BP神经网络实现
LabVIEW中BP神经网络的实现及应用

LabVIEW中BP神经网络的实现及应用
0 引言LabVIEW 是美国NI 公司开发的高效图形化虚拟仪器开发平台,它的图形化编程具有直观、简便、快速、易于开发和维护等优点,在虚拟仪器设计和测控系统开发等相关领域得到了日益广泛的应用,它无需任何文本程序代码,而是把复杂、繁琐的语言编程简化成图形,用线条把各种图形连接起来。
BP 神经网络属于前馈神经网络,它广泛应用函数逼近、模式识别、分类和数
据压缩等领域,若将神经网络与虚拟仪器有机结合,则可以为提高虚拟仪器测控系统的性能提供重要的依据。
1 BP 神经网络学习算法BP 模型是一种应用最广泛的多层前向拓扑结构,以三层BP 神经网络作为理论依据进行编程,它由输入层、隐层和输出层构成。
设输入层神经元个数为I,隐层神经元个数为J,输出层神经元个数为K,学习样本有N 个(x,Y,)向量,表示为:输入向量
X{x1,x2,…,xI},输出向量l,{Y1,Y2,…,Yx),理想输出向量为
T{tl,t2,…,tK}。
(1)输入层节点i,其输出等于xi(i=1,2,…,I,将控制变量值传输到隐含层,则隐层第j 个神经元的输入:
其中:Wji 是隐层第J 个神经元到输入层第i 个神经元的连接权值。
(2)隐层第J 个神经元的输出:
(3)神经网络输出层,第k 个神经元的输入为:
其中:Vkj 是输出层第k 个神经元到隐层第j 个神经元的连接权值。
(4)神经网络输出层,第志个神经元的输出为:
(5)设定网络误差函数E:
(6)输出层到隐层的连接权值调整量△Vkj:
(7)隐层到输入层的连接权值调整量wji:。
BP人工神经网络的基本原理模型与实例

BP人工神经网络的基本原理模型与实例BP(Back Propagation)人工神经网络是一种常见的人工神经网络模型,其基本原理是模拟人脑神经元之间的连接和信息传递过程,通过学习和调整权重,来实现输入和输出之间的映射关系。
BP神经网络模型基本上由三层神经元组成:输入层、隐藏层和输出层。
每个神经元都与下一层的所有神经元连接,并通过带有权重的连接传递信息。
BP神经网络的训练基于误差的反向传播,即首先通过前向传播计算输出值,然后通过计算输出误差来更新连接权重,最后通过反向传播调整隐藏层和输入层的权重。
具体来说,BP神经网络的训练过程包括以下步骤:1.初始化连接权重:随机初始化输入层与隐藏层、隐藏层与输出层之间的连接权重。
2.前向传播:将输入向量喂给输入层,通过带有权重的连接传递到隐藏层和输出层,计算得到输出值。
3.计算输出误差:将期望输出值与实际输出值进行比较,计算得到输出误差。
4.反向传播:从输出层开始,将输出误差逆向传播到隐藏层和输入层,根据误差的贡献程度,调整连接权重。
5.更新权重:根据反向传播得到的误差梯度,使用梯度下降法或其他优化算法更新连接权重。
6.重复步骤2-5直到达到停止条件,如达到最大迭代次数或误差小于一些阈值。
BP神经网络的训练过程是一个迭代的过程,通过不断调整连接权重,逐渐减小输出误差,使网络能够更好地拟合输入与输出之间的映射关系。
下面以一个简单的实例来说明BP神经网络的应用:假设我们要建立一个三层BP神经网络来预测房价,输入为房屋面积和房间数,输出为价格。
我们训练集中包含一些房屋信息和对应的价格。
1.初始化连接权重:随机初始化输入层与隐藏层、隐藏层与输出层之间的连接权重。
2.前向传播:将输入的房屋面积和房间数喂给输入层,通过带有权重的连接传递到隐藏层和输出层,计算得到价格的预测值。
3.计算输出误差:将预测的价格与实际价格进行比较,计算得到输出误差。
4.反向传播:从输出层开始,将输出误差逆向传播到隐藏层和输入层,根据误差的贡献程度,调整连接权重。
基于BP神经网络的应用及实现

2 B P 网络 的应 用 实 例
下面采用 B P算法 , 在 Ma t l a b中编程 , 建立 B P神经 网络模 型, 对其进行训练 , 最后用 于对癌细胞 的检测 。 图1 检测 的基 本原理[ 6 , 7 1 : 由于气体分子 或 固体 、 液体 的蒸气受 到一定 能量的电子流轰击或强 电场作用 , 丢失价 电子生成分子 离子 ; 同时 , 化学 键也发 生某些 有规律 裂解 , 生成 各种碎 片离 子。 这些带正 电荷 的离子在 电场和磁场作用下 , 按质荷 比( 即质 量 和电荷 比值 M/ Z) 的大小分开 , 排列成谱 , 记 录下来即为质谱 ( m a s s s p e c t r u m) 。因此 , 可 以根据质谱 中离子的强度判断其血 清蛋 白质样本有无癌症细胞 。 实 例 中的数据 是采用 F D A — N C I诊所 蛋 白质项 目中的数 据库 中的数据 。程序主要完成三部分功能 :一是通过 r a n k f e a — 图2 t u r e s 0 函数 , 从 1 5 0 0 0个 的特征 中选取 1 0 0 个影 响较大 的特征 ; 二是 通过神经 网络 的专用 函数 n e w f 0 建立 B P网络 , 并 对其进 T r a i n b r 函数对网络进行训 练。训练效果如图 2所示 。 行训练 和建模 ; 三是给 出测试的结果 。 表 1 列出 了上述实验 的关键数据 。分析可 知 : 基本梯 度下降算 2 . 1特征 的提取 法 ( T r a i n g d ) ,迭代次数多 ,耗时长 ,收敛 速度慢 ;共轭梯度算法 在数据集 中共有 2 1 6个病人 ,其 中有 1 2 1 个 卵巢癌患者 和 9 5 T r a i n c g p ) 和变梯 度法 与拟牛顿 法 的折 中算 法 ( T r a i n o s s ) 迭代 次数 个正常 的病人 。 每个病人的输入是其 具体 特征 ( M/ Z ) 下 的离子浓度 , ( 耗 时少 , 收敛速度 较快 ; 改进型 L M算法 ( T r i a n b r ) 虽然迭代 次数 由于数 据 中共有 1 5 0 0 0个特征用 于判 断 , 计 算量 过于庞大 , 而且 在 少 , 这些特征 当中也没有哪一种特征可以决定正确的分类 , 。 因此 , 需要 较少 ,但是 每 个训 练周 期很 长 ,网络 输 出与实 际输 出的均方 差 MS E) 偏大 。 个分类器— — T a n k f e a t u r e s 0 i  ̄数 , 用来从 1 5 0 0 0 个 特征中选取 1 0 0 ( 2 - 3神经 网络的性能测试 个重要 的特征用于分类 ; 每个病 人的输出则是一个二值矩 阵 , “ 0 ” 表 将 1 0 0个 测试结果 样本分别 输入到经过 训练 的 B P神经 网络 , 示正常病人 , “ 1 ” 表示患有癌症的病人。 其测试结果如表 2所示 。 2 . 2 B P神 经网络 的构建及训练 3 结 论 文 中用 于 癌症 检测 的神 经 网络含 有 一个 输 入层 ,节点 数 为 本文用 B P神经 网络对病 人样 本进行检测 ,在用大量的真实数 1 0 0 ; 一个输 出层 , 节点数为 2 1 6 ; 一个 隐含层 , 节点数为 l 0 。由于其 据进行训 练后 , 得到满足误差指标 的 B P神经网络 ; 根据不同的算法 输 出函数在 0到 1 之间 ,所 以隐含层和输 出层得 激励 函数 为 s i g — 训 练 网络 ,得 到 的训练 模 型的效 果也 不尽 相 同。结 果表 明使 用 m o i d对数 函数和线性函数。t r a i n根据在 n e w f函数 中确定的训练函
BP神经网络实验报告

BP神经网络实验报告一、引言BP神经网络是一种常见的人工神经网络模型,其基本原理是通过将输入数据通过多层神经元进行加权计算并经过非线性激活函数的作用,输出结果达到预测或分类的目标。
本实验旨在探究BP神经网络的基本原理和应用,以及对其进行实验验证。
二、实验方法1.数据集准备本次实验选取了一个包含1000个样本的分类数据集,每个样本有12个特征。
将数据集进行标准化处理,以提高神经网络的收敛速度和精度。
2.神经网络的搭建3.参数的初始化对神经网络的权重和偏置进行初始化,常用的初始化方法有随机初始化和Xavier初始化。
本实验采用Xavier初始化方法。
4.前向传播将标准化后的数据输入到神经网络中,在神经网络的每一层进行加权计算和激活函数的作用,传递给下一层进行计算。
5.反向传播根据预测结果与实际结果的差异,通过计算损失函数对神经网络的权重和偏置进行调整。
使用梯度下降算法对参数进行优化,减小损失函数的值。
6.模型评估与验证将训练好的模型应用于测试集,计算准确率、精确率、召回率和F1-score等指标进行模型评估。
三、实验结果与分析将数据集按照7:3的比例划分为训练集和测试集,分别进行模型训练和验证。
经过10次训练迭代后,模型在测试集上的准确率稳定在90%以上,证明了BP神经网络在本实验中的有效性和鲁棒性。
通过调整隐藏层结点个数和迭代次数进行模型性能优化实验,可以发现隐藏层结点个数对模型性能的影响较大。
随着隐藏层结点个数的增加,模型在训练集上的拟合效果逐渐提升,但过多的结点数会导致模型的复杂度过高,容易出现过拟合现象。
因此,选择合适的隐藏层结点个数是模型性能优化的关键。
此外,迭代次数对模型性能也有影响。
随着迭代次数的增加,模型在训练集上的拟合效果逐渐提高,但过多的迭代次数也会导致模型过度拟合。
因此,需要选择合适的迭代次数,使模型在训练集上有好的拟合效果的同时,避免过度拟合。
四、实验总结本实验通过搭建BP神经网络模型,对分类数据集进行预测和分类。
实训神经网络实验报告

一、实验背景随着人工智能技术的飞速发展,神经网络作为一种强大的机器学习模型,在各个领域得到了广泛应用。
为了更好地理解神经网络的原理和应用,我们进行了一系列的实训实验。
本报告将详细记录实验过程、结果和分析。
二、实验目的1. 理解神经网络的原理和结构。
