常用分布函数的数学期望与方差及级数
常用分布的数学期望及方差

方差的性质
方差具有可加性
对于两个独立的随机变量X和Y,有Var(X+Y) = Var(X) + Var(Y)。
方差具有对称性
对于一个常数a和随机变量X,有Var(aX) = |a|^2 * Var(X)。
方差具有非负性
对于随机变量X,有Var(X) >= 0,其中 Var(X) = 0当且仅当X是一个常数。
05 数学期望与方差的应用
在统计学中的应用
描述性统计
数学期望和方差用于描述一组数据的中心趋势和 离散程度,帮助我们了解数据的基本特征。
参数估计
通过样本数据的数学期望和方差,可以对总体参 数进行估计,如均值和方差的无偏估计。
假设检验
在假设检验中,数学期望和方差用于构建检验统 计量,判断原假设是否成立。
常见分布的数学期望
均匀分布的数学期望为
$E(X) = frac{a+b}{2}$,其中a和b是均匀分布的下限和上 限。
柯西分布的数学期望为
$E(X) = frac{pi}{beta} sinh(frac{1}{beta})$,其中β是柯西 分布的参数。
拉普拉斯分布的数学期望为
$E(X) = frac{beta}{pi} tan(frac{pi}{beta})$,其中β是拉普 拉斯分布的参数。
03
泊松分布
正态分布是一种常见的连续型随机变量 分布,其方差记作σ²。正态分布的方差 描述了随机变量取值的分散程度。
二项分布是一种离散型随机变量分布, 用于描述在n次独立重复的伯努利试验 中成功的次数。其方差记作σ²,且σ² = np(1-p),其中n是试验次数,p是单次 试验成功的概率。
泊松分布是一种离散型随机变量分布, 用于描述在一段时间内随机事件发生的 次数。其方差记作σ²,且σ² = λ,其中 λ是随机事件发生的平均速率。
8个常见分布期望和方差

8个常见分布期望和方差概率分布的期望和方差为了理解和预测复杂的概率分布,其中最重要的两个因素是期望和方差。
概率分布的期望是由可能的结果的各种频率的平均值。
它是一个数字,可以确定概率变量的未来值的变化,用来表明对分布结果的期望:方差是描述随机变量变化程度的数字,它表示数据离期望值多大程度。
期望和方差是描述统计定律的基本量,它们是用于理解和预测随机变量的行为的最重要的两个概念。
此外,方差也是可以利用的重要的统计概念,用来表明总体变化的大小,以及在给定范围内期望出现变化的可能性。
尽管,有很多不同的概率分布存在,但是在概率领域,最常用的概率分布可以分为三类:正态分布,二项分布和卡方分布。
下文将分别介绍这三类分布的期望和方差。
正态分布是指概率分布中,观测值的分布曲线呈现出钟形状,中心对称型的曲线。
正态分布的期望可以表示为:E(x)=μ,即随机变量的期望值就是均值。
正态分布的方差可以表示为:V(x)=σ2,其中σ2是样本数据的方差,表示数据的变化程度。
二项分布研究的是独立重复试验,其中均有概率p成功,概率q失败,这里p+q=1。
对二项分布,其期望值E(X)=np,即期望值取决于p值和重复次数n;其中变异系数V(x)=npq,表示数据变异的程度。
卡方分布也被称为卡方正态或卡方分位数分布,它描述的是数据来源于独立正态分布的累积分布,通常用于统计检验中的卡方检验。
对卡方分布,其期望值E(X)=n;变异系数V(x)=2n,表示数据变异的程度。
总的来说,概率分布的期望和方差是理解和预测复杂概率分布的基础,它们提供了一种可以用来确定观测值的有效值并预测观测结果的方法。
通过期望和方差,我们可以很容易地推断三类常见分布的理论值,进一步推断复杂概率分布的变化趋势,从而帮助更好地。
方差及常见分布的期望方差课件

,令 t ? y 得 2
? ? ? ? ? ? D()X ? 4 2 ?? y ed 2 ? y2 y ? 2 2 ? ()3
2
? ? 0
2
《概率统计》
返回
下页
结束
证明: (2) D(CX)=E{[CX-E(CX)]
(3) D(X+C)= E{[(X+C)- E(X+C)] (4) D(X+Y) = E{[(X+Y)-E(X+Y)] = E{[X-E(X)]
?
