数据挖掘作业集答案
数据挖掘习题答案

数据挖掘习题答案数据挖掘习题答案数据挖掘作为一门重要的技术和方法,广泛应用于各个领域。
在学习数据挖掘的过程中,习题是不可或缺的一部分。
通过解答习题,我们可以更好地理解和掌握数据挖掘的原理和应用。
以下是一些常见的数据挖掘习题及其答案,供大家参考。
一、选择题1. 数据挖掘的目标是什么?A. 发现隐藏在大数据中的模式和关联B. 提供数据存储和管理的解决方案C. 分析数据的趋势和变化D. 优化数据的存储和传输速度答案:A. 发现隐藏在大数据中的模式和关联2. 下列哪个不是数据挖掘的主要任务?A. 分类B. 聚类C. 回归D. 排序答案:D. 排序3. 数据挖掘的过程包括以下几个步骤,哪个是第一步?A. 数据清洗B. 数据集成C. 数据转换D. 数据选择答案:B. 数据集成4. 下列哪个不是数据挖掘中常用的算法?A. 决策树B. 支持向量机C. 朴素贝叶斯D. 深度学习答案:D. 深度学习5. 下列哪个不是数据挖掘的应用领域?A. 金融B. 医疗C. 娱乐D. 政治答案:D. 政治二、填空题1. 数据挖掘是从大量数据中发现________和________。
答案:模式,关联2. 数据挖掘的主要任务包括分类、聚类、回归和________。
答案:预测3. 数据挖掘的过程包括数据集成、数据清洗、数据转换和________。
答案:模式识别4. 决策树是一种常用的________算法。
答案:分类5. 数据挖掘可以应用于金融、医疗、娱乐等多个________。
答案:领域三、简答题1. 请简要介绍数据挖掘的主要任务和应用领域。
答:数据挖掘的主要任务包括分类、聚类、回归和预测。
分类是将数据集划分为不同的类别,聚类是将数据集中相似的样本归为一类,回归是根据已有的数据预测未知数据的值,预测是根据已有的数据预测未来的趋势和变化。
数据挖掘的应用领域非常广泛,包括金融、医疗、娱乐等。
在金融领域,数据挖掘可以用于信用评估、风险管理等方面;在医疗领域,数据挖掘可以用于疾病诊断、药物研发等方面;在娱乐领域,数据挖掘可以用于推荐系统、用户行为分析等方面。
浙江大学数据挖掘在线作业答案

您的本次作业分数为:100分1.【第001章】孤立点挖掘适用于下列哪种场合?A 目标市场分析B 购物篮分析C 模式识别D 信用卡欺诈检测正确答案:D2.【第01章】根据顾客的收入和职业情况,预测他们在计算机设备上的花费,所使用的相应数据挖掘功能是()。
A 关联分析B 分类和预测C 演变分析D 概念描述正确答案:B3.【第01章】数据挖掘应用和一些常见的数据统计分析系统的最主要区别在于()。
A 所涉及的算法的复杂性B 所涉及的数据量C 计算结果的表现形式D 是否使用了人工智能技术正确答案:B4.【第01章】下列几种数据挖掘功能中,()被广泛的应用于股票价格走势分析。
A 关联分析B 分类和预测C 聚类分析D 演变分析正确答案:D5.【第01章】下列几种数据挖掘功能中,()被广泛的用于购物篮分析。
A 关联分析B 分类和预测C 聚类分析D 演变分析正确答案:A6.【第01章】帮助市场分析人员从客户的基本信息库中发现不同的客户群,通常所使用的数据挖掘功能是()。
A 关联分析B 分类和预测C 聚类分析D 孤立点分析E 演变分析正确答案:C7.【第01章】下面的数据挖掘的任务中,()将决定所使用的数据挖掘功能。
A 选择任务相关的数据B 选择要挖掘的知识类型C 模式的兴趣度度量D 模式的可视化表示正确答案:B8.【第01章】假设现在的数据挖掘任务是解析数据库中关于客户的一般特征的描述,通常所使用的数据挖掘功能是()。
A 关联分析B 分类和预测C 孤立点分析D 演变分析E 概念描述正确答案:E9.【第02章】下列哪种可视化方法可用于发现多维数据中属性之间的两两相关性?A 空间填充曲线B 散点图矩阵C 平行坐标D 圆弓分割正确答案:B10.【第02章】计算一个单位的平均工资,使用哪个中心趋势度量将得到最合理的结果?A 算术平均值B 截尾均值C 中位数D 众数正确答案:B11.【第02章】字段Size = {small, medium, large}属于那种属性类型?A 标称属性B 二元属性C 序数属性D 数值属性正确答案:C12.【第02章】字段Hair_color = {auburn, black, blond, brown, grey, red, white}属于那种属性类型?A 标称属性B 二元属性C 序数属性D 数值属性正确答案:A13.【第03章】哪种数据变换的方法将数据沿概念分层向上汇总?A 平滑B 聚集C 数据概化D 规范化正确答案:C14.【第03章】下面哪种数据预处理技术可以用来平滑数据,消除数据噪声?A 数据清理B 数据集成C 数据变换D 数据归约正确答案:A15.【第03章】()通过将属性域划分为区间,从而减少给定连续值的个数。
大工20春《数据挖掘》课程大作业满分答案

大工20春《数据挖掘》课程大作业满分答案网络教育学院《数据挖掘》课程大作业题目:KNN算法原理及Python实现姓名:研究中心:第一大题:数据挖掘》是一门实用性非常强的课程,数据挖掘是大数据这门前沿技术的基础,拥有广阔的前景,在信息化时代具有非常重要的意义。
数据挖掘的研究领域非常广泛,主要包括数据库系统、基于知识的系统、人工智能、机器研究、知识获取、统计学、空间数据库和数据可视化等领域。
在研究过程中,我也遇到了不少困难,例如基础差,对于Python基础不牢,尤其是在进行这次课程作业时,显得力不从心;个别算法也研究的不够透彻。
在接下来的研究中,我仍然要加强理论知识的研究,并且在研究的同时联系实际,在日常工作中注意运用《数据挖掘》所学到的知识,不断加深巩固,不断发现问题,解决问题。
另外,对于自己掌握不牢的知识要勤复,多练,使自己早日成为一名合格的计算机毕业生。
第二大题:KNN算法介绍KNN算法,又叫K最邻近分类算法,是数据挖掘分类技术中最简单的方法之一。
所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
KNN算法的基本思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
KNN算法流程1.计算测试数据与各个训练数据之间的距离;2.按照距离的递增关系进行排序;3.选取距离最小的K个点;4.确定前K个点所在类别的出现频率;5.返回前K个点中出现频率最高的类别作为测试数据的预测分类。
Python实现算法及预测在Python中,我们可以使用sklearn库来实现KNN算法。
具体实现代码如下:pythonfrom sklearn.neighbors import KNeighborsClassifierknn = KNeighborsClassifier(n_neighbors=k)knn.fit(X_train。
数据挖掘考试题库及答案

