spss实践题分析及答案
spss实践题分析及答案

spss实践题分析及答案SPSS实践题习题1分析此班级不同性别的学⽣的物理和数学成绩的均值、最⾼分和最低分。
Report性别数学物理男⽣Mean 80.0769 74.5385N 13 13Std. Deviation 5.75125 5.17390Minimum 72.00 69.00Maximum 95.00 87.00⼥⽣Mean 80.7692 76.1538N 13 13Std. Deviation 8.91772 8.32512Minimum 70.00 65.00Maximum 99.00 91.00Total Mean 80.4231 75.3462N 26 26Std. Deviation 7.36029 6.84072Minimum 70.00 65.00Maximum 99.00 91.00结论:男⽣数学成绩最⾼分: 95 最低分: 72 平均分: 80.08物理成绩最⾼分: 87 最低分: 69 平均分: 74.54⼥⽣数学成绩最⾼分: 99 最低分: 70 平均分: 80.77 物理成绩最⾼分: 91 最低分: 65 平均分: 76.15 习题2分析此班级的数学成绩是否和全国平均成绩85存在显著差异。
One-Sample StatisticsNMean Std. Deviation Std. Error Mean数学2680.42317.360291.44347结论:由分析可知相伴概率为0.004,⼩于显著性⽔平0.05,因此拒绝零假设,即此班级数学成绩和全国平均⽔平85分有显著性差异习题3分析市2⽉份的平均⽓温在90年代前后有⽆明显变化。
Group Statistics分组 NMean Std. Deviation Std. Error Mean⼆⽉份⽓温0 11 -4.527273 1.2034043.3628400 118-3.2000001.3006786.3065729结论:由分析可知, ⽅差相同检验相伴概率为0.322,⼤于显著性⽔平0.05,因此接受零假设,90年代前后2⽉份温度⽅差相同。
spss试题及答案医学

spss试题及答案医学1. 单选题:在SPSS中,进行描述性统计分析的命令是?- A. DESCRIPTIVES- B. FREQUENCIES- C. CROSSTABS- D. MEANS答案:A2. 多选题:以下哪些选项是SPSS中用于数据输入的方法?- A. 数据编辑器- B. 导入Excel文件- C. 导入文本文件- D. 从数据库中导入答案:A, B, C, D3. 判断题:在SPSS中,可以通过“变换”菜单下的“计算变量”功能来创建新变量。
- 正确- 错误答案:正确4. 填空题:在SPSS中,使用________命令可以进行相关性分析。
答案:CORRELATIONS5. 简答题:请简述在SPSS中进行t检验的步骤。
答案:首先,需要打开数据文件或创建新的数据文件。
然后,选择“分析”菜单下的“比较均值”选项。
接着,选择“独立样本T检验”或“配对样本T检验”,根据需要选择相应的变量和组别。
最后,点击“确定”执行分析。
6. 操作题:打开SPSS软件,创建一个新的数据文件,输入以下数据:| 编号 | 年龄 | 性别 | 身高(cm) | 体重(kg) |||||-|-|| 1 | 25 | 男 | 175 | 65 || 2 | 30 | 女 | 165 | 55 || 3 | 28 | 男 | 180 | 70 || 4 | 22 | 女 | 170 | 60 |答案:操作步骤如下:- 打开SPSS软件。
- 点击“文件”菜单,选择“新建”。
- 选择“数据”选项卡,点击“数据视图”。
- 在数据视图中,按照表格格式输入上述数据。
7. 分析题:使用SPSS进行卡方检验,以判断性别和身高是否有关联。
答案:首先,需要将性别和身高变量编码为数值型数据。
然后,选择“分析”菜单下的“描述统计”选项,选择“交叉表”。
在“交叉表”对话框中,将性别变量放入“行”框中,将身高变量放入“列”框中。
点击“统计”按钮,勾选“卡方”选项,然后点击“继续”和“确定”执行分析。
SPSS题目及答案汇总版

《SPSS原理与运用》练习题数据对应关系:06-均值检验;07-方差分析;08-相关分析;09-回归分析;10-非参数检验;17-作图1、以data06-03为例,分析身高大于等于155cm的与身高小于155cm的两组男生的体重和肺活量均值是否有显著性。
分析:一个因素有2个水平用独立样本t检验,此题即身高因素有155以上和以下2个水平,因此用独立样本t检验(analyze->compare means->independent-samples T test)。
报告:一、体重①m+s:>=155cm 时, m= 40.838kg; s= 5.117;<155cm 时, m= 34.133kg;s= 3.816;②方差齐性检验结果:P=0.198>0.05,说明方差齐性。
③t=4.056; p=0.001< 0.01,说明身高大于等于155cm 的与身高小于155cm的两组男生的体重有极显著性差异。
二、肺活量①m+s: >=155cm 时,m=2.404; s=0.402;<155cm 时, m=2.016;s=0.423;②方差齐性检验结果:P=0.961>0.05,说明方差齐性。
③t=2.512; p=0.018 < 0.05,说明说明身高大于等于155cm的与身高小于155cm的两组男生的体重有显著性差异。
2、以data06-04为例,判断体育疗法对降低血压是否有效。
分析:比较前后2种情况有无显著差异,用配对样本t检验,(analyze->compare means-> paired-samples T test).报告:①m+s 治疗前舒展压:m=119.50; s=10.069;治疗后舒展压:m=102.50; s=11.118;②相关系数correlation=0.599; p=0.067>0.05,说明体育疗法与降低血压相关。
SPSS操作实验作业1(附答案)

