免疫克隆算法
基于正交设计的免疫克隆遗传算法

本 文在 免疫 克隆遗 传算 法 的基础 上 引入 了正交 实验设 计 的思想 , 应用 到杂 交算 子 中 。实 验结 果表 明 , 并
该算 法 收敛速 度 比经典算 法 更快 , 求解 精度 高 出几个 数量 级 。
1 算 法
1 1 基 本 步 骤 .
( )编码 1
采 用 实数 编码 。实数 编码 要 比二进 制编 码搜 索 的范 围大 , 度 也 更高 , 于 实数 编码 精 基
( ) 即 L ( 。 Q , 2) F 1 1
L2 I | ( 2 1
L 2 2
排 正交 试验 设计 , 到 子代种 群 P , 割形式 见式 ( ) 得 分 4
f 1 ( , 4 5 7 :2 , , ) p
I 2 1
( 3)
将 p , 的第 一个染 色 体看成 是 第一个 因素 , 三 个染 色体 看成 是第 二 个 因 素 。利用 正 交表 L ( 安 。 后 2)
一
领域 里 的新方 法 。免疫 克隆遗 传算 法 能够产 生一 定 的克隆个 体 , 中选 取较优 的个 体作 为后 代 , 从 提高 了搜 索 速度 , 且 加快 了算 法收 敛 。免 疫 克 隆遗 传 算 法 也 存 在 着 “ 熟 ” 局部 搜 索 能 力 差 的 问题 。 并 早 及 ]
的遗传 算法 能很 快 收敛到 最优 解附 近[ 。
( )选择 算子 2
在选择 操作 中 , 引入 一种适 应值 的非 单调 标度 变换 方法 , 目的是 让 适 应值 较 低 的
个体也 有较 大 的机会 参与 种群 的进 化 , 加种 群 的多 样性 , 利 于算 法 进 化 。在 每代 的进 化 中 , 保 留 增 有 都
免疫算法中的克隆变异操作

免疫算法中的克隆变异操作下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by the editor. I hope that after you download them, they can help yousolve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!In addition, our shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts,other materials and so on, want to know different data formats and writing methods, please pay attention!免疫算法是一种启发式优化算法,利用模拟免疫系统中的免疫机制进行问题求解。
基于免疫克隆选择算法的图像分割(精)

[4]
2
.
免疫克隆选择算法
人工免疫系统[6](Artificial Immune System,AIS)是模仿
第 28 卷第 7 期 2006 年 7 月
电 子 与 信 息 学 报 Journal of Electronics & Information Technology
Vol.28No.7 Jul.2006
基于免疫克隆选择算法的图像分割
丛
摘 要
琳
沙宇恒
焦李成
西安 710071)
(西安电子科技大学智能信息处理研究所
segmentation methods, a novel algorithm based on immune clone selection and optimal entropy theory is presented in this paper. Immune clone selection algorithm performs not only local but also global search, and has better performance than Genetic Algorithm(GA) in searching for the optimal entropy threshold of images. The algorithm is depicted in detail and the computational complexity is given. In experiments, natural image and SAR image are selected, and the algorithm runs ten times independently and the mean numbers of function values are presented as the evaluation of the algorithm complexity. It shows that the algorithm presented in this paper can find better solutions with small generation and mean numbers of function values. So this method has better performance in stabilization and convergence than GA. Experimental results show that this method is feasible and effective. Key words Image segmentation, Artificial immune system, Clone selection, Genetic Algorithm (GA) 克隆选择算法作为一种新的全局优化搜索算法,在其算 法实现上兼顾全局搜索和局部搜索,吸取了遗传算法并行搜 索优点,通过接种疫苗和计算亲合度,使得算法快速收敛, 同时保持一定的多样性,抑制了早熟现象。本文将免疫克隆 选择算法应用到图像分割中,根据适应度函数的大小,不断 更新种群克隆的规模,来求得最优的图像分割阈值,达到了 较好的图像分割效果。通过实验数据分析,本文方法优于传 统的遗传算法。
免疫克隆选择算法的改进及其应用

免疫克隆选择算法的改进及其应用邱亚龙;张昕;范妙炳;叶奕纯;陈婷【摘要】Based on the principle of biological immune system, an improved immune clonally selection algorithm(ICSA) was proposed. The algorithm introduced the analysis of antigenic determinant, calculated the network cut factor of antibody space and the end times of antibodies evolution, and created environment required to produce antibodies; shock variation method was adopted to make antibodies mutated; Innovative space adaptive mutation was proposed creatively; The improved ICSA was applied to analyze the parameters optimization problem of the atmospheric pollution harm rate universal formulaRi=1/(1+ae-bxi)c; The results show that the algorithm within the scope of the global and local search is more exquisite. Solution accuracy is significantly increased.%基于生物免疫系统原理,提出了改进的免疫克隆选择算法。
免疫算法基本流程 -回复

免疫算法基本流程 -回复免疫算法(Immune Algorithm,IA)是仿生学领域的一种元启发式算法,它模仿人类免疫系统的功能,用于解决复杂问题的优化问题。
其基本流程包括问题建模、个体编码、种群初始化、克隆操作、变异操作、选择操作等,接下来本文将从这些方面进一步展开详细描述。
一、问题建模在使用免疫算法解决优化问题之前,需要将问题进行合理的建模。
建模过程主要涉及问题的因素、目标和约束条件等问题,例如在TSP(Traveling Salesman Problem)中,需要定义地图中所有城市之间的距离以及行走路线的长度等因素。
建模完成后,将其转化为适合于免疫算法处理的数学表示形式,这有助于优化算法的精度和效率。
二、个体编码从问题建模后,需要将问题的变量转化为适合免疫算法处理的个体编码,即将问题的解转化成一些序列或数值,这样才能进行算法的操作。
对于不同的问题,需要设计合适的编码方式,例如对于TSP问题,可以将城市序列编码成01字符串等。
三、种群初始化在免疫算法中,需要构建一个种群,种群中的每个个体代表了问题的一个解。
种群初始化是在搜索空间中随机生成一组解,并且保证这些解满足约束条件。
种群大小需要根据问题规模和计算能力来合理安排,一般情况下,种群大小越大,搜索空间越大,但是计算成本也越高。
四、克隆操作在免疫算法中,克隆操作是其中一个重要的基因变异操作。
该操作的目的是产生大量近似于当前最优的个体,增加搜索空间的多样性。
克隆操作的流程如下:1.计算适应度函数值,根据适应度函数值进行排序。
2.选择适应度函数值最优的一部分个体进行克隆操作。
3.对克隆个体进行加密操作,增加其多样性。
5、变异操作变异操作是免疫算法中的一个基本操作,其目的是使部分克隆个体产生和原个体不同的搜索方向,增加搜索空间的变异性。
在变异操作中,采用随机、局部搜索或任意搜索等方法来对某些个体进行改变其参数或某些属性,以期望产生一些新的解。
变异操作的流程如下:1.从克隆群体中随机选择一定数量的个体进行变异操作。
桁架结构多目标优化的免疫克隆选择算法

