oracle 存储过程批量重建索引
oracle数据库创建索引例子

oracle数据库创建索引例子Oracle数据库创建索引例子在Oracle数据库中,创建索引是优化查询性能的重要手段之一。
下面列举了一些创建索引的例子,并进行详细的讲解。
创建简单索引的例子1.创建唯一索引–语法:CREATE UNIQUE INDEX index_name ON table_name(column_name);–示例:创建一个名为idx_unique_id的唯一索引,索引字段为id,索引表为employees。
CREATE UNIQUE INDEX idx_unique_id ON employees(id);–说明:唯一索引保证了索引字段的值是唯一的,用于字段中不能存在重复值的情况。
2.创建普通索引–语法:CREATE INDEX index_name ONtable_name(column_name);–示例:创建一个名为idx_lastname的普通索引,索引字段为last_name,索引表为employees。
CREATE INDEX idx_lastname ON employee s(last_name);–说明:普通索引可以加快查询速度,适用于频繁查询的字段。
创建复合索引的例子3.创建复合唯一索引–语法:CREATE UNIQUE INDEX index_name ON table_name(column1, column2);–示例:创建一个名为idx_unique_name_dept 的复合唯一索引,索引字段为name和dept_id,索引表为employees。
CREATE UNIQUE INDEX idx_unique_name_d ept ON employees(name, dept_id);–说明:复合唯一索引是基于多个字段的唯一索引,可以保证多个字段组合的值是唯一的。
4.创建复合普通索引–语法:CREATE INDEX index_name ON table_name(column1, column2);–示例:创建一个名为idx_firstname_lastname的复合普通索引,索引字段为first_name和last_name,索引表为employees。
Oracle删除和重建由primary约束建立的索引

Oracle 删除和重建由primary 约束建立的索引drop index时出现如下错误:SQL> drop index oos_index;drop index oos_indexERROR at line 1:ORA-02429: cannot drop index used for enforcement ofunique/primary key我们知道当创建Primary key和unique约束时,如果在该key上不存在索引,则Oracle会自动创建对应的unique索引,而当你要删除该索引时,必须先Disable或Drop该约束。
看下面的例子:SQL>CREATE TABLE employees2 (3 empno NUMBER(6) PRIMARY KEY,4 name VARCHAR2(30),5 dept_no NUMBER(2)6 );Table created.SQL> select index_name,owner,table_NAME from all_indexes where owner=’SFA’ AND table_name=’EMPLOYEES’;INDEX_NAME OWNER TABLE_NAME———————- ——————- —————–SYS_C007594 SFA EMPLOYEESSQL> SELECTCONSTRAINT_NAME,CONSTRAINT_TYPE,TABLE_NAME,INDE X_NAME FROM ALL_CONSTRAINTS WHERETABLE_NAME=’EMPLOYEES’;CONSTRAINT_NAME C TABLE_NAME INDEX_NAME ———————————————————- ——————SYS_C007594 P EMPLOYEES SYS_C007594SQL> DROP INDEX SYS_C007594;DROP INDEX SYS_C007594*ERROR at line 1:ORA-02429: cannot drop index used for enforcement ofunique/primary keySQL> ALTER TABLE employees MODIFY PRIMARY KEY DISABLE;Table altered.SQL> select index_name,owner,table_NAME from all_indexes where owner=’SFA’ AND table_name=’EMPLOYEES’;no rows selected这时看到由约束建立的索引已经删除了。
oracle重建分区索引语句

oracle重建分区索引语句摘要:1.Oracle 分区索引简介2.重建分区索引的原因3.重建分区索引的步骤4.示例:使用SQL 语句重建分区索引正文:一、Oracle 分区索引简介Oracle 分区索引是一种在分区表上的索引,它可以提高查询效率。
分区索引与普通索引类似,但它是基于分区表的,因此具有更高的查询性能。
当数据量较大时,分区索引能够有效地减少查询数据的范围,提高查询速度。
二、重建分区索引的原因重建分区索引通常有以下原因:1.索引损坏:当分区索引损坏时,需要进行重建。
2.数据表分区改变:当数据表的分区发生变化时,需要重建分区索引以适应新的分区结构。
3.优化查询性能:在某些情况下,重建分区索引可以提高查询性能。
三、重建分区索引的步骤1.备份数据:在进行分区索引重建之前,需要备份数据以防止数据丢失。
2.使用ALTER INDEX 命令:使用ALTER INDEX 命令可以重建分区索引。
需要指定要重建的索引名称以及分区信息。
3.检查重建结果:重建完成后,需要检查重建结果以确保索引正确无误。
四、示例:使用SQL 语句重建分区索引以下是一个使用SQL 语句重建分区索引的示例:```sqlALTER INDEX index_nameREBUILD PARTITION p_number;```其中,`index_name`是要重建的分区索引名称,`p_number`是要重建的分区编号。
可以根据实际情况修改相应的参数值。
通过以上步骤和示例,可以完成Oracle 分区索引的重建工作。
在进行分区索引重建时,需要谨慎操作,确保数据安全。
oracle创建索引

