NVIDIA GPU上的Linpack性能测试初探
什么是高性能计算,涉及哪些技术和知

什么是高性能计算,涉及哪些技术和知识高性能计算(HPC指通常使用很多处理器(作为单个机器的一部分)或者某一集群中组织的几台计算机(作为单个计算资源操作)的计算系统和环境。
高性能集群上运行的应用程序一般使用并行算法,把一个大的普通问题根据一定的规则分为许多小的子问题,在集群内的不同节点上进行计算,而这些小问题的处理结果,经过处理可合并为原问题的最终结果。
由于这些小问题的计算一般是可以并行完成的,从而可以缩短问题的处理时间。
高性能集群在计算过程中,各节点是协同工作的,它们分别处理大问题的一部分,并在处理中根据需要进行数据交换,各节点的处理结果都是最终结果的一部分。
高性能集群的处理能力与集群的规模成正比,是集群内各节点处理能力之和,但这种集群一般没有高可用性。
高性能计算的分类方法很多。
这里从并行任务间的关系角度来对高性能计算分类。
一、高吞吐计算(High-throughput Computing)有一类高性能计算,可以把它分成若干可以并行的子任务,而且各个子任务彼此间没有什么关联。
因为这种类型应用的一个共同特征是在海量数据上搜索某些特定模式,所以把这类计算称为高吞吐计算,而且算力也比较大。
所谓的In ternet计算都属于这一类。
按照Fly nn的分类,高吞吐计算属于SIMDSinglelnstruction/Multiple Data,单指令流-多数据流)的范畴。
二、分布计算(Distributed Computing)另一类计算刚好和高吞吐计算相反,它们虽然可以给分成若干并行的子任务,但是子任务间联系很紧密,需要大量的数据交换。
按照Flynn的分类,分布式的高性能计算属于MIMD(Multiple Instruction/MultipleData ,多指令流-多数据流)的范畴。
有许多类型的HPC系统,其范围从标准计算机的大型集群,到高度专用的硬件。
大多数基于集群的HPC系统使用高性能网络互连,基本的网络拓扑和组织可以使用一个简单的总线拓扑。
2013年中国高性能计算机性能TOP100排行榜

中国HPC TOP100自2002年至今,计算机系统的性能变化范围 覆盖了6个数量级(从13.17GFLOPS到33.86PFLOPS)
检测计算机系统的可靠性
HPL是检测计算机全系统能否持续稳定运行并给出正确结果的 最有效程序,这对当前有数万个甚至更多计算部件的超大型系 统尤为重要 以2011年第二名“神威蓝光”系统为例,运行一次完整的HPL 需8小时50分钟,这期间系统不能出任何错误
天河一号A-HN/2048x2 Intel Hexa Core Xeon X5670 2.93GHz + 2048 Nvidia Tesla M2050@1.15GHz/私有高速网络80Gbps
研制厂商/单位 国防科大
安装地点 国家超级计算广州 中心 国家超级计算天津 中心
应用领域 超算中心
Linpack值 峰值(Gflops) (Gflops) 33862700 54902400
提要
2013 中国HPC TOP100排行榜发布及简要分析 关于高性能计算机系统测试与评估的若干意见
系统测评的目的及困难 HPL测试及HPCG测试
对HPC系统进行测试评估的目的
应 用:是否满足应用需求目标? 计算机:是否达到系统设计目标?
计算结果的正确性 促进推动计算机系统的设计、 调试、改进和研制 计算机的稳定性和可靠性 对应用问题的适用性 促进推动应用软件的改进, 正确、高效的并行计算 计算速度、效率和能耗
这是计算机应用的大领域
关于TOP 100排行榜
数据来源包括厂商或应用单位提交、国际TOP500排行榜数据 引用分析、根据同类系统测算等,其真实性由数据提供方保证, TOP100发布单位负责数据合理性检查 部分数据经过TOP100发布单位测试认可,排行榜前5名必须经 认可 TOP100网站 即将开通 12月中旬在北京举行的2013年全国高性能算法软件研究开发研 讨会期间,将对如何更好的进行TOP100排行榜发布进行研讨, 诚邀请各厂商、系统研制单位以及用户单位参加
实验4--linpack

《系统结构》实验4准备知识(自学)一、HPL与High Performance Linpack目的与要求:使学生掌握Linpack和hpl的背景知识主要内容:1、Linpack背景及内容(1)背景介绍LINPACK全名Linear Equations Package,是近年来较为常用的一种计算机系统性能测试的线性方程程序包,内容包括求解稠密矩阵运算,带状的线性方程,求解最小平方问题以及其它各种矩阵运算。
它最早由来自Tennessee 大学的超级计算专家Jack Dongarra提出。
程序用FORTRAN编写,在此基础上还有C,JAVA等版本。
Linpack使用线性代数方程组,利用选主元高斯消去法在分布式内存计算机上按双精度(64 bits)算法,测量求解稠密线性方程组所需的时间。
Linpack的结果按每秒浮点运算次数(flops)表示。
第一个Linpack测试报告出现在1979年的Linpack用户手册上,最初LINPACK包并不是要制订一个测试计算机性能的统一标准,而是提供了一些很常用的计算方法的实现程序,但是由于这一程序包被广泛使用,就为通过Linpack 例程来比较不同计算机的性能提供了可能,从而发展出一套完整的Linpack 测试标准。
(2)测试标准的内容LINPACK标准可以解决的问题有:1) 各种矩阵分解(Matrix factorization),如LU分解,Cholesky分解, Schur,Gauss 分解,SVD分解,QR分解,generalized Schur分解等2) 矢量运算(Vector operation),如Copy,Add,scalar multiple,Interchange3) 存储模式(Storage Modes),如full,banded,symmetricLinpack原始版本的问题规模为100×100的矩阵,目前的Linpack测试分成三个层次的问题规模和优化选择:---- 100×100的矩阵在该测试中,不允许对Linpack测试程序进行任何修改,哪怕是注释行。
一个实用高性能PC集群的Linpack测试与分析-4

(2)
把式(1)中右下角部分矩阵仍记为 ABR ,下面对 ABR 继续 进行列主元 LU 分解,其步骤如下:
T把 ABR 划分为如下形式:
ABR =( aB1 I AB2 )
@找到 aB1 中绝对值最大的元素及所在行,假设为 k,得到
主元和置换矩阵 P +1 。
@作变换 P + 1 A,实际上是对( ABL I ABR )的第一行和主元
InteI PI 2. 53GB
C 编译器
Gcc ver 3. 0
1GB
MPI
LamMPI 6. 5. 6
100M 以太网
BLAS ATLAS 3. 4. (2 PI优化)
RedHat LinuX / 26
单节点 2. 53GfIop / s,8 节点 20. 24GfIop / s
文献标识码:A
文章编号:1001- 3695(2004)09- 0183- 02
HPL Benchmarking and Anaiysis of a Reai High Performance PC Ciuster
XIAO Ming- wang,XU Jian,CHE Yong- gang,WANG Zheng- hua
T用前面的算法分解 A11 得到 A11 = L11 U11 ,同时得到 A21 的更新,仍记为 A21 。
@解右端下三角线性代数方程组 L11 U11 = A12 ,仍把 U12 记 为 A12 。
@计算 ABR = ABR - A21 A12 。 @此 时 ABR 为( m - X b )X( n - X b )阶 矩 阵,若 min( m - X b,n - X b)> 1,则重复前面的步骤,否则结束。
