字符编码与解码
编码与解码的数学原理

编码与解码的数学原理在计算机领域中,编码和解码涉及到了很多数学原理。
编码是将信息转换为特定格式,而解码则是将该格式转换回原始信息。
编码和解码的过程是计算机中很重要的一部分,它们使得数据的传输和储存成为了可能。
1. 进制转换在计算机中,最基本的编码和解码功能就是进制转换。
进制是一种表示数字的方式,有二进制、八进制、十进制、十六进制等。
在计算机中,最常用的进制是二进制和十六进制。
二进制是由0和1组成,只有两个数字,但是可以通过不同的排列组合来表示其他进制的数字。
例如,十进制中的数字8可以用二进制的1000来表示。
2. 奇偶校验奇偶校验是一种简单的编码和解码技术,用于检测传输中是否有误。
在奇偶校验中,每一个传输的二进制位都有一个奇偶值,如果二进制位中出现了错误,奇偶值就不再是偶数或奇数了,这样就可以检测出误差了。
例如,如果我们要传输二进制数1011,我们可以在末尾添加一个校验位,变成10110。
如果在传输中该数字变成了10100,那么奇偶值就不再是奇数了,就可以检测出错误。
3. 循环冗余校验(CRC)循环冗余校验是一种检测数据传输中差错的方法,比奇偶校验更复杂。
在CRC中,数据被看作是一个多项式,通过一些数学运算,可以产生一个余数,把余数加到原数据中,得到一组新的数据,并将其发送给接收端。
接收端使用同样的算法,来计算接收到数据的余数,如果余数与发送端一样,则数据没有出错。
4. 海明码(Hamming Code)海明码是一种通过添加冗余码来检测和纠正一定数量的错误的编码技术。
海明码通过向原数据中添加一些额外的比特来实现错误检测和纠正。
例如,我们要传输一个四位的二进制数据1101,我们可以通过添加两个奇偶校验位,变成1011011。
这些单独的校验位可以检测出其中一个数字错误,而两个校验位的组合可以检测和纠正其中两个数字错误。
5. 压缩编码压缩编码是一种将大量信息转换成较小空间来减少储存或传输成本的技术。
压缩编码中常用的方法有霍夫曼编码、算术编码、贪心编码等。
编码与解码算法原理与实现

编码与解码算法原理与实现一、引言编码和解码是计算机科学中的两个重要概念。
编码是指将信息从一种形式转换为另一种形式,而解码则是将编码后的信息转换回原始形式。
在计算机领域,编码和解码算法被广泛应用于数据传输、存储以及安全等方面。
本文将详细介绍编码与解码算法的原理和实现步骤。
二、编码算法原理与实现步骤编码算法是将信息转换为另一种形式的过程。
常见的编码算法包括Base64、哈夫曼编码等。
下面以Base64编码算法为例,介绍其原理和实现步骤。
1. 原理Base64编码算法是一种用64个字符来表示任意二进制数据的方法。
它将原始信息分割成固定长度的块,并将每个块转换为对应的Base64字符。
转换的过程包括以下步骤:- 将原始信息转换为二进制数据;- 对二进制数据进行分割,每个分割后的块长度为24位,不足24位的在末尾补0;- 对每个24位块进行转换,将其分割为4个6位的块;- 将每个6位块转换为对应的Base64字符;- 将转换后的Base64字符拼接起来,即为编码后的结果。
2. 实现步骤Base64编码算法的实现可以分为以下几个步骤:- 将原始信息转换为二进制数据:首先,将原始信息转换为ASCII码表示的字符;然后,将每个字符转换为对应的二进制数据;- 对二进制数据进行分割,每个分割后的块长度为24位:将二进制数据按照每24位进行分割,并在末尾补0;- 对每个24位块进行转换,将其分割为4个6位的块:将每个24位块拆分为4个6位的块,保存起来备用;- 将每个6位块转换为对应的Base64字符:将每个6位的块转换为对应的Base64字符;- 将转换后的Base64字符拼接起来,即为编码后的结果:将转换后的Base64字符按照顺序拼接起来,即可得到编码后的结果。
三、解码算法原理与实现步骤解码算法是将编码后的信息转换回原始形式的过程。
下面以Base64解码算法为例,介绍其原理和实现步骤。
1. 原理Base64解码算法是将Base64编码后的信息转换回原始形式的方法。
64位字符串的编码解码[转]
![64位字符串的编码解码[转]](https://img.taocdn.com/s3/m/e44ed65668eae009581b6bd97f1922791688be05.png)
64位字符串的编码解码[转]⼀. Base64的编码规则Base64编码的思想是是采⽤64个基本的ASCII码字符对数据进⾏重新编码。
它将需要编码的数据拆分成字节数组。
以3个字节为⼀组。
按顺序排列24 位数据,再把这24位数据分成4组,即每组6位。
再在每组的的最⾼位前补两个0凑⾜⼀个字节。
这样就把⼀个3字节为⼀组的数据重新编码成了4个字节。
当所要编码的数据的字节数不是3的整倍数,也就是说在分组时最后⼀组不够3个字节。
这时在最后⼀组填充1到2个0字节。
并在最后编码完成后在结尾添加1到2个 “=”。
例:将对ABC进⾏BASE64编码:1、⾸先取ABC对应的ASCII码值。
A(65)B(66)C(67);2、再取⼆进制值A(01000001)B(01000010)C(01000011);3、然后把这三个字节的⼆进制码接起来(010000010100001001000011);4、再以6位为单位分成4个数据块,并在最⾼位填充两个0后形成4个字节的编码后的值,(00010000)(00010100)(00001001)(00000011),其中蓝⾊部分为真实数据;5、再把这四个字节数据转化成10进制数得(16)(20)(9)(3);6、最后根据BASE64给出的64个基本字符表,查出对应的ASCII码字符(Q)(U)(J)(D),这⾥的值实际就是数据在字符表中的索引。
注:BASE64字符表:ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/⼆.解码规则解码过程就是把4个字节再还原成3个字节再根据不同的数据形式把字节数组重新整理成数据。
三. C#中的实现编码:byte[] bytes = Encoding.Default.GetBytes("要转换的字符"); string str = Convert.ToBase64String(bytes);解码:byte[] outputb = Convert.FromBase64String(str); string orgStr = Encoding.Default.GetString(outputb);C#图⽚的Base64编码和解码图⽚的Base64编码:System.IO.MemoryStream m = new System.IO.MemoryStream();System.Drawing.Bitmap bp = new System.Drawing.Bitmap(@“c:\demo.GIF”);bp.Save(m, System.Drawing.Imaging.ImageFormat.Gif);byte[]b= m.GetBuffer();string base64string=Convert.ToBase64String(b);Base64字符串解码:byte[] bt = Convert.FromBase64String(base64string);System.IO.MemoryStream stream = new System.IO.MemoryStream(bt);Bitmap bitmap = new Bitmap(stream);pictureBox1.Image = bitmap;。
python 中文编解码

