计量经济学论文(eviews分析)计量经济作业
计量经济学的结课论文

计量经济学期末课程论文实验名称:影响中国税收收入的因素分析姓名:学号:班级:指导教师:时间:影响中国税收收入因素分析摘要:改革开放以来,随着经济体制改革的深化和经济的快速增长,中国的财政收支发生很大变化,中央和地方的税收收入1978年为519.28亿元,到2010年已经增长到73210.79亿元,33年间增长了141倍,平均每年增长4.3倍。
为了研究影响中国税收收入增长的主要原因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经济模型。
影响中国税收收入增长的因素很多,但据分析最主要的因素主要有:(1)经济整体增长。
(2)公共财政的需求(3)物价水平(4)税收政策因素。
运用Eviews统计软件的逐步回归对数据进行线性拟合,经过各种参数检验以及模型筛选,得到最后符合要求的模型,本论文给出了实证分析的结论并且提出了相应的政策建议。
关键字:中国税收收入国内生产总值财政支出商品零售价格指数多重共线性异方差性自相关性研究主题:为了全面反映中国税收增长的全貌,选择包括中央和地方税收的国家财政收入中的各项税收(简称税收收入)作为被解释变量,以反映国家税收的增长;解释变量设定为可观测的国内生产总值、财政支出、商品零售物价指数等变量。
数据类型:时间序列数据数据频度:年起止时间:1978-2010主要研究方法:多元线性回归以及多重共线性、异方差、序列相关的检验与修正一、数据收集与模型的建立:(一)影响因素的分析1、国内生产总值GDP国内生产总值是指在一定时期内(一个季度或一年),一个国家或地区的经济中所生产出的全部最终产品和劳务的价值,常被公认为衡量国家经济状况的最佳指标。
从宏观经济看,经济整体增长是税收增长的基本源泉。
2、财政支出税收收入是财政收入的主体,社会经济的发展和社会保障的完善等都对公共财政提出要求,因此对预算支出所表现的公共财政的需求对当年的税收收入可能会有一定的影响。
公共财政需求的数据较难得,但它与财政支出密切相关,所以选择财政支出作为公共财政需求的代表。
EViews统计分析在计量经济学中的应用EViews概述

5/7/2023
EViews统计分析在计量经济学中的应用
2
2
EViews历史
EViews是由Quantitative Micro Software 〔QMS〕公司开发的,专门从事数据分析、回归 分析和预测的工具。EViews结合了电子表格和 相关的数据库技术以及传统统计软件分析功能, 并且使用了单击图形用户界面。EViews特点是 对于时间序列数据有较强的分析能力,另外在 预测分析、科学数据分析与评价、金融分析、 经济预测、销售预测和本钱分析等领域应用非 常广泛。
5/7/2023
EViews统计分析在计量经济学中的应用
22 22
图形操作
将图形插入文献中:Eviews可以将图形插入到 Word文档中。首先将图形翻开,然后点击 Eviews主画面顶部主按钮Edit/Copy/click弹出 对话框。选择〞Copy to clipboard〞,点击 OK,然后在Word文档中指指定位置粘贴即可。
EViews统计分析在计量经 济学中的应用EViews概述
1
:EViews简介
o 实验目的:熟悉和掌握Eviews在一元线性回 归模型中的应用。
o 实验数据:2019年中国各地区城市居民人均 年消费支出〔CS〕和可支配收入〔INC〕 〔相关数据在文件夹“书中资料/第3章〞〕 。
o 实验原理:普通最小二乘法(OLS) o 实验预习知识:普通最小二乘法、t检验、
可翻开下拉式菜单〔或再下
一级菜单,如果有的话〕,
点击某个选项电脑就执行对 应的操作响应〔File,Edit的 编辑功能与Word, Excel中的 相应功能相似〕
图1-1 EViews主窗口界面
5/7/2023
计量经济学论文范文eviews

《我国财政收入影响因素分析》班级:09财政1班姓名:***学号:************指导教师:***完成时间:2011年12月4日摘要:对我国财政收入影响因素进行了定量分析,建立了数学模型,并提出了提高我国财政收入质量的政策建议。
关键词:财政收入实证分析影响因素一、引言财政收入对于国民经济的运行及社会发展具有重要影响。
首先,它是一个国家各项收入得以实现的物质保证。
一个国家财政收入规模大小往往是衡量其经济实力的重要标志。
其次,财政收入是国家对经济实行宏观调控的重要经济杠杆。
宏观调控的首要问题是社会总需求与总供给的平衡问题,实现社会总需求与总供给的平衡,包括总量上的平衡和结构上的平衡两个层次的内容。
财政收入的杠杆既可通过增收和减收来发挥总量调控作用,也可通过对不同财政资金缴纳者的财政负担大小的调整,来发挥结构调整的作用。
此外,财政收入分配也是调整国民收入初次分配格局,实现社会财富公平合理分配的主要工具。
在我国,财政收入的主体是税收收入。
因此,在税收体制及政策不变的情况下,财政收入会随着经济繁荣而增加,随着经济衰退而下降。
我国的财政收入主要包括税收、国有经济收入、债务收入以及其他收入四种形式,因此,财政收入会受到不同因素的影响。
从国民经济部门结构看,财政收入又表现为来自各经济部门的收入。
财政收入的部门构成就是在财政收入中,由来自国民经济各部门的收入所占的不同比例来表现财政收入来源的结构,它体现国民经济各部门与财政收入的关系。
我国财政收入主要来自于工业、农业、商业、交通运输和服务业等部门。
因此,本文认为财政收入主要受到总税收收入、国内生产总值、其他收入和就业人口总数的影响。
二、预设模型令财政收入Y(亿元)为被解释变量,总税收收入X1(亿元)、国内生产总值X2(亿元)、其他收入X3(亿元)、就业人口总数为X4(万人)为解释变量,据此建立回归模型。
二、数据收集从《2010中国统计年鉴》得到1990--2009年每年的财政收入、总税收收入、国内生产总值工、其他收入和就业人口总数的统计数据如下:obs 财政收入Y 总税收收入X1 国内生产总值X2 其他收入X3 就业人口总数X4 1990 2937.1 2821.86 18667.8 299.53 64749 1991 3149.48 2990.17 21781.5 240.1 65491 1992 3483.37 3296.91 26923.5 265.15 66152 1993 4348.95 4255.3 35333.9 191.04 66808 1994 5218.1 5126.88 48197.9 280.18 67455 1995 6242.2 6038.04 60793.7 396.19 68065 1996 7407.99 6909.82 71176.6 724.66 68950 1997 8651.14 8234.04 78973 682.3 69820 1998 9875.95 9262.8 84402.3 833.3 70637 1999 11444.08 10682.58 89677.1 925.43 71394 2000 13395.23 12581.51 99214.6 944.98 72085 2001 16386.04 15301.38 109655.2 1218.1 73025 2002 18903.64 17636.45 120332.7 1328.74 73740 2003 21715.25 20017.31 135822.8 1691.93 74432 2004 26396.47 24165.68 159878.3 2148.32 75200 2005 31649.29 28778.54 184937.4 2707.83 75825 2006 38760.2 34804.35 216314.4 3683.85 76400 2007 51321.78 45621.97 265810.3 4457.96 76990 2008 61330.35 54223.79 314045.4 5552.46 774802009 68518.3 59521.59 340506.9 7215.72 77995三、模型建立1、散点图分析2、单因素或多变量间关系分析Y X1 X2 X3 X4Y 1 0.9989134611478530.9934790452908040.8770144886795640.983602719841508X1 0.998913461147853 10.9937402677184690.8556377347447820.984935296593492X2 0.9934790452908040.993740267718469 10.8561835802284710.986241165680459X3 0.8770144886795640.8556377347447820.856183580228471 10.810940334650381X4 0.9836027198415080.9849352965934920.9862411656804590.810940334650381 1由散点图分析和变量间关系分析可以看出被解释变量财政收入Y与解释变量总税收收入X1、国内生产总值X2、其他收入X3、就业人口总数X4呈线性关系,因此该回归模型设为:μβββββ+++++=443322110X X X X Y3、 模型预模拟由eviews 做ols 回归得到结果:Dependent Variable: Y Method: Least Squares Date: 11/14/11 Time: 17:51 Sample: 1990 2009 Included observations: 20Variable Coefficient Std. Error t-Statistic Prob. C 7299.523 1691.814 4.314614 0.0006 X1 1.062802 0.021108 50.34972 0.0000 X2 0.001770 0.004528 0.391007 0.7013 X3 0.873369 0.119806 7.289852 0.0000 X4-0.1159750.026580-4.3631600.0006R-squared 0.999978 Mean dependent var 20556.75 Adjusted R-squared 0.999972 S.D. dependent var 19987.03 S.E. of regression 106.6264 Akaike info criterion 12.38886 Sum squared resid 170537.9 Schwarz criterion 12.63779 Log likelihood -118.8886 F-statistic 166897.9 Durbin-Watson stat1.496517 Prob(F-statistic)0.0000004321115975.0873369.0001770.0062802.1523.7299X X X X Y -+++=(4.314614) ( 50.34972 ) ( 0.391007) ( 7.289852) ( -4.363160)999978.02=R 999972.02=R 9.166897=F 496517.1.=W D四、 模型检验 1.计量经济学意义检验 ⑴多重共线性检验与解决求相关系数矩阵,得到:Correlation MatrixY X1 X2 X3 X4 1 0.998913461147853 0.9934790452908040.8770144886795640.9836027198415080.998913461110.99374026770.85563773470.984935296547853 18469 44782 934920.993479045290804 0.993740267718469 10.8561835802284710.9862411656804590.877014488679564 0.8556377347447820.856183580228471 10.8109403346503810.983602719841508 0.9849352965934920.9862411656804590.810940334650381 1发现模型存在多重共线性。
计量经济学eviews作业

