基于TMS320C6678 DSP的程序优化技术的研究
TMS320C6678多核DSP的加载配置和实现方法

TMS320C6678多核DSP的加载配置和实现方法邓豹【期刊名称】《航空计算技术》【年(卷),期】2017(047)001【摘要】The software code correct programming ,loading and operating is the foundation of multicore dsp application.The paper gives analysis to the DSP′s BootLoader and the code loading process.Taking the multicore DSP TMS320C6678 as an example,the article introduces the configuration management mode and processing flow of the multicore dsp,and detailed describes the EMIF16 boot implement ways used Nor FLASH.With these ways can be achieved correct and reliably software operating.%程序代码正确的固化加载运行是多核DSP应用的前提和基础.简要介绍了DSP的加载器和加载过程,阐述了多核处理器件的加载配置管理方法.以TI公司的多核DSPTMS320C6678为例,介绍了多核DSP的加载模式和流程,详细阐述了EMIF16的Nor FLASH加载实现方法,可以实现多核DSP软件的正确、可靠加载运行.【总页数】5页(P107-111)【作者】邓豹【作者单位】中航工业西安航空计算技术研究所,陕西西安 710068【正文语种】中文【中图分类】TP368.1【相关文献】1.基于TMS320C6678的多核程序加载研究与实现 [J], 李飞平;卿粼波;滕奇志;舒君;何小海2.TMS320C6678多核DSP的核间通信方法 [J], 吴灏;肖吉阳;范红旗;付强3.基于TMS320C6678的多核DSP加载模式研究 [J], 张乐年;关榆君4.基于TMS320C6678的多核DSP上电加载技术 [J], 刘章文;刘七华;谢川林;袁学文5.TMS320C6678多级程序加载模式的实现 [J], 杨舟;吉沛琦因版权原因,仅展示原文概要,查看原文内容请购买。
基于TMS320C6678的多核DSP上电加载技术

基于TMS320C6678的多核DSP上电加载技术
0 引言
在视频检测、医疗影像及红外图像快速跟瞄系统应用中,越来越复杂的二维、三维甚至四维的图像处理,需要并行化的处理系统,并能够运行复杂的算法。
要实现这些复杂的系统,高端FPGA+高性能DSP是目前普遍采
用的方案,而单个DSP的性能已发展至极限,所以解决复杂的并行算法,多核DSP是现在发展的全新方向,其中多核DSP的根加载技术是其难点之一。
TI公司推出的DSP芯片TMS320C6678(C6678)具有8个内核的高性能DSP,每个内核工作频率均达1 GHz。
其支持的Boot 模式有SPI、I2C、EMAC、SRIO 和并口Emif16 NOR-FLASH。
其中Emif16 NOR-FLASH模式是不用上位机参与、比较简单、独立成系统的一种,大多独立DSP系统采用该方式。
网上能搜索到关于C6472和C6678零星一些加载资料,都是借助于。
基于多片TMS320C6678的程序交互机制设计

交互层次之间的互联,提高整个系统通信的灵活性,
系统将 4 个处理器的所有 32 个核心进行统一编号,设
置 为 全 局 核 号 ,用 g_globalCoreID 表 示 ,并 且 用 g_
globalCoreID 对 8 取整得到各处理器的 SRIO 端口号,
这样由一个全局核号即可知道对应于哪一个 DSP 的
shared variables,and the communication of each thread in the core is realized through semaphore. In order
to verify the practicability and efficiency of the mechanism,a signal processing experiment of large amount
Core_0 根据目的核全局核号 g_globalCoreID,计算其
所 处 SRIO 端 口 号 ,加 之 传 输 变 量 的 源 地 址 addrSur
与目的地址 addrDest 进行 SRIO 数据传输,将源处理
器共享内存中的相应变量传输到目的处理器共享内
存 中 。 SRIO 数 据 发 送 之 后 源 处 理 器 Core_0 发 送
技术,
主要解决了嵌入式系统中板卡与板卡、
芯片与芯
片之间的高速数据交换的问题[11-12]。TMS320C6678 的
SRIO 支 持 两 种 数 据 传 输 机 制 :DirectIO 和 Message,
其 中 DirectIO 模 式 适 合 大 数 据 量 传 输 ,因 此 通 信 采
用 DirectIO 模 式 ,在 SRIO 进 行 传 输 时 ,需 要 对 SRIO
基于TMS320C6678的国产DSP操作系统引导程序设计