SPSS操作实验 (作业1)作为华夏儿女都曾为有着五千年的文化历史而骄傲过,作为时代青年都曾为中国所饱受的欺压而愤慨过,因为我们多是炎黄子孙。
然而,当代大学生对华夏文明究竟知道多少呢某研究机构对大学电气、管理、电信、外语、人文几个学院的同学进行了调查,各个学院发放问卷数参照各个学院的人数比例,总共发放问卷250余份,回收有效问卷228份。
调查问卷设置了调查大学生对传统文化了解程度的题目,如“佛教的来源是什么”、“儒家的思想核心是什么”、“《清明上河图》的作者是谁”等。
调查问卷给出了每位调查者对传统文化了解程度的总得分,同时也列出了被调查者的性别、专业、年级等数据信息。
请利用这些资料,分析以下问题。
问题一:分析大学生对中国传统文化的了解程度得分,并按了解程度对得分进行合理的分类。
问题二:研究获得文化来源对大学生了解传统文化的程度是否存在影响。
要求:直接导出查看器文件为.doc后打印(导出后不得修改)对分析结果进行说明,另附(手写、打印均可)。
于作业布置后,1周内上交本次作业计入期末成绩答案问题一操作过程1.打开数据文件作业。
同时单击数据浏览窗口的【变量视图】按钮,检查各个变量的数据结构定义是否合理,是否需要修改调整。
2.选择菜单栏中的【分析】→【描述统计】→【频率】命令,弹出【频率】对话框。
在此对话框左侧的候选变量列表框中选择“X9”变量,将其添加至【变量】列表框中,表示它是进行频数分析的变量。
3.单击【统计量】按钮,在弹出的对话框的【割点相等组】文本框中键入数字“5”,输出第20%、40%、60%和80%百分位数,即将数据按照题目要求分为等间隔的五类。
接着,勾选【标准差】、【均值】等选项,表示输出了解程度得分的描述性统计量。
再单击【继续】按钮,返回【频率】对话框。
4.单击【图表】按钮,勾选【直方图】和【显示正态曲线】复选框,即直方图中附带正态曲线。
再单击【继续】按钮,返回【频率】对话框。
最后,单击【确定】按钮,操作完成。
spss习题及其答案

spss习题及其答案
SPSS习题及其答案
SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,广泛应用于社会科学和商业研究。
它可以帮助研究人员对数据进行分析、建模和预测。
在学习和使用SPSS的过程中,习题和答案是非常重要的,可以帮助我们更好地理解和掌握SPSS的使用方法和技巧。
下面是一些常见的SPSS习题及其答案,供大家参考:
1. 问题:如何在SPSS中导入数据?
答案:在SPSS中,可以通过“文件”菜单中的“打开”选项来导入数据,也可以直接拖拽数据文件到SPSS的工作区。
2. 问题:如何计算变量的描述性统计量?
答案:在SPSS中,可以使用“分析”菜单中的“描述统计”选项来计算变量的描述性统计量,包括均值、标准差、最大值、最小值等。
3. 问题:如何进行相关性分析?
答案:在SPSS中,可以使用“分析”菜单中的“相关”选项来进行相关性分析,可以计算变量之间的皮尔逊相关系数或斯皮尔曼相关系数。
4. 问题:如何进行回归分析?
答案:在SPSS中,可以使用“回归”选项来进行回归分析,可以进行简单线性回归、多元线性回归等不同类型的回归分析。
5. 问题:如何进行因子分析?
答案:在SPSS中,可以使用“因子”选项来进行因子分析,可以帮助研究人员发现变量之间的潜在结构和关联。
通过以上习题及其答案的学习和实践,我们可以更好地掌握SPSS的使用方法,提高数据分析的效率和准确性。
希望大家在学习SPSS的过程中能够多多练习,不断提升自己的数据分析能力。
SPSS习题及其答案是我们学习的好帮手,也是我们进步的动力。
SPSS数据分析与应用试题及答案

SPSS数据分析与应用试题及答案一、单项选择题(本大题共15小题,每小题2分,共30分)1、下列用来描述一组数据的平均水平的是 [ ]A.均值 B.标准差 C.偏度 D.峰度2、下列用来描述数据的波动程度的是 [ ]A.中位数 B.均值 C. 方差 D.偏度3、在SPSS中双定性变量适合绘制下面那种图形 [ ]A.堆积百分比图 B.箱线图C. 直方图D.散点图4、在SPSS中双定量变量适合绘制下面那种图形 [ ]A.堆积百分比图B.箱线图C. 直方图D.散点图5、在SPSS中一个定性变量、一个定量变量适合绘制下面那种图形[ ] A.堆积百分比图B.箱线图C. 直方图D.散点图6、下列属于定性变量的是[ ]A.年龄B.驾龄C.性别D.销量7、以下不属于定量变量的是 [ ]A.婚姻B.收入C.工龄D.体重8、以下哪个变量适合做线性回归的因变量[ ]A.是否购买 B.是否出险 C.是否恋爱 D.房价9、以下哪个变量适合做逻辑回归的因变量 [ ]A.客户是否流失 B.酒店价格 C.二手房价 D.以上都不正确10、因子分析的作用是 [ ]A.分类 B.降维 C.回归D.以上都不正确11、关于聚类分析,下列说法错误的是 [ ]A.聚类就是把“类似”的对象聚到一起B.聚类分析首先要确定特征指标C.聚类分析中刻画相似度方法只有欧式距离D.层次聚类法是聚类分析的一种12“物以类聚,人以群分”与下列哪个模型特征相似 [ ]A.线性回归B.逻辑回归C.聚类分析D.因子分析13、以下哪个因变量可以用线性回归模型进行分析 [ ]A.大学生薪资影响因素分析B.信用卡是否逾期C.某用户是否患胃病的预测D.明天是否降雨的预测14、线性回归模型的整体评价,不包括以下哪一项 [ ]A.F检验的结果B.调整的R方C.AUC值D.R方的大小15、关于聚类分析的要点,错误的是 [ ]A.根据不同的特征指标聚出的类是不同的B.定义什么是“相似的研究对象”C.层次聚类就是k均值聚类D.如何归类二、多项选择题(本大题共5小题,每小题4分,共20分)在每小题列出的五个备用选项中至少有两个是符合题目要求的,请将其代码填写在题后的括号内。
spss考试题及答案