NVIDIA两款全新GPU首秀:刷新AI推理纪录、性能314倍于CPU

NVIDIA两款全新GPU首秀:刷新AI推理纪录、性能314倍于CPU时隔半年,MLPerf组织发布最新的MLPerf Inference v1.0结果,V1.0引入了新的功率测量技术、工具和度量标准,以补充性能基准,新指标更容易比较系统的能耗,性能和功耗。
V1.0版本的基准测试内容云端推理依旧包括推荐系统、自然语言处理、语音识别和医疗影像等一系列工作负载,边缘AI推理测试则不包括推荐系统。
MLPerf Inference v1.0所有主要的OEM都提交了MLPerf测试结果,其中,在AI领域占有优势地位的NVIDIA此次是唯一一家提交了从数据中心到边缘所有MLPerf基准测试类别数据的公司,并且凭借A100 GPU刷新了纪录。
不仅如此,超过一半提交成绩的系统都采用了NVIDIA的AI平台。
不过,初创公司提交其AI芯片推理性能Benchmark的依旧很少。
AI推理最高性能半年提升45%雷锋网在MLPerf Inference v0.7结果发布的时候已经介绍过,NVIDIA去年5月发布的安培架构A100 Tensor Core GPU在云端推理的基准测试性能是最先进英特尔CPU的237倍。
经过半年的优化,NVIDIA又将推荐系统模型DLRM、语音识别模型RNN-T和医疗影像3D U-Net模型的性能进一步提升,提升幅度达最高达45%,与CPU的性能差距也提升至314倍。
从架构的角度看,GPU架构用于推理优势并不明显,但NVIDIA 依旧凭借其架构设计配合软件优化刷新了MLPerf AI云端和边缘推理的Benchmark纪录。
MLPerf的Benchmark证明了A100 GPU性能,但其不菲的售价也是许多公司难以承受的。
今天,更具性价比的NVIDIAA30(功耗165W)和A10(功耗150W)GPU也在MLPerf Inference v1.0中首秀。
A30 GPU强于计算,支持广泛的AI推理和主流企业级计算工作负载,如推荐系统、对话式AI和计算机视觉。
什么是高性能计算,涉及哪些技术和知
什么是高性能计算,涉及哪些技术和知识高性能计算(HPC指通常使用很多处理器(作为单个机器的一部分)或者某一集群中组织的几台计算机(作为单个计算资源操作)的计算系统和环境。
高性能集群上运行的应用程序一般使用并行算法,把一个大的普通问题根据一定的规则分为许多小的子问题,在集群内的不同节点上进行计算,而这些小问题的处理结果,经过处理可合并为原问题的最终结果。
由于这些小问题的计算一般是可以并行完成的,从而可以缩短问题的处理时间。
高性能集群在计算过程中,各节点是协同工作的,它们分别处理大问题的一部分,并在处理中根据需要进行数据交换,各节点的处理结果都是最终结果的一部分。
高性能集群的处理能力与集群的规模成正比,是集群内各节点处理能力之和,但这种集群一般没有高可用性。
高性能计算的分类方法很多。
这里从并行任务间的关系角度来对高性能计算分类。
一、高吞吐计算(High-throughput Computing)有一类高性能计算,可以把它分成若干可以并行的子任务,而且各个子任务彼此间没有什么关联。
因为这种类型应用的一个共同特征是在海量数据上搜索某些特定模式,所以把这类计算称为高吞吐计算,而且算力也比较大。
所谓的In ternet计算都属于这一类。
按照Fly nn的分类,高吞吐计算属于SIMDSinglelnstruction/Multiple Data,单指令流-多数据流)的范畴。
二、分布计算(Distributed Computing)另一类计算刚好和高吞吐计算相反,它们虽然可以给分成若干并行的子任务,但是子任务间联系很紧密,需要大量的数据交换。
按照Flynn的分类,分布式的高性能计算属于MIMD(Multiple Instruction/MultipleData ,多指令流-多数据流)的范畴。
有许多类型的HPC系统,其范围从标准计算机的大型集群,到高度专用的硬件。
大多数基于集群的HPC系统使用高性能网络互连,基本的网络拓扑和组织可以使用一个简单的总线拓扑。
(完整word版)NVIDIAGPU上的Linpack性能测试初探

NVIDIA GPU上的Linpack性能测试初探1. Linpack测试简介Linpack性能测试是高性能计算机的标准测试之一,其测试性能是全球Top500超级计算机排行榜的排名依据[1]。
Top500每年公布两次排行榜,在2010年6月的榜单中,由曙光公司研制的星云超级计算机取得了第2名的好成绩,其采取了通用CPU (Intel Xeon 5650) 和异构加速部件(NVIDIA Tesla C2050)的混合架构。
在本次榜单中,以GPU作为加速部件的超级计算机还有国防科大研制的天河1号(第7名)和中科院过程所研制的IPE Mole-8.5(第19名)等。
简单来说,Linpack测试是用高斯消元法求解稠密线性方程组(64位的双精度浮点数)。
在CPU上,有标准的参考实现HPL软件包[2],其实现了二维块卷帘的数据分布,部分选主元的LU分解,递归的Panel分解,look-ahead技术,多种广播算法等多种算法和优化。
在进行Linpack测试时,可选取不同的HPL参数组合(比如:矩阵规模N,分块大小nb等),不同的BLAS与MPI库,不同的编译参数等进行调优,以得到较好的Linpack性能。
2. HPL软件包在NVIDIA GPU上移植和优化由于HPL软件包实现了较多的功能和优化,所以在NVIDIA GPU上的Linpack测试也以此为基础,进行移植和优化。
本文介绍的HPL软件包的移植与实现方式,主要参考了Fatica[3]的利用NVIDIA GPU加速Linpack的工作。
文献[4]中对于HPL软件包在Linpack测试时各个函数的运行时间进行了统计和分析,发现dgemm函数的执行时间占到了大部分(约90%左右),其次是dtrsm函数。
所以,我们的基本思想是关注利用GPU加速dgemm与dtrsm函数。
同时,此种方式也使代码的改动量较小。
具体如下:CPU与GPU混合的dgemm实现CPU与GPU混合的dgemm实现,就是将矩阵乘法中的一部分放到GPU上进行,调用NVIDIA CUBLAS中的dgemm函数;同时,另一部分调用CPU上BLAS库中的dgemm函数,比如Intel MKL,AMD ACML,GotoBLAS等。
Linpack测试综述

Linpack测试概述1引言近些年随着计算机软硬件技术的提高,尤其是网络部件性能的提高,集群技术得到不断的发展。
传统的PVP(Parallel Vector Processor)超级计算机以及MPP(Massively Parallel Processing)的成本很容易达到几千万美元,与此相比,具有相同峰值性能的机群价格则要低1到2个数量级。
机群大量采用商品化部件,它们的性能和价格遵循Moore定律,从而使机群的性能/成本比的增长速率远快于PVP和MPP。
在实际应用中,人们越来越发现峰值性能不能用作衡量计算机系统的指标, 从而开始开发各种测试程序来确定系统的实际性能。
计算峰值或者浮点计算峰值是指计算机每秒钟能完成的浮点计算最大次数,包括理论浮点峰值和实测浮点峰值。
理论浮点峰值是该计算机理论上能达到的每秒钟能完成浮点计算最大次数,它主要是由CPU的主频决定的。
计算公式为:理论浮点峰值=CPU 主频×CPU 每个时钟周期执行浮点运算的次数×系统中CPU 数。
实测浮点峰值是指Linpack 值,是在这台机器上运行Linpack 测试程序,通过各种调优方法得到的最优的测试结果。
在实际程序运行中,几乎不可能达到实测浮点峰值,更不用说理论浮点峰值了。
这两个值只是作为衡量机器性能的一个指标。
Linpack已经成为国际上最流行的用于测试高性能计算机系统浮点性能的benchmark。
通过利用高性能计算机,用高斯消元法求解一元N次稠密线性代数方程组的测试,评价高性能计算机的浮点性能。
