统计预测与决策(自适应过滤法课后作业)
统计预测与决策试题

试 卷 一3、进行预测的前提条件是()A 、经济现象变化模式或关系的存在B 、把经济现象量化C 、经济现象变化呈现规律性D 、经济现象相对稳定 答:A1、进行贝叶斯决策的必要条件是()。
A 、预后验分析B 、敏感性分析C 、完全信息价值分析D 、先验分析 答:D2、统计预测的研究对象是()A 、经济现象的数值B 、宏观市场C 、微观市场D 、经济未来变化趋势 答:A若一个线性组合输入12tt aX bX +产生相应的输出(),则称该系统为线性的。
A 、11t t aY bY + B 、12t t aY bY + C 、12t t abY Y D 、22t t aY bY + 答:B1、 信息搜集时间越长,成本越高,它所带来的边际效益随之()。
A 、递增B 、递减C 、先递增后递减D 、先递减后递增 答:C3、效用曲线是表示效用值和()之间的关系。
A 、时间B 、损益值C 、成本D 、先验概率值 答:B4、()需要人们根据经验或预感对所预测的事件事先估算一个主观概率。
A 德尔菲法B 主观概率法C 情景分析法D 销售人员预测法 答:B1、 在对X 与Y 的相关分析中()A 、X 是随机变量B 、Y 是随机变量C 、X ,Y 都是随机变量D 、X ,Y 都是非随机变量 答:C5、()是受各种偶然因素影响所形成的不规则变动。
A 、长期趋势因素B 、季节变动因素C 、周期变动因素D 、不规则变动因素 答:D6、温特线性和季节性指数平滑法包括的平滑参数个数()A 、1个B 、2个C 、3个D 、4个 答:C移动平均模型MA(q)的平稳条件是()A 、滞后算子多项式()p pB B B φφφ++-=...11的根均在单位圆外B 、任何条件下都平稳C 、视具体情况而定D 、()0=B φ的根小于1 答:B自回归模型AR(p)的平稳条件是()A 、滞后算子多项式()p pB B B φφφ++-=...11的根均在单位圆外B 、任何条件下都平稳C 、视具体情况而定D 、()0=B φ的根小于1 答:A黑色系统的内部特征是()A 、完全已知的B 、完全未知的C 、一部份信息已知,一部份信息未知D 、以上都可以 答:B3、干预变量与虚拟变量之间的主要差别是()A 、前者为动态模型,后者为静态模式B 、前者为静态模型,后者为动态模式C、前者是单个或多个变量,后者是一个过程D、后者更复杂答:A3、层次分析法的基本假设是()。
统计预测和决策练习答案(徐国祥第五版)

统计预测和决策练习二(CH6CH6--CH7) 一.单项选择:一.单项选择:1. 自适应法就是从一组初始值开始值开始,利用迭代寻找模型的(C )的最优化。
)的最优化。
A. 自回归系数自回归系数B.C.均方误差MSED.残差e 2. 在模型的(C )向一最小值收敛时就取得了最优权重。
)向一最小值收敛时就取得了最优权重。
A. 残差残差B. C.一个循环的均方误差MSE D.显著性F 值 3. 在自适应过滤法中,为了避免由于数据的波动很大而影响迭代的收敛性,需要对数据(B ) A. 差分差分 B.标准化标准化 C.中心化中心化 D.移动平均移动平均 4. 已知上一轮, 则新一轮的等于(B )A.0.9B.0.31C.0.19D.0.385. 时间序列取自某一个随机过程,我们称过程是平稳的若(A )A. 此随机过程的随机特征不随时间变化此随机过程的随机特征不随时间变化B. 此随机过程的随机特征随时间变化此随机过程的随机特征随时间变化C. 此随机过程的每一项观测的均值为0D. 此随机过程的每一项观测的方差为06. 已知时间序列,其中为一非零常数,则(B )A. 该时间序列宽平稳该时间序列宽平稳B.该时间序列的均值为常数该时间序列的均值为常数 B. 该时间序列不是宽平稳该时间序列不是宽平稳 D.无法判断无法判断i Φ2R 2R 0005.0,20,325.01====Φk y e ,'Φ1{})cos(ct x y t =c x ,二.不定项选择二.不定项选择1. 用自相关分析法可以测定时间序列的(ABC ) A. 随机性随机性 B.平稳性平稳性 C.季节性季节性 D.周期性周期性 E.截尾性截尾性2.确定模型阶数常用的方法有(CDE )A.菲利普斯-佩荣方法佩荣方法B.迪基-福勒方法福勒方法C.利用信息准则法定阶(AIC 准则和BIC 准则)准则)D.基于F 检验确定确定阶数检验确定确定阶数E.基于自相关函数和偏自相关函数的定阶方法基于自相关函数和偏自相关函数的定阶方法 三、分析计算题。
第6章自适应过滤法

