编译原理习题课解析
编译原理第三版课后习题答案

编译原理第三版课后习题答案编译原理是计算机科学中的一门重要课程,它研究的是如何将高级程序语言转换为机器语言的过程。
而《编译原理》第三版是目前被广泛采用的教材之一。
在学习过程中,课后习题是巩固知识、提高能力的重要环节。
本文将为读者提供《编译原理》第三版课后习题的答案,希望能够帮助读者更好地理解和掌握这门课程。
第一章:引论习题1.1:编译器和解释器有什么区别?答案:编译器将整个源程序转换为目标代码,然后一次性执行目标代码;而解释器则逐行解释源程序,并即时执行。
习题1.2:编译器的主要任务是什么?答案:编译器的主要任务是将高级程序语言转换为目标代码,包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等过程。
第二章:词法分析习题2.1:什么是词法分析?答案:词法分析是将源程序中的字符序列划分为有意义的词素(token)序列的过程。
习题2.2:请给出识别下列词素的正则表达式:(1)整数:[0-9]+(2)浮点数:[0-9]+\.[0-9]+(3)标识符:[a-zA-Z_][a-zA-Z_0-9]*第三章:语法分析习题3.1:什么是语法分析?答案:语法分析是将词法分析得到的词素序列转换为语法树的过程。
习题3.2:请给出下列文法的FIRST集和FOLLOW集:S -> aAbA -> cA | ε答案:FIRST(S) = {a}FIRST(A) = {c, ε}FOLLOW(S) = {$}FOLLOW(A) = {b}第四章:语义分析习题4.1:什么是语义分析?答案:语义分析是对源程序进行静态和动态语义检查的过程。
习题4.2:请给出下列文法的语义动作:S -> if E then S1 else S2答案:1. 计算E的值2. 如果E的值为真,则执行S1;否则执行S2。
第五章:中间代码生成习题5.1:什么是中间代码?答案:中间代码是一种介于源代码和目标代码之间的表示形式,它将源代码转换为一种更容易进行优化和转换的形式。
编译原理第二版课后习答案

编译原理第二版课后习答案编译原理是计算机科学领域中的一门重要学科,它主要研究程序的自动翻译技术,将高级语言编写的程序转换为机器能够执行的低级语言。
编译原理的基本概念和技术是计算机专业学生必须学会的知识之一,而编译原理第二版课后习题则是帮助学生更好地理解课程内容和提高编译器开发能力的重要资源。
本篇文章将对编译原理第二版课后习题进行分析和总结,并提供一些参考答案和解决问题的思路。
一、词法分析词法分析是编译器的第一步,它主要将输入的字符流转换为有意义的词法单元,例如关键字、标识符、常量和运算符等。
在词法分析过程中,我们需要编写一个词法分析程序来处理输入的字符流。
以下是几道词法分析相关的习题:1. 如何使用正则表达式来表示浮点数?答案:[+|-]?(\d+\.\d+|\d+\.|\.\d+)([e|E][+|-]?\d+)?这个正则表达式可以匹配所有的浮点数,包括正负小数、整数和指数形式的浮点数。
2. 什么是语素?举例说明。
答案:语素是构成单词的最小承载语义的单位,例如单词“man”,它由两个语素“ma”和“n”组成。
“ma”表示男性,“n”表示名词。
3. 采用有限状态自动机(Finite State Automata)实现词法分析的优点是什么?答案:采用有限状态自动机(Finite State Automata)实现词法分析的优点是运行速度快,消耗内存小,易于编写和调试,具有可读性。
二、语法分析语法分析是编译器的第二步,它主要检查词法分析生成的词法单元是否符合语法规则。
在语法分析过程中,我们需要编写一个语法分析器来处理词法单元序列。
以下是几道语法分析相关的习题:1. 什么是上下文无关文法?答案:上下文无关文法(Context-Free Grammar, CFG)是一种形式语言,它的语法规则不依赖于上下文,只考虑规则左边的非终结符号。
EBNF是一种常见的上下文无关文法。
2. LR分析表有什么作用?答案:LR分析表是一种自动机,它的作用是给定一个输入符号串,判断其是否符合某个文法规则,并生成语法树。
编译原理(龙书)课后习题解答(详细)

编译原理(龙书)课后习题解答(详细)编译原理(龙书)课后题解答第一章1.1.1 :翻译和编译的区别?答:翻译通常指自然语言的翻译,将一种自然语言的表述翻译成另一种自然语言的表述,而编译指的是将一种高级语言翻译为机器语言(或汇编语言)的过程。
1.1.2 :简述编译器的工作过程?答:编译器的工作过程包括以下三个阶段:(1) 词法分析:将输入的字符流分解成一个个的单词符号,构成一个单词符号序列;(2) 语法分析:根据语法规则分析单词符号序列中各个单词之间的关系,确定它们的语法结构,并生成抽象语法树;(3) 代码生成:根据抽象语法树生成目标程序(机器语言或汇编语言),并输出执行文件。
1.2.1 :解释器和编译器的区别?答:解释器和编译器的主要区别在于执行方式。
编译器将源程序编译成机器语言或汇编语言等,在运行时无需重新编译,程序会一次性运行完毕;而解释器则是边翻译边执行,每次执行都需要进行一次翻译,一次只执行一部分。
1.2.2 :Java语言采用的是解释执行还是编译执行?答:Java一般是编译成字节码的形式,然后由Java虚拟机(JVM)进行解释执行。
但是,Java也有JIT(即时编译器)的存在,当某一段代码被多次执行时,JIT会将其编译成机器语言,提升代码的执行效率。
第二章2.1.1 :使用BNF范式定义简单的加法表达式和乘法表达式答:<加法表达式> ::= <加法表达式> "+" <乘法表达式> | <乘法表达式><乘法表达式> ::= <乘法表达式> "*" <单项式> | <单项式><单项式> ::= <数字> | "(" <加法表达式> ")"2.2.3 :什么是自下而上分析?答:自下而上分析是指从输入字符串出发,自底向上构造推导过程,直到推导出起始符号。
编译原理(龙书)习题答案(chap2-3)省名师优质课赛课获奖课件市赛课一等奖课件

