fork()
fork的用法小结

fork的用法小结fork的用法小结“One day Alice came to a fork in the road and saw a Cheshire cat in a tree. ‘Which road do I take?’ she asked. ‘Where do you want to go?’ was his response. ‘I don’t know,’ Alice answered. ‘Then,’ said the cat, ‘it doesn’t matter.'”—— Lewis Carroll「有一天爱丽丝来到了一个路的`叉口,看到树上有一只猫。
爱丽丝问:「我该走哪条路呢?」猫答复:「妳想去哪里?」爱丽丝答复:「我不知道。
」猫说:「假设是如此,走哪条路都可以。
」」——路易斯· 卡罗一、下面我们来看看fork有几种含义n.1.餐叉 [C]Put your knife and fork down on the plate ifyou've finished eating.要是你吃完了就把刀叉放在盘子上。
2.叉,耙;车叉子;叉状物We came to a fork in the road, and we couldn't decide whether to take the left fork or the right.我们走到分叉路,无法决定该走左边的还是右边的岔道。
v.1.分叉;分歧;使成叉状 [I,T]Beyond the village the road forked.过了村子之后路分了岔。
2.走岔路 [T]Just before the town boundary fork left onto a minor road.快到城镇边界时要走岔路的左边一条小路。
3.叉,耙 [T]Fork the bales and lift them onto the wagon.用叉子把草捆挑到马车上去。
关于父进程和子进程关系,以及fork()进程数量

关于⽗进程和⼦进程关系,以及fork()进程数量⽗进程和⼦进程关系:⼦进程拥有⽗进程⼏乎所有资源的拷贝,重新复制存储空间,包括标准输⼊,输出的缓冲空间以及程序。
当程序中出现fork后,⼦进程将从fork语句开始复制程序代码,并且在⼦进程中执⾏。
关于fork()执⾏后,在⼦进程中返回值为0,在⽗进程中返回值为整数即⼦进程的ID。
1)循环fork()N次,产⽣多少个⼦进程/** fork_test.c* version 3* Created on: 2010-5-29* Author: wangth*/#include <unistd.h>#include <stdio.h>int main(void){int i=0;for(i=0;i<3;i++){pid_t fpid=fork();if(fpid==0)printf("son/n");elseprintf("father/n");}return 0;} 根据以上程序可知,产⽣的⼦进程数量为:1+2+4+……+2N-1执⾏printf的打印次数为:2*(1+2+4+……+2N-1)次2)⼦进程会复制⽗进程的输⼊输出缓冲区,如果⽗进程的输⼊输出缓冲区没有输出的话,⼦进程会复制int main() {pid_t fpid;//fpid表⽰fork函数返回的值//printf("fork!");printf("fork!/n");fpid = fork();if (fpid < 0)printf("error in fork!");else if (fpid == 0)printf("I am the child process, my process id is %d/n", getpid());elseprintf("I am the parent process, my process id is %d/n", getpid());return 0;}3)以下fork()连续中会产⽣多少个新的⼦进程#include <stdio.h>#include <unistd.h>int main(int argc, char* argv[]){fork();fork() && fork() || fork();fork();return 0;}如果有⼀个这样的表达式:cond1 && cond2 || cond3 这句代码会怎样执⾏呢?1、cond1为假,那就不判断cond2了,接着判断cond32、cond1为真,这⼜要分为两种情况:a、cond2为真,这就不需要判断cond3了b、cond2为假,那还得判断cond3fork调⽤的⼀个奇妙之处在于它仅仅被调⽤⼀次,却能够返回两次,它可能有三种不同的返回值:1、在⽗进程中,fork返回新创建⼦进程的进程ID;2、在⼦进程中,fork返回0;3、如果出现错误,fork返回⼀个负值(题⼲中说明了不⽤考虑这种情况)在fork函数执⾏完毕后,如果创建新进程成功,则出现两个进程,⼀个是⼦进程,⼀个是⽗进程。
fork函数超详解及其用法

3. 进程控制上一页第30 章进程下一页3. 进程控制3.1. fork函数#include <sys/types.h>#include <unistd.h>pid_t fork(void);fork调用失败则返回-1,调用成功的返回值见下面的解释。
我们通过一个例子来理解fork是怎样创建新进程的。
例30.3. fork#include <sys/types.h>#include <unistd.h>#include <stdio.h>#include <stdlib.h>int main(void){pid_t pid;char *message;int n;pid = fork();if (pid < 0) {perror("fork failed");exit(1);}if (pid == 0) {message = "This is the child\n"; n = 6;} else {message = "This is the parent\n"; n = 3;}for(; n > 0; n--) {printf(message);sleep(1);}return 0;}$ ./a.outThis is the childThis is the parentThis is the childThis is the parentThis is the childThis is the parentThis is the child$ This is the childThis is the child这个程序的运行过程如下图所示。
图30.4. fork父进程初始化。
父进程调用fork,这是一个系统调用,因此进入内核。
内核根据父进程复制出一个子进程,父进程和子进程的PCB信息相同,用户态代码和数据也相同。
linux操作系统下fork函数理解