Oracle创建索引Oracle在创建索引时要遵循以下的原则:●平衡查询和DML的需要。
在易挥发(DML操作频繁)的表上尽量减少索引的数量,因为索引虽然加快了查询的速度,但却降低了DML操作速度。
●将其放入单独的表空间,不要与表、临时段或还原(回滚)段放在一个表空间,因为索引段会与这些段竞争输入/输出(I/O)。
●使用统一的EXTENT尺寸:数据块尺寸的5倍,或表空间的MINIMUM EXTENT的尺寸。
这样做的目的是为了减少系统的转换时间。
●对大索引可以考虑使用NOLOGGING。
这样做的目的是通过减少REDO操作来提高系统的效率,但是如果一旦系统发生崩溃,则该索引一般是无法进行完全灰度的。
不过问题也不是很大,因为真正的数据还在表中,所以可以通过重建该索引来恢复与之前完全相同的效果。
●索引的INITRANS参数通常应该比相对应表的高。
以为索引项要比表中的数据行小的多,所以一个数据块可以存放更多的索引项(记录)。
创建索引的命令格式:CREA TE (UNIQUE|BITMAP) INDEX [用户名.]索引名ON [用户名.]表名(列名[ASC | DESC] [,列名[ASC| DESC ] ]…)[TABLESPACE 表空间名][PCTFREE 正整型数][INITRANS 正整型数][MAXTRANS 正整型数][存储子句][LOGGING | NOLOGGING][NOSORT]其中,●UNIQUE:说明该索引是唯一索引,默认是非唯一的●ASC:说明所创建的索引为升序●DESC:说明所创建的索引为降序●表空间名:说明将要创建的索引的表空间名●PCTFREE:在创建索引时每一个块中预留的空间●INITRANS:在每一个块中预分配的事物记录数,默认值为2●MAXTRANS:在每一个块中可以分配的事物记录数的上限,默认为255●存储子句:说明在索引中EXTENTS怎样分配●LOGGING:说明在创建索引是和以后的索引操作中要记录联机重做日志文件(默认)●NOLOGGING:说明索引的创建和一些数据装入操作将不记录联机重做日志文件●NOSORT:数据库中所存的数据行已经按升序排好,因此在创建索引时不需要再排序了●PCTUSED:在索引中不能说明该参数。
oracle重建索引

oracle重建索引⼀、重建索引的前提1、表上频繁发⽣update,delete操作;2、表上发⽣了alter table ..move操作(move操作导致了rowid变化)。
⼆、重建索引的标准1、索引重建是否有必要,⼀般看索引是否倾斜的严重,是否浪费了空间,那应该如何才可以判断索引是否倾斜的严重,是否浪费了空间,对索引进⾏结构分析(如下):SQL>Analyze index index_name validate structure;2、在执⾏步骤1的session中查询index_stats表,不要到别的session去查询。
SQL>select height,DEL_LF_ROWS/LF_ROWS from index_stats;说明:当查询出来的 height>=4 或者 DEL_LF_ROWS/LF_ROWS>0.2 的场合,该索引考虑重建。
举例: (t_gl_assistbalance 26 万多条信息 )SQL> select count(*) from t_gl_assistbalance ;输出结果:COUNT(*)----------265788SQL> Analyze index IX_GL_ASSTBAL_1 validate structure;Index analyzedSQL> select height,DEL_LF_ROWS/LF_ROWS from index_stats;输出结果:HEIGHT DEL_LF_ROWS/LF_ROWS---------- -------------------4 1三、重建索引的⽅式1、drop 原来的索引,然后再创建索引;举例:删除索引:drop index IX_PM_USERGROUP;创建索引:create index IX_PM_USERGROUP on T_PM_USER (fgroupid);说明:此⽅式耗时间,⽆法在24*7环境中实现,不建议使⽤。
重建索引语句

重建索引语句
哎呀,你知道啥是重建索引语句不?就好比你有一个乱糟糟的书架,书放得乱七八糟,找起来特别费劲。
这时候重建索引语句就像是一个
神奇的整理大师,能把书架重新整理得井井有条,让你一下子就能找
到想要的书。
比如说,在一个庞大的数据库里,数据就像那一堆堆杂乱无章的书。
没有重建索引语句,要找个关键信息,那可真是难上加难!就像在黑
暗中摸索,半天都找不到方向。
想象一下,你在一个大型图书馆,找一本书找得焦头烂额。
这时候
要是有人能迅速把书架重新整理,让你轻松找到,那得多爽!重建索
引语句就是干这个的呀!
我的朋友小李,之前就因为数据库没有重建索引语句,工作效率那
叫一个低,天天抱怨。
后来用上了,他直呼“这简直是救星啊!”
所以说,重建索引语句可太重要啦!它能让数据的查找和使用变得
高效又轻松,谁能不爱呢?。
oracle索引,索引的建立、修改、删除

oracle索引,索引的建⽴、修改、删除索引,索引的建⽴、修改、删除2007-10-05 13:29 来源: 作者:⽹友评论 0 条浏览次数 2986索引索引是关系数据库中⽤于存放每⼀条记录的⼀种对象,主要⽬的是加快数据的读取速度和完整性检查。
建⽴索引是⼀项技术性要求⾼的⼯作。
⼀般在数据库设计阶段的与数据库结构⼀道考虑。
应⽤系统的性能直接与索引的合理直接有关。
下⾯给出建⽴索引的⽅法和要点。
§3.5.1 建⽴索引1. CREATE INDEX命令语法:CREATE INDEXCREATE [unique] INDEX [user.]indexON [user.]table (column [ASC | DESC] [,column[ASC | DESC] ] ... )[CLUSTER [scheam.]cluster][INITRANS n][MAXTRANS n][PCTFREE n][STORAGE storage][TABLESPACE tablespace][NO SORT]Advanced其中:schema ORACLE模式,缺省即为当前帐户index 索引名table 创建索引的基表名column 基表中的列名,⼀个索引最多有16列,long列、long raw列不能建索引列DESC、ASC 缺省为ASC即升序排序CLUSTER 指定⼀个聚簇(Hash cluster不能建索引)INITRANS、MAXTRANS 指定初始和最⼤事务⼊⼝数Tablespace 表空间名STORAGE 存储参数,同create table 中的storage.PCTFREE 索引数据块空闲空间的百分⽐(不能指定pctused)NOSORT 不(能)排序(存储时就已按升序,所以指出不再排序)2.建⽴索引的⽬的:建⽴索引的⽬的是:l 提⾼对表的查询速度;l 对表有关列的取值进⾏检查。
但是,对表进⾏insert,update,delete处理时,由于要表的存放位置记录到索引项中⽽会降低⼀些速度。
Oracle数据库在线重新重建索引

