语音信号处理实验报告
语音信号处理实验报告.docx
在实验中,当P值增加到一定程度,预测平方误差的改善就不很明显了,而且会增加计算量,一般取为8~14,这里P取为10。
5.基音周期估计
①自互相关函数法
②短时平均幅度差法
二.实验过程
1. 系统结构
2.仿真结果
(1)时域分析
男声及女声(蓝色为时域信号,红色为每一帧的能量,绿色为每一帧的过零率)
某一帧的自相关函数
3.频域分析
①一帧信号的倒谱分析和FFT及LPC分析
②男声和女声的倒谱分析
③浊音和清音的倒谱分析
④浊音和清音的FFT分析和LPC分析(红色为FFT图像,绿色为LPC图像)
从男声女声的时域信号对比图中可以看出,女音信号在高频率分布得更多,女声信号在高频段的能量分布更多,并且女声有较高的过零率,这是因为语音信号中的高频段有较高的过零率。
2.频域分析
这里对信号进行快速傅里叶变换(FFT),可以发现,当窗口函数不同,傅里叶变换的结果也不相同。根据信号的时宽带宽之积为一常数这一性质,可以知道窗口宽度与主瓣宽度成反比,N越大,主瓣越窄。汉明窗在频谱范围中的分辨率较高,而且旁瓣的衰减大,具有频谱泄露少的有点,所以在实验中采用的是具有较小上下冲的汉明窗。
三.实验结果分析
1.时域分析
实验中采用的是汉明窗,窗的长度对能否由短时能量反应语音信号的变化起着决定性影响。这里窗长合适,En能够反应语音信号幅度变化。同时,从图像可以看出,En可以作为区分浊音和清音的特征参数。
短时过零率表示一帧语音中语音信号波形穿过横轴(零电平)的次数。从图中可以看出,短时能量和过零率可以近似为互补的情况,短时能量大的地方过零率小,短时能量小的地方过零率较大。从浊音和清音的时域分析可以看出,清音过零率高,浊音过零率低。
语音信号处理实验报告实验二

语音信号处理实验报告实验二一、实验目的本次语音信号处理实验的目的是深入了解语音信号的特性,掌握语音信号处理的基本方法和技术,并通过实际操作和数据分析来验证和巩固所学的理论知识。
具体而言,本次实验旨在:1、熟悉语音信号的采集和预处理过程,包括录音设备的使用、音频格式的转换以及噪声去除等操作。
2、掌握语音信号的时域和频域分析方法,能够使用相关工具和算法计算语音信号的短时能量、短时过零率、频谱等特征参数。
3、研究语音信号的编码和解码技术,了解不同编码算法对语音质量和数据压缩率的影响。
4、通过实验,培养我们的动手能力、问题解决能力和团队协作精神,提高我们对语音信号处理领域的兴趣和探索欲望。
二、实验原理(一)语音信号的采集和预处理语音信号的采集通常使用麦克风等设备将声音转换为电信号,然后通过模数转换器(ADC)将模拟信号转换为数字信号。
在采集过程中,可能会引入噪声和干扰,因此需要进行预处理,如滤波、降噪等操作,以提高信号的质量。
(二)语音信号的时域分析时域分析是对语音信号在时间轴上的特征进行分析。
常用的时域参数包括短时能量、短时过零率等。
短时能量反映了语音信号在短时间内的能量分布情况,短时过零率则表示信号在单位时间内穿过零电平的次数,可用于区分清音和浊音。
(三)语音信号的频域分析频域分析是将语音信号从时域转换到频域进行分析。
通过快速傅里叶变换(FFT)可以得到语音信号的频谱,从而了解信号的频率成分和分布情况。
(四)语音信号的编码和解码语音编码的目的是在保证一定语音质量的前提下,尽可能降低编码比特率,以减少存储空间和传输带宽的需求。
常见的编码算法有脉冲编码调制(PCM)、自适应差分脉冲编码调制(ADPCM)等。
三、实验设备和软件1、计算机一台2、音频采集设备(如麦克风)3、音频处理软件(如 Audacity、Matlab 等)四、实验步骤(一)语音信号的采集使用麦克风和音频采集软件录制一段语音,保存为常见的音频格式(如 WAV)。
语音信号处理实验报告

实验一 显示语音信号的语谱图一、实验目的综合信号频谱分析和滤波器功能,对语音信号的频谱进行 分析,并对信号含进行高通、低通滤波,实现信号特定处理 功能。
加深信号处理理论在语音信号中的应用;理解语谱图 与时频分辨率的关系。
二、实验原理语谱图分析语音又称语谱分析,语谱图中显示了大量的与语音的语句特性有关的信息,它总额了频谱图和时域波形的优点,明显地显示出语音频谱随时间的变化情况。
语谱图实际上是一种三维频谱,即同时在时间和频率上显示出语音的特性,或者说是一种动态的频谱。
窄带语谱图可以得到较好的频域分辨率,窗长通常为至少两个基音周期的“长窗”;而宽带语谱图可以给出较好的时域分辨率,窗长为小于一个基音周期的“短窗”。
三、实验内容实验数据为工作空间 ex3M2.mat 中数组 we_be10k 是单词“we ”和“be ”的语音波形(采样率为10000 点/秒) 。
1、 听一下 we_be10k (可用 sound )2、使用函数 specgram_ex3p19.显示语谱图和语音波形,如图一。
图一、参数窗长 20ms (200 点) 、帧间隔 1ms (10 点)0.511.5-2-1012Time (s)SPEECHTime (ms)F r e q u e n c y (H z )SPECTROGRAM00.51 1.5200040002、 对比调用参数窗长 20ms (200 点) 、帧间隔 1ms (10 点),(如图一)和参数窗长5ms (50点) 、帧间隔 1ms (10点)(如图二) ;图二、参数窗长5ms (50点) 、帧间隔 1ms (10点)图三、参数窗长30ms (300点) 、帧间隔 1ms (10点)0.511.5-2-1012Time (s)SPEECHTime (ms)F r e q u e n c y (H z )SPECTROGRAM00.51 1.5200040000.511.5-2-1012Time (s)SPEECHTime (ms)F r e q u e n c y (H z )SPECTROGRAM00.51 1.520004000图四、参数窗长20ms (200点) 、帧间隔 5ms (50点)3、 再对比窗长>20ms 或小于5ms ,以及帧间隔>1ms 时的语谱图说明宽带语谱图、窄带语谱图与时频分辨率的关系及如何得到时频折中。
心理学语音实验报告(3篇)

第1篇一、实验背景与目的随着科技的飞速发展,语音识别技术逐渐成为人机交互的重要方式。
为了探究语音信号在心理认知过程中的作用,本实验旨在通过一系列语音实验,探讨以下问题:1. 语音信号对记忆的影响;2. 语音信号对注意力的影响;3. 语音信号对情绪的影响。
二、实验方法1. 实验材料本实验选取了20名志愿者(男女各半,年龄在18-25岁之间)作为被试,均无听觉障碍。
实验材料包括以下内容:(1)语音刺激:选取了50个普通话单音节,分为清音和浊音两组,每组25个;(2)图片刺激:选取了50张与语音刺激对应的图片,分为清音组和浊音组;(3)情绪图片:选取了50张能够引起不同情绪的图片,分为积极情绪组和消极情绪组。
2. 实验程序(1)实验一:记忆实验被试在实验开始前进行听力测试,确保其听力正常。
实验过程中,被试依次听到清音和浊音刺激,并要求记住每个刺激的发音。
实验结束后,进行回忆测试,记录被试正确记忆的刺激数量。
(2)实验二:注意力实验被试在实验开始前进行注意力测试,确保其注意力集中。
实验过程中,被试依次看到清音和浊音图片,并要求在看到图片的同时,尽量忽略其他干扰信息。
实验结束后,记录被试在实验过程中出现的错误次数。
(3)实验三:情绪实验被试在实验开始前进行情绪测试,确保其情绪稳定。
实验过程中,被试依次看到积极情绪和消极情绪图片,并要求在看到图片的同时,尽量忽略其他干扰信息。
实验结束后,记录被试在实验过程中出现的心率变化。
3. 实验设备本实验使用以下设备:(1)计算机:用于播放语音刺激和图片刺激;(2)耳机:用于播放语音刺激;(3)心率仪:用于监测被试的心率变化。
三、实验结果与分析1. 实验一:记忆实验(1)结果:清音组被试正确记忆的刺激数量为15个,浊音组被试正确记忆的刺激数量为12个;(2)分析:结果表明,语音信号对记忆存在影响,清音刺激比浊音刺激更容易被记忆。
2. 实验二:注意力实验(1)结果:清音组被试错误次数为10次,浊音组被试错误次数为8次;(2)分析:结果表明,语音信号对注意力存在影响,清音刺激比浊音刺激更容易引起被试的注意力。
语音信号处理实验报告
实验一基于 MATLAB 的语音信号时域特征分析操作:报告:一. 实验目的语音信号是一种非平稳的时变信号,它携带着各种信息。
在语音编码、语音合成、语音识别和语音增强等语音处理中无一例外需要提取语音中包含的各种信息。
语音信号分析的目的就在与方便有效的提取并表示语音信号所携带的信息。
语音信号分析可以分为时域和变换域等处理方法,其中时域分析是最简单的方法,直接对语音信号的时域波形进行分析,提取的特征参数主要有语音的短时能量,短时平均过零率,短时自相关函数等。
本实验要求掌握时域特征分析原理,并利用已学知识,编写程序求解语音信号的短时过零率、短时能量、短时自相关特征,分析实验结果,并能掌握借助时域分析方法所求得的参数分析语音信号的基音周期及共振峰。
二. 实验内容1.窗口的选择通过对发声机理的认识,语音信号可以认为是短时平稳的。
在 5~50ms 的范围内,语音频谱特性和一些物理特性参数基本保持不变。
我们将每个短时的语音称为一个分析帧。
一般帧长取 10~30ms。
我们采用一个长度有限的窗函数来截取语音信号形成分析帧。
通常会采用矩形窗和汉明窗。
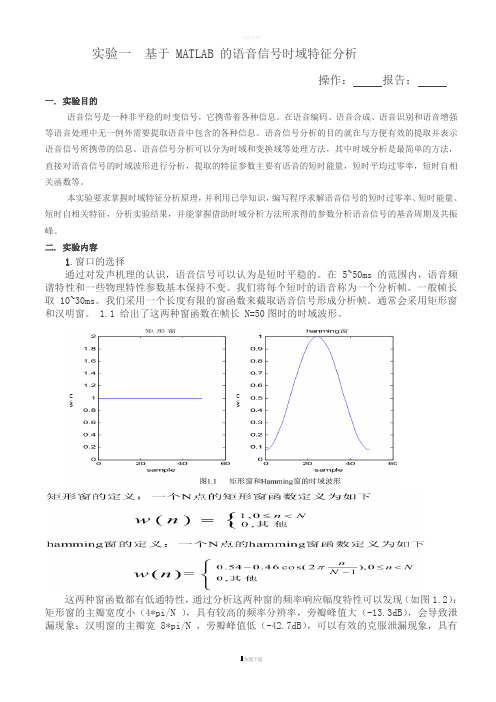
1.1 给出了这两种窗函数在帧长 N=50图时的时域波形。
这两种窗函数都有低通特性,通过分析这两种窗的频率响应幅度特性可以发现(如图1.2):矩形窗的主瓣宽度小(4*pi/N ),具有较高的频率分辨率,旁瓣峰值大(-13.3dB),会导致泄漏现象;汉明窗的主瓣宽 8*pi/N ,旁瓣峰值低(-42.7dB),可以有效的克服泄漏现象,具有更平滑的低通特性。
因此在语音频谱分析时常使用汉明窗,在计算短时能量和平均幅度时通常用矩形窗。
2. 短时能量由于语音信号的能量随时间变化,清音和浊音之间的能量差别相当显著。
因此对语音的短时能量进行分析,可以描述语音的这种特征变化情况。
定义短时能量为:在用短时能量反映语音信号的幅度变化时,不同的窗函数以及相应窗的长短均有影响。
hamming 窗的效果比矩形窗略好。
语音信号处理实验报告

