opencv之HOG特征详解与行人检测
目标检测学习_1(用opencv自带hog实现行人检测)

⽬标检测学习_1(⽤opencv⾃带hog实现⾏⼈检测) 本⽂主要介绍下opencv中怎样使⽤hog算法,因为在opencv中已经集成了hog这个类。
其实使⽤起来是很简单的,从后⾯的代码就可以看出来。
本⽂参考的资料为opencv⾃带的sample。
关于opencv中hog的源码分析,可以参考本⼈的另⼀篇博客: 开发环境:opencv2.4.2+Qt4.8.2+ubuntu12.04+QtCreator2.5. 实验功能: 单击Open Image按钮,选择需要进⾏⼈检测的⼀张图⽚,确定后⾃动显⽰出来。
该图⽚的⼤⼩没限制。
单击People Detect按钮,则程序会⾃动对该图⽚进⾏⾏⼈检测,且将检测到的效果显⽰出来,即⽤1个矩形框将⾏⼈框出来。
单击Close按钮,退出程序。
实验说明: 1. hog描述⼦在opencv中为HOGDescriptor。
2. 可以调⽤该描述⼦setSVMDetector⽅法给⽤于对hog特征进⾏分类的svm模型的系数赋值,这⾥的参数为HOGDescriptor::getDefaultPeopleDetector()时表⽰采⽤系统默认的参数,因为这些参数是⽤很多图⽚训练⽽来的。
3. 对输⼊图⽚进⾏⾏⼈检测时由于图⽚的⼤⼩不⼀样,所以要⽤到多尺度检测。
这⾥是⽤hog类的⽅法detectMultiScale。
参数解释如下:HOGDescriptor::detectMultiScale(const GpuMat& img, vector<Rect>& found_locations, doublehit_threshold=0, Size win_stride=Size(), Size padding=Size(),double scale0=1.05, int group_threshold=2) 该函数表⽰对输⼊的图⽚img进⾏多尺度⾏⼈检测img为输⼊待检测的图⽚;found_locations为检测到⽬标区域列表;参数3为程序内部计算为⾏⼈⽬标的阈值,也就是检测到的特征到SVM分类超平⾯的距离;参数4为滑动窗⼝每次移动的距离。
基于HOG和颜色特征的行人检测

第33卷 第4期2011年4月武 汉 理 工 大 学 学 报JOURNAL OF WUHAN UNIVERSITY OF TECHNOLOGY V ol.33 N o.4 A pr.2011DOI:10.3963/j.issn.1671 4431.2011.04.030基于HOG 和颜色特征的行人检测曲永宇,刘 清,郭建明,周生辉(武汉理工大学自动化学院,武汉430070)摘 要: 基于梯度方向直方图(H OG )特征的行人检测是目前检测精度较高的主流方法。
针对基于梯度直方图特征的行人检测存在检测精度还有待提高、向量维数大的问题,提出使用梯度直方图统计特征加颜色频率和肤色特征描述行人,选取一些分类能力较强的block 作为最后的特征,使用线性SV M 分类。
在IN RIA 库上的实验证明,该方法能有效地提高检测精度。
关键词: 行人检测; 梯度直方图(HO G); 颜色特征; block 选择中图分类号: T P 751.1文献标识码: A 文章编号:1671 4431(2011)04 0134 05HOG and Color Based Pedestrian DetectionQU Yong y u,L I U Qing ,G UO J ian ming ,ZH O U S heng hui(Scho ol o f A uto matio n,Wuhan U niv ersity of T echno lo gy ,W uhan 430070,China)Abstract: H istog r am o f or iented g radient(H OG )based on pedestr ian detect ion is the popular method w ith t he hig hest detection rat e curr ent ly.T o further im pr ove its detection r ate and decrease its larg e dimensions o f feat ur es,this paper in tegr ates HO G w ith color frequent and skin colo r feature to descr ibe pedestr ian,w e select some blo ck features w ith better classify ing ability as t he final featur e,then use linear SVM as our classifier.T he ex per iment o n IN RI A demo nstr ates t he hig h detection r ate of our met ho d.Key words: pedestr ian detection; hist og ram of o riented gr adient(HO G); color featur e; blo ck selection收稿日期:2010 08 15.基金项目:湖北省自然科学基金(2009CD B403)和武汉理工大学自主创新研究基金(2010 Va 012).作者简介:曲永宇(1987 ),女,硕士生.E mail:quyong yu163@ 行人检测在视频监控[1]、机器人学、虚拟现实技术等领域有广泛的应用,也是计算机视觉和模式识别领域中的重要研究方向。
【转载】opencv实现人脸检测

【转载】opencv实现⼈脸检测全⽂转载⾃CSDN的博客(不知道怎么将CSDN的博客转到博客园,应该没这功能吧,所以直接复制全⽂了),转载地址如下本篇⽂章主要介绍了如何使⽤OpenCV实现⼈脸检测。
本⽂不具体讲解⼈脸检测的原理,直接使⽤OpenCV实现。
OpenCV版本:2.4.10;VS开发版本:VS2012。
⼀、OpenCV⼈脸检测要实现⼈脸识别功能,⾸先要进⾏⼈脸检测,判断出图⽚中⼈脸的位置,才能进⾏下⼀步的操作。
1、OpenCV⼈脸检测的⽅法在OpenCV中主要使⽤了两种特征(即两种⽅法)进⾏⼈脸检测,Haar特征和LBP特征。
在OpenCV中,使⽤已经训练好的XML格式的分类器进⾏⼈脸检测。
在OpenCV的安装⽬录下的sources⽂件夹⾥的data⽂件夹⾥可以看到下图所⽰的内容:上图中⽂件夹的名字“haarcascades”、“hogcascades”和“lbpcascades”分别表⽰通过“haar”、“hog”和“lbp”三种不同的特征⽽训练出的分类器:即各⽂件夹⾥的⽂件。
"haar"特征主要⽤于⼈脸检测,“hog”特征主要⽤于⾏⼈检测,“lbp”特征主要⽤于⼈脸识别。
打开“haarcascades”⽂件夹,如下图所⽰图中的XML⽂件即是我们⼈脸检测所需要的分类器⽂件。
在实际使⽤中,推荐使⽤上图中被标记的“haarcascade_frontalface_alt2.xml”分类器⽂件,准确率和速度都⽐较好。
2、OpenCV中的⼈脸检测的类在OpenCV中,使⽤类“CascadeClassifier”进⾏⼈脸检测CascadeClassifier faceCascade; //实例化对象所需要使⽤的函数:faceCascade.load("../data/haarcascade_frontalface_alt2"); //加载分类器faceCascade.detectMultiScale(imgGray, faces, 1.2, 6, 0, Size(0, 0)); //多尺⼨检测⼈脸实现⼈脸检测主要依赖于detectMultiScale()函数,下⾯简单说⼀下函数参数的含义,先看函数原型:1. CV_WRAP virtual void detectMultiScale( const Mat& image,2. CV_OUT vector<Rect>& objects,3. double scaleFactor=1.1,4. int minNeighbors=3, int flags=0,5. Size minSize=Size(),6. Size maxSize=Size() );各参数含义:const Mat& image: 需要被检测的图像(灰度图)vector<Rect>& objects: 保存被检测出的⼈脸位置坐标序列double scaleFactor: 每次图⽚缩放的⽐例int minNeighbors: 每⼀个⼈脸⾄少要检测到多少次才算是真的⼈脸int flags:决定是缩放分类器来检测,还是缩放图像Size(): 表⽰⼈脸的最⼤最⼩尺⼨⼆、代码实现1、检测图⽚中的⼈脸#include<opencv2/objdetect/objdetect.hpp>#include<opencv2/highgui/highgui.hpp>#include<opencv2/imgproc/imgproc.hpp>using namespace cv;//⼈脸检测的类CascadeClassifier faceCascade;int main(){faceCascade.load("../data/haarcascade_frontalface_alt2.xml"); //加载分类器,注意⽂件路径Mat img = imread("../data/PrettyGirl.jpg");Mat imgGray;vector<Rect> faces;if(img.empty()){return1;}if(img.channels() ==3){cvtColor(img, imgGray, CV_RGB2GRAY);}else{imgGray = img;}faceCascade.detectMultiScale(imgGray, faces, 1.2, 6, 0, Size(0, 0)); //检测⼈脸if(faces.size()>0){for(int i =0; i<faces.size(); i++){rectangle(img, Point(faces[i].x, faces[i].y), Point(faces[i].x + faces[i].width, faces[i].y + faces[i].height), Scalar(0, 255, 0), 1, 8); //框出⼈脸位置}}imshow("FacesOfPrettyGirl", img);waitKey(0);return0;}结果如下图:2、检测视频中的⼈脸//头⽂件#include<opencv2/objdetect/objdetect.hpp>#include<opencv2/highgui/highgui.hpp>#include<opencv2/imgproc/imgproc.hpp>using namespace cv;//⼈脸检测的类CascadeClassifier faceCascade;int main(){faceCascade.load("../data/haarcascade_frontalface_alt2.xml"); //加载分类器,注意⽂件路径VideoCapture cap;cap.open(0); //打开摄像头//cap.open("../data/test.avi"); //打开视频Mat img, imgGray;vector<Rect> faces;int c = 0;if(!cap.isOpened()){return1;}while(c!=27)cap>>img;if(img.channels() ==3){cvtColor(img, imgGray, CV_RGB2GRAY);}else{imgGray = img;}faceCascade.detectMultiScale(imgGray, faces, 1.2, 6, 0, Size(0, 0)); //检测⼈脸if(faces.size()>0){for(int i =0; i<faces.size(); i++){rectangle(img, Point(faces[i].x, faces[i].y), Point(faces[i].x + faces[i].width, faces[i].y + faces[i].height),Scalar(0, 255, 0), 1, 8); //框出⼈脸位置}}imshow("Camera", img);c = waitKey(1);}return0;}在视频实时检测时,可能会出现卡顿,是因为检测⼈脸花费了过多的时间,这⾥代码只实现基本功能,并未优化。
HogSVM车辆行人检测