2. 掌握神经网络的训练和测试方法。
3. 分析不同神经网络模型在特定任务上的性能差异。
三、实验内容1. 实验一:BP神经网络(1)实验目的:掌握BP神经网络的原理和实现方法,并在手写数字识别任务上应用。
(2)实验内容:- 使用Python编程实现BP神经网络。
- 使用MNIST数据集进行手写数字识别。
- 分析不同学习率、隐层神经元个数对网络性能的影响。
(3)实验结果:- 在MNIST数据集上,网络在训练集上的准确率达到98%以上。
- 通过调整学习率和隐层神经元个数,可以进一步提高网络性能。
2. 实验二:卷积神经网络(CNN)(1)实验目的:掌握CNN的原理和实现方法,并在图像分类任务上应用。
(2)实验内容:- 使用Python编程实现CNN。
- 使用CIFAR-10数据集进行图像分类。
- 分析不同卷积核大小、池化层大小对网络性能的影响。
(3)实验结果:- 在CIFAR-10数据集上,网络在训练集上的准确率达到80%以上。
- 通过调整卷积核大小和池化层大小,可以进一步提高网络性能。
3. 实验三:循环神经网络(RNN)(1)实验目的:掌握RNN的原理和实现方法,并在时间序列预测任务上应用。
(2)实验内容:- 使用Python编程实现RNN。
- 使用Stock数据集进行时间序列预测。
- 分析不同隐层神经元个数、学习率对网络性能的影响。
(3)实验结果:- 在Stock数据集上,网络在训练集上的预测准确率达到80%以上。
- 通过调整隐层神经元个数和学习率,可以进一步提高网络性能。
四、实验分析1. BP神经网络:BP神经网络是一种前向传播和反向传播相结合的神经网络,适用于回归和分类问题。
BP算法程序实现

BP算法程序实现BP(Back Propagation)神经网络是一种常见的人工神经网络模型,是一种监督学习算法。
在BP算法中,神经网络的参数通过反向传播的方式得到更新,以最小化损失函数。
BP神经网络的实现主要分为前向传播和反向传播两个步骤。
首先,我们需要定义BP神经网络的结构。
一个典型的BP神经网络包括输入层、隐藏层和输出层。
输入层接收原始数据,隐藏层进行特征提取和转换,输出层进行最终的预测。
在实现BP神经网络时,我们首先需要进行初始化。
初始化可以为神经网络的权重和偏置添加一些随机的初始值。
这里我们使用numpy库来处理矩阵运算。
前向传播的过程实际上就是将输入数据通过神经网络的每一层,直到输出层。
在每一层中,我们将对应权重和输入数据进行点乘运算,并加上偏置项,然后通过一个激活函数进行非线性转换。
这里我们可以选择sigmoid函数作为激活函数。
在反向传播中,我们根据损失函数对权重和偏置进行调整。
首先,我们计算输出误差,即预测值与真实值之间的差异。
然后,我们根据链式法则来计算每一层的误差,并将误差传递回前一层。
根据误差和激活函数的导数,我们可以计算每个权重和偏置的更新量,然后使用梯度下降法对权重和偏置进行更新。
实现BP算法的程序如下:```pythonimport numpy as npclass NeuralNetwork:def __init__(self, layers):yers = layersself.weights = [np.random.randn(y, x) for x, y inzip(layers[:-1], layers[1:])]self.biases = [np.random.randn(y, 1) for y in layers[1:]] def forward(self, x):a = np.array(x).reshape(-1, 1)for w, b in zip(self.weights, self.biases):z = np.dot(w, a) + ba = self.sigmoid(z)return adef backward(self, x, y, lr=0.01):a = np.array(x).reshape(-1, 1)targets = np.array(y).reshape(-1, 1)# forward passactivations = [a]zs = []for w, b in zip(self.weights, self.biases):z = np.dot(w, a) + bzs.append(z)a = self.sigmoid(z)activations.append(a)# backward passdeltas = [self.loss_derivative(activations[-1], targets) * self.sigmoid_derivative(zs[-1])]for l in range(2, len(yers)):z = zs[-l]sp = self.sigmoid_derivative(z)deltas.append(np.dot(self.weights[-l + 1].T, deltas[-1]) * sp)deltas.reverse# update weights and biasesfor l in range(len(yers) - 1):self.weights[l] += -lr * np.dot(deltas[l], activations[l].T) self.biases[l] += -lr * deltas[l]def sigmoid(x):return 1 / (1 + np.exp(-x))def sigmoid_derivative(x):return NeuralNetwork.sigmoid(x) * (1 -NeuralNetwork.sigmoid(x))def loss_derivative(y_pred, y_true):return y_pred - y_true```上述代码中,首先我们定义一个NeuralNetwork类,包含两个主要方法:forward(和backward(。
神经网络的BP算法实验报告

计算智能基础实验报告实验名称:BP神经网络算法实验班级名称:341521班专业:探测制导与控制技术姓名:***学号:********一、 实验目的1)编程实现BP 神经网络算法;2)探究BP 算法中学习因子算法收敛趋势、收敛速度之间的关系;3)修改训练后BP 神经网络部分连接权值,分析连接权值修改前和修改后对相同测试样本测试结果,理解神经网络分布存储等特点。
二、 实验要求按照下面的要求操作,然后分析不同操作后网络输出结果。
1)可修改学习因子2)可任意指定隐单元层数3)可任意指定输入层、隐含层、输出层的单元数4)可指定最大允许误差ε5)可输入学习样本(增加样本)6)可存储训练后的网络各神经元之间的连接权值矩阵;7)修改训练后的BP 神经网络部分连接权值,分析连接权值修改前和修改后对相同测试样本测试结果 。
三、 实验原理1BP 神经网络算法的基本思想误差逆传播(back propagation, BP)算法是一种计算单个权值变化引起网络性能变化的较为简单的方法。
由于BP 算法过程包含从输出节点开始,反向地向第一隐含层(即最接近输入层的隐含层)传播由总误差引起的权值修正,所以称为“反向传播”。
BP 神经网络是有教师指导训练方式的多层前馈网络,其基本思想是:从网络输入节点输入的样本信号向前传播,经隐含层节点和输出层节点处的非线性函数作用后,从输出节点获得输出。
若在输出节点得不到样本的期望输出,则建立样本的网络输出与其期望输出的误差信号,并将此误差信号沿原连接路径逆向传播,去逐层修改网络的权值和节点处阈值,这种信号正向传播与误差信号逆向传播修改权值和阈值的过程反复进行,直训练样本集的网络输出误差满足一定精度要求为止。
2 BP 神经网络算法步骤和流程BP 神经网络步骤和流程如下:1) 初始化,给各连接权{},{}ij jt W V 及阈值{},{}j t θγ赋予(-1,1)间的随机值;2) 随机选取一学习模式对1212(,),(,,)k k k k k k k n k n A a a a Y y y y ==提供给网络;3) 计算隐含层各单元的输入、输出;1n j ij i j i s w a θ==⋅-∑,()1,2,,j j b f s j p ==4) 计算输出层各单元的输入、输出;1t t jt j t j l V b γ==⋅-∑,()1,2,,t t c f l t q ==5) 计算输出层各单元的一般化误差;()(1)1,2,,k k t t tt t t d y c c c t q =-⋅-=6) 计算中间层各单元的一般化误差;1[](1)1,2,,q kk jt jt j j t e d V b b j p ==⋅⋅-=∑7) 修正中间层至输出层连接权值和输出层各单元阈值;(1)()k jt jt t j V iter V iter d b α+=+⋅⋅(1)()k t t t iter iter d γγα+=+⋅8) 修正输入层至中间层连接权值和中间层各单元阈值;(1)()kk ij ij j i W iter W iter e a β+=+⋅⋅(1)()kj j j iter iter e θθβ+=+⋅9) 随机选取下一个学习模式对提供给网络,返回步骤3),直至全部m 个模式训练完毕;10) 重新从m 个学习模式对中随机选取一个模式对,返回步骤3),直至网络全局误差函数E 小于预先设定的一个极小值,即网络收敛;或者,当训练次数大于预先设定值,强制网络停止学习(网络可能无法收敛)。
BP神经网络实验详解(MATLAB实现)

BP神经网络实验详解(MATLAB实现)BP(Back Propagation)神经网络是一种常用的人工神经网络结构,用于解决分类和回归问题。
在本文中,将详细介绍如何使用MATLAB实现BP神经网络的实验。
首先,需要准备一个数据集来训练和测试BP神经网络。