BOOTMODE[I2:0]用 于 引 导 方 式 的 设 置 。 上 的高 性 能 国产 基 础 软 件 解 决 方 案 , 其 内 核 完 全
电后 ,内核 0执行 RBL代码 ,并采样这 13个 自主 设 计 ,并 针对 TI公 司 TMS320C6678芯
引 脚 的 状 态 , 决 定 采 用 哪 种 引 导 方 式 。 管脚 配 片 进 行 了系 统 优 化 。
启 动 其 它 DSP节 点 是 一 种 非 常 高 效 的 引 导 方
本 文 的 引 导 是 针 对 于 带 有 操 作 系 统 的 镜
式 。
像 ,操 作系 统选用 国产 的锐 华 DSP实时操 作
TMS320C6678芯 片 有 13个 外 部 引 脚 系 统,该操 作系统提 供 了面 向主 流 DSP芯片
2 DSP启 动 方 式
RBL是 固化 在 DSP内 部 的 一 段 程 序 ,非 常精简 ,但是 无法直 接对 ELF格 式 的文件进 行解析 。为 了实现镜 像 的加载 ,必须通 过 TI 提 供 的一系列 的工 具将 ELF文件 转换 成特定 的格式,而 且不同接 口转换后 的格 式也不尽相 同 , 例 如 通 过 网 络 、SPI、 I2C、EMIF等 加 载 必须通过不同的方法完成转换 ,通用性极差 。
基于TMS320C6678的通用嵌入式软件开发平台的研究

基于TMS320C6678的通用嵌入式软件开发平台的研究殷耀文(昆山登云科技职业学院,江苏昆山215300)[摘要]论述了基于TMS320C6678DSP通用嵌入式软件开发平台构建过程,从时钟、外设、资源分配三个维度的构建进行论述。
通用嵌入式软件平台具有高度集成性、通用性、可扩展性。
平台的构建成功为使用此款DSP开发的人员提供了极大的便利性。
[关键词]TMS320C6678;通用嵌入式软件开发平台;外设;时钟;资源[中图分类号]TP319[文献标志码]A[文章编号]2096-0603(2019)12-0158-02TMS320C6678是德州仪器公司研发的一款高性能定点计算和浮点计算数字信号处理器(DSP),基于TI 的KeyStone多核体系结构,集成了八个C66X CORIPAC DSP,每个DSP的主频为1~1.25GHz,最高能达到10GHz 主频。
该DSP功耗低,支持高性能信号处理应用,广泛应用于机器视觉领域、通信、雷达领域、嵌入式分析领域、高端机床领域、多媒体领域、成像领域和计算机处理等领域。
一、概述由于该DSP高速外设较多,主要有SRIO、PCIe、HyperLink、Gigabit Ethernet、64-Bit DDR3、EMIF、UART。
如此多的外设加上时钟、电源、存储资源划分的配置,通常情况下,都是按需选取一两种外设进行开发使用。
笔者结合多年的嵌入式软件开发工作经验,借鉴软件无线电的思想,将众多的外设、时钟配置、RAM存储资源整合在一个通用的软件开发平台上。
本文将重点论述构建此平台的过程。
构建此平台的核心思想是追求通用性与易用性,能确保使用此款DSP芯片的开发者不用关心芯片的各种外设和使用细节,开发者所要做的只是在这个平台上部署自己的编程逻辑,通过与各种封装好的函数来操控DSP,平台达到了封装DSP硬件细节的作用,通过在实际项目过程中的实际应用,极大地简化了发者的开发过程。
基于TMS320C6678核相关滤波器跟踪算法实现及改进

Abstract: Object tracking has become an important branch of computer vision eu ̄enf ly.In recent year s,because the tracking al—
做 了 改 进 ,提 出 了一 种 尺 度 更 新 算 法 以 及 目标 跟 踪 丢 失 后 由粗 到 精 的 重 定 位 算 法 , 最 后 算 法 在 8核 DSP 处 理 器
TMS320C6678上 成 功 实 现 了移 植 。 通 过 多核 并 行 处 理 ,达 到 30帧 /s的 实 时 跟 踪 帧 率 。
gorithm with kernel correlation filter rises the properties of circulant matr ix.the main operation is element—wise product in the fre— quency domain. It achieved the great performance and speed than the previous tracking a lgor ithm .However,when the target size changes and the target is seriously blocked, it couldn ’t track accurately. Based Of the above reasons, a scale updating algorithm and acoarse—to—fine target relocation algorithm are proposed to improve the KCF algor ithm .The algor ithm is transplanted on the eight—core DSP processor TMS320C6678 successfully.Through multi—core parallel processing.it achieved 30  ̄ames/s real—time tracking fram e rate. Key words:kernel correlation filter;scale update;target relocation;TMS320C6678
基于TMS320C6678的多核程序加载研究与实现