HogSVM车辆⾏⼈检测HOG SVM 车辆检测 近期需要对卡⼝车辆的车脸进⾏检测,⾸先选⽤⼀个常规的检测⽅法即是hog特征与SVM,Hog特征是由dalal在2005年提出的⽤于道路中⾏⼈检测的⽅法,并且取的了不错的识别效果。
在⼈脸检测⽅⾯⽬前主流的⽅法,先不考虑复杂的深度学习,⼤多采⽤Haar和Adaboost的⼿段来实现。
我接下来将会⽤着两种⽅法来实现对卡⼝的车辆检测。
⾸先引出 Hog特征,Hog特征是梯度⽅向直⽅图,是⼀种底层的视觉特征,主要描述的是图像中的梯度分布情况,⽽梯度分布信息主要是集中在图像中不同内容之间的边界之处,可以较好的反应图像的基本轮廓⾯貌。
在此处并不展开对描述⼦的详细介绍,给出⼀个我当时看的博客链接,对描述⼦原理分析的⽐较透彻。
接下来将整个特征提取、训练、检测的流程:1.⾸先是准备训练样本,分别是正样本和负样本以及测试样本。
正负样本⼀般来说负样本最好是正样本的2-3倍⽐较好,覆盖⾯不要是乱七⼋糟的图像,要贴合实际应⽤时的场景来选取,样本对训练过程很重要,很重要,很重要,不要以为随随便便弄⼀些照⽚就OK。
2.在程序中导⼊测试样本,分别提取相应的Hog特征,这个地⽅我有两点要说明 2.1.样本的尺度要正则化,也就是样本的尺⼨要⼀样,这样可以排除训练样本尺度对模型训练的影响,在正则化的时候,尽量是不要改变其⽐例。
2.2.在hog特征描述⼦初始化的时候,需要设置窗⼝⼤⼩,块⼤⼩,块滑动⼤⼩,以及细胞⼤⼩和直⽅图相应的bin的数⽬,窗⼝⼤⼩要和输⼊的训练样本的尺⼨⼀样。
3.提取正负样本的hog特征,我在这⾥采⽤的是128128的规模,是正⽅形的车脸,描述⼦规模是8100维。
4.SVM采⽤opencv中⾃带的,其实opencv中采⽤的也是某⼀个版本的LIBSVM,只是重新封装了借⼝的操作⽽已。
5.在SVM处,需要注意的是如果之后你要⽤SVM中⾃带的detector,也就是⽤setSVMDetector的话,这个检测器已经是写好了的转门⽤了处理线性核训练的模型,因为当时dalal ⽤的就是Hog与线性的SVM特征,⽽且opencv⾃带的只⽀持线性的,如果你要⽤⾼斯特征即RBF核,不可以采⽤setSVMDetector,你⽤了就会出错,根本检测不到真实的位置,这⾥⾮常关键,你如果要做分类的话可以直接调⽤predict,但此处应该只是对车脸与⾮车脸做,⽽不是在⼀张图中找出车脸,如果你要找出⽬标物,需要⾃⼰写相应的detector,来应⽤你训练好的模型6在检测时,检测窗⼝的⼤⼩必须和训练样本的尺⼨是⼀样的,就是训练时的Hog窗⼝⼤⼩和检测时Hog窗⼝⼤⼩必须保持⼀致,剩下的就是检测过程中看看没有没嵌套什么的,OK,⼀下是代码#include<opencv/cv.h>#include<opencv2/core/core.hpp>#include<opencv2/highgui/highgui.hpp>#include<opencv2/opencv.hpp>#include<opencv2/gpu/gpu.hpp>#include<opencv2/ml/ml.hpp>#include<opencv2/objdetect/objdetect.hpp>#include<iostream>#include<fstream>#include<string>#include<vector>using namespace std;using namespace cv;#define TRAIN//开关控制是否训练还是直接载⼊训练好的模型class MySVM: public CvSVM{public:double * get_alpha_data(){return this->decision_func->alpha;}double get_rho_data(){return this->decision_func->rho;}};void main(int argc, char ** argv){MySVM SVM;int descriptorDim;string buffer;string trainImg;vector<string> posSamples;vector<string> negSamples;vector<string> testSamples;int posSampleNum;int negSampleNum;int testSampleNum;string basePath = "";//相对路径之前加上基地址,如果训练样本中是相对地址,则都加上基地址double rho;#ifdef TRAINifstream fInPos("D:\\DataSet\\CarFaceDataSet\\PositiveSample.txt");//读取正样本ifstream fInNeg("D:\\DataSet\\CarFaceDataSet\\NegtiveSample.txt");//读取负样本while (fInPos)//讲正样本读⼊imgPathList中{if(getline(fInPos, buffer))posSamples.push_back(basePath + buffer);}posSampleNum = posSamples.size();fInPos.close();while(fInNeg)//读取负样本{if (getline(fInNeg, buffer))negSamples.push_back(basePath + buffer);}negSampleNum = negSamples.size();fInNeg.close();Mat sampleFeatureMat;//样本特征向量矩阵Mat sampleLabelMat;//样本标签HOGDescriptor * hog = new HOGDescriptor (cvSize(128, 128), cvSize(16, 16), cvSize(8, 8), cvSize(8, 8), 9);vector<float> descriptor;for(int i = 0 ; i < posSampleNum; i++)// 处理正样本{Mat inputImg = imread(posSamples[i]);cout<<"processing "<<i<<"/"<<posSampleNum<<" "<<posSamples[i]<<endl;Size dsize = Size(128,128);Mat trainImg = Mat(dsize, CV_32S);resize(inputImg, trainImg, dsize);hog->compute(trainImg, descriptor, Size(8, 8));descriptorDim = descriptor.size();if(i == 0)//⾸次特殊处理根据检测到的维数确定特征矩阵的尺⼨{sampleFeatureMat = Mat::zeros(posSampleNum + negSampleNum, descriptorDim, CV_32FC1);sampleLabelMat = Mat::zeros(posSampleNum + negSampleNum, 1, CV_32FC1);}for(int j = 0; j < descriptorDim; j++)//将特征向量复制到矩阵中{sampleFeatureMat.at<float>(i, j) = descriptor[j];}sampleLabelMat.at<float>(i, 0) = 1;}cout<<"extract posSampleFeature done"<<endl;for(int i = 0 ; i < negSampleNum; i++)//处理负样本{Mat inputImg = imread(negSamples[i]);cout<<"processing "<<i<<"/"<<negSampleNum<<" "<<negSamples[i]<<endl;Size dsize = Size(128,128);Mat trainImg = Mat(dsize, CV_32S);resize(inputImg, trainImg, dsize);hog->compute(trainImg, descriptor, Size(8,8));descriptorDim = descriptor.size();for(int j = 0; j < descriptorDim; j++)//将特征向量复制到矩阵中{sampleFeatureMat.at<float>(posSampleNum + i, j) = descriptor[j];}sampleLabelMat.at<float>(posSampleNum + i, 0) = -1;}cout<<"extract negSampleFeature done"<<endl;//此处先预留hard example 训练后再添加ofstream foutFeature("SampleFeatureMat.txt");//保存特征向量⽂件for(int i = 0; i < posSampleNum + negSampleNum; i++){for(int j = 0; j < descriptorDim; j++){foutFeature<<sampleFeatureMat.at<float>(i, j)<<" ";}foutFeature<<"\n";}foutFeature.close();cout<<"output posSample and negSample Feature done"<<endl;CvTermCriteria criteria = cvTermCriteria(CV_TERMCRIT_ITER, 1000, FLT_EPSILON);CvSVMParams params(CvSVM::C_SVC, CvSVM::LINEAR, 0, 1, 0, 0.01, 0, 0, 0, criteria); //这⾥⼀定要注意,LINEAR代表的是线性核,RBF代表的是⾼斯核,如果要⽤opencv⾃带的detector必须⽤线性核,如果⾃⼰写,或者只是判断是否为车 cout<<"SVM Training Start..."<<endl;SVM.train_auto(sampleFeatureMat, sampleLabelMat, Mat(), Mat(), params);SVM.save("SVM_Model.xml");cout<<"SVM Training Complete"<<endl;#endif#ifndef TRAINSVM.load("SVM_Model.xml");//加载模型⽂件#endifdescriptorDim = SVM.get_var_count();int supportVectorNum = SVM.get_support_vector_count();cout<<"support vector num: "<< supportVectorNum <<endl;Mat alphaMat = Mat::zeros(1, supportVectorNum, CV_32FC1);Mat supportVectorMat = Mat::zeros(supportVectorNum, descriptorDim, CV_32FC1);Mat resultMat = Mat::zeros(1, descriptorDim, CV_32FC1);for (int i = 0; i < supportVectorNum; i++)//复制⽀持向量矩阵{const float * pSupportVectorData = SVM.get_support_vector(i);for(int j = 0 ;j < descriptorDim; j++){supportVectorMat.at<float>(i,j) = pSupportVectorData[j];}}double *pAlphaData = SVM.get_alpha_data();for (int i = 0; i < supportVectorNum; i++)//复制函数中的alpha 记住决策公式Y= wx+b{alphaMat.at<float>(0, i) = pAlphaData[i];}resultMat = -1 * alphaMat * supportVectorMat; //alphaMat就是权重向量//cout<<resultMat;cout<<"描述⼦维数 "<<descriptorDim<<endl;vector<float> myDetector;for (int i = 0 ;i < descriptorDim; i++){myDetector.push_back(resultMat.at<float>(0, i));}rho = SVM.get_rho_data();myDetector.push_back(rho);cout<<"检测⼦维数 "<<myDetector.size()<<endl;HOGDescriptor myHOG (Size(128, 128), Size(16, 16), Size(8, 8), Size(8, 8), 9);myHOG.setSVMDetector(myDetector);//设置检测⼦//保存检测⼦int minusNum = 0;int posNum = 0;ofstream foutDetector("HogDetectorForCarFace.txt");for (int i = 0 ;i < myDetector.size(); i++){foutDetector<<myDetector[i]<<" ";//cout<<myDetector[i]<<" ";}//cout<<endl<<"posNum "<<posNum<<endl;//cout<<endl<<"minusNum "<<minusNum<<endl;foutDetector.close();//test partifstream fInTest("D:\\DataSet\\CarFaceDataSet\\testSample.txt");while (fInTest){if(getline(fInTest, buffer)){testSamples.push_back(basePath + buffer);}}testSampleNum = testSamples.size();fInTest.close();for (int i = 0; i < testSamples.size(); i++){Mat testImg = imread(testSamples[i]);Size dsize = Size(320, 240);Mat testImgNorm (dsize, CV_32S);resize(testImg, testImgNorm, dsize);vector<Rect> found, foundFiltered;cout<<"MultiScale detect "<<endl;myHOG.detectMultiScale(testImgNorm, found, 0, Size(8,8), Size(0,0), 1.05, 2);cout<<"Detected Rect Num"<< found.size()<<endl;for (int i = 0; i < found.size(); i++)//查看是否有嵌套的矩形框{Rect r = found[i];int j = 0;for (; j < found.size(); j++){if ( i != j && (r & found[j]) == r){break;}}if(j == found.size())foundFiltered.push_back(r);}for( int i = 0; i < foundFiltered.size(); i++)//画出矩形框{Rect r = foundFiltered[i];rectangle(testImgNorm, r.tl(), r.br(), Scalar(0,255,0), 1);}imshow("test",testImgNorm);waitKey();}system("pause");}总体效果还是不错的,如果对hardexample,进⾏进⼀步训练,以及样本的数据进⾏clean,相信精度还可以进⼀步提⾼,并且现在维数也⽐价⾼,位了加快检测还可以⽤PCA进⼀步降维,但必须⾃⼰重新写detector了哦,⼀定要好好理解⼀下detector,其实hog + svm的代码很多,本质上都是差不多的。
基于opencv的行人检测(支持图片视频)
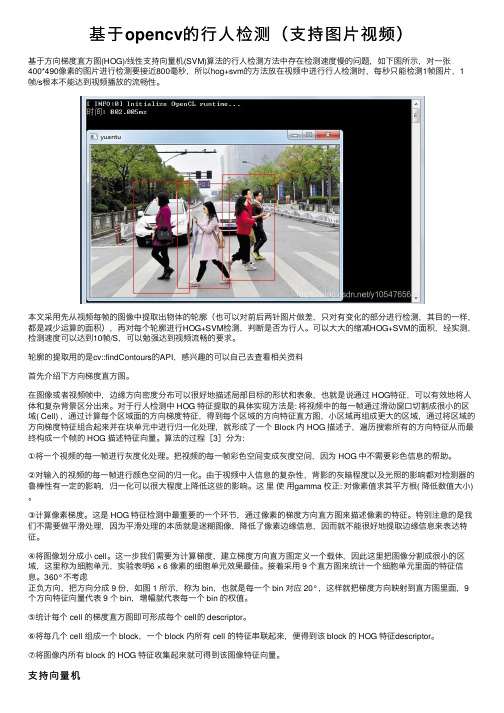
基于opencv的⾏⼈检测(⽀持图⽚视频)基于⽅向梯度直⽅图(HOG)/线性⽀持向量机(SVM)算法的⾏⼈检测⽅法中存在检测速度慢的问题,如下图所⽰,对⼀张400*490像素的图⽚进⾏检测要接近800毫秒,所以hog+svm的⽅法放在视频中进⾏⾏⼈检测时,每秒只能检测1帧图⽚,1帧/s根本不能达到视频播放的流畅性。
本⽂采⽤先从视频每帧的图像中提取出物体的轮廓(也可以对前后两针图⽚做差,只对有变化的部分进⾏检测,其⽬的⼀样,都是减少运算的⾯积),再对每个轮廓进⾏HOG+SVM检测,判断是否为⾏⼈。
可以⼤⼤的缩减HOG+SVM的⾯积,经实测,检测速度可以达到10帧/S,可以勉强达到视频流畅的要求。
轮廓的提取⽤的是cv::findContours的API,感兴趣的可以⾃⼰去查看相关资料⾸先介绍下⽅向梯度直⽅图。
在图像或者视频帧中,边缘⽅向密度分布可以很好地描述局部⽬标的形状和表象,也就是说通过 HOG特征,可以有效地将⼈体和复杂背景区分出来。
对于⾏⼈检测中 HOG 特征提取的具体实现⽅法是: 将视频中的每⼀帧通过滑动窗⼝切割成很⼩的区域( Cell) ,通过计算每个区域⾯的⽅向梯度特征,得到每个区域的⽅向特征直⽅图,⼩区域再组成更⼤的区域,通过将区域的⽅向梯度特征组合起来并在块单元中进⾏归⼀化处理,就形成了⼀个 Block 内 HOG 描述⼦,遍历搜索所有的⽅向特征从⽽最终构成⼀个帧的 HOG 描述特征向量。
算法的过程[3]分为:①将⼀个视频的每⼀帧进⾏灰度化处理。
把视频的每⼀帧彩⾊空间变成灰度空间,因为 HOG 中不需要彩⾊信息的帮助。
②对输⼊的视频的每⼀帧进⾏颜⾊空间的归⼀化。
由于视频中⼈信息的复杂性,背影的灰暗程度以及光照的影响都对检测器的鲁棒性有⼀定的影响,归⼀化可以很⼤程度上降低这些的影响。
这⾥使⽤gamma 校正: 对像素值求其平⽅根( 降低数值⼤⼩)。
③计算像素梯度。
这是 HOG 特征检测中最重要的⼀个环节,通过像素的梯度⽅向直⽅图来描述像素的特征。
opencv中 关于hog特征向量的个数的计算