数据集可以是一个CSV文件,每一行代表一个样本,每一列代表一个特征。
一般来说,数据集应该被分成训练集和测试集,用于训练和测试模型的性能。
在MATLAB中,可以使用`csvread`函数来读取CSV文件,并将数据集划分为输入和输出。
假设数据集的前几列是输入特征,最后一列是输出。
可以使用以下代码来实现:```matlabdata = csvread('dataset.csv');input = data(:, 1:end-1);output = data(:, end);```然后,需要创建一个BP神经网络模型。
可以使用MATLAB的`patternnet`函数来创建一个全连接的神经网络模型。
该函数的输入参数为每个隐藏层的神经元数量。
下面的代码创建了一个具有10个隐藏神经元的单隐藏层BP神经网络:```matlabhidden_neurons = 10;net = patternnet(hidden_neurons);```接下来,需要对BP神经网络进行训练。
可以使用`train`函数来训练模型。
该函数的输入参数包括训练集的输入和输出,以及其他可选参数,如最大训练次数和停止条件。
下面的代码展示了如何使用`train`函数来训练模型:```matlabnet = train(net, input_train, output_train);```训练完成后,可以使用训练好的BP神经网络进行预测。
可以使用`net`模型的`sim`函数来进行预测。
下面的代码展示了如何使用`sim`函数预测测试集的输出:```matlaboutput_pred = sim(net, input_test);```最后,可以使用各种性能指标来评估预测的准确性。
BP神经网络算法的C语言实现代码

BP神经网络算法的C语言实现代码以下是一个BP神经网络的C语言实现代码,代码的详细说明可以帮助理解代码逻辑:```c#include <stdio.h>#include <stdlib.h>#include <math.h>#define INPUT_SIZE 2#define HIDDEN_SIZE 2#define OUTPUT_SIZE 1#define LEARNING_RATE 0.1//定义神经网络结构体typedef structdouble input[INPUT_SIZE];double hidden[HIDDEN_SIZE];double output[OUTPUT_SIZE];double weights_ih[INPUT_SIZE][HIDDEN_SIZE];double weights_ho[HIDDEN_SIZE][OUTPUT_SIZE];} NeuralNetwork;//激活函数double sigmoid(double x)return 1 / (1 + exp(-x));//创建神经网络NeuralNetwork* create_neural_networNeuralNetwork* nn =(NeuralNetwork*)malloc(sizeof(NeuralNetwork));//初始化权重for (int i = 0; i < INPUT_SIZE; i++)for (int j = 0; j < HIDDEN_SIZE; j++)nn->weights_ih[i][j] = (double)rand( / RAND_MAX * 2 - 1;}}for (int i = 0; i < HIDDEN_SIZE; i++)for (int j = 0; j < OUTPUT_SIZE; j++)nn->weights_ho[i][j] = (double)rand( / RAND_MAX * 2 - 1;}}return nn;//前向传播void forward(NeuralNetwork* nn)//计算隐藏层输出for (int i = 0; i < HIDDEN_SIZE; i++)double sum = 0;for (int j = 0; j < INPUT_SIZE; j++)sum += nn->input[j] * nn->weights_ih[j][i];}nn->hidden[i] = sigmoid(sum);}//计算输出层输出for (int i = 0; i < OUTPUT_SIZE; i++)double sum = 0;for (int j = 0; j < HIDDEN_SIZE; j++)sum += nn->hidden[j] * nn->weights_ho[j][i];}nn->output[i] = sigmoid(sum);}void backpropagation(NeuralNetwork* nn, double target)//计算输出层误差double output_error[OUTPUT_SIZE];for (int i = 0; i < OUTPUT_SIZE; i++)double delta = target - nn->output[i];output_error[i] = nn->output[i] * (1 - nn->output[i]) * delta;}//更新隐藏层到输出层权重for (int i = 0; i < HIDDEN_SIZE; i++)for (int j = 0; j < OUTPUT_SIZE; j++)nn->weights_ho[i][j] += LEARNING_RATE * nn->hidden[i] * output_error[j];}}//计算隐藏层误差double hidden_error[HIDDEN_SIZE];for (int i = 0; i < HIDDEN_SIZE; i++)double delta = 0;for (int j = 0; j < OUTPUT_SIZE; j++)delta += output_error[j] * nn->weights_ho[i][j];}hidden_error[i] = nn->hidden[i] * (1 - nn->hidden[i]) * delta;}//更新输入层到隐藏层权重for (int i = 0; i < INPUT_SIZE; i++)for (int j = 0; j < HIDDEN_SIZE; j++)nn->weights_ih[i][j] += LEARNING_RATE * nn->input[i] * hidden_error[j];}}void train(NeuralNetwork* nn, double input[][2], double target[], int num_examples)int iteration = 0;while (iteration < MAX_ITERATIONS)double error = 0;for (int i = 0; i < num_examples; i++)for (int j = 0; j < INPUT_SIZE; j++)nn->input[j] = input[i][j];}forward(nn);backpropagation(nn, target[i]);error += fabs(target[i] - nn->output[0]);}//判断误差是否已达到允许范围if (error < 0.01)break;}iteration++;}if (iteration == MAX_ITERATIONS)printf("Training failed! Error: %.8lf\n", error); }void predict(NeuralNetwork* nn, double input[]) for (int i = 0; i < INPUT_SIZE; i++)nn->input[i] = input[i];}forward(nn);printf("Prediction: %.8lf\n", nn->output[0]); int maiNeuralNetwork* nn = create_neural_network(; double input[4][2] ={0,0},{0,1},{1,0},{1,1}};double target[4] =0,1,1,};train(nn, input, target, 4);predict(nn, input[0]);predict(nn, input[1]);predict(nn, input[2]);predict(nn, input[3]);free(nn);return 0;```以上代码实现了一个简单的BP神经网络,该神经网络包含一个输入层、一个隐藏层和一个输出层。
用Python实现BP神经网络(附代码)

⽤Python实现BP神经⽹络(附代码)⽤Python实现出来的机器学习算法都是什么样⼦呢?前两期线性回归及逻辑回归项⽬已发布(见⽂末链接),今天来讲讲BP神经⽹络。
