UU编码原理及应用
Python中的Unicode编码介绍

Python中的Unicode编码介绍Unicode编码是一种全球性的字符编码标准,它被广泛应用于现代计算机和通信领域。
Unicode编码是一种非常重要的编码方式,因为它为计算机系统提供了一种能够处理各种语言和字符的标准方式。
本文将深入了解Unicode编码的概念、历史背景、编码方式、应用领域以及未来发展方向。
一、概念Unicode编码是一种用于计算机中字符编码的标准。
它使用一些数字和字母来代表各种语言、文字和字符。
由于各国语言和字符具有多样性,传统ASCII编码只能表示英文字符以及其他一些语言的基本字符,对于其他语言的字符则不能准确表示。
而Unicode编码通过将全世界的各种语言、文字和符号都归结到一个集合中,这个集合中包含了所有字符的编码。
Unicode编码共有4个字节,即可表示32位二进制数,可以覆盖世界上所有需要表示的字符,不像老的编码方式只能用1个字节表示字符,所以在编码的数据量和编码的范围上,Unicode 编码都具有显然的优势。
二、历史背景在计算机发展的早期,各个地区使用各自的字码表,例如:美国采用ASCII编码,俄罗斯采用KOI8-R编码,日本采用EUC-JP编码等等。
这些编码虽然适合本地使用,但由于缺乏统一标准,导致在国际交流时无法顺畅地传输各种语言和字符。
为了解决这种问题,国际标准化组织ISO于1987年设立了工作组,专门研究计算机字符编码的标准化问题,最终该组织的成果是Unicode字符编码标准。
1991年,Unicode正式公布,至此,Unicode标准成为了用户存储、传输和表示所有自然语言的最新国际标准。
三、编码方式Unicode编码有三种常用的表示方式,分别是UTF-8、UTF-16和UTF-32。
1. UTF-8编码UTF-8编码是一种可变长度的编码方式,可以在1到4个字节之间动态地编码字符。
UTF-8是一种以8位为一个编码单位的变长编码,它可以使用1到4个字节编码Unicode码位。
unicode编码的原理。

unicode编码的原理。
Unicode是一种字符编码方案,它的原理是给每个字符分配一
个唯一的代码点(code point),并为这些代码点指定一个在
计算机中的标准表示方式。
每个字符对应的代码点是一个整数,可以用十六进制表示。
Unicode编码的目标是包含世界上所有的字符,无论是已知的
还是尚未发现的。
它将字符按照类别进行分组,例如拉丁字母、希腊字母、中文汉字等。
对于每一组字符,Unicode在整个代
码空间内为它们分配了连续的代码点。
Unicode编码可以使用不同的表示方式,其中最常见的是
UTF-8、UTF-16和UTF-32。
- UTF-8是一种可变长度编码方式,使用1到4个字节来表示
一个字符,根据字符所需要的位数来确定编码长度。
它的优点是可以兼容ASCII编码,节省存储空间。
- UTF-16是一种固定长度编码方式,使用2或4个字节来表示一个字符。
这种编码方式适用于大多数字符都使用2个字节表示的语言,如中日韩文字。
- UTF-32是一种固定长度编码方式,使用4个字节来表示一个字符。
它适用于需要处理所有Unicode字符的特殊应用场景。
通过使用Unicode编码,不同的计算机系统和软件可以在处理
多语言文本时达到互操作性,确保字符的正确显示和传输。
2019转 邮件乱码破解完全手册1.doc

转邮件乱码破解完全手册1转:邮件乱码破解完全手册12010-11-20 19:11邮件乱码破解完全手册1来源:ChinaUnix博客日期:2007.01.14 23:04(共有条评论)邮件乱码破解完全手册随着Internet的普及,在网上通过E-mail传递信息逐渐成为现代人生活的时尚,相信不久甚至还会成为一种生活的必需内容。
但我们在接收电子邮件的时候,不时会发现接收的邮件是些怪模怪样的乱码,根本无法阅读。
如果这些邮件的内容并不很重要,可能还不会有太大影响,可是假如是些紧急事件的通知或是生意场上的公函,则很可能就会给你带来不小的损失。
遇到这种情况,你打算怎么办呢?把邮件丢进垃圾筒就当没收到,麻烦发信人再重发一次,还是自己找方法破译?我们知道,计算机以及很多计算机网络协议的制定都是建立在ASCII码(美国国家标准信息交换码,它是一种最基本的字符表示方法)基础上的,但是随着信息内容的日益丰富,用ASCII码表示计算机信息开始暴露出很大的不足,这主要表现在表示多国文字、图形、声音等二进制文件和信息压缩、信息保密等诸多方面。
因此,在ASCII码和扩展ASCII码的基础上,用一定的规则定义一些新的信息表达形式就形成了信息传输和处理中的另一类概念和事物,这就是"编码"和"解码"。
当信息编码和解码能够统一的时候,信息无疑是可以交换和被理解的;反之,当信息编码和解码不能够得到统一的时候,信息就无法被用于交换和理解,于是就产生了所谓的"乱码"。
既然乱码的产生是由于信息编码和解码不能够得到统一,那么解决乱码的过程自然就是找到和编码相统一的解码方法,并对计算机软件不能全自动进行正确解码的信息进行重新处理和解码,最终使得所恢复的信息能被人们理解和交换,这就是所谓的"破解"。
可以说,常见的乱码都有这样一些共性:(1)和汉字或其他语种的文字有关;(2)最常发生在电子邮件的传输和阅读中;(3)和传送二进制文件有关;(4)和信息加密解密、编码解码有关。
游程编码原理

