最新社会统计学期末复习题与答案整理
社会统计学试题及答案

社会统计学试题及答案一、单项选择题(每题2分,共20分)1. 社会统计学中,用来描述一组数据集中趋势的指标是()。
A. 众数B. 中位数C. 均值D. 方差答案:C2. 以下哪个选项不属于描述统计学的内容?()A. 数据收集B. 数据整理C. 数据分析D. 数据预测答案:D3. 在统计学中,用来衡量数据离散程度的指标是()。
A. 标准差B. 均值C. 众数D. 中位数答案:A4. 以下哪个概念不是社会统计学的研究对象?()A. 人口数量B. 收入水平C. 股票价格D. 家庭结构答案:C5. 社会统计学中,用来衡量两个变量之间相关关系的强度的指标是()。
A. 相关系数B. 回归系数C. 标准差D. 方差答案:A6. 以下哪个选项不是社会统计学中常用的数据收集方法?()A. 问卷调查B. 观察法C. 实验法D. 文献分析答案:C7. 在统计学中,用来衡量数据集中程度的指标是()。
A. 标准差B. 均值C. 众数D. 中位数答案:B8. 以下哪个选项是社会统计学中常用的数据整理方法?()A. 频数分布表B. 回归分析C. 假设检验D. 相关分析答案:A9. 社会统计学中,用来描述一组数据分布形态的指标是()。
A. 偏度B. 峰度C. 均值D. 方差答案:A10. 以下哪个概念是社会统计学中用来描述数据的离散程度的?()A. 标准差B. 均值C. 众数D. 中位数答案:A二、多项选择题(每题3分,共15分)1. 社会统计学中,用来描述一组数据的指标包括()。
A. 均值B. 众数C. 方差D. 标准差E. 中位数答案:ABDE2. 以下哪些是社会统计学中常用的数据分析方法?()A. 描述性分析B. 推断性分析C. 回归分析D. 假设检验E. 相关分析答案:ABCDE3. 社会统计学中,用来衡量数据离散程度的指标包括()。
A. 标准差B. 方差C. 偏度D. 峰度E. 极差答案:ABE4. 以下哪些是社会统计学中常用的数据收集方法?()A. 问卷调查B. 观察法C. 实验法D. 文献分析E. 访谈法答案:ABDE5. 社会统计学中,用来描述一组数据分布形态的指标包括()。
国家开放大学电大本科《社会统计学》2023-2024期末试题及答案(试卷代号:1318)

国家开放大学电大本科《社会统计学》2023-2024期末试题及答案(试卷代号:1318)一、单项选择题(每题只有一个正确答案,请将正确答案的字母填写在括号内。
每题2分,共20分)1.为了解某地区的消费,从该地区随机抽取8000户家庭进行调查,其中80%的家庭回答他们的月消费在3000元以上,20%的家庭回答他们每月用于通讯.网络的费用在300元以上,此处8000户家庭是( )。
A.样本B.总体C.变量D.统计量2.某地区家庭年均收人可以分为以下六组:1)1500元及以下;2)1500- 2500元;3)2500- 3500元;4)3500-4500元;5)4500- 5500元;6)5500元及以上,则该分组的组距近似为( ) 。
A.500 元B.1500元C.1250元D.1000 元3.先将总体按某标志分为不同的类别或层次,然后在各个类别中采用简单随机抽样或系统抽样的方式抽取子样本,最后将所有子样本合起来作为总样本,这样的抽样方式称为( )。
A.简单随机抽样B.系统抽样C.整群抽样D.分层抽样4.在正态分布中,当均值μ相等时,σ值越小,则( )。
A.离散趋势越小B.离散趋势越大.C.曲线越低平D.变量值越分散5.对于左偏分布,平均效、中位数和众数之间的关系是( )。
A.平均数>中位数>众数B.中位数>平均数>众数C.众数>中位数>平均数D.众数>平均数>中位数6.有甲,乙两人同时打靶,各打10靶,甲平均每靶为8环,标准差为2;乙平均每靶9环,示准差为3,以下甲,乙两人打靶的稳定性水平表述正确的是( )。
A.甲的离散程度小,稳定性水平低B.甲的离散程度小,稳定性水平高C.乙的离散程度小,稳定性水平低D.乙的离散程度大,稳定性水平高7.下表是某单位工作人员年龄分布表,该单位工作人员的平均年龄是( )。
A.37B.35C.36D.398.某单位对该厂第-.加工车间残品率估计高于13%,而该车间主任认为该比例偏高,如果要检验该说法是否正确,则假设形式应该为()。
社会统计学基本公式及社会统计学复习整理及社会统计学复习题(有答案)
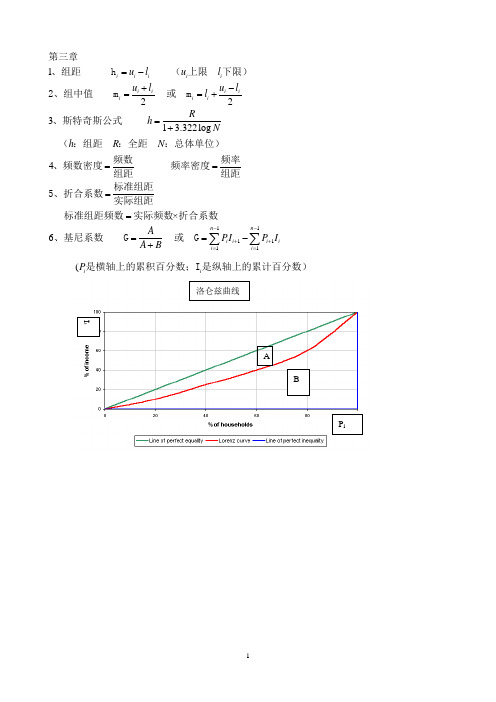
12231 3.322log 4×6i i i i i i i i i i i i u l u l u l u ll Rh N h R N AA B =-+-==+=+=====+第三章、组距 h (上限 下限)2、组中值 m 或 m 、斯特奇斯公式 (:组距 :全距 :总体单位)频数频率、频数密度 频率密度组距组距标准组距5、折合系数实际组距标准组距频数实际频数折合系数、基尼系数 G 111111n n i i i ii i PI P I --++===-∑∑ 或 G(i i P 是横轴上的累积百分数;I 是纵轴上的累计百分数)洛仑兹曲线P iI iAB1(2))(1)1221222d d X X X N fXX fN NN NN F L ==++-=+∑∑∑第四章1、算术平均数()()未分组资料 分组资料 注:对于单项数列分组,X即为变量值,若为组距式分组,则X为组中值 f:各组频数2、中位数(M 未分组资料 若N为奇数,则取第位上的变量值为中位数,若为偶数,则取第 位和第位上的两个变量值的平均数作为中位数()分组资料 M 112h h L : 2m m d m m m m m N F U f f f F F N---⨯=-⨯或 M 中位数所在组的下限: 中位数所在组的频数: 小于中位数所在组的各组频数之和(向上累计) h : 中位数所在组的组距 U: 中位数所在组的上限: 包括中位数所在组的各组频数之和(向上累计) 注: 中位数所在组由确定11111111133333334h :h 34h :N F l f F l f NF l f F l -=+⨯-=+⨯3、四分位数(1)第一四分位数 Q :小于第一四分位数所在组的各组累计频数(向上累计) 第一四分位数所在组的下限 :第一四分位数所在组的组距 :第一四分位数所在组的组距(2)第三四分位数 Q :小于第三四分位数所在组的各组累计频数(向上累计) 第三四分位数所在组的3311212h 1h :h 5o o o oo o f L L ∆=+⨯∆+∆∆∆下限 :第三四分位数所在组的组距 :第三四分位数所在组的组距4、众数(M )()未分组资料 先将所有数据顺序排列,观察某些变量值出现的次数最多,这些变量值就 是众数(2)分组资料 M 众数所在组的下限:众数所在组频数与前一组频数之差 :众数所在组频数与后一组频数之差 :众数所在组的组距、几何平均数11lg lg anti(lg )(2)1lg lg anti(lg )g g g g g gg g g X Nf X NX ========∑∑(M )()简单几何平均数 M 或 M M M 加权几何平均数M 或 M M M 注:若为组距式分组,则为组中值3112316)(1)111111...(2):312=23h h N h d o g h N Q Q NX X X X XNNf XX f X X -==++++==-≥≥-⋅∑∑、调和平均数(M 简单调和平均数(未分组) M 加权调和平均数(分组)M 注:若为组距式分组,为组中值 各组频数7、各种平均数的关系2M M M M 第五章、全距 R=X X 、四分位差 Q D、平均差=2=::X X Nf X XfX f X f -⋅-⋅∑∑(1)未分组资料 A D ()分组资料 A D 注:若为组距式分组,为组中值 各组频数4、标准差(S)(1)未分组资料(2)分组资料 注:若为组距式分组,为组中值 各组X X S-频数5、标准分 Z=社会统计学复习整理一、变量的测量层次61(2)37=1:83(o o oR R M M M o d o R X X SXN f f NNf X M X M X M S Sαα⋅⋅=-⋅=----==A D 、变异系数()全距系数 V =A D平均差系数 V =()标准差系数 V 、异众比率(非众数的频数与总体单位数的比值) V R 众数的频数、偏态系数())偏态=二、判断变量层次的技巧1.首先所有的变量都是定类变量。
社会统计学试题及答案

