模式匹配KMP算法实验步骤
模式匹配KMP算法研究报告

模式匹配的KMP算法研究学生姓名:黄飞指导老师:罗心摘要在计算机科学领域,串的模式匹配<以下简称为串匹配)算法一直都是研究焦点之一。
在拼写检查、语言翻译、数据压缩、搜索引擎、网络入侵检测、计算机病毒特征码匹配以及DNA序列匹配等应用中,都需要进行串匹配。
串匹配就是在主串中查找模式串的一个或所有出现。
在本文中主串表示为S=s1s2s3…sn,模式串表示为T=t1t2…tm。
串匹配从方式上可分为精确匹配、模糊匹配、并行匹配等,著名的匹配算法有BF算法、KMP算法、BM算法及一些改进算法。
本文主要在精确匹配方面对KMP算法进行了讨论并对它做一些改进以及利用改进的KMP来实现多次模式匹配。
关键字:模式匹配;主串;模式串;KMP算法Research and Analysis of KMP Pattern MatchingAlgorithmStudent:Huangfei Teacher:LuoxinAbstract In computer science,String pattern matching(Hereinafter referred to as the string matching>algorithmis always the focus of the study.In thespell check, language translation, data compression, search engine, thenetwork intrusion detection system, a computer virus signature matching DNAsequences and the application in the match,matched to string matching.String matching is in search of a string of pattern or all appear.In this paper, the string is S = s1s2s3... Sn, string pattern for T = t1t2... tm.String matching way can be divided from the accurate matching, fuzzy matching, parallel matching etc., the famous matching algorithms are KMP algorithm, BF algorithm, the algorithm and some BM algorithm.This paper in precise KMP algorithm for matching aspects are discussed and some improvement on it and using the improved KMP to realize the multiple pattern matching.Key words: pattern matching, The string。
kmp算法原理

kmp算法原理KMP算法(Knuth-Morris-Pratt算法)是一种用于快速搜索字符串中某个模式字符串出现位置的算法,由Knuth, Morris 和 Pratt于1977年提出。
KMP算法的工作方式如下:首先,给定一个主串S和一个模式串P,KMP算法的第一步就是先构造一个新的模式串P,其中的每一项存储着P中每一个字符前面由不同字符串组成的最长前缀和最长后缀相同的子串。
接着,在S中寻找P,它会从S的第一个字符开始,如果匹配上,就继续比较下一个字符,如果不匹配上,就根据P中相应位置上保存的信息跳到特定位置,接着再开始比较,如此不断循环下去,直到从S中找到P为止。
KMP算法的思路特别巧妙,比较效率很高,它的复杂度为O(m+n),其中m为主串的长度,n为模式串的长度。
它取代了以前的暴力搜索算法,极大地提高了程序的性能。
KMP算法的实现过程如下:(1)首先确定模式串P的每一个字符,构造模式串P的next数组:next[i]存储P中第i个字符之前最长相同前缀和后缀的长度(P中第i个字符之前最长相同前缀和后缀不包括第i个字符);(2)接着从S中的第一个字符开始比较P中的每一个字符,如果字符不匹配,则采用next数组中保存的信息跳到特定位置,而不是暴力比较,以此不断循环,直到从S中找到P为止。
KMP算法是由Don Knuth, Vaughan Pratt和James Morris在1977年提出的。
它的思想是利用之前遍历过的P的信息,跳过暴力比较,可以把字符串搜索时间从O(m×n)降低到O(m+n)。
KMP算法在很多领域有着重要的应用,如文本编辑,模式匹配,编译器设计与多项式字符串匹配等等,都是不可或缺的。
模式匹配KMP算法实验报告

实验四:KMP算法实验报告一、问题描述模式匹配两个串。
二、设计思想这种由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现的改进的模式匹配算法简称为KM P算法。
注意到这是一个改进的算法,所以有必要把原来的模式匹配算法拿出来,其实理解的关键就在这里,一般的匹配算法:int Index(String S,String T,int pos)//参考《数据结构》中的程序{i=pos;j=1;//这里的串的第1个元素下标是1while(i<=S.Length && j<=T.Length){if(S[i]==T[j]){++i;++j;}else{i=i-j+2;j=1;}//**************(1)}if(j>T.Length) return i-T.Length;//匹配成功else return 0;}匹配的过程非常清晰,关键是当‘失配’的时候程序是如何处理的?为什么要回溯,看下面的例子:S:aaaaabababcaaa T:ababcaaaaabababcaaaababc.(.表示前一个已经失配)回溯的结果就是aaaaabababcaaaa.(babc)如果不回溯就是aaaaabababcaaaaba.bc这样就漏了一个可能匹配成功的情况aaaaabababcaaaababc这是由T串本身的性质决定的,是因为T串本身有前后'部分匹配'的性质。
如果T为a bcdef这样的,大没有回溯的必要。
改进的地方也就是这里,我们从T串本身出发,事先就找准了T自身前后部分匹配的位置,那就可以改进算法。
如果不用回溯,那T串下一个位置从哪里开始呢?还是上面那个例子,T为ababc,如果c失配,那就可以往前移到aba最后一个a的位置,像这样:...ababd...ababc->ababc这样i不用回溯,j跳到前2个位置,继续匹配的过程,这就是KMP算法所在。
实验六 串的模式匹配