第六章 自适应过滤法教学目标:通过本章学习,使学生能掌握自适应过滤法的基本原理及其应用过程。
教学内容:第一节 自适应过滤法的基本原理自适应过滤法与移动平均法、指数平滑法一样,也是一种时间序列预测技术,即它是建立在时间序列的原始数据基础之上,通过对历史观察值进行某种加权平均来预测的。
这种方法在原始数据的基本模式比较复杂时使用(具有长期趋势性变动或季节性变动的确定型时间序列),常常可以取得优于指数平滑法和移动平均法的预测结果。
一、自适应过滤法的基本原理设t x x ,,1 为某一时间序列,则有如下有关时间序列的一般预测模型:11211+--+∧+++=p t p t t t x x x x φφφ 6-1式中,1+∧t x 是1+t 期的预测值,1+-i t x 是第1+-i t 期的观察值,i φ(p i ,,1 =)是权数,p 是权数的个数。
第五章中所讨论的移动平均法和指数平滑法以及本章所讨论的自适应过滤法,实际上都可以用上述模式来概括,如:对于一次移动平均法:pi 1=φ (p i ,,1 =) 对于一次指数平滑法:1)1(--=i i ααφ不同的是,上述两种方法的权数都是固定的,而自适应过滤法中的权数i φ则是根据预测误差i e 的大小不断调整修改而获得的最佳权数。
自适应过滤法的基本原理就在于通过其反复迭代以调整加权系数的过程,“过滤”掉预测误差,选择出“最佳”加权系数用于预测。
整个计算过程从选取一组初始加权系数开始,然后计算得到预测值及预测误差(预测值与实际值之差),再根据一定公式调整加权系数以减少误差,经过多次反复迭代,直至选择出“最佳”加权系数。
由于整个过程与通信工程中过滤传输噪声的过程极为接近,故被称为“自适应过滤法”。
运用自适应过滤法调整权数的计算公式为:112+-++='i t t i i x ke φφ 6-2式中i φ'(p i ,,1 =)是调整后的权数;i φ(p i ,,1 =)是调整前的权数,k 为调整系数,也称学习常数;111+∧++-=t t t x x e 是第1+t 期的预测误差;1+-i t x 是第1+-i t 期的观测值。
统计预测与决策练习题介绍

第一章¥第二章统计预测概述一、单项选择题8、统计预测的研究对象是()A、经济现象的数值B、宏观市场C、微观市场D、经济未来变化趋势答:A二、多项选择题4、定量预测方法大致可以分为()|A、回归预测法B、相互影响分析法C、时间序列预测法D、情景预测法E、领先指标法答:AC三、名词解释2、统计预测答:即如何利用科学的统计方法对事物的未来发展进行定量推测,并计算概率置信区间。
四、简答题1、试述统计预测与经济预测的联系和区别。
}答:两者的主要联系是:①它们都以经济现象的数值作为其研究的对象;②它们都直接或间接地为宏观和微观的市场预测、管理决策、制定政策和检查政策等提供信息;③统计预测为经济定量预测提供所需的统计方法论。
两者的主要区别是:①从研究的角度看,统计预测和经济预测都以经济现象的数值作为其研究对象,但着眼点不同。
前者属于方法论研究,其研究的结果表现为预测方法的完善程度;后者则是对实际经济现象进行预测,是一种实质性预测,其结果表现为对某种经济现象的未来发展做出判断;②从研究的领域来看,经济预测是研究经济领域中的问题,而统计预测则被广泛的应用于人类活动的各个领域。
第二章定性预测法一、单项选择题3、()需要人们根据经验或预感对所预测的事件事先估算一个主观概率。
A 德尔菲法B 主观概率法C 情景分析法D 销售人员预测法|答:B二、多项选择题2、主观概率法的预测步骤有:A 准备相关资料B 编制主观概率表C 确定专家人选D 汇总整理E 判断预测答:A B D E三、名词解释2、主观概率答:是人们对根据某几次经验结果所作的主观判断的量度。
\四、简答题1、定型预测有什么特点它和定量预测有什么区别和联系答:定型预测的特点在于:(1)着重对事物发展的性质进行预测,主要凭借人的经验以及分析能力;(2)着重对事物发展的趋势、方向和重大转折点进行预测。
定型预测和定量预测的区别和联系在于:定性预测的优点在于:注重于事物发展在性质方面的预测,具有较大的灵活性,易于充分发挥人的主观能动作用,且简单的迅速,省时省费用。
统计预测与决策练习题教案