湖 南 大 学 学 报 (自 然 科 学 版 )
J o u r n a l o f Hu n a n Un i v e r s i t y ( Na t u r a l S c i e n c e s )
c l o n a l s e l e c t i o n a l g o r i t h m ( M OI CS A)t o e n h a n c e t h e d i v e r s i t y,t h e u n i f o r mi t y a n d t h e c o n v e r g e n c e o f t h e
c l on a l s e l e c t i on a l g o r i t hm wa s a pp l i e d . Ba s e d o n t he i m mu no l o gy t h e o r y, t he no n — do mi n a t e d n e i g hb or —
S t r u c t u r e Mu l t i — o b j e c t i v e Op t i mi z a t i o n
TANG He — s h e n g ,H U Cha n g — y ua n ,XUE S o n g — t a o - 。 ・ 。
s ol u t i o n o bt a i ne d. Pe n a l t y f unc t i on me t h o d wa s u s e d t o de a l wi t h v i o l a t e d c ons t r a i nt s . Se v e r a l c l a s s i c a l p r obl e ms we r e s ol v e d t o d e mo ns t r a t e t he f e a s i bi l i t y a nd e f f e c t i v e ne s s o f t he M OI CSA a l g or i t hm ,a nd t he r e s ul t s we r e c o mp a r e d wi t h ot he r o p t The s i mu l a t i o n r e s u l t s s ho w t h a t t h e a l g o r i t hm ha s a d v a nt a ge s i n c o n v e r ge nc e s p e e d,t i me c o ns umi n g a nd s o l ut i on q u a l i t y .
一种用于风机故障诊断的免疫克隆特征选择算法

一种用于风机故障诊断的免疫克隆特征选择
算法
1. 引言
风机在工业生产和民用设施中均得到了广泛的应用。
由于风机长
时间运行,其叶片、轴承、齿轮等各部分易受磨损和损坏,导致故障
概率较高。
因此,对于风机的故障诊断和预测,具有重要的实用价值。
目前,传统的基于规则及统计分析的故障诊断方法已经逐渐显现了其
局限性,对于风机出现的复杂故障难以处理。
2. 免疫克隆特征选择算法
免疫克隆特征选择算法是一种基于免疫克隆算法的特征选择方法,该方法可以从众多特征中筛选出最重要的特征来进行风机故障诊断。
该方法独具特色,可用于从海量数据中进行特征选择和数据的降维处理,进而提高机器学习的分类预测能力。
3. 免疫克隆特征选择算法的流程
3.1 数据预处理
对于风机的故障数据,需要进行数据预处理,包括数据清洗、特
征提取、特征归一化等工作,以获得规范化的数据。
3.2 特征选择
将预处理后的数据特征构建成特征集,采用免疫克隆算法进行特征选择,从特征集中筛选出最优特征组合。
3.3 免疫克隆算法
该算法利用免疫系统中的克隆机制对特征进行筛选,根据特征的重要程度来构建特征权重,提高特征的分类预测能力,进而对故障数据进行准确的分类预测。
4. 结论
免疫克隆特征选择算法可以在风机故障诊断领域得到广泛应用,其特征选择能力和分类预测能力优越,可以提高风机故障预测的准确率。
该算法将成为未来风机故障诊断领域的重要研究手段。
免疫算法的克隆选择过程

免疫算法的克隆选择过程% 二维人工免疫优化算法% m--抗体规模% n--每个抗体二进制字符串长度% mn--从抗体集合里选择n个具有较高亲和度的最佳个体进行克隆操作% A--抗体集合(m×n),抗体的个数为m,每个抗体用n个二进制编码(代表参数) % T--临时存放克隆群体的集合,克隆规模是抗原亲和度度量的单调递增函数% FM--每代最大适应度值集合% FMN--每代平均适应度值集合% AAS--每个克隆的最终下标位置% BBS--每代最优克隆的下标位置% Fit--每代适应度值集合% tnum--迭代代数% xymin--自变量下限% xymax--自变量上限% pMutate--高频变异概率% cfactor--克隆(复制)因子% Affinity--亲和度值大小顺序%%clear allclctic;m=65;n=22;mn=60;xmin=0;xmax=8;tnum=100;pMutate=0.2;cfactor=0.1;A=InitializeFun(m,n); %生成抗体集合A,抗体数目为m,每个抗体基因长度为n F='X+10*sin(X.*5)+9*cos(X.*4)'; %目标函数FM=[]; %存放各代最优值的集合FMN=[]; %存放各代平均值的集合t=0;%%while t<tnumt=t+1;X=DecodeFun(A(:,1:22),xmin,xmax); %将二进制数转换成十进制数Fit=eval(F); %以X为自变量求函数值并存放到集合Fit中if t==1figure(1)fplot(F,[xmin,xmax]);grid onhold onplot(X,Fit,'k*')title('抗体的初始位置分布图')xlabel('自变量')ylabel('每代适应度值集合')endif t==tnumfigure(2)fplot(F,[xmin,xmax]);grid onhold onplot(X,Fit,'r*')title('抗体的最终位置分布图')xlabel('自变量')ylabel('每代适应度值集合')end%% 把零时存放抗体的集合清空T=[];%% 把第t代的函数值Fit按从小到大的顺序排列并存放到FS中[FS,Affinity]=sort(Fit,'ascend');%% 把第t代的函数值的坐标按从小到大的顺序排列并存放到XT中XT=X(Affinity(end-mn+1:end));%% 从FS集合中取后mn个第t代的函数值按原顺序排列并存放到FT中FT=FS(end-mn+1:end);%% 把第t代的最优函数值加到集合FM中FM=[FM FT(end)];%% 克隆(复制)操作,选择mn个候选抗体进行克隆,克隆数与亲和度成正比,AAS是每个候选抗体克隆后在T中的坐标[T,AAS]=ReproduceFun(mn,cfactor,m,Affinity,A,T);%% 把以前的抗体保存到临时克隆群体T里T=Hypermutation(T,n,pMutate,xmax,xmin);%% 从大到小重新排列要克隆的mn个原始抗体AF1=fliplr(Affinity(end-mn+1:end));%% 把以前的抗体保存到临时克隆群体T里%从临时抗体集合T中根据亲和度的值选择mn个T(AAS,:)=A(AF1,:);X=DecodeFun(T(:,1:22),xmin,xmax);Fit=eval(F);AAS=[0 AAS];FMN=[FMN mean(Fit)];for i=1:mn%克隆子群中的亲和度最大的抗体被选中[OUT(i),BBS(i)]=max(Fit(AAS(i)+1:AAS(i+1)));BBS(i)=BBS(i)+AAS(i);end%从大到小重新排列要克隆的mn个原始抗体AF2=fliplr(Affinity(end-mn+1:end));%选择克隆变异后mn个子群中的最好个体保存到A里,其余丢失A(AF2,:)=T(BBS,:);enddisp(sprintf('\n The optimal point is:'));disp(sprintf('\n x: %2.4f, f(x):%2.4f',XT(end),FM(end)));%%figure(3)grid onplot(FM)title('适应值变化趋势')xlabel('迭代数')ylabel('适应值')hold onplot(FMN,'r')hold offgrid on。
免疫优势克隆算法