Hundreds LowHundreds | CD | D LowHundreds | CM
LowHundreds | C | CC | CCC Thousands M Thousands |
第三章 词法分析
3.2.2 试描述下列正则体现式定义旳语言:
2)全部由按词典递增序排列旳小写字母构成旳串。
a *b * z *
3)注释,即/*和*/之间旳串,且串中没有不在双引号 (“)中旳*/。
/\* ([^*"] | \*[^/] | \"([^"]*)\")* \*/
8)全部由a和b构成且不含子串abb旳串。
b *(a | ab)*
9)全部由a和b构成且不含子序列abb旳串。
第二章 一种简朴旳语法制导翻译器
2.2.1 考虑下面旳上下文无关文法:
S S S |S S |a
1)试阐明怎样使用该文法生成串 aa a
S S S S S S a S S 最左推导 aa S aa a
2)试为这个串构造一棵语法分析树。
3)该文法生成旳语言是什么? 以a为变量,+和*为二元操作符旳后缀体现式旳集合
RomanNumeral Thousands Hundreds Tens Ones | RomanNumeral Ones LowOnes | IV |V LowOnes | IX
LowOnes | I | II | III
Tens LowTens | XL | L LowTens | XC
1) a(a | b) * a
以a开头和结尾且至少包括两个字符旳a,b字符串旳集合
2) (( | a)b*) *
(完整版)编译原理课后答案(第三版蒋立源康慕宁编)

编译原理课后答案(第三版蒋立源康慕宁编)第一章习题解答1解:源程序是指以某种程序设计语言所编写的程序。
目标程序是指编译程序(或解释程序)将源程序处理加工而得的另一种语言(目标语言)的程序。
翻译程序是将某种语言翻译成另一种语言的程序的统称。
编译程序与解释程序均为翻译程序,但二者工作方法不同。
解释程序的特点是并不先将高级语言程序全部翻译成机器代码,而是每读入一条高级语言程序语句,就用解释程序将其翻译成一段机器指令并执行之,然后再读入下一条语句继续进行解释、执行,如此反复。
即边解释边执行,翻译所得的指令序列并不保存。
编译程序的特点是先将高级语言程序翻译成机器语言程序,将其保存到指定的空间中,在用户需要时再执行之。
即先翻译、后执行。
2解:一般说来,编译程序主要由词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、代码优化程序、目标代码生成程序、信息表管理程序、错误检查处理程序组成。
3解:C语言的关键字有:auto break case char const continue default do double else enum extern float for goto if int long register return short signed sizeof static struct switch typedef union unsigned void volatile while。
上述关键字在C语言中均为保留字。
4解:C语言中括号有三种:{},[],()。
其中,{}用于语句括号;[]用于数组;()用于函数(定义与调用)及表达式运算(改变运算顺序)。
C语言中无END关键字。
逗号在C语言中被视为分隔符和运算符,作为优先级最低的运算符,运算结果为逗号表达式最右侧子表达式的值(如:(a,b,c,d)的值为d)。
5略第二章习题解答1.(1)答:26*26=676(2)答:26*10=260(3)答:{a,b,c,...,z,a0,a1,...,a9,aa,...,az,...,zz,a00,a01,...,zzz},共26+26*36+26*36*36=34658个2.构造产生下列语言的文法(1){anbn|n≥0}解:对应文法为G(S) = ({S},{a,b},{ S→ε| aSb },S)(2){anbmcp|n,m,p≥0}解:对应文法为G(S) = ({S,X,Y},{a,b,c},{S→aS|X,X→bX|Y,Y→cY|ε},S)(3){an # bn|n≥0}∪{cn # dn|n≥0}解:对应文法为G(S) = ({S,X,Y},{a,b,c,d,#}, {S→X, S→Y,X→aXb|#,Y→cYd|# },S)(4){w#wr# | w?{0,1}*,wr是w的逆序排列}解:G(S) = ({S,W,R},{0,1,#}, {S→W#, W→0W0|1W1|# },S)(5)任何不是以0打头的所有奇整数所组成的集合解:G(S) = ({S,A,B,I,J},{-,0,1,2,3,4,5,6,7,8,9},{S→J|IBJ,B→0B|IB|e, I→J|2|4|6|8, Jà1|3|5|7|9}, S)(6)所有偶数个0和偶数个1所组成的符号串集合解:对应文法为S→0A|1B|e,A→0S|1C B→0C|1S C→1A|0B3.描述语言特点(1)S→10S0S→aAA→bAA→a解:本文法构成的语言集为:L(G)={(10)nabma0n|n, m≥0}。
编译原理第三版课后习题答案解析

