ADF单位的根检验具体操作
adf检验名词解释

ADF检验名词解释1. 什么是ADF检验?ADF(Augmented Dickey-Fuller)检验是一种用于时间序列数据的单位根检验方法。
单位根是指时间序列数据中存在非随机趋势,即数据具有持续性的特征。
ADF检验可以帮助我们判断一个时间序列数据是否具有单位根,从而确定其是否为稳定的平稳过程。
2. 单位根和平稳过程单位根是时间序列数据中的非随机趋势,它表示数据存在长期依赖关系,即过去的值对未来值有预测能力。
相反,平稳过程是指时间序列数据的统计特性在时间上保持不变,不受外部因素影响。
在经济学和金融学中,平稳过程是进行预测和建模的基础。
如果一个时间序列数据包含单位根,则其统计性质会发生变化,使得预测和建模变得困难。
3. ADF检验的原理ADF检验基于Dickey-Fuller回归模型,在该模型中,被解释变量是时间序列数据的差分值(将原始数据进行一阶差分),解释变量包括差分值、滞后差分值以及其他可能影响时间序列数据的因素。
ADF检验的原假设(H0)是存在单位根,即时间序列数据是非平稳的。
备择假设(H1)是不存在单位根,即时间序列数据是平稳的。
通过对回归模型进行估计和假设检验,我们可以判断原假设是否成立,并得出结论。
4. ADF检验的步骤步骤1:提取差分值首先,我们需要对原始时间序列数据进行差分操作,获得一阶差分值。
这样做可以消除数据中的线性趋势。
步骤2:构建ADF回归模型在ADF检验中,我们使用自回归模型(AR)来对差分后的数据进行建模。
这个模型包括一个滞后项和其他可能影响时间序列数据的因素。
步骤3:估计ADF模型参数通过最小二乘法估计ADF模型中的参数,并计算出参数的标准误差。
这些参数和标准误差将用于后续的统计推断。
步骤4:进行假设检验在ADF检验中,我们需要对回归系数进行假设检验。
常见的方法是计算t统计量,并与相应的临界值进行比较。
如果t统计量大于临界值,则可以拒绝原假设,认为时间序列数据是平稳的。
ADF单位根检验

1.ADF单位根检验2.Engle-Granger协整检验3.Da-vdson误差修正模型4.Granger因果关系检验1、简单回归;2、工具变量回归;3、面板固定效应回归;4、差分再差分回归(difference in differnece);5、狂忒二回归(Quantile)。
大杀器就这几种,破绽最少,公认度最高,使用最广泛。
真是所谓的老少皆宜、童叟无欺。
其他的方法都不会更好,只会招致更多的破绽。
你在STATA里面还可以看到无数的其他方法,例如GMM、随机效应等。
GMM其实是一个没有用的忽悠,例如估计动态面板的diffGMM,其关键思想是当你找不到工具变量时,用滞后项来做工具变量。
结果你会发现令人崩溃的情况:不同滞后变量的阶数,严重影响你的结果,更令人崩溃的是,一些判断估计结果优劣的指标会失灵。
这GMM的唯一价值在于理论价值,而不在于实践价值。
你如果要玩计量,你就可以在GMM的基础上进行修改(玩计量的方法后面讲)。
有人会问:简单回归会不会太简单?我只能说你真逗。
STATA里面那么多选项,你加就是了。
什么异方差、什么序列相关,一大堆尽管加。
如果你实在无法确定是否有异方差和序列相关,那就把选项都加上。
反正如果没有异方差,结果是一样的。
有异方差,软件就自动给你纠正了。
这不很爽嘛。
如果样本太少,你还能加一个选项:bootstrap来估计方差。
你看爽不爽!bootstrap就是自己把脚抬起来扛在肩上走路,就这么牛。
这个bootstrap就是用30个样本能做到30万样本那样的效果。
有吸引力吧。
你说这个简单回归简单还是不简单!很简单,就是加选项。
可是,要理论推导,就不简单了。
我估计国内能推导的没几个人。
那些一流期刊上论文作者,最多只有5%的人能推导,而且大部分是海龟。
所以,你不需要会推导,也能把计量做的天花乱坠。
工具变量(IV)回归,这不用说了,有内生性变量,就用这个吧。
一旦有内生性变量,你的估计就有问题了。
单位根检验操作

利用EViews进行单位根检验 (ADF、DF检验的操作步骤基本相同)
在主菜单选择Quick / Series Statistics / Unit Root Test 输入待检验的序列名/单击OK / 出现单位根检验对话框
单位根检验对话框(由三部分构成) (1)检验类型(Test Type)
在原假设 H0 : 1或H0 : =0 下,单位根的t检验统计量的值为:
ˆ 或 ˆ ... 0.786011
ˆˆ ˆˆ
在1%、5%、10%三个显著性水平下,单位根检验的临界值分
别为- 4.4167、-3.6219、-3.2474,显然,上述 检验统计量值大于
相应DW临界值,从而接受
我们老师说样本较大时,选用bic ,较小时用 aic
先找出最小的AIC和SIC(不是绝对值),在 此基础上看ADF检验是否通过,即判断是否是 平稳序列。
我一般是根据VAR模型的最优滞后阶数-1 作为协整的最优滞后阶数
根据赤池信息准则或舒瓦茨信息准则
adf检验是在残差存在自相关时用的,滞后阶 数可以根据序列自相关和偏自相关图确定
H ,表明我国1978——2003年度GDP 0
序列存在单位根,是非平稳序列。
继续讨论: 对GDP的一阶差分进行检验
在10%的显著性水平下,单位根检验的临界值为 -3.2602,上述检验统计量值-3.62511小于相应DW临界值, 从而拒绝H0,表明我国1978——2003年D(GDP)序 列是平稳序列.
单位根是否应该包括常数项和趋势项可以通过 观察序列图确定,通过Quick-graph-line操作观 察你的数据,若数据随时间变化有明显的上升 或下降趋势,则有趋势项,若围绕0值上下波 动,则没有趋势项;其二,关于是否包括常数 项有两种观点,一种是其截距为非零值,则取 常数项,另一种是序列均值不为零则取常数项。
PythonADF单位根检验如何查看结果的实现