spss考试题及答案1. 单选题:在SPSS中,以下哪个选项不是数据清洗的步骤?A. 缺失值处理B. 异常值检测C. 数据转换D. 数据备份答案:D2. 多选题:在SPSS中进行描述性统计分析时,可以输出哪些统计量?A. 均值B. 中位数C. 众数D. 标准差E. 方差答案:A, B, C, D, E3. 判断题:在SPSS中,使用“描述统计”功能可以计算出数据的峰度。
对错答案:错4. 填空题:在SPSS中,进行相关性分析时,可以使用_________菜单下的“相关性”选项。
答案:分析5. 简答题:请简述SPSS中因子分析的步骤。
答案:因子分析的步骤包括:a. 确定分析变量b. 进行KMO和Bartlett的球形度检验c. 选择提取方法(如主成分分析或因子分析)d. 确定因子数量e. 进行因子旋转(如需要)f. 解释因子6. 案例分析题:某研究者收集了一组数据,想要使用SPSS进行方差分析。
请描述方差分析的一般步骤。
答案:方差分析的一般步骤如下:a. 确定研究假设b. 选择合适的方差分析类型(如单因素方差分析或多因素方差分析)c. 输入数据并设置因子和因变量d. 进行方差分析e. 检查方差齐性f. 进行后续多重比较(如果需要)g. 解释结果7. 操作题:使用SPSS进行回归分析,并解释回归系数的意义。
答案:进行回归分析的步骤包括:a. 选择分析菜单下的回归选项b. 选择线性回归c. 设置因变量和自变量d. 运行回归分析e. 查看输出结果f. 解释回归系数,即自变量每变化一个单位,因变量预期的变化量以上即为SPSS考试题及答案的排版及格式。
SPSS题目解答题答案解析

6、某百货公司9月份各天的服装销售数据如下(单位:万元)257 276 297 252 301 256 278 298 265 258286 234 210 322 310 278 301 290 256 249309 318 311 267 273 239 316 268 249 298(1)计算该百货公司日销售额的均值(277.4)、标准误差(5.15698)、中位数(277)、众数(249,256,278,298,301)、全距、方差(797.834)、标准差(28.24596)、四分位数、十分位数、百分位数、频数、峰度(-.518)和偏度(-.287);(2)计算日销售额的标准化Z分数及对其线性转换。
解:(1)频数298.00 2 6.7 6.7 73.3301.00 2 6.7 6.7 80.0309.00 1 3.3 3.3 83.3310.00 1 3.3 3.3 86.7311.00 1 3.3 3.3 90.0316.00 1 3.3 3.3 93.3318.00 1 3.3 3.3 96.7322.00 1 3.3 3.3 100.0合计30 100.0 100.0统计量日销售额N 有效30缺失0均值277.4000均值的标准误 5.15698中位数277a众数249.00b标准差28.24596方差797.834偏度-.287偏度的标准误.427峰度-.518峰度的标准误.833全距112.00极小值210.00极大值322.00和8322.00百分位数10 242.3333c20 253.333325 256.333330 257.500040 267.500050 276.666760 288.000070 298.000075 300.250080 306.3333.25.50,75为四分位数,10,20,30··90为十分位数百分位数 1 .c,d2 212.40003 219.60004 226.80005 234.00006 235.50007 237.00008 238.50009 240.333310 242.333311 244.333312 246.333313 248.333314 249.400015 250.000016 250.600017 251.200018 251.800019 252.533320 253.333321 254.133322 254.933323 255.733324 256.133325 256.333326 256.533327 256.733328 256.933329 257.200030 257.500031 257.800032 258.700033 260.800035 265.000036 265.600037 266.200038 266.800039 267.200040 267.500041 267.800042 268.500043 270.000044 271.500045 273.000046 273.900047 274.800048 275.700049 276.266750 276.666751 277.066752 277.466753 277.866754 279.066755 280.666756 282.266757 283.866758 285.466759 286.800060 288.000061 289.200062 290.700063 292.800064 294.900065 297.000066 297.200067 297.400068 297.600069 297.800070 298.000071 298.450073 299.350074 299.800075 300.250076 300.700077 301.533378 303.133379 304.733380 306.333381 307.933382 309.100083 309.400084 309.700085 310.000086 310.300087 310.600088 310.900089 312.000090 313.500091 315.000092 316.200093 316.800094 317.400095 318.000096 319.200097 320.400098 321.600099 .a. 利用分组数据进行计算。
spss的试题、答案、结果

统计复习题目一.某公司管理人员为了解某化妆品在一个城市的月销售量Y (单位:箱)与该城市中适合使用该化妆品的人数1X (单位:千人)以及他们 人均月收入2X (单位:元)之间的关系,在某个月中对15个城市做调查,得上述各量的观测值如表A1所示.假设Y 与1X ,2X 之间满足线性回归关系15,,2,1,22110 =+++=i x x y i i i i εβββ 其中i ε独立同分布于),0(2σN .(1)求回归系数210,,βββ的最小二乘估计值和误差方差2σ的估计值,写出回归方程并对回归系数作解释;analyze-regression-linear,y to dependent,x1 x2 to indepents ,statistics-confidence回归系数210,,βββ的最小二乘估计值和误差方差2σ的估计值分别为:3.453,0.496,0.009和2σ=4.740. 回归方程为y=0.496*x1+0.009*x2+3.453回归系数解释:3.453可理解为化妆品的月基本销售量,当人均月收入2X 固定时,适合使用该化妆品的人数1X 每提高一个单位,月销售量Y 将增加0.496个单位;当适合使用该化妆品的人数1X 固定时,人均月收入2X 每提高一个单位,月销售量 Y 将增加0.009个单位 (2)求出方差分析表,解释对线性回归关系显著性检验的结果.求复相关系数的平方2R 的值并由于P 值=0.000<0.05,所以回归关系显著.2R 值=0.999,说明Y 与1X ,2X 之间的线性回归关系是高度显著的…(3)分别求1β和2β的置信度为95.0的置信区间;coefficients 的后面部分.1β和2β的置信度为95.0的置信区间分别为(0.483,0.509),(0.007,0.011)(4)对05.0=α,分别检验人数1X 及收入2X 对销量Y 的影响是否显著;由于系数1β,2β对应的检验P 值分别为0.000,0.000都小于0.05,所以适合使用该化妆品的人数1X 和人均月收入2X 对月销售量Y 的影响是显著的(5)该公司欲在一个适宜使用该化妆品的人数22001=x ,人均月收入250002=x 的新城市中销售该化妆品,求其销量的预测值及置信为0.95的置信区间.Y 的预测值及置信度为0.95的置信区间分别为:135.5741和(130.59977,140.54305)在数据表中直接可以看见二、某班42名男女学生全部参加大学英语四级水平考试,数据如下:(数据表为A2)问男女生在英语学习水平上有无显著差异?单击weight cases-weight cases by-x, ok, analyze-descriptive statistics-crosstabs,(列联表分析)sex to rows,score to column, exact-exact, statistics chi-square ,ok.原假设不显著,看这个(Asymp. Sig. (2-sided))。
SPSS数据分析与应用(微课版)-实训案例参考答案 第1-8章