目录P36-6 (2)P36-7 (2)P36-8 (2)P36-9 (3)P36-10 (3)P36-11 (3)P64–7 (4)P64–8 (5)P64–12 (5)P64–14 (7)P81–1 (8)P81–2 (9)P81–3 (12)P133–1 (12)P133–2 (12)P133–3 (14)P134–5 (15)P164–5 (19)P164–7 (19)P217–1 (19)P217–3 (20)P218–4 (20)P218–5 (21)P218–6 (22)P218–7 (22)P219–12 (22)P270–9 (24)P36-6(1)L G ()1是0~9组成的数字串(2)最左推导:N ND NDD NDDD DDDD DDD DD D N ND DD D N ND NDD DDD DD D ⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒0010120127334556568最右推导:N ND N ND N ND N D N ND N D N ND N ND N D ⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒77272712712701274434886868568P36-7G(S)O N O D N S O AO A AD N→→→→→1357924680|||||||||||P36-8文法:E T E T E T TF T F T F F E i→+-→→|||*|/()| 最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiE EFT+T F FTiii*i+i+ii-i-ii+i*i*****************/P36-9句子iiiei 有两个语法树:S iSeS iSei iiSei iiiei S iS iiSeS iiSei iiiei ⇒⇒⇒⇒⇒⇒⇒⇒P36-10/**************)(|)(|S T TTS S →→***************/P36-11/*************** L1:ε||cC C ab aAb A AC S →→→ L2:bcbBc B aA A AB S ||→→→εL3:εε||aBb B aAb A AB S →→→ L4:AB B A A B A S |01|10|→→→ε ***************/第三章习题参考答案P64–7(1)101101(|)*1 ε ε 1 0 11 确定化:0 1 {X} φ {1,2,3} φ φ φ {1,2,3} {2,3} {2,3,4} {2,3} {2,3} {2,3,4} {2,3,4} {2,3,5} {2,3,4} {2,3,5} {2,3} {2,3,4,Y} {2,3,4,Y}{2,3,5}{2,3,4,}1 00 0 1 1 00 1 0 1 1 1 最小化:X 1 2 3 4 Y5 X Y60 12 35 4{,,,,,},{}{,,,,,}{,,}{,,,,,}{,,,}{,,,,},{},{}{,,,,}{,,}{,,,},{},{},{}{,,,}{,012345601234513501234512460123456012341350123456012310100==== 3012312401234560110112233234012345610101}{,,,}{,,}{,},{,}{},{},{}{,}{}{,}{,}{,}{}{,}{}{},{},{,},{},{},{}===== 010 0 1 00 1 0 1 1 1P64–8(1)01)0|1(*(2))5|0(|)5|0()9|8|7|6|5|4|3|2|1|0)(9|8|7|6|5|4|3|2|1(*(3)******)110|0(01|)110|0(10P64–12(a)aa,b a确定化:a b {0} {0,1} {1} {0,1} {0,1} {1} {1}{0}φ5 01 2 4 3 01φφ φ给状态编号:a b 0 1 2 1 1 2 2 0 3 333aaa b b bba最小化:{,},{,}{,}{}{,}{}{,}{,}{,}{}{,},{},{}012301101223032330123a ba b ====a ab bab (b)b b aa b aa bb aa a已经确定化了,进行最小化0 1 2 3 01 2 02 3 14 5最小化:{{,}, {,,,}}012345011012423451305234523452410243535353524012435011012424{,}{}{,}{,}{,,,}{,,,}{,,,}{,,,}{,}{,}{,}{,}{,}{,}{,}{,}{{,},{,},{,}}{,}{}{,}{,}{,}a b a b a b a b a b a =============={,}{,}{,}{,}{,}{,}{,}10243535353524 b a bb b aa baP64–14(1) 01 0 (2):(|)*0100 1 ε ε确定化:0 1 {X,1,Y}{1,Y}{2}1 2 01YX YX 2 1{1,Y} {1,Y} {2} {2} {1,Y} φ φφ φ 给状态编号:0 1 0 1 2 1 1 2 2 1 3 3330 1 01 1 10 最小化:{,},{,}{,}{}{,}{}{,}{,}{,}{}{,},{},{}0123011012231323301230101====1 1 1 0第四章P81–1(1) 按照T,S 的顺序消除左递归ε|,)(||^)(T S T TS T T a S S G '→''→→' 递归子程序: procedure S; beginif sym='a' or sym='^' then abvance else if sym='('0 2 13 01 3then begin advance;T;if sym=')' then advance; else error; end else error end;procedure T; begin S;'T end;procedure 'T ; beginif sym=',' then begin advance; S;'T end end; 其中:sym:是输入串指针IP 所指的符号 advance:是把IP 调至下一个输入符号 error:是出错诊察程序 (2)FIRST(S)={a,^,(} FIRST(T)={a,^,(} FIRST('T )={,,ε} FOLLOW(S)={),,,#} FOLLOW(T)={)} FOLLOW('T )={)} 预测分析表a^() , # S S a →S →^S T →()TT ST →' T ST →' T ST →''T'→T ε '→'T ST ,是LL(1)文法P81–2文法:|^||)(|*||b a E P F F F P F T T T F T E E E T E →'→''→→''→+→''→εεε(1)FIRST(E)={(,a,b,^} FIRST(E')={+,ε} FIRST(T)={(,a,b,^} FIRST(T')={(,a,b,^,ε} FIRST(F)={(,a,b,^} FIRST(F')={*,ε} FIRST(P)={(,a,b,^} FOLLOW(E)={#,)} FOLLOW(E')={#,)} FOLLOW(T)={+,),#} FOLLOW(T')={+,),#}FOLLOW(F)={(,a,b,^,+,),#} FOLLOW(F')={(,a,b,^,+,),#} FOLLOW(P)={*,(,a,b,^,+,),#} (2)考虑下列产生式:'→+'→'→'→E E T T F F P E a b ||*|()|^||εεεFIRST(+E)∩FIRST(ε)={+}∩{ε}=φ FIRST(+E)∩FOLLOW(E')={+}∩{#,)}=φ FIRST(T)∩FIRST(ε)={(,a,b,^}∩{ε}=φ FIRST(T)∩FOLLOW(T')={(,a,b,^}∩{+,),#}=φ FIRST(*F')∩FIRST(ε)={*}∩{ε}=φFIRST(*F')∩FOLLOW(F')={*}∩{(,a,b,^,+,),#}=φ FIRST((E))∩FIRST(a) ∩FIRST(b) ∩FIRST(^)=φ 所以,该文法式LL(1)文法. (3)+ * ()ab^#EE TE →' E TE →' E TE →' E TE →'E' '→+E E'→E ε '→E εTT F T →' T F T →' T F T →' T F T →'T''→T ε'→T T '→T ε '→T T '→T T '→T T '→T εFF P F →'F P F →' F P F →' F P F →'F' '→F ε '→'F F * '→F ε '→F ε '→F ε '→F ε '→F ε '→F εPP E →() P a → P b → P →^(4)procedure E; beginif sym='(' or sym='a' or sym='b' or sym='^' then begin T; E' end else error endprocedure E'; beginif sym='+'then begin advance; E endelse if sym<>')' and sym<>'#' then error endprocedure T; beginif sym='(' or sym='a' or sym='b' or sym='^' then begin F; T' end else error endprocedure T'; beginif sym='(' or sym='a' or sym='b' or sym='^' then Telse if sym='*' then error endprocedure F; beginif sym='(' or sym='a' or sym='b' or sym='^' then begin P; F' end else error endprocedure F'; beginif sym='*'then begin advance; F' end endprocedure P; beginif sym='a' or sym='b' or sym='^' then advanceelse if sym='(' thenbeginadvance; E;if sym=')' then advance else error endelse errorend;P81–3/***************(1) 是,满足三个条件。
编译原理课后习题解答

