模式识别 Fisher线性判别实验
机器学习实验1-Fisher线性分类器设计

一、实验意义及目的掌握Fisher分类原理,能够利用Matlab编程实现Fisher线性分类器设计,熟悉基于Matlab算法处理函数,并能够利用算法解决简单问题。
二、算法原理Fisher准则基本原理:找到一个最合适的投影周,使两类样本在该轴上投影之间的距离尽可能远,而每一类样本的投影尽可能紧凑,从而使分类效果为最佳。
内容:(1)尝试编写matlab程序,用Fisher线性判别方法对三维数据求最优方向w的通用函数(2)对下面表1-1样本数据中的类别w1和w2计算最优方向w(3)画出最优方向w 的直线,并标记出投影后的点在直线上的位置(4)选择决策边界,实现新样本xx1=(-0.7,0.58,0.089),xx2=(0.047,-0.4,1.04)的分类三、实验内容(1)尝试编写matlab程序,用Fisher线性判别方法对三维数据求最优方向w的通用函数程序清单:clcclear all%10*3样本数据w1=[-0.4,0.58,0.089;-0.31,0.27,-0.04;-0.38,0.055,-0.035;-0.15,0.53,0.011;-0.35,.47,0.034;0.17,0.69,0.1;-0.011,0.55,-0.18;-0.27,0.61,0.12;-0.065,0.49,0.0012;-0.12,0.054,-0.063];w2=[0.83,1.6,-0.014;1.1,1.6,0.48;-0.44,-0.41,0.32;0.047,-0.45,1.4;0.28,0.35,3.1;-0.39,-0.48,0.11;0.34,-0.079,0.14;-0.3,-0.22,2.2;1.1,1.2,-0.46;0.18,-0.11,-0.49];W1=w1';%转置下方便后面求s1W2=w2';m1=mean(w1);%对w1每一列取平均值结果为1*3矩阵m2=mean(w2);%对w1每一列取平均值结果为1*3矩阵S1=zeros(3);%有三个特征所以大小为3S2=zeros(3);for i=1:10%1到样本数量ns1=(W1(:,i)-m1)*(W1(:,i)-m1)';s2=(W2(:,i)-m2)*(W2(:,i)-m2)';S1=S1+s1;S2=S2+s2;endsw=S1+S2;w_new=transpose(inv(sw)*(m1'-m2'));%这里m1m2是行要转置下3*3 X 3*1 =3*1 这里提前转置了下跟老师ppt解法公式其实一样%绘制拟合结果数据画图用y1=w_new*W1y2=w_new*W2;m1_new=w_new*m1';%求各样本均值也就是上面y1的均值m2_new=w_new*m2';w0=(m1_new+m2_new)/2%取阈值%分类判断x=[-0.7 0.0470.58 -0.40.089 1.04 ];m=0; n=0;result1=[]; result2=[];for i=1:2%对待观测数据进行投影计算y(i)=w_new*x(:,i);if y(i)>w0m=m+1;result1(:,m)=x(:,i);elsen=n+1;result2(:,n)=x(:,i);endend%结果显示display('属于第一类的点')result1display('属于第二类的点')result2figure(1)scatter3(w1(1,:),w1(2,:),w1(3,:),'+r'),hold onscatter3(w2(1,:),w2(2,:),w2(3,:),'sg'),hold onscatter3(result1(1,:),result1(2,:),result1(3,:),'k'),hold onscatter3(result2(1,:),result2(2,:),result2(3,:),'bd')title('样本点及实验点的空间分布图')legend('样本点w1','样本点w2','属于第一类的实验点','属于第二类的实验点')figure(2)title('样本拟合结果')scatter3(y1*w_new(1),y1*w_new(2),y1*w_new(3),'b'),hold onscatter3(y2*w_new(1),y2*w_new(2),y2*w_new(3),'sr')(2)对下面表1-1样本数据中的类别w1和w2计算最优方向w(3)画出最优方向w 的直线,并标记出投影后的点在直线上的位置最优方向w 的直线投影后的位置(4)选择决策边界,实现新样本xx1=(-0.7,0.58,0.089),xx2=(0.047,-0.4,1.04)的分类决策边界取法:分类结果:四、实验感想通过这次实验,我学会了fisher线性判别相关的分类方法,对数据分类有了初步的认识,尽管在过程中有不少中间量不会算,通过查阅网络知识以及模式识别专业课ppt等课件帮助,我最终完成了实验,为今后继续深入学习打下良好基础。
模式识别上机实验报告

实验一、二维随机数的产生1、实验目的(1) 学习采用Matlab 程序产生正态分布的二维随机数 (2) 掌握估计类均值向量和协方差矩阵的方法(3) 掌握类间离散度矩阵、类内离散度矩阵的计算方法(4) 熟悉matlab 中运用mvnrnd 函数产生二维随机数等matlab 语言2、实验原理多元正态分布概率密度函数:11()()2/21/21()(2)||T X X d p X eμμπ---∑-=∑其中:μ是d 维均值向量:Td E X μμμμ=={}[,,...,]12Σ是d ×d 维协方差矩阵:TE X X μμ∑=--[()()](1)估计类均值向量和协方差矩阵的估计 各类均值向量1ii X im X N ω∈=∑ 各类协方差矩阵1()()iTi iiX iX X N ωμμ∈∑=--∑(2)类间离散度矩阵、类内离散度矩阵的计算类内离散度矩阵:()()iTi iiX S X m X m ω∈=--∑, i=1,2总的类内离散度矩阵:12W S S S =+类间离散度矩阵:1212()()Tb S m m m m =--3、实验内容及要求产生两类均值向量、协方差矩阵如下的样本数据,每类样本各50个。
1[2,2]μ=--,11001⎡⎤∑=⎢⎥⎣⎦,2[2,2]μ=,21004⎡⎤∑=⎢⎥⎣⎦ (1)画出样本的分布图;(2) 编写程序,估计类均值向量和协方差矩阵;(3) 编写程序,计算类间离散度矩阵、类内离散度矩阵; (4)每类样本数增加到500个,重复(1)-(3)4、实验结果(1)、样本的分布图(2)、类均值向量、类协方差矩阵根据matlab 程序得出的类均值向量为:N=50 : m1=[-1.7160 -2.0374] m2=[2.1485 1.7678] N=500: m1=[-2.0379 -2.0352] m2=[2.0428 2.1270] 根据matlab 程序得出的类协方差矩阵为:N=50: ]0628.11354.01354.06428.1[1=∑ ∑--2]5687.40624.00624.08800.0[N=500:∑--1]0344.10162.00162.09187.0[∑2]9038.30211.00211.09939.0[(3)、类间离散度矩阵、类内离散度矩阵根据matlab 程序得出的类间离散度矩阵为:N=50: ]4828.147068.147068.149343.14[=bS N=500: ]3233.179843.169843.166519.16[b =S根据matlab 程序得出的类内离散度矩阵为:N=50:]0703.533088.73088.71052.78[1=S ]7397.2253966.13966.18975.42[2--=S ]8100.2789123.59123.50026.121[=W SN=500: ]5964.5167490.87490.86203.458[1--=S ]8.19438420.78420.70178.496[2=S ]4.24609071.09071.06381.954[--=W S5、结论由mvnrnd 函数产生的结果是一个N*D 的一个矩阵,在本实验中D 是2,N 是50和500.根据实验数据可以看出,当样本容量变多的时候,两个变量的总体误差变小,观测变量各个取值之间的差异程度减小。
【线性判别】Fisher线性判别(转)