游程编码原理
游程编码是一种压缩算法,用于减少数据的存储空间。
它基于一
种简单的思想:将连续重复的数据块替换成一个标记符和重复的次数。
这样可以大大减小数据的体积。
游程编码的原理如下:
1. 扫描输入数据,找到连续重复的数据块。
2. 将连续重复的数据块替换成一个标记符和重复的次数。
3. 将处理后的数据存储起来。
4. 解码时,读取标记符和重复的次数,重复输出对应的数据块。
例如,假设输入数据为“AAAABBBCCDAA”,使用游程编码可以将
其压缩为“A4B3C2D1A2”。
在解码时,读取标记符和重复的次数,重
复输出对应的数据块,即可恢复原始数据。
游程编码在某些情况下可以极大地减小数据的体积,特别是对于
包含大量重复数据的情况。
然而,在一些数据模式下,它可能会导致
压缩效果不佳甚至变差。
因此,游程编码常常与其他压缩算法结合使用,以提高整体的压缩效果。
UUencode编码,UU编码介绍、UUencode编码转换原理与算法
UUencode编码,UU编码介绍、UUencode编码转换原理与算法UUencode编码起先⽤在unix⽹络中,先是Unix系统下将⼆进制的资料借由uucp邮件系统传输的⼀个编码程式,也是⼀种⼆进制到⽂字的编码。
不属于MIME编码中⼀员。
它也是定义了⽤可打印字符表⽰⼆进制⽂字⼀种⽅法,并不是⼀种新的编码集合。
主要解决,⼆进制字符在传输、存储中问题。
它早期在电⼦邮件中使⽤较多,最近这些年来基本上被MIME 中Base64所取代了。
E-mail中⼀般采⽤UU、MIME、BINHEX三种编码标准! 我想,了解下这种编码将⼆进制字符转换为可打印字符实现思路!对我们以后做类似处理⼯作,应该会有很多的启⽰。
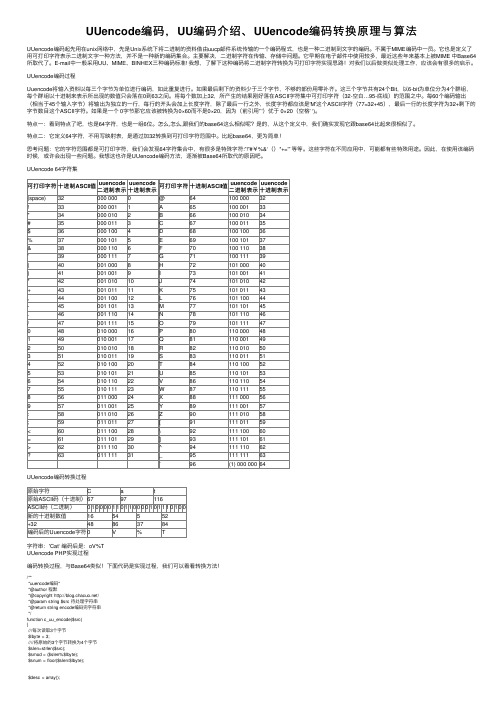
UUencode编码过程Uuencode将输⼊资料以每三个字节为单位进⾏编码,如此重复进⾏。
如果最后剩下的资料少于三个字节,不够的部份⽤零补齐。
这三个字节共有24个Bit,以6-bit为单位分为4个群组,每个群组以⼗进制来表⽰所出现的数值只会落在0到63之间。
将每个数加上32,所产⽣的结果刚好落在ASCII字符集中可打印字符(32-空⽩…95-底线)的范围之中。
每60个编码输出(相当于45个输⼊字节)将输出为独⽴的⼀⾏,每⾏的开头会加上长度字符,除了最后⼀⾏之外,长度字符都应该是'M'这个ASCII字符(77=32+45),最后⼀⾏的长度字符为32+剩下的字节数⽬这个ASCII字符。
如果是⼀个 0字节那它应该被转换为0×60⽽不是0×20,因为(前引⽤'`')优于 0×20(空格' ‘)。
特点⼀:看到特点了吧,也是64字符,也是⼀组6位。
怎么,怎么,跟我们的base64这么相似呢?是的,从这个定义中,我们确实发现它跟base64⽐起来很相似了。
特点⼆:它定义64字符,不⽤写映射表,是通过加32转换到可打印字符范围中。
⽐起base64,更为简单!思考问题:它的字符范围都是可打印字符,我们会发现64字符集合中,有很多是特殊字符:”!”#¥%&‘()*+='” 等等。
编码器的原理及其应用

编码器的原理及其应用1. 编码器的概述编码器是一种将模拟信号转换为数字信号的设备或电路。
通过对模拟信号进行采样、量化和编码处理,编码器将连续的模拟信号转换为离散的数字信号。
编码器在数字信号处理、通信系统、图像处理等领域有着广泛的应用。
2. 编码器的工作原理编码器主要由采样、量化和编码三个步骤组成。
2.1 采样编码器首先对模拟信号进行采样,即按照一定的时间间隔对模拟信号进行离散取样。
采样过程中,采样率的选择非常重要,过低的采样率会导致信号失真,而过高的采样率则会浪费存储空间。
2.2 量化在采样完成后,编码器对采样得到的离散信号进行量化处理。
量化是将连续的模拟信号转换为离散的数字信号的过程。
在量化过程中,采用一定的量化精度将采样值进行近似表示。
较高的量化精度会使得数字信号更加准确,但同时也会增加存储空间的消耗。
2.3 编码量化后,编码器将量化后的数字信号进行编码处理。
编码的目的是将离散的数字信号转换为可以传输和存储的数字格式。
常用的编码方法包括上采样、脉冲编码调制(PCM)等。
这些编码方法能够有效地压缩和表示数字信号,以满足不同的应用需求。
3. 编码器的应用编码器在多个领域都有广泛的应用,下面将介绍几个常见的应用领域。
3.1 通信系统在通信系统中,编码器用于将语音、视频等模拟信号转换为数字信号。
数字信号可以在通信系统中进行传输和处理,具有较强的抗干扰能力,可以有效提高通信质量。
3.2 数字音频在数字音频领域,编码器用于将模拟音频信号转换为数字音频格式。
通过选择合适的编码算法,可以实现高质量的音频压缩和传输。
常见的数字音频编码格式包括MP3、AAC等。
3.3 图像处理在图像处理领域,编码器被广泛应用于图像的压缩和存储。
编码器能够将图像转换为数字格式,并采用合适的压缩算法对图像进行压缩,以减少存储空间和传输带宽的消耗。
常见的图像编码格式包括JPEG、PNG等。
3.4 数字电视在数字电视领域,编码器将模拟电视信号转换为数字电视信号,并进行压缩和编码处理。
unicode编码规则