语⾳信号处理实验报告语⾳信号处理实验报告⼀、原理 1.端点检测语⾳信号⼀般可分为⽆声段、清⾳段和浊⾳段。
⽆声段是背景噪声段, 平均能量最低,波形变化缓慢,过零率最低; 浊⾳段为声带振动发出对应的语⾳信号段, 平均能量最⾼; 清⾳段是空⽓在⼝腔中的摩擦、冲击或爆破⽽发出的语⾳信号段, 平均能量居于前两者之间,波形上幅度变化剧烈, 过零率最⼤。
端点检测就是⾸先判断有声还是⽆声, 如果有声,则还要判断是清⾳还是浊⾳。
为正确地实现端点检测, ⼀般综合利⽤短时能量和过零率两个特征,采⽤/双门限检测法。
①语⾳信号x(n)进⾏分帧处理,每⼀帧记为Si (n ),n=1,2,…,N ,n 为离散语⾳信号时间序列,N 为帧长,i 表⽰帧数。
②短时能量:③过零率:2.基⾳检测能量有限的语⾳信号}{()s n 的短时⾃相关函数定义为: 10()[()()][()()]N n m R s n m w m s n m w m ττττ--==++++∑ 其中,τ为移位距离,()w m 是偶对称的窗函数。
短时⾃相关函数有以下重要性质:①如果}{()s n 是周期信号,周期是P ,则()R τ也是周期信号,且周期相同,即()()R R P ττ=+。
②当τ=0时,⾃相关函数具有最⼤值;当0,,2,3P P P τ=+++…处周期信号的⾃相关函数达到极⼤值。
③⾃相关函数是偶函数,即()()R R ττ=-。
短时⾃相关函数法基⾳检测的主要原理是利⽤短时⾃相关函数的第⼆条性质,通过⽐较原始信号和它移位后的信号之间的类似性来确定基⾳周期,如果移位距离等于基⾳周期,那么,两个信号具有最⼤类似性。
在实际采⽤短时⾃相关函数法进⾏基⾳检测时,使⽤⼀个窗函数,窗不动,语⾳信号移动,这是经典的短时⾃相关函数法。
3.⾃相关法解线性预测⽅程组⾃相关⽅法a.Levinson-durbin 递推算法()21N i n Ei s n ==∑()()1sgn sgn 1N i i n Zi s n s n ==--∑pj a a k k R E E k Ep j i p i i n p i i i j ...,3,2,1,1||,)1()0(,)1()(12)()1(2)(==≤-=-=∧=-∏ ki 称为反射系数,也称PARCOR 系数b.E(p)是预测残差能量在起始端,为了预测x(0),需要⽤到x(-1),x(-2),……,x(-p).但是这些值均为0,这样预测会带来误差。
语音信号处理试验报告