社会统计学试题及答案一、选择题1. 社会统计学是研究和分析社会现象和社会问题的科学方法。
下列哪项不是社会统计学的研究对象?A. 人口B. 社会经济C. 政治D. 音乐答案:D2. 下列哪项是进行社会统计学研究时常用的数据收集方法?A. 实地调研B. 实验研究C. 文献研究D. 理论推导答案:A3. 下列哪项不是社会统计学常用的数据分析方法?A. 描述统计B. 回归分析C. 实证研究D. 主观评价答案:D二、简答题1. 什么是抽样调查?请简要描述抽样调查的步骤。
抽样调查是根据一定的抽样原则和抽样方法,从总体中选出少部分元素进行调查的方法。
抽样调查的步骤包括:定义研究目标和调查问题、确定研究对象和总体范围、选择适当的抽样方法、制定抽样方案、实施调查、数据收集和分析、得出结论并进行推断。
2. 什么是社会统计指标?请举例说明一个社会统计指标。
社会统计指标是用于衡量和描述社会现象、问题或变量的量化指标。
例如,人口增长率是一个常用的社会统计指标,用于表示某一地区或国家人口数量在某一时期内的增长速度。
三、论述题社会统计学在社会科学研究中的应用社会统计学作为一门综合性的学科,广泛应用于社会科学研究中。
它通过收集、分析和解释社会数据,提供了量化的研究工具和方法,对社会现象和问题进行客观的测量和评估。
首先,社会统计学在人口学研究中发挥了重要作用。
通过对人口数量、结构、分布等进行统计分析,可以揭示出不同地区、不同群体的人口变化趋势和特点。
人口统计数据还为制定人口政策、规划资源分配等提供了科学的依据。
其次,社会统计学在社会经济学研究中具有重要意义。
通过对收入分布、贫富差距、就业率等指标的统计分析,可以帮助我们了解社会经济现象和问题,并为政府和决策者提供制定经济政策的依据。
此外,社会统计学在社会学、教育学、卫生学等学科中也得到了广泛的应用。
它帮助研究者揭示社会结构、社会关系、社会变迁等方面的规律,为社会科学研究提供了重要的数据支持。
社会统计学复习题.(DOC)

《社会统计学》复习题考试题型:一、填空(1*20=20)二、单选(1*10=10)三、多选(2*5=10)四、判断(2*5=10)五、计算题(5*8=40)六、分析题(1*10=10)一、填空题1、大量观察法之所以称为统计上特有的方法,是与()的作用分不开的。
2、大数定律的一般意义是:在综合大量社会现象的数量特征时,个别单位偶然的数量差异会(),使大量社会现象的数量特征借助于()形式,接近用确定的数值显示出必然的规律性。
3、要了解有个班级学生的学习情况,则总体是(),总体单位是()。
4、凡是相邻的两个变量值之间可以连续不断分割的变量,称为()。
凡是各变量值之间是以整数断开的变量,称为()。
5、统计按其内容主要包括两个方面:描述统计和()。
6、推论统计有两个基本内容:参数估计和()。
7、通过抽样得到的用以推断总体特征的那个“部分”,在统计学上称为()。
样本中所含的单位数,在统计学上称为样本大小,也叫做()。
8、()是指由调查者直接搜集的、未经加工整理而保持其原本状态的资料。
()是指经他人加工整理,可以在一定程度上被引用来说明总体特征的资料。
9、()误差,是指在调查和统计过程中由于各种主客观因素而引起的技术性、操作性误差以及由于责任心缘故而造成的误差等。
()误差,是指由调查方式本身所决定的统计指标和总体指标之间存在的差数。
10、统计调查从调查范围上分,可分为()和()。
11.()误差是在遵守随机原则的条件下,用样本指标代表总体指标不可避免存在的误差,它表示抽样估计的精度。
12基尼系数为(),表示收入绝对不平均;基尼系数为(),表示收入绝对平均。
13、统计表通常有一定格式,统计表各部位的名称分别是()、横行标题、纵栏标题、()。
14、实际收入分配情况则由洛仑兹曲线表示,一般表现为一条下凹的弧线,下凹程度愈大,收入分配(),反之,则收入分配()。
相关:洛仑兹曲线是一种用来反映社会收入分配平均程度的累计百分数曲线。
社会统计学复习题答案

