利用K-Means聚类进行航空公司客户价值分析知识分享
航空公司聚类分析报告

航空公司聚类分析报告本文将进行航空公司的聚类分析,旨在对航空公司进行分类,以便于更好地理解和比较不同航空公司之间的特点和业务模式。
在航空业这一复杂的行业中,航空公司扮演着重要角色。
航空公司的经营模式、服务质量、航线网络以及价格策略等因素将直接影响到乘客的选择和满意度。
为了实现对航空公司的分类,需要使用适当的聚类算法。
在本次分析中,我们选择使用聚类算法中的K-means算法。
该算法将航空公司的特征数据作为输入,通过迭代计算来将航空公司分成不同的簇。
在分析之前,我们需要对数据进行预处理。
首先,我们需要收集航空公司的相关数据,如市场份额、客户满意度、航线数量、抵达准时率等。
然后,对这些数据进行清洗和归一化处理,以确保数据的准确性和可比性。
接下来,我们将使用K-means算法对预处理后的数据进行聚类。
K-means算法的基本思想是根据簇内数据点的相似性,将数据分成不同的簇。
具体而言,算法首先选择K个初始中心点,然后将每个数据点分配给距离其最近的中心点所属的簇,接着重新计算每个簇的中心点,再次将每个数据点分配给距离其最近的中心点,重复这个过程,直到簇内的数据点不再发生变化。
在得到聚类结果后,我们可以对不同的航空公司进行比较。
通过观察每个簇的特征和表现,我们可以研究各个聚类的特点,并根据需要对航空公司进行分类。
最后,我们可以通过可视化的方式将聚类结果呈现出来。
利用散点图或者雷达图等可视化工具,我们可以清晰地展示不同航空公司在各个特征上的表现,并进一步探讨其在簇内与其他航空公司的相似性和差异性。
通过以上的分析,我们可以得出关于不同航空公司的结论,并基于这些结论提出适应性较强的建议。
这些建议可以帮助航空公司改进其经营战略,提高服务质量,增加市场竞争力。
航空公司客户价值分析Kmeans

数据变换由于原始数据没有直接给出LRFMC五个指标,需要自己计算,具体的计算方式为:(1)L=LOAD_TIME-FFP_DATE(2)R=LAST_TO_END(3)F=FLIGHT_COUNT(4) M=SEG_KM_SUM(5)C=avg_discount数据变换的Python代码如下:1.def reduction_data(datafile,reoutfile):2. data=(cleanoutfile,encoding='utf-8')3.data=data[['LOAD_TIME','FFP_DATE','LAST_TO_END','FLIGHT_COUNT','SEG _KM_SUM','avg_discount']]4.# data['L']=(data['LOAD_TIME'])(data['FFP_DATE'])5.#data['L']=int(((parse(data['LOAD_TIME'])-parse(data['FFP_ADTE'])).d ays)/30)6.####这四行代码费了我3个小时7. d_ffp=(data['FFP_DATE'])8. d_load=(data['LOAD_TIME'])9. res=d_load-d_ffp10. data['L']=(lambda x:x/(30*24*60,'m'))11.12. data['R']=data['LAST_TO_END']13. data['F']=data['FLIGHT_COUNT']14. data['M']=data['SEG_KM_SUM']15. data['C']=data['avg_discount']16. data=data[['L','R','F','M','C']]17.(reoutfile)变换结果如下:客户聚类采纳kMeans聚类算法对客户数据进行客户分组,聚成5组,Python代码如下:1.import pandas as pd2.from import KMeans3.import as plt4.from itertools import cycle5.6.datafile='./tmp/'7.k=58.classoutfile='./tmp/'9.resoutfile='./tmp/'10.data=(datafile)11.12.kmodel=KMeans(n_clusters=k,max_iter=1000)13.(data)14.15.# print16.r1=.value_counts()17.r2=18.r=([r2,r1],axis=1)19.=list+['类别数量']20.# print(r)21.# (classoutfile,index=False)22.23.r=([data,,index=],axis=1)24.=list+['聚类类别']25.# (resoutfile,index=False)对数据进行聚类分群的结果如下表所示:。
航空客户价值分析特色LRFMC模型——RFM升级

航空客户价值分析特色LRFMC模型——RFM升级本文转载自微信公众号TIpDM。
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~———————————————————————————我们说RFM模型由R(最近消费时间间隔)、F(消费频次)和M(消费总额)三个指标构成,通过该模型识别出高价值客户。
但该模型并不完全适合所有行业,如航空行业,直接使用M指标并不能反映客户的真实价值,因为“长途低等舱”可能没有“短途高等舱”价值高。
所以得根据实际行业灵活调整RFM模型的指标,本文就拿航空公司的数据为例,将RFM模型构建成L(入会至当前时间的间隔,反映可能的活跃时长)、R(最近消费时间距当前的间隔,反映当前的活跃状态)、F(乘机次数,反映客户的忠诚度)、M(飞行里程数,反映客户对乘机的依赖性)和C(舱位等级对应的折扣系数,侧面反映客户价值高低)5个指标。
下面就利用这5个指标进行客户价值分群的实战:#########设置工作空间####setwd('D:/spss modeler/数据')#######数据的读取datafile=read.csv('./air_data.csv',header=T)该数据集包含了62988条会员记录,涉及会员号、入会时间、首次登机时间、性别等44个字段。
发现这么多字段中,正真能使用到的字段只有FFP_DATE(入会时间)、LOAD_TIME(观测窗口结束时间,可理解为当前时间)、FLIGHT_COUNT(乘机次数)、SUM_YR_1(票价收入1)、SUM_YR_2(票价收入2)、SEG_KM_SUM(飞行里程数)、LAST_FLIGHT_DATE(最后一次乘机时间)和avg_discount(舱位等级对应的平均折扣系数)。
下面来看一下这些数据的分布情况:##确定探索分析变量col=c(15:18,20:29)#去掉日期型变量###输出变量最值,缺失情况summary(datafile[,col])发现数据中存在异常,如票价收入为空或0、舱位等级对应的平均折扣系数为0。
K均值算法在航空航天领域中的应用方法(Ⅲ)