PythonADF单位根检验如何查看结果的实现如下所⽰:from statsmodels.tsa.stattools import adfullerprint(adfuller(data))(-8.14089819118415, 1.028868757881713e-12, 8, 442, {'1%': -3.445231637930579, '5%': -2.8681012763264233, '10%': -2.5702649212751583}, -797.2906467666614)第⼀个是adt检验的结果,简称为T值,表⽰t统计量。
第⼆个简称为p值,表⽰t统计量对应的概率值。
第三个表⽰延迟。
第四个表⽰测试的次数。
第五个是配合第⼀个⼀起看的,是在99%,95%,90%置信区间下的临界的ADF检验的值。
第⼀点,1%、%5、%10不同程度拒绝原假设的统计值和ADF Test result的⽐较,ADF Test result同时⼩于1%、5%、10%即说明⾮常好地拒绝该假设。
本数据中,adf结果为-8,⼩于三个level的统计值第⼆点,p值要求⼩于给定的显著⽔平,p值要⼩于0.05,等于0是最好的。
本数据中,P-value 为 1e-15,接近0.ADF检验的原假设是存在单位根,只要这个统计值是⼩于1%⽔平下的数字就可以极显著的拒绝原假设,认为数据平稳。
注意,ADF值⼀般是负的,也有正的,但是它只有⼩于1%⽔平下的才能认为是及其显著的拒绝原假设。
对于ADF结果在1% 以上 5%以下的结果,也不能说不平稳,关键看检验要求是什么样⼦的。
补充知识:python 编写ADF 检验,代码结果参数所表⽰的含义我就废话不多说了,⼤家还是直接看代码吧!from statsmodels.tsa.stattools import adfullerimport numpy as npimport pandas as pdadf_seq = np.array([1,2,3,4,5,7,5,1,54,3,6,87,45,14,24])dftest = adfuller(adf_seq,autolag='AIC')dfoutput = pd.Series(dftest[0:4],index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])# 第⼀种显⽰⽅式for key,value in dftest[4].items(): dfoutput['Critical Value (%s)' % key] = value print(dfoutput)# 第⼆种显⽰⽅式print(dftest)(1)第⼀种显⽰⽅式如图所⽰:具体的参数含义如下所⽰:Test Statistic : T值,表⽰T统计量p-value: p值,表⽰T统计量对应的概率值Lags Used:表⽰延迟Number of Observations Used: 表⽰测试的次数Critical Value 1% : 表⽰t值下⼩于 - 4.938690 ,则原假设发⽣的概率⼩于1%,其它的数值以此类推。
单位根检验操作讲解

GDP序列,检验其是否为平稳序列。
方法1: 用时序图判断
由GDP的时序图初步判断序列是不平稳的(可以看出该序列可能 存在趋势项,若需用ADF检验则选择第三种模型进行检验)。
方法2: 用自相关系数图判断
中国GDP时间序列的自相关系数不是很快地(如滞后期K=2,3
趋于零,即缓慢下降,再次表明序列是非平稳的.
• 单位根是否应该包括常数项和趋势项可 以通过观察序列图确定,通过Quickgraph-line操作观察你的数据,若数据随 时间变化有明显的上升或下降趋势,则 有趋势项,若围绕0值上下波动,则没有 趋势项;其二,关于是否包括常数项有 两种观点,一种是其截距为非零值,则 取常数项,另一种是序列均值不为零则 取常数项。
方法3: 单位根检验
Quick
Series Statistics
Unit Root Test
输入变量名(本例:GDP)
选择ADF检验 / Level(水平序列)/ Trend and Intercept (趋势项和漂移项)/ 滞后期数:2
在原假设 H0 : 1或H0 : =0 下,单位根的t检验统计量的值为:
• • •
• •
判断用不用常数项和趋势项一般做法是: 先画原序列的曲线图,根据图形可以看出是否应该包含截距项(常数项) 或者趋势项(这种方法是比较常用、有效和易行的); 对于生成过程比较复杂的时间序列数据,比较难直观地判断其是否含有 时间趋势或常数项,而需要对常数项、时间趋势项及单位根项的系数进 行反复检验,以及它们之间较为复杂的联合检验,以确定具体被检验时 间序列的具体生成过程等,比较复杂。 所以,对于一般的序列,采用画图的方法就可以了。 至于你检验出现的这种情况则是正常现象,因为检验序列显著性水平的T 统计量在原假设下的渐进分布依赖于单位根检验的不同形式。
adf单位根检验法

