对应分析与典型相关分析习题
第七章 对应分析与典型相关分析

对应分析基本概念
➢ 对应分析(Correspondence Analysis)也称关联分析、R-Q型因子分 析,是最近几年发展起来的一种多元统计分析方法。
➢ 通过分析由定性变量构成的交互汇总表来揭示变量之间的联系。
➢ 可以揭示同一变量的各个类别之间的差异,以及不同变量各个类别之 间的对应关系。
➢这项研究是为了考察汉字具有的抽象图形符号的特性能否 会促进儿童空间和抽象思维能力。该数据以列联表形式展示 在表中:
9
例2.
➢人们可以对这个列联表进行前面所说的χ2检验来考察行 变量和列变量是否独立。 结果在下面表中(通过Analyze -Descriptive Statistics-Crosstabs)
如果研究的对象是变量,则需要采用R型因子分析。 ➢ Q型和R型因子分析通常是相互对立的,必须分别对样品和变量进行处
理。对于分析样品的属性和样品之间的内在联系比较困难。因为样品 的属性是变值,而样品却是固定的。 ➢ 对应分析克服上述缺点,它综合R型和Q型分析的优点,将它们统一起 来使得由R型的分析结果很容易得到Q型的分析结果,这就克服了Q型 分析计算量大的困难;更重要的是可以把变量和样品的载荷反映在相 同的公因子轴上。这就把变量和样品联系起来,便于解释和推断。
找出样本数量与行业之间的数量规律,对应分析是首选。
8
例2.
➢在研究读写汉字能力与数学的关系的研究时,人们取得了 232个美国亚裔学生的数学成绩和汉字读写能力的数据。
➢关于汉字读写能力的变量有三个水平:“纯汉字”意味着 可以完全自由使用纯汉字读写,“半汉字”意味着读写中只 有部分汉字(比如日文),而“纯英文”意味着只能够读写 英文而不会汉字。而数学成绩有4个水平(A、B、C、D)。
对应分析与典型相关分析

17
对应分析基本思想
v λ ... v λ 1m m 11 1 O M = ( λ1 v1 ,..., λm vm ), AR = M v λ L v p1 1 pm λm
u11 λ1 ... u1m λm AQ = M O M = ( λ1 u1,..., λm um ), un1 λ1 L unm λm
由于SR和 具有相同的非零特征值 具有相同的非零特征值, 由于 和SQ具有相同的非零特征值,而这些特征值又正好是各个 公共因子的方差,因此可以用相同的因子轴 相同的因子轴同时表示变量点和样品 公共因子的方差,因此可以用相同的因子轴同时表示变量点和样品 即把变量点和样品点同时反映在具有相同坐标轴的因子平面上, 点,即把变量点和样品点同时反映在具有相同坐标轴的因子平面上, 以便对变量点和样品点一起考虑进行分类。 以便对变量点和样品点一起考虑进行分类。
如果SR的特征值 如果 的特征值 λ i 对应的标准化特征向量为 vi , 则SQ的特征值 λi 对应的标准化特征向量: 的特征值 对应的标准化特征向量: 1 ui = Zv i
λi
由此可以方便地由R型因子分析而得到 型因子分析的结果 由此可以方便地由 型因子分析而得到Q型因子分析的结果。由SR的特征值和 型因子分析而得到 型因子分析的结果。 的特征值和 特征向量即可以写出R型因子分析的因子载荷矩阵 记为AR) 型因子分析的因子载荷矩阵( 特征向量即可以写出 型因子分析的因子载荷矩阵(记为 )和Q型因子分析的 型因子分析的 因子载荷矩阵(记为AQ): 因子载荷矩阵(记为 ):
3
引例1. 引例1.
下表为2006年年底我国 个省市按照行业(这里仅列出12 年年底我国31个省市按照行业 这里仅列出12 下表为 年年底我国 个省市按照行业( 个行业)城镇单位就业人数, 个行业)城镇单位就业人数,在一定程度上可以反映该地 区的经济结构。 区的经济结构。 我国地域辽阔,东西南北发展不平衡,是否按照地域划分 我国地域辽阔,东西南北发展不平衡,是否按照地域划分 就合理了呢? 就合理了呢? 自然地理位置对经济结构的影响固然重要,但是数据分析 自然地理位置对经济结构的影响固然重要,但是数据分析 显然更有说服力。 显然更有说服力。
对应分析练习题
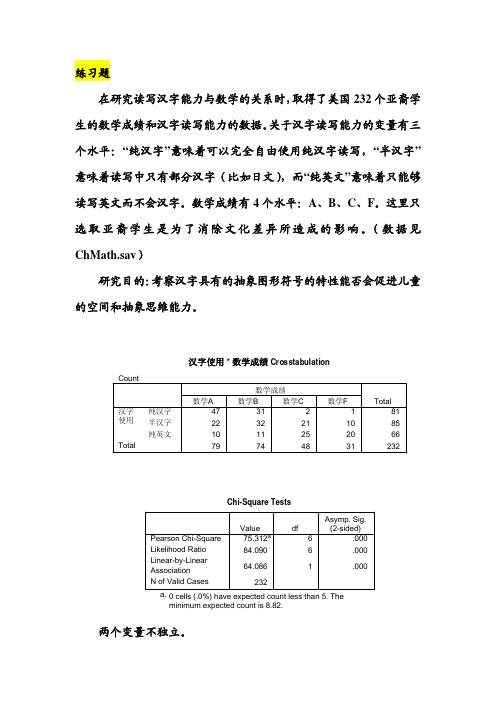
练习题在研究读写汉字能力与数学的关系时,取得了美国232个亚裔学生的数学成绩和汉字读写能力的数据。
关于汉字读写能力的变量有三个水平:“纯汉字”意味着可以完全自由使用纯汉字读写,“半汉字”意味着读写中只有部分汉字(比如日文),而“纯英文”意味着只能够读写英文而不会汉字。
数学成绩有4个水平:A、B、C、F。
这里只选取亚裔学生是为了消除文化差异所造成的影响。
(数据见ChMath.sav)研究目的:考察汉字具有的抽象图形符号的特性能否会促进儿童的空间和抽象思维能力。
两个变量不独立。
那么,两个变量各个类别之间存在什么关系呢?在对应分析中,可以找到行和列的若干有意义的代表,分别称为行记分(row score)和列记分(column score),它们互为对方的加权均值,而且它们之间有不同程度的相关性。
Inertia:惯量(也就是特征根),为每一维到其重心的加权距离的平方。
它度量的是行列关系的强度。
Singular Value:奇异值,是惯量的平方根,反映的是行与列各水平在二维图中分量的相关程度,是对行与列进行因子分析产生的新的综合变量的典型相关系数。
Chi Square:列联表行列独立性的2 检验值。
Proportion of Inertia:惯量比例,是各维度(公因子)分别解释总惯量的比例及累积百分比,类似于因子分析中公因子解释能力的说明。
从该表可以看出,由于第一维的惯量比例占了总比例的93.9%,因此,其他维的重要性可以忽略(虽然画图时需要两维,但主要看第一维,即横坐标的大小)。
Mass:行与列的边缘概率(各类别的百分比)。
Score in Dimension:各维度的分值(二维图中的坐标)纯汉字的点与最好的数学成绩A最接近,而不会汉字只会英文的点与最差的数学成绩F最接近,半汉字的和数学成绩B最接近。
多元统计复习题及答案