---------------------考试---------------------------学资学习网---------------------押题------------------------------语音信号处理实验班级:学号:姓名:实验一基于MATLAB的语音信号时域特征分析(2学时)短时能量)1.(1)加矩形窗a=wavread('mike.wav');a=a(:,1);subplot(6,1,1),plot(a);N=32;for i=2:6h=linspace(1,1,2.^(i-2)*N);%形成一个矩形窗,长度为2.^(i-2)*NEn=conv(h,a.*a);% 求短时能量函数Ensubplot(6,1,i),plot(En);if(i==2) ,legend('N=32');elseif(i==3), legend('N=64');elseif(i==4) ,legend('N=128');elseif(i==5) ,legend('N=256');elseif(i==6) ,legend('N=512');endend10-100.511.522.534x 104 20 N=3232.51.5200.514x 10 50 N=6431.50.51022.54x 10 1050 N=12831.5202.50.514x 10 20100 N=256322.50.511.504x 10 40200 N=5123100.51.522.54x 10(2)加汉明窗a=wavread('mike.wav');a=a(:,1);subplot(6,1,1),plot(a);N=32;for i=2:6h=hanning(2.^(i-2)*N);%形成一个汉明窗,长度为2.^(i-2)*NEn求短时能量函数En=conv(h,a.*a);%subplot(6,1,i),plot(En);if(i==2), legend('N=32');elseif(i==3), legend('N=64');elseif(i==4) ,legend('N=128');elseif(i==5) ,legend('N=256');elseif(i==6) ,legend('N=512');endend10-100.511.522.534x 102 10 N=3232.51.5020.514x 10 420 N=64311.522.50.504x 10 420 N=12831.5202.50.514x 10 1050 N=25631.522.500.514x 10 20100 N=512322.50.5011.54x 102)短时平均过零率a=wavread('mike.wav');a=a(:,1);n=length(a);N=320;subplot(3,1,1),plot(a);h=linspace(1,1,N);En=conv(h,a.*a); %求卷积得其短时能量函数Ensubplot(3,1,2),plot(En);for i=1:n-1if a(i)>=0b(i)= 1;elseb(i) = -1;endif a(i+1)>=0b(i+1)=1;elseb(i+1)= -1;endw(i)=abs(b(i+1)-b(i)); %求出每相邻两点符号的差值的绝对值endk=1;j=0;while (k+N-1)<nZm(k)=0;for i=0:N-1;Zm(k)=Zm(k)+w(k+i);endj=j+1;k=k+N/2; %每次移动半个窗endfor w=1:jQ(w)=Zm(160*(w-1)+1)/(2*N); %短时平均过零率endsubplot(3,1,3),plot(Q),grid;10-100.511.522.534x 102010000.511.522.534x 100.500204060801001201401601803)自相关函数N=240y=wavread('mike.wav');y=y(:,1);x=y(13271:13510);x=x.*rectwin(240);R=zeros(1,240);for k=1:240for n=1:240-kR(k)=R(k)+x(n)*x(n+k);endendj=1:240;plot(j,R);grid;2.521.510.50-0.5-1-1.5050100150200250分析语音信号频域特征MATLAB基于实验二1)短时谱cleara=wavread('mike.wav');a=a(:,1);subplot(2,1,1),plot(a);title('original signal');gridN=256;h=hamming(N);for m=1:Nb(m)=a(m)*h(m)endy=20*log(abs(fft(b)))subplot(2,1,2)plot(y);title('短时谱');gridoriginal signal10.50-0.5-100.511.522.534x 10谱时短10.5000.20.40.60.811.21.41.61.822)语谱图[x,fs,nbits]=wavread('mike.wav')x=x(:,1);specgram(x,512,fs,100);xlabel('时间(s)');ylabel('频率(Hz)'););'语谱图'title(语谱图50004000)3000zH(率频2000100000.511.52(s)时间3)倒谱和复倒谱(1)加矩形窗时的倒谱和复倒谱cleara=wavread('mike.wav',[4000,4350]);a=a(:,1);N=300;h=linspace(1,1,N);for m=1:Nb(m)=a(m)*h(m);endc=cceps(b);c=fftshift(c);d=rceps(b);d=fftshift(d);subplot(2,1,1)plot(d);title('加矩形窗时的倒谱')subplot(2,1,2)) '加矩形窗时的复倒谱'plot(c);title(加矩形窗时的倒谱10-1-2050100150200250300加矩形窗时的复倒谱1050-5-10050100150200250300(2)加汉明窗时的倒谱和复倒谱cleara=wavread('mike.wav',[4000,4350]);a=a(;,1);N=300;h=hamming(N);for m=1:Nb(m)=a(m)*h(m);endc=cceps(b);c=fftshift(c);d=rceps(b);d=fftshift(d);subplot(2,1,1)plot(d);title('加汉明窗时的倒谱')subplot(2,1,2)) '加汉明窗时的复倒谱'plot(c);title(加汉明窗时的倒谱10-1-2-3050100150200250300加汉明窗时的复倒谱1050-5-10050100150200250300实验三基于MATLAB的LPC分析MusicSource = wavread('mike.wav');MusicSource=MusicSource(:,1);Music_source = MusicSource';N = 256; % window length,N = 100 -- 1000;Hamm = hamming(N); % create Hamming windowframe = input('请键入想要处理的帧位置= ');% origin is current frameorigin = Music_source(((frame - 1) * (N / 2) + 1):((frame - 1) * (N / 2) + N));Frame = origin .* Hamm';%%Short Time Fourier Transform%[s1,f1,t1] = specgram(MusicSource,N,N/2,N);[Xs1,Ys1] = size(s1);for i = 1:Xs1FTframe1(i) = s1(i,frame);endN1 = input('请键入预测器阶数= '); % N1 is predictor's order[coef,gain] = lpc(Frame,N1); % LPC analysis using Levinson-Durbin recursionest_Frame = filter([0 -coef(2:end)],1,Frame); % estimate frame(LP)FFT_est = fft(est_Frame);err = Frame - est_Frame; % error% FFT_err = fft(err);subplot(2,1,1),plot(1:N,Frame,1:N,est_Frame,'-r');grid;title('原始语音帧vs.预测后语音帧') subplot(2,1,2),plot(err);grid;title('误差');pause%subplot(2,1,2),plot(f',20*log(abs(FTframe2)));grid;title('短时谱')%% Gain solution using G^2 = Rn(0) - sum(ai*Rn(i)),i = 1,2,...,P%fLength(1 : 2 * N) = [origin,zeros(1,N)];Xm = fft(fLength,2 * N);X = Xm .* conj(Xm);Y = fft(X , 2 * N);Rk = Y(1 : N);PART = sum(coef(2 : N1 + 1) .* Rk(1 : N1));G = sqrt(sum(Frame.^2) - PART);A = (FTframe1 - FFT_est(1 : length(f1'))) ./ FTframe1 ; % inverse filter A(Z)subplot(2,1,1),plot(f1',20*log(abs(FTframe1)),f1',(20*log(abs(1 ./ A))),'-r');grid;title('短时谱'); subplot(2,1,2),plot(f1',(20*log(abs(G ./ A))));grid;title('LPC谱');pause%plot(abs(ifft(FTframe1 ./ (G ./ A))));grid;title('excited')%plot(f1',20*log(abs(FFT_est(1 : length(f1')) .* A / G )));grid;%pause%% find_pitch%temp = FTframe1 - FFT_est(1 : length(f1'));% not move higher frequncepitch1 = log(abs(temp));pLength = length(pitch1);result1 = ifft(pitch1,N);% move higher frequncepitch1((pLength - 32) : pLength) = 0;result2 = ifft(pitch1,N);% direct do real cepstrum with errpitch = fftshift(rceps(err));origin_pitch = fftshift(rceps(Frame));subplot(211),plot(origin_pitch);grid;title('原始语音帧倒谱(直接调用函数)');subplot(212),plot(pitch);grid;title('预测误差倒谱(直接调用函数)');pausesubplot(211),plot(1:length(result1),fftshift(real(result1)));grid;title('预测误差倒谱(根据定义编写,没有去除高频分量)');subplot(212),plot(1:length(result2),fftshift(real(result2)));grid;title('预测误差倒谱(根据定义编);)'写,去除高频分量原始语音帧vs.预测后语音帧0.40.20-0.2-0.4050100150200250300差误0.20.10-0.1-0.2300250100050150200短时谱500-50-100010203040506070谱LPC100806040010203040506070原始语音帧倒谱(直接调用函数)0.50-0.5-1050100150200250300预测误差倒谱(直接调用函数)0.50-0.5-1050100150200250300预测误差倒谱(根据定义编写,没有去除高频分量)0.20-0.2-0.4-0.6050100150200250300预测误差倒谱(根据定义编写,去除高频分量)0.10-0.1-0.2-0.3050100150200250300预测误差倒谱(根据定义编写,没有去除高频分量)0.20-0.2-0.4-0.6050100150200250300预测误差倒谱(根据定义编写,去除高频分量)0.10-0.1-0.2-0.3050100150200250300预测误差倒谱(根据定义编写,没有去除高频分量)0.20-0.2-0.4-0.6050100150200250300预测误差倒谱(根据定义编写,去除高频分量)0.10-0.1-0.2-0.3050100150200250300实验四基于VQ的特定人孤立词语音识别研究1、mfcc.mccc = mfcc(x)function);'m'bank=melbankm(24,256,8000,0,0.5,bank=full(bank); bank=bank/max(bank(:));k=1:12for n=0:23; dctcoef(k,:)=cos((2*n+1)*k*pi/(2*24));endw = 1 + 6 * sin(pi * [1:12] ./ 12);w = w/max(w);xx=double(x);xx=filter([1 -0.9375],1,xx);xx=enframe(xx,256,80); i=1:size(xx,1)for y = xx(i,:); s = y' .*hamming(256); t = abs(fft(s)); t = t.^2; c1=dctcoef * log(bank * t(1:129));c2 = c1.*w'; m(i,:)=c2';enddtm = zeros(size(m)); i=3:size(m,1)-2for dtm(i,:) = -2*m(i-2,:) - m(i-1,:) + m(i+1,:) + 2*m(i+2,:);end dtm = dtm / 3;ccc = [m dtm];ccc = ccc(3:size(m,1)-2,:);2、vad.m[x1,x2] = vad(x)function x = double(x);x = x / max(abs(x));FrameLen = 240;FrameInc = 80;amp1 = 10;amp2 = 2;zcr1 = 10;zcr2 = 5;% 6*10ms = 30ms maxsilence = 8;% 15*10ms = 150ms minlen = 15;status = 0;count = 0;silence = 0;tmp1 = enframe(x(1:end-1), FrameLen, FrameInc);tmp2 = enframe(x(2:end) , FrameLen, FrameInc);signs = (tmp1.*tmp2)<0;diffs = (tmp1 -tmp2)>0.02;zcr = sum(signs.*diffs, 2);amp = sum(abs(enframe(filter([1 -0.9375], 1, x), FrameLen, FrameInc)),2);amp1 = min(amp1, max(amp)/4);amp2 = min(amp2, max(amp)/8);x1 = 0;x2 = 0; n=1:length(zcr)for goto = 0; status switch{0,1} caseif amp(n) > amp1x1 = max(n-count-1,1); status = 2; silence = 0; count = count + 1;... amp(n) > amp2 | elseif zcr(n) > zcr2status = 1; count = count + 1;else status = 0; count = 0;end2, caseamp(n) > amp2 | ...if zcr(n) > zcr2 count = count + 1; elsesilence = silence+1; if silence < maxsilencecount = count + 1; count < minlen elseifstatus = 0; silence = 0; count = 0;elsestatus = 3;endend3, case; break endcount = count-silence/2;x2 = x1 + count -1;3、codebook.m%clear; xchushi= codebook(m)function[a,b]=size(m);[m1,m2]=szhixin(m); [m3,m4]=szhixin(m2);[m1,m2]=szhixin(m1);[m7,m8]=szhixin(m4);[m5,m6]=szhixin(m3);[m3,m4]=szhixin(m2);[m1,m2]=szhixin(m1);[m15,m16]=szhixin(m8);[m13,m14]=szhixin(m7);[m11,m12]=szhixin(m6);[m9,m10]=szhixin(m5);[m7,m8]=szhixin(m4);[m5,m6]=szhixin(m3);[m3,m4]=szhixin(m2);[m1,m2]=szhixin(m1);chushi(1,:)=zhixinf(m1);chushi(2,:)=zhixinf(m2);chushi(3,:)=zhixinf(m3);chushi(4,:)=zhixinf(m4); chushi(5,:)=zhixinf(m5);chushi(6,:)=zhixinf(m6);chushi(7,:)=zhixinf(m7); chushi(8,:)=zhixinf(m8);chushi(9,:)=zhixinf(m9);chushi(10,:)=zhixinf(m10); chushi(11,:)=zhixinf(m11);chushi(12,:)=zhixinf(m12);chushi(13,:)=zhixinf(m13);chushi(14,:)=zhixinf(m14);chushi(15,:)=zhixinf(m15);chushi(16,:)=zhixinf(m16);sumd=zeros(1,1000);k=1;dela=1;xchushi=chushi;(k<=1000)while sum=ones(1,16); p=1:a fori=1:16 for d(i)=odistan(m(p,:),chushi(i,:));enddmin=min(d); sumd(k)=sumd(k)+dmin;i=1:16ford(i)==dmin if xchushi(i,:)=xchushi(i,:)+m(p,:); sum(i)=sum(i)+1;end endendi=1:16forxchushi(i,:)=xchushi(i,:)/sum(i);endk>1if dela=abs(sumd(k)-sumd(k-1))/sumd(k);end k=k+1; chushi=xchushi; end return4、testvq.mclear;)这是一个简易语音识别系统,请保证已经将您的语音保存在相应文件夹中'disp(')正在训练您的语音模版指令,请稍后...'disp(' i=1:10for,i-1);\\ú.wav'海儿的声音 fname =sprintf('D:\\matlab\\work\\dtw1\\ x = wavread(fname); [x1 x2] = vad(x); m = mfcc(x); m = m(x1:x2-5,:);ref(i).code=codebook(m);end)?''语音指令训练成功,恭喜!disp()...''正在测试您的测试语音指令,请稍后disp( i=1:10for,i-1);海儿的声音\\?.wav'fname = sprintf('D:\\matlab\\work\\dtw1\\ x = wavread(fname);[x1 x2] = vad(x); mn = mfcc(x); mn = mn(x1:x2-5,:);%mn = mn(x1:x2,:) test(i).mfcc = mn;end sumsumdmax=0;sumsumdmin=0;)''对训练过的语音进行测试disp( w=1:10for sumd=zeros(1,10); [a,b]=size(test(w).mfcc);i=1:10forp=1:a for j=1:16 ford(j)=odistan(test(w).mfcc(p,:),ref(i).code(j,:));dmin=min(d);%×üê§?? sumd(i)=sumd(i)+dmin;end end sumdmin=min(sumd)/a;sumdmin1=min(sumd);sumdmax(w)=max(sumd)/a; sumsumdmin=sumdmin+sumsumdmax;sumsumdmax=sumdmax(w)+sumsumdmax;)正在匹配您的语音指令,请稍后...'disp(' i=1:10for (sumd(i)==sumdmin1) if (i) switch 1 case);前'', '您输入的语音指令为:%s; 识别结果为%s\n','前fprintf(' 2 case);', ''后:%s; 识别结果为%s\n','后 fprintf('您输入的语音指令为 3case);', '左识别结果为%s\n','左' fprintf('您输入的语音指令为:%s;4case);''右,'右', 您输入的语音指令为 fprintf('a:%s; 识别结果为%s\n' 5case);''东'东', fprintf('您输入的语音指令为:%s; 识别结果为%s\n', 6case);南'南', ' fprintf('您输入的语音指令为:%s; 识别结果为%s\n',' 7 case);', '西,:%s; 识别结果为%s\n''西' fprintf('您输入的语音指令为 8case);''北,'北', 您输入的语音指令为 fprintf(':%s; 识别结果为%s\n' 9case);上'', ', fprintf('您输入的语音指令为a:%s; 识别结果为%s\n''上 10case);下', '下'',您输入的语音指令为 fprintf('a:%s; 识别结果为%s\n'otherwise); 'error' fprintf(endendend end delamin=sumsumdmin/10;delamax=sumsumdmax/10;)''对没有训练过的语音进行测试disp()正在测试你的语音,请稍后...'disp(' i=1:10for,i-1);fname =sprintf('D:\\matlab\\work\\dtw1\\o£?ùμ?éùò?\\?.wav' x = wavread(fname);[x1 x2] = vad(x); mn = mfcc(x); mn = mn(x1:x2-5,:);%mn = mn(x1:x2,:)test(i).mfcc = mn;endw=1:10for sumd=zeros(1,10); [a,b]=size(test(w).mfcc); i=1:10forp=1:a for j=1:16ford(j)=odistan(test(w).mfcc(p,:),ref(i).code(j,:));enddmin=min(d);%×üê§?? sumd(i)=sumd(i)+dmin;end end sumdmin=min(sumd);z=0; i=1:10for (((sumd(i))/a)>delamax)|| if z=z+1;endend)...'disp('正在匹配您的语音指令,请稍后z<=3if i=1:10for (sumd(i)==sumdmin) if (i)switch1case);'前', '前',%s\n'识别结果为:%s; 您输入的语音指令为' fprintf(2 case);'后', ':%s; 识别结果为%s\n','后 fprintf('您输入的语音指令为3case);', '左识别结果为%s\n','左' fprintf('您输入的语音指令为:%s;4case);''右,'右', 识别结果为 fprintf('您输入的语音指令为a:%s; %s\n' 5case);''东'东', fprintf('您输入的语音指令为:%s; 识别结果为%s\n', 6 case);南'南', ' fprintf('您输入的语音指令为:%s; 识别结果为%s\n',' 7 case);', '西西:%s; 识别结果为%s\n','' fprintf('您输入的语音指令为 8case );''北,'北', 识别结果为 fprintf('您输入的语音指令为:%s; %s\n' 9case);上'', '上 fprintf('您输入的语音指令为a:%s; 识别结果为%s\n',' 10case);下'','下', 识别结果为 fprintf('您输入的语音指令为a:%s; %s\n'otherwise ); fprintf('error'endendend else)您输入的语音无效?£?\n'' fprintf(end end。
语音信号处理实验报告