内 j ,乙 1
图象
图 1 函数的变换结果
( b ) 变换后的图象
1 9 2 0
电
子
与
信
』 L
学
报
第2 6卷
对于非函数优化问题, 对 目标函数进行变换是困难的; 而且, 对于复杂问题, 往往很难获得 有益的先验知识,因此,本文进一步提出在人工免疫系统中更一般的抗体免疫优势概念. 2 . 1 . 2 抗体免疫优势 本文用抗体免疫优势的概念来表示抗体编码每一位对抗原的不同重要 程度。这里没有完全遵循免疫优势的生物学定义,一方面是因为依据独特型调节网络理论,抗 体也具有抗原特性,因此将这一概念用于抗体是有生物学基础的;另一方面,在人工免疫系统 中主要操作是针对抗体,而非抗原。
- 1 2改回
和6 0 3 7 2 0 4 5 ) 资 助项目
第1 2期
杜海峰等:免疫优势克隆算法
1 9 1 9
似0 - 1 背包问题这样的组合优化问题以及复杂函数的优化问题,具有一定的通用性,而且性能 优于相应的进化算法.
2免疫优势
2 . 1定义[ 7 ] 免疫学认为,虽然一个抗原分子上可以有多个表位,但在诱导宿主免疫应答时可能只有一 种或一个表位起主要作用,使宿主产生以该特异性为主的免疫应答;这种现象称为免疫显性或 免疫优势 ( I m m u n o d o m i n a n c e ) , 起关键作用的表位称为显性表位。 免疫优势是在抗体与抗原相 互作用中产生的,其产生和作用都是一个动态的过程.免疫优势位点决定了在自 然选择中哪一
基于免疫克隆选择算法的TDOA定位技术

随着移动通信技术的飞速发展, 利用蜂 窝网络 对移 动 台进 行 定位 将 逐 渐 成 为蜂 窝 网络 的 一 项 重
要功 能 . 近年研 究 结 果 中 , D 在 T 0A方 法 由于对 设 备 改动 少 并且 不需要 移 动 台基 站 问进行 严 格 的 同步 , 因 而是一种 理想 的定 位方法 . 对 于 D A方式 , 多个 接 收机 位 于 一 r0 若 条直 线
法 , 种 迭代 需 要 一个 较 好 的 初 始值 , 则 容 易落 这 否 人局部 最小 点 , 而且 不能 保证 收敛Байду номын сангаас. 献【】 出 厂一 文 7提 种 2步 加权 L S方法 .在 洲量 参数 误 差 很小 的情况 下 , 能 逼 近最 优 值 , 性 但是 这 种 方法 由 于引 入 了测
量参 数 的平 方项 , 测量 误 差 较 大 时 , 当 噪声 的 二 次 项不 可忽 视 , 其性 能会 恶化 .
L, 许 多优 化处 理 方 法…但 如 果 接 收机在 空 间随 有 . 机分 佰 , 解 双 曲线 方程 组时 会遇 到非 线性 问题 . 在求 文献 l 给 了测 量 参 数个 数 与 源 信号 坐 标 个 数 相 2 1 同时 的精 确解 . 而 , 然 当测 量 参数 的个 数有 冗 余 时 , 这 种方 法 不 能 充 分 利 用 多余 的 测 量参 数 给 m 的统
3 5卷第 1 期 1
20 0 8年 l j I厂
应
Ap l f pi 1 e
用
科
技
Vn _5. . l 13 N0 1 N0 -00 v2 8
i n a d . h o ( y e( e n r n 1g r )
免疫克隆选择多目标优化算法与MATLAB实现

关键 词 : 免疫 克隆选 择多 目 标优化 ; M A T L A B ; 高频变异
中图分类号 : T P 3 1 1
文献标识码 : A
文章 编 号 : 2 0 9 5— 2 1 6 3 ( 2 0 1 4 ) 0 3— 0 0 4 5— 0 4
I mmu n e C l o n a l S e l e c i t o n Al g o r i t h m f o r Mu l i- t — o Ne c v t i v e Op t i mi z a t i o n
r i t h m e v o l u t i o na r y f o r c e i s t o t a l l y d e pe n d o n h yp e r mut a t i o n,d ue t o t h e r e i s no c r o s s i n c l o ne pr o c e s s .Fi n a l l y, t he c l a s s i c
选择 以及 种群 修剪。算法中采用实数编码 , 每个基因位对应一个 目标 函数值 , 由于克隆不存 在交叉 , 本 文算法 的进 化动力完全 依 靠 高频 变异。最后 , 选取了经典测试函数对算法进行 了测试 , 结果表 明 : P a r e t o 最 优解 的分 布范 围广 、 分 布均匀 , 用 M A T L A B实现
a n d M a t l a b I mp l e me nt a t i o n
Du Zh e n h u a ,Ya n S u ,Ch e n Ha i y u n ,Ze n g Hu a n
( 1 S c h o o l o f E l e c t r i c a l E n g i n e e r i n g a n d I n  ̄r ma i f o n,S o u t h w e s t p e t r o l e u m u n i v e r s i t y, Ch e n g d u 6 1 0 5 0 0, C h i n a ; 2 C NOOC En e r g y Co n s e r v a t i o n& E n v i r o n me n t a l P r o t e c t i o n S e r v i c e CO. , L t d ,T i a n j i n 3 0 0 4 5 7, C h i n a )
Ch7免疫克隆选择算法