【线性判别】Fisher线性判别(转)今天读paper遇到了Fisher线性判别的变体,所以来学习⼀下,所以到时候⼀定要把PRMl刷⼀遍呀在前⽂《贝叶斯决策理论》中已经提到,很多情况下,准确地估计概率密度模型并⾮易事,在特征空间维数较⾼和样本数量较少的情况下尤为如此。
实际上,模式识别的⽬的是在特征空间中设法找到两类(或多类)的分类⾯,估计概率密度函数并不是我们的⽬的。
前⽂已经提到,正态分布情况下,贝叶斯决策的最优分类⾯是线性的或者是⼆次函数形式的,本⽂则着重讨论线性情况下的⼀类判别准则——Fisher判别准则。
为了避免陷⼊复杂的概率的计算,我们直接估计判别函数式中的参数(因为我们已经知道判别函数式是线性的)。
⾸先我们来回顾⼀下线性判别函数的基本概念:应⽤统计⽅法解决模式识别问题时,⼀再碰到的问题之⼀就是维数问题。
在低维空间⾥解析上或计算上⾏得通的⽅法,在⾼维空间⾥往往⾏不通。
因此,降低维数有时就会成为处理实际问题的关键。
问题描述:如何根据实际情况找到⼀条最好的、最易于分类的投影线,这就是Fisher判别⽅法所要解决的基本问题。
考虑把d维空间的样本投影到⼀条直线上,形成⼀维空间,即把维数压缩到⼀维。
然⽽,即使样本在d维空间⾥形成若⼲紧凑的互相分得开的集群,当把它们投影到⼀条直线上时,也可能会是⼏类样本混在⼀起⽽变得⽆法识别。
但是,在⼀般情况下,总可以找到某个⽅向,使在这个⽅向的直线上,样本的投影能分得开。
下图可能会更加直观⼀点:从d维空间到⼀维空间的⼀般数学变换⽅法:假设有⼀集合Г包含N个d维样本x1, x2, …, xN,其中N1个属于ω1类的样本记为⼦集Г1, N2个属于ω2类的样本记为⼦集Г2 。
若对xn的分量做线性组合可得标量:yn = wTxn, n=1,2,…,N这样便得到N个⼀维样本yn组成的集合,并可分为两个⼦集Г1’和Г2’ 。
实际上,w的值是⽆关紧要的,它仅是yn乘上⼀个⽐例因⼦,重要的是选择w的⽅向。
模式识别FISHER线性判别实验

模式识别FISHER线性判别实验
人工知能领域中的模式识别是计算机实现人类识别物体的能力的一种
技术。
它的主要目的是根据给定模式的样本及其特征,自动识别出新的样
本的特征并做出判断。
其中最著名的技术之一就是FISHER线性判别法。
FISHER线性判别法基于正态分布理论,通过计算样本的统计特征来
分类,它是一种基于参数的最优分类算法。
算法的基本思想是通过计算两
个类别的最大类间差异度,以及最小类内差异度,来有效地分类样本。
具
体而言,FISHER线性判别法即求出一个线性超平面,使这个超平面把样
本区分开来,使样本离类中心向量之间的距离最大,同时使类中心向量之
间的距离最小。
FISHER线性判别法的具体实现过程如下:
1.准备好建立模型所需要的所有数据:训练样本集,其样本特征与对
应的类标号。
2.确定每个类的类中心向量c_1,c_2,…,c_m,其中m为类的数目。
3.根据类中心向量求出类间离散度矩阵S_b和类内离散度矩阵S_w。
4.将S_b与S_w相除,得到S_b/S_w,从而求出矩阵的最大特征值
λ_1及最小特征值λ_n。
5.将最大特征值λ_1进行特征值分解,求出其特征向量w,求出判
定函数:
f(x)=w·x+w_0。
6.根据判定函数,将样本进行分类。
武汉理工大学,模式识别实验报告,带数据!带代码!

武汉理工大学模式识别实验报告姓名:班级:学号:姓名:班级:学号:实验一总体概率密度分布的非参数方法一、实验目的1.了解使用非参数方法估计样本概率密度函数的原理。
2.了解Parzen窗法的原理及其参数h1,N对估计结果的影响。
3.掌握Parzen窗法的算法并用Matlab实现。
4.使用Matlab分析Parzen窗法的参数h1,N对估计结果的影响。
二、实验数据一维正态分布样本,使用函数randn生成。
三、实验结果选取的h1=0.25,1,4,N=1,16,256,4096,65536,得到15个估计结果,如下图所示。
由下面三组仿真结果可知,估计结果依赖于N和h1。
当N=1时,是一个以样本为中心的小丘。
当N=16和h1=0.25时,仍可以看到单个样本所起的作用;但当h1=1及h1=4时就受到平滑,单个样本的作用模糊了。
随着N的增加,估计量越来越好。
这说明,要想得到较精确的估计,就需要大量的样本。
但是当N取的很大,h1相对较小时,在某些区间内hN趋于零,导致估计的结果噪声大。
分析实验数据发现在h1=4,N=256时,估计结果最接近真实分布。
附录:1.Parzen窗法函数文件parzen.m function parzen=parzen(N,h1,x) %ParzenhN = h1/sqrt(N);num_x = numel(x);parzen = zeros(1, num_x);for u = 1:num_xfor i=1:Nparzen(u) = parzen(u)+exp(((x(u)-x(i))/hN).^2/-2);endparzen(u)=parzen(u)/sqrt(2*pi)/h1/sqrt(N);end2.例程文件parzen_sample.mx = randn(1,10000);%Normally distributed pseudorandom numberspx = normpdf(x,0,1);%Normal probability density function - normpdf(X,mu,sigma)h1 = [0.25, 1, 4];N = [1, 16, 256, 1024, 4096];num_h1 = numel(h1);%Number of array elementsnum_N = numel(N);figure('Name', '总体概率密度分布的非参数方法');%遍历h1for i_h1 = 1:length(h1)h1_offset = (i_h1-1)*(num_N+1)+1;%绘图位置的偏移量subplot(num_h1, num_N+1, h1_offset);plot(x, px, '.');ylabel(sprintf('%s%4.2f', 'h1=', h1(i_h1)));title('正态分布样本的概率密度函数')%遍历Nfor i_N = 1 : length(N)pNx=parzen(N(i_N), h1(i_h1), x);subplot(num_h1, num_N+1, h1_offset+i_N);plot(x, pNx, '.');title(sprintf('%s%d', 'N=', N(i_N)));endend姓名:班级:学号:实验二感知器准则算法实验一、实验目的1.了解利用线性判别函数进行分类的原理。
FISHER分类

