在Eviews中对时间序列进行预测的详细步骤
ARMA模型的eviews的建立--时间序列分析实验指导
时间序列分析实验指导42-2-450100150200250统计与应用数学学院前言随着计算机技术的飞跃发展以及应用软件的普及,对高等院校的实验教学提出了越来越高的要求。
为实现教育思想与教学理念的不断更新,在教学中必须注重对大学生动手能力的培训和创新思维的培养,注重学生知识、能力、素质的综合协调发展。
为此,我们组织统计与应用数学学院的部分教师编写了系列实验教学指导书。
这套实验教学指导书具有以下特点:①理论与实践相结合,书中的大量经济案例紧密联系我国的经济发展实际,有利于提高学生分析问题解决问题的能力。
②理论教学与应用软件相结合,我们根据不同的课程分别介绍了SPSS、SAS、MATLAB、EVIEWS等软件的使用方法,有利于提高学生建立数学模型并能正确求解的能力。
这套实验教学指导书在编写的过程中始终得到安徽财经大学教务处、实验室管理处以及统计与应用数学学院的关心、帮助和大力支持,对此我们表示衷心的感谢!限于我们的水平,欢迎各方面对教材存在的错误和不当之处予以批评指正。
统计与数学模型分析实验中心 2007年2月目录实验一 EVIEWS中时间序列相关函数操作···························- 1 - 实验二确定性时间序列建模方法 ····································- 8 - 实验三时间序列随机性和平稳性检验 ···························· - 18 - 实验四时间序列季节性、可逆性检验 ···························· - 21 - 实验五 ARMA模型的建立、识别、检验···························· - 27 - 实验六 ARMA模型的诊断性检验····································· - 30 - 实验七 ARMA模型的预测·············································· - 31 - 实验八复习ARMA建模过程·········································· - 33 - 实验九时间序列非平稳性检验 ····································· - 35 -实验一 EVIEWS中时间序列相关函数操作【实验目的】熟悉Eviews的操作:菜单方式,命令方式;练习并掌握与时间序列分析相关的函数操作。
EVIEWS时间序列实验指导(上机操作说明)

⒉在工作文件窗口中选取所要删除或更名的变量,点击工作文件窗口菜单栏中的Objects/Delete selected…(Rename selected…),即可删除(更名)变量
进行预测:打开对应的方程窗口,点forecast按纽,将出现对话框,修改对话框 sample range for forecast中的时间期限的截止日期为预测期.
相对误差的计算公式为:(实际值-预测值)/实际值
二、单参数和双参数指数平滑法进行预测的操作练习
2、某地区1996~2003年的人口数据如表1.2,运用二次指数平滑法预测该镇2004年底的人口数(单位:人)。
掌握确定性时间序列建立模型的几种常用方法。
【实验内容】
一、多项式模型和加权最小二乘法的建立;
二、单参数和双参数指数平滑法进行预测的操作练习;
三、二次曲线和对数曲线趋势模型建立及预测;
【实验步骤】
一、多项式模型和加权最小二乘法的建立;
1、我国1974—1994年的发电量资料列于表中,已知1995年的发电量为10077.26亿千瓦小时,试以表1.1中的资料为样本:
建立系列方程:smpl 1974 1994
ls y c t
ls y c t t^2
ls y c t t^2 t^3
通过拟合优度和外推检验的结果发现一元三次多项式模型效果最好。
首先生成权数序列:genr m=sqr(0.6^(21-t))
加权最小二乘法的命令方式:ls(w=m) y c t
普通最小二乘法命令方式:ls y c t
步骤:(1)打开该文件。
应用eviews分析数据和预测