Oracle数据库在线重新重建索引
在日常数据库维护中,需要对索引进行一些维护工作。
其中一个工作就是索引的重建,索引重建对SQL的执行效率有影响,重建工作应慎重。
为了能快速重建索引,下面介绍一下在线重新建立索引的方法:SQL>alter session set workarea_size_policy=manual;
此步骤将PGA修改为手工模式。
SQL>alter session set sort_area_size=1073741824;
此步骤将排序区修改为1G
SQL>alter session set sort_area_retained_size=1073741824;
此步骤将用户排序区修改为1G
SQL>alter session set db_file_multiblock_read_count=128;
此步骤将多块读调整为128,增加单次数据读取量。
SQL>alter index <index_name> rebuild online parallel <2> compute statistics;
此步骤以并行(parallel)方式重新创建索引,并行度根据主机CPU资源闲置情况而定(同时参考启动参数parallel_max_servers)。
此语句同时进行优化统计信息的更新操作。
在线索引重建步骤不能中断,如果中断索引会处于一种不确定性。
SQL>alter index <index_name> noparallel;
此步骤,将取消重建好的索引的并行度,使其恢复正常。
oracle重建索引的方法

oracle重建索引的方法在Oracle 数据库中,重建索引是一种优化数据库性能的方法之一。
索引的重建可以帮助数据库优化查询性能,减少碎片,提高查询效率。
以下是在Oracle 中重建索引的一般步骤:1. 查看索引状态:在执行重建索引之前,你可以查看索引的状态,以确定是否需要重建。
使用以下查询来获取索引的统计信息:```sqlSELECT index_name, table_name, table_owner, statusFROM dba_indexesWHERE table_owner = 'your_table_owner' AND table_name = 'your_table_name';```这将返回表中所有索引的信息,包括索引名称、表名称、所有者和状态等。
2. 禁用索引(可选):在进行索引重建之前,你可以选择禁用索引。
禁用索引可能会加快索引重建的过程。
使用以下语句禁用索引:```sqlALTER INDEX index_name NOPARALLEL;```在此语句中,`index_name` 是要禁用的索引名称。
3. 重建索引:使用`ALTER INDEX` 语句来重建索引。
重建索引的语法如下:```sqlALTER INDEX index_name REBUILD;```在此语句中,`index_name` 是要重建的索引名称。
4. 启用索引(可选):如果在第2步中禁用了索引,可以使用以下语句启用索引:```sqlALTER INDEX index_name PARALLEL;```在此语句中,`index_name` 是要启用的索引名称。
请注意,重建索引可能会导致数据库锁定和性能影响,因此在生产环境中建议在低负载时执行。
此外,重建索引的必要性取决于数据库的使用情况,有时候并不是每个索引都需要经常重建。
最好在进行此类维护任务之前,了解数据库性能和索引的使用情况,以确保执行这些操作是有益的。
Oracle 合并索引和重建索引
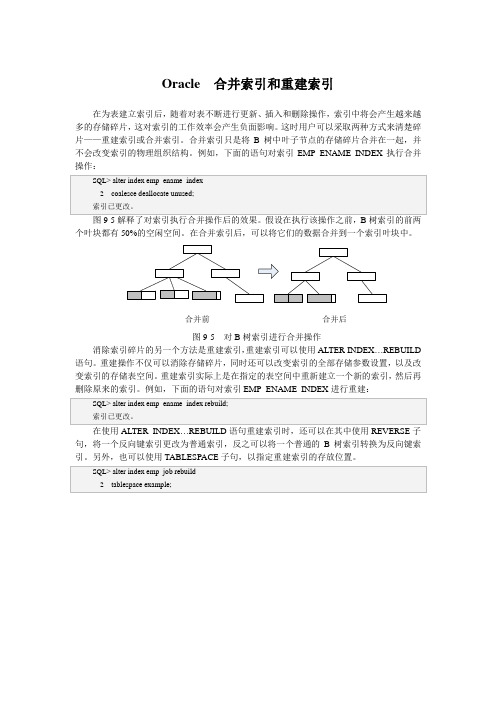
Oracle 合并索引和重建索引在为表建立索引后,随着对表不断进行更新、插入和删除操作,索引中将会产生越来越多的存储碎片,这对索引的工作效率会产生负面影响。
这时用户可以采取两种方式来清楚碎片——重建索引或合并索引。
合并索引只是将B树中叶子节点的存储碎片合并在一起,并不会改变索引的物理组织结构。
例如,下面的语句对索引EMP_ENAME_INDEX执行合并操作:SQL> alter index emp_ename_index2 coalesce deallocate unused;索引已更改。
图9-5解释了对索引执行合并操作后的效果。
假设在执行该操作之前,B树索引的前两个叶块都有50%的空闲空间。
在合并索引后,可以将它们的数据合并到一个索引叶块中。
合并前合并后图9-5 对B树索引进行合并操作消除索引碎片的另一个方法是重建索引,重建索引可以使用ALTER INDEX…REBUILD 语句。
重建操作不仅可以消除存储碎片,同时还可以改变索引的全部存储参数设置,以及改变索引的存储表空间。
重建索引实际上是在指定的表空间中重新建立一个新的索引,然后再删除原来的索引。
例如,下面的语句对索引EMP_ENAME_INDEX进行重建:SQL> alter index emp_ename_index rebuild;索引已更改。
在使用ALTER INDEX…REBUILD语句重建索引时,还可以在其中使用REVERSE子句,将一个反向键索引更改为普通索引,反之可以将一个普通的B树索引转换为反向键索引。
另外,也可以使用TABLESPACE子句,以指定重建索引的存放位置。
SQL> alter index emp_job rebuild2 tablespace example;。
oracle重建索引注意事项

