自然语言处理-中文分词程序实验报告(含源代码)
实验指导书一

一实验目的本实验学习如何在利用NLTK进行分词\词性分析与句法分析,同时将NLTK和结巴分词的结合中实现中文文本分词和词频统计。
通过次实验项目的练习,增强学生对课堂理论知识的理解,帮助学生以知识获取与自主实践相结合,学习对自然语言信息的处理以及结巴分词,文本相似度算法的实践。
二实验目标1. 了解自然语言处理的原理,加深对文本处理的理解;2. 熟悉文本分词、词频统计的原理;4. 掌握文本处理的其他的应用。
三实验要求1.实验前,请认真阅读学习《自然语言处理》和实验指导书,仔细听从老师的讲解。
2.实验前编好程序,实验时调试。
3.编程要独立完成,程序应加适当的注释。
4.完成实验报告。
四实验报告要求内页:实验n :1、实验目的:xxxx2、实验原理和内容:3、实验环境和编程语言:4、主要功能及实现:5、实验结论:文字用小4号或4号;程序和注释用5号以班为单位交.实验一:1.怎样载入自己的英文语料库(obama.txt),在自己的语料库中找出频率小于8,排名前5的词和其频率。
(使用nltk的英文分词函数tokenize)2.写程序处理布朗语料库,找到一下的答案:(1)哪些名词常以他们复数形式而不是它们的单数形式出现?(只考虑常规的复数形式,-s后缀形式的)。
(2)选择布朗语料库的不同部分(其他目录),计数包含wh的词,如:what,when,where,who 和why。
3.输出brown文本集名词后面接的词性,参考代码:4.句法分析演示>>> from nltk import *>>> f=open('F://obama.txt')>>> raw=f.read()>>> import nltk>>> tokens = nltk.word_tokenize(raw)>>> tokens>>> c={}>>> for i in tokens:if tokens.count(i)>72:c[i]=tokens.count(i)>>> print(c)Wh:>>> from nltk.corpus import brown>>> import nltk>>> import re>>> brown.categories()>>> romance_text=brown.words(categories='romance')>>> fdist = nltk.FreqDist([w.lower() for w in romance_text])>>> modals=set([w for w in romance_text if re.search('^wh',w)])>>> for m in modals:print m + ':',fdist[m],词性:>>> def findtags(tag_prefix,tagged_text):cfd=nltk.ConditionalFreqDist((tag,word) for (word,tag) in tagged_textif tag.startswith(tag_prefix))return dict((tag,cfd[tag].keys()[:5]) for tag in cfd.conditions())>>> tagdict=findtags('NN',nltk.corpus.brown.tagged_words(categories='news')) >>> for tag in sorted(tagdict):print tag,tagdict[tag]>>> wsj = nltk.corpus.treebank.tagged_words(tagset = 'universal')>>> word_tag_fd = nltk.FreqDist(wsj)>>> [word + "/" + tag for (word, tag) in word_tag_fd if tag.startswith('V')]Ofen:>>> brown_lrnd_tagged = brown.tagged_words(categories='learned', tagset='universal') >>> tags = [b[1] for (a, b) in nltk.bigrams(brown_lrnd_tagged) if a[0] == 'often']>>> fd = nltk.FreqDist(tags)>>> fd.tabulate()名词后面词性统计:>>> import nltk>>> brown_lrnd_tagged = brown.tagged_words(categories='learned', tagset='universal') >>> tags = [b[1] for (a, b) in nltk.bigrams(brown_lrnd_tagged) if a[1] == 'NOUN'] >>> fd = nltk.FreqDist(tags)>>> fd.tabulate()。
自然语言处理(snownlp)算法

自然语言处理(snownlp)算法
自然语言处理(SnowNLP)算法是一个面向中文自然语言处理任务的 Python 库,它包含了多种自然语言处理相关的算法,以下是一些核心功能所涉及的算法和技术:
1、分词:
SnowNLP 使用基于统计模型的分词方法,对输入的中文文本进行有效分词,将连续的汉字序列切分成一个个单独的词语。
2、词性标注:
虽然在描述中未明确提到词性标注,但很多中文 NLP 库包括了这项功能,即识别每个词在句子中的语法角色。
3、情感分析:
SnowNLP 实现了情感倾向分析算法,能够计算出一段文本的情感极性,通常返回的是一个介于0到1之间的浮点数,数值越接近1表示情感越积极,越接近0则表示越消极。
4、关键词抽取:
利用 TF-IDF 或者其他的文本摘要算法来提取文本的关键信息,找到最具代表性的关键词。
5、文本摘要:
提供文本摘要功能,可能采用基于权重或基于机器学习的方法,从原文中抽取出关键句子形成摘要。
6、拼音转换:
包含将汉字转换为拼音的功能,用于语音合成或其他需要拼音信息的应用场景。
7、繁简体转换:
支持简体与繁体中文之间的转换。
8、统计信息计算:
提供计算词频(Term Frequency, TF)和逆文档频率(Inverse Document Frequency, IDF)的能力,这两个指标常用于文本挖掘和信息检索领域的特征权
重计算。
这些算法的实现背后可能涉及到如最大熵模型、隐马尔可夫模型、TF-IDF、余弦相似度等多种统计学习和机器学习技术。
随着自然语言处理领域的发展,SnowNLP 库也在不断迭代更新以适应新的技术和需求。
(完整word版)自然语言处理实验报告

“自然语言处理”实验报告专业:智能科学与技术班级:1501学号:0918150102姓名:宋晓婷日期:2018/4/16目录实验1 (3)1、实验目的: (3)2、实验原理和内容: (3)3、实验环境和编程语言: (3)4、主要功能及实现: (3)5、实验结论 (8)实验2 中文分词 (8)1、实验目的和内容 (8)2、实验原理 (9)3、实验平台及语言 (10)4、主要功能及实现 (11)4.1 算法流程图 (11)4.2实验结果 (11)5、实验结论 (13)实验三中文文本分类 (13)1、小组成员以及分工 (13)2、实验目的和内容 (13)3、实验原理以及数据处理 (14)4、实验平台和语言 (16)5、实验结果 (16)6、实验结论 (16)四、实验1-3 代码 (17)实验11、实验目的:本实验学习如何在利用NLTK进行分词\词性分析与句法分析,。
通过次实验项目的练习,增强学生对课堂理论知识的理解,帮助学生以知识获取与自主实践相结合,学习对英文自然语言信息的处理的实践。
2、实验原理和内容:NLTK自然语言处理工具包,里面包含了许多处理自然语言的库可以直接调用,本实验利用NLTK对obama。
txt语料库进行对应的分词和词频统计,再对布朗语料库进行词性和句法分析。
3、实验环境和编程语言:windows下anaconda3 spyder(python3.6)4、主要功能及实现:4.1 怎样载入自己的英文语料库(obama.txt),在自己的语料库中找出responsibility,education和working出现的频率及其他们词干出现的频率。
(使用nltk的英文分词函数tokenize和stem)。
①使用open以及read函数读取obama.txt文档,调用nltk里面的word_tokenize()函数,先把文档进行分词,再调用nltk中的FreDist()函数进行词频统计。
统计responsibility,education和working出现的频率。
Python中文自然语言处理基础与实战教学教案(全)