Fisher 线性判别分类器成员姓名: 学号:莫文敏 201111921217 赵越 201111921229 顾瑞煌 201111921104一、实验目的1.实现基于FISHER 分类的算法程序;2.能够根据自己的设计加深对FISHER 分类的认识;3.掌握FISHER 分类的原理、特点。
二、实验设备1.手提电脑2.MATLAB三、FISHER 算法原理线性判别函数的一般形式可表示成0)(w X W X g T +=其中⎪⎪⎪⎭⎫ ⎝⎛=d x x X 1 ⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=d w w w W 21但是,在应用统计方法解决模式识别的问题时,经常会遇到“维数风暴”的问题,因此压缩特征空间的维数在此时十分重要,FISHER 方法实际上是涉及维数压缩的问题。
把多为特征空间的点投影到一条直线上,就能把特征空间压缩成一维,这在数学上是很容易做到的。
但是在高维空间里很容易一分开的样品,把它们投射到任意一条直线上,有可能不同类别的样品就混在一起,无法区分了,如图5-16(a )所示,投影1x 或2x 轴无法区分。
若把直线绕原点转动一下,就有可能找到一个方向,样品投射到这个方向的直线上,各类样品就能很好地分开,如图5-16(b )所示。
因此直线方向的选择是很重要的。
一般来说总能找到一个最好的方向,使样品投射到这个方向的直线上很容易分开。
如何找到这个最好的直线方向以及如何实现向最好方向投影的变换,这正是FISHER 算法要解决的基本问题,这个投影变换正是我们寻求的解向量*W 。
样品训练集以及待测样品的特征总数目为n ,为找到最佳投影方向,需要计算出各类样品的均值、样品类内离散度矩阵i S 和总类间矩阵w S 、样品类间离散度矩阵b S ,根据FISHER 准则找到最佳投影向量,将训练集内所有样品进行投影,投影到一维Y 空间,由于Y 空间是一维的,则需要求出Y 空间的划分边界点,找到边界点后,就可以对待测样品进行一维Y 空间的投影,判断它的投影点与分界点的关系将其归类。
《模式识别》线性分类器设计实验报告
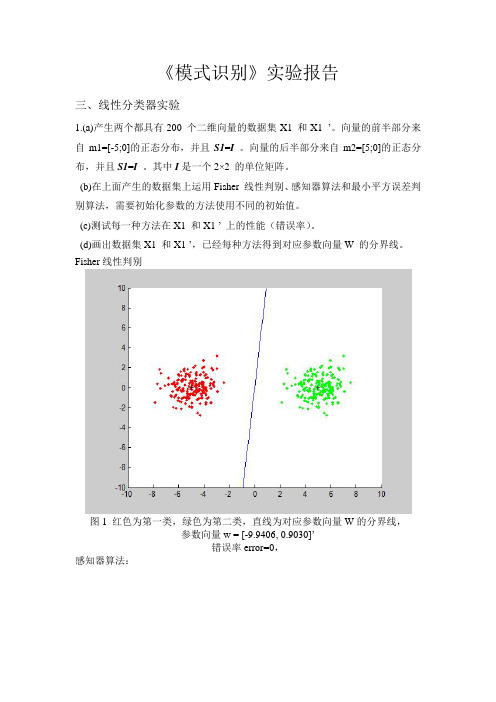
《模式识别》实验报告三、线性分类器实验1.(a)产生两个都具有200 个二维向量的数据集X1 和X1 ’。
向量的前半部分来自m1=[-5;0]的正态分布,并且S1=I 。
向量的后半部分来自m2=[5;0]的正态分布,并且S1=I。
其中I是一个2×2 的单位矩阵。
(b)在上面产生的数据集上运用Fisher 线性判别、感知器算法和最小平方误差判别算法,需要初始化参数的方法使用不同的初始值。
(c)测试每一种方法在X1 和X1 ’ 上的性能(错误率)。
(d)画出数据集X1 和X1 ’,已经每种方法得到对应参数向量W 的分界线。
Fisher线性判别图1 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数向量w = [-9.9406, 0.9030]’错误率error=0,感知器算法:图2 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.1;0.1];迭代次数iter=2参数向量w = [-4.8925, 0.0920]’错误率error=0图3 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 1];迭代次数iter=2参数向量w = [-3.9925, 0.9920]’错误率error=0图4 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[10; 10];迭代次数iter=122参数向量w = [-5.6569, 7.8096]’错误率error=0图5 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[50; 50];迭代次数iter=600参数向量w = [-27.0945, 37.4194]’错误率error=0图6 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[50; 100];迭代次数iter=1190参数向量w = [-54.0048, 74.5875]’错误率error=0最小平方误差判别算法:图7 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.1; 0.1];参数向量w = [-0.1908, -0.0001]’错误率error=0图8 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.5; 0.5];参数向量w = [-0.1924, 0.1492]’错误率error=0图9 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 0.5];参数向量w = [-0.1914, 0.0564]’错误率error=0图10 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 1];参数向量w = [-0.1943, 0.3359]’错误率error= 0.00502.重复1.中的实验内容,数据集为X2 和X2 ’。
模式识别Fisher线性判别实验