Oracle重建索引注意事项在Oracle数据库中,索引是提高查询性能的重要工具之一。
当索引出现问题或性能下降时,重建索引是一种解决方法。
本文将详细介绍Oracle重建索引的注意事项,以帮助您正确、高效地进行索引重建操作。
1. 索引重建的目的索引重建是为了优化数据库查询性能而进行的操作。
当索引存在碎片、数据分布不均匀、索引高度不合理等情况时,会导致查询效率下降。
通过重建索引可以重新组织和优化索引结构,提高查询效率和整体性能。
2. 索引选择和分析在进行索引重建之前,需要对当前的索引进行选择和分析。
可以通过以下几个步骤来完成:•使用ANALYZE命令对表进行分析,获取表的统计信息。
•使用EXPLAIN PLAN命令对常见的查询语句进行分析,查看执行计划和相关指标。
•使用DBMS_STATS.GATHER_TABLE_STATS过程收集表的统计信息,并使用DBMS_STATS.GET_INDEX_STATS过程获取当前索引的统计信息。
通过以上步骤可以得到表和索引的详细信息,包括数据分布、空间利用率、IO消耗等指标。
根据这些信息,可以判断是否需要进行索引重建。
3. 索引重建的类型索引重建可以分为在线重建和离线重建两种类型。
•在线重建:在数据库正常运行的情况下进行索引重建,不会影响用户的查询和更新操作。
可以使用ALTER INDEX ... REBUILD命令来实现在线重建。
•离线重建:需要停止数据库或表的访问,进行索引重建。
离线重建可以通过导出数据、删除旧索引、重新导入数据等方式来完成。
选择合适的索引重建类型需要根据具体情况来决定。
如果数据库负载较高,且有足够空闲时间,可以选择离线重建;如果对数据库的可用性有较高要求,可以选择在线重建。
4. 索引创建和维护在进行索引重建之前,需要先创建新的索引结构。
创建新索引时需要注意以下几个方面:•合理选择索引类型:根据查询需求和数据特点选择合适的索引类型,如B树索引、位图索引等。
oracle重建索引

重建索引有多种方式,如drop and re-create、rebuild、rebuild online等。
下面简单比较这几种方式异同以及优缺点:首先建立测试表及数据:SQL> CREATE TABLE TEST AS SELECT CITYCODE C1 FROM CITIZENINFO2;Table createdSQL> ALTER TABLE TEST MODIFY C1 NOT NULL;Table alteredSQL> SELECT COUNT(1) FROM TEST;COUNT(1)----------16000000一、drop and re-create和rebuild首先看看正常建立索引时,对表的加锁情况。
suk@ORACLE9I> @show_sidSID----------14suk@ORACLE9I> CREATE INDEX IDX_TEST_C1 ON TEST(C1);索引已创建。
SQL> SELECT obxxxxject_NAMELMODE FROM V$LOCK LDBA_obxxxxjectS O WHERE O.obxxxxject_ID=L.ID1 AND L.TYPE='TM' AND SID=14;obxxxxject_NAME LMODE------------------------------ ----------OBJ$ 3TEST 4可见,普通情况下建立索引时,oracle会对基表加share锁,由于share锁和 row-X是不兼容的,也就是说,在建立索引期间,无法对基表进行DML操作。
对于删除重建索引的方法就不介绍了,它与上面的描述是一样的,下面我们看看用rebuild的方式建立索引有什么特别。
suk@ORACLE9I> ALTER INDEX IDX_TEST_C1 REBUILD;索引已更改。
Oracle数据库中建立索引的基本方法讲解

Oracle数据库中建⽴索引的基本⽅法讲解怎样建⽴最佳索引?1、明确地创建索引create index index_name on table_name(field_name)tablespace tablespace_namepctfree 5initrans 2maxtrans 255storage(minextents 1maxextents 16382pctincrease 0);2、创建基于函数的索引常⽤与UPPER、LOWER、TO_CHAR(date)等函数分类上,例:create index idx_func on emp(UPPER(ename)) tablespace tablespace_name;3、创建位图索引对基数较⼩,且基数相对稳定的列建⽴索引时,⾸先应该考虑位图索引,例:create bitmap index idx_bitm on class (classno) tablespace tablespace_name;4、明确地创建唯⼀索引可以⽤create unique index语句来创建唯⼀索引,例:create unique index dept_unique_idx on dept(dept_no) tablespace idx_1;5、创建与约束相关的索引可以⽤using index字句,为与unique和primary key约束相关的索引,例:alter table table_nameadd constraint PK_primary_keyname primary key(field_name)using index tablespace tablespace_name;如何创建局部区索引?1)基础表必须是分区表2)分区数量与基础表相同3)每个索引分区的⼦分区数量与相应的基础表分区相同4)基础表的⾃分区中的⾏的索引项,被存储在该索引的相应的⾃分区中,例如create index TG_CDR04_SERV_ID_IDX on TG_CDR04(SERV_ID)Pctfree 5Tablespace TBS_AK01_IDXStorage(MaxExtents 32768PctIncrease 0FreeLists 1FreeList Groups 1)local/如何创建范围分区的全局索引?基础表可以是全局表和分区表create index idx_start_date on tg_cdr01(start_date)global partition by range(start_date)(partition p01_idx vlaues less than ('0106')partition p01_idx vlaues less than ('0111')...partition p01_idx vlaues less than ('0401'))/如何重建现存的索引?重建现存的索引的当前时刻不会影响查询重建索引可以删除额外的数据块提⾼索引查询效率alter index idx_name rebuild nologging;对于分区索引alter index idx_name rebuild partition partition_name nologging;删除索引的原因?1)不再需要的索引2)索引没有针对其相关的表所发布的查询提供所期望的性能改善3)应⽤没有⽤该索引来查询数据4)该索引⽆效,必须在重建之前删除该索引5)该索引已经变的太碎了,必须在重建之前删除该索引语句:drop index idx_name;drop index idx_name partition partition_name;建⽴索引的代价?基础表维护时,系统要同时维护索引,不合理的索引将严重影响系统资源,主要表现在CPU和I/O上。
浅谈oracle重建索引