SPSS数据分析与应用(微课版)-实训案例参考答案参考实训案例1数据分析案例:未来一周某电商平台手机的销量分析。
(1)在这个问题中,手机的销量就是不确定性因素,在未来一周,有的手机可以畅销、也可能滞销,具体销量会是多少,都是不确定性。
(2)为了分析未来一周手机的销量,可以通过网络爬虫获取该平台手机的相关信息,比如,手机的品牌、型号、主屏幕尺寸、重量、颜色、商家、价格、评论数、好评率、销量等。
参考实训案例2(1)利用SPSS分别导入数据集“个人信息.xlsx”“支出数据.xlsx”。
图1 数据导入(2)在菜单栏中选择【数据(D)】→【合并文件(G)】→【添加变量(V)】。
图2 合并文件菜单(3)在弹出的对话框中,将另一个打开数据集选中,点击继续。
图3 变量添加对话框(4)选择合并方法为“基于键值一对一合并(N)”,点击确定。
图4 合并方法(5)查看合并后的数据集,包括了5列。
图5 合并后数据样例(6)在菜单栏中选择【文件(F)】→【另存为(A)】,在弹出的对话框中选择存储的路径,并命名文件名为“学生消费信息”后保存。
图6 数据另存对话框参考实训案例3本案例通过2020条数据来探究信用卡是否按期还款问题。
数据集见“信用卡还款.csv”。
案例因变量为是否按期还款,是定性变量,共分为按期与逾期两个水平,分别用 1 和 0 表示。
案例自变量性别,是定性变量,分为男女两类,分别用 1 和 0 表示;已婚_未婚,是定 性变量,已婚用 1 表示,未婚用 0 表示;已育_未育,是定性变量,已育用 1 表示,未育用 0 表示;收入,是连续变量,取值范围为[426,120940];教育水平,是定性变量,共分为高中及以下、大专、本科、研究生及以上四个水平,分别用 1、2、3、4 来表示;英语水平,是定性变量,共分为三级及以下、四级、六级、八级及以上四个水平,分别用 1、2、3、4 来表示;微博好友数,是连续变量,取值范围为[6,114];消费理念,是连续变量,取值范围为[0,1]。
SPSS实验报告一题目和答案

广东金融学院实验报告课程名称:③由表报告可知,这三个行业平均收入最高:“科学研究、技术服务地质勘察业”的平均收入为8294.9983:“卫生、社会保障和社会福利业”的平均收入为5989.8982;“水利、环境和公共设施管理业”的平均收入为5076.2500。
报告总收入行业N 均值农林牧渔业24 4304.2083采矿业12 1658.3333制造业969 3554.4152电力、燃气及水的生产供应业120 4123.0724建筑业145 2759.1807交通运输、仓储和邮政业196 3222.4676信息传输、计算机服务和软件业123 3332.5672批发和零售业480 3202.4359住宿和餐饮业120 2772.3000金融业329 4350.7240房地产业82 2888.2317租赁和商务服务业87 2765.6685科学研究、技术服务地质勘察业12 8294.9983水利、环境和公共设施管理业36 5076.2500居民服务和其他服务业317 2447.8026教育368 4514.8723卫生、社会保障和社会福利业147 5989.8982文化、体育和娱乐业132 4300.9326公共管理和社会组织512 4427.6971无就职行业1356 2022.2584总计5567 3315.89423. ①由表描述量统计可知:筛选除去无收入者,对总收入进行标准化处理,其均值为0,标准差为1。
描述统计量N 均值标准差Zscore: 总收入5567 0.0000000 1.00000000有效的 N (列表状态)5567②由表异常值可知:异常值的比重是1.9%异常值频率百分比有效百分比累积百分比有效.00 105 1.9 1.9 1.91.00 5462 98.1 98.1 100.0合计5567 100.0 100.0(二)第二题:1. ①由表购买保险情况可知,商业保险、养老保险和医疗保险都买的人的比例是5.8%;一种保险都没买的人的比例是44.4%。
spss统计分析习题答案

spss统计分析习题答案SPSS统计分析习题答案在统计学中,SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件。
它提供了一系列功能强大的工具,用于数据处理、数据可视化和统计分析。
对于学习和实践统计分析的人来说,掌握SPSS的使用是非常重要的。
在学习SPSS统计分析过程中,我们常常会遇到一些习题,用以巩固和应用所学的知识。
下面,我将提供一些SPSS统计分析习题的答案,希望能对你的学习和实践有所帮助。
习题一:假设你有一份关于某个班级学生的成绩数据,包括数学成绩、语文成绩和英语成绩。
请使用SPSS计算每个学生的总分,并计算班级的平均总分。
答案:首先,打开SPSS软件并导入数据集。
然后,依次点击"Transform"、"Compute Variable"。
在弹出的对话框中,输入一个新的变量名,比如"Total_Score",然后在"Numeric Expression"框中输入数学成绩、语文成绩和英语成绩的变量名,并使用"+"符号将它们连接起来,最后点击"OK"按钮。
这样,SPSS将会计算每个学生的总分,并将结果保存在新的变量"Total_Score"中。
接下来,点击"Analyze"、"Descriptive Statistics"、"Frequencies"。
在弹出的对话框中,将"Total_Score"变量拖动到"Variables"框中,并点击"OK"按钮。
SPSS将会计算班级的平均总分,并在输出结果中显示。
习题二:假设你有一份关于某个公司员工的工资数据,包括性别、年龄和工资水平。
Spss试题(附解答和Spss数据库)