⑵用KMP算法进行匹配。 (3)程序运行的结果要在屏幕上显示:
简单的朴素模式匹配算法中,模式串的位置、出现的次数。 模式串的next函数值。 说明:下课前请将源代码的.c(或.cpp) KMP算法的匹配位置。 文件以及.h文件打包后重命名为
“p6_姓名简拼_学号后三位”, 然后提交到教师机!
【实验内容】编写程序,实现顺序串的模式匹配算法。 【基本要求】在主程序中调用算法,输入一个主串和模式串, 在主串中检索模式串,显示模式串在主串中出现的次数和 位置。 ⑴用简单的朴素模式匹配算法计模式串出现 的次数; 从主串的任意给定位置检索模式串。
【实现提示】
要统计模式串在主串中出现的次数,可以先确定从
主串中第一个字符起,模式串的位置,然后再利用 指定位置的匹配算法找出其他匹配的位置; 利用一个数组来存放所有模式串出现的位置,然后 将这些位置依次打印输出。 串值在数组中存储时,是从数组的0号单元开始存 放的。注意修改教材中Next函数和KMP算法函数 中的变量! 至少包含以下头文件: #include <stdio.h> #include <string.h> #include <conio.h>
KMP算法计算next值和nextVal值
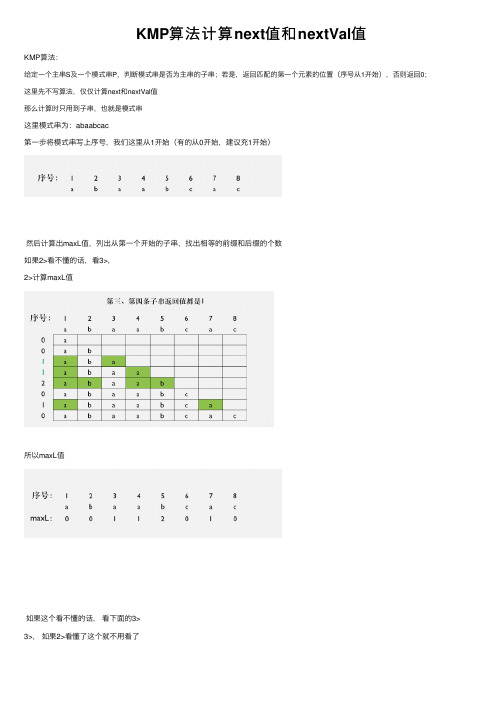
KMP算法计算next值和nextVal值
KMP算法:
给定⼀个主串S及⼀个模式串P,判断模式串是否为主串的⼦串;若是,返回匹配的第⼀个元素的位置(序号从1开始),否则返回0;这⾥先不写算法,仅仅计算next和nextVal值
那么计算时只⽤到⼦串,也就是模式串
这⾥模式串为:abaabcac
第⼀步将模式串写上序号,我们这⾥从1开始(有的从0开始,建议充1开始)
然后计算出maxL值,列出从第⼀个开始的⼦串,找出相等的前缀和后缀的个数
如果2>看不懂的话,看3>,
2>计算maxL值
所以maxL值
如果这个看不懂的话,看下⾯的3>
3>,如果2>看懂了这个就不⽤看了
依次类推4>计算next值
接下来将maxL复制⼀⾏,去掉最后⼀个数,在开头添加⼀个-1,向右平移⼀个格,然后每个值在加1的到next值
5>计算nextVal值,⾸先将第⼀个为0,然后看next和maxL是否相等(先计算不相等的)
当next和maxL不相等时,将next的值填⼊
当next和maxL相等时,填⼊对应序号为next值得nextVal值
所以整个nextVal值为:。
KMP算法(改进的模式匹配算法)——next函数

KMP算法(改进的模式匹配算法)——next函数KMP算法简介KMP算法是在基础的模式匹配算法的基础上进⾏改进得到的算法,改进之处在于:每当匹配过程中出现相⽐较的字符不相等时,不需要回退主串的字符位置指针,⽽是利⽤已经得到的部分匹配结果将模式串向右“滑动”尽可能远的距离,再继续进⾏⽐较。
在KMP算法中,依据模式串的next函数值实现字串的滑动,本随笔介绍next函数值如何求解。
next[ j ]求解将 j-1 对应的串与next[ j-1 ]对应的串进⾏⽐较,若相等,则next[ j ]=next[ j-1 ]+1;若不相等,则将 j-1 对应的串与next[ next[ j-1 ]]对应的串进⾏⽐较,⼀直重复直到相等,若都不相等则为其他情况题1在字符串的KMP模式匹配算法中,需先求解模式串的函数值,期定义如下式所⽰,j表⽰模式串中字符的序号(从1开始)。
若模式串p 为“abaac”,则其next函数值为()。
解:j=1,由式⼦得出next[1]=0;j=2,由式⼦可知1<k<2,不存在k,所以为其他情况即next[2]=1;j=3,j-1=2 对应的串为b,next[2]=1,对应的串为a,b≠a,那么将与next[next[2]]=0对应的串进⾏⽐较,0没有对应的串,所以为其他情况,也即next[3]=1;j=4,j-1=3 对应的串为a,next[3]=1,对应的串为a,a=a,所以next[4]=next[3]+1=2;j=5,j-1=4 对应的串为a,next[4]=2,对应的串为b,a≠b,那么将与next[next[4]]=1对应的串进⾏⽐较,1对应的串为a,a=a,所以next[5]=next[2]+1=2;综上,next函数值为 01122。
题2在字符串的KMP模式匹配算法中,需先求解模式串的函数值,期定义如下式所⽰,j表⽰模式串中字符的序号(从1开始)。
若模式串p为“tttfttt”,则其next函数值为()。
数据结构实验报告 模式匹配算法

return 1; } datatype DeQueue(SeqQueue *q) { datatype x; if(q->front==q->rear) { printf("\nempty!");return 0;} x=q->data[q->front]; q->front=(q->front+1)%max; return x; } void display(SeqQueue *q) { int s; s=q->front; if(q->front==q->rear) printf("empty!"); else while(s!=q->rear) { printf("->%d",q->data[s]); s=(s+1)%max; } printf("\n"); } main() { int a[6]={3,7,4,12,31,15},i; SeqQueue *p; p=InitQueue(); for(i=0;i<6;i++) EnQueue(p,a[i]); printf("output the queue values:"); display(p); printf("\n"); EnQueue(p,100);EnQueue(p,200);
ห้องสมุดไป่ตู้
元素并显示结果为4 ,12, 31, 15 ,100 ,200。
七、具体程序 #include "stdio.h" #include "conio.h" #define max 100 typedef int datatype; typedef struct { datatype data[max]; int front; int rear; }SeqQueue; SeqQueue *InitQueue() { SeqQueue *q; q=(SeqQueue *)malloc(sizeof(SeqQueue)); q->front=q->rear=0; return q; } int QueueEmpty(SeqQueue *q) { if (q->front==q->rear) return 1; else return 0; } int EnQueue(SeqQueue *q,datatype x) { if((q->rear+1)%max==q->front) {printf("\nfull!");return 0;} q->data[q->rear]=x; q->rear=(q->rear+1)%max;
字符串模式匹配