文章标题:探讨OpenCV中HOG特征向量个数的计算方法概述HOG(Histogram of Oriented Gradients,梯度方向直方图)是一种用于目标检测的特征描述子,它能够提取图像中目标的局部特征,并且对光照变化具有较好的鲁棒性。
在OpenCV中,HOG特征向量的计算对于目标检测和行人检测等任务非常重要。
本文将从简单到复杂,由浅入深地探讨OpenCV中关于HOG特征向量个数的计算方法,帮助读者更好地理解这一重要概念。
一、HOG特征向量简介HOG特征是一种描述图像局部梯度方向的特征,它将图像分成若干个小的局部区域,并计算每个区域内梯度方向的直方图。
通过计算梯度方向直方图可以描述目标的轮廓信息,从而实现目标的检测。
在OpenCV中,HOG特征向量的维度由参数决定,而这个参数即是我们所关心的HOG特征向量个数的计算方法。
二、HOG特征向量个数的计算方法在OpenCV中,HOG特征向量的个数可以通过如下公式进行计算:[公式1]。
其中,cellSize代表每个小单元的大小,blockSize代表每个块的大小,blockStride代表块的步长,winSize代表窗口的大小,nbins代表梯度方向的直方图数量。
通过调节这些参数,可以灵活地控制HOG特征向量的个数,进而影响目标检测的性能。
在实际应用中,我们可以根据具体的任务和图像特点来调节HOG特征向量的个数。
较大的特征向量个数可以提高目标检测的精度,但也会增加计算量和内存消耗;而较小的特征向量个数则可以降低计算量和内存消耗,但可能会降低检测的精度。
合理地计算HOG特征向量的个数对于实际应用非常重要。
三、HOG特征向量个数的影响HOG特征向量的个数对目标检测性能有着重要的影响。
较大的特征向量个数可以提高目标检测的精度,尤其是对于小尺寸目标的检测具有较好的效果;而较小的特征向量个数则可能会导致目标检测的误判和漏判。
在实际应用中,我们需要根据具体的场景和目标特点来调节HOG特征向量的个数,以达到最佳的检测效果。
基于HOG的行人特征检测答辩PPT