Spss试题(附解答和Spss数据库)一、对某型号的20根电缆依次进行耐压试验,测得数据如数据1,试在α=0.10的水平下检验这批数据是否受到非随机因素干扰。
解:本题采用单样本游程检验的方法来判断样本随机性。
原假设:这批数据是随机的;备择假设:这批数据不是随机的。
SPSS操作:Analyze -> Nonparametric Test -> Runs数据分析结果如下表所示:Runs Test耐电压值aTest Value 204.55Cases < Test Value 10Cases >= Test Value 10Total Cases 20Number of Runs 13Z .689Asymp. Sig. (2-tailed) .491a. Median结果:-- Test Value:204.55(即上面Cut Point设置的值)-- Asymp. Sig.=0.491,即P值=0.491大于显著水平0.10,则接受原假设,即样本是随机抽取的,这批数据未收到非随机因素干扰。
1二、为研究吸烟有害广告对吸烟者减少吸烟量甚至戒烟是否有作用。
从吸烟者总体中随机抽取33位吸烟者,调查他们在观看广告前后的每天吸烟量(支)。
试问影片对他们的吸烟量有无产生作用,(见数据2)解:本题采用配对样本T检验的方法。
原假设:影片对他们的吸烟量无显著影响;备择假设:影片对他们的吸烟量有显著影响。
SPSS操作:Analyze -> Compare Means -> Paired-Samples T Test… 数据分析结果如下表所示:Paired Samples StatisticsMean N Std. Deviation Std. Error MeanPair 1 21.58 33 10.651 1.854 看前(支)17.58 33 10.680 1.859 看后(支)Paired Samples CorrelationsN Correlation Sig.Pair 1 33 .878 .000 看前(支) & 看后(支)Paired Samples TestPaired Differences95% ConfidenceInterval of the Std.Difference Sig. Std. ErrorMean Deviation Mean Lower Upper t df (2-tailed)Pair 1 看前(支) 4.000 5.268 .917 2.132 5.868 4.362 32 .000 - 看后(支) 由表可知,看前样本均值为21.58,看后样本均值为17.58,此外,p值为0.000<0.05,因此,拒绝原假设,接受备择假设,即在α=0.05显著性水平下,影片对他们的吸烟量有显著影响。
spss实验题答案

实验题1.解:(1)将数据录入SPSS软件中。
(2)点击分析→回归→线性,得回归系数表:由表可知,线性回归方程为:y=0.379x+17.2192.解:(a)将数据录入SPSS软件中, 点击分析→回归→线性,得回归系数表:Y为保单推销数,X为保单推销经历(年数)由图可知,拟合回归方程y=3.364x+51.165( b ) 回归系数为0.410,与0相异,小于0.05(在5%的显著水平),即相应系数显著大于0(c)一个有10年推销经历的保单推销员的销售额为y=3.364×10+51.165=84.8053.解:(a)将数据录入SPSS软件中, 点击分析→回归→线性,得回归系数表:点击分析→相关→双变量,得到:点击图形→旧对话框→散点、点状→确定,即可得到散点图:Y为能力测验分数,X为完成任务时间由表可知,线性回归方程为:Y=-11.959x+125.267(b) 由散点图可看出,这两个变量呈负相关关系。
(c) 由表可知,两个变量的相关系数为—0.930>0.5,又0.865显著异于0,t统计量的显著性概率p为0.000<0.05,说明两个变量在0.05水平上呈显著性差异。
4.解:(1)将数据录入SPSS软件中。
(2)点击分析→回归→线性,得回归系数表:Y 为儿子身高,x 为父亲身高由表可知,经验回归方程y=0.465x+35.977 5.解:(1)将数据录入SPSS 软件中。
(2)点击转换→计算变量→线性→目标变量t=1/x;(3)点击分析→回归→线性→因变量y →自变量t,得回归系数表:Y 为销售额,X 为流通费用率由表可知,选用曲线xba y +=做曲线回归,得回归方程为y=9.707/x -1.2116.解:(1)将数据录入SPSS 软件中, 点击分析→回归→线性,y 为因变量,x 为自变量。
得到回归分析表:y 为上年专利数,x1为上三年R&D 投入,x2为高级工程师数由表可知,“上年专利数”对“上三年R&D 投入”和“高级工程师数”的线性回归方程为: y=0.008x1+0.615x2+7.040由表可得,估计标准误差为3.65724。
spss试题及答案