python 中文编解码
在Python中,如果需要将字符串进行编码或解码,可以使用内置函数`encode()`和`decode()`。
编码(encode)是将字符串转换为字节序列的过程,而解码(decode)则是将字节序列转换为字符串的过程。
下面是一些常用的编码和解码方法:- 将字符串编码为字节序列:使用字符串的`encode()`方法,可以指定要使用的编码格式。
例如,将字符串编码为UTF-8格式的字节序列可以使用以下方式:pythons = "中文"b = s.encode('utf-8')- 将字节序列解码为字符串:使用字节序列的`decode()`方法,也可以指定要使用的解码格式。
例如,将UTF-8格式的字节序列解码为字符串可以使用以下方式:pythonb =
b'\xe4\xb8\xad\xe6\x96\x87's = b.decode('utf-8')需要注意的是,编码和解码时要使用相同的编码格式,否则可能会导致解码错误或乱码。
通常情况下,UTF-8编码是一种常用且较为通用的选择。
同时,还可以使用`str.encode()`和`bytes.decode()`方法进行编码和解码,其用法与上述方法相同。
pythons = "中文"b = str.encode(s, 'utf-8')s = bytes.decode(b, 'utf-8')以上是在Python 中进行中文编解码的基本方法,需要根据具体使用场景和需求来选择合适的编码格式和方法。
编解码(编码解码)常识

编解码(编码解码)常识字符编码字符编码就是以⼆进制的数字来对应字符集的字符,常见字符编码⽅式有:ISO-8859-1(不⽀持中⽂),GB2312,GBK,UTF-8等.在JavaWeb中, 经常遇到的需要编码/解码的场景有响应编码/请求编码/URL编码:响应编码服务器发送数据给客户端由Response对象完成,如果响应数据是⼆进制流,就⽆需考虑编码问题.如果响应数据为字符流,那么就⼀定要考虑编码问题:response.getWriter()默认使⽤ISO-889-1发送数据,⽽该字符集不⽀持中⽂,因此遇到中⽂就⼀定会乱码.在需要发送中⽂时, 需要使⽤:response.setCharacterEncoding("UTF-8");// getWriter() ...设置编码⽅式,由于在getWriter()输出前已经设置了UTF-8编码,因此输出字符均为UTF-8编码,但我们并未告诉客户端使⽤什么编码来读取响应数据,因此我们需要在响应头中设置编码信息(使⽤Content-Type):response.setContentType("text/html;charset=UTF-8");// getWriter() ...注意: 这句代码不只在响应头中添加了编码信息,还相当于调⽤了⼀次response.setCharacterEncoding("UTF-8");请求编码1. 浏览器地址栏编码在浏览器地址栏书写字符数据,由浏览器编码后发送给服务器,因此如果在地址栏输⼊中⽂,则其编码⽅式由浏览器决定:浏览器编码IE/FireFox GB2312UTF-8Chrome2. 页⾯请求如果通过页⾯的超链接/表单向服务器发送数据,那么其编码⽅式由当前页⾯的编码⽅式确定:<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">3. GET当客户端发送GET请求时,⽆论客户端发送的数据编码⽅式为何,服务端均以ISO-8859-1解码(Tomcat8.x之后改⽤UTF-8Tomcat8.x之后改⽤UTF-8),这就需要我们在request.getParameter()获取数据后再转换成正确的编码:private Map<String, String> convertToParameterMap(HttpServletRequest request) throws UnsupportedEncodingException {Enumeration<String> names = request.getParameterNames();Map<String, String> parameters = new HashMap<String, String>();if (names != null) {while (names.hasMoreElements()) {String name = names.nextElement();String value = request.getParameter(name);parameters.put(name, new String(value.getBytes("ISO-8859-1"), "UTF-8"));}}return parameters;}4. POST当客户端发送POST请求时,服务端也是默认使⽤iOS-8859-1解码,但POST的数据是通过请求体传送过来,因此POST请求可以通过request.setCharacterEncoding()来指定请求体编码⽅式:private Map<String, String> convertToParameterMap(HttpServletRequest request) throws IOException {Map<String, String> parameters = new HashMap<String, String>();if (request.getMethod().equals("POST")) {request.setCharacterEncoding("UTF-8");Enumeration<String> names = request.getParameterNames();while (names.hasMoreElements()) {String key = names.nextElement();parameters.put(key, request.getParameter(key));}} else {Enumeration<String> names = request.getParameterNames();while (names.hasMoreElements()) {String key = names.nextElement();String value = request.getParameter(key);parameters.put(key, new String(value.getBytes("ISO-8859-1"), "UTF-8"));}}return parameters;}URL编码⽹络标准RFC 1738规定:“…Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL.”“只有字母和数字[0-9a-zA-Z]、⼀些特殊符号"$-_.+!*'(),"[不包括双引号]、以及某些保留字,才可以不经过编码直接⽤于URL。
[SAPABAP开发技术总结]字符编码与解码、Unicode
![[SAPABAP开发技术总结]字符编码与解码、Unicode](https://img.taocdn.com/s3/m/c821c412bfd5b9f3f90f76c66137ee06eff94e1c.png)
[SAPABAP开发技术总结]字符编码与解码、Unicode DATA : xstr TYPE xstring .DATA : l_codepage ( 4 ) TYPE n .DATA : l_encoding ( 20 ).********** 字符集名与内码转换" 将外部字符集名转换为内部编码CALL FUNCTION 'SCP_CODEPAGE_BY_EXTERNAL_NAME'EXPORTINGexternal_name = 'UTF-8'IMPORTINGsap_codepage = l_codepage .l_encoding = l_codepage .********** 编码DATA : convout TYPE REF TO cl_abap_conv_out_ce ." 创建编码对象convout = cl_abap_conv_out_ce => create ( encoding = l_encoding ).convout -> write ( data = ' 江正军 ' ). " 编码xstr = convout -> get_buffer ( ). " 获取码流WRITE : / xstr . "E6B19FE6ADA3E5869B********** 解码DATA : convin TYPE REF TO cl_abap_conv_in_ce ." 创建解码对象convin = cl_abap_conv_in_ce => create ( encoding = l_encoding input = xstr ).DATA : str TYPE string .CALL METHOD convin -> read " 解码IMPORTING data = str .WRITE : / str . " 江正军使⽤CL_ABAP_CODEPAGE类进⾏编解码:DATA: xstr TYPE xstring,str TYPE string,l_codepage(4) TYPE n ,l_encoding(20).**********字符集名与内码转换"将外部字符集名转换为内部编码CALL FUNCTION 'SCP_CODEPAGE_BY_EXTERNAL_NAME'EXPORTINGexternal_name = 'UTF-8'IMPORTINGsap_codepage = l_codepage.WRITE: / l_codepage."等同于下⾯类⽅法l_codepage = cl_abap_codepage=>sap_codepage( 'UTF-8' ).WRITE: / l_codepage."编码xstr = cl_abap_codepage=>convert_to(source = '江正军'codepage = `UTF-8` ).WRITE: / xstr."解码str = cl_abap_codepage=>CONVERT_FROM(source = xstrcodepage = `UTF-8` ).WRITE: / str.41104110E6B19FE6ADA3E5869B江正军ABAP中的特殊字符列表=>horizontal_tab — 09 TAB符cl_abap_char_utilities=>CR_LF ———-- 0D0A 回车换⾏cl_abap_char_utilities=>VERTICAL_TAB —- 0B 垂直制表符cl_abap_char_utilities=>NEWLINE —---- 0A 换⾏cl_abap_char_utilities=>FORM_FEED —--- 0C 换页cl_abap_char_utilities=>BACKSPACE —---08 退格符CL_ABAP_CHAR_UTILITIES=>BYTE_ORDER_MARK_LITTLE-----(utf-16le')的⽂件头CL_ABAP_CHAR_UTILITIES=>BYTE_ORDER_MARK_UTF8-------(utf-8)的⽂件头如果是要单独取得回车或者换⾏(不是回车加换⾏),可以采⽤:cl_abap_char_utilities=>CR_LF(1)cl_abap_char_utilities=>CR_LF 1(1)空⽩字符:System.out.println((int)' ');//12288: gc_result(50) TYPE c.CONSTANTS: c_tab TYPE c VALUE cl_abap_char_utilities=>horizontal_tab.CONCATENATE 'text01' c_tab 'text02' c_tab 'text03' INTO gc_result.Unicode字符串互转DATA: c(4) TYPE c VALUE'ABCD'.FIELD-SYMBOLS <fs1>."将字符串以⼗六进制的Unicode码来表⽰ASSIGN c TO <fs1> type'X'.WRITE: / <fs1>.0041004200430044这是在AIX上测试的结果。
计算机编码与解码

