grads处理多个ctl文件和nc文件
grads读取nc格式文件

grads读取nc格式⽂件
⼀、通常:
1、grads读取grd和ctl:open ****.ctl
2、执⾏gs脚本:run ****.gs
d命令,display展⽰数据,常⽤来显⽰变量,⽐如rh,rain等
q命令,显⽰数据内容,常⽤来显⽰数据,⽐如时间dim,ctlinfo等
gs脚本中,输出打印变量的值,⽤say命令
⼆、grads也可以读取nc⽂件
1 打开数据
命令:sdfopen +数据存放路径
2 查看nc数据的ctl
命令:q ctlinfo (注意查看缺省值,变量名等。
不同的nc数据缺省值通常不同,这点容易忽略)
3 ⽤fwrite命令提取数据,得到grd⽂件
'set gxout fwrite'
'set fwrite d:\*.grd'
.
'disable fwrite'
4 ⽤fortran读取⼆进制⽂件
读取时要注意,grads写⼊的数据循环从内到外依次为x 、y、z、变量、t,如果你需要确定某个数据的位置,那么,x是从西到东,y是从南到北,z是从地⾯到⾼空,t是从前到后的顺序。
(具体详见⽓象家园‘ grads提取nc数据及进⼀步编程常见问题及解决⽅法’)
三、将nc⽂件转换成grd和ctl。
GrADS学习资料:实习五各类参数设置综合练习 实习六

it=1
while(it<=5)
‘set lev 500 ’
‘set lon 120 270’ ‘set lat –10 10’
(设置维数环境)
‘set t ‘it’’
‘d u ’
it=it+1
endwhile
‘disable fwrite’
(关闭文件u.grd)
实习六 练习描述语言的使用
ctl写法见第二章,注意数据的维度设置要 按照数据实际大小来设置。
缺测值一定要与原数据一致。
fortran转换数据,与第一个实习刚好相反, 自己编程.
3.实习要求: 2)根据所得数据资料,利用For十进制数据文件sst.txt。 3)根据所得sst.grd数据文件,编写相应的数
据描述文件sst.ctl,并绘制图形。请将所绘 图形与使用原来sst.mnmean.nc资料在相同维 数环境下所画图形进行比较,看是否一致。
1. 实习目的: 掌握GrADS软件数据提取方法,学会资料处
理。
实习六 练习描述语言的使用
2.实习资料:
“data”文件夹下有全球海表温度资料 sst.mnmean.nc。
注意:海温时间从1854年1月开始。
nc文件打开:sdfopen 路径\ sst.mnmean.nc
nc文件的维数设置、格距、缺测值的查询: q ctlinfo
实习五 各类参数设置综合练习
3. 实习要求: 利用所提供的数据文件,编写.gs文件:
绘制出2002年1-12月120 E、 0-40N 200hPa 纬向风的纬度-时间剖面图。
(1)纬向风为西风时填色,东风绘制等值线, 给出色标,0值线加粗;
(2)X轴标注为“time”,Y轴标注为“lat”,标 题标注为“u 120E”。
grads处理多个ctl文件和nc文件

grads处理多个ctl文件和nc文件2011-10-10 21:03:59| 分类:grads学习| 标签:|举报|字号大中小订阅下载LOFTER我的照片书 |用grads处理多个相同格式的数据时若单个单个处理非常麻烦,当文件非常多的时候是单个处理是不实际的。
下面介绍一种方法;第一步,在这种情况下可以重新写一个ctl描述文件,其文件变量都和已知的ctl相同,若原来的n 文件只是时间不同,那么新描述文件的时间维数是所有原文件的时间的和。
同样,若其他维数不同时也用同样的方法处理。
第二步,在第一行之后添加一行:options template 表示多个时间序列原始数据文件想用一个描述文件统一地描述。
这些原数据的原文件名由dset定义的形势命名文件名。
第三步,修改dset 的文件名。
原路径不变,把文件名用%表示。
其中:%y2 代表两位数年%y4 代表四位数年%m1 代表一位或者两位数的月%m2 代表两位数月(用0补齐1位数)%mc 3个字符月份的缩写%d1 1或2位天%d2 两位天%h1 1或者2位时%h2 2位时例如:原文件其中之一的文件名为gdas2006050812f00,且所有文件只有天和时的变化那么新描述文件的文件名为:gdas200605%d2%h2f00另外如果源文件里有index项的话,需要修改其idx的文件名,假设改成fnl.idx。
并用在dos下用gribmap函数生成一个新的idx文件。
gribmap -e -i fnl.ctl(加绝对路径)open fnl.ctl就可以打开所有文件。
*************************************************************************************************************** *******************若想要提取从1951-2006年56年nc文件中的某些数据,一个一个处理非常麻烦,这里介绍种较为简易的方法。
IDL、GRAD、NCL绘图命令对应关系一览表

IDL、NCL、GRADS、MATLAB绘图命令对应关系一览表1.grads的数据文件与ncl的什么文件对应?grads只支持按照一定顺序存储的二进制数据文件,后缀名以.grd或者.dat或者.grb结束。
这种数据必须以时间为最外层,然后每个变量按照向量形式存储,每个变量由外向内的存储顺序是高度(或等压面)==》纬度==》经度。
这必须注意,否则画图容易出现一堆一堆的乱线条,这就说明你的数据没有按照grads的要求存储。
再看看ncl,可以说ncl支持绝大多数各种数据的读写,包括netcdf,hdf,以及二进制数据甚至ASCII码(如果说是十进制数据或许你会更熟悉),前两种数据一般都有头文件,不能用C 语言或者Fortran读取,都需要插件才可以读取,ncl可以直接读取,matlab中也可以直接读取NETCDF格式(.nc)的数据。
grads中可以读取按照说明存取的NC数据,这种数据必须又正确的时间说明,也就是说时间必须是真实的,有些模式模拟出来的数据grads的sdfopen 命令是打不开的,因为一般模式都是nonleap run,都是平年,没有设定闰年,造成了时间说明不真实,grads就会报错。
那么grads'如何使用NC数据呢?所以建议使用ncl转换数据,将NC数据,hdf数据或者十进制数据转换成grd数据,供grads使用。
这样说明是在是太空洞了,那么下面我举个例子吧。
eg1) 使用grads将netcdf数据转换成grd数据'reinit'var.1='air';var.2='hgt';var.3='uwnd'var.4='vwnd';var.5='omega';var.6='shum'j=6while (j<=6)'set fwrite/disk3/users/Rao_Jian/ERA-Interim-daily/entropy/'var.j'.daily.1979-2010.grd' 'set gxout fwrite'i=1979while (i<=2010)'sdfopen/disk3/users/lbq/ERA-Interim-daily/pressure/'var.j'.interim.'i'.nc'tt=1if(i=1980|i=1984|i=1988|i=1992|i=1996|i=2000|i=2004|i=2008)while (tt<=366)'set t 'ttzz=1while (zz<=37)'set x 1 240''set y 1 121''set z 'zz'd 'var.j''zz=zz+1endwhilett=tt+1endwhileelsewhile (tt<=365)'set t 'ttzz=1zz=1while (zz<=37)'set x 1 240''set y 1 121''set z 'zz'd 'var.j''zz=zz+1endwhilett=tt+1endwhileendifi=i+1name='/disk3/users/lbq/ERA-Interim-daily/pressure/'var.j'.interim.'i'.nc''close 1'endwhile'disable fwrite'j=j+1endwhileeg2)使用ncl将数据输出成二进制数据,grads可以使用(截取部分)patho = "/disk3/users/Rao_Jian/Hadley/"system("rm "+patho+"ev_ts.grd")system("rm "+patho+"ev_ts2.grd")system("rm "+patho+"ev_ts.txt")system("rm"+patho+"ev_ts2.txt")do nt=0,719fbindirwrite(patho+"ev_ts.grd",ev_ts(:,nt));写成二进制数据,供grads使用end dofbindirwrite(patho+"ev_ts2.grd",ev_ts(time|:,evn|:))asciiwrite(patho+"ev_ts.txt",ev_ts(time|:,evn|:));写成十进制数据,可以贴到EXCEL中使用asciiwrite(patho+"ev_ts2.txt",ev_ts);print(ev_ts(0,:))此外ncl中还有其他的读写函数,如fbinrecread,fbinrecwrite,fbinwrite,fbinreadncl读取netcdf3/4、hdf4、grib-1/2也是通过文件操作的eg3)ncl支持直接读取格式文件的读法fi = addfile(pathi+"HadISST_sst.nc","r")sst0 =fi->sst(960:1679,:,:) ; load 50 year data duringfrom 1950 to 2009注意:这类文件的后缀名一般为.nc /.hdf/ .grb/.hdfeos/.ccm2.grads中的描述文件与ncl中的什么对应描述文件(.ctl)是一个纯文本文件,我们有数据grads还是不能出图,需要一个描述文件来指定他的存储数据个数,维度(时间长度、层数和经纬度信息)。
关于nc文件的读取