基于TMS320C6678的多核程序加载研究与实现
李飞平;卿粼波;滕奇志;舒君;何小海
【期刊名称】《电子技术应用》
【年(卷),期】2015(041)003
【摘要】针对多核DSP系统程序加载复杂的问题,基于TMS320C6678对多核程序加载进行了研究与设计.从一级引导程序出发,设计并优化了多核程序内容存储格式.设计了简洁的二级引导程序,以修正一级引导程序只识别主核程序入口地址,而从核入口地址缺失的现象.为了快速生成特定格式的多核程序内容,设计了多个工具用于添加SPI启动参数表、DDR3启动表、从核程序入口地址以及完成程序内容格式的转换.实现了SPI Flash多核程序加载以及基于I2C主模式的Nand Flash多核程序加载.
【总页数】4页(P31-34)
【作者】李飞平;卿粼波;滕奇志;舒君;何小海
【作者单位】四川大学电子信息学院,四川成都610064;四川大学电子信息学院,四川成都610064;四川大学电子信息学院,四川成都610064;四川大学电子信息学院,四川成都610064;四川大学电子信息学院,四川成都610064
【正文语种】中文
【中图分类】TP368
【相关文献】
1.基于TMS320C6678的多核DSP加载模式研究 [J], 张乐年;关榆君
2.基于DSP的动态程序加载的研究与实现 [J], 李鹏;张营;陈立锋;吕永田
3.基于TMS320C6678的多核DSP上电加载技术 [J], 刘章文;刘七华;谢川林;袁学文
4.基于PC总线的HOST/DSP系统大型程序加载方法研究与实现 [J], 刘小勇;黄一川;施仁
5.基于DSP在线程序加载的研究与实现 [J], 祖文祥;丁劲涛
因版权原因,仅展示原文概要,查看原文内容请购买。
基于TMS320C6678 DSP的雷达数字信号处理软件设计

50 | 电子制作 2021年06月复杂的算法,但同时也要满足实时性要求。
在现阶段,雷达信号处理的架构大都是采用FPGA+DSP 的方式,FPGA 主要负责中频信号的采集、波束形成、脉冲压缩等算法逻辑操作,而DSP 主要负责实现MTI、MTD、CFAR、杂波图等较复杂的算法。
TMS320C6678 DSP 作为业界目前最先进的多核DSP、一共集成了8个核,每个内核有512Kbyte 的核内L2数据存储区、32KByte 的L1D 数据存储区和 32KByte 的L1P 程序存储区,片上集成了4MByte 的共享存储区,支持RapidIO 高速数据传输、支持外围扩展DDR3存储器,支持片内多核间EDMA 硬件传输数据 最高主频达到了1.25GHz,同时还提供了丰富的软件库函数,如算术操作库、数字信号处理库、图像库等,丰富的硬件与软件资源为其成为雷达信号处理的平台提供了保障。
1 雷达软件结构在某低慢小目标探测雷达设计中,雷达采用方位上360度机械扫描、俯仰上发射宽波束,接收上通过数字波束合成形式形成多个俯仰指向的多波束完成对俯仰空域的覆盖。
雷达的软件结构如图1所示。
雷达软件主要包含DBF (数字波束形成)软件、信号处理软件、数据处理软件、操控终端软件。
其中DBF 软件主要对雷达天线接收的回波信号进行数字采样,并且下变频到中频信号,最后通过形成多个指向的数字波束数据,并将数据传输到信号处理软件,信号处理软件主要完成脉冲压缩、相参积累与点迹检2 雷达信号处理软件某低慢小目标探测雷达共有4个波束,根据带宽和处理速度分析,雷达系统中信号处理共使用1片V7 FPGA+ 2片C6678 DSP 的硬件结构,首先在FPGA 内完成4路DBF 处理数据的数据提取、脉冲压缩、乒乓处理等,波束1和波束2的数据输出到DSP1,波束3和波束4的数据输出到DSP2,分别完成4路回波数据的数据重排、MTD、CFAR、杂波图处理等。
基于DSP6678的KCF算法实现及优化系统设计