处理方案:在检测到两种特征后,将两种特征通过并集方式结合到一起,组 成一个新特征,称之为融合特征。如将[1 2 3]和[4 5]两个向量变 为 [1 2 3 4 5]
基于HOG和LBP特征的行人检测算法设计
问题3.检测到行人后,标记结果的窗口过大。 处理方案:将窗口按一定比例缩小。经试验验证效果很好。
基于HOG和LBP特征的行人检测
算法设计方案
基于HOG和LBP特征的行人检测算法设计
HOG特征和LBP特征融合的方式进行检测:
3780维的HOG特征
3839维的 融合特征
距离 检测
59维的LBP特征
人与相机距离
基于HOG和LBP特征的行人检测算法设计
HOG特征提取过程:
基于HOG和LBP特征的行人检测算法设计
班 级:201332**** 学 号:28 姓 名:**** 指导 老师:*******
目录
研究背景及意义 算法设计方案 实验过程 遇到的问题及处理方案 总结与展望
研究背景及意义
从近些年来看,机器学习发展可谓 非常迅速。在此期间,行人检测算法是 机器学习学习的一个重要组成部分。行 人检测算法应用在很多领域,就像汽车 智能驾驶系统、人流量检测、智能照相 机等领域。行人检测算法也有很多种, 如HOG算法、VJ算法、SHAPELET 算法 等。但HOG算法由于其检测速度快、准 确率高和算法实用性高等综合性能不错 而受欢迎。
总张数:262
20%~30% 30%以上 13 0.55m
0.48m
百分比
38.5%
33.5%
22.9%
5.0%
表2 距离检测数据分析
测距功能也受到行人检测算法结果的影响,因为 其中成像高度是由行人检测结果得来的,行人检测的 误差的大小决定着距离检测功能的误差大小。
hog算法

1、HOG特征:方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。
它通过计算和统计图像局部区域的梯度方向直方图来构成特征。
Hog特征结合SVM分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。
需要提醒的是,HOG+SVM进行行人检测的方法是法国研究人员Dalal 在2005的CVPR上提出的,而如今虽然有很多行人检测算法不断提出,但基本都是以HOG+SVM的思路为主。
(1)主要思想:在一副图像中,局部目标的表象和形状(appearance and shape)能够被梯度或边缘的方向密度分布很好地描述。
(本质:梯度的统计信息,而梯度主要存在于边缘的地方)。
(2)具体的实现方法是:首先将图像分成小的连通区域,我们把它叫细胞单元。
然后采集细胞单元中各像素点的梯度的或边缘的方向直方图。
最后把这些直方图组合起来就可以构成特征描述器。
(3)提高性能:把这些局部直方图在图像的更大的范围内(我们把它叫区间或block)进行对比度归一化(contrast-normalized),所采用的方法是:先计算各直方图在这个区间(block)中的密度,然后根据这个密度对区间中的各个细胞单元做归一化。
通过这个归一化后,能对光照变化和阴影获得更好的效果。
(4)优点:与其他的特征描述方法相比,HOG有很多优点。
首先,由于HOG是在图像的局部方格单元上操作,所以它对图像几何的和光学的形变都能保持很好的不变性,这两种形变只会出现在更大的空间领域上。
其次,在粗的空域抽样、精细的方向抽样以及较强的局部光学归一化等条件下,只要行人大体上能够保持直立的姿势,可以容许行人有一些细微的肢体动作,这些细微的动作可以被忽略而不影响检测效果。
因此HOG特征是特别适合于做图像中的人体检测的。
2、HOG特征提取算法的实现过程:大概过程:HOG特征提取方法就是将一个image(你要检测的目标或者扫描窗口):1)灰度化(将图像看做一个x,y,z(灰度)的三维图像);2)采用Gamma校正法对输入图像进行颜色空间的标准化(归一化);目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰;3)计算图像每个像素的梯度(包括大小和方向);主要是为了捕获轮廓信息,同时进一步弱化光照的干扰。
基于HOG+SVM实现行人检测

2021.06科学技术创新基于H O G+SV M 实现行人检测任小康陈鸿享(西京学院,陕西西安710123)1概述方向梯度直方图(H i s t ogr am of O r i ent ed G r adi ent ,H O G )是用于计算机视觉识别和处理过程中对物体形状、轮廓进行检测的特征描述子。
通过计算并统计数字图像中被识别物体边缘的梯度方向直方图来构成特征描述子。
2005年在I EEE 国际计算机视觉与模式识别会议(I EEE Conf er ence on Com put er V i s i on and Pat t er n R ecogni t i on ,CV PR )[1]上,来自法国的研究人员N avneet D al al 和Bi l l Tr i ggs 提出利用H O G 对图像边缘特征进行提取,并利用支持向量机(Suppor t V ect or M achi ne ,SV M )作为二分类器训练此模型,该模型经过大量对测试样本测试后发现,H O G 与SV M 相结合的方法是速度和效果综合平衡性能较好的一种行人检测(Pedes t r i an D et ect i on)方法。
H O G +SV M 模型广泛应用于计算机视觉,尤其在行人检测领域获得了极大的成功。
行人检测技术可与行人跟踪、行人重识别等技术结合,应用于人工智能系统、车辆辅助驾驶系统、智能机器人、智能视频监控、人体行为分析、智能交通等领域,是当前的热门研究方向之一。
2H O G (梯度方向直方图)原理一幅数字图像,其梯度主要在与被检测图像的轮廓处,即目标区域的边缘部分可以很好地用方向密度分布进行描述。
2.1H O G 实现方法通过提取关键信息并丢弃冗余信息来简化图像,通常对于H O G 特征描述子,输入图像的大小为64×128×3,输出特征向量的长度为3780。
为了解决光照变化和阴影对结果的影响,将这些在细胞单元中获取到的局部直方图在图像的更大的范围,即区间(bl ock )进行对比度归一化[2](Cont r as t nor m al i z at i on )。
基于HOG特征的行人检测

3
统计局部图像梯度信息
4
对比度归一化
5 生成特征描述向量
1.全局图像归一化
目的:调节图像的对比度,降低图像局部的阴影和光 照变化所造成的影响,同时可以抑制噪音的干扰
方法:首先将输入的彩图转换为灰度图 采用Gamma校正法对输入图像进行颜色空间 的标准化(归一化)
2.计算图像梯度
目的:主要是为了捕获轮廓信息,同时进一步弱化光照的 干扰。
方法:对每个颜色通道分别计算梯度。
3.统计局部图像梯度信息
目的:为局部图像区域提供一个编码,同时能够保持对图 像中人体对象的姿势和外观的弱敏感性。
方法:求取梯度方向直方图,我们将图像窗口分成若干个 小区域,这些区域被称为“单元格”。然后将每个 单元格中所有象素的一维梯度直方图或者边缘方向 累加到其中。最后将这个基本的方向直方图映射到 固定的角度上,就形成了最终的特征。
5.生成特征描述向量:
最后一步就是将检测窗口中所有重叠的块进行HOG 特征的收集,并将它们结合成最终的特征向量供分类 使用。
运行结果:
Thank You !
行人检测
——基于H义: 方向梯度直方图(HOG)特征,是一种在计算机视觉
和图像处理中用来进行物体检测的特征描述子。 HOG特征通过计算和统计图像局部区域的梯度方向直
方图来构成特征。 本质:
梯度的统计信息,而梯度主要存在于边缘的地方
步骤:
1
全局图像归一化
2 计算图像梯度
4.块内归一化梯度直方图
目的:将所有单元格在块上进行归一化;归一化能够进一步 地对光照、阴影和边缘进行压缩。
方法:通常,每个单元格由多个不同的块共享,但它的归一 化是基于不同块的,所以计算结果也不一样。因此, 一个单元格的特征会以不同的结果多次出现在最后的 向量中。我们将归一化之后的块描述符就称之为HOG描 述符
行人检测算法HOG特征提取

关于HOG解释1关于计算梯度方向角的:首先用[-1,0,1]梯度算子对原图像做卷积运算,得到x方向(水平方向,以向右为正方向)的梯度分量gradscalx,然后用[1,0,-1]’梯度算子对原图像做卷积运算,得到y方向(竖直方向,以向上为正方向)的梯度分量gradscaly。
然后当gradscalx>=0, gradscaly>=0时,说明梯度方向是朝向第一象限的,当gradscalx>=0, gradscaly<0时,说明梯度方向是朝向第二象限的,诸如此类,结合象限信息,就可以利用反正切函数atan求出在signed和unsigned 各自情况下正确的梯度角度。
2关于扫描循环(四层for循环…有没有快一点的?有!但是我功力不够。
当时没编出来,就只好还是来四层for):假设检测窗为64(列)*128(行)大小,block为16*16大小,每个block划分为4个cell,block 每次滑动8个像素(也就是一个cell的宽),以及梯度方向划分为9个区间,在0~180度范围内统计,以下的说明都以上述假设为例.btly与btlx分别表示block所在位置左上角点处的坐标。
对于前述假设,一个检测窗内会有105个block存在,因此第一个block左上角的坐标是(1,1),第二个是(9,1)…,此行最后一个是block的左上角坐标是(49,1),然后下一个block就需要向下滑动8个像素,并回到最左边,此时的block左上角坐标为(1,9),接着block重新开始新的横向滑动…如此这般,在检测窗内最后一个block的坐标就是(49,113).block每滑动到一个新的位置,就需要停下来计算它内部的那四个cell中的梯度方向直方图.(bj,bi)就是来存储cell左上角的坐标的(cell的坐标以block左上角为原点).(j,i)就表示cell中的像素在整个检测窗(64*128的图像)中的坐标.另外,我在程序里有个jorbj 与iorbi,这在Localinterpolate的情况下(也就是标准的原始HOG情况),就是bj与bi. 关于hist3dbig:这是一个三维的矩阵,用来存储三维直方图。
基于OpenCV视觉库的行人检测与跟踪