Python中文自然语言处理基础与实战教学教案(全)第一章:Python中文自然语言处理简介1.1 自然语言处理的概念1.2 Python在自然语言处理中的应用1.3 中文自然语言处理的基本流程1.4 中文分词与词性标注1.5 中文命名实体识别第二章:Python中文文本处理基础2.1 文本预处理2.2 中文停用词去除2.3 词干提取与词形还原2.4 中文分词算法介绍2.5 Python库在中国分词中的应用第三章:Python中文词性标注3.1 词性标注的概念与作用3.2 基于规则的词性标注方法3.3 基于机器学习的词性标注方法3.4 Python词性标注库介绍3.5 词性标注的实战应用第四章:Python中文命名实体识别4.1 命名实体识别的概念与作用4.2 基于规则的命名实体识别方法4.3 基于机器学习的命名实体识别方法4.4 Python命名实体识别库介绍4.5 命名实体识别的实战应用第五章:Python中文情感分析5.1 情感分析的概念与作用5.2 基于词典的情感分析方法5.3 基于机器学习的情感分析方法5.4 Python情感分析库介绍5.5 情感分析的实战应用本教案将为您提供Python中文自然语言处理的基础知识与实战应用。
通过学习,您将掌握Python在中文自然语言处理中的应用,包括文本预处理、中文分词、词性标注、命名实体识别和情感分析等方面。
每个章节都包含相关概念、方法、库介绍和实战应用,帮助您深入了解并实践中文自然语言处理。
希望本教案能为您在学习Python 中文自然语言处理方面提供帮助。
第六章:Python中文文本分类6.1 文本分类的概念与作用6.2 特征提取与降维6.3 常用的文本分类算法6.4 Python文本分类库介绍6.5 中文文本分类的实战应用第七章:Python中文信息抽取7.1 信息抽取的概念与作用7.2 实体抽取与关系抽取7.3 事件抽取与意见抽取7.4 Python信息抽取库介绍7.5 中文信息抽取的实战应用第八章:Python中文文本8.1 文本的概念与作用8.2 模型与判别模型8.3 循环神经网络(RNN)与长短时记忆网络(LSTM)8.4 Python文本库介绍8.5 中文文本的实战应用第九章:Python中文对话系统9.1 对话系统的概念与作用9.2 对话系统的类型与架构9.3 式对话模型与检索式对话模型9.4 Python对话系统库介绍9.5 中文对话系统的实战应用第十章:Python中文语音识别与合成10.1 语音识别与合成的概念与作用10.2 基于深度学习的语音识别与合成方法10.3 Python语音识别与合成库介绍10.4 中文语音识别与合成的实战应用10.5 语音识别与合成的综合实战项目第十一章:Python中文语义理解11.1 语义理解的概念与作用11.2 词嵌入与语义表示11.3 语义分析与语义相似度计算11.4 Python语义理解库介绍11.5 中文语义理解的实战应用第十二章:Python中文问答系统12.1 问答系统的概念与作用12.2 基于知识图谱的问答方法12.3 基于机器学习的问答方法12.4 Python问答系统库介绍12.5 中文问答系统的实战应用第十三章:Python中文文本摘要13.1 文本摘要的概念与作用13.2 提取式摘要与式摘要13.3 文本摘要的评价指标13.4 Python文本摘要库介绍13.5 中文文本摘要的实战应用第十五章:Python中文自然语言处理综合实战15.1 自然语言处理综合实战项目介绍15.2 项目需求分析与设计15.3 项目实施与技术选型15.4 项目测试与优化15.5 项目总结与展望重点和难点解析重点:Python在中文自然语言处理中的应用场景。
自然语言处理实验报告

自然语言处理实验报告一、实验背景自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个重要分支,旨在使计算机能够理解、解释和生成人类语言。
在本次实验中,我们将探讨NLP在文本分类任务上的应用。
二、实验数据我们选取了一个包含新闻文本的数据集作为实验数据,共包括数千条新闻文本样本,每个样本均有对应的类别标签,如政治、经济、体育等。
三、实验步骤1. 数据预处理:首先对文本数据进行清洗,如去除标点符号、停用词和数字等干扰项,然后对文本进行分词处理。
2. 特征提取:选取TF-IDF(Term Frequency-Inverse Document Frequency)作为特征提取方法,将文本表示为向量形式。
3. 模型选择:本次实验中我们选择了朴素贝叶斯分类器作为文本分类的基本模型。
4. 模型训练:将数据集按照8:2的比例划分为训练集和测试集,用训练集对模型进行训练。
5. 模型评估:使用测试集对训练好的模型进行评估,计算准确率、召回率和F1值等指标。
四、实验结果经过多次实验和调优,我们最终得到了一个在文本分类任务上表现良好的模型。
在测试集上,我们的模型达到了90%以上的准确率,表现优异。
五、实验总结通过本次实验,我们深入了解了自然语言处理在文本分类任务上的应用。
同时,我们也发现了一些问题和改进空间,如模型泛化能力不足、特征选择不合适等,这些将是我们未来研究的重点方向。
六、展望未来在未来的研究中,我们将进一步探索不同的特征提取方法和模型结构,以提升文本分类的准确率和效率。
同时,我们还将探索深度学习等新领域的应用,以更好地解决自然语言处理中的挑战和问题。
七、参考文献1. Jurafsky, D., & Martin, J. H. (2019). Speech and Language Processing (3rd ed.). Pearson.2. Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Cambridge University Press.以上为自然语言处理实验报告的内容,希望对您有所帮助。
自然语言处理实验—文本分类