实验7、字符串查找目的掌握字符串模式匹配的经典算法。
问题描述分别用简单方法和KMP方法实现index在文本串中查找指定字符串的功能。
步骤1.定义字符串类型2.实现简单的index操作,从文本串中查找指定字符串。
3.实现KMP方法的index操作,从文本串中查找指定字符串。
4.[选]建立一个文本文件,读入每一行来测试自己完成的练习,观察并理解程序的各个处理。
设备和环境PC计算机、Windows操作系统、C/C++开发环境结论能够理解和掌握字符串模式匹配的典型算法。
思考题1.对KMP算法分别用手工和程序对某个模式串输出next和nextval。
朴素算法:#include<stdio.h>#include<string.h>#define NOTFOUND -1#define ERROR -2#define MAXLEN 100//字符串的最大长度char S[MAXLEN+10],T[MAXLEN+10],st[MAXLEN+10];//串S和串Tint S0,T0; //S0:串S的长度 T0:串T的长度int pos; //pos的起始位置void Init(char *S,int &S0)//读入字符串{int len,i;New_Input:scanf("%s",st);//读入字符串len=strlen(st);if (len>MAXLEN)//如果字符串的长度大于规定的字符串最大长度 {printf("This String is too long,Please Input a new one.nn");goto New_Input;//重新读入字符串}for (i=1;i<=len;i++) S[i]=st[i-1];S[len+1]='';S0=len;}int Index(char *S,char *T,int pos){if (pos<1 || pos>S0) return ERROR; // 输入数据不合法int i=pos,j=1;while (i<=S0 && j<=T0){if (S[i]==T[j]) {i++; j++;}else {i=i-j+2; j=1;}//不匹配时,对应S移到下一位进行匹配}if (j>T0) return i-T0; //返回S中找到的位置else return NOTFOUND;}int main(){int ret;//函数返回值Init(S,S0);Init(T,T0);scanf("%d",&pos);ret=Index(S,T,pos); //在S串中从pos这个位置起,找到第一个与T匹配的子串的起始位置if (ret==NOTFOUND) printf("Not Found.n");else if(ret==ERROR) printf("The Input Data is Error.n");else printf("In S,from %dth is equal to T.n",ret);return 0;}KMP:#include<stdio.h>#include<string.h>#define NOTFOUND -1#define ERROR -2#define MAXLEN 100//字符串的最大长度char S[MAXLEN+10],T[MAXLEN+10],st[MAXLEN+10]; //串S和串Tint S0,T0; //S0:串S的长度 T0:串T的长度int pos; //pos的起始位置int next[MAXLEN+10];void Init(char *S,int &S0)//读入字符串{int len,i;New_Input:scanf("%s",st);//读入字符串len=strlen(st);if (len>MAXLEN)//如果字符串的长度大于规定的字符串最大长度{printf("This String is too long,Please Input a new one.nn");goto New_Input; //重新读入字符串}for (i=1;i<=len;i++) S[i]=st[i-1];S[len+1]='';S0=len;}void Get_next(char *S,int *next){int i=1,j=0;next[1]=0;while (i<T0)if (j==0 || T[i]==T[j]) {i++; j++; next[i]=next[j];}else j=next[j];}int Index_KMP(char *S,char *T,int pos){int i=pos,j=1;while (i<=S0 && j<=T0)if (j==0 || S[i]==T[j]) {i++; j++;}else j=next[j];if (j>T0) return i-T0;else return NOTFOUND;}int main(){int ret;//函数返回值Init(S,S0);Init(T,T0);scanf("%d",&pos);Get_next(T,next);ret=Index_KMP(S,T,pos); //在S串中从pos这个位置起,找到第一个与T匹配的子串的起始位置if (ret==NOTFOUND) printf("Not Found.n");else if (ret==ERROR) printf("The Input Data is Error.n");else printf("In S,from %dth is equal to T.n",ret);return 0;}扩张KMP:#include<stdio.h>#include<string.h>#define NOTFOUND -1#define ERROR -2#define MAXLEN 100 //字符串的最大长度char S[MAXLEN+10],T[MAXLEN+10],st[MAXLEN+10]; //串S和串Tint S0,T0; //S0:串S的长度 T0:串T 的长度int pos; //pos的起始位置int nextval[MAXLEN+10];void Init(char *S,int &S0)//读入字符串{int len,i;New_Input:scanf("%s",st); //读入字符串len=strlen(st);if (len>MAXLEN) //如果字符串的长度大于规定的字符串最大长度{printf("This String is too long,Please Input a new one.nn");goto New_Input; //重新读入字符串}for (i=1;i<=len;i++) S[i]=st[i-1];S[len+1]='';S0=len;}void Get_nextval(char *S,int *nextval){int i=1,j=0;nextval[1]=0;while (i<T0)if (j==0 || T[i]==T[j]){i++; j++;if (T[i]!=T[j]) nextval[i]=j;else nextval[i]=nextval[j];}else j=nextval[j];}int Index_KMP(char *S,char *T,int pos){int i=pos,j=1;while (i<=S0 && j<=T0)if (j==0 || S[i]==T[j]) {i++; j++;}else j=nextval[j];if (j>T0) return i-T0;else return NOTFOUND;}int main(){int ret;//函数返回值Init(S,S0);Init(T,T0);scanf("%d",&pos);Get_nextval(T,nextval);ret=Index_KMP(S,T,pos); //在S串中从pos这个位置起,找到第一个与T匹配的子串的起始位置if (ret==NOTFOUND) printf("Not Found.n");else if (ret==ERROR) printf("The Input Data is Error.n");else printf("In S,from %dth is equal to T.n",ret);return 0;}。
KMP模式匹配算法

