内核数据包处理注意事项
linux pf_packet 例程

linux pf_packet 例程一、pf_packet 简介pf_packet 是 Linux 内核提供的一种网络数据包捕获和发送机制,它可以绕过网络协议栈,直接访问网络数据包。
它是一种基于套接字的接口,通过创建一个特殊类型的套接字,用户可以利用pf_packet 接口收发数据包。
二、pf_packet 的使用步骤1. 创建套接字使用 socket 函数创建一个 PF_PACKET 类型的套接字,并指定协议类型为 ETH_P_ALL,表示接收所有类型的数据包。
2. 绑定接口使用 bind 函数将套接字与特定的网络接口绑定,以便接收该接口上的数据包。
可以使用 if_nametoindex 函数将接口名称转换为接口索引。
3. 设置过滤器可以使用 setsockopt 函数设置一个过滤器,以筛选特定类型的数据包。
过滤器可以根据源 IP、目的 IP、协议类型等进行设置。
4. 接收数据包使用 recvfrom 函数从套接字中接收数据包,接收到的数据包存储在缓冲区中。
可以使用 sockaddr_ll 结构获取关于数据包的信息,如源 MAC 地址、目的 MAC 地址等。
5. 发送数据包使用sendto 函数将数据包发送到指定的目的地。
可以使用sockaddr_ll 结构指定目的地的 MAC 地址和接口索引。
三、注意事项和常见问题1. 权限问题pf_packet 接口需要 root 权限才能够正常使用,因为它可以绕过网络协议栈,可能会对系统安全造成一定的风险。
2. 数据包捕获问题使用 pf_packet 接口捕获数据包时,需要注意设置合适的过滤器,避免接收到不必要的数据包。
同时,需要注意接收缓冲区的大小,避免数据包丢失。
3. 数据包发送问题使用 pf_packet 接口发送数据包时,需要注意目的地的 MAC 地址和接口索引的正确设置,否则数据包可能无法正确送达。
4. 大量数据包处理问题当处理大量数据包时,需要注意性能问题。
数据包处理过程

数据包处理过程来⾃链接:这篇⽂档是基于 x86 体系结构和转发 IP 分组的。
数据包在 Linux 内核链路层路径2 接收分组2.1 接收中断如果⽹卡收到⼀个和⾃⼰ MAC 地址匹配或链路层⼴播的以太⽹帧,它就会产⽣⼀个中断。
此⽹卡的驱动程序会处理此中断:从 DMA/PIO 或其他得到分组数据,写到内存⾥去;接着,会分配⼀个新的套接字缓冲区 skb ,并调⽤与协议⽆关的、⽹络设备均⽀持的通⽤⽹络接收处理函数netif_rx(skb) 。
netif_rx() 函数让内核准备进⼀步处理 skb 。
然后, skb 会进⼊到达队列以便 CPU 处理(对于多核 CPU ⽽⾔,每个 CPU 维护⼀个队列)。
如果 FIFO队列已满,就会丢弃此分组。
在 skb 排队后,调⽤ __cpu_raise_softirq() 标记 NET_RX_SOFTIRQ 软中断,等待 CPU 执⾏。
⾄此, netif_rx() 函数调⽤结束,返回调⽤者状况信息(成功还是失败等)。
此时,中断上下⽂进程完成任务,数据分组继续被上层协议栈处理。
2.2 softirq 和 bottom half内核 2.4 以后,整个协议栈不再使⽤ bottom half (下半⽂,没找到好的翻译),⽽是被软中断 softirq 取代。
软中断 softirq 优势明显,可以同时在多个 CPU 上执⾏;⽽ bottom half ⼀次只能在⼀个 CPU 上执⾏,即在多个 CPU执⾏时严格保持串⾏。
中断服务程序往往都是在 CPU 关中断的条件下执⾏的,以避免中断嵌套⽽使控制复杂化。
但是 CPU 关中断的时间不能太长,否则容易丢失中断信号。
为此, Linux 将中断服务程序⼀分为⼆,各称作“ Top Half ”和“ Bottom Half ”。
前者通常对时间要求较为严格,必须在中断请求发⽣后⽴即或⾄少在⼀定的时间限制内完成。
因此为了保证这种处理能原⼦地完成, Top Half 通常是在 CPU 关中断的条件下执⾏的。
linux tap原理

linux tap原理Linux Tap是一种在Linux系统中实现网络桥接的方式,它允许用户在物理网络上创建虚拟网络接口,从而实现网络流量在多个设备之间的转发和隔离。
本文将介绍Linux Tap的基本原理、实现方式、应用场景和注意事项。
Linux Tap的核心思想是将物理网络接口(如eth0)虚拟化为多个网络接口,每个接口代表一个虚拟网络,从而实现网络流量的隔离和转发。
具体来说,Linux Tap通过使用内核中的tap-netdev和tap-module模块来实现虚拟网络的创建和管理。
这些模块允许用户将物理网络接口桥接到虚拟网络上,并配置相应的网络参数,如IP地址、子网掩码、网关等。
二、Linux Tap的实现方式Linux Tap的实现方式主要涉及内核模块、驱动程序和用户空间工具三个层次。