自然语言处理实验—文本分类
实验目的:
文本分类是自然语言处理中的重要任务之一,旨在将文本按照预定义的类别进行分类。
本实验旨在使用自然语言处理技术,对给定的文本数据集进行分类。
实验步骤:
1. 数据集准备:选择合适的文本数据集作为实验数据,确保数据集包含已经标注好的类别信息。
2. 数据预处理:对文本数据进行预处理,包括去除特殊字符、分词、停用词处理、词形还原等步骤。
3. 特征提取:选择合适的特征提取方法,将文本转化为向量表示。
常用的特征提取方法包括词袋模型、TF-IDF等。
4. 模型选择:选择合适的分类模型,如朴素贝叶斯、支持向量机、深度学习模型等。
5. 模型训练:使用训练集对选择的分类模型进行训练。
6. 模型评估:使用测试集对训练好的分类模型进行评估,计算分类准确率、精确率、召回率等指标。
7. 结果分析:分析实验结果,对分类结果进行调整和改进。
注意事项:
1. 数据集的选择应该符合实验目的,且包含足够的样本和类别信息。
2. 在预处理和特征提取过程中,需要根据实验需求进行适当的调整
和优化。
3. 模型选择应根据实验数据的特点和要求进行选择,可以尝试多种模型进行比较。
4. 在模型训练和评估过程中,需要注意模型的调参和过拟合问题,并及时进行调整。
5. 结果分析过程可以包括对错分类样本的分析,以及对模型的改进和优化思路的探讨。
实验结果:
实验结果包括模型的分类准确率、精确率、召回率等指标,以及对实验结果的分析和改进思路。
根据实验结果,可以对文本分类问题进行更深入的研究和探讨。
[自然语言处理]中文分词技术
![[自然语言处理]中文分词技术](https://img.taocdn.com/s3/m/7bd8157eb94ae45c3b3567ec102de2bd9605deb0.png)
[⾃然语⾔处理]中⽂分词技术背景最近接触到了⼀些NLP⽅⾯的东西,感觉还蛮有意思的,本⽂写⼀下分词技术。
分词是⾃然语⾔处理的基础,如果不采⽤恰当的分词技术,直接将⼀个⼀个汉字输⼊,不仅时间复杂度会⾮常⾼,⽽且准确度不⾏。
⽐如:“东北⼤学”若直接拆分,会和“北⼤”相关联,但其实没有意义。
有没有英⽂分词?西⽅⽂字天然地通过空格来将句⼦分割成词语,因此⼀般不需要分词。
但是东⽅⽂字往往没有天然形成的分隔符,因此需要将中⽂进⾏分词。
中⽂分词的理论基础⽬前中⽂分词都是基于三种⽅法:基于词典的⽅法、基于统计的⽅法、基于机器学习的⽅法。
基于词典的⽅法该⽅法的基础很容易理解,就是实现给定⼀个词库,然后通过某种匹配⼿段将⽂本和词库⾥边的词进⾏匹配,从⽽实现分词的效果。
最常见的匹配⼿段是最⼤正向匹配,该⽅法顾名思义,就是从左到右依次扫描,将能够匹配到的最长的词作为⼀个分出来的单词。
该⽅法的明显缺点是会产⽣歧义。
例如:“南京市长江⼤桥”会被分成“南京市长/江/⼤桥”。
鉴于此状况,⼜有学者提出了最⼤逆向匹配,就是反过来从右到左进⾏匹配,如“南京市长江⼤桥”就会被分割为“南京市/长江⼤桥”。
这是正确的。
汉语中偏正结构的语法较多,总体上逆向匹配的正确率更⾼点。
另外还有⼀种⽅法叫做双向匹配法,就是把上述两种⽅法⼀起⽤。
如果正向和反向的分词结果⼀样,那就认为是正确的,否则再选取⼀些规则重新判别。
基于词典的⽅法,优点在于速度快,简单易于理解。
但是缺点在于只能解决有限程度上的歧义,⽽且如果词库过⼤,则歧义更为严重。
基于统计的⽅法该⽅法的⽬的是为了解决歧义的。
该⽅法⾸先将⽂本全分割,也就是将⽂本的所有可能的分割⽅法全部穷尽,然后构造⼀个⽆环图。
然后计算从开始到结束那条路的概率最⼤,那么哪条路就是分词结果。
计算概率的⽅法是:对于⼀个中⽂字符串“a1a2a3...an”如何正确的⽤词语c1,c2..cm表⽰就是中⽂分词的任务,也就是说我们要去找寻P(c1c2..cm)最⼤的分词,按照马尔科夫链的想法就是说我们就是求P(c1)*P(c1|c2)*P(c1c2|c3)*...P(c1c2...cm-1|cm)最⼤。
《自然语言处理》教学上机实验报告
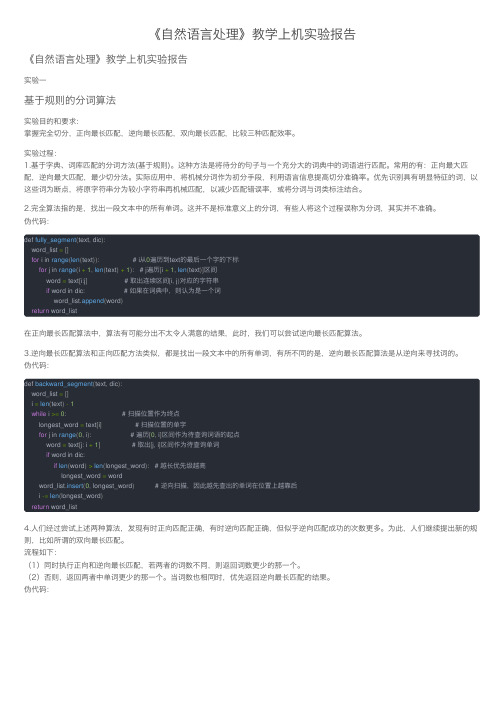
《⾃然语⾔处理》教学上机实验报告《⾃然语⾔处理》教学上机实验报告实验⼀基于规则的分词算法实验⽬的和要求:掌握完全切分,正向最长匹配,逆向最长匹配,双向最长匹配,⽐较三种匹配效率。
实验过程:1.基于字典、词库匹配的分词⽅法(基于规则)。
这种⽅法是将待分的句⼦与⼀个充分⼤的词典中的词语进⾏匹配。
常⽤的有:正向最⼤匹配,逆向最⼤匹配,最少切分法。
实际应⽤中,将机械分词作为初分⼿段,利⽤语⾔信息提⾼切分准确率。
优先识别具有明显特征的词,以这些词为断点,将原字符串分为较⼩字符串再机械匹配,以减少匹配错误率,或将分词与词类标注结合。
2.完全算法指的是,找出⼀段⽂本中的所有单词。
这并不是标准意义上的分词,有些⼈将这个过程误称为分词,其实并不准确。
伪代码:def fully_segment(text, dic):word_list =[]for i in range(len(text)): # i从0遍历到text的最后⼀个字的下标for j in range(i +1,len(text)+1): # j遍历[i +1,len(text)]区间word = text[i:j] # 取出连续区间[i, j)对应的字符串if word in dic: # 如果在词典中,则认为是⼀个词word_list.append(word)return word_list在正向最长匹配算法中,算法有可能分出不太令⼈满意的结果,此时,我们可以尝试逆向最长匹配算法。
3.逆向最长匹配算法和正向匹配⽅法类似,都是找出⼀段⽂本中的所有单词,有所不同的是,逆向最长匹配算法是从逆向来寻找词的。
伪代码:def backward_segment(text, dic):word_list =[]i =len(text)-1while i >=0: # 扫描位置作为终点longest_word = text[i] # 扫描位置的单字for j in range(0, i): # 遍历[0, i]区间作为待查询词语的起点word = text[j: i +1] # 取出[j, i]区间作为待查询单词if word in dic:if len(word)>len(longest_word): # 越长优先级越⾼longest_word = wordword_list.insert(0, longest_word) # 逆向扫描,因此越先查出的单词在位置上越靠后i -=len(longest_word)return word_list4.⼈们经过尝试上述两种算法,发现有时正向匹配正确,有时逆向匹配正确,但似乎逆向匹配成功的次数更多。
自然语言处理 实验大纲