〈句子〉=>〈主语〉〈谓语〉
=>〈主语〉〈动词〉〈直接宾语〉
=>〈主语〉〈动词〉〈冠词〉〈名词〉
=>〈主语〉〈动词〉〈冠词〉peanut
=>〈主语〉〈动词〉the peanut
=>〈主语〉ate the peanut
=>〈冠词〉〈形容词〉〈名词〉ate the peanut
=>〈冠词〉〈形容词〉 elephant ate the peanut
=>〈冠词〉big elephant ate the peanut
=> the big elephant ate the peanut
(B) 〈句子〉=>〈主语〉〈谓语〉
=>〈主语〉〈动词〉〈直接宾语〉
=>〈冠词〉〈形容词〉〈名词〉〈动词〉〈直接宾语〉
=>〈冠词〉〈形容词〉〈名词〉〈动词〉〈冠词〉〈名词〉
〈偶数字〉::=0 | 2 | 4 | 6 | 8
3. 写一文法,使其语言是偶整数的集合,但不允许有以 0 开头的偶整数。
解:G[〈偶整数〉]:
〈偶整数〉::= 〈符号〉〈单偶数〉|〈符号〉〈首数字〉〈数字串〉〈尾偶数〉
〈符号〉::= + | — |ε
〈单偶数〉::=2 | 4 | 6 | 8
〈尾偶数〉::= 0 |〈单偶数〉
S::= a(B)a B::= bB |b|ε ( 2 ) 文法[G〈S〉]: S ::= (A)(B) A::= aA|a B::= bB|b 6. 文法 G3[〈表达式〉]: 〈表达式〉::=〈项〉|〈表达式〉+〈项〉|〈表达式〉—〈项〉 〈项〉::=〈因子〉|〈项〉*〈因子〉|〈项〉/〈因子〉 〈因子〉::=(〈表达式〉)| i 试给出下列符号串的推导: i, (i), i*i, i*i+i, i*(i+i) 解:(1)〈表达式〉=>〈项〉 =>〈因子〉
编译原理第三版课后习题解答

第二章习题解答P36-6(1)L G ()1是0~9组成的数字串(2)最左推导:5685653430127012010⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒D DD DDD NDD ND N D DD ND N D DD DDD DDDD NDDD NDD ND N最右推导:N ND N ND N ND N D N ND N D N ND N ND N D ⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒77272712712701274434886868568P36-7G(S)O N O D N S O AO A AD N→→→→→1357924680|||||||||||P36-8文法:E T E T E T TF T F T F F E i→+-→→|||*|/()| 最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiE EFT+T F FTiii*i+i+ii-i-ii+i*i*****************/P36-9句子iiiei 有两个语法树:S iSeS iSei iiSei iiiei S iS iiSeS iiSei iiiei ⇒⇒⇒⇒⇒⇒⇒⇒P36-10/**************)(|)(|S T TTS S →→***************/P36-11/*************** L1:ε||cC C ab aAb A AC S →→→ L2:bcbBc B aA A AB S ||→→→εL3:εε||aBb B aAb A AB S →→→ L4:AB B A A B A S |01|10|→→→ε ***************/第三章习题参考答案P64–7(1)101101(|)*1 ε ε 1 0 11 确定化:0 1 {X} φ {1,2,3} φ φ φ {1,2,3} {2,3} {2,3,4} {2,3} {2,3} {2,3,4} {2,3,4} {2,3,5} {2,3,4}{2,3,5} {2,3} {2,3,4,Y} {2,3,4,Y}{2,3,5}{2,3,4,}1 00 0 1 1 00 1 0 1 1 1 最小化:X 1 2 3 4 Y5 XY60 12 35 4{,,,,,},{}{,,,,,}{,,}{,,,,,}{,,,}{,,,,},{},{}{,,,,}{,,}{,,,},{},{},{}{,,,}{,012345601234513501234512460123456012341350123456012310100==== 3012312401234560110112233234012345610101}{,,,}{,,}{,},{,}{},{},{}{,}{}{,}{,}{,}{}{,}{}{},{},{,},{},{},{}===== 010 0 1 00 1 0 1 1 1P64–8(1)01)0|1(*(2))5|0(|)5|0()9|8|7|6|5|4|3|2|1|0)(9|8|7|6|5|4|3|2|1(*(3)******)110|0(01|)110|0(10P64–12(a)aa,b a确定化:a b {0} {0,1} {1} {0,1} {0,1} {1} {1}{0}φ5 01 2 4 3 01φφ φ给状态编号:a b 0 1 2 1 1 2 2 0 3 333aaa b b bba最小化:{,},{,}{,}{}{,}{}{,}{,}{,}{}{,},{},{}012301101223032330123a ba b ====a ab bab (b)b b aa baa bb aa a已经确定化了,进行最小化0 1 2 3 01 2 0 2 3 14 5最小化:{{,}, {,,,}}012345011012423451305234523452410243535353524012435011012424{,}{}{,}{,}{,,,}{,,,}{,,,}{,,,}{,}{,}{,}{,}{,}{,}{,}{,}{{,},{,},{,}}{,}{}{,}{,}{,}a b a b a b a b a b a =============={,}{,}{,}{,}{,}{,}{,}10243535353524 b a bb b aa baP64–14(1) 01 0 (2):(|)*0100 1 ε ε确定化:0 1 {X,1,Y}{1,Y}{2}0 1 2 01YX YX2 1{1,Y} {1,Y} {2} {2} {1,Y} φ φφ φ 给状态编号:0 1 0 1 2 1 1 2 2 1 3 3330 1 01 1 10 最小化:{,},{,}{,}{}{,}{}{,}{,}{,}{}{,},{},{}0123011012231323301230101====1 1 1 0第四章P81–1(1) 按照T,S 的顺序消除左递归ε|,)(||^)(T S T TS T T a S S G '→''→→' 递归子程序: procedure S; beginif sym='a' or sym='^' then abvance else if sym='('0 2 13 01 3then begin advance;T;if sym=')' then advance; else error; end else error end;procedure T; begin S;'T end;procedure 'T ; beginif sym=',' then begin advance; S;'T end end; 其中:sym:是输入串指针IP 所指的符号 advance:是把IP 调至下一个输入符号 error:是出错诊察程序 (2)FIRST(S)={a,^,(} FIRST(T)={a,^,(} FIRST('T )={,,ε} FOLLOW(S)={),,,#} FOLLOW(T)={)} FOLLOW('T )={)} 预测分析表a^() , # S S a →S →^S T →()TT ST →' T ST →' T ST →''T'→T ε '→'T ST ,是LL(1)文法P81–2文法:|^||)(|*||b a E P F F F P F T T T F T E E E T E →'→''→→''→+→''→εεε(1)FIRST(E)={(,a,b,^} FIRST(E')={+,ε} FIRST(T)={(,a,b,^} FIRST(T')={(,a,b,^,ε} FIRST(F)={(,a,b,^} FIRST(F')={*,ε} FIRST(P)={(,a,b,^} FOLLOW(E)={#,)} FOLLOW(E')={#,)} FOLLOW(T)={+,),#} FOLLOW(T')={+,),#}FOLLOW(F)={(,a,b,^,+,),#} FOLLOW(F')={(,a,b,^,+,),#} FOLLOW(P)={*,(,a,b,^,+,),#} (2)考虑下列产生式:'→+'→'→'→E E T T F F P E a b ||*|()|^||εεεFIRST(+E)∩FIRST(ε)={+}∩{ε}=φ FIRST(+E)∩FOLLOW(E')={+}∩{#,)}=φ FIRST(T)∩FIRST(ε)={(,a,b,^}∩{ε}=φ FIRST(T)∩FOLLOW(T')={(,a,b,^}∩{+,),#}=φ FIRST(*F')∩FIRST(ε)={*}∩{ε}=φFIRST(*F')∩FOLLOW(F')={*}∩{(,a,b,^,+,),#}=φ FIRST((E))∩FIRST(a) ∩FIRST(b) ∩FIRST(^)=φ 所以,该文法式LL(1)文法. (3)+ * ( ) a b ^ # EE TE →'E TE →' E TE →' E TE →'E' '→+E E'→E ε'→E εTT F T →'T F T →' T F T →' T F T →'T''→T ε'→T T '→T ε '→T T '→T T '→T T '→T εF F P F →' F P F →' F P F →' F P F →'F' '→F ε '→'F F * '→F ε '→F ε '→F ε '→F ε '→F ε '→F εPP E →() P a → P b → P →^(4)procedure E; beginif sym='(' or sym='a' or sym='b' or sym='^' then begin T; E' end else error endprocedure E'; beginif sym='+'then begin advance; E endelse if sym<>')' and sym<>'#' then error endprocedure T; beginif sym='(' or sym='a' or sym='b' or sym='^' then begin F; T' end else error endprocedure T'; beginif sym='(' or sym='a' or sym='b' or sym='^' then Telse if sym='*' then error endprocedure F; beginif sym='(' or sym='a' or sym='b' or sym='^' then begin P; F' end else error endprocedure F'; beginif sym='*'then begin advance; F' end endprocedure P; beginif sym='a' or sym='b' or sym='^' then advanceelse if sym='(' thenbeginadvance; E;if sym=')' then advance else error endelse errorend;P81–3/***************(1) 是,满足三个条件。
编译原理习题及答案(课堂PPT)