第一章统计预测概述一、单项选择题8、统计预测的研究对象是()A、经济现象的数值B、宏观市场C、微观市场D、经济未来变化趋势答:A二、多项选择题4、定量预测方法大致可以分为()A、回归预测法B、相互影响分析法C、时间序列预测法D、情景预测法E、领先指标法答:AC三、名词解释2、统计预测答:即如何利用科学的统计方法对事物的未来发展进行定量推测,并计算概率置信区间。
四、简答题1、试述统计预测与经济预测的联系和区别。
答:两者的主要联系是:①它们都以经济现象的数值作为其研究的对象;②它们都直接或间接地为宏观和微观的市场预测、管理决策、制定政策和检查政策等提供信息;③统计预测为经济定量预测提供所需的统计方法论。
两者的主要区别是:①从研究的角度看,统计预测和经济预测都以经济现象的数值作为其研究对象,但着眼点不同。
前者属于方法论研究,其研究的结果表现为预测方法的完善程度;后者则是对实际经济现象进行预测,是一种实质性预测,其结果表现为对某种经济现象的未来发展做出判断;②从研究的领域来看,经济预测是研究经济领域中的问题,而统计预测则被广泛的应用于人类活动的各个领域。
第二章定性预测法一、单项选择题3、()需要人们根据经验或预感对所预测的事件事先估算一个主观概率。
A 德尔菲法B 主观概率法C 情景分析法D 销售人员预测法答:B二、多项选择题2、主观概率法的预测步骤有:A 准备相关资料B 编制主观概率表C 确定专家人选D 汇总整理E 判断预测答:A B D E三、名词解释2、主观概率答:是人们对根据某几次经验结果所作的主观判断的量度。
四、简答题1、定型预测有什么特点?它和定量预测有什么区别和联系?答:定型预测的特点在于:(1)着重对事物发展的性质进行预测,主要凭借人的经验以及分析能力;(2)着重对事物发展的趋势、方向和重大转折点进行预测。
定型预测和定量预测的区别和联系在于:定性预测的优点在于:注重于事物发展在性质方面的预测,具有较大的灵活性,易于充分发挥人的主观能动作用,且简单的迅速,省时省费用。
统计预测和决策课后答案

统计预测和决策课后答案【篇一:统计预测与决策的上级答案】,因此当m=1时,即当m=2时,即绘制散点图得?zt?stt1??b年以前(t?29)??0,1978stt???年及以后(t?29)?1,1978?由散点图和差分表可知,可知第一时期时,xt与t呈二次关系。
进行回归得?0t?97.74652?0.165166x*t2?0.4001*tr2?0.927622 f=166.6114 所以模型拟合的好。
然后依据第一期对第二期进行预测求出预测值和zt值,zt值为实际值减去预测值,对zt与z(t?1)进行回归得zt?4.417529?1.347132*zt?1f=23.21205 所以拟合效果显著。
r2?0.885549计算净化序列yt?xt?ztstt (t=30,t=1,2, (34)对净化序列建立模型yt?97.91656?0.166206*t2?0.43356*tr2?0.96481f=424.9629所以拟合效果显著。
所以干预分析预测模型为xt?97.91656?0.166206*t2?0.43356*t?4.417529stt1?1.347132b年以前(t?29)??0,1978stt???1,1978年及以后(t?29)??第十四章7题(1)以等概率标准,选择一个决策方案。
d1方案的损益值=(100+80-20)*1/3 =160/3 d2方案的损益值=(140+50-40)*1/3=50 d3方案的损益值=(60+30+10)*1/3=100/3因为e(d1) e(d2) e(d3)所以选择方案d1(2)如果p(s1)=0.3,p(s2)=0.5,p(s3)=0.2,以期望为标准选择一决策方案。
d1方案的损益值=0.3*100+0.5*80-0.2*20 =66 d2方案的损益值=0.3*140+0.5*50-0.2*40=59 d3方案的损益值=0.3*60+0.5*30+0.2*10=35 因为e(d1) e(d2) e(d3),所以选择方案d1 (3)补充条件(2),应用决策树进行决策分析。
统计预测与决策 习题答案