关于nc文件的读取2012-11-02 21:47:01| 分类:信号处理DSP | 标签:nc文件 panoply |举报|字号订阅最近在学习冰后回弹模型(http://www.atmosp.physics.utoronto.ca/~peltier/data.php),里面给出的数据为nc(netcdf)格式的,读取是个问题,在言深深的帮助下,成功读取,在这里将其总结出来,以备后用也希望可以方便有用之人。
有几种方式可以进行读取:1、Excel的一个插件,NetCDF4Excel可以完成相关的查看工作,需要的可以进行下载。
安装之后,我们可以得到,一个快捷方式,如图:打开之后,最上面标题栏点击加载项,我们可以看到下面的情形:然后打开nc文件,我们就可以进行查看操作:2、通过Grads进行相关的读取,主要是在言深深同学的帮助下完成,深深的感谢!第一步,安装相关的grads软件,这个这里不做介绍,相关可以参考气象论坛网站;第二步,打开grads软件,如图,回车之后的那个窗口千万不能关,那个窗口是图像显示的,关闭之后输入命令之后直接就退出了,刚开始我老犯这个低级错误(对菜鸟而言)。
第三步,可以通过两个命令简单的看到数据的头文件包含信息:①sdfopen d:\1.nc②q ctlinfo1.nc文件然后编写gs文件,如下:'reinit''sdfopen D:\1.nc''set gxout fwrite''set fwrite D:\1.dat''set x 1 360''set y 1 180''set z 1''set t 1 1''d dsea_250''disable fwrite'ps1:路径自己可以按需更改,不要有空格。
ps2:这里的dsea_250可不是随便取的,看上面的ctlinfo心里里最后一行,必须要一致!然后就可以生成一个1.dat的文件。
GrADS读取NetCDF和HDF的ctl文件SDF文件的描述文件

GrADS读取NetCDF和HDF的ctl⽂件SDF⽂件的描述⽂件翻译⾃使⽤GrADS阅读NetCDF和HDF⽂件NetCDF和HDF格式的⽂件被称作⾃描述⽂件(self-describing file, SDF),因为数据和元数据⼀块保存在同⼀个⽂件中。
GrADS可以读取NetCDF和HDF格式的⽂件,只要数据是存储在⼀个规范⽹格。
HDF格式是⾮常通⽤的;GrADS接⼝仅适⽤于5-D的(lon/lat/lev/time/ensemble)⽹格化数据集。
GrADS处理HDF4科学数据集和部分HDF5⽂件。
为了读取⾃描述⽂件SDF,GrADS需要⼀个特定的源数据为了将,GrADS需要⼀定数量的元数据,从⽽将数据放置在内部⽹格空间中。
有三种⽅式可以做到这些:1. 使⽤命令打开⽂件。
这为⽤户省去了最少的⼯作-只需提供⽂件名(或OPeNDAP URL),其余的⼯作由GrADS完成。
如果使⽤sdfopen命令打开SDF,则GrADS所需的⽂件中的所有元数据都必须符合。
"sdfopen"界⾯不⽀持HDF5格式。
如果sdfopen不起作⽤,则...2. 使⽤命令打开⽂件。
这需要进⾏更多的⼯作-您必须编写⼀个数据描述⽂件来补充或替换现有的元数据,以便GrADS能够理解它。
xdfopen使⽤的描述符⽂件的语法与栅格化⼆进制数据(gridded binary data)的描述符⽂件中使⽤的语法不完全相同-有关更多详细信息,请参见。
xdfopen命令提供对更多SDF⽂件的访问,包括许多不符合任何已知标准的SDF。
"xdfopen"界⾯不⽀持HDF5格式。
如果xdfopen不起作⽤,则...3. 使⽤命令打开⽂件。
这要求⽤户编写⼀个完整的GrADS描述符⽂件,以覆盖⽂件中的所有元数据。
下⾯给出了为NetCDF,HDF-SDS或HDF5⽹格数据⽂件组成完整描述符⽂件的指南。
另请参考。
grads批处理ctl文件和用cmd生成idx文件的步骤

grads批处理ctl文件和用cmd生成idx文件的步骤(2009-07-31 14:30:09)
分类:科研笔记标签:grads软件ctl idx批处理气
象教育
一:grads批处理涉及idx文件的grib资料时,编辑grads批处理所需要的ctl文件:(一般可以把已存在的第一个时次的ctl文件进行更改后另存为一个新的ctl文件即可,比如本次批处理的原来的ctl名字都是200206xxxx.ctl形式,则可以新建一个200206.ctl 作为grads将来要调用的ctl文件)
)
grib200206%d2%h2时间循环
options template多个时间序列原始数据文件想用一个数据描述文件统一地描述这些原始数据时采用的选项。
必不可少,且注意其位置。
grib200206.idx将要生成的idx文件
120本次批处理总共的时次个数
00Z01jun2002批处理的起始时间
6hr相邻时次的时间间隔
其他的部分不需要更改。
二:用cmd生成idx文件
进入cmd界面
“>”后输入’gribmap –e’,然后回车键,出现以下界面
提示行后输入ctl文件的路径和名字
按回车键后开始运行
运行结束后显示以下界面,idx文件生成。
至此,有了ctl文件和idx文件,然后就可以用GrADS软件快速方便的进行批处理了。
GrADSctl文件编写