Oracle 重建索引当我们创建索引时,oracle会为索引创建索引树,表和索引树通过rowid(伪列)来定位数据。
当表里的数据发生更新时,oracle会自动维护索引树。
但是在索引树中没有更新操作,只有删除和插入操作。
例如在某表id列上创建索引,某表id列上有值“101”,当我将“101”更新为“110”时,oracle同时会来更新索引树,但是oracle先将索引树中的“101”标示为删除(实际并未删除,只是标示一下),然后再将“110”写到索引树中。
如果表更新比较频繁,那么在索引中删除标示会越来越多,这时索引的查询效率必然降低,所以我们应该定期重建索引。
来消除索引中这些删除标记。
一般不会选择先删除索引,然后再重新创建索引,而是rebuild索引。
在rebuild期间,用户还可以使用原来的索引,并且rebuild新的索引时也会利用原来的索引信息,这样重建索引会块一些。
这个实验来察看索引中的删除标记,并且如何重建索引。
试验环境:oracle 8.1.7一、创建表、插入记录和创建索引SQL> create table ind (id number,name varchar2(100));表已创建。
SQL> create or replace procedure sp_insert_ind2 is3 begin4 for i in 1..10000 loop5 insert into ind values(i,to_char(i)||'aaaaaaaaaa');6 end loop;7 end;8 /过程已创建。
SQL> exec sp_insert_indPL/SQL 过程已成功完成。
SQL> create index ind_id_idx on ind(id);索引已创建。
二、收集索引信息--收集信息,没有更新数据字典,所以没有信息SQL> select lf_rows,lf_rows_len,del_lf_rows,del_lf_rows_len from index_stats;未选定行--更新数据字典SQL> ANALYZE INDEX ind_id_idx VALIDATE STRUCTURE;索引已分析--参数含义:--LF_ROWS Number of values currently in the index--LF_ROWS_LEN Sum in bytes of the length of all values--DEL_LF_ROWS Number of values deleted from the index--DEL_LF_ROWS_LEN Length of all deleted valuesSQL> select lf_rows,lf_rows_len,del_lf_rows,del_lf_rows_len from index_stats;LF_ROWS LF_ROWS_LEN DEL_LF_ROWS DEL_LF_ROWS_LEN---------- ----------- ----------- ---------------10000 149801 0 0--察看索引中已经标示为删除的行除以总共的行的数量,目前为0SQL> SELECT (DEL_LF_ROWS_LEN/LF_ROWS_LEN) * 100 AS index_usage FROM index_stats;INDEX_USAGE-----------三、更新索引,并且重新察看信息--更新表中1000行记录,这时会更新索引树SQL> update ind set id=id+1 where id>9000;已更新1000行。
oracle 存储过程批量重建索引

create o r r eplace p rocedure p_rebuild_all_index(tablespace_name i n v archar2)ass qlt v archar(200);beginf or i dx i n(select i ndex_name, t ablespace_name, s tatus f rom u ser_indexes w here t ablespace_name =tablespace_name a nd s tatus='VALID'a nd t emporary='N') l oopb egins qlt :='alter i ndex '||i dx.index_name ||'r ebuild ';d bms_output.put_line(idx.index_name);d bms_output.put_line(sqlt);E XECUTE I MMEDIATE s qlt;--错误后循环继续执行。
E XCEPTIONW HEN O THERS T HENd bms_output.put_line(SQLERRM);e nd;e nd l oop;end;declare--表空间名称t ablespace_name v archar2(100);begint ablespace_name:='dddd';p_rebuild_all_index(tablespace_name);end;方法2:定期重建索引(oracle)文章来源:本站原创更新时间:2009-9-23 13:47:38公司的所用的oracle数据库,因为数据增、删比较频繁,导致索引产生碎片,性能下降,并占用空间不能有效释放。
由于目前暂时找不到合适的DBA对数据库进行优化,于是写了一个简单的脚本来定期重建所有的索引。
oracle数据库关于索引建立及使用的详细介绍

oracle数据库关于索引建⽴及使⽤的详细介绍索引的说明索引是与表相关的⼀个可选结构,在逻辑上和物理上都独⽴于表的数据,索引能优化查询,不能优化DML操作,Oracle⾃动维护索引,频繁的DML操作反⽽会引起⼤量的索引维护。
如果SQL语句仅访问被索引的列,那么数据库只需从索引中读取数据,⽽不⽤读取表。
如果该语句同时还要访问除索引列之外的列,那么,数据库会使⽤rowid来查找表中的⾏。
通常,为检索表数据,数据库以交替⽅式先读取索引块,然后读取相应的表块。
索引的⽬的主要是减少IO,这是本质,这样才能体现索引的效率。
1⼤表,返回的⾏数<5%2经常使⽤where⼦句查询的列3离散度⾼的列4更新键值代价低5逻辑AND、OR效率⾼6查看索引在建在那表、列:select * from user_indexes;select * from user_ind_columns;索引结构oracle索引分为两⼤类结构:B树索引结构<balance>类似于字典查询,最后到leaf block ,存的是数据rowid和数据项1.叶块之间使⽤双向链连接,为了可以范围查询。
2.删除表⾏时,索引叶块也会更新,但只是逻辑更改,并不做物理的删除叶块。
3.索引叶块不保存表⾏键值null的信息。
位图索引结构<bitmap>在oracle中是根据rowid来定位记录的,因此,我们需要引⼊start rowid和end rowid,通过start rowid ,end rowid 和⼆进制位的偏移,我们就可以⾮常快速的计算出⼆进制位所代表的表记录rowid。
位图索引的最终逻辑结构如下图:我们称每⼀单元的<key ,startrowid,end rowid,bitmap>为⼀个位图⽚段。
当我们修改某⼀⾏数据的时候,我们需要锁定该⾏列值所对应的位图⽚段,如果我们进⾏的是更新操作,同时还会锁定更新后新值所在的位图⽚段。
oracle重建索引rebuild语句