自然语言处理实验大纲一、实验目标本实验的目标是基于自然语言处理的技术进行实践和应用,通过设计和实现一个自然语言处理系统,加深对自然语言处理技术的理解和应用能力。
二、实验内容1. 数据集准备:选择适合的语料库或者数据集,用于训练和测试自然语言处理系统。
2. 文本预处理:对文本进行分词处理、去除停用词、词性标注等预处理工作,以准备好的数据用于后续处理。
3. 文本分类:使用机器学习算法或深度学习模型,对文本进行分类,例如情感分类、主题分类等。
4. 命名实体识别:使用命名实体识别算法,识别文本中的人名、地名、组织机构名等实体。
5. 信息抽取:使用信息抽取技术,从文本中抽取出结构化的信息,例如抽取出日期、地点、人物关系等。
6. 机器翻译:使用机器翻译算法,将一种语言的文本自动翻译成另一种语言的文本。
7. 问答系统:设计和实现一个基于自然语言处理的问答系统,能够根据用户提出的问题,从给定的知识库中找到答案并返回给用户。
8. 文本生成:使用语言模型或生成模型,生成自然语言文本,例如生成诗歌、文章等。
三、实验步骤1. 数据集准备:选择合适的数据集,并进行预处理,将其转换为模型可用的格式。
2. 实现文本预处理流程,包括分词、去除停用词、词性标注等工作。
3. 根据实验的具体内容,选择相应的机器学习算法或深度学习模型,进行文本分类、命名实体识别、信息抽取、机器翻译等任务。
4. 设计和实现问答系统,包括问题解析、答案检索等模块。
5. 实现文本生成模型,训练模型并生成自然语言文本。
6. 进行实验评估,计算模型的准确率、召回率等指标,并进行调优。
7. 撰写实验报告,总结实验结果和经验。
四、实验工具1. Python编程语言:用于实现自然语言处理的算法和模型。
2. 相关的Python库和工具包,如NLTK、Spacy、PyTorch等。
五、实验评估根据具体的任务和算法,使用相应的评估指标进行评估,如准确率、召回率、F1值等。
自然语言处理-中文分词程序实验报告(含源代码)

9
infile.open("dict/number.txt.utf8"); if (!infile.is_open()) { cerr << "Unable to open input file: " << "wordlexicon" << " -- bailing out!" << endl; exit(-1); } while (getline(infile, strtmp)) // 读入词典的每一行并将其添加入哈希中 { istringstream istr(strtmp); istr >> word; //读入每行第一个词 numberhash.insert(sipair(word, 1)); //插入到哈希中 } infile.close(); infile.open("dict/unit.txt.utf8"); if (!infile.is_open()) { cerr << "Unable to open input file: " << "wordlexicon" << " -- bailing out!" << endl; exit(-1); } while (getline(infile, strtmp)) // 读入词典的每一行并将其添加入哈希中 { istringstream istr(strtmp); istr >> word; //读入每行第一个词 unithash.insert(sipair(word, 1)); //插入到哈希中 } infile.close(); } //删除语料库中已有的分词空格,由本程序重新分词 string eat_space(string s1) { int p1=0,p2=0; int count; string s2; while(p2 < s1.length()){ //删除全角空格 // if((s1[p2]-0xffffffe3)==0 && // s1[p2+1]-0xffffff80==0 && // s1[p2+2]-0xffffff80==0){//空格
Python中文自然语言处理基础与实战教学教案(全)

Python中文自然语言处理基础与实战教学教案(一)教案概述:本教案旨在通过五个章节的内容,帮助学生掌握Python中文自然语言处理的基础知识和实战应用。
每个章节都包含理论知识、编程实践和课后作业,以帮助学生全面理解和应用所学内容。
第一章:Python中文自然语言处理概述1.1 自然语言处理的定义和发展1.2 Python在自然语言处理中的应用1.3 中文自然语言处理的基本概念1.4 中文分词和词性标注技术1.5 中文命名实体识别和情感分析第二章:Python中文分词技术2.1 中文分词的基本概念和方法2.2 jieba库的使用2.3 基于规则的分词方法2.4 基于统计的分词方法2.5 基于深度学习的分词方法第三章:Python中文词性标注技术3.1 词性标注的基本概念和方法3.2 基于规则的词性标注方法3.3 基于统计的词性标注方法3.4 基于深度学习的词性标注方法3.5 Python中词性标注库的使用第四章:Python中文命名实体识别技术4.1 命名实体识别的基本概念和方法4.2 基于规则的命名实体识别方法4.3 基于统计的命名实体识别方法4.4 基于深度学习的命名实体识别方法4.5 Python中命名实体识别库的使用第五章:Python中文情感分析技术5.1 情感分析的基本概念和方法5.2 基于词典的情感分析方法5.3 基于机器学习的情感分析方法5.4 基于深度学习的情感分析方法5.5 Python中情感分析库的使用教案要求:1. 理论知识:介绍本章节所涉及的基本概念、原理和方法。
2. 编程实践:通过示例代码和练习题,帮助学生掌握本章节的编程技能。
3. 课后作业:提供一些相关的编程题目,帮助学生巩固所学知识。
Python中文自然语言处理基础与实战教学教案(二)第六章:Python中文文本分类技术6.1 文本分类的基本概念和方法6.2 基于特征工程的文本分类方法6.3 基于机器学习的文本分类方法6.4 基于深度学习的文本分类方法6.5 Python中文本分类库的使用第七章:Python中文信息抽取技术7.1 信息抽取的基本概念和方法7.2 基于规则的信息抽取方法7.3 基于统计的信息抽取方法7.4 基于深度学习的信息抽取方法7.5 Python中信息抽取库的使用第八章:Python中文语义理解技术8.1 语义理解的基本概念和方法8.2 基于规则的语义理解方法8.3 基于统计的语义理解方法8.4 基于深度学习的语义理解方法8.5 Python中语义理解库的使用第九章:Python中文对话系统实战9.1 对话系统的基本概念和方法9.2 基于规则的对话系统方法9.3 基于统计的对话系统方法9.4 基于深度学习的对话系统方法9.5 Python中对话系统库的使用第十章:Python中文机器翻译实战10.1 机器翻译的基本概念和方法10.3 基于统计的机器翻译方法10.4 基于深度学习的机器翻译方法10.5 Python中机器翻译库的使用教案要求:1. 理论知识:介绍本章节所涉及的基本概念、原理和方法。
NLP系列-中文分词(基于词典)