adf单位根检验法
ADF (Augmented Dickey-Fuller) 单位根检验法是一种常用的时间序列分析方法,用于检验时间序列数据是否具有单位根(非平稳性)。
单位根表示数据具有随机漂移或趋势,而非平稳性的数据在进行统计分析时可能会导致误导性的结果。
ADF 单位根检验法基于 Dickey-Fuller 测试统计量,该测试统计量的原假设为时间序列存在单位根。
如果原假设不能被拒绝,则说明时间序列是非平稳的;反之,如果原假设被拒绝,则说明时间序列是平稳的。
ADF 单位根检验法的步骤如下:
1. 建立原假设(H0):时间序列具有单位根,即非平稳。
2. 构建回归模型:将时间序列作为因变量,加入滞后项和可能的趋势项作为自变量。
3. 估计回归模型:利用最小二乘法估计回归模型的参数。
4. 计算测试统计量:根据估计的回归模型,计算 ADF 测试统计量。
5. 判断显著性:与临界值比较 ADF 测试统计量,若大于临界值,则拒绝原假设,认为时间序列是平稳的;否则,接受原假设,认为时间序列是非平稳的。
通过ADF 单位根检验法可以判断时间序列数据是否平稳,进而决定是否需要进行差分或其他预处理方法来使数据平稳化。
在经济学、金融学等领域,ADF 单位根检验法被广泛应用于时间序列数据的建模
和分析中。
adf检验表达式

adf检验表达式
ADF检验是一种常用的时间序列分析方法,用于检验一个时间序列是否具有单位根。
在经济学和金融学中,ADF检验被广泛应用于检验一个时间序列是否具有平稳性,以及是否存在长期关系。
ADF检验的基本思想是将时间序列进行差分,然后检验差分后的序列是否具有单位根。
如果差分后的序列不具有单位根,那么原序列就是平稳的,否则就是非平稳的。
ADF检验的统计量是ADF统计量,它的计算公式为:
ADF = (Yt - Yt-1) - δYt-1
其中,Yt表示时间序列的当前值,Yt-1表示时间序列的上一个值,δ表示时间序列的趋势,可以是常数或者线性趋势。
如果ADF统计量的值小于一定的临界值,就可以拒绝原假设,即时间序列具有单位根,否则就不能拒绝原假设。
ADF检验的优点是可以处理非平稳时间序列,而且可以考虑时间序列的趋势。
但是,ADF检验也有一些限制,比如不能处理季节性时间序列,而且对于样本量较小的时间序列,ADF检验的效果可能不太好。
在实际应用中,ADF检验常常用于检验股票价格、汇率、利率等金融时间序列的平稳性和长期关系。
例如,如果我们想要研究两个股票价格之间是否存在长期关系,可以先对它们进行ADF检验,如果
检验结果表明它们之间存在长期关系,那么就可以进一步进行协整分析,从而得到更深入的结论。
ADF检验是一种重要的时间序列分析方法,可以用于检验时间序列的平稳性和长期关系。
在实际应用中,我们需要根据具体情况选择合适的检验方法,并结合其他分析方法进行综合分析。
(完整版)ADF单位根检验_具体操作

ADF检验:
单位根检验,把数据输入Eviews之后,点击左上角的View--Unit Root Test,(但
好像更好用一些),之后可以选择一阶、二阶差分之后的序列是否存在单位根,同时可以选检验的方程中是否存在存在趋势项、常数项等。
一般进行ADF检验要分3步:
1 对原始时间序列进行检验,此时第二项选level,第三项选None.如果没通过检验,说明原始时间序列不平稳;
2 对原始时间序列进行一阶差分后再检验,即第二项选1st difference,第三
项选intercept,若仍然未通过检验,则需要进行二次差分变换;
3 二次差分序列的检验,即第二项选择2nd difference ,第四项选择Trend and intercept.一般到此时间序列就平稳了!
看结果:
1%,5%,10%指的是显著水平,如果ADF检验值(t值)大于某显著水平值(一般是5%),
则不通过检验,即存在单位根(不平稳),此时,可通过一阶差分再来查看单位根是否平稳,
p值指的是接受原假设的概率。
在报告上的写法:
:r=0
H
: r=1
H
1
,序列有单位根,非平缓。
反之……
如果ADF检验值>临界值,则接受H
(注:H
的写法,选中要设置为下标的字母,点击菜单栏格式——字体,选择效
果中的下标,确定。
或直接选中的那个红色项进行格式设置)
操作:图/line&symbol。
dfuller单位根检验流程

dfuller单位根检验流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!单位根检验流程。
单位根检验用于检验时间序列数据是否存在单位根,即是否存在不可平稳的趋势或波动。
r语言协整检验代码