统计预测与决策习题答案统计预测与决策习题答案统计预测与决策是统计学中的一个重要领域,它涉及了数据分析、模型建立和决策制定等多个方面。
在实际应用中,统计预测与决策能够帮助我们预测未来的趋势、评估风险和制定合理的决策方案。
下面是一些与统计预测与决策相关的习题及其答案,希望能够帮助读者更好地理解这一领域的知识。
1. 问题:某公司过去5年的销售额数据如下,请使用简单移动平均法预测下一年的销售额。
年份:2015 2016 2017 2018 2019销售额:100 120 130 140 150答案:简单移动平均法是一种常用的时间序列预测方法,它通过计算一定时间段内的观测值的平均数来进行预测。
在这个问题中,我们可以选择过去几年的销售额作为观测值,然后计算它们的平均数。
计算过程如下:(100 + 120 + 130 + 140 + 150) / 5 = 128因此,根据简单移动平均法,下一年的销售额预测值为128。
2. 问题:某电商平台的用户在一个月内的购买金额数据如下,请使用指数平滑法预测下一个月的购买金额。
月份:1 2 3 4 5 6 7购买金额:100 110 120 115 130 140 145答案:指数平滑法是一种常用的时间序列预测方法,它通过对观测值进行加权平均来进行预测。
在这个问题中,我们可以选择过去几个月的购买金额作为观测值,然后根据指数平滑法进行预测。
计算过程如下:首先,选择一个平滑系数α,一般取值在0到1之间。
假设α为0.3。
第一个预测值为第一个观测值,即100。
第二个预测值为上一个预测值与第二个观测值的加权平均,即:预测值2 = α * 观测值2 + (1 - α) * 预测值1预测值2 = 0.3 * 110 + 0.7 * 100 = 103依此类推,可以得到以下结果:预测值3 = 0.3 * 120 + 0.7 * 103 = 107.9预测值4 = 0.3 * 115 + 0.7 * 107.9 = 108.73预测值5 = 0.3 * 130 + 0.7 * 108.73 = 113.121预测值6 = 0.3 * 140 + 0.7 * 113.121 = 116.1847预测值7 = 0.3 * 145 + 0.7 * 116.1847 = 118.74929因此,根据指数平滑法,下一个月的购买金额预测值为118.74929。
233070 北交《预测与决策分析》在线作业一 15秋答案解读

北交《预测与决策分析》在线作业一一、单选题(共 15 道试题,共 30 分。
)1. 状态空间模型按所受影响因素的不同可分为()和()模型. 隐性、显性. 线性、非线性. 离散性、连续性. 确定性、随机性正确答案:2. 采用博克斯-詹金斯方法时,如果时间序列的自相关函数和偏自相关函数都是拖尾的,则可以判断此序列适合()模型。
. M. R. RM. 线性正确答案:3. 下列哪一项不是统计决策的公理()。
. 方案优劣可以比较. 效用等同性. 效用替换性. 效用递减性正确答案:4. 采用博克斯-詹金斯方法时,如果时间序列的自相关函数和偏自相关函数都是拖尾的,则可以判断此序列适合()模型。
. M. R. RM. 线性正确答案:5. ()需要人们根据经验或预感对所预测的事件事先估算一个主观概率。
. 德尔菲法. 主观概率法. 情景分析法. 销售人员预测法正确答案:6. 状态空间模型的特点之一是将多个变量时间序列处理为()。
. 矩阵序列. 向量序列. 连续序列. 离散序列正确答案:7. 情景预测法通常将研究对象分为()和环境两个部分。
. 情景. 主题. 事件. 场景正确答案:8. 根据经验-W统计量在()之间表示回归模型没有显著自相关问题。
. 1.0-1.5. 1.5-2.5. 1.5-2.0. 2.5-3.5正确答案:9. 自适应过滤法中自回归模型的一个重要特点是回归系数是()。
. 固定不变的. 可变的. 最佳估计值. 不确定的正确答案:10. 预测实践中,人们往往采纳判定系数R2()的模型.. 最高. 最低. 中等. 为零的正确答案:11. 不确定性决策中“乐观决策准则”以()作为选择最优方案的标准。
. 最大损失. 最大收益. 后悔值. α系数正确答案:12. 情景预测法通常将研究对象分为()和环境两个部分。
. 情景. 主题. 事件. 场景正确答案:13. 当时间序列各期值的二阶差分相等或大致相等时,可配合( )进行预测。
统计预测与决策的上级答案