统计预测与决策论文摘要:随着市场经济的多元化发展。
统计软件被广泛的应用,企业应用统计软件进行对下一期的生产值进行预测。
从而能更准确的做出决策。
本文利用eviews对某企业的下几期的生产值进行预测,便于企业做出最准确的决策。
关键字:平稳序列,模型识别,模型定阶,模型参数估计,模型检验,模型预测。
下表是某企业近期一百个生产数据值。
1、模型识别绘制序列时序图7680848892255075100125150175200PRODUCTI ON2模型定阶绘制序列相关图从相关图看出,自相关系数迅速衰减为0,说明序列平稳,但最后一列白噪声检验的Q 统计量和相应的伴随概率表明序列存在相关性,因此序列为平稳非白噪声序列。
模型定阶:由图2-5看出,偏自相关系数在k=3后很快趋于0即3阶截尾,尝试拟合AR (3);自相关系数在k=1处显著不为0,当k=2时在2倍标准差的置信带边缘,可以考虑拟合MA (1)或MA (2);同时可以考虑ARMA (3,1)模型等。
原序列做描述统计分析见图481216207880828486889092Series: PRODUCTION Sample 1 201Observations 201Mean 84.11940Median 84.10000Maximum 91.70000Minimum 76.50000Std. Dev. 2.906625Skewness 0.107191Kurtosis 2.752406Jarque-Bera 0.898321Probability0.638164可见序列均值非0,我们通常对0均值平稳序列做建模分析,所以需要在原序列基础上生成一个新的0均值序列。
这个序列是0均值的平稳非白噪声序列,新序列的描述统计量见图 048121620-8-6-4-22468Series: XSample 1 201Observations 201Mean 2.99e-06Median -0.019400Maximum 7.580600Minimum -7.619400Std. Dev. 2.906625Skewness 0.107191Kurtosis 2.752406Jarque-Bera 0.898321Probability0.6381643模型参数估计由伴随概率可知,AR (i )(i=1,2,3)均高度显著,表中最下方给出的是滞后多项式φ-1(x )=0的倒数根,只有这些值都在单位圆内时,过程才平稳。
时间序列 eviews操作

1.打开EVIEWS新建一个工作文件,步骤如下:
出现如下对话框,选择数据频率为季度,开始日期为1989年1季度,结束日期为2004年4季度,即为工作文件的范围区间。
点击ok生成工作文件
2.若要改变工作文件的范围区间,双击Range,出现如下对话框
3.利用命令series 生成时间序列gdp
点击Edit+/-改变数据的编辑状态,打开EXCEL文件将数据复制粘贴到数据区域,查看数据序列的折线图,步骤如下:
结果:
从图中可看出时间序列有明显的季节波动。
4.对gdp序列进行描述统计分析:
5.对原GDP数据进行季节调整,调整后时间序列存为GDP_SA
6.做出折线图:
由图知序列受季节影响程度变小。
7.进行单位根检验,结果如下:
计算自相关函数和偏相关函数如下:
9.利用方程建立ARMA(3,3)模型
10.建立组,包括gdp gdp_sa dgdp
建组后展示如下:
11.将建组后的收据以EXCEL格式输出:
点击ok即可。
在Eviews中对时间序列进行预测的详细步骤