填空题:1、费希尔(Fisher)判别法是1936年提出来的,该方法的主要思想是通过将多维数据投影到某个方向上。
2、因子分析的内容非常丰富,常用的因子分析类型是R型因子分析和Q型因子分析。
3、K均值聚类分析的基本思想是将每一个样品分配给最接近业壶些直的类中。
4、对应分析是将R型因子分析Q型因子分析结合起来进行的统计分析方法。
5、总体方差未知的情况下,采用样本方差代替总体方差的方法进行计算。
6、主成分分析数学模型中的正交变换,在几何上就是作一个坐标旋转7、设X、N2 ( U , N),其中X=(》1,》2),号),则CovQq +》2,*1 - *2)= _0__8、判别分析是判别样品所属类型的一种统计方法,常用的判别方法有距离判别法、Fisher 判另U法、Bayes判另U法、逐步判另U法9 多元正态分布的任何边缘分布为正态分布10、应用多元统计分析方法用于解决多指标问题,聚类分析就是分析如何对样品(或变量)进行量化分类的问题。
通常聚类分析分为Q型聚类和R型聚类。
11、总离差平方和可以分解为回归离差平方和和剩余离差平方和两个部分,各自的自由度为(P )和(n-p-1),其中回归离差平方和在总离差平方和中所占比重越大,则线性回归效果越显著。
12、系统聚类分析方法有最短距离法、最长距离法、中间距离法、重心法、类平均统和可变类平均法。
13、典型相关分析是研究两组变量之间相关关系的一种多元统计方法14、因子分析中因子载荷系数叫,•的统计意义是:(第i个变量与第j个公因子的相关系数)15、相应分析的特点是研究的变量是定性的16、公共因子方差与特殊因子方差之和为o17、设Z 是总体X=(X”…,乂皿)的协方差阵,X 的特征根人。
=1,2,..・田)与对应的单位正交化特征向量% =(%,%2,,则第一主成分的表达式=% ]X| + %2、2 + ・•• + /mX"],方差为2]18、相应分析的主要目的是寻求列联表行因素A和列因素B的基本分析特征和它们的最优联立表示19聚类分析一是分析如何对样品或变量进行量化分类的问题。
对应分析 SAS讲义12

对应分析SAS程序2010年5月一、对应分析的统计思想二、对应分析的原理三、对应分析的SAS程序与应用四、对应分析练习题第一节对应分析的基本理论对应分析又称相应分析,于1970年由法国统计学家J.P.Beozecri提出的.对应分析是将频数或计数表的各种联系用图来表示的方法。
对应分析本质是一种在低维空间中用图形方法表示联系的技术。
对应分析(Correspondence Analysis):通过分析由定性变量构成的交互汇总表来揭示变量间的联系。
对应分析可以揭示同一变量的各个类别之间的差异,不同变量各个类别之间的对应关系。
可以将两个变量的联系做在一个图里表示出来。
它是在R型和Q型因子分析基础上发展起来的多元统计分析方法,故也称为R-Q型因子分析. 因子分析方法是用少数几个公共因子去提取研究对象的绝大部分信息,既减少了因子的数目,又把握住了研究对象的相互关系.在因子分析中根据研究对象的不同,分为R型和Q型,如果研究变量间的相互关系时采用R型因子分析;如果研究样品间相互关系时采用Q型因子分析.第二节对应分析原理5、将因子载荷为座标作图,得到对应分析图()2211p qiji j i j i jpp p np p χ⋅⋅==⋅⋅-==∑∑总惯量奇异值是惯量(特征值)的平方根。
惯量用于说明对应分析各个维度的结果能够解释列联表中两个变量联系的程度。
第三节SAS对应分析程序例:生活自理能力完全自理1 部分自理2不能自理3合计自评健康状况很好A 129148151好B 931146961173一般C 66011674850差D 25110481436很差E 1172341没回答F 15132452合计19974003062703Data ex2;Input zipin$ zili renshu;datalines;a 1 129a 2 14a 3 8b 1 931b 2 146b 3 96c 1 660c 2 116c 3 74d 1 251d 2 104d 3 81e 1 11e 2 7e 3 23f 1 15f 2 13f 3 24;Proc corresp data=ex2 all outc=result; tables zipin , zili ;weight renshu;Run;%plotit(data= result, datatype=corresp)卡方分解表奇异值(Singular Value )是主惯量(Principal Inertia)特征值的平方根。
多元统计分析试题(A卷)(答案)