当前,用于科学与工程计算的集群系统在国内外得到愈来愈广泛的应用。
对集群系统进行Linpack性能测试一方面有助于考察系统的实际计算能力,另一方面可以通过测试找出系统的性能瓶颈从而对系统进行有针对性的改进。
2 Linpack测试程序简介LINPACK是线性系统软件包(Linear system package) 的缩写,主要开始于 1974 年4月,美国Argonne 国家实验室应用数学所主任 Jim Pool,在一系列非正式的讨论会中评估,建立一套专门解线性系统问题之数学软件的可能性。
Nehalem平台的Linpack参数训练与优化

第38卷 增刊 2010年 6月 华 中 科 技 大 学 学 报(自然科学版)J.H uazhong U niv.o f Sci.&T ech.(N atural Science Edition)Vo l.38Sup. Jun. 2010收稿日期:2010 03 04.作者简介:孟金涛(1982 ),男,助理研究员,E ma il:meng.jintao@g .基金项目:国家高技术研究发展计划资助项目(2006A A01A114).N ehalem 平台的Linpack 参数训练与优化孟金涛1贺鹏程2刘 涛1(1中国科学院深圳先进技术研究院,广东深圳518055;2华中师范大学计算机科学系,湖北武汉430079)摘要:针对如何配置L inpack 各参数并使得系统实测性能接近最优的问题,提出了一种L inpack 参数调优的训练方法,实现了分离关键参数及非关键参数,并通过小规模参数训练粗粒度设置关键参数与非关键参数,然后在大规模参数训练中逐步精细调优所有参数.在Intel 的N ehalem 平台上对实例逐步分析,实现了L inpack 的所有参数的最优化调整,使得Linpack 的实测峰值性能优化到理论峰值的80.6%.关 键 词:L inpack;参数分析;参数训练;性能测试;N ehalem 平台中图分类号:T P338.6 文献标识码:A 文章编号:1671 4512(2010)S1 0055 04Training and optimization of Linpack parameters on Nehalem platformM eng J intao 1 H e P engcheng 2 L iu T ao 1(1Shenzhen I nstit utes of A dvanced T echno lo gy ,Chinese A cademy of Sciences,Shenzhen 518055,Guangdong China;2Depar tment o f Computer Science,H uazhong No rmal U niver sity,Wuhan 430079,China)Abstract:H ow to maximize system practical peak per for mance by adjusting parameters of Linpack is a difficult problem in system perform ance test,a stratag em on training the parameters of Linpack to a chieved this object w as pr opo sed.The parameters of Linpack w er e fir st divided into tw o g roups,the impo rtant param eters and the less impo rtant ones,and then small scale par am eter training and large scale parameter training w ere taken to find the most suitable parameters value.All training w ere taken on Nehalem platform and analy zed in details her e.Finally w e find the optimized value for each parameter,and the practical peak performance w as 80.6%of the theoretical peak performance.Key words:Linpack;parameters analysis;parameters training;perfo rmance tests;Nehalem platform Linpack [1~3],SPEC [4],NAS parallel bench m ar ks (N PB)[5,6]为广泛采用的3个计算机性能的基准测试程序[7,8].其中Linpack 是目前最流行的用于测试高性能集群系统浮点运算性能的基准测试程序.Linpack 通过对稠密线性代数方程组求解能力的测试,评价高性能计算机系统的浮点性能.根据问题规模与优化选择的不同分为100 100,1000 1000,n n 3种测试[9].其中H PL (hig h performance Linpack)是第1个标准的公开版本并行Linpack n n 测试的MPI(message passing interface)实现,可适应多体系移植,目前广泛用于To p500测试[9].这一测试主要针对分布式存储大规模并行计算系统而设计,用户可以设置任意大小的问题规模,使用任意个数的处理器,利用基于高斯消去的各种优化方法寻求最佳的测试结果.如何进行Linpack 测试,并配置参数使得系统性能最优,当前的研究主要关注于一些经验性分析和指导上[10].测试人员对特定机群系统做了一些测试工作[11~17].然而对于一个特定的机群系统希望通过测试以找到其实测峰值,是非常费力的,而且面对众多参数,没有一个系统的参数选择和测试方法,要最大化系统的实测峰值也不容易.另外,新的混合体系结构的出现,使得根据以往的配置经验配置的Linpack 参数并不能得到最高的实测峰值.本文提出了一种Linpack 参数训练的性能测试方法.使用此方法,可不考虑具体系统的计算通信比,分块大小以及通信能力[1],而直接使用此方法自动训练参数,并得到较好的实测峰值,提高了系统效率.1 平台配置和符号定义本文所使用N ehalem 平台配置为Intel Ne halem X5570(4核, 2.93GH z)2路4核心,12GB 内存,软件配置为CentOS 5.2,BLAS 库为atlas,M PI 库为OpenM PI 2.0,Linpack 为H PL 2.0.Linpack 的系统性能相关符号定义如下:机器所能运行的最大矩阵规模为N max ,机器的理论峰值为R peak ,机器上的实测峰值为R max .其中,本系统的N max 最大可为37000,R peak 为93.76GFLOPS/s.因为区分关键参数和非关键参数在测试策略至为重要,所以这里特将测试矩阵的规模(N )、矩阵分块的大小(N B )和处理器网格的行列大小(P ,Q)设置为关键参数,其他参数均为非关键参数,例如:矩阵的消元方法(P FA CT ,R FACT ),矩阵分块的递归最小值(N BMIN ),每次递归划分矩阵的个数(N DIV ),矩阵向外广播的方式(B CAST ),横向通信递归深度(D),块交换的栅值(T ).2 参数训练策略本研究提出了如下的参数训练的性能测试方法,并将按照此参数训练方法一步步分析并逐个优化H PL.dat 里的所有参数.测试目标是单个结点,在以下的测试中,通过修改H PL.dat 文件中的参数,再使用$mpirun np 8./x hpl 命令得到测试结果.步骤1 首先进行小规模矩阵(这里矩阵规模N 的设定为8192)的参数测试训练阶段:a .