KMP模式匹配算法KMP算法是一种字符串匹配算法,用于在一个主串中查找一个模式串的出现位置。
该算法的核心思想是通过预处理模式串,构建一个部分匹配表,从而在匹配过程中尽量减少不必要的比较。
KMP算法的实现步骤如下:1.构建部分匹配表部分匹配表是一个数组,记录了模式串中每个位置的最长相等前后缀长度。
从模式串的第二个字符开始,依次计算每个位置的最长相等前后缀长度。
具体算法如下:-初始化部分匹配表的第一个位置为0,第二个位置为1- 从第三个位置开始,假设当前位置为i,则先找到i - 1位置的最长相等前后缀长度记为len,然后比较模式串中i位置的字符和模式串中len位置的字符是否相等。
- 如果相等,则i位置的最长相等前后缀长度为len + 1- 如果不相等,则继续判断len的最长相等前后缀长度,直到len为0或者找到相等的字符为止。
2.开始匹配在主串中从前往后依次查找模式串的出现位置。
设置两个指针i和j,分别指向主串和模式串的当前位置。
具体算法如下:-当主串和模式串的当前字符相等时,继续比较下一个字符,即i和j分别向后移动一个位置。
-当主串和模式串的当前字符不相等时,根据部分匹配表确定模式串指针j的下一个位置,即找到模式串中与主串当前字符相等的位置。
如果找到了相等的位置,则将j移动到相等位置的下一个位置,即j=部分匹配表[j];如果没有找到相等的位置,则将i移动到下一个位置,即i=i+13.检查匹配结果如果模式串指针j移动到了模式串的末尾,则说明匹配成功,返回主串中模式串的起始位置;如果主串指针i移动到了主串的末尾,则说明匹配失败,没有找到模式串。
KMP算法的时间复杂度为O(m+n),其中m为主串的长度,n为模式串的长度。
通过预处理模式串,KMP算法避免了在匹配过程中重复比较已经匹配过的字符,提高了匹配的效率。
总结:KMP算法通过构建部分匹配表,实现了在字符串匹配过程中快速定位模式串的位置,减少了不必要的比较操作。
串串的模式匹配

Brute-Force简称为BF算法,亦称简朴匹配算法。采用穷 举旳思绪。
s: a a a a b c d t: a ab bac cab bc c ✓
匹配成功
算法旳思绪是从s旳每一种字符开始依次与t旳字符进行匹配。
1
文档仅供参考,如有不当之处,请联系改正。
j
0
1
2
3
4
t[j]
a
a
a
a
b
next[j] -1
0
1
2
3
01 2 34 5678
s: a a a b a a a a b
i=3 j=1
t: a a a a b
01 23 4
失败:
i=3 j=1,j=next[1]=0
20
文档仅供参考,如有不当之处,请联系改正。
j
0
1
2
3
4
t[j]
a
a
a
a
b
next[j] -1
将s[i]与 将s[i+1]与 t[0]匹配 t[0]匹配
因为t[3]=t[2]=t[1]=t[0]='a' 是不必要旳
i=3
i=3
j=3
j=-1
23
将next改为nextval: 文档仅供参考,如有不当之处,请联系改正。
j
0
1
2
t[j]
a
a
a
next[j]
-1
0
1
nextval[j]
-1
-1
-1
01 23
s: a a a b
aaab
t: a a b
KMP算法-易懂版

KMP算法-易懂版⼀:定义 Knuth-Morris-Pratt 字符串查找算法,简称为 KMP算法,常⽤于快速查找⼀个母串S中是否包含⼦串(模式串)P,以及P出现的位置。
由于简单的暴⼒匹配中,每次遇到不匹配的位置时都要回溯到母串上⼀次的起点 i +1的位置上再次从⼦串的开头进⾏匹配,效率极其低下,故⽽KMP算法应运⽽⽣,减少回溯过程中不必要的匹配部分,加快查找速度。
⼆:kmp算法求解步骤描述 若当前不匹配的位置发⽣在母串位置 i,⼦串位置 j 上,则:1. 寻找⼦串位置 j 之前元素的最长且相等的前后缀,即最长公共前后缀。
记录这个长度。
2. 根据这个长度求 next 数组3. 若 j != 0, 则根据next [j] 中的值,将⼦串向右移动,也就是将公共前缀移到公共后缀的位置上,(代码表⽰为:j=next [j],注意 i 不变),即对位置 j 进⾏了更新,后续⼦串直接从更新后的 j 位置和母串 i 位置进⾏⽐较。
4. 若 j == 0,则 i+1,⼦串从j位置开始和母串 i+1 位置开始⽐较。
综上,KMP的next 数组相当于告诉我们:当⼦串中的某个字符跟母串中的某个字符匹配失败时,⼦串下⼀步应该跳到哪个位置开始和母串当前失配位置进⾏⽐较。
所以kmp算法可以简单解释为:如⼦串在j 处的字符跟母串在i 处的字符失配时,下⼀步就⽤⼦串next [j] 处的字符继续跟⽂本串 i 处的字符匹配,相当于⼦串⼀次向右移动 j - next[j] 位,跳过了⼤量不必要的匹配位置(OK,简单理解完毕之后,下⾯就是求解KMP的关键步骤,Let’s go! ) 三:kmp算法关键步骤之⼀,求最长的公共前后缀! 箭头表⽰当前匹配失败的位置,也就是当前的 j 位置。
⽩框表⽰最长公共前后缀AB!此时长度为2! 再来⼀个,此时最长公共前后缀为ABA!长度为3!四:kmp算法关键步骤之⼆,求next[ ] 数组 由步骤⼀,我们可以得到⼦串每个位置前⾯元素的最长共同前后缀,注意⼦串第⼀个位置是没有前后缀的,所以长度为0! 例:⼦串ABCDABD的最长公共前后缀可表⽰如下。
数据结构串的实验报告

