PDF合并与分割
PDF文件使用技巧大全

PDF文件使用技巧大全如果你经常使用计算机,就不可能不知道PDF格式。
它是公认的分享文档的最佳格式。
但是,这种格式的文件,必须用专门的阅读器打开,而且不能编辑,所以对使用者来说,会遇到很多问题。
下面是一个外国作者总结的常见问题清单,基本上涵盖了普通用户的大多数问题,而且解决方法全部都是免费的。
我觉得对我很有用,所以将它翻译了出来,也供大家参考。
需要说明的是,里面的解决方法,完全都是针对英语文档的,我没有试验过它们是否支持中文文档。
Adobe公司的PDF格式是分享文件的最佳格式,因为它体积适中,能够保存样式,在绝大多数平台下都能够打开和处理。
下面,我们将告诉你,如何应对你在使用PDF文件过程中,遇到的几乎所有问题,而且完全不需要你去购买Adobe Acrobat。
内容包括编辑PDF文件、合并多个PDF文件、在PDF中加入签名、如何在线填写PDF表格、在PDF中加入超级链接等等。
Q:我没有Adobe Acrobat,如何创建PDF文件?A:安装免费的DoPDF(该网站被屏蔽,中国大陆用户点击此处下载)软件,它会在Windows中增加一个虚拟打印机。
你通过它,以打印方式生成PDF文件。
Q:我不想安装任何软件,如何创建PDF文件?A: 将你的文档通过浏览器,上传到Google Docs,然后选择以PDF格式export,非常简单。
Q: 客户用Email发送给我一个PPT文件,但是我在出差,无法使用电脑,而我的智能手机打不开PPT文件,怎么办?A:将这封Email转发给pdf@(包括附件),他们会自动将附件转成PDF格式,然后再寄回给你。
大多数智能手机都能打开简单的PDF文件。
事实上,pdf@这个邮件地址,还接受.doc、.docx、.pptx、.xls、.xlsx、JPEG、GIF、RTF、TXT等格式的文档。
Q:我能否直接将一个网页存成PDF格式?A:访问PrimoPDF,直接键入你要保存的网址即可。
pdf拆分小妙招

pdf拆分小妙招
方法一:使用Adobe Acrobat
Adobe Acrobat是一个功能强大的PDF编辑器,可以用来拆分PDF文件。
它支持多种拆分选项,包括按页面数、按文件大小或者按书签等拆分方式。
不过,这个工具价格比较昂贵,适合需要经常编辑PDF文件的专业用户
方法二:截图
PDF文件是以“图片”形式存在的,所以这时可以以其人之道还治其人之身,也就是选择截图的方式来达到拆分的效果。
具体操作如下:首先,将需要分割PDF文件打开,并将内容移到需要的片段。
然后,使用操作系统自带的截图功能,竟将其复制到画图工具中进行粘贴即可。
不过,这个方法的操作效率很低,如果说一两个PDF文件需要分割的话还好,一旦文件数量较多时,操作会影响其它事情的进度。
C# 合并、拆分多个PDF文档

C#如何合并、拆分多个PDF文档在整理文件时,将多个同类型文档合并是实现文档归类的有效方法,也便于文档管理或者文档传输。
当然,也可以对一些比较大的文件进行拆分来获取自己想要的部分文档。
可以任意地对文档进行合并、拆分无疑为我们了提供极大的便利。
那么在C#语言环境中怎么来实现PDF文档的和被拆分呢?下面将介绍具体的代码操作方法。
所需工具:Free Spire.PDF for .NETVisual Studio 2013一、合并多个PDF文档C#using System;using Spire.Pdf;namespace MergePDF{class Program{staticvoid Main(string[] args){//创建一组数组实例,数组元素为需要合并的多个PDF文档的路径String[] files = new String[] { "test1.pdf", "test2.pdf", "test3.pdf" };//调用方法MergeFiles()合并文档PdfDocumentBase doc = PdfDocument.MergeFiles(files);//保存文档doc.Save("合并.pdf", FileFormat.PDF);}}}注意:这里合并的PDF文档是以新的一页来合并的文档,目的不是将多个文档合并为具有一定逻辑的文档,而是出于方便文档管理以及其他操作的目的来合并。
二、拆分PDF文档(一)按每页来拆分C#using System;using Spire.Pdf;namespace SplitPDF1{class Program{staticvoid Main(string[] args){//初始化一个PdfDocument类实例,并从文件中加载需要被拆分的PDF文档PdfDocument doc = new PdfDocument(@"C:\Users\Administrator\Desktop\test.pdf");//调用方法Split()方法将PDF文档按页拆分保存String pattern = "拆分{0}.pdf";doc.Split(pattern);}}}拆分结果:拆分的文档个数与原文档页数相同。
iText分割和合并pdf文件