语音信号处理实验报告专业:电子信息工程班级:电子信息二班姓名:学号:指导教师:杨立东目录实验一特征提取 (3)一、实验目的: (3)二、实验原理: (3)三、实验内容 (3)程序: (3)实验二基音周期估计 (9)一、实验目的 (9)二、实验原理 (9)三、实验内容 (10)程序: (10)实验三倒谱的获取与应用 (13)一、实验目的 (13)二、实验原理 (13)三、实验内容 (14)程序 (14)实验四 HMM的训练 (17)一、实验目的 (17)二、实验原理 (17)三、实验内容 (17)程序 (17)实验总结 (20)实验一语音信号的特征提取一、实验目的:1、了解语音信号处理基本知识,语音信号的生成的数学模型。
2、理解和掌握语音信号的特征提取。
二、实验原理:语音信号随时间变化的频谱特性可以用语谱图直观的表示,语谱图的纵坐标对应频率,横坐标对应时间,而图像的黑白度对应于信号的能量。
因此声道的谐振频率在图上就表示成为黑带,浊音部分则以出现条纹图形为其特征,这是因为此时的时域波形有周期性,而在浊音的时间间隔内图形显得很致密。
三、实验内容Matlab编程实验步骤:1.新建M文件,扩展名为“.m”,编写程序;2.选择File/Save命令,将文件保存在F盘新建文件夹中;3.运行程序;程序:语谱图clear all;[x,sr]=wavread('welcome.wav'); %sr为采样频率if (size(x,1)>size(x,2)) %size(x,1)为x的行数,size(x,2)为x的列数 x=x';ends=length(x);w=round(44*sr/1000); %窗长,取离44*sr/100最近的整数n=w; %fft的点数ov=w/2; %50%的重叠h=w-ov;% win=hanning(n)'; %哈宁窗win=hamming(n)'; %哈宁窗c=1;ncols=1+fix((s-n)/h); %fix函数是将(s-n)/h的小数舎去d=zeros((1+n/2),ncols);for b=0:h:(s-n)u=win.*x((b+1):(b+n));t=fft(u);d(:,c)=t(1:(1+n/2))';c=c+1;endtt=[0:h:(s-n)]/sr;ff=[0:(n/2)]*sr/n;imagesc(tt/1000,ff/1000,20*log10(abs(d)));colormap(gray);axis xyxlabel('时间/s');ylabel('频率/kHz');时间/s频率/k H z246810121416x 10-40246810时间/s频率/k H z0246810121416x 10-4246810预加重(高频提取)[x,sr]=wavread('mmm.wav'); %读数据ee=x(200:455); %选取原始文件e 的第200到455点的语音,也可选其他样点 r=fft(ee,1024); %对信号ee 进行1024点傅立叶变换 r1=abs(r); %对r 取绝对值 r1表示频谱的幅度值 pinlv=(0:1:255)*8000/512 %点和频率的对应关系 yuanlai=20*log10(r1) %对幅值取对数signal(1:256)=yuanlai(1:256);%取256个点,目的是画图的时候,维数一致 [h1,f1]=freqz([1,-0.98],[1],256,4000);%高通滤波器 pha=angle(h1); %高通滤波器的相位 H1=abs(h1); %高通滤波器的幅值 r2(1:256)=r(1:256)u=r2.*h1' % 将信号频域与高通滤波器频域相乘 相当于在时域的卷积 u2=abs(u) %取幅度绝对值 u3=20*log10(u2) %对幅值取对数un=filter([1,-0.98],[1],ee) %un 为经过高频提升后的时域信号 figure(1);subplot(211);plot(f1,H1);title('高通滤波器的幅频响应'); xlabel('频率/Hz'); ylabel('幅度');subplot(212);plot(pha);title('高通滤波器的相位响应'); xlabel('频率/Hz');ylabel('角度/radians');figure(2);subplot(211);plot(ee);title('原始语音信号'); xlabel('样点数'); ylabel('幅度');axis([0 256 -0.1 0.1]);subplot(212);plot(real(un)); title('经高通滤波后的语音信号'); xlabel('样点数'); ylabel('幅度'); axis([0 256 -1 1]);figure(3);subplot(211);plot(pinlv,ee);title('原始语音信号频谱'); xlabel('频率/Hz'); ylabel('幅度/dB');subplot(212);plot(pinlv,u3);title('经高通滤波后的语音信号频谱'); xlabel('频率/Hz'); ylabel('幅度/dB');05001000150020002500300035004000-50510x 10-3原始语音信号频谱频率/Hz幅度/d B05001000150020002500300035004000-80-60-40-20经高通滤波后的语音信号频谱频率/Hz幅度/d B50100150200250-0.1-0.0500.050.1原始语音信号样点数幅度50100150200250-1-0.500.51经高通滤波后的语音信号样点数幅度05001000150020002500300035004000-50510x 10-3原始语音信号频谱频率/Hz幅度/d B05001000150020002500300035004000-80-60-40-20经高通滤波后的语音信号频谱频率/Hz幅度/d B短时能量[x,sr]=wavread('welcome.wav'); %读入语音文件 %计算N=50,帧移=50时的语音能量 s=fra(50,50,x);s2=s.^2; %一帧内各样点的能量 energy=sum(s2,2); %求一帧能量subplot(2,2,1) %定义画图数量和布局plot(energy); %画N=50时的语音能量图xlabel('帧数') %横坐标ylabel('短时能量 E') %纵坐标legend('N=50') %曲线标识axis([0,1500,0,2*10]) %定义横纵坐标范围%计算N=100,帧移=100时的语音能量s=fra(100,100,x);s2=s.^2;energy=sum(s2,2);subplot(2,2,2)plot(energy) %画N=100时的语音能量图xlabel('帧数')ylabel('短时能量 E')legend('N=100')axis([0,600,0,4*10]) %定义横纵坐标范围%计算N=400,帧移=400时的语音能量s=fra(400,400,x);s2=s.^2;energy=sum(s2,2);subplot(2,2,3)plot(energy) %画N=400时的语音能量图xlabel('帧数')ylabel('短时能量 E')legend('N=400')axis([0,150,0,1.5*10^2]) %定义横纵坐标范围%计算N=800,帧移=800时的语音能量s=fra(800,800,x);s2=s.^2;energy=sum(s2,2);subplot(2,2,4)plot(energy) %画N=800时的语音能量图xlabel('帧数')ylabel('短时能量 E')legend('N=800')axis([0,95,0,3*10^2]) %定义横纵坐标范围定义fra()function f=fra(len,inc,x)fh=fix(((size(x,1)-len)/inc)+1);f=zeros(fh,len);i=1;n=1;while i<=fhj=1;while j<=lenf(i,j)=x(n); j=j+1;n=n+1; endn=n-len+inc; i=i+1; end5001000150005101520帧数短时能量 EN=50200400600010203040帧数短时能量 EN=100050100150050100150帧数短时能量 EN=400204060800100200300帧数短时能量 EN=800短时平均过零率clear all[x1,sr]=wavread('welcome.wav'); %读入语音文件 x=awgn(x1,15,'measured');%加入15dB 的噪声 s=fra(220,110,x);%分帧,帧移110 zcr=zcro(s);%求过零率 figure(1); subplot(2,1,1) plot(x);title('原始信号'); xlabel('样点数'); ylabel('幅度');axis([0,300,-2*10,2*10]); subplot(2,1,2) plot(zcr);xlabel('帧数'); ylabel('过零次数');title('原始信号的过零率');axis([0,360,0,200]); 定义zcro()function f=zcro(x)f=zeros(size(x,1),1); %生成全零矩阵 for i=1:size(x,1)z=x(i,:); %提取一行数据 for j=1:(length(z)-1); if z(j)*z(j+1)<0; f(i)=f(i)+1; end end end50100150200250300-20-1001020原始信号样点数幅度50100150200250300350050100150200帧数过零次数原始信号的过零率实验二 基音周期估计一、实验目的在理论学习的基础上,进一步的理解和掌握基音周期估计中两种最基本的方法:基于短时自相关法和基于短时平均幅度差法。
语音信号处理实验一报告
语⾳信号处理实验⼀报告实验⼀语⾳信号的采集及预处理⼀、实验⽬的在理论学习的基础上,进⼀步地理解和掌握语⾳信号预处理及短时加窗的意义及基于matlab的实现⽅法。
⼆、实验原理及内容1、语⾳信号的录⾳、读⼊、放⾳等:练习matlab中⼏个⾳频处理函数,利⽤函数wavread对语⾳信号进⾏采样,记住采样频率和采样点数,给出以下语⾳的波形图(2.wav),wavread的⽤法参见mablab帮助⽂件。
利⽤wavplay或soundview 放⾳。
也可以利⽤wavrecord⾃⼰录制⼀段语⾳,并进⾏以上操作(需要话筒)。
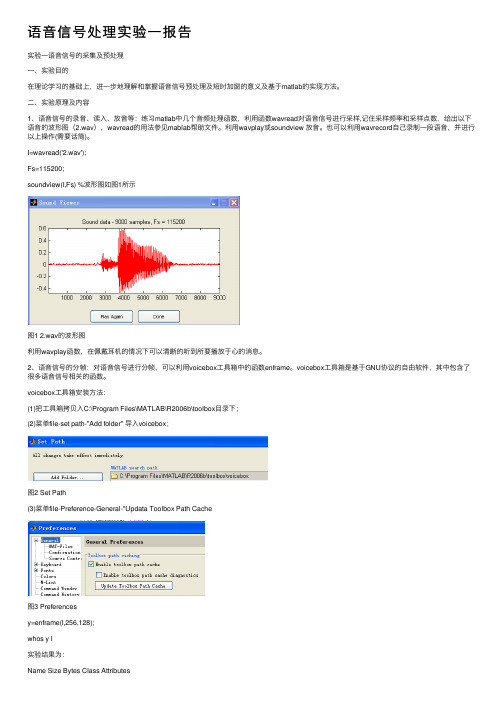
I=wavread('2.wav');Fs=115200;soundview(I,Fs) %波形图如图1所⽰图1 2.wav的波形图利⽤wavplay函数,在佩戴⽿机的情况下可以清晰的听到所要播放于⼼的消息。
2、语⾳信号的分帧:对语⾳信号进⾏分帧,可以利⽤voicebox⼯具箱中的函数enframe。
voicebox⼯具箱是基于GNU协议的⾃由软件,其中包含了很多语⾳信号相关的函数。
voicebox⼯具箱安装⽅法:(1)把⼯具箱拷贝⼊C:\Program Files\MATLAB\R2006b\toolbox⽬录下;(2)菜单file-set path-"Add folder" 导⼊voicebox;图2 Set Path(3)菜单file-Preference-General-"Updata Toolbox Path Cache图3 Preferencesy=enframe(I,256,128);whos y I实验结果为:Name Size Bytes Class AttributesI 9000x1 72000 doubley 69x256 141312 doubleI=wavread('2.wav');t=enframe(I,256,128);plot(t)图4 分帧后的波形图3、语⾳信号的加窗:本步要求利⽤window函数设计窗⼝长度为256(N=256)的矩形窗(rectwin)、汉明窗(hamming)及汉宁窗(hann)),利⽤wvtool函数观察其时域波形图及频谱特性,⽐较得出结论。
语音信号处理实验报告