内核模块负责注册tap设备,并提供基本的设备管理功能;驱动程序负责与内核模块进行交互,处理虚拟网络的创建、销毁和数据转发等操作;用户空间工具则提供用户接口,用于配置虚拟网络参数和管理tap设备。
三、Linux Tap的应用场景Linux Tap广泛应用于网络安全、云计算、物联网等领域。
在网络安全方面,Linux Tap可以实现网络流量的隔离和监控,提高网络安全性能;在云计算领域,Linux Tap可以实现虚拟机之间的网络通信和流量控制;在物联网方面,Linux Tap可以实现传感器数据传输和设备间通信。
四、注意事项在使用Linux Tap时,需要注意以下几点:1. 确保虚拟网络的安全性:Linux Tap可能会暴露物理网络接口给虚拟网络,因此需要采取适当的网络安全措施,如设置访问控制列表(ACL)来限制虚拟网络中设备的访问权限。
2. 配置正确的网络参数:用户需要正确配置虚拟网络的IP地址、子网掩码、网关等参数,以确保网络通信正常进行。
3. 考虑性能问题:由于Linux Tap需要将数据包从物理网络转发到虚拟网络,因此需要注意性能问题,如数据包丢失、延迟等。
内核 rps 原理

内核 rps 原理RPS(Receive Packet Steering)是一个在Linu某内核中使用的技术,用于自动分发网络数据包到不同的CPU核心处理。
它的目的是提高多核系统中网络处理的性能和伸缩性。
RPS通过在网络流量被处理时,将数据包分发到多个CPU核心上进行并行处理,从而减轻单个核心的负载,提高网络处理的吞吐量。
在传统的Linu某网络栈中,所有的网络流量都由内核通过协议栈处理。
内核将网络数据包接收到一个队列中,然后通过处理进程处理。
这种处理方式存在一个问题,即单个CPU核心负责处理所有的网络流量,如果流量很大,可能会导致CPU核心饱和,从而性能下降。
此外,由于网络流量被分散到不同的处理进程中,引起了多个进程之间的竞争条件和锁竞争。
RPS技术通过在网络接口上设置一个映射表,将接收到的数据包分发到不同的CPU核心上处理。
当数据包到达网卡驱动程序时,驱动程序会读取映射表,确定应该将数据包分发到哪个CPU核心进行处理。
这种分发的机制可以根据映射表中的规则来进行,如根据源IP地址、源端口、目的IP地址、目的端口等进行选择。
分发后,每个CPU核心都可以处理自己分配到的数据包,相互之间没有竞争条件,提高了并行处理的能力。
RPS的实现是通过一组内核线程来工作。
每个线程绑定到一个特定的CPU核心上,并通过等待网卡驱动程序中断的方式来触发数据包的接收和分发。
当驱动程序接收到一个数据包时,它会选择一个内核线程来处理,并在该线程的上下文中执行。
这样,数据包就可以在多个CPU核心上并行处理,提高了网络处理的性能。
RPS技术还能够在大规模的多核系统中提高负载均衡的能力。
通过将数据包分发到不同的CPU核心上处理,可以平均分配负载,避免某个核心负载过高,导致性能下降。
此外,RPS还可以减少多个核心之间对共享数据结构的竞争,提高系统的伸缩性。
总结来说,RPS是一个在Linu某内核中使用的技术,用于自动分发网络数据包到不同的CPU核心上处理。
br_dev_xmit_hook 用法

br_dev_xmit_hook 用法br_dev_xmit_hook是Linux内核中一个重要的网络设备驱动程序,用于实现对网络数据包的发送钩子,可以对数据包的发送过程进行定制和控制。
本文将介绍br_dev_xmit_hook的基本用法和注意事项。
一、基本概念br_dev_xmit_hook是一个网络设备驱动程序,它通过插入到网络设备的数据发送钩子中,实现对数据包发送过程的定制和控制。
该驱动程序允许用户自定义发送函数,以便在数据包发送前进行一些自定义的处理,如修改数据包、加入特殊标记等。
二、使用方法要使用br_dev_xmit_hook,需要按照以下步骤进行操作:1.包含相关头文件在代码中需要包含以下头文件:*linux/netfilter_ipv4.h:用于定义网络数据包钩子相关的结构和宏。
*linux/if_bridge.h:用于定义Linux桥接模块的相关结构和函数。
*内核模块相关头文件。
2.注册钩子函数在内核模块中,需要调用register_netdevice_queue()函数注册钩子函数。
该函数需要传入钩子函数的指针和相关参数。
3.实现钩子函数钩子函数需要按照一定的规范进行编写,以便在数据包发送前进行一些自定义的处理。
钩子函数通常需要包含以下步骤:*获取待发送的数据包。
*对数据包进行一些自定义的处理,如修改数据包、加入特殊标记等。
*将处理后的数据包放回队列中等待发送。
以下是一个简单的钩子函数示例:```cstaticvoidmy_xmit_hook(structsk_buff**skb){//对数据包进行一些自定义的处理,如修改数据包、加入特殊标记等//...//将处理后的数据包放回队列中等待发送return;}```4.加载内核模块将编写好的内核模块加载到Linux系统中,可以使用insmod命令或者通过内核配置菜单进行加载。
