实验报告-中文分词
中文分词研究报告

中文分词处理第一阶段报告通信10班201221*** ***目录第一部背景——有关中文分词第二部知识储备1.文件2.中文文件的存储格式3.字符编码4.GBK编码基本原理第三部实践操作1.截图2.学到的知识3.疑难问题的处理4.学习心得第一部分:背景——有关中文分词记得刚抢上案例教学名额的时候,有人问我选的是什么课题,我说中文分“字”。
可见当时对这个课题是有多么的不了解。
后来查了一些材料,问了老师学姐,一个学长推荐我读一下吴军老师的《数学之美》。
慢慢的,我开始了解。
自计算机诞生以来,计算机无与伦比的运算速度与稳定性使得计算机在很多事情上做得比人好。
但是计算机用数字记录信息,人用文字记录信息,这就好比两个来自不同地区的人说着互相不懂得话,那么计算机到底有没有办法处理自然语言呢?起初,我们希望计算机能从语法语义上理解人类的自然语言,这种希望催生了基于规则的自然语言处理方法,然而,20年的时间证明,这种办法是行不通的,语言博大的语法语义语境体系无法移植到计算机。
20年弯路之后,我们找到了一条合适的路径——基于统计的自然语言处理方法,这种方法的大体思想是:拥有一个庞大的语料库,对句子的分析变为概率分析,而概率分析是将每一个词出现的条件概率相乘,也就是说,统计语言模型是建立在词的基础上的,因为词是表达语义的最小单位。
分词处理对自然语言处理起着至关重要的作用!对于西方拼音语言来讲,词之间有明确的分界符,统计和使用语言模型非常直接。
而对于中、日、韩、泰等语言,词之间没有明确的分界符。
因此,首先需要对句子进行分词。
(补充一点的是,中文分词的方法其实不局限于中文应用,也被应用到英文处理,如手写识别,单词之间的空格就很清楚,中文分词方法可以帮助判别英文单词的边界。
)目前在自然语言处理技术中,中文处理技术比西文处理技术要落后很大一段距离,许多西文的处理方法中文不能直接采用,就是因为中文必需有分词这道工序。
中文分词是其他中文信息处理的基础,搜索引擎只是中文分词的一个应用。
中文分词算法的研究与实现

中文分词算法的探究与实现导言中文作为世界上最为复杂的语言之一,具有很高的纷繁变化性。
对于计算机来说,要理解和处理中文文本是一项极具挑战的任务。
中文分词作为自然语言处理的核心步骤之一,其目标是将连续的中文文本按照词语进行切分,以便计算机能够更好地理解和处理中文文本。
本文将谈论。
一、中文分词的重要性中文是一种高度语素丰富的语言,一个复杂的中文句子往往由若干个词汇组成,每个词汇之间没有明显的分隔符号。
若果不进行适当的中文分词处理,计算机将无法准确理解句子的含义。
例如,对于句子“我喜爱进修机器进修”,若果没有正确的分词,计算机将无法区分“进修”是动词仍是名词,从而无法准确理解这个句子。
因此,中文分词作为自然语言处理的重要工具,被广泛应用于查找引擎、信息检索、机器翻译等领域。
二、基于规则的中文分词算法基于规则的中文分词算法是最早出现的一类中文分词算法。
它通过事先定义一些规则来进行分词,如使用词表、词典、词性标注等方法。
这类算法的优点是原理简易,适用于一些固定语境的场景。
但是,这类算法对语言的变化和灵活性要求较高,对于新词和歧义词的处理效果较差。
三、基于统计的中文分词算法基于统计的中文分词算法以机器进修的方法进行训练和处理。
这类算法通过构建统计模型,利用大量的训练样本进行进修和猜测,从而裁定文本中哪些位置可以进行分词。
其中最著名的算法是基于隐马尔可夫模型(Hidden Markov Model,简称HMM)的分词算法。
该算法通过建立状态转移概率和观测概率来进行分词猜测。
此外,还有一些基于条件随机场(Conditional Random Field,简称CRF)的分词算法,通过模型的训练和优化,得到更准确的分词结果。
四、基于深度进修的中文分词算法随着深度进修的兴起,越来越多的中文分词算法开始接受深度进修的方法进行探究和实现。
深度进修通过构建多层神经网络,并利用大量的训练数据进行训练,在分词任务中表现出了很强的性能。
自然语言理解中文分词报告

中文分词工程报告课程:自然语言理解姓名:学号:班级:日期:2013/11/6一、研究背景1、发展历程:机器翻译(Machine Translation)是自然语言理解研究的最早领域。
17世纪:笛卡儿(Descartes)莱布尼兹(Leibniz)试图用统一的数字代码编写词典;17世纪中叶贝克(Cave Beck)等人出版类似的词典。
1930s:亚美尼亚法国工程师阿尔楚尼提出了用机器来进行语言翻译的想法,并在1933年7月22日获得了一项“翻译机”的专利,叫做机器脑(mechanical brain)。
1933 年,前苏联发明家特洛扬斯基设计了用机械方法把一种语言翻译成为另一种语言的机器。
1946 年,世界上第一台电子计算机ENIAC诞生。
此后,英国工程师A. D. Booth 和美国洛克菲勒基金会(Rockefeller Foundation) 副总裁W. Weaver提出了利用计算机进行机器翻译的设想。
1949年,W. Weaver 发表了以‘Translation’为题目的备忘录,正式提出机器翻译问题。
1954年Georgetown 大学在IBM 协助下,用IBM-701计算机实现了世界上第一个MT 系统,实现俄译英翻译,1954年1月该系统在纽约公开演示。
系统只有250条俄语词汇,6 条语法规则,可以翻译简单的俄语句子。
随后10 多年里,MT研究在国际上出现热潮。
1964年,美国科学院成立语言自动处理咨询委员会(Automatic Language Processing Advisory Committee, ALPAC),调查机器翻译的研究情况,并于1966年11月公布了一个题为“语言与机器”的报告,简称ALPAC 报告,宣称:“在目前给机器翻译以大力支持还没有多少理由”,“机器翻译遇到了难以克服的语义障碍(semantic barrier)”。
从此,机器翻译研究在世界范围内进入低迷状态。
中科院中文分词系统调研报告