spss试题及答案SPSS(Statistical Package for the Social Sciences)是一种用于统计分析和数据处理的软件工具,被广泛应用于社会科学领域。
本文将为您提供一些SPSS试题及答案,帮助您巩固和扩展SPSS的应用知识。
1. 选择题1.1 SPSS是以下哪种类型的软件?A. 文字处理软件B. 统计分析软件C. 图像处理软件D. 电子表格软件答案:B. 统计分析软件1.2 SPSS可以用于哪些数据类型的处理?A. 数值型数据B. 文字型数据C. 图像数据D. 所有类型的数据答案:D. 所有类型的数据1.3 SPSS的输入数据文件的扩展名是什么?A. .xlsB. .docC. .csvD. .spss答案:D. .spss2. 判断题2.1 在SPSS中,可以使用语法来进行数据操作和分析。
答案:正确2.2 SPSS中的数据视图是用来展示数据分析结果的。
答案:错误2.3 SPSS只适用于Windows操作系统。
答案:错误3. 简答题3.1 请解释“变量”在SPSS中的概念。
答:在统计学中,变量是指可变化的属性或特征。
在SPSS中,变量用于表示数据的不同维度或特征,例如性别、年龄、收入等。
变量在SPSS中可以是数值型或文字型,根据数据的属性选择合适的变量类型进行存储和分析。
3.2 请描述一下SPSS中数据分析的流程。
答:SPSS中数据分析的流程通常包括数据导入、数据清洗、数据转换、数据分析和结果报告等步骤。
首先,将待分析的数据导入SPSS软件中,可以选择打开Excel、CSV等格式的数据文件。
然后,对数据进行清洗,包括去除异常值、缺失值处理等。
接下来,可以进行数据转换,如计算新的变量、合并数据集等。
最后,进行具体的数据分析,例如描述性统计、相关分析、回归分析等。
完成数据分析后,生成结果报告并进行解释和讨论。
4. 计算题4.1 请利用SPSS计算以下数据的均值和标准差:样本数据:10, 8, 12, 15, 11, 9, 13, 14, 10, 9答:使用SPSS的描述性统计功能,计算得到均值为 11.1,标准差为 2.21。
spss试题解答

SPSS操作练习(t检验)要求:1、用SPSS进行统计分析;2、分析说明使用某一统计处理方法的依据;3、将统计结果正确地在论文中进行表达并进行结果分析。
1.计算下列两个玉米品种10个果穗长度(cm)的平均值、标准差和变异系数,并解释两个玉米品种的果穗长度有无差异。
【变异系数C·V=(标准偏差SD/平均值MN)×100%】玉米24号:19,21,20,20,18,19,22,21,21,19金皇后:16,21,24,15,26,18,20,19,22,19解:(1)选择分析方法:被比较的玉米24号、金皇后玉米是两个品种的玉米,试验中彼此独立、无配对关系。
先用SPSS对数据是否服从正态分布进行Kolmogorov-Smirnov 检验,得到,玉米24号的p=0.869>0.05,金皇后玉米的p=0.99>0.05,说明两个样本均服从正态分布(来自正态总体),因此选择独立样本t检验进行数据分析。
经Levene方差齐性检验得P=0.028<0.05,表明方差不齐,因此选择t检验的结果,使用方差不齐时的计算结果。
(2)结果:为比较玉米24号、金皇后两个品种果穗长度的差异,分别随机选定10株进行测定,结果见表1。
表1 玉米24号与金皇后玉米果穗长度的差异(X±SD)品种样品数/株果穗长度/cm 变异系数/% P值(双侧)玉米24号10 20±1.25 6.241.00金皇后10 20±3.40 17.00(3)分析与结论:从表1可以看出,果穗的长度,玉米24号为20±1.25cm,金皇后为20±3.40cm;玉米24号C·V是6.00%,金皇后的C·V为17.00%,金皇后的变异程度大于玉米24号。
两个品种的玉米果穗长度平均值一样,金皇后玉米的标准差、变异系数较大,表明金皇后玉米果穗长度的变异程度大。
双尾t检验分析的结果表明,比较两个品种的果穗长度差异性(P=1.00>0.05),所以,两个品种玉米的果穗长度差异无显著性。
spss实践题分析及答案(二)
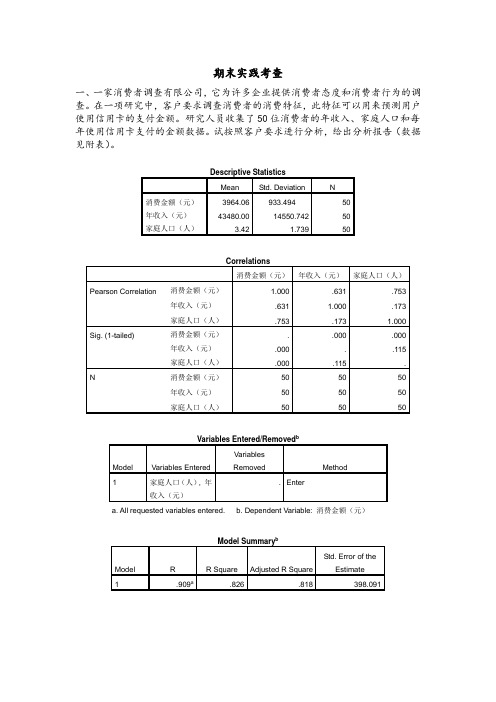
期末实践考查一、一家消费者调查有限公司,它为许多企业提供消费者态度和消费者行为的调查。
在一项研究中,客户要求调查消费者的消费特征,此特征可以用来预测用户使用信用卡的支付金额。
研究人员收集了50位消费者的年收入、家庭人口和每年使用信用卡支付的金额数据。
试按照客户要求进行分析,给出分析报告(数据见附表)。
Descriptive StatisticsMean Std. Deviation N消费金额(元)3964.06 933.494 50年收入(元)43480.00 14550.742 50家庭人口(人) 3.42 1.739 50Model Summary bModel R R Square Adjusted R Square Std. Error of the Estimate结果分析:由题目可知客户要求,是根据消费者年收入、家庭人口来预测其每年使用信用卡支付的金额数据,属于多元线性回归问题,其中年收入和家庭人口 看作两个自变量,每年信用卡支付金额看作因变量。
由分析得:121304.9050.033356.296y x x =++y :信用卡支付金额 1x :年收入 2x :家庭人口拟合优度检验2R为0.818,回归方程能很好的代表样本数据。
回归方程F检验和回归系数T检验的相伴概率都小于显著性水平,拒绝零假设即回归方程和回归系数都具显著型。
二、下表为运动员与大学生的身高(cm)与肺活量(cm3)的数据,考虑到身高与肺活量有关,而一般运动员的身高高于大学生,为进一步分析肺活量的差异是否由于体育锻炼所致,试作控制身高变量的协方差分析,并给出分析报告。
Between-Subjects FactorsValue Label N类别0 0 201 1 20Tests of Between-Subjects Effects Dependent Variable:肺活量Source Type III Sumof Squares dfMeanSquare F Sig.Corrected Model 6981685.135a2 3490842.56822.860 .000Intercept 208064.290 1 208064.290 1.363 .251身高1630762.635 1 1630762.63510.679 .002类别1407847.095 1 1407847.0959.220 .004Error 5649992.36537 152702.496 Total 6.633E8 40Corrected Total 12631677.50039a. R Squared = .553 (Adjusted R Squared = .529结果分析:控制变量的相伴概率值是0.004,小于显著性水平0.05,因此拒绝零假设,故在剔除身高对肺活量的影响前提下,是否经常进行体育锻炼对肺活量有显著影响;另外协变量相伴概率为0.002,说明身高的不同水平对肺活量也有显著影响。
spss试题及答案doc