三、注意事项在使用br_dev_xmit_hook时,需要注意以下几点:1.钩子函数的执行时间:钩子函数需要在数据包发送前执行,以确保对数据包的处理不会影响正常发送过程。
Linux内核污染

Linux内核污染
Linux内核的污染指的是对Linux内核代码的恶意修改或篡改,这可能会导致系统的安全性和稳定性受到威胁。
Linux内核的源代码是开放的,允许用户自由地进行修改和分发。
然而,如果有人恶意地修改了Linux内核的代码,添加了
恶意软件或后门等功能,就会发生内核污染的情况。
内核污染可以导致以下问题:
1. 安全问题:通过在内核中插入后门或恶意代码,黑客可以获得对系统的控制权,盗取用户的敏感信息,如密码、银行账户等。
2. 稳定性问题:恶意修改可能导致内核崩溃或错误,使系统无法正常工作。
这可能会导致数据丢失或系统不可用。
3. 兼容性问题:污染的内核可能与其他软件或驱动程序不兼容,导致系统出现错误或崩溃。
为了防止内核污染,可以采取以下措施:
1. 定期更新:及时安装Linux内核的最新版本,因为开发者通
常会修复已知的安全漏洞和问题。
2. 只从可信源下载内核:确保从官方或可信的软件源下载内核代码,避免从不可信的来源获取。
3. 使用数字签名验证:通过使用数字签名来验证内核的完整性和来源,可以确保内核代码没有被篡改。
4. 定期检查:使用专业的安全工具来定期扫描系统,以发现可能的威胁和污染。
总之,内核污染是对Linux系统安全和稳定性的威胁,用户应该采取措施来保护自己的系统免受这种威胁。
kthread_run 例子

[标题]:深入解析kthread_run函数的使用方法【摘要】:本文将介绍kthread_run函数的概念、使用方法和实际应用场景,帮助读者深入理解Linux内核中的线程调度机制。
1. 什么是kthread_run函数?在Linux内核中,kthread_run函数是用于创建和管理内核线程的函数之一。
内核线程是在内核态运行的轻量级进程,它们通常被用于执行一些后台任务或者处理一些不需要用户交互的工作。
kthread_run 函数是基于内核中的kthread API实现的,它允许开发人员在内核空间创建和管理线程,从而可以在内核态执行一些需要长时间运行的任务,而不会占用过多的系统资源。
2. kthread_run函数的使用方法使用kthread_run函数很简单,只需要传入一个指向线程函数的指针和一个指向传递给线程函数的参数的指针即可。
线程函数是一个普通的C函数,用于执行线程的具体逻辑,参数则可以用于传递需要的数据给线程函数。
开发人员还可以通过设置不同的线程属性来指定线程的优先级、调度策略以及绑定CPU等。
```c// 使用kthread_run函数创建内核线程struct task_struct *kthread_run(int (*threadfn)(void *data), void*data, const char *namefmt, ...);```3. kthread_run函数的实际应用场景kthread_run函数广泛应用于Linux内核中的各种模块和子系统中,例如网络子系统、文件系统和驱动程序等。
在网络子系统中,可以使用kthread_run函数创建专门用于数据包处理的线程,以避免阻塞网络服务进程。
在文件系统中,可以使用kthread_run函数创建用于数据同步和清理的线程,以提高文件系统的性能和稳定性。
在驱动程序中,可以使用kthread_run函数创建用于设备管理和状态监测的线程,以提供更完善的设备控制功能。
ebtables高级用法

ebtables高级用法ebtables(Ethernet Bridge tables)是一个用于Linux系统的高级网络工具,它为网络管理员和系统管理员提供了一种高级的方式来管理以太网桥设备上的数据流量。
在本文中,我们将探讨ebtables的高级用法,并逐步回答一些与此相关的问题。
第一步- 什么是ebtables?ebtables是一个用于Linux内核的包过滤工具,它允许您在网络层和链路层之间进行策略路由和过滤。
它通常与桥接设备一起使用,以实现对数据流量的细粒度控制,以及网络安全和网络性能的优化。
第二步- ebtables的主要特性是什么?ebtables具有以下主要特性:1. 支持桥接设备上的数据包过滤和修改。
2. 可以根据以太网帧中的各种字段(如MAC地址、协议类型、VLAN标记等)进行过滤。
3. 可以在数据包转发之前和之后执行特定的操作,如丢弃、转发、重定向等。
4. 支持用户定义的链和表,以及通过用户空间工具定制的多个规则集。
5. 提供了对特定协议(如ARP、IPv4、IPv6等)的支持,以便实现更高级的过滤和路由策略。