自然语言处理调研报告(课程论文、课程设计)题目:最大正向匹配中文分词系统作者:陈炳宏吕荣昌靳蒲王聪祯孙长智所在学院:信息科学与工程学院专业年级:信息安全14-1指导教师:努尔布力职称:副教授2016年10月29日目录一、研究背景、目的及意义 (3)二、研究内容和目标 (4)三、算法实现 (5)四、源代码 (7)1.seg.java 主函数 (7)2. dict.txt 程序调用的字典 (10)3.实验案例 (11)五、小结 (12)一、研究背景、目的及意义中文分词一直都是中文自然语言处理领域的基础研究。
目前,网络上流行的很多中文分词软件都可以在付出较少的代价的同时,具备较高的正确率。
而且不少中文分词软件支持Lucene扩展。
但不过如何实现,目前而言的分词系统绝大多数都是基于中文词典的匹配算法。
在这里我想介绍一下中文分词的一个最基础算法:最大匹配算法(Maximum Matching,以下简称MM算法) 。
MM算法有两种:一种正向最大匹配,一种逆向最大匹配。
二、研究内容和目标1、了解、熟悉中科院中文分词系统。
2、设计程序实现正向最大匹配算法。
3、利用正向最大匹配算法输入例句进行分词,输出分词后的结果。
三、算法实现图一:算法实现正向最大匹配算法:从左到右将待分词文本中的几个连续字符与词表匹配,如果匹配上,则切分出一个词。
但这里有一个问题:要做到最大匹配,并不是第一次匹配到就可以切分的。
算法示例:待分词文本: content[]={"中","华","民","族","从","此","站","起","来","了","。
"}词表: dict[]={"中华", "中华民族" , "从此","站起来"}(1) 从content[1]开始,当扫描到content[2]的时候,发现"中华"已经在词表dict[]中了。
搜索引擎-分词报告
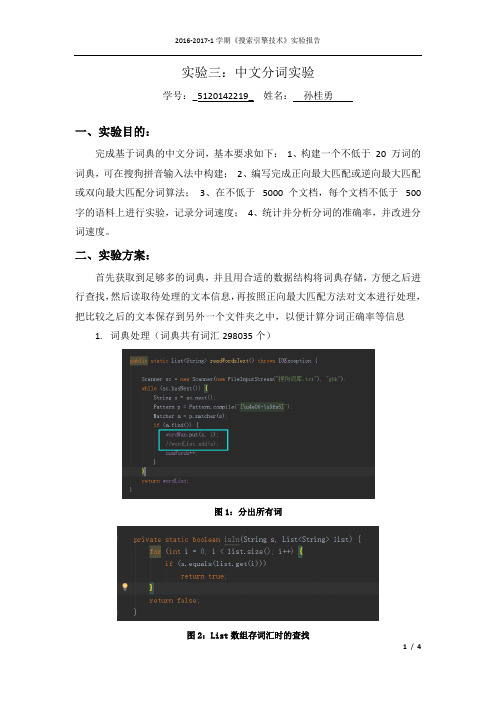
实验三:中文分词实验学号:_5120142219_姓名:孙桂勇一、实验目的:完成基于词典的中文分词,基本要求如下:1、构建一个不低于20 万词的词典,可在搜狗拼音输入法中构建;2、编写完成正向最大匹配或逆向最大匹配或双向最大匹配分词算法;3、在不低于5000 个文档,每个文档不低于500 字的语料上进行实验,记录分词速度;4、统计并分析分词的准确率,并改进分词速度。
二、实验方案:首先获取到足够多的词典,并且用合适的数据结构将词典存储,方便之后进行查找,然后读取待处理的文本信息,再按照正向最大匹配方法对文本进行处理,把比较之后的文本保存到另外一个文件夹之中,以便计算分词正确率等信息1.词典处理(词典共有词汇298035个)图1:分出所有词图2:List数组存词汇时的查找图3:hash表存词汇时的查找第一次存词典用的是数组,但是在进行查找比较的时候效率十分的低,基本一个文本要处理20·30秒左右,所以将存词典的数据结构换位效率为O(1)的哈希表,效率有理非常大的提高。
2.读取待处理文本信息图4:找到所有txt文档并读取内容3.正向最大匹配算法实现图5:最大正向匹配算法实现三、实验结果及分析:图6:分词结果1.处理效率:图7:当正向最大匹配6个字符;图8:当正向最大匹配8个字符;图9:当正向最大匹配12个字符;图10:当正向最大匹配30个字符;根据以上四次实验结果可以看出,最大匹配长度设置为8是最合适的,因为运行效率是最高的,而且按照中国人的习惯,词语一般都不会超过八个字,所以可以将匹配长度设置为8。
2.处理正确率:图11:匹配6个字符时的正确率图12:匹配8字符与6字符结果比较在处理正确率的时候,将自己的文本处理结果与老师所给的结果进行比较,但是发现很多词语分法不一致,比如“涉毒”在我的词典里边是一个词,但是在老师给的结果中就是分成了两个词,所以我认为所用词典不同,正确率是没有办法计算的。
中文分词实验报告

实验:中文分词实验小组成员:黄婷苏亮肖方定山一、实验目的:1.实验目的(1)了解并掌握基于匹配的分词方法、改进方法、分词效果的评价方法等2.实验要求(1)从互联网上查找并构建不低于10万词的词典,构建词典的存储结构;(2)选择实现一种机械分词方法(双向最大匹配、双向最小匹配、正向减字最大匹配法等),同时实现至少一种改进算法。
(3)在不低于1000个文本文件(可以使用附件提供的语料),每个文件大于1000字的文档中进行中文分词测试,记录并分析所选分词算法的准确率、召回率、F-值、分词速度。
二、实验方案:1. 实验环境系统:win10软件平台:spyder语言:python2. 算法选择(1)选择正向减字最大匹配法(2)算法伪代码描述:3. 实验步骤● 在网上查找语料和词典文本文件; ● 思考并编写代码构建词典存储结构;●编写代码将语料分割为1500 个文本文件,每个文件的字数大于1000 字;●编写分词代码;●思考并编写代码将语料标注为可计算准确率的文本;●对测试集和分词结果集进行合并;●对分词结果进行统计,计算准确率,召回率及 F 值(正确率和召回率的调和平均值);●思考总结,分析结论。
4. 实验实施实验过程:(1)语料来源:语料来自SIGHAN 的官方主页(/ ),SIGHAN 是国际计算语言学会(ACL )中文语言处理小组的简称,其英文全称为“Special Interest Group for Chinese Language Processing of the Association for Computational Linguistics”,又可以理解为“SIG 汉“或“SIG 漢“。
SIGHAN 为我们提供了一个非商业使用(non-commercial )的免费分词语料库获取途径。
我下载的是Bakeoff 2005 的中文语料。
有86925 行,2368390 个词语。
语料形式:“没有孩子的世界是寂寞的,没有老人的世界是寒冷的。
实验1 中文分词实验