Ch7 免疫克隆选择算法7.1生物学知识1、免疫系统免疫力也就是我们俗称“抵抗力”、“体质”等,人体之所以能抵御体内、外的各种致病因子的侵袭,全仗我们拥有健全的免疫系统。
免疫系统共有三道防线。
人体的皮肤和粘膜构成免疫战线上的第一道防线,阻挡着各种致病微生物的侵入。
健康完整的皮肤与粘膜、鼻孔中的鼻毛、呼吸道粘膜表面的粘液和纤毛,均能阻挡并排除微生物。
皮肤和粘膜还会分泌杀菌的物质,如皮肤的汗腺能分泌乳酸,使汗液呈酸性,不利于病菌等生长;皮脂腺分泌的脂肪酸,也有一定的杀灭病菌作用。
胃粘膜分泌的胃液里有胃酸,也具有杀菌作用,但如果暴饮,胃酸就会被冲淡,杀菌能力降低。
这样一来,病菌就有入侵机会,人就容易得胃肠疾病。
当病原体突破第一道防线后,它们会在人体内部处处遭到打击。
遍及全身的像蜘蛛网似的淋巴结,就像撒下的天罗地网,使“敌人”寸步难行。
假使病原体侵入血液或组织中,我们机体仍可沉着应战。
因为人体内有许许多多能够吞噬病原体的吞噬细胞。
它们紧紧缠住病菌,置敌于死地。
战斗进行有时很激烈,以致伤口发生红肿或长成疖肿。
由此可见,吞噬细胞的作用就是把侵入人体的病菌消灭在局部,不使它们向全身扩散。
如果侵入人体的病菌数量多、毒性大,或者在疖肿还没有充分化脓熟透的时候就用手去挤,这些病菌就可能冲破第二道防线,进入血液循环系统,病变就会由局部扩展到全身,引起全身严重的症状。
如果病原体冲破第一道和第二道防线,在人体中获得了立足点,并大量生长繁殖,就会引起感染。
此时机体与病原体展开了针锋相对的斗争,斗争的胜负取决于第三道防线的牢固与否,以及敌我之间大量的对比。
这道防线上的主力军有T淋巴细胞和B淋巴细胞。
据估计,一个健康人体内大约有一百亿的淋巴细胞在活动。
当T和B细胞接到“敌情报告”后马上动员起来,T细胞产生各种淋巴因子,B细胞装备成能产生抗体(即所说的免疫球蛋白)的浆细胞。
各种病原体碰到这一支多兵种的免疫大军——吞噬细胞、抗体、补体、淋巴细胞和浆细胞等,只好乖乖地举手投降。
量子免疫克隆多目标优化算法

标优化算法 ,并对算法进行 了理论分析;与 R GA、S E 和 MIA 等算法 的比较表 明,该算法对低维多 目标优 W P A S
化 问题 更有 效 。
关键 词:人工免疫系统;量子位编码 ;多 目标优化
中图分 类号 : P 0 . 0 2 T 31 , 24 6
文献标识码 : A
文章编 号: 09 8620)616- 10— 9( 8 —37 5 5 0 0 0
1 引言
自上 世 纪 8 年 代 开 始 进 化 算 法逐 步发 展 成 为有 效 解 决 0 多 目标 优 化 问题 的 重 要 技术 。早 在 1 6 ,Roeb r 其 9 7年 sn eg在 博 士 学 位 论 文 中 曾提 到 可 用 遗 传 算 法 来 求 解 多 目标 的优 化 问题 _,但 直 到 18 年 才 出现 基 于 向量 评 估 的 VE l J 95 GA 算 法 这 是 第 一 个 多 目标进 化算 法 ,但 VE GA 算 法 本 质 上 仍
维普资讯
第 3 卷 第 6期 0
2 0 年 6月 08
电
子
与
信
息
学
报
Vo1 N O. . 30 6
J u n l fElc r n c o r a e t o is& I f r t n T c n lg o n o ma i e h o o y o
(nt ueo tlg n nomainP oesn , da nvri , ’n7 0 7 , hn ) Isi t fI eie t fr t rcsig Xiin U ies y Xi 10 1 C ia t n l I o t a
Ab t a t Ba e n t ec n e to mu o o i a c , n i o y co a e e t n t e r n u n u b ts r t g , s r c : s d o h o c p fi m n d m n n e a tb d l n l l c i h o y a d q a t m i t a e y s o
桁架结构优化设计的免疫克隆选择算法

的用 于求解 问 题 的系 统 或 计 算 工 具 _ . 一 领 域 出 8这 ]
现于 2 0世 纪 8 0年代 中期 , 的 应用 涵 盖 了从 生物 它 学 到 机器 人技 术 等诸 多领 域l . 而 , _ g 1 然 在结 构 工程
L F n A GH s e g , / e g ,T N eh n XUR i XU S n to ’ u , E o ga
(1 Re e r h I siue f Sr cu a En n e i g n Dia tr . s ac n tt t o tu tr l gie rn a d s se
对 于 桁 架 结 构 , 给 定 结 构 形 式 、 料 、 局 拓 在 材 布
扑 和 形状 的情 况 下 , 化各 个 杆 件 的截 面 尺 寸 使 结 优
构最 轻 , 即尺 寸优 化 . 尺寸 优化 中取 杆 件 的横 截 面 在
积 为 设 计 变 量 . 结 构 优 化 领 域 中 , 化 准 则 在 优 ( p i l y r e i,O o t i ci r ma t t a C) 法 _ 与 数 学 规es y S a g a 2 0 9 eut , o nj nvri , h nh i 0 0 2, C ia 2 t hn ; .
De a t n fAr htcu e, c o l fEn ie rn To o uI siueo p rme t c i tr S h o gn e ig, h k n tt t f o e o
题. 但启发 式 算法 共 同的 缺点 是 参数 不 易 确定 , 参数 的设 置通 常会 影 响算法 收 敛 的效果 . 人工 免疫 系统 (ric lmmuesse , I) atii f a i n ytmsA S
人体免疫系统的克隆技术