linux操作系统下fork函数理解在Linux操作系统中,fork函数是一个非常重要的系统调用,它用于创建一个新的进程。
本文将详细解释fork函数的作用、用法和实现原理,并介绍如何利用fork函数实现进程间通信以及避免一些常见的问题。
一、fork函数的作用和用法在Linux系统中,fork函数用于创建一个新的进程,该进程是调用fork函数的进程的一个副本。
具体而言,fork函数会创建一个新的进程,称为子进程,而调用fork函数的进程被称为父进程。
子进程从fork函数返回的地方开始执行,而父进程则继续执行fork函数之后的代码。
简单来说,fork函数的作用就是将一个进程复制成两个几乎完全相同的进程,但它们具有不同的进程ID(PID)。
fork函数的用法非常简单,只需要在程序中调用fork()即可。
具体代码如下所示:```c#include <stdio.h>#include <sys/types.h>#include <unistd.h>int main() {pid_t pid = fork();if (pid == 0) {// 子进程代码} else if (pid > 0) {// 父进程代码} else {// fork失败的处理代码}return 0;}```在上述代码中,首先使用pid_t类型的变量pid存储fork函数的返回值。
如果pid等于0,则表示当前执行的是子进程的代码;如果pid大于0,则表示当前执行的是父进程的代码;如果pid小于0,则表示fork函数调用失败。
二、fork函数的实现原理在Linux系统中,fork函数的实现是通过复制父进程的内存空间来创建子进程的。
具体来说,fork函数会创建一个新的进程控制块(PCB),并将父进程的PCB全部复制到子进程的PCB中,包括代码段、数据段、堆栈等。
由于子进程是父进程的一个副本,所以它们的代码和数据是完全相同的。
操作系统实验fork()

并发程序设计【实验目的】:掌握在程序中创建新进程的方法,观察并理解多道程序并发执行的现象。
【实验原理】:fork():建立子进程。
子进程得到父进程地址空间的一个复制。
返回值:成功时,该函数被调用一次,但返回两次,fork()对子进程返回0,对父进程返回子进程标识符(非0值)。
不成功时对父进程返回-1,没有子进程。
【实验内容】:首先分析一下程序运行时其输出结果有哪几种可能性,然后实际调试该程序观察其实际输出情况,比较两者的差异,分析其中的原因。
void main (void){ int x=5;if( fork(()){x+=30;printf (“%d\n”,x);}elseprintf(“%d\n”,x);printf((“%d\n”,x);}【实验要求】:每个同学必须独立完成本实验、提交实验报告、源程序和可执行程序。
实验报告中必须包含预计的实验结果,关键代码的分析,调试记录,实际的实验结果,实验结果分析等内容。
一.源程序1.1程序.#include<stdio.h>#include<sys/types.h>//pid_t类型的定义#include<unistd.h>//函数fork().getpid()定义void main (void){int x=5;if( fork( ) ){x+=30;printf ("%d\n",x);}elseprintf("%d\n",x);printf("%d\n",x);}1.2预测结果:(1)553535(2)353555(3)535535(4)535355(5)355355(6)355535(7)35351.3实际结果:administrator@ubuntu:~/yanhong$ cc 1.cadministrator@ubuntu:~/yanhong$ ./a.out353555administrator@ubuntu:~/yanhong$ cc 1.cadministrator@ubuntu:~/yanhong$ ./a.out5535351.4结果分析:结果表明,子进程先执行还是父进程先执行是不确定的。
fork函数