oracle重建索引rebuild语句一、Oracle重建索引Rebuild语句Oracle重建索引Rebuild语句是Oracle数据库中常用的语句之一,它可以在不改变索引结构的情况下,对索引进行重建。
重建索引可以改善索引的性能,减少其拥有的空间,也可以用于索引的修复。
重建索引Rebuild语句的格式如下:ALTER INDEX index_name REBUILD [PARAMETERS('parameter1=value1[,parameter2=value2]. ..')] [TABLESPACE tablespace_name] [PCTFREE integer] [INITRANS integer] [MAXTRANS integer] [STORAGE (storage_clause)] [COMPUTE STATISTICS];其中,index_name 是要重建的索引名称。
PARAMETERS 参数指定了一些重建的选项,这些参数可以让我们指定重建时包含的数据,例如ONLINE、MONITORING 等。
TABLESPACE 参数指定了重建时使用的表空间,可以是索引原来使用的表空间,也可以是新的表空间,如果不指定,则会使用索引原来使用的表空间。
PCTFREE 和 PCTUSED 参数指定了重建时所使用的空闲空间大小,它们可以在重建的同时为索引提供更好的性能。
INITRANS 和 MAXTRANS 参数指定了重建时所使用的事务数,它们可以影响索引的性能。
STORAGE 参数指定了重建时使用的存储参数,它可以影响索引的性能。
COMPUTE STATISTICS 参数指定了是否重新计算索引的统计信息,这可以提高索引的性能。
二、重建索引Rebuild语句的作用1、重建索引Rebuild语句可以改善索引的性能。
重建索引可以把索引中的数据重新排列,使索引更有效,提高索引的性能;2、重建索引Rebuild语句可以减少索引的空间。
Oracle收集统计信息和重建索引

Oracle收集统计信息和重建索引1.统计信息介绍:Statistic对Oracle是非常重要的。
它会收集数据库中对象的详细信息,并存储在相应的数据字典里。
根据这些统计信息,optimizer可以对每个SQL去选择最好的执行计划。
2.Oracle的Statistic信息的收集分两种:自动收集和手工收集。
(1)Oracle的Automatic Statistics Gathering是通过Scheduler来实现收集和维护的。
Job名称是GATHER_STATS_JOB,该Job收集数据库所有对象的2种统计信息:(a)Missing statistics(统计信息缺失)(b)Stale statistics(统计信息陈旧)该Job是在数据库创建的时候自动创建,并由Scheduler来管理。
Scheduler在maintenance windows open时运行gather job。
默认情况下,job会在每天晚上10到早上6点和周末全天开启。
该过程首先检测统计信息缺失和陈旧的对象。
然后确定优先级,再开始进行统计信息。
Gather_stats_job调用dbms_stats.gather_database_stats_job_proc过程来收集statistics 的信息。
该过程收集对象statistics的条件如下:(a)对象的统计信息之前没有收集过。
(b)当对象有超过10%的rows被修改,此时对象的统计信息也称为stale statistics。
查看该Job信息:SQL> select * from dba_scheduler_jobs where lower(job_name) ='gather_stats_job';(2)Oracle Statistic手工收集,可以使用analyze命令,也可以使用DBMS_STATS包来收集,Oracle建议使用DBMS_STATS包来收集统计信息,因为DBMS_STATS包收集的更广,并且更准确。
ORACLE相关:表空间、序列、索引、分区、游标、存储过程、分区等创建