模式识别Fisher线性判别实验实验三 Fisher线性判别实验姓名:徐维坚学号:2220103484 日期:2012/7/7 一、实验目的:1)加深对Fisher线性判别的基本思想的认识和理解。
2)编写实现Fisher线性判别准则函数的程序。
二、实验原理:1.基本原理:一般情况下,我们总可以找到某个方向,使得这个方向的直线上,样本的投影能分开的最好,而Fisher法所要解决的基本问题就是找到这条最好的、最易于分类的投影线。
X先从d维空间到一维空间的一维数学变换方法。
假设有一集合包含N个d维样本,其中个属于类的样本记为子集,个属于类的样本记为。
x,x,...,x,N,XNX212N11122若对的分量做线性组合可得标量 xN T, n,1,2,...,Ny,wxinn这样便得到N个一维样本组成的集合,并可分为两个子集和。
的绝对值是无关ywYYn12紧要的,它仅使乘上一个比例因子,重要的是选择的方向,从而转化为寻找最好的投ywn*w影方向,是样本分开。
2.基本方法:先定义几个基本参量:m(1)各类样本均值向量 i1m,x,i,1,2 ,iNx,XiSS(2)样本类内离散度矩阵和总类内离散度矩阵 i,TS,(x,m)(x,m),i,1,2 i,iix,XiS,S,S ,12S(3)样本类间离散度矩阵 bTS,(m,m)(m,m) 1212b(m,m)我们希望投影后,在低维空间里个样本尽可能的分开些,即希望两类均值越大越12Authord: Vivid Xu;好,同时希望各类样本内部尽量密集,即越小越好。
因此,我们定义Fisher 准则函数为 Si2,(mm)12 ,J(w)F,SS12但不显含,因此必须设法将变成的显函数。
wwJ(w)J(w)FF由式子111TTTm,y,wx,w(x),wm ,,,iiNNN,,,yYxXxXiiiiii2TT2TTT (m,m),(wm,wm),w(m,m)(m,m)w,wSw12121212bTTTTT22S,(y,m),(wx,wm),w(x,m)(x,m)w,wSw ,,iiiiii,,yYyYii从而得到TwSwbJw, (),FTwSw,*w采用Lagrange乘子法求解它的极大值TT L(w,,),wSw,,(wSw,c),b**对其求偏导,得,即 Sw,,Sw,0b,** Sw,,Swb,从而我们很容易得到*,1*,1T* ,w,S(Sw),S(m,m)R,其中R,(m,m)w,,b1212R*1,w,S(m,m) ,12,R/,忽略比例因子,得*1, w,S(m,m),12这就是我们Fisher准则函数J(w)取极大值时的解。
fisher判别函数

Fisher判别函数,也称为线性判别函数(Linear Discriminant Function),是一种经典的模式识别方法。
它通过将样本投影到一维或低维空间,将不同类别的样本尽可能地区分开来。
一、算法原理:Fisher判别函数基于以下两个假设:1.假设每个类别的样本都服从高斯分布;2.假设不同类别的样本具有相同的协方差矩阵。
Fisher判别函数的目标是找到一个投影方向,使得同一类别的样本在该方向上的投影尽可能紧密,而不同类别的样本在该方向上的投影尽可能分开。
算法步骤如下:(1)计算类内散度矩阵(Within-class Scatter Matrix)Sw,表示每个类别内样本之间的差异。
Sw = Σi=1 to N (Xi - Mi)(Xi - Mi)ᵀ,其中Xi 表示属于类别i 的样本集合,Mi 表示类别i 的样本均值。
(2)计算类间散度矩阵(Between-class Scatter Matrix)Sb,表示不同类别之间样本之间的差异。
Sb = Σi=1 to C Ni(Mi - M)(Mi - M)ᵀ,其中 C 表示类别总数,Ni 表示类别i 中的样本数量,M 表示所有样本的均值。
(3)计算总散度矩阵(Total Scatter Matrix)St,表示所有样本之间的差异。
St =Σi=1 to N (Xi - M)(Xi - M)ᵀ(4)计算投影方向向量w,使得投影后的样本能够最大程度地分开不同类别。
w= arg max(w) (wᵀSb w) / (wᵀSw w),其中w 表示投影方向向量。
(5)根据选择的投影方向向量w,对样本进行投影。
y = wᵀx,其中y 表示投影后的样本,x 表示原始样本。
(6)通过设置一个阈值或使用其他分类算法(如感知机、支持向量机等),将投影后的样本进行分类。
二、优点和局限性:Fisher判别函数具有以下优点:•考虑了类别内和类别间的差异,能够在低维空间中有效地区分不同类别的样本。
Fisher线性判别分析实验(模式识别与人工智能原理实验1)

F i s h e r线性判别分析实验(模式识别与人工智能原理实验1)-CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN实验1 Fisher 线性判别分析实验一、摘要Fisher 线性判别分析的基本思想:通过寻找一个投影方向(线性变换,线性组合),将高维问题降低到一维问题来解决,并且要求变换后的一维数据具有如下性质:同类样本尽可能聚集在一起,不同类的样本尽可能地远。
Fisher 线性判别分析,就是通过给定的训练数据,确定投影方向W 和阈值y0,即确定线性判别函数,然后根据这个线性判别函数,对测试数据进行测试,得到测试数据的类别。
二、算法的基本原理及流程图 1 基本原理(1)W 的确定各类样本均值向量mi样本类内离散度矩阵i S 和总类内离散度矩阵w S12w S S S =+样本类间离散度矩阵b S在投影后的一维空间中,各类样本均值T i i m '= W m 。
样本类内离散度和总类内离散度 T T i i w w S ' = W S W S ' = W S W 。
样本类间离散度T b b S ' = W S W 。
Fisher 准则函数满足两个性质:·投影后,各类样本内部尽可能密集,即总类内离散度越小越好。
·投影后,各类样本尽可能离得远,即样本类间离散度越大越好。
根据这个性质确定准则函数,根据使准则函数取得最大值,可求出W :-1w 12W = S (m - m ) 。
(2)阈值的确定实验中采取的方法:012y = (m ' + m ') / 2。
(3)Fisher 线性判别的决策规则T x S (x m)(x m ), 1,2ii ii X i ∈=--=∑T1212S (m m )(m m )b =--对于某一个未知类别的样本向量x,如果y=W T·x>y0,则x∈w1;否则x∈w2。
模式识别fisher判别

论文(设计)《模式识别》题目Fisher线性判别的基本原理及应用Fisher判别准则一、基本原理思想Fisher线性判别分析的基本思想:通过寻找一个投影方向(线性变换,线性组合),将高维问题降低到一维问题来解决,并且要求变换后的一维数据具有如下性质:同类样本尽可能聚集在一起,不同类的样本尽可能地远。
Fisher线性判别分析,就是通过给定的训练数据,确定投影方向W和阈值y0,即确定线性判别函数,然后根据这个线性判别函数,对测试数据进行测试,得到测试数据的类别。
二、算法的实现及流程图1 算法实现 (1)W 的确定x 1m x, 1,2ii X ii N ∈==∑各类样本均值向量mi样本类内离散度矩阵和总类内离散度矩阵Tx S (x m )(x m ), 1,2ii i i X i ∈=--=∑样本类间离散度矩阵T1212S (m m )(m m )b =--在投影后的一维空间中,各类样本均值。
样本类内离散度和总类内离散度。
样本类间离散度。
Fisher 准则函数满足两个性质:·投影后,各类样本内部尽可能密集,即总类内离散度越小越好。
·投影后,各类样本尽可能离得远,即样本类间离散度越大越好。
根据这个性质确定准则函数,根据使准则函数取得最大值,可求出W :。
(2)阈值的确定采取的方法:【1】【2】【3】(3)Fisher 线性判别的决策规则对于某一个未知类别的样本向量x ,如果y=W T·x>y0,则x ∈w1;否则x ∈w2。
2 流程图归一化处理载入训练数据三、实验仿真1.实验要求试验中采用如下的数据样本集:ω1类: (22,5),(46,33),(25,30),(25,8),(31, 3),(37,9),(46,7),(49,5),(51,6),(53,3)(19,15),(23,18),(43,1),(22,15),(20,19),(37,36),(22,22),(21,32),(26,36),(23,39)(29,35),(33,32),(25,38),(41,35),(33,2),(48,37)ω2类: (40,25),(63,33),(43,27),(52,25),(55,27),(59,22) ,(65,59),(63,27)(65,30),(66,38),(67,43),(52,52),(61,49) (46,23),(60,50),(68,55) (40,53),(60,55),(55,55) (48,56),(45,57),(38,57) ,(68,24)在实验中采用Fisher线性判别方法设计出每段线性判别函数。
模式识别——感知器准则与Fisher算法实验-推荐下载