父进程
父进程
#include <sys/types.h> main() 执 { 行 pid_t val; printf(“PID…); 分裂 val=fork(); if(val!=0) printf(“parent…”); else printf(“child…); }
main( ) { pid_t val; printf(“PID…); val=fork(); if(val!=0) printf(“parent…”); else printf(“child…); }
运行结果1 global=5,vari=4;
global=4,vari=5;
运行结果2
global=4,vari=5; global=5,vari=4
分析:子进程和父进程的数据段、堆栈段不同。子进程执 行语句“global++,vari—”时,只是对自己的数据段 进行了修改,并未影响到父进程的数据段,
exec()—执行一个文件的调用
子进程如何执行一个新的程序文本?
通过exec()调用族,加载新的程序文本
通过一个系统调用exec,子进程可以拥有自己的可 执行代码。即exec用一个新进程覆盖调用进程。 它的参数包括新进程对应的文件和命令行参数。成 功调用时,不再返回;否则,返回出错原因。 六种exec调用格式:各种调用的区别在于参数的处 理方法不同,常用的格式有:
void main(void) { printf(“Hello \n”); fork(); printf(“Bye \n”); }
运行结果 Hello Bye Bye
fork()调用例子(2)
#include<stdio.h> #Include<sys/types.h> #include<unistd.h> void main(void){ if (fork()==0) printf(“In the CHILD process\n”); else printf(“In the PARENT process\n”); }
do_fork()分析报告
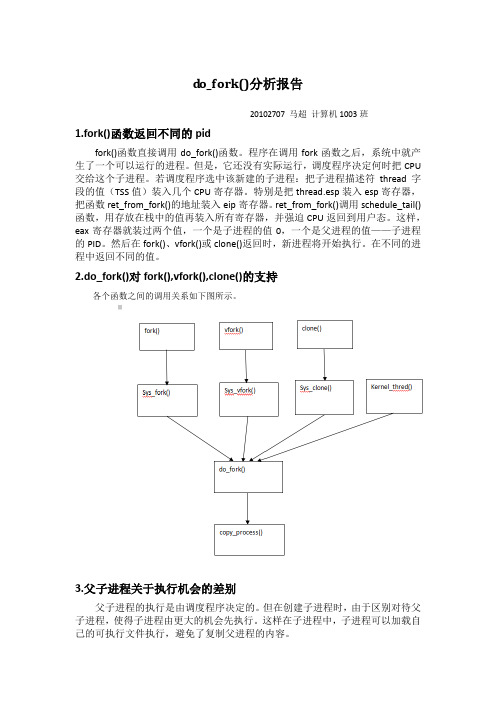
d o_fork()分析报告
20102707 马超计算机1003班
1.fork()函数返回不同的pid
fork()函数直接调用do_fork()函数。
程序在调用fork函数之后,系统中就产生了一个可以运行的进程。
但是,它还没有实际运行,调度程序决定何时把CPU 交给这个子进程。
若调度程序选中该新建的子进程:把子进程描述符thread字段的值(TSS值)装入几个CPU寄存器。
特别是把thread.esp装入esp寄存器,把函数ret_from_fork()的地址装入eip寄存器。
ret_from_fork()调用schedule_tail()函数,用存放在栈中的值再装入所有寄存器,并强迫CPU返回到用户态。
这样,eax寄存器就装过两个值,一个是子进程的值0,一个是父进程的值——子进程的PID。
然后在fork()、vfork()或clone()返回时,新进程将开始执行。
在不同的进程中返回不同的值。
2.do_fork()对fork(),vfork(),clone()的支持
各个函数之间的调用关系如下图所示。
3.父子进程关于执行机会的差别
父子进程的执行是由调度程序决定的。
但在创建子进程时,由于区别对待父子进程,使得子进程由更大的机会先执行。
这样在子进程中,子进程可以加载自己的可执行文件执行,避免了复制父进程的内容。
fork()系统调用

fork系统调用分类:LINUX1.预备知识不妨简单理解为,一个进程表示的,就是一个可执行程序的一次执行过程中的一个状态。
操作系统对进程的管理,典型的情况,是通过进程表完成的。
进程表中的每一个表项,记录的是当前操作系统中一个进程的情况。
对于单 CPU的情况而言,每一特定时刻只有一个进程占用 CPU,但是系统中可能同时存在多个活动的(等待执行或继续执行的)进程。
一个称为“程序计数器(program counter, pc)”的寄存器,指出当前占用CPU的进程要执行的下一条指令的位置。
当分给某个进程的CPU时间已经用完,操作系统将该进程相关的寄存器的值,保存到该进程在进程表中对应的表项里面;把将要接替这个进程占用 CPU的那个进程的上下文,从进程表中读出,并更新相应的寄存器(这个过程称为“上下文交换(process context switch)”,实际的上下文交换需要涉及到更多的数据,那和fork无关,不再多说,主要要记住程序寄存器pc指出程序当前已经执行到哪里,是进程上下文的重要内容,换出 CPU的进程要保存这个寄存器的值,换入CPU的进程,也要根据进程表中保存的本进程执行上下文信息,更新这个寄存器)。
2.fork系统调用当你的程序执行到下面的语句:pid=fork();操作系统创建一个新的进程(子进程),并且在进程表中相应为它建立一个新的表项。
新进程和原有进程的可执行程序是同一个程序;上下文和数据,绝大部分就是原进程(父进程)的拷贝,但它们是两个相互独立的进程!此时程序寄存器pc,在父、子进程的上下文中都声称,这个进程目前执行到fork调用即将返回(此时子进程不占有CPU,子进程的pc不是真正保存在寄存器中,而是作为进程上下文保存在进程表中的对应表项内)。
问题是怎么返回,在父子进程中就分道扬镳。
父进程继续执行,操作系统对fork的实现,使这个调用在父进程中返回刚刚创建的子进程的pid(一个正整数),所以下面的if语句中pid<0, pid==0的两个分支都不会执行。
linux中fork的语法及用法