多元统计分析试题(A卷)(答案)《多元统计分析》试卷一、填空题(每空2分,共40分)1、若且相互独立,则样本均值向量X服从的分布为2、变量的类型按尺度划分有_间隔尺度_、_有序尺度_、名义尺度_。
3、判别分析是判别样品的一种统计方法,常用的判别方法有___、、、。
4、Q型聚类是指对_进行聚类,R型聚类是指对进行聚类。
'5、设样品,总体X~Np(,对样品进行分类常用的距离有:明氏距离,马氏距离,兰氏距离6、因子分析中因子载荷系数aij的统计意义是_第i个变量与第j个公因子的相关系数。
7、一元回归的数学模型是:,多元回归的数学模型是:。
8、对应分析是将和结合起来进行的统计分析方法。
9、典型相关分析是研究两组变量之间相关关系的一种多元统计方法。
二、计算题(每小题10分,共40分)1、设三维随机向量,其中130,问X1与X2是否独立?和X3是否独立?为什么?解:因为,所以X1与X2不独立。
把协差矩阵写成分块矩阵,的协差矩阵为因为,而,所以和X3是不相关的,而正态分布不相关与相互独立是等价的,所以和X3是独立的。
2、设抽了五个样品,每个样品只测了一个指标,它们分别是1 ,2 ,4.5 ,6 ,8。
若样本间采用明氏距离,试用最长距离法对其进行分类,要求给出聚类图。
x1013.55702.54601.53.502x2x3解:样品与样品之间的明氏距离为:D(0)样品最短距离是1,故把X1与X2合并为一类,计算类与类之间距离(最长距离法){x1,x2}03.55701.53.502x3x4得距离阵 D(1)类与类的最短距离是1.5,故把X3与X4合并为一类,计算类与类之间距离(最长距离法)得距离阵D(2){x1,x2}057{x3,x4}x5类与类的最短距离是3.5,故把{X3,X4}与X5合并为一类,计算类与类之间距离(最{x1,x2}07长距离法)得距离阵D(3)分类与聚类图(略)(请你们自己做)3、设变量X1,X2,X3的相关阵为0.631.000.350.35,R的特征值和单位化特征向量分别为TTT(1)取公共因子个数为2,求因子载荷阵A。
统计学对应分析

r ( R x) ( R AC )( R AC ) '( R x)
2
1 2
1 2
1 2
1 2
1 2
1 2
r (C y) ( R AC ) '( R AC )(C y )
2
1 2
1 2
1 2
1 2
1 2
1 2
令
Z ( R AC ), v R x, u C y
SPSS的实现
• 打开 ChMath.sav 数据,其形式和本章开始 的列联表有些不同。其中 ch 列代表汉字使 用的三个水平;而 math 列代表数学成绩的 四个水平;第一列count实际上是ch和math 两个变量各个水平组合的出现数目,也就 是列联表中间的数目。 • 由于 count 把很大的本应有 232 行的原始数 据简化成只有 12 行的汇总数据,在进行计 算之前必须进行加权。也就是点击图标中 的小天平,再按照count加权即可。
本章难点
1、一般正态分布标准正态分布; 2、t分布; 3、区间估计的原理; 4、分层抽样、整群抽样中总方差的分解。
8.1总体均值的区间估计(大样本n>30)
点估计的缺点:不能反映估计的误差和精确程度
STAT
区间估计:利用样本统计量和抽样分布估计总体参数的可能区 间 【例1】CJW公司是一家专营体育设备和附件的公司,为了监控 公司的服务质量, CJW公司每月都要随即的抽取一个顾客样本 进行调查以了解顾客的满意分数。根据以往的调查,满意分数 的标准差稳定在20分左右。最近一次对100名顾客的抽样显示, 满意分数的样本均值为82分,试建立总体满意分数的区间。 8.1.1抽样误差 抽样误差:一个无偏估计与其对应的总体参数之差的绝对值。
应用统计学对应分析等
重庆交通大学管理学院
22:22:28
1、什么是典型相关分析? 典型相关分析是研究两组变量之间相关关系 的多元统计分析方法.它借用主成分分析降维的 思想,分别对两组变量提取主成分,且使两组变 量提取的主成分之间的相关程度达到最大,而从 同一组内部提取的各主成分之间互不相关,用从 两组之间分别提取的主成分的相关性来描述两组 变量整体的线性相关关系.
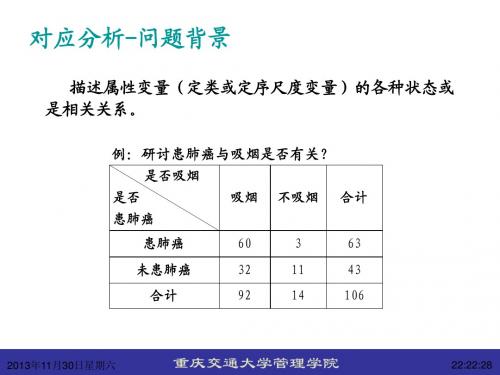
对应分析-问题背景
描述属性变量(定类或定序尺度变量)的各种状态或 是相关关系。
例:研讨患肺癌与吸烟是否有关?
是否吸烟 是否 患肺癌 患肺癌 未患肺癌 合计 60 32 92 3 11 14 63 日星期六
重庆交通大学管理学院
22:22:28
当属性变量A和B的状态较多时,很难透过列联表作 出判断。 怎样简化列联表的结构? 利用降维的思想。如因子分析和主成分分析。但因 子分析的缺陷是在于无法同时进行R型因子分析和Q 型因子分析。 怎么办?
2013年11月30日星期六
重庆交通大学管理学院
22:22:28
其优点是可以把方差分析和线性模型方法相结合,估 计模型中各个参数,而这些参数值使各个变量的效应和变 量间的交互作用效应得以数量化。
(2)Logistic 模型 是将概率比取对数后,再进行参数化而获得。设因变 量y为二值定性变量,用0和1表示两个不同状态,y=1的概 率p=P(y=1)是研究对象。若有多个因素影响y的取值,这 些因素就是自变量,记为:x1,x2…xk(既可以是定性变量 也可以是定量变量)。 Logistic 线性回归模型:
信度分类
内在信度:调查表中的一组问题(或整个调查表)是否测 量的是同一个概念,也就是这些问题之间的内在一致性 如何。 • 最常用的内在信度系数为克朗巴哈α系数和折半信度。 外在信度:在不同时间进行测量时调查表结果的一致性程 度。最常用的外在信度指标是重测信度,即用同一问卷 在不同时间对同一对象进行重复测量,然后计算一致程 度。
14 SAS中对应分析(含因子分析、典型相关分析作业解答)