--创建表空间create tablespace textdatafile'F:/db/ordata/hibernate/text.dbf'size10mAUTOEXTEND ON NEXT10M MAXSIZE UNLIMITEDLOGGINGEXTENT MANAGEMENT LOCALSEGMENT SPACE MANAGEMENT AUTO;--创建用户create user textidentified by textdefault tablespace text--为用户分配权限grant connect,resource,dba to text;--用户登录表的结构create table street(id NUMBER(5) primary key not null,p_id NUMBER(5),name VARCHAR2(18) not null,constraint s_fk_p_id foreign key (p_id) references district(id) );--创建表create table district(id NUMBER(5) primary key not null,name VARCHAR2(18) not null);--创建序列create sequence seq_streetstart with1increment by1nomaxvaluecache10;create sequence seq_districtstart with1increment by1nomaxvaluecache10;drop table street;drop table district;delete district;delete street;select * from street;select * from district;delete district where id != 6;--PL/SQL--插入数据DECLAREv_id NUMBER(5) := 7;v_name VARCHAR2(18) := '汉阳区';BEGINinsert into district values(v_id,v_name); EXCEPTIONWhen others thenDBMS_OUTPUT.PUT_LINE('插入数据失败');END;--IF-THEN语句DECLAREnum1 number := 5;num2 number := 1;num3 number := 3;result varchar2(20);BEGINIF num1 > num2 THENresult := 'num1 is big';ELSIF num1 < num2 THENresult := 'num3 is big';ELSEresult := 'num2';END IF;DBMS_OUTPUT.PUT_LINE(result);END;--CASE 语句DECLAREchap char := 'c';result varchar2(20);BEGINCASE chapWHEN'A'THEN result := 'is A';WHEN'B'THEN result := 'is B';ELSE result := 'Ok!';END CASE;DBMS_OUTPUT.put_line(RESULT);END;--LOOP循环DECLAREnum4 number := 0;BEGINLOOPnum4 := num4+1;IF num4 > 10THENEXIT;END IF;DBMS_OUTPUT.PUT_LINE(num4);END LOOP;END;--WHILE LOOP循环DECLAREnum5 number := 1;BEGINWHILE num5 < 5LOOPnum5 := num5 + 1;DBMS_OUTPUT.PUT_LINE(num5);END LOOP;END;--FOR LOOP循环DECLAREnum6 number := 1;BEGINFOR i IN1..10 LOOPnum6 := num6+i;END LOOP;DBMS_OUTPUT.PUT_LINE(num6);END;--动态SQL,执行DDLBEGINEXECUTE IMMEDIATE'create table temp_table'|| '(id integer,name varchar2(20))';END;SELECT * FROM temp_table;DROP TABLE temp_table;--执行PL/SQL语句块,以下代码中如果district表中有多行数据将会出错DECLAREplsql varchar2(200);BEGINplsql := 'DECLARE name varchar2(20);'||'BEGINselect ''桥口区'' into name from district ;DBMS_OUTPUT.PUT_LINE(''当前日期是:''||name);END;';EXECUTE IMMEDIATE plsql;END;--绑定变量DECLAREid2 tab_t.id1%type;name2 tab_1%type;plsql varchar2(200);BEGINplsql := 'insert into tab_t values(1)';EXECUTE IMMEDIATE plsql returning id1 into id2 ; DBMS_OUTPUT.PUT_LINE(id2);END;create table tab_t(id1 integer);drop table tab_t;--异常DECLAREtemp_ex exception;t_num integer;BEGINselect count(id) into t_num from district where id = '6';IF t_num >= 1THENRAISE temp_ex;END IF;DBMS_OUTPUT.PUT_LINE('用户不存在!');EXCEPTIONWHEN temp_ex THENDBMS_OUTPUT.PUT_LINE('用户已存在!');END;--游标DECLAREid1 number(5);name1 varchar2(18);--声明一个游标CURSOR c_district isselect * from district where id='6';BEGIN--打开游标OPEN c_district;--判断游标是否返回记录IF c_district %NOTFOUND THENDBMS_OUTPUT.PUT_LINE('没有找到相应的数据!');ELSE--从游标中读取数据FETCH c_district into id1,name1;DBMS_OUTPUT.PUT_LINE(id1||' '||name1);END IF;--关闭游标CLOSE c_district;END;--FOR循环操作游标DECLAREid1 number(5);name1 varchar2(18);CURSOR c_dis isselect * from district;BEGINFOR c_dis1 IN c_dis LOOPid1 := c_dis1.id;name1 := c_;DBMS_OUTPUT.PUT_LINE(id1||name1);END LOOP;END;--存储过程--创建过程CREATE OR REPLACE PROCEDURE proc_showInfo--声明一个输入参数(name1 IN varchar2)as--声明一个游标,在查询语句中使用输入参数作为查询条件CURSOR c_dist IS select id,name from district where name = name1;BEGINFOR c_diss IN c_dist LOOPDBMS_OUTPUT.PUT_LINE(c_diss.id||c_);END LOOP;END;--调用过程BEGINproc_showInfo('123');END;--删除过程DROP PROCEDURE proc_showInfo;--创建函数CREATE OR REPLACE FUNCTION getCount--声明输入参数(id1 IN number)--声明返回类型return number AS f_count number;BEGIN--使用INTO语句将结果赋值给变量select count(*) into f_count from district where id = id1;--使用RETURN语句返回return f_count;END;--调用函数DECLARE--声明变量接收函数的返回值v_count number;BEGINv_count := getCount(6);DBMS_OUTPUT.PUT_LINE(v_count);END;--删除函数DROP FUNCTION GETCOUNT;--创建包头CREATE OR REPLACE PACKAGE emp_package AS--声明存储过程,用于插入一条记录PROCEDURE my_proc(id1 number,name1 varchar2);END emp_package;--创建包体CREATE OR REPLACE PACKAGE BODY emp_package AS--存储过程的实现PROCEDURE my_proc(id1 number,name1 varchar2)ASBEGININSERT INTO district VALUES(id1,name1);END my_proc;END emp_package;--包的调用BEGINemp_package.my_proc(9,123);END;--创建视图CREATE OR REPLACE VIEW v_district AS select * from district;--查询视图里的数据SELECT * FROM v_district;--删除视图DROP VIEW v_district;--创建数据库链CREATE DATABASE LINK link_goodsconnect to text identified by textUSING'(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 10.0.0.11)(PORT = 1521))(CONNECT_DATA =(SERVICE_NAME = PRD32)))';--访问数据链SELECT * FROM goods@link_goods;--提高数据库性能--查看库高速缓存在执行调用阶段的不命中数select sum(pins) "请求数",sum(reloads) "不命中数" from v$librarycache;--查看库缓存的使用率select (sum(pins-reloads))/sum(pins) "library cache" from v$librarycache; --查看数据字典高速缓存不命中数select sum(gets) "请求数" , sum(getmisses) "不命中数" from v$rowcache;--查看数据字典高速缓存的使用率select (sum(gets-getmisses-usage-fixed))/sum(gets) "数据字典使用率" fromv$rowcache;--查看数据库缓存的命中率select(1-(select value from v$sysstat where name = 'physical reads')/((select value from v$sysstat where name = 'consistent gets')+(select value from v$sysstat where name = 'db block gets')))from(select name , value from v$sysstat where name in('db block gets' , 'consistent gets' , 'physical reads'));--创建索引create unique index d_name on street (name);--修改索引alter index d_name rebuild storage (initial1m next512k);--删除索引drop index d_name;--创建范围分区create table rang_active(id number,name varchar2(20))partition by range(id)(partition p_1 values less than (6) tablespace space1,partition p_2 values less than (7) tablespace space2,partition p_3 values less than (maxvalue) tablespace space3 );--创建列表分区create table list_active(id number,address varchar2(20))partition by list(address)(partition l_1 values('北京') tablespace space1,partition l_1 values('广州') tablespace space1,partition l_1 values('上海') tablespace space1,)--创建散列分区create table hash_active(id number,name varchar2(20))partition by hash(id)(partition h_1 tablespace space1,partition h_2 tablespace space2);--本地索引与分区表的创建create table dept(id number,name varchar2(20))partition by range(id)(partition d_p1 values less than (10) tablespace dp1,partition d_p2 values less than (20) tablespace dp2,partition d_p3 value less than(maxvalue) tablespace dp3);--根据表分区创建本地索引分区create index d_index on dept(id) local(partition d_p1 tablespace dp1,partition d_p2 tablespace dp2,partition d_p3 tablespace dp3);--全局索引分区的创建create index g_index on dept(id) global partition by range(id)( partition g1 values less than (100),partition g2 values less than (200),partition g3 values less than (maxvalue));。
oracle数据库如何重建索引