基于OpenCV视觉库的行人检测与跟踪摘要由于视频的信息量大,处理的速度慢,同时又要满足时间的要求,所以提出了高效的图像处理算法。
如果所有底层的算法都要自己编码实现,既浪费时间和精力,又难以保证稳定性、实用性和通用性。
针对这种情况,本文采用了OpenCV图像处理函数库与VS2010相结合,省去了很多底层代码的编写,对于视频能够正确地进行行人的检测和跟踪,并具有良好的鲁棒性。
本文的主要工作如下:系统地分析了梯度方向直方图(HOG)特征、支撑向量机(SVM)分类器并给出了其性能分析,实现了HOG结合SVM分类器的行人检测方法,取得了较好的实验结果。
关键词行人检测;跟踪视频;OpenCVHOG1 引言人类通过视觉信息获得对外界世界的最直接感知,人脑获得的大量信息都来自于视觉。
如果计算机可以像人类一样获得并理解信息,对人类社会的发展将会起到举足轻重的作用。
计算机视觉的研究目标就是让计算机理解图像或视频信息,从而代替人类完成一些视觉信息相关的工作[1]。
近年来,图像采集及处理设备的更新、计算机软件和硬件的发展,都为计算机视觉的研究发展提供了基础。
这些因素使得计算机视觉成为近年来的一个研究热点。
2 基于HOG特征的行人检测2.1 算法概述算法主要由两部分组成:HOG特征提取和目标检测[2]。
首先,选取含不同数量的正负样本,提取并保存图像的HOG描述子。
之后,将保存的HOG描述子输入适当的分类器算法进行训练并得到分类器。
对于待检测的图像或视频,把提取的特征向量输入给支持向量机(SVM),根据计算的结果进行判断是否包含目标。
HOG提取特征过程如下:首先对图像的颜色空间进行归一化,以减小光照因素的影响;其次,将检测窗口划分成大小相同的单元格(cell),在每个单元格中分别提取相应的梯度直方图信息,然后将相邻的单元格组合成相互有重叠的块(block),以有效的利用重叠的边缘信息,统计整个块的直方图特征,并对每个块内的直方图进行归一化,进一步减少背景颜色和噪声的影响;最后对整个窗口收集所有块的HOG特征,并以特征向量的形式来表示整个目标窗口的HOG特征。
opencv hog特征提取

opencv hog特征提取OpenCV HOG特征提取目录一、什么是HOG特征二、OpenCV中HOG的使用三、OpenCV进行HOG特征提取的步骤一、什么是HOG特征HOG(Histogram of Oriented Gradients)梯度方向直方图,是用来提取图像中目标的特征。
它主要由梯度方向直方图和纹理直方图组成,可以提取图像的纹理特征和形状特征,是一种常用的目标检测方法。
二、OpenCV中HOG的使用OpenCV是一个开源的计算机视觉库,用于实现图像处理、计算机视觉等功能,它拥有强大的计算机视觉函数,可以通过调用这些函数来实现HOG特征提取的功能,其中包括HOGDescriptor类。
HOGDescriptor类可以提取图像的HOG特征,其中包含着关于梯度角度和长度的信息,以及有关纹理的信息,可以用来提取图像中的目标形状和纹理特征。
三、OpenCV进行HOG特征提取的步骤1、安装OpenCV首先,需要安装好OpenCV的库文件,可以使用pip或者anaconda 等方式安装,也可以在opencv官网上下载源码自行编译安装。
2、导入必要的库使用HOGDescriptor类提取HOG特征,因此需要导入OpenCV拥有的库文件,如:import cv23、读取图片读取要提取HOG特征的图片,使用cv2.imread()函数读取图片,同时转化为灰度图片,如:image = cv2.imread('image.jpg')gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)4、定义HOGDescriptor类接下来,定义一个HOGDescriptor类,设置HOG检测器的参数,如blockSize,cellSize,nbins等,全部参数的详细说明可以参考OpenCV官方文档,如:hog = cv2.HOGDescriptor(...)5、计算HOG特征然后,调用pute()函数,计算图片中的HOG特征,如: features = pute(gray)6、得到HOG特征最后,得到HOG特征,这些HOG特征可以作为输入,用于后续的目标检测任务。
行人检测算法HOG特征提取

行人检测算法HOG特征提取行人检测是计算机视觉领域的一个重要问题,其目标是从图像中自动识别和定位行人。
HOG(Histogram of Oriented Gradients)特征提取是一种常用的行人检测算法,它通过计算图像中局部区域的梯度直方图来描述图像的特征。
本文将详细介绍HOG特征提取算法,并探讨其在行人检测中的应用。
1.HOG特征提取算法HOG特征提取算法主要包括以下几个步骤:(1)图像预处理:将图像转换成灰度图像,并对图像进行归一化和平滑处理,以增强图像的特征。
(2)计算梯度:通过计算图像中各像素点的梯度大小和方向来获取图像的局部特征。
(3)划分图像:将图像划分成小的局部区域(cell),通常是16×16像素的正方形。
(4)计算直方图:对每个小的局部区域计算梯度的直方图,将局部区域内的梯度方向分组,得到一个包含多个方向的直方图。
(5)归一化:对每个小的局部区域的直方图进行归一化处理,以减小光照变化对特征提取的影响。
(6)连接直方图:将所有局部区域的直方图连接起来,得到整个图像的特征描述向量,即HOG特征向量。
2.行人检测流程行人检测主要包括以下几个步骤:(1)图像预处理:对输入图像进行尺度归一化、平滑处理等操作,以增强图像的特征。
(2)HOG特征提取:对预处理后的图像进行HOG特征提取,得到每个局部区域的特征描述向量。
(3)滑窗检测:采用滑窗方式在图像上进行行人检测,将滑窗移动到图像的不同位置,并在每个位置上计算HOG特征向量的相似度。
(4)非极大值抑制:对检测结果进行非极大值抑制,以消除重叠的检测框。
(5)输出结果:将最终的检测结果输出,并将检测框绘制在原图像上。
3.HOG特征的优缺点HOG特征提取算法具有以下优点:(1)HOG特征能够有效地描述图像的局部纹理和结构特征,对光照变化、姿态变化和遮挡具有较好的鲁棒性。
(2)HOG特征适合于基于机器学习方法的行人检测,可以与支持向量机(SVM)等分类器结合使用。
基于HOG特征的智能行人检测(SVM分类器)

有关行人的智能检测,近年来可谓是一个热门话题。
日益流行的“智慧城市”的设想中,行人检测也可以应用在例如智能交通、安防等事业中。
来自法国的研究人员Navneet Dalal 等软件高手在2005年首次提出了HOG,即梯度直方图特征。
并以线性SVM作为分类器训练大量样本。
在他们大量的实验后证明,这样的研发成品可以很好得实现行人检测。
令人欣喜的是,强大的计算机视觉库OPENCV中现在已经有了HOG特征描述算子的API,而线性支持向量机SVM也是早早得就集成于OPENCV中了。
以上关于算法的介绍很粗线条,如果有对此感兴趣的朋友,给你们推荐个网址吧:/publications我想这个应该是最详实也是最权威的了,重点是2005年和2006年两篇,不过是全英文的,写得相当不错。
好了现在进入正题吧,我接触这个领域时间并不是很久,有幸现在到一家公司实习加上导师给的一些机会研究了一段时间,相信也有很多朋友在领域的门槛处跌倒了又跌倒,当然更有很多高手勇攀高峰。
所谓众口难调,我把这些天来的成果代码放在下面“示众”,跟我同一水平线的新手们可以看看,我保证这份代码是可以跑通的。
天外有天,人外有的那些高手们也可以赏光一览,若可朱笔一批,小生定不胜感激。
首先有几点说明的是:1.我用的win7 64位+vs2008+opencv2.3完成的项目,关于这个配置网上有很详细的资料。
也并不是很难。
如果是新手你还是听我唠叨两句:必须看好自己的电脑配置和软件版本,兼容问题不容小视;不要随意相信网上乱七八糟的说法,可以去CSDN或者OPENCV中文论坛上搜索文档配置方法。
那才是最靠谱儿的王道啊!2.关于OPENCV读取视频。
这个问题纠结了我大半天时间,cvCreateFileCapture这个函数比较逗,并不是所有的视频都可以进来。
我一开始以为.avi作为后缀的没有问题,后来试试才发现A VI也有很多种编码方式。
因此,如果这个地方有问题的朋友们可以尝试下一个Xvid编码器进行编码后,一切定迎刃而解。
基于改进hog特征和svm分类器的行人检测