1
(a 2
?
ab
?
b2
)
?
a (
?
b )2
?
(b ? a)2
3
2
12
《概率统计》
返回
下页
结束
4. 常见分布的期望与方差
5) 指数分布 设X ~E(λ) 概率密度为:
?? e??x , x ? 0
fp((xx))?? ? ? 0, x ? 0
? ? ? ? ??
??
E ( X ) ? xf ( x)dx ?
《概率统计》
返回
下页
结束
§4.2 方 差 0. 方差概念的引入
随机变量的数学期望是一个重要的数学特征,反应了随机变量 取值的平均大小,但只知道随机变量的数学期望是不够的 .
引例1:从甲、乙两车床加工的零件中各取5件,测得尺寸如下: 甲:8,9,10,11,12; 乙:9.6,9.8,10,10.2,10.4 已知标准尺寸为 10(cm), 公差d=0.5cm, 问那一台车床好?
3) 泊松分布 设随机变量X~π(λ),其概率分布为:
P{X ? k} ? ?k e? ? ,k = 0,1,2,3,…,λ>0
六个常用分布的数学期望和方差

即
12
若随机变量X~U( a , b ),则
ab
(b a)2
E(X)
, D( X )
2
12
五.指数分布
随机变量X服从参数为λ的指数分布,其概率密度为:
f
(
x)
1
θ
e
x θ
0
x0 x0
E(X )
xf ( x)dx
x
1
e
x θ
dx
x
( x)de θ
0
θ
0
(
x)e
x
x
e dx
X X1 X2 Xn
E( X ) E( X1 ) E( X 2 ) E( X n ) np
D( X ) D( X1 ) D( X 2 ) D( X n ) np(1 p)
即: 若随机变量X~B( n , p ),则
E( X ) np,D( X ) np(1 p)
E[3( X 2 1)] 3E( X 2 ) 3
3{D( X ) [E( X )]2 } 3 33
例2.已知X和Y相互独立,且X在区间(1,5)上服从
均匀分布, Y ~ N (1,求9)(1, ) (X,Y)的联合概率密度;(2)
E(3X 4Y 2) , D(3X 4Y 2)
E( X ) xf ( x)dx
b
x
1
dx
a ba
1 x2 b
ba 2 a
ab 2
E( X 2 ) b x 2
1
b3 a3 dx
a 2 ab b2
a ba
3(b a)
3
D( X )
E( X 2 ) [E( X )]2
常用的分布函数公式

常用的分布函数公式
常用的分布函数公式分布函数是概率论和统计学中重要的概念,用于描述随机变量的概率分布。
在实际应用中,我们经常需要使用一些常用的分布函数公式来计算概率或进行统计推断。
以下是一些常见的分布函数公式:1. 正态分布函数:正态分布是自然界中许多现象的模型,其分布函数可以用以下公式表示:
F(x) = 1/2 [1 + erf((x-μ)/(σ√2))] 其中,μ是正态分布的均值,σ是标准差,erf是误差函数。
2. 二项分布函数:二项分布是一种离散概率分布,用于描述在n次独立重复试验中成功次数的概率。
其分布函数可以用以下公式表示:
F(x) = Σ(i=0 to x) [C(n, i) * p^i * (1-p)^(n-i)] 其中,C(n, i)是组合数,p是每次试验成功的概率。
3. 泊松分布函数:泊松分布是一种离散概率分布,用于描述单位时间或空间内随机事件发生的次数。
其分布函数可以用以下公式表示:
F(x) = Σ(i=0 to x) [e^(-λ) * λ^i / i!] 其中,λ是单位时间或空间内随机事件的平均发生率。
4. t分布函数:t分布是用于小样本情况下进行统计推断的概率分布。
其分布函数可以用以
下公式表示:
F(x) = 1/2 + 1/2 * I(x/√(n-1), (n-1)/2, 1/2) 其中,n是样本容量,I是不完全贝塞尔函数。
以上是一些常用的分布函数公式,它们在概率论和统计学中具有广泛的应用。
通过了解和掌握这些公式,我们可以更好地理解和分析随机变量的概率分布,从而进行相应的统计推断和决策。
常见分布的期望和方差

