卫生统计学重点笔记之欧阳家百创编
中医基础理论重点整理之欧阳体创编

中医基础理论重点整理1、中医学是发祥于中国古代的研究人体生命、健康、疾病的科学。
它具有独特的理论体系,丰富的临床经验和科学的思维方法,是以自然科学知识为主体,与人文社会科学相融洽的科学知识体系。
2、中医基础体系形成标志,四大经典:《内经》、《难经》、《伤寒杂病论》、《神农本草经》3、金元四大家:①刘完素(河间)—火热论—寒凉派,《河间六书》②李东垣(李杲)—内伤脾胃学说—补土派,《脾胃论》③张从正(子和)—病由邪生—攻邪派,《儒门事亲》④朱丹溪(震亨)—相火论—滋阴派,《格致余论》4、温病四大家:①清·叶天士——《温热论》②清·吴鞠通——《温病条辨》③清·薛生白——《湿热条辨》④清·王士雄——《温热经纬》5、整体——是指联系性、统一性和完整体。
整体观念:认为事物是一个整体,事物内部的各部分是互相联系不可分割的,事物和事物之间也有着密切的联系。
中医整体观即人体是一个有机整体、人体与外界环境(自然界、社会)的统一性。
(1)整体观念·人体是一个有机的整体①结构上:构成人体的各个组成部分事不可分割的(以心为主宰,五脏为中心,通过经络联系)②生理上:五脏一体观、形神合一③功能上:相互协调,相互为用④病理上:相互影响,局部病变与整体病变⑤诊断上:察外知内⑥治疗上:局部病变与脏腑病变,治未病,五行传变(2)整体观念·人与自然界的统一性①生理方面②病理方面(季节气候变化的影响、昼夜晨昏变化的影响、地方区域变化的影响、环境条件变化的影响)(3)整体观念·人与社会环境关系密切6、辨证论治·病、证、症的区别症:症状:疾病的临床表现(主观异常感觉和某些病态变化):发热、咳喘。
体征:能被觉察到的客观表现:面黄、目赤、脉数。
证:指疾病过程中某一阶段或某一类型的病理概括(含病因、病位、病性和邪正盛衰变化),是确定治法、处方遣药的依据。
病:是指有特定病因、发病形式、病机、发展规律和转归的一种完整的过程。
学前卫生学笔记之欧阳家百创编

学前卫生学笔记第一章欧阳家百(2021.03.07)第二章婴幼儿的生理解剖特点及其生长发育注;人体通常可分为运动系统,呼吸系统,循环系统,消化系统,泌尿系统,感觉器官系,内分泌系统,神经系统,免疫系统,生殖系统。
一、动作的执行者——运动系统(一)什么是运动系统运动系统由骨、骨连结和骨胳肌三部分组成。
(具有支持体重、保护体内脏器和运动功能。
此外,骨也是体内制造血液,贮存钙、磷的器官。
根据骨的所在部位,可分为躯干骨、颅骨和四肢骨三部分;根据骨的外形,又可分为长骨、短骨、扁骨和不规则骨四类。
)(骨连结——骨与骨的连结。
有的骨连结为不动连结,例如颅骨;有的骨连结为微动连结,例如脊椎骨;有的骨连结可以活动,叫关节,例如,下颌关节、肩关节、肘关节等等。
直接连结——是骨与骨之间借结缔组织膜或软骨直接连结。
如颅骨之间的骨缝,椎骨之间的椎间盘等。
特点:活动范围很小。
间接连结(关节)——最主要的连结方式,借结缔组织囊把骨连结起来。
)(1)关节面——是组成关节的相邻两骨的接触面。
特点:一凸一凹,相互适应。
其上有一层薄而光滑的关节软骨。
功能:使两个关节面更加光滑而富有弹性,以减缓运动时的摩擦、冲击和震动。
(2)关节囊特点:附着在关节面周围及其附近骨面上的结缔组织囊。
功能:把两块骨连结起来。
(3)关节腔特点:由关节囊围成的密闭空腔,含少量的滑液。
功能:腔内为负压,有助于关节的稳固。
【关节的特点:在肌肉的牵引下,能够产生屈和伸、内收和外展、旋内和旋外等运动,活动范围较大。
但关节的运动范围、灵活性和牢固性与关节的构造、形状有关。
如肩关节灵活性大,牢固性小;髋关节灵活性小,稳定性大。
】骨骼肌——运动系统的动力部分【长肌(多分布于四肢、能引起大幅度运动),短肌(多位于躯干深部、运动幅度较小),阔肌(长在胸、腹、背部浅层,引起躯干运动)轮匝肌(多分布于孔裂周围、关闭孔裂)]骨骼肌可以受意识支配,附着在骨骼上。
但如肠道等上的平滑肌则不受意识控制。
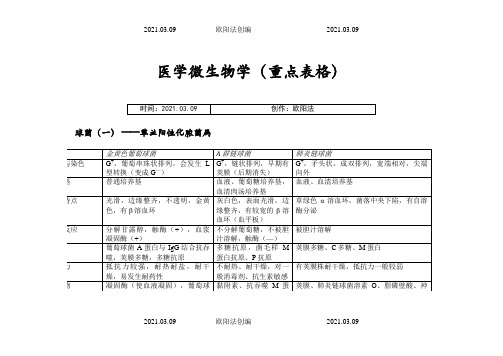
医学微生物学(重点表格)之欧阳法创编
需氧或兼性厌氧,全血血清培养基(吕氏培养基)
菌落特点
颗粒状乳酪色菜花样菌落
灰白色粗糙菌落(卷发状边缘)
灰白色光滑菌落;还原亚碲酸钾菌落呈黑色
致病物
磷脂(刺激单核细胞,形成结核结节和干酪样坏死);分枝菌酸(引发慢性肉芽肿);蜡质D(迟发型超敏反应);硫酸脑苷脂(利于细胞内存活);结核菌素(迟发型超敏反应)
脂多糖、MOMP
其他
冷凝集实验、酚红检测解脲脲原体
斑疹伤寒:鼠为储蓄宿主,鼠蚤和鼠虱传播流行性斑疹伤寒:人虱传播
地方性斑疹伤寒:鼠蚤传播
恙虫病:恙螨传播
流感病毒
麻疹病毒
腮腺炎病毒
风疹病毒
种属
正粘病毒科
副粘病毒科
副粘病毒科
其他
血清型
NP、MP分型(A、B、C三型);NA、HA分亚型
一种
一种
一种
致病Leabharlann 流感医学微生物学(重点表格)
时间:2021.03.09
创作:欧阳法
球菌(一) ——革兰阳性化脓菌属
金黄色葡萄球菌
A群链球菌
肺炎链球菌
形态与染色
G+,葡萄串珠状排列,会发生L型转换(变成G—)
G+,链状排列,早期有荚膜(后期消失)
G+,矛头状,成双排列,宽端相对,尖端向外
培养基
普通培养基
血液、葡萄糖培养基,血清肉汤培养基
免疫
牢固型特异性免疫(体液免疫),sIgA、IgG、IgM
特异性抗体IgM、IgG、sIgA,可重复感染
预后较好,有抗体产生,但无明显作用
防治
肌肉注射灭活脊髓灰质炎疫苗(IPV),口服脊髓灰质炎减毒活疫苗(OPV)
卫生统计学重点笔记