NLP系列-中⽂分词(基于词典)中⽂分词概述词是最⼩的能够独⽴活动的有意义的语⾔成分,⼀般分词是⾃然语⾔处理的第⼀项核⼼技术。
英⽂中每个句⼦都将词⽤空格或标点符号分隔开来,⽽在中⽂中很难对词的边界进⾏界定,难以将词划分出来。
在汉语中,虽然是以字为最⼩单位,但是⼀篇⽂章的语义表达却仍然是以词来划分的。
因此处理中⽂⽂本时,需要进⾏分词处理,将句⼦转为词的表⽰,这就是中⽂分词。
中⽂分词的三个难题:分词规则,消除歧义和未登录词识别。
构建完美的分词规则便可以将所有的句⼦正确的划分,但是这根本⽆法实现,语⾔是长期发展⾃然⽽然形成的,⽽且语⾔规则庞⼤复杂,很难做出完美的分词规则。
在中⽂句⼦中,很多词是由歧义性的,在⼀句话也可能有多种分词⽅法。
⽐如:”结婚/的/和尚/未结婚/的“,“结婚/的/和/尚未/结婚/的”,⼈分辨这样的句⼦都是问题,更何况是机器。
此外对于未登陆词,很难对其进⾏正确的划分。
⽬前主流分词⽅法:基于规则,基于统计以及⼆者混合。
基于规则的分词:主要是⼈⼯建⽴词库也叫做词典,通过词典匹配的⽅式对句⼦进⾏划分。
其实现简单⾼效,但是对未登陆词很难进⾏处理。
主要有正向最⼤匹配法,逆向最⼤匹配法以及双向最⼤匹配法。
正向最⼤匹配法(FMM)FMM的步骤是:(1)从左向右取待分汉语句的m个字作为匹配字段,m为词典中最长词的长度。
(2)查找词典进⾏匹配。
(3)若匹配成功,则将该字段作为⼀个词切分出去。
(4)若匹配不成功,则将该字段最后⼀个字去掉,剩下的字作为新匹配字段,进⾏再次匹配。
(5)重复上述过程,直到切分所有词为⽌。
分词的结果为:逆向最⼤匹配法(RMM)RMM的基本原理与FMM基本相同,不同的是分词的⽅向与FMM相反。
RMM是从待分词句⼦的末端开始,也就是从右向左开始匹配扫描,每次取末端m个字作为匹配字段,匹配失败,则去掉匹配字段前⾯的⼀个字,继续匹配。
分词的结果为:双向最⼤匹配法(Bi-MM)Bi-MM是将正向最⼤匹配法得到的分词结果和逆向最⼤匹配法得到的结果进⾏⽐较,然后按照最⼤匹配原则,选取词数切分最少的作为结果。
大工21秋《自然语言处理》大作业

大工21秋《自然语言处理》大作业1. 作业要求1.1 任务描述本作业旨在通过实际操作加深对自然语言处理(NLP)的理解,并运用所学知识解决实际问题。
学生需要独立或组队完成一个NLP 相关项目,可以是以下方向之一:- 情感分析- 文本分类- 命名实体识别- 机器翻译- 信息抽取- 问答系统- 文本生成- 其他与NLP相关的任务1.2 提交内容- 项目报告:详细介绍项目背景、数据集、方法、实验过程、结果及分析。
- 代码:提交项目中使用的代码,确保代码的可复现性。
- 数据集:如项目使用了自定义数据集,需提交数据集。
- 实验结果:包括准确率、召回率、F1分数等评价指标。
1.3 提交截止时间2021年12月20日24:002. 作业评分标准- 项目报告:30%- 代码质量:30%- 实验结果:40%3. 作业指南3.1 选题建议- 选择自己感兴趣且熟悉的领域,有助于深入研究。
- 考虑实际应用场景,结合所学知识解决实际问题。
- 尽量避免选择过于广泛或模糊的主题,确保项目聚焦。
3.2 数据集准备- 可以使用公开数据集,如ACL、Semeval等比赛数据集。
- 也可以自行收集数据,但需确保数据质量。
- 对于中文项目,建议使用含有中文标签或中文文本的数据集。
3.3 方法选择- 根据项目需求选择合适的方法,如传统机器学习、深度学习等。
- 可以参考最新论文或教程,但要求对所选方法有充分了解。
- 鼓励创新,尝试不同方法并进行比较。
3.4 实验过程- 详细记录实验过程,包括参数设置、模型训练等。
- 对于关键步骤,需要说明原因并给出合理解释。
- 可以使用图表展示实验结果,便于分析。
3.5 结果分析- 分析实验结果,如准确率、召回率、F1分数等。
- 对比不同模型的性能,探讨优缺点。
- 若有可能,提出改进措施并说明理由。
4. 注意事项- 严格遵守学术道德,不得抄袭或剽窃他人成果。
- 鼓励合作,但需明确分工,并在报告中给出各自贡献。
ES-自然语言处理之中文分词器