K均值算法在航空航天领域中的应用方法引言航空航天领域一直是科技创新的重要领域之一,而在这个领域中,数据分析和模式识别算法的应用尤为重要。
K均值算法作为一种常用的聚类算法,在航空航天领域中也有着广泛的应用。
本文将详细探讨K均值算法在航空航天领域中的应用方法。
K均值算法概述K均值算法是一种经典的聚类算法,其基本思想是将n个样本分成k个簇,使得簇内的样本相似度较高,而簇间的相似度较低。
具体而言,算法首先随机初始化k个质心,然后根据样本到质心的距离将样本分配到最近的簇中,接着更新每个簇的质心,重复这个过程直至收敛。
最终得到k个簇和它们的质心。
K均值算法在航空航天领域中的应用在航空航天领域中,K均值算法被广泛应用于飞行器状态监测、航线优化、航空器设计等方面。
下面将分别详细介绍这些应用方法。
飞行器状态监测飞行器状态监测是航空航天领域中的一个关键问题,通过监测飞行器的状态数据,可以及时发现飞行器的异常情况,以确保飞行器的安全飞行。
K均值算法可以应用于飞行器状态数据的聚类分析,将相似状态的数据聚集到一起,从而帮助工程师更好地理解不同状态下的飞行器性能特点,为异常检测和故障诊断提供支持。
航线优化航线优化是航空公司运营中的一个重要问题,通过合理优化航线可以降低航空公司的运营成本、提高飞行效率和舒适度。
K均值算法可以应用于对航班数据进行聚类分析,找出相似的航班,进而为航线优化提供决策支持。
例如,可以根据不同航班的起降时间、飞行时间、飞行高度等特征进行聚类分析,找出相似的航班并对其进行优化调整。
航空器设计在航空器设计中,K均值算法可以应用于对客户需求进行聚类分析,找出相似的需求并设计相应的航空产品。
例如,可以根据客户对飞机的使用需求、舒适度要求、价格敏感度等特征进行聚类分析,找出相似的客户需求并设计出相应的航空产品,从而更好地满足市场需求。
结论K均值算法作为一种经典的聚类算法,在航空航天领域中有着广泛的应用。
本文对K均值算法在飞行器状态监测、航线优化和航空器设计等方面的应用方法进行了探讨。
python数据分析与挖掘实战---航空公司客户价值分析

python数据分析与挖掘实战---航空公司客户价值分析航空公司客户价值分析⼀、背景与挖掘⽬标客户关系管理是企业的核⼼问题,关键在于客户的分类:区别⽆价值客户,⾼价值客户,针对不同客户群体有的放⽮投放具体服务⽅案,实现企业利润最⼤化的⽬标。
各⼤航空公司采取优惠措施喜迎更多客户,国内航司⾯对客户流失和资源未完全利⽤等危机,因此建⽴⼀个客户价值评估模型来实现对客户的分类。
⼆、分析⽅法与过程本次的分析⽬的在于客户价值识别,客户价值识别最常⽤的模型是RFM模型:R(最近消费时间间隔)F(消费频率)M(消费⾦额)。
飞机票价取决于飞⾏距离和仓位等级,消费同等⾦额票价的旅客对航司的价值不⼀定相同:购买短程头等舱的旅客和购买长途经济舱的旅客,明显前者对航司的贡献更⼤。
所以对M(消费⾦额)建模时要进⾏修改:⽤⾥程数平均值M和仓位折扣系数平均值C来代替消费的⾦额。
同时,考虑旅客中,加⼊会员的时间越长,客户的潜在价值⼀般越⾼,所以定义⼀个客户关系长度L,作为区分客户的另⼀指标。
接下来针对LRFMC模型,对客户进⾏区分。
LRFMC模型:(1)客户关系长度L:航空公司会员时间的长短。
(2)是消费时间间隔R。
(3)消费频率F。
(4) 飞⾏⾥程M。
(5) 折扣系数的平均值C。
LRFMC模型指标含义:(1) L:会员⼊会时间距观测窗⼝结束的⽉数。
(2) R:客户最近⼀次乘坐公司飞机距离观测窗⼝结束的⽉数。
(3) F:客户在观测窗⼝内乘坐公司飞机的次数。
(4) M:客户在观测窗⼝内累计的飞⾏⾥程碑。
(5) C:客户在观测窗⼝内乘坐仓位所对应的折扣系数的平均值。
⽅法:本案例采⽤聚类的⽅法,通过对航空公司客户价值的LRFMC模型的五个指标进⾏K-Means聚类,识别客户价值。
三、数据描述给出所有属性的基本信息,共25个属性,均⽆⼤量缺失现象或缺失现象很少。
四、建模1、数据探索分析对数据进⾏缺失值分析与异常值分析,分析出数据的规律以及异常值查找每列属性观测值个数,最⼤值,最⼩值。
基于K-means聚类算法的机场客流量变化对机场出租车数量影响情况

基于K-means聚类算法的机场客流量变化对机场出租车数量影响情况引言:一、K-means聚类算法简介K-means聚类算法是一种经典的无监督学习算法,它可以将数据集划分为K个不重叠的簇,每个簇的数据点都与簇内的均值最为接近。
该算法的基本思想是通过迭代的方式将数据点划分为K个簇,使得每个数据点到其所属簇的中心点的距离之和最小。
K-means算法的过程可以描述为以下几个步骤:1. 选择K个初始的簇中心点;2. 将每个数据点分配到最近的簇中心点所在的簇;3. 更新每个簇的中心点为该簇内所有数据点的平均值;4. 重复步骤2和步骤3直到收敛。
K-means算法适用于处理具有数字特征的数据集,其能够有效地发现数据集中的分布模式和簇结构。
在本文的研究中,我们将利用K-means算法来对机场客流量的变化进行聚类分析,以探究客流量的变化对机场出租车数量的影响情况。
二、数据搜集和预处理为了进行研究,我们需要搜集到机场客流量和出租车数量的相关数据。
通常机场的客流量数据可以通过机场运营管理系统或者相关调查数据来获取,而出租车数量可以通过机场附近交通管理部门或者出租车公司进行获取。
在数据搜集过程中,需要注意保护用户隐私,确保数据的合法性和真实性。
在搜集到数据后,我们需要进行数据预处理工作。
首先需要对数据进行清洗,去除重复数据和错误数据。
其次需要对数据进行转换和标准化处理,将不同维度的数据统一到相同的尺度上,以便于进行聚类分析。
三、客流量变化分析在对机场客流量数据进行分析时,我们首先需要对客流量数据进行时间序列分析,以了解客流量的变化规律。
通常来说,机场客流量的变化会受到一些外部因素的影响,比如航班的到达和出发时间、旅游旺季和淡季、节假日等因素。
通过时间序列分析,我们可以找出客流量的周期性变化规律和趋势性变化规律,从而为后续的聚类分析提供有益的参考。
在完成客流量数据的预处理和分析后,接下来我们将利用K-means聚类算法对客流量数据进行聚类分析。
基于K-means聚类算法的机场客流量变化对机场出租车数量影响情况