一、实验目的1. 理解串的定义、性质和操作;2. 掌握串的基本操作,如串的创建、复制、连接、求子串、求逆序、求长度等;3. 熟练运用串的常用算法,如串的模式匹配算法(如KMP算法);4. 培养编程能力和算法设计能力。
二、实验环境1. 操作系统:Windows 102. 编程语言:C++3. 开发环境:Visual Studio 2019三、实验内容1. 串的创建与初始化2. 串的复制3. 串的连接4. 串的求子串5. 串的求逆序6. 串的求长度7. 串的模式匹配算法(KMP算法)四、实验步骤1. 串的创建与初始化(1)创建一个串对象;(2)初始化串的长度;(3)初始化串的内容。
2. 串的复制(1)创建一个目标串对象;(2)使用复制构造函数将源串复制到目标串。
3. 串的连接(1)创建一个目标串对象;(2)使用连接函数将源串连接到目标串。
4. 串的求子串(1)创建一个目标串对象;(2)使用求子串函数从源串中提取子串。
5. 串的求逆序(1)创建一个目标串对象;(2)使用逆序函数将源串逆序。
6. 串的求长度(1)获取源串的长度。
7. 串的模式匹配算法(KMP算法)(1)创建一个模式串对象;(2)使用KMP算法在源串中查找模式串。
五、实验结果与分析1. 串的创建与初始化实验结果:成功创建了一个串对象,并初始化了其长度和内容。
2. 串的复制实验结果:成功将源串复制到目标串。
3. 串的连接实验结果:成功将源串连接到目标串。
4. 串的求子串实验结果:成功从源串中提取了子串。
5. 串的求逆序实验结果:成功将源串逆序。
6. 串的求长度实验结果:成功获取了源串的长度。
7. 串的模式匹配算法(KMP算法)实验结果:成功在源串中找到了模式串。
六、实验总结通过本次实验,我对串的定义、性质和操作有了更深入的了解,掌握了串的基本操作和常用算法。
在实验过程中,我遇到了一些问题,如KMP算法的编写和调试,但在老师和同学的指导下,我成功地解决了这些问题。
基于BF和KMP的串模式匹配算法设计与实现(C语言)

基于BF和KMP的串模式匹配算法设计与实现(C语言)数据结构KMF算法//代码#include "stdafx.h"#include"string.h"#include"malloc.h"#define MAXSTRLEN 255int k;//定义全局变量typedef char SString[MAXSTRLEN+1];//0号元素存放串的长度。
int StrAssign(SString T,char *chars){ // 生成一个其值等于chars的串Tint i;if(strlen(chars)>MAXSTRLEN)return 0;else{T[0]=strlen(chars);for(i=1;i<=T[0];i++)T[i]=*(chars+i-1);return 1;}}int StrLength(SString S){ // 返回串的元素个数return S[0];}int StrCompare(SString S,SString T){//操作结果: 若S>T,则返回值>0;若S=T,则返回值=0;若S<t,则返回值<="" int="" p=""></t,则返回值for(i=1;i<=S[0]&&i<=T[0];++i)if(S[i]!=T[i])return S[i]-T[i];return S[0]-T[0];}///////////////////int SubString(SString Sub,SString S,int pos,int len){ // 用Sub返回串S的第pos个字符起长度为len的子串。
int i;if(pos<1||pos>S[0]||len<0||len>S[0]-pos+1)return 0;for(i=1;i<=len;i++)Sub[i]=S[pos+i-1];Sub[0]=len;return 1;}///////////int Index(SString S,SString T,int pos){ // 返回子串T在主串S中第pos个字符之后的位置。
第3章 蛮力法——串的模式匹配

模式匹配——BF算法
例:主串S="ababcabcacbab",模式T="abcac"
i
第 5 趟
a b a b c a b c a c b a b a b c a c
j
i=5,j=1失败 i回溯到6,j回溯到1
模式匹配——BF算法
例:主串S="ababcabcacbab",模式T="abcac"
i i i i i
第 3 趟
a b a b c a b c a c b a b a b c a c
j j j j j
i=7,j=5失败 i回溯到4,j回溯到1
模式匹配——BF算法
例:主串S="ababcabcacbab",模式T="abcac"
i
第 3 趟
a b a b c a b c a c b a b a b c a c
k
算法3.4——KMP算法中求next数组
void GetNext(char T[ ], int next[ ]) { 位置j 1 2 3 4 5 next[1]=0; j=1; k=0; 模式串 a b c a c while (j<T[0]) if ((k= =0)| |(T[j]= =T[k])) j next[j] { j++; 1 0 k++; 2 1 next[j]=k; 3 1 } 4 1 else k=next[k]; } 5 2
next数组的求解方法是: 1、第一位的next值为0,第二位的next值为1,
2、第三位开始首先将当前位的前一位字符与其next值 对应的字符进行比较, 相等:则该位的next值就是前一位的next值加上1;
数据结构实验报告-基于字符串模式匹配算法的病毒感染检测问题

《数据结构》实验报告
abcd abcde abc def
00 输出结果为:
YES
NO 四、分析过程
在主函数中利用键盘输入 human[ ]、virus[ ],即 cin>>human>>virus; ,输入时要注意模 式串 virus 的长度不要超过主串 human 的长度。
调用 BF 子函数,输入的两个实参会送到 BF 算法里进行比较,当比较次数小于各自的长 度 时 , 开 始 匹 配 , 即 while(i<strlen(human)&&j<strlen(virus)) 。 如 果 模 式 串 和 主 串 相 同 human[i]==virus[j]时,i 和 j 都要加 1,否则 i=i-j+1; j=0;。当 j 等于 virus 的长度时,说明匹 配成功,令输出返回值 1;否则返回值为 0。
实验时间 实验地点 指导教师
年月日 电气楼 308
实验项目
实验类别
实 验 目 的 及 要 求
基于字符串模式匹配算法的病毒感染检测问题
基础实验
实验学时
4 学时
实验目的: 1.掌握字符串的顺序存储表示方法 2.掌握字符串模式匹配算法 BF 算法或 KMP 算法的实现
实验要求: 输入多组数据,每组数据占 1 行,输入 0 0 时结束输入;每组数据输
BF 算法的基本思想是:从主串的第 pos 个字符起与模式串的第一个字符比较,若相等, 则继续逐个比较后续字符;否则从主串的下一个字符起再重新和模式串进行比较。直至模式 串中的每一个字符和主串中的一个连续字符序列相同,则称匹配成功,否则不成功。
(1)首先全局定义了两个一定长度的数组用来存储人类和病毒的 DNA,分别是 human[100] 和 virus[100]。分别用 i 和 j 来指示主串 human 和模式串 virus 当前正待比较的字符位置。
实验三-串的模式匹配