r语言协整检验代码一、背景介绍协整是指两个或多个时间序列之间存在长期的稳定关系,即它们的差分序列是平稳的。
协整检验是时间序列分析中非常重要的一部分,可以用来判断变量之间是否存在长期关系,同时也可以用来构建多元回归模型。
二、协整检验方法在R语言中,我们可以使用adf.test()函数进行ADF单位根检验,判断序列是否平稳。
如果两个序列都不平稳,则需要对它们进行差分处理,直到得到平稳序列。
然后,我们可以使用ca.jo()函数进行Johansen共整检验,并使用summary()函数查看结果。
三、ADF单位根检验1. 安装并加载tseries包```Rinstall.packages("tseries")library(tseries)```2. 使用adf.test()函数进行ADF单位根检验```R# 假设我们有一个名为x的时间序列result <- adf.test(x)```3. 查看ADF单位根检验结果```R# 输出p值和ADF统计量值cat("p-value:", result$p.value, "\n")cat("ADF statistic:", result$statistic, "\n") ```四、Johansen共整检验1. 安装并加载urca包```Rinstall.packages("urca")library(urca)```2. 使用ca.jo()函数进行Johansen共整检验```R# 假设我们有两个时间序列x和ydata <- cbind(x, y)result <- ca.jo(data, type = "trace", K = 2)```参数说明:- data:要进行共整检验的时间序列数据- type:选择使用trace统计量还是maximum eigenvalue统计量。
平稳性检验公式学习平稳性检验的关键公式

平稳性检验公式学习平稳性检验的关键公式在统计学和经济学中,平稳性检验是一个重要的概念。
它用于确定时间序列数据是否表现出平稳性,即是否存在趋势、季节性或周期性。
本文将介绍平稳性检验的关键公式,帮助读者深入了解并应用这一方法。
1. 单位根检验公式单位根检验是最常用的平稳性检验方法之一。
它的核心思想是检验时间序列数据中是否存在单位根,若存在,则表明数据不具备平稳性。
单位根检验常用的公式是ADF(Augmented Dickey-Fuller)检验公式。
ADF检验基于以下模型:△Y_t = α + β t + γ Y_(t-1) + ∑_(i=1)^(p-1) θ_i △Y_(t-i) + ε_t其中,△表示差分操作,Y_t表示原始时间序列数据,α、β和γ分别是常数项、时间趋势项和滞后值系数,ε_t是误差项。
ADF检验的原假设是存在单位根,备择假设是不存在单位根。
通过对检验统计量的显著性检验,可以判断时间序列数据是否平稳。
2. 平稳性检验的拓展公式除了ADF检验,还有其他拓展的平稳性检验公式可以应用。
其中,KPSS(Kwiatkowski–Phillips–Schmidt–Shin)检验是另一个常用的方法。
KPSS检验模型可以表示为:Y_t = μ_t + ε_t其中,Y_t是时间序列数据,μ_t是趋势项,ε_t是误差项。
KPSS检验的原假设是数据是平稳的,备择假设是数据存在单位根。
通过对检验统计量的显著性检验,可以判断时间序列数据是否平稳。
3. 平稳性检验的实例为了更好地理解平稳性检验的应用,以下是一个实例:假设我们有一组月度销售额数据,我们想要判断这组数据是否表现出平稳性。
我们可以运用ADF检验和KPSS检验来进行判断。
首先,我们可以使用ADF检验公式来计算ADF统计量。
根据计算结果,如果ADF统计量的值显著小于某个临界值,我们可以拒绝原假设,即数据不具备单位根,从而表明数据是平稳的。
而对于KPSS检验,如果检验统计量的值显著小于某个临界值,我们可以拒绝备择假设,即数据存在单位根,从而表明数据是平稳的。
eviews中adf检验结果的辅助回归方程

eviews中adf检验结果的辅助回归方程在EViews中,可以使用内置的ADF测试来检验时间序列数据的单位根。
ADF检验的结果会输出一个辅助回归方程。
以下是在EViews中进行ADF检验的步骤:1. 导入或创建时间序列数据。
2. 打开你想要执行ADF检验的系列的对象。
3. 在对象窗口中,点击“View”菜单,然后选择“Unit Root Test (单位根检验)”。
4. 在弹出的对话框中,选择“ADF-Test”。
5. 在“Variables”列表中,选择你想要进行ADF检验的变量。
6. 在“Speciffication”选项中,可以选择具体的ADF模型,如“ADF-GLS”、“ADF-t”等。
7. 在“Test type”选项中,选择适当的单位根检验类型,如“Level”、“First Difference”等。
8. 选择是否包含截距项和趋势项,点击“OK”开始检验。
9. 检验结果会显示在输出窗口的“ADF Test Equation”部分。
在这个部分中,将会显示辅助回归方程的估计结果,包括系数、标准误差、t值和p值。
辅助回归方程的模型形式取决于所选择的ADF模型和检验类型。
一般来说,该方程的形式为:Yt = α + β1 * Yt-1 + β2 * ΔYt-1 + β3 * ΔYt-2 + ... + βk * ΔYt-k + εt其中,Yt是你选择进行ADF检验的时间序列变量,Δ表示差分运算符,εt是残差项。
α是截距项,β1, β2, ..., βk是ADF检验中估计的系数。
通过观察辅助回归方程的结果,可以判断时间序列数据是否具有单位根,从而判断其是否是平稳的。
通常,如果辅助回归方程中的系数是显著不为零的,就意味着数据具有单位根,即非平稳;如果系数都不显著,就意味着数据是平稳的。
stata中adf检验命令