unicode编码规则摘要:一、Unicode 编码简介1.Unicode 的定义和作用2.Unicode 的发展历程二、Unicode 编码规则1.编码方式与字符集2.编码的基本原则3.编码的实现方式a.字节编码b.字符编码c.变长编码三、Unicode 字符的编码1.基本多文种平面(BMP)2.辅助平面(Supplementary Plane)3.统一码的兼容性与实现四、Unicode 编码的应用1.计算机系统中的Unicode 编码2.网络通信中的Unicode 编码3.移动设备中的Unicode 编码五、我国对Unicode 编码的贡献1.参与Unicode 制定2.我国主导的CJK 统一汉字编码正文:Unicode 编码规则是一种用于表示世界上所有字符的标准编码方式,它的出现解决了不同国家和地区字符编码不统一的问题,使得全球范围内的文本交流成为可能。
Unicode 编码自1991 年开始制定,至今已经经历了多个版本。
它的发展历程反映了计算机技术的发展,也体现了人们对全球字符编码统一的不断追求。
Unicode 编码规则主要包括编码方式与字符集,编码的基本原则,编码的实现方式等。
其中,编码方式与字符集规定了Unicode 可以表示的字符范围,编码的基本原则确定了编码的逻辑关系,编码的实现方式则决定了如何在计算机中实际存储和传输Unicode 字符。
在Unicode 编码中,字符的编码分为基本多文种平面(BMP)和辅助平面(Supplementary Plane)。
BMP 包含了所有常用的字符,而辅助平面则包含了较为罕见的字符。
这样的设计使得常用的字符可以被高效地编码和传输,同时也有足够的空间来容纳未来的字符需求。
Unicode 编码在我国得到了广泛的应用。
在计算机系统中,Unicode 编码被广泛应用于操作系统、编程语言、文本处理软件等。
在网络通信中,Unicode 编码也被广泛应用于网页、电子邮件等。
音频编码技术及其应用领域

音频编码技术及其应用领域音频编码技术是一种将模拟音频信号转换为数字音频信号的过程。
通过压缩数字音频信号,可以减少数据量,提高传输效率,并保证音质的同时降低存储和传输成本。
本文将介绍音频编码技术的原理、分类以及在各个应用领域中的具体应用。
一、音频编码技术的原理音频编码技术的原理是将音频信号进行采样、量化和编码。
首先,通过采样技术,对模拟音频信号进行采样,将连续的模拟信号转换为离散的数字信号。
然后,通过量化技术对采样后的数字信号进行量化,将连续的取值范围划分为有限个离散的取值。
最后,通过编码技术对量化后的数字信号进行编码,将离散的取值表示为二进制码流。
二、音频编码技术的分类1. 有损压缩编码技术:有损压缩编码技术通过舍弃信号中的冗余和不重要的信息来实现数据压缩,并以较低的比特率传输音频数据。
其中,最常用的有损压缩编码技术包括MP3(MPEG-1 Audio Layer 3)、AAC(Advanced Audio Coding)等。
这些技术能够在保证较高音质的前提下实现较低的比特率,广泛应用于音乐下载、在线音乐流媒体等领域。
2. 无损压缩编码技术:无损压缩编码技术通过压缩音频数据,减少数据量,但不损失音频信号的质量和可还原性。
常用的无损压缩编码技术包括FLAC(Free Lossless Audio Codec)和APE(Monkey's Audio)等。
这些技术适用于对音质要求较高的领域,如音乐制作和无损音乐传输等。
三、音频编码技术在不同应用领域的具体应用1. 通信领域:音频编码技术在通信领域扮演着重要的角色,如VoIP(Voice over Internet Protocol)和视频会议系统中的语音编码。
采用适当的音频编码技术可以降低带宽占用,实现高质量的语音通信。
2. 广播领域:音频编码技术在广播领域广泛应用,如数字广播系统中的音频编码。
通过采用先进的音频编码技术,可以实现更多信号的传输,提高广播效率。
unicode 原理

unicode 原理
Unicode是一种字符编码标准,它为世界上几乎所有的字符指
定了一个唯一的数字编码。
它的原理是使用一个Unicode字符
集来为每个字符分配一个独一无二的码位,每个码位对应一个字符。
Unicode字符集定义了超过100,000个码位,可以用来
表示世界上几乎所有的字符,包括各种语言的字母、符号、数字和特殊字符。
Unicode使用的编码方案有多种,其中最常用的是UTF-8。
UTF-8是一种可变长度的编码方式,它使用1到4个字节来表
示一个Unicode码位。
对于ASCII字符(码位范围为0到127),UTF-8编码与ASCII编码兼容,使用一个字节表示;
对于大部分非ASCII字符,UTF-8编码使用2到3个字节表示;对于一些特殊字符,UTF-8编码则使用4个字节。
使用Unicode编码的好处是可以在不同的系统和平台之间准确
地传输和显示文本。
不同的软件和操作系统可以根据Unicode
字符集来解码和显示文本,确保文本的一致性和可移植性。
同时,Unicode的增加了字符集范围,可以满足更多语言和字符
的需求。
由于Unicode的广泛应用,现在大多数编程语言和操
作系统都原生支持Unicode编码。
总之,Unicode的原理是通过为每个字符分配一个唯一的码位
来表示字符,使用不同的编码方案将码位映射到字节序列中。
这样可以实现在不同系统和平台之间准确传输和显示文本。
Unicode的应用广泛,成为了全球字符编码的标准。
编码器的工作原理及应用

