机器翻译研究奠定了坚实的数学基础。
2008年第4期 俄语语言文学研究 2008, №4 总第22期 Russian Language and Literature Studies Serial №22
76
在机器翻译方面,1933年,苏联发明家特洛扬斯基(П. П. Троянский)设计了用机械方法把一种语言翻译为另一种语言的机器,并在同年9月5日登记了他的发明。特洛扬斯基认为翻译可以分为三个阶段,第一个阶段由只懂源语言的编辑,将输入的原文分析成特定的逻辑形式,将带有屈折词尾的变形词还原成原形词,并分析出各个单词的句法功能,为此,他创造了一套逻辑分析符号。第二阶段是利用他的翻译机,把源语言的原形词和逻辑符号转换成目标语言的原形词和符号。第三阶段由只懂目标语言的编辑,把目标语言的原形词和符号转换成目标语言。1939年,特洛扬斯基在他的翻译机上增加了一个用“光元素”操作的存储装置;1941年5 月,这部实验性的翻译机已经可以运作;1948年,他计划在此基础上研制一部“电子机械机”(electro-mechanical machine)。但是,由于当时苏联的科学家和语言学家对此反映十分冷淡,特洛扬斯基的翻译机没有得到支持,最后以失败告终了。
《2024年元学习框架下情景级蒙汉机器翻译系统的实现》范文

《元学习框架下情景级蒙汉机器翻译系统的实现》篇一一、引言随着全球化的深入发展,不同语言间的信息交流显得愈发重要。
尤其是在大数据、人工智能技术的加持下,机器翻译成为了促进国际交流的关键手段。
而元学习作为一种新型的学习策略,能够提高机器翻译的效率和准确度。
本文旨在介绍元学习框架下情景级蒙汉机器翻译系统的实现过程。
二、相关背景1. 元学习:元学习是一种新兴的机器学习方法,其核心思想是利用元知识来指导模型的学习过程,从而提高模型的泛化能力和适应性。
2. 蒙汉机器翻译:蒙汉机器翻译是指将蒙古语和汉语之间的文本进行自动翻译的技术。
随着中蒙两国的交流日益频繁,蒙汉机器翻译的需求也在不断增加。
三、系统架构本系统主要分为四个模块:数据预处理模块、模型训练模块、翻译模块和后处理模块。
数据预处理模块负责对原始数据进行清洗和标注;模型训练模块利用元学习框架对蒙汉翻译模型进行训练;翻译模块负责根据输入的文本进行翻译;后处理模块负责对翻译结果进行优化和后处理。
四、元学习框架下的模型训练1. 元知识提取:从大量蒙汉平行语料中提取出元知识,包括句法结构、词汇关系等。
2. 模型初始化:利用元知识对初始模型进行初始化,提高模型的泛化能力。
3. 训练过程:在元学习框架下,将训练数据分为多个任务,每个任务都包含一个蒙文句子和一个汉文句子的对应关系。
在每个任务中,模型都会根据元知识进行自我调整,以适应不同的翻译任务。
五、情景级翻译策略本系统采用情景级翻译策略,即在翻译过程中充分考虑上下文信息。
具体实现包括:1. 上下文理解:通过分析待翻译句子的上下文信息,理解句子的语义和语境。
2. 词汇选择:根据上下文信息,选择最合适的词汇进行翻译。
3. 句法结构调整:根据上下文信息和目标语言的句法结构,对原句进行适当的调整,以使翻译结果更符合目标语言的表达习惯。
六、实验与结果分析本系统在大量蒙汉平行语料上进行实验,并与其他传统机器翻译系统进行对比。
实验结果表明,本系统在翻译准确度和流畅度方面均取得了显著提升。
一个实用化的俄汉机器翻译系统
《夏感》课堂实录课堂实录是对教学过程的一个书面记录。
今天,语文网小编跟大家分享《夏感》课堂实录。