c a n n o l n l C C I l h e r e q u i r e me n t s o f r e a l t i me t r a c k i n g i n t l l e a c t u a l p r o j e c t .Ba s e d o n DS I ’e mb e d d e d p l a t f o r m .1 I i r s p a p e r
摘
要: 仫十 f I 火滤 波 算 法 H标 旋 转 、 部分遮挡等情况下具 秆很强 的鲁棒性 , f J = _ i 是其在 实际 1 程 L无 法 满 足 寅 1 ) S l 嵌 入式 平 台 , 捉} I J 一种实时 【 | 标跟踪 系统实现方案。首先 . 基 于 TMS 3 2 C 6 6 7 8处 理 器 的硬 件 台 , 埘 ■维 快 述 傅里I I f 变换( F I I 、 2 I ) ) 进 行算法优化 ; 其次 , 对K C F算 法 进 行 c语 言 级 代 码 优 化 , 包括 循环 腱 开、 使 用 内 联 数 、 使 用 火 键
c o n s t 等 测结 果表H J 】 . 对 6 4 0 ×l 1 8 0像 素 的 像 . 跟 踪 目标 为 3 2 ×6 4像 素 时 , 波 门人小 为 6 l ×l 2 8 。在 满 足 跟 踪 效 粜 的 ¨ 时, 跟踪速度最高达 到 2 5 h i S / 帧, 符 合实 时 性 要 求 。
a n d o p t i mi z a t i o n s y s t e m d e s i g n
I ) u We n b i n Ma o Z h e n g Me t We t j u n J i a We n y a n g I - l a n J i a l o n g
基于TMS320C6678的多核DSP并行处理应用技术研究共3篇

基于TMS320C6678的多核DSP并行处理应用技术研究共3篇基于TMS320C6678的多核DSP并行处理应用技术研究1随着信息技术的发展和科技应用的不断提升,现代社会对计算处理能力的需求也越来越高。
但传统的单核张量处理器受到性能瓶颈的限制,在处理大规模数据和高负载任务时面临着无法满足需求的问题。
为此,多核处理器正在被广泛应用和研究,并成为当前高性能计算领域的热点技术。
基于TMS320C6678的多核DSP并行处理就是其中一种应用技术,它利用DSP(Digital Signal Processor)的特殊结构和灵活性,在数据处理、信号处理、声音处理等方面表现出眼花缭乱的性能。
该技术在信息处理、通信、影像处理、控制及自动化等领域广泛应用,并在科技创新和社会进步中发挥着巨大的作用。
多核DSP并行处理技术的核心是通过利用多个处理核心的协作,将每个处理核心的任务进行分解并行执行。
TMS320C6678作为TI公司推出的多核DSP,通过采用基于C66x核心的对称多处理(SMP)和低延迟互联技术,在多处理器之间实现高效通信、高性能计算和低功耗运行,实现高性能计算需求的快速响应。
多核DSP并行处理技术在应用中还可以选用一些常用的并行编程模型来进行代码开发与优化。
其中,OpenMP模型适用于多线程程序,可以在多核心某一个处理器上执行,可以较容易地实现自动化并行计算; pthread模型为应用提供了多线程机制,可以用于多核DSP系统共享内存下的多线程并行计算; MPI模型则是适用于多节点通信和分布式计算,更适合大规模的并行计算,这种模型需要考虑数据分布等问题,对编程能力要求较高。
在多核DSP并行处理的应用实例中,通信领域是其中之一。
以TMS320C6678为核心的网关系统,将数据在两个不同的网络之间转发,通过在不同节点的DSP中使用OpenMP编程模型,提高数据处理并行性能。
此外,多核DSP并行处理技术还在无线通信、人工智能、视觉、图像分析、智能检测等领域有着广泛的应用,其应用广泛性和高并发性也确实满足了现代社会高速发展的需求。
TMS320C6678平台软件设计优化策略综述
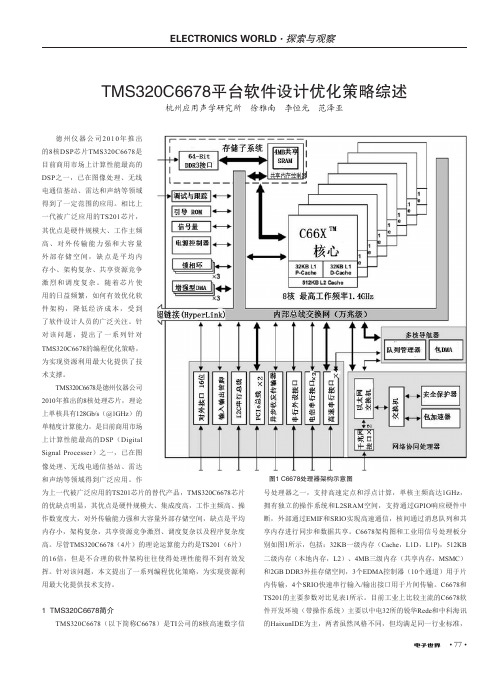
德州仪器公司2010年推出的8核DSP 芯片TMS320C6678是目前商用市场上计算性能最高的DSP 之一,已在图像处理、无线电通信基站、雷达和声纳等领域得到了一定范围的应用。
相比上一代被广泛应用的TS201芯片,其优点是硬件规模大、工作主频高、对外传输能力强和大容量外部存储空间,缺点是平均内存小、架构复杂、共享资源竞争激烈和调度复杂。
随着芯片使用的日益频繁,如何有效优化软件架构,降低经济成本,受到了软件设计人员的广泛关注。
针对该问题,提出了一系列针对TMS320C6678的编程优化策略,为实现资源利用最大化提供了技术支撑。
TMS320C6678是德州仪器公司2010年推出的8核处理芯片,理论上单核具有128Gb/s (@1GHz )的单精度计算能力,是目前商用市场上计算性能最高的DSP (Digital Signal Processer )之一,已在图像处理、无线电通信基站、雷达和声纳等领域得到广泛应用。
作TMS320C6678平台软件设计优化策略综述杭州应用声学研究所 徐雅南 李恒光 范泽亚图1 C6678处理器架构示意图为上一代被广泛应用的TS201芯片的替代产品,TMS320C6678芯片的优缺点明显,其优点是硬件规模大、集成度高,工作主频高、操作数宽度大,对外传输能力强和大容量外部存储空间,缺点是平均内存小,架构复杂,共享资源竞争激烈、调度复杂以及程序复杂度高。
尽管TMS320C6678(4片)的理论运算能力约是TS201(6片)的16倍,但是不合理的软件架构往往使得处理性能得不到有效发挥。
针对该问题,本文提出了一系列编程优化策略,为实现资源利用最大化提供技术支持。
1 TMS320C6678简介TMS320C6678(以下简称C6678)是TI 公司的8核高速数字信号处理器之一,支持高速定点和浮点计算,单核主频高达1GHz ,拥有独立的操作系统和L2SRAM 空间,支持通过GPIO 响应硬件中断,外部通过EMIF 和SRIO 实现高速通信,核间通过消息队列和共享内存进行同步和数据共享。
TMS320C6678多核DSP并行访问存储器性能的研究