在Eviews中对时间序列进行预测的详细步骤一、输入数据1.1打开Eviews6.0,按照如图所示打开工作表创建框。
1.2在右上角的data specification框中输入起止年份(start data和end data)1.3输入数据:在输入框中输入data gdp(本文采用的数据为1990—2012年的GDP值)。
当然,data后面可以输入任何你想要定义的“英文名字”输入data gdp后注意按回车键,弹出表格窗口后在其中输入数据(也可复制进去数据:ctrl+v键)二、平稳性检验2.1在打开的数据窗口中点击View→Correlogram(1)在弹出的窗口中直接点OK即可↓2.2自相关图和偏相关图进行分析:最简单粗暴的方法就是看最右边的Prob值(即P值),当这列数据有多数都大于0.05(置信水平)时为白噪声序列=序列是平稳的。
本文中GDP数据P值均小于0.05,则为非白噪声。
需对序列进行差分。
三、取一阶差分3.1在输入框中输入第二列代码,这代表将数据gdp进行一阶差分,一阶差分后的值命名为dgdp.按回车键3.2在dgdp数据的窗口中重复2.1的操作,对序列的平稳性进行检验得到结果如下:惨!还是非白噪声,只能进行二阶差分了!四、取二阶差分4.1如第三列代码所示(记得不能重复命名)4.2对新的序列dgdp2进行平稳性检验,步骤同上,结果如下:MY GOD! 看见了木有,这回是白噪声了,P值多数都大于0.05!五、用最小二乘法对模型进行估计:输入ls dgdp2 c ar(2)(探索性建模)5.1AR(2)模型结果(准确的说这个模型应该是ARIMA的疏系数模型,本文重点不在这!如有需要请私信我!)5.2MA(2)模型结果5.3优化模型:根据AIC和SBC准则选择模型,值越小的拟合效果越好,本文的选择MA(2)模型。
5.4对模型进行检验:View→Residual Tests→Correlogram Q statistics检验结果如下:P值大于0.05,为白噪声序列,则平稳。
时间序列经济模型EVIEWS操作
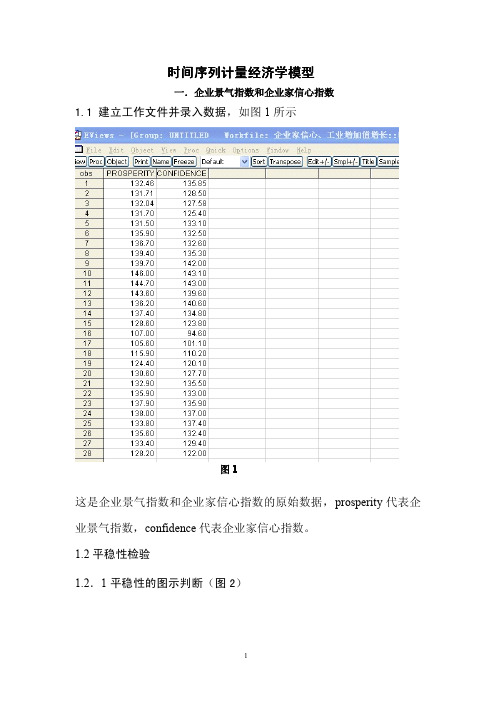
时间序列计量经济学模型一.企业景气指数和企业家信心指数1.1建立工作文件并录入数据,如图1所示图1这是企业景气指数和企业家信心指数的原始数据,prosperity代表企业景气指数,confidence代表企业家信心指数。
1.2平稳性检验1.2.1平稳性的图示判断(图2)图2从图中可以看出企业景气指数和企业家信心指数这两序列都是非平稳的。
1.2.2样本自相关图判断点击主界面Quick\Series Statistics\Correlogram...,在弹出的对话框中输入prosperity,点击OK就会弹出Correlogram Specification对话框,选择Level,并输入要输出的阶数(一般默认为24),点击OK,即可得到prosperity的样本相关函数图,如图3所示。
图3从上述样本相关函数图,可以看到企业景气指数(prosperity)的样本相关函数是缓慢的递减趋于零的,但随着时间的推移,在0附近波动并呈发散趋势。
所以,通过企业景气指数(prosperity)的样本相关图,可初步判定该企业景气指数(prosperity)时间序列非平稳。
同理得:confidence的样本相关函数图,如图4所示图4从上述样本相关函数图,可以看到企业家信心指数(confidence)的样本相关函数是缓慢的递减趋于零的,但随着时间的推移,在0附近波动并呈发散趋势。
所以,通过企业家信心指数(confidence)的样本相关图,可初步判定该企业家信心指数(confidence)时间序列非平稳。
1.2.3单位跟检验单位跟检验((ADF检验检验))(1)企业景气指数(prosperity)采用ADF检验对prosperity序列进行平稳性的单位根检验。
点击主界面Quick\Series Statistics\Unit Root Test...,在弹出的Series对话框中输入prosperity,点击OK,就会出现UnitRoot Test对话框,如图5所示。
在Eviews中对时间序列进行预测的详细步骤

预测是计量经济学的目的,也是建模的目的,预测效果的好坏是评价所建模型的好坏的标准之一,Eviews软件中带有对时间序列进行预测的功能。
工具/原料∙电脑∙Eviews软件方法/步骤1.运用下面的数据案例,从1980到2009的GDP和农业作物栽培的产值的数据,这是一份时间序列数据,设GDP为y,农业作物栽培为x2.首先用create命令建立workfile,在workfile structure type 中选择Dated-regular frequency ,在Frequency中选择Annual,在Start date 和End date 中分别输入1980以及2009,点击键盘OK键,如下图。
3.在主窗口中用命令data y x ,如下图,再将数据导入Eviews中,excel的数据可以直接复制粘贴到group中,4.用最小二乘估计中的命令方式ls y c x,建立方程,在主窗口中输入ls y c x,点击enter键,如下图5.在上面的Equation窗口中选择forecast按钮,弹出预测设置窗口,如下图,在窗口中的Forecast name自动在预测变量后加一个f, 在预测范围Forecast sample 中可以根据需要确定要预测的起止时间,Output则是要输出的内容,包括预测图和预测评价指标,可以根据需要勾选。
6.选好之后,点击OK,则出现下图,有预测值曲线和各个评价指标,同时在主窗口生成预测值序列yf,如图红色标记7.点击yf,得出下图,这就是所建模型的预测值yf情况END注意事项∙注意Forecast设置窗口里面根据自己的需要进行勾选∙预测值的序列名为yf,一般是系统默认在预测变量加f。
如何用eviews分析时间序列课程