Components of a GrADS Data Descriptor FileDSET data_filenameback to topThis entry specifies the filename of the data file being described. If the data and the descriptor file are not in the same directory, then data_filename must include a full path. If a ^ character is placed in front of data_filename,then data_filename is assumed to be relative to the path of the descriptor file. If you are using the ^ character in the DSET entry, then the descriptor file and the data file may be moved to a new directory without changing any entries in the data descriptor file, provided their relative paths remain the same. For example:If the data descriptor file is:/data/wx/grads/sa.ctland the binary data file is:/data/wx/grads/sa.datthen the data file name in the data descriptor file can be:DSET ^sa.datinstead of:DSET /data/wx/grads/sa.datIf data_filename does not include a full path or a ^, then GrADS will only look for data files in the directory where you are running GrADS.GrADS allows you use a single DSET entry to aggregate multiple data files and handle them as if they were one individual file. The individual data files must be identical in all dimensions except time, and the time range of each individual file must be indicated it its filename. To accomplish this, the DSET entry has a substitution template instead of a filename. See the section on Using Templates for a description of all the possible components of the template. Second, the OPTIONS entry must contain the template keyword.CHSUB t1 t2 stringback to top(GrADS version 1.9b4) This entry is used with a new option for templating data files that allows for any user-specified string substitution, instead of only date string substitution. This is useful when none of the standard template options match the time ranges in the files you wish to aggregate, or if the files are located on different disks. When you put the %ch template inyour DSET entry, then you also need to put additional CHSUB entries in the descriptor file. The string will be substituted for%ch in the data file name for the time steps beginning with t1 and ending with t2.See the section on Using Templates for examples.DTYPE keywordback to topThe DTYPE entry specifies the type of data being described. There are four options: grib, hdfsds, netcdf, or station. If the data type is none of these, then the DTYPE entry is omitted completely from the descriptor file and GrADS will assume the data type is gridded binary.bufr (GrADS version 1.9) Data file is a BUFR station data file. This data type must be accompanied by the following special entries: XVAR, YVAR, TVAR, STID. Optional special entries are: ZVAR, TOFFVAR.grib Data file is an indexed GRIB (version 1) file. This data type requires a secondary entry in the descriptor file:INDEX. The INDEX entry provides the filename (including the full path or a ^) for the GRIB index file. Theindex file is created by the gribmap utility. You must run gribmap and create the index file before you candisplay the GRIB data in GrADS.grib2 (GrADS version 2.0) Data file is an indexed GRIB2 file. This data type requires a secondary entry in the descriptor file: : INDEX. The INDEX entry provides the filename (including the full path or a ^) for the GRIB2index file. The index file is created by the gribmap utility. You must run grib2map and create the index filebefore you can display the GRIB2 data in GrADS.hdfsds (GrADS version 1.9) Data file is an HDF Scientific Data Set (SDS). Although HDF-SDS files are self-describing and may be read automatically using the sdfopen/xdfopen commands, this DTYPE gives youthe option of overriding the file's own metadata and creating a descriptor file for some or all of the variablesin the file. This DTYPE may also be used if the metadata in the HDF-SDS file is insufficient or is notcoards-compliant. This data type requires a special entry in the units field of the variabledeclaration. The undef and unpack entries contain special options for this dtype.hdf5_grid (GrADS version 2.0.a7+) Data file is HDF5 gridded format. The HDF5 format is extremely general and is designed to store a variety of data types. The GrADS interface is only for grids, and requires a completedescriptor file -- there is no sdfopen/xdfopen interface for HDF5.netcdf (GrADS version 1.9) Data file is NetCDF. Although NetCDF files are self-describing and may be read automatically using the sdfopen/xdfopen commands, this DTYPE gives you the option of overriding the file'sown metadata and creating a descriptor file for some or all of the variables in the file. This DTYPE may alsobe used if the metadata in the NetCDF file is insufficient or is not coards-compliant. This data type requires aspecial entry in the units field of the variable declaration. The undef and unpack entries contain specialoptions for this dtype.station Data file is in GrADS station data format. This data type requires a secondary entry in the descriptor file: STNMAP. The STNMAP entry provides the filename (including the full path or a ^) for the station data mapfile. The map file is created by the stnmap utility. You must run stnmap and create the map file before youcan display the station data in GrADS.INDEX filenameback to topThis entry specifies the name of the grib map file. It is required when using the DTYPE grib or grib2 entry to read GRIB formatted data. The file is generated by running the external utility gribmap. or grib2map. Filenaming conventions are the same as those described for the DSET entry.STNMAP filenameback to topThis entry specifies the name of the station map file. It is required when using the DTYPE station entry to readGrADS-formatted station data. The file is generated by running the external utility stnmap. Filenaming conventions are thesame as those described for the DSET entry.TITLE stringback to topThis entry gives brief description of the contents of the data set. String will be included in the output from a query command and it will appear in the directory listing if you are serving this data file with the GrADS-DODS Server (GDS), so it is helpful to put meaningful information in the title field. For GDS use, do not use double quotation marks (") in the title.UNDEF value<undef_attribute_name>back to topThis entry specifies the undefined or missing data value. UNDEF is a required entry even if there are no undefined data. GrADS operations and graphics routines will ignore data with this value from this data set.(GrADS version 1.9b4) An optional second argument has been added for data sets of DTYPE netcdf or hdfsds -- it is the name of the attribute that contains the undefined value. This should be used when individual variables in the data file have different undefined values. After data I/O, the missing values in the grid are converted from the variable undef to the file-wide undef (the numerical value in the first argument of the UNDEF record). Then it appears to GrADS that all variables have the same undef value, even if they don't in the original data file. If the data require a transformation using the attributes named in the UNPACK entry, GrADS assumes the variable undef value corresponds to the data values as they appear in the file,i.e.,before they are transformed using a scale factor and offset. Missing packed data values are thus assigned the file-wide undef value and are never unpacked. Attribute names are case sensitive, and it is assumed that the name is identical for all variables in the netcdf or hdfsds data file. If the name given does not match any attributes, or if no name is given, the file-wide undef value will be used.Example: UNDEF 1e+33 _FillValueUNPACK scale_factor_attribute_name <add_offset_attribute_name>back to top(GrADS version 1.9) This entry is used with DTYPE netcdf, hdfsds, or hdf5_grid (GrADS version 2.0.a7+) for data variables that are 'packed' -- i.e. non-float data that need to be converted to float by applying the following formula:y = x * scale_factor + add_offsetIf your self-describing file does not have an offset attribute, the 2nd argument may be omitted, and the offset will be assigned the default value of 0.0. If your self-describing file has an offset attribute, but not a scale factor, use "NULL" forthe scale_factor_attribute_name. (This "NULL" option is in GrADS version 2.0.0+). Attribute names are case sensitive, and it is assumed that the names are identical for all variables in the netcdf or hdfsds data file. If the names given do not match any attributes, the scale factor will be assigned a value of 1.0 and the offset will be assigned a value of 0.0. The transformation of packed data is done after the undef test has been applied.Examples:UNPACK scale_factor add_offsetUNPACK NULL add_offsetUNPACK Slope InterceptFILEHEADER lengthback to topThis optional entry tells GrADS that your data file has a header record of length bytes that precedes the data. GrADS will skip past this header, then treat the remaineder of the file as though it were a normal GrADS binary file after that point. This optional descriptor file entry is only valid for GrADS gridded data sets.THEADER length HEADERBYTES length<back to topThese two equivalent optional entries tell GrADS that the data file has a header record of length bytes preceding each time block of binary data. Use one or the other but not both. These entries are only valid for GrADS gridded data sets. See the section on structure of a gridded binary data file for more information.TRAILERBYTES lengthback to topThis optional entry tell GrADS that the data file has a trailer record of length bytes following each time block of binary data. This entry is only valid for GrADS gridded data sets. See the section on structure of a gridded binary data file for more information.XYHEADER lengthback to topThis optional entry tells GrADS that the data file has a header record of length bytes preceding each horizontal grid (XY block) of binary data. This entry is only valid for GrADS gridded data sets. See the section on structure of a gridded binary datafile for more information.XVAR x,yback to top(GrADS version 1.9) This entry provides the x,y pair for the station's longitude. This entry is required for DTYPE bufr.YVAR x,yback to top(GrADS version 1.9) This entry provides the x,y pair for the station's latitude. This entry is required for DTYPE bufr.ZVAR x,yback to top(GrADS version 1.9) This entry provides the x,y pair for the station data's vertical coordinate (e.g., pressure). This is an optional entry for DTYPE bufr.STID x,yback to top(GrADS version 1.9) This entry provides the x,y pair for the station ID. This entry is required for DTYPE bufr.TVAR yr x,y mo x,y dy x,y hr x,y mn x,y sc x,yback to top(GrADS version 1.9) This entry provides the x,y pairs for all the base time coordinate variables. Each time unit (year=yr, month=mo, day=dy, hour=hr, minute=mn, second=sc) is presented as a 2-letter abbreviation followed by the x,y pair that goes with that time unit. The time for any individual station report is the base time plus the offset time (see TOFFVAR). All six base time units are not required to appear in the TVAR record, only those that are in the data file. This entry is requiredfor DTYPE bufr.TOFFVAR yr x,y mo x,y dy x,y hr x,y mn x,y sc x,yback to top(GrADS version 1.9) This entry provides the x,y pairs for all the offset time coordinate variables. The syntax is the same as TVAR. The time for any individual station report is the base time plus the offset time. All six offset time units are not required to appear in the TOFFVAR record, only those that are in the data file. This is an optional entry for DTYPE bufr.CACHESIZE bytesback to top(GrADS version 2.0.a8+) This entry overrides the default size of the cache for reading HDF5 or NetCDF4 files. It is not relevant for other data types. It should not be necessary to set the cache size explicitly unless the data file has especially large chunks. Please see the documentation on compression.OPTIONS keywordback to topThis entry controls various aspects of the way GrADS interprets the raw data file. It replaces the old FORMAT record.The keyword argument may be one or more of the following:pascals (GrADS version 2.0) (For DTYPE grib2 only) Indicates that pressure values that appear in the descriptor file (in the ZDEF entry and in the GRIB2 codes in the variable declarations) are given inunits of Pascals. The gribmap utility requires pressure to be given in Pascals. If this keyword ispresent, the pressure level values will be converted to millibars after the gribmap index is generatedand the descriptor file is opened with GrADS. If this keyword is omitted, pressure levels will remain inPascals, and many of the internal functions (which assume a vertical dimension in units of millibars)will not work properly.yrev Indicates that the Y dimension (latitude) in the data file has been written in the reverse order from what GrADS assumes. An important thing to remember is that GrADS still presents the view that thedata goes from south to north. The YDEF statement does not change; it still describes thetransformation from a grid space going from south to north. The reversal of the Y axis is done as thedata is read from the data file.zrev Indicates that the Z dimension (pressure) in the data file has been written from top to bottom, rather than from bottom to top as GrADS assumes. The same considerations as noted above for yrev alsoapply.template Indicates that a template for multiple data files is in use. For more information, see the section on Using Templates.sequential Indicates that the file was written in sequential unformatted I/O. This keyword may be used with either station or gridded data. If your gridded data is written in sequential format, then each record must bean X-Y varying grid. If you have only one X and one Y dimension in your file, then each record in thefile will be one element long (it may not be a good idea to write the file this way).365_day_calendar Indicates the data file was created with perpetual 365-day years, with no leap years. This is used for some types of model ouput.byteswapped Indicates the binary data file is in reverse byte order from the normal byte order of your machine.Putting this keyword in the OPTIONS record of the descriptor file tells GrADS to swap the byte orderas the data is being read. May be used with gridded or station data.The best way to ensure hardware independence for gridded data is to specify the data's source platform. This facilitates moving data files and their descriptor files between machines; the data may be used on any type of hardware without having to worry about byte ordering. The following three OPTIONS keywords are used to describe the byte ordering of a gridded or station data file:big_endian Indicates the data file contains 32-bit IEEE floats created on a big endian platform (e.g., sun, sgi)little_endian Indicates the data file contains 32-bit IEEE floats created on a little endian platform (e.g., iX86, and dec)cray_32bit_ieee Indicates the data file contains 32-bit IEEE floats created on a cray.PDEFback to topPDEF is so powerful it has its own documentation page.XDEF xnum mapping <additional arguments>back to topThis entry defines the grid point values for the X dimension, or longitude. The first argument, xnum, specifies the number of grid points in the X direction. xnum must be an integer >= 1. mapping defines the method by which longitudes are assigned to X grid points. There are two options for mapping:LINEAR Linear mappingLEVELS Longitudes specified individuallyThe LINEAR mapping method requires two additional arguments: start and increment. start is a floating point value that indicates the longitude at grid point X=1. Negative values indicate western longitudes. increment is the spacing between grid point values, given as a positive floating point value.The LEVELS mapping method requires one additional argument, value-list, which explicitly specifies the longitude value for each grid point. value-list should contain xnum floating point values. It may continue into the next record in the descriptor file, but note that records may not have more than 255 characters. There must be at least 2 levels in value-list; otherwise use the LINEAR method.Here are some examples:XDEF 144LINEAR 0.0 2.5XDEF 72LINEAR 0.0 5.0XDEF 12LEVELS 0 30 60 90 120 150 180 210 240 270 300 330XDEF 12LEVELS 15 45 75 105 135 165 195 225 255 285 315 345YDEF ynum mapping <additional arguments>back to topThis entry defines the grid point values for the Y dimension, or latitude. The first argument, ynum, specifies the number of gridpoints in the Y direction. ynum must be an integer >= 1. mapping defines the method by which latitudes are assigned to Y grid points. There are several options for mapping:LINEAR Linear mappingLEVELS Latitudes specified individuallyGAUST62 Gaussian T62 latitudesGAUSR15 Gaussian R15 latitudesGAUSR20 Gaussian R20 latitudesGAUSR30 Gaussian R30 latitudesGAUSR40 Gaussian R40 latitudesThe LINEAR mapping method requires two additional arguments: start and increment. start is a floating point value that indicates the latitude at grid point Y=1. Negative values indicate southern latitides. increment is the spacing between grid point values in the Y direction. It is assumed that the Y dimension values go from south to north, so increment is always positive.The LEVELS mapping method requires one additional argument, value-list, which explicitly specifies the latitude for each grid point, from south to north. value-list should contain ynum floating point values. It may continue into the next record in the descriptor file, but note that records may not have more than 255 characters. There must be at least 2 levels in value-list; otherwise use the LINEAR method.The Gaussian mapping methods require one additional argument: start. This argument indicates the first gaussian grid number. If the data span all latitudes, start would be 1, indicating the southernmost gaussian grid latitude.Here are some examples:YDEF 73LINEAR -90 2.5YDEF 180LINEAR -90 1.0YDEF 18LEVELS -85 -75 -65 -55 -45 -35 -25 -15 -5 5 15 25 35 45 55 65 75 85YDEF 94GAUST62 1YDEF 20GAUSR40 15The NCEP/NCAR Reanalysis surface variables are on the GAUST62 grid.The final example shows that there are 20 Y dimension values which start at Gaussian Latitude 15 (64.10 south) on the Gaussian R40 gridZDEF znum mapping <additional arguments>back to topThis entry defines the grid point values for the Z dimension. The first argument, znum, specifies the number of pressure levels. znum must be an integer >= 1. mapping defines the method by which level values are assigned to Z grid points. There are two options for mapping:LINEAR Linear mappingLEVELS Pressure levels specified individuallyThe LINEAR mapping method requires two additional arguments: start and increment. start is a floating point value that indicates the level value at grid point Z=1. increment is the spacing between grid point values in the Z direction, or from lower to higher. increment must be non-zero and non0negative.The LEVELS mapping method requires one additional argument, value-list, which explicitly specifies the pressure level for each grid point in ascending order. value-list should contain znum floating point values. It may continue into the next record in the descriptor file, but note that records may not have more than 255 characters.Here are some examples:ZDEF 7LEVELS 1000 850 700 500 300 200 100ZDEF 17LEVELS 1000 925 850 700 600 500 400 300 250 200 150 100 70 50(GrADS version 2.0) (For DTYPE grib2 only) If your Z axis is pressure, the gribmap utility requires the level values to be given in units of Pascals instead of millibars. Use the "options pascals" keyword to convert the unit of the level values to millibars after the gribmap index is generated and when the descriptor file is opened with GrADS. Pressure level values may remain in Pascals, but then many of the internal functions (which assume a vertical dimension in units of millibars) will not work properly.TDEF tnum LINEAR start incrementback to topThis entry defines the grid point values for the T dimension. The first argument, tnum, specifies the number of timesteps.tnum must be an integer >= 1. The method by which times are assigned to T grid points is always LINEAR.start indicates the initial time value at grid point T=1. start must be specified in the GrADS absolute date/time format:hh:mm Z ddmmmyyyywhere:hh = hour (two digit integer)mm = minute (two digit integer)dd = day (one or two digit integer)mmm = 3-character monthyyyy = year (may be a two or four digit integer; 2 digits implies a year between 1950 and 2049)If not specified, hh defaults to 00, mm defaults to 00, and dd defaults to 1. The month and year must be specified. No intervening blanks are allowed in the GrADS absolute date/time format.increment is the spacing between grid point values in the T direction. increment must be specified in the GrADS absolute time increment format:vvkkwhere:vv = an integer number, 1 or 2 digitskk = mn (minute)hr (hour)dy (day)mo (month)yr (year)Here are some examples:TDEF 60LINEAR 00Z31dec1999 1mnTDEF 73LINEAR 3jan1989 5dyTDEF 730LINEAR 00z1jan1990 12hrTDEF 12LINEAR 1jan2000 1moTDEF 365LINEAR 12Z1jan1959 1dyTDEF 40LINEAR 1jan1950 1yrEDEF enum NAMES <list of names>back to topEDEF enumensemble_record_1 ensemble_record_2 ...ensemble_record_enum ENDEDEFback to top(GrADS version 2.0) This entry defines the ensemble dimension. All ensemble members must have identical X, Y, and Z dimensions, the same list of variables, and the same time axis increment. There are two different syntaxes for the EDEF entry: the first is simpler and requires only the names for each ensemble member, the second expanded form contains a name, individual time axis information, and optional GRIB2 codes.Both EDEF syntaxes begin with the enum argument, an integer >=1 which specifies the number of ensemble members.If all of the ensemble members have an identical time axis (i.e. length, initial time, and increment are the same for each one), then it is only necessary to distinguish the ensembles by their names, and the simplified EDEF syntax with the NAMES keyword may be used. A simple space-delimited list of names is all that is required. Ensemble names must have between 1 and 15 alphanumeric characters, lower case only. (In version 2.0.0 and later, mixed case ensemble names are allowed). Some examples are:EDEF 10NAMES 1 2 3 4 5 6 7 8 9 10EDEF 12NAMES m01 m02 m03 m04 m05 m06 m07 m08 m09 m10 m11 ensmEDEF 7NAMES e1 e2 e3 e4 e5 e6 e7When the OPTIONS TEMPLATE entry is used with EDEF, the ensemble names are used in the %e substitution template to generate the file name. See Using Templates for more details.If the ensemble members do not have identical time axes (i.e., their lengths or initial times are not the same), or if you need to include the GRIB2 codes, then you must use the expanded EDEF syntax: a collection of records framed by EDEF and ENDEDEF. The format of the ensemble records is as follows:ensname length start <grib2 codes>The ensname is the 1-15 character "name" for the ensemble member. The length is the size of the time axis of the ensemble, which must be less than or equal to the tnum argument in the TDEF entry. (The time axis described by TDEF must span all the ensemble members.) The start argument is the initial time of the ensemble member and must be given in GrADS absolute date/time format. (See TDEF for details).The grib2 codes are required if (1) the DTYPE is grib2 and (2) there is more than one ensemble member (enum > 1). The expanded form of the EDEF entry must be used when grib2 codes are required, even if the length and start times are the same for all members. For GRIB2 ensembles, support currently exists for four different Product Definition Template (PDT) numbers: 1, 2, 11, and 12. These are grouped into two types: individual ensemble forecasts (PDT 1 and 11) or derived forecasts based on all ensemble members (PDT 2 and 12). For individual ensemble forecasts (PDT 1 and 11), twocomma-delimited grib2 codes are required: the ensemble type and perturbation number. For derived forecasts based on all ensemble members (PDT 2 and 12), only one grib2 code is required: the derived forecast. Clarification of all the GRIB2 nomenclature may be found in the documentation at WMO and NCEP. Two examples are given below.The first example illustrates ensemble members with different lengths and start times:TDEF 591 linear 12z09dec1980 12hrEDEF 16ensm 591 12z09dec1980m01 591 12z09dec1980m02 589 12z10dec1980m03 587 12z11dec1980m04 585 12z12dec1980m05 583 12z13dec1980m06 571 12z19dec1980m07 569 12z20dec1980m08 567 12z21dec1980m09 565 12z22dec1980m10 563 12z23dec1980m11 549 12z30dec1980m12 547 12z31dec1980m13 545 12z01jan1981m14 543 12z02jan1981m15 541 12z03jan1981ENDEDEFThe second example illustrates the use of GRIB2 codes:TDEF 31 linear 00z24apr2007 12hrEDEF 23p01 31 00z24apr2007 3,1p02 31 00z24apr2007 3,2p03 31 00z24apr2007 3,3p04 31 00z24apr2007 3,4p05 31 00z24apr2007 3,5p06 31 00z24apr2007 3,6p07 31 00z24apr2007 3,7p08 31 00z24apr2007 3,8p09 31 00z24apr2007 3,9p10 31 00z24apr2007 3,10p11 31 00z24apr2007 3,11p12 31 00z24apr2007 3,12p13 31 00z24apr2007 3,13p14 31 00z24apr2007 3,14p15 31 00z24apr2007 3,15p16 31 00z24apr2007 3,16p17 31 00z24apr2007 3,17p18 31 00z24apr2007 3,18p19 31 00z24apr2007 3,19p20 31 00z24apr2007 3,20c00 31 00z24apr2007 1,0avg 31 00z24apr2007 0spr 31 00z24apr2007 2ENDEDEFVECTORPAIRS U-component,V-componentback to top(GrADS version 1.9b4) This entry is for explicity identifying vector component pairs. This is only necessary if the data are on a native projection other than lat/lon (i.e. you are using PDEF) and if the winds have to be rotated from a grid-relative sense to an Earth-relative sense. (GrADS has to retrieve both the u and v component in order to do the rotation calculation.)Using this entry replaces the old technique of putting 33 (for U) or 34 (for V) in the first element of the units field in the variable declaration. The U-component and V-component arguments should be variable names that appear in the VARS list. They are separated by a comma, with no spaces. More than one pair of components may be listed; in this case, the pairs should be separated by a space. For example:VECTORPAIRS u,v u10,v10 uflx,vflxVARS varnum variable_record_1back to topvariable_record_2...variable_record_varnumENDVARSThis ensemble of entries describes all the variables contained in the data set. varnum indicates the number of variables in the data set and is therefore also equal to the number of variable records that are listed between the VARS and ENDVARS entries. ENDVARS must be the final line of the Grads data descriptor file. Any blank lines after the ENDVARS statement may cause open to fail!The format of the variable records is as follows:varname levs units description (Version 2.0.1 or earlier)varname levs <additional_codes> units description (Version 2.0.2 or later)The syntax of varname and units is different depending on what kind of data format (DTYPE) you are describing.The<additional_codes> are only necessary for certain types of GRIB2 data sets. Details provided below:varname This is a 1-15 character "name" or abbreviation for the data variable. varname may contain alphabetic and numeric characters but it must start with an alphabetic character (a-z).varname (DTYPE netcdf, hdfsds, orhdf5_grid) (GrADS version 1.9+) For DTYPE netcdf or hdfsds, varname may have a different syntax. This syntax is required when the name of the data variable in the SDF does not conform to the GrADS naming conventions (see below for list of criteria), but it may also be used to shorten or change the variable name to make it easier to work with inside GrADS. The syntax is:SDF_varname=>grads_varnameSDF_varname is the name the data variable was given when the SDF file was originally created. For NetCDF files, this name appears in the output from ncdump. It is important that SDF_varname exactly matches the variable name in the data file. SDF_varname may contain uppercase letters andnon-alpha-numeric characters.The classic varname syntax (i.e., when "SDF_varname =>" is omitted) may be used if SDF_varname meets the criteria for GrADS variable names: it must be less than 16 characters, start with an alphabetic character, and cannot contain any upper case letters or non-alpha-numeric characters.(GrADS version 2.0.a3+) If the SDF_varname contains spaces, substitute "~" for each space -- the spaces in the variable name string will be swapped back in later after the descriptor file has been parsed.(GrADS version 2.0.a7+) For dtype hdf5_grid, the SDF_varname may be particularly long since it must contain the names of all the nested groups (separated by "/") to which the data set belongs.For example:/HDFEOS/GRIDS/EarthSurfaceReflectanceClimatology/Data~Fields/MonthlySurfaceReflectance=>msr。
grads处理grib资料