1、复习感知器算法; 2、写出实现批处理感知器算法的程序 1)从 a=0 开始,将你的程序应用在 ω1 和 ω2 的训练数据上。记下收敛的步 数。 2)将你的程序应用在 ω2 和 ω3 类上,同样记下收敛的步数。 3)试解释它们收敛步数的差别。 3、提高部分:ω3 和 ω4 的前 5 个点不是线性可分的,请手工构造非线性映 射,使这些点在映射后的特征空间中是线性可分的,并对它们训练一个感
本实验通过编制程序让初学者能够体会 Fisher 线性判别的基本思路,理解线性判别的 基本思想,掌握 Fisher 线性判别问题的实质。
2、[实验内容]
1.实验所用样本数据如表 2-1 给出(其中每个样本空间(数据)为两维, x 1 表示第一维的值、x 2 表示第二维的值),编制程序实现 ω1、ω 2 类 ω 2、ω 3 类的分类。分析分类器算法的性能。
x1 X
xd
根据 Fisher 选择投影方向 W 的原则,即使原样本向量在该方向上的投影能兼顾类间分
布尽可能分开,类内样本投影尽可能密集的要求,用以评价投影方向 W 的函数为:
J F (W ) (m~S~112m~S~222)2
W * SW1(m1 m2 )
上面的公式是使用 Fisher 准则求最佳法线向量的解,该式比较重要。另外,该式这种
2
对全部高中资料试卷电气设备,在安装过程中以及安装结束后进行高中资料试卷调整试验;通电检查所有设备高中资料电试力卷保相护互装作置用调与试相技互术关,系电通,力1根保过据护管生高线产中0不工资仅艺料可高试以中卷解资配决料置吊试技顶卷术层要是配求指置,机不对组规电在范气进高设行中备继资进电料行保试空护卷载高问与中题带资2负料2,荷试而下卷且高总可中体保资配障料置2试时32卷,3各调需类控要管试在路验最习;大题对限到设度位备内。进来在行确管调保路整机敷使组设其高过在中程正资1常料中工试,况卷要下安加与全强过,看度并25工且52作尽22下可护都能1关可地于以缩管正小路常故高工障中作高资;中料对资试于料卷继试连电卷接保破管护坏口进范处行围理整,高核或中对者资定对料值某试,些卷审异弯核常扁与高度校中固对资定图料盒纸试位,卷置编工.写况保复进护杂行层设自防备动腐与处跨装理接案资要,料求编试技5写、卷术重电保交要气护底设设装。备备置管4高调、动线中试电作敷资高气,设料中课并技3试资件且、术卷料中拒管试试调绝路包验卷试动敷含方技作设线案术,技槽以来术、及避管系免架统不等启必多动要项方高方案中式;资,对料为整试解套卷决启突高动然中过停语程机文中。电高因气中此课资,件料电中试力管卷高壁电中薄气资、设料接备试口进卷不行保严调护等试装问工置题作调,并试合且技理进术利行,用过要管关求线运电敷行力设高保技中护术资装。料置线试做缆卷到敷技准设术确原指灵则导活:。。在对对分于于线调差盒试动处过保,程护当中装不高置同中高电资中压料资回试料路卷试交技卷叉术调时问试,题技应,术采作是用为指金调发属试电隔人机板员一进,变行需压隔要器开在组处事在理前发;掌生同握内一图部线纸故槽资障内料时,、,强设需电备要回制进路造行须厂外同家部时出电切具源断高高习中中题资资电料料源试试,卷卷线试切缆验除敷报从设告而完与采毕相用,关高要技中进术资行资料检料试查,卷和并主检且要测了保处解护理现装。场置设。备高中资料试卷布置情况与有关高中资料试卷电气系统接线等情况,然后根据规范与规程规定,制定设备调试高中资料试卷方案。
fisher线性判别

fisher线性判别
fisher 判决⽅式是监督学习,在新样本加⼊之前,已经有了原样本。
原样本是训练集,训练的⽬的是要分类,也就是要找到分类线。
⼀⼑砍成两半!
当样本集确定的时候,分类的关键就在于如何砍下这⼀⼑!
若以⿊⾊的来划分,很明显不合理,以灰⾊的来划分,才是看上去合理的
1.先确定砍的⽅向
关键在于如何找到投影的向量u,与u的长度⽆关。
只看⽅向
找到样本点的中⼼均值m1,m2,以及在向量u上的投影的m1~,m2~。
因为u的⽅向与样本点都有关,所以需要考虑⼀个含有所有样本点的表达式
不妨算出离差阵
算出类内离差矩阵,两个都要求出来,并求和
并且投影的离差阵
根据聚类的理想情况,类内距离⼩,类间距离⼤,所以就⽤类间去处理类内,我们现在的变量是向量u,我们就对u求导,算出max存在的时后u的条件。
为了⽅便化简,引⼊⼀个参数不要以为下⾯除以是向量,(1*2)*(2*2)(2*1)=1 维度变成1,这是⼀个常数。
当求导公式
分⼦为0的时候,推出
所以
⽽且是(1*2)*(2*1)等于1,也是⼀个常数
到此为⽌,u的⽅向已经确定了
2.具体切哪⼀个点。
a,切
切投影均值的终点
2.
切贝叶斯概率的⽐例点
⽅向和具体点均已找到,分析完毕。
实验1 Fisher线性判别实验
实验1 Fisher线性判别实验一、实验目的应用统计方法解决模式识别问题的困难之一是维数问题,低维特征空间的分类问题一般比高维空间的分类问题简单。
因此,人们力图将特征空间进行降维,降维的一个基本思路是将d维特征空间投影到一条直线上,形成一维空间,这在数学上比较容易实现。
问题的关键是投影之后原来线性可分的样本可能变为线性不可分。
一般对于线性可分的样本,总能找到一个投影方向,使得降维后样本仍然线性可分。
如何确定投影方向使得降维以后,样本不但线性可分,而且可分性更好(即不同类别的样本之间的距离尽可能远,同一类别的样本尽可能集中分布),就是Fisher线性判别所要解决的问题。
本实验通过编制程序让初学者能够体会Fisher线性判别的基本思路,理解线性判别的基本思想,掌握Fisher线性判别问题的实质。
二、实验要求1、改写例程,编制用Fisher线性判别方法对三维数据求最优方向W的通用函数。
2、对下面表1-1样本数据中的类别ω1和ω2计算最优方向W。
3、画出最优方向W的直线,并标记出投影后的点在直线上的位置。
表1-1 Fisher线性判别实验数据4、选择决策边界,实现新样本xx1=(-0.7,0.58,0.089),xx2=(0.047,-0.4,1.04)的分类。
5、提高部分(可做可不做):设某新类别ω3数据如表1-2所示,用自己的函数求新类别ω3分别和ω1、ω2分类的投影方向和分类阈值。
表1-2 新类别样本数据三、部分参考例程及其说明求取数据分类的Fisher投影方向的程序如下:其中w为投影方向。
clear %Removes all variables from the workspace.clc %Clears the command window and homes the cursor.% w1类训练样本,10组,每组为行向量。
w1=[-0.4,0.58,0.089;-0.31,0.27,-0.04;-0.38,0.055,-0.035;-0.15,0.53,0. 011;-0.35,0.47,0.034;...0.17,0.69,0.1;-0.011,0.55,-0.18;-0.27,0.61,0.12;-0.065,0.49,0.0012;-0 .12,0.054,-0.063];% w2类训练样本,10组,每组为行向量。
模式识别作业