如何用eviews分析时间序列课程时间序列分析是一种常用的数据分析方法,通过对一系列时间上连续测量的数据进行观察、描述和分析,可以发现其中的规律和趋势,从而预测未来的发展走势。
Eviews是一种专业的时间序列分析软件,具有强大的数据处理和统计分析功能。
本文将介绍如何使用Eviews进行时间序列分析。
首先,打开Eviews软件,并导入需要分析的时间序列数据。
在Eviews的工作区中,选择“File”菜单下的“Open”选项,然后选择需要导入的数据文件,点击“Open”按钮导入数据。
导入数据后,可以在Eviews的对象浏览器中看到导入的数据对象。
接下来,对时间序列数据进行初步的观察和描述分析。
在对象浏览器中,选择需要分析的数据对象,右键点击并选择“Open as Group”选项,将数据对象打开为一个分析组。
然后,在Eviews的对象浏览器中,选择分析组,在右侧窗口中可以看到该组中包含的所有时间序列数据。
可以通过列出每个时间序列的统计概要、绘制时间序列图、查看自相关和偏自相关等方式对数据进行初步的观察和描述分析。
接下来,进行时间序列模型的构建和估计。
在Eviews的操作菜单中,选择“Quick”菜单下的“Estimate Equation”选项,打开方程估计窗口。
在方程估计窗口中,选择需要构建的时间序列模型类型,如AR、MA、ARMA等。
然后,在“Dependent Variable”栏目中选择需要分析的时间序列数据,将其作为因变量。
在“Independent Variables”栏目中选择需要作为自变量的时间序列数据,可以根据需求选择多个自变量。
点击“OK”按钮,Eviews将根据所选择的时间序列模型类型和数据进行模型的估计。
估计完成后,可以查看估计结果。
在方程估计窗口中,可以看到估计结果的统计指标、系数估计值、显著性水平等信息。
可以根据需要查看和分析各个系数的显著性水平、置信区间等信息,判断模型的有效性和可靠性。
eviews时间序列分析

方差分解
❖ 利用VAR模型,还可以进行方差分解研究模 型的动态特征。其主要思想是,把系统中每 个内生变量(m)的波动按其成因分解为与 各方程新息相关联的m个组成部分,从而了 解各新息对模型内生变量的相对重要性。
• 9、春去春又回,新桃换旧符。在那桃花盛开的地方,在这醉人芬芳的季节,愿你生活像春天一样阳光,心情像桃花一样美丽,日子像桃子一样甜蜜。21. 11.1821.11.18Thursday, November 18, 2021
❖ 例3 下面以1949 ~2001年中国人口时间序列 数据(case42)为例介绍: (1)时间序列图; (2)求 中国人口序列的相关图和偏相关图,识别模 型形式; (3)估计时间序列模型; (4)样本外预 测。
❖ 1、画时间序列图
❖ 点击View键,选择Graph/Line功能
❖ 从人口序列y的变化特征看,这是一个非平 稳序列。
yt c t yt1 j yt j t j 1
❖ PP检验
❖ 例1:661天的深证成指(SZ)序列见case37。
❖ 初步选择①ADF检验,②对原序列sz,做单 位根检验,③检验式中不包括趋势项,但包 括截距项。
❖ 因为常数项没有显著性。从检验式中去掉截 距项,继续迸行单位根检验。
第三节 模型的预测
❖ 比如用估计的模型Dyt = 0. 0547 + 0. 6171 Dy t- 1+ vt预测2001年的中国总人口,在窗口 中点击forecast键,弹出对话窗口。在S. E. (optional)选择区填入yfse,把Forecast sample (预测样本区间)改为2001 ~2001,预 测方法(Method)选静态预测(Static)
❖ 输出结果由两部分组成。左半部分是序列的
用EVIEWS实现预测第三讲新