编码器的工作原理及应用概述编码器是一种光电转换器件,用于将机械位置或动作转化为数字信号,常用于测量、控制和位置反馈等应用。
编码器广泛应用于自动化控制系统、机器人、数控机床、电梯等领域。
工作原理编码器的工作原理主要基于光电传感器和编码盘之间的相互作用。
1.光电传感器光电传感器通常包含发光器和接收器。
发光器发射光束,而接收器接收被反射的光束。
当物体靠近或远离光电传感器时,光束的反射程度会发生变化。
2.编码盘编码盘是一个圆形或圆环形的盘片,其表面分成若干等分。
线型编码盘是在编码盘上绘制一条连续的、等分的线条。
脉冲编码盘是在盘上刻上若干等距的脉冲。
3.工作原理当编码器与物体一起旋转或移动时,物体上的编码盘与光电传感器之间的光束会发生干涉。
通过检测光束的变化,可以测量物体的运动状态。
编码器将光电传感器接收到的信号转化为数字信号输出。
应用编码器具有很广泛的应用范围。
1.位置测量编码器可将物体的位置转化为数字信号,用于测量位置。
例如,机械手臂中的关节可以通过编码器测量其运动的角度和位置,从而实现精确的控制。
2.自动化控制系统编码器常用于自动化控制系统中的位置反馈和位置控制。
例如,在数控机床中,编码器用于测量工作台的位置,以实现精确的切削。
3.速度测量编码器可通过计算单位时间内脉冲的数量来测量物体的速度。
这对于需要实时监控物体运动状态的应用非常有用,如电梯上行/下行的速度控制。
4.姿态测量编码器可以被用于测量物体的倾斜角度和方向。
在飞行器中,编码器可测量航向、俯仰和横滚角。
5.机器人技术编码器在机器人技术中发挥着重要的作用。
编码器可以用于测量机器人关节的位置信息,实现精确的手臂控制和运动轨迹规划。
6.电动汽车在电动汽车中,编码器用于测量电机的旋转角度和速度,实现对电机的精确控制。
7.医疗设备编码器在医疗设备中也经常应用。
例如,编码器可以用于精确测量手术台或治疗设备的位置和角度。
结论编码器是一种重要的光电转换器件,其工作原理基于光电传感器和编码盘之间的相互作用。
计算机科学:编码的神奇之处

计算机科学:编码的神奇之处计算机科学中的编码无处不在,它是一种将信息转换成特定格式的方法,使得计算机能够理解和处理各种类型的数据。
在本篇文章中,我们将探讨编码的神奇之处,了解它如何在计算机科学中发挥重要作用。
一、编码的种类与应用1.字符编码:字符编码是将字符转换为计算机可以识别的二进制数值。
例如,ASCII码将字母、数字和一些特殊字符映射到0-127的整数范围内。
Unicode编码则是为了解决字符集的多样性而设计的,它将全球所有的字符分为若干个区,每个区包含一定数量的符号。
2.数值编码:数值编码是将数字转换为二进制或十六进制等形式。
例如,二进制编码可以用来表示整数和浮点数,而十六进制编码则常用于表示颜色值。
3.音频、视频编码:音频和视频编码是将声音和图像数据转换为计算机可以处理的数字格式。
例如,MP3是一种流行的音频压缩格式,而MP4则是一种常见的视频和音频编码格式。
4.数据压缩编码:数据压缩编码是为了减少存储空间和传输带宽而设计的。
常见的压缩编码方法有霍夫曼编码(Huffman Coding)和算术编码(Arithmetic Coding)等。
二、编码在计算机科学中的应用1.存储和传输:编码使得计算机可以高效地存储和传输各种类型的数据。
例如,通过字符编码,计算机可以将文本数据存储为文件或数据库,以便后续处理和检索。
2.数据处理和分析:编码有助于计算机对数据进行处理和分析。
例如,在数值计算、图像处理和音频分析等领域,编码技术使得计算机可以对数字信号进行运算、滤波和变换等操作。
3.编程和算法设计:编码是编程和算法设计的基础。
通过编码,程序员可以编写指令来控制计算机执行特定任务,同时也可以设计高效的算法来处理各种问题。
4.跨平台通信:编码保证了在不同操作系统和设备之间进行通信时,数据的正确传输和解析。
例如,互联网通信协议(如HTTP、FTP 等)都依赖于编码技术来确保数据的一致性和可解析性。
三、编码的未来发展随着科技的不断进步,编码技术也在不断发展。
编码器的原理和应用是什么

编码器的原理和应用是什么1. 编码器的原理:什么是编码器?编码器是一种将输入信号转换为特定编码格式的设备或电路。
它将模拟信号转换为数字信号,以便在数字系统中进行处理、传输和存储。
编码器的原理基于数字编码技术,通过将连续模拟信号分成离散的量化级别来表示信号。
编码器的主要功能是将模拟信号转换为数字信号,以实现信号的数字化处理和传输。
2. 编码器的工作原理编码器的工作原理基于信号的采样和量化。
它将连续的模拟信号离散化,并将其转换为数字信号。
编码器包括以下关键组件:•采样器:采样器负责对连续模拟信号进行采样。
它按照固定的时间间隔来测量信号的电压值,并将其转换为离散的样本点。
•量化器:量化器将采样后的模拟信号离散化为数字信号。
它将每个样本点的电压值映射为最接近的数字值,以表示信号的强度。
•编码器:编码器将量化后的数字信号转换为特定的编码格式。
它使用数字编码技术,如二进制编码或格雷码,将每个样本点映射为相应的编码值。
3. 编码器的应用编码器在数字系统中被广泛应用。
以下是几个常见的应用领域:3.1 通信系统编码器在通信系统中起着重要作用。
它们将模拟信号转换为数字信号,以便在通信网络中传输和接收。
编码器通过将信号进行数字化处理,提高了信号的稳定性和传输质量。
3.2 数字音频和视频编码编码器在数字音频和视频编码中被广泛使用。
它们将模拟音频和视频信号转换为数字格式,以便在数字媒体设备上存储和播放。
编码器有助于减小文件大小,提供更高的压缩比,并保持较高的音视频质量。
3.3 控制系统编码器在控制系统中用于测量和控制位置、速度和方向。
它们可用于机器人技术、自动化工艺控制和精密仪器。
编码器通过将运动转换为相应的电信号,使控制系统能够准确地检测和控制物体的位置和运动。
3.4 数字传感器和测量仪器编码器在数字传感器和测量仪器中被广泛应用。
它们将物理量,如温度、压力和位置转换为数字信号,以便进行数据采集和分析。
编码器有助于提高测量精度、减小干扰和噪音,并提供更可靠的测量结果。
编码器的原理及应用 (2)