BP神经⽹络全部代码https:///lawlite19/MachineLearning_Python/blob/master/NeuralNetwok/NeuralNetwork.py神经⽹络model先介绍个三层的神经⽹络,如下图所⽰输⼊层(input layer)有三个units(为补上的bias,通常设为1)表⽰第j层的第i个激励,也称为为单元unit为第j层到第j+1层映射的权重矩阵,就是每条边的权重所以可以得到:隐含层:输出层,其中,S型函数,也成为激励函数可以看出为3x4的矩阵,为1x4的矩阵==》j+1的单元数x(j层的单元数+1)代价函数假设最后输出的,即代表输出层有K个单元,其中,代表第i个单元输出与逻辑回归的代价函数差不多,就是累加上每个输出(共有K个输出)正则化L-->所有层的个数-->第l层unit的个数正则化后的代价函数为共有L-1层,然后是累加对应每⼀层的theta矩阵,注意不包含加上偏置项对应的theta(0)正则化后的代价函数实现代码:# 代价函数def nnCostFunction(nn_params,input_layer_size,hidden_layer_size,num_labels,X,y,Lambda):length = nn_params.shape[0] # theta的中长度# 还原theta1和theta2Theta1 = nn_params[0:hidden_layer_size*(input_layer_size+1)].reshape(hidden_layer_size,input_layer_size+1)Theta2 = nn_params[hidden_layer_size*(input_layer_size+1):length].reshape(num_labels,hidden_layer_size+1)# np.savetxt("Theta1.csv",Theta1,delimiter=',')m = X.shape[0]class_y = np.zeros((m,num_labels)) # 数据的y对应0-9,需要映射为0/1的关系# 映射yfor i in range(num_labels):class_y[:,i] = np.int32(y==i).reshape(1,-1) # 注意reshape(1,-1)才可以赋值'''去掉theta1和theta2的第⼀列,因为正则化时从1开始'''Theta1_colCount = Theta1.shape[1]Theta1_x = Theta1[:,1:Theta1_colCount]Theta2_colCount = Theta2.shape[1]Theta2_x = Theta2[:,1:Theta2_colCount]# 正则化向theta^2term = np.dot(np.transpose(np.vstack((Theta1_x.reshape(-1,1),Theta2_x.reshape(-1,1)))),np.vstack((Theta1_x.reshape(-1,1),Theta2_x.reshape(-1,1))))'''正向传播,每次需要补上⼀列1的偏置bias'''a1 = np.hstack((np.ones((m,1)),X))z2 = np.dot(a1,np.transpose(Theta1))a2 = sigmoid(z2)a2 = np.hstack((np.ones((m,1)),a2))z3 = np.dot(a2,np.transpose(Theta2))h = sigmoid(z3)'''代价'''J = -(np.dot(np.transpose(class_y.reshape(-1,1)),np.log(h.reshape(-1,1)))+np.dot(np.transpose(1-class_y.reshape(-1,1)),np.log(1-h.reshape(-1,1)))-Lambda*term/2)/mreturn np.ravel(J)反向传播BP上⾯正向传播可以计算得到J(θ),使⽤梯度下降法还需要求它的梯度BP反向传播的⽬的就是求代价函数的梯度假设4层的神经⽹络,记为-->l层第j个单元的误差《===》(向量化)没有,因为对于输⼊没有误差因为S型函数的倒数为:,所以上⾯的和可以在前向传播中计算出来反向传播计算梯度的过程为:(是⼤写的)for i=1-m:--正向传播计算(l=2,3,4...L)-反向计算、...;--最后,即得到代价函数的梯度实现代码:# 梯度def nnGradient(nn_params,input_layer_size,hidden_layer_size,num_labels,X,y,Lambda):length = nn_params.shape[0]Theta1 = nn_params[0:hidden_layer_size*(input_layer_size+1)].reshape(hidden_layer_size,input_layer_size+1) Theta2 = nn_params[hidden_layer_size*(input_layer_size+1):length].reshape(num_labels,hidden_layer_size+1) m = X.shape[0]class_y = np.zeros((m,num_labels)) # 数据的y对应0-9,需要映射为0/1的关系# 映射yfor i in range(num_labels):class_y[:,i] = np.int32(y==i).reshape(1,-1) # 注意reshape(1,-1)才可以赋值'''去掉theta1和theta2的第⼀列,因为正则化时从1开始'''Theta1_colCount = Theta1.shape[1]Theta1_x = Theta1[:,1:Theta1_colCount]Theta2_colCount = Theta2.shape[1]Theta2_x = Theta2[:,1:Theta2_colCount]Theta1_grad = np.zeros((Theta1.shape)) #第⼀层到第⼆层的权重Theta2_grad = np.zeros((Theta2.shape)) #第⼆层到第三层的权重Theta1[:,0] = 0;Theta2[:,0] = 0;'''正向传播,每次需要补上⼀列1的偏置bias'''a1 = np.hstack((np.ones((m,1)),X))z2 = np.dot(a1,np.transpose(Theta1))a2 = sigmoid(z2)a2 = np.hstack((np.ones((m,1)),a2))z3 = np.dot(a2,np.transpose(Theta2))h = sigmoid(z3)'''反向传播,delta为误差,'''delta3 = np.zeros((m,num_labels))delta2 = np.zeros((m,hidden_layer_size))for i in range(m):delta3[i,:] = h[i,:]-class_y[i,:]Theta2_grad = Theta2_grad+np.dot(np.transpose(delta3[i,:].reshape(1,-1)),a2[i,:].reshape(1,-1))delta2[i,:] = np.dot(delta3[i,:].reshape(1,-1),Theta2_x)*sigmoidGradient(z2[i,:])Theta1_grad = Theta1_grad+np.dot(np.transpose(delta2[i,:].reshape(1,-1)),a1[i,:].reshape(1,-1))'''梯度'''grad = (np.vstack((Theta1_grad.reshape(-1,1),Theta2_grad.reshape(-1,1)))+Lambda*np.vstack((Theta1.reshape(-1,1),Theta2.reshape(-1,1))))/mreturn np.ravel(grad)BP可以求梯度的原因实际是利⽤了链式求导法则因为下⼀层的单元利⽤上⼀层的单元作为输⼊进⾏计算⼤体的推导过程如下,最终我们是想预测函数与已知的y⾮常接近,求均⽅差的梯度沿着此梯度⽅向可使代价函数最⼩化。
LabVIEW中BP神经网络的实现及应用

0 引言LabVIEW是美国NI公司开发的高效图形化虚拟仪器开发平台,它的图形化编程具有直观、简便、快速、易于开发和维护等优点,在虚拟仪器设计和测控系统开发等相关领域得到了日益广泛的应用,它无需任何文本程序代码,而是把复杂、繁琐的语言编程简化成图形,用线条把各种图形连接起来。
BP神经网络属于前馈神经网络,它广泛应用函数逼近、模式识别、分类和数据压缩等领域,若将神经网络与虚拟仪器有机结合,则可以为提高虚拟仪器测控系统的性能提供重要的依据。
1 BP神经网络学习算法BP模型是一种应用最广泛的多层前向拓扑结构,以三层BP神经网络作为理论依据进行编程,它由输入层、隐层和输出层构成。
设输入层神经元个数为I,隐层神经元个数为J,输出层神经元个数为K,学习样本有N个(x,Y,)向量,表示为:输入向量X{x1,x2,…,xI},输出向量l,{Y1,Y2,…,Yx),理想输出向量为T{tl,t2,…,tK}。
(1)输入层节点i,其输出等于xi(i=1,2,…,I,将控制变量值传输到隐含层,则隐层第j个神经元的输入:其中:Wji是隐层第J个神经元到输入层第i个神经元的连接权值。
(2)隐层第J个神经元的输出:(3)神经网络输出层,第k个神经元的输入为:其中:Vkj是输出层第k个神经元到隐层第j个神经元的连接权值。
(4)神经网络输出层,第志个神经元的输出为:(5)设定网络误差函数E:(6)输出层到隐层的连接权值调整量△Vkj:(7)隐层到输入层的连接权值调整量wji:2 用LabVlEW实现BP神经网络的两种方法用LabVIEw实现BP神经网络的两种方法为:(1)由于Matlab具有强大的数学运算能力以及在测控领域的广泛应用。
在LabVIEW中提供了MatlabScript节点,用户可在节点中编辑Matlab程序,并在Lab—VIEW中运行;也可以在LabVIEW程序运行时直接调用已经存在的Matlab程序,如使用节点则必须在系统中安装:Matlab5以上版本,在写入Matlab节点前要将程序先调试通过,并确保其中变量的数据类型匹配。
BP神经网络算法代码

BP神经网络算法代码以下是一个简单实现的BP神经网络算法代码,实现了一个简单的二分类任务。