罕有散布的期望和方差(0,1)N 2()Yx n t =概率与数理统计重点摘要1.正态散布的盘算:()()()X F x P X x μσ-=≤=Φ.2.随机变量函数的概率密度:X 是屈服某种散布的随机变量,求()Y f X =的概率密度:()()[()]'()Y X f y f x h y h y =.(拜见P66~72)3.散布函数(,)(,)xyF x y f u v dudv -∞-∞=⎰⎰具有以下基赋性质:⑴.是变量x,y 的非降函数;⑵.0(,)1F x y ≤≤,对于随意率性固定的x,y 有:(,)(,)0F y F x -∞=-∞=; ⑶.(,)F x y 关于x 右持续,关于y 右持续;⑷.对于随意率性的11221212(,),(,),,x y x y x x y y << ,有下述不等式成立:4.一个主要的散布函数:1(,)(arctan )(arctan )23x y F x y πππ2=++22的概率密度为:22226(,)(,)(4)(9)f x y F x y x y x y π∂==∂∂++ 5.二维随机变量的边沿散布:边沿概率密度:()(,)()(,)X Y f x f x y dyf y f x y dx+∞-∞+∞-∞==⎰⎰边沿散布函数:()(,)[(,)]()(,)[(,)]xX yY F x F x f u y dy du F y F y f x v dx dv+∞-∞-∞+∞-∞-∞=+∞==+∞=⎰⎰⎰⎰二维正态散布的边沿散布为一维正态散布.6.随机变量的自力性:若(,)()()X Y F x y F x F y =则称随机变量X,Y 互相自力.简称X 与Y 自力.7.两个自力随机变量之和的概率密度:()()()()()Z X Y Y X f z f x f z x dx f y f z y dy +∞+∞-∞-∞=-=-⎰⎰个中Z =X +Y8.两个自力正态随机变量的线性组合仍屈服正态散布,即22221212(,Z aX bY N a b a b μμσσ=+++). 9.期望的性质:……(3).()()()E X Y E X E Y +=+;(4).若X,Y 互相自力,则()()()E XY E X E Y =. 10.方差:22()()(())D X E X E X =-.若X,Y不相干,则()()()D X Y D X D Y +=+,不然()()()2(,)D X Y D X D Y Cov X Y +=++,()()()2(,)D X Y D X D Y Cov X Y -=+-11.协方差:(,)[(())(())]Cov X Y E X E X Y E Y =--,若X,Y 自力,则(,)0Cov X Y =,此时称:X 与Y 不相干. 12.相干系数:(,)()()XY Cov X Y X Y ρσσ==1XY ρ≤,当且仅当X 与Y 消失线性关系时1XY ρ=,且1,b>0;1,b<0XY ρ⎧=⎨-⎩ 当 当。
常见分布的期望和方差
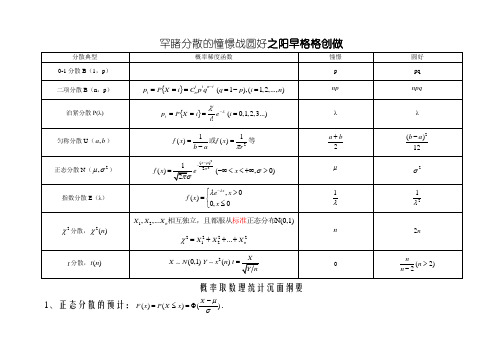
罕睹分散的憧憬战圆好之阳早格格创做(0,1)N 2()Yx n t =概率取数理统计沉面纲要1、正态分散的预计:()()()X F x P X x μσ-=≤=Φ.2、随机变量函数的概率稀度:X是遵循某种分散的随机变量,供()Y f X =的概率稀度:()()[()]'()Y X f y f x h y h y =.(拜睹P66~72)3、分散函数(,)(,)xyF x y f u v dudv -∞-∞=⎰⎰具备以下基赋本量:⑴、是变量x ,y 的非落函数;⑵、0(,)1F x y ≤≤,对付于任性牢固的x ,y 有:(,)(,)0F y F x -∞=-∞=; ⑶、(,)F x y 闭于x 左连绝,闭于y 左连绝;⑷、对付于任性的11221212(,),(,),,x y x y x x y y << ,有下述没有等式创造:4、一个要害的分散函数:1(,)(arctan )(arctan )23x y F x y πππ2=++22的概率稀度为:22226(,)(,)(4)(9)f x y F x y x y x y π∂==∂∂++ 5、二维随机变量的边沿分散:边沿概率稀度:()(,)()(,)X Y f x f x y dyf y f x y dx+∞-∞+∞-∞==⎰⎰边沿分散函数:()(,)[(,)]()(,)[(,)]xX yY F x F x f u y dy du F y F y f x v dx dv+∞-∞-∞+∞-∞-∞=+∞==+∞=⎰⎰⎰⎰二维正态分散的边沿分散为一维正态分散.6、随机变量的独力性:若(,)()()X Y F x y F x F y =则称随机变量X ,Y 相互独力.