实验内容
• 请分别使用正向最大匹配算法和逆向最大匹配 算法及给定的字典对以下句子进行分词,并分 别显示结果:
一把青菜 幼儿园地节目
实验一作业
• 请选择以下任意一个完成:
1.请使用双向匹配算法对给定测试文本进行分词:
• 给定测试文本为:实验1作业测试文本.txt • 词典为:chineseDic.txt • 要求:编程实现,并计算分词的P, R,F值和分词时间。
2.请使用概率最大方法及给定语料库对以下句子分词:
• “对外经济技术合作与交流不断扩大。” • 要求:利用人民日报语料库来计算每个候选词的概率值及 最佳左邻词,及分词结果。并计算分词的P,R,F值和分词 时间。
注意作业完成时间:
2周,请在第4周上课前提交,4人以内小组提交。 最好是C++或JAVA 报告标题、理论描述、算法描述、详例描述、软件演 示图, 请看样板
• 详例描述:
以“一把青菜”为例,详细描述算法如下
将程序实现的截图粘贴过来
• 软件演示:
另外,请每个小组将每次的作业实现在同一个软件平台中,班级及 成员不要变化,这样学期结束,就实现了一个NLP的工具集,最后 添加一个应用就是你的大作业了。
• 语言可以任意:
• 作业以程序软件+报告的格式,要求:
• 作业提交格式:
作业内容放置一个文件夹中,并压缩交给我 文件夹命名:实验一+班级+姓名.rar
实验报告1 双向匹配中文分词 • 理论描述:
中文分词是。。。。,
• 算法描述:
本文实现双向匹配算法,具体算法描述如下: MM: RMM:
自然语言理解课程实验报告

实验一、中文分词一、实验内容用正向最大匹配法对文档进行中文分词,其中:(1)wordlist.txt 词表文件(2)pku_test.txt 未经过分词的文档文件(3)pku_test_gold.txt 经过分词的文档文件二、实验所采用的开发平台及语言工具Visual C++ 6.0三、实验的核心思想和算法描述本实验的核心思想为正向最大匹配法,其算法描述如下假设句子: , 某一词 ,m 为词典中最长词的字数。
(1) 令 i=0,当前指针 pi 指向输入字串的初始位置,执行下面的操作:(2) 计算当前指针 pi 到字串末端的字数(即未被切分字串的长度)n,如果n=1,转(4),结束算法。
否则,令 m=词典中最长单词的字数,如果n<m, 令 m=n;(3) 从当前 pi 起取m 个汉字作为词 wi,判断:(a) 如果 wi 确实是词典中的词,则在wi 后添加一个切分标志,转(c);(b) 如果 wi 不是词典中的词且 wi 的长度大于1,将wi 从右端去掉一个字,转(a)步;否则(wi 的长度等于1),则在wi 后添加一个切分标志,将wi 作为单字词添加到词典中,执行 (c)步;(c) 根据 wi 的长度修改指针 pi 的位置,如果 pi 指向字串末端,转(4),否则, i=i+1,返回 (2);(4) 输出切分结果,结束分词程序。
四、系统主要模块流程、源代码(1) 正向最大匹配算法12n S c c c 12i mw c c c(2) 原代码如下// Dictionary.h#include <iostream>#include <string>#include <fstream>using namespace std;class CDictionary{public:CDictionary(); //将词典文件读入并构造为一个哈希词典 ~CDictionary();int FindWord(string w); //在哈希词典中查找词private:string strtmp; //读取词典的每一行string word; //保存每个词string strword[55400];};//将词典文件读入并CDictionary::CDictionary(){ifstream infile("wordlist.txt"); // 打开词典if (!infile.is_open()) // 打开词典失败则退出程序{cerr << "Unable to open input file: " << "wordlist.txt"<< " -- bailing out!" << endl;exit(-1);}int i=0;while (getline(infile, strtmp)) // 读入词典的每一行并将其添加入哈 希中{strword[i++]=strtmp;}infile.close();}CDictionary::~CDictionary(){}//在哈希词典中查找词,若找到,则返回,否则返回int CDictionary::FindWord(string w){int i=0;while ((strword[i]!=w) && (i<55400))i++;if(i<55400)return 1;elsereturn 0;}// 主程序main.cpp#include "Dictionary.h"#define MaxWordLength 14 // 最大词长为个字节(即个汉字)# define Separator " " // 词界标记CDictionary WordDic; //初始化一个词典//对字符串用最大匹配法(正向)处理string SegmentSentence(string s1){string s2 = ""; //用s2存放分词结果string s3 = s1;int l = (int) s1.length(); // 取输入串长度int m=0;while(!s3.empty()){int len =(int) s3.length(); // 取输入串长度if (len > MaxWordLength) // 如果输入串长度大于最大词长 {len = MaxWordLength; // 只在最大词长范围内进行处理 }string w = s3.substr(0, len); //(正向用)将输入串左边等于最大词长长度串取出作为候选词int n = WordDic.FindWord(w); // 在词典中查找相应的词while(len > 1 && n == 0) // 如果不是词{int j=len-1;while(j>=0 && (unsigned char)w[j]<128){j--;}if(j<1){break;}len -= 1; // 从候选词右边减掉一个英文字符,将剩下的部分作为候选词 w = w.substr(0, len); //正向用n = WordDic.FindWord(w);}s2 += w + Separator; // (正向用)将匹配得到的词连同词界标记加到输出串末尾s3 = s1.substr(m=m+w.length(), s1.length()); //(正向用)从s1-w处开始}return s2;}int main(int argc, char *argv[]){string strtmp; //用于保存从语料库中读入的每一行string line; //用于输出每一行的结果ifstream infile("pku_test.txt"); // 打开输入文件if (!infile.is_open()) // 打开输入文件失败则退出程序{cerr << "Unable to open input file: " << "pku_test.txt"<< " -- bailing out!" << endl;exit(-1);}ofstream outfile1("SegmentResult.txt"); //确定输出文件if (!outfile1.is_open()){cerr << "Unable to open file:SegmentResult.txt"<< "--bailing out!" << endl;exit(-1);}while (getline(infile, strtmp)) //读入语料库中的每一行并用最大匹配法处理{line = strtmp;line = SegmentSentence(line); // 调用分词函数进行分词处理outfile1 << line << endl; // 将分词结果写入目标文件cout<<line<<endl;}infile.close();outfile1.close();return 0;}五、实验结果及分析(1)、实验运行结果(2) 实验结果分析在基于字符串匹配的分词算法中,词典的设计往往对分词算法的效率有很大的影响。
实验报告-中文分词参考模板