代码主要分为四个部分:数据准备、网络搭建、训练和预测。
```pythonimport numpy as np#数据准备def prepare_data(:X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) # 输入数据return X, y#网络搭建def build_network(X, y, hidden_dim):input_dim = X.shape[1] # 输入维度output_dim = y.shape[1] # 输出维度#初始化权重和偏置np.random.seed(0)W1 = np.random.randn(input_dim, hidden_dim) /np.sqrt(input_dim)b1 = np.zeros((1, hidden_dim))W2 = np.random.randn(hidden_dim, output_dim) / np.sqrt(hidden_dim)b2 = np.zeros((1, output_dim))return W1, b1, W2, b2#前向传播def forward_propagation(X, W1, b1, W2, b2):z1 = np.dot(X, W1) + b1a1 = sigmoid(z1)z2 = np.dot(a1, W2) + b2a2 = sigmoid(z2)return a1, a2#激活函数def sigmoid(x):return 1 / (1 + np.exp(-x))#反向传播def backward_propagation(X, y, a1, a2, W1, W2): m = X.shape[0] # 样本数量#计算损失loss = np.sum((a2-y)**2) / (2*m)#计算梯度delta2 = 1/m * (a2-y) * a2 * (1-a2)dW2 = np.dot(a1.T, delta2)db2 = np.sum(delta2, axis=0, keepdims=True)delta1 = np.dot(delta2, W2.T) * a1 * (1-a1)dW1 = np.dot(X.T, delta1)db1 = np.sum(delta1, axis=0)return loss, dW1, db1, dW2, db2#更新参数def update_parameters(W1, b1, W2, b2, dW1, db1, dW2, db2, learning_rate):W1 -= learning_rate * dW1b1 -= learning_rate * db1W2 -= learning_rate * dW2b2 -= learning_rate * db2return W1, b1, W2, b2#训练def train(X, y, hidden_dim, num_epochs, learning_rate):W1, b1, W2, b2 = build_network(X, y, hidden_dim)for epoch in range(num_epochs):a1, a2 = forward_propagation(X, W1, b1, W2, b2)loss, dW1, db1, dW2, db2 = backward_propagation(X, y, a1, a2, W1, W2)W1, b1, W2, b2 = update_parameters(W1, b1, W2, b2, dW1, db1, dW2, db2, learning_rate)if (epoch+1) % 100 == 0:print("Epoch {}: loss = {}".format(epoch+1, loss))return W1, b1, W2, b2#预测def predict(X, W1, b1, W2, b2):_, a2 = forward_propagation(X, W1, b1, W2, b2)predictions = (a2 > 0.5).astype(int)return predictions#主函数def main(:X, y = prepare_datahidden_dim = 3num_epochs = 1000learning_rate = 0.1W1, b1, W2, b2 = train(X, y, hidden_dim, num_epochs, learning_rate)predictions = predict(X, W1, b1, W2, b2)print("Predictions:", predictions)if __name__ == "__main__":main```注意:这段代码只是一个简单的实现,可能在复杂任务上效果不佳。
神经网络激活函数[BP神经网络实现函数逼近的应用分析]
![神经网络激活函数[BP神经网络实现函数逼近的应用分析]](https://img.taocdn.com/s3/m/6f4ac08759f5f61fb7360b4c2e3f5727a5e924b1.png)
神经网络激活函数[BP神经网络实现函数逼近的应用分析]神经网络激活函数是神经网络中非常重要的组成部分,它决定了神经网络的非线性特性,并且对于神经网络的求解效果和性能有着重要的影响。
本文将对神经网络激活函数进行详细的分析和探讨,并以BP神经网络实现函数逼近的应用为例进行具体分析。
1.神经网络激活函数的作用(1)引入非线性:神经网络通过激活函数引入非线性,使其具备处理非线性问题的能力,能够更好的逼近任意非线性函数。
(2)映射特征空间:激活函数可以将输入映射到另一个空间中,从而更好地刻画特征,提高神经网络的表达能力,并且可以保留原始数据的一些特性。
(3)增强模型的灵活性:不同的激活函数具有不同的形状和性质,选择合适的激活函数可以增加模型的灵活性,适应不同问题和数据的特点。
(4)解决梯度消失问题:神经网络中经常会遇到梯度消失的问题,通过使用合适的激活函数,可以有效地缓解梯度消失问题,提高神经网络的收敛速度。
2.常用的神经网络激活函数(1)Sigmoid函数:Sigmoid函数是一种常用的激活函数,它的输出值范围在(0,1)之间,具有平滑性,但是存在梯度消失问题。
(2)Tanh函数:Tanh函数是Sigmoid函数的对称形式,它的输出值范围在(-1,1)之间,相对于Sigmoid函数来说,均值为0,更符合中心化的要求。
(3)ReLU函数:ReLU函数在输入为负数时输出为0,在输入为正数时输出为其本身,ReLU函数简单快速,但是容易出现神经元死亡问题,即一些神经元永远不被激活。
(4)Leaky ReLU函数:Leaky ReLU函数是对ReLU函数的改进,当输入为负数时,输出为其本身乘以一个小的正数,可以解决神经元死亡问题。
(5)ELU函数:ELU函数在输入为负数时输出为一个负有指数衰减的值,可以在一定程度上缓解ReLU函数带来的神经元死亡问题,并且能够拟合更多的函数。
3.BP神经网络实现函数逼近的应用BP神经网络是一种常用的用于函数逼近的模型,它通过不断调整权重和偏置来实现对目标函数的拟合。
(完整word版)BP神经网络实验报告

BP 神经网络实验报告一、实验目的1、熟悉MATLAB中神经网络工具箱的使用方法;2、经过在MATLAB下面编程实现BP网络逼近标准正弦函数,来加深对BP网络的认识和认识,理解信号的正向流传和误差的反向传达过程。
二、实验原理由于传统的感知器和线性神经网络有自己无法战胜的弊端,它们都不能够解决线性不能分问题,因此在实质应用过程中碰到了限制。
而BP 网络却拥有优异的繁泛化能力、容错能力以及非线性照射能力。
因此成为应用最为广泛的一种神经网络。
BP 算法的根本思想是把学习过程分为两个阶段:第一阶段是信号的正向流传过程;输入信息经过输入层、隐层逐层办理并计算每个单元的实质输出值;第二阶段是误差的反向传达过程;假设在输入层未能获取希望的输出值,那么逐层递归的计算实质输出和希望输出的差值〔即误差〕,以便依照此差值调治权值。
这种过程不断迭代,最后使得信号误差到达赞同或规定的范围之内。
基于 BP 算法的多层前馈型网络模型的拓扑结构如上图所示。
BP 算法的数学描述:三层BP 前馈网络的数学模型如上图所示。
三层前馈网中,输入向量为: X ( x1 , x2 ,..., x i ,..., x n )T;隐层输入向量为:Y( y1 , y2 ,..., y j ,...y m ) T;输出层输出向量为: O (o1 , o2 ,..., o k ,...o l )T;希望输出向量为:d(d1 ,d 2 ,...d k ,...d l )T。
输入层到隐层之间的权值矩阵用 V 表示,V(v1 , v2 ,...v j ,...v m ) Y,其中列向量v j为隐层第 j 个神经元对应的权向量;隐层到输出层之间的权值矩阵用W 表示,W( w1 , w2 ,...w k ,...w l ) ,其中列向量 w k为输出层第k个神经元对应的权向量。
下面解析各层信号之间的数学关系。
对于输出层,有y j f (net j ), j1,2,..., mnet j v ij x i , j1,2,..., m对于隐层,有O k f (net k ), k1,2,...,lm net k wjkyi, k1,2,...,lj0以上两式中,转移函数 f(x) 均为单极性Sigmoid 函数:1f ( x)x1 ef(x) 拥有连续、可导的特点,且有 f ' (x) f ( x)[1 f ( x)]以上共同构成了三层前馈网了的数学模型。
BP神经网络算法的C语言实现代码