简称X 取Y 独力.7、二个独力随机变量之战的概率稀度:()()()()()Z X Y Y X f z f x f z x dx f y f z y dy +∞+∞-∞-∞=-=-⎰⎰其中Z =X +Y8、二个独力正态随机变量的线性推拢仍遵循正态分散,即22221212(,Z aX bYN a b a b μμσσ=+++).9、憧憬的本量:……(3)、()()()E X Y E X E Y +=+;(4)、若X ,Y 相互独力,则()()()E XY E X E Y =. 10、圆好:22()()(())D X E X E X =-. 若X ,Y 没有相闭,则()()()D X Y D X D Y +=+,可则()()()2(,)D X Y D X D Y Cov X Y +=++,()()()2(,)D X Y D X D Y Cov X Y -=+-11、协圆好:(,)[(())(())]Cov X Y E X E X Y E Y =--,若X ,Y 独力,则(,)0Cov X Y =,此时称:X 取Y 没有相闭. 12、相闭系数:(,)()()XYCov X Y X Y ρσσ==1XY ρ≤,当且仅当X 取Y 存留线性闭系时1XYρ=,且1,b>0;1,b<0XYρ⎧=⎨-⎩ 当 当。
概率论与数理统计:六大基本分布及其期望和方差

概率论与数理统计:六大基本分布及其期望和方差绪论:概率论中有六大常用的基本分布,大致可分成两类:离散型(0-1分布、二项分布、泊松分布),连续型(均匀分布、指数分布、正态分布)。
补充:在进入正文之前先讲一下期望和均值的一些区别:期望和均值都具有平均的概念,但期望是指的随机变量总体的平均值,而均值则是指的从总体中抽样的样本的平均值,即前者是理想的均值,而后者则是实际观测出来的数据的均值。
例如:对于一个六面的骰子,其期望E = (1+2+3+4+5+6)/ 6 = 3.5。
然后掷5次骰子,每次掷的点数分别为1,3,5,5,1,则平均值为(1+3+5+5+1)/ 5 = 3。
可以发现两者并不相等。
方差(variance):方差是各个数据与平均数之差的平方的平均数,方差度量了随机变量与期望(也可说均值)之间的偏离程度。
标准差为方差的开根号。
协方差(Covariance):用于衡量两个变量之间的误差,而方差是协方差的特殊情况,即当两个变量相同的情况。
其公式如下:,表示含义为:E(∑(“X与其均值之差” * “Y与其均值之差”))当协方差为正时:表示两变量正相关(即同时变大变下)。
当协方差为负时:表示两变量负相关(即你变大,我变小,反之亦然)。
当协方差为0时:两变量相互独立。
相关系数:其公式如下,表示的含义为用X和Y的协方差除以X 和Y的标准差。
所以相关系数也可以看成协方差,一种剔除两个变量量纲影响,标准化后的特殊协方差。
正文:1、0-1分布已知随机变量X,其中P{X=1} = p,P{X=0} = 1-p,其中 0 < p< 1,则成X服从参数为p的0-1分布。
其中期望为E(X) = p 方差D(X) = p(1-p);2、二项分布n次独立的伯努利实验(伯努利实验是指每次实验有两种结果,每种结果概率恒定,比如抛硬币)。
其中期望E(X) = np 方差D(X) = np(1-p);3、泊松分布表示单位时间内某稀有事件发生k次的概率,其公式为其中方差和期望均为,详细了解请☞戳4、均匀分布若连续型随机变量X具有概率密度,则称X在(a,b)上服从均匀分布其中期望E(X) = (a+b)/ 2 ,方差D(X) = (b-a)^2 / 12。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