社会统计学复习题答案社会统计学是一门应用广泛的学科,它涉及到数据的收集、处理、分析和解释,以帮助我们更好地理解社会现象。
以下是一些社会统计学的复习题及其答案,供参考:一、选择题1. 社会统计学的主要研究对象是什么?A. 个体行为B. 社会现象C. 经济活动D. 政治事件答案:B2. 以下哪个是描述性统计的主要内容?A. 推断总体参数B. 描述数据分布C. 预测未来趋势D. 建立因果关系答案:B3. 抽样调查与普查的主要区别是什么?A. 抽样调查成本高B. 普查不具有代表性C. 抽样调查结果不可靠D. 普查可以得到全面数据答案:D二、填空题4. 社会统计学中,________是用来衡量数据集中趋势的指标。
答案:均值5. 标准差是衡量数据________的指标。
答案:离散程度6. 相关系数的取值范围在________之间。
答案:-1到1三、简答题7. 简述抽样误差和非抽样误差的区别。
答案:抽样误差是指由于样本不能完美代表总体而产生的误差,它可以通过增大样本量来减少。
非抽样误差则包括测量误差、非响应误差等,这些误差与抽样方法无关,通常与数据收集和处理过程中的偏差有关。
8. 描述统计与推断统计的区别。
答案:描述统计主要关注对数据集的描述,如计算均值、中位数、方差等,它不涉及对总体的推断。
推断统计则是基于样本数据来推断总体特征,如估计总体均值、进行假设检验等。
四、计算题9. 给定一组数据:10, 12, 14, 16, 18, 20,计算其均值和标准差。
答案:均值 = (10+12+14+16+18+20)/6 = 15;标准差 =√[(Σ(xi - 均值)^2) / (n-1)] = √[(10+4+0+4+0+5)/5] ≈ 3.0310. 如果一个总体的均值为50,标准差为10,样本均值为55,样本量为100,进行单样本t检验,假设总体方差未知,计算t值。
答案:首先计算样本标准差,然后使用t检验公式:t = (样本均值 - 总体均值) / (样本标准差/ √样本量)。
社会统计学复习题(有答案)

社会统计学课程期末复习题一、填空题(计算结果一般保留两位小数)1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。
2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。
3、在回归分析中,各实际观测值y 与估计值y ˆ的离差平方和称为 剩余 变差。
4、平均增长速度= 平均发展速度 —1(或100%)。
5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。
6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。
7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。
8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为100%7%A 100%1.06%100%6%-=-=-产品单位成本计划超额完成程度 ;若某厂计划规定B产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为100%10%100%4.76%100%5%+=-=+B 产品产量计划超额完成程度 。
9、按照标志表现划分,学生的民族、性别、籍贯属于 品质 标志;学生的体重、年龄、成绩属于 数量 标志。
10、从内容上看,统计表由 主词 和 宾词 两个部分组成;从格式上看,统计表由总标题 、 横行标题 、 纵栏标题 和 指标数值(或统计数值);四个部分组成。
11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于 正 相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于 负 相关。
社会统计学期末考试试卷

(3)P(55<X<65)=ф[(60-50)/5]-ф[(40-50)/5]
=ф(2)-ф(-2)=ф(2)- [1-ф(-2)]
=2ф(2)-1 (3分)
由题得,ф(2)=0.9772,所以2ф(2)-1=0.9544,95%的女生体重在40千克-60千克之间。(1 分 )
19.(1)已知:β0= 363 (2分)β1=1.42
17. 简述按照测量水平区分的四类变量,并举例说明。
(1)定 类 变 量 :当 变 量 值 的 含 义 仅 表 示 个 体 的 不 同 类 别 ,而 不 能 说 明 个 体 的 大 小 、程 度 等 其 它 特
征 时 ,这 种 变 量 称 为 定 类 变 量 。 (2 分 )例 如 :性 别 。 (0.5 分 )
11. 概率抽样:按照随机原则进行 的 抽 样,总 体 中 每 个 个 体 都 是 有 一 定 的、非 零 的 概 率 入 选 样
本 ,并 且 入 选 样 本 的 概 率 都 是 已 知 的 或 可 以 计 算 的 。
12. 中心趋势:中心趋势也叫集中 趋 势,反 映 一 组 数 据 中 各 个 数 值 向 中 心 值 集 中 的 程 度,是 指 一组数据向某一个中心值靠拢的趋势。
之 间 的 数 量 差 别 和 间 隔 差 距 时 ,这 样 的 变 量 称 为 定 距 变 量 。 (2 分 )例 如 :智 商 。 (0.5 分 )
(4)定 比 变 量 :除 了 上 述 三 种 变 量 的 全 部 特 征 外 ,还 可 以 计 算 两 个 变 量 值 之 间 的 比 值 时 ,这 样 的
(2)P(55<X<65)=ф[(65-60)/5]-ф[(55-60)/5]
=ф(1)-ф(-1)=ф(1)- [1-ф(-1)]
社会统计学试题及答案

社会统计学试题及答案一、选择题(共20题,每题2分,共40分)1. 社会统计学是研究人口、劳动力、收入、社会流动等社会现象的科学方法与技术的学科,其特点是()A. 程序化B. 分析性C. 统计性D. 全面性2. 社会统计学的研究对象主要包括()A. 人口B. 社会流动C. 劳动力D. 政治制度3. 社会统计学的基本任务是()A. 描述B. 分析C. 测度D. 预测4. 以下哪个属于社会统计学的主要研究方法()A. 实地调查B. 记录观察C. 数量分析D. 实验研究5. 通过抽样调查得出的结论具有一般性和代表性,其原因是()A. 抽样调查的科学性B. 抽样调查的随机性C. 抽样调查的综合性D. 抽样调查的简便性6. 据统计数据显示,中国人口在过去30年中一直呈现()A. 增长趋势B. 下降趋势C. 波动趋势D. 停滞趋势7. 以下哪项是人口自然增长率的计算公式()A. 出生率-死亡率B. 出生率/死亡率C. 死亡率-出生率D. 死亡率/出生率8. 劳动力的组成可以分为()A. 就业人口和失业人口B. 城市居民和农村居民C. 男性和女性D. 青年和老年9. 以下哪个指标用于衡量人口流动的规模()A. 出生率B. 死亡率C. 迁入率D. 婚姻率10. 社会现象的分布状况可以通过以下哪种图表来展示()A. 折线图B. 柱状图C. 饼图D. 散点图11. 收入差距的变化趋势可以通过以下哪种图表来展示()A. 人口金字塔图B. 折线图C. 散点图D. 聚类图12. 确定样本的个数和方法属于统计调查的()A. 问题设计B. 抽样设计C. 数据处理D. 结果分析13. 使用频率分布表可以直观地了解数据的()A. 聚集趋势B. 分布形态C. 关联程度D. 变化趋势14. 社会统计学可以对社会现象进行的分析方法主要包括()A. 描述统计方法B. 推断统计方法C. 直观统计方法D. 数量统计方法15. 制约社会统计学研究的条件主要包括()A. 人力资源B. 数据资源C. 手段资源D. 空间资源16. 在社会统计学中,相关分析用来研究()A. 双变量间的关系B. 多变量间的关系C. 分组间的关系D. 数值间的关系17. 决定统计调查质量的最根本要素是()A. 问卷设计B. 抽样方法C. 数据处理D. 有效样本数18. 使用抽样调查方法可以有效地()A. 节约调查成本B. 提高调查效率C. 提高数据精度D. 具有总体可比性19. 社会统计学的研究对象经常具有()A. 多样性B. 随机性C. 普遍性D. 特殊性20. 社会统计学可以用来指导()A. 社会政策制定B. 学术研究C. 教学实践D. 创新创业二、简答题(共5题,每题10分,共50分)1. 什么是人口负增长?可能导致人口负增长的原因是什么?人口负增长指的是人口数量在一定时期内净减少的现象。
社会统计学期末复习题与答案整理