编码器的原理及应用1. 引言编码器是一种用于将输入信号转换为相应输出信号的电子设备。
它广泛应用于通信、计算机、音视频等领域。
本文将介绍编码器的原理以及其在实际应用中的各种场景。
2. 编码器的原理编码器通常由输入、编码和输出三部分组成。
输入部分接受来自外部的输入信号,编码部分根据特定的编码规则对输入信号进行处理,输出部分将编码后的信号输出给其他设备或系统。
下面将介绍几种常见的编码器原理。
2.1 旋转编码器旋转编码器是一种常用的编码器,它通过旋转编码盘的方式将旋转角度转换为数字信号输出。
旋转编码器拥有两个输出信号通道:A 相和 B 相。
当旋转编码盘顺时针旋转时,A 相和 B 相的状态会发生连续的变化,从而产生一系列脉冲信号。
通过对脉冲信号的计数和方向判断,可以实现对旋转角度的准确测量。
2.2 压缩编码器压缩编码器是一种常用于按钮、滑块等输入设备的编码器。
它通过检测输入设备的压力变化来编码输入信号。
压缩编码器通常由两个金属片构成,当输入设备被按下或滑动时,两个金属片之间的距离发生变化,从而产生相应的电阻值变化。
编码器通过测量电阻值的变化来输出相应的信号。
2.3 光电编码器光电编码器利用光电传感器和光栅编码盘之间的光遮挡来实现编码。
光电传感器会不断检测光栅编码盘上的条纹遮挡情况,进而产生相应的脉冲信号。
光电编码器的分辨率取决于编码盘上的条纹数量,通常分辨率越高,编码器的精度就越高。
3. 编码器的应用编码器在现代电子设备中有着广泛的应用,下面将介绍几个常见的应用场景。
3.1 通信领域在通信领域中,编码器常用于对音频、视频等信号进行压缩编码。
压缩编码可以将信号的冗余信息去除,从而减小信号的体积并提高传输效率。
常见的压缩编码算法包括MP3、H.264等。
3.2 计算机领域在计算机领域中,编码器用于数据的存储和传输。
例如,硬盘驱动器中使用的磁盘编码器将数字信息转化为磁场的变化,以实现数据在磁盘上的存储。
另外,网络传输中使用的调制解调器(Modem)也是一种编码器,它将数字信号转换为模拟信号,以便通过电话线路进行传输。
Unicode 码与字符串编码的应用

Unicode 码与字符串编码的应用随着计算机和互联网的快速发展,我们已经离不开计算机和编码。
如果我们想要在计算机上编辑或阅读文字,那么我们就必须要使用一种字符串编码方式。
而Unicode码则是其中最广泛使用的一种编码标准。
本文将探讨Unicode码与字符串编码的应用。
Unicode简介Unicode是一种国际标准编码,它包括了世界上大多数的字符集合。
Unicode是由Unicode联盟(Unicode Consortium)所制定的一个用于文本编码的标准。
Unicode是一种统一的字符编码标准,它为所有的语言、符号和操作系统而设计。
Unicode的历史可以追溯到20世纪八十年代,当时计算机的各种字符集已经不足以满足互联网的需求。
为了解决这个问题,当时的许多科学家和工程师开始研究开发一种新的字符编码标准,这就是Unicode。
Unicode的编码方式Unicode基于一种称为“码位”的标识符来表示每个字符。
每个字符都有一个唯一的码位,其定义方式是通过不同的数字或者字母组成。
例如,字母A的码位是U+0041。
其中U代表Unicode,0041则表示它的十六进制编码。
Unicode码的范围从U+0000到U+d7ff和U+e000到U+10ffff。
除了标准的Unicode之外,还有一些Unicode编码的扩展标准,比如UTF-8、UTF-16和UTF-32等。
其中,UTF-8是最为广泛使用的一种编码方式。
UTF-8使用一个字节来表示ASCII字符,使用两个字节来表示拉丁文字符,使用三个字节来表示汉字和其他东亚字符。
字符串编码字符串编码是一种将字符集中的字符映射到计算机上的二进制表示,以便于存储和传输的方式。
每种字符串编码都有自己的字符集,并且针对不同的字符集,字符串编码也有不同的设计方式。
ASCII码是最早的字符串编码标准之一。
ASCII码仅包含了英文字母、数字和一些特殊字符。
ASCII码使用七位二进制数来表示每个字符,所以最多只能表示128个字符。
编码器的原理与应用

编码器的原理与应用编码器是一种电子器件或电路,用于将输入信号转换成相应的编码输出信号。
它的原理是通过对输入信号进行逻辑判断和处理,将不同的信号状态转换成不同的编码。
编码器常用于数字通信、自动控制系统和计算机等领域,具有广泛的应用。
编码器的原理主要包括信号采样、信号处理、编码输出等几个步骤。
首先,编码器会对输入信号进行采样,即按照一定的时间间隔对信号进行离散化处理。
然后,信号会被处理成逻辑状态或数字化的形式,例如二进制代码。
最后,按照特定编码规则,将不同的逻辑状态或数字化形式转换成相应的编码输出信号。
在自动控制系统中,编码器用于将传感器检测到的物理量转换成数字量,以便进行系统控制。
例如,温度传感器可以通过编码器将检测到的温度转换成数字信号,传递给控制器,从而实现温度控制。
编码器还常用于机器人和工业自动化领域,用于获取运动轨迹和位置信息。
在计算机领域,编码器广泛应用于数据存储和传输。
例如,硬盘和光盘等存储设备中的编码器可以将数字数据编码成磁场或光信号,以便存储和读取。
此外,网络通信中的编码器也起到重要作用,例如将数据包编码成网络传输的格式,实现网络通信。
编码器还有其他一些特殊的应用,例如音频编码器和视频编码器。
音频编码器可以将声音信号编码成数字音频格式(例如MP3),实现音乐的存储和传输。
视频编码器可以将视频信号编码成数字视频格式(例如H.264),实现视频的存储和传输。
总的来说,编码器作为一种重要的电子器件,其原理和应用十分广泛。
它可以将输入信号转换成不同的编码输出信号,通过实现数字化、传输和存储,为数字通信、自动控制系统和计算机等领域提供了便利。
随着科技的不断发展,编码器将继续发挥更大的作用,为各个领域的技术创新和进步做出贡献。
uuencode编码