医师资格考试蓝宝书-预防医学医学统计学方法第一节基本概念和基本步骤(非常重要)一、统计工作的基本步骤设计(最关键、决定成败)、搜集资料、整理资料、分析资料。
总体:根据研究目的决定的同质研究对象的全体,确切地说,是性质相同的所有观察单位某一变量值的集合。
总体的指标为参数。
实际工作中,经常是从总体中随机抽取一定数量的个体,作为样本,用样本信息来推断总体特征。
样本的指标为统计量。
由于总体中存在个体变异,抽样研究中所抽取的样本,只包含总体中一部分个体,这种由抽样引起的差异称为抽样误差。
抽样误差愈小,用样本推断总体的精确度愈高;反之,其精确度愈低。
某事件发生的可能性大小称为概率,用P表示,在0~1之间,0和1为肯定不发生和肯定发生,介于之间为偶然事件,<0.05或0.01为小概率事件。
二、变量的分类变量:观察单位的特征,分数值变量和分类变量。
第二节数值变量数据的统计描述(重要考点)一、描述计量资料的集中趋势的指标有1.均数均数是算术均数的简称,适用于正态或近似正态分布。
2.几何均数适用于等比资料,尤其是对数正态分布的计量资料。
对数正态分布即原始数据呈偏态分布,经对数变换后(用原始数据的对数值lgX代替X)服从正态分布,观察值不能为0,同时有正和负。
3.中位数一组按大小顺序排列的观察值中位次居中的数值。
可用于描述任何分布,特别是偏态分布资料的集中位置,以及分布不明或分布末端无确定数据资料的中心位置。
不能求均数和几何均数,但可求中位数。
百分位数是个界值,将全部观察值分为两部分,有X%比小,剩下的比大,可用于计算正常值范围。
二、描述计量资料的离散趋势的指标1.全距和四分位数间距。
2.方差和标准差最为常用,适于正态分布,既考虑了离均差(观察值和总体均数之差),又考虑了观察值个数,方差使原来的单位变成了平方,所以开方为标准差。
均为数值越小,观察值的变异度越小。
3.变异系数多组间单位不同或均数相差较大的情况。
变异系数计算公式为:CV=s/X×100%,公式中s为样本标准差,X为样本均数。
卫生化学重点整理之欧阳治创编

第一章绪论一、分析方法的分类1. 按分析任务分类定性分析(qualitative analysis):含何种元素、何种官能团定量分析(quantitative analysis):测定组分的相对含量结构分析(structure analysis):形态分析、立体结构、结构与活性2.按分析对象分类:无机分析和有机分析3.按待测组分含量分:常量、微量、痕量、超痕量4.按分析手段分类化学分析:以物质的化学反应及其计量关系为基础的分析方法,包括:重量分析和容量分析仪器分析:以物质的物理性质和物理化学性质为基础的分析方法,需要较特殊的仪器,通常称为仪器分析,包括电化学分析、光化学分析、色谱分析、其它仪器分析方法5. 按分析目的分类常规分析:例行分析,日常分析仲裁分析:权威机构、法定分析,具法律效力:司法鉴定等二、计量单位第二章样品的采集与处理一、样品采集的原则:代表性、典型性、适时性二、样品溶液的制备:(一)溶解法:酸性水溶法、水溶液浸出法、碱性水溶液浸出法、有机溶剂浸出法(二)分解法:高温灰化——经高温分解有机物使被测成份能够溶于适当溶剂成可测定状态;低温灰化——利用高频电场作用下产生的激发态氧等离子体消化生物样品中的有机体;湿消化法——利用浓无机酸和强氧化剂消化样品;密封加压——利用高温高压,结合湿消化法消化样品微波消化——密闭加压、湿消化与微波能结合消化样品。
三、分离与富集方法:溶剂萃取法、固相萃取法、固相微萃取法、超临界流体萃取法、蒸馏与挥发法、膜分离法第三章卫生分析数据处理与分析工作的质量保证一、了解三种误差1、随机误差(偶然误差):在相同条件下多次测量同一量时,误差的绝对值和符号均以不可预定方式变化的误差。
特点:不恒定、难以校正、服从正态分布(统计规律)、单峰性、有界性、抵偿性。
原因:仪器波动、读数误差、实验室环境中条件的变化、操作人员的视觉误差和取样误差……减免:增加平行测定的次数2、系统误差:在相同条件下多次测量同一量时,误差的绝对值和符号保持恒定,或在条件改变时按一定规律变化的误差叫系统误差。
基础护理学重点之欧阳治创编

基础护理学1.医院物理环境正常值:室温坚持在18~22℃较为适宜,新生儿及老年病人,室温以坚持在22~24℃为佳。
病室湿度以50%~60%为宜,白日病室较理想的强度是35~40分贝2分级护理的适用对象:.3,平车运送法注意:推行中,平车小轮端在前,转弯灵活;速度不成过快;上下坡时,患者头部应位于高处,减轻患者的不适,并嘱咐患者抓紧扶手,包管患者平安。
4. 舒适(comfort):指个体身心处于轻松自在、满意、无焦虑、无疼痛的健康、安定状态时的一种自我感觉。
不舒适(discomfort):指个体身心不健全或有缺陷,生理、心理需求不克不及全部满足,或周围环境有不良安慰,身体呈现病理修改,身心负荷过重的一种自我感觉。
5.卧位的分类:主动卧位(active lying position):患者根据自己的意愿和习惯采纳最舒适、最随意的卧位,并能随意修改卧床姿势,称之为主动卧位。
见于轻症患者、术前及恢复期患者。
主动卧位(passive lying position):患者自身无力变换卧位,躺卧于他人安顿的卧位,称之为主动卧位。
罕见于昏迷、极度衰弱的患者。
自愿卧位(compelled lying position):患者意识清晰,也有变换卧位的能力,但为了减轻疾病所致的痛苦或因治疗需要而自愿采纳的卧位,称之为自愿卧位。
6..去枕仰卧位适用规模:(1)昏迷或全身麻醉未清醒的患者。
采取去枕仰卧位,头偏向一侧,可避免呕吐物误入气管而引起窒息或肺部并发症。
(2)椎管内麻醉或脊髓腔穿刺后的患者。
采取此种卧位,可预防颅内压减低而引起的头痛。
中凹卧位适用规模:休克患者。
抬高头胸部,有利于坚持气道通畅,改良通气功能,从而改良缺氧症状;抬高下肢,有利于静脉血回流,增加心输出量而使休克症状获得缓解。
屈膝仰卧位适用规模:腹部检查或接受导尿、会阴冲刷等。
侧卧位适用规模:(1)灌肠、肛门检查及配合胃镜、肠镜检查等(2)预防压疮(3)臀部肌内注射半坐卧位适用规模某些面部及颈部手术后患者。
卫生统计学_赵耐青习题答案之欧阳家百创编

习题答案欧阳家百(2021.03.07)第一章一、是非题1. 家庭中子女数是离散型的定量变量。
答:对。
2. 同质个体之间的变异称为个体变异。
答:对。
3. 学校对某个课程进行1 次考试,可以理解为对学生掌握该课程知识的一次随机抽样。
答:对。
4. 某医生用某个新药治疗了100 名牛皮癣患者,其中55 个人有效,则该药的有效率为55%。
答:错。
只能说该样本有效率为55%或称用此药总体有效率的样本估计值为55%。
5.已知在某个人群中,糖尿病的患病率为8%,则可以认为在该人群中,随机抽一个对象,其患糖尿病的概率为8%。
答:对,人群的患病率称为总体患病率。
在该人群中随机抽取一个对象,每个对象均有相同的机会被抽中,抽到是糖尿病患者的概率为8%。
二、选择题1. 下列属于连续型变量的是A 。
A 血压B 职业C 性别D 民族2. 某高校欲了解大学新生心理健康状况,随机选取了1000 例大学新生调查,这1000 例大学生新生调查问卷是A 。
A 一份随机样本B 研究总体C 目标总体D 个体3. 某研究用X 表示儿童在一年中患感冒的次数,共收集了1000 人,请问:儿童在一年中患感冒次数的资料属于C 。
A 连续型资料B 有序分类资料C 不具有分类的离散型资料D 以上均不对4. 下列描述中,不正确的是D 。
A 总体中的个体具有同质性B 总体中的个体大同小异C 总体中的个体在同质的基础上有变异D 如果个体间有变异那它们肯定不是来自同一总体5.用某个降糖药物对糖尿病患者进行治疗,根据某个大规模随机抽样调查的研究结果得到该药的降糖有效率为85%的结论,请问降糖有效率是指D 。
A 每治疗100 个糖尿病患者,正好有85 个人降糖有效,15 个人降糖无效B 每个接受该药物治疗的糖尿病患者,降糖有效的机会为85%C 接受该药物治疗的糖尿病人群中,降糖有效的比例为85%D 根据该研究的入选标准所规定的糖尿病患者人群中,估计该药降糖有效的比例为85%三、简答题1. 某医生收治200 名患者,随机分成2 组,每组100 人。
医学统计学课后习题答案之欧阳歌谷创作