6. 可以与其他Linux网络工具(如iptables和iproute2)相结合,以实现更复杂的网络配置。
第三步- ebtables的工作原理是什么?ebtables基于Linux内核的netfilter框架,通过在桥接设备上注册一个数据包过滤的钩子函数,来拦截和处理数据包。
当一个网络数据包通过一个桥接设备时,内核将探测到这个数据包,然后将其传递给ebtables进行处理。
根据配置的规则,ebtables可以选择丢弃、转发或重定向数据包。
第四步- 如何安装和配置ebtables?1. 安装ebtables工具包:在Linux系统上,您可以使用各个发行版的包管理器来安装ebtables 工具包。
例如,在Ubuntu上,可以使用以下命令安装ebtables:sudo apt-get install ebtables2. 配置ebtables:配置ebtables需要编辑ebtables规则集。
内核丢包定位方法

内核丢包定位方法一、查看网络接口1.确认网络接口是否正常工作,检查网线是否插好,接口是否有损坏。
2.检查网络接口的驱动程序是否正确安装,如有需要,可以尝试更新驱动程序。
二、检查网络配置1.检查网络设备的配置,包括IP地址、子网掩码、网关等,确保配置正确。
2.检查路由器的配置,确认是否有路由错误或阻塞。
3.检查网络防火墙的配置,确认是否有阻止数据包通过的规则。
三、查看网络协议1.检查网络上使用的协议是否正确,包括TCP/IP协议和其他相关的协议。
2.检查协议的版本和兼容性,确保没有使用不兼容的版本。
3.检查是否存在不安全的协议,如Telnet、FTP等,如有需要,可以尝试升级到更安全的协议。
四、诊断工具1.使用诊断工具进行网络故障排查,如ping、traceroute等命令可以用来检查网络连接是否正常。
2.可以使用网络分析仪等工具来分析网络数据包,查找丢包的原因。
五、抓包分析1.通过抓取网络数据包进行分析,可以深入了解网络通信的情况。
2.使用抓包工具如Wireshark等,可以查看数据包的详细信息,包括源IP地址、目标IP地址、协议类型等。
3.分析数据包可以发现丢包的原因,如数据包丢失、重复、乱序等。
六、检查应用程序1.检查应用程序是否存在问题,如程序崩溃、内存泄漏等可能导致丢包的问题。
2.检查应用程序的网络连接设置,确保连接配置正确。
3.对于复杂的应用程序,可以进行压力测试,模拟大量用户访问以检查程序稳定性。
七、查看系统日志1.查看系统日志可以了解系统运行的情况,包括网络接口的工作状态、系统资源的使用情况等。
2.分析系统日志可以发现丢包的相关信息,如错误提示、警告信息等。
3.可以根据日志信息进行故障排除,找到导致丢包的原因。
八、安全扫描1.进行安全扫描可以发现网络中的安全问题,如漏洞、恶意攻击等可能导致丢包的问题。
2.使用安全扫描工具如Nmap等,可以对网络进行扫描,发现漏洞并采取相应的措施进行修复。
linux内核收包流程

linux内核收包流程Linux内核是开源的,它的内核源代码可以被任何人查看、修改和分发。
内核是操作系统的核心,它负责管理和协调系统硬件和软件资源,为应用程序提供一致的接口。
在Linux内核中,收包是指当接收到网络数据包时,内核如何处理和分发这些数据包。
下面将详细介绍Linux内核收包的流程。
首先,当数据包到达网卡时,网卡会将这个数据包拷贝到内核的内存中。
然后,内核会通过网络设备驱动程序检查这个数据包的合法性,包括检查以太网帧头、校验和等。
如果数据包合法,那么内核会将其拷贝到内核的套接字缓冲区中。
接下来,内核会分析数据包的目标IP地址,以确定数据包是发给本地还是需要转发到其他主机。
如果目标IP地址是本地主机,那么内核会查找与目标IP地址对应的本地套接字,并将数据包传递给该套接字。
如果目标IP地址是其他主机,那么内核会将数据包传递给路由子系统进行进一步的处理。
在路由子系统中,内核会根据路由表来确定下一跳的IP地址,并将数据包传递给相应的网络设备驱动程序。
网络设备驱动程序将数据包发送到下一跳主机。
如果目标主机和当前主机在同一局域网中,那么内核会使用ARP协议获取对应目标IP地址的MAC地址,然后通过以太网帧发送数据包。
当数据包到达目标主机后,目标主机的网卡会将数据包拷贝到内存中。
然后,内核会根据数据包的协议字段来识别上层协议类型,如TCP、UDP或ICMP等。
然后,将数据包传递给相应的协议处理函数进行处理。
协议处理函数会对数据包进行相应的处理,如IP协议处理函数会进行IP分片重组、IP头校验等操作;TCP协议处理函数会对TCP连接进行状态管理、流量调整等操作;UDP协议处理函数会进行端口匹配和应用程序通信等操作。
最后,协议处理函数会将处理后的数据包传递给相应的套接字,并唤醒等待在该套接字上的应用程序。
应用程序可以通过调用系统调用来读取数据包或向其发送数据包。