固定非关键参数(这里保持H PL.dat 文件里参数的默认值),测试并去训练主要参数(N B ,P Q ),使机器实测峰值最大,并将H PL.dat 中的主要参数取定为最大实测峰值时的参数值,并进入下步参数训练.b .固定上步取定的关键参数,开始逐个调节非关键参数(P FA CT ,R FA CT ,N BMIN ,N DIV ,B CAST ,D,T ),根据训练结果,逐个取得机器最大实测峰值的时候的参数,并进入下步参数训练.步骤2 然后进行大规模矩阵(这里矩阵规模N 设定为32768)的参数训练阶段:a .固定以下非关键参数,测试并训练主要参数(N B ,P Q),使机器实测峰值最大,并将H PL.dat 中的主要参数取定为最大实测峰值时的参数值,并进入下步参数训练.b .固定上步取定的关键参数,逐个调节非关键参数,根据训练结果,逐个取得机器最大实测峰值的时候的参数.参数训练结束.步骤3 根据以上参数设置,将矩阵规模设定到N max ,并进行几次测试,取得该机器的最大实测峰值R max ,并计算系统效率.3 试验过程优化分析实验开始时,采用H PL.dat 文件中设定的非关键参数初始值,在此策略中除了N ,N B ,P Q 其他的参数都被认为是非关键参数.非关键参数对性能影响比较小,特定的系统也有经验参数值.这里为最优化系统性能或者使本策略具有系统普适性,参数测试也包含了非关键参数.3.1 小规模矩阵的参数训练3.1.1 关键参数训练按照测试策略固定非关键参数,将所有非关键参数保持为H PL.dat 文件的默认值,然后训练关键参数.a .分析并确定关键参数!!!N B .对N B 从16到416,进行测试训练,阶差为4,训练结果见图1.图中可以看到当N B 为60和120时,R max 接近最大.所以在以后测试中都将N B 设置为120.图1 N B 的小规模测试结果b .选取并确定关键参数!!!处理器网格的行列P Q.对P (1,2,4,8),Q(1,2,4,8),且P Q =8的所有可能的4种组合进行测试,测试结果见表1.表中显示2 4和4 2网格可以得到更好的峰值性能,所以把P ,Q 的参数锁定为2 4.3.1.2 非关键参数训练非关键参数包括:分解算法参数组合(P FA CT ,∀56∀ 华 中 科 技 大 学 学 报(自然科学版) 第38卷R FA CT,N BM I N,N DIV),B CA ST,D,T.对于非关键参数的小规模测试中,首先训练分解算法参数组合,再训练B CA ST,接着是D,最后是T.表1 P Q的小规模测试结果P Q R ma x/GF LO PS1862.112464.214264.228156.41a.分析并确定非关键参数!!!分解算法参数组合(P FA CT,R FACT,N DIV,N BM IN).P FACT和R FACT的取值范围为0,1,2,分别表示L分解,R分解,C分解,N BMIN和N DIV的取值范围为2,4,8.分解算法参数组合的测试结果见表2.从表中可知,当分解算法参数P FACT为0,R FA CT 为0,N D IV为4,N BM IN为2,参数简写为L4L2时,系统性能最优,R max达到64.89GFLOPS.另外,由本测试结果可知,在本轮参数选取过程中,分解算法的参数选择能够使得实测峰值性能的波动幅度收敛到[(6.5- 6.2)/6.5]100%= 4.6%.表2 分解算法参数组合小规模试结果P FACT R FACT R ma x/GF LO PSL4L264.89L2C264.15R2R264.59C2L264.61C2C263.88L2R263.92R2L263.79R2C263.71C2R263.78b.分析并确定非关键参数!!!B CA ST.此次测试中,B CAS T的取值范围为0~5,相应的测试结果见图2.由图2可知,当B CAST取值为1时,其性能能够到达64.9GFLOPS,所以在以后的实验中B CAST取值为1.并且从实验结果中可以发现,数据切割后的传送方式可以使得系统R max 的波动为[(64.9-63.9)/65]100%= 1.5%.c.分析并确定非关键参数!!!D.此次测试中D的取值范围为0~7,其测试结果见图3.从图3中可以找到在D取值为0时其性能能够到达65.29GFLOPS,所以在以后的实验中D取值为0.并且从实验结果中可以发现系统实测峰值随着D的增加而减小.d.分析并确定非关键参数!!!T.测试中T的键值为16,32,48,64,#,320.图2 B C AST小规模测试结果图3 算法的递归深度D测试结果测试结果见图4.从图4可以看出,R max随着T的变化很不规则,并且T使实测峰值R max产生的波动幅度约为[(65.84-64.37)/66.84]100%= 2.2%,这里设定T值为120.图4 块交换的栅值T测试结果3.2 大规模矩阵的参数训练因为此处单节点只有12GB的内存,由NN8∃12GB80%[11],可得N=32768.这时Linpack程序大约会使用8GB内存.但是根据实测经验本系统的N max可以达到37000.首先,还是先训练关键参数,然后再训练非关键参数,基本操作步骤同3.1小节.最终得到实测峰值为75.6 GFLOPS.此时的系统效率为80.6%.鉴于这里使用的BLAS库是atlas,所以此结果比较满意.如果使用GotoBLA S,性能会有提升[10].Linpack为机群测试提供了标准,众多的参数使Linpack测试成为一个复杂耗时的过程. Linpack参数配置规律以及各参数对测试结果影∀57∀增刊 孟金涛等:N ehalem平台的L inpack参数训练与优化响程度,为利用Linpack 快速测试机群性能提供了理论基础.实验的验证表明,以此为理论基础并借鉴最优路径法提出的Linpack 快速测试方法是有效和可行的,可大量减少盲目测试的次数,节省测试的人力和物力,快速获得较满意的实际测试结果,提供相关测试参考.因测试条件的限制,提出的快速测试方法的通用性尚待开发为专用工具,并在更多的系统上进行进一步的测试和验证.参考文献[1]Petit et A ,Whaley R C,Dong arr a J,et al.A por tableimplementation of the hig h perfo rmance L inpack benchmar k fo r dist ributed memo ry comput ers [EB/OL ].[2010 01 10].http:%w lib.o rg /bench mar k/hpl/.[2]Do ng arr a J J,L uszczek P,P etitet A.T he L IN P ACKbenchmar k:past,present and fut ur e[J].Concurr en cy and Computat ion:Pr actice and Experience,15(9):803 820.[3]Dong arr a J J.T he L IN PA CK benchmark:an ex planatio n in evaluating superco mputers:strateg ies for explo iting ,evaluating and benchmar king comput er s with adv anced ar chitectur es [M ].L ondon:Chapman and H all Ltd,1990.[4]Dix it K M.SPEC Benchmark [EB/O L ].[2010 0110].htt p:%ww /.[5]Ba iley D.N AS NP B[EB/OL ].[2010 01 10].htt p:%w w w.nas.nasa.go v/Reso urces/Softw are/npb.ht ml.