41 63 49 46 34
46 52 53 41 40
SAS程序:
data data808; input x1-x5 @@; label x1='力学(闭)' x2='物理(闭)' x3='代数(开)' x4='分析(开)' x5='统计(开)'; n=_n_; cards; 77 82 67 67 81 63 78 80 70 81 75 73 71 66 81 55 72 63 70 68 63 63 65 70 63 53 61 72 64 73 51 67 65 65 68 59 70 68 62 56 62 60 58 62 70 64 72 60 62 45 52 64 60 63 54 55 67 59 62 44 50 50 64 55 63 65 63 58 56 37 31 55 60 57 73 60 64 56 54 40 44 69 53 53 53 42 69 61 55 45 62 46 61 57 45 31 49 62 63 62 44 61 52 62 46 49 41 61 49 64 12 58 61 63 67 49 53 49 62 47 54 49 56 47 53 54 53 46 59 44 44 56 55 61 36 18 44 50 57 81 46 52 65 50 35 32 45 49 57 64 30 69 50 52 45 46 49 53 59 37 40 27 54 61 61 31 42 48 54 68 36 59 51 45 51 56 40 56 54 35 46 56 57 49 32 45 42 55 56 40 42 60 54 49 33 40 63 53 54 25 23 55 59 53 44 48 48 49 51 37 41 63 49 46 34 46 52 53 41 40 ; proc factor data=data808 p=0.8 method=prin priors=one simple; var x1-x5; run;
多元统计复习题 附答案

复习题原文: 答案:4.2 试述判别分析的实质。
4.3 简述距离判别法的基本思想和方法。
4.4 简述贝叶斯判别法的基本思想和方法。
4.5 简述费希尔判别法的基本思想和方法。
4.6 试析距离判别法、贝叶斯判别法和费希尔判别法的异同。
4.2 试述判别分析的实质。
答:判别分析就是希望利用已经测得的变量数据,找出一种判别函数,使得这一函数具有某种最优性质,能把属于不同类别的样本点尽可能地区别开来。
设R1,R2,…,Rk 是p 维空间R p 的k 个子集,如果它们互不相交,且它们的和集为 ,则称 , 为 的一个划分。
判别分析问题实质上就是在某种意义上,以最优的性质对p 维空间 构造一个“划分”,这个“划分”就构成了一个判别规则。
4.3 简述距离判别法的基本思想和方法。
答:距离判别问题分为①两个总体的距离判别问题和②多个总体的判别问题。
其基本思想都是分别计算样本与各个总体的距离(马氏距离),将距离近的判别为一类。
①两个总体的距离判别问题设有协方差矩阵∑相等的两个总体G 1和G 2,其均值分别是?1和? 2,对于一个新的样品X ,要判断它来自哪个总体。
计算新样品X 到两个总体的马氏距离D 2(X ,G 1)和D 2(X ,G 2),则X ,D 2(X ,G 1) D 2(X ,G 2)X ,D 2(X ,G 1)> D 2(X ,G 2, 具体分析,记()()W '=-X αX μ 则判别规则为 X ,W(X) X ,W(X)<0②多个总体的判别问题。
设有k 个总体k G G G ,,,21 ,其均值和协方差矩阵分别是和k ΣΣΣ,,,21 ,且ΣΣΣΣ====k 21。
计算样本到每个总体的马氏距离,到哪个总体的距离最小就属于哪个总体。
具体分析,21(,)()()D G ααα-'=--X X μΣX μ取ααμΣI 1-=,αααμΣμ121-'-=C ,k ,,2,1 =α。
对应分析,典型相关分析,定性数据分析,

现实中: 如鸡蛋、猪肉的价格(作为第一组变量)和 相应产品的销量(第二组变量)有相关关系。如投资 性变量(劳力投入、财力投入、固定资产投资等)与 国民收入(工农业收入、建筑业收入、等)具有相关 关系。 如何研究两组变量之间的相关关系? 设两组变量用X1,X2….,XP以及Y1,Y2…YP表示。 (1)分别研究Xi和Yj之间的相关关系,列出相关系数表。 其缺陷:当两组变量较多时,处理较烦琐,不易抓住 问题的实质。(2)采用主成分分析的方法,每组变量 分别提取主成分,再通过主成分之间的关系反映两组 变量之间的关系。
ln 1 p a0 a1 x1 .... ak xk
17 cxt 2014-5-20
第七章 对应分析
zf
对应分析的重点
1、什么是对应分析? 2、理解对应分析的基本思想 3、对应分析的基本步骤 4、结合SPSS软件进行案例分析
2014-5-20
2 cxt
7.1 交叉列联表
描述属性变量(定类或定序尺度变量)的各种状态 或是相关关系。
例:研讨患肺癌与吸烟是否有关?
是否吸烟 是否 患肺癌 患肺癌 未患肺癌 合计
2014-5-20
4 cxt
***7.2
对应分析的基本理论
1、什么是对应分析?
对应分析是利用“降维”的方法,以两变量的交叉 列联表为研究对象,通过图形的方式,直接揭示变量 之间以及变量的不同类别之间的联系,特别适合于多 分类属性变量研究的一种多元统计分析方法。
2、对应分析的基本思想:
首先,编制两品质型变量的交叉列联表,将交叉列联表中的每个 数据单元看成两变量在相应类别上的对应点; 然后,对应分析将变量及变量之间的联系同时反映在一张二维或 三维的散点图上,并使联系密切的类别点较集中,联系疏远的类别 点较分散; 最后,通过观察对应分布图就能直观地把握变量类别之间的联 系.
统计师职称考试多元统计分析与应用考试 选择题 60题