1.import java.io.FileOutputStream;2.import java.io.IOException;3.import java.util.ArrayList;4.5.import com.lowagie.text.Document;6.import com.lowagie.text.DocumentException;7.import com.lowagie.text.pdf.PdfCopy;8.import com.lowagie.text.pdf.PdfImportedPage;9.import com.lowagie.text.pdf.PdfReader;10.11.12.public class pdfOperate13.{14.private static final int N = 3;15.16.public static void main(String[] args)17. {18. String[] files = {"C:\\a.pdf", "C:\\b.pdf"};19. String savepath = "C:\\temp.pdf";20. mergePdfFiles(files, savepath);21.22. partitionPdfFile("C:\\a.pdf");23. }24.25.public static void mergePdfFiles(String[] files, String savepath) //合并26. {27.try28. {29. Document document = new Document(new PdfReader(files[0]).getPageSize(1));30.31. PdfCopy copy = new PdfCopy(document, new FileOutputStream(savepath));32.33. document.open();34.35.for(int i=0; i<files.length; i++)36. {37. PdfReader reader = new PdfReader(files[i]);38.39.int n = reader.getNumberOfPages();40.41.for(int j=1; j<=n; j++)42. {43. document.newPage();44. PdfImportedPage page = copy.getImportedPage(reader, j);45. copy.addPage(page);46. }47. }48.49. document.close();50.51. } catch (IOException e) {52. e.printStackTrace();53. } catch(DocumentException e) {54. e.printStackTrace();55. }56. }57.58.public static void partitionPdfFile(String filepath) // 分割59. {60. Document document = null;61. PdfCopy copy = null;62.63.try64. {65. PdfReader reader = new PdfReader(filepath);66.67.int n = reader.getNumberOfPages();68.69.if(n < N)70. {71. System.out.println("The document does not have " + N + " pages to partition !");72.return;73. }74.75.int size = n/N;76. String staticpath = filepath.substring(0, stIndexOf("\\")+1);77. String savepath = null;78. ArrayList<String> savepaths = new ArrayList<String>();79.for(int i=1; i<=N; i++)80. {81.if(i < 10)82. {83. savepath = filepath.substring(stIndexOf("\\")+1, filepath.length()-4);84. savepath = staticpath + savepath + "0" + i + ".pdf";85. savepaths.add(savepath);86. }87.else88. {89. savepath = filepath.substring(stIndexOf("\\")+1, filepath.length()-4);90. savepath = staticpath + savepath + i + ".pdf";91. savepaths.add(savepath);92. }93. }94.95.for(int i=0; i<N-1; i++)96. {97. document = new Document(reader.getPageSize(1));98. copy = new PdfCopy(document, new FileOutputStream(savepaths.get(i)));99. document.open();100.for(int j=size*i+1; j<=size*(i+1); j++)101. {102. document.newPage();103. PdfImportedPage page = copy.getImportedPage(reader, j);104. copy.addPage(page);105. }106. document.close();107. }108.109.110. document = new Document(reader.getPageSize(1));111. copy = new PdfCopy(document, new FileOutputStream(savepaths.get(N-1)));112. document.open();113.for(int j=size*(N-1)+1; j<=n; j++)114. {115. document.newPage();116. PdfImportedPage page = copy.getImportedPage(reader, j);117. copy.addPage(page);118. }119. document.close();120.121. } catch (IOException e) {122. e.printStackTrace();123. } catch(DocumentException e) {124. e.printStackTrace();125. }126. }127.}。
pdfcpu用法

pdfcpu用法pdfcpu是一个用于处理PDF文件的工具,它支持多种功能,例如合并、分割、加密和解密等。
下面是pdfcpu的一些具体用法:1、合并PDF文件:使用pdfcpu可以将多个PDF文件合并成一个文件。
例如,假设有两个PDF 文件A.pdf和B.pdf,可以使用以下命令将它们合并成一个文件:csspdfcpu A.pdf B.pdf output.pdf2、分割PDF文件:使用pdfcpu可以将一个PDF文件分割成多个文件。
例如,假设有一个PDF 文件C.pdf,可以使用以下命令将它分割成多个文件:csspdfcpu split C.pdf output_prefix上述命令将会将C.pdf分割成多个文件,并以output_prefix作为前缀命名每个文件。
3、加密PDF文件:使用pdfcpu可以加密PDF文件,以保护文件中的内容。
例如,假设有一个PDF文件D.pdf,可以使用以下命令对它进行加密:csspdfcpu encrypt D.pdf output.pdf password上述命令将会对D.pdf进行加密,并使用指定的密码保护文件内容。
只有输入正确的密码才能打开和阅读加密后的PDF文件。
4、解密PDF文件:使用pdfcpu可以解密PDF文件,以便可以轻松地打开和阅读文件。
例如,假设有一个加密的PDF文件E.pdf,可以使用以下命令对其进行解密:csspdfcpu decrypt E.pdf output.pdf password上述命令将会对E.pdf进行解密,并使用指定的密码打开文件。
解密后的文件可以轻松地打开和阅读。
这只是pdfcpu的一些基本用法示例。
要了解更多用法和详细信息,建议参考pdfcpu的官方文档。
使用WPS进行PDF文件合并和拆分

使用WPS进行PDF文件合并和拆分PDF文件合并和拆分是我们在工作和学习中经常遇到的需求。
使用专业的PDF编辑软件可以轻松实现这些操作,而WPS Office作为一款多功能办公软件,也提供了PDF文件合并和拆分的功能。
本文将介绍如何使用WPS进行PDF文件合并和拆分。
一、PDF文件合并PDF文件合并是将多个PDF文件合并成一个文件,方便我们进行整理和分享。
下面是使用WPS进行PDF文件合并的步骤:1. 打开WPS Office软件,点击左上角的“文件”菜单,选择“PDF转Word/Excel/PPT”。
2. 在弹出的窗口中,点击下方的“PDF合并”按钮。
3. 点击“添加文件”按钮,选择需要合并的PDF文件,可以同时选择多个文件。
4. 在选择文件的同时,可以通过上下移动按钮调整文件的顺序,也可以通过删除按钮删除不需要的文件。
5. 完成文件选择和调整后,点击“开始合并”按钮。
6. 合并过程可能需要一定的时间,等待合并完成后,会弹出合并后的PDF文件保存窗口。
7. 在保存窗口中,选择保存的位置和文件名,点击“保存”按钮即可。
成一个文件。
这样,我们就可以方便地进行整理和分享了。
二、PDF文件拆分PDF文件拆分是将一个PDF文件拆分成多个文件,方便我们对其中的内容进行细分和管理。
下面是使用WPS进行PDF文件拆分的步骤:1. 打开WPS Office软件,点击左上角的“文件”菜单,选择“PDF转Word/Excel/PPT”。
2. 在弹出的窗口中,点击下方的“PDF拆分”按钮。
3. 点击“添加文件”按钮,选择需要拆分的PDF文件。
4. 点击“设置拆分”按钮,可以根据需要选择以下拆分方式:- 按页拆分:将整个PDF文件按页数均分成多个文件。
- 根据书签拆分:根据PDF文件中的书签进行拆分,每个书签对应一个文件。
- 根据内容进行拆分:根据PDF文件中的文字内容进行拆分,每个内容块对应一个文件。
5. 在设置完拆分方式后,点击“开始拆分”按钮。
合并pdf文件最简单的方法