基于K-means聚类算法的机场客流量变化对机场出租车数量影响情况机场作为城市的重要交通枢纽,承担着连接城市与世界各地的重要使命。
随着航空业的不断发展,机场的客流量也在不断增加。
随之而来的问题之一就是机场周边交通的运营情况,特别是出租车数量是否足够满足旅客的需求。
本文将通过K-means聚类算法分析机场客流量变化对机场出租车数量的影响情况。
一、研究背景随着民航业的快速发展,全球各大城市的机场客流量也呈现出持续增长的趋势。
机场客流量的增加不仅对机场设施、服务质量提出了更高的要求,同时也对机场周边交通的运营提出了挑战。
出租车作为重要的机场交通方式之一,其数量是否足够满足旅客的需求,成为了一个亟待解决的问题。
K-means聚类算法是一种常用的机器学习算法,主要用于对数据集进行聚类分析。
通过对机场客流量数据进行K-means聚类分析,可以研究不同客流量情况下对机场出租车数量的影响,为机场管理部门提供科学数据支持,优化出租车运营策略,提高出租车的服务质量和效率。
二、研究内容和方法本文将通过收集机场客流量数据和机场出租车数量数据,利用K-means聚类算法对机场客流量进行分析,研究不同客流量情况下对机场出租车数量的影响。
具体研究内容和方法如下:1.数据收集:收集某一机场一定时间内的客流量数据和出租车数量数据,包括每日客流量、每小时客流量以及出租车数量等。
2.数据预处理:对收集到的原始数据进行清洗和处理,包括去除异常值、填补缺失值等,保证数据的可靠性和准确性。
3.K-means聚类分析:利用K-means聚类算法对客流量数据进行聚类分析,将客流量分为不同的类别,划分不同的客流量水平。
三、研究结果和讨论1.客流量增加对出租车数量的影响:客流量增加对机场出租车数量的需求量会产生一定影响,客流量较大的时段出租车需求量明显增加。
3.出租车运营策略优化:结合客流量变化对出租车数量的影响情况,机场管理部门可以针对不同客流量水平优化出租车运营策略,提高出租车的服务质量和效率。
kmeans聚类算法应用实例

kmeans聚类算法应用实例K-Means聚类算法应用实例一、K-Means聚类算法简介K-Means聚类算法是一种基于凝聚属性的迭代算法,它旨在将数据集中的样本点分类划分到指定数量的簇中,以达到相关性最强的分组效果。
算法的核心思想是,寻找代表簇中心的聚类中心,并根据距离聚类中心的远近,将样本分类到不同的簇中。
K-Means聚类的目的是要求出最优的聚类中心,使得样本集可以被完美划分成K个簇。
二、K-Means聚类算法的应用实例(1)客群分析K-Means聚类算法可以帮助分析客户行为及消费习惯,自动归类用户构成不同客群,如:高价值客户,积极向上的客户,偶尔购买的客户,交易历史较短的客户,低价值客户等,使企业更明确地识别其客户,选择最佳的沟通方式,创造出最大的收益。
(2)市场营销用户的社会属性,行为属性和品牌属性等,都可以利用K-Means算法对用户进行分类,进而分析用户喜好,细分市场,在不同市场中采取不同的营销战略,从而从更佳的维度去理解市场消费行为,深入分析和把握客户的行为,改善企业的市场营销效果。
(3)图像聚类K-Means聚类算法也可以用于图像处理中的相似图像聚类,以减少用户在查看数据时需要处理太多图像。
它旨在将图像划分为几个集群,使得每个簇中的样本相似度最高。
K-Means聚类算法可以用于解决视觉识别任务中的分类问题,提高图像识别系统的正确率以及效率。
(4)故障诊断K-Means聚类也可以用于故障诊断,将系统参数情况分类,来区分出系统的故障,当某一参数的值远低于正常值时,可以准确的将其分类为异常值,从而确定系统存在什么故障,从而可以有效降低系统故障率,提高系统稳定性和可靠性。
三、四、K-Means聚类算法的优缺点(1)优点a. K-Means算法效率高,计算量少;b. K-Means算法易于实现,调参相对容易;c. K-Means算法执行简单,可轻松融入现有系统;d. K-Means具有 translation invariant, scale invariant等特性,可解决非线性问题;(2)缺点a. K-Means算法的缺点是受初始聚类中心的影响较大,其结果可能受噪声干扰;b. K-Means算法可能收敛到局部最佳解;c. K-Means算法不能解决不同量级聚类间隔差异大的问题;d. K-Means算法对异常值存在敏感性,容易影响到聚类结果。
基于数据挖掘的航空客户价值分析研究

基于数据挖掘的航空客户价值分析研究第一章:绪论随着航空业的持续发展,航空公司已经拥有了大量的客户数据。
这些数据可以包括客户的购票记录、飞行里程、升舱频率、忠诚度等。
通过对这些数据进行挖掘与分析,航空公司可以了解客户群体的特征,并制定相应的客户维护策略。
因此,本文通过挖掘航空公司客户数据,对航空客户价值进行分析研究,旨在探讨如何通过数据挖掘和分析得到客户的价值信息,以及利用这些信息制定相关的市场策略。
第二章:相关理论研究2.1 客户价值客户价值是指客户对企业产生的效益和利益。
在航空业中,客户价值可以体现在购票金额、飞行里程等方面。
通过分析客户价值,企业可以了解客户的重要性和贡献度,并据此采取相应的市场营销策略。
2.2 数据挖掘数据挖掘是一种从大量数据中自动发现有意义的模式和规律的技术。
在航空业中,数据挖掘可以帮助航空公司发现客户群体的特征,挖掘客户的行为模式,提高客户满意度,从而达到客户维护和市场营销的效果。
第三章:研究方法3.1 数据采集本文使用某航空公司的客户数据进行分析。
数据包括客户的姓名、购票记录、飞行里程、升舱频率、忠诚度等。
3.2 数据预处理预处理是数据挖掘过程中的重要一步,主要是对原始数据进行清洗和规整。
本文中使用了数据清洗、缺失值填充、特征选择等技术对数据进行预处理。
3.3 模型建立本文使用K-Means聚类模型对客户进行分类,对每个客户群体的购买金额、飞行里程、升舱频率等指标进行统计和分析,最终得出每个客户群体的客户价值。
第四章:案例分析本文利用某航空公司的客户数据,进行客户价值分析。
首先使用K-Means聚类算法对客户进行分类,得到四个客户群体。
然后分别对每个客户群体的购买金额、飞行里程、升舱频率等指标进行分析,得出每个客户群体的客户价值,如图1所示。
图1:客户价值分析结果图(以购票金额为例)通过对客户的价值进行分析,可以对每个客户群体进行市场细分和营销策略的制定。
例如,对于价值较高的客户群体,航空公司可以通过一些优惠政策来提高客户的忠诚度,如加大积分兑换力度、升舱优惠政策等。
利用KMeans聚类进行航空公司客户价值分析