计算机编码与解码计算机编码与解码是计算机科学中的重要概念,它们在数字通信、数据存储和信息处理等领域起着至关重要的作用。
本文将从编码和解码的基本概念入手,并介绍几种常用的编码与解码方式,以及它们在实际应用中的一些案例。
一、编码的概念编码是将信息转换为特定形式的过程,也可以说是对信息进行表示和传输的方式。
计算机编码是指将字符、数字、图像、声音等信息转换为计算机可识别的二进制形式,用于计算机的存储、传输和处理。
计算机编码主要有字符编码(如ASCII码)、图像编码(如JPEG、PNG)、音频编码(如MP3)等各种形式。
二、解码的概念解码是对编码后的信息进行还原的过程,将编码后的二进制数据转换为可读的字符、图像或声音等形式。
解码的过程涉及到解析和识别编码格式的算法以及特定的解码器。
解码的目的是恢复编码前的原始信息,使其能够被计算机或人类理解和使用。
三、常用的编码方式1. ASCII码ASCII(American Standard Code for Information Interchange)码是一套简单的字符编码方案,它将常用英文字符和特殊字符分别映射到了0到127的整数。
通过ASCII码,计算机可以识别和表示字符,并进行相关的处理和传输。
然而,ASCII码只能表示128种字符,不适用于其他语言的字符表示。
2. Unicode编码Unicode是一种国际字符集标准,它将世界上几乎所有的字符和符号都进行了统一的编码,可以容纳几乎所有的已知文字系统,并被广泛应用于计算机系统中。
Unicode编码通过不同位数的码点来表示各种字符,比如UTF-8编码使用1到4个字节来表示字符。
3. URL编码URL编码是一种特殊的编码方式,用于将URL中的特殊字符转换为%xx的形式(xx为字符的ASCII码十六进制表示)。
URL编码常用于处理URL中的特殊字符或非ASCII字符,以便它们能够被计算机识别和处理,避免引起错误或歧义。
哈夫曼编码与解码

哈夫曼编码与解码
哈夫曼编码(Huffman coding)和哈夫曼解码(Huffman decoding)是一种用于数据压缩的技术,由美国计算机科学家 David A. Huffman 于 1952 年提出。
哈夫曼编码的基本思想是根据字符在文本中出现的频率来分配二进制编码的长度。
出现频率较高的字符将被分配较短的编码,而出现频率较低的字符将被分配较长的编码。
这样,通过使用较短的编码来表示常见字符,可以实现更有效的数据压缩。
哈夫曼编码的过程包括以下步骤:
1. 统计字符出现频率:对要编码的文本进行分析,统计每个字符出现的次数。
2. 构建哈夫曼树:根据字符出现频率构建一棵二叉树,其中频率较高的字符靠近树的根节点,频率较低的字符位于树的叶子节点。
3. 分配编码:从根节点开始,根据字符出现频率为每个字符分配二进制编码。
左子节点表示 0,右子节点表示 1。
4. 编码文本:将文本中的每个字符替换为其对应的哈夫曼编码。
哈夫曼解码是哈夫曼编码的逆过程,用于将已编码的数据还原为原始文本。
解码过程根据哈夫曼树的结构和编码规则,从编码中解析出原始字符。
哈夫曼编码与解码在数据压缩领域具有广泛的应用,例如图像、音频和视频压缩。
它通过有效地利用字符频率分布的不均匀性,实现了较高的压缩率,从而减少了数据传输和存储的开销。
需要注意的是,哈夫曼编码是一种无损压缩技术,意味着解码后可以完全还原原始数据。
但在实际应用中,可能会结合其他有损压缩技术来进一步提高压缩效果。
编码与解码的区别