计量经济学eviews作业摘要:计量经济学eviews 作业I.简介- 计量经济学eviews 作业的背景和意义II.计量经济学eviews 软件的介绍- Eviews 软件的作用和特点- Eviews 软件在计量经济学中的应用III.计量经济学eviews 作业的步骤- 数据收集和处理- 建立模型和估计参数- 模型检验和优化- 结果分析和解释IV.计量经济学eviews 作业的实践应用- 具体案例分析- 结果展示和讨论V.总结- 计量经济学eviews 作业的收获和展望正文:计量经济学eviews 作业I.简介计量经济学是研究经济现象数量规律的学科,通过收集、处理、分析和解释经济数据,以揭示经济变量之间的关系和规律。
Eviews 软件是一款功能强大的计量经济学软件,广泛应用于经济学研究、实证分析、政策评估等领域。
在本篇文章中,我们将介绍计量经济学eviews 作业的相关内容。
II.计量经济学eviews 软件的介绍Eviews 软件是一款专业的计量经济学软件,具有强大的数据处理和分析功能。
它能够支持各种数据格式,包括时间序列数据、横断面数据和面板数据等。
Eviews 软件的特点如下:- 操作简便:界面友好,易于上手- 功能强大:支持多种计量经济学模型和方法- 结果可靠:提供丰富的统计检验和稳健性检验在计量经济学中,Eviews 软件可以用于建立各种模型,如线性回归模型、时间序列模型、面板数据模型等,以研究经济变量之间的关系。
III.计量经济学eviews 作业的步骤计量经济学eviews 作业主要包括以下几个步骤:1.数据收集和处理:收集所需数据,检查数据质量,进行数据清洗和处理。
2.建立模型和估计参数:根据研究目的和数据特点,选择合适的计量经济学模型,使用Eviews 软件进行参数估计。
3.模型检验和优化:对模型进行显著性检验、参数稳定性检验等,根据检验结果对模型进行优化。
4.结果分析和解释:分析模型结果,解释各经济变量之间的关系,撰写分析报告。
计量经济学案例分析(Eviews操作)

美股行情对A股的影响性分析——标普500与沪深300相关性分析摘要:本文主要通过分析标准普尔500指数与沪深300指数的相关性,以标普500指数为解释变量,以沪深300指数为被解释变量,利用Eviews软件,使用其中的最小二乘法对其进行线性回归分析,最终得出方程。
并对其进行显著性检验(F,t)、异方差检验、自相关性检验来验证方程的可靠性。
然后解释方程的经济意义,并利用软件对未来指数变动进行预测。
最后在未来几天比较预测结果与实际两个指数的变化情况,验证实际应用情况。
关键词:标普500、沪深300、Eviews、显著性检验、异方差检验、自相关性检验。
一、研究背景1.全球化大环境在经济全球化不断深入发展的今天,全球资本市场,尤其是中美两个超级大国之间的资本流通,早已彼此嵌入,密不可分。
全世界早有不少学者对中美资本流通做了深入研究。
但美国股市发展早于中国十几年,其内部的资金也远远超过中国股市,美国股市的资本流动势必会对中国股市产生一定影响,这种影响不仅体现在情绪面,更反映在指数变动方向上。
2.对外开放资本市场的QFII政策Qualified Foreign Institutional Investor,作为一种过渡性制度安排,QFII制度是在资本项目尚未完全开放的国家和地区,实现有序、稳妥开放证券市场的特殊通道。
外资对中国股市的影响早已不可忽视,而美国市场的变动也一定程度会影响在中国股市外资的操作行为。
所以研究两个指数的变动是很有意义的。
二、数据1.数据选择沪深两个市场各自均有独立的综合指数和成份指数,这些指数不能用来反映沪深两市的整体情况,而沪深300指数则同时考虑了两市的交易情况,是中国A股市场的“晴雨表”。
标准普尔500指数英文简写为S&P 500 Index,是记录美国500家上市公司的一个股票指数。
与道琼斯指数等其他指数相比,标准普尔500指数包含的公司更多,因此风险更为分散,能够反映更广泛的市场变化。
计量经济学论文居民消费水平影响因素的计量分析