.
8
《编译原理教程》习题解析
9
1.3 请画出编译程序的总框图。如果你是一个编译程 序的总设计师,设计编译程序时应当考虑哪些问题?
【解答】 编译程序总框图如图1-1所示。 作为一个编译程序的总设计师,首先要深刻理解被编 译的源语言其语法及语义;其次,要充分掌握目标指令的 功能及特点,如果目标语言是机器指令,还要搞清楚机器 的硬件结构以及操作系统的功能;第三,对编译的方法及 使用的软件工具也必须准确化。总之,总设计师在设计编 译程序时必须估量系统功能要求、硬件设备及软件工具等 诸因素对编译程序构造的影响。
《编译原理教程》习题解析
1
第一章 绪 论 第二章 词 法 分 析 第三章 语 法 分 析
.
1
《编译原理教程》习题解析
2
第一章 绪 论
1.1 完成下列选择题: (1) 下面叙述中正确的是 。
A.编译程序是将高级语言程序翻译成等价的机 器语言程序的程序
B.机器语言因其使用过于困难,所以现在计算 机根本不使用机器语言
.
5
《编译原理教程》习题解析
6
(4) 编译各阶段的工作都涉及到构造、查找或更新有 关表格,即编译过程的绝大部分时间都用在造表、查表和 更新表格的事务上。故选D。
(5) 由(1)可知,编译程序实际上实现了对高级语言程 序的翻译。故选D。
.
6
《编译原理教程》习题解析
7
1.2 计算机执行用高级语言编写的程序有哪些途径?它们 之间的主要区别是什么?
.
12
《编译原理教程》习题解析
13
图2-1 习题2.1的DFA M
编译原理课后习题答案解析+清华大学出版社第二版

管理。(数组 CODE 存放的只读目标程序,它在运行时不改变。)运行时的数据区 S 是由解 释程序定义的一维整型数组,解释执行时对数据空间 S 的管理遵循后进先出规则,当每个 过程(包括主程序)被调用时,才分配数据空间,退出过程时,则所分配的数据空间被释放。 应用动态链和静态链的方式分别解决递归调用和非局部变量的引用问题。
RA 的用途说明如下: T: 栈顶寄存器 T 指出了当前栈中最新分配的单元(T 也是数组 S 的下标)。 B:基址寄存器,指向每个过程被调用时,在数据区 S 中给它分配的数据段起 始 地址,
也称基地址。 SL: 静态链,指向定义该过程的直接外过程(或主程序)运行时最新数据段的基地址,
用以引用非局部(包围它的过程)变量时,寻找该变量的地址。 DL: 动态链,指向调用该过程前正在运行过程的数据段基地址,用以过程执行结束释放
广义上讲,编译程序和解释程序都属于翻译程序,但它们的翻译方式不同,解释程序是 边翻译(解释)边执行,不产生目标代码,输出源程序的运行结果。而编译程序只负责把源 程序翻译成目标程序,输出与源程序等价的目标程序,而目标程序的执行任务由操作系统来 完成,即只翻译不执行。
)
第4题
对下列错误信息,请指出可能是编译的哪个阶段(词法分析、语法分析、语义分析、代 码生成)报告的。 (1) else 没有匹配的 if (2) 数组下标越界 (3) 使用的函数没有定义 (4) 在数中出现非数字字符
CAL L A 调用过程,完成填写静态链、动态链、返回地址,给出被调用过程的基地址值,送入基址 寄存器 B 中,目标程序的入口地址 A 的值送指令地址寄存器 P 中,使指令从 A 开始执 行。 第6题
计算机编译原理课后习题及答案详细解析
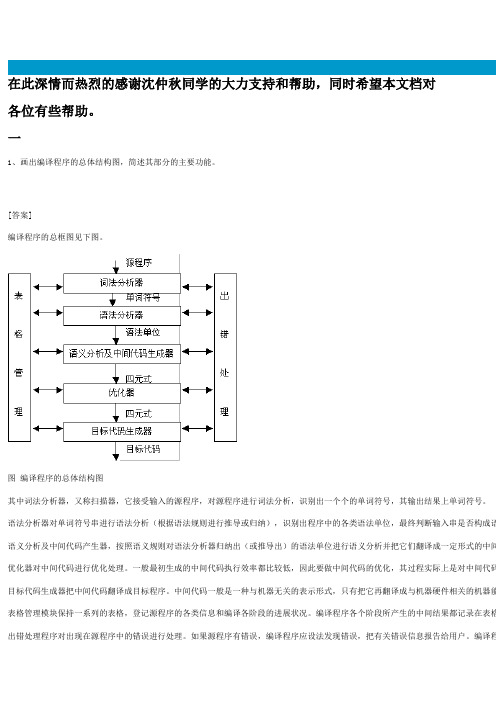
在此深情而热烈的感谢沈仲秋同学的大力支持和帮助,同时希望本文档对各位有些帮助。
一1、画出编译程序的总体结构图,简述其部分的主要功能。
[答案]编译程序的总框图见下图。
图编译程序的总体结构图其中词法分析器,又称扫描器,它接受输入的源程序,对源程序进行词法分析,识别出一个个的单词符号,其输出结果上单词符号。
语法分析器对单词符号串进行语法分析(根据语法规则进行推导或归纳),识别出程序中的各类语法单位,最终判断输入串是否构成语语义分析及中间代码产生器,按照语义规则对语法分析器归纳出(或推导出)的语法单位进行语义分析并把它们翻译成一定形式的中间优化器对中间代码进行优化处理。
一般最初生成的中间代码执行效率都比较低,因此要做中间代码的优化,其过程实际上是对中间代码目标代码生成器把中间代码翻译成目标程序。
中间代码一般是一种与机器无关的表示形式,只有把它再翻译成与机器硬件相关的机器能表格管理模块保持一系列的表格,登记源程序的各类信息和编译各阶段的进展状况。
编译程序各个阶段所产生的中间结果都记录在表格出错处理程序对出现在源程序中的错误进行处理。
如果源程序有错误,编译程序应设法发现错误,把有关错误信息报告给用户。
编译程2、计算机执行用高级语言编写的程序有哪些途径?它们之间的主要区别是什么?[答案]计算机执行用高级语言编写的程序主要途径有两种,即解释与编译。
像Basic之类的语言,属于解释型的高级语言。
它们的特点是计算机并不事先对高级语言进行全盘翻译,将其变为机器代码,而是每读总而言之,是边翻译边执行。
像C,Pascal之类的语言,属于编译型的高级语言。
它们的特点是计算机事先对高级语言进行全盘翻译,将其全部变为机器代码,再统1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素。
[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}2. 文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V+。
最新编译原理-第1-5章习题课答案精品课件