例1 、断调和级数1111123n n==++++∑∞1……n 的敛散性。
解 因为 1111123n n ==++++∑∞1……n 可以按如下加括号,得,级数....)16115114113112111110191()81716151()4131()211(++++++++++++++++而上述加括号后的级数的各项大于级数....212121.......)161161161161161161161161()81818181()4141(21+++=+++++++++++++++的对应项,又后一级数112n =∑∞是发散的,所以原调和级数11n n=∑∞是发散的。
例2 、判断级数231111123n n n==++++∑∞n1……n 的敛散性。
解 因为n 1n ≤n-112而等比级数1112n n -=∑∞是收敛的,且1112n n -=∑∞=2,所以是收敛的。
例3 、察∑∞=+-1211n n n 的收敛性。
解:由于当2≥n 时,有222)1(1)1(1111-≤-=-≤+-n n n n n n n , 因正项级数∑∞=-22)1(1n n 收敛,故∑∞=+-1211n n n 收敛。
例4、级数∑n1的发散性,可知级数∑n1sin 是发散的。
增加例题:级数∑n 1s i n = ++++n1sin 21sin 1sin 是发散的。
为111sinlim =∞→nn n 根据推论以及调和级数∑n 1发散,所以级数∑n 1sin 也发散。
例5、讨论级数+-+⋅⋅-+⋅⋅++⋅⋅⋅⋅+⋅⋅+)]1(41[951)]1(32[852951852515212n n 的收敛性。
由于 ,1434132lim lim1<=++=∞→+∞→n n u u n nn n 根据上述推论级数是收敛的。
例6、 讨论级数)0(1>∑-x nxn 的收敛性。
解 因为()(),1111∞→→+⋅=+=-+n x n n x nx x n u u n n n n 根据推论1,当10<<x 时级数收敛;当1>x 时级数发散;而当1=x 时,所考察的级数是∑n ,它显然也是发散的。
若(9)中1=q ,这时用比式判别法不能对级数的敛散性作出判断,因为它可能是收敛的,也可能是发散的。
如级数∑21n 和∑n 1,它们的比式极限都是(),n u u nn ∞→→+11但∑21n 是收敛的(§1例4),而∑n 1却是发散的。
若某级数的(9)式的极限不存在,则可应用上、下极限来判别。
例7、研究级数 ++++++++-n n n nc b cb c b c b bc b 12221 (10)的敛散性,其中c b <<0。
解 由于⎩⎨⎧=+n c n b u u n n ,,1为偶数为奇数,故有 ,lim ,lim 11b u u c u u n n n nn n ==+∞→+∞→ 于是,当1<c 时,级数(10)收敛;当1>b 时,级数(10)发散;但当c b <<1,比式判别法无法判断级数(10)的敛散性。
例8、 讨论级数 ∑-+n n 2)1(2的敛散性。
解:由于 (),21212lim lim =-+=∞→∞→nnn n nn u 所以级数是收敛的。
若在(13)式中l =1,则根式判别法仍无法对级数的敛散性作出判断.例如,对,112∑∑n n 和都有1→n nu ()∞→n 但∑21n 是收敛的,而∑n 1却是发散的。
若(13)式的极限不存在,则可根据根式n n u 的上极限来判断。
例9、讨论下列级数(1) ∑∞=11n p n ,(2)∑∞=2)(ln 1n p n n , (3) ∑∞=3)ln )(ln (ln 1n pn n n 的敛散性。
解 (1)函数()p x x f 1=,当0>p 时在[]+∞,1上是非负减函数。
知道反常积分⎰+∞1p xdx 在1>p 时收敛,1≤p 时发散.故由定理4得∑p x1去当1>p 时收敛,当10≤<p 时发散。
至于0≤p 的情形,则可由定理12.1推论知道它也是发散的。
(2)研究反常积分⎰+∞2)(ln px x dx,由于⎰⎰⎰+∞+∞+∞==2ln 22)(ln )(ln )(ln p p p u du x x d x x dx 当1>p 时收敛,1≤p 时发散;根据定理4知级数(2)在1>p 时收敛,1≤p 时发散。