2020 年 第 41 卷 第 2 期
软
件பைடு நூலகம்
COMPUTER ENGINEERING & SOFTWARE
2020, Vol. 41, No. 2 国际 IT 传媒品牌
基于改进 HOG 特征和 SVM 分类器的行人检测
纪 冕,张 欣,徐 海
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
摘 要: 本文首先研究了行人检测的方法和面临的难点,然后根据高斯平滑滤波器和双线性插值法对传统方向 梯度直方图做了改进,并搭建了支持向量机模型,从而构建了基于改进 HOG 特征和 SVM 分类器的行人检测系统。 实验结果显示,在明亮且无遮挡的场景下,矩形框精确地定位行人,在光照不足或存在轻微遮挡时可以大体定位到 行人,表明该系统在明亮无遮挡的情况下有准确的结果,并且在昏暗和轻度遮挡下检测效果良好,最后通过对比可 以得出,本文提出的方法总体效果优于传统 HOG 特征和 SVM 分类器的方法。
【Abstract】: This paper first studies the pedestrian detection method and the difficulties it faces, then improves the traditional direction gradient histogram according to Gaussian smoothing filter and bilinear interpolation method, and builds the support vector machine model to construct the improved HOG feature. And the pedestrian detection system of the SVM classifier. The experimental results show that in a bright and unobstructed scene, the rectangular frame accurately locates the pedestrian, and when the brightness is not bright enough or there is slight occlusion, the pedestrian can be generally positioned, indicating that the system has accurate results in the case of bright unobstructed, and The detection effect is good under dim and light occlusion. It can be concluded that the overall effect of the proposed method is better than the traditional HOG feature and SVM classifier. 【Key words】: Pedestrian detection; HOG features; SVM classifier; Tracking algorithm; Gradient; Optimum classification surface
openCV_cvhog详解