193.2
7.7
-6.7
11
96.4
-14.0
3.4
26
202.1
8.9
1.2
12
94.1
-2.3
11.7
27
207.1
5.0
-3.9
13
99.9
5.8
8.1
28
210.6
3.5
-1.5
14
111.6
11.7
5.9
29
229.6
19.0
15.5
15
126.7
15.1
3.4
其中,干预影响选取以下模式
091656972??????1??年及以后年以前29197829t19780tstt需求高03需求中05需求低02需求高03需求中05需求低02需求高03需求中05需求低02扩建原厂建设新厂转包外厂66593566第十四章7题1以等概率标准选择一个决策方案
第五章12题
由题可知 ,
所以
因此
当m=1时,即
由散点图和差分表可知,可知第一时期时,Xt与t呈二次关系。
进行回归得
F=166.6114所以模型拟合的好。
然后依据第一期对第二期进行预测
求出预测值和Zt值,Zt值为实际值减去预测值,对Zt与 进行回归得
F=23.21205所以拟合效果显著。
计算净化序列
(T=30,t=1,2,……,34)
得净化序列
时序t
因为E(D1)>E(D2)>E(D3)所以选择方案D1
(2)如果P(S1)=0.3,P(S2)=0.5,P(S3)=0.2,以期望为标准选择一决策方案。
D1方案的损益值=0.3*100+0.5*80-0.2*20 =66
《统计预测与决策》复习题

一、单项选择题1 统计预测方法中,以逻辑判断为主的方法属于(C)。
A 回归预测法B 定量预测法C 定性预测法D 时间序列预测法2 下列哪一项不是统计决策的公理(D)。
A 方案优劣可以比较B 效用等同性C 效用替换性D 效用递减性3 根据经验D-W统计量在(B)之间表示回归模型没有显著自相关问题。
A 1.0-1.5B 1.5-2.5C 1.5-2.0D 2.5-3.54 当时间序列各期值的二阶差分相等或大致相等时,可配合(B)进行预测。
A 线性模型 B抛物线模型 C指数模型 D修正指数模型5 (C)是指国民经济活动的绝对水平出现上升和下降的交替。
A 经济周期B 景气循环C 古典经济周期D 现代经济周期6 灰色预测是对含有(C)的系统进行预测的方法。
A 完全充分信息B 完全未知信息C 不确定因素D 不可知因素7 状态空间模型的假设条件是动态系统符合(C)。
A 平稳特性B 随机特性C 马尔可夫特性D 离散性8 不确定性决策中“乐观决策准则”以(B)作为选择最优方案的标准。
A 最大损失B 最大收益C 后悔值D α系数9 贝叶斯定理实质上是对(C)的陈述。
A 联合概率B 边际概率C 条件概率D 后验概率10 景气预警系统中绿色信号代表(B)。
A 经济过热B 经济稳定C 经济萧条D 经济波动过大二、多项选择题1 构成统计预测的基本要素有(ACD)。
A 经济理论 B预测主体 C数学模型 D实际资料2 统计预测中应遵循的原则是(BD)。
A 经济原则 B连贯原则 C可行原则 D 类推原则3 按预测方法的性质,大致可分为(ACD)预测方法。
A 定性预测B 情景预测 C时间序列预测 D回归预测4 一次指数平滑的初始值可以采用以下(BD)方法确定。
A 最近一期值 B第一期实际值 C最近几期的均值 D最初几期的均值5 常用的景气指标的分类方法有(ABCD)。
A 马场法 B时差相关法 C KL信息量法 D峰谷对应法三、名词解释1 同步指标:是指景气指标中与总体经济变化相一致或同步的那些指标。
统计预测与决策——徐国祥第三章参考答案

第三章3、(1)解:代码:y=c(12.5,13.8,14.25,14.25,14.5,13,14,15,15.75,16.5)x1=c(0.41,0.54,0.63,0.54,0.48,0.46,0.62,0.61,0.64,0.71)cor(y,x1)截图:由R语言运算结果可知,广告费支出与销售额的相关系数约为0.8479,有显著的相关关系。
(2)代码:cc<-data.frame(y,x1)model<-lm(y~x1,data=cc)summary(model)截图:由R语言运算结果知回归模型为y=8.304+10.729x。
(3)由上题运算结果可知,Multiple R-squared的值为0.719,即可决系数,表明回归模型能解释的销售额变动的比例为71.9%。
(4)代码:install.packages("installr") #更新R版本require(installr)updateR()library(lmtest) #安装DW检验函数dwtest(model)截图:DW统计量的值为1.562,无显著自相关性。
(5)代码:new<-data.frame(x1=0.67)ypred<-predict(model,new,interval="prediction",level=0.95)ypred #预测区间截图:在置信度为0.05的情况下,广告费支出为0.67万元时,预测下周销售额区间约为(13.77,17.21)。
7、代码:y=c(150,140,160,170,150,162,185,165,190,185)x1=c(40,42,48,55,65,79,88,100,120,140)cor(y,x1)model<-lm(y~x1,data=cc)summary(model)截图:(1)由上题运算结果可知,Multiple R-squared即可决系数的值为0.6525,相关系数值约为0.8078。
《统计预测与决策》复习试卷(共4套、含答案)(1)只是分享