uuencode编码一、任务概述在计算机科学中,uuencode编码是一种算法,用于将二进制数据转换为可打印字符。
该编码算法最初用于电子邮件传输,因为在早期的电子邮件系统中,只能传输文本字符而不能传输二进制数据。
uuencode编码通过将二进制数据转换为可打印字符,从而实现了在邮件中传输二进制文件的目的。
二、UU编码的基本原理UU编码是一种传输二进制文件的编码方法。
它将二进制文件中的每个字节转换为一个可打印字符。
基本的编码原理如下:1.将二进制数据按照每3个字节分为一组。
2.将每组字节的每个字节的数值加上32,得到一个新的字节。
3.将新的字节转换为一个可打印字符。
转换规则是将新的字节的数值加上32后对64取模,再加上一个固定的偏移值(通常为32),得到一个可打印字符。
4.将所有的可打印字符连接在一起形成一个编码后的字符串。
三、UU编码的用途UU编码主要用于在早期的电子邮件系统中传输二进制文件。
由于邮件系统只能传输文本字符,而不能传输二进制数据,因此需要一种方法将二进制文件转换为可打印字符。
UU编码通过将二进制数据转换为可打印字符,从而实现了在邮件中传输二进制文件的目的。
四、UU编码的优点UU编码具有以下优点:1.简单易实现:UU编码的算法相对简单,容易实现,并且不需要额外的库或工具。
2.可逆性:UU编码是一种可逆的编码方式,编码后的数据可以通过解码还原为原始的二进制文件。
3.跨平台兼容:由于UU编码只使用了可打印字符,因此编码后的数据可以在不同的操作系统和网络环境中传输和解码。
五、使用UU编码进行文件传输的步骤使用UU编码进行文件传输的步骤如下:1.将待传输的二进制文件拆分为每3个字节一组的数据块。
2.对每个数据块进行UU编码,得到可打印字符。
3.将所有的编码后的数据块连接在一起,形成一个编码后的字符串。
4.将编码后的字符串按照每行不超过64个字符的规则进行分行处理。
5.在编码后的字符串的开头添加文件名和文件权限信息。
uuencode编码

uuencode编码一、概述uuencode是Unix系统中的一种编码方式,用于将二进制文件转换为可打印的ASCII码字符,方便在网络上传输。
它是由Bell实验室的Mimic程序员Steve Daniel和Landon Curt Noll开发的。
二、uuencode编码原理1. 将二进制文件转换为ASCII码字符uuencode将每3个字节(24位)作为一组进行处理,然后将这24位分成4组,每组6位。
接着,在每组前面加上一个32(即空格的ASCII码值),这样就得到了4个8位的ASCII字符。
如果最后不足3个字节,则用0补齐。
例如,对于一个3字节的二进制文件,其内容为:10110010 11110101 00101110首先将其分成三组:10110010 11110101 00101110然后在每组前加上32得到:00101100 11011011 10011101 01001000最后将这4个ASCII字符连接起来得到:`Ij7ZSA==`2. 加上头部信息为了便于接收方解码,uuencode会在编码结果前面加上一些头部信息。
头部信息包含了原始文件名、权限等信息。
例如:begin 666 myfile.txtM1TE&.#=W=W=RYW=RYW=RYW=RYW=RYW=RYW=R_ M1TE&.#=end三、uuencode的使用1. 编码使用uuencode命令可以将二进制文件编码为ASCII字符。
语法:uuencode [选项] 原始文件名 [编码后的文件名]例如:将myfile.txt编码为myfile.txt.uueuuencode myfile.txt myfile.txt.uue2. 解码使用uudecode命令可以将编码后的文件解码为原始二进制文件。
语法:uudecode [选项] 编码后的文件名例如:将myfile.txt.uue解码为myfile.txtuudecode myfile.txt.uue四、优缺点分析1. 优点:(1)可打印:由于ASCII字符可以在各种终端上显示,所以通过uuencode编码后的文件可以方便地在网络上传输。
UU编码简介