数据挖掘考试题库及答案一、选择题1. 数据挖掘是从大量数据中提取有价值信息的过程,以下哪项不是数据挖掘的主要任务?A. 预测B. 分类C. 聚类D. 数据可视化答案:D2. 以下哪种技术不属于数据挖掘的常用方法?A. 决策树B. 支持向量机C. 关联规则D. 数据仓库答案:D3. 数据挖掘中,以下哪项技术常用于分类和预测?A. 神经网络B. K-均值聚类C. 主成分分析D. 决策树答案:D4. 在数据挖掘中,以下哪个概念表示数据集中的属性?A. 数据项B. 数据记录C. 数据属性D. 数据集答案:C5. 数据挖掘中,以下哪个算法用于求解关联规则?A. Apriori算法B. ID3算法C. K-Means算法D. C4.5算法答案:A二、填空题6. 数据挖掘的目的是从大量数据中提取______信息。
答案:有价值7. 在数据挖掘中,分类任务分为有监督学习和______学习。
答案:无监督8. 决策树是一种用于分类和预测的树形结构,其核心思想是______。
答案:递归划分9. 关联规则挖掘中,支持度表示某个项集在数据集中的出现频率,置信度表示______。
答案:包含项集的记录中同时包含结论的记录的比例10. 数据挖掘中,聚类分析是将数据集划分为若干个______的子集。
答案:相似三、判断题11. 数据挖掘只关注大量数据中的异常值。
()答案:错误12. 数据挖掘是数据仓库的一部分。
()答案:正确13. 决策树算法适用于处理连续属性的分类问题。
()答案:错误14. 数据挖掘中的聚类分析是无监督学习任务。
()答案:正确15. 关联规则挖掘中,支持度越高,关联规则越可靠。
()答案:错误四、简答题16. 简述数据挖掘的主要任务。
答案:数据挖掘的主要任务包括预测、分类、聚类、关联规则挖掘、异常检测等。
17. 简述决策树算法的基本原理。
答案:决策树算法是一种自顶向下的递归划分方法。
它通过选择具有最高信息增益的属性进行划分,将数据集划分为若干个子集,直到满足停止条件。
数据挖掘作业集答案

数据挖掘作业集答案《数据挖掘》作业集答案第一章引言一、填空题(1)数据清理,数据集成,数据选择,数据变换,数据挖掘,模式评估,知识表示(2)算法的效率、可扩展性和并行处理(3)统计学、数据库技术和机器学习(4)WEB挖掘(5)一些与数据的一般行为或模型不一致的孤立数据二、单选题(1)B;(2)D;(3)D;(4)B;(5)A;(6)B;(7)C;(8)E;三、简答题(1)什么是数据挖掘?答:数据挖掘指的是从大量的数据中挖掘出那些令人感兴趣的、有用的、隐含的、先前未知的和可能有用的模式或知识。
(2)一个典型的数据挖掘系统应该包括哪些组成部分?答:一个典型的数据挖掘系统应该包括以下部分:数据库、数据仓库或其他信息库数据库或数据仓库服务器知识库数据挖掘引擎模式评估模块图形用户界面(3)请简述不同历史时代数据库技术的演化。
答:1960年代和以前:研究文件系统。
1970年代:出现层次数据库和网状数据库。
1980年代早期:关系数据模型, 关系数据库管理系统(RDBMS)的实现1980年代后期:出现各种高级数据库系统(如:扩展的关系数据库、面向对象数据库等等)以及面向应用的数据库系统(空间数据库,时序数据库,多媒体数据库等等。
1990年代:研究的重点转移到数据挖掘, 数据仓库, 多媒体数据库和网络数据库。
2000年代:人们专注于研究流数据管理和挖掘、基于各种应用的数据挖掘、XML 数据库和整合的信息系统。
(4)请列举数据挖掘应用常见的数据源。
(或者说,我们都在什么样的数据上进行数据挖掘)答:常见的数据源包括关系数据库、数据仓库、事务数据库和高级数据库系统和信息库。
其中高级数据库系统和信息库包括:空间数据库、时间数据库和时间序列数据库、流数据、多媒体数据库、面向对象数据库和对象-关系数据库、异种数据库和遗产(legacy)数据库、文本数据库和万维网(WWW)等。
(5)什么是模式兴趣度的客观度量和主观度量?答:客观度量指的是基于所发现模式的结构和关于它们的统计来衡量模式的兴趣度,比如:支持度、置信度等等;主观度量基于用户对数据的判断来衡量模式的兴趣度,比如:出乎意料的、新颖的、可行动的等等。
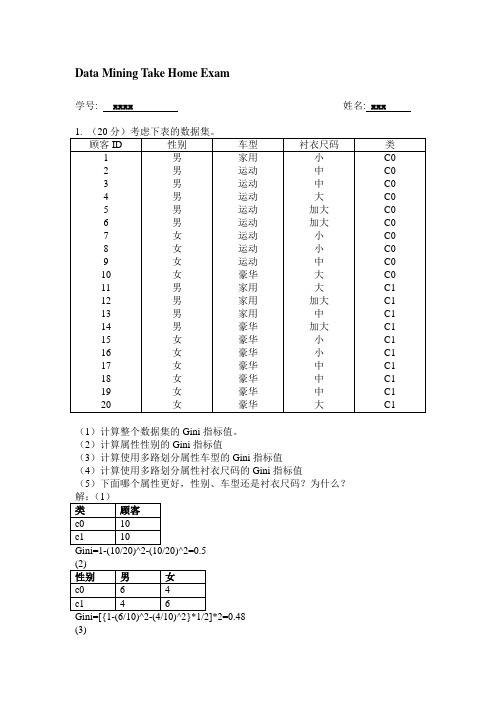
数据挖掘习题及解答-完美版

Data Mining Take Home Exam学号: xxxx 姓名: xxx 1. (20分)考虑下表的数据集。
(1)计算整个数据集的Gini 指标值。
(2)计算属性性别的Gini 指标值(3)计算使用多路划分属性车型的Gini 指标值 (4)计算使用多路划分属性衬衣尺码的Gini 指标值(5)下面哪个属性更好,性别、车型还是衬衣尺码?为什么? 解:(1) Gini=1-(10/20)^2-(10/20)^2=0.5 (2)Gini=[{1-(6/10)^2-(4/10)^2}*1/2]*2=0.48 (3)Gini={1-(1/4)^2-(3/4)^2}*4/20+{1-(8/8)^2-(0/8)^2}*8/20+{1-(1/8)^2-(7/8)^2}*8/2 0=26/160=0.1625(4)Gini={1-(3/5)^2-(2/5)^2}*5/20+{1-(3/7)^2-(4/7)^2}*7/20+[{1-(2/4)^2-(2/4)^2}*4/ 20]*2=8/25+6/35=0.4914(5)比较上面各属性的Gini值大小可知,车型划分Gini值0.1625最小,即使用车型属性更好。
2. (20分)考虑下表中的购物篮事务数据集。
(1) 将每个事务ID视为一个购物篮,计算项集{e},{b,d} 和{b,d,e}的支持度。
(2)使用(1)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
(3)将每个顾客ID作为一个购物篮,重复(1)。
应当将每个项看作一个二元变量(如果一个项在顾客的购买事务中至少出现一次,则为1,否则,为0)。
(4)使用(3)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
答:(1)由上表计数可得{e}的支持度为8/10=0.8;{b,d}的支持度为2/10=0.2;{b,d,e}的支持度为2/10=0.2。
(2)c[{b,d}→{e}]=2/8=0.25; c[{e}→{b,d}]=8/2=4。
数据挖掘复习题集和答案解析