1. 在多元统计分析中,主成分分析的主要目的是什么?A. 减少变量数量B. 增加变量数量C. 提高模型复杂度D. 降低模型复杂度2. 下列哪项不是多元回归分析的假设条件?A. 线性关系B. 正态性C. 独立性D. 等方差性3. 在因子分析中,公因子的数量通常如何确定?A. 主观选择B. 根据特征值大于1的原则C. 随机选择D. 根据样本大小4. 聚类分析中,Ward's方法属于哪一类?A. 层次聚类B. 非层次聚类C. 密度聚类D. 网格聚类5. 在判别分析中,Fisher判别法的主要思想是什么?A. 最大化类间差异B. 最小化类内差异C. 最大化类内差异D. 最小化类间差异6. 多元方差分析(MANOVA)与单因素方差分析(ANOVA)的主要区别是什么?A. 处理单个因变量B. 处理多个因变量C. 处理单个自变量D. 处理多个自变量7. 在结构方程模型(SEM)中,路径分析的主要目的是什么?A. 描述变量间的因果关系B. 描述变量间的相关关系C. 描述变量间的线性关系D. 描述变量间的非线性关系8. 在多维尺度分析(MDS)中,常用的距离度量是什么?A. 欧几里得距离B. 曼哈顿距离C. 切比雪夫距离D. 马氏距离9. 在对应分析中,主要用于分析什么类型的数据?A. 连续数据B. 分类数据C. 时间序列数据D. 混合数据10. 在多元统计分析中,偏最小二乘回归(PLS)主要用于解决什么问题?A. 多重共线性B. 异方差性C. 自相关D. 非线性关系11. 在多元统计分析中,典型相关分析(CCA)主要用于分析什么关系?A. 两个变量组之间的关系B. 单个变量组内部的关系C. 多个变量组之间的关系D. 单个变量与多个变量组之间的关系12. 在多元统计分析中,岭回归主要用于解决什么问题?A. 多重共线性B. 异方差性C. 自相关D. 非线性关系13. 在多元统计分析中,LASSO回归主要用于解决什么问题?A. 多重共线性B. 异方差性C. 自相关D. 变量选择14. 在多元统计分析中,支持向量机(SVM)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析15. 在多元统计分析中,随机森林主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析16. 在多元统计分析中,神经网络主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析17. 在多元统计分析中,决策树主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析18. 在多元统计分析中,关联规则挖掘主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析19. 在多元统计分析中,时间序列分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 预测问题20. 在多元统计分析中,生存分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 时间至事件的分析21. 在多元统计分析中,贝叶斯网络主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 概率推理22. 在多元统计分析中,马尔可夫链蒙特卡罗(MCMC)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 概率推理23. 在多元统计分析中,高斯过程回归主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 概率推理24. 在多元统计分析中,核密度估计主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 概率密度估计25. 在多元统计分析中,EM算法主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 参数估计26. 在多元统计分析中,K均值聚类主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析27. 在多元统计分析中,层次聚类主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析28. 在多元统计分析中,DBSCAN聚类主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析29. 在多元统计分析中,谱聚类主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析30. 在多元统计分析中,自组织映射(SOM)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 数据可视化31. 在多元统计分析中,主成分回归主要用于解决什么问题?A. 多重共线性B. 异方差性C. 自相关D. 非线性关系32. 在多元统计分析中,偏最小二乘判别分析(PLS-DA)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析33. 在多元统计分析中,典型相关分析(CCA)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析34. 在多元统计分析中,岭判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析35. 在多元统计分析中,LASSO判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析36. 在多元统计分析中,支持向量机判别分析(SVM-DA)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析37. 在多元统计分析中,随机森林判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析38. 在多元统计分析中,神经网络判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析39. 在多元统计分析中,决策树判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析40. 在多元统计分析中,关联规则挖掘判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析41. 在多元统计分析中,时间序列判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析42. 在多元统计分析中,生存判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析43. 在多元统计分析中,贝叶斯网络判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析44. 在多元统计分析中,马尔可夫链蒙特卡罗判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析45. 在多元统计分析中,高斯过程回归判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析46. 在多元统计分析中,核密度估计判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析47. 在多元统计分析中,EM算法判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析48. 在多元统计分析中,K均值聚类判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析49. 在多元统计分析中,层次聚类判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析50. 在多元统计分析中,DBSCAN聚类判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析51. 在多元统计分析中,谱聚类判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析52. 在多元统计分析中,自组织映射判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析53. 在多元统计分析中,主成分回归判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析54. 在多元统计分析中,偏最小二乘判别分析(PLS-DA)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析55. 在多元统计分析中,典型相关分析(CCA)判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析56. 在多元统计分析中,岭判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析57. 在多元统计分析中,LASSO判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析58. 在多元统计分析中,支持向量机判别分析(SVM-DA)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析59. 在多元统计分析中,随机森林判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析60. 在多元统计分析中,神经网络判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析1. A2. C3. B4. A5. A6. B7. A8. A9. B10. A11. A12. A13. D14. A15. A16. A17. A18. D19. D20. D21. D22. D23. B24. D25. D26. C27. C28. C29. C30. D31. A32. A33. A34. A35. A36. A37. A38. A39. A40. A41. A42. A43. A44. A45. A46. A47. A48. A49. A51. A52. A53. A54. A55. A56. A57. A58. A59. A60. A。
多元统计分析智慧树知到课后章节答案2023年下浙江工商大学

多元统计分析智慧树知到课后章节答案2023年下浙江工商大学浙江工商大学第一章测试1.在采用多元统计分析技术进行数据处理、建立宏观或微观系统模型时,可以解决下面哪几方面的问题。
()A:简化系统结构、探讨系统内核 B:进行数值分类,构造分类模型 C:变量之间的相依性分析 D:构造预测模型,进行预报控制答案:简化系统结构、探讨系统内核;进行数值分类,构造分类模型;变量之间的相依性分析;构造预测模型,进行预报控制2.只有调查来的才是数据。
()A:对 B:错答案:错3.以下都属于大数据范畴。
()A:行车轨迹 B:交易记录 C:问卷调查 D:访谈文本答案:行车轨迹;交易记录;问卷调查;访谈文本4.只要是数据,就一定有价值。
()A:对 B:错答案:错5.统计是研究如何搜集数据,如何分析数据的学问,它既是科学,也是艺术.()A:错 B:对答案:对第二章测试1.考虑了量纲影响的距离测度方法有()。
A:欧氏距离 B:Minkowski距离 C:马氏距离 D:切比雪夫距离答案:马氏距离2.不具有单调性的系统聚类方法有()。
A:离差平方和法 B:最短距离法 C:中间距离法 D:重心法 E:类平均距离法答案:中间距离法;重心法3.聚类分析是研究分类问题的一种多元统计分析方法。
()A:对 B:错答案:对4.聚类分析是有监督学习。
()A:错 B:对答案:错5.动态聚类法的凝聚点可以人为主观判别。
()A:对 B:错答案:对第三章测试1.判别分析是通过对已知类别的样本数据的学习、构建判别函数来最大程度区分各类,Fisher判别的准则要求()。
A:各类之间各个类内部变异尽可能大B:各类之间和各类内部变异尽可能小 C:各类之间变异尽可能大、各类内部变异尽可能小D:各类之间变异尽可能小、各类内部变异尽可能大答案:各类之间变异尽可能大、各类内部变异尽可能小2.常用判别分析的方法有()。
A:逐步判别法 B:贝叶斯判别法 C:费舍尔判别法 D:距离判别法答案:逐步判别法;贝叶斯判别法;费舍尔判别法;距离判别法3.较聚类分析,判别分析是根据已知类别的样本信息,对新样品进行分类。
6典型相关与对应分析