在Linux中,fork()函数是用于创建一个新进程的系统调用。
以下是fork()函数的语法和用法:
语法:
fork()`函数返回两次:一次是在父进程中,另一次是在新创建的子进程中。
在父进程中,fork()函数返回新创建子进程的进程ID(PID)。
在子进程中,fork()函数返回0。
如果fork()函数出现错误,它会返回一个负值,通常为-1。
用法:
1.在父进程中调用fork()函数,创建一个子进程。
2.父进程和子进程从fork()函数返回处开始执行。
3.父进程和子进程可以继续执行不同的代码路径,实现并行执行。
4.可以通过wait()或waitpid()函数等待子进程结束,以回收子进程的资
源。
示例:
在上述示例中,父进程和子进程分别打印不同的消息,并使用wait()函数等待子进程结束。
注意,在子进程中,我们使用return 0;语句来结束子进程的执行。
fork()函数的理解

对于刚刚接触Unix/Linux操作系统,在Linux下编写多进程的人来说,fork是最难理解的概念之一:它执行一次却返回两个值。
首先我们来看下fork函数的原型:#i nclude <sys/types.h>#i nclude <uni ST d.h>pid_t fork(void);返回值:负数:如果出错,则fork()返回-1,此时没有创建新的进程。
最初的进程仍然运行。
零:在子进程中,fork()返回0正数:在负进程中,fork()返回正的子进程的PID其次我们来看下如何利用fork创建子进程。
创建子进程的样板代码如下所示:pid_t child;if((child = fork())<0)/*错误处理*/else if(child == 0)/*这是新进程*/else/*这是最初的父进程*/fock函数调用一次却返回两次;向父进程返回子进程的ID,向子进程中返回0,这是因为父进程可能存在很多过子进程,所以必须通过这个返回的子进程ID来跟踪子进程,而子进程只有一个父进程,他的ID可以通过getppid取得。
下面我们来对比一下两个例子:第一个:#include <unistd.h>#include <stdio.h>int main(){pid_t pid;int count=0;pid = fork();printf( "This is first time, pid = %d\n", pid );printf( "This is sec ON d time, pid = %d\n", pid );count++;printf( "count = %d\n", count );if ( pid>0 ){printf( "This is the parent process,the child has the pid:%d\n", pid );}else if ( !pid ){printf( "This is the child Process.\n")}else{printf( "fork failed.\n" );}printf( "This is third time, pid = %d\n", pid );printf( "This is fouth time, pid = %d\n", pid );return 0;}运行结果如下:问题:这个结果很奇怪了,为什么printf的语句执行两次,而那句“count++;”的语句却只执行了一次接着看:#include <unistd.h>#include <stdio.h>int main(void){pid_t pid;int count=0;pid = fork();printf( "Now, the pid returned by calling fork() is %d\n", pid );if ( pid>0 ){printf( "This is the parent proc ESS,the child has the pid:%d\n", pid );printf( "In the parent process,count = %d\n", count );}else if ( !pid ){printf( "This is the child process.\n");printf( "Do your own things here.\n" );count ++;printf( "In the child process, count = %d\n", count );}else{printf( "fork failed.\n" );}return 0;}运行结果如下:现在来解释上面提出的问题。
fork函数的2个返回值说明

fork简介:fork英文原意是“分岔,分支”的意思,而在操作系统中,乃是著名的Unix(或类Unix,如Linux,Minix)中用于创建子进程的系统调用。
【NOTE1】fork () 的作用是什么?换句话说,你用fork () 的目的是什么?――是为了产生一个新的进程,地球人都知道:)产生一个什么样的进程?――和你本来调用fork () 的那个进程基本一样的进程,其实就是你原来进程的副本;真的完全一样吗?――当然不能完全一样,你要两个除了pid 之外其它一模一样的进程干什么,就算memory 再多也不用这么摆谱吧?哪里不一样?――当然最重要的是fork () 之后执行的代码不一样,you know, i know :)怎么实现呢?――如果是Windows,它会让你在fork () 里面提供一大堆东西,指明这个那个什么的…… 我用的是unix 啊――所以很简单,unix 会让两个进程(不错,原来是一个,unix 替你复制了一个,现在有两个)在fork () 之后产生不同:返回值不同。
其中一个进程(使用新的pid)里面的fork () 返回零,这个进程就是“子进程”;而另一个进程(使用原来的pid)中的fork () 返回前面那个子进程的pid,他自己被称为“父进程”然后呢?――写代码的人又不笨,当然就根据返回值是否非零来判断了,现在我是在子进程里面呢,还是在父进程里面?在子进程里面就执行子进程该执行的代码,在父进程里面就执行父进程的代码……有铁杆windows fans 借此说明,windows 好啊,子进程用子进程的代码,父进程用父进程的,你unix 笨了吧,子进程包含父进程、子进程的代码,父进程包含父进程子进程的代码,岂不是多占用内存了吗?――据我所知,unix 代码段都是可重入代码,也就是说,进程复制,并不复制代码段,若干个进程共享同一代码段,增加的只是全局共享数据和对文件描述符的引用等,另外就是堆栈。
操作系统实验 fork()