实验报告1 双向匹配中文分词•小组信息目录摘要--------------------------------------------------------------------------------------- 1理论描述--------------------------------------------------------------------------------- 1算法描述--------------------------------------------------------------------------------- 2详例描述--------------------------------------------------------------------------------- 3软件演示--------------------------------------------------------------------------------- 4总结--------------------------------------------------------------------------------------- 6•摘要这次实验的内容是中文分词,现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。
而我们用到的分词算法是基于字符串的分词方法(又称机械分词方法)中的正向最大匹配算法和逆向匹配算法。
一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。
统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。
•理论描述中文分词指的是将一个汉字序列切分成一个一个单独的词。
自然语言理解实验报告

自然语言理解课程实验报告实验一、中文分词1、实验内容用最大匹配算法设计分词程序实现对文档分词,并计算该程序分词的正确率、召回率及F-测度。
实验数据:(1)wordlist.txt 词表文件(2)pku_test.txt 未经过分词的文档文件(3)pku_test_gold.txt 经过分词的文档文件2、实验所采用的开发平台及语言工具开发平台:Eclipse软件语言工具:Java语言3、实验的核心思想和算法描述核心思想:正向最大匹配算法 (Forward MM, FMM)算法描述:正向最大匹配法算法如下所示:逆向匹配法思想与正向一样,只是从右向左切分,这里举一个例子:输入例句:S1="计算语言学课程有意思" ;定义:最大词长MaxLen = 5;S2= " ";分隔符 = “/”;假设存在词表:…,计算语言学,课程,意思,…;最大逆向匹配分词算法过程如下:(1)S2="";S1不为空,从S1右边取出候选子串W="课程有意思";(2)查词表,W不在词表中,将W最左边一个字去掉,得到W="程有意思";(3)查词表,W不在词表中,将W最左边一个字去掉,得到W="有意思";(4)查词表,W不在词表中,将W最左边一个字去掉,得到W="意思"(5)查词表,“意思”在词表中,将W加入到S2中,S2=" 意思/",并将W 从S1中去掉,此时S1="计算语言学课程有";(6)S1不为空,于是从S1左边取出候选子串W="言学课程有";(7)查词表,W不在词表中,将W最左边一个字去掉,得到W="学课程有";(8)查词表,W不在词表中,将W最左边一个字去掉,得到W="课程有";(9)查词表,W不在词表中,将W最左边一个字去掉,得到W="程有";(10)查词表,W不在词表中,将W最左边一个字去掉,得到W="有",这W 是单字,将W加入到S2中,S2=“ /有 /意思”,并将W从S1中去掉,此时S1="计算语言学课程";(11)S1不为空,于是从S1左边取出候选子串W="语言学课程";(12)查词表,W不在词表中,将W最左边一个字去掉,得到W="言学课程";(13)查词表,W不在词表中,将W最左边一个字去掉,得到W="学课程";(14)查词表,W不在词表中,将W最左边一个字去掉,得到W="课程";(15)查词表,“意思”在词表中,将W加入到S2中,S2=“课程/ 有/ 意思/”,并将W从S1中去掉,此时S1="计算语言学";(16)S1不为空,于是从S1左边取出候选子串W="计算语言学";(17)查词表,“计算语言学”在词表中,将W加入到S2中,S2=“计算语言学/ 课程/ 有/ 意思/”,并将W从S1中去掉,此时S1="";(18)S1为空,输出S2作为分词结果,分词过程结束。
中文分词算法开题报告

中文分词算法开题报告中文分词算法开题报告一、引言中文分词是自然语言处理中的一个重要任务,其目的是将连续的中文文本切分成有意义的词语。
中文分词在文本处理、信息检索、机器翻译等领域都扮演着重要的角色。
然而,中文的特殊性使得分词任务相对于英文等其他语言更加复杂和困难。
本报告将探讨中文分词算法的研究现状、挑战以及可能的解决方案。
二、中文分词算法的研究现状目前,中文分词算法可以分为基于规则的方法和基于统计的方法两大类。
基于规则的方法主要是通过人工定义一系列规则来进行分词,例如利用词典、词性标注等。
这种方法的优点是准确性较高,但需要大量的人工工作,并且对于新词和歧义词处理较为困难。
基于统计的方法则是通过大规模语料库的统计信息来进行分词,例如利用隐马尔可夫模型(HMM)、最大熵模型等。
这种方法的优点是能够自动学习分词规则,但对于未登录词和歧义词的处理效果较差。
三、中文分词算法面临的挑战中文分词算法面临着以下几个挑战:1. 歧义词处理:中文中存在大量的歧义词,即一个词可能有多种不同的词性和含义。
例如,“银行”既可以是名词也可以是动词。
如何准确地判断一个歧义词的词性和含义是中文分词算法的难点之一。
2. 未登录词处理:未登录词是指没有出现在分词词典中的词语,例如新词、专有名词等。
由于未登录词的特殊性,常规的分词算法往往不能正确切分。
如何有效地识别和处理未登录词是中文分词算法的另一个挑战。
3. 复合词处理:中文中存在大量的复合词,即由多个词语组合而成的词语。
例如,“北京大学”是一个复合词,由“北京”和“大学”组成。
如何准确地识别和切分复合词是中文分词算法的难点之一。
四、可能的解决方案为了克服中文分词算法面临的挑战,可以考虑以下解决方案:1. 结合规则和统计:可以将基于规则的方法和基于统计的方法相结合,利用规则进行初步的切分,然后利用统计模型进行进一步的优化和修正。
这样可以兼顾准确性和自动学习能力。
2. 引入上下文信息:可以利用上下文信息来帮助歧义词处理和未登录词处理。
中文分词程序实验报告