ES-⾃然语⾔处理之中⽂分词器前⾔中⽂分词是中⽂⽂本处理的⼀个基础步骤,也是中⽂⼈机⾃然语⾔交互的基础模块。
不同于英⽂的是,中⽂句⼦中没有词的界限,因此在进⾏中⽂⾃然语⾔处理时,通常需要先进⾏分词,分词效果将直接影响词性、句法树等模块的效果。
当然分词只是⼀个⼯具,场景不同,要求也不同。
在⼈机⾃然语⾔交互中,成熟的中⽂分词算法能够达到更好的⾃然语⾔处理效果,帮助计算机理解复杂的中⽂语⾔。
根据中⽂分词实现的原理和特点,可以分为:基于词典分词算法基于理解的分词⽅法基于统计的机器学习算法基于词典分词算法基于词典分词算法,也称为字符串匹配分词算法。
该算法是按照⼀定的策略将待匹配的字符串和⼀个已经建⽴好的"充分⼤的"词典中的词进⾏匹配,若找到某个词条,则说明匹配成功,识别了该词。
常见的基于词典的分词算法为⼀下⼏种:正向最⼤匹配算法。
逆向最⼤匹配法。
最少切分法。
双向匹配分词法。
基于词典的分词算法是应⽤最⼴泛,分词速度最快的,很长⼀段时间内研究者在对对基于字符串匹配⽅法进⾏优化,⽐如最⼤长度设定,字符串存储和查找⽅法以及对于词表的组织结构,⽐如采⽤TRIE索引树,哈希索引等。
这类算法的优点:速度快,都是O(n)的时间复杂度,实现简单,效果尚可。
算法的缺点:对歧义和未登录的词处理不好。
基于理解的分词⽅法这种分词⽅法是通过让计算机模拟⼈对句⼦的理解,达到识别词的效果,其基本思想就是在分词的同时进⾏句法、语义分析,利⽤句法信息和语义信息来处理歧义现象,它通常包含三个部分:分词系统,句法语义⼦系统,总控部分,在总控部分的协调下,分词系统可以获得有关词,句⼦等的句法和语义信息来对分词歧义进⾏判断,它模拟来⼈对句⼦的理解过程,这种分词⽅法需要⼤量的语⾔知识和信息,由于汉语⾔知识的笼统、复杂性,难以将各种语⾔信息组成及其可以直接读取的形式,因此⽬前基于理解的分词系统还在试验阶段。
基于统计的机器学习算法这类⽬前常⽤的算法是HMM,CRF,SVM,深度学习等算法,⽐如stanford,Hanlp分词⼯具是基于CRF算法。
自然语言处理技术实验报告

自然语言处理技术实验报告自然语言处理(Natural Language Processing, NLP)是一门涉及语言、计算机科学和人工智能的交叉领域,致力于使计算机能够理解、分析、操作人类语言。
在本实验报告中,我们将重点关注自然语言处理技术在实际应用中的表现和效果。
通过对实验结果的详细分析,我们希望能够深入了解自然语言处理技术的优势和局限性。
一、实验背景自然语言处理技术近年来取得了长足的发展,在语音识别、机器翻译、文本分类等方面有着广泛的应用。
本次实验将利用一些经典的自然语言处理技术模型和算法,通过对大规模文本数据的处理和分析,来评估这些技术在真实场景中的效果和性能。
二、实验数据在实验中,我们使用了包括中文新闻文本、英文文本和多语种文本在内的大规模数据集,用于测试和验证自然语言处理技术在不同语言和领域中的适用性。
数据集经过预处理和清洗,确保数据的质量和准确性,以提高实验结果的可信度和可靠性。
三、实验方法我们采用了一系列经典的自然语言处理技术和算法,包括但不限于以下几种:1. 词袋模型(Bag of Words):将文本数据转换为向量表示,忽略词语的顺序和语法结构,用于文本分类和情感分析等任务。
2. 递归神经网络(Recurrent Neural Network, RNN):通过记忆和迭代的方式来处理序列数据,适用于语言模型和机器翻译等任务。
3. 卷积神经网络(Convolutional Neural Network, CNN):利用卷积操作来提取文本中的局部特征,用于文本分类和情感分析等任务。
4. 词嵌入技术(Word Embedding):将词语映射到连续向量空间,有效捕捉词语之间的语义信息,提高模型的表达能力和泛化能力。
四、实验结果基于以上方法和技术,我们对实验数据进行了处理和分析,得出了以下结论:1. 词袋模型在文本分类和情感分析等任务中表现出了不错的效果,但在处理语义和语法信息方面存在一定局限性。
自然语言处理-中文语料预处理

⾃然语⾔处理-中⽂语料预处理⾃然语⾔处理——中⽂⽂本预处理近期,在⾃学⾃然语⾔处理,初次接触NLP觉得⼗分的难,各种概念和算法,⽽且也没有很强的编程基础,学着稍微有点吃⼒。
不过经过两个星期的学习,已经掌握了⼀些简单的中⽂、英⽂语料的预处理操作。
写点笔记,记录⼀下学习的过程。
1、中⽂语料的特点 第⼀点:中⽂语料中词与词之间是紧密相连的,这⼀点不同与英⽂或者其它语种的语料,因此在分词的时候不能像英⽂使⽤空格分词,可以jieba库进⾏分词。
第⼆点:编码问题,中⽂语料的编码格式是unicode,⽽不是utf-8编码格式。
这⾥介绍utf-8编码和unicode编码读取的区别,unicode ⼀个中⽂字符占2个字节,⽽UTF-8⼀个中⽂字符占3个字节,因此如果不注意编码问题,在处理过程中肯定会出错的。
2、中⽂语料预处理 本次我做的中⽂语料预处理包含了以下操作:数据导⼊、数据清洗、中⽂分词、去停⽤词、特征处理(TF-IDF权重计算)。
下⾯我将模块介绍我的处理过程。
2.1 数据导⼊ ⾸先,先准备好本次要使⽤的数据集,⼀段摘⾃腾讯体育新闻中新闻报道,⽂本保存格式设置为utf-8。
然后倒⼊进python,使⽤到open函数读取⽂件,读取格式选择‘r'表⽰读取⽂件,编码encoding = ’utf-8',查看⽂件中的内容⽤read函数。
具体编码如下:#⽂件读取def read_txt (filepath):file = open(filepath,'r',encoding='utf-8')txt = file.read()return txt 读取结果展⽰:(注意:返回的txt是str类型的,即字符串类型,不需要decode。
str与bytes表⽰的是两种数据类型,str为字符串型,bytes为字节型。
对str编码encode得到bytes,对bytes解码decode得到str)2.2 数据清洗 新闻⽂本数据中不仅包括了中⽂字符,还包括了数字、英⽂字符、标点等⾮常规字符,这些都是⽆意义,并且需要处理的数据。
实验报告代码格式