合并pdf文件最简单的方法
最简单的合并PDF文件的方法有:
1. 使用Adobe Acrobat Pro:Adobe Acrobat Pro是最常用的合并PDF文
件的工具,可以轻松地整合多个PDF文件,是强大的PDF编辑和创建
工具。
2. 使用PDFMerge:PDFMerge是一款免费的PDF文件合并工具,可以
合并多个PDF文件并保留原结构和格式。
3.使用SmallPDF:SmallPDF是一款功能强大的PDF合并工具,可以免费合并多个PDF文件。
4.使用PDFsam:PDFsam是一款开源的PDF文件合并工具,可以合并
多个PDF文件,并支持批处理。
5.使用Abdio PDF Editor:Abdio PDF Editor是一个专业的PDF文件合
并工具,可以合并多个PDF文件并对其进行分析和编辑。
6.使用Foxit PDF Editor:Foxit PDF Editor是一款专业的PDF合并工具,可以快速合并多个PDF文件,并可以将PDF合并后的文件发送到桌面上。
7.使用Adolix Split & Merge PDF:Adolix Split & Merge PDF是一款免费的PDF文件合并工具,可以将多个PDF文件轻松合并。
8.使用Neevia PDF Merger:Neevia PDF Merger是一款简单易用的PDF 文件合并工具,可以轻松地合并多个PDF文件,并保留原有的格式和结构。
9.使用MergePDF:MergePDF是一款简单实用的PDF文件合并工具,用于合并多个PDF文件,并支持图像拖拽功能。
PDF合并怎么操作?就用烁光PDF转换器

在工作中处理一些PDF文件时发现有些文档被分割成多个PDF文件要怎么办呢?最简单的方法把它们进行合并再一起,要怎么进行合并呢?介绍一款合并工具。
使用烁光PDF转换器
这是一款功能齐全的PDF文件格式转换和处理工具,软件内包含各种PDF格式转换功能,可以支持多种不同格式的文件相互转换,比如【PDF转Word】【PDF 转Excel】【PDF转图片】等。
PDF合并操作如下:
1、打开烁光PDF转换器的主页面,选择主页面中的【PDF合并】功能进入(可以发现,主页面的功能还是很全面的,一般PDF文件转换和处理在这个软件内都是可以完成的,接下来就看看转换速度和转换效果吧。
)
2、点击中间的转化框添加需要进行合并的PDF文件或者点击右上角【添加文件】按键添加PDF文件。
3、需要合并的文件添加好后,点击排序按键下面的箭头,可以按需要的顺序排列文件,最后在文件排序完成后,点击【开始合并】按键,等待进度条达到100%即可合并。
到这PDF文件的合并就完成了,转换速度和转换效果也是很好的,这个软件在工作中能帮助大家解决文件转换和处理的难题,减少大家的工作量,大家可以放心使用啦。
简单的pdf拆分和合并