汉语分词程序实验报告一、程序功能描述:本程序每次处理时都用缓冲区的数据从头开始去存储语料库的链表中匹配一个最长的词语来输出,如若没有匹配到的词语则单独输出该首字。
为了简化程序所以语料库和预备分词文章都统一采用ASCII码的编码方式,并且不允许文中出现英语单字节编码。
别且本程序没有对未登录词和未声明数据结构格式进行处理,都按照普通汉字进行了分词,因此在最后的性能比较中这部分的准确率很差,但是在语料库有存储的部分中都是用最长匹配原则进行了分词,准确率还是达到了很高的水平。
分词符采用//+空格的方式来标记分词。
语料库的名字默认为:语料库.txt,打开方式为只读读取的文件名字默认为:resource.txt,打开方式为只读输出的文件名字默认为:result.txt,打开方式默认为追加的方式二、算法思路:(1)、从文件中读取语料库存储在内存中,组织成单链表的存储方式(2)、组织以首字的ASCII码为下标的哈希表指向语料库链表(3)、从文件中读满输入缓冲区,以缓冲区的首字的ASCII码做为下标从哈希表中查找首字相同的内存地址。
(4)、从该地址开始逐条匹配,记录其中匹配最长的词语的长度和地址。
写入文件中并写入分词符。
(5)、读满缓冲区,若文件已经读取完毕则查看缓冲区是否用尽,若已经用完则执行第(6)步,否则重复(4)过程。
(6)、释放申请的内存空间,程序结束。
三、数据结构:typedef struct coredict{//使用链表来存储语料库char data[9];struct coredict*nextPtr;}CoreDict,*CoreDictPtr;CoreDictPtr tablePtr=NULL,tailPtr=NULL,newPtr;//指向语料库链表的头和尾CoreDictPtr Hash[65536]={NULL};//一个以匹配词语的第一个字的ASCII码为下标的指向链表的哈希表int MatchLength=0;//在一个单词匹配过程中用来记录能够匹配到的最长的词语的长度CoreDictPtr MatchPtr=NULL;//在一个单词匹配过程中用来记录能够匹配到的最长的词语在链表中的地址四、函数功能:int IsEqual(char[],char[]);//判断两个汉字是否相等int LongMatch(char[],char[]);//void read(char[],FILE*);//将读入缓冲区读满void setoff(char[],int);//将已经匹配好的词语从缓冲区中删除五、性能对比分析:结果分析程序性能描述:在语义的判别和歧义消除方法只是用最长匹配法来降低误差,因此这部分的性能提升不是很明显。
《自然语言处理导论》中文分词程序实验报告

《自然语言处理导论》中文分词实验报告一、实验目的了解中文分词意义掌握中文分词的基本方法二、实验环境Win7 64位DEV-C++编译器三、实验设计(一)分词策略目前较为成熟的中文分词方法主要有:1、词典正向最大匹配法2、词典逆向最大匹配法3、基于确定文法的分词法4、基于统计的分词方法一般认为,词典的逆向匹配法要优于正向匹配法。
基于确定文法和基于统计的方法作为自然语言处理的两个流派,各有千秋。
我设计的是根据词典逆向最大匹配法,基本思路是:1、将词典的每个词条读入内存,最长是4字词,最短是1字词;2、从语料中读入一段(一行)文字,保存为字符串;3、如果字符串长度大于4个中文字符,则取字符串最右边的4个中文字符,作为候选词;否则取出整个字符串作为候选词;4、在词典中查找这个候选词,如果查找失败,则去掉这个候选词的最左字,重复这步进行查找,直到候选词为1个中文字符;5、将候选词从字符串中取出、删除,回到第3步直到字符串为空;6、回到第2步直到语料已读完。
(二)程序设计查找算法:哈希表汉字编码格式:UTF-8程序流程图:源代码:#include <iostream>#include <string>#include <fstream>#include <sstream>#include <ext/hash_map>#include <iomanip>#include <stdio.h>#include <time.h>#define MaxWordLength 12 // 最大词长字节(即4个汉字)#define Separator " " // 词界标记#define UTF8_CN_LEN 3 // 汉字的UTF-8编码为3字节using namespace std;using namespace __gnu_cxx;namespace __gnu_cxx{template<> struct hash< std::string >{size_t operator()( const std::string& x ) const{return hash< const char* >()( x.c_str() );}};}hash_map<string, int> wordhash; // 词典//读入词典void get_dict(void){string strtmp; //读取词典的每一行string word; //保存每个词typedef pair<string, int> sipair;ifstream infile("CoreDict.txt.utf8");if (!infile.is_open()){cerr << "Unable to open input file: " << "wordlexicon"<< " -- bailing out!" << endl;system("pause");exit(-1);}while (getline(infile, strtmp)) // 读入词典的每一行并将其添加入哈希中{istringstream istr(strtmp);istr >> word; //读入每行第一个词wordhash.insert(sipair(word, 1)); //插入到哈希中}infile.close();}//删除语料库中已有的分词空格,由本程序重新分词string del_space(string s1){int p1=0,p2=0;int count;string s2;while (p2 < s1.length()){//删除半角空格if (s1[p2] == 32){if (p2>p1)s2 += s1.substr(p1,p2-p1);p2++;p1=p2;}else{p2++;}}s2 += s1.substr(p1,p2-p1);return s2;}//用词典做逆向最大匹配法分词string dict_segment(string s1){string s2 = ""; //用s2存放分词结果while (!s1.empty()) {int len = (int) s1.length(); // 取输入串长度if (len > MaxWordLength) // 如果输入串长度大于最大词长{len = MaxWordLength; // 只在最大词长范围内进行处理}string w = s1.substr(s1.length() - len, len);int n = (wordhash.find(w) != wordhash.end()); // 在词典中查找相应的词while (len > UTF8_CN_LEN && n == 0) // 如果不是词{len -= UTF8_CN_LEN; // 从候选词左边减掉一个汉字,将剩下的部分作为候选词w = s1.substr(s1.length() - len, len);n = (wordhash.find(w) != wordhash.end());}w = w + Separator;s2 = w + s2;s1 = s1.substr(0, s1.length() - len);}return s2;}//中文分词,先分出数字string cn_segment(string s1){//先分出数字和字母string s2;int p1,p2;p1 = p2 = 0;while (p2 < s1.length()){while ( p2 <= (s1.length()-UTF8_CN_LEN) &&( s1.substr(p2,UTF8_CN_LEN).at(0)<'0'||s1.substr(p2,UTF8_CN_LEN).at(0)>'9' )){/ /不是数字或字母p2 += UTF8_CN_LEN;}s2 += dict_segment(s1.substr(p1,p2-p1));//之前的句子用词典分词//将数字和字母分出来p1 = p2;p2 += 3;while ( p2 <= (s1.length()-UTF8_CN_LEN) &&( s1.substr(p2,UTF8_CN_LEN).at(0)>='0'&&s1.substr(p2,UTF8_CN_LEN).at(0)<= '9' )){//是数字或字母p2 += UTF8_CN_LEN;}p1 = p2;} //end whilereturn s2;}//在执行中文分词前,过滤半角空格以及其他非UTF-8字符string seg_analysis(string s1){string s2;string s3 = "";int p1 = 0;int p2 = 0;int count;while ( p2 < s1.length()){if (((s1[p2]>>4)&14) ^ 14){//过滤非utf-8字符count = 0;do{p2++;count++;}while((((s1[p2]>>4)&14) ^ 14) && p2 < s1.length());s2 = s1.substr(p1,p2-count-p1);//数字前的串s3 += cn_segment(s2) + s1.substr(p2-count,count) + Separator;//数字if (p2 <= s1.length()){//这个等号,当数字是最后一个字符时!s1 = s1.substr(p2,s1.length()-p2);//剩余串}p1 = p2 = 0;}elsep2 += UTF8_CN_LEN;}if (p2 != 0){s3 += cn_segment(s1);}return s3;};int main(int argc, char* argv[]){ifstream infile("1998-01-qiefen-file.txt.utf8"); // 打开输入文件if (!infile.is_open()) // 打开输入文件失败则退出程序{cerr << "Unable to open input file: " << argv[1] << " -- bailing out!"<< endl;system("pause");exit(-1);}ofstream outfile1("result.txt.utf8"); //确定输出文件if (!outfile1.is_open()) {cerr << "Unable to open file:SegmentResult.txt" << "--bailing out!"<< endl;system("pause");exit(-1);}clock_t start, finish;double duration;start = clock();get_dict();finish = clock();duration = (double)(finish - start) / CLOCKS_PER_SEC;cout << "词典读入完毕,耗时" << duration << " s" << endl;string strtmp; //用于保存从语料库中读入的每一行string line; //用于输出每一行的结果start = clock();cout << "正在分词并输出到文件,请稍候..." << endl;while (getline(infile, strtmp)) //读入语料库中的每一行并用最大匹配法处理{line = del_space(strtmp);line = seg_analysis(line); // 调用分词函数进行分词处理outfile1 << line << endl; // 将分词结果写入目标文件}finish = clock();duration = (double)(finish - start) / CLOCKS_PER_SEC;cout << "分词完毕,耗时" << duration << " s" << endl;cout << "分词结果保存在result.txt.utf8中。
自然语言处理技术中的中文分词研究