[6]Ba iley D H,Bar szcz E,Bar ton J T.et al.T he N A Spar allel benchmar ks !summary and pr elim ina ry re sults[C]%Pro ceedings o f the 1991A CM /I EEE Con fer ence o n Supercomputing.A lbuquerque,N ewM ex ico:A CM ,1991:158 165.[7]Gustafson J L,T o di R.Conventional benchmarks asa sam ple of the per for mance spect rum[J].T he Jour nal of Super co mputing ,1999,13(3):321 342.[8]冯圣中.高性能计算机性能评价研究进展[J].高性能计算发展与应用,2005,2(1):1 5.[9]Dongar ra J J.Perfo rmance of var io us co mputers usingstandard linear equations so ftwar e [J ].A CMSIGA RCH Co mputer A r chitectur e New s,20(3):2244.[10]曹振南.如何做L inpack 测试及性能优化[EB/OL ].[2010 01 10].http:%w ww.samss.or /linpack doc/how to do.pdf.[11]姜晓玲,任国林.基于IBM 1350机群的L inpack 快速测试[J].计算机技术与发展,2007,17(3):1 6.[12]都志辉,吴 博,刘 鹏.L inpack 与机群系统的L inpack 测试[J].计算机科学,2002,29(5):9 13.[13]罗水华,杨广文,张林波,等.并行集群系统的L inpack 性能测试分析[J].数值计算与计算机应用,2003,24(4):12 16.[14]何 昱,历 军.基于Clear Speed 硬件加速器的L inpack 性能评测与优化[EB/O L ].[2010 01 10].http:%w ww.aozhu123.blo /job htm actio n dow nlo ad itemid 209871 aid 34568.ht ml.[15]Papado po ulos P M ,P apadopoulo s C A ,K atz M J,et al.Config ur ing larg e hig h per for mance clusters at lig htspeed:a case study [J].I nter nat ional Journal o f H ig h Per formance Com puting A pplicatio ns,2004,18(3):317 326.[16]张文力,陈明宇,樊建平.H P L 测试性能仿真与预测[J].计算机研究与发展,2006,43(3):23 31.[17]张文力,陈明宇,冯圣中.并行linpack 分析与优化探讨[EB/OL ].[2010 01 10].w w /hp cog /paper /zhang wlcmy linpack cn.pdf.∀58∀ 华 中 科 技 大 学 学 报(自然科学版) 第38卷。
ARM Cortex A8、Cortex A9具体测评

本文章由vcii在/thread-980322-1-1.html,发表的文章。
想写一篇关于主流平板方案横向评测的文章的想法在大脑里已经存在很久了,迟迟没能下笔的原因有很多,一方面因为目前平板方案百草齐放杂乱无章毫无公平的规律可寻;另一方面也是因为经手的产品还不够丰富,担心视野不够开阔,最终的文章横向不够广,纵向不够深;再有就是也在等待 CES2011展会,看看有没有即现的黑马出来。
不过从目前的情况来看,概念远远大过实际,很多的新方案最终成为产品一时半会儿还很难实现,所以我们也该回到现实中来,从目前市面上已有的产品角度出发,去找寻值得横向评测的平板方案。
我大概统计了下,加上此次CES2011展会上公布的新品,目前平板方案约有20余款,主要集中在10余家芯片商手里,它们的名字基本上都是耳熟能详的。
国外有NVIDIA、德州仪器、飞思卡尔、三星、高通等;国内有瑞芯微、盈方微、威盛等。
方案的架构也是五花八门,有ARM9、ARM11,也有 Cortex A8、Cortex A9,这给横测造成了不小的麻烦,与ARM9比起来ARM11表现肯定更好一些,而如果与Cortex A9相比,两者的差距又过于大了,就好比是拿几百块钱的所谓山寨平板与苹果iPad对比一样,用以卵击石来形容毫不夸张。
经过再三考虑,最后决定将 Cortex A8与A9分在同一组,而ARM9与ARM11分在同一组,这样的话避免了不同架构芯片方案差距过大的问题,也避免了单架构产品过于单一的问题。
第一部分:挑选用于横向对比评测的平板方案以及各方案对应的产品本篇为Cortex A8/A9架构平板方案横向对比评测篇,我简单整理了目前相对主流的ARM Cortex A8、Cortex A9平板方案,如下:Cortex-A8组:瑞芯微RK29XX(Cortex-A8,1.2GHz,Neon协处理器和512KB二级缓存,支持OpenGL ES 2.0和Open VG)CES2011发布Telechips TCC8803(Cortex-A8,1.2GHz,集成512MB DDR3,全格式1080,集成G-sensor)近期发布高通QSD8250(Cortex-A8,1GHz,256/512MB mDDR 32bits)google N1, Dell streak德州仪器OMAP3430/3530(Cortex-A8,550/720MHz,256MB mDDR,32bits)moto milestone,爱可视5,维智A81三星S5PC100(Cortex-A8,667/800MHz,256MB mDDR 32bit)iPod Touch3、iPhone 3GS三星S5PC110/S5PV210(Cortex-A8,800/1GHz,512K L2,512M mDDR2 32bit,45nm)三星i9000,Galaxy Tab飞思卡尔i.MX515(Cortex-A8,800/1GHz,256/512M DDR2 32bit)山寨i.mx515德州仪器OMAP3630/3640(Cortex-A8,800/1GHz,512MB mDDR2 32bit,45nm)Moto Droidx/Droid2,爱可视2010款Cortex-A9组:NVidia Tegra2(Cortex-A9 1GHz双核+VFP,512M/1G DDR2 32bit,40nm)微星Harmony,万利达Zpad、东芝Folio德州仪器OMAP4430/4440(Cortex-A9 1GHz/1.3GHz双核+Neon,512M/1G+ DDR3 64bits)近期发布Ambarella iOne(Cortex-A9,1GHz,533MHz ARM11处理数字讯号处理,1080P 解码,整合WiFi蓝牙GPS等)近期发布逐一来说吧,先是Cortex A8架构级别。
标准Linpack测试详细指南

标准LinPack测试详细指南云计算系统的一个重要作用是向用户提供计算力,评价一个系统的总体计算力的方法就是采用一个统一的测试标准作为评判,现在评判一个系统计算力的方法中最为知名的就是LinPack测试,世界最快500台巨型机系统的排名采用的就是这一标准。
掌握LinPack测试技术对于在云计算时代评判一个云系统的计算力也有着重要意义。
本附录将对LinPack测试技术作详细的介绍。
1.LinPack安装在安装之前,我们需要做一些软件准备,相关的软件及下载地址如下。
(1)Linux平台,最新稳定内核的Linux发行版最佳,可以选择Red hat, Centos等。