spss试题及答案doc一、单项选择题(每题2分,共20分)1. SPSS中,用于描述数据分布特征的统计图是:A. 条形图B. 散点图C. 直方图D. 折线图答案:C2. 在SPSS中,进行方差分析的命令是:A. T-TESTB. ANOVAC. REGRESSIOND. CORRELATE答案:B3. 以下哪个选项不是SPSS中数据录入的方法?A. 直接输入B. 导入Excel文件C. 导入文本文件D. 导入PDF文件答案:D4. SPSS中,用于计算变量之间相关性的统计方法是:A. 回归分析B. 因子分析C. 聚类分析D. 相关分析答案:D5. 在SPSS中,进行线性回归分析的命令是:A. REGRESSIONB. CORRELATEC. T-TESTD. ANOVA答案:A6. SPSS中,用于创建数据文件的命令是:A. CREATEB. SAVEC. OPEND. NEW答案:D7. 在SPSS中,用于计算数据集中位数的函数是:A. MEANB. MEDIANC. MODED. SUM答案:B8. SPSS中,用于创建变量的命令是:A. COMPUTEB. COMPUTE VARIABLESC. CREATED. DEFINE答案:A9. 在SPSS中,用于进行数据清洗的方法是:A. DESCRIPTIVESB. FREQUENCIESC. DETECTD. CLEAN答案:B10. SPSS中,用于进行数据分组的命令是:A. GROUPB. SPLITC. CLUSTERD. SEGMENT答案:B二、多项选择题(每题3分,共15分)1. 在SPSS中,以下哪些选项是数据转换的方法?A. 变量计算B. 数据排序C. 数据筛选D. 变量重新编码答案:A, B, D2. SPSS中,以下哪些命令用于数据的描述性统计分析?A. DESCRIPTIVESB. FREQUENCIESC. CROSSTABSD. EXAMINE答案:A, B, D3. 在SPSS中,以下哪些选项是进行数据可视化的方法?A. CHARTSB. GRAPHSC. PLOTSD. MAPS答案:A, B, C三、简答题(每题5分,共10分)1. 请简述SPSS中数据导入的步骤。
北语2024春《SPSS统计分析实践》满分作业答案

北语2024春《SPSS统计分析实践》满分
作业答案
一、问题描述:
作业要求对一份调查问卷数据进行统计分析,包括描述统计、
相关分析和回归分析。
数据集包含了以下变量:性别、年龄、收入、教育水平、购物偏好、购买力、满意度等。
二、数据预处理:
1. 查看数据集的整体情况,包括数据类型、缺失值等。
2. 处理缺失值,可以选择删除含有缺失值的样本或使用插值法
进行填充。
三、描述统计分析:
1. 性别比例统计:计算男女比例并绘制饼图。
2. 年龄分布统计:计算年龄的平均值、标准差,并绘制年龄分
布直方图。
3. 收入水平统计:计算收入的最大值、最小值、中位数和四分
位数。
4. 教育水平统计:计算各教育水平的人数比例,并绘制教育水平柱状图。
四、相关分析:
1. 计算各变量之间的相关系数矩阵。
2. 绘制变量之间的散点图,并观察相关关系。
五、回归分析:
1. 选择一个自变量和一个因变量进行回归分析。
2. 计算回归方程的斜率、截距和决定系数。
3. 绘制回归线和残差图,并观察拟合情况。
六、结论:
根据以上统计分析结果,可以得出一些结论和建议,如性别比例接近1:1,年龄主要分布在30-40岁之间,收入水平较为分散,教育水平以本科为主等。
以上是《SPSS统计分析实践》满分作业的答案,希望能对你有所帮助。
spss统计试题及答案