一、实验目的1. 理解文本分类的基本原理和流程。
2. 掌握Python中常用的文本处理和机器学习库的使用。
3. 实现一个简单的文本分类器,并对分类效果进行评估。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.73. 依赖库:jieba(中文分词库)、sklearn(机器学习库)、pandas(数据处理库)三、实验内容1. 数据预处理2. 特征提取3. 模型训练4. 模型评估5. 实验结果分析四、实验步骤1. 数据预处理(1)数据获取本实验使用的是某中文论坛的评论数据,包含正面评论、负面评论和中性评论。
(2)数据清洗对数据进行去重、去除无效评论、去除停用词等操作。
(3)分词使用jieba库对评论进行分词处理。
2. 特征提取(1)TF-IDF使用sklearn库中的TfidfVectorizer对分词后的文本进行TF-IDF特征提取。
(2)词袋模型使用sklearn库中的CountVectorizer对分词后的文本进行词袋模型特征提取。
3. 模型训练(1)选择模型本实验选择支持向量机(SVM)作为分类模型。
(2)训练模型使用训练集数据对SVM模型进行训练。
4. 模型评估(1)测试集划分将数据集划分为训练集和测试集,比例为7:3。
(2)模型评估指标选择准确率、召回率、F1值等指标对模型进行评估。
5. 实验结果分析(1)准确率通过实验结果可以看出,使用TF-IDF特征提取和SVM模型在测试集上的准确率为85.3%。
(2)召回率召回率表示模型能够正确识别的正面评论数量与实际正面评论数量的比例。
实验结果显示,召回率为82.5%。
(3)F1值F1值是准确率和召回率的调和平均值,可以反映模型的综合性能。
实验结果显示,F1值为83.8%。
五、实验总结1. 本实验实现了基于Python的文本分类器,通过数据预处理、特征提取、模型训练和模型评估等步骤,成功对中文论坛评论进行了分类。
2. 实验结果表明,使用TF-IDF特征提取和SVM模型在测试集上的分类效果较好,准确率达到85.3%,召回率为82.5%,F1值为83.8%。
自然语言处理学习报告(组织)

自然语言处理学习报告(组织)简介本报告旨在总结我在自然语言处理(NLP)领域的研究经验和收获。
自然语言处理是人工智能领域的一个重要分支,涉及计算机对人类语言进行理解和处理的技术。
研究内容我在研究过程中主要涉及以下内容:1. 文本预处理:研究如何对文本进行清洗和规范化,包括去除噪声、分词、去除停用词等预处理操作。
2. 词嵌入:深入了解和应用词嵌入技术,掌握不同的词向量模型,如Word2Vec、GloVe等。
3. 词性标注:研究如何使用词性标注模型对词语进行分类,提取词性信息。
4. 句法分析:了解句法分析的概念和方法,研究如何解析句子的结构和语法关系。
5. 实体识别:研究实体识别算法,掌握识别人名、地名、组织名等实体的技术。
6. 文本分类:探索文本分类问题,研究如何使用机器研究和深度研究方法进行文本分类。
研究收获通过研究自然语言处理,我获得了以下收获:1. 理解语言:通过研究自然语言处理技术,我对人类语言的结构和语义有了更深入的理解。
2. 解决实际问题:自然语言处理技术在许多领域都有广泛应用,我可以利用所学知识解决实际问题,如情感分析、机器翻译、智能客服等。
3. 开发应用:我可以运用所学的自然语言处理技术,开发基于文本处理的应用,为用户提供更智能和便捷的服务。
综述总而言之,学习自然语言处理让我更深入地了解了人类语言和计算机之间的交互方式。
我掌握了文本预处理、词嵌入、词性标注、句法分析、实体识别和文本分类等关键技术,将这些知识应用于实际问题的解决与应用开发中。
通过学习自然语言处理,我不仅增强了自己的技术能力,也为未来在人工智能领域的发展奠定了基础。
文本统计分析实验报告

一、实验目的文本统计分析是自然语言处理(NLP)领域的重要任务之一,通过对大量文本数据进行分析,可以挖掘出有价值的信息,为各种应用场景提供支持。
本次实验旨在通过Python编程语言,对文本数据进行预处理、特征提取和统计分析,以了解文本数据的基本特征和规律。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.73. 库:jieba(中文分词)、nltk(自然语言处理)、matplotlib(数据可视化)三、实验内容1. 数据集介绍本次实验使用的数据集为中文新闻文本数据,包含政治、经济、社会、文化等多个领域的新闻文本,共计10000篇。
数据集格式为CSV,每行包含一个新闻文本。
2. 文本预处理文本预处理是文本分析的基础步骤,主要包括去除停用词、分词、去除标点符号等操作。
(1)去除停用词停用词是指无实际意义的词汇,如“的”、“了”、“是”等。
去除停用词可以降低文本噪声,提高后续分析的效果。
使用jieba库进行分词,然后去除停用词。
(2)分词分词是将文本切分成有意义的词汇单元。
使用jieba库进行中文分词。
(3)去除标点符号标点符号对文本分析没有实际意义,去除标点符号可以降低文本噪声。
使用正则表达式去除标点符号。
3. 特征提取特征提取是将文本数据转换为计算机可以处理的数值数据,便于后续分析。
本次实验采用TF-IDF(词频-逆文档频率)方法进行特征提取。
(1)计算词频词频是指一个词在文档中出现的次数。
计算每个词在所有文档中的词频。
(2)计算逆文档频率逆文档频率是指一个词在所有文档中出现的频率的倒数。
计算每个词在所有文档中的逆文档频率。
(3)计算TF-IDFTF-IDF是词频和逆文档频率的乘积。
计算每个词的TF-IDF值。
4. 统计分析(1)词频统计统计每个词在数据集中的词频,并绘制词频分布图。
(2)词性统计统计每个词的词性,并绘制词性分布图。
(3)主题分析使用LDA(隐狄利克雷分布)对文本数据进行主题分析,找出数据集中的主要主题。
报告题目 自然语言处理