语⾳信号处理实验报告语⾳信号处理实验报告【实验⼀】⼀、实验题⽬Short time analysis⼆、实验要求Write a MA TLAB program to analyze a speech and simultaneously, on a single page, plot the following measurements:1. the entire speech waveform2. the short-time energy, En3. the short-time magnitude, Mn4. the short-time zero-crossing, Zn5. the narrowband spectrogram6. the wideband spectrogramUse both the speech waveforms in the wznjdx_normal.wav. Choose appropriate window sizes, window shifts, and window for the analysis. Explain your choice of these parameters.三、实验程序clear[x,fs]=wavread('wznjdx_normal.wav');n=length(x);N=320;subplot(4,1,1);plot(x);h=linspace(1,1,N);En=conv(h,x.*x);subplot(4,1,2);plot(En);Mn=conv(h,abs(x));subplot(4,1,3);plot(Mn);for i=1:n-1if x(i)>=0 y(i)=1;else y(i)=-1;endif x(i+1)>=0 y(i+1)=1;else y(i+1)=-1;endw(i)=abs(y(i+1)-y(i));endk=1;j=0;while (k+N-1)Zm(k)=0;for i=0:N-1Zm(k)=Zm(k)+w(k+i);endj=j+1;k=k+N/2;endfor w=1:jQ(w)=Zm(160*(w-1)+1)/(2*N);endsubplot(4,1,4);plot(Q);grid;figure(2);subplot(2,1,1);spectrogram(x,h,256,200,0.0424*fs); subplot(2,1,2);spectrogram(x,h,256,200,0.0064*fs);四、实验结果语谱图:(Matlab 7.0 ⽤不了spectrogram)【实验⼆】⼀、实验题⽬Homomorphic analysis⼆、实验要求Write a MATLAB program to compute the real cepstrums of a section of voiced speech and unvoiced speech. Plot the signal, the log magnitude spectrum, the real cepstrum, and the lowpass liftered log magnitude spectrum.三、实验程序nfft=256;[x,fs] = wavread('wznjdx_normal.wav');fx=x;Xvm=log(abs(fft(fx,nfft)));xhv=real(ifft(Xvm,nfft));lifter=zeros(1,nfft);lifter(1:30)=1;lifter(nfft-28:nfft)=1;fnlen=0.02*fs; % 20mswin=hamming(fnlen);%加窗n=fnlen;%窗宽度赋给循环⾃变量nnoverlap=0.5*fnlen;while(n<=length(x)-1)fx=x(n-fnlen+1:n).*win;n=n+noverlap;endxhvp=xhv.*lifter';figure;subplot(4,1,1)plot(lifter);title('倒谱滤波器');subplot(4,1,2)plot(x);title('语⾳信号波形');subplot(4,1,3)plot(Xvm);title('Xvm');subplot(4,1,4)plot(xhv);title('xhv');四、实验结果【实验三】⼀、实验题⽬LP analysis⼆、实验要求Write a MATLAB program to convert from a frame of speech to a set of linear prediction coefficients. Plot the LPC spectrum superimposed on the corresponding STFT.三、实验程序clear;[x,fs]=wavread('wznjdx_normal.wav');fx=x(4000:4160-1);p=10;[a,e,k]=aryule(fx,p);G=sqrt(e*length(fx));f=log(abs(fft(fx)));h0=zeros(1,160);h=log(G)-log(abs(fft(a,160)));figure(1);subplot(211);plot(fx);subplot(212);plot(f);hold on;plot((0:160-1),h,'r');四、实验结果【实验四】⼀、实验题⽬Pitch estimation⼆、实验内容Write a program to implement the pitch estimation and the voiced/unvoiced decision using the LPC-based method.三、实验程序clear[x,fs]=wavread('wznjdx_normal.wav');n=length(x);Q = x';NFFT=512;N = 256;Hamm = hamming(N);frame = 30;M = Q(((frame -1) * (N / 2) + 1):((frame - 1) * (N / 2) + N)); Frame = M .* Hamm';% lowpass filter[b2,a2]=butter(2,900/4000);speech2=filter(b2,a2,Frame); % filter% residual[a,e] = lpc(speech2,20);errorlp=filter(a,1,speech2); % residual% Short-term autocorrelation.re = xcorr(errorlp);% Find max autocorrelation for lags in the interval minlag to maxlag. minlag = 17; % F0: 450Hzmaxlag =160; % F0: 50Hz[remax,idx] = max(re(fnlen+minlag:fnlen+maxlag));figuresubplot(3,1,1);plot(Frame);subplot(3,1,2);plot(speech2);subplot(3,1,3);plot(re);text(500,0,'idx');idx=idx-1+minlagremax四、实验结果【实验五】⼀、实验题⽬Speech synthesis⼆、实验内容Write a program to analyze a speech and synthesize it using the LPC-based method.三、实验程序主程序clear;[x,sr] = wavread('wznjdx_normal.wav');p=[1 -0.9];x=filter(p,1,x);N=256;inc=128;y=lpcsyn(x,N,inc);wavplay(y,sr);⼦程序lpcsynfunction y=lpcsyn(x,N,inc)%[x,sr] = wavread('wznjdx_normal.wav');%pre = [1 -0.97];%x = filter(pre,1,x);%N=256;%inc=128;fn=floor(length(x)/inc);y=zeros(1,50000);for (i=1:fn)x(1:N,i)=x((i-1)*inc+1:(i+1)*inc);[A(i,:),G(i),P(i),fnlen,fnshift] = lpcana(x(1:N,i),order); if (P(i)) % V oiced frame.e = zeros(N,1);e(1:P(i):N) = 1; % Impulse-train excitation.else % Unvoiced frame.e = randn(N,1); % White noise excitation.endyt=filter(G(i),A(i,:),e);j=(i-1)*inc+[1:N];y(j) = y(j)+yt';end;end⼦程序lpcanafunction [A,G,P,fnlen,fnshift] = lpcana(x,order) fnlen=256;fnshift=fnlen/2;n=length(x);[b2,a2]=butter(2,900/4000);speech2=filter(b2,a2,x);[A,e]=lpc(speech2,order);errorlp=filter(A,1,speech2);re=xcorr(errorlp);G=sqrt(e*length(speech2));minlag=17;maxlag=160;[remax,idx]=max(re(n+minlag:n+maxlag));P=idx-1+minlag;end四、实验结果【实验六】⼀、实验题⽬Speech enhancement⼆、实验内容Write a program to implement the basic spectral magnitude subtraction.三、实验程序clear[speech,fs,nbits]=wavread('wznjdx_normal.wav');%读⼊数据alpha=0.04;%噪声⽔平winsize=256;%窗长size=length(speech);%语⾳长度numofwin=floor(size/winsize);%帧数hamwin=zeros(1,size);%定义汉明窗长度enhanced=zeros(1,size);%定义增强语⾳的长度ham=hamming(winsize)';%%产⽣汉明窗x=speech'+alpha*randn(1,size);%信号加噪声noisy=alpha*randn(1,winsize);%噪声估计N=fft(noisy);nmag=abs(N);%噪声功率谱%分帧for q=1:2*numofwin-1frame=x(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2);%对带噪语⾳帧间重叠⼀半取值hamwin(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2)=...hamwin(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2)+ham;%加窗y=fft(frame.*ham);mag=abs(y);%带噪语⾳功率谱phase=angle(y);%带噪语⾳相位%幅度谱减for i=1:winsizeif mag(i)-nmag(i)>0clean(i)=mag(i)-nmag(i);else clean(i)=0;endend%频域中重新合成语⾳spectral=clean.*exp(j*phase);%反傅⾥叶变换并重叠相加enhanced(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2)=...enhanced(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2)+real(ifft(spectral));endfigure(1);subplot(3,1,1);plot(speech);xlabel('样点数');ylabel('幅度');title('原始语⾳波形'); subplot(3,1,2);plot(x);xlabel('样点数');ylabel('幅度');title('语⾳加噪波形'); subplot(3,1,3);plot(enhanced);xlabel('样点数');ylabel('幅度');title('增强语⾳波形');四、实验结果。
语音信号处理 实验报告