实验三串的模式匹配一、实验目的1.利用顺序结构存储串,并实现串的匹配算法。
2.掌握简单模式匹配思想,熟悉KMP算法。
二、实验要求1.认真理解简单模式匹配思想,高效实现简单模式匹配;2.结合参考程序调试KMP算法,努力算法思想;3.保存程序的运行结果,并结合程序进行分析。
三、实验内容1、通过键盘初始化目标串和模式串,通过简单模式匹配算法实现串的模式匹配,匹配成功后要求输出模式串在目标串中的位置;2、参考程序给出了两种不同形式的next数组的计算方法,请完善程序从键盘初始化一目标串并设计匹配算法完整调试KMP算法,并与简单模式匹配算法进行比较。
四、程序流程图、算法及运行结果3-1#include <stdio.h>#include <string.h>#define MAXSIZE 100int StrIndex_BF(char s[MAXSIZE],char t[MAXSIZE]){int i=1,j=1;while (i<=s[0] && j<=t[0] ){if (s[i]==t[j]){i++;j++;}else {i=i-j+2;j=1;}}if (j>t[0])return (i-t[0]);elsereturn -1;}int main(){char s[MAXSIZE];char t[MAXSIZE];int answer, i;printf("S String -->\n ");gets(s);printf("T String -->\n ");gets(t);printf("%d",StrIndex_BF(s,t)); /*验证*/if((answer=StrIndex_BF(s,t))>=0){printf("\n");printf("%s\n", s);for (i = 0; i < answer; i++)printf(" ");printf("%s", t);printf("\n\nPattern Found at location:%d\n", answer); }elseprintf("\nPattern NOT FOUND.\n");getch();return 0;}3-2#include <stdio.h>#include <string.h>#define MAXSIZE 100void get_nextval(unsigned char pat[],int nextval[]){int length = strlen(pat);int i=1;int j=0;nextval[1]=0;while(i<length){if(j==0||pat[i-1]==pat[j-1]){++i;++j;if(pat[i-1]!=pat[j-1]) nextval[i]=j;else nextval[i]=nextval[j];}else j=nextval[j];}}int Index_KMP(unsigned char text[], unsigned char pat[],int nextval[]) {int i=1;int j=1;int t_len = strlen(text);int p_len = strlen(pat);while(i<=t_len&&j<=p_len){if(j==0||text[i-1]==pat[j-1]){++i;++j;}else j=nextval[j];}if(j>p_len) return i-1-p_len;else return -1;}int main(){unsigned char text[MAXSIZE];unsigned char pat[MAXSIZE];int nextval[MAXSIZE];int answer, i;printf("\nBoyer-Moore String Searching Program"); printf("\n====================================");printf("\n\nText String --> ");gets(text);printf( "\nPattern String --> ");gets(pat);get_nextval(pat,nextval);if((answer=Index_KMP(text, pat,nextval))>=0){printf("\n");printf("%s\n", text);for (i = 0; i < answer; i++)printf(" ");printf("%s", pat);printf("\n\nPattern Found at location %d\n", answer); }elseprintf("\nPattern NOT FOUND.\n");getch();return 0;}3-3#include "stdio.h"void GetNext1(char *t,int next[]){int i=1,j=0;next[1]=0;while(i<=9){if(j==0||t[i]==t[j]){++i; ++j; next[i]=j; }elsej=next[j];}}void GetNext2(char *t , int next[]){int i=1, j = 0;next[1]= 0;while (i<=9){while (j>=1 && t[i] != t[j] )j = next[j];i++; j++;if(t[i]==t[j]) next[i] = next[j];else next[i] = j; }}void main(){char *p="abcaababc";int i,str[10];GetNext1(p,str);printf("Put out:\n");for(i=1;i<10;i++)printf("%d",str[i]);GetNext2(p,str);printf("\n");for(i=1;i<10;i++)printf("%d",str[i]);printf("\n");getch();}.。
K M P 算 法 详 解

KMP算法详解(转)此前一天,一位MS的朋友邀我一起去与他讨论快速排序,红黑树,字典树,B树、后缀树,包括KMP算法,唯独在讲解KMP算法的时候,言语磕磕碰碰,我想,原因有二:1、博客内的东西不常回顾,忘了不少;2、便是我对KMP算法的理解还不够彻底,自不用说讲解自如,运用自如了。
所以,特再写本篇文章。
由于此前,个人已经写过关于KMP算法的两篇文章,所以,本文名为:KMP算法之总结篇。
本文分为如下六个部分:第一部分、再次回顾普通的BF算法与KMP算法各自的时间复杂度,并两相对照各自的匹配原理;第二部分、通过我此前第二篇文章的引用,用图从头到尾详细阐述KMP算法中的next数组求法,并运用求得的next数组写出KMP算法的源码;第三部分、KMP算法的两种实现,代码实现一是根据本人关于KMP算法的第二篇文章所写,代码实现二是根据本人的关于KMP算法的第一篇文章所写;第四部分、测试,分别对第三部分的两种实现中next数组的求法进行测试,挖掘其区别之所在;第五部分、KMP完整准确源码,给出KMP算法的准确的完整源码;第六步份、一眼看出字符串的next数组各值,通过几个例子,让读者能根据字符串本身一眼判断出其next数组各值。
力求让此文彻底让读者洞穿此KMP算法,所有原理,来龙去脉,让读者搞个通通透透(注意,本文中第二部分及第三部分的代码实现一的字符串下标i从0开始计算,其它部分如第三部分的代码实现二,第五部分,和第六部分的字符串下标i 皆是从1开始的)。
第一部分、KMP算法初解1、普通字符串匹配BF算法与KMP算法的时间复杂度比较KMP算法是一种线性时间复杂的字符串匹配算法,它是对BF算法(Brute-Force,最基本的字符串匹配算法的)改进。
对于给的原始串S 和模式串P,需要从字符串S中找到字符串P出现的位置的索引。
BF算法的时间复杂度O(strlen(S) * strlen(T)),空间复杂度O(1)。
《KMP 字符串模式匹配算法》教学课例