TMS320C6678多核DSP并行访问存储器性能的研究摘要:为充分挖掘多核DSP能力,结合TI的TMS320C6678 DSP的存储器架构,分析了各个关键节点的理论数据传输带宽,展开了对多核DSP主设备(CPU内核、EDMA控制器)并行访问存储器(共享SL2、外部DDR3)的性能研究,并采用数据拷贝测试实验进行验证,最后讨论了影响带宽的因素,对多核软件设计具有一定的指导意义。
关键词:多核DSP;存储器性能;TMS320C6678嵌入式领域的处理器设计已向多核处理器迅速发展,TI最新的8核DSP处理器TMS320C6678(以下简称C6678),每个内核频率为1.25 GHz,提供高达40 GB/s MAC定点运算和20 GB/s FLOP浮点运算能力[1],在信号处理、图像处理等对定浮点运算能力及实时性要求较高的领域得到了广泛应用。
多核环境下并行访问存储器的性能是多核系统设计和应用开发的难点之一。
郝朋朋[2]研究了多核处理器的体系结构,但没有对带宽进行实验测试和结果分析;吴灏[3]分析了多核DSP的核间通信方法。
而本文基于TMS320C6678 DSP,详细阐述了多核DSP并行访问存储器的性能,分析了影响带宽的因素以及瓶颈所在,对多核软件设计具有一定的指导意义。
1 C6678多核DSP存储器架构存储器访问性能对于DSP的软件运行是至关重要的。
C6678 DSP所有的存储器都可以被DSP内核和多个DMA主设备访问。
图1显示了C6678的存储器系统架构框图,总线上的数字代表总线宽度,大部分模块运行在1/2或1/3 DSP内核频率[1]。
1.1 C66x内核C6678集成了8个C66x核,每个内核具有以下性能。
(1)32 KB L1D(Level 1 Data)SRAM,运行在DSP内核频率,可用于数据存储或缓存;(2)32 KB L1P(Level 1 Program)SRAM,运行在DSP内核频率,可用于程序存储或缓存;(3)512 KB LL2(Local Level2)SRAM,运行在1/2 DSP内核频率,可用于程序或数据的存储RAM或缓存[4]。
基于tms320c6678的激光测距实时信号处理研究