计量经济学论文居民消费水平影响因素的计量分析居民消费水平影响因素的计量分析摘要:居民消费水平反映着人们对于满足生存、发展和享受需要方面所达到的程度;本文就我国近阶段消费方面出现的一些情况,利用Eviews软件对我国1993年至2011年的居民消费水平的影响因素相关数据进行实证分析;建立居民消费水平的影响因素模型,通过对该模型的经济含义分析得出各种主要因素对我国居民消费水平的影响程度,揭示中国居民消费水平的现状及问题,并在此基础上提出了提高我国居民消费水平的对策;关键词:居民消费水平影响因素回归分析正文:一、文献综述:1.居民消费水平经济学背景消费,消费是人类通过消费品满足自身欲望的一种经济行为;是社会再生产过程中的一个重要环节,也是最终环节;通常讲的消费,是指个人消费;生产决定消费,消费反过来影响生产;它是指利用社会产品来满足人们各种需要的过程;消费又分为生产消费和个人消费;前者指物质资料生产过程中的生产资料和活劳动的使用和消耗;后者是指人们把生产出来的物质资料和精神产品用于满足个人生活需要的行为和过程,是“生产过程以外执行生活职能”;它是恢复人们劳动力和劳动力再生产必不可少的条件;所以消费的水平对一个国家的发展有着十分重要的影响;居民消费水平,是按国内生产总值口径,即包括劳务消费在内的总消费进行计算的;是居民在物质产品和劳务的消费过程中,对满足人们生存、发展和享受需要方面所达到的程度的数量指标;消费进行计算的;计算公式为:2.反映居民消费水平的主要指标有:⑴平均实物消费量指标;平均每人全年主要有消费品的消费量、平均每百户耐用消费品拥有量、人均居住面积、平均每人生活用水量、平均每人生活用电量等;⑵现代化生活设施的普及程度指标;自来水普及率、煤气普及率、平均每百户主要家用电器拥有量、电话普及率等;⑶反映消费水平的消费结构指标;居民生活消费支出中食品的比例、居民生活消费支出中文化生活服务支出比例、不同质量消费晶的消费比例等;⑷平均消费量的价值指标;平均每人消费基金、平均每人生活消费额、平均每人用于各项生活消费的支出等;3.我国居民消费水平的问题新中国成立后,由于国家经济基础薄弱,物质上长时间处于相对短缺的状态,居民消费受到严重制约,中国社会传统的重积累、倡节约的消费观念没有得到根本改观;随着经济的发展和社会的进步,人们开始逐渐抛弃了自然经济模式下自给自足的消费观念,代之以量入为出、注重消费效益,强调消费带来的精神满足等新型消费观念;特别是2改革开放后以来,住房、通信及电子产品、节假日消费及旅游、文化教育、汽车等逐渐成为市场消费热点,信贷消费、理性消费、个性消费等消费形式也开始在人们的消费行为中发挥重要作用;因此,也就形成了当前中国居民西方消费主义与东方重积累思想并重的有中国特色的消费观念;2008年以来,美国次贷危机席卷全球,我国出口贸易也因此受挫,政府启动4万亿投资拉动内需;如何刺激国内消费以拉动经济一时间成为全国热点话题,这引起我们对影响城镇居民消费水平因素的思考;二、实证模型1. 变量选取:居民的消费水平往往受到许多因素影响,需要分析各因素对居民消费水平的影响程度;本文以分析居民消费水平为目的,同时考虑了其他一些指标的分析需要,共选取1993~2011年的数据,将居民消数据来源:国家统计局年度数据2. 模型初步提出为了具体分析各要素对我国居民消费水平的影响大小,我们选取Y 为居民消费水平,X2为国内生产总值,X3为城镇居民家庭人均可支配收入,X4城镇居民家庭恩格尔系数,X5城乡居民人民币储蓄存款年底余额,X6人口自然增长率进行回归分析;采用的对数模型如下:Y=β0+β1X 2+β2X 3+β3X 4+β4X 5+β5X 6+u i(1) 用Eviews 计量经济学分析软件作最小二乘回归,分析结果如下:通过结果可以看出,变量x2、x3、x4、x6的t 检验值均大于临界值145.2)519(025.0=-t ;说明经t 检验这4个参数均显着不为0,即为国内生产总值、城镇居民家庭人均可支配收入、城镇居民家庭恩格尔系数、人口自然增长率对居民消费水平均有显着影响;并且,模型中149.4247=F ,明显大于18.2)19,5(05.0=F ,说明各因素联合起来对居民消费水平影响显着;3. 多重共线性检验 1计算变量间相关系数:从上图可知, x2与x3,x3与x5,x3与x6,x5与x6之间都存在较高的线性相关;可能存在多重共线性;2 进行逐步回归,直至模型符合需要研究的问题,具有实际的经济意义和统计意义;采用逐步回归的办法,去检验和解决多重共线性问题;分别作Y 对X2,X3,X4,X5,X6的一元回归,结果如下:其中加入X2的方程调整的可决系数最大, 以X2为基础, 顺次加入其他变量逐步回归;结果如下表:经比较,新加入X4的方程调整可决系数改进最大, 各参数的t 检验也都显着,但是x4参数的符号与经济意义不符合;所以提出变量x4,以x2,x3为基础继续做逐步回归;结果如下表:当加入x5时,2R 有所增加,但其参数的t 检验不显着;加入x6时,2R 也有所增加,但其参数为负值不合理;综上可以看出x4、x5、x6引起了多重共线性,予以剔除;保留x2和x3;得出Y 对x2 x3的回归结果如下:最后修正严重多重共线性影响后的回归结果为:4. 异方差检验1分别绘制残差平方序列e2对变量x2和x3的散点图,如下:由散点图中可以看出,残差平方e2对解释变量x2和x3的散点图主要分布在图形的下三角部分,大致看出残差平方e2随x2和x3的变动增大的趋势,因此,模型很可能存在异方差;但是否确定存在需要进一步检验;2采用White 检验法,得到下图结果:从图中可以看出,nR 2=,有White 检验可知,在05.0=α下,071.11505.02=)(χnR 2 =>071.11505.02=)(χ,所以拒绝原假设,表明模型存在异方差; 3异方差修正选取多个权数分别做回归分析后比较,发现w1=1/x2x3的效果最好;下面仅给出权数w1的结果: 最终;消除异方差后的模型为:R 2 = DW= F=5.自相关处理样本量为19,两个解释变量模型,10%显着水平,查DW 统计表可知,835.0d =L 265.1d U = 模型中DW<L d ,显然模型中有自相关;由残差图也可以看出,残差的变动有系统模式,连续为正和连续为负,表明残差项存在一阶正自相关,模型中t 统计量和F 统计量的结论不可信,需要采取补救措施;生成残差序列,使用e t 进行滞后一期的自回归,可得到方程其中6948.0ˆ=ρ,对原模型进行广义差分,得到广义差分方程: 由上图可得回归方程为:Se=t= R2= F= DW=其中,133*3122*21*6948.0,6948.0,6948.0----=-=-=t t t t t t t X X X X X X Y Y Y由于使用了广义差分法数据,样本容量减少了1个,为18个;查1%显着水平的DW 统计表可知259.1,805.0d ==U L d ,模型中U DW d 109.2>=,说明在1%显着性水平下广义差分模型中已无自相关,不必再进行迭代;可决系数R 2、t 、F 统计量也均达到理想水平;由差分方程式有由此,得到最终的居民消费水平模型为通过最终的模型可以看出,国内生产总值和城镇居民家庭人均可支配收入两项指标对居民消费水平影响较大,其中国民收入每增加1亿元,居民消费水平提高元;城镇居民家庭人均可支配收入每增加1元,居民消费水平提高元; 三、提高居民消费水平的对策综上所述,大力发展国民经济,提高居民整体收入水平,才是促进居民消费水平提高的根本途径;因此,国家应当着重于发展生产力,促进我国居民可支配收入的增加;对此,我有如下建议:1.加强基础设施建设;增加对农村基础设施建设的投入,加强水、电、路、通讯等基础设施建设;要继续加大电网改造力度、降低民用电价,要对垄断行业和部门加强监管,规范公路收费和降低信息通信服务价格,减少商品流通成本;目前我国公路违规收费、超期收费问题突出,大大提高了区域经济之间的物流成本,严重影响了公路的利用率和运输效率,制约了旅游、运输等与交通行业密切相连的行业的发展;在信息通信领域,由于垄断和垄断经营的存在,信息通信服务价格明显高于国际上发展水平相近的国家,在抑制潜在消费能力增长的同时,也提高了信息获取的成本;2.保持物价稳定;平稳的物价水平是稳定居民消费预期,促进居民消费健康增长的前提;2002年以来,随着新一轮经济扩张期的到来,我国居民住宅价格快速上升,近两年来出现加速上升的趋势;虽然住宅作为居民投资品不直接计入居民消费蓝子中,但房价大幅上涨对居民其他消费产生明显的挤出效应;从中长期看,导致居民消费物价上涨的原因还很多,包括劳动力成本上升、原材料价格上涨、资源性产品价格改革、环境保护成本的显性化,以及粮价上涨的推动等;为此,应该从加强企业间竞争、为企业减负和提高供给能力等方面维护物价的基本稳定;3.完善社会保障体系;我国的社会保证体系包括养老、医疗、就业、住房、教育等一系列社会福利制度;目前我国社会保障体系的框架虽然已经基本构建,但这一制度仍处于不断探索和完善之中,一些重要问题仍有待解决;无论是医疗保障还是养老保险,都存在着覆盖面较小,保障水平较低的问题;因此应该完善社会保障制度,是居民能够放心的消费,降低人们对未来的预期消费;。
计量经济学论文(eviews分析)