一、考虑表中二元分类问题的训练样本集1.整个训练样本集关于类属性的熵是多少?2.关于这些训练集中a1,a2的信息增益是多少?3.对于连续属性a3,计算所有可能的划分的信息增益。
4.根据信息增益,a1,a2,a3哪个是最佳划分?5.根据分类错误率,a1,a2哪具最佳?6.根据gini指标,a1,a2哪个最佳?答1.P(+) = 4/9 and P(−) = 5/9−4/9 log2(4/9) −5/9 log2(5/9) = 0.9911.答2:(估计不考)答3:答4:According to information gain, a1 produces the best split. 答5:For attribute a1: error rate = 2/9.For attribute a2: error rate = 4/9.Therefore, according to error rate, a1 produces the best split.答6:二、考虑如下二元分类问题的数据集1.计算a.b信息增益,决策树归纳算法会选用哪个属性2.计算a.b gini指标,决策树归纳会用哪个属性?这个答案没问题3.从图4-13可以看出熵和gini指标在[0,0.5]都是单调递增,而[0.5,1]之间单调递减。
有没有可能信息增益和gini指标增益支持不同的属性?解释你的理由Yes, even though these measures have similar range and monotonous behavior, their respective gains, Δ, which are scaled differences of the measures, do not necessarily behave in the same way, as illustrated by the results in parts (a) and (b).贝叶斯分类1.P(A = 1|−) = 2/5 = 0.4, P(B = 1|−) = 2/5 = 0.4,P(C = 1|−) = 1, P(A = 0|−) = 3/5 = 0.6,P(B = 0|−) = 3/5 = 0.6, P(C = 0|−) = 0; P(A = 1|+) = 3/5 = 0.6,P(B = 1|+) = 1/5 = 0.2, P(C = 1|+) = 2/5 = 0.4,P(A = 0|+) = 2/5 = 0.4, P(B = 0|+) = 4/5 = 0.8,P(C = 0|+) = 3/5 = 0.6.2.3.P(A = 0|+) = (2 + 2)/(5 + 4) = 4/9,P(A = 0|−) = (3+2)/(5 + 4) = 5/9,P(B = 1|+) = (1 + 2)/(5 + 4) = 3/9,P(B = 1|−) = (2+2)/(5 + 4) = 4/9,P(C = 0|+) = (3 + 2)/(5 + 4) = 5/9,P(C = 0|−) = (0+2)/(5 + 4) = 2/9.4.Let P(A = 0,B = 1, C = 0) = K5.当的条件概率之一是零,则估计为使用m-估计概率的方法的条件概率是更好的,因为我们不希望整个表达式变为零。
(完整word版)数据挖掘题目及答案

(完整word版)数据挖掘题⽬及答案⼀、何为数据仓库?其主要特点是什么?数据仓库与KDD的联系是什么?数据仓库是⼀个⾯向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,⽤于⽀持管理决策。
特点:1、⾯向主题操作型数据库的数据组织⾯向事务处理任务,各个业务系统之间各⾃分离,⽽数据仓库中的数据是按照⼀定的主题域进⾏组织的。
2、集成的数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加⼯、汇总和整理得到的,必须消除源数据中的不⼀致性,以保证数据仓库内的信息是关于整个企业的⼀致的全局信息。
3、相对稳定的数据仓库的数据主要供企业决策分析之⽤,⼀旦某个数据进⼊数据仓库以后,⼀般情况下将被长期保留,也就是数据仓库中⼀般有⼤量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。
4、反映历史变化数据仓库中的数据通常包含历史信息,系统记录了企业从过去某⼀时点(如开始应⽤数据仓库的时点)到⽬前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
所谓基于数据库的知识发现(KDD)是指从⼤量数据中提取有效的、新颖的、潜在有⽤的、最终可被理解的模式的⾮平凡过程。
数据仓库为KDD提供了数据环境,KDD从数据仓库中提取有效的,可⽤的信息⼆、数据库有4笔交易。
设minsup=60%,minconf=80%。
TID DATE ITEMS_BOUGHTT100 3/5/2009 {A, C, S, L}T200 3/5/2009 {D, A, C, E, B}T300 4/5/2010 {A, B, C}T400 4/5/2010 {C, A, B, E}使⽤Apriori算法找出频繁项集,列出所有关联规则。
解:已知最⼩⽀持度为60%,最⼩置信度为80%1)第⼀步,对事务数据库进⾏⼀次扫描,计算出D中所包含的每个项⽬出现的次数,⽣成候选1-项集的集合C1。
(完整word版)数据挖掘课后答案

第一章1.6(1)数据特征化是目标类数据的一般特性或特征的汇总。
例如,在某商店花费1000元以上的顾客特征的汇总描述是:年龄在40—50岁、有工作和很好的信誉等级。
(2)数据区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。
例如,高平均分数的学生的一般特点,可与低平均分数的学生的一般特点进行比较.由此产生的可能是一个相当普遍的描述,如平均分高达75%的学生是大四的计算机科学专业的学生,而平均分低于65%的学生则不是.(3)关联和相关分析是指在给定的频繁项集中寻找相关联的规则.例如,一个数据挖掘系统可能会发现这样的规则:专业(X,“计算机科学”)=〉拥有(X,”个人电脑“)[support= 12%,confidence = 98%],其中X是一个变量,代表一个学生,该规则表明,98%的置信度或可信性表示,如果一个学生是属于计算机科学专业的,则拥有个人电脑的可能性是98%。
12%的支持度意味着所研究的所有事务的12%显示属于计算机科学专业的学生都会拥有个人电脑。
(4)分类和预测的不同之处在于前者是构建了一个模型(或函数),描述和区分数据类或概念,而后者则建立了一个模型来预测一些丢失或不可用的数据,而且往往是数值,数据集的预测。
它们的相似之处是它们都是为预测工具:分类是用于预测的数据和预测对象的类标签,预测通常用于预测缺失值的数值数据。
例如:某银行需要根据顾客的基本特征将顾客的信誉度区分为优良中差几个类别,此时用到的则是分类;当研究某只股票的价格走势时,会根据股票的历史价格来预测股票的未来价格,此时用到的则是预测。
(5)聚类分析数据对象是根据最大化类内部的相似性、最小化类之间的相似性的原则进行聚类和分组。
聚类还便于分类法组织形式,将观测组织成类分层结构,把类似的事件组织在一起。
例如:世界上有很多种鸟,我们可以根据鸟之间的相似性,聚集成n类,其中n可以认为规定. (6)数据演变分析描述行为随时间变化的对象的规律或趋势,并对其建模。
数据挖掘 习题及参考答案