//BP神经网络算法,c语言版本//VS2010下,无语法错误,可直接运行//添加了简单注释//欢迎学习交流#include <yerNum>#include <yerNum>#include <yerNum>#include <yerNum>#define N_Out 2 //输出向量维数#define N_In 3 //输入向量维数#define N_Sample 6 //样本数量//BP人工神经网络typedef struct{int LayerNum; //中间层数量double v[N_In][50]; //中间层权矩阵i,中间层节点最大数量为50double w[50][N_Out]; //输出层权矩阵double StudyRate; //学习率double Accuracy; //精度控制参数int MaxLoop; //最大循环次数} BPNet;//Sigmoid函数double fnet(double net){return 1/(1+exp(-net));}//初始化int InitBpNet(BPNet *BP);//训练BP网络,样本为x,理想输出为yint TrainBpNet(BPNet *BP, double x[N_Sample][N_In], int y[N_Sample][N_Out]) ; //使用BP网络int UseBpNet(BPNet *BP);//主函数int main(){//训练样本double x[N_Sample][N_In] = {{0.8,0.5,0},{0.9,0.7,0.3},{1,0.8,0.5},{0,0.2,0.3},{0.2,0.1,1.3},{0.2,0.7,0.8}};//理想输出int y[N_Sample][N_Out] = {{0,1},{0,1},{0,1},{1,1},{1,0},{1,0}};BPNet BP;InitBpNet(&BP); //初始化BP网络结构TrainBpNet(&BP, x, y); //训练BP神经网络UseBpNet(&BP); //测试BP神经网络return 1;}//使用BP网络int UseBpNet(BPNet *BP){double Input[N_In];double Out1[50];double Out2[N_Out]; //Out1为中间层输出,Out2为输出层输出//持续执行,除非中断程序while (1){printf("请输入3个数:\n");int i, j;for (i = 0; i < N_In; i++)scanf_s("%f", &Input[i]);double Tmp;for (i = 0; i < (*BP).LayerNum; i++){Tmp = 0;for (j = 0; j < N_In; j++)Tmp += Input[j] * (*BP).v[j][i];Out1[i] = fnet(Tmp);}for (i = 0; i < N_Out; i++){Tmp = 0;for (j = 0; j < (*BP).LayerNum; j++)Tmp += Out1[j] * (*BP).w[j][i];Out2[i] = fnet(Tmp);}printf("结果:");for (i = 0; i < N_Out; i++)printf("%.3f ", Out2[i]);printf("\n");}return 1;}//训练BP网络,样本为x,理想输出为yint TrainBpNet(BPNet *BP, double x[N_Sample][N_In], int y[N_Sample][N_Out]) {double f = (*BP).Accuracy; //精度控制参数double a = (*BP).StudyRate; //学习率int LayerNum = (*BP).LayerNum; //中间层节点数double v[N_In][50], w[50][N_Out]; //权矩阵double ChgH[50], ChgO[N_Out]; //修改量矩阵double Out1[50], Out2[N_Out]; //中间层和输出层输出量int MaxLoop = (*BP).MaxLoop; //最大循环次数int i, j, k, n;double Tmp;for (i = 0; i < N_In; i++)// 复制结构体中的权矩阵for (j = 0; j < LayerNum; j++)v[i][j] = (*BP).v[i][j];for (i = 0; i < LayerNum; i++)for (j = 0; j < N_Out; j++)w[i][j] = (*BP).w[i][j];double e = f + 1;//对每个样本训练网络for (n = 0; e > f && n < MaxLoop; n++){e = 0;for (i= 0; i < N_Sample; i++){//计算中间层输出向量for (k= 0; k < LayerNum; k++){Tmp = 0;for (j = 0; j < N_In; j++)Tmp = Tmp + x[i][j] * v[j][k];Out1[k] = fnet(Tmp);}//计算输出层输出向量for (k = 0; k < N_Out; k++){Tmp = 0;for (j = 0; j < LayerNum; j++)Tmp = Tmp + Out1[j] * w[j][k];Out2[k] = fnet(Tmp);}//计算输出层的权修改量for (j = 0; j < N_Out; j++)ChgO[j] = Out2[j] * (1 - Out2[j]) * (y[i][j] - Out2[j]);//计算输出误差for (j = 0; j < N_Out ; j++)e = e + (y[i][j] - Out2[j]) * (y[i][j] - Out2[j]);//计算中间层权修改量for (j = 0; j < LayerNum; j++){Tmp = 0;for (k = 0; k < N_Out; k++)Tmp = Tmp + w[j][k] * ChgO[k];ChgH[j] = Tmp * Out1[j] * (1 - Out1[j]);}//修改输出层权矩阵for (j = 0; j < LayerNum; j++)for (k = 0; k < N_Out; k++)w[j][k] = w[j][k] + a * Out1[j] * ChgO[k];for (j = 0; j < N_In; j++)for (k = 0; k < LayerNum; k++)v[j][k] = v[j][k] + a * x[i][j] * ChgH[k];}if (n % 10 == 0)printf("误差: %f\n", e);}printf("总共循环次数:%d\n", n);printf("调整后的中间层权矩阵:\n");for (i = 0; i < N_In; i++){for (j = 0; j < LayerNum; j++)printf("%f ", v[i][j]);printf("\n");}printf("调整后的输出层权矩阵:\n");for (i = 0; i < LayerNum; i++) {for (j = 0; j < N_Out; j++)printf("%f ", w[i][j]);printf("\n");}//把结果复制回结构体for (i = 0; i < N_In; i++)for (j = 0; j < LayerNum; j++)(*BP).v[i][j] = v[i][j];for (i = 0; i < LayerNum; i++)for (j = 0; j < N_Out; j++)(*BP).w[i][j] = w[i][j];printf("BP网络训练结束!\n");return 1;}//初始化int InitBpNet(BPNet *BP){printf("请输入中间层节点数,最大数为100:\n");scanf_s("%d", &(*BP).LayerNum);printf("请输入学习率:\n");scanf_s("%lf", &(*BP).StudyRate); //(*BP).StudyRate为double型数据,所以必须是lf printf("请输入精度控制参数:\n");scanf_s("%lf", &(*BP).Accuracy);printf("请输入最大循环次数:\n");scanf_s("%d", &(*BP).MaxLoop);int i, j;srand((unsigned)time(NULL));for (i = 0; i < N_In; i++)for (j = 0; j < (*BP).LayerNum; j++)(*BP).v[i][j] = rand() / (double)(RAND_MAX);for (i = 0; i < (*BP).LayerNum; i++)for (j = 0; j < N_Out; j++)(*BP).w[i][j] = rand() / (double)(RAND_MAX);return 1;}。
bp算法的设计与实现

bp算法的设计与实现一、BP算法的概述BP算法,全称为反向传播算法,是一种常用的人工神经网络学习算法。
其主要思想是通过不断地调整神经元之间的权重和阈值,使得网络输出与期望输出之间的误差最小化。
BP算法的核心在于误差反向传播,即将输出层的误差逐层向前传播至输入层,从而实现对权值和阈值的更新。
二、BP算法的设计1. 神经网络结构设计BP算法需要先确定神经网络的结构,包括输入层、隐藏层和输出层。
其中输入层负责接收外部输入数据,隐藏层通过变换将输入数据映射到高维空间中,并进行特征提取和抽象表示。
输出层则将隐藏层处理后的结果映射回原始空间中,并得出最终结果。