6典型相关与对应分析7.1.1 典型相关分析的概念与步骤1. 典型相关分析的基本思想典型相关分析采⽤主成分的思想浓缩信息,根据变量间的相关关系,寻找少数⼏对综合变量(实际观测变量的线性组合),⽤它们替代原始观测变量,从⽽将⼆组变量的关系集中到少数⼏对综合变量的关系上,通过对这些综合变量之间相关性的分析,回答两组原始变量间相关性的问题。
除了要求所提取的综合变量所含的信息量尽可能⼤以外,提取时还要求第⼀对综合变量间的相关性最⼤,第⼆对次之,依次类推。
这些综合变量被称为典型变量,或典则变量,第1对典型变量间的相关系数则被称为第1典型相关系数。
典型相关系数能简单、完整地描述两组变量间关系的指标。
当两个变量组均只有⼀个变量时,典型相关系数即为简单相关系数;当其中的⼀组只有⼀个变量时,典型相关系数即为复相关系数。
7.1.4 ⽤CANCORR过程实现典型相关分析1. CANCORR过程CANCORR过程的常⽤语法格式如下:PROC CANCORR <选项列表>;WITH <变量列表>;VAR <变量列表>;RUN;其中PROC CANCORR语句、WITH语句是每个过程中必不可少的,其余语句可视情况使⽤。
下⾯分别介绍各语句的⽤法和功能。
(1) PROC CANCORR语句:标⽰典型相关分析开始,可以规定输⼊输出数据集,指定分析⽅法和控制输出结果的显⽰等。
语句中可设置的常⽤选项及其功能见表7-3。
(2) VAR语句:列出要进⾏典型相关分析的第⼀组变量,变量必须是数值型的。
如果VAR语句被忽略,所有未被其他语句提到的数值型变量都将被视为第⼀组变量。
(3) WITH语句:列出要进⾏典型相关分析的第⼆组变量,变量必须是数值型的。
该语句是每⼀个PROC CANCORR中必不可少的。
表7-3 常⽤选项及其功能2. 使⽤CANCORR过程【例7-3】家庭特征与家庭消费之间的关系。
为了了解家庭的特征与其消费模式之间的关系。
应用多元统计分析习题解答典型相关分析

0
( j r)
袄螅袇蚃莆蚈螇 9.3 试分析一组变量的典型变量与其主成分的联系与区别。
薇芁膁薆膆袇蒂答:一组变量的典型变量和其主成分都是经过线性变换计算矩阵特征值与特征向量 得出的。主成分分析只涉及一组变量的相互依赖关系而典型相关则扩展到两组变量之间的相
互依赖关系之中,度量了这两组变量之间联系的强度。
(2)选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大 的一对。 蚅羅虿袃羄螈蕿(3)如此继续下去,直到两组变量之间的相关性被提取完毕为此。 螆蝿莀肃莅蝿薂 9.2 什么是典型变量?它具有哪些性质? 羈膂芃膇衿莃袅答:在典型相关分析中,在一定条件下选取系列线性组合以反映两组变量之间的线 性关系,这被选出的线性组合配对被称为典型变量。具体来说,
螀蒃X蚅肈(1羁)羅薈在(XD1(1)(,aX(1)2(1X) , (1) ), X Dp(1)()b、(1)XX((22)) )(1X的1(2)条, X件2(2下) ,,使, X得q(2))(a(1)X(1) ,b(1)X(2) ) 达到最大,
则称 a(1)X(1) 、 b(1)X(2) 是 X(1) 、 X(2) 的第一对典型相关变量。
Vˆ Bˆ *zZ(2) 。
前 蒄蒅蒈莃螂艿莈 r 对典型变量对样本总方差的贡献为
rp
芇蚇袁芆袆薈肂则第一组样本方差由前 r 个典型变量解释的比例为 Rdz(1)|Uˆ
i 1
r2
k 1 z蚈螇蚀蚄第二组样本方差由前 r 个典型变量解释的比例为 Rdz(2)|Vˆ
a(
p
)
b(
p)
U
p
Vp
请下载支持!
其中 肀羃蚂芆羀袀芅 A* , B* 为 p 对典型变量系数向量组成的矩阵, U 和 V 为 p 对典型变量
多元统计分析题

多元统计分析模拟试题(两套:每套含填空、判断各二十道)A 卷判别分析常用的判别方法有距离判别法、贝叶斯判别法、费歇判别法、逐步 判别法。
Q 型聚类分析是对 样品 的分类,R 型聚类分析是对 变量—的分类。
主成分分析中可以利用协 方差矩阵和相关矩阵求解主成分。
因子分析中对于因子载荷的求解最常用的方法是 主成分法、主轴因子法、极 大似然法聚类分析包括系统聚类法、模糊聚类分析、K-均值聚类分析分组数据的Logistic 回归存在异方差性,需要采用加权最小二乘估计 误差项的路径系数可由多元回归的决定系数算出,他们之间的关系为最短距离法适用于条形的类,最长距离法适用于椭圆形的类。
主成分分析是利用降维的思想,在损失很少的信息前提下,把多个指标转化 为几个综合指标的多元统计方法。
在进行主成分分析时,我们认为所取的 m (m<p,p 为所有的主成分)个主成 分的累积贡献率达到85%以上比较合适。
聚类分析的目的在于使类内对象的 同质性最大化和类间对象的 异质性最大 化是随机变量,并且有,那么、服从(卡方)分布在对数线性模型中,要先将概率取对数,再分解处理,公式:皿二 InoiL z 血h 二 皿丄 ± z L2—将每个原始变量分解为两部分因素, 一部分是由所有变量共同具有的少数几 个 公共因子 组成的,另一部分是每个变量独自具有的因素, 即 特殊因 子_判别分析的最基本要求是分组类型在两组之上,每组案例的规模必须至少一 个以上,解释变量必须是可测量的 当被解释变量是属性变量而解释变量是度量变量时 判别分析是合适的统计分析方法多元正态分布是一元正态分布的推广多元分析的主要理论都是建立在多元正态总体基础上的,多元正态分布是多 元分析的基础因子分析中,把变量表示成 各因子的线性组合,而主成分分析中,把主成分表示成各变量的线性组合统计距离包括欧氏距离和马氏距离两类因子负荷量是指因子结构中原始变量与因子分析时抽取出的公共因子的相 关程度。
相关分析作业试题及答案