stata中adf检验命令
Stata中adf检验命令
ADF检验(Augmented Dickey-Fuller Test)是时间序列分析中常用的一种方法,用于检验序列的平稳性。
在Stata软件中,可以通过内置的命令来进行ADF检验,帮助研究人员进行时间序列数据的分析和建模。
要在Stata中进行ADF检验,首先需要加载所需的数据集。
可以使用命令“use 文件路径\文件名.dta, clear”来加载数据。
接下来,可以使用命令“dfuller 变量名”来进行ADF检验。
在这个命令中,变量名是要进行检验的时间序列数据的变量名。
ADF检验的原假设是序列具有单位根,即序列是非平稳的。
如果检验结果的p值小于显著性水平(通常取0.05),则可以拒绝原假设,认为序列是平稳的。
反之,则不能拒绝原假设,序列是非平稳的。
除了简单的ADF检验外,Stata还提供了更多高级的ADF检验方法,如ADF-GLS检验和PP检验。
这些方法对序列的特性和数据分布做了更多的假设,并能够提供更准确的判断结果。
在实际应用中,ADF检验是时间序列分析的重要工具之一。
通过对序列的平稳性进行检验,可以为后续的建模和预测提供可靠的基础。
在金融领域和宏观经济领域,ADF检验被广泛应用于股票价格、汇率、GDP等时间序列数据的分析。
Stata中的ADF检验命令为研究人员提供了方便快捷的工具,帮助他们进行时间序列数据的分析和建模。
通过对序列平稳性的检验,可以更准确地理解数据的特性,为决策提供科学依据。
希望本文的介绍能够帮助读者更好地理解和应用ADF检验命令。
stata中进行adf检验的命令