总结起来,Linux内核收包的流程主要包括:数据包到达网卡、网卡拷贝数据包到内存、检查数据包合法性、目标IP地址分析、传递给本地套接字或路由子系统、路由子系统发送数据包到下一跳、目标主机网卡拷贝数据包到内存、协议处理函数对数据包进行处理、将处理后的数据包传递给套接字、应用程序读取或发送数据包。
内核构造skb数据包的实现总结

/macrossdzh/article/details/5438306一、IPv4、TCP和UDP的校验和计算校验和是网络协议用来识别传输错误的冗余域。
有些校验和不但能检测错误,还能自动修正某些类型的错误。
校验和的想法很简单。
在传输一个数据包之前,发送方计算出一个很小的、固定长度的域(校验和)包含数据的某种散列。
如果在传输过程中某几位数据被改变,很可能损坏的数据会产生一个不同的校验和。
取决于你用来产生校验和使用的函数,校验和提供不同级别的可靠性。
IP协议采用的校验和是简单的一个包括求和取反码,这个方法太弱了,不能被认为是可靠的。
对于更可靠的完整性检查,你必须依赖于L2 CRC或者SSL/IPSec消息认证码。
不同的协议可以使用不同的校验和算法。
IP协议校验和只覆盖IP头。
大多数L4协议的校验和均覆盖头和数据。
看起来在L2(比如,以太网)有校验和,L3(比如,IP)有另一个,L4(比如,TCP)还有一个的做法是冗余的,因为它们全都应用于数据的重叠部分,但是检查是有价值的。
错误不只在传输过程中发生,也会在层之间移动中发生。
而且,每个协议负责保证他自己的正确传输,不能假设高或低的层完成这个任务。
举一个可能发生的复杂情况的例子,想象LAN1上的PC A通过Internet发送数据给LAN2上的PC B。
假设LAN1中使用的L2协议使用校验和而LAN2上的不使用。
那么最少一个高层提供某种形式的校验和来减小接受损坏数据的可能性是很重要的。
每个协议的定义中都建议使用校验和,虽然它不是必须的。
然而,必须承认的是一个好的相关协议的设计可以去掉一些不同层协议之间的重叠特性带来的开销。
因为大多数L2和L4协议提供校验和,在L3中也有校验和就不是严格必须的。
正是由于这个原因,IPv6中去掉了这个校验和。
在IPv4中,IP校验和是一个16位域覆盖整个IP头,包括选项。
校验和最初由数据包源来计算,并在整个到目标的过程中一个跳跃一个跳跃的被更新以反映每个路由器带来的头部变化。
内核对icmp报文的处理流程

内核对icmp报文的处理流程icmp报文是互联网控制报文协议(Internet Control Message Protocol)的一种数据格式,主要用于网络设备之间的通信和错误报告。
在网络通信过程中,icmp报文起着非常重要的作用,它能够检测网络的可达性、传输速度以及错误处理等。
当源主机向目标主机发送icmp报文时,目标主机会先检查该报文的合法性,包括源主机的IP地址和数据校验和等。
如果报文合法,则目标主机会根据报文的类型进行相应的处理。
icmp报文的处理流程如下:1. 接收报文目标主机首先接收到icmp报文,并对报文进行解析和处理。
接收到的报文包括icmp报文的首部和数据部分。
2. 检查报文类型目标主机会检查icmp报文的类型字段,以确定该报文是响应报文还是请求报文。
常见的icmp报文类型包括回显请求和回显应答,路由器通告等。
3. 根据报文类型进行处理根据icmp报文的类型,目标主机会进行相应的处理。
以回显请求和回显应答为例,当目标主机接收到回显请求时,会立即向源主机发送一个回显应答,以确认源主机的可达性。
而当目标主机接收到回显应答时,会对源主机的可达性进行验证。
4. 生成错误报文如果目标主机在处理icmp报文时发现错误,比如目标不可达、超时等,它会生成一个错误报文,并将该报文发送给源主机。
错误报文中包含了错误信息和相关的网络信息,以便源主机进行错误处理。
5. 发送报文目标主机根据icmp报文的处理结果,生成相应的报文并发送给源主机。
报文中包含了处理结果、错误信息等。
6. 检查报文完整性源主机接收到目标主机发送的icmp报文后,会检查报文的完整性,包括首部和数据部分的校验和,以确保报文没有被篡改或损坏。
7. 处理报文源主机接收到icmp报文后,会根据报文的内容进行相应的处理。
比如,如果是回显应答报文,源主机会检查回显数据是否正确,并计算往返时间等。
总结起来,icmp报文的处理流程包括接收报文、检查报文类型、根据报文类型进行处理、生成错误报文、发送报文、检查报文完整性和处理报文等步骤。
linuxip透传总结

linuxip透传总结Linux IP透传是一种网络技术,它允许将网络流量在不同的网络接口之间进行传递,使得数据包可以直接在内核中进行处理,而无需经过用户空间的应用程序。
这种技术在网络通信中起到了重要的作用,本文将对Linux IP透传进行详细介绍和总结。
一、什么是Linux IP透传Linux IP透传是指将数据包在内核中进行处理和转发的技术。