2. 激活函数设计激活函数用于计算神经元输出值,在BP算法中起到了非常重要的作用。
常见的激活函数有sigmoid函数、ReLU函数等。
其中sigmoid函数具有平滑性和可导性等优点,在训练过程中更加稳定。
3. 误差计算方法设计误差计算方法是决定BP算法效果好坏的关键因素之一。
常见的误差计算方法有均方误差法、交叉熵误差法等。
其中均方误差法是最常用的一种方法,其计算公式为:E = 1/2*(y - t)^2,其中y为网络输出值,t为期望输出值。
4. 权重和阈值调整方法设计权重和阈值调整方法是BP算法的核心所在。
常见的调整方法有梯度下降法、动量法、RMSprop等。
其中梯度下降法是最基础的一种方法,其核心思想是通过不断地迭代来更新权重和阈值。
三、BP算法的实现1. 数据预处理在使用BP算法进行训练前,需要对输入数据进行预处理。
常见的预处理方式包括归一化、标准化等。
2. 神经网络初始化神经网络初始化需要设置初始权重和阈值,并将其赋给神经元。
初始权重和阈值可以随机生成或者根据经验设置。
3. 前向传播前向传播过程中,输入数据从输入层开始逐层传递至输出层,并通过激活函数计算出每个神经元的输出值。
4. 反向传播反向传播过程中,先计算出输出层误差,并逐层向前传播至输入层。
BP人工神经网络的基本原理、模型与实例
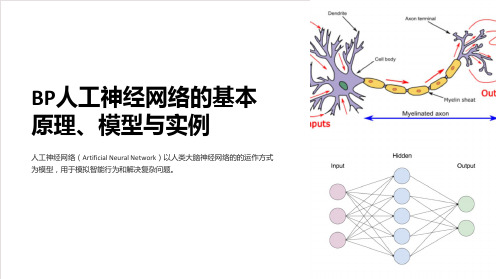
BP人工神经网络的实例
BP人工神经网络可以应用于多个领域,如图像识别、语音处理、预测分析等,为解决复杂问题提供了有效的神经网络的输入是具体问题的相关数据,比如图像数据、声音数据等。 输出是经过神经网络计算后得出的结果。
神经元和连接权重
神经元是BP人工神经网络的基本单元,通过调整连接权重来不断优化神经网 络的表现和学习能力。
前向传播和反向传播
前向传播是指输入数据从输入层经过隐藏层到达输出层的过程。反向传播是指根据误差计算,通过调整连接权 重来优化神经网络的过程。
训练和优化算法
BP人工神经网络的训练过程是通过不断调整连接权重使得神经网络的输出结 果接近于期望结果的过程。优化算法如梯度下降算法等可以加速训练的过程。
BP人工神经网络的基本 原理、模型与实例
人工神经网络(Artificial Neural Network)以人类大脑神经网络的的运作方式 为模型,用于模拟智能行为和解决复杂问题。
BP人工神经网络的基本原理
BP人工神经网络通过多层神经元和连接权重的组合,实现输入数据到输出结 果的计算和转换过程。
BP人工神经网络的模型
人工智能实验报告-BP神经网络算法的简单实现

⼈⼯智能实验报告-BP神经⽹络算法的简单实现⼈⼯神经⽹络是⼀种模仿⼈脑结构及其功能的信息处理系统,能提⾼⼈们对信息处理的智能化⽔平。
它是⼀门新兴的边缘和交叉学科,它在理论、模型、算法等⽅⾯⽐起以前有了较⼤的发展,但⾄今⽆根本性的突破,还有很多空⽩点需要努⼒探索和研究。
1⼈⼯神经⽹络研究背景神经⽹络的研究包括神经⽹络基本理论、⽹络学习算法、⽹络模型以及⽹络应⽤等⽅⾯。
其中⽐较热门的⼀个课题就是神经⽹络学习算法的研究。
近年来⼰研究出许多与神经⽹络模型相对应的神经⽹络学习算法,这些算法⼤致可以分为三类:有监督学习、⽆监督学习和增强学习。
在理论上和实际应⽤中都⽐较成熟的算法有以下三种:(1) 误差反向传播算法(Back Propagation,简称BP 算法);(2) 模拟退⽕算法;(3) 竞争学习算法。
⽬前为⽌,在训练多层前向神经⽹络的算法中,BP 算法是最有影响的算法之⼀。
但这种算法存在不少缺点,诸如收敛速度⽐较慢,或者只求得了局部极⼩点等等。
因此,近年来,国外许多专家对⽹络算法进⾏深⼊研究,提出了许多改进的⽅法。
主要有:(1) 增加动量法:在⽹络权值的调整公式中增加⼀动量项,该动量项对某⼀时刻的调整起阻尼作⽤。
它可以在误差曲⾯出现骤然起伏时,减⼩振荡的趋势,提⾼⽹络训练速度;(2) ⾃适应调节学习率:在训练中⾃适应地改变学习率,使其该⼤时增⼤,该⼩时减⼩。
使⽤动态学习率,从⽽加快算法的收敛速度;(3) 引⼊陡度因⼦:为了提⾼BP 算法的收敛速度,在权值调整进⼊误差曲⾯的平坦区时,引⼊陡度因⼦,设法压缩神经元的净输⼊,使权值调整脱离平坦区。
此外,很多国内的学者也做了不少有关⽹络算法改进⽅⾯的研究,并把改进的算法运⽤到实际中,取得了⼀定的成果:(1) 王晓敏等提出了⼀种基于改进的差分进化算法,利⽤差分进化算法的全局寻优能⼒,能够快速地得到BP 神经⽹络的权值,提⾼算法的速度;(2) 董国君等提出了⼀种基于随机退⽕机制的竞争层神经⽹络学习算法,该算法将竞争层神经⽹络的串⾏迭代模式改为随机优化模式,通过采⽤退⽕技术避免⽹络收敛到能量函数的局部极⼩点,从⽽得到全局最优值;(3) 赵青提出⼀种分层遗传算法与BP 算法相结合的前馈神经⽹络学习算法。
人工神经网络的数学模型建立及成矿预测BP网络的实现

人工神经网络的数学模型建立及成矿预测BP网络的实现一、本文概述本文旨在探讨人工神经网络的数学模型建立及其在成矿预测中的应用,特别是使用反向传播(Backpropagation,简称BP)网络的具体实现。
我们将对人工神经网络的基本原理和数学模型进行概述,包括其结构、学习机制以及优化算法。
然后,我们将深入研究BP网络的设计和实现过程,包括网络层数、节点数、激活函数、学习率等关键参数的选择和优化。
在理解了BP网络的基本原理和实现方法后,我们将进一步探讨其在成矿预测中的应用。
成矿预测是一个复杂的地质问题,涉及到众多的影响因素和不确定性。
BP网络作为一种强大的非线性映射工具,能够有效地处理这类问题。
我们将详细介绍如何根据地质数据的特点,设计合适的BP网络模型,并通过实例验证其预测效果。
我们将对BP网络在成矿预测中的优势和局限性进行讨论,并展望未来的研究方向。
通过本文的研究,我们希望能够为地质领域的决策和预测提供一种新的、有效的工具和方法。
二、人工神经网络的数学模型建立人工神经网络(ANN)是一种模拟人脑神经元网络结构的计算模型,它通过学习大量的输入输出样本数据,自动调整网络权重和阈值,从而实现对新数据的分类、识别或预测。
在建立ANN的数学模型时,我们首先需要明确网络的拓扑结构、激活函数、学习算法等关键要素。
拓扑结构决定了神经网络的层次和连接方式。
在成矿预测中,我们通常采用前馈神经网络(Feedforward Neural Network),也称为多层感知器(MLP)。
这种网络结构包括输入层、隐藏层和输出层,每一层的神经元与下一层的神经元全连接,但同一层内的神经元之间不连接。
输入层负责接收原始数据,隐藏层负责提取数据的特征,输出层负责给出预测结果。
激活函数决定了神经元如何对输入信号进行非线性变换。
常用的激活函数包括Sigmoid函数、Tanh函数和ReLU函数等。
在成矿预测中,由于数据的复杂性和非线性特征,我们通常选择ReLU函数作为隐藏层的激活函数,因为它在负值区域为零,可以有效缓解梯度消失问题。
Keras实现简单BP神经网络

Keras实现简单BP神经⽹络BP 神经⽹络的简单实现from keras.models import Sequential #导⼊模型from yers.core import Dense #导⼊常⽤层train_x,train_y #训练集test_x,text_y #测试集model=Sequential() #初始化模型model.add(Dense(3,input_shape=(32,),activation='sigmoid',init='uniform'))) #添加⼀个隐含层,注:只是第⼀个隐含层需指定input_dimmodel.add(Dense(1,activation='sigmoid')) #添加输出层pile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy']) # 编译,指定⽬标函数与优化⽅法model.fit(train_x,train_y ) # 模型训练model.evaluate(test_x,text_y ) #模型测试常⽤层常⽤层对应于core模块,core内部定义了⼀系列常⽤的⽹络层,包括全连接、激活层等Dense层yers.core.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, Dense就是常⽤的全连接层,所实现的运算是output = activation(dot(input, kernel)+bias)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