首先关于HOG算法:#include "_cvaux.h"/*****************************************************************************************struct CV_EXPORTS HOGDescriptor{public:enum { L2Hys=0 };HOGDescriptor() : winSize(64,128), blockSize(16,16), blockStride(8,8),cellSize(8,8), nbins(9), derivAperture(1), winSigma(-1),histogramNormType(L2Hys), L2HysThreshold(0.2), gammaCorrection(true){}HOGDescriptor(Size _winSize, Size _blockSize, Size _blockStride,Size _cellSize, int _nbins, int _derivAperture=1, double _winSigma=-1,int _histogramNormType=L2Hys, double _L2HysThreshold=0.2, bool _gammaCorrection=false): winSize(_winSize), blockSize(_blockSize), blockStride(_blockStride), cellSize(_cellSize), nbins(_nbins), derivAperture(_derivAperture), winSigma(_winSigma), histogramNormType(_histogramNormType), L2HysThreshold(_L2HysThreshold), gammaCorrection(_gammaCorrection){}HOGDescriptor(const String& filename){load(filename);}virtual ~HOGDescriptor() {}size_t getDescriptorSize() const;bool checkDetectorSize() const;double getWinSigma() const;virtual void setSVMDetector(const vector<float>& _svmdetector);virtual bool load(const String& filename, const String& objname=String());virtual void save(const String& filename, const String& objname=String()) const;virtual void compute(const Mat& img,vector<float>& descriptors,Size winStride=Size(), Size padding=Size(),const vector<Point>& locations=vector<Point>()) const;virtual void detect(const Mat& img, vector<Point>& foundLocations,double hitThreshold=0, Size winStride=Size(),Size padding=Size(),const vector<Point>& searchLocations=vector<Point>()) const;virtual void detectMultiScale(const Mat& img, vector<Rect>& foundLocations,double hitThreshold=0, Size winStride=Size(),Size padding=Size(), double scale=1.05,int groupThreshold=2) const;//Mat& angleOfs,与后文Mat& qangle不一致,怀疑是笔误,由于qangle与angleOfs有不同含义,尽量改过来virtual void computeGradient(const Mat& img, Mat& grad, Mat& angleOfs,Size paddingTL=Size(), Size paddingBR=Size()) const;static vector<float> getDefaultPeopleDetector();Size winSize;//窗口大小Size blockSize;//Block大小Size blockStride;//block每次移动宽度包括水平和垂直两个方向Size cellSize;//Cell单元大小int nbins;//直方图bin数目int derivAperture;//不知道什么用double winSigma;//高斯函数的方差int histogramNormType;//直方图归一化类型,具体见论文double L2HysThreshold;//L2Hys化中限制最大值为0.2bool gammaCorrection;//是否Gamma校正vector<float> svmDetector;//检测算子};**********************************************************************************/namespace cv{size_t HOGDescriptor::getDescriptorSize() const{//检测数据的合理性CV_Assert(blockSize.width % cellSize.width == 0 &&blockSize.height % cellSize.height == 0);CV_Assert((winSize.width - blockSize.width) % blockStride.width == 0 &&(winSize.height - blockSize.height) % blockStride.height == 0 );//Descriptor的大小return (size_t)nbins*(blockSize.width/cellSize.width)*(blockSize.height/cellSize.height)*((winSize.width - blockSize.width)/blockStride.width + 1)*((winSize.height - blockSize.height)/blockStride.height + 1);//9*(16/8)*(16/8)*((64-16)/8+1)*((128-16)/8+1)=9*2*2*7*15=3780,实际上的检测算子为3781,多的1表示偏置}double HOGDescriptor::getWinSigma() const{//winSigma默认为-1,然而有下式知,实际上为4;否则自己选择参数return winSigma >= 0 ? winSigma : (blockSize.width + blockSize.height)/8.;}bool HOGDescriptor::checkDetectorSize() const{//size_t:unsigned intsize_t detectorSize = svmDetector.size(), descriptorSize = getDescriptorSize();//三种情况任意一种为true则表达式为true,实际上是最后一种return detectorSize == 0 ||detectorSize == descriptorSize ||detectorSize == descriptorSize + 1;}void HOGDescriptor::setSVMDetector(const vector<float>& _svmDetector){svmDetector = _svmDetector;CV_Assert( checkDetectorSize() );}bool HOGDescriptor::load(const String& filename, const String& objname){//XML/YML文件存储FileStorage fs(filename, FileStorage::READ);//objname为空,!1=0,选择fs.getFirstT opLevelNode();否则为fs[objname]//注意到FileStorage中[]重载了:FileNode operator[](const string& nodename)(returns the top-level node by name )FileNode obj = !objname.empty() ? fs[objname] : fs.getFirstTopLevelNode();if( !obj.isMap() )return false;FileNodeIterator it = obj["winSize"].begin();it >> winSize.width >> winSize.height;it = obj["blockSize"].begin();it >> blockSize.width >> blockSize.height;it = obj["blockStride"].begin();it >> blockStride.width >> blockStride.height;it = obj["cellSize"].begin();it >> cellSize.width >> cellSize.height;obj["nbins"] >> nbins;obj["derivAperture"] >> derivAperture;obj["winSigma"] >> winSigma;obj["histogramNormType"] >> histogramNormType;obj["L2HysThreshold"] >> L2HysThreshold;obj["gammaCorrection"] >> gammaCorrection;FileNode vecNode = obj["SVMDetector"];if( vecNode.isSeq() ){vecNode >> svmDetector;CV_Assert(checkDetectorSize());}return true;}void HOGDescriptor::save(const String& filename, const String& objName) const{FileStorage fs(filename, FileStorage::WRITE);//空的对象名则取默认名,输出有一定格式,对象名后紧接{fs << (!objName.empty() ? objName : FileStorage::getDefaultObjectName(filename)) << "{";//之后依次为:fs << "winSize" << winSize<< "blockSize" << blockSize<< "blockStride" << blockStride<< "cellSize" << cellSize<< "nbins" << nbins<< "derivAperture" << derivAperture<< "winSigma" << getWinSigma()<< "histogramNormType" << histogramNormType<< "L2HysThreshold" << L2HysThreshold<< "gammaCorrection" << gammaCorrection;if( !svmDetector.empty() )fs << "SVMDetector" << "[:" << svmDetector << "]";//注意还要输出"}"fs << "}";//img:原始图像//grad:记录每个像素所属bin对应的权重的矩阵,为幅值乘以权值//这个权值是关键,也很复杂:包括高斯权重,三次插值的权重,在本函数中先值考虑幅值和相邻bin间的插值权重//qangle:记录每个像素角度所属的bin序号的矩阵,均为2通道,为了线性插值//paddingTL:Top和Left扩充像素数//paddingBR:类似同上//功能:计算img经扩张后的图像中每个像素的梯度和角度void HOGDescriptor::computeGradient(const Mat& img, Mat& grad, Mat& qangle,Size paddingTL, Size paddingBR) const{//先判断是否为单通道的灰度或者3通道的图像CV_Assert( img.type() == CV_8U || img.type() == CV_8UC3 );//计算gradient的图的大小,由64*128==》112*160,则会产生5*7=35个窗口(windowstride:8)//每个窗口105个block,105*36=3780维特征向量//paddingTL.width=16,paddingTL.height=24Size gradsize(img.cols + paddingTL.width + paddingBR.width,img.rows + paddingTL.height + paddingBR.height);//注意grad和qangle是2通道的矩阵,为3D-trilinear插值中的orientation维度,另两维为坐标x与ygrad.create(gradsize, CV_32FC2); // <magnitude*(1-alpha), magnitude*alpha>qangle.create(gradsize, CV_8UC2); // [0..nbins-1] - quantized gradient orientation//wholeSize为parent matrix大小,不是扩展后gradsize的大小//roiofs即为img在parent matrix中的偏置//对于正样本img=parent matrix;但对于负样本img是从parent img中抽取的10个随机位置//至于OpenCv具体是怎么操作,使得img和parent img相联系,不是很了解//wholeSize与roiofs仅在padding时有用,可以不管,就认为传入的img==parent img,是否是从parent img中取出无所谓Size wholeSize;Point roiofs;img.locateROI(wholeSize, roiofs);int i, x, y;int cn = img.channels();//产生1行256列的向量,lut为列向量头地址Mat_<float> _lut(1, 256);const float* lut = &_lut(0,0);//gamma校正,作者的编程思路很有意思//初看不知道这怎么会与图像的gamma校正有关系,压根img都没出现,看到后面大家会豁然开朗的if( gammaCorrection )for( i = 0; i < 256; i++ )_lut(0,i) = std::sqrt((float)i);elsefor( i = 0; i < 256; i++ )_lut(0,i) = (float)i;//开辟空间存xmap和ymap,其中各占gradsize.width+2和gradsize.height+2空间//+2是为了计算dx,dy时用[-1,0,1]算子,即使在扩充图像中,其边缘计算梯度时还是要再额外加一个像素的//作者很喜欢直接用内存地址及之间的关系,初看是有点头大的//另外再说说xmap与ymap的作用:其引入是因为img图像需要扩充到gradsize大小//如果我们计算img中位于(-5,-6)像素时,需要将基于img的(-5,-6)坐标,映射为基于grad和qangle的坐标(xmap,ymap)AutoBuffer<int> mapbuf(gradsize.width + gradsize.height + 4);int* xmap = (int*)mapbuf + 1;int* ymap = xmap + gradsize.width + 2;// BORDER_REFLECT_101:(左插值)gfedcb|abcdefgh(原始像素)|gfedcba(右插值),一种插值模式 const int borderType = (int)BORDER_REFLECT_101;//borderInterpolate函数完成两项操作,一是利用插值扩充img,二是返回x-paddingTL.width+roiofs.x映射后的坐标xmap//例如,ximg=x(取0)-paddingTL.width(取24)+roiofs.x(取0)=-24 ==>xmap[0]=0//即img中x=-24,映射到grad中xmap=0,并且存在xmap[0]中,至于borderInterpolate的具体操作可以不必细究for( x = -1; x < gradsize.width + 1; x++ )xmap[x] = borderInterpolate(x - paddingTL.width + roiofs.x,wholeSize.width, borderType);for( y = -1; y < gradsize.height + 1; y++ )ymap[y] = borderInterpolate(y - paddingTL.height + roiofs.y,wholeSize.height, borderType);// x- & y- derivatives for the whole row// 由于后面的循环是以行为单位,每次循环内存重复使用,所以只要记录一行的信息而不是整个矩阵int width = gradsize.width;AutoBuffer<float> _dbuf(width*4);float* dbuf = _dbuf;//注意到内存的连续性方便之后的编程Mat Dx(1, width, CV_32F, dbuf);Mat Dy(1, width, CV_32F, dbuf + width);Mat Mag(1, width, CV_32F, dbuf + width*2);Mat Angle(1, width, CV_32F, dbuf + width*3);int _nbins = nbins;float angleScale = (float)(_nbins/CV_PI);//9/pifor( y = 0; y < gradsize.height; y++ ){//指向每行的第一个元素,img.data为矩阵的第一个元素地址const uchar* imgPtr = img.data + img.step*ymap[y];const uchar* prevPtr = img.data + img.step*ymap[y-1];const uchar* nextPtr = img.data + img.step*ymap[y+1];float* gradPtr = (float*)grad.ptr(y);uchar* qanglePtr = (uchar*)qangle.ptr(y);//1通道if( cn == 1 ){for( x = 0; x < width; x++ ){int x1 = xmap[x];//imgPtr指向img第y行首元素,imgPtr[x]即表示第(x,y)像素,其亮度值位于0~255,对应lut[0]~lut[255]//即若像素亮度为120,则对应lut[120],若有gamma校正,lut[120]=sqrt(120)//由于补充了虚拟像素,即在imgPtr[-1]无法表示gradsize中-1位置元素,而需要有个转换//imgPtr[-1-paddingTL.width+roiofs.x],即imgPtr[xmap[-1]],即gradsize中-1位置元素为img 中xmap[-1]位置的元素dbuf[x] = (float)(lut[imgPtr[xmap[x+1]]] - lut[imgPtr[xmap[x-1]]]);//由于内存的连续性,隔width,即存Dydbuf[width + x] = (float)(lut[nextPtr[x1]] - lut[prevPtr[x1]]);}}else//3通道,3通道中取最大值{for( x = 0; x < width; x++ ){int x1 = xmap[x]*3;const uchar* p2 = imgPtr + xmap[x+1]*3;const uchar* p0 = imgPtr + xmap[x-1]*3;float dx0, dy0, dx, dy, mag0, mag;dx0 = lut[p2[2]] - lut[p0[2]];dy0 = lut[nextPtr[x1+2]] - lut[prevPtr[x1+2]];mag0 = dx0*dx0 + dy0*dy0;dx = lut[p2[1]] - lut[p0[1]];dy = lut[nextPtr[x1+1]] - lut[prevPtr[x1+1]];mag = dx*dx + dy*dy;if( mag0 < mag ){dx0 = dx;dy0 = dy;mag0 = mag;}dx = lut[p2[0]] - lut[p0[0]];dy = lut[nextPtr[x1]] - lut[prevPtr[x1]];mag = dx*dx + dy*dy;if( mag0 < mag ){dx0 = dx;dy0 = dy;mag0 = mag;}dbuf[x] = dx0;dbuf[x+width] = dy0;}}//函数cvCartToPolar 计算二维向量(x(I),y(I))的长度,角度://magnitude(I) = sqrt(x(I)2 + y(I)2),angle(I) = atan(y(I) / x(I)),注意属于-pi/2~pi/2 cartToPolar( Dx, Dy, Mag, Angle, false );for( x = 0; x < width; x++ ){float mag = dbuf[x+width*2];float angle = dbuf[x+width*3]*angleScale - 0.5f;//-5<=angle<=4//判断angle属于哪个binint hidx = cvFloor(angle);angle -= hidx;//hidx=-5~-1===>4~8if( hidx < 0 )hidx += _nbins;else if( hidx >= _nbins )hidx -= _nbins;//检测是否<9assert( (unsigned)hidx < (unsigned)_nbins );qanglePtr[x*2] = (uchar)hidx;hidx++;//hidx = hidx & 1111 1111 当hidx<nbins,即hidx=hidx//hidx = hidx & 0000 0000 当hidx>=nbins,即hidx=0//注意到nbins=9时,hidx最大值只为8hidx &= hidx < _nbins ? -1 : 0;//qangle两通道分别存放相邻的两个binqanglePtr[x*2+1] = (uchar)hidx;//幅度,注意此时的0<angle<1,由于hidx = cvFloor(angle),angle -= hidx;gradPtr[x*2] = mag*(1.f - angle);gradPtr[x*2+1] = mag*angle;}}}//HOG存储结构,每个window包含105block,每个block包含36binstruct HOGCache{struct BlockData{BlockData() : histOfs(0), imgOffset() {}//以block为单位,譬如block[0]中的36个bin在内存中位于最前面//而block[1]中的36个bin存储位置在连续内存中则有一个距离起点的偏置,即为histOfs:hist offsetint histOfs;//imgOffset表示该block在检测窗口window中的位置Point imgOffset;};//PixData是作者程序中比较晦涩的部分,具体见后面程序分析//gradOfs:该pixel的grad在Mat grad中的位置,是一个数:(grad.cols*i+j)*2,2表示2通道//qangleOfs:pixel的angle在Mat qangle中的位置,是一个数:(qangle.cols*i+j)*2,2表示2通道//histOfs[4]:在后面程序中,作者把一个block中的像素分为四个区域,每个区域的像素最多对四个不同Cell中的hist有贡献//即一个区域中进行直方图统计,则最多包含四个Cell的不同直方图,histOfs[i]表示每个区域中的第i个直方图//在整个block直方图存储空间中的距离原始位置的偏置//显然第一个Cell的hist其对应的histOfs[0]=0,依次类推有:histOfs[1]=9,histOfs[2]=18,histOfs[3]=27//|_1_|_2_|_3_|_4_|一个block四个cell,这里把每个cell又分四分,1,2,5,6中像素统计属于hist[0],3,4,7,8在hist[1]...//|_5_|_6_|_7_|_8_|作者将一个block分为了四块区域为:A:1,4,13,16/B:2,3,14,15/C:5,9,8,12/D:6,7,10,11//|_9_|_10|_11|_12|作者认为A区域中的像素只对其所属的Cell中的hist有贡献,即此区域的像素只会产生一个hist//|_13|_14|_15|_16|而B区域2,3的像素会对Cell0与Cell1中的hist有贡献,相应的会产生hist[0]与hist[1],14,15类似//C区域与B区域类似,会对上下两个Cell的hist产生影响,而D区域会对相邻四个Cell 的hist产生影响//histWeights:每个像素对不同cell的hist贡献大小,由像素在block中的位置决定//个人觉得这是论文中trilinear插值中对于position中x和y两个维度的插值//其中像素的角度对于相邻两个bin的权重在HOGDescriptor::computerGradient中已有体现,至此trilinear完成//其实作者认为每个像素对于其他cell的hist的影响,其大小与该像素距各个cell中心的距离决定//譬如处于中心的像素(8,8)可以认为对每个cell的hist贡献一样,后面程序中权重的分配也可以看出//gradWeight:为幅值与高斯权重的乘积//其中高斯权重选择exp^(-(dx^2+dy^2)/(2*sigma^2)),sigma在HOGDescriptor中决定,以block中(8,8)为中心//区别gradWeight和histWeight,gradWeight认为在同一个Cell中不同元素对hist的贡献是不一样的,由二维高斯分布决定//而histweight说的是一个元素对不同cell中的hist的贡献不同,其贡献由其坐标距离各个cell的距离决定struct PixData{size_t gradOfs, qangleOfs;int histOfs[4];float histWeights[4];float gradWeight;};HOGCache();HOGCache(const HOGDescriptor* descriptor,const Mat& img, Size paddingTL, Size paddingBR,bool useCache, Size cacheStride);virtual ~HOGCache() {};virtual void init(const HOGDescriptor* descriptor,const Mat& img, Size paddingTL, Size paddingBR,bool useCache, Size cacheStride);//windowsInImage返回Image中横竖可产生多少个windowsSize windowsInImage(Size imageSize, Size winStride) const;//依据img大小,窗口移动步伐,即窗口序号得到窗口在img中的位置Rect getWindow(Size imageSize, Size winStride, int idx) const;//buf为存储blockdata的内存空间,pt为block在parent img中的位置const float* getBlock(Point pt, float* buf);virtual void normalizeBlockHistogram(float* histogram) const;vector<PixData> pixData;vector<BlockData> blockData;//以下的参数是为了充分利用重叠的block信息,避免重叠的block信息重复计算采用的一种缓存思想具体见后面代码bool useCache;//是否存储已经计算的block信息vector<int> ymaxCached;//见后文Size winSize, cacheStride;//cacheStride认为等于blockStride,降低代码的复杂性Size nblocks, ncells;int blockHistogramSize;int count1, count2, count4;Point imgoffset;//img在扩展后图像中img原点关于扩展后原点偏置Mat_<float> blockCache;//待检测图像中以检测窗口进行横向扫描,所扫描的block信息存储在blockCache中Mat_<uchar> blockCacheFlags;//判断当前block的信息blockCache中是否有存储,1:存储,于是直接调用;0:未存储,需要把信息存储到blockCache中Mat grad, qangle;const HOGDescriptor* descriptor;};HOGCache::HOGCache(){useCache = false;blockHistogramSize = count1 = count2 = count4 = 0;descriptor = 0;}HOGCache::HOGCache(const HOGDescriptor* _descriptor,const Mat& _img, Size _paddingTL, Size _paddingBR,bool _useCache, Size _cacheStride){init(_descriptor, _img, _paddingTL, _paddingBR, _useCache, _cacheStride);}//初始化主要包括:1、block中各像素对block四个bin的贡献权重,以及在存储空间中的位置记录//2、block的初始化,以及每个block在存储空间中的偏置及在检测窗口中的位置记录//3、其他参数的赋值//并没有实际计算HOGvoid HOGCache::init(const HOGDescriptor* _descriptor,const Mat& _img, Size _paddingTL, Size _paddingBR,bool _useCache, Size _cacheStride){descriptor = _descriptor;cacheStride = _cacheStride;useCache = _useCache;descriptor->computeGradient(_img, grad, qangle, _paddingTL, _paddingBR);imgoffset = _paddingTL;//16,24winSize = descriptor->winSize;//64*128Size blockSize = descriptor->blockSize;//16*16Size blockStride = descriptor->blockStride;//8*8Size cellSize = descriptor->cellSize;//8*8Size winSize = descriptor->winSize;//64*128int i, j, nbins = descriptor->nbins;//9int rawBlockSize = blockSize.width*blockSize.height;//16*16=256nblocks = Size((winSize.width - blockSize.width)/blockStride.width + 1,(winSize.height - blockSize.height)/blockStride.height + 1);//7*15=105ncells = Size(blockSize.width/cellSize.width, blockSize.height/cellSize.height);//2*2=4 blockHistogramSize = ncells.width*ncells.height*nbins;//9*2*2=36//对于训练时,该段代码不起作用;对于检测时,该段代码可以提高运行速度。
利用HOG+SVM实现行人检测