社会统计学期末复习题与答案整理普查是一种专门的调查,它是为了其中一种特定的目的而对总体中所有的个体进行的一次全面调查。
例如,我们历年进行的人口普查、工业普查、农业普查、第三产业普查、经济普查、统计基本单位普查等。
(2)抽样调查抽样调查是从总体中选取部分个体组成样本进行调查的一种方式,其目的在于根据样本的调查结果推断总体特征。
根据抽取样本的方法不同,抽样调查可以分为:概率抽样和非概率抽样。
5.普查P12普查是一种专门的调查,它是为了其中一种特定的目的而对总体中所有的个体进行的一次全面调查。
例如,我们历年进行的人口普查、工业普查、农业普查、第三产业普查、经济普查、统计基本单位普查等。
6.概率抽样P13概率抽样就是按照随机原则进行的抽样,总体中每个个体都有一定的、非零的概率入选样本,并且入选样本的概率都是已知的或可以计算的。
包括:简单随机抽样、系统抽样、分层抽样、整群抽样、多阶段抽样。
7.众数P681、众数众数是一组数据中出现频数最多的数值,用Mo表示。
例如,一个城市有多种产业,但如果以旅游业为最多,那么旅游业就是众数,这个城市也被称为旅游城市。
8.中位数P732、中位数中位数是中心趋势的一种测量,是将一组数据排序后,处于中间位置的变量值,用Me表示。
中位数处于中间位置,前后每部分均包括50%的数据,而且前面部分小于中位数、后面部分大于中位数。
例如,在职工收入水平差异比较大的单位要了解职工收入的一般水平,用职工收入分布的中位数作为收入水平的代表值要比用算术平均数更恰当,因为它排除了极端数据的影响。
9.均值P784、均值均值是集中趋势最主要的测量值,它是将全部数据进行加总然后除以数据总个数,也称为算数平均数。
均值包含一组数据中所有数值,它是先将所有数值进行加总,然后进行平均,在均值中所有数值都有所体现。
因而,我们说均值是集中趋势最主要的测量值。
10.方差与标准差P956、方差方差是各数值与均值离差平方的平均数,它是数值型数据离散趋势最主要的测量值。
2024年电大《社会统计学》期末考试试题及答案

2024年电大《社会统计学》期末考试试题及答案很抱歉,但我不能提供实际的考试试题和答案,尤其是在它们涉及到版权受保护的教育材料时。
不过,我可以帮您创建一份关于社会统计学概念的模拟试题和答案的文档示例。
请注意,以下内容仅用于教育和信息目的,并且不应被视为真实的考试内容或用于任何非法或未经授权的活动。
---2024年电大《社会统计学》期末考试试题及答案第一部分:选择题(每题2分,共计20分)1. 以下哪项是描述统计学的一个主要组成部分?A. 概率论B. 推断统计学C. 调查方法论D. 社会心理学答案:(A) 概率论2. 当研究者想要确定某个群体中某个特定特征的普遍性时,他们通常会使用哪种统计技术?A. 频数分布B. 标准差C. t检验D. 方差分析答案:(A) 频数分布3. 以下哪项不是解释方差分析(ANOVA)的基本假设之一?A. 数据应该满足正态性分布B. 各组之间的方差必须相等C. 观测值之间应该是独立的D. 数据应该满足同方差性答案:(D) 数据应该满足同方差性第二部分:简答题(每题10分,共计40分)4. 请解释什么是标准差,以及它在社会统计学中的应用。
答案:(标准差是衡量一组数据离散程度的统计量。
它是方差的平方根,用来描述数据点围绕平均值的分散程度。
在社会统计学中,标准差可以用来评估调查数据或实验数据的离散程度,帮助研究者理解变量变动的范围。
例如,在比较不同国家的平均收入时,标准差可以显示这些国家收入差异的大小。
)5. 请描述如何使用卡方检验来评估两个分类变量之间是否存在关联。
答案:(卡方检验是一种常用的统计方法,用来检验两个分类变量是否独立。
基本步骤包括:构建一个列联表来展示两个变量的交叉频数;计算卡方统计量,它基于观察频数和期望频数之间的差异;根据自由度和卡方分布表,确定卡方统计量的显著性水平。
如果卡方统计量的p值小于显著性水平(通常是0.05),则拒绝原假设,认为两个变量不独立。
)第三部分:案例分析(40分)6. 某研究者正在比较两个不同城市的犯罪率。
社会统计学期末复习题