利⽤KMeans聚类进⾏航空公司客户价值分析准确的客户分类的结果是企业优化营销资源的重要依据,本⽂利⽤了航空公司的部分数据,利⽤Kmeans聚类⽅法,对航空公司的客户进⾏了分类,来识别出不同的客户群体,从来发现有⽤的客户,从⽽对不同价值的客户类别提供个性化服务,指定相应的营销策略。
⼀、分析⽅法和过程1.数据抽取——>2.数据探索与预处理——>3。
建模与应⽤传统的识别客户价值应⽤最⼴泛的模型主要通过3个指标(最近消费时间间隔(Recency)、消费频率(Frequency)和消费⾦额(Monetary))来进⾏客户细分,识别出价值⾼的客户,简称RFC模型。
点击查看在RFC模型中,消费⾦额表⽰在⼀段时间内,客户购买产品的总⾦额。
但是不适⽤于航空公司的数据处理。
因此我们⽤客户在⼀段时间内的累计飞⾏⾥程M和客户在⼀定时间内乘坐舱位的折扣系数C代表消费⾦额。
再在模型中增加客户关系长度L,所以我们⽤LRFMC模型。
因此本次数据挖掘的主要步骤:1).从航空公司的数据源中进⾏选择性抽取与新增数据抽取分别形成历史数据和增量数据2).对步骤1)中形成的两个数据集进⾏数据探索分析和预处理,包括数据缺失值和异常值分析。
即数据属性的规约、清洗和变换3).利⽤步骤2)中的处理的数据进⾏建模,利⽤Python下Sklearn库中提供的KMeans⽅法,进⾏聚类4)。
针对模型的结果进⾏分析。
⼆。
数据处理1.下⾯是本次试验数据集的⼀部分截图,数据集抽取2012-4-1到2014-3-31内乘客的数据,⼀个62988条数据。
包括了会员卡号、⼊会时间、性别、年龄等44个属性。
2.数据探索分析:主要是对数据进⾏缺失值分析与异常值的分析。
通过发现原始数据中存在票价为空值,票价最⼩值为0,折扣率最⼩值为0、总飞⾏公⾥数⼤于0的记录。
其Python代码如下:def explore(datafile,exploreoutfile):"""进⾏数据的探索@Dylan:param data: 原始数据⽬录:return: 探索后的结果"""data=pd.read_csv(datafile,encoding='utf-8')explore=data.describe(percentiles=[],include='all').T####包含了对数据的基本描述,percentiles参数是指定计算多少分位数explore['null']=len(data)-explore['count'] ##⼿动计算空值数explore=explore[['null','max','min']]####选取其中的重要列explore.columns=['空值数','最⼤值','最⼩值']"""describe()函数⾃动计算的字段包括:count、unique、top、max、min、std、mean。
基于K-means聚类算法的客户价值分析研究概要

基于K-means聚类算法的客户价值分析研究摘要本文重点讨论了聚类分析方法中K-means聚类算法在客户价值分析中的作用,通过对客户的现有价值和潜在价值进行分析,对客户进行细分。
在此基础上,企业可结合行业的特征找出各类客户的特点,实行差异化服务策略,让更好的资源和服务提供给最有价值客户,从而达到顾客满意、企业盈利的目的。
关键词聚类分析 K-means聚类算法客户价值1 引言市场分析理论认为,20%的客户带来约80%的利润,即帕累托所谓“关键的少数与次要的多数”的关于市场分布的一般规律[1]。
通常情况下,只有少部分高价值的客户才能够为企业带来大部分利润。
进行客户细分后,企业可以为高价值客户提供足够的技术和人力试粗С郑猿浞致闫涠云笠悼突Х竦钠谕O喾矗俨糠值图壑档目突в惺焙蛏踔粱岣笠荡锤豪蟆6蠖嗍突г虼τ诟呒壑涤氲图壑抵屑洌瞧笠抵匾目突海;岫云笠档牟莆褚导ú艽蟮挠跋臁R环矫妫腔岽锤嗟目突Х⒄够幔涣硪环矫妫且不嵬贝春芨叩脑擞缦铡6云笠道唇玻呒壑悼突峁┯胖实姆窈苤匾煌忝娴目突峁┫嘤Φ挠姓攵孕缘姆褚餐匾?lt;/DIV>作为数据挖掘技术中的一种重要的方法,聚类分析可以用于大量客户群细分。
按不同特征将客户分群后,就可以为每一群开发独立的预测模型,并根据每一群的不同特点进行分析,从而提供差异化服务或产品。
常见的聚类分析算法主要有以下三类:(1)划分法:给定一个有N个(K<N)元组或者记录的数据集,构造K个分组,每一个分组就代表一个聚类。
对于给定的K,算法首先给出一个初始的分组方法,以后通过反复迭代的方法改变分组,使得每一次改进之后的分组方案都较前一次好。
使用该基本思想的算法有K-means算法、K-medoids 算法和CLARANS算法。
(2)层次法:对给定的数据集进行层次似的分解,直到某种条件满足为止。
具体又可分为“自底向上”和“自顶向下”两种方案。
代表算法有BIRCH算法、CURE算法以及CHAMELEON算法等。
《R语言数据分析》课程教案—03航空公司客户价值分析