利⽤HOG+SVM实现⾏⼈检测利⽤HOG+SVM实现⾏⼈检测很久以前做的⾏⼈检测,现在稍加温习,上传记录⼀下。
⾸先解析视频,提取视频的每⼀帧形成图⽚存到磁盘。
代码如下import osimport cv2videos_src_path = 'D:\\test1'videos_save_path = 'D:\\test2'videos = os.listdir(videos_src_path)videos = filter(lambda x: x.endswith('avi'), videos)for each_video in videos:print (each_video)# get the name of each video, and make the directory to save frameseach_video_name, _ = each_video.split('.')os.mkdir(videos_save_path + '/' + each_video_name)each_video_save_full_path = os.path.join(videos_save_path, each_video_name) + '/'# get the full path of each video, which will open the video tp extract frameseach_video_full_path = os.path.join(videos_src_path, each_video)cap = cv2.VideoCapture(each_video_full_path)frame_count = 1success = Truewhile(success):success, frame = cap.read()print ('Read a new frame: ', success)params = []params.append(1)params.append(1)cv2.imwrite(each_video_save_full_path + each_video_name + "_%05d.ppm" % frame_count, frame, params)frame_count = frame_count + 1cap.release()对于图⽚的⾏⼈检测应⽤了梯度⽅向直⽅图和⽀持向量机。
hog行人检测原理

hog行人检测原理
HOG(HistogramofOrientedGradient)是一种用于行人检测的特征提取方法。
它的原理是基于图像中物体边缘的梯度方向进行计算,并将其转换为直方图形式,用于描述图像的局部特征。
通过对局部特征的统计分析,可以判断图像中是否存在行人。
HOG 特征提取的流程主要包括以下几个步骤:
1. 图像预处理:将图像进行灰度化、归一化和平滑化处理,以便提高计算效率和减少图像噪声对结果的影响。
2. 计算梯度幅值和方向:在图像中计算每个像素点的梯度幅值和方向,以便确定局部梯度信息。
3. 划分 cell 和块:将图像划分为多个 cell 和块,每个 cell 包含多个像素点,每个块由多个 cell 组成。
4. 统计梯度直方图:在每个 cell 中统计像素点的梯度方向,并将其转换为梯度直方图,用于描述局部特征。
在每个块中将多个cell 的梯度直方图进行归一化处理,以便提高特征的鲁棒性和可靠性。
5. 构建行人模型:通过对多个块的特征进行统计分析,构建行人模型,并使用分类器对其进行分类,以判断图像中是否存在行人。
HOG 行人检测方法具有较高的准确率和鲁棒性,在实际应用中得到了广泛应用。
它不仅可以用于行人检测,还可以应用于车辆检测、人脸识别等领域。
- 1 -。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
HOG(Histogram of Oriented Gradient)特征在对象检测与模式匹配中是一种常见的特征提取算法,是基于本地像素块进行特征直方图提取的一种算法,对象局部的变形与光照影响有很好的稳定性,最初是用HOG特征来来识别人像,通过HOG特征提取+SVM训练,可以得到很好的效果,OpenCV已经有了。
HOG特征提取的大致流程如下:
详细步骤
第一步:灰度化
对HOG特征提取来说第一步是对输入的彩色图像转换为灰度图像,图像灰度化的方法有很多,不同灰度化方法之间有一些微小的差异,从彩色到灰度的图像转换可以表示如下:
第二步:计算图像梯度
计算图像的X方向梯度dx与Y方向梯度dy,根据梯度计算mag与角度,计算梯度时候可以先高斯模糊一下(可选步骤),然后使用sobel或者其它一阶导数算子计算梯度值dx、dy、mag、angle:
第三步:Cell分割与Block
对于图像来说,分成8x8像素块,每个块称为一个Cell,每个2x2大小的
Cell称为一个Block,每个Cell根据角度与权重建立直方图,每20度为一
个BIN,每个Cell得到9个值、每个Block得到36个值(4x9), 图像如下:
每个Block为单位进行L2数据归一化,作用是抵消光照/迁移影响,L2的归一化的公式如下:
第四步:生成描述子
对于窗口64x128范围大小的像素块,可以得到8x16个Cell,使用Block
在窗口移动,得到输出的向量总数为7x15x36=3780特征向量,每次Block
移动步长是八个像素单位,一个Cell大小。
使用HOG特征数据
HOG特征本身是不支持旋转不变性与多尺度检测的,但是通过构建高斯金字塔实现多尺度的开窗检测就会得到不同分辨率的多尺度检测支持。
OpenCV中HOG多尺度对象检测API如下:
virtual void cv::HOGDescriptor::detectMultiScale(
InputArray img,
std::vector< Rect > & foundLocations,
double hitThreshold = 0,
Size winStride = Size(),
Size padding = Size(),
double scale = 1.05,
double finalThreshold = 2.0,
bool useMeanshiftGrouping = false
)
Img-表示输入图像
foundLocations-表示发现对象矩形框
hitThreshold-表示SVM距离度量,默认0表示,表示特征与SVM分类超平面之间
winStride-表示窗口步长
padding-表示填充
scale-表示尺度空间
finalThreshold-最终阈值,默认为2.0
useMeanshiftGrouping-不建议使用,速度太慢拉
使用OpenCV预训练SVM行人HOG特征分类器实现多尺度行人检测的代码如下:
import cv2 as cv
if __name__ == '__main__':
src = cv.imread("D:/images/pedestrian.png")
cv.imshow("input", src)
hog = cv.HOGDescriptor()
hog.setSVMDetector(cv.HOGDescriptor_getDefaultPeopleDetector()) # Detect people in the image
(rects, weights) = hog.detectMultiScale(src,
winStride=(4, 4),
padding=(8, 8),
scale=1.25,
useMeanshiftGrouping=False)
for (x, y, w, h) in rects:
cv.rectangle(src, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv.imshow("hog-detector", src)
cv.waitKey(0)
cv.destroyAllWindows()
原图显示如下:
运行显示如下:。