编码与解码的区别有的人会以为编码和解码是程序员的事,其实,我们生活中自己也会编码,现在的信息网络都是数字的,很多东西要保存传输就得编码,比如你要保存一篇文章,里面的字就是一些二进制编码。
编码和解码其实就是两个相反的过程。
下面店铺告诉你这两者的区别。
1.编码和解码的区别编码就是如何把信息转换成数字序列,解码则是把数字序列转换成信息。
编码是正过程,解码是逆过程。
编码/解码本质上是一种映射(对应关系),比如‘a’用ascii编码则是65,计算机中存储的就是00110101,但是显示的时候不能显示00110101,还是要显示'a',但计算机怎么知道00110101是'a'呢,这就需要解码,当选择用ascii解码时,当计算机读到00110101时就到对应的ascii表里一查发现是'a',就显示为'a'。
编码就是真实字符与二进制串的对应关系,真实字符转换成二进制串。
解码就是二进制串与真实字符的对应关系,二进制串转换成真实字符。
2.编码的含义编码是信息从一种形式或格式转换为另一种形式的过程也称为计算机编程语言的代码简称编码。
用预先规定的方法将文字、数字或其它对象编成数码,或将信息、数据转换成规定的电脉冲信号。
编码在电子计算机、电视、遥控和通讯等方面广泛使用。
编码是信息从一种形式或格式转换为另一种形式的过程。
解码,是编码的逆过程。
3.解码的含义将信息从已经编码的形式恢复到编码前原状的过程。
也就是用特定方法把数码还原成它所代表的内容或将电脉冲信号、光信号、无线电波等转换成它所代表的信息、数据等的过程。
解码在无线电技术和通讯等方面广泛应用。
4.霍尔的编码/解码模式加拿大传播学者麦克卢汉(McLuhan)从"技术决定论"出发,预言性地提出了"地球村"、"媒介即信息"、"媒介是人的延伸"、"热媒介和冷媒介"等著名概念,开创了电子传播时代的媒介文化研究。
解码与编码的过程

解码与编码的过程
解码和编码是信息传输过程中非常重要的部分。
在信息传输时,需要将信息转化为一种规定的方式进行传输,这就需要进行编码。
而接收方在接收到信息后,需要将信息再转化为原始形式,这就需要进行解码。
在编码的过程中,需要将信息按照一定的规则转化为固定的编码形式,这样才能够在传输过程中不发生错误。
常见的编码方式有二进制编码和 ASCII 编码等。
其中,二进制编码是将信息转化为由 0 和1 组成的二进制数列进行传输,而 ASCII 编码则是将字符转化为数字进行传输。
在解码的过程中,需要将编码后的信息转化为原始的信息形式。
如果接收方使用的解码方式与发送方不同,则接收到的信息可能会出现乱码或错误。
因此,在进行信息传输时,编码和解码方式需要事先进行统一,确保信息正确传输。
总之,编码和解码是信息传输过程中必须要进行的操作,它们的正确性和一致性决定了信息能否正确传输和解读。
utf-8编码解码的原理

utf-8编码解码的原理UTF-8(Unicode Transformation Format-8)是一种针对Unicode字符进行编码的可变长度字符编码方案。
它是全球范围内最常用的Unicode 字符编码方式之一,也是网页和电子邮件等计算机系统中最常见的字符编码之一。
在本文中,我们将深入探讨UTF-8编码解码的原理。
什么是编码和解码?在谈论编码和解码之前,我们需要了解一些基础概念。
计算机存储和处理的是数字,为了将字符(如字母、数字、标点符号等)转换成数字,就需要字符编码。
编码是指将字符映射到相应的数字表示,而解码则是将数字转换回相应的字符。
在早期的计算机系统中,使用ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)进行字符编码。
ASCII 编码使用7位二进制数字表示标准英语字符,并为其他一些特殊字符提供了额外的8位编码。
然而,ASCII编码只适用于英语字符,无法表示其他非拉丁字符(如汉字、日语等)。
随着计算机的普及和互联网的发展,需要一种能够支持全球字符集的编码方式。
Unicode应运而生,它是一种用于统一字符编码的标准。
Unicode 为每个字符分配一个唯一的数字码点,这个数字码点可以在所有计算机系统和软件中统一表示。
然而,Unicode字符具有很高的存储和传输成本,因为每个字符都需要相应的码点。
为了解决这个问题,出现了多种可变长度字符编码方案,UTF-8就是其中之一。
UTF-8编码原理UTF-8编码方案通过使用1到4个字节来表示Unicode字符,这样就能够根据字符的范围选择合适的编码长度。
下面是UTF-8编码的原理步骤:步骤1:确定Unicode字符的范围。
UTF-8编码方案将Unicode字符划分为7个范围,每个范围有不同的编码方式:- Unicode码点范围U+0000 - U+007F (0-127)可以使用1个字节编码。
Python编码(encode)和解码(Decode)常见的两个错误

Python编码(encode)和解码(Decode)常见的两个错误和分别介绍了 Python 中的字符串类型(str)和字节类型(byte),以及 Python 编码中最常见也是最顽固的两个错误:UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 0-1: invalid continuation byte这⼀期就从这两个错误⼊⼿,分析 Python 中 Unicode 的正确⽤法。
这篇短⽂并不能保证你可以永远杜绝上⾯两个错误,但是希望在下次遇到这个错误的时候知道错在哪⾥、应该从哪⾥⼊⼿。
编码与解码上⾯的两个错误分别是UnicodeEncodeError和UnicodeDecodeError,也就是说分别在 Unicode 编码(Encode)和解码(Decode)过程中出现了错误,那么编码和解码究竟分别意味着什么?根据维基百科的定义:字符编码(英语:Character encoding)、字集码是把字符集中的字符编码为指定集合中某⼀对象(例如:⽐特模式、⾃然数序列、8位组或者电脉冲),以便⽂本在计算机中存储和通过通信⽹络的传递。
简单来说就是把⼈类通⽤的语⾔符号翻译成计算机通⽤的对象,⽽反向的翻译过程⾃然就是解码了。
Python 中的字符串类型代表⼈类通⽤的语⾔符号,因此字符串类型有encode()⽅法;⽽字节类型代表计算机通⽤的对象(⼆进制数据),因此字节类型有decode()⽅法。
print(" ".encode())b'\xf0\x9f\x8c\x8e\xf0\x9f\x8c\x8f'print(b'\xf0\x9f\x8c\x8e\xf0\x9f\x8c\x8f'.decode())既然说编码和解码都是翻译的过程,那么就需要⼀本字典将⼈类和计算机的语⾔⼀⼀对应起来,这本字典的名字叫做字符集,从最早的ASCII 到现在最通⽤的 Unicode,它们的本质是⼀样的,只是两本字典的厚度不同⽽已。
base58编码、解码