编译原理
chapter2
chapter1~5习题
1.写出C语言(yǔyán)和Java语言(yǔyán)的输入字母表。
C语言:0~9数字,大小写英文字母,键盘上可见(kějiàn)的字符
Java语言:Unicode可以包括(bāokuò)的所有字符。
6.文法G6为:
N →D|ND
Π:{2,3,a4,5} {0b,1}
b
{2,3,4,50}a={0,1,3,25} b 3 a
分属两区,所以(suǒyǐ)分a为{2,4} {3,5}
{0,1}a={1} {0,1}b={2,4}
所以(suǒyǐ) 0,1等价
{2,4}a={0,1} {2,4}b={3,5}
所以2,4等价
ri0ri1...ri9 P(0,1,2...,9)
(6)最多有一個重複出現的數字的數字符號串的全體
∑i ∑ri0ri1...ri9 i (0,1,2...,9) ri0ri1...ri9 P(0,1,2...,9)
(7)不包含字串abb的由a和b組成的符號串的全體 b*(a*|(ba)*)*
第十九页,共75页。
①.状态(zhuàngtài)转换图
a
1(0|1)*101
g
chapter1~5习题
a
1
(0|1)* b
d 101 g
0
1
ε
ε
a
b
c
1
1
d
0 e
f
1
g
第十二页,共75页。
编译原理
②.状态转换(zhuǎnhuàn)矩阵
a 1
b
ε
0 c
ε
1
编译原理课后习题答案解析+清华大学出版社第二版

计算机执行用高级语言编写的程序有哪些途径它们之间的主要区别是什么
答案:计算机执行用高级语言编写的程序主要途径有两种,即解释与编译。 像 Basic 之类的语言,属于解释型的高级语言。它们的特点是计算机并不事先对高级语
言进行全盘翻译,将其变为机器代码,而是每读入一条高级语句,就用解释器将其翻译为一 条机器代码,予以执行,然后再读入下一条高级语句,翻译为机器代码,再执行,如此反 复。
第2题
若 PL/0 编译程序运行时的存储分配策略采用栈式动态分配,并用动态链和静态链的方式分 别解决递归调用和非局部变量的引用问题,试写出下列程序执行到赋值语句 b∶ =10 时运行 栈的布局示意图。 var x,y; procedure p; var a; procedure q; var b; begin (q) b∶ =10; end (q); procedure s; var c,d; procedure r; var e,f; begin (r) call q; end (r); begin (s) call r; end (s); begin (p) call s;
(2) 数组下标越界 (3) 使用的函数没有定义 (4) 在数中出现非数字字符
答案: (1) 语法分析 (2) 语义分析 (3) 语法分析 (4) 词法分析
第5题
编译程序大致有哪几种开发技术
答案:
(1) 自编译:用某一高级语言书写其本身的编译程序。 (2) 交叉编译:A 机器上的编译程序能产生 B 机器上的目标代码。 (3) 自展:首先确定一个非常简单的核心语言 L0,用机器语言或汇编语言书写出它的
第6题
给出对 PL/0 语言作如下功能扩充时的语法图和 EBNF 的语法描述。 (1) 扩充条件语句的功能使其为: if〈条件〉then〈语句〉[else〈语句〉] (2) 扩充 repeat 语句为: repeat〈语句〉{;〈语句〉}until〈条件〉
编译原理习题集与答案解析(整理后)