相关附件:(共323223 字节)funny给你一个小程序,是用perl写的,然后funny转成了exe文件,你可以用它生成ctl,但生成的ctl文件还需要自己去掉这个程序强制添加上去的一些信息,然后,你用gribmap.exe生成index文件,就可以显示了。
这个zip包里有原始的perl程序,转好的exe文件和gribmap.exe三个文件。
C:\drawing\ncep-monthly\ex>grib2ctl -i prs.grib.mean.y1980>y1980.ctlUsing NCEP reanalysis table, see -ncep_opn, -ncep_rean optionsUsing NCEP reanalysis table, see -ncep_opn, -ncep_rean optionsC:\drawing\ncep-monthly\ex>gribmap -i y1980.ctlOpen Error: Unknown keyword in description file--> The invalid description file record is:--> this exe file was created with the evaluation version of perl2exe.The data file was not opened.File name is: y1980.ctl"Using NCEP reanalysis table, see -ncep_opn, -ncep_rean options"就是说你应该用-ncep_opn 或-ncep_rean 的选项,具体看帮助下面就不用说了,ctl都没有形成,自然不行的了Hi,funnyThanks!错误与“-ncep_opn, -ncep_rean options”无关,是ctl中endvars后“--> this exe file was created with the evaluation version of perl2exe.”的这句话作怪,删掉后可正常得到idx。
GrADS绘图学习技巧与实例