医学统计学课后习题答案欧阳歌谷(2021.02.01)第一章医学统计中的基本概念练习题一、单向选择题1. 医学统计学研究的对象是A.医学中的小概率事件B. 各种类型的数据C. 动物和人的本质D. 疾病的预防与治疗E.有变异的医学事件2. 用样本推论总体,具有代表性的样本指的是A.总体中最容易获得的部分个体B.在总体中随意抽取任意个体C.挑选总体中的有代表性的部分个体D.用配对方法抽取的部分个体E.依照随机原则抽取总体中的部分个体3. 下列观测结果属于等级资料的是A.收缩压测量值 B.脉搏数C.住院天数D.病情程度E.四种血型4. 随机误差指的是A. 测量不准引起的误差B. 由操作失误引起的误差C. 选择样本不当引起的误差D.选择总体不当引起的误差E. 由偶然因素引起的误差5. 收集资料不可避免的误差是A. 随机误差B. 系统误差C. 过失误差D. 记录误差E.仪器故障误差答案: E E D E A二、简答题常见的三类误差是什么?应采取什么措施和方法加以控制?[参考答案]常见的三类误差是:(1)系统误差:在收集资料过程中,由于仪器初始状态未调整到零、标准试剂未经校正、医生掌握疗效标准偏高或偏低等原因,可造成观察结果倾向性的偏大或偏小,这叫系统误差。
要尽量查明其原因,必须克服。
(2)随机测量误差:在收集原始资料过程中,即使仪器初始状态及标准试剂已经校正,但是,由于各种偶然因素的影响也会造成同一对象多次测定的结果不完全一致。
譬如,实验操作员操作技术不稳定,不同实验操作员之间的操作差异,电压不稳及环境温度差异等因素造成测量结果的误差。
对于这种误差应采取相应的措施加以控制,至少应控制在一定的允许范围内。
一般可以用技术培训、指定固定实验操作员、加强责任感教育及购置一定精度的稳压器、恒温装置等措施,从而达到控制的目的。
(3)抽样误差:即使在消除了系统误差,并把随机测量误差控制在允许范围内,样本均数(或其它统计量)与总体均数(或其它参数)之间仍可能有差异。
护理学基础重点学习之欧阳计创编

护理学基础重点1. 医院物理环境正常值:室温坚持在18~22℃较为适宜,新生儿及老年病人,室温以坚持在22~24℃为佳。
病室湿度以50%~60%为宜,白日病室较理想的强度是35~40分贝。
2.护理法度分为五个步调:护理评估、诊断、计划、实施、评价。
3.护理诊断的陈述方法:问题(P)即护理诊断的名称;相关因素(S)与。
有关症状和体征(S)4.分级护理的适用对象:.5.掌握卧位的分类和概念,掌握经常使用卧位的适用规模及要求:(一)仰卧位1、去枕仰卧位:1昏迷和全身麻醉未清醒的病人;2椎管麻醉及脊髓穿刺的病人2、屈膝位:经常使用于腹部检查、导尿、会阴冲刷3、中凹位:(休克卧位)经常使用于休克病人4、头低脚高位:1胎膜早破的产妇,避免脐带脱垂;2下肢或骨盆骨折后行骨牵引术的病人;3严重失血性休克的病人;4十二指肠引流及胆汁引流的病人;5体位引流的病人,利于肺底部的排泄物向外引流操纵办法:将床尾处的床脚垫高15~30cm5、头高脚位置:1脑水肿的病人,降低颅内压,预防或减轻脑水肿;2颅脑手术后或头部外伤的病人,减轻颅内出血;3颈椎牵引的病人(二)侧卧位1灌肠术、肛门检查和配合胃镜检查等;2长期卧床的病人,侧卧位于平卧位交替,预防压疮;3臀部肌注(三)半坐卧位1颜面及颈部手术后,利于减少局部出血;2腹部手术后;3盆腔手术后及盆腔或腹腔有炎症者;4心肺疾患和呼吸困难者;5疾病恢复期操纵办法:先摇起床头支架40°~50°,再摇起膝下支架。
(四)危坐卧位心包积液、心力衰竭、支气管哮喘爆发的病人操纵办法:床头支架抬高60°~70°,膝下支架抬高15°~20°。
胸前置床桌,上放一枕。
需要时背部盖毛毯以保暖,加床档避免坠床。
(五)仰卧位腰背部检查:腰背部手术及腰背部或臀部有伤口,不克不及平卧和侧卧的病人(六)膝胸卧位1肛门、直肠、乙状结肠镜检查及治疗的病人;2矫正胎位不正及子宫后倾的病人(七)截石位会阴、肛门区域的检查、治疗及手术,产妇临蓐注意保暖和遮挡病人。
护理三基名词解释之欧阳法创编

护理:是诊断和处理人类对现存和潜在健康问题的反响.护理学:以自然科学和社会科学理论为基础的研究维护、增进、恢复人类健康的护理理论、知识、技能及其成长规律的综合性应用科学。
整体护理:以护理对象为中心,视护理对象为生物、心理、社会多因素构成的开放性有机整体,以满足护理对象身心需要,恢复健康为目标,运用护理法度的理论和办法,实施系统,计划,全面地护理思想和护理实践活动.基本需要:维持身心平衡并求得生存、生长、及成长,在生理和心理上最低限度的需要。
压力: 在生理学上,是指人体对任何加诸于他的需求所作出的非特异性反响.压力原:又称应激原,是指对个体的适应能力进行挑战,增进个体产生压力反响的因素。
适应:是指人与其周围环境的关系产生较年夜变更,致使个人的行为有所修改以维持平衡,它包含个体和宇宙间的各种呵护性调整。
护理理念:是引导护理人员认识及判断护理及其相关方面的价值观及信念。
护理法度:是指导护理人员以满足护理对象的身心需要,恢复或增进护理对象的健康为目标,运用系统办法实施计划性、连续性、全面整体护理的一种理论与实践模式。
主观资料:护理对象的主观感觉,是护理对象对自己健康问题的体验和认识。
客观资料:护理人员通过观察、体检以及借助医疗仪器设备检查所获得的有关护理对象健康状况的资料。
护理诊断:是关于个人、家庭或社区对现存的或潜在的健康问题以及生命过程的反响的一种临床判断,是护士为达到预期结果选择护理办法的基础,这些结果是应由护士担任的。
护理目标:是针对护理诊断而提出的,期望护理对象在接受护理活动后达到健康状态或行为的修改,也是评价护理效果的标准。
护理质量:反应的是当护理办事活动合适规按时,满足办事对象明确与隐含需要的效果。
继续护理学教育:是继规范化专业培训后,以学习新理论、新知识、新技术和新办法为主的一种终生性护理学教育。
学分制管理:教育对象每年介入经认可的继续护理学教育活动,并要修满最低学分,才干再次注册、聘任及晋升高一级专业技术职务。
伤寒论名词解释之欧阳与创编