spss统计试题及答案SPSS统计试题及答案1. 单项选择题- 1.1 SPSS中,用于进行数据描述性分析的命令是()。
- A. DESCRIPTIVES- B. FREQUENCIES- C. MEANS- D. T-TEST- 答案:A- 1.2 在SPSS中,要进行方差分析,应该使用以下哪个命令?() - A. DESCRIPTIVES- B. ANOVA- C. REGRESSION- D. CROSSTABS- 答案:B2. 多项选择题- 2.1 下列哪些选项是SPSS中的数据类型?()- A. Numeric- B. String- C. Date- D. Time- 答案:A、B、C、D- 2.2 在SPSS中,进行相关性分析可以使用以下哪些命令?()- A. CORRELATIONS- B. REGRESSION- C. CROSSTABS- D. MEANS- 答案:A、B3. 简答题- 3.1 简述SPSS中如何进行数据的导入和导出。
- 答案:在SPSS中,数据的导入可以通过“文件”菜单下的“打开”选项,选择“数据”并导入不同格式的数据文件。
数据的导出则可以通过“文件”菜单下的“另存为”选项,选择导出为SPSS、Excel、CSV等格式。
- 3.2 解释在SPSS中进行回归分析的步骤。
- 答案:在SPSS中进行回归分析的步骤包括:打开数据文件,选择“分析”菜单下的“回归”选项,选择“线性”或“逻辑”回归,指定因变量和自变量,点击“确定”进行分析。
4. 计算题- 4.1 假设有一组数据:10, 15, 20, 25, 30。
计算这组数据的平均值和标准差。
- 答案:平均值 = (10+15+20+25+30)/5 = 20;标准差 =√[(10-20)²+(15-20)²+(20-20)²+(25-20)²+(30-20)²]/5 =7.071。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS实践题
习题1
分析此班级不同性别的学生的物理和数学成绩的均值、最高分和最低分。
结论:男生数学成绩最高分: 95 最低分: 72 平均分:
物理成绩最高分: 87 最低分: 69 平均分:
女生数学成绩最高分: 99 最低分: 70 平均分:
物理成绩最高分: 91 最低分: 65 平均分:
习题2
分析此班级的数学成绩是否和全国平均成绩85存在显著差异。
One-Sample Statistics
N Mean Std. Deviation Std. Error Mean
数学26
结论:由分析可知相伴概率为,小于显著性水平,因此拒绝零假设,即此班级数学成绩和全国平均水平85分有显著性差异
习题3
分析兰州市2月份的平均气温在90年代前后有无明显变化。
Group Statistics
分组N Mean Std. Deviation Std. Error Mean
二月份气温011.3628400
118.3065729
结论:由分析可知, 方差相同检验相伴概率为,大于显著性水平,因此接受零假设,90年代前后2月份温度方差相同。
双侧检验相伴概率为, 小于显著性水平,拒绝零假设,即2月份平均气温在90年代前后有显著性差异
习题4
分析15个居民进行体育锻炼3个月后的体质变化。
Paired Samples Statistics
Mean N Std. Deviation Std. Error Mean
Pair 1锻炼前15
锻炼后15
Paired Samples Correlations
N Correlation Sig.
Pair 1锻炼前 & 锻炼后15.277
结论:由分析可知,锻炼前后差值与零比较,相伴概率小于显著性水平,拒绝零假设,即锻炼前后有显著性差异
习题5
为了农民增收,某地区推广豌豆番茄青菜的套种生产方式。
为了寻找该种方式下最优豌豆品种,进行如下试验:选取5种不同的豌豆品种,每一品种在4块条件完全相同的田地上试种,其它施肥等田间管理措施完全一样。
根据表中数据分析不同豌豆品种对平均亩产的影响是否显著。
结论:由以上分析可知,F统计量F(4,15)=,对应的相伴概率为,小于显著性水平,拒绝零假设,即不同品种豌豆与亩产量之间存在显著性差
异。
1、2、3、4号品种与5号有明显差异, 5号品种产量最低, 因此购种选择前四种均可。
习题6
由于时间安排紧张,公司决定安排4名员工操作设备A、B、C各一天,得到日产量数据如表所示。
试分析4名员工和3台设备是否有显著性差异,以便制定进一步的采购计划。
Tests of Between-Subjects Effects
Dependent Variable:日生产量
Source Type III Sum of
Squares df Mean Square F Sig.
Corrected Model433.167a5.002 Intercept1.000 equipment2.001 staff3.022 Error6
Total12
Corrected Total11
设备 * 员工
Dependent Variable:日生产量
设备员工Mean Std. Error
95% Confidence Interval Lower Bound Upper Bound
11
2
3
4 21
2
3
4 31
2
3
4
日生产量
员工N
Subset
12
Student-Newman-Keuls a,b23
33
43
13
Sig..070.335
3*.000
31.079.55
2*.000
日生产量
设备N
Subset
12
Student-Newman-Keuls a,b34
14
24
Sig..079
结论:由以上假设检验分析可知,不同人员、不同设备各自以及他们的交互作用对日生产量都有显著影响。
由上图可知,要提高员工日生产量,应该选购设备2。
习题7
数据记录了18个试验地里杨树一年生长量与施用氮肥和钾肥的关系,考虑杨树初始高度的影响,分析氮肥和钾肥的施肥量和杨树生长量之间的关系。
Between-Subjects Factors
N
钾肥量.006
6
6
氮肥量多9
少9
Tests of Between-Subjects Effects Dependent Variable:树苗生长量
Source Type III Sum of
Squares df Mean Square F Sig.
Corrected Model.538a6.090.000 Intercept.6271.627.000初始高度.1291.129.000钾肥.3132.157.000氮肥.0411.041.013钾肥 * 氮肥.0212.011.150 Error.05111.005
Total18
Corrected Total.59017
a. R Squared = .913 (Adjusted R Squared = .866)
结论:由分析可知,剔除树苗初始高度的影响,树苗生长量与钾肥、氮肥施肥量有显著性差异。
习题8
试分析表中的全国各地区城镇居民消费性支出和总收入的相关性。
Descriptive Statistics
Mean Std. Deviation N
总收入31
消费性支出31
Correlations
总收入消费性支出
总收入Pearson Correlation1.987**
Sig. (2-tailed).000
N3131
消费性支出Pearson Correlation.987**1
Sig. (2-tailed).000
N3131
**. Correlation is significant at the level (2-tailed).
结论:由分析可知,总收入和支出的pearson相关系数为,为高度相关。
假设检验得出的相伴概率小于显著水平,因此拒绝零假设,即可以用样本相关系数r代替总体相关系数ρ。
习题9
试分析表中各地区科研投入的人年数和课题总量之间的相关关系。
Correlations
Control Variables投入人年数课题总数投入高级职称的人年数
-none-a投入人年数Correlation.959.988
Significance
(2-tailed)
..000.000
df02929课题总数Correlation.959.944
Significance
(2-tailed)
.000..000
df29029投入高级职称的人年数Correlation.988.944
Significance
(2-tailed)
.000.000.
df29290投入高级职称的人年数投入人年数Correlation.507
Significance
(2-tailed)
..004
df028
课题总数Correlation.507
Significance
(2-tailed)
.004.
df280
a. Cells contain zero-order (Pearson) correlations.
结论:由分析可知,投入高级职称的人年数对投入人年数和课题总数都
有影响,剔除它的影响,采用偏相关分析。
投入人年数和课题总数相关
系数为,为中度相关,可以用样本相关系数代替总体相关系数。