计量经济学论文(eviews分析)我国限额以上餐饮企业营业额的影响因素分析摘要:本文收集了1999年至2009年共11年的相关数据,选取餐饮企业数量、城镇居民人均年消费性支出、全国城镇人口数以及公路里程数作为解释变量构建模型,对我国限额以上餐饮企业营业额的影响因素进行分析。
利用Eviews软件对模型进行参数估计和检验,并加以修正,最后根据模型的最终结果进行经济意义分析,提出自己的看法。
关键词:餐饮企业营业额、影响因素、计量分析一、研究背景近十年来,投资者进入餐饮企业的数量不断增加。
在他们进入一个行业之前,势必要对该行业的营业额、营业利润等进行估计,当这些因素的估计值能够达到他们的预期时,他们才会对其进行投资。
由于餐饮企业的营业额是影响投资者是否进入餐饮业的一个重要因素,对于我国餐饮企业的营业额问题的深入研究就显得尤为必要,这有助于投资者作出合理的决策。
因此,本文进行了对我国限额以上餐饮企业营业额的计量模型研究。
二、变量的选取影响餐饮企业营业额的因素有很多,包括餐饮企业的数量、营业面积、从业人员、城镇居民人均年消费性支出、全国城镇人口数、餐饮企业的平均价格水平及公路里程数(表示交通状况)。
但综合考虑后,本文选取了其中的一部分变量(企业数、城镇居民人均年消费性支出、全国城镇人口数、公路里程数)进行研究,并对各个变量对餐饮企业营业额的影响进行预测。
1.企业数本文认为餐饮企业营业额与餐饮企业的数量有关,并预测两者之间呈正相关。
2.城镇居民人均年消费性支出本文认为餐饮企业营业额与城镇居民人均年消费性支出有关,并预测两者之间呈正相关。
3.全国城镇人口数本文认为餐饮企业营业额与全国城镇人口数有关,并预测两者之间呈正相关。
4.公路里程数本文认为餐饮企业营业额与公路里程数有关,并预测两者之间呈正相关。
三、相关数据本文收集了1999年至2009年共11年的相关数据,包括营业额(单位:亿元)、企业数(单位:个)、人均年消费性支出(单位:元)、全国城镇人口数(单位:万人)以及公路里程数(单位:万公里)。
计量经济学课程作业分析
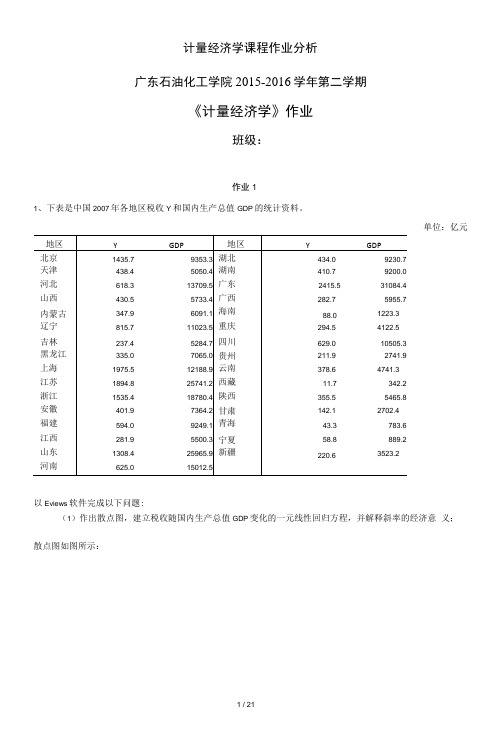
广东石油化工学院2015-2016学年第二学期《计量经济学》作业班级:作业11、下表是中国2007年各地区税收Y和国内生产总值GDP的统计资料。
单位:亿元地区Y GDP地区Y GDP北京1435.7 9353.3 湖北434.0 9230.7天津438.4 5050.4 湖南410.7 9200.0河北618.3 13709.5 广东2415.5 31084.4山西430.5 5733.4 广西282.7 5955.7内蒙古347.9 6091.1 海南88.0 1223.3辽宁815.7 11023.5 重庆294.5 4122.5吉林237.4 5284.7 四川629.0 10505.3黑龙江335.0 7065.0 贵州211.9 2741.9上海1975.5 12188.9 云南378.6 4741.3江苏1894.8 25741.2 西藏11.7 342.2浙江1535.4 18780.4 陕西355.5 5465.8安徽401.9 7364.2 甘肃142.1 2702.4福建594.0 9249.1 青海43.3 783.6江西281.9 5500.3 宁夏58.8 889.2山东1308.4 25965.9 新疆220.6 3523.2河南625.0 15012.5以Eviews软件完成以下问题:(1)作出散点图,建立税收随国内生产总值GDP变化的一元线性回归方程,并解释斜率的经济意义;散点图如图所示:回Group: UNTITLED Workfile UNTITLED::Untitled\ - B XView | Proc | Object | Print | Name | Freeze Default ▼ Options | Position Sample32,00028,00024,00020,000g 16,00012,0008,0004,0000 500 1.000 1,500 2.000 2,500Y(=)Equation: UNTITLED Worlcfile: UNTITLED!:Untitled\ _ n X View|Proc|Object Print Name Freeze |Estimate Forecast|Stats Resids Dependent Variable: YMethod': Least SquaresDate: 05/12/16 Time: 21:04Sample: 1 31In eluded observati ons: 31Variable Coefficient Std. Error t-Statistic Prob.C -10.62963 86.06992 -0.123500 0.9026GDP 0.071047 0.007407 9.591245 0.0000R-squared0.760315Mean dependentvar621.054-8 Adjusted R-squared 0.752050 S.D. dependent var 619.5803S.E. of regression308.5176 Aka ike info criterion 14.36378Sum squared resid2760310.Schwarz criterion14.45629Log likelihood-220.6385 Hannan-Quinn crite匚14.39393F-statistic91.99198Du「bi rrWetson stat 1.570523Prob(F-statistic)0.000000建立如下的回归模型孑=A)+ B&DP +ii计量经济学课程作业分析根据Eviews软件对表中数据进行回归分析的计算结果知:£ =-10.63+ 0.071GDPR A2 = 0.760315 F=91.99198斜率的经济意义:国内生产总值GDP每增加1亿元,国内税收增加0.071亿元。
计量经济学论文范文