完整的python 用BP网络实现的iris数据处理#coding:utf-8from __future__ import divisionimport pandas as pdimport matplotlib.pyplot as pltimport numpy as npfrom sklearn.metrics import roc_auc_scorefrom sklearn.metrics import confusion_matrix################定义激活函数~##########################################def sigmoid_activation(x, theta):x = np.asarray(x)theta = np.asarray(theta)return 1 / (1 + np.exp(-np.dot(theta.T, x)))# 将模型的函数凝结为一个类,这是很好的一种编程习惯class NNet3:# 初始化必要的几个参数def __init__(self, learning_rate=0.5,maxepochs=1e4, convergence_thres=1e-5,hidden_layer=4):self.learning_rate = learning_rateself.maxepochs = int(maxepochs)self.convergence_thres = 1e-5self.hidden_layer = int(hidden_layer)# 计算最终的误差def _multiplecost(self, X, y):# l1是中间层的输出,l2是输出层的结果l1, l2 = self._feedforward(X)# 计算误差,这里的l2是前面的hinner = y * np.log(l2) + (1 - y) * np.log(1 - l2)# 添加符号,将其转换为正值return -np.mean(inner)# 前向传播函数计算每层的输出结果def _feedforward(self, X):# l1是中间层的输出l1 = sigmoid_activation(X.T, self.theta0).T# 为中间层添加一个常数列l1 = np.column_stack([np.ones(l1.shape[0]),l1])# 中间层的输出作为输出层的输入产生结果l2l2 = sigmoid_activation(l1.T, self.theta1)return l1, l2# 传入一个结果未知的样本,返回其属于1的概率def predict(self, X):_, y = self._feedforward(X)return y# 学习参数,不断迭代至参数收敛,误差最小化def learn(self, X, y):nobs, ncols = X.shapeself.theta0 = np.random.normal(0, 0.01,size=(ncols, self.hidden_layer))self.theta1 = np.random.normal(0, 0.01,size=(self.hidden_layer + 1, 1))self.costs = []cost = self._multiplecost(X, y)self.costs.append(cost)costprev = cost + self.convergence_thres + 1counter = 0for counter in range(self.maxepochs):# 计算中间层和输出层的输出l1, l2 = self._feedforward(X)# 首先计算输出层的梯度,再计算中间层的梯度l2_delta = (y - l2) * l2 * (1 - l2)l1_delta = l2_delta.T.dot(self.theta1.T) * l1 * (1 - l1)# 更新参数self.theta1 += l1.T.dot(l2_delta.T) / nobs * self.learning_rateself.theta0 += X.T.dot(l1_delta)[:, 1:] / nobs * self.learning_ratecounter += 1costprev = costcost = self._multiplecost(X, y) # get next costself.costs.append(cost)if np.abs(costprev - cost) <self.convergence_thres and counter > 500:breakif __name__ == '__main__':###################################################数据处理##########################################读取数据##################iris = pd.read_csv("iris.csv")# 打乱数据顺序################shuffled_rows = np.random.permutation(iris.index) iris = iris.iloc[shuffled_rows]print(iris.species.unique())# 添加一个值全为1的属性iris["ones"],截距iris["ones"] = np.ones(iris.shape[0])X = iris[['ones', 'sepal_length', 'sepal_width', 'petal_length', 'petal_width']].values# 将Iris-versicolor类标签设置为1,Iris-virginica设置为0y = (iris.species == 'Iris-versicolor').values.astype(int)# First 70 rows to X_train and y_train# Last 30 rows to X_train and y_trainX_train = X[:70]y_train = y[:70]X_test = X[-30:]y_test = y[-30:]###################################################训练模型################################### Set a learning ratelearning_rate = 0.5# Maximum number of iterations for gradientdescentmaxepochs = 10000# Costs convergence threshold, ie. (prevcost - cost) > convergence_thresconvergence_thres = 0.00001# Number of hidden unitshidden_units = 8# Initialize modelmodel = NNet3(learning_rate=learning_rate, maxepochs=maxepochs,convergence_thres=convergence_thres, hidden_layer=hidden_units)model.learn(X_train, y_train)train_yhat = model.predict(X_train)[0]print(y_train)print(train_yhat)train_auc = roc_auc_score(y_train, train_yhat) print(train_auc)########################################预测数据############################### 因为predict返回的是一个二维数组,此处是(1,30),取第一列作为一个列向量yhat = model.predict(X_test)[0]print(y_test)print(yhat)predict=[]for each in yhat:if each>0.5:predict.append(1)else:predict.append(0)print(predict)auc = roc_auc_score(y_test, yhat)print(auc)#################################写出数据################################################合并各列数据#########################result=np.column_stack([X_test,y_test,predict]) print (result)count=0for i in range(0,len(result)):if result[i,5]==result[i,6]:count+=1################计算准确率#############################print(count,len(result))acurate=count/len(result)print("分类正确率是:%.2f%%" % (acurate * 100))labels = list(set(predict))print(labels)conf_mat = confusion_matrix(y_test, predict, labels=labels)print(conf_mat)#####################数组转换为数据框##########################result=pd.DataFrame(result[:,1:])result.columns = ['sepal_length','sepal_width','petal_length', 'petal_width','species', 'predict']print(result)#########################写出数据到excel################summaryDataFrame = pd.DataFrame(result)# summaryDataFrame.to_excel(filePath,summaryDataFrame.to_excel('iris_test.xlsx', encoding='utf-8', index=False)# Plot costsplt.plot(model.costs,color="red")plt.title("Convergence of the Cost Function") plt.ylabel("J($\Theta$)")plt.xlabel("Iteration")plt.show()。