自然语言处理技术中的中文分词研究
中文分词是自然语言处理技术中的重要研究领域之一,其目的是将连
续的中文文本切分成有意义的词语或词组。
中文分词的研究主要包括以下几个方面:
1.词典匹配法:基于预先构建的词典,通过匹配文本中的词语来进行
分词。
这种方法简单快速,但对新词和歧义词处理效果较差。
2.基于统计的方法:通过分析大规模语料库中的统计信息,例如词频、互信息等,来确定词语的切分边界。
这种方法能够较好地处理新词和歧义词,但对于上下文信息的利用较少。
3.基于规则的方法:根据语法规则和语义规则,在语料库中可以找到
一些固定模式的词语,通过应用规则来进行分词。
这种方法需要较多的人
工设计和维护规则,对语言的灵活性要求较高。
4. 基于机器学习的方法:通过构建分词模型,利用机器学习算法自
动学习分词规则。
常用的机器学习方法包括隐马尔可夫模型(Hidden Markov Model,HMM)、条件随机场(Conditional Random Fields,CRF)等。
这种方法能够较好地利用上下文信息进行分词,具有较高的准确性。
当前,中文分词的研究趋势主要集中在深度学习方法上,如循环神经
网络(Recurrent Neural Networks,RNN)、长短时记忆网络(Long Short-Term Memory,LSTM)等。
这些方法在大规模语料库上进行训练,
能够学习到更多的上下文信息,提高分词的准确性和鲁棒性。
此外,中文分词还面临一些挑战,如新词识别、歧义消解、命名实体识别等。
未来的研究方向主要包括结合多种方法进行分词、跨语言分词、领域自适应分词等。
自然语言理解实验报告

根据学院要求,专业课都需要有实验。
我们这个课设计了以下几个实验,同学们可以3-5人一组进行实验,最后提交一个报告给我。
实验一汉语分词及词性标注
【实验目的】
1.熟悉基本的汉语分词方法;
2.能综合运用基于规则和概率的方法进行词性标注。
3.理解课堂讲授的基本方法,适当查阅文献资料,在此基础上实现一个分词与词性标
注的系统;
实验二实现一个基于整句转换的拼音汉字转换程序
【实验目的】
1.分析现有拼音输入法的优缺点,采用n元语法的思想,实现一个拼音汉字转换程序。
2.提出自己的一些新思想对原有基于n元语法的方法进行改进。
实验三实现一个(汉语/英语)词义自动消歧系统
【实验目的】
很多词汇具有一词多义的特点,但一个词在特定的上下文语境中其含义却是确定的。
本
项目要求实现系统能够自动根据不同上下文判断某一词的特定含义。
实验四实现一个(汉语/英语)自动摘要系统
【实验目的】
能根据目标对任意给定的一篇文章进行自动摘要生成。
实验五实现一个汉语命名实体自动识别系统
【实验目的】
命名实体一般指如下几类专有名词:中国人名、外国人译名、地名、组织机构名、数字、
日期和货币数量。
实验1 中文分词实验
• 语பைடு நூலகம்可以任意:
• 作业以程序软件+报告的格式,要求:
• 作业提交格式:
作业内容放置一个文件夹中,并压缩交给我 文件夹命名:实验一+班级+姓名.rar
实验报告1 双向匹配中文分词 • 理论描述:
中文分词是。。。。,
• 算法描述:
本文实现双向匹配算法,具体算法描述如下: MM: RMM:
• 详例描述:
以“一把青菜”为例,详细描述算法如下
将程序实现的截图粘贴过来
• 软件演示:
另外,请每个小组将每次的作业实现在同一个软件平台中,班级及 成员不要变化,这样学期结束,就实现了一个NLP的工具集,最后 添加一个应用就是你的大作业了。
2.请使用概率最大方法及给定语料库对以下句子分词:
• “对外经济技术合作与交流不断扩大。” • 要求:利用人民日报语料库来计算每个候选词的概率值及 最佳左邻词,及分词结果。并计算分词的P,R,F值和分词 时间。
注意作业提交要求:看后一个PPT
作业提交要求
• 作业完成时间:
2周,请在第4周上课前提交,4人以内小组提交。 最好是C++或JAVA 报告标题、理论描述、算法描述、详例描述、软件演 示图, 请看样板
实验一 中文分词
实验内容
• 请分别使用正向最大匹配算法和逆向最大匹配 算法及给定的字典对以下句子进行分词,并分 别显示结果:
一把青菜 幼儿园地节目
实验一作业
• 请选择以下任意一个完成:
1.请使用双向匹配算法对给定测试文本进行分词:
• 给定测试文本为:实验1作业测试文本.txt • 词典为:chineseDic.txt • 要求:编程实现,并计算分词的P, R,F值和分词时间。
汉语自动分词词典机制的实验研究