计量经济学论文范文本文旨在通过实证分析,探讨影响我国自1988年至2007年税收收入的主要因素。
选取国内生产总值、财政支出和零售商品物价水平作为自变量,并利用EVIEWS软件对计量模型进行参数估计和检验。
最终得出结论,即国内生产总值、财政支出和零售商品物价水平三者均对我国税收收入有很大影响。
二、研究背景和意义税收是我国财政收入的基本因素,对我国经济的发展具有重要影响。
近年来,我国税收收入呈现快速增长的趋势,这引起了人们的广泛关注。
因此,对税收增长进行因素分析和预测分析非常重要,可以帮助研究我国税收增长规律,制定经济政策,促进经济的可持续发展。
三、研究方法和数据来源本文采用计量经济学方法,选取国内生产总值、财政支出和零售商品物价水平作为自变量,利用EVIEWS软件对计量模型进行参数估计和检验。
数据来源为国家统计局和财政部公布的相关数据。
四、实证结果分析通过实证分析,得出结论:国内生产总值、财政支出和零售商品物价水平三者均对我国税收收入有很大影响。
其中,国内生产总值的影响最大,其次是财政支出,零售商品物价水平的影响最小。
五、结论和建议本文的研究结果表明,国内生产总值、财政支出和零售商品物价水平是影响我国税收收入的主要因素。
因此,政府应当注重经济增长,加强财政支出管理,控制通货膨胀,以提高税收收入水平。
同时,也需要进一步研究税收增长的规律,为制定经济政策提供科学依据。
影响税收收入的因素有很多,但主要的因素可能包括以下几个方面。
首先,从宏观经济角度看,经济整体增长是税收增长的基本源泉,而国内生产总值是反映经济增长的重要指标。
其次,公共财政需求对税收收入有很大的影响,社会经济的发展和社会保障的完善等对公共财政提出了要求。
第三,物价水平对税收收入也有很大的影响,因为我国的税制结构以流转税为主,与现行价格计算的GDP等指标和经营者的收入水平都与物价水平有关。
最后,税收政策因素也会对税收增长速度产生影响。
我国自1978年以来经历了两次大的税制改革,但税制改革对税收增长速度的影响不是非常大。
计量经济学论文(eviews分析)计量经济作业

计量经济学论文(eviews分析)计量经济作业计量经济学论文(EViews分析)导言计量经济学是一门研究经济现象及其相互关系的学科,通过运用统计学方法和经济学理论,对经济数据进行分析和解释。
在本篇论文中,我们将运用EViews软件进行计量经济分析,以探讨某一经济问题的核心要素和关系。
第一部分:数据收集与描述性统计在这一部分中,我们将介绍数据的来源和收集方法,并进行描述性统计分析,以便了解数据的基本特征。
数据来源和收集方法我们收集了关于某国家的宏观经济数据,包括国内生产总值(GDP)、物价指数、失业率、人口数量等。
这些数据可以通过政府统计局、国际组织或经济学研究机构的报告来获取。
描述性统计分析在这一部分,我们将计算各个变量的平均值、标准差、最小值、最大值和偏度等统计指标,并绘制相应的直方图和散点图,以便对数据的分布和相关关系有更直观的了解。
第二部分:计量经济模型的建立与估计在这一部分中,我们将构建计量经济模型,并通过使用EViews软件进行参数估计,以分析各个变量之间的关系。
模型的建立根据我们对经济问题的研究目标和数据的特点,我们选择了某一计量经济模型,以解释变量Y与自变量X1、X2之间的关系。
在模型中,我们还考虑了可能的误差项。
参数估计使用EViews软件,我们可以通过最小二乘法对模型进行参数估计。
这将帮助我们确定各个变量的系数估计值,并评估其统计显著性。
模型诊断在参数估计后,我们将进行模型的诊断检验,以评估模型的拟合优度和误差项的符合性。
通过观察残差图和假设检验等方法,我们可以确定模型是否符合计量经济学的基本假设。
第三部分:计量经济模型的解释与预测在这一部分中,我们将解释计量经济模型的估计结果,并利用该模型进行未来情景的预测。
模型解释通过对模型中各个变量的系数估计进行解释,我们可以理解自变量与因变量之间的经济关系,并得出相应的经济学解释。
模型预测利用模型的参数估计结果和最新的经济数据,我们可以进行未来情景的预测。
计量经济学论文(eviews分析)计量经济作业

计量经济学论文(eviews分析)计量经济作业计量经济学论文分析的重要性不言而喁。
在经济学领域中,计量经济学是一门研究经济现象的学科,通过数学模型和统计分析对经济数据进行量化分析,以揭示经济规律和探寻经济发展规律。
eviews是一个专门用于时间序列分析和计量经济学建模的软件工具,广泛应用于经济学研究和金融领域。
在进行计量经济学论文分析时,首先需要明确研究问题和假设,然后收集相关数据。
随后,利用eviews软件对数据进行清洗和整理,进行描述性统计分析,绘制图表,进行回归分析等。
通过计量经济学方法,可以验证假设、识别变量之间的关系、预测未来趋势等。
举例来说,假设我们要研究某国家的经济增长与通货膨胀之间的关系。
首先,我们收集相关数据,包括国内生产总值(GDP)、通货膨胀率等。
然后,利用eviews软件导入数据,进行描述性统计分析,观察数据的分布特征。
接下来,可以进行回归分析,建立经济增长与通货膨胀之间的模型,分析它们之间的关系及影响因素。
在计量经济学论文中,需要注重数据的准确性和分析的科学性。
同时,也需要注意论文的结构和组织,合理安排内容,确保表达清晰,逻辑严谨。
最后,对研究结果进行讨论和总结,提出建议和展望,为相关研究和政策制定提供参考。
综上所述,计量经济学论文分析是一项复杂而重要的研究工作,需要研究者具备扎实的理论基础和专业的技能。
利用eviews软件进行数据分析和建模,可以帮助研究者更好地理解经济现象、揭示规律、做出预测,为经济学研究和实践提供理论支持和决策依据。
愿更多的学者和研究人员投身于计量经济学领域,不断推动学科进步和实践应用,为经济发展和社会进步做出贡献。
EVIEWS论文

一、背景分析2009年国民经济继续朝着宏观调控预期方向发展,总体保持了平稳较快的运行状态,国际贸易迅速发展,外汇储备再创新高,人民币汇率升值仍然保持一个较高的预期。
汇率受到诸多方面的影响,其变动原因较为复杂。
很明显,汇率首先受到一国外汇储备的制约。
汇率是不同货币之间的比率关系,而外汇储备是一个国家拥有的非本国货币的金额。
2009年6月,我国外汇储备已经超过2.1万亿美元。
如此庞大的外汇储备导致人民币升值的压力进一步加大。
在外汇储备不断增加的情况下,流通中的货币量也在增加,央行不得不发行更多的人民币来兑换贸易或投资中得到的外汇。
利益方面,在经济起飞过程中汇率升值的问题是肯定会出现的,汇率和人均GDP之间的影响非常之大.。
如韩国,台湾与日本,以起飞过程中汇率都升值了一倍以上.而韩国从2000年到两面仅仅七年时间,汇率就涨了四成.而日本仅在1987年日元的汇率就涨了差不多100%.但中国呢则非常奇怪,在经济起飞的前二十年,1980-1996,中国的汇率不但不升,反而贬值了560%.1996的时候,中国经济已经高速增长了二十年,按日本四小龙的经验,货币已经开始一倍两倍地大幅升值了,但中国人民币却不动如山的稳定了十年,直到2005.而2005到现在,人民币虽然开始了升值,却依然是虫子爬行般地升值.而如果从1980年算起综合起来看,人民币在1980-2007年期间,不但没有升值,反而贬了了差不多500%.这都说明,人民币升值压力加大。
不管中国有何感觉,鉴于此次危机的严重程度,实际上针对中国出口的保护主义力度并不是很大。
其次,中国低汇率的政策相当于提供出口补贴和以统一的税率征收关税,换句话说,带有保护主义色彩。
第三,截至今年9月,中国已积累了2.273万亿美元的外汇储备,由此压低人民币汇率,达到世界经济史上从未曾见的水平。
尽管中国的经济增长率和经常账户盈余居世界之首,但中国的实际汇率不高于1998年初的水平,过去7个月,人民币已累计贬值12%。
计量经济学实验一 计量经济学软件EViews