UU编码简介1、简介uu 编码将3字节BIN数据转换成4字节可打印ASCII字符。
uuencode 编码方式用于将任意的二进制文件转换为文本文件,比如email.转换后的文件中仅包含可打印字符.uuencode 运算法则将连续的3字节编码转换成4字节(8-bit 到6-bit)的可打印字符.2、示例从二进制文件中读取 3字节的数据, 表示如下(a7 表示 a字节的第7位):a7a6a5a4a3a2a1a0 b7b6b5b4b3b2b1b0 c7c6c5c4c3c2c1 c0转换它们到4字节里为如下所示:0 0 a7a6a5a4a3a2 0 0 a1a0b7b6b5b4 0 0 b3b2b1b0c7c6 0 0 c5c4c3c2c1c0然后, 每个字节再加 0x20转换为可打印的字符.注意: 如果是一个 0字节那它应该被转换为0x60而不是0x20, 因为(前引用'`')优于 0x20(空格' ').例如: 从文件中读取的 3字节如下:14 0F A800010100 00001111 10101000转换为 6-bit:000101 000000 111110 101000每字节高两位补 0后为:00000101 00000000 00111110 00101000最后每字节再加 0x20,则 4字节输出应该为:25 60 5E 48注意: 00字节被转换为 0x60而不是 0x20.因此, 在一个 uuencoded文件中仅包含字符 0x21 '!'到 0x60 '`',它们都是可打印和可被 email传送的.这个转换过程也意味着 uuencoded 文件要比原文件大 33%的.3、编码与解码3.1编码outbuf [4] 输出 uu编码数据.inbytep [3] 输入二进制数据.#define ENCODE_BYTE(b) (((b) == 0) ? 0x60 : ((b) + 0x20)) outbuf [0] = ENCODE_BYTE ((inbytep [0] & 0xFC) >> 2);outbuf [1] = ENCODE_BYTE (((inbytep [0] & 0x03) << 4) + ((inbytep [1] & 0xF0) >> 4));outbuf [2] = ENCODE_BYTE (((inbytep [1] & 0x0F) << 2) + ((inbytep [2] & 0xC0) >> 6));outbuf [3] = ENCODE_BYTE (inbytep [2] & 0x3F);3.2 解码linep [4] 输入 uu编码数据.outbyte [3] 输出二进制数据.#define DECODE_BYTE(b) ((b == 0x60) ? 0 : b - 0x20)outbyte [0] = DECODE_BYTE (linep [0]);outbyte [1] = DECODE_BYTE (linep [1]);outbyte [0] <<= 2;outbyte [0] |= (outbyte [1] >> 4) & 0x03;outbyte [1] <<= 4;outbyte [2] = DECODE_BYTE (linep [2]);outbyte [1] |= (outbyte [2] >> 2) & 0x0F;outbyte [2] <<= 6;outbyte [2] |= DECODE_BYTE (linep [3]) & 0x3F;4、源码4.1编码#include "stdio.h"#include "stdlib.h"#define MAX_LINELEN 45#define ENCODE_BYTE(b) (((b) == 0) ? 0x60 : ((b) + 0x20)) typedef unsigned char BYTE;int main (int argc, char *argv []){FILE *infile = NULL;FILE *outfile = NULL;int linelen;int linecnt;BYTE inbuf [MAX_LINELEN];BYTE *inbytep;char outbuf [5];if (argc != 3){fprintf (stderr, "Syntax: uuencode <infile> <outfile>\n"); exit (1);}/* Try and open the input file (binary) */infile = fopen (argv[1], "rb");if (infile == NULL)fprintf (stderr, "uuencode: Couldn't open input file %s\n", argv[1]);exit (1);}/* Try and open the output file (text) */outfile = fopen (argv[2], "wt");if (outfile == NULL){fprintf (stderr, "uuencode: Couldn't open output file %s\n", argv[2]);exit (1);}/* Write the 'begin' line, giving it a mode of 0600 */fprintf (outfile, "begin 600 %s\n", argv[1]);do{/* Read a line from input file */linelen = fread (inbuf, 1, MAX_LINELEN, infile);/* Write the line length byte */fputc (ENCODE_BYTE (linelen), outfile);/* Encode the line */for (linecnt = linelen, inbytep = inbuf;linecnt > 0;linecnt -= 3, inbytep += 3){/* Encode 3 bytes from the input buffer */outbuf [0] = ENCODE_BYTE ((inbytep [0] & 0xFC) >> 2);outbuf [1] = ENCODE_BYTE (((inbytep [0] & 0x03) << 4) + ((inbytep [1] & 0xF0) >> 4));outbuf [2] = ENCODE_BYTE (((inbytep [1] & 0x0F) << 2) + ((inbytep [2] & 0xC0) >> 6));outbuf [3] = ENCODE_BYTE (inbytep [2] & 0x3F);outbuf [4] = '\0';/* Write the 4 encoded bytes to the file */fprintf (outfile, "%s", outbuf);}fprintf (outfile, "\n");} while (linelen != 0);/* Write the 'end' marker */fprintf (outfile, "end\n");/* Tidy up and return */fclose (infile);fclose (outfile);return 0;}4.2 解码/** uudecode.c -* Simple uudecode utility* Jim Cameron, 1997*/#include <ctype.h>#include <stdio.h>#include <stdlib.h>#include <string.h>/* We all hate magic numbers! */#define LINE_BUF_SIZE 256/* Decode a byte */#define DECODE_BYTE(b) ((b == 0x60) ? 0 : b - 0x20) typedef unsigned char BYTE;int main (int argc, char *argv[]){FILE *infile = NULL;FILE *outfile = NULL;char linebuf [LINE_BUF_SIZE];char *linep = NULL;char *tempcp = NULL;int linelen = 0;int linecnt = 0;char outfname [LINE_BUF_SIZE];BYTE outbyte [3];/* Check that we have the right number of arguments */ if (argc != 2){fprintf (stderr, "Syntax: uudecode <filename>\n");exit (1);}/* Open the input file */infile = fopen (argv[1], "rt");if (infile == NULL){fprintf (stderr, "uudecode: Couldn't open file %s\n", argv[1]);exit (1);}/* uu-encoded files always have a 'begin' marker, so go and look for this */for (;;){/* Read a line */if (fgets (linebuf, LINE_BUF_SIZE, infile) == NULL){fprintf (stderr, "uudecode: Not a valid uu-encoded file\n");exit (1);}/* See if it is the 'begin' marker */if ((strncmp (linebuf, "begin", 5) == 0) && isspace (linebuf[5])) {break;}}/* If we have reached this point, we have found a beginmarker */linep = linebuf + 5;/* Next comes the mode, which we ignore */while (isspace (*linep)){linep++;}if (*linep == '\0'){fprintf (stderr, "uudecode: Not a valid uu-encoded file\n");exit (1);}while (isdigit (*linep)){linep++;}while (isspace (*linep)){linep++;}if (*linep == '\0'){fprintf (stderr, "uudecode: Not a valid uu-encoded file/n");exit (1);}/* The rest of the begin line is the output file name */strcpy (outfname, linep);tempcp = outfname;while (!isspace (*tempcp) && (*tempcp != '\0')){tempcp++;}*tempcp = '\0';/* Now open the output file */outfile = fopen (outfname, "wb");if (outfile == NULL){fprintf (stderr, "uudecode: Couldn't open output file %s\n", outfname);exit (1);}/* Now for the uu-decode proper */do{if (fgets (linebuf, LINE_BUF_SIZE, infile) == NULL){fprintf (stderr, "uudecode: Read error\n");exit (1);}/* The first byte of the line represents the length of the DECODED line */linelen = DECODE_BYTE (linebuf[0]);linep = linebuf + 1;for (linecnt = linelen; linecnt > 0; linecnt -= 3, linep += 4) {/* Check for premature end-of-line */if ((linep[0] == '\0') || (linep[1] == '\0') ||(linep[2] == '\0') || (linep[3] == '\0')){fprintf (stderr, "uudecode: Error in encoded block\n"); exit (1);}/* Decode the 4-byte block */outbyte[0] = DECODE_BYTE (linep[0]);outbyte[1] = DECODE_BYTE (linep[1]);outbyte[0] <<= 2;outbyte[0] |= (outbyte[1] >> 4) & 0x03;outbyte[1] <<= 4;outbyte[2] = DECODE_BYTE (linep[2]);outbyte[1] |= (outbyte[2] >> 2) & 0x0F;outbyte[2] <<= 6;outbyte[2] |= DECODE_BYTE (linep[3]) & 0x3F;/* Write the decoded bytes to the output file */if (linecnt > 3){if (fwrite (outbyte, 1, 3, outfile) != 3){fprintf (stderr, "uudecode: Error writing to output file\n"); exit (1);}}else{if (fwrite (outbyte, 1, linecnt, outfile) != linecnt){fprintf (stderr, "uudecode: Error writing to output file\n"); exit (1);}linecnt = 3;}}} while (linelen != 0);/* All is ok, tidy up and exit */fclose (infile);fclose (outfile);return 0;}。
sgrnauuuuu序列