课堂实录是一种鲜活的教学资源,通过情景再现,教师们可以对教学案例进行分析研讨,可亲、可近、可学、可用,非常有益处,《夏感》课堂实录,一起来看看吧!《夏感》课堂实录一、教学目标:1、品析优美的语句,掌握生动的词汇。
2、体会文章生动、准确的语言特点,感受文章的语言魅力。
3、体会作者在文中所表达的对夏天的热爱和对劳动的赞美之情。
二、教学重点:感受夏天的特点,体会作者的思想感情三、教学难点:体会文章生动准确的语言特点,感受语言的魅力。
四、教学设想:倡导自主、合作、探究的课堂学习方式,实现读写结合。
1、反复诵读,感知景物的特点和作者的思想感情。
2、创设氛围,充分发挥学生的主动性,放手让学生去谈。
3、体验总结,渗透学法指导,学以致用,进行读写结合的有益尝试。
五、教学时数:1课时教学过程:一、创设情境,导入新课师:同学们,《水浒传》智取生辰纲里有这样一首童谣(投影),师读,你们知道这是描述的哪个季节吗?特点是什么?生:夏季,炎热。
师:你们觉得夏天还有哪些特点?你们喜欢夏天吗? 生:……师:是啊,夏天有它的烦恼,但也有它的快乐,喜欢它,有100个理由,不喜欢它,也会有101个理由。
有一个当代作家梁衡,他不仅喜欢夏天,而且还要大声赞美夏天。
今天我们就一起来欣赏他的散文《夏》。
(板书夏梁衡)二、整体感知,感受夏画同学们,春夏秋冬,四季分明。
春天,春暖花开,鸟语花香;秋天,秋高气爽,丹桂飘香;冬天,白雪皑皑,银装素裹。
那夏呢?下面就让我们一起走进文本,捕捉夏天特有的画面,感受夏。
思考:1、作者笔下的夏天充满着怎样的旋律?2、你能概括出作者从哪些方面表现夏天的旋律的吗?师:同学们朗读课文之后,觉得哪些词语需要注意一下生自由说,1-2名学生师:老师这里也总结了一些,请同学们关注,掌握,齐读。
师:同学们,你们说说作者笔下的夏天的主要旋律是什么?生:紧张,热烈,急促。
“俄汉机器翻译+译后编辑”新型模式

“俄汉机器翻译+译后编辑”新型模式
李思迪;贺涵薇;曾艺梅
【期刊名称】《中国新通信》
【年(卷),期】2022(24)6
【摘要】本文通过介绍机器翻译和译后编辑的基本概念,对机器翻译的主要问题加以分析与探讨,在此基础上,根据机器翻译误译类型,以译后编辑的原则设计为指导思想,总结了译后编辑所应采取的处理对策,并着重阐述了“俄汉机器翻译+译后编辑”新模型的结构与意义。
【总页数】4页(P79-81)
【作者】李思迪;贺涵薇;曾艺梅
【作者单位】中南林业科技大学外国语学院
【正文语种】中文
【中图分类】TP3
【相关文献】
1.维汉/汉维机器翻译译后编辑器的设计与实现
2.译前编辑与译后编辑分别使用机
器翻译的对比——以英国诺里奇市城堡博物馆的荷兰画作简介的翻译为例3.机器
翻译的译前与译后编辑在科技文本翻译中的探究4.机器翻译的译前与译后编辑在
科技文本翻译中的探究5."机器翻译+译后编辑"模式下的经济史文本翻译研究——以《20世纪经济理论知识史(1890—1918):
资本主义黄金时代的经济学》自译章节为例
因版权原因,仅展示原文概要,查看原文内容请购买。
俄汉机器翻译:历史、任务与展望

俄汉机器翻译:历史、任务与展望
王利众;于水
【期刊名称】《中国俄语教学》
【年(卷),期】2006(25)4
【摘要】机器翻译是利用计算机实现从一种自然语言文本到另一种自然语言文本的翻译,它是用计算机模拟人工翻译的智能过程,是受程序指令控制的一种自动化的翻译系统.本文回顾了我国俄汉机器翻译发展的历史,论述了现阶段俄汉机器翻译面临的问题及解决途径,同时对俄汉机器翻译的前景做出展望.