以下技巧总结都是笔者从学习实践过程中总结出来的,基本的问题。
不求全面,希望对读者学习有用,如果有问题,敬请留言指正,以促进交流学习!1、软件综述:grads软件‘sdfopen’命令,最稳定的版本是版本,所以笔者推荐学习者安装2.0版本,选择默认安装路径就可以。
2、文件类型简述:grads处理的是网格数据,可以处理的数据类型有:grd、grib、nc(海洋常用的数据),cdf(雷达卫星数据),其中nc、cdf数据都是自带描述文件,不需要ctl,grib数据要通过命令生成ctl、index数据才可以调用,常用的是grd数据,需要ctl。
3、数据文件转换:grads软件识别的数据是二进制无格式数据,文件类型是‘binary’,写入和生成时是不需要格式的如read(20) sst(i,j,iz,it),20为文件号,通常是十进制数据与grd数据间转换,这里给一个grd转换成txt数据的fortran程序:parameter(nx=56,ny=41,nz=1,nt=360)dimension sst(nx,ny,nz,nt)real sstopen(15,file='sst.grd',form='binary') !固定的用form=‘binary’就是二进制数据open(16,file='sst.txt') !新建txt文件do it=1,ntdo iz=1,nzread(15) ((sst(i,j,iz,it),i=1,nx),j=1,ny) !read后只有文件号,数据是无格式的enddoenddodo it=1,ntdo iz=1,nzwrite(16,*) ((sst(i,j,iz,it),i=1,nx),j=1,ny) !输出时是txt文件可直接看的数据,有格式输出,有*enddoenddoclose(15)close(16)end写程序时:注意格点数要与数据对应,如:上程序对应的数据是经度90~200,纬度-20~60,时间:1971.01~2000.12共360个月的海面温度数据,数据格点精度2*2 ,nx=(200-90)/2+1,ny=(60-(-20))/2+1,nt=360,nz=1,大气的数据要根据数据的层次确定几层。
grads处理多个ctl文件和nc文件解析