第五章相关分析一、判断题二、1.若变量X的值增加时,变量Y的值也增加,说明X与Y之间存在正相关关系;若变量X的值减少时,Y变量的值也减少,说明X与Y之间存在负相关关系;三、2.回归系数和相关系数都可以用来判断现象之间相关的密切程度四、3.回归系数既可以用来判断两个变量相关的方向,也可以用来说明两个变量相关的密切程度;五、4.计算相关系数的两个变量,要求一个是随机变量,另一个是可控制的量;六、5.完全相关即是函数关系,其相关系数为±1;1、×2、×3、×4、×5、√.七、单项选择题1.当自变量的数值确定后,因变量的数值也随之完全确定,这种关系属于 ;2. A.相关关系 B.函数关系 C.回归关系 D.随机关系3.现象之间的相互关系可以归纳为两种类型,即 ;4. A.相关关系和函数关系 B.相关关系和因果关系 C.相关关系和随机关系 D.函数关系和因果关系5.在相关分析中,要求相关的两变量 ;6. A.都是随机的 B.都不是随机变量 C.因变量是随机变量 D.自变量是随机变量7.现象之间线性依存关系的程度越低,则相关系数 ;8. A.越接近于-1 B. 越接近于1 C. 越接近于0 D. 在0.5和0.8之间9.若物价上涨,商品的需求量相应减少,则物价与商品需求量之间的关系为 ;10. A.不相关 B. 负相关 C. 正相关 D. 复相关11.能够测定变量之间相关关系密切程度的主要方法是 ;12. A.相关表 B.相关图 C.相关系数 D.定性分析13.下列哪两个变量之间的相关程度高 ;14. A.商品销售额和商品销售量的相关系数是0.915. B.商品销售额与商业利润率的相关系数是0.8416. C.平均流通费用率与商业利润率的相关系数是-0.9417. D.商品销售价格与销售量的相关系数是-0.9118.回归分析中的两个变量 ;19. A、都是随机变量 B、关系是对等的 C、都是给定的量20. D、一个是自变量,一个是因变量21.当所有的观察值y都落在直线上时,则x与y之间的相关系数为 ;22. A.r = 0 B.| r | = 1 C.-1<r<1 D.0 < r < 123.每一吨铸铁成本元倚铸件废品率%变动的回归方程为:y c=56+8x, 这意味着24. A.废品率每增加1%,成本每吨增加64元 B.废品率每增加1%,成本每吨增加8%25. C.废品率每增加1%,成本每吨增加8元 D.废品率每增加1%,则每吨成本为561、B2、A3、A4、C5、B6、C7、C8、D9、B 10、C.八、多项选择题1.测定现象之间有无相关关系的方法有2.A、对现象做定性分析 B、编制相关表 C、绘制相关图 D.计算相关系数 E、计算估计标准3.下列属于负相关的现象有4.A、商品流转的规模愈大,流通费用水平越低 B、流通费用率随商品销售额的增加而减少5. C、国内生产总值随投资额的增加而增长 D、生产单位产品所耗工时随劳动生产率的提高而减少 E、产品产量随工人劳动生产率的提高而增加6.变量x值按一定数量增加时,变量y 也按一定数量随之增加,反之亦然,则x和y之间存在7. A、正相关关系 B、直线相关关系 C、负相关关系 D、曲线相关关系8. E、非线性相关关系9.直线回归方程 y c=a+bx 中的b 称为回归系数,回归系数的作用是10. A、确定两变量之间因果的数量关系 B、确定两变量的相关方向 C、确定两变量相关的密切程度 D、确定因变量的实际值与估计值的变异程度11. E 确定当自变量增加一个单位时,因变量的平均增加量12.设产品的单位成本元对产量百件的直线回归方程为y c=76-1.85x,这表示13. A、产量每增加100件,单位成本平均下降1.85元 B、产量每减少100件,单位成本平均下降1.85元 C、产量与单位成本按相反方向变动 D、产量与单位成本按相同方向变动 E、当产量为200件时,单位成本为72.3元1、ABCD2、ABD3、AB4、ABE5、ACE九、填空题1.相关分析研究的是关系,它所使用的分析指标 ;2.从相关方向上看, 产品销售额与销售成本之间属于相关关系,而产品销售额与销售利润之间属于相关关系;3.相关系数的取值范围是 ,r为正值时则称 ;4.相关系数г=+1时称为相关,г为负值时则称 ;5.正相关的取值范围是 ,负相关的取值范围是 ;6.相关密切程度的判断标准中,0.5<|r|<0.8称为 ,0.8<|r|<1称为7.回归直线参数a . b是用计算的,其中b也称为 ;8.设回归方程y c=2+3x, 当x=5时,y c= ,当x每增加一个单位时,y c增加 ;1、相关相关系数2、负正3、1-r正相关 4、完全正负相关 5、0<r≤+1 -1≤r<0 6、≤1≤显著相关高度相关 7、最小平方法回归系数 8、17 3.十、简答题1.从现象总体数量依存关系来看,函数关系和相关关系又何区别答:函数关系是:当因素标志的数量确定后,结果标志的数量也随之确定;相关关系是:作为因素标志的每个数值,都有可能有若干个结果标志的数值,是一种不完全的依存关系;2、现象相关关系的种类划分主要有哪些答:现象相关关系的种类划分主要有:1.按相关的程度不同,可分为完全相关.不完全相关和不相关;2.按相关的方向,可分为正相关和负相关;3.按相关的形式,可分为线性相关和非线性相关;4.按影响因素的多少,可分为单相关复相关六、计算题1、某部门5个企业产品销售额和销售利润资料如下:试计算产品销售额与利润额的相关系数,并进行分析说明;要求列表计算所需数据资料,写出公式和计算过程,结果保留四位小数;2.某班40名学生,按某课程的学习时数每8人为一组进行分组,其对应的学习成绩如下表:试根据上述资料建立学习成绩y倚学习时间x的直线回归方程;要求列表计算所需数据资料,写出公式和计算过程,结果保留两位小数;3、某公司所辖八个企业生产同种产品的有关资料如下:企业编号月产量千件生产费用万元A B C D E F G H 6.13.85.08.02.07.21.23.1132110115160861356280要求:1计算相关系数,测定月产量与生产费用之间的相关方向和程度;2确定自变量和因变量,并求出直线回归方程;3根据回归方程,指出当产量每增加1000件时,生产费用平均上升多少4、某企业第二季度产品产量与单位成本资料如下:要求:1配合回归方程,指出产量每增加1000件时单位成本平均变动多少 2产量为8000件--10000件时,单位成本的区间是多少元5、某地居民1983-1985年人均收入与商品销售额资料如下:要求建立以销售额为因变量的直线回归方程,并估计人均收入为40元时商品销售额为多少 要求列表计算所需数据资料,写出公式和计算过程,结果保留两位小数; 1、解:设销售额为x,销售利润额y.相关系数:9999.0]5.22125.116435][351027403005[5.22135101779805)(][)([222222=-⨯-⨯⨯-⨯=---=∑∑∑∑∑∑∑y y n x x n yx xy n r 从相关系数可以看出,产品销售额和利润额之间存在高度正相关关系; 2、解:设直线回归方程为y c =a+bx,列表计算所需资料如下: 89.11052617531010572905)(222=-⨯⨯-⨯=--=∑∑∑∑∑x x n y x xy n b31.22510589.15310=⨯-=-=-=∑∑nx b ny x b y a直线回归方程为: y c = 22.31+1.89x 3、参考答案:设月产量为x,生产费用为y 1高度正相关⇒≈∑∑∑∑∑∑∑=-⋅-⋅-97.02222)()(y y n x x n yx xy nr 6分2令直线趋势方程为:x y⋅+=βαˆˆˆ 31.51ˆˆ,9.12ˆ22)(=⋅-=≈∑∑∑∑∑=-⋅-x y x x n y x xy n βαβ则 x y9.1231.51ˆ+=∴直线趋势方程为:8分 3当月产量增加1个单位时,生产费用将增加12.9万元1分4、解:设产量为自变量x,单位成本为因变量y,列表计算如下:(1) 配合加归方程 y c = a + bx50.212503210128353)(222-=-⨯⨯-⨯=--=∑∑∑∑∑x x n y x xy n b即产量每增加1000件时,单位成本平均下降2.50元;80312)50.2(3210=⨯--=-=-=∑∑nx b ny x b y a故单位成本倚产量的直线回归方程为y c =80-2.5x2当产量为8000件时,即x=8,代入回归方程: y c = 80-2.5×8 = 60元当产量为10000件时,即x=10,代入回归方程: y c = 80-2.5×10 = 55元即产量为8000件~10000件时,单位成本的区间为60元~55元; 5、解:列表计算如下:44.08625003408611623)(222=-⨯⨯-⨯=--=∑∑∑∑∑x x n y x xy n b72.038644.0340=⨯-=-=-=∑∑nx b ny x b y a销售额与人均收入直线回归方程为:y c =0.72+0.44x将x=40代入直线回归方程:y c=0.72+0.44x=0.72+0.44×40=18.32万元即:当人均收入为40元时,销售额为18.32万元;。
第十一届全国大学生市场调查与分析大赛题库答案