【总页数】4页(P49-52)
【作者】王利众;于水
【作者单位】哈尔滨工业大学;哈尔滨工业大学
【正文语种】中文
【中图分类】H3
【相关文献】
1.俄汉机器翻译中第五格地点意义的语义识别 [J], 孙爽
2.俄汉-汉俄平行语料库的构建设想与应用展望 [J], 崔卫;李峰
3.面向俄汉机器翻译的C+N5结构语义识别研究 [J], 孙爽
4.智能型俄汉机器翻译系统的句法规则库的设计原则 [J], 李向东;黄河燕
5.跨语言多任务学习深层神经网络在蒙汉机器翻译的应用 [J], 张振;苏依拉;仁庆道尔吉;高芬;王宇飞
因版权原因,仅展示原文概要,查看原文内容请购买。
苏滂转 译文

苏滂转一、苏滂转是什么?苏滂转,也称苏滂机器翻译系统,是一种基于机器学习和人工智能技术的翻译工具。
它的目标是实现高质量、快速、准确的自动翻译,将一种语言的文本转化成另一种语言。
二、苏滂转的技术原理苏滂转使用了深度学习技术,主要基于神经网络翻译模型。
它的核心是神经机器翻译(Neural Machine Translation,NMT)模型,该模型将源语言中的句子作为输入,通过神经网络进行编码和解码,然后生成目标语言的翻译结果。
苏滂转的技术原理主要包括以下几个步骤:1. 数据预处理在使用苏滂转进行翻译之前,首先需要对原始数据进行预处理。
这包括词法分析、标记化、分词等操作,以便将文本转化为机器可理解的形式。
2. 神经网络训练苏滂转通过大量的语料库进行训练,使用由源语言和目标语言构成的平行语料,通过神经网络进行训练。
训练的目标是使得机器能够准确地学习到源语言和目标语言之间的对应关系,在翻译时可以生成准确的结果。
3. 编码和解码在进行翻译时,苏滂转将源语言的句子输入神经网络进行编码,生成一个表示源语言句子语义的向量。
然后,解码器使用这个向量来生成目标语言的翻译结果。
4. 翻译结果生成经过神经网络的编码和解码过程,苏滂转能够生成目标语言的翻译结果。
生成的结果会根据训练数据中的概率分布进行调整,以提高翻译的准确性和流畅度。
三、苏滂转的优缺点苏滂转作为一种机器翻译系统,具有一定的优点和缺点。
1. 优点•自动化程度高:苏滂转可以实现自动化的翻译过程,减少人工操作,提高工作效率。
•翻译速度快:相比传统的人工翻译,苏滂转可以在较短的时间内生成翻译结果,适用于大量翻译的场景。
•可扩展性强:苏滂转可以通过不断的训练和优化来提高翻译准确度和性能,具有很好的扩展性。
2. 缺点•对比人工翻译,苏滂转的翻译质量仍有一定差距。
特别是在处理特定领域或者复杂句子时,翻译结果常常需要人工进行修正和优化。
•苏滂转对于上下文的理解能力有限,容易出现歧义翻译的问题。
ECMT—78英汉机器翻译系统简介

ECMT—78英汉机器翻译系统简介刘涌泉;吴逊;王广义;傅爱平【期刊名称】《语言研究》【年(卷),期】1982()1【摘要】中国社会科学院语言研究所机器翻译研究室刘涌泉等同志与中国科学院计算技术研究所吴逊同志协作,自1978年下半年开始研制ECMT—78英汉机器翻译系统②。
经过上机实验,于1979年11月输出了汉语译文,取得可喜结果。
英文文句输入后,以平均12—15秒一句的速度输出汉语译文。
该系统不加任何控制,既可翻译句子,又能翻译题录。
本文将介绍ECMT—78系统的语言学原理、程序设计,并以实例、图示说明翻译过程中的各个步骤和方法。
全文分四个部分:一、ECMT—78系统概述;二、ECMT—78系统的语言学原理和程序设计,三、ECMT—78系统进行自动译翻的基本过程;四、后记。
最后还附有实验输出的英语原文及其汉译文实例。