grads处理多个ctl文件和nc文件2011-10-10 21:03:59| 分类:grads学习| 标签:|举报|字号大中小订阅下载LOFTER我的照片书 |用grads处理多个相同格式的数据时若单个单个处理非常麻烦,当文件非常多的时候是单个处理是不实际的。
下面介绍一种方法;第一步,在这种情况下可以重新写一个ctl描述文件,其文件变量都和已知的ctl相同,若原来的n文件只是时间不同,那么新描述文件的时间维数是所有原文件的时间的和。
同样,若其他维数不同时也用同样的方法处理。
第二步,在第一行之后添加一行:options template 表示多个时间序列原始数据文件想用一个描述文件统一地描述。
这些原数据的原文件名由dset定义的形势命名文件名。
第三步,修改dset 的文件名。
原路径不变,把文件名用%表示。
其中:%y2 代表两位数年%y4 代表四位数年%m1 代表一位或者两位数的月%m2 代表两位数月(用0补齐1位数)%mc 3个字符月份的缩写%d1 1或2位天%d2 两位天%h1 1或者2位时%h2 2位时例如:原文件其中之一的文件名为gdas2006050812f00,且所有文件只有天和时的变化那么新描述文件的文件名为:gdas200605%d2%h2f00另外如果源文件里有index项的话,需要修改其idx的文件名,假设改成fnl.idx。
并用在dos下用gribmap函数生成一个新的idx文件。
gribmap -e -i fnl.ctl(加绝对路径)open fnl.ctl就可以打开所有文件。
*************************************************************************************************************** *******************若想要提取从1951-2006年56年nc文件中的某些数据,一个一个处理非常麻烦,这里介绍种较为简易的方法。
GrADS第2章 数据处理解读

格式,压缩率高,占用空间小。例如 NCEP提供的数据资料。
NETCDF(.nc)等通用数据格式:自
定义数据格式,精确性好,便于传输。
文件中自带描述文件。
2.2 数据文件的转换
1. 转换方法
转换文件的数据存放格式,一般 是通过Power Station或Visual Fortran等软件使用Fortran或者C 语言来编程转换。
irec=0 do 200 it=1,nt do 30 iz=1,nz irec=irec+1 write(12,rec=irec) ((u(i,j,iz,it),i=1,nx),j=1,ny) 30 Continue do 31 iz=1,nz irec=irec+1 write(12,rec=irec) ((v(i,j,iz,it),i=1,nx),j=1,ny) 31 continue irec=irec+1 write(12,rec=irec) ((sst(i,j,it),i=1,nx),j=1,ny) 200 continue
y………5
2.数据存放形式
二进制数据排放顺序 从内循环到外循环依次是: Z x(经度):从西到东 y(纬度):从南到北 1 2 3 4 5……….. x z(高度层数):从低层到高层 vars(各种物理变量) t(时次) x(lon) y(lat) z(lev) vars(不同变量) time 任何一维可省略。
open(1,file='u.dat') open(2,file='v.dat') open(3,file='sst.dat&#n(12,file='mhy.grd',form='binary')
grads处理多个时次的ncep数据