base58编码、解码字符串编码流程将字符串的每个字节换算成ASCII(0-255) (字符串实际上就是256进制的数字组合)源字符串为:ABD换算后: 65 66 68将256进制的数字转换成10进制数字256进制数:65 66 68转成10进制:(65 * 256 + 66) * 256 + 68 = 4276804将10进制数字转换成58进制数字10进制数:427680458进制数: 21 53 20 0将58进制数字的每⼀位按照表格转换成对应的字符58进制数:21 53 20 0码表:123456789abcdefghijkmnopqrstuvwxyzABCDEFGHJKLMNPQRSTUVWXYZ转换后的字符:nVm1字符串解码流程字符串每⼀位按码表替换成数字(58进制)源字符: nVm158进制数:21 53 20 058进制转10进制58进制数:21 53 20 010进制数:427680410进制转256进制10进制数:4276804256进制: 65 66 68256进制转字符(按ascii转)256进制: 65 66 68字符:ABD总结:编码流程:将ascii编码的字符串(256进制),转换成58进制。
然后按照58进制的码表转换成相应的字符。
解码流程:按码表把字符转成58进制数字,再转256进制,按ascii把256进制数字转字符注:任意进制之间的转换,先将数字转10进制再转其它进制附:php代码⼀份<?php$num = 9999;$encode = base58_encode($num);echo "\n 转码:" . $encode;$decode = base58_decode($encode);echo "\n 解码:" . $decode;// 将数字压缩function base58_encode($decimal){$alphabet = 'EofdCnw9sRZmjuLcHDBJeArW5FhxaYp64zVvMgTN1PX2yqU3kiSG78tKQb'; // 随机字符$base = strlen($alphabet);$output = '';if (!is_numeric($decimal)) {return $output;}while ($decimal >= $base) {$div = bcdiv($decimal, $base, 0);$mod = bcmod($decimal, $base);$output .= $alphabet[$mod];$decimal = $div;}if ($decimal > 0) {$output .= $alphabet[$decimal];}return strrev($output);}// 字符串转成数字function base58_decode($base58){$alphabet = 'EofdCnw9sRZmjuLcHDBJeArW5FhxaYp64zVvMgTN1PX2yqU3kiSG78tKQb'; // 同加密⼀样的字符 $base = strlen($alphabet);$indexes = array_flip(str_split($alphabet));$decimal = 0;for ($i = 0; $i < strlen($base58); $i++) {$decimal = bcmul($decimal, $base);$decimal = bcadd($decimal, $indexes[$base58[$i]]);}return $decimal;}。
C++字符数字的编码(Encode)与解码(Decode)
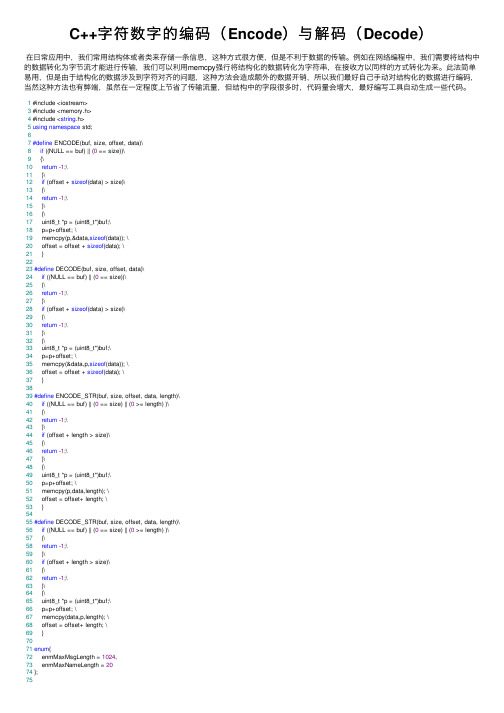
C++字符数字的编码(Encode)与解码(Decode)在⽇常应⽤中,我们常⽤结构体或者类来存储⼀条信息,这种⽅式很⽅便,但是不利于数据的传输。
例如在⽹络编程中,我们需要将结构中的数据转化为字节流才能进⾏传输,我们可以利⽤memcpy强⾏将结构化的数据转化为字符串,在接收⽅以同样的⽅式转化为来。
此法简单易⽤,但是由于结构化的数据涉及到字符对齐的问题,这种⽅法会造成额外的数据开销,所以我们最好⾃⼰⼿动对结构化的数据进⾏编码,当然这种⽅法也有弊端,虽然在⼀定程度上节省了传输流量,但结构中的字段很多时,代码量会增⼤,最好编写⼯具⾃动⽣成⼀些代码。
1 #include <iostream>3 #include <memory.h>4 #include <string.h>5using namespace std;67#define ENCODE(buf, size, offset, data)\8if ((NULL == buf) || (0 == size))\9 {\10return -1;\11 }\12if (offset + sizeof(data) > size)\13 {\14return -1;\15 }\16 {\17 uint8_t *p = (uint8_t*)buf;\18 p=p+offset; \19 memcpy(p,&data,sizeof(data)); \20 offset = offset + sizeof(data); \21 }2223#define DECODE(buf, size, offset, data)\24if ((NULL == buf) || (0 == size))\25 {\26return -1;\27 }\28if (offset + sizeof(data) > size)\29 {\30return -1;\31 }\32 {\33 uint8_t *p = (uint8_t*)buf;\34 p=p+offset; \35 memcpy(&data,p,sizeof(data)); \36 offset = offset + sizeof(data); \37 }3839#define ENCODE_STR(buf, size, offset, data, length)\40if ((NULL == buf) || (0 == size) || (0 >= length) )\41 {\42return -1;\43 }\44if (offset + length > size)\45 {\46return -1;\47 }\48 {\49 uint8_t *p = (uint8_t*)buf;\50 p=p+offset; \51 memcpy(p,data,length); \52 offset = offset+ length; \53 }5455#define DECODE_STR(buf, size, offset, data, length)\56if ((NULL == buf) || (0 == size) || (0 >= length) )\57 {\58return -1;\59 }\60if (offset + length > size)\61 {\62return -1;\63 }\64 {\65 uint8_t *p = (uint8_t*)buf;\66 p=p+offset; \67 memcpy(data,p,length); \68 offset = offset+ length; \69 }7071enum{72 enmMaxMsgLength = 1024,73 enmMaxNameLength = 2074 };7576class Msg{77int iAge;78char szName[enmMaxNameLength];79double dScore;80public:81 Msg()82 {8384 }85 Msg(int age,const char* name,double score):iAge(age),dScore(score)86 {87 strcpy(szName,name);88 }89virtual ~Msg(){}90virtual int encode(char *buf)91 {92 size_t offset = 0;93 memset(buf,'0',enmMaxMsgLength);94 ENCODE(buf,enmMaxMsgLength,offset,iAge);95 ENCODE_STR(buf,enmMaxMsgLength,offset,szName,enmMaxNameLength);96 ENCODE(buf,enmMaxMsgLength,offset,dScore);97return offset;98 };99virtual int decode(char *buf,size_t bufSize)100 {101 size_t offset = 0;102 DECODE(buf,bufSize,offset,iAge);103 DECODE_STR(buf,bufSize,offset,szName,enmMaxNameLength);104 DECODE(buf,bufSize,offset,dScore);105return offset;106 }107void display()108 {109 cout<<iAge<<""<<szName<<""<<dScore<<endl;110 }111 };112113int main(int argc, char* argv[])114 {115 size_t offset = 0;116char buf[enmMaxMsgLength],*recv = NULL;117 Msg msg(23,"hwllo world",23.69),msg1;118 msg.display();119 offset = msg.encode(buf);120 cout<<offset<<endl;121 cout<<sizeof(Msg)<<endl;122 recv = new char[offset];123 memcpy(recv,buf,offset);124 msg1.decode(recv,offset);125 msg1.display();126return0;127 }。
字符编码与解码详解