【总页数】13页(P39-51)【关键词】机器翻译系统;英汉机器翻译;程序设计;译文;语法分析;直接成分;句法成分;名词词组;翻译过程;成语词典【作者】刘涌泉;吴逊;王广义;傅爱平【作者单位】【正文语种】中文【中图分类】H0【相关文献】1.机器翻译系统文法中语法和语义研究——《天语》英汉翻译系统的文法概要 [J], 王广义2.英汉机器翻译中译文自动生成系统设计 [J], 邢蕾3.“智能型英汉机器翻译系统IMT/EC-863”项目简介 [J],4.英汉机器翻译系统的建造—用于英语词典翻译出版的专用系统 [J], 郑保山;刘群;张祥5.基于B/S框架的交互式英汉机器翻译系统设计 [J], 张启振;孙先洪因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一个实用化的俄汉机器翻译系统侯敏孙建军陈英奇薛选民侯方黑龙江大学机器翻译研究室“全译通俄汉机器翻译系统”是一个实用型的全自动的电脑翻译系统。
该系统已通过黑龙江省科委组织的专家鉴定。
系统包括电子词典(基本词典六万词条、专业词典(经贸方面的二万词条、词组词典八千余条、语言翻译规则(共一千八百余条、以及为实现翻译加工过程而编写的程序。
整个软件系统的流程,从原文输入到译文输出,要经历查词典、生词处理、规范化处理、同形判别、句法分析、语义分析、结构转换、译文处理等步骤。
从语言分析的角度看,分析是以句子为单位来进行的。
通过对原文进行词法、句法、语义等多层次的分析,得到一个原文句子的多结点的带有语义标记的句法树结构。
然后再根据源语言 (俄语和目标语 (汉语的对比分析,并按照目标语的语法规律,把原文的树结构转换成相应的译文的线性结构, 从而生成译文句子。
显然,整个分析过程,也是自始至终不断运用各类规则的过程。
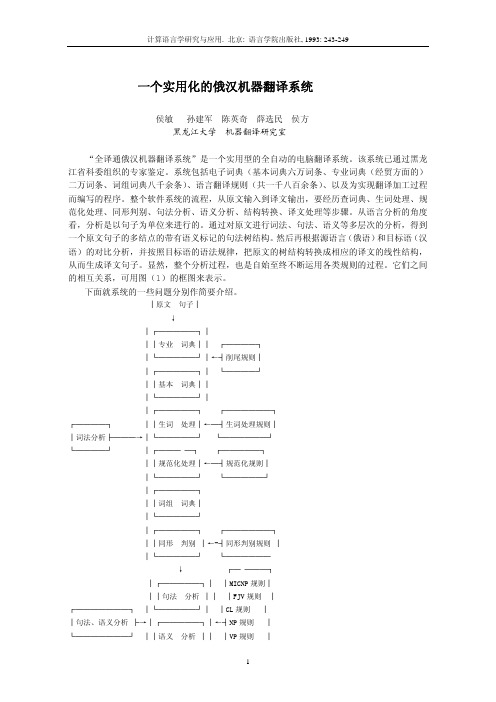
它们之间的相互关系,可用图(1的框图来表示。
下面就系统的一些问题分别作简要介绍。
│原文句子│↓│┌─────┐│││专业词典││ ┌────┐│└─────┘│←┤削尾规则││┌─────┐│ └────┘││基本词典│││└─────┘││┌─────┐ ┌──────┐┌────┐ ││生词处理│←─┤生词处理规则││词法分析├───→│└─────┘ └──────┘└────┘ │┌─── ─┐ ┌─────┐││规范化处理│←─┤规范化规则││└─────┘ └─────┘│┌─────┐││词组词典││└─────┘│┌─────┐ ┌──────┐││同形判别│←-┤同形判别规则││└─────┘ └──────↓ ┌─ ───┐│┌─────┐│ │MICNP 规则│││句法分析││ │FJV 规则│┌───────┐ │└─────┘│ │CL 规则││句法、语义分析├→│┌─────┐│←┤NP 规则│└───────┘ ││语义分析││ │VP 规则││└─────┘│ │PP 规则│ ↓ └── ──┘ │┌──── ┐ ┌────┐ ││结构转换│←─┤转换规则│ ┌────┐ │└──── ┘ └────┘ │译文生成├───→│┌──── ┐ ┌─ ────┐ └────┘ ││译文处理│←─┤汉语修饰规则│ │└─────┘└───── │译文输出│计算语言学研究与应用 . 北京 : 语言学院出版社 , 1993: 243-249一、电子词典我们建立了基本词典、词组词典和专业词典等几种电子词典。
目前,专业词典还只有经贸专业领域一种。
俄语是综合型语言。
根据俄语的特点,为节省存贮空间和提高检索效率,在建立词典时, 对俄文中没有形态变化的词,如副词、连词、前置词等,我们存入该词本身;但对有形态变化的词来说,如动词、名词、形容词,我们只把其原形或词干存放在词典中。
系统查词典时,应先按照“削尾规则”将该单词恢复为其原形或词干,然后再在电子词典中查找。
不规则变化的词则应将各种特殊形态变化的词形都存放在词典中。