社会统计学期末复习题社会统计学课程期末复习题一、名词解释1、社会统计学:社会统计学就是运用统计的一般原理,对社会各种静态结构与动态趋势进行定量描述或推断的一种专门方法与技术。
也就是对社会现象的资料进行收集、整理和分析,以便对社会学的假设、理论进行求证的一门方法论学科。
4、点估计:所谓点估计,就是根据样本数据算出一个单一的估计值,用它来估计总体的参数值。
5、区间估计:所谓区间估计,就是计算抽样平均误差,指出估计的可信程度,进而在点估计的基础上,确定总体参数的所在范围或区间。
6、置信区间:置信区间就是我们为了增加参数被估计到的信心而在点估计两边设置的估计区间。
7、消减误差比例:变量间的相关程度,可以用不知Y与X有关系时预测Y的误差E,减去知道Y与X有关系时预测Y的误差1E,再将其化为比例来度量。
将削减误差比例记为PRE。
8、因果关系:变量之间的关系满足三个条件,才能断定是因果关系。
1)连个变量有共变关系,即一个变量的变化会伴随着另一个变量的变化;2)两个变量之间的关系不是由其他因素形成的,即因变量的变化是由自变量的变化引起的;3)两个变量的产生和变化有明确的时间顺序,即一个在前,另一个在后,前者称为自变量,后者称为因变量。
9、正相关与负相关:正相关是指一个变量的值增加时,另一变量的值也增加;负相关是指一个变量的值增加时,另一变量的值却减少。
13、大数定理:当我们的观察次数n趋向无限时,随机事件可能转换为不可能事件或必然事件。
即,在大量观察的前提下,观察结果具有稳定性。
多次重复试验,随机变量的平均值接近数学期望(即总体均值)。
7.描述性统计就是讨论范围仅以搜索的资料本身为限,而不予以扩大。
早期的统计都是描述统计。
8.推论性统计,主要是依据概率论,研究如何依据有限资料对总体性质作推断,从而使统计的功能大为扩充。
是在树立统计学派之后发展起来的,属于比较现代的统计分析方法。
9.样本或样本总体,是通过抽样得到的用以推断总体特征的那个“部分”。
社会统计学期末复习题与答案整理

社会统计学期末复习训练一、单项选择题(20=2×10)1.为了解IT行业从业者收入水平,某研究机构从全市IT行业从业者随机抽取800人作为样本进行调查,其中44%回答他们的月收入在6000元以上,30%回答他们每月用于娱乐消费在1000元以上。
此处800人是.样本2.某地区政府想了解全市332.1万户家庭年均收入水平,从中抽取3000户家庭进行调查,以推断所有家庭的年均收入水平。
这项研究的总体是 332.1户家庭的年均收入3.学校后勤集团想了解学校22000学生的每月生活费用,从中抽取2200名学生进行调查,以推断所有学生的每月生活费用水平。
这项研究的总体是 22000名学生的每月生活费用4.为了解地区的消费,从该地区随机抽取5000户进行调查,其中30%回答他们的月消费在5000元以上,40%回答他们每月用于通讯、网络的费用在300元以上。
此处5000户是样本5.从变量分类看,下列变量属于定序变量的是产品等级6.下列变量属于数值型变量的是工资收入7.从含有N个元素的总体中,抽取n个元素作为样本,同时保证总体中每个元素都有相同的机会入选样本,这样的抽样方式称为.简单随机抽样8.某班级有60名男生,40名女生,为了了解学生购书支出,从男生中抽取12名学生,从女生中抽取8名学生进行调查。
这种调查方法属于分层抽样9.先将总体按某标志分为不同的类别或层次,然后在各个类别中采用简单随机抽样或系统抽样的方式抽取子样本,这样的抽样方式称为分层抽样10.某班级有100名学生,为了了解学生消费水平,将所有学生按照学习成绩排序后,在前十名学生中随机抽出成绩为第3名的学生,后面依次选出第13、23、33、43、53、63、73、83、93九名同学进行调查。
这种调查方法属于系统抽样11.在频数分布表中,某一小组中数据个数占总数据个数的比例称为频率12.在频数分布表中,将各个有序类别或组的百分比逐级累加起来称为累积频率13.在频数分布表中,频率是指各组频数与总频数之比14.在频数分布表中,比率是指不同小组的频数之比15.如果用一个图形描述比较两个或多个样本或总体的结构性问题时,适合选用环形图16.某地区2001-2010年人口总量(单位:万人)分别为98,102,103,106,108,109,110,111,114,115,下列哪种图形最适合描述这些数据线图17.当我们用图形描述甲乙两地区的人口年龄结构时,适合选用哪种图形环形图18.在某市随机抽取10家企业,7月份利润额(单位:万元)分别为72.0、63.1、20.0、23.0、54.7、54.3、23.9、25.0、26.9、29.0,那么这10家企业7月份利润额均值为 39.19 19.某班级10名同学期末统计课考试分数分别为76、93、95、80、92、83、88、90、92、72,那么该班考试成绩的中位数是 8920.某企业职工的月收入水平分为五组:1)1500元及以下;2)1500-2000元;3)2000-2500元;4)2500-3000元;5)3000元及以上,则3000元及以上这一组的组中值为 3250元21.为了解某行业12月份利润状况,随机抽取5家企业,12月份利润额(单位:万元)分别为65、23、54、45、39,那么这5家企业12月份利润额均值为 45.222.某专业共8名同学,他们的统计课成绩分别为86、77、97、94、82、90、83、92,那么该班考试成绩的中位数是8823.某班级学生平均每天上网时间可以分为以下六组:1)1小时及以下;2)1-2小时;3)2-3小时;4)3-4小时;5)4-5小时;6)5小时及以上,则5小时及以上这一组的组中值近似为5.5小时24.对于左偏分布,平均数、中位数和众数之间的关系是众数>中位数>平均数25.对于右偏分布,平均数、中位数和众数之间的关系是平均数>中位数>众数26.离散系数的主要目的是比较多组数据的离散程度27.两组数据的平均数不相等,但是标准差相等。
社会统计学试题及答案

社会统计学试题及答案一、选择题(每题2分,共20分)1. 社会统计学是研究社会现象数量特征和数量关系的科学,其主要研究方法不包括以下哪一项?A. 描述性统计B. 推断性统计C. 定性分析D. 指数分析2. 以下哪一项不是社会统计学中常用的数据类型?A. 计数数据B. 顺序数据C. 比率数据D. 定性数据3. 在社会统计学中,中位数是衡量数据集中趋势的一种方法,以下关于中位数的描述不正确的是?A. 中位数是将数据从小到大排序后位于中间位置的数值B. 中位数不受极端值的影响C. 中位数是数据的平均值D. 中位数适用于任何类型的数据4. 标准差是衡量数据离散程度的指标,以下关于标准差的描述不正确的是?A. 标准差越大,数据越集中B. 标准差是方差的平方根C. 标准差可以为负数D. 标准差反映了数据的波动大小5. 以下哪个统计量可以用来衡量变量之间的线性相关程度?A. 相关系数B. 方差C. 标准差D. 均值...(此处省略剩余选择题)二、简答题(每题10分,共30分)1. 简述描述性统计和推断性统计的区别。
2. 解释什么是正态分布,并说明其在社会统计学中的应用。
3. 什么是抽样误差?它是如何影响统计推断的?三、计算题(每题15分,共30分)1. 给定一组数据:10, 12, 14, 16, 18, 20。
计算这组数据的均值、中位数和标准差。
2. 如果一个样本的均值为50,标准差为10,样本量为100,求95%置信区间。
四、案例分析题(每题20分,共20分)某社会调查机构对1000名居民进行了收入调查,调查结果显示,平均收入为5000元,标准差为1500元。
请根据这些信息,分析可能存在的收入分布情况,并讨论如果样本量减少到500,对统计推断的影响。
答案一、选择题1. C2. C3. C4. A, C, D5. A二、简答题1. 描述性统计主要关注数据的收集、组织、描述和呈现,目的是对数据进行总结和解释,而推断性统计则是基于样本数据对总体进行推断,目的是做出关于总体的结论。
社会统计学复习题(有答案)