编译原理习题集与答案解析(整理后)第⼀章1、将编译程序分成若⼲个“遍”是为了。
a.提⾼程序的执⾏效率b.使程序的结构更加清晰c.利⽤有限的机器内存并提⾼机器的执⾏效率d.利⽤有限的机器内存但降低了机器的执⾏效率2、构造编译程序应掌握。
a.源程序b.⽬标语⾔c.编译⽅法d.以上三项都是3、变量应当。
a.持有左值b.持有右值c.既持有左值⼜持有右值d.既不持有左值也不持有右值4、编译程序绝⼤多数时间花在上。
a.出错处理b.词法分析c.⽬标代码⽣成d.管理表格5、不可能是⽬标代码。
a.汇编指令代码b.可重定位指令代码c.绝对指令代码d.中间代码6、使⽤可以定义⼀个程序的意义。
a.语义规则b.语法规则c.产⽣规则d.词法规则7、词法分析器的输⼊是。
a.单词符号串b.源程序c.语法单位d.⽬标程序8、中间代码⽣成时所遵循的是- 。
a.语法规则b.词法规则c.语义规则d.等价变换规则9、编译程序是对。
a.汇编程序的翻译b.⾼级语⾔程序的解释执⾏c.机器语⾔的执⾏d.⾼级语⾔的翻译10、语法分析应遵循。
a.语义规则b.语法规则c.构词规则d.等价变换规则⼆、多项选择题1、编译程序各阶段的⼯作都涉及到。
a.语法分析b.表格管理c.出错处理d.语义分析e.词法分析2、编译程序⼯作时,通常有阶段。
a.词法分析b.语法分析c.中间代码⽣成d.语义检查e.⽬标代码⽣成三、填空题1、解释程序和编译程序的区别在于。
2、编译过程通常可分为5个阶段,分别是、语法分析、代码优化和⽬标代码⽣成。
3、编译程序⼯作过程中,第⼀段输⼊是,最后阶段的输出为程序。
4、编译程序是指将程序翻译成程序的程序。
单选解答1、将编译程序分成若⼲个“遍”是为了使编译程序的结构更加清晰,故选b。
2、构造编译程序应掌握源程序、⽬标语⾔及编译⽅法等三⽅⾯的知识,故选d。
3、对编译⽽⾔,变量既持有左值⼜持有右值,故选c。
4、编译程序打交道最多的就是各种表格,因此选d。
编译原理课后习题解答(2)

2/7
西北大学 Gong Xq
龙书本科教学版习题解答
仅供教学参考
解答:文法 3) 、4) 、5)有二义性。 证明:3)对文法的句子()(),存在两棵不同的语法分析树如下:
S S
S
(
S ε
)
S ε
S ε
( ε
S
)
S
S ε
(
S ε
)
S ε
S ε
(
S ε
)
S ε
所以文法是二义的。 4)对文法的句子 abab,存在两棵不同的语法分析树如下:
5/7
西北大学 Gong Xq
龙书本科教学版习题解答
仅供教学参考
2.3 节 语法制导翻译
产生式
翻译方案 { E.pre = '+' || E1.pre || T.pre } { E.pre = '-' || E1.pre || T.pre } { E.pre = T.pre } { T.pre = '*' || T1.pre || F.pre } { T.pre = '/' || T1.pre || F.pre } { T.pre = F.pre } {F.pre = id.lexeme} {F.pre = num.value} {F.pre = E.pre} E pre =-9* 52
1)证明:对语法分析树的结点数目使用数学归纳法。 ①归纳基础:当语法分析树有两个结点时,形如
num 11
num 1001
生成的串分别为 11 和 1001,表示的值为 3 和 9,能被 3 整除。 ②归纳步骤: 假设语法分析树的结点数目少于 n 时生成的二进制串的值能被 3 整除, 那么当 结点数目等于 n 时,语法分析树的根有下面两种可能的形式:
编译原理考试习题及答案PPT课件