第十一届全国大学生市场调查与分析大赛题库答案(总525页)1. * 测量抽样误差最常用的指标是()。
变异系数标准差抽样方差置信区间2A3.* 关于回归模型的有关说法,哪些是正确的()。
拟合优度R2 的取值范围是-1≤R2≤1回归的残差平方和占总离差平方和的比重越大,说明拟和的效果越好拟合优度 R2 越接近 1,说明拟合的效果越好t 检验是用来检验方程整体的显著性的4.* 方差分析是用来判断()。
数值型自变量对数值型应变量是否有显著影响数值型自变量对分类型应变量是否有显著影响分类型自变量对分类型应变量是否有显著影响分类型自变量对数值型应变量是否有显著影响5.* 对高维变量空间进行降维处理的方法包括()。
主成分分析和因子分析聚类分析和对应分析聚类分析和主成分分析因子分析和聚类分析6.* 某企业生产某种产品的产量每年增加10 万吨,则该产品产量的环比增长速度()。
无法得出结论年年增长年年保持不变年年下降7* 下列各项中不会影响到抽样误差大小的是()。
样本容量总体方差总体均值抽样方式8.*利用方差分析表进行方差分析时,该表不包括的项目有()。
离差平方和及其分解方差来源原假设的统计判断各离差平方和的自由度9.* 在问卷设计中,敏感性问题放在()有助于提高回答率。
随机位置调查中期调查前期调查后期10* Fisher 判别方法的主要特点是()。
如果点 x 到总体 1 的距离小于到总体 2 的距离,点x 应该判为总体2对数据利用马氏距离计算出距离进行判别先对数据进行投影然后再利用距离进行判别如果点 x 到总体 1 的距离大于到总体 2 的距离,点x 应该判为总体111* 全球各大都市的气温资料,属于何种尺度顺序尺度比率尺度定类尺度等距尺度12* 企业的调查部门、独立的调查公司和学术性调查机构的组织模式多采用()。
矩阵式职能式直线式直线职能式13* 深度访谈在定性调研中具有很重要的作用,任何一个深度访谈的成败取决于()。