第3章航空公司客户价值分析教案一、材料清单(1)《R语言商务数据分析实战》教材。
(2)配套PPT。
(3)引导性提问。
(4)探究性问题。
(5)拓展性问题。
二、教学目标与基本要求1.教学目标结合航空公司客户价值分析的案例,重点介绍数据分析算法中K-Means聚类算法在客户价值分析中的应用。
针对RFM客户价值分析模型的不足,使用K-Means算法构建航空客户价值分析LRFMC模型,详细描述数据分析的整个过程。
2.基本要求(1)熟悉航空公司客户价值分析的步骤与流程。
(2)了解RFM模型的基本原理,以及K-Means算法的基本原理。
(3)构建航空客户价值分析的关键特征。
(4)比较不同类别客户的客户价值,制定相应的营销策略。
三、问题1.引导性提问引导性提问需要教师根据教材内容和学生实际水平,提出问题,启发引导学生去解决问题,提问,从而达到理解、掌握知识,发展各种能力和提高思想觉悟的目的。
(1)客户价值分析是什么?(2)影响航空公司客户价值的相关因素有哪些?(3)航空公司客户价值分析的意义在哪里?2.探究性问题探究性问题需要教师深入钻研教材的基础上精心设计,提问的角度或者在引导性提问的基础上,从重点、难点问题切入,进行插入式提问。
或者是对引导式提问中尚未涉及但在课文中又是重要的问题加以设问。
(1)客户价值分析的使用场景有哪些?(2)航空客户价值分析的步骤与流程有哪些?(3)为何要构建关键特征?3.拓展性问题拓展性问题需要教师深刻理解教材的意义,学生的学习动态后,根据学生学习层次,提出切实可行的关乎实际的可操作问题。
亦可以提供拓展资料供学生研习探讨,完成拓展性问题。
(1)除了K-Means算法,能否使用其他算法进行客户价值分析?(2)构建K-Means模型时,为何要选取3为聚类数?四、主要知识点、重点与难点1.主要知识点(1)了解航空公司现状与客户价值分析。
(2)熟悉航空公司客户价值分析的步骤与流程。
(3)处理数据的缺失值与异常值。
Python数据分析与应用实例-航空公司客户价值分析

航空公司客户价值分析1预处理航空客户数据目录了解航空公司现状与客户价值分析2使用K-Means算法进行客户分群3小结41. 行业内竞争民航的竞争除了三大航空公司之间的竞争之外,还将加入新崛起的各类小型航空公司、民营航空公司,甚至国外航空巨头。
航空产品生产过剩,产品同质化特征愈加明显,于是航空公司从价格、服务间的竞争逐渐转向对客户的竞争。
2. 行业外竞争随着高铁、动车等铁路运输的兴建,航空公司受到巨大冲击。
Ø目前航空公司已积累了大量的会员档案信息和其乘坐航班记录。
Ø以2014-03-31为结束时间,选取宽度为两年的时间段作为分析观测窗口,抽取观测窗口内有乘机记录的所有客户的详细数据形成历史数据,44个特征,总共62988条记录。
数据特征及其说明如右表所示。
航空公司数据特征说明特征名称特征说明客户基本信息MEMBER_NO 会员卡号FFP_DATE 入会时间FIRST_FLIGHT_DATE第一次飞行日期GENDER性别FFP_TIER 会员卡级别WORK_CITY 工作地城市WORK_PROVINCE 工作地所在省份WORK_COUNTRY工作地所在国家AGE年龄航空公司客户数据说明表 名特征名称特征说明乘机信息FLIGHT_COUNT观测窗口内的飞行次数LOAD_TIME观测窗口的结束时间LAST_TO_END最后一次乘机时间至观测窗口结束时长AVG_DISCOUNT平均折扣率SUM_YR观测窗口的票价收入SEG_KM_SUM观测窗口的总飞行公里数LAST_FLIGHT_DATE末次飞行日期AVG_INTERVAL平均乘机时间间隔MAX_INTERVAL最大乘机间隔积分信息EXCHANGE_COUNT积分兑换次数EP_SUM总精英积分PROMOPTIVE_SUM促销积分PARTNER_SUM合作伙伴积分POINTS_SUM总累计积分POINT_NOTFLIGHT非乘机的积分变动次数BP_SUM总基本积分续表思考原始数据中包含40多个特征,利用这些特征做些什么呢?我们又该从哪些角度出发呢?项目目标结合目前航空公司的数据情况,可以实现以下目标。
Kmeans聚类算法在数据分析中的使用方法总结

Kmeans聚类算法在数据分析中的使用方法总结摘要:数据分析是当今社会中非常重要的一项技术。
在大数据时代,如何高效地处理和挖掘海量数据成为了一项关键任务。
K-means 聚类算法是数据分析中最常用的算法之一。
本文将对K-means聚类算法在数据分析中的使用方法进行总结和讨论。
引言:数据分析是通过对数据进行解析和推断来获取有价值信息的过程。
在现实世界中,我们经常会遇到许多复杂的问题,如市场细分、个人兴趣分析、异常检测等。
K-means聚类算法是一种常用的数据分析方法,可用于将大量数据分组并揭示数据之间的隐藏信息。
一、K-means聚类算法原理K-means聚类算法是一种基于距离度量的非监督学习算法。
其原理相对简单,主要分为以下几个步骤:1. 初始化:随机选择K个中心点作为初始聚类中心;2. 分配数据点:将每个数据点分配到与其最近的中心点;3. 更新聚类中心:重新计算每个聚类中心的坐标;4. 重复步骤2和3,直到收敛或达到最大迭代次数。
二、K-means聚类算法的使用方法1. 数据预处理:在应用K-means聚类算法之前,首先需要对数据进行预处理。
常见的预处理步骤包括数据清洗、特征选择和特征缩放等。
通过去除噪声数据和选择重要特征,可以提高聚类算法的准确性。
2. 确定聚类数K:在使用K-means聚类算法之前,需要预先确定聚类数K的值。
聚类数的选择通常基于经验和领域知识。
可以使用一些评估指标(如轮廓系数和加权K-means)来帮助确定最佳的聚类数。
3. 选择初始中心点:K-means算法对初始中心点的选择十分敏感。
常见的选择方法有随机选择和基于K-means++的选择。
K-means++算法可以有效地避免初始中心点选择不合理导致的局部最优解问题。
4. 运行K-means算法:根据确定好的聚类数和初始中心点,运行K-means算法。
根据每个数据点与聚类中心之间的距离,将数据点分配到最近的中心点所属的聚类中。
基于K-means的航空旅客聚类研究