为加快查找速度,我们采用建立索引文件帮助查找的方法。
索引文件的建立是采取分类与 B 树技术相结合的方法实现的。
实践证明,建立的索引文件是高效的。
用 C 语言编程,其查找速度在 286机上为每秒 35个词, (词典容量为6万词条左右。
与此相同,由于采用了 B 树技术,整个词典在工作过程中仅占几K内存空间,克服了一般词典空间开销大的缺点。
为方便用户参与开发扩展本系统,我们还专门设计了用户词典。
用户只需具有初步俄语知识,就能独立胜任工作,根据需要,利用这部词典,随时增添词条。
其具体做法是,由用户给出所要增添词的索引词、词性以及汉义(如有可能,给出与该词用法相近的参照词更好 ,系统即能自动填补其他必要的信息。
用户词典主要用来增加系统词典中缺少的词,也可用来改变系统词典内中已有词的汉义。
例如,用户在一篇经系统翻译加工的文章中,对某个词的汉语译法不满意,则可在用户词典中再存放该词,并给出所要求的汉义,从而得到满意的译文。
如果这一修改只是一时性的需要,事后可将该词条在用户词典中删去。
可以看出,用户词典在诸多词典中是最为优先的。
二、词法分析1.查词典查词典的目的在于获取词的信息。
无形态变化的词的信息全部存放在词典中,而有形态变化词的部分信息,如名词、形容词的数、格,动词的时态、人称等属性则需通过应用削尾规则才能随机给出。
2.生词处理生词指的是没有存放在词典里的词,或者说,是经过查词典查不到的词。
生词处理这一环节之所以必要,不仅在于词典可能不完善,会有遗漏;也不仅在于自然语言在演变过程中会不断产生新词,这些只是问题的一个方面。
而更重要的,还在于在具体翻译实践中,往往会遇到一些不成其为词的词,如象有些商标名、不常用的缩写词、人名、地名、符号等。
这些词, 在人用的词典里没有把它收录进去,当然也不可能把它们全部编到机器词典里去。
如果可以把前面提到的漏词、新词看成是临时性生词的话,那么,后面的那些就是固定性生词。
它们将永远存在。
对生词的处理需要根据词的形态来判定其词性及数、格等,以便参与分析加工。
如词尾为ый、ая、ое等的,可断定为形容词、单数、第一格;词尾为ому、ему的,可断定为形容词、单数、第三格;词尾为ами、ями的,可断定为名词、复数、第五格。
至于汉义,可以词原样给出。
这样做虽说是不得已而为之,但对那些固定性生词来说,却不失为一种合适的求解。
3.规范化处理规范是就系统进行翻译加工是否方便而言的。
规范化处理就是把系统难以加工的结构,施用某种手段,调整为系统易于分析的形式。
俄语句子中,有时会出现某个成分被省略,或者在句子中间插入了一些词语,或者正常的词序颠倒了等情况。
这些现象给分析带来很大困难。
设法把省略的成分找出补上,插入的词语挪置一边,颠倒的顺序正过来,就能顺利匹配规则。
俄语中有时还会出现结构分离现象,例如在有的从句中,前置词往往要随关联词一起移到从句句首,这时,如果该前置词同时又恰好应该与从句动词组合成动词短语,那么它们之间的密切联系在线性结构中就被分离开了。
如“Мне не совсем ясно,над кемвы смеётесь. (我不很清楚,您在笑话谁。
”句中动词“смеяться” 是“笑”的意思,当它和前置词组合在一起“смеяться над(кем~чем ” 才是“嘲笑” “笑话”的意思。
然而现在动词不仅与前置词颠倒了顺序,而且中间被隔断了。
处理这类问题,我们反向应用乔姆斯基的“踪迹理论” (Trace Theory ,把前置词及其支配的关联词一起移到从句动词后, 也就是从表层结构形式又返回到深层结构, 移走的地方留下踪迹, 作为从句的标记。
这样,动词和前置词的密切联系得到恢复,而作为从句标志的关联词的踪迹仍然存在,分析问题也就迎刃而解了。
4.同形判别俄语中有些词类是可以互相演变转化的。