字符编码与解码详解 先简单介绍⼀下编码的情况,我们都知道机器上显⽰的字符最终存在计算机内存⾥都是以⼆进制码的形式存在的。
最开始的计算机字符只能⽤ASCII编码的⽅式去存储,⽽⼀个ASCII码占⽤⼀个字节,也就是说ASCII编码最多只能编码256个字符(键盘上所有的半⾓字符)。
但为了表⽰别的国家⽂字,就必须对原有的字符编码⽅式进⾏扩充。
⽽对于中⽂来说,主要有两种编码⽅式,分别是gb2312和gbk,前者主要是⽤于编码简体中⽂字符,⽽后者除了简体中⽂字符还包括繁体中⽂字符。
计算机迅速国际化之后,编码便不能只局限于英⽂字符和中⽂字符,于是出现了⼀个叫Unicode编码的⽅式,这种编码⽅式对每个字符都使⽤四个字节的⽅式存储,这样⼀来就⾜够表⽰所有字符了,但事实上所有的半⾓字符我们只需要1个字节来表⽰便⾜够了,全部字符都⽤Unicode编码⽅式的话,很容易造成资源浪费的情况,所以作为折中的考虑,UTF-8逐渐成为全球的流⾏的编码标准,UTF-8编码能够根据字符分别不同的字节⼤⼩,英⽂字符依然⽤⼀个字节表⽰,⽽中⽂有些则是两个字节表⽰,有些则是三个字节。
本⽂直接通过三个例⼦来讲解字符编码和解码的原理: - 记事本字符的编码 - 前端页⾯中的<meta charset='utf-8'> - 编程语⾔中读写⽂件的编码(python3.x) 顾名思义,编码就是把⼀个字符编码成⼆进制码存起来的⽅式,⽽解码就是把这个⼆进制码按照原本编码的规则还原成原来的字符。
1. 记事本字符编码 当我们打开记事本,然后打下⼀⾏字符的时候,对机器来说都是⼀串不可识别的字符,于是我们保存的时候,就是要对这些我们输⼊的字符进⾏编码了。
如果你输⼊⼀串⾮英⽂字符,计算机会提醒你有些字符不能正确编码(windows中⽂版的话没有这种情况,因为你按下ctrl+s计算机会有⼀个默认的中⽂编码⽅式,则没有出现⽆法编码的情况。
编码与解码名词解释

编码与解码名词解释
编码(Encoding)和解码(Decoding)是信息传输和处理中的两个关键过程,通常用于数字通信、计算机科学、电子学和许多其他领域。
它们有以下含义:一、编码(Encoding):
定义:编码是将信息从一个形式转换为另一个形式的过程。
在信息传输和存储中,编码通常将原始信息转化为数字、符号、信号或其他特定的表示形式,以便更有效地传输、处理或存储信息。
编码可以是可逆的(无信息损失)或不可逆的(信息可能会有损失)。
示例:在计算机科学中,将文字信息编码为二进制代码是一种常见的编码方式,使得计算机可以理解和处理文本。
二、解码(Decoding):
定义:解码是将经过编码的信息从其表示形式还原为原始形式的过程。
它是编码的逆过程,用于从数字、符号或信号中还原原始信息,以便人们能够理解或计算机能够处理。
示例:在数字通信中,接收端通常会对接收到的编码信息进行解码,以还原发送端发送的原始数据。
总之,编码是将信息从一种形式转换为另一种形式的过程,而解码则是将已编码的信息还原为原始形式的过程。
这两个过程在信息传输和处理中起着至关重要的作用,确保信息可以有效地传递和理解。
不同领域和应用程序中可能会使用不同的编码和解码方法,以适应特定的需求和条件。
java与python encode和decode的用法

java与python encode和decode的用法摘要:1.Java 与Python 编码和解码介绍2.Java 编码和解码方法3.Python 编码和解码方法4.Java 与Python 编码和解码的异同正文:编码和解码在计算机中是一个非常重要的概念,尤其是在处理文本和数据传输时。
Java 和Python 作为两种不同的编程语言,它们的编码和解码方法也有所不同。
首先,我们来了解一下Java 和Python 的编码和解码。
在Java 中,字符串的编码和解码是通过`getBytes()`和`String(byte[] bytes, Charset charset)`方法实现的。
而在Python 中,字符串的编码和解码则是通过`encode()`和`decode()`方法实现的。
接下来,我们来详细了解一下Java 和Python 的编码和解码方法。
在Java 中,字符串的编码是通过`getBytes()`方法实现的,该方法接收一个字符串和一个字符集作为参数,返回一个字节数组。
例如:```javaString str = "Hello, world!";byte[] bytes = str.getBytes(StandardCharsets.UTF_8);```字符串的解码则是通过`String(byte[] bytes, Charset charset)`方法实现的,该方法接收一个字节数组和一个字符集作为参数,返回一个字符串。
例如:```javabyte[] bytes = new byte[] {72, 101, 108, 108, 111, 44, 32, 87, 111, 114, 108, 100};String str = new String(bytes, StandardCharsets.UTF_8);```在Python 中,字符串的编码和解码则是通过`encode()`和`decode()`方法实现的。
编码与解码理解