《计算机操作系统》实验报告学号:S030802107 姓名:杨霞学院:数计(软件)学院专业:计算机系年级:2008级班级:1班实验时间:2010-2011学年第一学期并发程序设计(实验1)【实验目的】:掌握在程序中创建新进程的方法,观察并理解多道程序并发执行的现象。
【实验原理】:fork():建立子进程。
子进程得到父进程地址空间的一个复制。
返回值:成功时,该函数被调用一次,但返回两次,fork()对子进程返回0,对父进程返回子进程标识符(非0值)。
不成功时对父进程返回-1,没有子进程。
【实验内容】:首先分析一下程序运行时其输出结果有哪几种可能性,然后实际调试该程序观察其实际输出情况,比较两者的差异,分析其中的原因。
void main (void){ int x=5;if( fork( ) ){x+=30;printf (“%d\n”,x);}elseprintf(“%d\n”,x);printf((“%d\n”,x);}【实验过程】:实验源码:#include<stdio.h>#include<sys/types.h> #include<unistd.h> int main(){int x=5;if(fork()){x+=30;printf("%d\n",x); }elseprintf("%d\n",x); printf("%d\n",x); return 0;}【结果预测】:(1) 5 5 35 35 (2) 35 35 5 5 (7) 35 35 (3)535535(4)535355(5)355355(6)355535【实验结果】:(1) 5 5 35 35 (2) 35 35 5 5预测分析和结果分析:fork()函数是程序创建子进程的调用函数,若子程序创建成功,则对子程序返回0,对父进程返回子程序的ID;若不成功,则返回-1。
C语言fork函数解析

首先看下fork的基本知识:函数原型:pid_t fork( void);返回值:若成功调用一次则返回两个值,子进程返回0,父进程返回子进程ID;否则,出错返回-1一个现有进程可以调用fork函数创建一个新进程。
由fork创建的新进程被称为子进程(child process)。
fork函数被调用一次但返回两次。
两次返回的唯一区别是子进程中返回0值而父进程中返回子进程ID。
注意要点:1、子进程是父进程的副本,它将获得父进程数据空间、堆、栈等资源的副本。
此处先简要介绍下COW(Copy-on-write)机制,大致原理如下:在复制一个对象的时候并不是真正的把原先的对象复制到内存的另外一个位置上,而是在新对象的内存映射表中设置一个指针,指向源对象的位置,并把那块内存的Copy-On-Write位设置为1.这样,在对新的对象执行读操作的时候,内存数据不发生任何变动,直接执行读操作;而在对新的对象执行写操作时,将真正的对象复制到新的内存地址中,并修改新对象的内存映射表指向这个新的位置,并在新的内存位置上执行写操作。
linux内核下fork使用COW机制工作原理:进程0(父进程)创建进程1(子进程)后,进程0和进程1同时使用着共享代码区内相同的代码和数据内存页面, 只是执行代码不在一处,因此他们也同时使用着相同的用户堆栈区。
在为进程1(子进程)复制其父进程(进程0)的页目录和页表项时,进程0的640KB页表项的属性没有改动过(仍然可读写),但是进程1的640KB对应的页表项却被设置成只读。
因此当进程1(子进程)开始执行时,对用户堆栈的入栈操作将导致页面写保护异常,从而使得内核的内存管理程序为进程1在主内存区中分配一内存页面,并把进程0中的页面内容复制到新的页面上。
从此时开始,进程1开始有自己独立的内存页面,由于此时的内存页面在主内存区,因此进程1中继续创建新的子进程时也可以采用COW技术。
内核调度进程运行时次序是随机的,进程0创建进程1后,可能先于进程1修改共享区,进程0是可读写的,在未分开前,进程1是只读的,由于两个进程共享内存空间,为了不出现冲突问题,就必须要求进程0在进程1执行堆栈操作(进程1的堆栈操作会导致页面保护异常,从而使得进程1在主内存区得到新的用户页面区,此时进程1和进程0才算是真正独立,如前面所述)之前禁止使用用户堆栈区。
f o r k ( ) 介 绍 ( 2 0 2 0 )

fork函数与vfork函数的区别与联系详解创建一【导师实操追-女教-程】个新进程的方法只有由某个已存在的进程调用fork()或vfork(),当然某些进程如init等是作为系统启动的一部分【Q】而被内核创建的。
1.f【1】ork函数介绍#in【0】clude?#inc【⒈】lude?pid【6】_t fork (void );正确返回【9】:父进程中返回子进程的进程号;子进程中返回0;(单调用双返【5】回函数)错误返回【2】:-1;子进程是【б】父进程的一个拷贝。
具体说,子进程从父进程那得到了数据段和堆栈段,但不是与父进程共享而是单独分配内存。
fork函数返回后,子进程和父进程都是从fork函数的下一条语句开始执行。
由于子进程与父进程的运行是无关的,父进程可先于子进程运行,子进程也可先于父进程运行,所以下段程序可以有两种运行结果。
[root@happy src]# cat simplefork.c#include?#include?#includeint globa = 4;int main (void )pid_t pid;int vari = 5;printf ("before fork" );if ((pid = fork()) 0){printf ("fork error");exit (0);else if (pid == 0){globa++ ;printf("Child changed");printf("Parent did not changde");printf("globa = %d vari = %d",globa,vari); exit(0);运行结果:(可能出现的一种结果)[root@happy src]# .-a.outbefore forkChild changedgloba = 5 vari = 4Parent did not changdegloba = 4 vari = 52.vfork函数介绍vfork创建新进程的主要目的在于用exec函数执行另外的程序,实际上,在没调用exec或exit之前子进程的运行中是与父进程共享数据段的。
c语言fork函数