社会统计学课程期末复习题一、填空题(计算结果一般保留两位小数)1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。
2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。
3、在回归分析中,各实际观测值y 与估计值y ˆ的离差平方和称为 剩余 变差。
4、平均增长速度= 平均发展速度 —1(或100%)。
5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。
6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。
7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。
8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为100%7%A 100% 1.06%100%6%-=-=-产品单位成本计划超额完成程度 ;若某厂计划规定B产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为100%10%100% 4.76%100%5%+=-=+B 产品产量计划超额完成程度 。
9、按照标志表现划分,学生的民族、性别、籍贯属于 品质 标志;学生的体重、年龄、成绩属于 数量 标志。
10、从内容上看,统计表由 主词 和 宾词 两个部分组成;从格式上看,统计表由总标题 、 横行标题 、 纵栏标题 和 指标数值(或统计数值);四个部分组成。
11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于 正 相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于 负 相关。
(完整版)《社会统计学》样题附答案

华南农业大学期末考试试卷(A卷)学年第学期考试科目:社会统计学考试类型:(开卷)考试时间:120 分钟一、单项选择题(请将正确选项的序号填在答题纸相应的位置。
)1.社会统计中的变量一般分四个层次,其中最高层次的变量是。
A、定类变量B、定序变量C、定距变量D、定比变量2.标准正态分布的均值一定。
A、等于1B、等于-1C、等于0D、不等于03.计算中位值时,对于未分组资料,先把原始资料按大小顺序排列成数列,然后用公式确定中位值所在位置。
A、n/2B、(n-1)/2C、(n+2)/2D、(n+1)/24.下列统计指标中,对极端值的变化最不敏感的是。
A、众值B、中位值C、四分位差D、均值5.如果原假设是总体参数不小于某一数值,即大于和等于某一数值,应采用的检验是。
A、两端检验B、右端检验C、左端检验D、无法判断6.在一个右偏的分布中,大于均值的数据个数将。
A、不到一半B、等于一半C、超过一半D、视情况而定7.下列关于“回归分析和相关分析的关系”的说法中不正确的是。
A、回归分析可用于估计和预测B、相关分析是研究变量之间的相互依存关系的密切程度C、相关分析不需区分自变量和因变量D、回归分析是相关分析的基础8.假定男性总是与比自己年轻3岁的女性结婚,那么夫妻年龄之间的积距相关系数r为。
A、-1 < r< 0B、0 < r< 1C、r = 1D、r = -19.“4、6、8、10、12、26”这组数据的集中趋势宜用测量。
A、众值B、中位值C、均值D、平均差10.某校期末考试,全校语文平均成绩为80分,标准差为4.5分,数学平均成绩为87分,标准差为9.5分。
某学生语文得了83分,数学得了92分,从相对名次的角度看,该生的成绩考得更好。
A、数学B、语文C、两门课程一样D、无法判断二、多项选择题(多选、错选均不得分,漏选得部分分。
请将正确选项的序号填在答题纸相应的位置。
)1.下列变量中属于定类层次的是。
《社会统计学》期末复习试题及答案.doc