①电信行业中利用数据挖掘技术进行客户行为分析,包含客户通话记录、通话时间、所 开通的服务等,据此进行客户群体划分以及客户流失性分析。
②天文领域中利用决策树等数据挖掘方法对上百万天体数据进行分类与分析,帮助天文 学家发现其他未知星体。
③制造业中应用数据挖掘技术进行零部件故障诊断、资源优化、生产过程分析等。
第 4 页 共 27 页
(b)对于数据平滑,其它方法有: (1)回归:可以用一个函数(如回归函数)拟合数据来光滑数据; (2)聚类:可以通过聚类检测离群点,将类似的值组织成群或簇。直观地,落在簇集合 之外的值视为离群点。
2.6 使用习题 2.5 给出的 age 数据,回答以下问题: (a) 使用 min-max 规范化,将 age 值 35 转换到[0.0,1.0]区间。 (b) 使用 z-score 规范化转换 age 值 35,其中,age 的标准偏差为 12.94 年。 (c) 使用小数定标规范化转换 age 值 35。 (d) 指出对于给定的数据,你愿意使用哪种方法。陈述你的理由。
回归来建模,或使用时间序列分析。 (7) 是,需要建立正常心率行为模型,并预警非正常心率行为。这属于数据挖掘领域
的异常检测。若有正常和非正常心率行为样本,则可以看作一个分类问题。 (8) 是,需要建立与地震活动相关的不同波形的模型,并预警波形活动。属于数据挖
掘领域的分类。 (9) 不是,属于信号处理。
1.6 根据你的观察,描述一个可能的知识类型,它需要由数据挖掘方法发现,但本章未列出。 它需要一种不同于本章列举的数据挖掘技术吗?
答:建立一个局部的周期性作为一种新的知识类型,只要经过一段时间的偏移量在时间序列 中重复发生,那么在这个知识类型中的模式是局部周期性的。需要一种新的数据挖掘技 术解决这类问题。
大工19秋《数据挖掘》大作业题目及要求答案

网络教育学院《数据挖掘》课程大作业题目:题目一:Knn算法原理以及python实现姓名:报名编号:学习中心:层次:专升本专业:计算机科学与技术第一大题:讲述自己在完成大作业过程中遇到的困难,解决问题的思路,以及相关感想,或者对这个项目的认识,或者对Python与数据挖掘的认识等等,300-500字。
数据挖掘是指从大量的数据中通过一些算法寻找隐藏于其中重要实用信息的过程。
这些算法包括神经网络法、决策树法、遗传算法、粗糙集法、模糊集法、关联规则法等。
在商务管理,股市分析,公司重要信息决策,以及科学研究方面都有十分重要的意义。
数据挖掘是一种决策支持过程,它主要基于人工智能、机器学习、模式识别、统计学、数据库、可视化技术,从大量数据中寻找其肉眼难以发现的规律,和大数据联系密切。
如今,数据挖掘已经应用在很多行业里,对人们的生产生活以及未来大数据时代起到了重要影响。
第二大题:完成下面一项大作业题目。
2019秋《数据挖掘》课程大作业注意:从以下5个题目中任选其一作答。
题目一:Knn算法原理以及python实现要求:文档用使用word撰写即可。
主要内容必须包括:(1)算法介绍。
(2)算法流程。
(3)python实现算法以及预测。
(4)整个word文件名为 [姓名奥鹏卡号学习中心](如戴卫东101410013979浙江台州奥鹏学习中心[1]VIP )答:KNN算法介绍KNN是一种监督学习算法,通过计算新数据与训练数据特征值之间的距离,然后选取K(K>=1)个距离最近的邻居进行分类判(投票法)或者回归。
若K=1,新数据被简单分配给其近邻的类。
KNN算法实现过程(1)选择一种距离计算方式, 通过数据所有的特征计算新数据与已知类别数据集中的数据点的距离;(2)按照距离递增次序进行排序,选取与当前距离最小的k个点;(3)对于离散分类,返回k个点出现频率最多的类别作预测分类;对于回归则返回k个点的加权值作为预测值;算法关键(1)数据的所有特征都要做可比较的量化若是数据特征中存在非数值的类型,必须采取手段将其量化为数值。
数据挖掘第二次作业

数据挖掘第二次作业第一题:1.a) Compute the Information Gain for Gender, Car Type and Shirt Size.b) Construct a decision tree with Information Gain.答案:a)因为class分为两类:C0和C1,其中C0的频数为10个,C1的频数为10,所以class元组的信息增益为Info(D)==11.按照Gender进行分类:Info gender(D)==0.971Gain(Gender)=1-0.971=0.0292.按照Car Type进行分类Info carType(D)==0.314 Gain(Car Type)=1-0.314=0.6863.按照Shirt Size进行分类:Info shirtSize(D)==0.988Gain(Shirt Size)=1-0.988=0.012b)由a中的信息增益结果可以看出采用Car Type进行分类得到的信息增益最大,所以决策树为:第二题:2. (a) Design a multilayer feed-forward neural network (one hidden layer) for thedata set in Q1. Label the nodes in the input and output layers.(b) Using the neural network obtained above, show the weight values after oneiteration of the back propagation algorithm, given the training instance “(M, Family, Small)". Indicate your initial weight values and biases and the learning rate used.a)x 11x 12x 21x 22x 23x 31x 32x 33x 34输入层隐藏层输出层b) 由a 可以设每个输入单元代表的属性和初始赋值由于初始的权重和偏倚值是随机生成的所以在此定义初始值为:净输入和输出:每个节点的误差表:10 0.0089 11 0.0030 12 -0.12权重和偏倚的更新: W 1,10 W 1,11 W 2,10 W 2,11 W 3,10 W 3,11 W 4,10 W 4,11 W 5,10 W 5,11 0.201 0.198 -0.211 -0.099 0.4 0.308 -0.202 -0.098 0.101 -0.100 W 6,10 W 6,11 W 7,10 W 7,11 W 8,10 W 8,11 W 9,10 W 9,11 W 10,12 W 11,12 0.092 -0.211 -0.400 0.198 0.201 0.190 -0.110 0.300 -0.304 -0.099 θ10 θ11 θ12 -0.287 0.1790.344第三题:3.a) Suppose the fraction of undergraduate students who smoke is 15% and thefraction of graduate students who smoke is 23%. If one-fifth of the college students are graduate students and the rest are undergraduates, what is the probability that a student who smokes is a graduate student?b) Given the information in part (a), is a randomly chosen college student morelikely to be a graduate or undergraduate student?c) Suppose 30% of the graduate students live in a dorm but only 10% of theundergraduate students live in a dorm. If a student smokes and lives in the dorm, is he or she more likely to be a graduate or undergraduate student? You can assume independence between students who live in a dorm and those who smoke.答:a) 定义:A={A 1 ,A 2}其中A 1表示没有毕业的学生,A 2表示毕业的学生,B 表示抽烟则由题意而知:P(B|A 1)=15% P(B|A 2)=23% P(A 1)= P(A 2)=则问题则是求P(A 2|B)由()166.0)()|B ()()|B (B 2211=+=A P A p A P A P P则()277.0166.02.023.0)()()|(|222=⨯=⨯=B P A P A B P B APb) 由a 可以看出随机抽取一个抽烟的大学生,是毕业生的概率是0.277,未毕业的学生是0.723,所以有很大的可能性是未毕业的学生。
完整word版数据挖掘课后答案