实验一、语音信号采集与分析一、实验目的:1)了解语音信号处理基本知识:语音信号的生成的数学模型。
2)在理论学习的基础上,进一步地理解和掌握语音信号的读入、回放、波形显示。
语音信号时域和频域分析方法。
二、实验原理一定时宽的语音信号,其能量的大小随时间有明显的变化。
其中清音段(以清音为主要成份的语音段),其能量比浊音段小得多。
短时过零数也可用于语音信号分析中,发浊音时,其语音能量约集中于3kHz以下,而发清音时,多数能量出现在较高频率上,可认为浊音时具有较低的平均过零数,而清音时具有较高的平均过零数,因而,对一短时语音段计算其短时平均能量及短时平均过零数,就可以较好地区分其中的清音段和浊音段,从而可判别句中清、浊音转变时刻,声母韵母的分界以及无声与有声的分界。
这在语音识别中有重要意义。
FFT在数字通信、语音信号处理、图像处理、匹配滤波以及功率谱估计、仿真、系统分析等各个领域都得到了广泛的应用。
本实验通过分析加噪的语音信号频谱,可以作为分离信号和噪声的理论基础。
三、实验内容:Matlab编程实验步骤:1.新建M文件,扩展名为“.m”,编写程序;2.选择File/Save命令,将文件保存在F盘中;3.在Command Window窗中输入文件名,运行程序;程序一、用MATLAB对原始语音信号进行时域分析,分析短时平均能量及短时平均过零数。
程序二、用MATLAB对原始语音信号进行频域分析,画出它的时域波形和频谱给原始的语音信号加上一个高频余弦噪声,频率为5kHz。
画出加噪后的语音信号时域和频谱图。
程序1.a=wavread(' D:\II.wav'); %读取语音信号的数据,赋给变量x1,这里的文件的全路径和文件名由个人设计n=length(a);N=320;subplot(3,1,1),plot(a);h=linspace(1,1,N);%形成一个矩形窗,长度为NEn=conv(h,a.*a);%求卷积得其短时能量函数Ensubplot(3,1,2),plot(En);for i=1:n-1if a(i)>=0b(i)= 1;elseb(i) = -1;endif a(i+1)>=0b(i+1)=1;elseb(i+1)=-1;endw(i)=abs(b(i+1)-b(i));end%求出每相邻两点符号的差值的绝对值k=1;j=0;while (k+N-1)<nZm(k)=0;for i=0:N-1;Zm(k)=Zm(k)+w(k+i);endj=j+1;k=k+160; %每次移动半个窗endfor w=1:jQ(w)=Zm(160*(w-1)+1)/640;%短时平均过零率endsubplot(3,1,3),plot(Q);实验结果打印粘贴到右侧:程序2:fs=22050; %语音信号采样频率为22050x1=wavread('D:\II.wav'); %读取语音信号的数据,赋给变量x1sound(x1,22050); %播放语音信号f=fs*(0:511)/1024;t=0:1/22050:(size(x1)-1)/22050; %将所加噪声信号的点数调整到与原始信号相同Au=0.03;d=[Au*cos(2*pi*5000*t)]'; %噪声为5kHz的余弦信号x2=x1+d;sound(x2,22050); %播放加噪声后的语音信号y2=fft(x2,1024); %对信号做1024点FFT变换figure(1)subplot(2,1,1);plot(x1) %做原始语音信号的时域图形title('原始语音信号');xlabel('time n');ylabel('幅值 n');subplot(2,1,2);plot(t,x2)title('加噪后的信号');xlabel('time n');ylabel('幅值 n');figure(2)subplot(2,1,1);plot(f,abs(x1(1:512)));title('原始语音信号频谱');xlabel('Hz');ylabel('幅值');subplot(2,1,2);plot(f,abs(y2(1:512)));title('加噪后的信号频谱');xlabel('Hz'); ylabel('幅值');实验结果打印粘贴到右侧:050010001500200025003000350040004500原始语音信号time n幅值 n加噪后的信号time n幅值 n020004000600080001000012000原始语音信号频谱Hz幅值加噪后的信号频谱Hz幅值四、实验分析加入噪声后音频文件可辨性下降,波形的平缓,频谱图上看,能量大部分集中在2000HZz到4000Hz之间。
语音信号处理实验报告

一、实验目的1. 理解语音信号处理的基本原理和流程。
2. 掌握语音信号的采集、预处理、特征提取和识别等关键技术。
3. 提高实际操作能力,运用所学知识解决实际问题。
二、实验原理语音信号处理是指对语音信号进行采集、预处理、特征提取、识别和合成等操作,使其能够应用于语音识别、语音合成、语音增强、语音编码等领域。
实验主要包括以下步骤:1. 语音信号的采集:使用麦克风等设备采集语音信号,并将其转换为数字信号。
2. 语音信号的预处理:对采集到的语音信号进行降噪、去噪、归一化等操作,提高信号质量。
3. 语音信号的特征提取:提取语音信号中的关键特征,如频率、幅度、倒谱等,为后续处理提供依据。
4. 语音信号的识别:根据提取的特征,使用语音识别算法对语音信号进行识别。
5. 语音信号的合成:根据识别结果,合成相应的语音信号。
三、实验步骤1. 语音信号的采集使用麦克风采集一段语音信号,并将其保存为.wav文件。
2. 语音信号的预处理使用MATLAB软件对采集到的语音信号进行预处理,包括:(1)降噪:使用谱减法、噪声抑制等算法对语音信号进行降噪。
(2)去噪:去除语音信号中的杂音、干扰等。
(3)归一化:将语音信号的幅度归一化到相同的水平。
3. 语音信号的特征提取使用MATLAB软件对预处理后的语音信号进行特征提取,包括:(1)频率分析:计算语音信号的频谱,提取频率特征。
(2)幅度分析:计算语音信号的幅度,提取幅度特征。
(3)倒谱分析:计算语音信号的倒谱,提取倒谱特征。
4. 语音信号的识别使用MATLAB软件中的语音识别工具箱,对提取的特征进行识别,识别结果如下:(1)将语音信号分为浊音和清音。
(2)识别语音信号的音素和音节。
5. 语音信号的合成根据识别结果,使用MATLAB软件中的语音合成工具箱,合成相应的语音信号。
四、实验结果与分析1. 语音信号的采集采集到的语音信号如图1所示。
图1 语音信号的波形图2. 语音信号的预处理预处理后的语音信号如图2所示。
语音信号处理实验报告

实验报告一、 实验目的、要求(1)掌握语音信号采集的方法(2)掌握一种语音信号基音周期提取方法(3)掌握短时过零率计算方法(4)了解Matlab 的编程方法二、 实验原理基本概念:(a )短时过零率:短时内, 信号跨越横轴的情况, 对于连续信号, 观察语音时域波形通过横轴的情况;对于离散信号, 相邻的采样值具有不同的代数符号, 也就是样点改变符号的次数。
对于语音信号, 是宽带非平稳信号, 应考察其短时平均过零率。
其中sgn[.]为符号函数⎪⎩⎪⎨⎧<=>=0 x(n)-1sgn(x(n))0 x(n)1sgn(x(n))短时平均过零的作用1.区分清/浊音:浊音平均过零率低, 集中在低频端;清音平均过零率高, 集中在高频端。
2.从背景噪声中找出是否有语音, 以及语音的起点。
(b )基音周期基音是发浊音时声带震动所引起的周期性, 而基音周期是指声带震动频率的倒数。
基音周期是语音信号的重要的参数之一, 它描述语音激励源的一个重要特征, 基音周期信息在多个领域有着广泛的应用, 如语音识别、说话人识别、语音分析与综合以及低码率语音编码, 发音系统疾病诊断、听觉残障者的语音指导等。
因为汉语是一种有调语言, 基音的变化模式称为声调, 它携带着非常重要的具有辨意作用的信息, 有区别意义的功能, 所以, 基音的提取和估计对汉语更是一个十分重要的问题。
由于人的声道的易变性及其声道持征的因人而异, 而基音周期的范围又很宽, 而同—个人在不同情态下发音的基音周期也不同, 加之基音周期还受到单词∑--=-=10)]1(sgn[)](sgn[21N m n n n m x m x Z发音音调的影响, 因而基音周期的精确检测实际上是一件比较困难的事情。
基音提取的主要困难反映在: ①声门激励信号并不是一个完全周期的序列, 在语音的头、尾部并不具有声带振动那样的周期性, 有些清音和浊音的过渡帧是很难准确地判断是周期性还是非周期性的。
语音信号_实验报告