简单的pdf拆分和合并咱来唠唠PDF拆分和合并这事儿,简单得很呢!一、PDF拆分。
1. 为啥要拆分PDF呢?有时候一个PDF文件里内容太多太杂啦,比如说一个PDF文档里既有文章,又有表格,还有一些图片啥的,你可能只想把其中某一部分拿出来单独用,这时候就需要拆分。
2. 怎么拆分呢?如果您用的是Adobe Acrobat(这可是个处理PDF的神器哦),打开PDF文件后,在菜单里找“页面”这个选项,然后就会看到“提取页面”之类的命令。
您可以选择要提取的页面范围,比如说从第3页到第5页,然后点击确定,就把这几页单独拆分成一个新的PDF文件啦。
还有一些免费的小软件也能做到,像Smallpdf在线工具。
您把PDF文件上传到这个网站,然后按照它的提示操作,也能轻松拆分PDF。
比如说您想把一个10页的PDF 按每5页拆成两个小PDF,在它的页面上找到拆分功能,设置一下拆分的方式(按页数啦或者按书签之类的,如果有的话),然后就等着下载拆分好的文件就成。
3. 注意事项。
在使用在线工具拆分的时候,要注意文件的大小限制哦。
要是您的PDF文件太大,可能得先想办法压缩一下再上传拆分。
而且要小心网络情况,万一网络不好,上传或者下载可能会出问题。
二、PDF合并。
1. 合并的用途。
想象一下,您有几个PDF文件,分别是一本书的不同章节,您想把它们整合成一个完整的电子书,这时候合并PDF就派上用场啦。
或者您要把一些相关的报告、文件啥的放到一起方便查看和发送,合并也是个好办法。
2. 合并的方法。
还是说Adobe Acrobat,打开这个软件后,在菜单里有个“组合文件”或者“合并文件”的选项。
然后您就可以把要合并的PDF文件都添加进去,可以调整它们的顺序哦,按照您想要的顺序排好,最后点击合并,就生成一个合并后的大PDF文件啦。
免费的PDFsam(PDF Split and Merge的缩写,名字就很直白呢)这个软件也很方便。
您打开PDFsam,在界面上找到合并功能,然后把要合并的PDF文件一个一个添加进来,设置好保存的路径,点击合并按钮,就大功告成了。
怎么把PDF文件分割?这招教你成为大神
怎么把PDF文件分割?这招教你成为大神
怎么把PDF文件分割?在众多职场小白的心里面,PDF格式文件就好比一尊大佛,是只能“看”、不能“摸”的。
所以,当需要编辑PDF文件时(例如分割),很多人都一筹莫展。
其实,想要把PDF文件分割开来,小伙伴们大可不必觉得这是一件太困难的事情。
下面,小李子会给各位小伙伴支一招。
学会这一招,小伙伴们不仅可以快速、有效地分割PDF文件,还能成为PDF编辑大神!想要继续学习的小伙伴们,记得往下看哦。
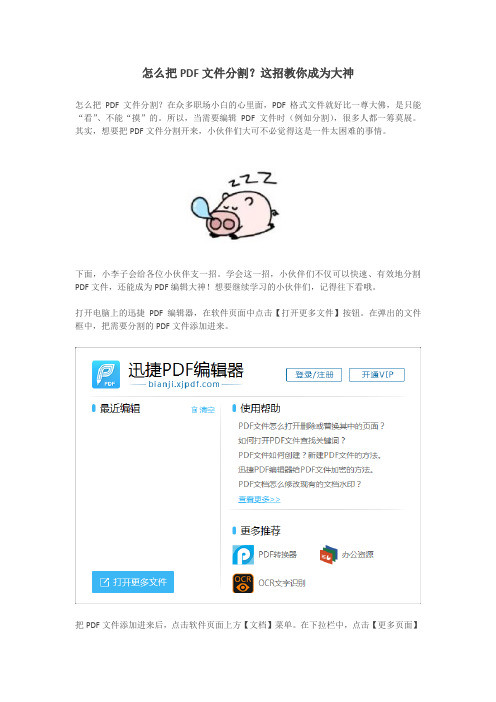
打开电脑上的迅捷PDF编辑器,在软件页面中点击【打开更多文件】按钮。
在弹出的文件框中,把需要分割的PDF文件添加进来。
把PDF文件添加进来后,点击软件页面上方【文档】菜单。
在下拉栏中,点击【更多页面】
-【拆分页面】功能,进行PDF文件的页面拆分。
点击【更多页面】-【拆分页面】功能后,进入该功能的设置页面。
点击【添加水平拆分】或【添加垂直拆分】,进行PDF文件的水平拆分或者垂直拆分。
根据需要,点击软件页面左上方的【编辑拆分】,以修改拆分的百分比数值。
完成PDF文件的拆分设置后,点击【确定】按钮,PDF文件的页面拆分就完成啦。
学会了这招,小伙伴们想要分割PDF文件的时候,就能做到不匆不忙、气定神闲啦。
想要早日成为PDF编辑大神,记得进入“迅捷PDF编辑器”好好学习学习哦。
福昕拆分pdf文件最简单的方法

福昕拆分pdf文件最简单的方法福昕拆分PDF文件最简单的方法介绍在工作或学习中,我们经常会遇到需要将PDF文件拆分成多个部分的情况。
福昕PDF编辑器是一款功能强大的软件,它不仅可以编辑PDF文件,还可以轻松拆分成多个文件。
本文将介绍几种使用福昕拆分PDF文件的最简单方法。
方法一:利用福昕PDF编辑器1.首先,下载并安装福昕PDF编辑器。
2.打开待拆分的PDF文件。
3.在工具栏中找到“页面”选项。
4.点击“页面”选项中的“拆分”按钮。
5.在弹出的窗口中,选择拆分方式,如按页数、按书签等。
6.点击“拆分”按钮,等待拆分完成。
7.拆分完成后,你将得到与原PDF文件相同页数的多个PDF文件。
方法二:通过福昕PDF阅读器1.下载并安装福昕PDF阅读器。
2.打开待拆分的PDF文件。
3.在工具栏中找到“编辑”选项。
4.点击“编辑”选项中的“页面”按钮。
5.在弹出的页面编辑窗口中,选择需要拆分的页面。
6.点击“拆分”按钮,等待拆分完成。
7.拆分完成后,保存拆分后的PDF文件。
方法三:使用福昕在线PDF拆分工具1.打开福昕PDF官方网站(2.在导航栏中找到“在线工具”选项。
3.在在线工具页面中,选择“PDF拆分”工具。
4.上传待拆分的PDF文件。
5.在页面上选择拆分方式,如按页数、按大小等。
6.点击“开始”按钮,等待拆分完成。
7.拆分完成后,下载拆分后的PDF文件。
方法四:利用命令行工具1.打开命令行工具(如Windows系统中的CMD)。
2.使用命令行进入福昕PDF编辑器的安装目录。
3.输入命令-split output_directory。
–将``替换为待拆分的PDF文件名。
–将output_directory替换为拆分后文件保存的目录。
4.按下回车键执行命令,等待拆分完成。
5.拆分完成后,你将在指定的输出目录中找到拆分后的PDF文件。
结论通过福昕PDF编辑器、福昕PDF阅读器、福昕在线PDF拆分工具或命令行工具,我们可以简单快捷地拆分PDF文件。
office合并pdf文件最简单的方法