(2)MPICH2,这是并行计算的软件,可以点击下面链接下载最新的源码包:/research/projects/mp ich2/downloads/index.php?s=downloads (3)Gotoblas,BLAS库(Basic Linear Algebra Subprograms)是执行向量和矩阵运算的子程序集合,这里我们选择公认性能最好的Gotoblas,最新版可点击下面链接下载(需要注册):/tacc- projects(4)HPL,LinPack测试的软件,可在点击下面链接下载最新版本:/benchmark/hpl/安装方法和步骤如下。
(1)安装MPICH2,并配置好环境变量,本书前面已作介绍。
(2)进入Linux系统,建议使用root用户,在/root下建立LinPack文件夹,解压下载的Gotoblas和HPL文件到LinPack文件夹下,改名为Gotoblas和hpl。
#tar xvf GotoBLAS-*.tar.gz#mv GotoBLAS-* ~/linpack/Gotoblas#tar xvf hpl-*.tar.gz#mv hpl-* ~/linpack/hpl(3)安装Gotoblas。
进入Gotoblas文件夹,在终端下执行./ quickbuild.64bit(如果你是32位系统,则执行./ quickbuild.31bit)进行快速安装,当然,你也可以依据README里的介绍自定义安装。
超级计算机系统架构分析

参考资料O 天河一号 - 百科 O 天河一号 - 维基百科O 我国首台千万亿次超级计算机系统天河一
号研制成功 O TOP500 见证全球超级计算机十五年 O 勇闯天河 探秘“天河一号”超级计算机 O 超级计算机的多层架构抽象及描述
小组成员
O 唐
翰(PPT制作及资料查找) O 李宇龙(PPT制作及资料查找) O 黄宏愿(纲要制作及资料查找) O 杨锐晨(PPT讲解及资料查找)
系统架构
O 组织架构
O 理论基础架构
O 软件架构
组织架构
O 处理器(CPU),峰值速度达1206TFlops, 内存总容量为 98TB,Linpack实测性能为563.1TFlops。其计算量若由一台 微型计算机来执行大约连续计算160万年才能完成。“天河 一 号”是采用并行体系结构的超级计算机,采用的是AMD的 图形核心。其特殊之处在于多阵列、可配置、协同并行,实 现了“CPU+GPU”的异构协同计算,提 高了计算效能。 O “天河一号”超级计算机采用了多阵列、可配置、协同并行 体系结构,系统由计算阵列、加速阵列和服务阵列组成,其 中计算阵列、服务阵列分别由采用通用处理器 (CPU)的计算 节点机、服务节点机构成,加速阵列则由基于图形加速处理 器(GPU)的大量加速节点机构成,实现了“CPU+GPU”的异构 协同计算,提 高了计算效能。此外,“天河一号”采用了便 于维护和高密度的刀片式(Blade)结构,每个机位都有几十个 可热插拔的刀片,每个“刀片”实际上就相当于一 块计算机 主板,组成一台配置有处理器、内存等模块的节点计算机。
GPU计算卡
“天河一号A”占据了HPC TOP500的第一,那么它制胜 的关键是什么?那就是GPU部分采用了NVIDIA Tesla M2050/M2070计算模块解决方案,核心威力在于会 以二十分之一的功耗与十分之一的成本即可实现超级 计算能力,从而为部门集群与数据中心的部署提供 了 全球最高的计算密度。至于Tesla M2050与M2070计 算模块,它们是基于代号为“Fermi”的GPU核心,双精 度性能超过四核x86 CPU十倍。值得一提的是它拥有 ECC存储器,保证了数据的一致性。在进行GPU计算时, 所有的标准优势和最高可靠性都可以实现,无缝紧密 地集成了系统监 控与管理工具,其中包括各种各样的 架上型与刀片式系统。此外,这些系统还包含了用户 所需的远程监控与远程管理功能,从而可满足高性能 计算与大型数据中心以 及横向扩展等部署需求。
曙光5000A 超级计算机的Linpack 测试
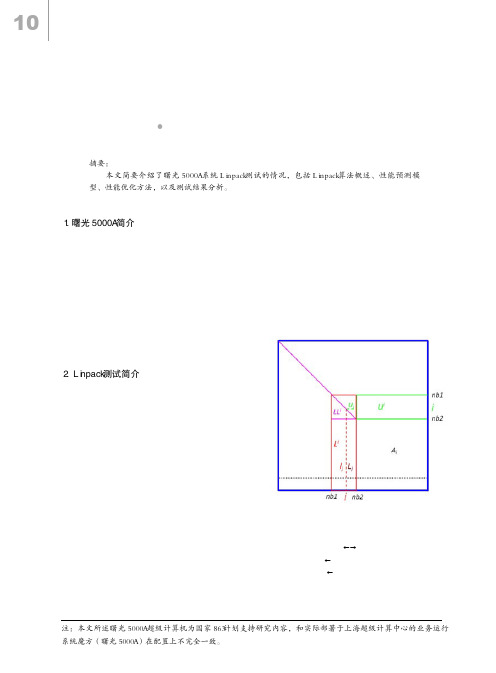
2. Linpack测试简介
Linpack是当前国际上流行的性能测试基准。 它通过对高性能计算机求解稠密线性代数方程组能 力的测试,评价高性能计算机系统的浮点性能。 根据问题规模与优化选择的不同,Linpack分为 100×100,1000×1000, n × n 三种测试 [3] 。HPL [4] (High Performance Linpack) 是第一个标准的公开版本 并行Linpack测试软件包,是n×n测试的MPI实现,可 适应多种体系结构。该软件包主要针对分布式存储 大规模并行计算系统而设计,用户可以设定任意大 小的问题规模,使用任意个数的CPU,使用基于高斯 消去法的各种优化方法寻求最佳的测试结果。由于 高斯消去LU分解法求解规模为n 的线性代数方程问题 的浮点运算次数(2n3/3 +3n2/2)是一定的,因此只要 给出问题规模n,根据线性方程组求解过程中消元和 回代部分的耗时t就可以计算出机器的性能参数,即 每秒执行的浮点运算次数: ( 2n3/3 + 3n2/2 ) / t (1) 一般而言,要获得HPL实测峰值,需要使用与内 [1] nb1=i×NB, nb2=nb1+NB [2] for(j=nb1; j<nb2; j++) [2.1] 找主元,P[j] s.t. |LiP[j],j|>=| Lij:N,j | [2.2] Lij, nb1:nb2LiP[j], nb1:nb2 [2.3] lj lj/Lij, j [2.4] Lj Lj - ljuj
该性能预估模型在本质上是将实际的CPU计算、 网络通信等操作分别抽象成相应的符合实际测试流 程逻辑的开销,从而能在单机内以秒计的时间内完 成大规模系统中以小时计的实际运算的开销估测。 经曙光4000、曙光5000系列的反复验证和调整,该模 型给出的总体性能预估误差在10%以内。
Linpack的安装、测试与优化

Linpack的安装调试、优化目录一.Linpack的安装与调试 (2)1.编译器的安装 (2)2.并行环境MPI的安装 (2)3.数学库的安装 (3)4.HPL的安装 (3)二.Linpack的优化与运行 (5)1.HPL.dat中参数的优化 (5)2.xhpl运行的方式 (5)3.查看分析结果 (6)一.Linpack的安装与调试Linpack是国际上最流行的用于测试高性能计算机系统浮点性能的benchmark。
通过对高性能计算机采用高斯消元法求解一元N次稠密线性代数方程组的测试,评价高性能计算机的浮点性能,Linpack测试包括三类,Linpack100、Linpack1000和HPLHPL是针对现代并行计算机提出的测试方式。
用户在不修改任意测试程序的基础上,可以调节问题规模大小(矩阵大小)、使用CPU数目、使用各种优化方法等等来执行该测试程序,以获取最佳的性能1.编译器的安装常用的编译器有:GNU PGI Intel编译器如果CPU是Intel的产品,最好使用Intel的编译器,它针对自己的产品做了一些优化,可能效果要好一些。
这里使用全安装方式下CentOS6.2操作系统自带的GNU编译器。
2.并行环境MPI的安装常用的MPI并行环境有:MPICH OpenMPI Intel的MPI等。
如果CPU是Intel的产品,提议使用Intel的MPI。
这里使用OpenMPI 。