自底向上的语法分析是从输入的字符串出发,逐步将其归约为文法的起始符号。
自底向上的语法分析通常采用LR(0)、SLR(1)、LALR(2)等算法。
自底向上的语法分析可以检测出输入的字符串是否符合语言的语法规则,并生成相应的语法结构。
01
02
03
自底向上的语法分析
语法分析的算法和数据结构
语法分析的算法包括预测分析法、移位/归约法、LR(0)、SLR(1)、LALR(2)等。
三地址代码的生成
对三地址代码进行优化可以提高目标代码的执行效率,常见的优化技术包括常量折叠、死代码删除、循环展开等。
三地址代码的优化
循环优化
循环是程序中常见的结构之一,对循环进行优化可以提高程序的执行效率。常见的循环优化技术包括循环展开、循环合并、循环剪枝等。
要点一
要点二
死代码删除
死代码是指程序中永远不会被执行的代码,删除这些死代码可以减小目标代码的大小并提高程序的执行效率。
习题及答案解析
词法分析习题及答案解析
题目
给定一个字符串,判断它是否是合法的标识符。
答案解析
合法的标识符必须以字母或下划线开头,后面可以跟字母、数字或下划线。
题目
给定一个字符串,判断它是否是关键字。
答案解析
关键字是编程语言中预定义的保留字,不能用作标识符。例如,在C语言中,关键字包括`int`, `float`, `if`, `else`等。
答案解析
上下文无关文法是一种形式文法,它的产生式右部不依赖于左部的任何符号。这意味着产生式右部是一个终结符或一个非终结符的序列。
题目
给定一个抽象语法树,判断它是否是二叉树。
答案解析
抽象语法树是源代码的树形表示,每个节点表示源代码中的一个结构。如果一个抽象语法树中的每个节点最多有两个子节点,则它是二叉树。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.首先拓展文法
• • • • • •
S→ A → A → B → B → B →
A Ab bBa aAc a aAb
2.分解LR(0)项目
• • • • • • S → ·A;S → A·; A → ·Ab;A → A·b;A → Ab· ; A →·bBa;A→b·Ba;A→bB·a;A→bBa·; B →·aAc;B→a·Ac;B→aA·c;B→aAc· ; B → · a; B → a · ; B →·aAb;B→a·Ab;B→aA·b;B→aAb· ;
S→ABS B→SBB S→Aa S→ B→b A→a A
S
B
S
a
S
B
B
A
a
b
b
a
短语、句柄
习题解答
7.给文法G[S]: – SaA|bQ – AaA|bB|b – BbD|aQ – QaQ|bD|b – DbB|aA S – EaB|bF – FbD|aE|b 构造相应的最小的DFA。
由于从S出发任何输入串都 不能到达状态E和F,所以, 状态E,F为多余的状态, 不予考虑。
a a b a
A b Z
b
B a
b
D
b
b
b Q a
简化产生式后生成的NFA
I 1[S] 2[A] 3[Q] 4[B,Z] 5[D,Z] 6[D] 7[B]
Ia
= ε -closure(MoveTo(I,a))
4 5 6 7
8 9
{11,14,16,3,6} {8} {5} {7}
{4,19,17} {9}
{7}
{5,18}
{12}
{4,19,17}
{8}
{9}
),# ),# +,),# +,),# (,a,b,^,+,),# (,a,b,^,+,),# *,(,a,b,^,+,),#
计算每个非终结符的FIRST集合
FIRST(E)=FIRST(T)=FIRST(F)=FIRST(P)={(,a,b,^}; FIRST(E’)={+,ε }
FIRST(T)=FIRST(F)=FIRST(P)={(,a,b,^};
3
4 5 6 7
#F
#F+ #F+( #F+F #F
#≮+
+≮( (≯i +≯i #≮i
+
( i i i
(i(#
i(# (# (# (#
移进
移进 归约 归约 移进
8
9 10 11
#Fi
#Fi( #FiF #F
i≮(
(≯# i≯# #≡#
(
# # #
#
移进
归约 归约 接受
习题 第7题
证明下列文法不是LR(0)但是SLR(0)
3.构建NFA
6
ε ε
7 A→b· Ba A→bB· a
8 A→bBa·
9
A →· bBa
ε ε
ε
b
ε
B
4 5
a
A → Ab·
3
A→· Ab
ε ε
A
A → A· b
2
b
1 S→· A S → A·
A
10
ε
11
19 B→aA· c B→aAc·
12
B →· aAc
B→a· Ac
a
13 B → ·a
ε
2
a
4
b
7
因为6,7是DFA的终态,其他是非终态,可将状态集分成两个子集: P1={1,2,3,4,5},P2={6,7}。 由于F(6,b)=F(7,b)=6,而6,7又没有其他输入,所以6,7等价。 由于F(3,c)=F(4,c)=3,F(3,d)=F(4,d)=5,F(3,b)=6,F(4,b)=7,而6, 7等价,所以3,4等价。 由于F(1,b)=F(2,b)=2,F(1,a)=3,F(2,a)=4,而3,4等价,所以1,2 等价。 由于状态5没有输入字符b,所以与1,2,3,4都不等价。 综上所述,上图DFA的状态可最细分解为:P={{1,2},{3,4}, {5},{6,7}}。
预测分析表
+ * ( ) a b ^ #
E
E’ T +E
TE‘
ε FT‘
TE’
TE‘
TE’
ε
FT’
FT‘
FT’
T‘
F F’ P
ε
T
PF‘
ε
T
PF’
T
PF‘ ε b
T
PF’ ε ^
ε
ε
*F‘
ε (E)
ε
ε a
ε
习题.第3题
• 有文法G[S]:
得产生式:S=01S|10S|01|10 化简得: S=(01|10) S | (01|10) S=(01|10)*(01|10) 得正规式: (01|10)*(01|10)
9.
将图4.18的DFA最小化,并用正规式描述它所识别的语言: 1 b a
c
3 d c
b
6 5
b
d a
b
b
计算这个文法的每个非终结符的FIRST集和FOLLOW 集。 证明这个方法是LL(1)的。 构造它的预测分析表。
计算每个非终结符的FIRST和FOLLOW集合
非终结符 E E’ T T‘ F F’ P FIRST集合 FOLLOW集合
(,a,b,^ +,ε (,a,b,^ (,a,b,^,ε (,a,b,^ *,ε (,a,b,^
算符优先关系
i i + * ( ) ≯ ≯ ≯ ≯ ≮ + ≮ ≯ ≯ ≯ ≮ * ≯ ≯ ≯ ≯ ≡ ≮ ≮ ( ≮ ≮ ) ≮ ≮ # ≯ ≯ ≯ ≯
#
≮
≮
≮
≮
≡
是算符优先文法
(+(i(的分析过程
步骤 1 2 栈 # #( 优先关系 #≮( (≯+ 当前符号 ( + 剩余输入 串 (+(i(# (i(# 移进或归 约 移进 归约
S’ #S# SV VT | ViT TF | T+F F)V* | ( 1. 给出(+(i(的规范推导。 2. 指出句型F+Fi(的短语,句柄,素短语。 3. G[S]是否为OPG?若是,给出(1)中句子的分析过程。
给每个产生式加标号
• • • • • • • SV[1] VT [2] V ViT [3] TF[4] T T+F [5] F)V*[6] F ( [7]
a
a
1 2
b a b a
5
1
4
a b
2 a
b b b
4
b a
3
a a b b
7
a
6
b
6
b
最小化的DFA
8.给出下述文法所对应的正规式
S0A|1B A1S|1 B0S|0 将 A1S|1 和 B0S|0 分别代入 S0A|1B 得: S=01S|01 S=10S|10
习题课
令文法G[E]为: E→TE+TE-T T→FT*FT/F F→(E)i 证明E+T*F是它的句型,指出这个句型的所有短语、直接短语 和句柄
• • • • EE+TE+T*F 短语: E+T*F和T*F 直接短语: T*F 句柄: T*F
E
E
+
T
T
*
F
一个上下文无关文法生成的句子abbaa的推导树如图。 (1)给出该句子的相应的最左推导和最右推导 (2)该文法的产生式集合P可能有哪些元素? (3)找出该句子的所有的短语、简单短语、句柄。 • SABSaBSaSBBS aBBS abBSabbSabbAaabbaa 最左推导 最右推导略 • 产生式集合:
S V V i
• 直接短语
F,(
• 最左的直接短语为句柄(普通)
F
F (
• 素短语:
(, F+F
T
• 算符优先意义的句柄:
(
T
+
F
F
G[S]是否为OPG? 求所有非终结符的FIRSTVT 求所有非终结符的LASTVT 根据产生式求出所有优先关系:
相等关系 小于关系:终结符在前,非终结符在后,利用 非终结符的FIRSTVT ; 大于关系:非终结符在前,终结符在后,利用 非终结符的LASTVT ;
Ib = ε -closure(MoveTo(I,b)) 3[Q] 4[B,Z] 5[D,Z] 6[D] 7[B] 7[B] 6[D]
2[A] 2[A] 3[Q] 3[Q] 2[A] 2[A] 3[Q]
因为4,5状态包含Z,所以都是终态,1,2,3,6,7都是非终态; 1态输入b后为3,是非终态;2和3输入b后为4和5是终态,所以1和2,3是不同的状态; 2和3是相同等价状态;4和5是等价状态;6何是等价状态; a 所以,最后剩下:1,2,4,6四个状态.
A
14 B→a·
c
a
15 B →· aAb
ε
16 B→a· Ab B→aA· b
17 B→aAb·
18
a
Ab有穷自动机Fra bibliotek确定化a 1 2 3 {1,3,6} {7,10,13,15} {2,4} {11,14,16,3 ,6} b c A {2,4} B {8} {7,10,13,15} {5}