人体免疫系统的克隆技术人体免疫系统是我们身体中很重要的一个系统,它能够抵御各种病毒、细菌和其他病原体的攻击。
然而,有些疾病比如艾滋病、癌症等,会让我们的免疫系统变得脆弱,无法有效地对抗这些病原体的入侵。
因此,科学家们一直在探索一种能够增强人体免疫系统的方法,其中克隆技术是一个研究方向。
克隆技术可以被定义为利用细胞或者分子高精度地制作相似的复制品。
在治疗人类疾病的方面,克隆技术可以用来制作免疫细胞、疫苗和抗体等物质,这些物质都可以被用于提升人体的免疫系统效率。
在免疫细胞的制作方面,克隆技术可以被用于制作大量复制品。
研究人员可以从一个单独的免疫细胞中提取其基因,然后将它们插入到其他细胞中,使得这些细胞也具有同样的基因。
这些复制后的细胞可以被用于提升人体的免疫系统,因为它们具有相同的能力,能够有效地对抗各种病原体的攻击。
另一种克隆技术的用途是制作疫苗。
疫苗通常是由病原体的一些特定部分组成的,这些部分可以在人身体中唤起免疫反应。
克隆技术可以用于合成这些部分。
然后,这些部分就可以被用于制作疫苗,这样我们就可以预防许多常见的传染病。
抗体是另一种克隆技术的产品,这些抗体也被称为单克隆抗体。
这些抗体是由单个细胞制作的,它们可以特异性地与入侵人体的病原体结合,从而帮助人体抵御疾病。
通过克隆技术,科学家们可以制作大量相同的抗体,这些抗体可以被用于治疗各种疾病,包括癌症、感染性疾病等等。
尽管克隆技术在提升人体免疫系统上有着重要的作用,但是人们仍然存在着对它的担忧,其中一项就是安全性问题。
科学家们必须确保克隆产品的安全性,这意味着必须要进行大量的测试和实验,以确保这些克隆产品是安全有效的。
除此之外,人们也对克隆技术所产生的道德问题进行了讨论。
克隆技术可能会导致人类基因被操纵,这样就会对人类社会产生严重的影响。
因此,对于克隆技术来说,伦理问题和道德问题都需要被重视。
综上所述,克隆技术在提升人体免疫系统方面有着非常大的潜力,它可以被用于制作免疫细胞、疫苗和抗体等等。
自适应克隆免疫算法应用于宽带匹配网络设计