如,形容词可以演化为名词,больной, 是形容词“有病的” ,但又用作名词“病人” ;副词可以演化为前置词,впереди,作副词表示“在前面” ,作前置词表示“在……前面” 。
这种词,我们把它叫做同形词。
同形词是同一个形式具有两个或更多的词性,但是,它们在一定的语言环境中只能有一个确定的词性,如“впереди”在“Он шёл впереди. ” (他走在前面中是副词。
在“Он шёлвпереди всех. ” (他走在大家的前面中是前置词。
这种同形词是语言本身具有的。
另外,由于有形态变化的词我们在词典中是以词干或原形的方式存入的,所以有些原本不是同形的词也变得同形了。
如добро是名词,добрый是形容词,词形本不同,但削去词尾以后,都是добр,在词典中也成了“同形词” 。
还有,俄语形态变化丰富,有些不相干的词,变化后却面貌相同了。
如“ряд”是名词,可它的单数第五格形式却与副词“рядом”同形,于是也成了“同形词” 。
要想顺利翻译句子,就需要对这些词作同形判别。
同形判别就是根据词在句子中的前后环境条件,来确定它的词性归属,以便正确给出词性及汉义, 参与句子分析。
例如, 判断当前词是副词还是前置词要根据下面的同形判别规则:*/V|C|, |EW=:F*=:P这条规则中, *号表示当前词,如果它后面是动词、或连词、或逗号、或句末标记,那么这个词就判定为副词,否则就判定为前置词。
三、句法分析1.规则描述语言规则描述语言是我机器翻译研究所在十几年机器翻译实践中摸索并建立的一套形式化的描述语言,建立规则描述语言是为了保证语言规则和程序设计完全分开,从而真正做到语言规则可以任意增、删、改而无须更动程序。
规则描述语言要根据各个机译系统进行语言分析综合所需要的种种功能来设计。
我们主要采用模式匹配技术,要求具有绝对匹配、或匹配、可有可无匹配、预示匹配等逻辑匹配功能,以及调序、增词,删词、归结、分枝等操作功能。
2.句法规则库句法规则库主要由以下几个子规则库组成:1微型名词短语规则(MICNP这类规则把名词前可能出现的修饰语,如数词、形容词等,与该名词合并在一起,组成一个初步的微型名词短语。
2并列结构规则(FJV并列结构规则主要处理并列的副词、并列的形容词或并列的动词等, 不涉及并列句的处理。
3句子结构规则(CL句子结构指的是句子最顶层的框架结构。
CL 规则除了处理一般句型外, 还包括一些特殊的句型。
4名词短语规则(NPNP规则是在 MICNP 规则的基础上,把微型名词短语再进一步加以扩展,也就是把名词后可能出现的该名词的修饰语,如二格名词、前置词短语、不定式短语、定语从句等再和微型名词短语合并,组成一个完整的名词短语。
5动词短语规则(VP动词短语规则是说明动词用法的规则。
我们根据动词的不同类别如系动词、不及物动词、及物动词等,将动词分为 V1、 V2、 V3、 V4、 V5等类,其中有些类的动词如及物动词等,还可以再细分为若干小类,如 V3A 、 V3B 、 V3C 、V3D ……等。
6前置词短语规则(PP俄语前置词短语中,前置词的含义往往随着它所支配的名词短语的不同而不同。
因此,前置词短语规则的制订必须落实到每一个具体的前置词上。
它们实质上是一些特殊词的词处理规则,每一个前置词都有它自己的若干条规则。
PP 规则只是这些子规则库的总称。
3.句法分析过程分析是以句子为单位进行的。
句法分析的过程是不断应用句法规则的过程,也是逐步进行模式匹配的过程。
应用句法规则时,在同一规则库中,不同的规则之间是“或”的关系,即只要有一条规则执行成功,就认为该规则库的执行是成功的。
在同一规则中,扫描动作中各个匹配动作之间是“与”的关系。
它们依次匹配待处理序列中的结点,当所有匹配动作都匹配成功后才执行生成部分的操作,并认为该规则的执行是成功的。