试卷一一、单项选择题(共10小题,每题1分,共10分)1 统计预测方法中,以逻辑判断为主的方法属于()。
A 回归预测法B 定量预测法C 定性预测法D 时间序列预测法2 下列哪一项不是统计决策的公理()。
A 方案优劣可以比较B 效用等同性C 效用替换性D 效用递减性3 根据经验D-W统计量在()之间表示回归模型没有显著自相关问题。
A 1.0-1.5B 1.5-2.5C 1.5-2.0D 2.5-3.54 当时间序列各期值的二阶差分相等或大致相等时,可配合( )进行预测。
A 线性模型B抛物线模型C指数模型D修正指数模型5 ()是指国民经济活动的绝对水平出现上升和下降的交替。
A 经济周期B 景气循环C 古典经济周期D 现代经济周期6 灰色预测是对含有()的系统进行预测的方法。
A 完全充分信息B 完全未知信息C 不确定因素D 不可知因素7 状态空间模型的假设条件是动态系统符合()。
A 平稳特性B 随机特性C 马尔可夫特性D 离散性8 不确定性决策中“乐观决策准则”以()作为选择最优方案的标准。
A 最大损失B 最大收益C 后悔值D α系数9 贝叶斯定理实质上是对()的陈述。
A 联合概率B 边际概率C 条件概率D 后验概率10 景气预警系统中绿色信号代表()。
A 经济过热B 经济稳定C 经济萧条D 经济波动过大二、多项选择题(共5小题,每题3分,共15分)1 构成统计预测的基本要素有()。
A 经济理论B预测主体C数学模型D实际资料2 统计预测中应遵循的原则是()。
A 经济原则B连贯原则C可行原则 D 类推原则3 按预测方法的性质,大致可分为()预测方法。
A 定性预测B 情景预测C时间序列预测D回归预测4 一次指数平滑的初始值可以采用以下()方法确定。
A 最近一期值B第一期实际值C最近几期的均值D最初几期的均值5 常用的景气指标的分类方法有()。
A 马场法B时差相关法 C KL信息量法D峰谷对应法三、名词解释(共4小题,每题5分,共20分)1 同步指标2 预测精度3 劣势方案4 层次分析法(AHP法)四、简答题(共3小题,每题5分,共15分)1在实际预测中,为什么常常需要将定性预测与定量预测两种方法结合起来使用?2 请说明在回归预测法中包含哪些基本步骤?3 什么是风险决策的敏感性分析?五、计算题(共4题,共40分)1 下表是序列{Y t}的样本自相关函数和偏自相关函数估计值,请说明对该序列应当建立什么样的预测模型?(本题10分)K 1 2 3 4 5r k Φkk 0.64 0.07 -0.2 -0.14 0.09 0.64 0.47 0.35 0.24 0.15K 6 7 8 9 10r k Φkk 0.03 -0.05 -0.09 0.04 -0.07 0.04 -0.01 -0.05 0.03 -0.03试用龚珀兹曲线模型预测第11期的销售额。
统计预测与决策试题0