自适应克隆免疫算法应用于宽带匹配网络设计李文涛;郭玉春;史小卫【摘要】针对克隆选择算法的不足,提出了一种自适应克隆免疫算法.直接根据抗体的多样性来确定克隆规模,通过引入抗体的自适应变异操作,增加对精英抗体的记忆和相似抑制操作来产生种群新个体,以保证算法的全局收敛性和抗体的多样性.将该算法应用于宽带匹配网络的拓扑结构和元件值的综合优化设计中,并分析了优化过程中频率采样点数的合理选取问题.仿真结果通过与实频法、遗传算法和克隆选择算法相比较,表明该算法具有更快的收敛速度,设计的匹配网络具有更优的匹配性能.【期刊名称】《中北大学学报(自然科学版)》【年(卷),期】2010(031)003【总页数】5页(P243-247)【关键词】宽带匹配网络;实频法;自适应克隆免疫算法;遗传算法【作者】李文涛;郭玉春;史小卫【作者单位】西安电子科技大学,天线与微波技术国家重点实验室,陕西,西安,710071;西安电子科技大学,天线与微波技术国家重点实验室,陕西,西安,710071;西安电子科技大学,天线与微波技术国家重点实验室,陕西,西安,710071【正文语种】中文【中图分类】TN802宽带匹配问题是通讯、雷达、导航和其它电子系统中经常遇到的一个关于功率传输的基本问题,在网络综合,特别在天线系统和微波网络电路中得到了广泛的应用.因此,宽带匹配网络的设计一直是研究的热点.宽带匹配网络的设计方法主要有解析法和数值法.由于解析法无法应用于负载形式未知的工程中,其应用受到限制.文献 [1]给出了目前宽带匹配网络设计主要采用的数值方法,然而数值法具有计算过程复杂且对初值的严格近似要求等缺点.虽然遗传算法被成功地应用于匹配网络设计[2-4],但由于其搜索方式的单一性和排它性,使得其对于初始群体依赖性较大且更多地强调全局搜索而忽视局部搜索很容易陷入局部最佳值.免疫算法[5]是一种最新的启发式高效智能仿生算法,由于其搜索目标的分散性和独立性,故该算法不仅可以收敛到全局最优,而且可以加快收敛速度[6].De Castro等人提出的克隆选择算法[7](CLONALG),成功用于模式识别和多峰函数优化.与遗传算法有性繁殖(交叉、变异)不同,克隆选择算法是通过无性繁殖(克隆、变异)连续传代形成群体.CLONALG虽然解决了遗传算法局部搜索能力差的问题,但是用较小的变异概率来提高局部搜索能力的同时,降低了全局搜索能力;而较大的变异概率尽管能提高全局寻优能力,但收敛精度下降[7-8].本文在克隆选择算法[8]的基础上,引入基于浓度的克隆规模算子、自适应变异算子以及记忆算子和相似抑制算子,提出了自适应克隆免疫算法,在保证全局搜索能力的同时提高了收敛精度.以典型的宽带匹配问题为例,对宽带匹配网络的拓扑结构和元件值进行综合优化设计,设计结果与实频法、遗传算法以及克隆选择算法进行了比较,显示了该方法的有效性.1 优化模型宽带匹配网络的设计目标是设计一个最佳的无耗互易均衡网络,使一个任意的负载与信号源相匹配,并且在给定的频带内实现预定的转换功率增益.图 1为宽带匹配系统模型,图中 Zs为信号源内阻抗,Zi为负载阻抗,N表示宽带匹配网络,它一般是由电容、电感组成的无耗互易二端口网络.匹配网络形式很多,通常采用 T型或∏型网络为基本的网络拓扑结构.一般而言,网络的拓扑结构对匹配性能的影响要大于元件参数的影响[2].当对网络的拓扑结构和元件值同时进行优化时,问题变为既有离散变量又有连续变量的混合型优化问题.这类问题用一般方法难于求解,而免疫算法则是解决该问题的一种有效方案.通常表征匹配的参量主要有转换功率增益(T PG)和反射系数,如图 1所示.转换功率增益和反射系数的定义分别由式(1)和式(2)给出图1 宽带匹配系统Fig.1 Broadband matching system式中:P为负载得到的平均功率;Pav为信号源能够给出的最大平均功率,即信号源资用功率.式中:Zin为输入阻抗;Zg为源阻抗,工程中 Zg一般为50Ω.综合考虑带内反射系数和转换功率增益这两个指标,并采用加权法来设计目标函数,其定义为式中:m为工作频带内采样频率点数;p,q为指定的常数;Γ0为期望反射系数;U为加权系数;W(j)为加权函数,由式(4)确定式中:v和 e分别为两个指定的常数;d(wj)是驻波比.仿真中发现,后一项的引入可以加快收敛速度,并且克服了目标函数对匹配元件数值微小变化敏感的缺点.2 自适应克隆免疫算法采用克隆选择算法求解优化问题时,将待求解的问题视为抗原,待求的解作为抗体的评价函数,通过模拟生物体的克隆选择机制来优化抗体,从而找到相应的解.然而,克隆选择算法不具备完全收敛性[9],但该算法在解决优化问题时,若采用新的操作算子,则可以使算法有更好的收敛性能.为此,本文提出自适应克隆免疫算法,对原克隆选择算法的改进主要有 3个方面:①引进“浓度抑制”,保证克隆规模不是仅由亲和力的大小而决定,而是由亲和力与抗体的浓度共同决定,从而保证了解群体的多样性;②引进“自适应变异”,即变异概率随抗体与抗原亲和力的不同而自适应地改变,自适应的变异概率能够提供相对某个解的最佳变异概率;③引进“记忆算子”,以保证精英抗体不被破坏.2.1 克隆规模函数按式得抗体的平均信息熵,其中为 N个抗体第j位的信息熵,pij为 N个抗体第j位为 ks(0或 1)的概率;M为抗体长度.按公式 ayvw=1/(1+ H(2))计算抗体 v和 w之间的亲和力,抗体 i的浓度可定义为式中:mi为与抗体 i的亲和力大于θ的抗体数;θ为预先设定的阀值,一般取0.7≤θ≤0.9.根据式(5)计算抗体的浓度,并根据抗体浓度进行免疫调节,增进抗体的多样性.选择抗体的标准由抗体亲和力和浓度抑制两个部分组成式中:λ和Z为加权系数.算法中克隆规模定义为式中:U为克隆系数;i为按抗体适应度降序排列后的编号.显然,抗体的克隆规模不仅与该抗体的适应度有关,而且与其浓度有关.适应度越大,浓度越低的抗体,则克隆规模越大;抗体浓度越大,反映所在群体中与其相同或相似的抗体越多.而克隆选择算法的克隆规模只与抗体的适应度有关,即适应度越大克隆规模越大,这样容易导致算法陷入局部极值,通常表现为抗体聚集度越来越高,全局最优抗体长时间保持不变.本文算法中既鼓励适应度高的抗体又抑制浓度高的抗体,有利于保证抗体群的多样性.2.2 自适应变异算子本文对抗体变异采用自适应变异算子,定义为式中:Pm1=0.1;Pm2=0.01;fmax是群体最大适应度值;favg是群体平均适应度值;f为变异抗体的适应度值.可以看出,当抗体与抗原的亲和力,即其适应度比较集中或分散时,可适当增大或减小其变异概率.另外,对于适应度高于群体平均适应度的抗体,对应较低的 Pm,使得该解得以保护;而低于平均适应度的抗体,对应于较高的 Pm.因此,自适应的 Pm能够提供相对某个解的最佳变异概率.这样不仅能够保持解群体多样性而且保证了算法的收敛性.2.3 记忆算子文献 [8]提出的算法对每代产生的精英抗体没有保存,继续参加下一代进化.这样处理很可能导致原精英抗体遭到破坏,使搜索结果不稳定,并且增加算法的冗余计算量.为此,本文引入记忆算子,将每代的精英抗体加入记忆库,并对其进行相似抑制操作,即若两抗体的亲和力大于抑制阀值θ时,则只保留其中亲和力高的抗体.经过抑制算子操作,能保证记忆库中每个峰仅有一个抗体保存下来.经过本文算法,使得每个峰对应的抗体都有进入下一代和记忆库的机会.通过记忆算子的择优记忆和相似抑制算子的作用,保证每个峰都有一个且只有一个相应抗体保留在记忆库中,从而保证了本文算法的收敛性.ACIA算法步骤如下:1)初始化抗体群 Ab并编码.对于匹配网络,一旦单元的数目和每个单元的属性确定,则整个匹配网络的结构即可确定.本文采用一维顺序编码,每个单元的编码方式如图2所示.图中,k1k2为控制位,表示每个单元的属性.00代表一个电感,01代表一个电容,10代表一个电感串联一个电容,11代表一个电感并联一个电容.2)计算抗体的亲和力(适应度).3)按式(5)计算抗体浓度.4)在 Ab中选择前 r个高亲和力抗体,组成一个新的集合Ab{n}.同时在此进行记忆操作,检查记忆库中是否有相似抗体,如果有,则删除其中亲和力小的抗体.5)按式(7)对 Ab{n}进行克隆操作,得到规模为 Nc的抗体群Abc;6)对 Abr中的抗体进行自适应变异,得到规模为 Nc的抗体群 Abm;7)计算种群 Abm的适应度值,根据亲和力从 Abm中选取 r个亲和力最高的抗体,进入 Ab.8)随机产生规模为 N~r个新抗体,代替 Ab中亲和力最低的 N~r个亲和力最低的抗体.重复执行步骤 2)~步骤 8),直到结束条件满足.图2 编码图Fig.2 Coding diagram3 算法实例为了验证本文算法的有效性,以图 3所示负载 L=2.3 H,C=1.2 F,为例设计匹配网络,使负载与内阻为R0=2.2Ω的信号源相匹配,工作频率为(0,1),并与实频法[10]、遗传算法和克隆选择算法[8]进行比较.在优化中,采样点数是一个重要的参数,如果采样点数过少,则不能精确代替整个频带,而文献[3,11]并未讨论取样频率点数的选取.从图 4可以看出,当采样频点数M≥70时,平均反射系数和最大反射系数变化趋势都趋于平缓.因此本文在仿真中,所有的算法采样频点数均取为 100.