摘要摘要本课题来源于科技部重大仪器专项,与某研究所共同合作进行激光测距仪的研制,此项目的关键技术能够用于合成孔径激光雷达(SAL)。
在激光测距的实现方法中,相比于调频式激光测距法,脉冲相位式应用得更早、也更广泛,本课题针对传统的脉冲式激光测距对峰值功率要求高的缺点,研究采用连续波体制的相干式线性调频来实现远距离探测的信号处理方法。
伴随雷达信号处理领域相关技术的日趋成熟,且信号处理任务的算法越来越复杂,待处理的源数据量也越来越大,因此,传统的单核数字信号处理器远不能达到系统的要求。
为此,本课题采用能提高整个信号处理系统性能的多核DSP。
因为多核DSP 能够同时在八个核中处理任务,这使得信号处理的速度更快,成本和功耗也更低。
本设计以TMS320C6678多核DSP为基础,研究了激光测距的实时信号处理过程,具体内容涵盖以下几个部分:1、以脉冲式、相位式以及调频式这三种常用激光测距方法的原理为基础,针对相位式和调频式激光测距提出相应的算法设计,并给出MATLAB仿真结果来验证算法的可行性,重点研究调频式激光测距的实现过程、采用的下采样预滤波方式,以及CZT频谱细化方法。
2、针对信号处理对于高精度和实时性的要求,本文设计的信号处理板卡采用的是FPGA与多核DSP配合使用的架构形式,使用双通道AD采样数据,其中单通道的AD数据传输率即可达到200MBps,并为整个算法的实时信号处理设计了整体工作流程,详细介绍了C6678多核DSP的内核情况、CPU架构和存储器结构。
3、重点研究整个激光测距实时信号处理在C6678上的实现,为多核间的工作任务进行合理分配,并阐述多核间的通信方式以及代码的优化方案。
4、对整个实时信号处理的过程进行时间评估和实时性分析,并给出激光测距实时信号处理的结果,验证最终结果完全符合高精度以及实时性的要求。
5、对本课题的研究成果进行简单总结,并提出论文的不足之处,后续将会相应的组织外场试验,并可以将DSP从单片扩展到多片,使运行速度更快。
基于TMS320C6678DSP+天熠嵌入式操作系统的软件模块动态加载的研究与实现

基于TMS320C6678DSP+天熠嵌入式操作系统的软件模块动态加载的探究与实现摘要:随着嵌入式系统的不息进步,软件模块动态加载技术在实际应用中变得越来越重要。
本文以TMS320C6678DSP处理器和天熠嵌入式操作系统为基础,对软件模块动态加载的探究与实现进行了详尽探讨。
通过对嵌入式系统中的软件模块动态加载技术的原理、应用场景和实现方法的分析,本文提出了一种基于同一个代码段实现软件模块动态加载的方法,并在实际嵌入式系统上进行了验证。
试验结果表明,该方法能够有效地实现软件模块动态加载,提高系统的灵活性和可扩展性。
关键词:TMS320C6678DSP;嵌入式操作系统;软件模块动态加载;灵活性;可扩展性1. 引言随着科技的进步,嵌入式系统在各个领域的应用越来越广泛。
传统的静态部署系统对于系统的灵活性和可扩展性存在一定的限制,无法满足日益增长的需求。
为了解决这一问题,软件模块动态加载技术应运而生。
通过动态加载技术,系统可以在运行时依据需要加载不同的软件模块,提供更高的灵活性和可扩展性。
2. 相关工作软件模块动态加载技术已经在许多领域得到了广泛的探究和应用。
其中,嵌入式操作系统是实现软件模块动态加载的重要平台之一。
TMS320C6678DSP是一种高性能的数字信号处理器,天熠嵌入式操作系统是专门为该处理器设计的。
3. 系统架构本文使用TMS320C6678DSP处理器作为嵌入式系统的核心处理器,天熠嵌入式操作系统作为系统的操作平台。
系统架构包括应用层、操作系统层和硬件层。
在操作系统层中,接受天熠嵌入式操作系统进行开发和管理。
软件模块动态加载模块作为操作系统的一个重要组成部分,负责管理和加载软件模块。
4. 软件模块动态加载的实现4.1 软件模块动态加载的原理软件模块动态加载是指在系统运行时依据需要,将软件模块加载到系统内存中,并执行相应的功能。
该过程主要包括模块加载、符号解析和链接等步骤。
4.2 软件模块动态加载的应用场景软件模块动态加载广泛应用于各种领域的嵌入式系统中。
基于TMS320C6678的多核DSP加载模式研究