基于K-means的航空旅客聚类研究作者:龚婷普慧洁张嘉伟吴昊辰来源:《价值工程》2018年第35期摘要:本文采用K-means聚类方法,通过分析国内外民航业的旅客细分及产品打包方法的优缺点,以自己调研收集的数据,对一定范围内的人群进行了旅客细分。
在使用SPSS对旅客细分的过程中,经过多次尝试,最终确定K=3时聚类效果最好,即将旅客分为三类:公/商务旅客、探亲旅游旅客、回家/返校学生团体,并为其设计了不同的产品组合。
Abstract: This paper adopts the K-means clustering method and analyzes the advantages and disadvantages of the passenger segmentation and product packaging methods in the civil aviation industry at home and abroad. Based on the data collected by the survey and study, the passengers within a certain range are subdivided. In the process of using SPSS to segment passengers, we have tried several times to finally determine the best clustering effect when K=3. This means that passengers are divided into three categories: public/business travelers, visiting relatives and tourists, home/back to school student groups and different product mixes were designed for them. However, due to the strong uncertainty in passenger demand, in the final APP, we will mainly push product accessories/free choice, and the product portfolio will supplement the sales approach to meet the needs of passengers for personalized and customized services.关键词:K-means;数据挖掘;产品组合;旅客细分Key words: K-means;data mining;product portfolio;passenger segmentation中图分类号:F560; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ;文献标识码:A; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; 文章编号:1006-4311(2018)35-0052-030; 引言在大数据时代,民航业有大量的旅客数据被闲置,得不到充分地利用。
基于聚类分析的航空公司客户群细分及营销策略

基于聚类分析的航空公司客户群细分及营销策略航空公司作为服务性行业,客户需求差异化明显且竞争激烈。
为了满足不同客户群体的需求,并制定针对性的营销策略,航空公司可以利用聚类分析对客户进行细分。
本文将探讨基于聚类分析的航空公司客户群细分及营销策略。
首先,航空公司需要收集大量的客户数据,包括个人信息、消费行为、航班偏好等。
接下来,将这些数据输入到聚类分析模型中,通过聚类算法将客户划分为具有相似特征的群体。
常用的聚类算法包括K-means和层次聚类等。
基于聚类分析的结果,我们可以将客户细分为不同的群体。
例如,可以将客户分为商务旅客和休闲旅客两大类。
商务旅客通常需要频繁出差,对航班时间和服务质量要求较高;而休闲旅客则更注重价格和行程的灵活性。
此外,还可以根据客户的购买力和消费水平进行细分,例如高消费客户和低消费客户。
在细分客户群体的基础上,航空公司可以制定相应的营销策略。
以商务旅客为例,可以通过提供更多的商务舱座位、灵活的航班时间和优质的服务来吸引他们。
与此同时,还可以加强与高端酒店的合作,提供一站式的商务旅行服务。
对于休闲旅客,航空公司可以通过降低票价、推出旅游套餐和增加航班频次等方式来吸引他们。
此外,还可以针对不同的休闲旅客群体提供不同的促销活动,例如针对家庭旅客的亲子优惠、针对情侣旅客的情侣套餐等。
对于高消费客户,航空公司可以推出会员制度,给予他们更多的积分和专属服务。
与此同时,还可以通过提供豪华的机舱设施、个性化的餐食和增值服务等方式来满足他们的需求。
对于低消费客户,航空公司可以通过降低票价、提供经济舱折扣或增加航班频次等方式来吸引他们。
此外,还可以通过与合作伙伴(如租车公司、酒店等)的联动促销、增值服务等方式增加其购买意愿。
在制定营销策略时,航空公司还应考虑客户的生命周期价值,即客户在整个购买过程中的潜在价值。
在推出促销活动时,应结合客户的购买习惯和偏好,采用精准的定向营销策略,提高客户的忠诚度和转化率。
基于k-means的客户细分
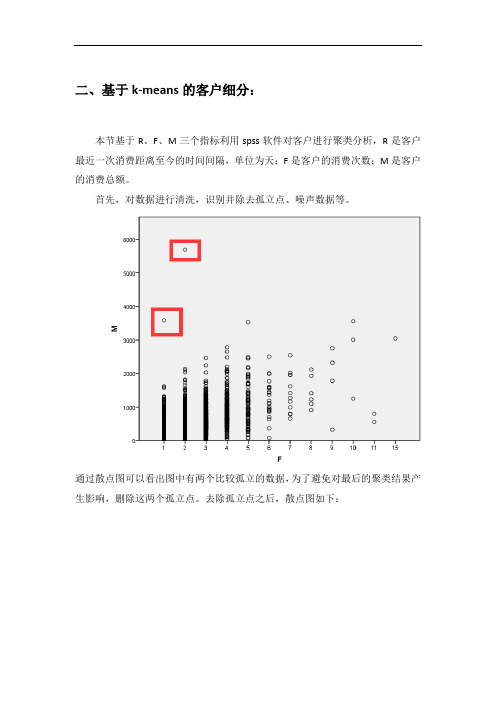
二、基于k-means的客户细分:本节基于R、F、M三个指标利用spss软件对客户进行聚类分析,R是客户最近一次消费距离至今的时间间隔,单位为天;F是客户的消费次数;M是客户的消费总额。
首先,对数据进行清洗,识别并除去孤立点、噪声数据等。
通过散点图可以看出图中有两个比较孤立的数据,为了避免对最后的聚类结果产生影响,删除这两个孤立点。
去除孤立点之后,散点图如下:因为R、F、M三个指标的量纲不同,大小也不同,所以为了消除这些差异,分别对这三个指标标准化。
采用标准差标准化的方法对这三个指标进行标准化,标准差标准化是将变量中的观察值(原数据)减去该变量的平均数,然后除以该变量的标准差。
经过标准化的数据都是没有单位的纯数量。
对变量进行的标准差标准化可以消除量纲影响和变量自身变异的影响。
根据R、F、M三个值与各指标的均值的对比,可以将用户分为8个等级,对标准化后的数据进行聚类分析,采用k-means聚类法将客户聚为8组,从上图的聚类结果可以看出各分类中客户数量,1类1442人,2类76人,3类2747人,4类370人,5类7745人,6类742人,7类10389人,8类19342人,一共42853人。
上图中的结果是依据标准化后的数据得来的,为了观察原数据的情况,需要将数据还原到原始数据。
上图是原始数据的情况,1类客户R均值为36.4,F均值为1.78,M均值为702.892类客户R均值为23.32,F均值为6.50,M均值为1659.673类客户R均值为27.44,F均值为2.00,M均值为305.424类客户R均值为27.08,F均值为3.31,M均值为1178.735类客户R均值为70.60,F均值为1.03,M均值为192.816类客户R均值为29.04,F均值为3.23,M均值为486.997类客户R均值为25.57,F均值为1.00,M均值为333.708类客户R均值为26.52,F均值为1.00,M均值为137.87所有客户R均值为34.69,F均值为1.17,M均值为242.76将每类客户的R、F、M三个指标的均值与所有客户对应的指标均值进行对比,可以看出8类客户共划分为5类上图为各类客户客户总人数。
Python数据分析与应用_第7章_航空公司客户价值分析报告