② 季节滤波(Seasonal Filter) 当估计季节因子时,允许选择季节移动平均滤波项数,缺省是X12自动确 定。近似地可选择(X11 defaul)缺省选择。
③ 趋势滤波(Trend Filter (Henderson)) 当估计趋势—循环分量时,允许指定亨德松移动平均的项数,可以输入 大于1和小于等于101的奇数,缺省是由X12自动选择。
如果将指数平滑的预测结果和原观测值共同显示 在同一张图上,可以看起来更清楚。 首先在工作文件菜单中同时选中两个序列SALES 和SALESSM,方法是先点击一个序列,之后按 住键盘上的Shift键再点击另外一个序列。 然后点击工作文件菜单工具栏中的Show,在弹出 的对话框中点击OK。此时,系统将弹出一个类似 序列对象窗口的群窗口,窗口中以Excel表格的形 式同时显示出SALES和SALESSM。最后点击该 窗口上方的View→Graph→Line。
X-11简要的输出及错误信息也会在序列窗口中显示。
关于调整后的序列的名字。EViews在原序列名后加SA, 但你也可以改变,这将被存储在工作文件中。 需要注意,季节调整的观测值的个数是有限制的。X-11 只作用于含季节数据的序列,需要至少4整年的数据,最多能 调整20年的月度数据及30年的季度数据。
ct 为加法模型的季节因子:
这时存在3个衰减系数,同样可以给定它们的值或让EVIEWS估 计它们。
5.Holt-winters乘法模型(三个参数) 这种方法适用于序列具有线性时间趋势以及乘法模型的季节变 ˆ 差。 y t 的平滑序列 y t由下式给出
yt k a bk ct k
4.Holt-Winter加法模型(三个参数)
如果序列中存在季节变化,且季节效应的大小不随序列变化, 那 么 应 该 使 用 加 法 性 季 节 Holt-Winter 方 法 , 平 滑 后 的 序 列y t ˆ 由下式给出 其中:a表示截距: b表示趋势:
运用Eviews软件进行ARIMA模型的识别、诊断、估计和预测121页word文档

运用Eviews软件进行ARIMA模型的识别、诊断、估计和预测121页word文档Eviews在时间序列建模中的应用一、工作文件的建立、保存和调用(一)工作文件的建立有两种方式创建工作文件,一是菜单方式,另一个是命令方式。
1 菜单方式运行Eviews软件,在打开的主窗口中,进行如下操作:File/new/workfile/在出现的对话框中对workfile structure type 进行选择/Dated-regular frequency/OKWorkfile structure type选项区共有3种类型:Unstructured/Undated(非结构/非日期)、Dated-regular frequency和Balanced Panel(平衡面板)。
其中默认的状态是Dated-regular frequency类型。
(1)Unstructured/Undated此类数据的观测标识代码用整数表示,只需给出总的数据观测值个数,系统将自动从1开始依次为每个样本观测值分配整数型的标识代码。
(2)Dated-regular frequency在默认状态Dated-regular frequency类型下,另一选项区Date specification(日期设定)中有8个选择,分别是Annual(年度的),Semi-annual (半年度的),Quarterly(季度的)、Monthly(月度的)、Weekly(周度的)、Daily-5 day week(一周5个工作日)、Daily-7 day week(一周7工作日)和Integer date(整序数的),其输入格式如下:Annual选项:用四位数表示年份,如2019,2019等。
在start date后输入起始年份,End date后输入终止年份。
在1900和2000年之间的年份可以只输入后2位;semi Annual选项:输入格式同Annual选项,每一年有上半年和下半年两个数据;Quarterly选项:输入格式为年份:季度,如2019:1,或98:1。
时间序列的eview操作步骤

1.打开eviews软件,点击file-new-workfile,见对话框又三块空白处,选择时间序列dated-regular frequency。
在date specification中选择monthly,start(起始时间)输入2005M11,end(终止时间)输入2008M6(eviews的时间序列没有间隔序列输入就将时间进行调整)。
右下角为工作间取名字tmd。
点击ok。
在所创建的workfile中点击object-new object,选择series,以及填写名字tmd,点击OK。
将数据填写入内就生成了以tmd为名的数据集2. 点击view-United root test,test type选择ADF检验,滞后阶数中lag length 选择SIC检验,点击ok得结果如下:一阶差分:点击GENR命令按钮,在输入框中输入bod1=D(bod),得到一阶差分后的结果:再对一阶差分后的数据同样进行平稳性检验(单根值检验)ADF序列零均值化①在命令窗口输入如下命令(如下图所示):Scalar m=@mean(tmd)其中:Scalar命令在Eviews中表示生成标量数据(均值只是一个数,而不是序列)。
在tmd窗口下选择菜单操作方式:单击Genr在对话框中输入BOD1=BOD-m得到零均值后的新序列tmd1与之前的数据完全不同。
3. 在工作区双击序列图标tmd1,再选用菜单操作方式:View—>Correlogram,在出现的对话框点击OK。
4.估计模型中的未知参数识别透明度这组时间序列适合的模型后,需要进一步的估计模型中的具体参数,下面就用eviews软件进行估计。
由前面的图形看出:自相关系数和偏相关系数具有相似的衰减特点:衰减快,偏相关图中,2阶以后函数值趋于0,呈截尾性选AR(2);而在自相关图中,在4阶以后函数值趋于0,呈拖尾性,因此可将q取3故可选MA(3)模型。
利用菜单操作建立ARMA模型。
运用Eviews软件进行ARIMA模型的识别、诊断、估计和预测121页word文档