( 1 . G r a d u a t e S c h o o l , He b e i U n i t e d U n i v e r s i t y , T a n g s h a n 0 6 3 0 0 0 , C h i n a ; 2 . I 伽 m C o l l e g e , T a n g s h a n 0 6 3 0 0 9 , C h i n a )
Ab s t r a c t :T e x a s I n s t r u me n t s ( TI )l a u n c h e d e i g h t n u c l e a r TM¥ 3 2 0 C 6 6 7 8 DS P c h i p w h i c h i S b a s e d o n t h e K e y s t o n e
a r c h i t e c t u r e o f h i g h p e fo r r ma n c e DS P d e v i c e s ,a r e w i d e l y u s e d o n t h e ma r k e t o f t h e C 6 4 5 5 h i g h - e n d p r o c e s s i n g p l a t f o m r t o
4期 第2 1卷 第 2
V0 1 . 21 No . 2 4
电 子 设 计 工 程
El e c t r o n i c De s i g n En g i n e e r i n g
2 0 1 3年 l 2月
De e .2 01 3
基 T MS 3 2 0 C 6 6 7 8呐 多 核D S P加载模 式研 究
基于TMS320C6678多核DSP实现大尺寸快速傅里叶变换

基于TMS320C6678多核DSP实现大尺寸快速傅里叶变换一、需求分析当前,计算机处理器已经全面进入了多核时代,无论是超级计算机、服务器、专用数据处理器(如数字信号处理器)等用于科研和企业服务的大型计算设备,还是适用于家庭和个人的人计算机、智能手机、平板电脑、智能电视、路由器等小型计算设备都无一例外的向着采用多核处理器的方向发展。
处理器设计的兼容性使得先前运行在单核处理器上的程序仍然可以在多核处理器上运行。
但是人们却发现,同样的程序运行在多核处理器上,运算和执行速率却没有得到应有的提升。
人们意识到仅仅将原先在单核处理器上运行的程序原封不动地搬至多核处理器上并不能完全利用多核处理器上每个处理核心的运算性能。
但是人类在几十年的串行程序开发历程中,积累了大量的串行程序和算法以及相应的开发经验。
如何将这些串行化的程序和算法并行化,使其可以更好的利用多核处理器的并行处理能力,以提高程序的执行速度在程序设计领域具有极高的研究价值。
随着多核DSP的出现,语音、图像和视频处理算法的并行处理在多核DSP 的平台上得到了极大的效率提升。
本文采用TI的多核DSP TMS320C6678来实现大尺寸单精度浮点FFT运算。
把需要输入的数据放到外部存储器上,并把需要计算的原始数据分配给不同的DSP内核。
不同的DSP内核进行计算然后把输出的数据输出到外部存储器上。
可以配置不同的内核参与计算,并且可以计算以下尺寸的FFT:16K,32K,64K,128K,256K,512K,1024K。
统计不同内核参与运算以及不同尺寸下大尺寸快速傅里叶变换所需的时间,来对多核运算效率有个清晰地认识。
二、硬件设计及处理器描述2.1TMS320C6678简介TMS320C6678是德州仪器(TI)公司于2011年发布的一款基于KeyStone 架构的8核数字信号处理器(DSP)。
该DSP支持浮点与定点混合运算,定位的主要应用领域有:关键任务、高性能计算系统、通信、音视频处理、成像、图像处理、网络、媒体处理、工业自动化、自动化控制等。
关于基于TMS320C6678的粒子群算法并行的设计