图3 3种不同的方法设计的匹配网络结构Fig.3 Matching network structures by three methods图4 频率反射系数Fig.4 Reflection coefficient表1 4种方法的设计结果Tab.1 Desig n results by four methodsRFM GA CLON ALGACSAC C1 0.9320 0.9980 1.0450 1.1118 L2 2.8900 2.9589 2.8180 2.8425 C3 0.3510 0.4521 0.3581 0.3941 L3 1.0802 1.0577|Γ|max 0.40080.3863 0.3792 0.3750|Γ|min 0.3355 0.3098 0.2987 0.2551 Gmax 0.88740.9040 0.9108 0.9350 NF 28800 11400 7800优化设计的匹配网络拓扑结构如图 3所示,加匹配网络后输入端反射系数模值和转换功率增益曲线如图 5所示.表 1给出了匹配网络的各元件值及加匹配网络后工作频带内最大和最小反射系数|Γ|max,|Γ|min,带内最大转换功率增益 Gmax和目标函数计算次数 Nr.遗传算法参数设置为:种群规模 Mp=120,交叉概率 Pc=0.8,变异概率 Pm=0.01;克隆选择算法的参数设置为:抗体数 N=100,阈值 Tac=0.73.由表 1知,本文算法设计的匹配网络的带内最大反射系数为 0.3750,最小反射系数为 0.2551,最大转换功率增益为 0.9350,均明显优于 RFM,GA和 CLONALG的设计结果.由图 5可知,与其它算法相比,自适应克隆免疫算法设计的匹配网络的带外特性较陡,但匹配网络的复杂度为 4,可见获得较好的性能是以增加匹配网络的复杂度为代价的.由表 1中对目标函数的计算次数可以得出各算法的收敛速度为 ACIA>CLON ALG >GA.这是因为克隆选择算法随着进化代数的增加收敛速度变慢,而遗传算法很容易早熟,时常陷入局部极值,跳出局部最优解需要靠变异等待更好的机会,因此消耗大量的代数.而自适应克隆免疫算法直接根据抗体的多样性而确定抗体的克隆规模,且自适应变异算子和记忆算子的引入,使得该算法相比其它算法收敛速度更快.图 3(c)和图 5结果显示,采用自适应克隆免疫算法可以设计出匹配性能更好的匹配网络.图5 反射系数和转换功率增益曲线Fig.5 Comparison of magnitude of reflection coefficient and transducer power gain using GA,ACIA,CLON ALG and RFM4 结束语宽带匹配网络优化问题一直是一个研究的重点,本文提出基于浓度克隆规模和记忆细胞精英抗体遗传策略的自适应克隆免疫算法,并将其应用于典型宽带匹配网络的优化设计中.由于本文算法避免了搜索的盲目性,保证了算法的收敛性和解群体的多样性,故该算法设计的匹配网络性能明显优于实频法、遗传算法和克隆选择算法的优化设计结果,有望进一步在其它领域得到广泛的应用.参考文献:[1]陈轶鸿,孙琰.宽带匹配网络的现代设计方法[J].电波科学学报,1996,11(2),102-109.Chen Yihong,Sun Yan.Modern methods for the design of broadband matching networks[J].Chinese Journal of Radio Science,1996,11(2):102-109.(in Chinese)[2]Weile D S,Michielssen E.Genetic algorithms optimization applied to electromagnetics:A review[J].IEEE Trans.On AntennasPropagation,1997,45(3):343-353.[3]马国田,梁昌洪.基于遗传算法的宽带匹配网络的优化设计[J].微波学报,2000,16(1):73-77.Ma Guotian,Liang Changhong.Optimal design of broadband matching networks based on GA[J].Journal of Microwaves,2000,16(1):73-77.(in Chinese)[4]Yegin K,Martin A Q.On the design of broad-band loaded wire antennas using the simplified real frequency technique and a geneticalgorithm[J].IEEE Trans.On Antennas Propagation,2003,51(2):220-228. [5]Adnan A.Clonal selection algorithm with operator multiplicity[J].IEEE Trans.On Evolutionary Computation,2004,2(2):1909-1915.[6]Zhou Honggang,Yang ing immune algorithm to optimize anomaly detection based on SVM[C].IEEE Proceedings of the Fifth International Conference on Machine Learning and Cybernetics,2006:4257-4261. [7]Castro L N,Von Zuben F J.The clonal selection algorithm with engineering applications[C].In workshop Proceedings ofGECCO’00,Workshop on Artificial Immune Systems and their Applicatons,2000.[8]DE Castro L N,Von Zuben F J.Learning and optimization using the clonal selection principle[J].IEEE Trans.On Evolutionary Computation,2002,6(3):239-251.[9]郑士芹,王秀峰.基于多模态函数优化的改进克隆选择算法[J].计算机工程与应用,2006,42(3),15-18.Zheng Shiqin,Wang Xiufeng.An improved clonal selection algorithm for multi-modal function optimization[J].Computer Engineering and Applications,2006,42(3):15-18.(in Chinese)[10]Carlin H J.A new approach to gain bandwidth problem[J].IEEE Trans.On Circuit Theory,1977,24(4):170-175.[11]Rogers S D,Bulter C M,Martin A Q.Design and realization of GA-Optimized wire monopole and matching network with20:1bandwidth[J].IEEE Trans.On Antennas Propagation,2003,51(3):493-501.。
基于克隆选择原理的免疫识别算法研究
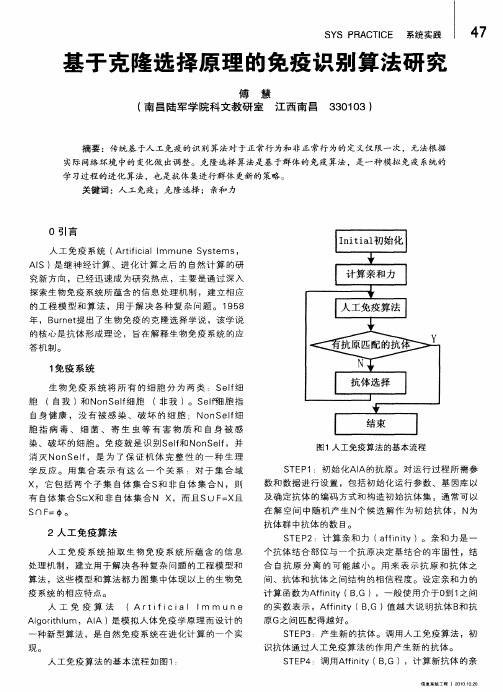
抗体 群 中抗体 的数 目。 S E 2:计 算 亲和 力 ( fi i T P af t n y)。亲和 力 是 一 个抗 体结 合部位 与一个抗 原决定 基结合 的牢 固性 ,结
合 自抗 原 分离 的可 能越 小。 用 来 表 示抗 原 和抗 体 之
间、抗 体和抗 体 之间结构 的相信 程度 。设定亲和 力 的 计算 函数 为A f i BG ),一般使用 介于O 1 间 fi t n y( , 到 之
s s P A Tc 系统 实践 Y R c .E
l 4 7
基于克 隆选择原 理 的免疫识 别算法研 究
傅 慧 ( 昌陆 军 学 院科 文教 研 室 江 西 南 昌 南
300 3 1 3)
摘要 :传 统基 于人工免疫 的识 别算法对 于正 常行 为和 非正常行为的定 义仅 限一 次,无法根 据 实际 网络环境 中的变化做 出调整 。克隆选择 算法是基 于群体 的免 疫算法 ,是一种模拟免 疫 系统的
和度 的n 个抗体 组成新一代抗体 群 ,更新抗体 集合。 SE6 T P :如果 满足终止条件 ,则 结束 :否则转至
S EP 继 续 执 行 。 T 1
从 算 法 流程 分 析得 知 ,克 隆选 择 的 主要 特征 是
免疫 细 胞在 抗 原 刺激 下 产生 克 隆增 殖 ,随后 通过 遗
答 机制 。
1 疫 系 统 免
生 物 免 疫 系统 将 所 有 的细 胞 分 为 两 类 :S f ef 细 胞 (自我 )和No S l n ef 细胞 ( 非我 )。S l 胞 指 ef 蜘
自身 健 康 ,没 有被 感 染 、破 坏 的细 胞 ;NO S I n ef 细 胞 指 病 毒 、 细 菌 、 寄 生 虫 等 有 害 物 质 和 自身 被 感
一种改进的免疫克隆选择算法