在Stata中进行ADF检验(Augmented Dickey-Fuller Test)是研究单位根(unit root)存在与否的一种常用方法。
单位根指的是时间序列数据中的根(根是指方程的解),如果单位根存在,意味着时间序列数据具有非平稳性。
而ADF检验则是用来检验单位根是否存在的统计方法。
在Stata中,进行ADF检验可以使用dfuller命令。
下面将详细介绍如何使用这个命令进行ADF检验。
1. 环境设置在使用dfuller命令之前,需要先加载Stata的时间序列数据扩展包(timeseries package)。
通过输入以下命令加载扩展包:ssc install tsset2. 数据准备在进行ADF检验之前,需要准备好相关的时间序列数据。
可以使用tsset命令将数据设置为Stata的时间序列数据格式。
tsset date这里的date是数据中表示日期的变量名,需要将其替换为实际使用的日期变量名。
3. 进行ADF检验使用dfuller命令可以进行ADF检验。
下面是该命令的基本语法:dfuller dependent_variable [if] [in], [options]其中,dependent_variable是要进行ADF检验的变量名。
可以使用if子句和in子句进行数据筛选。
在进行ADF检验时,需要考虑以下两个核心问题: - 是否包含截距项(constant):使用-c选项来指定。
如果添加了-c选项,表示模型中包含截距项。
如果没有添加该选项,则表示模型中不包含截距项。
- 是否包含时间趋势项(trend):使用-t选项来指定。
同样地,如果添加了-t选项,表示模型中包含时间趋势项。
如果没有添加该选项,则表示模型中不包含时间趋势项。
如果要进行包含截距项和时间趋势项的ADF检验,可以使用以下命令:dfuller dependent_variable, lags(#) trend其中,#需要用实际的滞后阶数替换,表示在ADF检验中使用的滞后阶数。
第十讲单位根的ADF检验
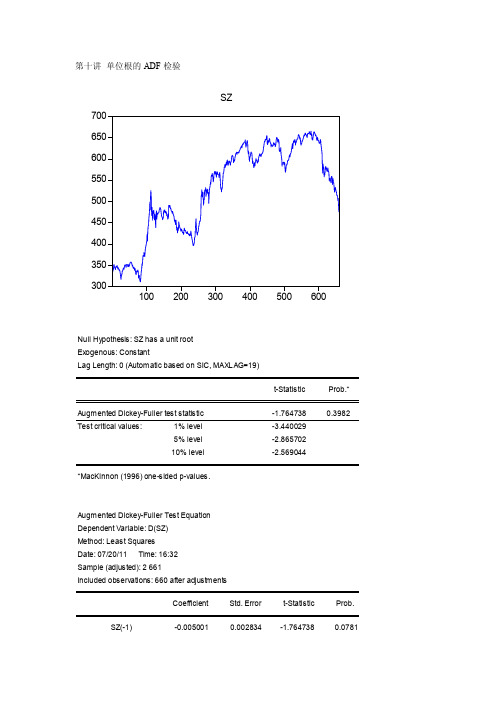
第十讲单位根的ADF检验Null Hypothesis: SZ has a unit rootExogenous: ConstantLag Length: 0 (Automatic based on SIC, MAXLAG=19)t-Statistic Prob.*Augmented Dickey-Fuller test statistic -1.764738 0.3982 Test critical values: 1% level -3.4400295% level -2.86570210% level -2.569044*MacKinnon (1996) one-sided p-values.Augmented Dickey-Fuller Test EquationDependent Variable: D(SZ)Method: Least SquaresDate: 07/20/11 Time: 16:32Sample (adjusted): 2 661Included observations: 660 after adjustmentsCoefficient Std. Error t-Statistic Prob.SZ(-1) -0.005001 0.002834 -1.764738 0.0781C 2.854051 1.519721 1.878009 0.0608R-squared 0.004711 Mean dependent var 0.224076 Adjusted R-squared 0.003198 S.D. dependent var 7.658427 S.E. of regression 7.646171 Akaike info criterion 6.909313 Sum squared resid 38469.27 Schwarz criterion 6.922926 Log likelihood -2278.073 Hannan-Quinn criter. 6.914589 F-statistic 3.114300 Durbin-Watson stat 2.003960 Prob(F-statistic) 0.078072Null Hypothesis: D(SZ) has a unit rootExogenous: ConstantLag Length: 0 (Automatic based on SIC, MAXLAG=19)t-Statistic Prob.*Augmented Dickey-Fuller test statistic -25.69239 0.0000 Test critical values: 1% level -3.4400445% level -2.86570810% level -2.569047*MacKinnon (1996) one-sided p-values.Augmented Dickey-Fuller Test EquationDependent Variable: D(SZ,2)Method: Least SquaresDate: 07/20/11 Time: 16:32Sample (adjusted): 3 661Included observations: 659 after adjustmentsCoefficient Std. Error t-Statistic Prob.D(SZ(-1)) -1.002561 0.039022 -25.69239 0.0000C 0.227541 0.298905 0.761250 0.4468R-squared 0.501176 Mean dependent var -0.003854 Adjusted R-squared 0.500417 S.D. dependent var 10.85111 S.E. of regression 7.669693 Akaike info criterion 6.915461 Sum squared resid 38647.50 Schwarz criterion 6.929089 Log likelihood -2276.644 Hannan-Quinn criter. 6.920744 F-statistic 660.0991 Durbin-Watson stat 1.999094 Prob(F-statistic) 0.000000Null Hypothesis: SH has a unit rootExogenous: ConstantLag Length: 0 (Automatic based on SIC, MAXLAG=19)t-Statistic Prob.*Augmented Dickey-Fuller test statistic -1.844818 0.3587 Test critical values: 1% level -3.4400295% level -2.86570210% level -2.569044*MacKinnon (1996) one-sided p-values.Augmented Dickey-Fuller Test EquationDependent Variable: D(SH)Method: Least SquaresDate: 07/20/11 Time: 16:26Sample (adjusted): 2 661Included observations: 660 after adjustmentsCoefficient Std. Error t-Statistic Prob.SH(-1) -0.005231 0.002836 -1.844818 0.0655C 9.982310 5.036766 1.981889 0.0479R-squared 0.005146 Mean dependent var 0.856833 Adjusted R-squared 0.003634 S.D. dependent var 24.42587 S.E. of regression 24.38145 Akaike info criterion 9.228548 Sum squared resid 391151.6 Schwarz criterion 9.242161 Log likelihood -3043.421 Hannan-Quinn criter. 9.233825 F-statistic 3.403353 Durbin-Watson stat 1.984278 Prob(F-statistic) 0.065513Null Hypothesis: D(SH) has a unit rootExogenous: ConstantLag Length: 0 (Automatic based on SIC, MAXLAG=19)t-Statistic Prob.*Augmented Dickey-Fuller test statistic -25.43433 0.0000 Test critical values: 1% level -3.4400445% level -2.86570810% level -2.569047*MacKinnon (1996) one-sided p-values.Augmented Dickey-Fuller Test EquationDependent Variable: D(SH,2)Method: Least SquaresDate: 07/20/11 Time: 16:30Sample (adjusted): 3 661Included observations: 659 after adjustmentsCoefficient Std. Error t-Statistic Prob.D(SH(-1)) -0.995676 0.039147 -25.43433 0.0000C 0.863648 0.953367 0.905892 0.3653R-squared 0.496129 Mean dependent var 0.089302 Adjusted R-squared 0.495362 S.D. dependent var 34.43430 S.E. of regression 24.46139 Akaike info criterion 9.235100 Sum squared resid 393122.4 Schwarz criterion 9.248728 Log likelihood -3040.965 Hannan-Quinn criter. 9.240383 F-statistic 646.9052 Durbin-Watson stat 1.992013 Prob(F-statistic) 0.000000。
adf检验表达式