一、实验目的1. 理解语音信号的基本特性及其在数字信号处理中的应用。
2. 掌握语音信号的采样、量化、编码等基本处理方法。
3. 学习语音信号的时域、频域分析技术。
4. 熟悉语音信号的增强、降噪等处理方法。
二、实验原理语音信号是一种非平稳信号,其特性随时间变化。
在数字信号处理中,我们通常采用采样、量化、编码等方法将语音信号转换为数字信号,以便于后续处理和分析。
三、实验内容1. 语音信号的采集与预处理- 使用麦克风采集一段语音信号。
- 对采集到的语音信号进行预加重处理,提高高频成分的幅度。
- 对预加重后的语音信号进行采样,采样频率为8kHz。
2. 语音信号的时域分析- 画出语音信号的时域波形图。
- 计算语音信号的短时能量和短时平均过零率,分析语音信号的时域特性。
3. 语音信号的频域分析- 对语音信号进行快速傅里叶变换(FFT)分析,得到其频谱图。
- 分析语音信号的频谱特性,提取关键频段。
4. 语音信号的增强与降噪- 在语音信号中加入噪声,模拟实际应用场景。
- 使用谱减法对加噪语音信号进行降噪处理。
- 对降噪后的语音信号进行主观评价,比较降噪效果。
5. 语音信号的回放与对比- 对原始语音信号和降噪后的语音信号进行回放。
- 对比分析两种语音信号的时域波形、频谱图和听觉效果。
四、实验步骤1. 采集语音信号- 使用麦克风采集一段时长为5秒的语音信号。
- 将采集到的语音信号保存为.wav格式。
2. 预处理- 使用Matlab中的preemphasis函数对采集到的语音信号进行预加重处理。
- 设置预加重系数为0.97。
3. 时域分析- 使用Matlab中的plot函数画出语音信号的时域波形图。
- 使用Matlab中的energy和zero crossing rate函数计算语音信号的短时能量和短时平均过零率。
4. 频域分析- 使用Matlab中的fft函数对语音信号进行FFT变换。
- 使用Matlab中的plot函数画出语音信号的频谱图。
语音信处理实验报告
语音信号处理实验报告——语音信号分析实验一.实验目的及原理语音信号分析是语音信号处理的前提和基础,只有分析出可表示语音信号本质特征的参数,才有可能利用这些参数进行高效的语音通信、语音合成和语音识别等处理,并且语音合成的音质好坏和语音识别率的高低,都取决于对语音信号分析的准确性和精确性.贯穿语音分析全过程的是“短时分析技术”.因为从整体来看,语音信号的特性及表征其本质特征的参数均是随时间变化的,所以它是一个非平稳态过程,但是在一个短时间范围内一般认为在0~30ms的时间内,其特性基本保持不变,即相对稳定,可将其看做一个准稳态过程,即语音信号具有短时平稳性.所以要将语音信号分帧来分析其特征参数,帧长一般取为0ms~30ms.二.实验过程2.仿真结果(1) 时域分析男声及女声蓝色为时域信号,红色为每一帧的能量,绿色为每一帧的过零率 某一帧的自相关函数3. 频域分析一帧信号的倒谱分析和FFT 及LPC 分析050100150200250300-1-0.500.510510152025303540-50050100150050100150200250300-1-0.500.5100.51 1.52 2.53 3.5-40-2002040②男声和女声的倒谱分析③浊音和清音的倒谱分析④浊音和清音的FFT 分析和LPC 分析红色为FFT 图像,绿色为LPC 图像三. 实验结果分析 1. 时域分析实验中采用的是汉明窗,窗的长度对能否由短时能量反应语音信号的变对应的倒谱系数:,,……对应的LPC 预测系数:,,,,,……原语音一帧语音波形一帧语音的倒化起着决定性影响.这里窗长合适,En能够反应语音信号幅度变化.同时,从图像可以看出,En可以作为区分浊音和清音的特征参数.短时过零率表示一帧语音中语音信号波形穿过横轴零电平的次数.从图中可以看出,短时能量和过零率可以近似为互补的情况,短时能量大的地方过零率小,短时能量小的地方过零率较大.从浊音和清音的时域分析可以看出,清音过零率高,浊音过零率低.从男声女声的时域信号对比图中可以看出,女音信号在高频率分布得更多,女声信号在高频段的能量分布更多,并且女声有较高的过零率,这是因为语音信号中的高频段有较高的过零率.2.频域分析这里对信号进行快速傅里叶变换FFT,可以发现,当窗口函数不同,傅里叶变换的结果也不相同.根据信号的时宽带宽之积为一常数这一性质,可以知道窗口宽度与主瓣宽度成反比,N越大,主瓣越窄.汉明窗在频谱范围中的分辨率较高,而且旁瓣的衰减大,具有频谱泄露少的有点,所以在实验中采用的是具有较小上下冲的汉明窗.为了使频域信号的频率分辨率较高,所取的DFT及相应的FFT点数应该足够多,但时域信号的长度受到采样率和和短时性的限制,这里可以采用补零的办法,对补零后的序列进行FFT变换.从实验仿真图可以看出浊音的频率分布比清音高.3.倒谱分析通过实验可以发现,倒谱的基音检测与语音加窗的选择也是有关系的.如果窗函数选择矩形窗,在许多情况下倒谱中的基音峰将变得不清晰,窗函数选择汉明窗较为合理,可以发现,加汉明窗的倒谱基音峰较为突出.在典型的浊音清音倒谱对比中,理论上浊音倒谱基音峰应比较突出,而清音不出现这种尖峰,只是在倒谱的低时域部分包含声道冲激响应的信息.实验仿真的图形不是很理想.4.线性预测分析从实验中可以发现,LPC谱估计具有一个特点,在信号能量较大的区域即接近谱的峰值处,LPC谱和信号谱很接近;而在信号能量较低的区域即接近谱的谷底处,则相差比较大.在浊音清音对比中,可以发现,对呈现谐波特征的浊音语音谱来说这个特点很明显,就是在谐波成分处LPC谱匹配信号谱的效果要远比谐波之间好得多.在实验中,当P值增加到一定程度,预测平方误差的改善就不很明显了,而且会增加计算量,一般取为8~4,这里P取为0.5.基音周期估计自互相关函数法②短时平均幅度差法③倒谱分析法共偏移92+32=24个偏移点6000/24=可以发现,上面三种方法计算得到的基音周期基本相同.。
播音语音实验报告总结(3篇)

第1篇一、实验目的本次播音语音实验旨在通过一系列的语音处理和分析,深入了解语音信号的基本特性,掌握语音信号处理的基本方法,并学会使用相关软件进行语音信号的采集、处理和分析。
通过实验,提高对语音信号处理技术的认识和实际操作能力。
二、实验原理语音信号处理是现代通信、语音识别、语音合成等领域的基础技术。
实验过程中,我们主要学习了以下原理:1. 语音信号采集:通过麦克风采集语音信号,将其转换为数字信号。
2. 时域分析:分析语音信号的波形、幅度、频率等特性。
3. 频域分析:将时域信号转换为频域信号,分析信号的频谱特性。
4. 语音处理算法:如滤波、降噪、增强、压缩等,提高语音信号质量。
5. 语音识别:通过特征提取和模式识别技术,实现语音信号到文字的转换。
三、实验过程1. 语音信号采集:使用麦克风采集一段普通话语音信号,并将其保存为WAV格式。
2. 时域分析:- 使用MATLAB软件打开WAV文件,观察语音信号的波形。
- 计算语音信号的幅度、频率等参数。
- 分析语音信号的时域特性,如过零率、平均幅度等。
3. 频域分析:- 使用MATLAB软件进行快速傅里叶变换(FFT),将时域信号转换为频域信号。
- 分析语音信号的频谱特性,如频率成分、能量分布等。
4. 语音处理:- 使用MATLAB软件实现滤波、降噪、增强、压缩等处理算法。
- 观察处理前后语音信号的变化,评估处理效果。
5. 语音识别:- 使用现有的语音识别工具(如Google语音识别API)对处理后的语音信号进行识别。
- 分析识别结果,评估语音识别系统的性能。
四、实验结果与分析1. 时域分析:- 观察到语音信号的波形具有明显的周期性,频率成分集中在200Hz到4kHz之间。
- 语音信号的幅度随时间变化较大,具有非线性特性。
2. 频域分析:- FFT结果显示,语音信号的频谱具有明显的频带特性,主要集中在300Hz到3.5kHz之间。
- 频谱能量分布不均匀,存在明显的峰值,对应语音信号的基频及其谐波。
语音信号实验报告

一、实验目的1. 理解语音信号的基本特性和处理方法。
2. 掌握语音信号的采样、量化、编码等基本过程。
3. 学习使用相关软件对语音信号进行时域和频域分析。
4. 了解语音信号的降噪、增强和合成技术。
二、实验原理语音信号是一种非平稳的、时变的信号,其频谱特性随时间变化。
语音信号处理的基本过程包括:信号采集、信号处理、信号分析和信号输出。
三、实验仪器与软件1. 仪器:计算机、麦克风、耳机。
2. 软件:Matlab、Audacity、Python。
四、实验步骤1. 信号采集使用麦克风采集一段语音信号,并将其存储为.wav格式。
2. 信号处理(1)使用Matlab读取.wav文件,提取语音信号的采样频率、采样长度和采样数据。
(2)将语音信号进行时域分析,包括绘制时域波形图、计算信号的能量和过零率等。
(3)将语音信号进行频域分析,包括绘制频谱图、计算信号的功率谱密度等。
3. 信号分析(1)观察时域波形图,分析语音信号的幅度、频率和相位特性。
(2)观察频谱图,分析语音信号的频谱分布和能量分布。
(3)计算语音信号的能量和过零率,分析语音信号的语音强度和语音质量。
4. 信号输出(1)使用Audacity软件对语音信号进行降噪处理,比较降噪前后的效果。
(2)使用Python软件对语音信号进行增强处理,比较增强前后的效果。
(3)使用Matlab软件对语音信号进行合成处理,比较合成前后的效果。
五、实验结果与分析1. 时域分析从时域波形图可以看出,语音信号的幅度、频率和相位特性随时间变化。
语音信号的幅度较大,频率范围一般在300Hz~3400Hz之间,相位变化较为复杂。
2. 频域分析从频谱图可以看出,语音信号的能量主要集中在300Hz~3400Hz范围内,频率成分较为丰富。
3. 信号处理(1)降噪处理:通过对比降噪前后的时域波形图和频谱图,可以看出降噪处理可以显著降低语音信号的噪声,提高语音质量。
(2)增强处理:通过对比增强前后的时域波形图和频谱图,可以看出增强处理可以显著提高语音信号的幅度和频率,改善语音清晰度。
信号处理综合实验报告(3篇)

第1篇一、实验目的1. 深入理解信号处理的基本原理和方法。
2. 掌握信号处理在各个领域的应用,如语音信号处理、图像处理等。
3. 熟悉实验设备的使用,提高实际操作能力。
4. 培养团队协作和问题解决能力。
二、实验内容本次实验主要分为以下几个部分:1. 语音信号处理(1)采集语音信号:使用麦克风采集一段语音信号,并将其转换为数字信号。
(2)频谱分析:对采集到的语音信号进行频谱分析,观察其频谱特性。
(3)噪声消除:设计并实现噪声消除算法,对含噪语音信号进行处理,提高信号质量。
(4)语音增强:设计并实现语音增强算法,提高语音信号的清晰度。
2. 图像处理(1)图像采集:使用摄像头采集一幅图像,并将其转换为数字图像。
(2)图像增强:对采集到的图像进行增强处理,如对比度增强、亮度增强等。
(3)图像滤波:设计并实现图像滤波算法,去除图像中的噪声。
(4)图像分割:设计并实现图像分割算法,将图像中的不同区域分离出来。
3. 信号处理算法实现(1)傅里叶变换:实现离散傅里叶变换(DFT)和快速傅里叶变换(FFT)算法,对信号进行频谱分析。
(2)小波变换:实现离散小波变换(DWT)算法,对信号进行时频分析。
(3)滤波器设计:设计并实现低通滤波器、高通滤波器、带通滤波器等,对信号进行滤波处理。
三、实验原理1. 语音信号处理(1)语音信号采集:通过麦克风将声音信号转换为电信号,再通过模数转换器(ADC)转换为数字信号。
(2)频谱分析:利用傅里叶变换将时域信号转换为频域信号,分析信号的频谱特性。
(3)噪声消除:采用噪声消除算法,如维纳滤波、谱减法等,去除信号中的噪声。
(4)语音增强:利用语音增强算法,如谱峰增强、长时能量增强等,提高语音信号的清晰度。
2. 图像处理(1)图像采集:通过摄像头将光信号转换为电信号,再通过模数转换器(ADC)转换为数字图像。
(2)图像增强:通过调整图像的亮度、对比度等参数,提高图像的可视效果。
(3)图像滤波:利用滤波器去除图像中的噪声,如均值滤波、中值滤波、高斯滤波等。
语音信号处理实验报告