我们希望通过本次实验研究,探索一种基于机器学习算法的汉语自动分词技 术,提高分词的准确性和效率。
二、文献综述
近年来,已有很多研究者致力于汉语自动分词技术的研发。根据不同方法, 可分为基于规则的分词方法和基于统计的分词方法。基于规则的分词方法主要依 靠人工设定的词典和语法规则进行分词,如最大匹配法、最少词数法等。此类方 法往往需要耗费
三、实验设计与方法
本次实验采用了基于统计的分词方法。我们自建了一个包含千万级词数的词 典,并使用双向长短期记忆网络(BiLSTM)模型进行分词。具体实验流程如下:
1、数据集处理:我们使用了两个公开数据集进行训练和测试,共计800万余 个句子。对数据集进行预处理,包括去除停用词、标点符号等。
2、模型训练:我们将词典中的词作为输入,每个句子作为输出,使用 BiLSTM模型进行训练。通过反向传播算法优化模型参数,降低损失函数值。
四、总结
汉语分词词典设计是自然语言处理中的一项重要任务。一个准确、高效、全 面的汉语分词词典可以为自然语言处理应用提供有力的支持。本次演示介绍了基 于规则和基于统计的分词算法,并详细阐述了汉语分词词典的设计原则、词典结 构和实现方式。希望对大家有所帮助。
汉语自动分词是自然语言处理领域中的一项基本任务,旨在将一段连续的文 本分割成一个个独立的词语。这项任务在中文信息处理领域中具有尤为重要的地 位,因为中文的词语往往没有明显的分隔符,且存在大量的歧义词和语境依赖。
取得了一定的成果,但仍然存在一些不足。例如,如何处理歧义词和未登录 词的问题,以及如何提高分词的精度和速度等。
困难与挑战
语自动分词面临的困难和挑战主要包括语言特点、数据采集和算法模型等 方面。首先,中文词语之间没有明显的分隔符,这使得分词成为一项颇具挑战性 的任务。其次,汉语中存在大量的歧义词和未登录词,如何准确地区分它们是一 个难题。
分词技术研究报告