office合并pdf文件最简单的方法1. 引言1.1 概述在现代办公环境中,合并多个PDF文件成为一个文件是一个常见的需求。
在工作中,我们通常会遇到需要将多个文档、图片或报告等转化为PDF格式并合并在一起的情况。
但是,很多人可能会遇到不知道如何进行操作或者使用麻烦的方法来实现这一目标的问题。
本文旨在介绍office合并PDF文件最简单的方法,并提供两种简单易行的解决方案。
通过阅读本文,您将了解到使用在线工具和专业软件两种简便高效的方法,帮助您快速完成多个PDF文件的合并任务。
1.2 文章结构本文内容共分为五个部分:引言、office合并pdf文件的需求和问题、office合并pdf文件的简单方法一、office合并pdf文件的简单方法二以及结论与总结。
下面我们将从需求和问题入手,分析现有方法及其局限性,并提供两种最简单且易于操作的解决方案。
1.3 目的本文主要旨在帮助那些需要将多个PDF文件进行合并处理但却苦于找不到简便方法或者对现有方法存在疑问和困惑的用户。
通过详细介绍两种最简单的合并PDF文件的方法,读者将能够轻松处理合并文件的任务,提高工作效率和便捷性。
接下来,我们将探讨office合并pdf文件的需求和问题部分。
2. office合并pdf文件的需求和问题2.1 需求分析:在办公场景中,经常会遇到需要合并多个PDF文件的需求。
例如,当我们撰写报告或制作演示文稿时,可能会将不同章节或幻灯片保存为单独的PDF文件。
但是,在最终提交或分享文件之前,我们通常需要将这些分散的PDF文件合并成一个整体,以方便管理和分享。
因此,“office合并pdf文件”的需求主要体现在以下几个方面:首先,合并PDF文件可以提高工作效率。
将多个相关的文件合并成一个文件可以减少重复操作,并且使得整个流程更加简洁和高效。
其次,合并PDF文件有利于信息整理与归档。
多个PDF文件合并后可以更好地组织和管理文档内容,便于后续查阅和检索。
PDF文件合并方法与步骤
PDF文件合并方法与步骤(pdf-tools 4软件应用)
下载后安装,我们会看到是全英文版的,然后我们点击右上角的prdferences,就会弹出设置栏
然后在语言栏里我们选择中文(chinese),然后关闭就OK啦,界面就了中文啦。
然后回到界面,选择分割/合并,进入界面
在分割/合并页面,我们就添加要合并的PDF文件,点击下一步
然后会进入一下个页面,他这里叫作动作组,就是你按照自己的要求设定页面跟书签之类的。
点击下一步,又会进入下一个页面,这个页面就是你合并文档的页数,你可以选择性的排版,感觉这个很人性化呀。
设定好后我们又是下一次,这时候就是常规一些的设置啦,在常规设置里我们可以看到有PDF版本的设置,查看器参数的设置,甚至页面布局的设置。
在这个设置页面我们可以看到除了常规还有优化,安全,信息,高级等设置,每一项都有他的内容,我们进去按照自己的要求设置好就再点击下一步。
下一步后就是路径的选择,基本我们不管是安装还是建议文件都不能忽视这个环节,选择好后点击处理,软件就会开始处理文件啦。
pdf文件合并
大约几秒钟,反正我感觉很快就OK啦,这时候就是完成啦,然后他在左下角还有一些其它的功能,我们在这里就不选择啦,因为我们要合并的已经成功啦。
然后打开我们刚保存的路径,就可以看到文档在那里啦,打开看是不是合并的很好呢(至少我是这么认为的。
)
.。
PDFShaperProfessional操作说明