语音信号处理实验报告语音信号处理实验报告一、引言语音信号处理是一门研究如何对语音信号进行分析、合成和改善的学科。
在现代通信领域中,语音信号处理起着重要的作用。
本实验旨在探究语音信号处理的基本原理和方法,并通过实验验证其有效性。
二、实验目的1. 了解语音信号处理的基本概念和原理。
2. 学习使用MATLAB软件进行语音信号处理实验。
3. 掌握语音信号的分析、合成和改善方法。
三、实验设备和方法1. 设备:计算机、MATLAB软件。
2. 方法:通过MATLAB软件进行语音信号处理实验。
四、实验过程1. 语音信号的采集在实验开始前,我们首先需要采集一段语音信号作为实验的输入。
通过麦克风将语音信号输入计算机,并保存为.wav格式的文件。
2. 语音信号的预处理在进行语音信号处理之前,我们需要对采集到的语音信号进行预处理。
预处理包括去除噪声、归一化、去除静音等步骤,以提高后续处理的效果。
3. 语音信号的分析语音信号的分析是指对语音信号进行频谱分析、共振峰提取等操作。
通过分析语音信号的频谱特征,可以了解语音信号的频率分布情况,进而对语音信号进行进一步处理。
4. 语音信号的合成语音信号的合成是指根据分析得到的语音信号特征,通过合成算法生成新的语音信号。
合成算法可以基于传统的线性预测编码算法,也可以采用更先进的基于深度学习的合成方法。
5. 语音信号的改善语音信号的改善是指对语音信号进行降噪、增强等处理,以提高语音信号的质量和清晰度。
常用的语音信号改善方法包括时域滤波、频域滤波等。
六、实验结果与分析通过实验,我们得到了经过语音信号处理后的结果。
对于语音信号的分析,我们可以通过频谱图观察到不同频率成分的分布情况,从而了解语音信号的特点。
对于语音信号的合成,我们可以听到合成后的语音信号,并与原始语音信号进行对比。
对于语音信号的改善,我们可以通过降噪效果的评估来判断处理的效果。
七、实验总结通过本次实验,我们深入了解了语音信号处理的基本原理和方法,并通过实验验证了其有效性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
语音信号处理实验报告一、原理 1.端点检测语音信号一般可分为无声段、清音段和浊音段。
无声段是背景噪声段, 平均能量最低,波形变化缓慢,过零率最低; 浊音段为声带振动发出对应的语音信号段, 平均能量最高; 清音段是空气在口腔中的摩擦、冲击或爆破而发出的语音信号段, 平均能量居于前两者之间,波形上幅度变化剧烈, 过零率最大。
端点检测就是首先判断有声还是无声, 如果有声,则还要判断是 清音还是 浊音。
为正确地实现端点检测, 一般综合利用短时能量和过零率两个特征,采用/双门限检测法。
① 语音信号x(n)进行分帧处理,每一帧记为Si (n ),n=1,2,…,N ,n 为离散语音信号时间序列,N 为帧长,i 表示帧数。
② 短时能量:③ 过零率:2.基音检测 能量有限的语音信号}{()s n 的短时自相关函数定义为: 10()[()()][()()]N n m R s n m w m s n m w m ττττ--==++++∑ 其中,τ为移位距离,()w m 是 偶对称的窗函数。
短时自相关函数有以下重要性质:①如果}{()s n 是周期信号,周期是P ,则()R τ也是周期信号,且周期相同,即()()R R P ττ=+。
②当τ=0时,自相关函数具有最大值;当0,,2,3P P P τ=+++…处周期信号的自相关函数达到极大值。
③自相关函数是偶函数,即()()R R ττ=-。
短时自相关函数法基音检测的主要原理是利用短时自相关函数的第二条性质,通过比较原始信号和它移位后的信号之间的类似性来确定基音周期,如果移位距离等于基音周期,那么,两个信号具有最大类似性。
在实际采用短时自相关函数法进行基音检测时,使用一个窗函数,窗不动,语音信号移动,这是经典的短时自相关函数法。
3.自相关法解线性预测方程组自相关方法a.Levinson-durbin 递推算法()21N i n Ei s n ==∑()()1sgn sgn 1N i i n Zi s n s n ==--⎡⎤⎡⎤⎣⎦⎣⎦∑pj a a k k R E E k Ep j i p i i n p i i i j ...,3,2,1,1||,)1()0(,)1()(12)()1(2)(==≤-=-=∧=-∏ ki 称为反射系数,也称PARCOR 系数b.E(p)是预测残差能量在起始端,为了预测x(0),需要用到x(-1),x(-2),……,x(-p).但是这些值均为0,这样预测会带来误差。
对于结尾有类似的结果。
所以选择汉明窗。
c.当N>>P 时,误差比例比较小,一般也符合这个条件。
4.Lpc 倒谱11111)()1(+-=+-∞=∧-=∑∑∑=-i p i i n n ip i i z ia z n h n z a⎪⎪⎪⎪⎩⎪⎪⎪⎪⎨⎧>--=≤≤--+==∑∑=∧∧-=∧∧p n i n h a n i n h p n i n h a n i a n h a h p i i n i i n ),(^)/1()(1),()/1()()1(1111二、设计流程图1. 端点检测2.基音检测3.总流程图三、结果分析1.端点检测2.基音检测四、测试程序1.端点检测[y fs bits]=wavread('e:\1.wav')length(y)t=0:1:length(y)-1plot(t,y)title('原始语音信号')xlabel('时间')ylabel('振幅')figure(2)y = double(y);y = y / max(abs(y))%归一化plot(t,y)title('归一化后')xlabel('时间')ylabel('振幅');figure(3)f=enframe(y(1:end),120,60)%分帧plot(f)title('分帧后')xlabel('时间')ylabel('振幅')FrameLen = 256; %帧长inc = 90; %未重叠部分,这里涉及到信号分帧的问题,在后边再解释。
amp1 = 10; %短时能量阈值amp2 = 2; %即设定能量的两个阈值。
zcr1 = 10; %过零率阈值zcr2 = 5; %过零率的两个阈值,感觉第一个没有用到。
minsilence = 6; %用无声的长度来判断语音是否结束minlen = 15; %判断是语音的最小长度status = 0; %记录语音段的状态count = 0; %语音序列的长度silence = 0; %无声的长度%计算过零率tmp1 = enframe(y(1:end-1), FrameLen,inc);tmp2 = enframe(y(2:end) , FrameLen,inc);signs = (tmp1.*tmp2)<0;diffs = (tmp1 - tmp2)>0.02;zcr = sum(signs.*diffs,2);%推测存的是各帧的过零率,放到zcr矩阵中。
%计算短时能量amp = sum((abs(enframe( y, FrameLen, inc))).^2, 2);%求出x各帧的能量值就行。
%调整能量门限amp1 = min(amp1, max(amp));amp2 = min(amp2, max(amp));%min函数是求最小值的%开始端点检测for n=1:length(zcr)%从这里开始才是整个程序的思路。
Length(zcr)得到的是整个信号的帧数。
goto = 0;switch statuscase {0,1} % 0 = 静音, 1 = 可能开始if amp(n) > amp1 % 确信进入语音段x1 = max(n-count-1,1); % 记录语音段的起始点status = 2;silence = 0;count = count + 1;elseif amp(n) > amp2 || zcr(n) > zcr2 % 可能处于语音段status = 1;count = count + 1;else % 静音状态status = 0;count = 0;endcase 2, % 2 = 语音段if amp(n) > amp2 ||zcr(n) > zcr2 % 保持在语音段count = count + 1;else % 语音将结束silence = silence+1;if silence < minsilence % 静音还不够长,尚未结束count = count + 1;elseif count < minlen % 语音长度太短,认为是噪声status = 0;silence = 0;count = 0;else % 语音结束status = 3;endendcase 3,break;endendcount = count-silence;x2 = x1 + count ; %记录语音段结束点%后边的程序是找出语音端,然后用红线给标出来figure(4)subplot(3,1,1)plot(y)axis([1 length(y) -1 1])%限制x轴与y轴的范围。
ylabel('Speech');line([x1*inc x1*inc], [-1 1], 'Color', 'red');line([x2*inc x2*inc], [-1 1], 'Color', 'red');%注意下line函数的用法:基于两点连成一条直线,就清楚了。
subplot(3,1,2)plot(amp);axis([1 length(amp) 0 max(amp)])ylabel('Energy');line([x1 x1], [min(amp),max(amp)], 'Color', 'red');line([x2 x2], [min(amp),max(amp)], 'Color', 'red');subplot(3,1,3)plot(zcr);axis([1 length(zcr) 0 max(zcr)])ylabel('ZCR');line([x1 x1], [min(zcr),max(zcr)], 'Color', 'red');line([x2 x2], [min(zcr),max(zcr)], 'Color', 'red');2.基音检测x=wavread('e:/1.wav');n=5000; %取t秒的声音片段,采样频率10kHZ,即100000t个样点for m=1:length(x)/n; %对每一帧求短时自相关函数for k=1:n;Rm(k)=0;for i=(k+1):n;Rm(k)=Rm(k)+x(i+(m-1)*n)*x(i-k+(m-1)*n);endendp=Rm(10:n); %防止误判,去掉前边10个数值较大的点[Rmax,N(m)]=max(p); %读取第一个自相关函数的最大点end %补回前边去掉的10个点N=N+10;T=N/8; %算出对应的周期figure(1);plot(Rm);xlabel('帧数(n)');ylabel('短时自相关');title('短时自相关');figure(2);stem(T,'.');axis([0 length(T) 0 15]);xlabel('帧数(n)');ylabel('周期(ms)');title('各帧基音周期');T1= medfilt1(T,5); %去除野点一维中值滤波figure(3);stem(T1,'.');axis([0 length(T1) 0 15]);xlabel('帧数(n)');ylabel('周期(ms)');title('各帧基音周期');%求AR系数[a_p,var_p]=levinson(Rm,16); %a_p: p阶AR模型的系数,var_p:p阶AR模型的预测误差功率。