实验一计量经济学软件EViews一、计量经济学软件EViews的使用实验目的:熟悉EViews软件的基本使用功能。
实验要求:快速熟悉描述统计和线性回归分析。
实验原理:软件使用。
实验数据:1978-2005年广东省消费和国内生产总值统计数据。
实验步骤:(一)启动EViews软件进入Windows以后,双击桌面EViews6图标启动EViews,进入EViews窗口。
EViews的四种工作方式:(1)鼠标图形导向方式;(2)简单命令方式;(3)命令参数方式(1与2相结合);(4)程序(采用EViews命令编制程序)运行方式。
(二)创建工作文件假定我们要研究广东省消费水平与国内生产总值(支出法)之间的关系,收集了1978—2005年28年的样本资料(表1-1),消费额记作XF(亿元),国内生产总值记作GDP(亿元)。
根据资料建立消费函数。
进入EViews后的第一件工作,通常应由创建工作文件开始。
只有建立(新建或调入原有)工作文件,EViews才允许用户输入,开始进行数据处理。
建立工作文件的方法是点击File/New/Workfile。
选择新建对象的类型为工作文件。
选择数据类型和起止日期,并在对话框中提供必要的信息:适当的时间频率(年、季度、月度、周、日);最早日期和最晚日期。
开始日期是项目中计划的最早的日期;结束日期是项目计划的最晚日期,以后还可以对这些设置进行修改。
非时间序列提供最大观察个数。
建立工作文件对话框如图1-2所示,按OK确认,得新建工作文件窗口(图1-3)。
表1-1图1-2工作文件窗口是EViews的子窗口。
它也有标题栏、控制栏、控制按钮。
标题栏指明窗口的类型是Workfile、工作文件名和存储路径。
标题栏下是工作文件窗口的工具条。
工具条上是一些按钮。
图1-3View —观察按钮;Proc —过程按钮;Save —保存工作文件;Show —显示序列数据;Fetch —读取序列;Store —存储序列;Delete —删除对象;Genr —生成新的序列;Sample —设置观察值的样本区间。
计量经济学论文eviews分析计量经济作业

计量经济学论文e v i e w s 分析计量经济作业The document was prepared on January 2, 2021我国旅游收入的计量分析一、经济理论陈述在研读了大量统计和计量资料的基础上,选择了三个大方面进行研究,既包括旅游人数,人均旅游花费和基本交通建设.其中,在旅游人数这个解释变量的划分上,我们考虑到随着全球经济一体化的发展,越来越多的外国游客来中国旅游消费.中国旅游的国际市场是个有发展潜力的新兴市场,尽管外国游客前来旅游的方式包罗万象而且消费能力也不尽相同,但从国际服务贸易的角度出发,我们在做变量选择时,运用国际营销的知识进行市场细分,划分了国际和国内两个市场.这样,在旅游人数这个解释变量的最终确定上,我们选择了2X国内旅游人数,3X入境旅游人数.这点选择除了理论支持外,在现实旅游业发展中我们也看到很多景区包括成都的近郊也有不少外国游客的身影.所以,我们选取这两个解释变量等待下一步进行模型设计和检验.另外,对于人均旅游花费,我们在进行市场细分时,没有延续前两个变量的选择模式,有几个原因.首先,外国游客前来旅游的形式和消费方式各异且很难统计.我们在花大力气收集数据后,仍然没有比较权威的统计数据资料.其次,随着国家对农业的不断重视和扶持,我国农业有了长足发展.农村居民纯收入增加,用于旅游的花费也有所上升.而且鉴于农村人口较多,前面的市场细分也不够细化,在这个解释变量的确定上,我们选择农村人均旅游花费,既是从我国基本国情出发,也是对第一步研究分析的补充.所以我们确定了4X城镇居民人均旅游花费和5X农村居民人均旅游花费.旅游发展除了对消费者市场的划分研究,还应考虑到该产业的基础硬件设施.在众多可选择对象中我们经分析研究结合大量文献资料决定从交通建设着手.在我国,交通一般分布为公路,铁路,航班,航船等.由于考虑到我国一般大众的旅游交通方式集中在公路和铁路上,为了避免解释变量的过多过繁以及可能带来的多重共线形等问题,我们只选取了前二者.即确定了6X公路长度和7X铁路长度这两个解释变量.其中,考虑到我国旅游业不断发展过程中,高速公路的修建也不断增多,在6X的确定过程中,我们已经将其拟合,尽量保证解释变量的完整和真实.二、相关数据三、计量经济模型的建立Y=c1+c2X2+c3X3+c4X4+c5X5+c6X6+U我们建立了下述的一般模型:其中Y——1994-2003年各年全国旅游收入C1——待定参数X——国内旅游人数万人2X——入境旅游人数万人3X——城镇居民人均旅游花费元4X——农村居民人均旅游花费元5X——公路长度含高速万公里6X——铁路长度万公里7U——随即扰动项四、模型的求解和检验利用Eviews软件,采用以上数据对该模型进行OLS回归,结果如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 01:56Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.CX2X3X4X5X6X7R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic由此可见,该模型可决系数很高,F检验显着,但是2X、6X、7X的系数t检验不显着,且7X的系数符号不符合经济意义,说明存在严重的多重共线性.所以进行以下修正:〈一〉.计量方法检验及修正多重共线性的检验:首先对Y进行各个解释变量的逐步回归, 由最小二乘法,结合经济意义和统计检验得出拟合效果最好的两个解释变量如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 02:00Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.CX4X5R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic继续采用逐步回归法将其余解释变量代入,得出拟合效果最好的三个解释变量,结果如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 02:01Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.CX2X4X5R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic以上模型估计效果最好,继续逐步回归得到以下结果:Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 02:40Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.CX2X3X4X5R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic各项拟合效果都较好.虽然2X的t检验不是很显着,但考虑到其经济意义在模型中的重要地位,暂时保留.继续引入6X.Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 02:41Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.CX2X3X4X5X6R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic根据以上回归结果可得,6X的引入使得模型中2X、6X的t检验均不显着,再考察二者的相关系数为,说明2X、6X高度相关,模型产生了多重共线性,因此将6X去掉.再将7X代入检验.Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 02:42Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.CX2X3X4X5X7R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statisticX的系数为负,与经济意义相悖,因此也去掉.由此确定带入模型的解7释变量为2X、3X、4X、5X.异方差性的检验:再对模型的异方差性进行检验:鉴于我们的样本资料是时间序列数据,选用ARCH检验.ARCH Test:F-statistic ProbabilityObsR-squared ProbabilityTest Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 12/23/10 Time: 02:43Sample adjusted: 1995 2003Included observations: 9 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.CRESID^2-1R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid +08 Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic这里ObsR-squared为,P=>所以接受0H,表明模型中随机误差项不存在异方差.再考虑P=3的情况:ARCH Test:F-statistic ProbabilityObsR-squared ProbabilityTest Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 12/23/10 Time: 02:46Sample adjusted: 1997 2003Included observations: 7 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.CRESID^2-1RESID^2-2RESID^2-3R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid +08 Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic这里ObsR-squared为,P=>.所以仍然接受0H,表明模型中随机误差项不存在异方差.自相关性的检验:随机扰动项可能存在一阶负自相关.借助残差项和其一阶滞后项的二维坐标图进一步分析:由图示可看出,残差项和其一阶滞后项显然存在负自相关,然后利用对数线形回归修正自相关性,得到相应结果如下:Dependent Variable: LOGYMethod: Least SquaresDate: 12/23/10 Time: 02:52Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.CLOGX2LOGX3LOGX4LOGX5R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic从估计的结果看,DW=,说明修正后有了明显好转,随机扰动项几乎不存在一阶自相关.我们进行了一系列检验和修正后的最终结果如下:2R= 2R= F=五、经济意义解释C3和C3分别衡量我国旅游收入国内和入境旅游人数的弹性,也就是表示当旅游人数每变动百分之一时,平均来说,旅游收入变动的百分比.这里要特别注意,例如1998年国内旅游人数为69450万人,入境旅游人数为万人,则国内旅游人数每增加1%,即增加万人,国内旅游收入增加%,而入境旅游人数每增加1%,即增加万人,国内旅游收入增加%.C4和C5分别衡量我国旅游收入我国城镇居民和农村居民人均旅游花费的弹性,也就表示当人均花费每变动百分之一时,平均来说,旅游收入变动的百分比.城镇居民人均旅游花费每增加1%,国内旅游收入增加%;农村居民人均旅游花费每增加1%,国内旅游收入增加 %.六、政策建议为了促进我国旅游事业的快速发展,我们提出了以下几点建议:1、实施政府主导型旅游发展战略政府主导型旅游发展战略是按照旅游业自身的特点,在以市场为主,合理配置资源的基础上,充分发挥政府的主导作用,促进旅游业更快发展.1建设和完善旅游法制体系,力争旅游法的尽早出台.2提高旅游管理部门的地位,或组织高层次的协调机制,以适应旅游产业大规模和大发展的前景.3中央政府的主导需要相应的资金基础.从1992年起,财政部建立了旅游发展基金,其来源是在出境机场费中加收20元人民币,对旅游业的发展起到了积极的作用.考虑到旅游大发展的需要,多渠道,多形式开辟政府基金来源是必要的.4加大促销投入.长期以来我国促销经费严重缺乏.中央一年所能提供的促销经费不足500万美元,这大大限制了我国对国际旅游市场大面积,深层次的开发,难以产生影响客源流向的招徕效果.从国际上看,为了使自己处在有利的市场竞争地位,每个国家每年都投入相当数量的旅游经费,用于开展旅游对外促销活动.按照世界一般规律,吸引一个国际旅游者平均需要3—5美元的促销经费,而我国尚不足美元,这种状态,显然无法适应国际旅游市场竞争的需要. 因此,在政府主导型战略的实施中加大促销投入是一项重要的工作.2、旅游市场创新旅游经济是特色经济,而特色就需要充分地发扬创新意识,做到人无我有,人有我精,人精我专. 对于旅游市场的开拓,各地旅游开发和建设模式大同小异,无论是山水风景区,历史文化名城,滨海沙滩度假地,还是温泉休养区,大都只是大众旅游市场的共同特征,因此,重复建设的模式正成为旅游开拓市场的通病.随着现代旅游者需求日益成熟,伴随着主题公园等人造景区大规模发展之势,生态旅游由于世界各国重视人和自然共生共存共荣环保概念的强化,以可持续发展为方向的生态旅游正在世界各地呈方兴未艾之势.区域旅游的发展开始以若干不同旅游项目满足相应不同分众市场的开发模式以获得综合整体效益,形成规模经济的发展趋势.3、不同产业匹配发展产业之间相互联系,旅游业的存在不是独立的,在促进旅游业的同时也要加大工业和农业的发展.如我国农业人口占据很大比例,而国内旅游收入的主要来源集中在为数不多的城镇居民上,农村市场还存在很大的空白.可以说,我国的国内旅游市场还没有开发完全,农村市场非常广阔,具有很大潜力,所以发展农业,必然会极大促进我国的旅游事业.。
计量经济学期末论文-中国股市有效性分析eviews