PDFShaperProfessional操作说明要点:1.PDF转TXT:从PDF文档中提取文本,另存为TXT文档。
2.PDF转RTF:转换PDF文档为RTF文档。
3.PDF转图像:转换PDF文档,另存为图像文件。
4.图像转PDF:转换任意图像为PDF文档。
5.DOC转PDF:转换DOC文档为PDF文档。
6.合并文档:合并多个PDF文档为一个。
7.分割文档:按文档数或页面数分割PDF文档。
8.提取文本:从PDF文档提取全部或部分文本。
9.提取图像:从PDF文档中提取全部图像素材。
10.删除图片:删除PDF文档中的全部或部分图片。
11.旋转页面:旋转PDF文档的页面。
12.裁剪页面:裁剪PDF文档页面四周多余的部分。
13.提取页面:提取PDF文档页面并保存为单独的PDF文件。
14.删除页面:删除PDF文档中的某些页面。
15.添加水印:为PDF文档的全部或部分页面添加水印。
16.文档加密:加密PDF文档,设置用户访问密码,禁止某些操作。
17.文档解密:解密受保护的PDF文档,取消某些操作限制。
18.文档属性:添加、更新或删除有关PDF文档的个人信息。
19.添加证书:为PDF文档添加PFX证书。
1.PDF 转 TXT从PDF文档中提取文本,另存为TXT文档。
即使文档设置密码,且禁止:打印文档、修改文档、复制文本、提取页面、添加批注。
(1)添加支持一次添加多个文档;支持拖放方式添加文档;支持粘贴方式添加文档。
(2)处理先确定(选项)是否保存源文档的排版格式;后从PDF中提取文本并保存为TXT文档。
(3)信息可以查看:PDF版本;文档作者;文档标题;创建工具;创建日期;修改日期。
(4)预览可以按照以下尺寸预览:实际尺寸(Actual Size);适合页面(Zoom to Page);适合宽度(Fit Width)。
(5)向上在文档列表中,向上移动被选中的文档。
(6)向下在文档列表中,向下移动被选中的文档。
合并和分割PDF文件的方法
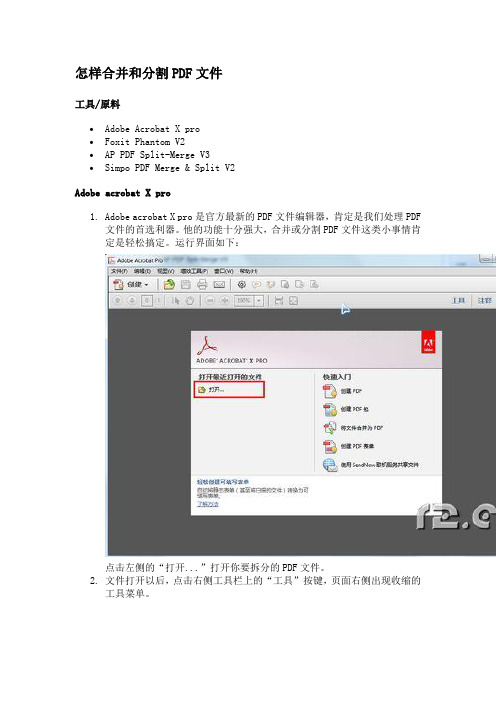
怎样合并和分割PDF文件工具/原料∙Adobe Acrobat X pro∙Foxit Phantom V2∙AP PDF Split-Merge V3∙Simpo PDF Merge & Split V2Adobe acrobat X pro1.Adobe acrobat X pro是官方最新的PDF文件编辑器,肯定是我们处理PDF文件的首选利器。
他的功能十分强大,合并或分割PDF文件这类小事情肯定是轻松搞定。
运行界面如下:点击左侧的“打开...”打开你要拆分的PDF文件。
2.文件打开以后,点击右侧工具栏上的“工具”按键,页面右侧出现收缩的工具菜单。
3.点击工具菜单的“页面”前的三角形,点击“拆分文档”按键4.弹出拆分界面。
设置拆分的方式,是按照页数还是拆分后文件的大小,本经验以页数限制为例,设置如图:输出选项是设置拆分文件的输出文件夹,输出文件的文件名等设置的。
应用到多个文档是批量拆分多个文件用的。
点击“确定”按键,拆分很快就完成了。
5.我们到输出文件夹内查看,因为文件是64页的,按照设置的每6页一个文件的话,刚好是拆分为11个文件。
这就是文件拆分的方法。
怎么样,看了以后就知道很容易吧。
6.接下来我们讲文件合并。
点击开始界面上的“将文件合并为PDF”7.弹出合并界面,点击添加文件(如果文件很多,可以把文件集中在一个新建文件夹内,然后选择添加文件夹的方式)8.添加我们刚才已经拆分的文件。
点击“打开”9.文件全部被添加到合并界面中,但是其中有2个文件的顺序错误了,我们选中顺序错误的文件(按住ctrl键可以多选),然后点击界面下方的“上移”和“下移”按键来调整顺序。
10.调整好以后,点击右下角的“合并文件”按键合并。
11.合并完毕后,我们把文件另存12.文件名会被自动命名为“组合X”,当然你也可以自己命名这个文件。
13.到输出文件夹内查看,文件存在,合并完毕。
怎么样,合并文件也是很简单的吧。
pdf分割带书签

PDF分割带书签:大大提升PDF文档的阅读效率PDF是一种较为常见和流行的文件格式,应用广泛,比如读者、学生、图书馆、科学家、医生等等都需要处理大量的PDF文档。
随着现代科技的发展,很多功能和工具都被引入到PDF文档中,它们为PDF的编辑和浏览提供了很多新的可能性。
其中,PDF分割带书签就是这其中的一个非常实用的功能,它的出现在大大提高PDF文档的阅读效率和用户体验。
PDF分割带书签:什么是?PDF分割带书签是指对一份PDF文档进行分割,并在新生成的文档中添加书签,用户可以通过点击书签,直接跳转到相应的章节或者页面,方便快捷。
在处理大型PDF文档时,PDF分割带书签能极大地缩短寻找特定内容的时间。
除了提高效率,它还能保护原始PDF文档,避免对原文件造成不必要的改动。
PDF分割带书签:如何操作?下面简单介绍几种PDF分割带书签的方法。
1.Adobe Acrobat Pro DCAdobe Acrobat Pro DC是一款功能强大的PDF编辑器,它提供了非常丰富的工具和功能,分割带书签就是其中之一。
用户可以通过“工具”下的“分割与合并”功能完成PDF文档的分割,并通过“导航窗格”添加书签。
2.Foxit ReaderFoxit Reader是一款轻量级的PDF阅读器,但其提供了不少实用的编辑功能。
用户可以在打开PDF文档后选择“视图”下的“书签”选项卡,通过右键点击添加书签,并在书签菜单中选择“新建书签”来添加自己需要的书签。
3.Online Converter除了本地软件,网上还有一些PDF分割工具可以使用,比如Online Converter。
用户可以将需要分割的PDF文档上传至网站,选择“Split PDF”选项并根据需求选择分割方式,并在“Advanced Options”中添加书签名称。
点击“Split PDF”按钮后,新的PDF文档就会生成,并可以直接下载或通过电子邮件发送。
PDF分割带书签:使用建议使用PDF分割带书签功能时,用户需要先了解文档的结构和主要内容,然后根据需要添加书签。
pdf 分割页面的方法