《社会统计学》作业一、单项选择题1、从历史上看,在社会经济统计学的形成过程中,首先使用“统计学”这一术语的是()0A.政治算术学派B.国势学派C,数理统计学派 D.社会经济统计学派2、社会统计的研究对象是()。
A.抽象的数量关系B.社会现象的规律性C.社会现象的数理特征和数量关系D.社会统计认识过程的规律和方法3、对某城市社区居民收入情况进行调查,统计总体是()。
A,每个社区B,该城市全部社区C,每个社区的全部居民D,该城市全部社区的全部居民4、社会统计调查分为一次性调查和经常性调查,是根据()oA.是否定期进行B,组织方式不同C.是否调查全部单位D,时间是否连续5、对学校的教师进行身体普查,调查单位是()。
A.学校全部教师B.学校每一位教师C.每所学校的教师D.学校6、某地区的社会扶贫投入2009年比2004年增长了58.6%,则该地区2004—2009年间扶贫投入的平均发展速度为(A. ^58.6%B.边58.6%C. 058.6%D. §158.6%7、如果采用三项移动平均修匀时间数列,那么所得修匀数列比原数列首尾各少()。
A.一项数值B.二项数值C,三项数值 D.四项数值8、在社会统计指数的计算中,可变权数是指在一个指数数列中,各个指数的()o A,同度量因素是变动的 B.基期是变动的C,指数化因数是变动的 D.时期是变动的9、某企业的职工工资水平比上年提高5%,职工人数增加2%,则企业工资总额增长()。
A.10%B. 7. 1%C. 7%D. 11%10、2009年某市下岗职工已安置了13. 7万人,安置率达80. 6%,安置率是()。
B.变异指标 D,相对指标A. 总量指标 C.平均指标13、 重点调查的重点单位是( )。
A. 这些单位的单位总量占总体单位总量的比重很大B. 标志值很大C. 这些单位的标志总量占总体标志总量的比重很大D. 在社会中的重点单位或部门14、 某村企业职工最高工资为852元,最低工资为540元,据此分为六个组,形成闭口式等距数列,则组距应为( )oA. 142B. 52C. 312D. 26415、某领导小组成员的年龄分别为29, 45, 35, 43, 45, 58,他们年龄的中位数为()A. 45B. 40C. 44D. 43 16、 采用几何平均法计算平均发展速度的依据是( )oA, 各年环比发展速度之积等于总速度 B, 各年环比发展速度之和等于总速度 C, 各年环比增长速度之积等于总速度 D, 各年环比增长速度之和等于总速度17、 某商品报告期与基期相比,商品销售额增长10%,商品销售量增长10%,则商品价格( )oA 、 增长20%B 、 增长10%C 、 增长1%D 、 不增不减 18、 社会统计指数划分为个体指数和总指数的依据是( )=A,反映的对象范围不同 B.指标性质不同 C.采用的基期不同D.编制指数的方法不同19、 对某市1999-2009年教育投资支出(万元)的时间数列配合方程为y = 500 + 52?,这意味着该市教育投资支出每年平均( )。
(完整版)《社会统计学》样题附答案
华南农业大学期末考试试卷(A卷)学年第学期考试科目:社会统计学考试类型:(开卷)考试时间:120 分钟一、单项选择题(请将正确选项的序号填在答题纸相应的位置。
)1.社会统计中的变量一般分四个层次,其中最高层次的变量是。
A、定类变量B、定序变量C、定距变量D、定比变量2.标准正态分布的均值一定。
A、等于1B、等于-1C、等于0D、不等于03.计算中位值时,对于未分组资料,先把原始资料按大小顺序排列成数列,然后用公式确定中位值所在位置。
A、n/2B、(n-1)/2C、(n+2)/2D、(n+1)/24.下列统计指标中,对极端值的变化最不敏感的是。
A、众值B、中位值C、四分位差D、均值5.如果原假设是总体参数不小于某一数值,即大于和等于某一数值,应采用的检验是。
A、两端检验B、右端检验C、左端检验D、无法判断6.在一个右偏的分布中,大于均值的数据个数将。
A、不到一半B、等于一半C、超过一半D、视情况而定7.下列关于“回归分析和相关分析的关系”的说法中不正确的是。
A、回归分析可用于估计和预测B、相关分析是研究变量之间的相互依存关系的密切程度C、相关分析不需区分自变量和因变量D、回归分析是相关分析的基础8.假定男性总是与比自己年轻3岁的女性结婚,那么夫妻年龄之间的积距相关系数r为。
A、-1 < r< 0B、0 < r< 1C、r = 1D、r = -19.“4、6、8、10、12、26”这组数据的集中趋势宜用测量。
A、众值B、中位值C、均值D、平均差10.某校期末考试,全校语文平均成绩为80分,标准差为4.5分,数学平均成绩为87分,标准差为9.5分。
某学生语文得了83分,数学得了92分,从相对名次的角度看,该生的成绩考得更好。
A、数学B、语文C、两门课程一样D、无法判断二、多项选择题(多选、错选均不得分,漏选得部分分。
请将正确选项的序号填在答题纸相应的位置。
)1.下列变量中属于定类层次的是。
社会统计学复习题(有答案)
社会统计学课程期末复习题一、填空题(计算结果一般保留两位小数)1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。
2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。
3、在回归分析中,各实际观测值y 与估计值y ˆ的离差平方和称为 剩余 变差。
4、平均增长速度= 平均发展速度 —1(或100%)。
5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。
6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。
7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。
8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为100%7%A 100%1.06%100%6%-=-=-产品单位成本计划超额完成程度 ;若某厂计划规定B产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为100%10%100%4.76%100%5%+=-=+B 产品产量计划超额完成程度 。
9、按照标志表现划分,学生的民族、性别、籍贯属于 品质 标志;学生的体重、年龄、成绩属于 数量 标志。
10、从内容上看,统计表由 主词 和 宾词 两个部分组成;从格式上看,统计表由总标题 、 横行标题 、 纵栏标题 和 指标数值(或统计数值);四个部分组成。
11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于 正 相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于 负 相关。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
社会统计学期末复习训练一、单项选择题(20=2×10)1.为了解IT行业从业者收入水平,某研究机构从全市IT行业从业者随机抽取800人作为样本进行调查,其中44%回答他们的月收入在6000元以上,30%回答他们每月用于娱乐消费在1000元以上。
此处800人是.样本2.某地区政府想了解全市332.1万户家庭年均收入水平,从中抽取3000户家庭进行调查,以推断所有家庭的年均收入水平。
这项研究的总体是 332.1户家庭的年均收入3.学校后勤集团想了解学校22000学生的每月生活费用,从中抽取2200名学生进行调查,以推断所有学生的每月生活费用水平。
这项研究的总体是 22000名学生的每月生活费用4.为了解地区的消费,从该地区随机抽取5000户进行调查,其中30%回答他们的月消费在5000元以上,40%回答他们每月用于通讯、网络的费用在300元以上。
此处5000户是样本5.从变量分类看,下列变量属于定序变量的是产品等级6.下列变量属于数值型变量的是工资收入7.从含有N个元素的总体中,抽取n个元素作为样本,同时保证总体中每个元素都有相同的机会入选样本,这样的抽样方式称为.简单随机抽样8.某班级有60名男生,40名女生,为了了解学生购书支出,从男生中抽取12名学生,从女生中抽取8名学生进行调查。
这种调查方法属于分层抽样9.先将总体按某标志分为不同的类别或层次,然后在各个类别中采用简单随机抽样或系统抽样的方式抽取子样本,这样的抽样方式称为分层抽样10.某班级有100名学生,为了了解学生消费水平,将所有学生按照学习成绩排序后,在前十名学生中随机抽出成绩为第3名的学生,后面依次选出第13、23、33、43、53、63、73、83、93九名同学进行调查。