《伤寒论》释词(1)头项强痛:头痛项强。
强,强硬、不柔和意。
(3)脉阴阳俱紧:即寸关尺三部脉均见紧象。
关前为阳,关后为阴。
(10)风家:经常易患伤风感冒的人。
(10)不了了:余邪少除,精神不爽,身体不适之意。
了,完毕、结束、清楚、明了。
(42)外证:相对于里证而言,此指表证。
(36)合病:两经或三经症状同时出现者。
(84)淋家:指素患小便淋沥、尿道疼痛之人。
(85)疮家:指久患疮疡之人。
(86)衄血:经常鼻衄之人。
(87)亡血家:平素经常失血之人。
(88)汗家:平素易出汗之人,包括自汗、盗汗在内。
(21)脉促:脉象急促,上壅两寸,关尺以下脉势渐衰,即内经中“中手促上击”意,非后世脉数中一止之谓。
(40)噎:咽喉部有气逆梗塞感。
(90)清谷:大便中夹有未消化物。
清名词活用为动词。
(16上)坏病:六经病经失治误治后产生新的证候而不能归属于六经病时称坏病。
此指太阳表证因误治而变为里证,病情恶化。
(64)叉手自冒心:两手交叉覆按在心胸部。
(118)火逆:指用熏、灸、熨、烧针、温针等法逼汗所致的变证。
火泛指火疗;逆者错也误也。
(65)奔豚:证候名。
以豚之奔形容患者自觉有气从少腹上冲心胸直至咽喉,发作欲死须臾复止。
(65)甘澜水:一名劳水。
程林云<扬之无力,取其不助肾邪>钱天来云<动则其性属阳,扬则其势下走>(67)动经:动摇经气。
(67)身为振振摇:身体震颤摇动不能自持。
(20)遂漏不止:形容汗出不断。
遂,于是之意;漏,渗泻之意。
(91)脚挛急:小腿肌肉痉挛,屈伸不利。
脚指小腿。
(76)虚烦:指无形邪热扰于胸膈而至的烦躁。
虚意指热邪之无形而非正气虚,与有形实热相对而言。
(76)心中懊憹:指心中烦乱不安至甚。
一说心中烦郁闷乱莫可名状。
(76)少气:气息微弱,似不能接续的样子。
非短气。
(143)血室:指胞宫,即子宫。
(71)消渴:形容口渴太甚,急欲饮水之状。
(71)白饮:米汤。
稻曰白。
执业中药师药综考点打印版之欧阳计创编

1、中医基础理论整体观念,人与自然环境、社会环境之间联系性和统一性的学术思想。
2.中医基础理论整体观念的内容,人是一个有机的整体3.五脏一体观人体以五脏为中心。
4.辨证是决定治疗的前提和依据,论治是治疗疾病的手段和方法。
5.“同病异治”与“异病同治”,中医治病主要不是着眼于“病”的异同,而是着眼于“证”的区别。
6、阴阳的属性,白天的上午与下午相7.阴阳的互根互用,是阴阳转化的内在根据。
8.阴阳的消长(量变)和转化“重阴必阳,重阳必阴”“寒极生热,热极生寒”“寒甚生热,热甚生寒”9、阴阳学说的临床应用,在诊法方面,用阴阳的属性来分析四诊收集到的临床症状和体征。
如以色泽的明暗分阴阳,鲜明者为病在阳分,晦暗者为病在阴分。
以声息的动态分阴阳属性,语声高亢洪亮、多言而躁动者,多属实、属热,为阳;语声低微无力、少言而沉静者,多属虚、属寒,为阴;呼吸微弱,声低气怯,多属于阴证;呼吸有力,声高气粗,多属于阳证。
以脉象部位分阴阳,则寸为阳,尺为阴;以至数分,则数者为阳,迟者为阴;以形态分,则浮大洪滑为阳,沉小细涩为阴。
10.外科病症中的阴证、阳证,又有特殊的含义。
属于阳证类型的疾病,如疖、痈、丹毒、脓肿等,表现为红、肿、热、痛等症状;属于阴证类型疾病,如结核性感染、肿瘤等,表现为苍白、平塌、不热、麻木、不痛或隐痛等症状。
11.确定治疗原则,“损其有余”、“实则泻之”。
12.阴虚不能制阳而致阳亢者,属虚热证,一般不能用寒凉药直折其热,须用“壮水之主,以制阳光”即用滋阴壮水之法,以抑制阳亢火盛,这种治疗原则亦称为“阳病治阴”。
若阳虚不能制阴而造成阴盛者,属虚寒证,不宜用辛温发散药以散阴寒,须用“益火之源,以消阴翳”即扶阳益火之法,以消退阴盛,这种治疗原则也称为“阴病治阳”。
13.对阴阳偏衰的治疗,提出了阴中求阳、阳中求阴的治疗14.归纳药物的性能一般具有寒性或凉性,如黄芩、栀子等。
反之,具有减轻或消除寒证作用的中药,一般具有温性或热性,如附子、干姜之类。
卫生统计学重点笔记之欧阳索引创编

医师资格考试蓝宝书预防医学欧阳家百(2021.03.07)医学统计学方法第一节基本概念和基本步骤(非常重要)一、统计工作的基本步骤设计(最关键、决定成败)、搜集资料、整理资料、分析资料。
总体:根据研究目的决定的同质研究对象的全体,确切地说,是性质相同的所有观察单位某一变量值的集合。
总体的指标为参数。
实际工作中,经常是从总体中随机抽取一定数量的个体,作为样本,用样本信息来推断总体特征。
样本的指标为统计量。
由于总体中存在个体变异,抽样研究中所抽取的样本,只包含总体中一部分个体,这种由抽样引起的差异称为抽样误差。
抽样误差愈小,用样本推断总体的精确度愈高;反之,其精确度愈低。
某事件发生的可能性大小称为概率,用P表示,在0~1之间,0和1为肯定不发生和肯定发生,介于之间为偶然事件,<0.05或0.01为小概率事件。
二、变量的分类变量:观察单位的特征,分数值变量和分类变量。
第二节数值变量数据的统计描述(重要考点)一、描述计量资料的集中趋势的指标有1.均数均数是算术均数的简称,适用于正态或近似正态分布。
2.几何均数适用于等比资料,尤其是对数正态分布的计量资料。
对数正态分布即原始数据呈偏态分布,经对数变换后(用原始数据的对数值lgX代替X)服从正态分布,观察值不能为0,同时有正和负。
3.中位数一组按大小顺序排列的观察值中位次居中的数值。
可用于描述任何分布,特别是偏态分布资料的集中位置,以及分布不明或分布末端无确定数据资料的中心位置。
不能求均数和几何均数,但可求中位数。
百分位数是个界值,将全部观察值分为两部分,有X%比小,剩下的比大,可用于计算正常值范围。
二、描述计量资料的离散趋势的指标1.全距和四分位数间距。
2.方差和标准差最为常用,适于正态分布,既考虑了离均差(观察值和总体均数之差),又考虑了观察值个数,方差使原来的单位变成了平方,所以开方为标准差。
均为数值越小,观察值的变异度越小。
3.变异系数多组间单位不同或均数相差较大的情况。
卫生统计学名词解释之欧阳家百创编

卫生统计学名词解释欧阳家百(2021.03.07)总体(population):根据研究目的确定的同质观察单位的观察值全体所构成的集合。
样本(sample):从研究总体中抽取的一部分满足代表性的个体观察值所构成的集合。
计量资料:对每个观察单位用定量的方法测定某项指标量的大小,所得的资料称为计量资料。
计数资料:将观察单位按某种属性或类别分组,所得的观察单位数称为计数资料。
等级资料:将观察单位按测量结果的某种属性的不同程度分组,所得各组的观察单位数,称为等级资料变量:观察单位或个体的某种属性或标志称为变量变量值:对变量进行测量或观察的值称为变量值。
分类变量变异:在自然状态下,个体间测量结果的差异称为变异(variation)。
变异是生物医学研究领域普遍存在的现象。
严格的说,在自然状态下,任何两个患者或研究群体间都存在差异,其表现为各种生理测量值的参差不齐。
数值变量:概率:又称几率,是度量某一随机事件A发生可能性大小的一个数值,随机事件A发生的概率记为P(A),随机事件的概率取值在0~1之间,即0≤P≤1.小概率事件:如果随机事件发生的概率P≤0.05,或P≤0.01,表示该事件发生的可能性很小,对于一次随机抽样,一般认为是不可能发生的事件。
频数表:用来表示一批数据各观察值或在不同取值区间的出现的频繁程度(频数)。
对于离散数据,每一个观察值即对应一个频数,如某医院某年度一日内死亡0,1,2…20个病人的天数。
对于散布区间很大的离散数据和连续型数据,数据散布区间由若干组段组成,每个组段对应一个频数。
算术均数:描述一组数据在数量上的平均水平。
总体均数用μ表示,样本均数用 X 表示。
几何均数:用以描述对数正态分布或数据呈倍数变化资料的水平。
记为G。
中位数:将一组观察值由小到大排列,n为奇数时取位次居中的变量值;为偶数时,取位次居中的两个变量的平均值。
极差:亦称全距,即最大值与最小值之差,用于资料的粗略分析,其计算简便但稳定性较差。
内科医学实习笔记之欧阳法创编