pdf 分割页面的方法在将 PDF 文件分割成单独的页面时,你可以使用各种工具和编程语言。
下面是两种常见的方法:方法一:使用 Adobe Acrobat Pro(图形用户界面)打开 PDF 文件:使用 Adobe Acrobat Pro 打开你想要分割的PDF 文件。
选择页面:进入页面缩略图视图,在左侧的导航栏中找到“页面缩略图”选项。
选择页面范围:通过按住 Shift 键(或 Ctrl 键)选择要分割的页面。
你也可以右键单击选择的页面,然后选择“提取页面”。
保存新的PDF 文件:将选择的页面拖动到桌面或其他文件夹中,或者使用“文件”菜单中的“另存为”选项保存新的 PDF 文件。
方法二:使用 PDF 分割工具(命令行或编程)如果你更喜欢使用命令行或编程的方式,可以使用一些 PDF 处理库或工具。
以下是一个使用 Python 和 PyPDF2 库的简单示例:import PyPDF2def split_pdf(input_path, output_path, page_range):with open(input_path, 'rb') as file:pdf_reader = PyPDF2.PdfFileReader(file)pdf_writer = PyPDF2.PdfFileWriter()for page_num in range(page_range[0] - 1, page_range[1]):pdf_writer.addPage(pdf_reader.getPage(page_num))with open(output_path, 'wb') as output_file:pdf_writer.write(output_file)# 用法示例split_pdf('input.pdf', 'output.pdf', (1, 5))在这个例子中,split_pdf 函数从输入 PDF 文件中提取指定页码范围的页面,并将它们保存到输出 PDF 文件中。
怎么把pdf文件合并成一个?合并多个pdf文件的方法
怎么把pdf文件合并成一个?在工作中我们常常会把多个excel或ppt文件合并成一个以达到整理文件的效果。
同样的,如果想把多个pdf文件合并成一个要怎么办呢?下面就来介绍用迅捷PDF转换器合并pdf文件的方法。
首先需要打开PDF转换器使其处于运行状态,然而我们现在要把转换器导航栏的功能选择为我们即将要使用到的‘PDF操作’,然后在这个系列下选择‘PDF合并’功能。
随后把准备好的多个pdf文件添加到‘pdf合并’功能下,因为我们所要做的是把多个pdf文件合并成一个,因此要添加多个文件。
这时可以把需要合并的多个pdf文件放入到一个文件夹,然后点击‘添加文件夹’按钮直接添加文件夹内的pdf文件。
添加好多个pdf文件后我们可以根据‘属性栏’看到各个pdf文件对应的名称、页数等参数。
而我们可以在‘页面选择’和‘排序’属性的下方调整pdf文件合并的页数、页码以及合并的前后顺序。
之后可以在下方的‘输出目录’中设置文件合并后输出到电脑的目录(路径)。
设置时可以选择输出为‘原文件夹目录’,也可以‘自定义’输出目录。
而小编因为方便把输出目录自定义到了‘电脑桌面’上。
最后点击右下角的‘开始转换’按钮就可以把添加好的多个pdf文件根据所选页面按顺序从上往下合并成一个pdf文件,并根据我们前面预设好的参数输出到指定目录,接下来只需要在预设的输出目录查找合并后的pdf文件即可。
以上就是把多个pdf文件合并成一个的方法,有需要的小伙伴们可以自己试着用转换器合并哦。
pdftk案例 (2)

pdftk案例标题:PDFTK案例引言概述:PDFTK(PDF Toolkit)是一个用于处理PDF文件的开源工具。
它提供了多种功能,包括合并、分割、旋转、加密和解密等。
本文将通过五个大点来详细阐述PDFTK的应用案例。
正文内容:一、合并PDF文件1.1 合并多个PDF文件为一个文件1.2 合并指定页码的PDF文件1.3 合并不同大小的PDF文件二、分割PDF文件2.1 按页码分割PDF文件2.2 按文件大小分割PDF文件2.3 按书签分割PDF文件三、旋转PDF文件3.1 顺时针旋转PDF文件3.2 逆时针旋转PDF文件3.3 批量旋转PDF文件四、加密和解密PDF文件4.1 使用密码加密PDF文件4.2 解密已加密的PDF文件4.3 修改密码或权限五、其他功能5.1 提取PDF文件中的页面5.2 压缩PDF文件大小5.3 添加水印或页眉页脚总结:通过使用PDFTK工具,我们可以方便地处理PDF文件,包括合并、分割、旋转、加密和解密等操作。
在合并PDF文件方面,我们可以合并多个PDF文件为一个文件,也可以合并指定页码的PDF文件,甚至可以合并不同大小的PDF文件。
在分割PDF文件方面,我们可以按页码、文件大小或书签进行分割。
此外,PDFTK还提供了旋转PDF文件、加密和解密PDF文件、提取页面、压缩文件大小以及添加水印或页眉页脚等功能。
通过这些功能,我们可以更好地管理和处理PDF文件,提高工作效率。
总的来说,PDFTK是一个功能强大且易于使用的PDF处理工具,可以满足各种PDF文件处理需求。
无论是个人用户还是企业用户,都可以通过使用PDFTK来简化PDF文件的操作,提高工作效率。
pypdf2的用法