编码与解码理解概述1. 为什么要对字符编码?在计算机中只能存储0或1,因此所有字符都必须转化为⼀串01表⽰的数字,把字符通过⼀种规则转换成对应的数字的过程就是字符的编码。
2. 字符编码的规则有多种,如ASCII、unicode、utf-8、gbk等等,因此同⼀个字符通过不同⽅式会得到不同的编码结果。
3. ⼀种字符编码并不能覆盖所有字符,所以需要进⾏选择,如ASCII只⽀持所有的英⽂字符、字符和数字,其他字符⽆法进⾏编码;⽽GBK对简体中⽂⽀持良好,其他国家的⽂字就不太⾏了。
4. 如果⽤⼀种编码⽅式进⾏编码,然后⽤另⼀种编码⽅式解码,会发⽣乱码。
简单理解编码,就是把⼀种格式的数据转换成另⼀种格式;解码,就是将编码后的数据还原回原始格式。
举例字符串在Python3内部的表⽰是unicode编码,unicode是⼀个包含所有语⾔字符的编码格式,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另⼀种编码。
decode的作⽤是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312’),表⽰将gb2312编码的字符串str1转换成unicode编码。
括号中是原始编码格式encode的作⽤是将unicode编码转换成其他编码的字符串,如str2.encode(‘gb2312’),表⽰将unicode编码的字符串str2转换成gb2312编码。
括号中是⽬的编码格式因此,转码的时候⼀定要先搞明⽩,原始字符串str是什么类型的编码,然后decode成unicode格式,然后再encode成其他编码。
python 中文编码解码