sgrnauuuuu序列
摘要:
1.介绍sgrnauuuuu 序列
2.sgrnauuuuu 序列的特点
3.sgrnauuuuu 序列的应用
4.总结
正文:
sgrnauuuuu 序列是一种在生物信息学领域中广泛应用的序列,它是由核糖体RNA(rRNA)与蛋白质结合形成的核糖体亚基。
sgrnauuuuu 序列具有独特的结构和功能,使其在细胞内的生物合成和调控过程中扮演着重要角色。
sgrnauuuuu 序列的特点在于其高度保守性,这意味着它在不同生物体和生物细胞中具有相似的序列和结构。
此外,sgrnauuuuu 序列在细胞内具有多种功能,包括参与核糖体的生物合成、调控基因表达以及参与细胞内的信号传导等。
近年来,随着生物信息学技术的发展,sgrnauuuuu 序列在生物学研究中的应用越来越广泛。
研究人员可以利用sgrnauuuuu 序列来研究细胞内的生物合成和调控过程,进而揭示生命现象的本质规律。
同时,sgrnauuuuu 序列的研究也有助于科学家们开发新型药物和治疗方法,以治疗与sgrnauuuuu 序列相关的疾病。
总之,sgrnauuuuu 序列作为一种重要的生物信息学序列,具有广泛的应用前景。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
exit (1); }
/* Write the 'begin' line, giving it a mode of 0600 */
fprintf (outfile, "begin 600 %s\n", argv [1]);
In addition, the start of the encoding is marked by the line "start <mode> <filename>", where
<mode> consists of 3 octal digits which are the Unix mode of the file, and
Then convert these bytes to printable characters by adding 0x20 (32). EXCEPTION: if you end up with a zero byte it should be converted to 0x60 (back-quote '`') rather than 0x20 (space ' ').
Lines in the encoded file are always a multiple of 4 + 1 characters long; this sometimes means that 1 or 2 bytes are thrown away at the end of the decoding.
a7a6a5a4a3a2a1a0 b7b6b5b4b3b2b1b0 c7c6c5c4c3c2c1c0
and convert them into 4 bytes with values in the range 0-63 as follows:
0 0 a7a6a5a4a3a2 0 0 a1a0b7b6b5b4 0 0 b3b2b1b0c7c6 0 0 c5c4c3c2c1c0
00000101 00000000 00111110 00101000
Note that the zero byte has been translated to 0x60 instead of 0x20. The body of a uuencoded file therefore only contains the characters 0x21 '!' to 0x60 '`', which are all printable and capable of being transmitted by email. (Note: this of course means that uuencoded files are slightly more than 33% longer than the originals. uuencoding text-only files is redundant and a silly thing to do. Standard and sensible practice is to compress the files first using a standard compression utility and then to uuencode them).
(Note: I can't see any reason why lines shouldn't be an arbitrary length, and don't know whether the proper definition disallows this. I've never seen a uuencoded file where any line apart from the last one wasn't 'M' followed by 60 characters, though)
if (argc != 3) {
fprintf (stderr, "Syntax: uuencode <infile> <outfile>\n"); exit (1); }
/* Try and open the input file (binary) */
infile = fopen (argv [1], "rb"); if (infile == NULL) {
Date: Wed, 09 Apr 1997 13:04:11 +0100 From: jim <j.cameron@> To: webmaster@
Uuencode.txt
===== UUENCODE ======
uuencode is a utility designed to enable arbitrary binary files to be transmitted using text-only media such as email. It does this by encoding the files in such a way that the encoded file contains only printable characters.
do {
第2页
/* Read a line from input file */
Uuencode.txt
linelen = fread (inbuf, 1, MAX_LINELEN, infile);
/* Write the line length byte */
fputc (ENCODE_BYTE (linelen), outfile);
(IMPORTANT Note: this file is the result of an afternoon's hacking by myself. I make no guarantees as to its completeness and accuracy. I have coded my own uuencode and uudecode programs which haven't let me down yet)
typedef unsigned char BYTE;
int main (int argc, char *argv []) {
FILE *infile = NULL; FILE *outfile = NULL; int linelen; int linecnt; BYTE inbuf [MAX_LINELEN]; BYTE *inbytep; chancode.txt To decode, simply perform the inverse of the encoding algorithm.
===== SAMPLE CODE =====
I include here the C source code to a small uuencode and uudecode utility I coded myself. It isn't very sophisticated and probably not very complete, but it does its job, and is very useful for my PC where I don't have access to the standard Unix stuff. It took me about half an hour to write, and another hour or so to iron out the obvious bugs. It works quite happily under DOS (uuencoding needs practically no internal storage). It isn't a great masterpiece of software design and coding, but might be worth a look. Feel free to do whatever you want to it, up to and including throwing it in the bin.
/* Encode the line */
for (linecnt = linelen, inbytep = inbuf; linecnt > 0; linecnt -= 3, inbytep += 3)
So if you read 3 bytes from the file as follows: 14 0F A8 (hex) i.e.
00010100 00001111 10101000
your 4 bytes output should be 25 60 5E 48 ("%`^H"). The intermediate 4 bytes in this case were
The uuencode algorithm hinges around a 3-byte-to-4-byte (8-bit to 6-bit data) encoding to convert all data to printable characters. To perform this encoding read in 3 bytes from the file to be encoded whose binary representation is
<filename> is the original filename of the file encoded.