第一章6.1 数据特征化是目标类数据的一般特性或特征的汇总。
(1)岁、有工5040—元以上的顾客特征的汇总描述是:年龄在例如,在某商店花费1000 作和很好的信誉等级。
数据区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比)(2 较。
由可与低平均分数的学生的一般特点进行比较。
例如,高平均分数的学生的一般特点,%的学生是大四的计算机科学专业75此产生的可能是一个相当普遍的描述,如平均分高达的学生则不是。
的学生,而平均分低于65% )关联和相关分析是指在给定的频繁项集中寻找相关联的规则。
(3”X,)=>拥有(X 例如,一个数据挖掘系统可能会发现这样的规则:专业(,“计算机科学”是一个变量,代表一个学生,该规,其中Xconfidence = 98%]%,个人电脑“)[support= 12的置信度或可信性表示,如果一个学生是属于计算机科学专业的,则拥有个人则表明,98%显示属于计算机科学专的支持度意味着所研究的所有事务的12%98%。
12%电脑的可能性是业的学生都会拥有个人电脑。
(4)分类和预测的不同之处在于前者是构建了一个模型(或函数),描述和区分数据类或概念,而后者则建立了一个模型来预测一些丢失或不可用的数据,而且往往是数值,数据集的预测。
它们的相似之处是它们都是为预测工具:分类是用于预测的数据和预测对象的类标签,预测通常用于预测缺失值的数值数据。
例如:某银行需要根据顾客的基本特征将顾客的信誉度区分为优良中差几个类别,此时用到的则是分类;当研究某只股票的价格走势时,会根据股票的历史价格来预测股票的未来价格,此时用到的则是预测。
(5)聚类分析数据对象是根据最大化类内部的相似性、最小化类之间的相似性的原则进行聚类和分组。
聚类还便于分类法组织形式,将观测组织成类分层结构,把类似的事件组织在一起。
例如:世界上有很多种鸟,我们可以根据鸟之间的相似性,聚集成n类,其中n可以认为规定。
数据挖掘习题及解答-完美版
Data Mining Take Home Exam学号: xxxx 姓名: xxx(1)计算整个数据集的Gini指标值。
(2)计算属性性别的Gini指标值(3)计算使用多路划分属性车型的Gini指标值(4)计算使用多路划分属性衬衣尺码的Gini指标值(5)下面哪个属性更好,性别、车型还是衬衣尺码?为什么?(3)=26/160=0.1625]*2=8/25+6/35=0.4914(5)比较上面各属性的Gini值大小可知,车型划分Gini值0.1625最小,即使用车型属性更好。
2. ((1) 将每个事务ID视为一个购物篮,计算项集{e},{b,d} 和{b,d,e}的支持度。
(2)使用(1)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
(3)将每个顾客ID作为一个购物篮,重复(1)。
应当将每个项看作一个二元变量(如果一个项在顾客的购买事务中至少出现一次,则为1,否则,为0)。
(4)使用(3)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
答:(1)由上表计数可得{e}的支持度为8/10=0.8;{b,d}的支持度为2/10=0.2;{b,d,e}的支持度为2/10=0.2。
(2)c[{b,d}→{e}]=2/8=0.25; c[{e}→{b,d}]=8/2=4。
(3)同理可得:{e}的支持度为4/5=0.8,{b,d}的支持度为5/5=1,{b,d,e}的支持度为4/5=0.8。
(4)c[{b,d}→{e}]=5/4=1.25,c[{e}→{b,d}]=4/5=0.8。
3. (20分)以下是多元回归分析的部分R输出结果。
> ls1=lm(y~x1+x2)> anova(ls1)Df Sum Sq Mean Sq F value Pr(>F)x1 1 10021.2 10021.2 62.038 0.0001007 ***x2 1 4030.9 4030.9 24.954 0.0015735 **Residuals 7 1130.7 161.5> ls2<-lm(y~x2+x1)> anova(ls2)Df Sum Sq Mean Sq F value Pr(>F)x2 1 3363.4 3363.4 20.822 0.002595 **x1 1 10688.7 10688.7 66.170 8.193e-05 ***Residuals 7 1130.7 161.5(1)用F检验来检验以下假设(α = 0.05)H0: β1 = 0H a: β1≠ 0计算检验统计量;是否拒绝零假设,为什么?(2)用F检验来检验以下假设(α = 0.05)H0: β2 = 0H a: β2≠ 0计算检验统计量;是否拒绝零假设,为什么?(3)用F检验来检验以下假设(α = 0.05)H0: β1 = β2 = 0H a: β1和β2 并不都等于零计算检验统计量;是否拒绝零假设,为什么?解:(1)根据第一个输出结果F=62.083>F(2,7)=4.74,p<0.05,所以可以拒绝原假设,即得到不等于0。
数据挖掘作业答案

数据挖掘作业答案第二章数据准备5.推出在[-1,1]区间上的数据的最小-最大标准化公式。
解:标准化相当于按比例缩放,假如将在[minA,maxA]间的属性A的值v映射到区间[new_minA,new_maxA],根据同比关系得:(v-minA)/(v’-new_minA)=(maxA-minA)/(new_maxA-new_minA)化简得:v’=(v-minA)* (new_maxA-new_minA)/ (maxA-minA)+ new_minA6.已知一维数据集X={-5.0 , 23.0 , 17.6 , 7.23 , 1.11},用下述方法对其进行标准化:a) 在[-1,1]区间进行小数缩放。
解:X’={-0.050 ,0.230 ,0.176 ,0.0723 ,0.0111}b) 在[0,1]区间进行最小-最大标准化。
解:X’={0 , 1 , 0.807 ,0.437 ,0.218 }c) 在[-1,1]区间进行最小-最大标准化。
解:X’={-1 , 1 , 0.614 , -0.126 , 0.564}d) 标准差标准化。
解:mean=8.788 sd=11.523X’={-1.197 , 1.233 , 0.765 , -0.135 , -0.666}e) 比较上述标准化的结果,并讨论不同技术的优缺点。
解:小数缩放标准化粒度过大(以10为倍数),但计算简单;最小-最大值标准化需要搜索整个数据集确定最小最大数值,而且最小最大值的专家估算可能会导致标准化值的无意识的集中。
标准差标准化对距离测量非常效,但会把初始值转化成了未被认可的形式。
8.已知一个带有丢失值的四维样本。
X1={0,1,1,2}X2={2,1,*,1}X3={1,*,*,-1}X4={*,2,1,*}如果所有属性的定义域是[0,1,2],在丢失值被认为是“无关紧要的值”并且都被所给的定义域的所有可行值替换的情况下,“人工”样本的数量是多少?解:X1 “人工”样本的数量为 1X2 “人工”样本的数量为 3X3 “人工”样本的数量为9X4 “人工”样本的数量为9所以“人工”样本的数量为1×3×9×9=24310.数据库中不同病人的子女数以矢量形式给出:C={3,1,0,2,7,3,6,4,-2,0,0,10,15,6}a)应用标准统计参数——均值和方差,找出C中的异常点:mean=3.9286 sd=4.4153在3个标准差下的阈值:阈值=均值±3*标准差=3.928±3*4.4153=[-9.318,17.174]根据实际情况子女数不可能为负数,所以其范围可缩减为:[0,17.174]C中的异常点有:-2b)在2个标准差下的阈值:阈值=均值±2*标准差=3.928±2*4.4153=[-4.903,12.758]根据实际情况子女数不可能为负数,所以其范围可缩减为:[0,12.758]C中的异常点有:-2, 1511.已知的三维样本数据集X:X=[{1,2,0},{3,1,4},{2,1,5},{0,1,6},{2,4,3},{4,4,2},{5,2,1},{7,7,7},{0,0,0},{3,3,3}]。
数据挖掘习题参考答案