c语言fork函数fork函数是Unix和类Unix操作系统中的一个系统调用函数,用于创建一个新的进程。
在调用fork函数时,操作系统会为当前进程创建一个副本,生成一个新的进程,即子进程。
子进程和父进程拥有相同的代码、数据和堆栈段,但是拥有独立的进程ID,并且子进程的PID与父进程不同,子进程的PPID为父进程的PID。
下面将通过四个方面详细介绍fork函数的使用和相关注意事项。
一、fork函数的原型和返回值```#include <sys/types.h>#include <unistd.h>pid_t fork(void);```fork函数没有参数,返回值为pid_t类型,它代表进程的ID。
在父进程中,fork函数返回子进程的PID;而在子进程中,fork函数返回0。
如果创建子进程时出现错误,fork函数返回一个负数,代表错误的类型。
二、父进程和子进程的代码段在调用fork函数之后,操作系统会将父进程的整个代码段、数据段和堆栈段复制到子进程中。
这也意味着,父进程和子进程会从fork函数之后的那一行代码开始执行。
所以,在调用fork函数之前,应该通过其中一种方式使父进程和子进程的执行路径不同,以免它们会执行相同的代码。
三、父进程和子进程共用的文件描述符在fork函数调用之后,父进程和子进程共用相同的文件描述符。
这个特性对于父子进程之间的通信非常方便。
当父子进程中的一个进程读取或写入了共享的文件描述符时,假设是读取操作,它会将文件的读取位置记录在文件描述符对应的数据结构中。
另一个进程也会使用相同的文件描述符操作同一个文件,并且它会从上一个进程读取的位置开始。
这样,父进程和子进程之间就可以通过读取和修改文件描述符来进行相互通信。
四、子进程的退出状态在子进程执行完毕后,它会以存在两种情况:一种是正常终止,一种是异常终止。
1. 正常终止:子进程可以通过调用exit(函数或者从main函数中返回来正常终止。
Fork函数

Fork函数计算机程序设计中的分叉函数。
一个进程,包括代码、数据和分配给进程的资源。
fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。
然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。
相当于克隆了一个自己。
返回值:若成功调用一次则返回两个值,子进程返回0,父进程返回子进程标记;否则,出错返回-1一个现有进程可以调用fork函数创建一个新进程。
由fork创建的新进程被称为子进程(child process)。
fork函数被调用一次但返回两次。
两次返回的唯一区别是子进程中返回0值而父进程中返回子进程ID。
子进程是父进程的副本,它将获得父进程数据空间、堆、栈等资源的副本。
注意,子进程持有的是上述存储空间的“副本”,这意味着父子进程间不共享这些存储空间。
UNIX将复制父进程的地址空间内容给子进程,因此,子进程有了独立的地址空间。
在不同的UNIX (Like)系统下,我们无法确定fork之后是子进程先运行还是父进程先运行,这依赖于系统的实现。
所以在移植代码的时候我们不应该对此作出任何的假设。
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。
然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。
相当于克隆了一个自己。
我们来看一个例子:int main (){pid_t fpid; //fpid表示fork函数返回的值int count=0;fpid=fork();if (fpid < 0)printf("error in fork!");else if (fpid == 0) {printf("i am the child process, my process id is %d/n",getpid());printf("我是爹的儿子/n");//对某些人来说中文看着更直白。
fork的用法