特征名称 最小值 最大值
L 12.17 114.57
R 0.03 24.37
F
M
C
2
368
0.14
213
580717
1.5
大数据挖掘专家
17
标准化LRFMC五个特征
L、R、F、M和C五个特征的数据示例,上图为原始数据,下图为标准差标准化处理后的数据。
LOAD_TIME
FFP_DATE
LAST_ TO_END
1.34
大数据挖掘专家
18
目录
1
了解航空公司现状与客户价值分析
2
预处理航空客户数据
3
使用K-Means算法进行客户分群
4
小结
大数据挖掘专家
19
了解K-Means聚类算法
1. 基本概念
K-Means聚类算法是一种基于质心的划分方法,输入聚类个数k,以及包含n个数据对象的数据库,输出满足 误差平方和最小标准的k个聚类。算法步骤如下。 ➢ 从n个样本数据中随机选取k个对象作为初始的聚类中心。 ➢ 分别计算每个样本到各个聚类质心的距离,将样本分配到距离最近的那个聚类中心类别中。 ➢ 所有样本分配完成后,重新计算k个聚类的中心。 ➢ 与前一次计算得到的k个聚类中心比较,如果聚类中心发生变化,转(2),否则转(5)。 ➢ 当质心不发生变化时停止并输出聚类结果。
最大乘机间隔 积分兑换次数 总精英积分
促销积分 合作伙伴积分 总累计积分 非乘机的积分变动次数 总基本积分
6
思考
原始数据中包含40多个特征,利用这些特征做些什么呢?我们又该 从哪些角度出发呢?
大数据挖掘专家
7
项目目标
结合目前航空公司的数据情况,可以实现以下目标。
K均值算法在航空安全领域中的应用技巧(八)