这种调查方法属于系统抽样11.在频数分布表中,某一小组中数据个数占总数据个数的比例称为频率12.在频数分布表中,将各个有序类别或组的百分比逐级累加起来称为累积频率13.在频数分布表中,频率是指各组频数与总频数之比14.在频数分布表中,比率是指不同小组的频数之比15.如果用一个图形描述比较两个或多个样本或总体的结构性问题时,适合选用环形图16.某地区2001-2010年人口总量(单位:万人)分别为98,102,103,106,108,109,110,111,114,115,下列哪种图形最适合描述这些数据线图17.当我们用图形描述甲乙两地区的人口年龄结构时,适合选用哪种图形环形图18.在某市随机抽取10家企业,7月份利润额(单位:万元)分别为72.0、63.1、20.0、23.0、54.7、54.3、23.9、25.0、26.9、29.0,那么这10家企业7月份利润额均值为 39.19 19.某班级10名同学期末统计课考试分数分别为76、93、95、80、92、83、88、90、92、72,那么该班考试成绩的中位数是 8920.某企业职工的月收入水平分为五组:1)1500元及以下;2)1500-2000元;3)2000-2500元;4)2500-3000元;5)3000元及以上,则3000元及以上这一组的组中值为 3250元21.为了解某行业12月份利润状况,随机抽取5家企业,12月份利润额(单位:万元)分别为65、23、54、45、39,那么这5家企业12月份利润额均值为 45.222.某专业共8名同学,他们的统计课成绩分别为86、77、97、94、82、90、83、92,那么该班考试成绩的中位数是8823.某班级学生平均每天上网时间可以分为以下六组:1)1小时及以下;2)1-2小时;3)2-3小时;4)3-4小时;5)4-5小时;6)5小时及以上,则5小时及以上这一组的组中值近似为5.5小时24.对于左偏分布,平均数、中位数和众数之间的关系是众数>中位数>平均数25.对于右偏分布,平均数、中位数和众数之间的关系是平均数>中位数>众数26.离散系数的主要目的是比较多组数据的离散程度27.两组数据的平均数不相等,但是标准差相等。
那么 平均数大的,离散程度小28.已知某单位平均月收入为3500元,离散系数为0.2,那么他们月收入的标准差为70029.一班学生的平均体重均为55千克,二班学生的平均体重为52千克,两个班级学生体重的标准差均为5千克。
那么 二班学生体重的离散程度大30.已知某单位平均月收入标准差为700元,离散系数为0.2,那么他们月收入的均值为350031. 正态分布中,σ值越小,则 离散趋势越小32.已知某单位职工平均每月工资为3000元,标准差为500元。
如果职工的月收入是正态分布,可以判断月收入在2500元—3500元之间的职工人数大约占总体的68%33.如果一组数据中某一个数值的标准分值为-1.5,这表明该数值比平均数低1.5个标准差34.某班级学生期末英语考试平均成绩为75分,标准差为10分。
如果已知这个班学生的考试分数服从正态分布,可以判断成绩在65-85之间的学生大约占全班学生的68%35.经验法则表明,当一组数据正太分布时,在平均数加减2个标准差的范围之内大约有 95%的数据36.期中考试中,某班级学生统计学平均成绩为80分,标准差为4分。
如果学生的成绩是正太分布,可以判断成绩在72分-88分之间的学生大约占总体的95%37.如果一组数据中某个数值的标准分值为1.8,这表明该数值比平均数高出1.8个标准差38.某班级学生期末统计学考试平均成绩为82分,标准差为5分。
如果已知这个班学生的考试分数服从正态分布,可以判断成绩在77-87之间的学生大约占全班学生的68%39.经验法则表明,当一组数据正态分布时,在平均数加减1个标准差的范围之内大约有 68%的数据40.用样本统计量的值直接作为总体参数的估计值,这种方法称为点估计41.用样本统计量的值构造一个置信区间,作为总体参数的估计,这种方法称为区间估计42.某单位对该厂第一加工车间残品率的估计高达10%,而该车间主任认为该比例(π)偏高。
如果要检验该说法是否正确,则假设形式应该是0H :π≥0.1;1H :π<0.143.某单位对该厂第一加工车间残品率估计高达13%,而该车间主任认为该比例(π)偏高。
如果要检验该说法是否正确,则假设形式应该为0H :π≥0.13;1H :π<0.1344.在假设检验中,不拒绝虚无假设意味着没有证据证明虚无假设是错误的45.在假设检验中,虚无假设和备择假设有且只有一个成立46.在假设检验中,如果所计算出的P 值越大,那么检验的结果 越不显著47.在假设检验中,如果所计算出的P 值越小,那么检验的结果 越显著48.根据一个具体的样本求出的总体均值90%的置信区间以90%的概率包含总体均值49.根据一个样本均值求出的90%的置信区间表明总体均值有90%的概率会落入该区间内50.根据一个具体的样本求出的总体均值95%的置信区间以95%的概率包含总体均值51.用于说明回归方程中拟合优度的统计量主要是判定系数52.两个定类变量之间的相关分析可以使用λ系数53.判断下列哪一个不可能是相关系数1.254.判断下列哪一个不可能是相关系数1.3255.如果收入与支出之间的线性相关系数为0.92,那么二者之间存在着高度相关56.如果物价与销售量之间的线性相关系数为-0.87,而且二者之间具有统计显著性,那么二者之间存在着高度相关57. 某项研究中欲分析受教育年限每增长一年,收入如何变化,下列哪种方法最合适回归58.在回归方程中,若回归系数等于0,这表明自变量x对因变量y的影响是不显著的59.对消费的回归分析中,学历、年龄、户口、性别、收入都是因变量,其中收入的回归系数为0.8,这表明消费每增加1元,收入增加0.8元60.在因变量的总离差平方和中,如果回归和所占的比例越大,则两变量之间相关程度越高61.回归平方和(SSR)反映y的总变差中由于x与y之间的线性关系引起的y的变化部分62.对于线性回归,在因变量的总离差平方和中,如果残差平方和所占比例越大,那么两个变量之间相关程度越小63.对于线性回归,在因变量的总离差平方和中,如果回归平方和所占比例越大,那么两个变量之间相关程度越大64.在因变量的总离差平方和中,如果回归平方和所占的比例越小,则自变量和因变量之间相关程度越低65.方差分析的目的是研究各分类自变量对数值型因变量的影响是否显著66.下面哪一项不是方差分析中的假定各总体的方差等于067.下列哪种情况不适合用方差分析年龄对收入的影响68.从两个总体中各选取了6个观察值,得到组间平方和为234,组内平方和为484,则组间方差和组内方差分别为234,48.469.从两个总体中共选取了8个观察值,得到组间平方和为432,组内平方和为426,则组间均方和组内均方分别为432,7170.在方差分析中,某一水平下样本数据之间的误差称为组内误差二、名词解释1.离散变量与连续变量P10(1)离散变量如果一个变量的变量值是间断的,可以一一列举的,这种变量称为离散变量。
例如,某人兄弟姐妹数、结婚次数、工厂生产产品的数量等,其变量值的取值是0,1,2,3…。
离散变量的取值是有限个值,而且其取值都是以整数位断开的,是有最小计量单位的。
例如,某人的兄弟姐妹数,只能是1个、2个、3个等,而不能是1.3个、2.5个等。
(2)连续变量如果一个变量的变量值是连续不断的,即可以取无数多个数值,这种变量称为连续变量。
例如,年龄、温度、灯泡的寿命等,它们的取值是连续不断的。
连续变量可以取无数多个值,其取值是连续不断,不可以一一列举的,而且,它们没有最小计量单位。
例如,年龄可以是1岁整,也可以是1.2岁、1.45岁、2.544岁等。
2.总体与样本 P11总体是构成它的所有个体的集合,个体则是构成总体的最基本的单位。
样本就是从总体中按照一定方式抽取的一部分个体的集合。
例如,要从某省所有育龄妇女中抽取1000人进行调查进行调查,那么,该省所有育龄妇女就是研究总体,其中每一位育龄妇女就是个体,而抽取出的1000名育龄妇女就构成为了该总体的一个样本。
3.抽样单位与抽样框 P11抽样单位就是一次直接的抽样所使用的基本单位。
抽样单位有时与构成总体的个体是相同的,有时是不同的。
例如对育龄妇女的调查,当直接抽取育龄妇女时,两者是相同的;当我们从总体中一次直接抽取户时,以抽中的户中的育龄妇女作为样本时,抽样单位(户)与个体(育龄妇女)就不相同了。
抽样框是指一次直接抽样时样本中所有抽样单位的名单。
例如,从某校中抽取200名学生进行就业观的调查,那么这所学校的所有学生的名单就是这次抽样的抽样框。
但是,当我们先抽取班级,以抽中班级中的所有学生作为样本时,这所学校所有班级的名单就是这次抽样的抽样框。