fork的用法"Fork" 是一个常见的开发术语,它通常用于描述从一个项目的源代码仓库(repository)中复制一份代码到你自己的仓库,从而可以在不影响原始项目的情况下进行独立的开发。
这个过程通常发生在分布式版本控制系统(如Git)中。
下面是使用Git 进行fork 的一般步骤:1. 在网站上Fork 项目:-打开代码托管平台(如GitHub、GitLab、Bitbucket)上的原始项目。
-在项目页面的右上角,你会看到一个"Fork" 按钮。
点击该按钮将原始项目的代码复制到你自己的账户下的仓库中。
2. 克隆Fork 的仓库到本地:-在你的账户下的Fork 仓库页面上,复制仓库的URL。
-在本地打开终端,执行以下命令克隆你Fork 的仓库到本地:```bashgit clone <你的仓库URL>```3. 添加上游远程仓库:-进入克隆下来的本地仓库目录:```bashcd <你的仓库目录>```-添加原始项目的远程仓库作为上游仓库:```bashgit remote add upstream <原始项目URL>```4. 从上游仓库获取更新:-在你本地仓库中,执行以下命令从原始项目的上游仓库获取最新的更新:```bashgit fetch upstream```5. 创建分支进行开发:-在本地仓库中,创建一个新的分支来进行你的开发工作:```bashgit checkout -b feature-branch```6. 进行修改和提交:-在新创建的分支上进行你的修改和开发工作。
-使用`git add` 和`git commit` 命令将修改提交到你的本地分支。
7. 将修改推送到你的远程仓库:-使用`git push` 命令将本地分支的修改推送到你的Fork 仓库中:```bashgit push origin feature-branch```8. 创建Pull Request:-在你Fork 仓库的页面上,点击"New Pull Request" 按钮,选择你要创建Pull Request 的分支。
fork()的用法