pypdf2的用法PyPDF2 是一个用于处理PDF 文件的Python 库,它可以用于合并、分割、旋转和提取PDF 文件的文本和页面等操作。
以下是PyPDF2 的一些基本用法示例:1. 安装PyPDF2:使用以下命令安装PyPDF2:```bashpip install PyPDF2```2. 合并两个PDF 文件:```pythonimport PyPDF2# 打开两个PDF 文件pdf1 = open('file1.pdf', 'rb')pdf2 = open('file2.pdf', 'rb')# 创建一个PDF 文件写入对象pdf_writer = PyPDF2.PdfFileWriter()# 添加两个PDF 文件的内容到写入对象中pdf_reader1 = PyPDF2.PdfFileReader(pdf1)pdf_reader2 = PyPDF2.PdfFileReader(pdf2)for page_num in range(pdf_reader1.numPages):page = pdf_reader1.getPage(page_num)pdf_writer.addPage(page)for page_num in range(pdf_reader2.numPages):page = pdf_reader2.getPage(page_num)pdf_writer.addPage(page)# 创建一个新的合并后的PDF 文件merged_pdf = open('merged_file.pdf', 'wb')pdf_writer.write(merged_pdf)# 关闭文件pdf1.close()pdf2.close()merged_pdf.close()```3. 提取文本内容:```pythonimport PyPDF2# 打开一个PDF 文件pdf_file = open('example.pdf', 'rb')# 创建一个PDF 文件读取对象pdf_reader = PyPDF2.PdfFileReader(pdf_file)# 提取每一页的文本内容for page_num in range(pdf_reader.numPages):page = pdf_reader.getPage(page_num)text = page.extractText()print(text)# 关闭文件pdf_file.close()```4. 旋转页面:```pythonimport PyPDF2# 打开一个PDF 文件pdf_file = open('example.pdf', 'rb')# 创建一个PDF 文件读取对象pdf_reader = PyPDF2.PdfFileReader(pdf_file)# 创建一个PDF 文件写入对象pdf_writer = PyPDF2.PdfFileWriter()# 旋转每一页并添加到写入对象中for page_num in range(pdf_reader.numPages):page = pdf_reader.getPage(page_num)page.rotateClockwise(90) # 顺时针旋转90 度pdf_writer.addPage(page)# 创建一个新的旋转后的PDF 文件rotated_pdf = open('rotated_file.pdf', 'wb')pdf_writer.write(rotated_pdf)# 关闭文件pdf_file.close()rotated_pdf.close()```这些例子只是PyPDF2 的一小部分功能演示。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
package com.wizrole.pdfMerge.util;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.ArrayList;
import com.lowagie.text.Document;
import com.lowagie.text.DocumentException;
import com.lowagie.text.pdf.PdfCopy;
import com.lowagie.text.pdf.PdfImportedPage;
import com.lowagie.text.pdf.PdfReader;
public class pdfOperate{
private static final int N = 3;
public static void main(String[] args) {
String[] files = { "E:\\1.pdf", "E:\\2.pdf"};
String savepath = "E:\\7.pdf";
mergePdfFiles(files, savepath);
//partitionPdfFile("E:\\1.pdf");
}
/**
* 合并pdf
*
* @param files
* @param savepath
*/
public static void mergePdfFiles(String[] files, String savepath) {
try {
Document document = new Document(new PdfReader(files[0])
.getPageSize(1));
PdfCopy copy = new PdfCopy(document, new FileOutputStream(savepath));
document.open();
for (int i = 0; i < files.length; i++) {
PdfReader reader = new PdfReader(files[i]);
int n = reader.getNumberOfPages();
for (int j = 1; j <= n; j++) {
document.newPage();
PdfImportedPage page = copy.getImportedPage(reader, j);
copy.addPage(page);
}
}
document.close();
} catch (IOException e) {
e.printStackTrace();
} catch (DocumentException e) {
e.printStackTrace();
}
}
/**
* 分离pdf
*
* @param filepath
*/
public static void partitionPdfFile(String filepath) {
Document document = null;
PdfCopy copy = null;
try {
PdfReader reader = new PdfReader(filepath);
int n = reader.getNumberOfPages();
if (n < N) {
System.out.println("The document does not have " + N
+ " pages to partition !");
return;
}
int size = n / N;
String staticpath = filepath.substring(0, filepath
.lastIndexOf("\\") + 1);
String savepath = null;
ArrayList<String> savepaths = new ArrayList<String>();
for (int i = 1; i <= N; i++) {
if (i < 10) {
savepath = filepath.substring(
stIndexOf("\\") + 1,
filepath.length() - 4);
savepath = staticpath + savepath + "0" + i + ".pdf";
savepaths.add(savepath);
} else {
savepath = filepath.substring(
stIndexOf("\\") + 1,
filepath.length() - 4);
savepath = staticpath + savepath + i + ".pdf";
savepaths.add(savepath);
}
}
for (int i = 0; i < N - 1; i++) {
document = new Document(reader.getPageSize(1));
copy = new PdfCopy(document, new FileOutputStream(savepaths
.get(i)));
document.open();
for (int j = size * i + 1; j <= size * (i + 1); j++) {
document.newPage();
PdfImportedPage page = copy.getImportedPage(reader, j);
copy.addPage(page);
}
document.close();
}
document = new Document(reader.getPageSize(1));
copy = new PdfCopy(document, new FileOutputStream(savepaths
.get(N - 1)));
document.open();
for (int j = size * (N - 1) + 1; j <= n; j++) {
document.newPage();
PdfImportedPage page = copy.getImportedPage(reader, j);
copy.addPage(page);
}
document.close();
} catch (IOException e) {
e.printStackTrace();
} catch (DocumentException e) {
e.printStackTrace();
}
}
}。