安装步骤:本例中各软件安装在/home/richard目录下下载openmpi‐1.4.5.tar.gz#tar zxvf openmpi‐1.4.5.tar.gz#mv openmpi‐1.4.5 openmpi#cd openmpi#./configure –prefix=/home/ ichard/openmpi#make all install安装过程比较长,请耐心等待……安装完成后,#export PATH=/home/ ichard/openmpi/bin:$PATH#export LD_LIBRARY_PATH=/home/ ichard/openmpi/lib:$LD_LIBRARY_PATH#source在命令行输入mpi加两次Tab键,如果下面能正常显示mpirun,mpicc…就说明变量添加成功,但在每次重启都会消失,需重新添加,可在~/.bashrc中永久添加3.数学库的安装采用BLAS库的性能对最终测得的Linpack性能有密切的关系,常用的BLAS库有GOTO、Atlas、ACML、MKL等,测试经验是GOTO库性能最优。
linpack Benchmark

Linpack简要说明文档LINPACK是线性系统软件包(Linear system package)的缩写,主要开始于1974年4月,美国Argonne国家实验室应用数学所主任Jim Pool,在一系列非正式的讨论会中评估,建立一套专门解线性系统问题之数学软件的可能性。
后来便提出了LINPACK。
LINPACK主要的特色是:●率先开创了力学(Mechanics)分析软件的制作。
●建立了将来数学软件比较的标准。
●提供软件链接库,允许使用者加以修正以便处理特殊问题,(当然程序名称必须改写,并应注明修改之处,以尊重原作者,并避免他人误用。
)●兼顾了对各计算机系统的通用性,并提供高效率的运算。
至目前为止,LINPACK还是广泛地应用于解各种数学和工程问题。
也由于它高效率的运算,使得其它几种数学软件例如IMSL、MATLAB纷纷加以引用来处理矩阵问题,所以足见其在科学计算上有举足轻重的地位。
LINPACK性能测试基准:Linpack现在在国际上已经成为最流行的用于测试高性能计算机系统浮点性能的benchmark。
通过利用高性能计算机,用高斯消元法求解一元N次稠密线性代数方程组的测试,评价高性能计算机的浮点性能。
Linpack测试包括三类,Linpack100、Linpack1000和HPL。
Linpack100求解规模为100阶的稠密线性代数方程组,它只允许采用编译优化选项进行优化,不得更改代码,甚至代码中的注释也不得修改。
Linpack1000要求求解规模为1000阶的线性代数方程组,达到指定的精度要求,可以在不改变计算量的前提下做算法和代码上做优化。
HPL即High Performance Linpack,也叫高度并行计算基准测试,它对数组大小N没有限制,求解问题的规模可以改变,除基本算法(计算量)不可改变外,可以采用其它任何优化方法。
前两种测试运行规模较小,已不是很适合现代计算机的发展,因此现在使用较多的测试标准为HPL,而且阶次N也是linpack测试必须指明的参数。
LinPACK简介

LinPACKLinpack 是当前国际上流行的性能测试基准,通过对高性能计算机求解稠密线性代数方程组能力的测试,评价高性能计算机系统的浮点性能,由Jack Dongarra 在1979 年首次提出,多为Fortran 版本。
它提供多种程序并在其它函数库的支持下解决线性方程问题,包括求解稠密矩阵运算,带状的线性方程,求解最小平方问题以及其它各种矩阵运算,但它们都是基于高斯消去法的原理。
Linpack 根据问题规模与优化选择的不同分为100×100,1000×1000,n×n 三种测试[1]。
HPL[2] (High performance linpack) 是第一个标准的公开版本并行Linpack 测试软件包,是n×n 测试的MPI 实现,可适应多体系移植,目前广泛用于top500 测试[3]。
这一测试主要针对分布式存储大规模并行计算系统而设计,它的要求也是Linpack 标准中最为宽松的,用户可以对任意大小的问题规模,使用任意个数的CPU,使用基于高斯消去法的各种优化方法来执行该测试程序,寻求最佳的测试结果。
性能测试实际就是要计算浮点运算率。
美国Tennessee大学的Jack J.Dongarra 博士开发的计算测量电脑性能(基准)的程序。
在著名的超级电脑性能比较项目[TOP500 Supercomputer Sites]中作为标准被采用。
是寻求连立一次方程式的解的程序,主要可以测量浮点运算能力。
在TOP500目录单中使用的基准是把LINPACK高度并行化的项目「HPL」(High-Performance Linpack)。
LINPACK本身并不是专门用来做超级计算机的,也可以运行个人计算机和UNIX workstation等。
LINPACK标准是近年来很有名的一种进行浮点性能测试的标准。
它由Jack Dongarra 最早提出。
LINPACK的名字也是来自于利用高斯消去法求解稠密矩阵线性方程的线性代数包。
英伟达Tegra 2完胜高通8260
高通双核性能落败NVIDIA Tegra2【IT168厂商动态】手机CPU和电脑CPU是类似的,主频不能完全决定性能,并不是主频越高,性能就一定越高!现在处理器早已经不是看主频就决定性能的时代了,手机也是一样的。
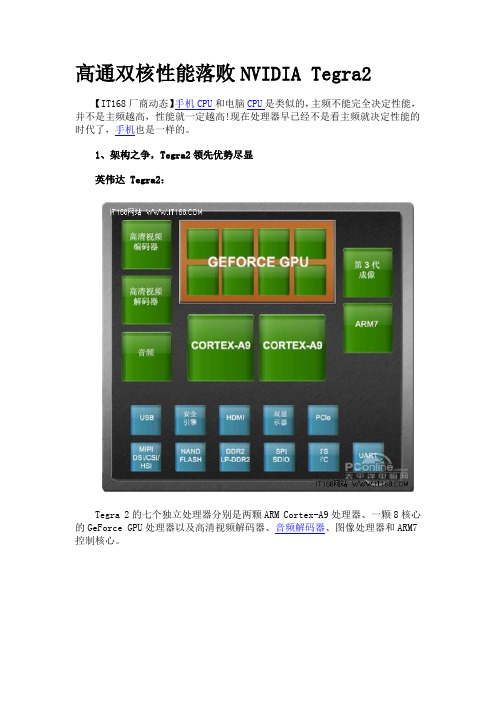
1、架构之争,Tegra2领先优势尽显英伟达 Tegra2:Tegra 2的七个独立处理器分别是两颗ARM Cortex-A9处理器、一颗8核心的GeForce GPU处理器以及高清视频解码器、音频解码器、图像处理器和ARM7控制核心。
七个处理器独立处理任务七颗独立的处理器让Tegra 2无论在上网、音视频播放、图像处理器以及3D游戏的Flash加速方面都能得心应手。
高通MSM8260和NVIDA Tegra2相比,前者为A8双核-总线结构链接双核,以及每颗单独的256K二级缓存(双核A9统一是共享1M的),严重拖慢了adreno220(GPU)的表现,俗称胶水双核,而Tegra2是双核的A9。
从架构上高通8260就显落败之势。
2、使用体验比较:Tegra2全面取胜在使用体验尤其是游戏体验上,凭借规格强大的硬件支持下,Tegra2在和对手高通MSM8260的较量中,优势更是十分明显。
作为老牌显卡厂商,在显示方面的出色表现可谓是NVIDIA的拿手好戏。
没错,NVIDIA却是做到了这一点,基于Tegra2核心的手机可以享受到于其他手机完全不同的视觉冲击,而这就是NVIDIA一直推崇的专属游戏,这在PC市场早有历史,但是在手机市场却非常创新。
NVIDIA在图形计算领域的地位毋庸置疑,在移动平台方面,从一代开始,内建GeForce GPU的Tegra家族就展现出3D图形运算和高清编解码方面的实力,三年的发展让Tegra处理器成为智能手机和平板电脑上高娱乐性的代表。
目前NVIDIA专门针对双核手机推出了Tegra Zone平台,在这里面可以下载到专属的Tegra游戏,在整个游戏体验当中让我们可以更加了解双核心的澎湃性能。
3计算资源的发展
“曙光5000”高性能计算机是国家863计划支持的研究项目。 其浮点运算处理能力可以达到230万亿次 (交付用户使用能力200万亿次), Linpack速度预测将达到160万亿次, 这个速度将有望让中国高性能计算机再次跻身世界前十(2008)。
C/S架构是伴随着局域网计算平台的发展而发 展的,尤其是PC组网的广泛普及导致C/S架构 获得了廉价而有相当计算能力的客户机。
服务器硬件的选择
从CPU处理器的体系结构来看,服务器分 为
基于RISC(精简指令集计算机) 体系结构
典型的RISC体系结构的服务器是小型机。 国外提供该类型产品的公司主要是SUN、HP 和
IA 体系结构由于其价格适中,性能优良,可作 为中小型系统购买服务器时选择的目标。在IA 体系产品中,企业级服务器占有相当大的比例。
INTEL和HP公司推出了IA-64 的处理器芯片 Itanium,使IA体系结构进入了64 位的高端计算 环境
ASCI White
ASCI White在2004年NEC“地球模拟器”系统 推出之前一直占据TOP500第一的位置,从 2001年到2004年一直是IBM安装的最大的计算 机系统 .