adf检验表达式
ADF检验表达式是用于检验时间序列数据是否具有单位根的统计方法。
在经济学和金融领域中,时间序列数据的平稳性是进行分析和预测的关键前提。
如果一个时间序列数据具有单位根,则它是不平稳的,即其统计性质随时间变化而变化。
这会导致错误的统计推断和预测。
因此,ADF检验表达式可以帮助分析人员确定时间序列数据是否平稳,并在此基础上进行进一步分析和预测。
ADF检验表达式的基本形式是:
ΔYt = α + βt + γYt-1 + δ1ΔYt-1 + … + δpΔYt-p + εt
其中,Yt表示时间t的观察值,ΔYt表示该观察值与前一时刻的差异,α、β、γ、δ1、…、δp是常数或系数,εt是误差项。
ADF检验表达式的核心在于检验系数β是否显著不等于零,如果不等于零,则说明时间序列数据具有单位根,否则说明时间序列数据平稳。
通过ADF检验表达式可以对多种类型的时间序列数据进行检验,包括金融市场数据、宏观经济数据、气象数据等。
对于经济学和金融领域的分析人员来说,掌握ADF检验表达式是十分重要的技能之一。
- 1 -。
计量经济学实验报告
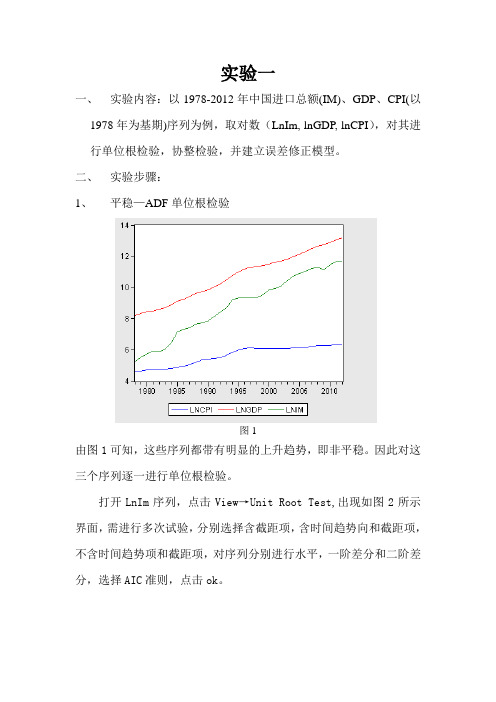
实验一一、实验内容:以1978-2012年中国进口总额(IM)、GDP、CPI(以1978年为基期)序列为例,取对数(LnIm, lnGDP, lnCPI),对其进行单位根检验,协整检验,并建立误差修正模型。
二、实验步骤:1、平稳—ADF单位根检验图1由图1可知,这些序列都带有明显的上升趋势,即非平稳。
因此对这三个序列逐一进行单位根检验。
打开LnIm序列,点击View→Unit Root Test,出现如图2所示界面,需进行多次试验,分别选择含截距项,含时间趋势向和截距项,不含时间趋势项和截距项,对序列分别进行水平,一阶差分和二阶差分,选择AIC准则,点击ok。
图2对另外连个序列做同样的操作。
最后三个序列的单位根检验结果如下:表1注:检验形式(C,T,L)中,C、T、L分别代表常数项、时间趋势和滞后阶数。
***表示在1%显著水平上拒绝零假设。
根据单位根检验结果,LnIm、LnGDP、LnCPI的水平序列的ADF 值在5%的显著性水平上大于其临界值,不能拒绝单位根假设。
一阶差分后,其ADF值小于5%的临界值,则应拒绝单位根假设。
因此,LnIm、LnGDP、LnCPI是非平稳的,服从I(1)过程,而其一阶差分是平稳的,服从I(0)过程。
2、协整检验根据前面的实验结果可知,LnIm、LnGDP、LnCPI都是一阶单整,因此符合协整检验的前提条件。
①建立VAR模型点击Quick→Estimate VAR,出现如图3所示界面:输入内生变量(Endogenous Variables)LnIm、LnGDP、LnCPI,点击确定。
图3 其运行结果如图4所示,三列分别代表三个方程式,第一行的三个变量表示三个方程式等号左边的被解释变量,不带括号的数字分别表示相应方程式右侧变量的回归系数估计值,回归系数下面第一个带括号的数字表示相应回归系数估计量的标准差,第二个括号里的数字表示相应回归系数估计量的t统计量的值。
图4②VAR模型最佳滞后期的选择在VAR模型估计结果窗口点击View→Lag structure→Lag Length Criteria,在弹出的对话框中填2,其结果如图5所示。
PP检验法和ADF检验法

第4节 PP 单位根检验法与ADF 单位根检验法DF 检验要求模型的随机扰动项t ε独立同分布。
但在实际应用中这一条件往往不能满足(如上一节中的有关例子)。
一般来说,如果估计模型的DW 值偏离2较大,表明随机扰动项是序列相关的,在这种情况下使用DF 检验可能会导致偏误,需要寻找新的检验方法。
本节我们将介绍在随机扰动项服从一般平稳过程的情况下,检验单位根的PP 检验法和ADF 检验法。
一、 PP (Phillips&Perron )检验首先考虑上一节情形二中扰动项为一平稳过程的单位根检验。
假设数据由(真实过程)φφ∑∞t t -1t t t j t -j j =0y =ρy +u ,u =(B)ε=ε (1) 产生,其中{}t ε独立同分布,∞<==2)(,0)(σεεt t D E 。
∑∞==0)(j j j B B ϕϕ,其中B 为滞后算子,其系数满足条件∞<∑∞=0j j j ϕ。
在回归模型t t t u y y ++=-1ρα中检验假设:0;1:0==αρH与DF 检验(情形二)一样,模型参数的OLS 估计为:⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫ ⎝⎛=⎪⎪⎭⎫ ⎝⎛∑∑∑∑∑-----t t t t t t y y y y y y N 112111ˆˆρα 在1,0:0==ραH 成立时,上式可改写为:1121111t t t t t t ˆT y u ˆy y y u αρ-----⎛⎫⎛⎫⎛⎫= ⎪ ⎪ ⎪ ⎪ ⎪-⎝⎭⎝⎭⎝⎭∑∑∑∑∑ 以矩阵()12A diag T ,T =左乘上式两端,得()123122321111121111112211111t t t t t t t t t t t t ˆTyu T A A A ˆy yy u T T y T u T y u T y T y αρ------------------⎧⎫⎧⎫⎛⎫⎛⎫⎛⎫⎪⎪⎪⎪= ⎪ ⎪ ⎪⎨⎬⎨⎬⎪ ⎪ ⎪-⎪⎪⎪⎪⎝⎭⎝⎭⎝⎭⎩⎭⎩⎭⎛⎫⎛⎫⎪= ⎪ ⎪⎪⎝⎭⎝⎭∑∑∑∑∑∑∑∑∑∑利用有关单位根过程的极限分布(参见第2节),可得()12110221122000111112L W ()W (r )dr ˆT ˆT [W ()]W (r )dr W (r )dr λλαρλγλλ-⎛⎫⎛⎫⎛⎫⎪ ⎪−−→ ⎪ ⎪ ⎪ ⎪-- ⎪ ⎪⎝⎭⎝⎭⎝⎭⎰⎰⎰ 其中)1(σϕλ=,∑∞==0220s sϕσγ。
协整检验的操作方法