K均值算法在航空安全领域中的应用技巧在当今社会,航空安全一直是备受关注的话题。
随着航空业的不断发展和人们出行需求的增加,航空安全问题也愈发凸显。
为了确保航班的安全和准时性,航空公司和相关部门不断探索和运用先进的技术手段。
其中,K均值算法作为一种常见的聚类分析方法,被广泛应用于航空安全领域。
本文将就K均值算法在航空安全领域的应用技巧进行探讨。
一、航空安全概述航空安全一直是航空业最为关注的问题之一。
自从20世纪初出现民用飞机以来,航空安全问题一直备受人们关注。
随着航空业的不断发展和航班密度的增加,航空安全问题变得尤为重要。
各国航空公司和相关部门都在不断加强航空安全管理工作,以确保航班的安全和准时性。
二、K均值算法简介K均值算法是一种常见的聚类分析方法,广泛应用于数据挖掘领域。
它通过迭代的方式,将数据集划分为K个簇,每个簇内的数据点与该簇的质心距离最近。
K均值算法的核心思想是不断更新簇的质心,直到达到收敛条件为止。
在航空安全领域,K均值算法可以帮助航空公司和相关部门对飞行数据进行聚类分析,发现潜在的风险因素,从而及时采取相应的措施。
三、K均值算法在航空安全领域中的应用1. 数据预处理在应用K均值算法进行聚类分析之前,需要对原始数据进行预处理。
航空安全领域的数据通常包括飞行数据、机务数据、乘客信息等多个方面。
在预处理阶段,需要对数据进行清洗、归一化等操作,以确保数据的质量和一致性。
只有经过有效的数据预处理,才能保证K均值算法的准确性和有效性。
2. 聚类分析在数据预处理完成之后,可以利用K均值算法对航空数据进行聚类分析。
以飞行数据为例,可以根据飞行时间、飞行高度、飞行速度等指标进行聚类分析,发现不同飞行状态下的数据模式和规律。
通过聚类分析,可以发现潜在的风险因素和异常情况,为航空安全管理提供重要参考。
3. 风险预测基于K均值算法的聚类分析结果,可以对航空安全风险进行预测。
通过监控飞行数据的变化趋势,及时发现飞行异常和潜在风险,采取相应的措施进行预警和应对。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
利用K-Means聚类进行航空公司客户价值分析1.背景与挖掘目标1.1背景航空公司业务竞争激烈,从产品中心转化为客户中心。
针对不同类型客户,进行精准营销,实现利润最大化。
建立客户价值评估模型,进行客户分类,是解决问题的办法1.2挖掘目标借助航空公司客户数据,对客户进行分类。
对不同的客户类别进行特征分析,比较不同类客户的客户价值对不同价值的客户类别提供个性化服务,制定相应的营销策略。
详情数据见数据集内容中的air_data.csv和客户信息属性说明2.分析方法与过程2.1分析方法首先,明确目标是客户价值识别。
识别客户价值,应用最广泛的模型是三个指标(消费时间间隔(Recency),消费频率(Frequency),消费金额(Monetary))以上指标简称RFM 模型,作用是识别高价值的客户消费金额,一般表示一段时间内,消费的总额。
但是,因为航空票价收到距离和舱位等级的影响,同样金额对航空公司价值不同。
因此,需要修改指标。
选定变量,舱位因素=舱位所对应的折扣系数的平均值=C,距离因素=一定时间内积累的飞行里程=M。
再考虑到,航空公司的会员系统,用户的入会时间长短能在一定程度上影响客户价值,所以增加指标L=入会时间长度=客户关系长度总共确定了五个指标,消费时间间隔R,客户关系长度L,消费频率F,飞行里程M和折扣系数的平均值C以上指标,作为航空公司识别客户价值指标,记为LRFMC模型如果采用传统的RFM模型,如下图。
它是依据,各个属性的平均值进行划分,但是,细分的客户群太多,精准营销的成本太高。
综上,这次案例,采用聚类的办法进行识别客户价值,以LRFMC模型为基础本案例,总体流程如下图2.2挖掘步骤从航空公司,选择性抽取与新增数据抽取,形成历史数据和增量数据对步骤一的两个数据,进行数据探索性分析和预处理,主要有缺失值与异常值的分析处理,属性规约、清洗和变换利用步骤2中的已处理数据作为建模数据,基于旅客价值的LRFMC模型进行客户分群,对各个客户群再进行特征分析,识别有价值客户。
针对模型结果得到不同价值的客户,采用不同的营销手段,指定定制化的营销服务,或者针对性的优惠与关怀。
(重点维护老客户)2.3数据抽取选取,2014-03-31为结束时间,选取宽度为两年的时间段,作为观测窗口,抽取观测窗口内所有客户的详细数据,形成历史数据对于后续新增的客户信息,采用目前的时间作为重点,形成新增数据2.4探索性分析本案例的探索分析,主要对数据进行缺失值和异常值分析。
发现,存在票价为控制,折扣率为0,飞行公里数为0。
票价为空值,可能是不存在飞行记录,其他空值可能是,飞机票来自于积分兑换等渠道,查找每列属性观测值中空值的个数、最大值、最小值的代码如下。
import pandas as pddatafile= r'/home/kesci/input/date27730/air_data.csv' #航空原始数据,第一行为属性标签resultfile = r'/home/kesci/work/test.xls' #数据探索结果表data = pd.read_csv(datafile, encoding = 'utf-8') #读取原始数据,指定UTF-8编码(需要用文本编辑器将数据装换为UTF-8编码)explore = data.describe(percentiles = [], include = 'all').T #包括对数据的基本描述,percentiles参数是指定计算多少的分位数表(如1/4分位数、中位数等);T是转置,转置后更方便查阅print(explore)explore['null'] = len(data)-explore['count'] #describe()函数自动计算非空值数,需要手动计算空值数explore = explore[['null', 'max', 'min']]explore.columns = [u'空值数', u'最大值', u'最小值'] #表头重命名print('-----------------------------------------------------------------以下是处理后数据')print(explore)'''这里只选取部分探索结果。
describe()函数自动计算的字段有count(非空值数)、unique(唯一值数)、top(频数最高者)、freq(最高频数)、mean (平均值)、std(方差)、min(最小值)、50%(中位数)、max(最大值)'''-----------------------------------------------------------------以下是处理前数据count unique top freq mean stdMEMBER_NO 62988 NaNNaN NaN 31494.5 18183.2FFP_DATE 62988 3068 2011/01/13 184 NaN NaNFIRST_FLIGHT_DATE 62988 3406 2013/02/16 96 NaN NaNGENDER 62985 2男48134 NaN NaNFFP_TIER 62988 NaN NaN NaN 4.10216 0.373856WORK_CITY 60719 3310 广州9385 NaN NaNWORK_PROVINCE 59740 1185广东17507 NaN NaNWORK_COUNTRY 62962 118CN 57748 NaN NaN...-----------------------------------------------------------------以下是处理后数据空值数最大值最小值MEMBER_NO 0 62988 1 FFP_DATE 0 NaN NaN FIRST_FLIGHT_DATE 0 NaN NaN GENDER 3 NaN NaN FFP_TIER 0 6 4 WORK_CITY 2269 NaN NaN WORK_PROVINCE 3248 NaN NaN WORK_COUNTRY 26 NaN NaN AGE 420 110 6 LOAD_TIME 0 NaN NaN FLIGHT_COUNT 0 213 2BP_SUM 0 505308 0 ...2.3数据预处理数据清洗丢弃票价为空记录丢弃票价为0、平均折扣率不为0、总飞行公里数大于0的记录import pandas as pddatafile= '/home/kesci/input/date27730/air_data.csv' #航空原始数据,第一行为属性标签cleanedfile = '' #数据清洗后保存的文件data = pd.read_csv(datafile,encoding='utf-8') #读取原始数据,指定UTF-8编码(需要用文本编辑器将数据装换为UTF-8编码)data = data[data['SUM_YR_1'].notnull() &data['SUM_YR_2'].notnull()] #票价非空值才保留#只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录。
index1 = data['SUM_YR_1'] != 0index2 = data['SUM_YR_2'] != 0index3 = (data['SEG_KM_SUM'] == 0) &(data['avg_discount'] == 0) #该规则是“与”,书上给的代码无法正常运行,修改'*'为'&'data = data[index1 | index2 | index3] #该规则是“或”print(data)# data.to_excel(cleanedfile) #导出结果————————————————————以下是处理后数据————————MEMBER_NO FFP_DATEFIRST_FLIGHT_DATE GENDER FFP_TIER \0 54993 2006/11/02 2008/12/24男 61 28065 2007/02/19 2007/08/03男 62 55106 2007/02/01 2007/08/30男 63 21189 2008/08/22 2008/08/23男 54 39546 2009/04/10 2009/04/15男 65 56972 2008/02/10 2009/09/29男 66 44924 2006/03/22 2006/03/29男 67 22631 2010/04/09 2010/04/09女 68 32197 2011/06/07 2011/07/01男 59 31645 2010/07/05 2010/07/05女 6属性规约原始数据中属性太多,根据航空公司客户价值LRFMC模型,选择与模型相关的六个属性。
删除其他无用属性,如会员卡号等等def reduction_data(data):data = data[['LOAD_TIME', 'FFP_DATE','LAST_TO_END', 'FLIGHT_COUNT', 'SEG_KM_SUM','avg_discount']]#data['L']=pd.datetime(data['LOAD_TIME'])-pd.datetime(data['F FP_DATE'])#data['L']=int(((parse(data['LOAD_TIME'])-parse(data['FFP_AD TE'])).days)/30)d_ffp = pd.to_datetime(data['FFP_DATE'])d_load = pd.to_datetime(data['LOAD_TIME'])res = d_load - d_ffpdata2=data.copy()data2['L'] = res.map(lambda x: x / np.timedelta64(30 * 24 * 60, 'm'))data2['R'] = data['LAST_TO_END']data2['F'] = data['FLIGHT_COUNT']data2['M'] = data['SEG_KM_SUM']data2['C'] = data['avg_discount']data3 = data2[['L', 'R', 'F', 'M', 'C']]return data3data3=reduction_data(data)print(data3)————————————以下是以上代码处理后数据————————————L R F M C0 90.200000 1 210 580717 0.9616391 86.566667 7 140 293678 1.2523142 87.166667 11 135 283712 1.2546763 68.233333 97 23 281336 1.0908704 60.5333335 152 309928 0.9706585 74.700000 79 92 294585 0.9676926 97.700000 1 101 287042 0.9653477 48.400000 3 73 287230 0.9620708 34.266667 6 56 321489 0.828478数据变换意思是,将原始数据转换成“适当”的格式,用来适应算法和分析等等的需要。