Eviews在时间序列建模中的应用一、工作文件的建立、保存和调用(一)工作文件的建立有两种方式创建工作文件,一是菜单方式,另一个是命令方式。
1 菜单方式运行Eviews软件,在打开的主窗口中,进行如下操作:File/new/workfile/在出现的对话框中对workfile structure type进行选择/Dated-regular frequency/OKWorkfile structure type选项区共有3种类型:Unstructured/Undated(非结构/非日期)、Dated-regular frequency和Balanced Panel(平衡面板)。
其中默认的状态是Dated-regular frequency类型。
(1)Unstructured/Undated此类数据的观测标识代码用整数表示,只需给出总的数据观测值个数,系统将自动从1开始依次为每个样本观测值分配整数型的标识代码。
(2)Dated-regular frequency在默认状态Dated-regular frequency类型下,另一选项区Date specification(日期设定)中有8个选择,分别是Annual(年度的),Semi-annual (半年度的),Quarterly(季度的)、Monthly(月度的)、Weekly(周度的)、Daily-5 day week(一周5个工作日)、Daily-7 day week(一周7工作日)和Integer date(整序数的),其输入格式如下:Annual选项:用四位数表示年份,如2019,2019等。
在start date后输入起始年份,End date后输入终止年份。
在1900和2000年之间的年份可以只输入后2位;semi Annual选项:输入格式同Annual选项,每一年有上半年和下半年两个数据;Quarterly选项:输入格式为年份:季度,如2019:1,或98:1。
eviews的garch模型预测步骤

eviews的garch模型预测步骤Eviews中的GARCH模型预测步骤引言:GARCH模型是一种用于预测金融市场波动性的模型,它结合了ARCH模型和时间序列模型的优点,能够更准确地预测金融资产的风险。
在Eviews软件中,通过一系列简单的步骤,我们可以利用GARCH模型进行预测。
本文将介绍Eviews中使用GARCH模型进行预测的具体步骤。
步骤一:导入数据我们需要在Eviews中导入需要进行预测的数据。
可以通过多种方式导入数据,例如从Excel文件中导入或直接在Eviews中输入。
在导入数据时,确保数据的时间顺序正确,以便后续分析和预测。
步骤二:建立GARCH模型在Eviews中,建立GARCH模型非常简单。
首先,选择要建立GARCH模型的变量,在菜单栏中选择“Quick/Estimate Equation”或直接点击工具栏中的“Estimate Equation”按钮。
然后,在弹出的对话框中选择“ARCH/GARCH”模型,并设置相关参数,如模型阶数、残差类型等。
点击“OK”按钮后,Eviews会根据选择的参数自动建立GARCH模型。
步骤三:模型估计在建立GARCH模型后,需要对模型进行估计,以获得模型的参数估计值和其他统计信息。
在Eviews中,点击工具栏中的“Estimate”按钮或选择菜单栏中的“View/Estimation Output”选项,即可进行模型估计。
Eviews会自动计算模型的参数估计值、标准误差、t值等统计信息。
步骤四:模型诊断模型估计完成后,需要对模型进行诊断,以评估模型的拟合效果和可靠性。
在Eviews中,可以通过查看估计结果的统计信息和图形来进行模型诊断。
例如,可以检查模型的残差是否服从正态分布,是否存在异方差性等。
如果发现模型存在问题,可以对模型进行调整或选择其他模型。
步骤五:模型预测在进行模型诊断后,可以利用已估计的GARCH模型进行预测。
在Eviews中,选择菜单栏中的“Forecast/Forecast”选项,即可进行模型预测。
EVIEWS时间序列实验指导(上机操作说明)