《KMP字符串模式匹配算法》教学课例程玉胜安庆师范学院计算机与信息学院KMP字符串模式匹配是数据结构课程中一个重要的知识点,也是一个难点(学过KMP 算法的同学100%认为:KMP是数据结构课程中最难的部分)。
为了消除他们对KMP算法学习的恐惧心理,激发他们的学习兴趣,调动其积极性,显得尤为重要。
基于以上,我们根据学生的认知特点和接受水平,对教材内容进行了重新构建,并按照数据结构中“时间复杂度”概念,增加了不同模式匹配算法的运行时间,动态逼真的显示了算法的“时间”性能,获得了较好的教学效果。
一、教学目标知识目标:让学生了解KMP算法应用的普遍性。
如:在目前众多的文字处理软件中得到广泛应用,如Microsoft Word中的“查找”或“替换”操作。
而这种操作实现的机制,同学们特别是计算机专业的学生很少去想过。
能力目标:要求学生体验一个完整的抽象数据类型(ADT)的实现方法和过程,并学会判断、计算算法优劣的方法。
价值目标:消除恐怖的学习心态,让学生感悟数据结构算法实际应用价值,从而激发学习的兴趣,形成积极主动式学习的态度。
二、教材分析使用教材是清华大学严蔚敏教授并由清华大学出版社出版的《数据结构(C语言版)》,该教材难度较大,其实验方法特别是ADT方法在教材中介绍较少,而且KMP算法更是从理论分析的角度介绍了匹配算法和next的计算,自学难度很大;虽然该节知识点属于“**(表示难度较大,可以不讲)”,但是其又是考研的一个热点,所以我们又不得不讲。
三、教学重点、难点教学重点:KMP算法中的next和改进的nextval计算教学难点:KMP算法中如何计算next值四、教具准备卡片:多个字符串,字符串指针强力磁吸:6个五、互动式教学过程教学内容教师活动学生活动目标状态创设情境引入课题目前的众多软件中,“查找”、“替换”等操作实现方法,要求学生举例。
给出一篇word文档完成在上述文档中从当前位置向后查找“计算机”或者向前查找“计算机”字符串的方法。
KMP算法(推导方法及模板)