内科医学实习笔记(2000年)第一部分:常用检验参考值(部分)血常规:RBC(红细胞计数)男(4-5.5)*10 女(3.5-5.0)*10HCT(红细胞压积)男40-50% 女37-48%MCV(平均红细胞体积)82-92flHGB(血红蛋白)男120-160g/L 女110-150g/LMCH(平均血红蛋白含量)27-31pgMCHC(平均血红蛋白浓度)310-350g/LPLT(血小板计数)(100-300)*10MPV(平均血小板容积)7-11flWBC(白细胞计数)(4-10)*10LYM(淋巴细胞)20-40%MID(单核细胞)1-8%GRA(中性粒细胞)50-70%血沉:(ESR)男0-15mm/h 女0-20mm/h凝血四项:PT(凝血酶原时间测定) 11-14秒APTT(活化部分凝血活酶时间) 男37±3.3秒,女37.5±2.8秒. TT(凝血酶时间测定) 16-18秒纤维蛋白原测定 2-4g/L(200-400mg%)尿常规:GLU(尿糖)BIL(胆红素)KET(酮体)SG(比重)1.020PH(酸碱度)PRO(蛋白质)URO(尿胆原)NIT(亚硝酸盐)BLO(潜血)LEU(白细胞)注:Negative(-)Trace(±)Small(+)Moderate(++)Large(+++)Positive(阳性)24小时尿蛋白定量:0-0.12g/日正常人总尿量:1000-2000ml/日空腹血糖:(BS)3.9-6.1mmol/L空腹(或餐后小时)胰岛素(INS):4.0-15.6IU/LC肽:0.55-3.8ng/ml肝功能:AST(谷草转氨酶)5-40u/LALT(谷丙转氨酶)0-40u/LTTT(麝香草酚浊度实验)1-6u乙肝五项(二对半):HBsAg(乙肝表面抗原)抗HBs(乙肝表面抗体)HBeAg(e抗原)抗HBe(e抗体)抗HBc(核心抗体)注:其中抗HBs、抗HBe为有益指标;抗HBc提示正在复制或既往已感染而现在已停止复制,故应结合其他标志综合判断。
南方医科大学病生考试重点整理之欧阳数创编

病生考试重点目前确定会出的简答题:休克第一期第二期呼吸衰竭一型二型绪论稍微看一下,可以了解大标题的内容。
病理生理学:研究疾病发生、发展规律及其机制的科学。
着重从功能与代谢角度探讨患病机体的生命活动规律,其任务是揭示疾病的本质,为疾病的防治提供理论和实验依据。
第一章疾病概论(2;0;0)名词解释:疾病(disease)病因作用下,机体自稳调节紊乱,发生的异常生命过程亚健康(sub-health)是指非健康非患病的中间状态死亡(death)是个体生命活动的终止,是生命的必然规律。
病因学的原因与条件辩证关系(如条件不一定致命等等)物理、化学、生物、营养、精神、先天、遗传、免疫(决定疾病特异性)疾病的原因是引起疾病必不可少的、决定疾病特异性的因素。
条件对于疾病不是必不可少的,但其存在可以影响病因对机体的作用。
原因和条件针对具体疾病而言,有时可以互相转化。
第三节的发病学普遍规律和基本机制都要掌握自稳态的失衡与调节,损害与抗损害规律(减轻损害,增强抗力),因果转化规律(打断恶性循环),局部与整体的影响。
神经。
体液。
细胞。
分子机制第二章水、电解质代谢紊乱(8;1;0)名词解释:低渗性脱水(hypotonic dehydration)以体液容量减少,失钠多于失水,血清钠浓度<130mmol/L,血浆渗透压<280mOsm/L为主要特征的病理变化过程。
高渗性脱水(hypertonic dehydration)以体液容量减少,失水多于失钠,血清钠浓度>150mmol/L,血浆渗透压>310mOsm/L为主要特征的病理变化过程。
等渗性脱水(isotonic dehydration)水与钠在正常血浆中等比例丢失引起的体液容量减少。
水肿(edema)过多的液体在组织间隙或体腔中积聚的病理过程水中毒(低血钠性体液容量过多,waterintoxication)给ADH分泌过多或肾排水功能低下的患者输入过多的水分时,引起水分潴留,伴有低钠血症在内的一系列症状和体征。
全科医学常见病之欧阳治创编

全科医学对常见病、多发病的急诊处理、诊疗规范及转诊要求一、发热1 定义:指致热原直接作用于体温调节中枢、体温中枢功能紊乱或各种原因引起的产热过多、散热减少,导致体温升高超过正常范围的情形。
按体温状况,发热分为:低热:37.3-38℃,中等发热:38.1-39℃;高热:39.1-41℃;超高热:41℃以上。
热型:稽留热、弛张热、双峰热、间歇热、波状热、回归热、不规则热。
2 伴随症状起病迅速,发热伴寒战者:多见于输液(血)反应、急性胆囊炎、急性肾盂肾炎、败血症、疟疾、大叶性肺炎等伴头痛、呕吐者:常见于感染性脑病、蛛网膜下腔出血、脑出血者伴咳嗽、胸痛者:常见于流感、肺炎、肺结核、胸膜炎、病毒性上呼吸道道感染伴肝(脾)肿大者:可见于伤寒、病毒性肝炎、肝脓肿、疟疾、血吸虫病、亚急性心内膜炎。
伴出血倾向者:可见于血液病、钩端螺旋体病、流行性出血热、急性溶血、流行性脑膜炎、恶性组织细胞病、急性白血病等伴腹痛者:应问清部位、性质、传导及压痛等伴皮疹者:应了解出疹次序、皮疹特点、是否伴有脱屑、皮肤瘙痒等伴昏迷者:先发热后昏迷常见于流行性乙脑、斑疹伤寒、流行性脑脊髓膜炎、中毒性痢疾、中暑等;先昏迷后发热见于脑出血、巴比妥类中毒等.3 相关检查(1)常规检查:血、尿、粪常规(2)器械检查:可根据病情需要选择B超、X线拍片等4 急诊处理(1)一般处理(2)降温(3)病因治疗(4)防止并发症注意:(1)必须详细询问病史(包括流行病史)、细致全面但有重点的体格检查、必要的实验室检查或其他检查之尽可能明确诊断,作出恰当处理(2)一时难以明确诊断时,应根据临床特点、发病季节、常规检查作出“倾向”性处理(3)合理选用退热措施:以物理降温为主,不要盲目使用激素退热(4)根据临床特征进行处理,应严密并动态观察5 转诊要求经初步处理后发热反复或效差,仍不能明确病因者,经降温、抗炎等对症处理病人生命体征平稳后再向上级医院转诊。
二、肺炎肺炎定义及分类:肺炎指终末气道、肺泡和肺间质的炎症,可由病原微生物、理化因素、免疫损伤、过敏及药物所致。
中医诊断笔记之欧阳术创编