统计预测与决策试题0试卷一3、进行预测的前提条件是()A 、经济现象变化模式或关系的存在B 、把经济现象量化C 、经济现象变化呈现规律性D 、经济现象相对稳定答:A1、进行贝叶斯决策的必要条件是()。
A 、预后验分析B 、敏感性分析C 、完全信息价值分析D 、先验分析答:D2、统计预测的研究对象是()A 、经济现象的数值B 、宏观市场C 、微观市场D 、经济未来变化趋势答:A若一个线性组合输入12tt aX bX +产生相应的输出(),则称该系统为线性的。
A 、11t t aY bY + B 、12t t aY bY + C 、12t t abY Y D 、22t t aY bY + 答:B1、信息搜集时间越长,成本越高,它所带来的边际效益随之()。
A 、递增B 、递减C 、先递增后递减D 、先递减后递增答:C3、效用曲线是表示效用值和()之间的关系。
A 、时间B 、损益值C 、成本D 、先验概率值答:B4、()需要人们根据经验或预感对所预测的事件事先估算一个主观概率。
A 德尔菲法B 主观概率法C 情景分析法D 销售人员预测法答:B1、在对X 和Y 的相关分析中()A 、X 是随机变量B 、Y 是随机变量C 、X ,Y 都是随机变量D 、X ,Y 都是非随机变量答:C5、()是受各种偶然因素影响所形成的不规则变动。
A 、长期趋势因素B 、季节变动因素C 、周期变动因素D 、不规则变动因素答:D6、温特线性和季节性指数平滑法包括的平滑参数个数()A 、1个B 、2个C 、3个D 、4个答:C移动平均模型MA(q)的平稳条件是()A 、滞后算子多项式()p pB B B φφφ++-=...11的根均在单位圆外B 、任何条件下都平稳C 、视具体情况而定D 、()0=B φ的根小于1 答:B自回归模型AR(p)的平稳条件是()A 、滞后算子多项式()p pB B B φφφ++-=...11的根均在单位圆外B 、任何条件下都平稳C 、视具体情况而定D 、()0=B φ的根小于1 答:A黑色系统的内部特征是()A 、完全已知的B 、完全未知的C 、一部份信息已知,一部份信息未知D 、以上都可以答:B3、干预变量和虚拟变量之间的主要差别是()A 、前者为动态模型,后者为静态模式B 、前者为静态模型,后者为动态模式C、前者是单个或多个变量,后者是一个过程D、后者更复杂答:A3、层次分析法的基本假设是()。
统计预测与决策大作业word版
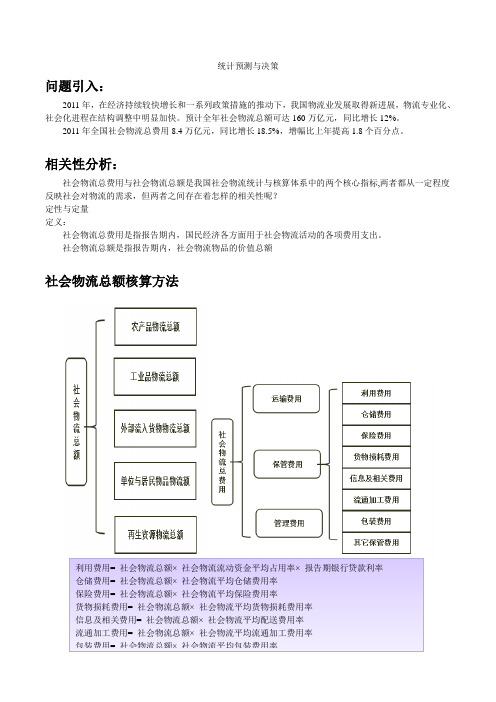
统计预测与决策问题引入:2011年,在经济持续较快增长和一系列政策措施的推动下,我国物流业发展取得新进展,物流专业化、社会化进程在结构调整中明显加快。
预计全年社会物流总额可达160万亿元,同比增长12%。
2011年全国社会物流总费用8.4万亿元,同比增长18.5%,增幅比上年提高1.8个百分点。
相关性分析:社会物流总费用与社会物流总额是我国社会物流统计与核算体系中的两个核心指标,两者都从一定程度反映社会对物流的需求,但两者之间存在着怎样的相关性呢?定性与定量定义:社会物流总费用是指报告期内,国民经济各方面用于社会物流活动的各项费用支出。
社会物流总额是指报告期内,社会物流物品的价值总额社会物流总额核算方法利用费用= 社会物流总额×社会物流流动资金平均占用率×报告期银行贷款利率仓储费用= 社会物流总额×社会物流平均仓储费用率保险费用= 社会物流总额×社会物流平均保险费用率货物损耗费用= 社会物流总额×社会物流平均货物损耗费用率信息及相关费用= 社会物流总额×社会物流平均配送费用率流通加工费用= 社会物流总额×社会物流平均流通加工费用率包装费用= 社会物流总额×社会物流平均包装费用率社会物流总费用与社会物流总额关系的定量分析:从图中可以看出,当对散点图进行描述的趋势线是一条线性的曲线时,点与趋势线的匹配度很高,因此可以先假设点对应的曲线是一条直线。
如此,可以从一元线性回归模型的角度对这条曲线与其对应的函数关系进行分析。
一元线性回归模型表示如下:上式表示变量和之间的真实关系。
其中:称作被解释变量,在模型中表示第t 年的社会社会物流总费用; 称作解释变量,在模型中表示第t 年的社会物流总额;称作随机误差项,包括除以外的影响 变化的众多微小因素,它的变化不可控,它的值可为0,为方便其见,模ty型中取其值为0; t 表示序数,本文中t 表示时间序数,相应地, 和 称为时间序列数据;称作常数项或截距项,称作斜率,和也称作回归参数。
统计预测与决策知识点考试必过和《统计预测与决策》复习试卷(共4套、含答案)