对于(3),考察反常积分⎰∞3)ln )(ln (ln px x x dx,同样可推得级数(3)在1>p 时收敛,在1≤p 时发散。
例10、证明级数∑∞=+1221n n 是收敛的。
证 由于222n n >+,所以22121n n <+,而级数∑∞=121n n为p=2 的p-级数且收敛, 故由比较审敛法,级数∑∞=+1221n n 是收敛的。
例11、判别下列级数∑∞=+1222n n n的敛散性。
分析 这是一个典型的例题,通项222+n n是关于n 的一个有理分式。
应注意分母和分子中n 的最高幂次之差,通项为关于n 的一个有理分式的级数和相应的p-级数有相同的敛散性。
本题中这一差数为1,故应和p=1的p-级数∑∞=11n n做比较。
解 n n n n n n n 1322222222⋅=++≥+,而级数∑∞=⋅1)132(n n 与∑∞=11n n 有相同的敛散性,即同时发散,故由比较审敛法,级数∑∞=+1222n n n是收敛的。
在例中,由于级数的通项比较复杂,使得敛散性的判别过程较为复杂,为使比较审敛法的应用更为方便,给出其极限形式。
比较审敛法的极限形式 设∑∞=1n n u 和∑∞=1n n v 为两个正项级数,如果l v u nnn =∞→lim (+∞<<l 0),则级数∑∞=1n n u 和∑∞=1n n v 有相同的敛散性。
如果正项级数∑∞=1n n v 发散,且满足),3,2,1( =≥n v u n n ,则∑∞=1n n u 发散;例12、判别级数∑∞=11sinn n的敛散性。
解 因为111sinlim=∞→nn n ,故由比较审敛法的极限形式得知此级数收敛。
如果不用比较审敛法的极限形式,例3中的级数敛散性的判别较为困难。
例13、用比较审敛法的极限形式判别例3中的级数∑∞=+1222n n n 的敛散性。
解 因为2122lim2=+∞→nn nn ,故由比较审敛法得知此级数收敛。
比值审敛法 设正项级数∑∞=1n n u 的后项与前项的比值的极限等于ρ:ρ=+∞→n n n u u1lim (3)则当1<ρ时级数收敛;1>ρ时级数发散。
例14、判别级数+++⋅⋅+⋅+nn 10!10321102110132的敛散性。
解 因为n n n u 10!=,故101!1010)!1(11+=⋅+=++n n n u u n n n n ,从而∞=+=∞→+∞→n n u u n n n n 1lim lim 1。
由比值审敛法可知级数发散。
易知,当级数的通项含有阶乘或n 出现在指数位置时,一般可用比值审敛法判别其敛散性。
例15、判别级数∑∞=⋅1!2n nn nn 的敛散性。
分析 此级数的通项n n n n n u !2⋅=中既含有n 的阶乘,又含有n 2和nn ,所以可用比值审敛法判断其敛散性。
解 因为n n n n n u !2⋅=,所以nn n n n n n nn n n n u u )11(2!2)1()!1(2111+=⋅⋅++=+++从而12l i m 1<=+∞→e u u nn n ,由比值审敛法可知,此级数收敛。
当(3)中ρ等于1时,用比值审敛法不能判别级数的敛散性。
可用其它方法判别其敛散性。
根值审敛法 设正项级数∑∞=1n n u 的通项n u 的n 次方根的极限等于ρ:ρ=∞→n n n u lim , (4)则当1<ρ时级数收敛;1>ρ时级数发散。
例16、证明级数 +++++nn 13121132收敛。
分析 当级数的通项中含有nn 或类似的表达式时,通常采用根值审敛法判别级数的敛散性。
证 因为011→==nn u nn nn (∞→n )故由根值审敛法得知所给级数收敛。
以上给出了正项级数的各种判别法。
对于给定的正项级数,可以按照以下顺序对其敛散性进行判别: 1.首先观察其通项是否趣于零,如果通项不趣于零,则级数发散。
2.如果通项趣于零,可根据级数通项的特点,考虑用比较审敛法、比值审敛法或根值审敛法。
3.极其特殊的情况下,也可以用级数的部分和数列来判断级数的敛散性。