一、中医诊断原则:整体审察;诊法合参;病证结合。
二、问诊:关于寒热的重点:1、风寒表证的主要临床症状特征是——恶寒重、发热轻。
2、风热表证的主要临床症状特征是——发热重、恶寒轻。
3、伤风表证的主要临床症状特征是——发热轻而恶风。
4、里实寒证的主要临床症状特征是——但寒不热。
5、里虚寒证的主要临床症状特征是——畏寒不热。
6、里实热证的主要临床症状特征是——壮热。
7、阳明实热的主要临床症状特征是——日晡潮热。
(申时PM:3-5时)8、阴虚发热的主要临床症状特征是——骨蒸潮热。
(午后或入夜)9、微热(低热)的主要分类——气虚;阴虚;血虚。
10、郁热的主要临床症状特征是——具有情志因素。
11、疟疾发热的主要临床症状特征是——寒热往来。
12、少阳病发热的主要临床症状特征是——寒热往来——病机为‘半表半里’。
关于汗的重点:1、自汗——气虚;阳虚——自汗时出,活动尤甚。
2、盗汗——阴虚;血虚——入睡汗出,醒则汗止。
3、绝汗——亡阴;亡阳——病情危重,大汗不止。
4、战汗——正邪相争——恶寒战栗而后汗出。
——病情的转折点。
5、头汗的基本病机分类——上焦热盛;中焦湿热蕴结;虚阳上越。
6、手足出汗——阴经郁热熏蒸;阳明热盛;脾虚湿盛。
7、半身出汗的特点——汗出自健侧。
关于疼痛的重点:1、区别疼痛的性质:胀、刺、冷、热(灼)、重、酸、绞、空、隐、窜。
2、阳明头疼——前额连眉棱骨。
3、太阳头疼——后头连项。
4、少阳头疼——两侧头疼。
5、厥阴头疼——颠顶头痛。
6、胁痛——责于肝胆。
7、胸痛与真心痛的区别——疼痛剧烈,‘手足青至节’(寒邪)。
8、区分胃脘、腹疼痛——前者为心下;后者为脐周。
头晕的重点:区分肝阳、湿热、气虚、阳虚、痰热、肾虚、瘀血。
心悸的类型:心胆气虚;心阳不振;心气不足;心血不足;心脉闭阻。
耳鸣的类型:耳鸣如蝉——多虚证。
耳鸣如潮——多本虚标实。
目眩,既‘眩晕’——视物旋转。
目昏,既‘目暗’——视物昏暗不清。
卫生经济学题库之欧阳育创编

卫生经济学1、卫生资源配置实际操作原则除了卫生资源高效利用外还应考虑 AA.供需平衡B.政府干预C.节约资源D.市场作用2、卫生资源计划配置方式说法错误的是 CA、以行政手段为主B、强调法律的作用C、卫生资源有效利用D、公平性3、卫生资源配置做好计划和市场调节的策略是 DA、合理确定计划控制与市场调节的力度、范围和层次B、正确处理以计划调节为主与市场调节为辅的关系C、正确处理卫生机构内部计划管理与市场调节的关系D、以上都是4、关于卫生资源配置总原则说法错误的是 DA、与国民经济相适应B、效率与公平兼顾C、考虑成本与效益D、以上都不是5、属于卫生资源中硬件资源的是 DA.卫生信息 B、卫生技术 C.卫生管理 D.卫生人力6、我国目前卫生资源配置通常不包括CA.床位设置B.卫生经费C.卫生信息D.卫生设备7、卫生资源优化配置除达到有效性外还应达到 AA、经济性B、针对性C、可控性D、完善性8、卫生资源配置效益评价常用的指标是 DA、居民卫生总费用B、人均卫生费用C、医护人员比例D、以上都是9、实施区域卫生规划的背景不包括 AA、传统卫生机构交叉管理(行政机构)B、原有体制卫生资源条块分割C、原有卫生服务体系不合理D、卫生资源短缺和浪费10、成本核算单元不包括 BA、服务量B、诊次C、病种D、床日11、对卫生服务价格波动影响不大的是 AA、价值量B、货币C、供求变化D、服务项目12、对于医疗卫生服务,下述属于医院直接成本的是 BA、后勤人员工资B、医疗器械C、院长办公式材料费D、以上都是13、随医疗服务产出量变化成本不按比例变化的成本是 DA、变动成本B、半固定成本C、半变动成本D、固定成本14、成本与环境变化没有关系的未来成本是 BA、可缩减成本B、既定成本C、增量成本D、机会成本15、医院成本差异分析中成本指数是下述那个不变的情况下考虑成本上涨的指数 AA、单元服务成本不变B、服务项目数不变C、货币价值不变D、供需不变16、医院总成本包括 DA、药品经营成本B、卫生材料费C、职工福利费用D、以上都是 17、我国医院医疗服务成本核算框架不包括 DA、医院成本核算B、科室成本核算C、服务项目成本核算D、卫生行政成本核算18、成本构成包括 DA、人力成本B、固定资产折旧C、公务费D、以上都是19、卫生事业单位定项补助是针对 DA、离退休人员工资B、预防保健工作补助C、医学重点学科建设D、以上都是20、卫生服务需求形成的条件中除消费者购买愿望外还有 AA.支付能力B.医生指导C.健康状况D.服务质量21、构成卫生服务主体的是:CA、认识到需要但没有转化为需求B、没有需要的需求C、消费者有购买愿望和能力且医生也认为必须的卫生服务D、消费者有购买愿望和能力但医生认为不必要的卫生服务22、卫生服务需求法则研究最主要的理论是:AA、需求量与价格之间的反向变动关系B、卫生服务需求影响因素分析C、需求量与价格之间的正向变动关系D、卫生服务需要与需求相互关系分析23、卫生服务需求特点说法错误的是:DA、消费者信息缺乏B、卫生服务需求的主动性主C、卫生服务利用的效益外在性D、卫生服务需求的不确定性24、影响需求弹性的因素中说法正确的是DA、某服务可替代的物品越多其弹性越小B、紧迫性的卫生服务其需求弹性小C、卫生服务持续时间短则需求弹性大D、门诊挂号费变化对卫生服务需求量变动很大25、下列说法错误的是 BA、替代品与卫生服务需求成正向关系B、互补品与卫生服务需求成反向关系C、时间成本较大者其卫生服务需求弹性较小D、医保起付线内与 D 线一致26、卫生服务供给者对卫生服务需求影响最主要的是CA、诱导需求B、服务质量C、服务价格D、以上都不是27、下列为富有弹性的需求曲线是:AA PB P D D QC PD D P D Q28、需求交叉弹性为正值表示两种服务:AA、具有替代功能B、具有互补功能C、相互独立D、以上都不是 29、构成供给的条件除外:DA、生产者须有生产愿望B、生产者须有出售愿望C、生产者须有供应能力D、消费者需求30、卫生服务供给的决定因素是:DA、生产者目标B、生产成本的变化C、产品的价格D、以上都是 31、卫生服务供给说法错误的是 CA、垄断性B、外部性C、供给者处于被动地位D、即时性32、卫生服务供给弹性说法正确的是:CA、弹性系数大于1、供给量的变化率小于价格的变化率表示富有弹性B、弹性系数小于 1、供给量的变化率小于价格的变化率表示富有弹性C、弹性系数大于 1、供给量的变化率大于价格的变化率表示富有弹性D、弹性系数等于 0 表示弹性无穷大33、卫生服务供给弹性的影响因素是:DA、供给者对服务价格变化后的产量调整能力B、时间因素C、替代品数目D、以上都是34、市场机制一般不包括:DA.价格机制B.竞争机制C.供求机制D.政府调控35、充分发挥市场机制作用的条件是: AA、经济信息对称B、规模增加使成本增加C、经济活动正外部效应D、以上都是36、公共物品特点是:CA、供给具有竞争性B、消费具有排他性C、具有较高的社会效益D、公共物品市场均较活跃37、下列说法正确的是:CA、必须消费品价格弹性大B、特须消费品需求价格弹性小C、必须消费品成本效益好D、特须消费品成本效益好38、卫生服务市场供需信息不对称的结果是:CA、服务价格降低B、服务量萎缩C、供给者道德损害D、消费者过多利用39、卫生服务垄断的结果是:DA、服务质量下降B、低效率C、技术进步受限D、以上都是40、下列说法正确的是: BA、市场调节能兼顾公平和效率B、市场机制不能解决宏观总量的平衡问题C、市场机制可使卫生服务待续发展D、市场调节是二次调节41、卫生服务市场中完全的市场需求调节结果是:DA、公共卫生服务产品充分供给B、无须政府干预C、能解决总量控制问题D、导致不公平和效率低下42、政府与市场在卫生领域中的作用是:CA、准公共物品市场作用增强B、特需医疗产品政府作用增强C、准公共物品政府作用增强D、特需医疗产品市场作用增强43、医疗机构成本核算中应掌握医疗卫生服务成本信息者除外: BA、医院内工作人员B、患者C、保险部门D、卫生行政人员一、单项选择题1、卫生服务需求曲线是一条 AA 自左上方向右下方倾斜的曲线B 自右上方向左下方倾斜的曲线C 凹向原点的曲线D 凸向原点的曲线2、下列属于卫生服务机构长期成本要研究的内容是 (D )A 机会成本B 固定成本C 变动成本D 平均成本3、卫生服务费用支付具有多源性,下列不属于此范围的是(D )A 政府的支付B 社会的支付C 保险的支付D 医生的支付4、某项经济指标的各个组成部分与总体的比率,反映部分与总体关系的是(C)A 相关比率B 效率比率C 构成比率D 财务比率5、医疗保险需求增加的因素之一,是因为疾病发生概率接近于(B ) A0 B 0.5 C1 D26、政府对卫生服务价格的调控管理应严格价格监督和(A)A 合理规定价格水平B 依法制定价格C 计划指导价格D 计划指令价格7、下列不属于政府在卫生服务领域所发挥作用的内容的是(D)A 政府是卫生事业的建设者B 政府是卫生事业的组织者C 政府是卫生事业的宏观调控者D 政府是卫生事业的指挥者和监督者8、在卫生服务必需消费品中,政府作用最强的是BA 必需医疗产品B 必需预防产品C 必需保健产品D 必需康复产品 9、下列属于卫生服务特需消费品的是( C)A 急诊症治疗服务B 戒烟服务C 器官移植D 计划免疫服务10、卫生服务供给的价格弹性系数大于 1,表示 BA 完全弹性B 富有弹性C 缺乏弹性D 单位弹性11、在生产函数中,规模报酬递减则(D)A α+β>0B α+β<0C α+β>1D α+β<112、卫生服务的生产行为和消费行为是同时发生的,这是指(D)A 反应性B 敏感性C 相关性D 即时性13、某医院 3 年后筹资 100 万元建一外科病房,若今后 3 年银行利率为 8%, 3 年中平均每年应当向则银行存入(A)A 30.8034 万元B 33.3333 万元C 35 万元D 30 万元答:整付现值计算设平均每年存入X 万元X+X(1+8%)+X(1+8%)2=100 X=100/1+(1+8%)+(1+8%)2=100/3.2464=30.803414、某医院花9 万元买一台医疗设备开展新医疗服务,第一年、第二年、第三年的净收入分别为 3 万元、4 万元、5 万元。
临床试验术语之欧阳音创编