1.统计预测的概念:预测就是根据过去和现在估计未来,预测未来。
2.三要素:实际资料是预测的依据,经济理论是预测的基础,数学建模是预测的手段3.统计预测、经济预测的联系和区别:主要联系它们都以经济现象的数值作为其研究的对象:它们都直接或间接地为宏观和微观的市场预测、管理决策、制定政策和检查政策等提供信息;统计预测为经济定量预测提供所需的统计方法论;主要区别:从研究的角度看,统计预测和经济预测都以经济现象的数值作为其研究对象,但着眼点不同。
前者属于方法论研究,其研究的结果表现为预测方法的完善程度;后者则是对实际经济现象进行预测,是一种实质性预测,其结果表现为对某种经济现象的未来发展做出判断。
从研究的领域来看,经济预测是研究经济领域中的问题,而统计预测则被广泛地应用于人类活动的各个领域。
4统计预测的分类:定性预测和定量预测两类,其中定量预测法又可大致分为回归预测和时间序列预测;按预测时间长短,分为近期预测-1个月、短期预测-1-3个月、中期预测-3个月-2年和长期预测– 2年以上;按预测是否重复,分为一次性预测和反复预测5.预测方法考虑三个问题:合适性,费用,精确性6.统计预测的原则:连贯原则,类推原则7.统计预测的步骤:确定预测目的,搜索和审核资料选择预测类型和方法,分析误差改进模型,提出预测报告8.德尔菲法:是根据有专门知识的人的直接经验,对研究的问题进行判断、预测的一种方法,也称专家调查法。
它是美国兰德公司于1964年首先用于预测领域的。
特点:反馈性,匿名性,统计性;优点:加快预测速度节约预测费用,获得不同的价值观点和意见,适用长期预测和对新产品的预测,历史资料不足或不可预测因素多时尤为适用;缺点:分地区的顾客群或产品的预测可能不可靠,责任分散,专家的意见未必完整9.主观概率法步骤:1准备相关资料2编制主观概率调查表3汇总整理4判断预测10.情景预测法特点:1使用范围广不受假设条件限制2考虑问题全面应用灵活3定性和定量分析结合4能及时发现可能出现的难题减轻影响。
统计预测和决策自适应过滤法

j 1
其中:
ˆk , j ˆk 1, j ˆkk k 1,k j
k 1
k 2,3,...
回总目录 回本章目录
当前您正浏览第20页,共31页。
第二节 时间序列的自相关分析
一、自相关分析
• 时间序列的随机性,是指时间序列各项之间没有相关关系的特征。
• 判断时间序列是否平稳,是一项很重要的工作。
• [解答] Yule-Walker方程为:
0 1
1
1
1 2
2
2
即: 0.3 0 0.41 1
0.31 0.4 0 2
且: 0 0.31 0.4 2 2 1
回总目录 回本章目录
当前您正浏览第29页,共31页。
第四节 ARMA模型的建模
• [解答] 联合上面三个方程,解出:
0 100 / 63
1=0.54, =20.541
因此,可计算得到预测值:
xˆ6=0.54×53+0.541×50=56 (百万元)
=0.54×56+0.541×53=59 (百万元)
该xˆ7商品在2012和2013年的销售额分别为56和59百万元。
回总目录 回本章目录
当前您正浏览第11页,共31页。
第二节 自适应过滤法的应用
• AR(p)模型预测 • ARMA(p,q)模型预测
• 预测误差
• 预测的置信区间
回总目录 回本章目录
当前您正浏览第28页,共31页。
第四节 ARMA模型的建模
• [例] 设 Xt 0.3Xt1 0.4Xt2 为t 一AR(2)序列,其
中 t ~ WN (0,1)。求 Xt的 自协方差函数 k。
…… 反复迭代下去,直到预测误差没有明显改善时,就认为获得了 一组最佳权数,能实际用来预测2012、2013年的销售额。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1. 应用回归预测法进行预测时,应注意哪些问题? ①应用回归预测法时,应首先确定变量之间是否存在相关关系。
如果变量之间不存在相关关系,对这些变量应用回归预测法就会得出错误的结果 ②用定性分析判断现象之间的依存关系; ③避免回归预测的任意外推; ④应用合适的数据资料
2.
解:
̂=2.546567+0.008895 i̇
当x=1400时, ̂=
14.997625
t . 5(6)=2.447
t . 5=1.943
预测区间:
̂±t a
SE
(1) 广告费支出与销售额之间是否存在显著的相关关系? (2) 计算回归模型参数
(3) 回归模型能解释销售额变动的比例有多大? (4) 计算D-W 统计量
(5)如下周的广告费支出为6700元,试预测下周的销售额(取置信度α=0.05) 解:令每周广告支出为x ,每周的销售额为y 。
每周的广告支出费与销售量的相关系数r=。
两者存在显著的相关关系。
(2)设回归模型为:
̂i=+i
=∑(x−x )(y−y)
=0.001072885,==8.303927492
∑(x−x )2
(3)每周的广告支出费占销售量的75%。