6.题目:Fisher 分类和基于核的Fisher 分类的设计与实现研究 具体内容:1.简述Fisher 分类和基于核的Fisher 分类的算法原理; 2.举出实例;3.用MATlAB 软件编写程序实现;4.分析实验结果。
Fisher 分类和基于核的Fisher 分类的设计与实现研究1 Fisher 分类和基于核的Fisher 分类的算法原理1.1 Fisher 线性判别的算法原理Fisher 判别分析法对样本数据也没什么要求,而且可以弥补距离判别作外延计算时计算量大的问题,一般情况下,其判别的效果也比距离判别更好些。
由于Fisher 判别分析法不需要对样本数据进行检验,而且有一定的正确率,因此在实际中它被广泛的应用。
假设有一集合X 包含n 个d 维样本X={x 1,…,x n },其中n 1个属于w 1类的样本记为X 1={11x ,…,11n x },n 2个属于w 2类的样本记为X 2={21x ,…,22n x }。
Tnny w x= ,n=1,2,3,…i N(1.1)根据上式从几何上看,如果w =1,则每个ny就是相对应得n x到方向为w 的直线上的投影,w 的方向不同,将使样本投影后的分离程度不同,从而直接影响识别效果。
Fisher 线性判别所要解决的基本问题是找到一个最好的投影方向(如图1所示),使样本在这个方向上的投影能最好,最易于分类。
寻找最好投影方向的问题在数学上就是寻找最好的变换向量*w 的问题。
因此Fisher 判别分析的基本思想就是投影,即将k 类n 维数据投影到某个方向,是组与组间的距离最大,也即采用方差分析的思想。
判别函数的参数向量如下:在D 维X 空间: 1)各样本均值向量∑∈=iX x i i x n m )/1(,2,1=i (1.2)2)样本类内离散度矩阵i s 和各类内离散矩阵w s (),1,2()iTi i x x i i x x s m m ∈=-=-∑ (1.3)12ws s s=+ (1.4)3)样本间离散度矩阵b s12()12()Tb s m m m m =-- (1.5)我们最终可得Fisher 准则函数为:)/()()(w S w w S w w J w T b T = (1.6)其希望各类样本内部尽量密集,样本间尽可能分得开些。
(模式识别)Fisher线性判别

Fisher 判别
各类样本均值
1
mi Ni yi y, i 1, 2
样本类内离散度和总类内离散度
Si ( y mi )2, i 1,2 yi
样本类间离散度
Sw S1 S2 Sb (m1 m2 )2
以上定义描述d维空间样本点到一向量投影的分 散情况,因此也就是对某向量w的投影在w上的 分布。样本离散度的定义与随机变量方差相类似
Sw1(m1 m2 )R
w*
R
Sw1(m1
m2 )
Sw1(m1 m2 )
10
8
判别函数的确定
Fisher 判别
前面讨论了使Fisher准则函数极大的d维向 量w*的计算方法,判别函数中的另一项w0 (阈值)可采用以下几种方法确定:
w0
m1
2
m2
w0
N1m1 N2m2 N1 N2
m
w0
m1
m2 2
lnP(1) / P( 1 y wT x w0 0 x 2
Fisher线性判别
线性判别函数y=g(x)=wTx:
• 样本向量x各分量的线性加权 • 样本向量x与权向量w的向量点积 • 如果|| w ||=1,则视作向量x在向量w上的投
影
Fisher准则的基本原理:找到一个最合适的 投影轴,使两类样本在该轴上投影之间的距 离尽可能远,而每一类样本的投影尽可能紧 凑,从而使分类效果为最佳。
Si (x mi )(x mi )T , i 1,2 xi
Sw S1 S2
样本类间离散度矩阵Sb:Sb (m1 m2 )(m1 m2 )T
离散矩阵在形式上与协方差矩阵很相似,但协方 差矩阵是一种期望值,而离散矩阵只是表示有限 个样本在空间分布的离散程度
模式识别大作业136
模式识别大作业姓名:杨铠烨学号:02125136一、对sonar中数据(如表1所示)进行分类,用fisher判别法:表1 实验数据类别数特征维数样本个数=97(rock)sonar 2 60=111(mine)二、设计思路1、fisher 线性判别算法思路:用训练样本求出d维空间到一维空间的投影方向w,带入测试样本求出一维样本集合y,进而求出样本均值,接着可求出阈值y0,将y和y0比较即可分类。
注:(1)、先在matlab中进行数据的导入,用fisher线性判别时,将所调用的数据转置。
(2)、每一类数据调用一半作为训练样本,fisher线性判别中,调用mean 函数计算样本均值向量。
(3)、累加可用for循环实现,最后输出用disp函数。
三、代码1、fisher-----sonarn=1;for i=2:12:1154rock1(n,:)=reshape(rock(i:i+9,1:6)',1,60);n=n+1;endn=1;for i=2:12:1322mine1(n,:)=reshape(mine(i:i+9,1:6)',1,60);n=n+1;end//由于Excel中的数据不规整,先初步处理数据so11=rock1(1:49,:);so22=mine1(1:56,:);so1=so11’;so2=so22’;m1=mean(so1,2);m2=mean(so2,2);s1=zeros(60,60);s2=zeros(60,60);for n=1:49s1=s1+(so1(:,n)-m1)*(so1(:,n)-m1)’;endfor n=1:56s2=s2+(so2(:,n)-m2)*(so2(:,n)-m2)’; endsw=s1+s2;w=inv(sw)*(m1-m2);sonar11=rock1(50:97,:);sonar22=mine1(57:111,:);sonar1=sonar11’;sonar2=sonar22’;y1=w’*sonar1;y2=w’*sonar2;m11=mean(y1,2);m22=mean(y2,2);y01=(m11+m22)/2;count1=0;count2=0;for n=1:48if y1(1,n)>y01count1=count1+1;elsecount2=count2+1;endendfor n=1:55if y2(1,n)>y01count1=count1+1;elsecount2=count2+1;endenddisp(count1);disp(count2);四、matlab部分程序运行截图1、向matlab中导入数据,并初步整理2、分别取两组数据的前半部分求出到一维空间的投影方向w3、用剩下的一半数据作为测试样本,分别求出一维样本集合y1和y2,进而求出样本均值m11和m22,接着求出阈值y01,进而比较分类4、最后得到的count1和count2的值,可以说明fisher判别法的效果。
机器学习:线性判别式分析(LDA)