临床试验代表含义: 指任何在人体(病人或健康志愿者)进行药物的系统性研究,以证实或揭示试验药物的作用、不良反应及/或试验药物的吸收、分布、代谢和排泄,目的是确定试验药物的疗效与安全性。
Ⅰ临床研究代表含义: 首次在人体进行研究药物的周密试验计划,受试对象是少量(开放20~30例)正常成年健康自愿者。
目的是观察药物在人体内的作用机制。
Ⅱ临床研究代表含义: 在只患有确立的适应症的病患者(盲法不小于100对)上进行的研究,目的是找出最佳的剂量范围和考虑治疗可行性Ⅲ临床研究代表含义: 确定研究药物的有效性和安全性、受益和危害比率。
(试验组不小于300例。
)Ⅳ临床研究代表含义: 新药获准注册上市后的大型研究,检察普遍临床使用时的不良反应和毒性。
药品临床试验管理规范代表含义: 对临床试验的设计、实施和执行,监查、稽查、记录、分析和报告的标准。
该标准是数据和报告结果的可信和精确的保证;也是受试者权益、公正和隐私受保护的保证。
伦理委员会代表含义: 是指一个由医学,科学专业人员及非医学,非科学人员共同组成的独立体,其职责是通过对试验方案、研究者资格、设备、以及获得并签署受试者知情同意书的方法和资料进行审阅、批准或提出建议来确认临床试验所涉及的人类受试者的权益、安全性和健康受到保护,并对此保护提供公众保证。
申办者代表含义: 发起一项临床试验,并对该试验的启动、管理、财务和监查负责的公司、机构或组织。
研究者代表含义: 实施临床试验并对临床试验的质量及受试者安全和权益的负责者。
研究者必须经过资格审查,具有临床试验的专业特长、资格和能力。
协调研究者代表含义: 在多中心临床试验中负责协调参加各中心研究者工作的一名研究者。
监查员代表含义: 由申办者任命并对申办者负责的具备相关知识的人员,其任务是监查和报告试验的进行情况和核实数据。
合同研究组织代表含义: 一种学术性或商业性的科学机构。
申办者可委托其执行临床试验中的某些工作和任务,此种委托必须作出书面规定。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
医师资格考试蓝宝书预防医学欧阳家百(2021.03.07)医学统计学方法第一节基本概念和基本步骤(非常重要)一、统计工作的基本步骤设计(最关键、决定成败)、搜集资料、整理资料、分析资料。
总体:根据研究目的决定的同质研究对象的全体,确切地说,是性质相同的所有观察单位某一变量值的集合。
总体的指标为参数。
实际工作中,经常是从总体中随机抽取一定数量的个体,作为样本,用样本信息来推断总体特征。
样本的指标为统计量。
由于总体中存在个体变异,抽样研究中所抽取的样本,只包含总体中一部分个体,这种由抽样引起的差异称为抽样误差。
抽样误差愈小,用样本推断总体的精确度愈高;反之,其精确度愈低。
某事件发生的可能性大小称为概率,用P表示,在0~1之间,0和1为肯定不发生和肯定发生,介于之间为偶然事件,<0.05或0.01为小概率事件。
二、变量的分类变量:观察单位的特征,分数值变量和分类变量。
第二节数值变量数据的统计描述(重要考点)一、描述计量资料的集中趋势的指标有1.均数均数是算术均数的简称,适用于正态或近似正态分布。
2.几何均数适用于等比资料,尤其是对数正态分布的计量资料。
对数正态分布即原始数据呈偏态分布,经对数变换后(用原始数据的对数值lgX代替X)服从正态分布,观察值不能为0,同时有正和负。
3.中位数一组按大小顺序排列的观察值中位次居中的数值。
可用于描述任何分布,特别是偏态分布资料的集中位置,以及分布不明或分布末端无确定数据资料的中心位置。
不能求均数和几何均数,但可求中位数。
百分位数是个界值,将全部观察值分为两部分,有X%比小,剩下的比大,可用于计算正常值范围。
二、描述计量资料的离散趋势的指标1.全距和四分位数间距。
2.方差和标准差最为常用,适于正态分布,既考虑了离均差(观察值和总体均数之差),又考虑了观察值个数,方差使原来的单位变成了平方,所以开方为标准差。
均为数值越小,观察值的变异度越小。
3.变异系数多组间单位不同或均数相差较大的情况。
变异系数计算公式为:CV=s/×100%,公式中s为样本标准差,为样本均数。
三、标准差的应用表示观察值的变异程度(或离散程度)。
在两组(或几组)资料均数相近、度量单位相同的条件下,标准差大,表示观察值的变异度大,即各观察值离均数较远,均数的代表性较差;反之,表示各观察值多集中在均数周围,均数的代表性较好。
(常考!)四、医学参考值的计算方法,单双侧问题,医学为95%医学参考值是指正常人体或动物体的各种生理常数,由于存在变异,各种数据不仅因人而异,而且同一个人还会随机体内外环境的改变而改变,因而需要确定其波动的范围,即正常值范围。
医学参考值的计算公式:①正态分布资料95%医学参考值:±1.96s(双侧);+1.645s或 1.645s(单侧),s为标准差。
②百分位数法P2.5和P97.5(双侧);P5或P95(单侧)。
第三节数值变量数据的统计推断(重要考点)一、标准误,标准误与标准差和样本含量的关系标准差和标准误的区别。
样本标准误等于样本标准差除以根号下样本含量。
标准误与标准差成正比;与样本含量的平方根成反比。
因此。
为减少抽样误差,应尽可能保证足够大的样本含量。
样本标准差与样本标准误是既有联系又有区别的两个统计量,二者的联系是公式:二者的区别在于:样本标准差是反映样本中各观测值X1,X2,……,Xn变异程度大小的一个指标,它的大小说明了对该样本代表性的强弱。
样本标准误是样本平均数1,2,……的标准差,它是抽样误差的估计值,其大小说明了样本间变异程度的大小及精确性的高低。
(掌握!)二、t分布和标准正态u分布关系均以0为中心左右两侧完全对称的分布,只是t分布曲线顶端较u分布低,两端翘。
(v逐渐增大,t分布逐渐逼近u分布)。
正态分布的特点:①以均数为中心左右两侧完全对称分布;②两个参数,均数u(位置参数)和s(变异参数);③对称均数的两侧面积相等。
三、总体均数的估计样本统计量推算总体均数有两个重要方面:区间估计和假设检验。
样本均数估计总体均数称点估计。
总体均数区间估计(可信区间)的概念:按一定的可信度估计未知总体均数所在范围。
其统计上习惯用95%(或99%)可信区间表示总体均数μ有95%(或99%)的可能在某一范围。