fork()的用法
fork() 是一个用于创建新进程的系统调用。
具体来说,它会复制当前进程,然后创建一个与原进程几乎完全相同的新进程。
新进程(子进程)会继承父进程的所有资源,包括代码、数据和系统资源。
fork() 的基本用法如下:
1. 调用 fork() 函数,它会返回两次:一次是在父进程中,返回新创建子进程的 PID;另一次是在子进程中,返回 0。
2. 在父进程中,fork() 返回新创建子进程的 PID,可以通过这个 PID 对子进程进行操作。
3. 在子进程中,fork() 返回 0,可以通过返回值来区分当前是父进程还是子进程。
fork() 的常见用法包括:
1. 创建新的子进程:通过调用 fork() 函数,可以创建一个与原进程几乎完全相同的新进程。
新进程会继承父进程的所有资源,包括代码、数据和系统资源。
2. 实现多线程:fork() 可以用来实现多线程编程。
在每个线程中调用 fork() 函数,可以创建多个子进程,从而实现并发执行。
3. 实现并行计算:通过 fork() 函数创建多个子进程,每个子进程执行不同的任务,可以实现并行计算,提高程序的执行效率。
需要注意的是,fork() 函数的使用需要谨慎,因为它涉及到进程的创建和复制。
如果使用不当,可能会导致资源泄漏、竞争条件等问题。
因此,在使用fork() 函数时需要仔细考虑程序的逻辑和安全性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Linux系统调用fork()用法详解这学期在学操作系统,老师布置了一个关于进程的实验题,是在Linux 系统中实现的,其中有涉及到fork()函数的调用,恰好我研究Ubuntu 也有一段时间了,就了解了下fork()函数,下面把自己实验的一点心得贴上来,也希望能帮到各位初学者(我也是个初学者)。
先看下我在网上搜索到的一篇文章,至于原作者找不到了,望谅解。
如下:1. 先看下面代码:#include<stdio.h>#include <sys/types.h> //pid_t类型定义#include <unistd.h> //函数fork(),getpid()定义void main (){pid_t pid;pid=fork();if (pid < 0)printf("error in fork!");else if (pid == 0)printf("i am the child process, my process id is %d\n",getpid());elseprintf("i am the parent process, my process id is %d\n",getpid());}要搞清楚fork的执行过程,就必须先讲清楚操作系统中的“进程(process)”概念。
一个进程,主要包含三个元素:o. 一个可以执行的程序;o. 和该进程相关联的全部数据(包括变量,内存空间,缓冲区等等);o. 程序的执行上下文(execution context)。
不妨简单理解为,一个进程表示的就是一个可执行程序的一次执行过程中的一个状态。
操作系统对进程的管理,典型的情况,是通过进程表完成的。
进程表中的每一个表项,记录的是当前操作系统中一个进程的情况。
对于单CPU的情况而言,每一特定时刻只有一个进程占用CPU,但是系统中可能同时存在多个活动的(等待执行或继续执行的)进程。
一个称为“程序计数器(program counter, pc)”的寄存器,指出当前占用CPU的进程要执行的下一条指令的位置。
当分给某个进程的CPU时间已经用完,操作系统将该进程相关的寄存器的值,保存到该进程在进程表中对应的表项里面;把将要接替这个进程占用CPU 的那个进程的上下文,从进程表中读出,并更新相应的寄存器(这个过程称为“上下文交换(proces s context switch)”,实际的上下文交换需要涉及到更多的数据,那和fork无关,不再多说,主要要记住程序寄存器pc指出程序当前已经执行到哪里,是进程上下文的重要内容,换出CPU的进程要保存这个寄存器的值,换入CPU的进程,也要根据进程表中保存的本进程执行上下文信息,更新这个寄存器)。
好了,有这些概念打底,可以说fork了。
当你的程序执行到下面的语句:pid=fork();操作系统创建一个新的进程(子进程),并且在进程表中相应为它建立一个新的表项。
新进程和原有进程的可执行程序是同一个程序;上下文和数据,绝大部分就是原进程(父进程)的拷贝,但它们是两个相互独立的进程!此时程序寄存器pc,在父、子进程的上下文中都声称,这个进程目前执行到fork调用即将返回(此时子进程不占有CPU,子进程的pc 不是真正保存在寄存器中,而是作为进程上下文保存在进程表中的对应表项内)。
问题是怎么返回,在父子进程中就分道扬镳。
父进程继续执行,操作系统对fork的实现是,这个调用在父进程中返回刚刚创建的子进程的pid(一个正整数),所以下面的if语句中pid<0, pid==0的两个分支都不会执行。
所以输出i am the parent process...子进程在之后的某个时候得到调度,它的上下文被换入,占据CPU,操作系统对fork的实现,使得子进程中fork调用返回0。
所以在这个进程(注意这不是父进程了哦,虽然是同一个程序,但是这是同一个程序的另外一次执行,在操作系统中这次执行是由另外一个进程表示的,从执行的角度说和父进程相互独立)中pid=0,所以输出i am the child process...我想你比较困惑的就是,为什么看上去程序中互斥的两个分支都被执行了。
在一个程序的一次执行中,这当然是不可能的;但是你看到的两行输出是来自两个进程,这两个进程来自同一个程序的两次执行。
下面是我的一点心得,关于子进程的调用点问题,如下:2. 子进程的调用点详解子进程是从fork()函数开始执行的。
范例:#include<stdio.h>#include <sys/types.h> //pid_t类型定义#include <unistd.h> //函数fork(),getpid()定义void main(){pid_t p1,p2;p1=fork();if(p1<0)printf("error in fork!");else if (p1 == 0)printf("child process pid: %d\n",getpid());elseprintf("parent process pid: %d\n",getpid());p2=fork();if(p2<0)printf("error in fork!");else if (p2 == 0)printf("child process pid: %d\n",getpid());elseprintf("parent process pid: %d\n",getpid());}上述程序的编译执行结果如下:jenner@Intrepid:~/Desktop$ gcc 01.c -o 01jenner@Intrepid:~/Desktop$ ./01child process pid: 14844child process pid: 14845parent process pid: 14844parent process pid: 14843child process pid: 14846parent process pid: 14843注释:最初的43号进程执行两个fork(),输出两个parent43,并产生子进程44号和45号;44号进程从第一个fork()函数开始执行,输出child44,调用第二个fork(),输出parent44,并产生子进程46号;45号进程从第二个fork()函数开始执行,输出child45;46号进程从第二个fork()函数开始执行,输出child46;至此程序结束。
注意:以上过程不是程序的先后运行过程,那六个输出的先后顺序是不确定的!程序中所有进程的父子关系如下:父进程43 ---子进程44---子进程的子进程46---子进程45其中44号进程既是43号进程的子进程,又是46号进程的父进程。
以上是我的一些心得,看着可能有点绕口,耐心点,我也研究了好久呢,如果你看懂了,fork()函数也就算基本理解了!顺便也把老师布置的作业题也贴上来吧,呵呵,如下:3. 题目:进程的创建:编制一段程序,使用系统调用fork( )创建两个子进程,这样在此程序运行时,在系统中就有一个父进程和两个子进程在活动。
让每一个进程在屏幕上显示一个字符:父进程显示字符a,子进程分别显示字符b和字符c。
试观察、记录并分析屏幕上,进程调度的情况。
代码如下:#include<stdio.h>#include <sys/types.h>#include <unistd.h>void main(){pid_t p1,p2;p1=fork();if(p1<0)printf("error in fork!\n");else if (p1 == 0)printf("child process b\n");else{p2=fork();if(p2<0)printf("error in fork!\n");else if (p2 == 0)printf("child process c\n");elseprintf("parent process a\n");}}linux中fork系统调用(简介)2009-07-31 02:21linux中用户程序调用fork 实际上就是执行内核中的do_fork()函数,fork 调用的作用是复制调用它的进程(父进程) 从而产生一个几乎一样的进程(子进程)下面将举一个简单的例子,以便更好地理解#include<sys/types.h>//包含数据类型pid-t的定义#include<unistd.h>//包含系统调用的定义int main(){ pid_t PID;printf("before the fork()my PID is %d",(int)getpid());PID=fork();// fork系统调用if(PID==0)printf("i am the children process and my PIDis %d",(int)(getpid());else if(PID>=0)printf("i am the parents process and my PIDis %d',(int)(getpid());else printf("error");}将以上代码编译生成可执行文件后程序的执行结果为如下before the fork()my PID is 1991i am the parents process and my PID is 1991i am the children process and my PID is 1992补充:fork 的返回值有以下三种情况1:父进程中返回父进程的PID,在上例中为19912:子进程中返回 0 ,在上例中执行 if(PID==0)3:当进程数达到最上限或者没有空闲内存空间可供分配时返回一个负值。