传统上,网络流量需要经过用户空间的应用程序才能进行处理,而Linux IP透传则直接在内核中进行操作,提高了网络传输的效率和性能。
二、Linux IP透传的优势1. 提高网络传输性能:Linux IP透传可以直接在内核中进行操作,省去了数据包在用户空间的传输过程,提高了网络传输的效率和性能。
2. 简化网络架构:通过使用Linux IP透传技术,可以简化网络架构,减少了网络设备和传输路径的数量,降低了网络的复杂性。
3. 增强网络安全性:Linux IP透传可以在内核中对数据包进行处理,提供了更高的安全性和防护能力,可以有效防止网络攻击和数据泄露。
三、Linux IP透传的应用场景1. 虚拟化环境:在虚拟化环境中,Linux IP透传可以实现虚拟机之间的高性能网络通信,提高了虚拟化环境的网络效率和性能。
2. 高性能计算:在高性能计算领域,Linux IP透传可以提高数据传输的效率和性能,加快计算任务的执行速度。
3. 网络安全监控:通过使用Linux IP透传技术,可以在内核中对网络流量进行实时监控和分析,提供更高的网络安全防护能力。
四、Linux IP透传的实现方式1. 使用IPT ables:IPTables是Linux内核自带的一种过滤数据包的工具,可以通过配置IPTables规则来实现IP透传。
2. 使用Netfilter框架:Netfilter是Linux内核中的一个网络包过滤框架,可以通过在Netfilter中添加透传规则来实现IP透传。
3. 使用Linux网络设备驱动:通过在Linux网络设备驱动中添加透传功能,可以实现IP透传。
数据包处理流程
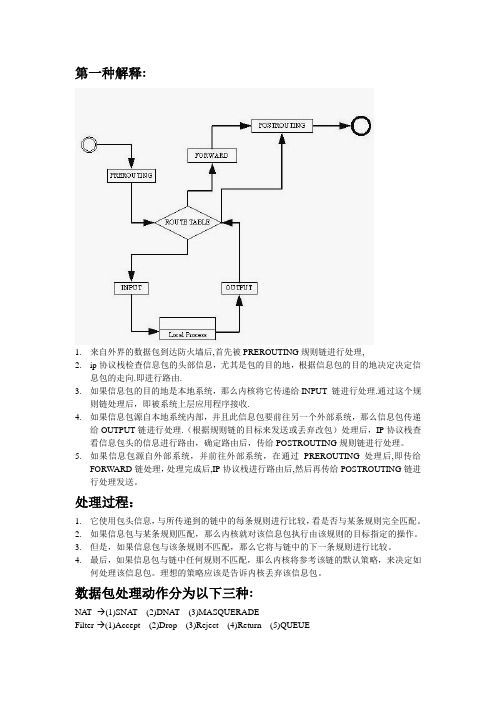
第一种解释:1.来自外界的数据包到达防火墙后,首先被PREROUTING规则链进行处理,2.ip协议栈检查信息包的头部信息,尤其是包的目的地,根据信息包的目的地决定决定信息包的走向.即进行路由.3.如果信息包的目的地是本地系统,那么内核将它传递给INPUT 链进行处理.通过这个规则链处理后,即被系统上层应用程序接收.4.如果信息包源自本地系统内部,并且此信息包要前往另一个外部系统,那么信息包传递给OUTPUT链进行处理.(根据规则链的目标来发送或丢弃改包)处理后,IP协议栈查看信息包头的信息进行路由,确定路由后,传给POSTROUTING规则链进行处理。
5.如果信息包源自外部系统,并前往外部系统,在通过PREROUTING处理后,即传给FORWARD链处理,处理完成后,IP协议栈进行路由后,然后再传给POSTROUTING链进行处理发送。
处理过程:1.它使用包头信息,与所传递到的链中的每条规则进行比较,看是否与某条规则完全匹配。
2.如果信息包与某条规则匹配,那么内核就对该信息包执行由该规则的目标指定的操作。
3.但是,如果信息包与该条规则不匹配,那么它将与链中的下一条规则进行比较。
4.最后,如果信息包与链中任何规则不匹配,那么内核将参考该链的默认策略,来决定如何处理该信息包。
理想的策略应该是告诉内核丢弃该信息包。
数据包处理动作分为以下三种:NA T--→(1)SNAT (2)DNA T (3)MASQUERADEFilter-→(1)Accept (2)Drop (3)Reject (4)Return (5)QUEUERouting- (1)本地系统(2)外部系统PREROUTING:SNATINPUT:FilterOUTPUT:(NAT) Filter FORWARD:Filter POSTROUTING: DNAT MASQUERADE。
基于多Agent内核级网络数据包的研究与应用

中图分 类号 :t 1 Tr 1 3
文献 标识码 : A
文章 编号 :6 3 2 X 2 0 )2 2 6 3 17 —69 (0 70 —0 1 —0
Re e r h a plc to o r e t r s a c nd Ap i a i n f r Ke n lNe wo k
pee t n ti h ss Oi rv h p e f a digTC 1 p c esa d r u et els go ak t .S h tic ne h n et ee— rs ne i hstei,t o etese do n l P/P ak t n e c h i fp c es Ot a t a n a c h f d mp h n d on
I P网络数据 包 的处 理速 度 , 少丢包 率 , 高 Wi w 操 作 系统 下 的网络数 据包 的处理 效率 , 以应用于 Wi w 操作 系 减 提 n s o d 可 n s o d 统 下软 件 , 如分 布式 防火墙 ( 内核级 )V N客 户端 及服 务 器端 软 件 、 L N 软件 、 n w 网络 数据 加 密等 。解 决 了以 前 、P VA Wi o d s 对 Wi o 网络数 据包 的处 理 只局限 于应 用 程 序 接 口层 . Wiok 次 . Wi o s n w ds 如 nc层 s 对 n w 网络 数 据 包 的处 理效 率 不 高 . d 对 Wi o 网络数据 的拦 截不彻底 , n w ds 不能 在 网络底层 进行拆 包 和封包等 问题 。