可信区间的两个要素,一为准确度,反映在可信度1α的大小,即区间包含总体均数的概率大小,当然愈接近1愈好;二是精度,反映在区间的长度,当然长度愈小愈好。
在样本例数确定的情况下,二者是矛盾的,需要兼顾。
总体均数可信区间的计算方法:1.当n小按t分布的原理用式计算可信区间为:±tα/2,vS2.当n足够大因n足够大时,t分布逼近μ分布,按正态分布原理。
用式估计可信区间为:±μα/2S可信区间与医学参考值范围的区别:二者的意义和算法不同。
四、假设检验的步骤1.建立假设:H0(无效,两样本代表的总体均数相同),H1(备择,两样本来自不同总体),当拒绝H0就接受H1,不拒绝就不接受H1。
2.确定显著性水平:区分大概率和小概率事件的标准,通常取α=0.05。
3.计算统计量:根据资料类型和分析目的选择适当的公式计算。
4.确定概率P值:将计算得到的t值或u值查界值表得到P值和α值比较。
5.做出推断结论。
|t|值、P值与统计结论五、两均数的假设检验(常考!)1.样本均数与总体均数比较u检验和t检验用于样本均数与总体均数的比较。
理论上要求样本来自正态分布总体实际中,只要样本例数n较大,或n小但总体标准差σ已知,就选用u检验。
n 较小且σ未知时,用于t检验。
两样本均数比较时还要求两总体方差等。
以算得的统计量t,按表所示关系作判断。
2.配对资料的比较在医学研究中,常用配对设计。
配对设计主要有四种情况:①同一受试对象处理前后的数据;②同一受试对象两个部位的数据;③同一样品用两种方法(仪器等)检验的结果;④配对的两个受试对象分别接受两种处理后的数据。
情况①的目的是推断其处理有无作用;情况②、③、④的目的是推断两种处理(方法等)的结果有无差别。
v=对子数1;如处理前后或两法无差别,则其差数d的总体均数应为0,可看作样本均数和总体均数0的比较。
为差数的均数;为差数均数的标准误,Sd为差数的标准差;n为对子数。
因计算的统计量是t,按表所示关系作判断。
3.完全随机设计的两样本均数的比较亦称成组比较。
目的是推断两样本各自代表的总体均数μ1与μ2是否相等。
根据样本含量n的大小,分u检验与t检验。
t检验用于两样本含量n1、n2较小时,且要求两总体方差相等,即方差齐。
若被检验的两样本方差相差显著则需用t′检验。
u检验:两样本量足够大,n>50。
=v=(n11)+(n21)=n1+n22式中,为两样本均数之差的标准误,Sc2为合并估计方差(combined estimate variance)。
算得的统计量为t,按表所示关系做出判断。
4.Ⅰ型错误和Ⅱ型错误弃真,拒绝正确的H0为Ⅰ型错误α表示,若显著性水平α定为0.05,则犯Ⅰ型错误的概率0.05;接受错误的H0为Ⅱ型错误,概率用β表示,β值的大小很难确切估计。
当样本含量一定时,两者反比,增大n,当α一定时,可减少β。
1β称为检验效能或把握度,其统计意义是若两总体确有差别,按α水准能检出其差别的能力。
客观实际拒绝H0 不拒绝H0H0成立Ⅰ型错误(α)推断正确1αH0不成立推断正确(1β)Ⅱ型错误(β)5.假设检验注意事项保证组间可比性;根据研究目的、资料类型和设计类型选用适当的检验方法,熟悉各种检验方法的应用条件;“显著与否”是统计学术语,为“有无统计学意义”,不能理解为“差别是不是大”;结论不能绝对化。
第四节分类变量资料的统计描述(一般考点)相对数是两个有关联事物数据之比。
常用的相对数指标有构成比、率、相对比等。
一、构成比表示事物内部各个组成部分所占的比重,通常以100为例基数,故又称为百分比。
其公式如下:构成比=×100%该式可用符号表达如下:构成比=×100%构成比有两个特点:(1)各构成部分的相对数之和为100%.(2)某一部分所占比重增大,其他部分会相应地减少。
二、率用以说明某种现象发生的频率或强度,故又称频率指标,以100,1000,10000或100000为比例基数(K)均可,原则上以结果至少保留一位整数为宜,其计算公式为:率和构成比不同之处:率的大小仅取决于某种现象的发生数和可能发生该现象的总数,不受其他指标的影响,并且各率之和一般不为1。
率=×K该式亦可用符号表达如下阳性率=×K(若算阴性率则分子为A())式中A(+)为阳性人数,A()为阴性人数。
三、相对比表示有关事物指标之对比,常以百分数和倍数表示,其公式为:相对比:甲指标/乙指标(或×100%)或用符号表示为:A/B×K四、注意事项①构成比和率的不同,不能以比代率;②计算相对数时,观察例数不宜过小;③率的比较注意可比性,特别是混杂因素的问题,有的话,可用标准化法和分层分析消除;④观察单位不同的几个率的平均率不等于几个率的算术均数;⑤样本率或构成比的比较应做假设检验。
第五节分类变量资料的统计推断(非常重要)一、率的抽样误差用抽样方法进行研究时,必然存在抽样误差。
率的抽样误差大小可用率的标准误来表示,计算公式如下:σp=式中:σp为率的标准误,π为总体阳性率,n为样本含量。
因为实际工作中很难知道总体阳性率π,故一般采用样本率P来代替,而上式就变为Sp=二、总体率的可信区间由于样本率与总体率之间存在着抽样误差,所以也需根据样本率来推算总体率所在的范围,根据样本含量n和样本率P的大小不同,分别采用下列两种方法:(一)正态近似法(常考!)当样本含量n足够大,且样本率P和(1P)均不太小,如nP 或n(1P)均≥5时,样本率的分布近似正态分布。
则总体率的可信区间可由下列公式估计:总体率(π)的95%可信区间:p±1.96sp总体率(π)的99%可信区间:p±2.58sp(二)查表法当样本含量n较小,如n≤50,特别是P接近0或1时,则按二项分布原理确定总体率的可信区间,其计算较繁,读者可根据样本含量n和阳性数x参照专用统计学介绍的二项分布中95%可信限表。
三、u检验(非常重要!)当样本含量n足够大,且样本率P和(1P)均不太小,如nP 或n(1P)均≥5时,样本率的分布近似正态分布。
样本率和总体率之间、两个样本率之间差异的判断可用u检验。
1.样本率和总体率的比较公式u=|Pπ|/σP=|Pπ|/;2.两样本率比较公式u=|P1P2|/Sp1P2=|P1P2|/也可用χ2检验,两者相等。
四、χ2检验(非常重要!)可用于两个及两个以上率或构成比的比较;两分类变量相关关系分析。