在Python中,处理中文编码和解码通常使用`utf-8`编码。
`utf-8`是一种可变长度的Unicode编码,可以表示世界上几乎所有的字符。
以下是一些基本的编码和解码操作:
编码(将字符串转换为字节):
```python
# 将字符串转换为utf-8 编码的字节
s = '中文'
bytes_s = s.encode('utf-8')
print(bytes_s) # 输出:b'\xe4\xbd\xa0\xe5\xa5\xbd'
```
解码(将字节转换为字符串):
```python
# 将utf-8 编码的字节转换为字符串
bytes_s = b'\xe4\xbd\xa0\xe5\xa5\xbd'
s = bytes_s.decode('utf-8')
print(s) # 输出:中文
```
如果你需要处理的文本包含多种不同的字符集,可能需要使用更加复杂的编码方案,例如`base64`或者`quopri`等。
注意,Python 3 默认使用`utf-8` 编码,因此在大多数情况下,你不需要显式地指定编码。
但是,如果你需要处理一些特殊的字符集,或者与旧的API交互,那么显式地指定编码可能会很有用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
蒋刚毅
字符编码方式
ASCII 扩展ASCII 扩展ASCII Unicode UTFUTF-8 GBK Little endian和Big endian endian和 URL
ASCII
计算机是讲英语的人发明的。英语只有26个英 计算机是讲英语的人发明的。英语只有26个英 文字母。加上特殊符号,整个键盘不超过100 文字母。加上特殊符号,整个键盘不超过100 个符号。所以,他们采用了一个字节表示所有 符号的方式。最多能表示128个编码。ASCII码 符号的方式。最多能表示128个编码。ASCII码 只占用了一个字节的后面7位,最前面的1 只占用了一个字节的后面7位,最前面的1位统 一规定为0 一规定为0。 上个世纪60年代,美国制定了一套字符编码, 上个世纪60年代,美国制定了一套字符编码, 对英语字符与二进制位之间的关系,做了统一 规定。这被称为ASCII码,一直沿用至今。 规定。这被称为ASCII码,一直沿用至今。
Unicode的问题 Unicode的问题
需要注意的是,Unicode只是一个符号集,它只规定了符号的二 需要注意的是,Unicode只是一个符号集,它只规定了符号的二 进制代码,却没有规定这个二进制代码应该如何存储。 比如,汉字“严”的unicode是十六进制数4E25,转换成二进制 比如,汉字“严”的unicode是十六11000100101),也就是说这个符号的表示 数足足有15位(100111000100101),也就是说这个符号的表示 至少需要2个字节。表示其他更大的符号,可能需要3 至少需要2个字节。表示其他更大的符号,可能需要3个字节或 者4个字节,甚至更多。 这里就有两个严重的问题,第一个问题是,如何才能区别 unicode和ascii?计算机怎么知道三个字节表示一个符号,而不 unicode和ascii?计算机怎么知道三个字节表示一个符号,而不 是分别表示三个符号呢?第二个问题是,我们已经知道,英文 字母只用一个字节表示就够了,如果unicode统一规定,每个符 字母只用一个字节表示就够了,如果unicode统一规定,每个符 号用三个或四个字节表示,那么每个英文字母前都必然有二到 三个字节是0 三个字节是0,这对于存储来说是极大的浪费,文本文件的大小 会因此大出二三倍,这是无法接受的。
联通记事本问题解释
“联通”的内码是:c1 aa cd a8 联通”的内码是:c1 c1 1100 0001 aa 1010 1010 cd 1100 1101 a8 1010 1000 注意到了吗?第一二个字节、第三四个字节的起始部分的都是"110"和"10", 注意到了吗?第一二个字节、第三四个字节的起始部分的都是"110"和"10", 正好与UTF8规则里的两字节模板是一致的,于是再次打开记事本时,记事本 正好与UTF8规则里的两字节模板是一致的,于是再次打开记事本时,记事本 就误认为这是一个UTF8编码的文件,让我们把第一个字节的110和第二个字节 就误认为这是一个UTF8编码的文件,让我们把第一个字节的110和第二个字节 的10去掉,我们就得到了"00001 101010",再把各位对齐,补上前导的0,就得 10去掉,我们就得到了"00001 101010",再把各位对齐,补上前导的0 到了"0000 到了"0000 0000 0110 1010",不好意思,这是UNICODE的006A,也就是小写 1010",不好意思,这是UNICODE的006A,也就是小写 的字母"j",而之后的两字节用UTF8解码之后是0368,这个字符什么也不是。 的字母"j",而之后的两字节用UTF8解码之后是0368,这个字符什么也不是。 这就是只有"联通" 这就是只有"联通"两个字的文件没有办法在记事本里正常显示的原因。 而如果你在“联通”之后多输入几个字,其他的字的编码不见得又恰好是110和 而如果你在“联通”之后多输入几个字,其他的字的编码不见得又恰好是110和 10开始的字节,这样再次打开时,记事本就不会坚持这是一个utf8编码的文件, 10开始的字节,这样再次打开时,记事本就不会坚持这是一个utf8编码的文件, 而会用ANSI的方式解读之,这时乱码又不出现了。 而会用ANSI的方式解读之,这时乱码又不出现了。
UTFUTF-8
Unicode提供了编码方案,没有提供存储方 Unicode提供了编码方案,没有提供存储方 案。 于是产生了很多的编码方案。Utf- utf于是产生了很多的编码方案。Utf-8,utf-16 等。应用最广泛的,是utf-8,其他编码可以忽 等。应用最广泛的,是utf-8,其他编码可以忽 略了。 重复一遍,这里的关系是,UTF-8是 重复一遍,这里的关系是,UTFUnicode的实现方式之一 Unicode的实现方式之一
GBK编码 GBK编码
非英语国家使用的语言较为复杂,尤其是欧 亚语系。 采用多字节去编码一个字。 中国的GBK编码。(兼容简繁体,简体是 中国的GBK编码。(兼容简繁体,简体是 GB2312).使用两个字节表示一个汉字,所以 GB2312).使用两个字节表示一个汉字,所以 理论上最多可以表示256x256=65536个符号 理论上最多可以表示256x256=65536个符号 其他国家也都有自己的编码方案。计算机方 言产生。
Little endian和Big endian endian和
以汉字“ 为例,Unicode码是4E25,需要用两个字节存储,一 以汉字“严”为例,Unicode码是4E25,需要用两个字节存储,一 个字节是 4E,另一个字节是25。存储的时候,4E在前,25在后, 4E,另一个字节是25。存储的时候,4E在前,25在后, 就是Big endian方式;25在前,4E在后,就是Little endian方式。 就是Big endian方式;25在前,4E在后,就是Little endian方式。 第一个字节在前,就是“大头方式” 第一个字节在前,就是“大头方式”(Big endian),第二个字节 endian),第二个字节 在前就是“小头方式” 在前就是“小头方式”(Little endian)。 endian)。 Unicode规范中定义,每一个文件的最前面分别加入一个表示编 Unicode规范中定义,每一个文件的最前面分别加入一个表示编 码顺序的字符,这个字符的名字叫做“零宽度非换行空格” 码顺序的字符,这个字符的名字叫做“零宽度非换行空格” (ZERO WIDTH NO-BREAK SPACE),用FEFF表示。这正好 NOSPACE),用FEFF表示。这正好 是两个字节,而且FF比FE大 是两个字节,而且FF比FE大1。 如果一个文本文件的头两个字节是FE FF,就表示该文件采用大 如果一个文本文件的头两个字节是FE FF,就表示该文件采用大 头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。 头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
扩展ASCII 扩展ASCII
英语用128个符号编码就够了,但是用来表示其他语 英语用128个符号编码就够了,但是用来表示其他语 言,128个符号是不够的。比如,在法语中,字母上 言,128个符号是不够的。比如,在法语中,字母上 方有注音符号,它就无法用ASCII码表示。于是,一 方有注音符号,它就无法用ASCII码表示。于是,一 些欧洲国家就决定,利用字节中闲置的最高位编入 新的符号。比如,法语中的é的编码为130(二进制 新的符号。比如,法语中的é的编码为130(二进制 10000010)。这样一来,这些欧洲国家使用的编码 10000010)。这样一来,这些欧洲国家使用的编码 体系,可以表示最多256个符号。 体系,可以表示最多256个符号。 不同国家的编码方式中,0 127表示的符号是一样 不同国家的编码方式中,0—127表示的符号是一样 的,不一样的只是128—255的这一段。比如,130在 的,不一样的只是128—255的这一段。比如,130在 法语编码中代表了é 法语编码中代表了é,在希伯来语编码中却代表了字 母Gimel (,)ג在俄语编码中又会代表另一个符号。
编码方式转换举例1 编码方式转换举例1
打开”记事本“程序Notepad.exe, 打开”记事本“程序Notepad.exe,新建一个文本文件,内容就 是一个”严“字,依次采用ANSI,Unicode, 是一个”严“字,依次采用ANSI,Unicode,Unicode big endian 和 UTF-8编码方式保存。 UTF1)ANSI:文件的编码就是两个字节“D1 CF”,这正是“严”的 ANSI:文件的编码就是两个字节“D1 CF”,这正是“严”的 GB2312编码,这也暗示GB2312是采用大头方式存储的。 GB2312编码,这也暗示GB2312是采用大头方式存储的。 2)Unicode:编码是四个字节“FF FE 25 4E”,其中“FF FE”表明 Unicode:编码是四个字节“FF 4E”,其中“FF FE”表明 是小头方式存储,真正的编码是4E25。 是小头方式存储,真正的编码是4E25。 3)Unicode big endian:编码是四个字节“FE FF 4E 25”,其中“FE endian:编码是四个字节“FE 25”,其中“FE FF”表明是大头方式存储。 FF”表明是大头方式存储。 4)UTF-8:编码是六个字节“EF BB BF E4 B8 A5”,前三个字节 UTF- :编码是六个字节“EF A5”,前三个字节 “EF BB BF”表示这是UTF-8编码,后三个“E4B8A5”就是“严” BF”表示这是UTF- 编码,后三个“E4B8A5”就是“严” 的具体编码,它的存储顺序与编码顺序是一致的。
举例2 举例2:联通记事本惨案
如果你的电脑操作系统是WIN2000或WINXP的话,那么: 如果你的电脑操作系统是WIN2000或WINXP的话,那么: 1、在桌面上点右键,选择新建 ― 文本文档; 2、打开“新建 文本文档”,录入“移动”两字后存盘退出; 3、重新打开“新建 文本文档”,看到什么了? 4、是不是刚刚录入的“移动”两字? 咱们换过来 1、在桌面上点右键,选择新建 ― 文本文档; 2、打开“新建 文本文档”,录入“联通”两字后存盘退出; 3、重新打开“新建 文本文档”,看到什么了? 4、是不是刚刚录入的“联通”两字不见了,取而代之是个烧焦 的手机电池。 ============ 是什么原因? 是什么原因?