数据挖掘习题参考答案数据挖掘习题参考答案数据挖掘作为一门热门的学科,已经在各个领域得到广泛应用。
它的目标是从大量的数据中发现有用的信息,并且用这些信息来解决实际问题。
为了帮助读者更好地理解数据挖掘的概念和技术,本文将提供一些数据挖掘习题的参考答案,希望能够对读者有所帮助。
习题一:什么是数据挖掘?它有哪些应用领域?答案:数据挖掘是指从大量的数据中发现有用的信息,并且用这些信息来解决实际问题的过程。
它可以帮助我们发现数据中的模式、规律和趋势,从而提供决策支持和预测能力。
数据挖掘的应用领域非常广泛,包括但不限于市场营销、金融风险管理、医疗诊断、社交网络分析等。
习题二:数据挖掘的主要任务有哪些?答案:数据挖掘的主要任务包括分类、聚类、关联规则挖掘和异常检测。
分类是指根据已有的数据样本来预测新的数据样本所属的类别。
聚类是指将数据样本分成几个不同的组,使得同一组内的数据样本相似度较高,而不同组之间的相似度较低。
关联规则挖掘是指发现数据中的关联关系,例如购物篮分析中的“如果购买了商品A,则更有可能购买商品B”。
异常检测是指发现与其他样本不同的数据点,可能是潜在的异常或异常行为。
习题三:数据挖掘的过程有哪些步骤?答案:数据挖掘的过程通常包括问题定义、数据收集、数据预处理、特征选择和转换、模型选择和建立、模型评估和模型应用等步骤。
首先,我们需要明确问题的定义,确定我们需要从数据中挖掘出什么样的信息。
然后,我们收集相关的数据,并对数据进行预处理,包括数据清洗、数据集成、数据变换和数据规约等。
接下来,我们选择合适的特征,并进行特征转换,以便于模型的建立和分析。
在模型选择和建立阶段,我们选择合适的数据挖掘算法,并进行模型的训练和优化。
最后,我们评估模型的性能,并将模型应用于实际问题中。
习题四:数据挖掘中常用的算法有哪些?答案:数据挖掘中常用的算法包括决策树、朴素贝叶斯、支持向量机、神经网络、聚类算法(如K-means算法和DBSCAN算法)、关联规则挖掘算法(如Apriori算法)等。
数据挖掘部分作业答案

一、概述数据挖掘概念:数据挖掘是对大量数据进行探索和分析、以便发现有意义的模式和规则的过程.数据仓库:数据仓库就是面向主题的、集成的、非易失的(稳定性)、随时间变化(不同时间)的数据集合,用以支持经营管理中的决策制定过程。
数据立方体:允许以多维对数据建模和观察.由维和事实组成.其中事实是数值的度量.分类:就是通过学习获得一个目标函数f, 将每个属性集x映射到一个预先定义好的类标号y. 分类任务的输入数据是纪录的集合,每条记录也称为实例或者样例.用元组(X,y)表示,其中,X 是属性集合,y是一个特殊的属性,指出样例的类标号(也称为分类属性或者目标属性).信息检索:信息检索(Information Retrieval)是指信息按一定的方式组织起来,并根据信息用户的需要找出有关的信息的过程和技术。
狭义的信息检索就是信息检索过程的后半部分,即从信息集合中找出所需要的信息的过程,也就是我们常说的信息查寻(Information Search 或Information Seek)。
知识发现(KDD):知识发现是从数据集中识别出有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程。
OLAP:OLAP是针对特定问题的联机数据访问和分析.通过对信息(这些信息已经从原始的数据进行了转换,以反映用户所能理解的企业的实的“维”)的很多可能的观察形式进行快速、稳定一致和交互性的存取,允许管理决策人员对数据进行深入观察.维:是人们观察数据的特定角度.企业常常关心产品销售随着时间推移而产生的变化的情况,这时企业是从时间的角度来观察产品的销售,所以时间就是一个维(时间维).企业也常常关心自己的产品在不同地区的销售分布情况,这时企业是从地理分布的角度来观察产品的销售,所以地理分布也是一个维(地理维).上卷:--通过一个维的概念分层向上攀升或者通过维归约,在数据立方体上进行聚集,也称为聚合操作.下卷:--是上钻的逆操作.它由不太详细的数据到更详细的数据.钻取可以通过沿维的概念分层向下或引入新的维来实现.切片:--设有(维1,维2,…,维i,…,维n,观察变量)多维数据集,对维i选定了某个维成员,则(维1,维2,…,维i成员,…,维n,观察变量)就是多维数据集(维1,维2,…,维I,…,维n,观察变量)在维i上的一个切片.切块:--将完整的数据立方体切取一部分数据而得到的新的数据立方体.在(维1,维2,…,维i,…,维k,…,维n,观察变量)多维数据集上,对维i,…,维k,选定了维成员,则(维1,维2,…,维i成员,…,维k成员,…,维n,观察变量)就是多维数据集(维1,维2,…,维i,…,维k,…,维n,观察变量)在维i,…,维k上的一个切块.二、简述1、KDD的主要过程KDD过程是多个步骤相互连接、反复进行人机交互的过程。
数据挖掘作业答案

要求:1.进行归一化; 2.聚类计算(计算到第 3 步).
答案如下
1.数据预处理 定量化 产品 成本 效益 一 10 95 二 6 75 三 4 75 四 7 85 五 6 60 六 9 85 七 8 85 八 6 75 九 7 95 十 5 60
a.对成本型指标(“越小越优型”)
xi'
' i
max(x) xi max(x) min(x)
b.对效益型指标(“越大越优型”)
yi min(y) y max(y) min(y)
归一化后结果如下表所示 成本 x’ 效益 y’ 成本 x’ 效益 y’ 成本 x’ 效益 y’ 与1号 中心 与2号 中心 0.0 1.0 0.0 1.0 0.0 1.0 0.0 0.0 0.0 0.8 1.0 1.28 0.7 0.4 0.7 0.4 0.7 0.4 0.7 0.6 0.92 0.1 0.4 0.41 1.0 0.4 1.0 0.4 1.0 0.4 1.0 0.6 1.16 0.2 0.4 0.45 0.5 0.7 0.5 0.7 0.5 0.7 0.5 0.3 0.58 0.3 0.7 0.76 0.7 0.0 0.7 0.0 0.2 0.7 0.2 0.7 0.7 0.0 0.7 1.0 1.2 0.1 0.0 0.1 0.3 0.7 0.3 0.7 0.2 0.7 0.2 0.3 0.36 0.6 0.7 0.92 0.7 0.4 0.7 0.4 0.3 0.7 0.3 0.3 0.42 0.5 0.7 0.91 0.5 1.0 0.5 1.0 0.7 0.4 0.7 0.6 0.92 0.1 0.4 0.41 0.8 0.0 0.8 0.0 0.5 1.0 0.5 0 0.5 0.3 1.0 1.04 0.8 0.0 0.8 1.0 1.28 0.0 0.0 0.0
该数据挖掘文档是高校必做的题目的精华版本,附准确,详细的答案数据挖掘作业 答案