当索引的碎片过多时,会影响执行查询的速度,从而影响到我们的工作效率。
这时候采取的最有利的措施莫过于重建索引了。
本文主要介绍了Oracle数据库中检查索引碎片并重建索引的过程,接下来我们就开始介绍这一过程。
重建索引的步骤如下:1. 确认基本信息登入数据库,找到专门存放index 的tablespace,并且这个tablespace下所有index的owner都是tax.将index专门存放在一个独立的tablespace, 与数据表的tablespace分离,是常用的数据库设计方法。
2. 查找哪些index需要重建通过anlyze index .... validate structure命令可以分析单个指定的index,并且将单个index 分析的结果存放到index_stats试图下。
一般判断的依据是:height >4 pct_used < 50% del_lf_rows / lf_rows +0.001 > 0.03 g )3. google上下载了遍历所有index脚本发现anlyze index .... validate structure只能填充单个index分析信息,于是google了下,从网上下了个Loop 脚本,遍历索引空间下所有的索引名字,并且可以把所有index的分析信息存放到自己建立的一个用户表中。
4. anlyze index 锁定index发现下载的脚本不好用,应为anlyze index在分析索引前要争取独占锁,锁住index,很明显有些index正在被应用系统的使用,所以运行anlyze失败。
这里吸取的教训是,尽量晚上做这种事。
但是本人比较喜欢准时回家,所以在语句中添加Exception Handler,抛出anlyze index执行失败的那些index 名称,使脚本正常运行完毕。
并且根据打印到前台的index name手动执行那些index分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
create o r r eplace p rocedure p_rebuild_all_index
(tablespace_name i n v archar2)
as
s qlt v archar(200);
begin
f or i dx i n(select i ndex_name, t ablespace_name, s tatus f rom u ser_indexes w here t ablespace_name =tablespace_name a nd s tatus='VALID'a nd t emporary='N') l oop
b egin
s qlt :='alter i ndex '||i dx.index_name ||'r ebuild ';
d bms_output.put_line(idx.index_name);
d bms_output.put_line(sqlt);
E XECUTE I MMEDIATE s qlt;
--错误后循环继续执行。
E XCEPTION
W HEN O THERS T HEN
d bms_output.put_line(SQLERRM);
e nd;
e nd l oop;
end;
declare
--表空间名称
t ablespace_name v archar2(100);
begin
t ablespace_name:='dddd';
p_rebuild_all_index(tablespace_name);
end;
方法2:
定期重建索引(oracle)文章来源:本站原创更新时间:2009-9-23 13:47:38
公司的所用的oracle数据库,因为数据增、删比较频繁,导致索引产生碎片,性能下降,并占用空间不能有效释放。
由于目前暂时找不到合适的DBA对数据库进行优化,于是写了一个简单的脚本来定期重建所有的索引。
本文提到的脚
本创建一张表用来记录索引重建的日志,建立一个存储过程,并建立一个job 来每7 天调用一次该存储过程。
声明:因为我不是DBA,个人感觉这个的方法不正规(不是best practice),仅供没有更好办法的时候参考。
-----------------------------------------
-- 因为系统中很对表的数据变化比较频繁,导致索引空间膨胀,系统性能下降-- 因此需要定期重建系统中的索引,以优化性能,回收空间
-- 这项维护性工作通过Oracle 的job 进行调度
-- 建立一张表,存放索引重建日志
CREATE TABLE tmMTNLog (
fLogDate char ( 19 ),
fLogMsg varchar2 ( 4000 )
);
-- 首先创建一个存储过程,该存储过程重建所有的索引
CREATE OR REPLACE procedure mtn_rebuild_all_idx
as
cursor indexCursor is
select * from user_indexes where table_owner = 'XXXXX' and index_type = 'NORMAL' ; --请将XXXXX替换为oracle用户名
indexRow indexCursor %ROWTYPE;
sqlText varchar2 ( 1024 );
begin
open indexCursor ;
loop
fetch indexCursor into indexRow ;
exit when indexCursor %NOTFOUND;
sqlText := ' alter index ' || indexRow . index_name || ' rebuild ' ;
BEGIN
execute immediate ( sqlText );
insert into tmMTNLog ( fLogDate , fLogMsg ) values( sysdate , 'rebuild index success:' || indexRow . index_name );
EXCEPTION
WHEN OTHERS THEN
insert into tmMTNLog ( fLogDate , fLogMsg ) values( sysdate , 'rebuild index fail:' || indexRow . index_name );
END;
end loop;
end;
/
-- 然后建立一个Oracle 任务,这个任务每隔七天调度一次mtn_rebuild_all_idx 这个存储过程
-- 请注意,Oracle 的任务创建脚本不能多次执行,因为每次执行都会生成一个新的任务,如果要修改,请先删除原有任务
-- 因为Oracle 中用编号表示任务,所以脚本不清楚该任务是否已经存在,无法做到自动删了新建
DECLARE
X NUMBER ;
BEGIN
SYS .DBMS_JOB.SUBMIT
(
job => X
, what => 'ITIMS.MTN_REBUILD_ALL_IDX;'
, next_date => TRUNC ( SYSDATE + 7 )
,interval => 'TRUNC(SYSDATE+7)'
, no_parse => FALSE
);
END;。