维普资讯
第
卷
2 7 0 0
年 期 12 第 月
crashkernel参数

crashkernel参数一、什么是crashkernel参数在计算机系统中,crashkernel参数是用于指定内核在系统崩溃时保存内存转储信息的参数。
当系统发生严重错误导致崩溃时,crashkernel参数可以帮助开发人员分析问题,找到错误的原因并进行修复。
通过保存内存转储信息,开发人员可以还原系统崩溃时的状态,从而更好地进行故障排除和调试工作。
二、为什么需要crashkernel参数崩溃是计算机系统中常见的问题,可能是由于硬件故障、软件错误或其他原因引起。
在系统崩溃时,操作系统会停止运行,导致用户无法继续使用计算机。
为了解决这个问题,开发人员需要能够追踪系统崩溃的原因,并进行修复。
crashkernel参数的作用就是在系统崩溃时保存内存转储信息,为开发人员提供了一个还原系统状态的机会。
三、如何配置crashkernel参数配置crashkernel参数需要编辑操作系统的启动配置文件,具体的配置方法因操作系统而异。
以下是在Linux系统中配置crashkernel参数的步骤:1.打开终端,以root用户身份登录系统。
2.使用文本编辑器打开/boot/grub/grub.conf文件。
3.在文件中找到以“kernel”开头的行,该行指定了内核的启动参数。
4.在该行的末尾添加“crashkernel=128M”,其中128M表示为crashkernel分配的内存大小,可以根据需要进行调整。
5.保存文件并退出编辑器。
6.重启系统,新的crashkernel参数将生效。
四、crashkernel参数的常见问题和解决方法在配置和使用crashkernel参数时,可能会遇到一些常见的问题。
以下是一些常见问题及其解决方法:1. 操作系统无法识别crashkernel参数有时候,在编辑启动配置文件后,操作系统可能无法正确识别crashkernel参数。
这可能是由于配置文件中的语法错误或其他原因导致的。
解决方法: - 检查启动配置文件中的语法错误,确保crashkernel参数的格式正确。
linux内核收包流程

linux内核收包流程摘要:I.引言- 介绍Linux 内核收包流程的重要性II.Linux 内核收包流程概述- 网卡接收数据包- 数据包处理流程III.网卡接收数据包- 硬件中断处理- 数据包接收和缓冲IV.数据包处理流程- 数据包的解析和分类- 数据包的过滤和处理- 数据包的发送和转发V.总结- 概括Linux 内核收包流程的关键步骤正文:I.引言Linux 内核收包流程是计算机网络中至关重要的一个环节。
它负责接收来自网络的数据包,并对数据包进行处理和转发。
了解Linux 内核收包流程对于理解计算机网络的工作机制以及优化网络性能有着重要的意义。
II.Linux 内核收包流程概述Linux 内核收包流程主要包括网卡接收数据包和数据包处理两个环节。
III.网卡接收数据包网卡接收数据包是整个收包流程的第一步。
在这一环节中,网卡通过硬件中断处理接收到的数据包。
当网卡接收到数据包时,会产生一个硬件中断,Linux 内核会通过中断处理程序来响应这个硬件中断。
接着,内核会从网卡的接收队列中取出数据包,并进行缓冲。
IV.数据包处理流程数据包处理流程是收包流程的第二步。
在这一环节中,内核会对数据包进行解析和分类,以确定数据包的类型和目的。
接着,内核会根据数据包的类型和目的进行相应的过滤和处理。
对于需要发送或转发的数据包,内核会将它们发送到相应的队列中,等待后续的发送和转发操作。
V.总结总的来说,Linux 内核收包流程包括网卡接收数据包和数据包处理两个主要环节。
其中,网卡接收数据包通过硬件中断处理和缓冲完成;数据包处理则涉及数据包的解析、分类、过滤和处理等操作。
内核隔离处理方法

内核隔离处理方法以下是 9 条关于“内核隔离处理方法”的内容:1. 内核隔离的第一步,嘿,那就是要像给宝贝盖被子一样细心啊!比如说电子设备,你得把那些不必要运行的程序统统关掉。
就像你收拾房间一样,把不用的东西都清理掉,给内核腾出空间来呀!不然怎么能让它好好工作呢,对吧?2. 哎呀呀,内核隔离处理还有一招很关键哟!那就是给它设置一个专属的“保护区”。
好比你给自己最喜欢的玩具找个安全的地方放着,不让别人随便碰。
像一些关键文件和进程,就得这样好好保护起来呢!3. 你知道吗,定期给内核做个“体检”也是很重要的呢!就像我们要去医院检查身体一样。
看看有没有什么“小毛病”,及时发现及时处理呀!比如说检查有没有恶意软件在偷偷捣乱,这不是很重要嘛!4. 还有嘞,要像是照顾小朋友一样照顾内核哟!给它提供稳定的“环境”。