KMP算法(推导⽅法及模板)介绍克努斯-莫⾥斯-普拉特算法Knuth-Morris-Pratt(简称为KMP算法)可在⼀个主⽂本S内查找⼀个词W的出现位置。
此算法通过运⽤对这个词在不匹配时本⾝就包含⾜够的信息来确定下⼀个匹配将在哪⾥开始的发现,从⽽避免重新检查先前匹配的。
此算法可以在O(n+m)时间数量级上完成串的模式匹配操作,其改进在于:每当⼀趟匹配过程中出现字符⽐较不等时,不需回溯i的指针,⽽是利⽤已经得到的“部分匹配”的结果将模式向右“滑动”尽可能远的距离后,继续进⾏⽐较。
kmp的核⼼之处在于next数组,⽽为了⽅便理解,我先介绍KMP的思想KMP匹配当开始匹配时,如果匹配过程中产⽣“失配”时,指针i(原串的下标)不变,指针j(模式串的下标)退回到next[j] 所指⽰的位置上重新进⾏⽐较,并且当指针j退回⾄零时,指针i和指针j需同时加⼀。
即主串的第i个字符和模式的第⼀个字符不等时,应从主串的第i+1个字符起重新进⾏匹配。
简单来说,就是两个串匹配,如果当前字符相等就⽐较两个字符串的下⼀个字符,如果当前匹配不相等时,就让j(待匹配串的下标)回到next[j] 的位置,因为我们已经知道next数组的作⽤是利⽤已经得到的“部分匹配”的结果将模式向右“滑动”尽可能远的距离,如ababac与abac⽐较时i=4,j=4时不匹配,则利⽤next数组让j=2继续匹配⽽不⽤重新开始。
(⽬前先不⽤管next数组的值时如何得到的,只要明⽩它的作⽤即可,下⾯回介绍)所以我们可以写出kmp的代码int KMP(char str[],char pat[]){int lenstr=strlen(str);int lenpat=strlen(pat);int i=1,j=1;while(i<=lenstr){if(j==0 || str[i]==pat[j]) //匹配成功继续往后匹配++i,++j;elsej=next[j]; //否则根据next数组继续匹配if(j==lenpat) //说明匹配完成return 1;}return 0;}接下来就是关键的求next数组了next数组⾸先,next数组取决于模式串本⾝⽽与相匹配的主串⽆关,我们可以对其递推得到。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、问题描述
模式匹配两个串。
二、设计思想
这种由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现的改进的模式匹配算法简称为KM P算法。
注意到这是一个改进的算法,所以有必要把原来的模式匹配算法拿出来,其实理解的关键就在这里,一般的匹配算法:
int Index(String S,String T,int pos)//参考《数据结构》中的程序
{
i=pos;j=1;//这里的串的第1个元素下标是1
while(i<=S.Length && j<=T.Length)
{
if(S[i]==T[j]){++i;++j;}
else{i=i-j+2;j=1;}//**************(1)
}
if(j>T.Length) return i-T.Length;//匹配成功
else return 0;
}
匹配的过程非常清晰,关键是当‘失配’的时候程序是如何处理的?为什么要回溯,看下面的例子:
S:aaaaabababcaaa T:ababc
aaaaabababcaaa
ababc.(.表示前一个已经失配)
回溯的结果就是
aaaaabababcaaa
a.(babc)
如果不回溯就是
aaaaabababcaaa
aba.bc
这样就漏了一个可能匹配成功的情况
aaaaabababcaaa
ababc
这是由T串本身的性质决定的,是因为T串本身有前后'部分匹配'的性质。
如果T为a bcdef这样的,大没有回溯的必要。
改进的地方也就是这里,我们从T串本身出发,事先就找准了T自身前后部分匹配的位置,那就可以改进算法。
如果不用回溯,那T串下一个位置从哪里开始呢?
还是上面那个例子,T为ababc,如果c失配,那就可以往前移到aba最后一个a的位置,像这样:
...ababd...
ababc
->ababc
这样i不用回溯,j跳到前2个位置,继续匹配的过程,这就是KMP算法所在。
这个当T[j]失配后,j应该往前跳的值就是j的next值,它是由T串本身固有决定的,与S串无关。
《数据结构》上给了next值的定义:
0 如果j=1
next[j]={Max{k|1<k<j且'p1...pk-1'='pj-k+1...pj-1'
1 其它情况
其实它就是描述前面表述的情况,关于next[1]=0是规定的,这样规定可以使程序简单一些,如果非要定为其它的值只要不和后面的值冲突也是可以的;而那个Max是什么意思,举个例子:
T:aaab
...aaaab...
aaab
->aaab
->aaab
->aaab
像这样的T,前面自身部分匹配的部分不止两个,那应该往前跳到第几个呢?最近的一个,也就是说尽可能的向右滑移最短的长度。
到这里,就实现了KMP的大部分内容,然后关键的问题是如何求next值?先看如何用它来进行匹配操作。
将最前面的程序改写成:
int Index_KMP(String S,String T,int pos)
{
i=pos;j=1;//这里的串的第1个元素下标是1
while(i<=S.Length && j<=T.Length)
{
if(j==0 || S[i]==T[j]){++i;++j;} //注意到这里的j==0,和++j的作用就
知道为什么规定next[1]=0的好处了 else j=next[j];//i不变(不回溯),j跳动
}
if(j>T.Length) return i-T.Length;//匹配成功
else return 0;
}
求next值,这也是整个算法成功的关键。
前面说过了,next值表达的就是T串的自身部分匹配的性质,那么,我只要将T串和T串自身来一次匹配就可以求出来了,这里的匹配过程不是从头一个一个匹配,而是从T[1]和T[2]开始匹配,给出算法如下:
void get_next(String T,int &next[])
{
i=1;j=0;next[1]=0;
while(i<=T.Length)
{
if(j==0 || T[i]==T[j]){++i;++j; next[i]=j;/**********(2)*/}
else j=next[j];
}
}
看这个函数非常像KMP匹配的函数!注意到(2)语句逻辑覆盖的时候是T[i]==T[j]以及i前面的、j前面的都匹配的情况下,于是先自增,然后记下来next[i]=j,这样每当i有自增就会求得一个next[i],而j一定会小于等于i,于是对于已经求出来的next,可以继续求后面的next,而next[1]=0是已知,所以整个就这样递推的求出来了,方法非常巧妙。
这样的改进已经是很不错了,但算法还可以改进,注意到下面的匹配情况:
...aaac...
aaaa.
T串中的'a'和S串中的'c'失配,而'a'的next值指的还是'a',那同样的比较还是会失配,而这样的比较是多余的,如果我事先知道,当T[i]==T[j],那next[i]就设为next[j],在求next值的时候就已经比较了,这样就可以去掉这样的多余的比较。
于是稍加改进得到:
void get_nextval(String T,int &next[])
{
i=1;j=0;next[1]=0;
while(i<=T.Length)
{
if(j==0 || T[i]==T[j])
{ ++i;++j;
if(T[i]!=T[j]) next[i]=j;
else next[i]=next[j];//消去多余的可能的比较,next再向前跳 }
else j=next[j];
}
}
三、分析理论时间复杂性
这个程序或许比想像中的要简单,因为对于i值的不断增加,代码用的是for循环。
因此,这个代码可以这样形象地理解:扫描字符串S,并更新可以匹配到T的什么位置。
为什么这个程序是O(n)的? KMP的时间复杂度分析可谓摊还分析的典型。
我们从上述程序的j 值入手。
每一次执行while循环都会使j减小(但不能减成负的),而另外的改变j值的地方只有第五行。
每次执行了这一行,j都只能加1;因此,整个过程中j 最多加了n个1。
于是,j最多只有n次减小的机会(j值减小的次数当然不能超过n,因为j永远是非负整数)。
这告诉我们,while循环总共最多执行了n次。
按照摊还分析的说法,平摊到每次for循环后,一次for循环的复杂度为O(1)。
整个过程显然是O(n)的。
这样的分析对于后面P数组预处理的过程同样有效,同样可以得到预处理过程的复杂度为O(m)。
四、原程序和调试结果
package kmp;
public class kmp {
String s="aaaaaaaa";
String p="aaaab";
int[] next=new int[s.length()];
//主要计算next[]的值
void calnext()
{
int i,j=0;
next[1] = 0;
next[0]=-1;
for(i=2;i<s.length();i++)
{
if(s.charAt(j)==s.charAt(i-1))
{
next[i]=next[i-1]+1;j++;
}
else
{
if(next[j]<0)
next[i]=0;
else
next[i]=next[j];
j=next[i];
}
}
}
//输出实际运算次数
void display()
{
int i=0,j=0,v;
int count=0;
while(i<s.length()&&j<p.length())
{
if(s.charAt(i)==p.charAt(j))
{
i++;j++;
}
else if(j==0)i++;
else j=next[j];
count++;
}
System.out.println(""+count);
}
public static void main(String[] args) {
// TODO code application logic here
kmp k=new kmp();
k.calnext();
k.display();
}
}
五、对结果的分析
进行了12次匹配,匹配成功。