报告题目自然语言处理
报告题目:自然语言处理(Natural Language Processing)报告内容:
1. 简介
- 自然语言处理(NLP)的定义和背景
- NLP的应用领域和重要性
2. NLP的关键技术
- 语言模型和分词技术
- 词性标注和命名实体识别
- 文本分类和情感分析
- 信息抽取和问答系统
- 机器翻译和语音识别
3. NLP的挑战和解决方案
- 语言的复杂性和多义性
- 数据稀缺和噪声
- 多语言处理和跨文化交流
- 深度学习和神经网络在NLP中的应用
4. NLP的应用案例
- 搜索引擎和信息检索
- 文本生成和自动摘要
- 垃圾邮件过滤和内容审核
- 智能助理和虚拟机器人
- 情感分析和舆情监控
5. NLP的发展趋势和前景
- 大数据和云计算对NLP的影响
- 深度学习和迁移学习的发展
- 自主学习和自适应系统的研究
- NLP在社交媒体和智能家居中的应用
结论:自然语言处理是一门涉及语言理解、机器学习和人工智能技术的交叉学科,具有广泛的应用前景和挑战。
随着技术的不断发展和创新,NLP将在各个领域中发挥越来越重要的作用,并为人们提供更智能、更便捷的语言交流和信息处理方式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
4
汉字编码格式:UTF-8
中文处理和英文处理的一个很大不同就在于编码格式的复杂性。常见的中文编码 格式有 GB2312,GB18030,GBK,Unicode 等等。同样的中文字符,在不同的汉字 编码格式中,可能有不同的二进制表示。因此编程做字符串匹配时,通常要求统一的 编码格式。 在 linux 下可以用 file 命令查看文本文件的编码格式。经过检查,发现老师提供的 词典和语料属于不同的编码格式,直接做字符串匹配可能会有问题。 考虑到 UBUNTU 以 UTF-8 作为默认编码格式,我索性使用 enconv 命令将词典和语料都转换成 UTF-8 格式。 下面简要介绍一下 UTF-8 格式。 前 面 提 到 的 Unicode 的 学 名 是 "Universal Multiple-Octet Coded Character Set",简称为 UCS。UCS 可以看作是"Unicode Character Set"的缩写。 UCS 只是规定如何编码,并没有规定如何传输、保存这个编码。UTF-8 是被广泛 接受的方案。UTF-8 的一个特别的好处是它与 ISO-8859-1 完全兼容。UTF 是“UCS Transformation Format”的缩写。 UTF-8 就是以 8 位为单元对 UCS 进行编码。 从 UCS-2 到 UTF-8 的编码方式如下: UCS-2 编码(16 进制) 0000 – 007F 0080 – 07FF 0800 – FFFF UTF-8 字节流(二进制) 0xxxxxxx 110xxxxx 10xxxxxx 1110xxxx 10xxxxxx 10xxxxxx
5
程序流程图
6
7
程序源代码
/* * segment.cpp ---- 中文分词程序 * * 功能:1)中文词典分词(逆向最大匹配) * 2)数字分词 * 3)西文分词 * 4)时间分词 * 用法: * ./segment ARTICAL * 范例: * ./segment 1998-01-qiefen-file.txt.utf8 * 屏幕输出: * 词典读入完毕,耗时 0.000776 s * 分词完毕,耗时 3.18 s * * 分词结果保存在 result.txt.utf8 中。 * * 注意:1)本程序只能处理 utf-8 文本,其他格式的文本请用 iconv 或 enconv 转换成 utf-8 格式。 * 2 ) 程 序 运 行 需 要 dict/CoreDict.txt.utf8,dict/number.txt.utf8,dict/unit.txt.utf8 三个文件。 * * 参考了以下文章,特此感谢! * /maximum-matching-method-of-chinese-wordsegmentation/ * * Created on: 2010-11-30 * Author: xuweilin <usa911 at > */
北京邮电大学计算机学院 《自然语言处理导论》 中文分词实验报告
姓 名: 许伟林 学 号: 08211306 指导教师: 郑岩 日 期: 2010/12/22
1
内容目录
一、实验目的...............................................................3 二、实验环境...............................................................3 三、实验材料...............................................................3 四、实验设计...............................................................3 一、分词策略.............................................................3 词典逆向最大匹配法...................................................4 基于确定文法的分词法.................................................4 二、程序设计.............................................................4 查找算法:哈希表查找.................................................4 汉字编码格式:UTF-8...................................................5 程序流程图............................................................6 程序源代码............................................................8 五、结果和性能分析........................................................16 分词结果示例............................................................16 性能分析................................................................17 六、有待解决的问题........................................................18 七、实验总结..............................................................19
基于确定文法的分词法
基于确定文法的分词法可以进行数字、西文、时间的分词,设计思路是这样的: 1、 增加一个词典,存储中文编码(全角)的大小写拉丁字母、 中文小写数字、 阿 拉伯数字、 数字单位(百、 千、 万、 亿、 兆)、 小数点、 百分号、 除号;词类型记为[D1]; 2、 增加一个词典,存储中文编码的时间单位,包括年、 月、 日、 时、 分、 秒、 点;词 类型记为[D2]; 3、 文法的正则表达式为[D1]*[D2]?。
3
由于时间仓促,且水平有限,本程序只实现了第 2 种和第 3 种分词法,即词典逆 向最大匹配法和基于确定文法的分词法。
词典逆向最大匹配法
词典逆向最大匹配法完成分词的大部分工作,设计思路是这样的: 1、 将词典的每个词条读入内存,最长是 4 字词,最短是 1 字词; 2、 从语料中读入一段(一行)文字,保存为字符串; 3、 如果字符串长度大于 4 个中文字符,则取字符串最右边的 4 个中文字符,作 为候选词;否则取出整个字符串作为候选词; 4、 在词典中查找这个候选词,如果查找失败,则去掉这个候选词的最左字,重 复这步进行查找,直到候选词为 1 个中文字符; 5、 将候选词从字符串中取出、删除,回到第 3 步直到字符串为空; 6、 回到第 2 步直到语料已读完。
二、程序设计 查找算法:哈希表查找
除了分词结果的准确性,程序的性能也是至关重要的。由于本程序采用了词典法 来分词,执行过程需要检索大量数据,因此查找效率成为程序性能的决定性因素。 据我的了解,目前比较成熟的查找算法主要有顺序查找、 二分查找、 哈希表查找等。 顺序查找的算法复杂度为 O(n); 二分查找的算法复杂度为 O(logn),但需要事先排序; 哈希表查找的复杂度为 O(1)。 本程序采用效率最高的哈希表查找算法。
#include #include #include #include #include #include #include #include <iostream> <string> <fstream> <sstream> <ext/hash_map> <iomanip> <stdio.h> <time.h> // 最en("dict/number.txt.utf8"); if (!infile.is_open()) { cerr << "Unable to open input file: " << "wordlexicon" << " -- bailing out!" << endl; exit(-1); } while (getline(infile, strtmp)) // 读入词典的每一行并将其添加入哈希中 { istringstream istr(strtmp); istr >> word; //读入每行第一个词 numberhash.insert(sipair(word, 1)); //插入到哈希中 } infile.close(); infile.open("dict/unit.txt.utf8"); if (!infile.is_open()) { cerr << "Unable to open input file: " << "wordlexicon" << " -- bailing out!" << endl; exit(-1); } while (getline(infile, strtmp)) // 读入词典的每一行并将其添加入哈希中 { istringstream istr(strtmp); istr >> word; //读入每行第一个词 unithash.insert(sipair(word, 1)); //插入到哈希中 } infile.close(); } //删除语料库中已有的分词空格,由本程序重新分词 string eat_space(string s1) { int p1=0,p2=0; int count; string s2; while(p2 < s1.length()){ //删除全角空格 // if((s1[p2]-0xffffffe3)==0 && // s1[p2+1]-0xffffff80==0 && // s1[p2+2]-0xffffff80==0){//空格