像电压啦、温度啦,都得保持在合适的范围。
不然它不开心了,“闹脾气”了可咋办呀!5. 嘿,别忘了给内核打“防疫针”呀!也就是安装可靠的安全软件,这就像给我们自己打疫苗预防疾病一样。
能把那些坏家伙都挡在外面,保护我们的内核呀!比如有病毒想来攻击,一下就被拦住啦,是不是很棒?6. 内核隔离可没那么简单哦,要随时保持警惕呢!就好像战士守卫边疆一样。
不能放过任何一个可疑的“信号”,一旦发现有异常,立马采取行动呀!这可不是开玩笑的呀!7. 哇塞,内核隔离还得注意“劳逸结合”呀!不能让它一直拼命工作。
适当的时候让它休息休息,就跟我们人一样嘛。
不然它累垮了怎么办呢?8. 真的呀,要想内核隔离处理得好,就得学会“察言观色”呢!看看它什么时候需要“帮助”,什么时候能“独当一面”。
这可是需要细心和耐心的哦!难道不是吗?9. 总之呢,内核隔离处理方法要灵活运用,根据实际情况来调整呀!不能死板地套公式。
要像个聪明的指挥官一样,指挥着内核好好工作。
只有这样,才能让我们的设备高效稳定地运行呀!。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据包处理注意事项
前言
我们大部分功能都需要解析数据,进行一系列的包匹配完成,但是目前,我们没有一个很好的框架来简化这个过程,大家处理数据包都是采用原生的linux内核接口,并且没有统一的规范要求如何使用这些接口,所以,存在大量的陷阱,一不留神就造成宕机。
获取IP头部
1)__netif_receive_skb()在进入三层处理前就对network_header进行了设置。
2)ip_rcv()中详细的检查保证了IP头部到netfilter后是完整的。
3)netfilter可以尽情使用ip头部。
获取tcp头部
错误1:
陷阱:
netfilter的钩子点是属于TCP/IP协议栈的三层流程中,而四层的TCP头部此时还没有正确获取,只是初始化为IP头部的值,无法直接使用。
错误2:
陷阱:
数据包可能是非线性的
改进:
计算三层头部相对于skb->data的偏移
从skb的指定偏移取制定长度的数据,如果要取的数据位于线性区,直接返回其开始指针,否则,则拷贝到buffer中,并将buffer指针返回。
打印信息
1) IP 地址输出
Ipv4:%pI4%pi4
IPv6:%pI6
%pi6
2) MAC 地址
%pM %pm
3)字节序的转换
ntohs()ntohl()htons() htonl()
__const_ntohl()__const_ntohs() __const_htonl() __const_htons() 区别:__const_*()是编译时处理的。
获取TCP 负载
风险:
陷阱1:
数据包可能是非线性的,同TCP 头部。
陷阱2:
TCP 头部数据有可能是被篡改过的,tcph->doff 如果很大怎么办?
改进1:
接口介绍:
判断skb的数据是否是非线性的改进2:
改进3:
接口介绍:
将skb线性化
解析数据
1)判断数据包内容
风险1:
风险2:
陷阱:
如果payload的长度只有1个字节怎么办?
改进:
2) 查找数据包中的某个字符串
风险:
陷阱:
可能会越界,数据包不一定是以'\0'结束。
payload_len
payload
改进:
一定要使用这一系列的函数:
strnchr
strncpy
strncat
strncmp
strnicmp
strnlen
memcpy
3)移动指向数据包的指针
风险:
payload_len
payload
陷阱:
查找的字符串有可能是数据包的最后一部分。
payload_len
payload
改进:
4)数据包操作
错误:
陷阱:
无符号数的强制类型转换,u32类型永远都是大于等于0的,当payload_len小于512时,判断就会不生效。
改进:
或者
5)
风险:
陷阱:
可能是异常数据包,offset不是你想要的
正确做法:
综述:数据包处理要时刻保持警醒,它可能不是你想象的样子!
内存分配
风险:
改进:
问题:kmalloc(0, ...)返回值是什么?
建议:相同的内存反复申请释放的情况下,请使用kmem_cache_alloc
建议的同步与互斥方法
1)rcu锁
使用场景:进程上下文用来配置,软中断上下文只读配置的情况
好处:性能高,接口简单
方法:
hook函数读取配置,中断上下文:
基于proc文件等的配置下发,进程上下文:
另一种方法:
注意1:synchronize_rcu()只能用于进程上下文,call_rcu()可以用于中断上下文。
注意2:data_free_rcu的调用是软中断上下文,不能使用vfree。
模块卸载:
2)每CPU变量
使用场景:
在钩子函数中使用的临时缓存区,不用每次申请释放,使用全局变量。
方法:
hook函数:
模块加载:
模块卸载:
注意:
alloc_percpu()上限32k。