分词技术研究报告研究内容目前,国内的每个行业、领域都在飞速发展,这中间产生了大量的中文信息资源,为了能够及时准确的获取最新的信息,中文搜索引擎是必然的产物。
中文搜索引擎与西文搜索引擎在实现的机制和原理上大致雷同,但由于汉语本身的特点,必须引入对于中文语言的处理技术,而汉语自动分词技术就是其中很关键的部分。
汉语自动分词到底对搜索引擎有多大影响?对于搜索引擎来说,最重要的并不是找到所有结果,最重要的是把最相关的结果排在最前面,这也称为相关度排序。
中文分词的准确与否,常常直接影响到对搜索结果的相关度排序。
分词准确性对搜索引擎来说十分重要,但如果分词速度太慢,即使准确性再高,对于搜索引擎来说也是不可用的,因为搜索引擎需要处理数以亿计的网页,如果分词耗用的时间过长,会严重影响搜索引擎内容更新的速度。
因此对于搜索引擎来说,分词的准确性和速度,二者都需要达到很高的要求。
研究汉语自动分词算法,对中文搜索引擎的发展具有至关重要的意义。
快速准确的汉语自动分词是高效中文搜索引擎的必要前提。
本课题研究中文搜索引擎中汉语自动分词系统的设计与实现,从目前中文搜索引擎的发展现状出发,引出中文搜索引擎的关键技术------汉语自动分词系统的设计。
首先研究和比较了几种典型的汉语自动分词词典机制,指出各词典机制的优缺点,然后分析和比较了几种主要的汉语自动分词方法,阐述了各种分词方法的技术特点。
针对课题的具体应用领域,提出改进词典的数据结构,根据汉语中二字词较多的特点,通过快速判断二字词来优化速度;分析中文搜索引擎下歧义处理和未登陆词处理的技术,提出了适合本课题的自动分词算法,并给出该系统的具体实现。
最后对系统从分词速度和分词准确性方面进行了性能评价。
本课题的研究将促进中文搜索引擎和汉语自动分词新的发展。
二、汉语自动分词系统的研究现状1、几个早期的自动分词系统自80年代初中文信息处理领域提出了自动分词以来,一些实用性的分词系统逐步得以开发,其中几个比较有代表性的自动分词系统在当时产生了较大的影响。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验报告1 双向匹配中文分词
•小组信息
目录
摘要--------------------------------------------------------------------------------------- 1
理论描述--------------------------------------------------------------------------------- 1
算法描述--------------------------------------------------------------------------------- 2
详例描述--------------------------------------------------------------------------------- 3
软件演示--------------------------------------------------------------------------------- 4
总结--------------------------------------------------------------------------------------- 6
•摘要
这次实验的内容是中文分词,现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。
而我们用到的分词算法是基于字符串的分词方法(又称机械分词方法)中的正向最大匹配算法和逆向匹配算法。
一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。
统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。
•理论描述
中文分词指的是将一个汉字序列切分成一个一个单独的词。
中文分词是文本挖掘的基础,对于输入的一段中文,成功的进行中文分词,可以达到电脑自动识别语句含义的效果。
它是信息提取、信息检索、机器翻译、文本分类、自动文摘、语音识别、文本语音转换、自然语言理解等中文信息处理领域的基础。
双向最大匹配算法是两个算法的集合,主要包括:正向最大匹配算法和逆向最大匹配算法.如果两个算法得到相同的分词结果,那就认为是切分成功,否则,就出现了歧义现象或者是未登录词问题。
正向最大匹配算法:从左到右将待分词文本中的几个连续字符与词表匹配,如果匹配上,则切分出一个词。
逆向最大匹配算法:从右到左将待分词文本中的几个连续字符与词表匹配,如果匹配上,则切分出一个词。
•算法描述
本文实现双向匹配算法,具体算法描述如下:
正向最大匹配算法MM:
//对纯中文句子s1的正向减字最大匹配分词
string CHzSeg::SegmentHzStrMM(CDict &dict,string s1)const
{
string s2="";//保存句子s1的分词结果
while(!s1.empty())
{
unsigned int len=s1.size();
//如果待切分的句子大于最大切分单元
//len=最大切分单元,否则len=句子的长度
if(len>MAX_WORD_LENGTH)
len=MAX_WORD_LENGTH;
//取s1句子最左边长度len为的子句子
string w=s1.substr(0,len);
//判断刚刚取出来的子句子是不是一个词
bool isw=dict.IsWord(w);
//当w中至少有一个中文字&&不能构成字的时候,减去最右边的一个中文字while(len>2&&isw==false)
{
///减去最右边的一个中文字
len-=2;
w=w.substr(0,len);
//再次判断减字后的w是不是构成一个词
isw=dict.IsWord(w);
}
s2+=w+SEPARATOR;
s1=s1.substr(w.size());
}//end while
return s2;
}
逆向最大匹配算法RMM:
//对纯中文句子s1的逆向减字最大匹配分词
string CHzSeg::SegmentHzStrRMM(CDict &dict,string s1)const
{
string s2="";//保存句子s1的分词结果
while(!s1.empty())
{
unsigned int len=s1.size();
//如果待切分的句子大于最大切分单元
//len=最大切分单元,否则len=句子的长度
if(len>MAX_WORD_LENGTH)
len=MAX_WORD_LENGTH;
//取s1句子最右边长度len为的子句子
string w=s1.substr(s1.length()-len,len);
//判断刚刚取出来的子句子是不是一个词
bool isw=dict.IsWord(w);
//当w中至少有一个中文字&&不能构成字的时候,减去最左边的一个中文字while(len>2&&isw==false)
{
//减去最左边的一个中文字
len-=2;
w=s1.substr(s1.length()-len,len);
//再次判断减字后的w是不是构成一个词
isw=dict.IsWord(w);
}
w=w+SEPARATOR;
s2=w+s2;
//分出一个词后的s1
s1=s1.substr(0,s1.length()-len);
}
return s2;
}
•详例描述:
逆向最大匹配思想是从右向左切分,以“对外经济技术合作与交流不断扩大”为例,详细描述算法如下:
输入例句:S1=“对外经济技术合作与交流不断扩大”;
定义:最大词长MaxLen = 6;S2= “”;分隔符= “/ ”;
逆向减字最大匹配分词算法过程如下:
(1)S2=“”;S1不为空,从S1右边取出候选子串W=“断扩大”;
(2)查词表,W不在词表中,将W最左边一个字去掉,得到W=“扩大”;(3)查词表,“扩大”在词表中,将W加入到S2中,S2=“扩大/ ”,并将W 从S1中去掉,此时S1=“对外经济技术合作与交流不断”;
(4)S1不为空,于是从S1左边取出候选子串W=“流不断”;
(5)查词表,W不在词表中,将W最左边一个字去掉,得到W=“不断”;(6)查词表,“不断”在词表中,将W加入到S2中,S2=“不断/ 扩大/ ”,并将W从S1中去掉,此时S1=“对外经济技术合作与交流”;
(7)S1不为空,于是从S1左边取出候选子串W=“与交流”;
(8)查词表,W不在词表中,将W最左边一个字去掉,得到W=“交流”;(9)查词表,“交流”在词表中,将W加入到S2中,S2=“交流/ 不断/ 扩大/ ”,并将W从S1中去掉,此时S1=“对外经济技术合作与”;
(10)S1不为空,于是从S1左边取出候选子串W=“合作与”;
(11)查词表,W不在词表中,将W最左边一个字去掉,得到W=“作与”;(12)查词表,W不在词表中,将W最左边一个字去掉,得到W=“与”;(13)查词表,“与”在词表中,将W加入到S2中,S2=“与/ 交流/ 不断/ 扩大/ ”,并将W从S1中去掉,此时S1=“对外经济技术合作”;
(14)S1不为空,于是从S1左边取出候选子串W=“术合作”;
(15)查词表,W不在词表中,将W最左边一个字去掉,得到W=“合作”;(16)查词表,“交流”在词表中,将W加入到S2中,S2=“合作/ 与/ 交流/ 不断/ 扩大/ ”,并将W从S1中去掉,此时S1=“对外经济技术”;
(17)S1不为空,于是从S1左边取出候选子串W=“济技术”;
(18)查词表,W不在词表中,将W最左边一个字去掉,得到W=“技术”;(19)查词表,“交流”在词表中,将W加入到S2中,S2=“技术/ 合作/ 与/ 交流/ 不断/ 扩大/”,并将W从S1中去掉,此时S1=“对外经济
(20)S1不为空,于是从S1左边取出候选子串W=“外经济”;
(21)查词表,W不在词表中,将W最左边一个字去掉,得到W=“经济”;(22)查词表,“交流”在词表中,将W加入到S2中,S2=“经济/ 技术/ 合作/ 与/ 交流/ 不断/ 扩大/ ”,并将W从S1中去掉,此时S1=“对外”;(23)S1不为空,由于此时S1只剩下“对外”于是从S1左边取出候选子串W=“对外”;
(24)查词表,“对外”在词表中,将W加入到S2中,S2=“对外/ 经济/ 技术/ 合作/ 与/ 交流/ 不断/ 扩大/ ”,并将W从S1中去掉,此时S1=“”;(25)S1为空,输出S2作为分词结果,分词过程结束。
正向匹配法思想与逆向一样,只是从左向右切分,因此只举例逆向最大匹配算法描述。
•软件演示:
软件界面:
选择分词所要的方式(正向或逆向),然后输入所要分词的内容,分词结果就会在右边显示出来。
正向最大匹配分词结果:
逆向最大匹配分词结果:
•总结:
1.使用哈希表存储字典,启动时间延长,内存占用增加,但是,可以实现实时分词。
2.两个算法相对而言,逆向算法的出错率更低,例如“幼儿园地节目”,正向会分为幼儿园/地/节目,而逆向为幼儿/园地/节目。
3.对于最大长度的选择要谨慎,若太长会导致运行时间太长,而太短则可能
会导致一些词语无法识别。