一种改进的免疫克隆选择算法牛永洁;马亚玲【摘要】为了提高传统的克隆选择算法收敛速度慢、搜索能力弱、易局部最优化的缺陷,对基本的克隆选择算法进行了改进.改进的措施主要包括4个方面,分别是新的克隆方法、变异概率的自适应变化、替换策略的自适应变化、变异概率的突变.改进的克隆选择算法经过多个多峰值标准函数的仿真测试,具有较快的收敛速度和较强的寻找峰值的优点,改进的效果显著.【期刊名称】《电子设计工程》【年(卷),期】2014(022)004【总页数】3页(P23-25)【关键词】克隆选择;变异概率;克隆策略;自适应;突变【作者】牛永洁;马亚玲【作者单位】延安大学计算中心,陕西延安716000;河南中医学院图书馆,河南郑州450008【正文语种】中文【中图分类】TN711.1克隆选择算法是人工免疫系统中一种经典的免疫算法模型,2002年由De Castro 根据生物免疫系统理论中的克隆选择学说而提出[1],这种算法简称为CLONALG。
由于克隆选择算法具有并行性、自适应性、学习、识别和记忆等优点,很快被应用到函数优化[2-3]、特征选择[4]、入侵检测[5]、图像分割[6-7]、机器学习[8]等领域。
但是CLONALG算法具有收敛速度慢、搜索能力弱、易陷入局部最优的缺点,本文对CLONALG算法在4各方面进行了改进,改进后的算法在收敛速度、搜索能力等方面都有显著的改善。
通过实验仿真,发现效果良好。
1 克隆选择算法克隆选择算法主要经过初始化、选择、克隆、变异、替换5个阶段,在系统初始化阶段随机生成N个问题域的可能解,在算法中被称为抗体,抗体被分为两个部分,一部分为记忆细胞M和剩余群体P,按照抗体和抗原的结合程度衡量抗体的优劣,结合度高的抗体表示能够解决抗原带来的问题,即结合度高的抗体更接近于问题的解,从种群中选择n个结合度较高的抗体,然后进行克隆,对克隆后的抗体进行高频变异,变异完成后将种群中C个抗体用重新随机生成的抗体替换,然后重新进行选择。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
免疫克隆算法
免疫克隆算法(Immune Clone Algorithm, ICA)是一种基于免疫系统启发的优化算法,它模拟了人类免疫系统的克隆选择过程。
免疫克隆算法首次由英国科学家John Timmis于2000年提出,并在解决优化问题中取得了很好的效果。
免疫系统是人体的一种重要防御机制,它能够识别和消灭入侵体内的病原体。
免疫系统的核心是B细胞和T细胞,它们能够通过克隆选择机制产生大量的抗体来应对不同的病原体。
免疫克隆算法就是将免疫系统的克隆选择过程应用到优化问题中。
在免疫克隆算法中,解空间中的个体被称作抗体。
算法的初始种群由一组随机生成的抗体组成。
然后,通过计算适应度函数来评估每个抗体的适应度。
适应度较高的抗体会被选中进行克隆操作,即产生一定数量的克隆体。
克隆体的数量与该抗体的适应度成正比。
克隆体之间还会引入一定的变异操作,以增加种群的多样性。
接下来,对克隆体进行选择操作,选择适应度较高的克隆体作为下一代种群。
同时,为了保持种群的多样性,算法也会引入一定的随机选择机制,选择适应度较低的抗体作为下一代种群的一部分。
这样可以保证算法在搜索过程中既能够快速收敛到局部最优解,又能够保持全局搜索的能力。
免疫克隆算法的核心思想是通过不断的克隆和选择操作来提高种群
中优秀个体的数量。
通过增加种群中优秀个体的数量,算法能够更好地探索解空间,并且有更高的可能找到全局最优解。
免疫克隆算法在解决旅行商问题、函数优化、机器学习等领域都取得了显著的效果。
与其他优化算法相比,免疫克隆算法具有以下优点:
1. 免疫克隆算法能够在保证收敛速度的同时,保持较高的全局搜索能力。
2. 算法不依赖于问题的具体形式,适用于各种不同类型的优化问题。
3. 免疫克隆算法具有较好的鲁棒性和抗干扰能力,能够应对问题中的噪声和扰动。
然而,免疫克隆算法也存在一些不足之处:
1. 算法的收敛速度较慢,可能需要较长的时间才能找到较好的解。
2. 算法对问题的初始解比较敏感,不同的初始解可能会导致不同的优化结果。
免疫克隆算法是一种基于免疫系统的优化算法,通过模拟免疫系统的克隆选择过程来解决优化问题。
它具有较好的全局搜索能力和鲁棒性,适用于各种不同类型的优化问题。
然而,算法的收敛速度相对较慢,对问题的初始解比较敏感。
在实际应用中,可以根据具体问题的特点选择合适的优化算法,包括免疫克隆算法在内,以获得更好的优化效果。