中国股市有效性分析摘要:传统的有效市场理论(Efficient Market Hypothesis,EMH)认为证券价格完全反映了证券的内在价值,证券价格的变动仅受未来的信息影响,信息的变动能够在证券的价格上得到充分及时且准确的反映。
同时,有效市场理论认为,风险中性投资者所组成的一个竞争市场中,证券的内在价值与价格都是服从随机游走规则的,因而未来的证券价格具有不可预测性,但近年来出现了很多理论挑战有效市场假说,均值回归理论就是其中之一,均值回归理论认为,从长期的角度来看,证券价格服从均值回归,也就是长期收益率服从负的相关性。
本文采用时间序列回归方法,对上证指数过去十年的周收益率进行实证验证,证明上证指数具有显著的均值回归特性,为统计套利方法提供了理论依据。
关键词:时间序列;自回归;均值回归;序列相关-稳健推断一、均值回归的由来与发展传统的有效市场理论(Efficient Market Hypothesis,EMH)认为证券价格完全反映了证券的内在价值,证券价格的变动仅受未来的信息影响,信息的变动能够在证券的价格上得到充分及时且准确的反映。
同时,有效市场理论认为,风险中性投资者所组成的一个竞争市场中,证券的内在价值与价格都是服从随机游走规则的,因而未来的证券价格具有不可预测性,投资者只能获得市场平均收益。
萨缪尔森(Samuelson,1957)认为,信息是决定股票价格波动的主要因素,但由于信息是不可预测的,所以股票的未来价格也是不可测的。
法玛(Fama,1965)用间隔天数不同的价格变化来求它们之间的自相关性,得出了1958至1962年期间道·琼斯工业股票的股价变动的自相关系数近似于零,论证了股价是随机游走的,。
自有效市场理论提出以来,该理论一直处于现代金融的主流地位。
但近些年来,尤其是21世纪以来,该理论在理论和实证方面遭遇了前所未有的挑战。
De Bondt和Thaler(1985)[1]第一个对有效市场理论发起了质疑,他们认为股票市场存在着和心理学上类似的过度反应现象,过度反应一般来说是指市场上过分悲观或乐观的心理,过去表现的更好的股票(赢家)被投资者追捧,而过去表现不好的股票(输家)无人理睬。
宏观经济学计量经济学模型eviews实证论文