关于基于TMS320C6678的粒子群算法并行的设计0 引言粒子群优化(Particle Swarm Optimization,PSO)算法[1]是由KENNEDY J和EBERHART R C等开发的一种新的进化算法。
相对于遗传算法[2]等,该算法参数较少、容易实现,能够解决复杂的优化问题,因此在众多优化问题领域都得到了广泛的应用[3],如控制决策、目标跟踪、深度学习等。
然而,粒子群优化算法在实际应用中往往难以达到实时性的要求,特别是求解复杂的多维问题时,速度问题更加突出,难以满足实际应用的需求。
随着嵌入式领域对性能、功耗和成本越来越高的要求,多核处理器应运而生[4]。
其中TI 公司推出的基于KeyStone架构的多核处理器TMS320C6678[5]是目前业界最高性能的量产多核DSP。
其具有8个1.25 GHz DSP内核,最高可实现160 GFLOP的性能。
与FPGA相比其具有更好的浮点性能和实时处理能力,并且具有较高的灵活性和可编程性,为实现更为复杂的算法提供了便利。
因此其在4G通信、航空电子、机器视觉等领域得到了广泛的应用。
本文针对粒子群算法在实际应用中的实时性需求,在对算法进行并行性分析的基础上,根据TMS320C6678多核处理器的架构特点,设计出高效的应用程序,充分发挥了TMS320C6678的性能优势,有效地提高了系统的实时处理能力。
实验数据表明了该设计的合理性与有效性。
1 PSO算法简介PSO流程图如图1所示。
粒子群算法的数学描述如下:m维的解空间中,X={x1,x2,…,xn}表示整个种群,该种群由n个粒子组成。
因此整个种群中的第i个粒子的位置可以表示为xi={xi1,xi2,…,xim},该粒子对应的求解速度可以表示为vi={vi1,vi2,…,vim},每个粒子对应的个体最优解表示为pi={pi1,pi2,…,pim},整个种群的全局最优解可以表示为gi={gi1,gi2,…,gim}。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
期 的优 化 效 果
【 关键 词 】 I ) S F ' 程序 优 化 ;存储 资 源分 配 ;C 语 言 的优 化 ;软件 流 水 :编译 器的优 化
.
f e r e n t me t h o d s a p p r o p r i a t e l y t o a c h i e v e t h e d e s i r e d o p t i mi z a t i o n r e s u l t s . Th e me t h o d s i nc l u de di s t r i b u t i o n o f t he me mo y r r e s o u r c e s , op t i mi z a t i o n o f C c o d e, s of t wa r e pi p e l i n e・ op t i mi z a t i o n o ft h e c o mp i l e r ,a n d s o o n. Al s o, DSP p r o g r a m o p t i mi z a t i o n i s t h e p r o c e s s of c o mbi n i n g t h e o r y wi t h p r a c t i c e
Re s e a r c h o n pr o g r a m o p t i mi z a t i o n t e c hn i qu e ba s e d o n DSP TM S3 2 0 C6 6 7 8 Wa ng Gu n— g a n g , Ya n g Yu n — ga o
.
Ke y wor ds : DSP p r o g r a m o p t i mi z a t i o n: di s t r i b u t i o n of t h e me mo y r r e s o u r c e s :o p t i mi z a t i o n o fC c o d e: s of t wa r e pi p e l i n e :o p t i mi z a t i o n o ft h e c o mp l i e r
0 引言
数卞 信 处理 ( Di g i t a l S i g n a l P r o c e s s i n g ,简 称 DS P)技 术发
2 基于T MS 3 2 0 C6 6 7 8 DS P 程序优化的技术
2 . 1 底层 存储 资 源的 合理 分 配
胰 迅 速 ,现 已广 泛 应 川 j 像 处理 技 术 、通 信 、 自动控 制 系统 等 许 彩新 技术 领域 … 荚 德州 仪 器 公司 推 … 了一款 摹 于K e y S t o n e 多 核 心 架 构 体 系 的高 能 数 7 ’ 处 理器 T MS 3 2 0 C 6 6 7 8 。该 处砰 器
E L E C T R ONI C S W OR L D・ 技 术 交流
基 于T MS 3 2 0 C 6 6 7 8 D SP 的 程序 I /  ̄ 1 1 J 技 市硇 研 究
海军驻 第七一 六研 究所军代 室 王 国刚
江 苏 自动化研 究所 杨 云 高
【 摘 要 】基  ̄ - T MS 3 2 0 C 6 6 7 8 1 3 S I 的程 序优 化是 一 个 完整的技 术体 系 程 序优 化首 先要 对 所用DS P @ 架构体 系和 存储 资源 有一 个清 晰的 认识 .
(1 . Na v a l Re p r e s e n t a t i ve O衔 c e o ft h e 7l 6 I n s t i t u t e o fCSI C , Li a n y un g a n g 2 2 20 6】 , Ch i n a: 2 . J i a ng s u Aut o ma t i o n Re s e a r c h I ns t i t ut e o f CSI C , Li a n y un g a n g 2 2 2 06 l , Ch i n a) Abs t r a c t : Pr og r a m o p t i mi z a t i o n b a s e d o n DSP TM S3 2 0 C6 6 7 8 i s a c o mp l e t e t e c h n i c a l s y s t e m T o o p t i mi z e t h e DSP p r o g r a m , we mu s t h a v e a c l e a r v i s i o n o l ’ t h e a r c hi t e c t u r e a nd t h e l r l e n l o r y r e s o u r c e s of t h e DSP, a n d un d e r s t a n d t h e a s s e mbl y l a n g u a g e o f t he e x h a v e t he a bi l i t y t o a p pl y d i f -