Step1:利用grib2ctl.exe生成初始时刻ncep数据的ctl文件;示例中生成的是fnl_20090801_00_00_c数据的文件。
Step2:将ctl中相应的信息进行修改:a、将dset的数据集文件名写成代换模块格式;如:dset D:\fog\fnl_200212%d2_%h2_00_c%y2 ===> 两位数年;%y4 ===> 四位数年;%m1 ===> 1或2位数月;%m2 ===> 2位数月(用0补齐一位数);%mc ===> 3字符月份缩写;%d1 ===> 1或2位天;%d2 ===> 2位天;%h1 ===> 1或2位时;%h2 ===> 2位时;b、在第一行后添加一行“options template”定义时间范围和增量;c、tdef number LINEAR start increment,将其中的number和increment(ncep时间间隔为6小时,可写成6hr)设成与所拥有的ncep资料一致;(修改后的信息如图所示,里面的路径需自己设置);Step3:利用gribmap.exe生成与改过后的ctl相对应的idx文件;这样就可以编写gs文件提取所需要时刻的ncep数据了。
gs如下:'reinit''open E:\Morakot_fnl\fnl200908Morakot.ctl''set lat 15 40''set lon 110 145''set fwrite E:\program\data.dat''set gxout fwrite't=1while(t<=61)'set t ' tz=1while(z<=21)'set z ' z'd HGTprs''d RHprs''d TMPprs''d UGRDprs''d VGRDprs''d VVELprs'z=z+1endwhilet=t+1endwhile'disable fwrite''reinit'(注意:此过程为基于GrADs 2.0.a3.oga.1版本的试验,其它版本是否一致不敢保证)。
grads处理多个ctl文件和nc文件

grads处理多个ctl文件和nc文件2011-10-10 21:03:59| 分类:grads学习| 标签:|举报|字号大中小订阅下载LOFTER我的照片书 |用grads处理多个相同格式的数据时若单个单个处理非常麻烦,当文件非常多的时候是单个处理是不实际的。
下面介绍一种方法;第一步,在这种情况下可以重新写一个ctl描述文件,其文件变量都和已知的ctl相同,若原来的n文件只是时间不同,那么新描述文件的时间维数是所有原文件的时间的和。
同样,若其他维数不同时也用同样的方法处理。
第二步,在第一行之后添加一行:options template 表示多个时间序列原始数据文件想用一个描述文件统一地描述。
这些原数据的原文件名由dset定义的形势命名文件名。
第三步,修改dset 的文件名。
原路径不变,把文件名用%表示。
其中:%y2 代表两位数年%y4 代表四位数年%m1 代表一位或者两位数的月%m2 代表两位数月(用0补齐1位数)%mc 3个字符月份的缩写%d1 1或2位天%d2 两位天%h1 1或者2位时%h2 2位时例如:原文件其中之一的文件名为gdas2006050812f00,且所有文件只有天和时的变化那么新描述文件的文件名为:gdas200605%d2%h2f00另外如果源文件里有index项的话,需要修改其idx的文件名,假设改成fnl.idx。
并用在dos下用gribmap函数生成一个新的idx文件。
gribmap -e -i fnl.ctl(加绝对路径)open fnl.ctl就可以打开所有文件。
****************************************************************************************************** ****************************若想要提取从1951-2006年56年nc文件中的某些数据,一个一个处理非常麻烦,这里介绍种较为简易的方法。
GrADS,NCL一些经验