命名为“ASCI White”的超级计算机是由512个 RS/6000 SMP节点机构成的机群系统, “ASCI White”采用了IBM的AIX操作系统,美国能源部 用它来开发模拟核弹头安全性 .
其上的执行环境与传统pc系统相同通常在iaas服务中提供分布式集群方式分布式集群方式分布式集群方式的原理是首先由云操作系统组织一批物理服务器或者虚拟服务器构成集群然后再在集群上部署分布式软件系统作为上层软件的开发和执行环境包括等等两种资源组织方式比较虚拟化架构虽然也可用于整合分布式的服务器节点但其思想是一种分裂思想也就是把服务器分裂成多台虚拟机来调度
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
NVIDIA GPU上的Linpack性能测试初探
1. Linpack测试简介
Linpack性能测试是高性能计算机的标准测试之一,其测试性能是全球Top500超级计算机排行榜的排名依据[1]。
Top500每年公布两次排行榜,在2010年6月的榜单中,由曙光公司研制的星云超级计算机取得了第2名的好成绩,其采取了通用CPU (Intel Xeon 5650) 和异构加速部件(NVIDIA Tesla C2050)的混合架构。
在本次榜单中,以GPU作为加速部件的超级计算机还有国防科大研制的天河1号(第7名)和中科院过程所研制的IPE Mole-8.5(第19名)等。
简单来说,Linpack测试是用高斯消元法求解稠密线性方程组(64位的双精度浮点数)。
在CPU上,有标准的参考实现HPL软件包[2],其实现了二维块卷帘的数据分布,部分选主元的LU分解,递归的Panel分解,look-ahead技术,多种广播算法等多种算法和优化。
在进行Linpack测试时,可选取不同的HPL参数组合(比如:矩阵规模N,分块大小nb等),不同的BLAS与MPI库,不同的编译参数等进行调优,以得到较好的Linpack性能。
2. HPL软件包在NVIDIA GPU上移植和优化
由于HPL软件包实现了较多的功能和优化,所以在NVIDIA GPU上的Linpack测试也以此为基础,进行移植和优化。
本文介绍的HPL软件包的移植与实现方式,主要参考了Fatica[3]的利用NVIDIA GPU加速Linpack的工作。
文献[4]中对于HPL软件包在Linpack测试时各个函数的运行时间进行了统计和分析,发现dgemm函数的执行时间占到了大部分(约90%左右),其次是dtrsm函数。
所以,我们的基本思想是关注利用GPU加速dgemm与dtrsm函数。
同时,此种方式也使代码的改动量较小。
具体如下:
CPU与GPU混合的dgemm实现
CPU与GPU混合的dgemm实现,就是将矩阵乘法中的一部分放到GPU上进行,调用NVIDIA CUBLAS中的dgemm函数;同时,另一部分调用CPU上BLAS库中的dgemm函数,比如Intel MKL,AMD ACML,GotoBLAS等。
使得CPU与CPU可以同时进行计算。
矩阵的划分如图1所示,分成了图1中左(竖切B)和右(横切A)两种情况。
原因是在HPL 调用中,矩阵乘法的参数M,N,K存在两种情况,一个是K较小,M与N较大,如图1左的情况,此时划分矩阵B会得到较好的性能;另一种是K与N相等并较小,而M相对较大,如图1右,此时划分矩阵A会得到较好的性能。
通过调节比例因子R,可以达到CPU与GPU间负载的均衡。
最佳的情况是,CPU上的计算时间=数据从CPU到GPU的传输时间+GPU计算时间+结果从GPU传回CPU的传输时间。
最佳的比例因子R可以通过多次的实验获得。
从实现细节上,有两点需要注意的地方:1)CUBLAS的dgemm,使用了Volkov[5]等人的算法。
对于参数M,N,K的不同情况性能变化明显,在M为64的倍数,N和K为16的倍数时,性能最佳。
所以在划分的时候需要尽量使GPU上矩阵满足此规则;2)过小的数据规模下,GPU 并不能发挥作用,所以当规模小于一定阈值的情况下,可以直接调用CPU的dgemm函数。
CPU与GPU混合的dtrsm实现
采取与dgemm函数类似的划分策略,分别调用NVIDIA CUBLAS的dtrsm函数与CPU上的BLAS库等。
类似的调节比例因子,是GPU与CPU间的负载尽量均衡。
不再进行过多的叙述。
使用PINNED Memory和stream优化CPU与GPU数据传输
CPU与GPU间的数据传输是此种实现的瓶颈之一。
使用PINNED Memory可以显著提升PCIe 的传输带宽。
此外,还需使用CUBLAS 3.1 beta中支持的stream方式,使GPU上的计算和数据传输重叠。
3. Linpack测试结果
我们分别在单卡和多卡的情况下,进行了Linpack测试,单机的测试平台表1所示。
单机NVIDIA GPU的HPL输出如图2所示,Linpack性能为85.98GFlops,效率为68.23%。
在进行多卡的测试时,我们使用了中科院过程所的NVIDIA GPU机群,其配置如表2所示。
由于时间所限,从使用1个GPU到使用16个GPU的初步Linpack性能结果如图3所示,16个GPU Linpack性能为761.2GFlops,效率为50%。
4. 结论
本文初步介绍了一种在CPU和GPU的混合架构下的HPL软件包的移植和优化方法。
在单机与16个GPU的机群环境下进行了初步的Linpack测试,分别为85.98GFLops和
761.2GFlops。
本文介绍的实现方式,存在两个比较明显的不足:一个是CPU与GPU对于dgemm和dtrsm 是采取静态划分的策略,比例因子R是固定的,可知随着矩阵的分解,计算量是变化并逐渐减小的,所以静态划分存在一定的负载不均衡的情况,应该使用动态划分策略,即根据本次CPU与GPU的实际运行时间,更新下一次的R值;另一个是CPU与GPU间传输的数据量比较大(进行了大量矩阵的传输),对PCIe的带宽压力较大,需要进一步的优化数据传输。