机器学习:线性判别式分析(LDA)1.概述线性判别式分析(Linear Discriminant Analysis),简称为LDA。
也称为Fisher线性判别(Fisher Linear Discriminant,FLD),是模式识别的经典算法,在1996年由Belhumeur引⼊模式识别和⼈⼯智能领域。
基本思想是将⾼维的模式样本投影到最佳鉴别⽮量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的⼦空间有最⼤的类间距离和最⼩的类内距离,即模式在该空间中有最佳的可分离性。
LDA与PCA都是常⽤的降维技术。
PCA主要是从特征的协⽅差⾓度,去找到⽐较好的投影⽅式。
LDA更多的是考虑了标注,即希望投影后不同类别之间数据点的距离更⼤,同⼀类别的数据点更紧凑。
但是LDA有两个假设:1.样本数据服从正态分布,2.各类得协⽅差相等。
虽然这些在实际中不⼀定满⾜,但是LDA被证明是⾮常有效的降维⽅法,其线性模型对于噪⾳的鲁棒性效果⽐较好,不容易过拟合。
2.图解说明(图⽚来⾃⽹络)可以看到两个类别,⼀个绿⾊类别,⼀个红⾊类别。
左图是两个类别的原始数据,现在要求将数据从⼆维降维到⼀维。
直接投影到x1轴或者x2轴,不同类别之间会有重复,导致分类效果下降。
右图映射到的直线就是⽤LDA⽅法计算得到的,可以看到,红⾊类别和绿⾊类别在映射之后之间的距离是最⼤的,⽽且每个类别内部点的离散程度是最⼩的(或者说聚集程度是最⼤的)。
3.图解LAD与PCA的区别(图⽚来⾃⽹络)两个类别,class1的点都是圆圈,class2的点都是⼗字。
图中有两条直线,斜率在1左右的这条直线是PCA选择的映射直线,斜率在 -1左右的这条直线是LDA选择的映射直线。
其余不在这两条直线上的点是原始数据点。
可以看到由于LDA考虑了“类别”这个信息(即标注),映射后,可以很好的将class1和class2的点区分开。
D与PCA的对⽐(1)PCA⽆需样本标签,属于⽆监督学习降维;LDA需要样本标签,属于有监督学习降维。
判别分析中Fisher判别法的应用