GrADS,NCL⼀些经验GrADS经纬度⽐例⽅法*取消经纬⽐例⾃动调整'set mproj scaled'设置绘图区域,使得⼀致'set vpage 1 7 1 7'GrADS画特定经线⽅法set clevs 23.5; d latset clevs 120;d lonGrADS 查看多个打开⽂件的ctlq ctlinfo 1q ctlinfo 2...2个不同的缺测值 fwrite更改默认缺测值GrADS⽤fwrite输出时,默认的缺测值是-9.9900000E+08,如果输⼊源的缺测值与之不⼀致,则会出现两种缺测值的情况。
解决的办法,可以在fwrite 声明后⾯设置默认缺测值设置。
⽐如'reinit''open J:/ec79-15/ansnablameansst79_15.ctl''set t 1 12''save=ave(absnablamsst,t+0,t=444,12)''modify save seasonal''set gxout fwrite''set undef 9.999E+20''set x 1 480''set y 1 89''set fwrite J:/ec79-15/seasonal.grd''d save''disable fwrite''reinit';(注:modify save seasonal命令意为将save变量修改成季节变量,⽅便与其它不同⼤⼩的变量计算(⽐如求季节距平),此外modify还有另外⼀个选项diurnal⽇变化)NCL使⽤⾃定义⾊标清风给的调⾊盘确实好⽤,⽣成的rgb格式也可以。
但是最近再次遇到了ncl⽆法正常读取colormap错误的问题,参考了⼀下官⽹。
GrADS应用中fnl资料下载以及解码
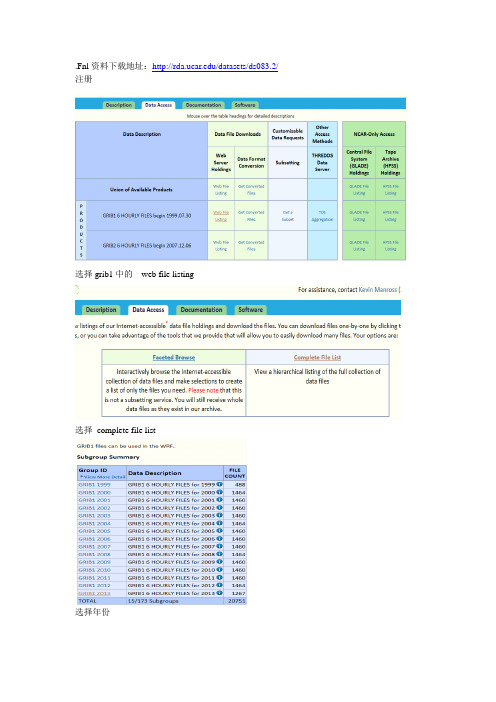
.Fnl资料下载地址:/datasets/ds083.2/注册选择grib1中的web file listing选择complete file list选择年份选择月份点击点击即可完成下载如需下载grib2资料,步骤也是一样的。
下面介绍如何解码grib1资料,grib2资料目前还不会解码。
安装grads1.9进入安装目录C:\GrADS19\win32将目录下的四个文件拷入fnl所在文件夹目录(本次示范数据放在F:\ncep)在网上下载grib2ctl 程序同样放入fnl目录F:\ncep打开运行(window键+R)输入cmd进入dos环境生成ctl文件PS:如果出现:missing or not grib file or wgrib is not on your path则需要以管理员什么运行Win7默认的是,用户平时都不以管理员模式运行任何程序,即便你是管理员帐户也是如此,这是为了安全起见。
命令提示符模式也是Windows 7 里面的一个子程序,因此当你需要用它进行一些系统级别的操作时,必须使用管理员模式运行。
在开始菜单里找到“命令提示符”,右键点击,从弹出的菜单里选择“以管理员身份运行”就可以了。
生成idx文件至此,单个文件解码完成。
批处理fnl资料介绍:批处理的结果就是多个fnl资料公用一个ctl和idx。
现将2013年8月11日00时至18日18时资料存入F:\ncep\201308按照上述步骤生成fnl_20130811_00_00_c 的ctl文件和idx文件,将生成好的ctl文件做如下修改(红色字体为改动部分),其中32代表共有32个文件,可根据具体文件数量的多少做相应改动,其他地方保留原有即可。
重新gribmap -i 这个改完之后的ctl文件,生成一个公用的fnl.idx。
由于是不同时刻的数据共用一个ctl和idx,在grads作图的时候,需要对时间t进行设置,在本例中,201308011_00_00_c的时间为1,201308011_0,6_00_c的时间为2,依次类推。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
grads处理多个ctl文件和nc文件2011-10-10 21:03:59| 分类:grads学习| 标签:|举报|字号大中小订阅下载LOFTER我的照片书 |用grads处理多个相同格式的数据时若单个单个处理非常麻烦,当文件非常多的时候是单个处理是不实际的。
下面介绍一种方法;第一步,在这种情况下可以重新写一个ctl描述文件,其文件变量都和已知的ctl相同,若原来的n 文件只是时间不同,那么新描述文件的时间维数是所有原文件的时间的和。
同样,若其他维数不同时也用同样的方法处理。
第二步,在第一行之后添加一行:options template 表示多个时间序列原始数据文件想用一个描述文件统一地描述。
这些原数据的原文件名由dset定义的形势命名文件名。
第三步,修改dset 的文件名。
原路径不变,把文件名用%表示。
其中:%y2 代表两位数年%y4 代表四位数年%m1 代表一位或者两位数的月%m2 代表两位数月(用0补齐1位数)%mc 3个字符月份的缩写%d1 1或2位天%d2 两位天%h1 1或者2位时%h2 2位时例如:原文件其中之一的文件名为gdas2006050812f00,且所有文件只有天和时的变化那么新描述文件的文件名为:gdas200605%d2%h2f00另外如果源文件里有index项的话,需要修改其idx的文件名,假设改成fnl.idx。
并用在dos下用gribmap函数生成一个新的idx文件。
gribmap -e -i fnl.ctl(加绝对路径)open fnl.ctl就可以打开所有文件。
*************************************************************************************************************** *******************若想要提取从1951-2006年56年nc文件中的某些数据,一个一个处理非常麻烦,这里介绍种较为简易的方法。
例如想提取6-8月的位势高度资料。
'reinit't5=1951*作文件名循环while(t5<=2006)'set gxout fwrite''set fwrite D:\sichuan\hgt1\'%t5%'.dat''sdfopen e:\ncep1\hgt\hgt.'%t5%'.nc't3=t5-1950*判断是否为闰年if(t3=2|t3=6|t3=10|t3=14|t3=18|t3=22|t3=26|t3=30|t3=34|t3=38|t3=42|t3=46|t3=50|t3=54)to=153elseto=152endift4=to+91while(to<=t4)'set t 'tot1=1while(t1<=12)'set z 't1'set lon 80 140''set lat 15 55''d hgt't1=t1+1endwhileto=to+1endwhile*这里必须先观点上述运行的文件,grads最多同时可以打开20个文件左右。
'reinit't5=t5+1endwhile'reinit'这样可以提取你想要的年数据,然后你大可运用fortran对数据进行随心所欲的处理。
能否直接生成一个文件还正在探索中。
/forum.php?mod=viewthread&tid=7310&extra=&page=1批量读取nc数据,用你的方法成功了,谢谢!!!直接配个批量描述的ctl就可以了有一批nc数据,一个月一个文件,现将文件名改为:197901.nc,197902.nc,依次类推,对二进制的数据知道写ctl文件来进行批处理运算,那么nc数据应该怎么做呢?试过了写ctl 文件,sdfopen ***\%y4%m2.nc,year=1978while(year<=2011)month=01while(month<=12)'sdfopen ***\'year''month'.nc'...month=month+1endwhileyear=year+1endwhile实我也是糊里糊涂的解决了。
ctl文件如下:dset ^%y4%m2.ncundef 1e+15options templatetitle MERRA datadtype NetCDFydef 144 linear -90 1.25xdef 288 linear -180 1.25zdef 21 levels 1000 975 950 925 900 875 850 825 800 775 750 725 700 650 600 550 500 450 400 350 300tdef 396 linear 00Z01JAN1979 1movars 3qv 21 t,z,y,x Specific humidityu 21 t,z,y,x Eastward wind componentv 21 t,z,y,x Northward wind componentendvars然后open ***.ctl就行了,之前的问题是打不开ctl文件,怎么改也不行,后来换了台机子就好了。
所以我说我也不知道怎么回事,希望对你有帮助。
我之前就这样做的,能打开ctl文件,但是d之后,都显示all undefined values,我的ctl如下,麻烦帮我看看哪里错了?dset ^%y4%m2.ncundef 1e+15options templatetitle MERRA datadtype netcdfxdef 288 linear -179.375 1.25ydef 144 linear -89.375 1.25zdef 21 levels 1000 975 950 925 900 875 850 825 800 775 750 725 700 650 600 550 500 450 400 350 300tdef 396 linear 00Z01JAN1979 1mnvars 3qv 21 t,z,y,x Specific humidityu 21 t,z,y,x Eastward wind componentv 21 t,z,y,x Northward wind componentendvars可以的,但文件名一定要连续这个时间长度一定要和你的文件对应好最近发了一个利用grads批量合并nc文件的帖子/forum.php?mod=viewthread&tid=14459,因为那不是最好的方法,所以非常推荐了利用ctl批量描述nc的方法。
很多人也都问怎么批量描述,,很多人也都去自己尝试,尝试过程中出了各种问题。
推荐兰溪给nc文件写ctl的帖子/forum.php?mod=viewthread&tid=6008,尤其是使用sdfopen后出现“SDF file has no discernable X coordinate”的同学们,非常推荐这个帖子。
肯定很多人已经看过这个帖子,也照着做过,还是出了问题。
其实论坛还有很多其他有关ctl批量描述nc的帖子,大家参考一下,对照自己出现的问题,应该大部分情况下都能解决。
但是有一些人很着急,连一个nc文件的描述文件都写不对,就直接批量的,那肯定只会出更多的错误,还一时半会儿改不对。
只会造成时间的浪费。
我不是来说教的,只是我觉得什么事儿都是循序渐进的,不要那么浮躁。
俗话说磨刀不误砍柴工,其实真的是这么回事。
就说批量描述nc 文件,它也是在正确描述一个nc文件的基础上来修改的。
只要描述一个的出来了,往上加一两个语句,用正确的替代格式替代了文件名,再改一下时间长度就出来了。
那能正确描述一个nc文件的ctl就是你磨得很锋利的砍柴刀,有了它后面的柴就相当好砍了。
下面我就以ncep逐日再分析资料为例说一下nc文件的描述和批量描述。
文件名连续,hgt.1948.nchgt.1949.nc hgt.1950.nc`````````首先看一下它自带的ctl,如下图红色圈起来的部分,就不详细解释了,对grads有一定了解的人,看一下就知道什么下面就可以根据这个自己编写一个ctl文件来描述这个nc文件了。
照着自带的写下来先,存成1948.ctl然后使用open命令打开,画图,发现出来的图和缺测值设置错误时差不多。
那就想方设法的改缺测值,比如用在grads中使用q attr查看有一句missing_value 32766,修改缺测值,再画图,还是那样;q undef出来的是-999000000.000000,再改,再画还是那样。
无论怎么改,都还是那样。
如果你这么反复折腾,最后还没发现问题,那就说明你没有好好利用论坛的搜索功能,也没有看到兰溪的帖子,也没看到黎大叶子的用Fortran批量为nc写ctl的帖子/forum.php?mod=viewthread&tid=7267。
但是不用着急,我看见了,其中最重要的是打开netcdf格式数据的描述文件是需要用xdfopen命令的,那就先要去看看xdfopen能打开的ctl 需要怎么写/grads/gadoc/gadocindex.html。
看完了,差不多就能明白了,有这么多前人的成果,那就照着修改呗,最终我修改出来了,图画的也很正常了。
写出来的如下1.dset F:/ncep/daily/hgt.1948.nc2.title mean daily NMC Reanalysis (1948)3.undef -9994.xdef lon 144 linear 0 2.55.ydef lat 73 linear -90 2.56.zdef level 17 levels 1000 925 850 700 600 500 400 300 250 200 150 10070 50 30 20 107.tdef time 366 linear 00Z01Jan1948 1440mn8.vars 19.hgt=>hgt 17 t,z,y,x mean Daily Geopotential height10.endvars复制代码光看着正常不行啊,需要和原始的图对比验证了才能确定是对的吧。
所以在grads里面用sdfopen命令打开hgt.1948.nc画第一层第一个时次的图,再用xdfopen打开你编写的ctl,也画第一层第一个时次的图看看。