协整检验的操作方法协整检验是一种用于检验两个或多个时间序列是否存在长期均衡关系的统计方法。
在时间序列分析中,我们通常假设时间序列之间是独立的,但是在现实生活中,很多时间序列之间存在着长期的相关性和相互影响,这就需要通过协整检验来确定它们之间的关系。
协整检验的操作方法如下:第一步:确定时间序列首先,我们需要确定参与协整检验的时间序列。
一般情况下,我们选择两个或多个可能存在长期均衡关系的时间序列。
第二步:进行单位根检验使用单位根检验来判断时间序列是否为非平稳序列。
常用的单位根检验方法包括ADF检验(Augmented Dickey-Fuller test)和PP检验(Phillips-Perron test)。
如果时间序列存在单位根,即为非平稳序列,我们需要进行差分,直到得到平稳序列。
第三步:构建误差修正模型(ECM)协整检验是通过构建误差修正模型来判断时间序列之间是否存在长期均衡关系。
误差修正模型是一个包含差分项(D)和滞后误差修正项(ECM)的模型。
具体构建方法如下:1. 定义模型误差修正模型一般为以下形式:Yt = α+ β1Xt + γ1D(L) + γ2ECMt-1 + εt其中,Yt表示因变量的一阶差分,Xt表示自变量的一阶差分,D(L)表示差分延迟项,ECMt-1表示滞后误差修正项,εt表示误差项。
2. 估计模型参数对误差修正模型进行参数估计。
一般使用最小二乘法进行估计。
3. 进行协整检验对估计得到的误差修正模型进行协整检验。
常用的协整检验方法有ADF检验、Johansen检验等。
如果协整检验结果显著,即拒绝原假设,说明这些时间序列之间存在长期均衡关系。
第四步:识别均衡关系如果协整检验结果为显著,说明时间序列之间存在长期均衡关系,接下来我们需要通过识别均衡关系来进行分析。
具体方法包括:1. 通过回归分析确定均衡关系方程,得到均衡关系的系数。
2. 进行残差分析,检验均衡关系的合理性。
3. 进行统计检验,验证均衡关系是否显著。
单位根检验 python

单位根检验(ADF检验)是一种用于检验时间序列数据是否平稳的方法。
在Python中,可以使用`statsmodels`库中的`adfuller`函数进行单位根检验。
首先,确保已经安装了`statsmodels`库,如果没有安装,可以使用以下命令进行安装:
```bash
pip install statsmodels
```
然后,可以使用以下代码进行单位根检验:
```python
import numpy as np
import pandas as pd
from statsmodels.tsa.stattools import adfuller
# 示例数据
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 进行单位根检验
result = adfuller(data)
# 输出结果
print('ADF统计量:', result[0])
print('p值:', result[1])
print('临界值:')
for key, value in result[4].items():
print('\t{}: {}'.format(key, value))
```
在这个例子中,我们使用了一个简单的线性递增的数据序列作为示例。
`adfuller`函数返回一个包含多个元素的元组,其中第一个元素是ADF统计量,第二个元素是p值,第三个元素是一个字典,包含了各种显著性水平下的临界值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ADF检验:
单位根检验,把数据输入Eviews之后,点击左上角的View--Unit Root Test,(但好像更好用
一些),之后可以选择一阶、二阶差分之后的序列是否存在单位根,同时可以选检验的方程中是否存在存在趋势项、常数项等。
一般进行ADF检验要分3步:
1 对原始时间序列进行检验,此时第二项选level,第三项选None.如果没通过检验,说明原始时间序列不平稳;
2 对原始时间序列进行一阶差分后再检验,即第二项选1st difference,第三项选intercept,若仍然未通过检验,则需要进行二次差分变换;
3 二次差分序列的检验,即第二项选择2nd difference ,第四项选择Trend and intercept.一般到此时间序列就平稳了!
看结果:
1%,5%,10%指的是显著水平,如果ADF检验值(t值)大于某显著水平值(一般是5%),则不通过检验,即存在单位根(不平稳),此时,可通过一阶差分再来查看单位根是否平稳,p值指的是接受原假设的概率。
在报告上的写法:
:r=0
H
: r=1
H
1
,序列有单位根,非平缓。
反之……
如果ADF检验值>临界值,则接受H
(注:H
的写法,选中要设置为下标的字母,点击菜单栏格式——字体,选择效
果中的下标,确定。
或直接选中的那个红色项进行格式设置)
操作:图/line&symbol。