姓名:王燕学号:109070018数据挖掘思考和练习题第一章1.1 什么是数据挖掘?什么是知识发现?简述KDD的主要过程。
答:(1)数据挖掘(Data Mining)是指从大量结构化和非结构化的数据中提取有用的信息和知识的过程,它是知识发现的有效手段。
(2)知识发现是从大量数据中提取有效的、新颖的、潜在的有用的,以及最终可理解的模式的非平凡过程。
(3)KDD的过程主要包括:KDD的过程主要由数据整理、数据挖掘、结果的解释评论三部分组成。
可以由模型表示出来:1.确定挖掘目标:了解应用领域及相关的经验知识,从用户的观点出发确定数据挖掘的目标。
这一步是实现数据挖掘的重要因素,相当于系统分析,需要系统分析员和用户的共同参与。
2.建立目标数据集:从现有的数据中,确定哪些数据是与本次数据分析任务相关的。
根据挖掘目标,从原始数据中选择相关数据集,并将不同数据源中的数据集中起来。
在这一阶段需要解决数据挖掘平台、操作系统和数据源数据类型等不同所产生的数据格式差异。
3.数据清洗和预处理:这一阶段即是将数据转变成“干净”的数据。
目标数据集中不可避免地存在着不完整、不一致、不精确和冗余地数据。
数据抽取之后必须利用专业领域地知识对“脏数据”进行清洗。
然后再对它们实施相应的方法,神经网络方法和模糊匹配技术分析多数据源之间联系,然后再对它们实施相应的处理。
4.数据降维和转换:在对数据库和数据子集进行预处理之后,考虑了数据的不变表示或发现了数据的不变的表示情况下,减少变量的实际数目,设法将数据转换到一个更易找到了解的空间上。
5.选择挖掘算法使用合适的数据挖掘算法完成数据分析。
确定实现挖掘目标的数据挖掘功能,这些功能方法包括概念描述、分类、聚类、关联规则。
其次选择合适的模式搜索算法,包括模型和参数的确定。
6.模式评价和解释根据最终用户的决策目的对数据挖掘发现的模式进行评价,将有用的模式或描述有用模式的数据以可视化技术和知识表示技术展示给用户,让用户能够对模型结果作出解释,评价模式的有效性。
数据挖掘作业答案