1 绪 论1.1课题背景随着社会经济不断发展,科学技术的不断进步,人们已经进入了信息时代,要在大量的信息中获得有科学价值的结果,从而统计方法越来越成为人们必不可少的工具和手段。
多元统计分析是近年来发展迅速的统计分析方法之一,应用于自然科学和社会各个领域,成为探索多元世界强有力的工具。
判别分析是统计分析中的典型代表,判别分析的主要目的是识别一个个体所属类别的情况下有着广泛的应用。
潜在的应用包括预测一个公司是否成功;决定一个学生是否录取;在医疗诊断中,根据病人的多种检查指标判断此病人是否有某种疾病等等。
它是在已知观测对象的分类结果和若干表明观测对象特征的变量值的情况下,建立一定的判别准则,使得利用判别准则对新的观测对象的类别进行判断时,出错的概率很小。
而Fisher 判别方法是多元统计分析中判别分析方法的常用方法之一,能在各领域得到应用。
通常用来判别某观测量是属于哪种类型。
在方法的具体实现上,采用国内广泛使用的统计软件SPSS(Statistical Product and Service Solutions ),它也是美国SPSS 公司在20世纪80年代初开发的国际上最流行的视窗统计软件包之一 1.2 Fisher 判别法的概述根据判别标准不同,可以分为距离判别、Fisher 判别、Bayes 判别法等。
Fisher 判别法是判别分析中的一种,其思想是投影,Fisher 判别的基本思路就是投影,针对P 维空间中的某点x=(x1,x2,x3,…,xp)寻找一个能使它降为一维数值的线性函数y(x): ()j j x C x ∑=y然后应用这个线性函数把P 维空间中的已知类别总体以及求知类别归属的样本都变换为一维数据,再根据其间的亲疏程度把未知归属的样本点判定其归属。
这个线性函数应该能够在把P 维空间中的所有点转化为一维数值之后,既能最大限度地缩小同类中各个样本点之间的差异,又能最大限度地扩大不同类别中各个样本点之间的差异,这样才可能获得较高的判别效率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验三 Fisher 线性判别实验
姓名:徐维坚 学号:2220103484 日期:2012/7/7
一、实验目的:
1)加深对Fisher 线性判别的基本思想的认识和理解。
2)编写实现Fisher 线性判别准则函数的程序。
二、实验原理:
1.基本原理:
一般情况下,我们总可以找到某个方向,使得这个方向的直线上,样本的投影能分开的最好,而Fisher 法所要解决的基本问题就是找到这条最好的、最易于分类的投影线。
先从d 维空间到一维空间的一维数学变换方法。
假设有一集合X 包含N 个d 维样本
N x x x ,...,,21,其中1N 个属于1ω类的样本记为子集1X ,2N 个属于2ω类的样本记为2X 。
若对N x 的分量做线性组合可得标量
n T n x w y =,i N n ,...,2,1=
这样便得到N 个一维样本n y 组成的集合,并可分为两个子集1Y 和2Y 。
w 的绝对值是无关紧要的,它仅使n y 乘上一个比例因子,重要的是选择w 的方向,从而转化为寻找最好的投影方向*
w ,是样本分开。
2.基本方法:
先定义几个基本参量: (1)各类样本均值向量i m
2,1,1==
∑∈i x N
m i
X x i
(2)样本类内离散度矩阵i S 和总类内离散度矩阵ωS
2,1,)
)((=--=
∑∈i m x m x S i
X x T
i
i
i
21S S S +=ω
(3)样本类间离散度矩阵b S
T b m m m m S ))((2121--=
我们希望投影后,在低维空间里个样本尽可能的分开些,即希望两类均值)(21m m -越大越
好,同时希望各类样本内部尽量密集,即i S 越小越好。
因此,我们定义Fisher 准则函数为
2
12
21)()(S S m m w J F +-=
但)(w J F 不显含w ,因此必须设法将)(w J F 变成w 的显函数。
由式子
i T X x i
T X x T i
Y y i
i m w x N w x w N y N m i
i
i
===
=
∑
∑∑∈∈∈)1(
11
w S w w m m m m w m w m w m m b T T T T T =--=-=-))(()()(2121221221
w S w w m x m x w m w x w m y S i T T i i T Y y i T T Y y i i i
i
=--=-=-=∑∑∈∈))(()()(22
从而得到
w
S w w
S w w J T
b T F ω=)(, 采用Lagrange 乘子法求解它的极大值*
w
)(),(c w S w w S w w L T b T --=ωλλ
对其求偏导,得0*
*=-w S w S b ωλ,即
**w S w S b ωλ=
从而我们很容易得到
*21211
*1*)(,)()(w m m R R m m S w S S w T b -=-==--其中ωωλ
)(211
*m m S R
w -=
-ωλ
忽略比例因子λ/R ,得
)(211
*m m S w -=-ω
这就是我们Fisher 准则函数)(w J F 取极大值时的解。
三、实验内容:
依据实验基本原理和基本方法,对下面表3-1样本数据中的类别1ω和2ω计算最优方向
w ,画出最优方向w 的直线,并标记出投影后的点在直线上的位置。
选择决策边界,实现
新样本xx1=(-0.7,0.58,0.089),xx2=(0.047,-0.4,1.04)的分类。
设某新类别3ω数据如表3-2所示,用自己的函数求新类别3ω分别和1ω、2ω分类的投
影方向和分类阀值。
表3-2 新类别实验数据
四、实验程序及其说明:
1)Fisher 准则函数算法:
其中w 为我们要找到的投影方向*
w ,w1、w2是我们的样本1ω、2ω,s1、s2是相应样本的类内离散度矩阵i S ,sw 是总类内离散度矩阵ωS ,m1、m2是相应样本均值。
在进行
3ω分别和1ω、2ω分类的投影方向和分类阀值时,将对应的s1、s2;sw ;m1、m2以及输
出坐标换成相应的样本符号。
由于代码除此之外均相同,没有必要再重复列出,只需在运行时修改上述值即可。
注意:在画出w 时(即*
w ),由于样本的不同,输出系数应作相应的调整。
如:
1ω、2ω时,plot3(30*x,30*x*w(2,:)/w(1,:),30*x*w(3,:)/w(1,:),'k'); 1ω、3ω时,plot3(x,x*w(2,:)/w(1,:),x*w(3,:)/w(1,:),'k');
2ω、3ω时,plot3(5*x,5*x*w(2,:)/w(1,:),5*x*w(3,:)/w(1,:),'k');
代码:clear;
w1=[-0.4 0.58 0.089;-0.31 0.27 -0.04;-0.38 0.055 -0.035;-0.15 0.53 0.011;-0.35 0.47 0.034; -0.17 0.69 0.1;-0.011 0.55 -0.18;-0.27 0.61 0.12;-0.065 0.49 0.0012;-0.12 0.054 -0.063]; w2=[0.8 1.6 -0.014;1.1 1.6 0.48;-0.44 -0.41 0.32;0.047 -0.45 1.4;0.28 0.35 3.1; -0.39 -0.48 0.11;0.34 -0.079 0.14;-0.3 -0.22 2.2;1.1 1.2 -0.46;0.18 -0.11 -0.49]; w3=[1.58 2.32 -5.8;0.67 1.58 -4.78;1.04 1.01 -3.63;-1.49 2.18 -3.39;-0.41 1.21 -4.73; 1.39 3.61 2.87;1.2 1.4 -1.89;-0.92 1.44 -3.22;0.45 1.33 -4.38;-0.76 0.84 -1.96];
xx1=[-0.7 0.58 0.089];
xx2=[0.047 -0.4 1.04];
s1=cov(w2,1);%样本类间离散度S1
m1=mean(w2);%样本均值m1
s2=cov(w3,1);%样本类间离散度S2
m2=mean(w3);%样本均值m2
sw=s1+s2;%总类内离散度Sw
w=inv(sw)*(m1-m2)';%Fisher准则函数w*
h1=figure(1);
for i=1:1:10%打印样本
plot3(w2(i,1),w2(i,2),w2(i,3),'r*');
hold on;
plot3(w3(i,1),w3(i,2),w3(i,3),'bo');
end;
figure(2)
%画出fisher判别函数
xmin=min(min(w2(:,1)),min(w3(:,1)));
xmax=max(max(w2(:,1)),max(w3(:,1)));
x=xmin-1:(xmax-xmin)/100:xmax;
plot3(5*x,5*x*w(2,:)/w(1,:),5*x*w(3,:)/w(1,:),'k'); hold on;
%将样本投影到fisher判别函数上
y1=w'*w2';%yn=w^*T * xn,n=1,2
y2=w'*w3';
figure(2)
for i=1:1:10
plot3(y1(i)*w(1),y1(i)*w(2),y1(i)*w(3),'rx');
hold on;
plot3(y2(i)*w(1),y2(i)*w(2),y2(i)*w(3),'bp'); end;
五、实验结果及其说明:
1)Fisher线性判别算法输出结果:
1.样本1ω、2ω
实验结果图3-1
2.样本1ω、3ω
实验结果图3-2
3.样本2ω、2ω
实验结果图2-3
六、实验小结:
试验时阅读课本发现公式很多,中间推导式较复杂,以为会很难写代码。
但参考例代码,并结合课本发现所需要的公式就那几个基本参量,以及最终推导出来的*
w 。
为了画出最优方
向*
w ,我想起了高数里讲过三维空间直线
00z z y y x x ==,从而引导我利用此式,画出了*
w ,如上所示(2ω、3ω时,plot3(5*x,5*x*w(2,:)/w(1,:),5*x*w(3,:)/w(1,:),'k');)。
特别值得说的是试验中w=inv(sw)*(m1-m2)';后面是(m1-m2)',而不是(m1-m2),从推导式我们可以看出这无关紧要,只不过要将后续矩阵——y1=w'*w2';相应的求其转置,以使得矩阵可以相乘。
最终我们可以得到*
w ,以使得样本X 从d 维空间投影到一维Y 空间。