EVIEWS时间序列实验指导(上机操作说明)时间序列分析实验指导42-2-450100150200250NRND数学与统计学院目录实验一 EVIEWS中时间序列相关函数操作···························- 1 - 实验二确定性时间序列建模方法 ····································- 8 - 实验三时间序列随机性和平稳性检验 ···························· - 18 - 实验四时间序列季节性、可逆性检验 ···························· - 21 - 实验五 ARMA模型的建立、识别、检验···························· - 27 - 实验六 ARMA模型的诊断性检验····································· - 30 - 实验七 ARMA模型的预测·············································· - 31 - 实验八复习ARMA建模过程·········································· - 34 - 实验九时间序列非平稳性检验 ····································· - 37 -实验一 EVIEWS中时间序列相关函数操作【实验目的】熟悉Eviews的操作:菜单方式,命令方式;练习并掌握与时间序列分析相关的函数操作。
时间序列分析应用实例(使用Eviews软件实现)

时间序列分析应⽤实例(使⽤Eviews软件实现)引⾔某公司的苹果来货量数据是以时间先后为顺序记录的⼀组数据,从计量经济学的⾓度来分类就是⼀组时间序列数据。
为了提⾼苹果来货量预测的准确度以及预测结果的可信度,下⾯运⽤Eviews软件包(即Econometrics Views 计量经济学软件包)并结合计量经济学的理论知识,选取2017年1⽉⾄2019年4⽉的苹果来货量⽉度数据(事前对原始数据进⾏处理,把数值单位从吨转换为万吨)为样本数据,⽤⼀个时间序列模型来拟合上述样本数据,然后利⽤建⽴好的模型预测苹果未来⼏个⽉的来货量情况,并对预测结果进⾏分析。
1 平稳性检验1.1 初步检验设来货量时间序列为Qt,⾸先观察Qt的折线图,如图1所⽰:图1 Qt的折线图从图1可知,苹果来货量的⽉度数据总体呈下降趋势,并存在季节性因素,进⽽通过序列原⽔平的⾃相关系数图进⼀步探讨序列的平稳性,结果如图2所⽰:图2 Qt的⾃相关系数图从图2可以看到,所有的⾃相关系数(Autocorrelation)均落在2倍标准差之内(垂⽴的两道虚线表⽰2倍标准差),初步判定序列Qt是平稳的。
下⾯运⽤ADF单位根检验法证明序列的平稳性。
1.2 ADF单位根检验假设序列Qt的特征⽅程存在多个特征根,那么序列平稳的条件为所有特征根λi的绝对值均⼩于1,即所有特征根都在单位圆内。
构造该ADF 检验的原假设H0:存在i,使得λi>1,备择假设H1:λ1, λ2, … , λp<1,运⽤Eviews软件对序列Qt的原⽔平进⾏带常数项(Intercept)的ADF检验,采⽤SC准则⾃动选择滞后阶数,检验结果如图3所⽰:图3 ADF检验根据图3的检验结果可知,t统计量(t-Statistic)的伴随概率p为0.00,在显著性⽔平α=0.05下,因此我们有理由拒绝原假设(p<α),说明序列Qt是平稳的。
2 模型识别从图2可知,序列Qt的⾃相关系数(Autocorrelation)和偏⾃相关系数(Partial correlation)均在阶数1处突然衰减为在零附近⼩值波动,因此我们初步选择AR(1)、ARMA(1,1)这两个模型拟合样本数据3 模型参数估计3.1 AR(1)模型的拟合与参数估计设AR(1)模型为:Qt=C + Φ*Qt-1 +εt,其中C为常数项,Φ为待估计的Qt滞后⼀阶的系数,εt为服从均值为零、⽅差为常数正态分布的正态分布(即⽩噪声序列),下⾯运⽤Eviews软件对AR(1)模型的参数采⽤最⼩⼆乘估计法(⽆偏估计)进⾏参数估计,模型估计结果如图4所⽰:图4 AR(1)模型拟合结果根据图4的参数估计结果来看,在显著性⽔平α=0.05下,常数项显著不为零,⽽参数Φ的显著性估计结果并不是太好,另外AR(1)模型的特征⽅程的根(Inverted AR Roots)为-0.16,印证了序列Qt是平稳的。