宏观经济学计量经济学模型eviews实证论文班级:会计0901 学号:20091720125 姓名:许艺瀚【摘要】宏观计量经济学模型是在一国的宏观经济总量水平上,把握和反映经济运动的全面特征,研究宏观经济主要指标间的相互依存关系,用数学的语言描述国民经济和社会再生产过程各环节之间的联系,并可以用以进行宏观经济的结构分析、政策评价、决策研究和发展预测。
本文通过对统计年鉴中的数据进行实证分析,构建关于国民生产总值、居民消费、政府消费和投资总额的联立方程,并对参数进行估计和检验,并分析。
【关键词】联立方程国民生产总值居民消费政府消费投资总额两阶段最小二乘法估计【模型的构建】首先描写包含三个内生变量,即国内生产总值Y,居民消费总额C和投资总额I;3个先决变量,即政府消费G,前期居民消费总额Ct-1和常数项。
根据这些设定,我们分别建立居民消费和投资的方程,完备的结构式模型如下:C t=a0+a1Y t+a2C t-1+μ1tI t=β0+β1Y t+μ2tY t=I t+C t+G t ,t=1978,1979,…,2002易判断,消费方程是恰好识别的方程,投资方程是过渡是别的方程,模型是可以识别的。
对模型进行估计。
有以下数据。
(1)用两阶段最小二乘法估计消费方程用普通最小二乘法估计内生解释变量的简化式方程,Dependent Variable: YMethod: Least SquaresDate: 05/25/11 Time: 19:22Sample (adjusted): 1979 2009Included observations: 31 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.C 87.15681 68.69478 1.268755 0.2150C01(-1) 0.927200 0.137270 6.754560 0.0000G 0.898030 0.499515 1.797802 0.0830 R-squared 0.996165 Mean dependent var 3869.540Adjusted R-squared 0.995891 S.D. dependent var 4383.683S.E. of regression 280.9951 Akaike info criterion 14.20632Sum squared resid 2210830. Schwarz criterion 14.34509Log likelihood -217.1979 F-statistic 3636.668Durbin-Watson stat 0.707811 Prob(F-statistic) 0.000000得到Ŷt=87.15681+0.927200C t-1+0.898030G t据此计算Ŷ,替换结构方程中的Yt,再用普通最小二乘法估计变换了的结构式方程Dependent Variable: C01Method: Least SquaresDate: 05/25/11 Time: 19:24Sample (adjusted): 1979 2009Included observations: 31 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.C -125.2910 60.16079 -2.082603 0.0465YF 1.635985 0.361948 4.519941 0.0001C01(-1) -0.791635 0.424566 -1.864573 0.0728R-squared 0.998239 Mean dependent var 3670.504Adjusted R-squared 0.998114 S.D. dependent var 4209.922S.E. of regression 182.8467 Akaike info criterion 13.34694Sum squared resid 936121.9 Schwarz criterion 13.48571Log likelihood -203.8776 F-statistic 7937.790Durbin-Watson stat 1.168426 Prob(F-statistic) 0.000000 得到消费方程的两阶段最小二乘参数估计量为â0=-125.2910â1=1.635985â2=-0.791635比较上述消费方程的3种估计结果,证明这3种方法对于恰好识别的结构方程是等价的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
我国旅游收入的计量分析一、经济理论陈述在研读了大量统计和计量资料的基础上,选择了三个大方面进行研究,既包括旅游人数,人均旅游花费和基本交通建设。
其中,在旅游人数这个解释变量的划分上,我们考虑到随着全球经济一体化的发展,越来越多的外国游客来中国旅游消费。
中国旅游的国际市场是个有发展潜力的新兴市场,尽管外国游客前来旅游的方式包罗万象而且消费能力也不尽相同,但从国际服务贸易的角度出发,我们在做变量选择时,运用国际营销的知识进行市场细分,划分了国际和国内两个市场。
这样,在旅游人数这个解释变量的最终确定上,我们选择了2X国内旅游人数,3X入境旅游人数。
这点选择除了理论支持外,在现实旅游业发展中我们也看到很多景区包括成都的近郊也有不少外国游客的身影。
所以,我们选取这两个解释变量等待下一步进行模型设计和检验。
另外,对于人均旅游花费,我们在进行市场细分时,没有延续前两个变量的选择模式,有几个原因。
首先,外国游客前来旅游的形式和消费方式各异且很难统计。
我们在花大力气收集数据后,仍然没有比较权威的统计数据资料。
其次,随着国家对农业的不断重视和扶持,我国农业有了长足发展。
农村居民纯收入增加,用于旅游的花费也有所上升。
而且鉴于农村人口较多,前面的市场细分也不够细化,在这个解释变量的确定上,我们选择农村人均旅游花费,既是从我国基本国情出发,也是对第一步研究分析的补充。
所以我们确定了4X城镇居民人均旅游花费和5X农村居民人均旅游花费。
旅游发展除了对消费者市场的划分研究,还应考虑到该产业的基础硬件设施。
在众多可选择对象中我们经分析研究结合大量文献资料决定从交通建设着手。
在我国,交通一般分布为公路,铁路,航班,航船等。
由于考虑到我国一般大众的旅游交通方式集中在公路和铁路上,为了避免解释变量的过多过繁以及可能带来的多重共线形等问题,我们只选取了前二者。
即确定了6X公路长度和7X铁路长度这两个解释变量。
其中,考虑到我国旅游业不断发展过程中,高速公路的修建也不断增多,在6X的确定过程中,我们已经将其拟合,尽量保证解释变量的完整和真实。
二、相关数据三、计量经济模型的建立Y=c(1)+c(2)*X2+c(3)*X3+c(4)*X4+c(5)*X5+c(6)*X6+U我们建立了下述的一般模型:其中Y——1994-2003年各年全国旅游收入C(1)——待定参数X——国内旅游人数(万人)2X——入境旅游人数(万人)3X——城镇居民人均旅游花费(元)4X——农村居民人均旅游花费(元)5X——公路长度(含高速)(万公里)6X——铁路长度(万公里)7U——随即扰动项四、模型的求解和检验利用Eviews软件,采用以上数据对该模型进行OLS回归,结果如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 01:56Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.C -340.5047 1357.835 -0.250770 0.0882X2 -0.001616 0.013520 -0.119529 0.1524X3 0.232358 0.128017 1.815050 0.1671X4 6.391052 1.716888 3.722463 0.0337X5 -1.046757 1.224011 -0.855187 0.0453X6 5.673429 6.667266 0.850938 0.4573X7 -474.3909 355.7167 -1.333620 0.2745R-squared 0.996391 Mean dependent var 2494.200Adjusted R-squared 0.989174 S.D. dependent var 980.4435S.E. of regression 102.0112 Akaike info criterion 12.28407Sum squared resid 31218.86 Schwarz criterion 12.49588Log likelihood -54.42035 F-statistic 138.0609Durbin-Watson stat 3.244251 Prob(F-statistic) 0.000944 由此可见,该模型可决系数很高,F检验显著,但是2X、6X、7X的系数t检验不显著,且7X的系数符号不符合经济意义,说明存在严重的多重共线性。
所以进行以下修正:〈一〉.计量方法检验及修正多重共线性的检验:首先对Y进行各个解释变量的逐步回归, 由最小二乘法,结合经济意义和统计检验得出拟合效果最好的两个解释变量如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 02:00Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.C -3193.041 606.2101 -5.267217 0.0012X4 9.729003 1.435442 6.777703 0.0003X5 -1.197036 2.059371 -0.581263 0.1293R-squared 0.957285 Mean dependent var 2494.200Adjusted R-squared 0.945081 S.D. dependent var 980.4435S.E. of regression 229.7654 Akaike info criterion 13.95532Sum squared resid 369544.9 Schwarz criterion 14.04609Log likelihood -66.77660 F-statistic 78.43859Durbin-Watson stat 0.791632 Prob(F-statistic) 0.000016继续采用逐步回归法将其余解释变量代入,得出拟合效果最好的三个解释变量,结果如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 02:01Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.C -3391.810 514.1119 -6.597416 0.0006X2 0.029414 0.014525 2.025042 0.0393X4 6.355459 2.050175 3.099959 0.0211X5 -0.284542 1.772604 -0.160522 0.1077R-squared 0.974627 Mean dependent var 2494.200Adjusted R-squared 0.961940 S.D. dependent var 980.4435S.E. of regression 191.2739 Akaike info criterion 13.63446Sum squared resid 219514.3 Schwarz criterion 13.75550Log likelihood -64.17232 F-statistic 76.82334Durbin-Watson stat 1.328513 Prob(F-statistic) 0.000035以上模型估计效果最好,继续逐步回归得到以下结果:Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 02:40Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.C -1973.943 441.5947 -4.470034 0.0066X2 -0.005095 0.011431 -0.445729 0.6744X3 0.328279 0.080682 4.068802 0.0096X4 4.665485 1.158665 4.026602 0.0101X5 -1.714020 0.999029 -1.715686 0.1469R-squared 0.994114 Mean dependent var 2494.200Adjusted R-squared 0.989406 S.D. dependent var 980.4435S.E. of regression 100.9150 Akaike info criterion 12.37329Sum squared resid 50919.23 Schwarz criterion 12.52458Log likelihood -56.86644 F-statistic 211.1311Durbin-Watson stat 3.034041 Prob(F-statistic) 0.000009各项拟合效果都较好。
虽然2X的t检验不是很显著,但考虑到其经济意义在模型中的重要地位,暂时保留。
继续引入6X。
Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 02:41Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.C -2034.155 525.2137 -3.873004 0.0179。