数据挖掘作业答案数据挖掘作业题⽬+答案华理计算机专业选修课第⼆章:假定⽤于分析的数据包含属性age。
数据元组中age值如下(按递增序):13 ,15 ,16 ,16 ,19 ,20 ,20,21 ,22 ,22,25 ,25 ,25 ,25 ,30 ,33 ,33 ,35 ,35 ,35,35,36,40,45,46,52,70.分别⽤按箱平均值和边界值平滑对以上数据进⾏平滑,箱的深度为3.使⽤最⼩-最⼤规范化,将age值35转换到[0.0,1.0]区间使⽤z-Score规范化转换age值35 ,其中age的标准差为12.94年。
使⽤⼩数定标规范化转换age值35。
画⼀个宽度为10的等宽直斱图。
该数据的均值是什么?中位数是什么?该数据的众数是什么?讨论数据的峰(即双峰,三峰等)数据的中列数是什么?(粗略地)找出数据的第⼀个四分位数(Q1 )和第三个四分位数(Q3 )给出数据的五数概括画出数据的盒图第三章假定数据仓库包含三个维:time doctor和patient ;两个度量:count和charge;其中charge是医⽣对病⼈⼀次诊治的收费。
画出该数据仓库的星型模式图。
由基本⽅体[day, doctor, patient]开始,为列出2004年每位医⽣的收费总数,应当执⾏哪些OLAP操作。
如果每维有4层(包括all ),该⽴⽅体包含多少⽅体(包括基本⽅体和顶点⽅体)?第五章数据库有4个事务。
设min_sup=60%,min_conf=80%TID Itmes_boughtT100 {K,A,D,B}T200 {D,A,C,E,B}T300 {C,A,B,E}T400 {B,A,D}分别使⽤Apriori和FP-增长算法找出频繁项集。
列出所有的强关联规则(带⽀持度s和置信度c ),它们不下⾯的元规则匹配,其中,X是代表顼客的变量,itmei是表⽰项的变量(例如:A、B等)下⾯的相依表会中了超级市场的事务数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(4)事务操作,只读查询
(5)分布的、代数的和整体的
(6)自顶向下视图、数据源视图、数据仓库视图、商务查询视图
(7)关系OLAP服务器(ROLAP)、多维OLAP服务器(MOLAP)和混合OLAP服务器(HOLAP)
(8)分布的
(9)海量数据,有限的内存和时间
(3)两者有着不同的数据
数据仓库中存放历史数据;日常操作数据库中存放的往往只是最新的数据。
(2)为什么说数据仓库具有随时间而变化的特征?
答:(1)数据仓库的时间范围比操作数据库系统要长的多。操作数据库系统主要保存当前数据,而数据仓库从历史的角度提供信息(比如过去5-10年)。
(2)数据仓库中的每一个关键结构都隐式或显式地包含时间元素,而操作数据库中的关键结构可能就不包括时间元素。
(7)在数据仓库中,元数据的主要用途包括哪些?
答:在数据仓库中,元数据的主要用途包括:
(1)用作目录,帮助决策支持系统分析者对数据仓库的内容定义
(2)作为数据仓库和操作性数据库之间进行数据转换时的映射标准
(3)用于指导当前细节数据和稍加综合的数据之间的汇总算法,指导稍加综合的数据和高度综合的数据之间的汇总算法。
1990年代:研究的重点转移到数据挖掘,数据仓库,多媒体数据库和网络数据库。
2000年代:人们专注于研究流数据管理和挖掘、基于各种应用的数据挖掘、XML数据库和整合的信息系统。
(4)请列举数据挖掘应用常见的数据源。
(或者说,我们都在什么样的数据上进行数据挖掘)
答:常见的数据源包括关系数据库、数据仓库、事务数据库和高级数据库系统和信息库。其中高级数据库系统和信息库包括:空间数据库、时间数据库和时间序列数据库、流数据、多媒体数据库、面向对象数据库和对象-关系数据库、异种数据库和遗产(legacy)数据库、文本数据库和万维网(WWW)等。
(4)请简述几种典型的多维数据的OLAP操作
答:典型的OLAP操作包括以下几种
上卷:通过一个维的概念分层向上攀升或者通过维归约,在数据立方体上进行聚集;
下钻:上卷的逆操作,由不太详细的数据得到更详细的数据;通常可以通过沿维的概念分层向下或引入新的维来实现;
切片:在给定的数据立方体的一个维上进行选择,导致一个子方;
(1)忽略元组。当类标号缺少时通常这么做(假定挖掘任务设计分类或描述),当每个属性缺少值的百分比变化很大时,它的效果非常差。
(2)人工填写空缺值。这种方法工作量大,可行性低
(3)使用一个全局变量填充空缺值:比如使用unknown或-∞
(4)使用属性的平均值填充空缺值
(5)使用与给定元组属同一类的所有样本的平均值
用于指导挖掘的背景知识;
模式评估、兴趣度量;
如何显示发现的知识。
(2)为什么需要数据挖掘原语和语言来指导数据挖掘?
答:如果不使用数据挖掘原语和语言来指导数据挖掘
(1)会产生大量模式(重新把知识淹没)
(2)会涵盖所有数据,使得挖掘效率低下
(3)大部分有价值的模式集可能被忽略
(4)挖掘出的模式可能难以理解,缺乏有效性、新颖性和实用性——令人不感兴趣。
(8)数据仓库后端工具和程序包括哪些?
答:数据仓库后端工具主要指的是用来装入和刷新数据的工具,包括:
(1)数据提取:从多个外部的异构数据源收集数据
(2)数据清理:检测数据种的错误并作可能的订正
(3)数据变换:将数据由历史或主机的格式转化为数据仓库的格式
(4)装载:排序、汇总、合并、计算视图,检查完整性,并建立索引和分区
(5)刷新:将数据源的更新传播到数据仓库中
五、计算题
(1)答:a.内存空间需求量最小的块计算次序和内存空间需求量最大的块计算次序分别如下图所示:
b.这两个次序下计算二维平面所需要的内存空间的大小:
内存空间需求最小的次序:10,000×1,000(用于整个BC平面)+(100,000/10)×1,000(用于AC平面的一行)+(100,000/10)×(10,000/10)(用于AB平面的一格)=30,000,000
《数据挖掘》作业集答案
第一章引言
一、填空题
(1)数据清理,数据集成,数据选择,数据变换,数据挖掘,模式评估,知识表示
(2)算法的效率、可扩展性和并行处理
(3)统计学、数据库技术和机器学习
(4)WEB挖掘
(5)一些与数据的一般行为或模型不一致的孤立数据
二、单选题
(1)B;(2)D;(3)D;(4)B;(5)A;(6)B;(7)C;(8)E;
(3)整合不同数据源中的元数据,实体识别问题
(4)沿概念分层向上概化
(5)有损压缩,无损压缩
(6)线性回归方法,多元回归,对数线性模型
(7)五数概括、中间四分位数区间、标准差
二、单选题
(1)C;(2)A;(3)D;(4)C;(5)C;(6)B
三、多选题
(1)ABC;(2)BD;(3)ABC;(4)BD;(5)ACD
(6)使用最可能的值填充空缺值。如使用像Bayesian公式或判定树这样的基于推断的方法
(4)常见的数据归约策略包括哪些?
答:数据归约策略包括:
(1)数据立方体聚集
(2)维归约
(3)数据压缩
(4)数值归约
(5)离散化和概念分层产生
第四章数据挖掘原语、语言和系统结构
一、填空题
(1)模式分层,集合分组分层,操作导出的分层,基于规则的分层
(2)简单性、确定性、实用性、新颖性
(3)最小置信度临界值、最小支持度临界值
二、单选题
(1)C;(2)D
三、多选题
(1)AC
四、简答题
(1)定义数据挖掘任务的原语,主要应该包括哪些部分?
答:一个定义数据挖掘任务的原语主要应该包括以下部分的说明:
说明数据库的部分或用户感兴趣的数据集;
要挖掘的知识类型;
(2)数据仓库不需要事务处理,恢复,和并发控制等机制。
(3)数据仓库只需要两种数据访问:数据的初始转载和数据访问(读操作)。
(6)假定Big_University的数据仓库包含如下4个维:student, course, semester和instructor;2个度量:count和avg_grade。在最低得到概念层(例如,对于给定的学生、课程、学期和教师的组合),度量avg_grade存放学生的实际成绩。在较高的概念层,avg_grade存放给定组合的平均成绩。
(3)试述对于多个异种信息源的集成,为什么许多公司宁愿使用更新驱动的方法(update-driven),而不愿使用查询驱动(query-driven)的方法?
答:因为对于多个异种信息源的集成,查询驱动方法需要复杂的信息过滤和集成处理,并且与局部数据源上的处理竞争资源,是一种低效的方法,并且对于频繁的查询,特别是需要聚集操作的查询,开销很大。而更新驱动方法为集成的异种数据库系统带来了高性能,因为数据被处理和重新组织到一个语义一致的数据存储中,进行查询的同时并不影响局部数据源上进行的处理。此外,数据仓库存储并集成历史信息,支持复杂的多维查询。
(5)什么是模式兴趣度的客观度量和主观度量?
答:客观度量指的是基于所发现模式的结构和关于它们的统计来衡量模式的兴趣度,比如:支持度、置信度等等;主观度量基于用户对数据的判断来衡量模式的兴趣度,比如:出乎意料的、新颖的、可行动的等等。
(6)在哪些情况下,我们认为所挖掘出来的模式是有趣的?
答:一个模式是有趣的,如果(1)它易于被人理解;(2)在某种程度上,对于新的或测试数据是有效的;(3)具有潜在效用;(4)新颖的;(5)符合用户确信的某种假设。
半紧密耦合:除了将DM系统连接到一个DB/DW系统之外,一些基本数据挖掘原语(通过分析频繁遇到的数据挖掘功能确定)可以在DB/DW系统中实现。如此一来,一些中间的挖掘结果可以在DB/DW上实现计算或有效的即时计算,性能会有较大提高。
(a)为数据仓库画出雪花模式图。
(b)由基本方体[student, course, semester, instructor]开始,为列出Big_University每个学生的CS课程的平均成绩,应当使用哪些OLAP操作(如,由学期上卷到学年)。
(c)如果每维有5层(包括all),如student < major < status < university <all,该数据方包含多少方体(包含基本方体和顶点方体)?
四、简答题
(1)常用的数值属性概念分层的方法有哪些?
答:常用的数值属性概念分层的方法有分箱、直方图分析、聚类分析、基于熵的离散化和通过自然划分分段。
(2)典型的生成分类数据的概念分层的方法有哪些?
答:典型的生成分类数据的概念分层的方法包括:
(1)由用户或专家在模式级显示的说明属性的部分序;
(2)通过显示数据分组说明分层结构的一部分。
(1)提高两个系统的性能
操作数据库是为OLTP而设计的,没有为OLAP操作优化,同时在操作数据库上处理OLAP查询,会大大降低操作任务的性能;而数据仓库是为OLAP而设计,为复杂的OLAP查询,多维视图,汇总等OLAP功能提供了优化。
(2)两者有着不同的功能
操作数据库支持多事务的并行处理,而数据仓库往往只是对数据记录进行只读访问;这时如果将事务处理的并行机制和恢复机制用于这种OLAP操作,就会显著降低OLAP的性能。
(3)说明属性集,但不说明它们的偏序,然后系统根据算法自动产生属性的序,构造有意义的概念分层。
(4)对只说明部分属性集的情况,则可根据数据库模式中的数据语义定义对属性的捆绑信息,来恢复相关的属性。
(3)在现实世界的数据中,元组在某些属性上缺少值是常有的。描述处理该问题的各种方法。
答:处理空缺值的方法有:
切块:通过对两个或多个维执行选择,定义子方;